Linux内核同步
Linux内核剖析 之 内核同步
主要内容
1、内核请求何时以交错(interleave)的方式执行以及交错程度如何。
2、内核所实现的基本同步机制。
3、通常情况下如何使用内核提供的同步机制。
内核如何为不同的请求服务
哪些服务?
====>>>
为了更好地理解内核是如何执行的,我们把内核看做必须满足两种请求的侍者:一种请求来自顾客,另一种请求来自数量有限的几个不同的老板。对于不同的请求,侍者采用如下的策略:
1、老板提出请求时,如果侍者空闲,则侍者开始为老板服务。
2、如果老板提出请求时侍者正在为顾客服务,那么侍者停止为顾客服务,开始为老板提供服务。
3、如果一个老板提出请求时侍者正在为另一个老板服务,那么侍者停止为第一个老板提供服务,而开始为第二个老板服务,服务完毕后再继续为第二个老板服务。
4、一个老板可能命令侍者停止正在为顾客提供的服务。侍者在完成对老板最近请求的服务之后,可能暂时不理会原来的顾客而去为新选中的顾客服务。
这里,将其对应到内核中的功能:
侍者提供的服务 <<<————>>> CPU处于内核态时所执行的代码和程序。如果CPU在用户态执行,则侍者被认为处于空闲状态。
老板的请求 <<<————>>> 中断。
顾客的请求 <<<————>>> 用户态进程发出的系统调用或异常。
====>>>
1、2、3对应于中断和异常处理程序的嵌套执行,4对应于内核抢占(kernel preemption)。
内核抢占与非内核抢占
简单定义,如果进程正执行内核函数时,即它在内核态运行时,允许发生内核切换(被替换的进程是正执行内核函数的进程),那么这个内核就是抢占的。
*
无论在抢占内核还是非抢占内核中,运行在内核态的进程都可以自动放弃CPU,例如,其可能的原因是,进程由于等待资源而不得不转入睡眠状态。我们把这种进程切换称为计划性进程切换。但是,抢占式内核在响应引起进程切换的异步事件(例如唤醒高优先权的中断处理程序)的方式与非抢占式内核是有着极大差别的,我们将这种进程切换称为强制性进程切换。
* 所有的进程切换都由宏(switch_to)来完成。在抢占式内核和非抢占式内核中,当进程执行完某些具有内核功能的线程,而且调度程序被调用后,就发生进程切换。不过,在非抢占内核中,当前进程是不可能被替换的,除非它打算切换到用户态。
Linux 2.6版本提出的可抢占式内核是指内核抢占,即当进程位于内核空间时,有一个更高优先级的任务出现时,如果当前内核允许抢占,则可以将当前任务挂起,执行优先级更高的进程。在2.5版本及之前,Linux内核是不可抢占的,高优先级的进程不能中止正在内核中运行的低优先级的进程而抢占CPU运行。进程一旦处于核心态(例如用户进程执行系统调用),则除非进程自愿放弃CPU,否则该进程将一直运行下去,直至完成或退出内核。与此相反,一个可抢占的Linux内核可以让Linux内核如同用户空间一样允许被抢占。当一个高优先级的进程到达时,不管当前进程处于用户态还是核心态,如果当前允许抢占,可抢占内核的Linux都会调度高优先级的进程运行。
现在,总结一下抢占式内核与非抢占式内核的特点与区别:
1、非抢占式内核
非抢占式内核是由任务主动放弃CPU的使用权。非抢占式调度法也称为合作型多任务,各个任务彼此共享一个CPU。异步事件由中断服务处理。中断服务可以使一个高优先级的任务由挂起状态转为就绪状态。但中断服务以后的控制权还是回到原来被中断了的那个任务,直到该任务主动放弃CPU的使用权时,那个高优先级的任务才能获得CPU的使用权。非抢占式内核如下图。

非抢占式内核的优点:
* 中断响应快(与抢占式内核相比);
* 允许使用不可重入函数;
* 几乎不需要使用信号量保护共享数据。运行的任务占有CPU,不必担心被其他任务抢占。
非抢占式内核的缺点:
* 任务相应时间慢。高优先级的任务已经进入就绪态,但还不能运行,要等到当前运行着的任务释放CPU后才能进行任务执行。
* 非抢占式内核的任务级响应时间是不确定的,最高优先级的任务获得CPU的控制权的时间,完全取决于已经运行进程何时释放CPU。
2、抢占式内核
使用抢占式内核可以保障系统响应时间。最高优先级的任务一旦就绪,总能得到CPU的使用权。当一个运行着的任务使一个比它优先级高的任务进入了就绪态,当前任务的CPU使用权就会被剥夺,或者说被挂起了,那个高优先级的任务便会立刻得到CPU的控制权。如果是中断服务子程序使一个高优先级的任务进入就绪状态,中断完成时,中断了的任务就会被挂起,优先级高的任务便开始控制CPU。抢占式内核如下图:
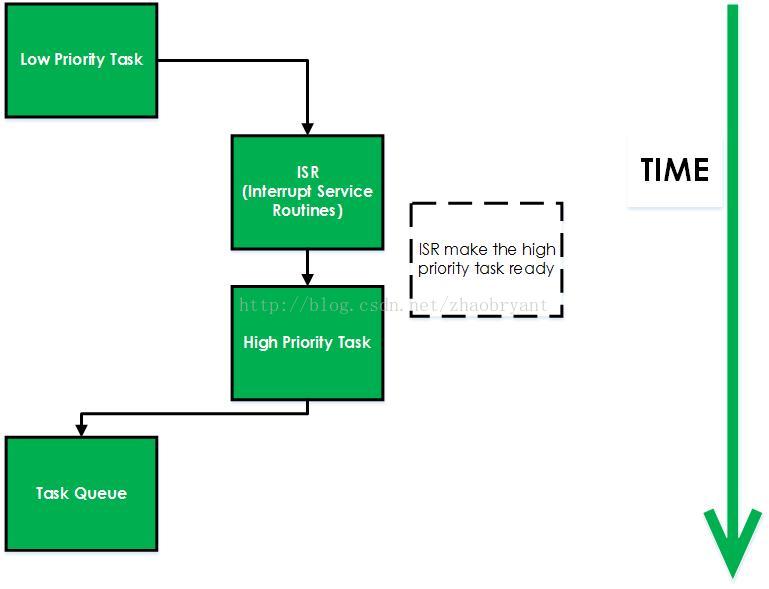
抢占式内核的优点:
* 使用抢占式内核,最高优先级的任务能够得到最快程度的相应,高优先级任务肯定能够获得CPU使用权。抢占式内核使得任务优先级相应时间机制得以最优化。
* 使内核可抢占的目的是减少用户态进程的分派延迟(dispatch latency),即从进程变为可执行状态到它实际开始运行之间的时间间隔。内核抢占对执行及时被调度的任务(如硬件控制器,环境监视器,电影播放器等)的进程确实是由好处的,因为它降低了这种进程被另一个运行在内核态的进程延迟的风险。
抢占式内核的缺点:
* 不能直接使用不可重入型函数。调用不可重入函数时,要满足互斥条件,可以使用互斥性信号量来实现。如果调用不可重入型函数时,对于低优先级的任务,其CPU使用权会被高优先级任务剥夺,不可重入型函数中的数据可能会被破坏。
3、内核态抢占的设计:
首先,需要做何种改进才能支持内核可抢占性呢?
只有当内核正在执行异常处理程序(尤其是系统调用),而且内核抢占没有被显式地禁用时,才可能抢占内核。此外,由从中断和异常中返回的知识,本地CPU必须打开本地中断,否则无法完成内核抢占。
另外,Linux2.6独具特色的允许用户在编译内核时通过设置选项来禁用或启用内核抢占,当然,通过内核内部,也可以显式地禁用内核抢占。那么,应该如何设置来禁止内核抢占呢?
由从中断和异常中返回可知,当被current_thread_info()宏所引用的thread_info描述符的preempt_count字段大于0时,就禁止内核抢占。
这样,我们可以通过控制以下三个不同情况来控制内核抢占禁用:a、内核正在执行中断服务例程;b、可延迟函数被禁止;c、通过把抢占计数器设置为正数而显式地禁用内核抢占。
关于preempt_count字段,有如下操作宏:
| 宏 | 说明 |
| preempt_count() | 在thread_info描述符中选择preempt_count字段 |
| preempt_disable() | 使抢占计数器的值加1 |
| preempt_enable_no_resched() | 使抢占计数器的值减1 |
| preempt_enable() | 使抢占计数器的值减1,并在 |
对于preempt_enable宏递减抢占计数器,然后检查TIF_NEED_RESCHED标志是否被设置。在这种情况下,进程切换请求是挂起的,因此宏调用preempt_schedule()函数,preempt_schedule()函数本质执行下面代码:
if (!current_thread_info->preempt_count && !irqs_disabled()){ current_thread_info->preempt_count = PREEMPT_ACTIVE; schedule(); current_thread_info->preempt_count = 0;} 其次,要满足什么条件时,其他的内核态任务才可以抢占已运行任务的内核态呢?
* 没有持有锁(lock)。锁用于保护临界区,不能被抢占。
* 内核态任务代码可重入(code reentrant)。
那么,如何判断当前上下文(context)(中断处理例程,系统调用,内核线程等)是没有持有锁的?
我们在前面已经提及过thread_info中的preempt_count可以通过设置正数来显式地禁用内核抢占。这里,通过控制此变量即可实现持有锁机制,preempt_count初始为0,当加锁时便执行加1操作,当解锁时便执行减1操作,由此可以实现控制内核抢占的目的。
另外,这里需要补充一些关于可重入函数的知识。
所谓可重入是指一个可以被多个任务调用的过程,任务在调用时不必担心数据是否会出错。不可重入函数在实时系统设计中被视为不安全函数。
若一个函数是可重入的,则该函数必须满足以下必要条件:
* 不能含有静态(全局)非常量数据。
* 不能返回静态(全局)非常量数据的地址。
* 只能处理由调用者提供的数据。
作为可重入函数的输入参数,只能由调用者提供,而且所提供的输入数据必须满足下面三点要求。
* 不能依赖于单实例模式资源的锁。
* 不能调用不可重入的函数。
* 在函数内部,尽量不能用 malloc 和 free 之类的方法进行内存分配和释放,如果使用,一般情况下会造成该函数的不可重入。
可重入函数主要用于多任务环境中。一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误。
不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
可重入函数也可以这样理解,重入即表示重复进入,首先它意味着这个函数可以被中断,其次意味着它除了使用自己栈上的变量以外不依赖于任何环境(包括 static),这样的函数就是purecode(纯代码)可重入,可以允许有该函数的多个副本在运行,由于它们使用的是分离的栈,所以不会互相干扰。
再则,我们来讨论一下关于内核态需要抢占的触发条件:
内核提供了一个need_resched标志(这个标志在任务结构thread_info中,其返回的是TIF_NEED_RESCHED)来表明是否需要重新执行调度。当执行调度程序时,内核抢占会根据内核抢占是否禁止来进行内核抢占操作。
在触发内核抢占及重新调度时,有以下几个重要的函数:
set_tsk_need_resched():设置指定进程中的need_resched标志;
clear_tsk_need_resched():清除指定进程中的need_resched标志;
need_resched():检查need_resched标志的值:如果被设置就返回真,否则返回假。
那么,何时触发重新调度呢?
* 时钟中断处理例程检查当前任务的时间片,当任务的时间片消耗完时,scheduler_tick()函数就会设置need_resched标志;
* 信号量、等待队列等机制唤醒时都是基于等待队列(waitqueue)的,而等待队列的唤醒函数为default_wake_function,其调用try_to_wake_up将被唤醒的任务更改为就绪状态并设置need_resched标志;
* 设置用户进程的nice值时,可能会使高优先级的任务进入就绪状态;
* 改变任务的优先级时,可能会使高优先级的任务进入就绪状态;
* 对CPU(SMP)进行负载均衡时,当前任务可能需要移动至另外一个CPU上运行。
另外,抢占发生的时机:
* 当一个中断处理例程退出,在返回到内核态时,此时隐式调用schedule()函数,当前任务没有主动放弃CPU使用权,而是被剥夺了CPU使用权。
* 当内核代码(程序)从不可抢占状态变为可抢占状态时(preemptible),也就是preempt_count从正数变为0时,此时同样隐式调用schedule()函数。
* 一个任务在内核态中,显式的调用schedule()函数,任务主动放弃CPU使用权。
* 一个任务在内核态中被阻塞,导致需要调用schedule()函数,任务主动放弃CPU使用权。
那些时候不允许内核抢占呢?
* 内核正在进行中断处理。在Linux内核中不能抢占中断(中断只能被其他中断中止和抢占,进程不能中止和抢占中断,内核抢占是被进程抢占和中止),在中断例程中不允许进行进程调度。进程调度函数schedule()会对此做出判断,如果是在中断中调用,会打印错误。
* 内核正在进行中断上下文的下半部处理时,硬件中断返回前会执行软中断,此时仍然处于中断上下文中,所以此时无法进行内核抢占。
* 内核的代码段正持有自旋锁(spinlock)、读写锁(writelock/readlock)时,内核代码段处于锁保护状态。此时,内核不能被抢占,否则由于抢占将导致其他CPU长期不能获得锁而出现死锁状态。
* 内核正在对每CPU私有的数据结构(Per-CPU data structures)进行操作。在SMP(对称多处理器)中,对于每CPU数据结构并未采用自旋锁进行保护,因为这些数据结构隐含地被保护了(不同的CPU上有不同的每CPU数据,其他CPU上运行的进程不能访问另一个CPU的每CPU数据)。在这种情况下,虽然并未采用锁机制,同样不能进行内核抢占,因为如果允许内核抢占,一个进程被抢占后重新调度,有可能调度到其他的CPU上去,这时定义的每CPU数据变量就会发生错位。因此,对于每CPU数据访问时,同样也无法进行内核抢占。
同步原语
如何避免由于对共享数据的不安全访问导致的数据崩溃?
内核使用的各种同步技术:
| 技术 | 说明 | 适用范围 |
| 每CPU变量 | 在CPU之间复制数据结构 | 所有CPU |
| 原子操作 | 对一个计数器原子地“读-修改-写”的指令 | 所有CPU |
| 内存屏障 | 避免指令重新排序 | 本地CPU或所有CPU |
| 自旋锁 | 加锁时忙等 | 所有CPU |
| 信号量 | 加锁时阻塞等待 | 所有CPU |
| 顺序锁 | 基于访问计数器的锁 | 所有CPU |
| 本地中断的禁止 | 禁止单个CPU上的中断处理 | 本地CPU |
| 本地软中断的禁止 | 禁止单个CPU上的可延迟函数处理 | 本地CPU |
| 读-复制-更新(RCU) | 通过指针而不是锁来访问共享数据结构 | 所有CPU |
每CPU变量
最好的同步技术是把设计不需要同步的临界资源放在首位,这是一种思维方法,因为每一种显式的同步原语都有不容忽视的性能开销。最简单也是最重要的同步技术包括把内核变量或数据结构声明为每CPU变量(per-cpu variable)。每CPU变量主要是数据结构的数组,系统的每个CPU对应数组的一个元素。
多核情况下,CPU是同时并发运行的,但是它们共同使用其他的硬件资源,因此我们需要解决多个CPU之间的同步问题。每CPU变量(per-cpu-variable)是内核中一种重要的同步机制。顾名思义,每CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU相互操作各自的副本,互不干涉。比如我们标识当前进程的变量current_task就被声明为每CPU变量。
一个CPU不应该访问与其他CPU对应的数组元素,另外,它可以随意读或修改它自己的元素而不用担心出现竞争条件,因为它是唯一有资格这么做的CPU。但是,这也意味着每CPU变量基本上只能在特殊情况下使用,也就是当它确定在系统的CPU上的数据在逻辑上是独立的时候。
每CPU变量的特点:
1、用于多个CPU之间的同步,如果是单核结构,每CPU变量没有任何用处。
2、每CPU变量不能用于多个CPU相互协作的场景(每个CPU的副本都是独立的)。
3、每CPU变量不能解决由中断或延迟函数导致的同步问题。
4、访问每CPU变量的时候,一定要确保关闭内核抢占,否则一个进程被抢占后可能会更换CPU运行,这会导致每CPU变量的引用错误。
我们可以用数组来实现每CPU变量吗?比如,我们要保护变量var,我们可以声明int var[NR_CPUS],CPU num就访问var[num]不就可以了吗?
显然,每CPU变量的实现不会这么简单。理由:我们知道为了加快内存访问,处理器中设计了硬件高速缓存(也就是CPU的cache),每个处理器都会有一个硬件高速缓存。如果每CPU变量用数组来实现,那么任何一个CPU修改了其中的内容,都会导致其他CPU的高速缓存中对应的块失效,而频繁的失效会导致性能急剧的下降。因此,每CPU的数组元素在主存中被排列以使每个数据结构存放在硬件高速缓存的不同行,这样,对每CPU数组的并发访问不会导致高速缓存行的窃用和失效(这种操作会带来昂贵的系统开销)。
虽然每CPU变量为来自不同CPU的并发访问提供保护,但对来自异步函数(中断处理程序和可延迟函数)的访问不提供保护,在这种情况下需要另外的同步技术。
每CPU变量分为静态和动态两种,静态的每CPU变量使用DEFINE_PER_CPU声明,在编译的时候分配空间;而动态的使用alloc_percpu和free_percpu来分配回收存储空间。
每CPU变量的函数和宏:
每CPU变量的定义在include\linux\percpu.h以及include\asm-generic\percpu.h中。这些文件中定义了单核和多核情况下的每CPU变量的操作,这是为了代码的统一设计的,实际上只有在多核情况下(定义了CONFIG_SMP)每CPU变量才有意义。
常见的操作和含义如下:
| 函数名 | 说明 |
| DECLARE_PER_CPU(type, name) | 声明每CPU变量name,类型为type |
| DEFINE_PER_CPU(type, name) | 静态分配一个每CPU数组,数组名为name,类型为type |
| alloc_percpu(type) | 动态为type类型的每CPU变量分配空间,并返回它的地址 |
| free_percpu(pointer) | 释放为动态分配的每CPU变量的空间,pointer是起始地址 |
| per_cpu(name, cpu) | 获取编号cpu的处理器上面的变量name的副本 |
| get_cpu_var(name) | 获取本处理器上面的变量name的副本,该函数禁用内核抢占,主要由__get_cpu_var来完成具体的访问 |
| get_cpu_ptr(name) | 获取本处理器上面的变量name的副本的指针,该函数禁用内核抢占,主要由__get_cpu_var来完成具体的访问 |
| put_cpu_var(name) & put_cpu_ptr(name) | 表示每CPU变量的访问结束,启用内核抢占(不使用name) |
| __get_cpu_var(name) | 获取本处理器上面的变量name的副本,该函数不禁用内核抢占 |
原子操作
若干汇编语言指令具有“读-修改-写”类型——也就是说,它们访问存储器单元两次,第一次读原值,第二次写新值。
假定运行在两个CPU上的两个内核控制路径试图通过执行非原子操作来同时“读-修改-写”同一存储器单元,首先,两个CPU都试图读同一单元,但是存储器仲裁器(对访问RAM芯片的操作进行串行化的硬件电路)插手,只允许其中的一个访问而让另一个延迟,然而,当第一个读操作已经完成后,延迟的CPU从那个存储器单元正好读到同一个值(旧值)。然后,两个CPU都试图向那个存储器单元写一新值,总线存储器访问再一次被存储器仲裁器串行化,最终,两个写操作都成功。但是,全局的结果是不正确的,因为两个CPU写入同一(新)值。因此,两个交错的“读-修改-写”操作成了一个单独的操作。
避免由于“读-修改-写”指令引起的竞争条件的最容易的办法,就是确保这样的操作在芯片上是原子的。任何一个这样的操作都必须以单个指令执行,中间不能中断,且避免其他的CPU访问同一存储单元。这些很小的原子操作(atomic operations)可以建立在其他更灵活机制的基础之上以创建临界区。
原子操作可以保证指令以原子的方式执行,执行过程不被打断。它通过把读取和修改变量的行为包含在一个单步中执行,从而防止了竞争的发生,保证操作结果总是一致的。
例如:
int i=9;
线程1: i++;
===>>> i=9 OR i=8
线程2: i–-;
===>>> i=9 OR i=8
两个线程并发的执行,导致结果不确定性。原子操作的作用和信号量机制是一样,都是为了防止同时访问临界资源,保证结果的一致性。大多数硬件体系结构要么本来就支持简单的原子操作,要么就提供了锁内在总线的指令,例如x86平台上,就支持CPU锁总线操作,汇编指令前缀“LOCK”就可以将总线锁作,直到指令结束时锁打开;而有些硬件体系结构本身就不太支持原子操作,比如SPARC,但是Linux内核通过一些方法,做到了原子操作。
原子操作在Linux内核里分为原子整数操作和原子位操作,下面我们来看看这两个操作用法。
原子整数操作:
针对整数的原子操作只能对atomic_t类型的数据进行处理,之所以没有用C语言的int类型,主要有三个原因:
1、让原子函数只接受atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用,防止该类型数据不会传给其它非原子操作。
2、使用atomic_t类型确保编译器不对相应的值进行访问优化。
3、在不同体系结构上实现原子操作的时候,使用atomic_t可以屏蔽其间的差异。
在Linux内核中提供了一系统的原子整数操作函数。
| 原子整数操作 | 描述 |
| ATOMIC_INIT(int i) | 在声明一个atmoic_t变量时,将它初始化为i |
| int atmoic_read(atmoic_t *v) | 原子地读取整数变量v |
| void atmoic_set(atmoic_t *v, int i) | 原子地设置v值为i |
| void atmoic_add(atmoic_t *v, int i) | 原子地从v值加i |
| void atmoic_sub(atmoic_t *v, int i) | 原子地从v值减i |
| void atmoic_inc(atmoic_t *v) | 原子地从v值加1 |
| void atmoic_dec(atmoic_t *v) | 原子地从v值减1 |
| int atmoic_sub_and_test(int i,atmoic_t *v) | 原子地从v值减i,如果结果等于0返回真,否则返回假 |
| int atmoic_add_negative(int i,atmoic_t *v) | 原子地从v值减i,如果结果是负数返回真,否则返回假 |
| int atmoic_dec_and_test(atmoic_t *v) | 原子地给v减1,如果结果等于0返回真,否则返回假 |
| int atmoic_inc_and_test(atmoic_t *v) | 原子地给v加1,如果结果等于0返回真,否则返回假 |
原子操作最常见的用途就是实现计数器,使用复杂的锁机制来保护一个单纯的计数是很笨拙的,原子操作比起复杂的同步方法来说,给系统带来的开销小,对高速缓存行的影响也小。
原子位操作:
除了原子整数操作外,内核还提供了一组针对位这一级数据进行操作的函数,位操作函数是对普通的内在地址进行操作的,它的参数是一个指针和一个位号。由于是对普通的指针进程操作,所以没有像atomic_t这样的类型约束。
| 原子位操作 | 描述 |
| void set_bit(int nr, void *addr) | 原子地设置addr所指对象的第nr位 |
| void clear_bit(int nr, void *addr) | 原子地清空addr所指对象的第nr位 |
| void change_bit(int nr, void *addr) | 原子地翻转addr所指对象的第nr位 |
| int test_and_set_bit(int nr, void *addr) | 原子地设置addr所指对象的第nr位,并返回原先的值 |
| int test_and_clear_bit(int nr, void *addr) | 原子地清空addr所指对象的第nr位,并返回原先的值 |
| int test_and_change_bit(int nr, void *addr) | 原子地翻转addr所指对象的第nr位,并返回原先的值 |
| int test_bit(int nr, void *addr) | 原子地返回addr所指对象的第nr位 |
| void atomic_clear_mask(void *mask, void *addr) | 清零mask指定的*addr的所有位 |
| void atomic_set_mask(void *mask, void *addr) | 设置mask指定的*addr的所有位 |
优化和内存屏障
当使用优化的编译器是,指令并不会严格地按照它们在源代码中出现的顺序执行。例如,编译器可能重新安排汇编语言指令以使寄存器以最优的方式使用。此外,现代CPU通常并行地执行若干条指令,且可能重现安排内存访问,这种重新排序可能极大地加速程序的执行。
然而,当处理同步时,必须避免指令重新排序,如果放在同步原语之后的一条指令在同步原语本身之前执行,事情很快就会变得失控。事实上,所有的同步原语起优化和内存屏障的作用。
优化屏障(optimization barrier)原语保证编译程序不会混淆放在原语操作之前的汇编语言指令和放在原语操作之后的汇编语言指令,这些汇编语言指令在C中都由对应的语句。在Linux中,优化屏障就是barrier()宏。
内存屏障(memory barrier)原语确保,在原语之后的操作开始执行之前,原语之前的操作已经完成。因此,内存屏障类似于防火墙,让任何汇编语言指令都不能通过。
在《独辟蹊径品内核》一书中,如此定义内存屏障:为了防止编译器和硬件的不正确优化,使得对存储器的访问顺序(其实就是变量)和书写程序时的访问顺序不一致而提出的一种解决办法。
内存屏障不是一种错误的现象,而是一种对错误现象提出的一种解决方法。
前面概述了内存屏障,现在我们进行一些详细说明:
1、为什么会乱序执行?
现在的CPU一般采用流水线来执行指令。一个指令的执行被分划成:取指、译码、访存、执行、写回等若干个阶段。然后,多条指令可以同时存在于流水线中,同时被执行。
指令流水线并不是串行的,并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。相反,流水线是并行的,多个指令可以同时处于同一个阶段,只要CPU内部相应的处理部件未被占满即可。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段,而两条加法指令在“执行”阶段就只能串行工作。
可见,相比于串行+阻塞的方式,流水线像这样并行的工作,效率是非常高的。
然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
指令流水线除了在资源不足的情况下会阻塞之外(如前所述的一个加法器应付两条加法指令的情况),指令之间的相关性也是导致流水线阻塞的重要原因。
CPU的乱序执行并不是任意的乱序,而是以保证程序上下文因果关系为前提的。有了这个前提,CPU执行的正确性才有保证。比如:
a++;b=f(a);c--;由于b=f(a)这条指令依赖于前一条指令a++的执行结果,所以b=f(a)将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c--跟前面没有依赖,它可能在b=f(a)之前就能执行完。(注意,这里的f(a)并不代表一个以a为参数的函数调用,而是代表以a为操作数的指令。C语言的函数调用是需要若干条指令才能实现的,情况要更复杂些。)
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开一定的距离,以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++;c--;b=f(a);相比于CPU的乱序,编译器的乱序才是真正对指令顺序做了调整。但是编译器的乱序也必须保证程序上下文的因果关系不发生改变。
2、乱序的后果
乱序执行,有了“保证上下文因果关系”这一前提,一般情况下是不会有问题的。因此,在绝大多数情况下,我们写程序都不会去考虑乱序所带来的影响。
但是,有些程序逻辑,单纯从上下文是看不出它们的因果关系的。比如:
*addr=5;val=*data;从表面上看,addr和data是没有什么联系的,完全可以放心的去乱序执行。但是如果这是在某设备驱动程序中,这两个变量却可能对应到设备的地址端口和数据端口。并且,这个设备规定了,当你需要读写设备上的某个寄存器时,先将寄存器编号设置到地址端口,然后就可以通过对数据端口的读写而操作到对应的寄存器。那么,对前面那两条指令的乱序执行就可能造成错误。
对于这样的逻辑,我们姑且将其称作隐式的因果关系;而指令与指令之间直接的输入输出依赖,也姑且称作显式的因果关系。CPU或者编译器的乱序是以保持显式的因果关系不变为前提的,但是它们都无法识别隐式的因果关系。再举个例子:
obj->data = 123;obj->ready = 1;当设置了data之后,记下标志,然后在另一个线程中可能执行:
Thread 2:if (obj->ready) do_something(obj->data);虽然这个代码看上去有些别扭,但是似乎没错。不过,考虑到乱序,如果标志被置位先于data被设置,那么结果很可能就悲剧了(本来不会执行do_something函数,但是由于乱序导致执行了该函数)。因为从字面上看,前面的那两条指令其实并不存在显式的因果关系,乱序是有可能发生的。
总的来说,如果程序具有显式的因果关系的话,乱序一定会尊重这些关系;否则,乱序就可能打破程序原有的逻辑。这时候,就需要使用屏障来抑制乱序,以维持程序所期望的逻辑。
3、优化和内存屏障的作用
内存屏障主要有:读屏障、写屏障、通用屏障、优化屏障几种。
以读屏障为例,它用于保证读操作有序。屏障之前的读操作一定会先于屏障之后的读操作完成,写操作不受影响,同属于屏障的某一侧的读操作也不受影响。类似的,写屏障用于限制写操作。而通用屏障则对读写操作都有作用。而优化屏障则用于限制编译器的指令重排,不区分读写。前三种屏障都隐含了优化屏障的功能。比如:
tmp = 2048;*addr = 5;mb();val = *data;有了内存屏障就了确保先设置地址端口,再读数据端口。而至于设置地址端口与tmp的赋值孰先孰后,屏障则不做干预。有了内存屏障,就可以在隐式因果关系的场景中,保证因果关系逻辑正确。
4、内存屏障原语
Linux使用六个内存屏障原语。这些原语也被当做优化屏障,因为我们必须保证编译器程序不在屏障前后移动汇编语言指令。
| 宏 | 说明 |
| mb() | 适用于MP和UP的内存屏障 |
| rmb() | 适用于MP和UP的读内存屏障 |
| wmb() | 适用于MP和UP的写内存屏障 |
| smp_mb() | 仅适用于MP的内存屏障 |
| smp_rmb() | 仅适用于MP的读内存屏障 |
| smp_wmb() | 仅适用于MP的写内存屏障 |
内存屏障既用于多处理器系统(MP),也用于单处理器系统(UP)。当内存屏障应该防止仅出现在多处理器系统上的竞争条件时,就使用smp_xxx()原语;在单处理器系统上,它们什么也不做。其他的内存屏障原语防止出现在单处理器和多处理器系统上的竞争条件。
内存屏障原语的实现依赖于系统地体系结构。
在80x86微处理器上,如果CPU支持lfence汇编语言指令,就把rmb()宏展开为 asm
volatile("lfence"),否则就展开为 asm volatile("lock;addl $0,
0(%%esp)")。asm指令告诉编译器插入一些汇编语言指令并起优化屏障的作用。lock;addl $0,
0(%%esp)汇编指令把0加到栈顶的内存单元;这条指令本身没有什么价值,但是,lock前缀使得这条指令成为CPU的一个内存屏障。
而对于wmb()宏,其实现即为barrier()宏,这是因为Intel处理器不对写内存访问进行重新排序,因此,没有必要在代码中插入一条串行化汇编指令。不过,此宏禁止编译器重新组合指令。
5、多处理器系统情况
前面只是考虑了单处理器指令乱序的问题,而在多处理器下,除了每个处理器要独自面对上面讨论的问题之外,当多个处理器之间存在交互的时候,同样要面对乱序的问题。
一个处理器(记为a)对内存的写操作并不是直接就在内存上生效的,而是要先经过自身的cache。另一个处理器(记为b)如果要读取相应内存上的新值,先得等a的cache同步到内存,然后b的cache再从内存同步这个新值。而如果需要同步的值不止一个的话,就会存在顺序问题。举一个例子:
<CPU-a>: | <CPU-b>: |obj->data = 123; | if (obj->ready)wmb(); | do_something(obj->data);obj->ready = 1; |前面也说过,必须要使用屏障来保证CPU-a不发生乱序,从而使得ready标记置位的时候,data一定是有效的。但是在多处理器情况下,这还不够。原因在于,data和ready标记的新值可能以相反的顺序更新到CPU-b上。
其实这种情况在大多数体系结构下并不会发生,不过内核文档memory-barriers.txt举了alpha机器的例子。alpha机器可能使用分列的cache结构,每个cache列可以并行工作,以提升效率。而每个cache列上面缓存的数据是互斥的(如果不互斥就还得解决cache列之间的一致性),于是就可能引发cache更新不同步的问题。
假设cache被分成两列,而CPU-a和CPU-b上的data和ready都分别被缓存在不同的cache列上。
首先是CPU-a更新了cache之后,会发送消息让其他CPU的cache来同步新的值,对于data和ready的更新消息是需要按顺序发出的。如果cache只有一列,那么指令执行的顺序就决定了操作cache的顺序,也就决定了cache更新消息发出的顺序。但是现在假设了有两个cache列,可 能由于缓存data的cache列比较繁忙而使得data的更新消息晚于ready发出,那么程序逻辑就没法保证了。不过好在SMP下的内存屏障在解决指令乱序问题之外,也将cache更新消息乱序的问题解决了。只要使用了屏障,就能保证屏障之前的cache更新消息先于屏障之后的消息被发出。
然后就是CPU-b的问题。在使用了屏障之后,CPU-a已经保证data的更新消息先发出了,那么CPU-b也会先收到data的更新消息。不过同样,CPU-b上缓存data的cache列可能比较繁忙,导致对data的更新晚于对ready的更新。这里同样会出问题。
所以,在这种情况下,CPU-b也得使用屏障。CPU-a上要使用写屏障,保证两个写操作不乱序,并且相应的两个cache更新消息不乱序。CPU-b上则需要使用读屏障,保证对两个cache单元的同步不乱序。可见,SMP下的内存屏障一定是需要配对使用的。
所以,上面的例子应该改写成:
<CPU-a>: | <CPU-b>: |obj->data = 123; | if (obj->ready){wmb(); | rmb();obj->ready = 1; | do_something(obj->data); | }CPU-b上使用的读屏障还有一种弱化版本,它不保证读操作的有序性,叫做数据依赖屏障。顾名思义,它是在具有数据依赖情况下使用的屏障,因为有数据依赖(也就是之前所说的显式的因果关系),所以CPU和编译器已经能够保证指令的顺序。
<CPU-a>: | <CPU-b>: |init(newval); | p = data;<write barrier> | <data dependency barrier>data = &newval; | val = *p;这里的屏障就可以保证:如果data指向了newval,那么newval一定是初始化过的。
自旋锁
一种广泛应用的同步技术是加锁(locking)。当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。由于锁机制保护的资源非常类似与限制于房间内的资源,当某人进入房间时,就把门锁上。如果内核控制路径希望访问资源,就试图获取钥匙“打开门”。当且仅当资源空闲时,它才能成功。然后,只要它还想使用这个资源,门就依然锁着。当内核控制路径释放锁时,门就打开,另一个内核控制路径就可以进入房间使用资源。
下图展现了锁的使用。
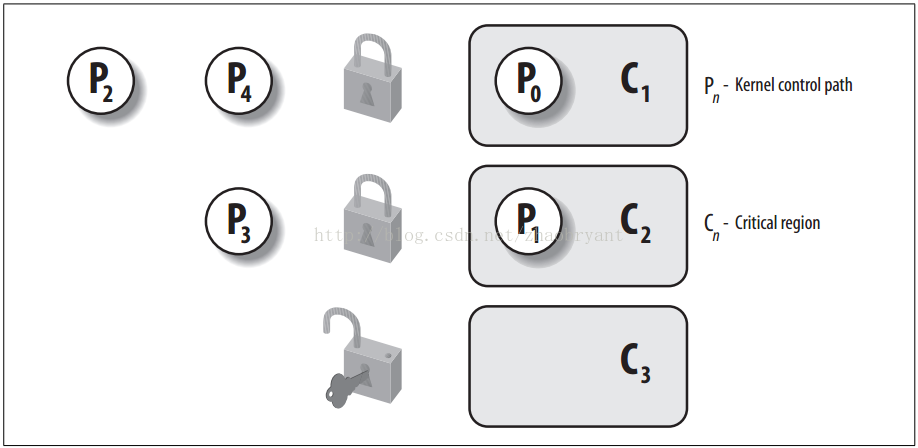
5个内核控制路径(P1, P2, P3, P4和P0)试图访问两个临界区(C1, C2)。内核控制路径P0正在C1中,而P2和P4正等待进入C1。同时,P1正在C2中,而P3正在等待进入C2。注意P0和P1可以并行运行。临界区C3的锁处于打开状态,因为没有内核控制路径需要进入C3。
自旋锁(spinlock)是用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径(内核态进程)发现自旋锁“开着”,就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由运行在另一个CPU上的内核控制路径“锁着”,就在周围“旋转”,反复执行一条紧凑的循环指令,直到锁被释放。
自旋锁的循环指令表示“忙等”。即使等待的内核控制路径无事可做(除了浪费时间),它也在CPU上保持运行。不过,自旋锁通常非常方便,因为很多内核资源只锁1毫秒的时间片段,所以说,释放CPU和随后又获得CPU都不会消耗很多时间。
一般来说,由自旋锁所保护的每个临界区都是禁止内核抢占的。在单处理器系统上,这种锁本身不起锁的作用,自旋锁原语仅仅是禁止或启用内核抢占。请注意,在自旋锁忙等期间,内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的进程所替代。
下面,进行几个方面对自旋锁进行相关说明:
1、为什么使用自旋锁?
操作系统锁机制的基本原理,就是在某个锁操作过程中不能与其他锁操作交织执行,以免多个执行路径对内核中某些重要的数据及数据结构进行同时操作而造成系统混乱。在不同的系统环境中,根据系统特点和操作需要,锁机制可以用多种方式来实现。在Linux中,其系统内核的锁机制一般通过3种基本方式来实现,即原语、关中断和总线锁。在单CPU系统中,CPU 的读—修改—写原语可以保证是原子的,即执行过程过中不会被中断,所以CPU通过关中断的方式,从芯片级保证该操作所存取的数据不能被多个内核控制路径同时访问,避免交叉执行。然而,在对称多处理器 (SMP) 环境中,单CPU涉及读—修改—写原语不再是原子的,因为在某个CPU执行读—修改—写指令时有多次总线操作,其他CPU竞争总线,可导致对同一存储单元的读—写操作与其他CPU对这一存储单元交叉,这时我们就需要用一个称为自旋锁(spin lock)的原始对象为CPU 提供锁定总线的方法。
2、关于自旋锁的几个事实
自旋锁实际上是忙等锁,当锁不可用时,CPU一直循环执行“测试并设置(test-and-set)”,直到该锁可用而取得该锁,CPU在等待自旋锁时不做任何有用的工作,仅仅是等待。这说明只有在占用锁的时间极短的情况下,使用自旋锁是合理的,因为此时某个CPU可能正在等待这个自旋锁。当临界区较为短小时,如只是为了保证对数据修改的原子性,常用自旋锁;当临界区很大,或有共享设备的时候,需要较长时间占用锁,使用自旋锁就不是一个很好的选择,会降低CPU的效率。
自旋锁也存在死锁(deadlock)问题。引发这个问题最常见的情况是要求递归使用一个自旋锁,即如果一个已经拥有某个自旋锁的CPU希望第二次获得这个自旋锁,则该CPU将死锁。自旋锁没有与其关联的“使用计数器”或“所有者标识”;锁或者被占用或者空闲。如果你在锁被占用时获取它,你将等待到该锁被释放。如果碰巧你的CPU已经拥有了该锁,那么用于释放锁的代码将得不到运行,因为你使CPU永远处于“测试并设置”某个内存变量的自旋状态。另外,如果进程获得自旋锁之后再阻塞,也有可能导致死锁的发生。由于自旋锁造成的死锁,会使整个系统挂起,影响非常大。
自旋锁一定是由系统内核调用的。不可能在用户程序中由用户请求自旋锁。当一个用户进程拥有自旋锁期间,内核是把代码提升到管态的级别上运行。在内部,内核能获取自旋锁,但任何用户都做不到这一点。
3、Linux 自旋锁
在Linux中,每个自旋锁都用spinlock_t结构表示,其中包含两个字段:
slock:该字段表示自旋锁的状态:值为1时,表示未加锁状态,而任何负数和0都表示加锁状态。
break_lock:表示进程正在忙等自旋锁。
自旋锁宏:
| 宏 | 说明 |
| spin_lock_init() | 把自旋锁置为1(未锁) |
| spin_lock() | 循环,直到自旋锁变为1(未锁),然后,把自旋锁置为0(锁上) |
| spin_unlock() | 把自旋锁置为1(未锁) |
| spin_unlock_wait() | 等待,直到自旋锁变为1(未锁) |
| spin_is_lock() | 如果自旋锁被置为1(未锁),返回0;否则,返回1 |
| spin_trylock() | 把自旋锁置为0(锁上),如果原来锁的值为1,则返回1;否则,返回0 |
具有内核抢占的spin_lock宏
针对支持SMP系统的抢占式内核,该宏获取自旋锁的地址slp作为其参数,并执行下面的操作:
a、调用preempt_disable()以禁用内核抢占;
b、调用函数_raw_spin_trylock(),它对自旋锁的slock字段执行原子性的测试和设置操作。该函数首先执行等价于下面汇编语言片段的一些指令:
movb $0, %a1xchgb %a1, slp->slock汇编语言指令xchg原子性地交换8位寄存器%a1(存0)和slp->slock指示的内存单元中的内容。随后,如果存放在自旋锁中的旧值是正数,函数就返回1,否则返回0。
c、如果自旋锁中的旧值是正数,宏结束:内核控制路径已经获得自旋锁。
d、否则,内核控制路径无法获得自旋锁,因此,宏必须执行循环一直到在其他CPU上运行的内核控制路径释放自旋锁。调用preempt_enable()递减在第一步递增了的抢占计数器。如果在执行spin_lock宏之前内核抢占被启用,那么其他进程此时可以取代等待自旋锁的进程。
e、如果break_lock字段等于0,则把它设置为1。通过检测该字段,拥有锁并在其他CPU上运行的进程可以知道是否有其他进程在等待这个锁。如果进程持有某个自旋锁时间太长,它可以提前释放锁以使等待相同自旋锁的进程能够继续向前运行。
f、执行等待循环:
while (spin_is_locked(slp) && slp->break_lock) cpu_relax();宏cpu_relax()简化为一条pause汇编语言指令。
g、跳转到a步骤,再次试图获取自旋锁。
非抢占式内核中的spin_lock宏
如果在内核编译时没有选择内核抢占选项,spin_lock宏就与前面描述的spin_lock宏有着很大的区别。在这种情况下,宏生成一个汇编语言程序片段,本质上等价于下面紧凑的忙等待:
1: lock; decb slp->slock (递减slp->slock, 判断其是否为正数) jns 3f (f表示向前的,它在程序后面出现)2: pause cmpb $0, slp->slock (判断slp->slock是否为0) jle 2b (b表示向后的,前跳回标签2代码) jmp lb (前跳回标签1代码)3: JNS(jump if not sign),汇编语言中的条件转移指令 。结果为正则转移。
JLE(或JNG)(jump if less or equal or not greater),汇编语言中的条件转移指令。小于或等于,或者不大于则转移。
汇编语言指令decb递减自旋锁的值,该指令是原子的,因为它带有lock字节前缀。随后检测符号标志,如果它被清零,说明自旋锁被设置为1(未锁),因此,从标记3处继续正常执行。否则,在标签2处执行紧凑循环直到自旋锁出现正值。然后,从标签1处开始重新执行,因为不检查其他的处理器是否抢占了锁就继续执行是不安全的。
spin_unlock宏
spin_unlock宏释放以前获得的自旋锁,它本质上执行了下面的汇编语言指令:
movb $1, slp->slock (slock赋值为1,标为未锁)读/写自旋锁
我们从如下几个点进行讨论:
1、什么是读写自旋锁?
自旋锁(Spinlock)是一种常用的互斥(Mutual Exclusion)同步原语(Synchronization Primitive),试图进入临界区(Critical Section)的线程使用忙等待(Busy Waiting)的方式检测锁的状态,若锁未被持有则尝试获取。这种忙等待的做法无谓地消耗了处理器资源,因此只适用于临界区非常短小的代码片段,例如Linux内核的中断处理函数。
由于互斥的特点,使用自旋锁的代码毫无线程并发性可言,多处理器系统的性能受到限制。通过观察线程(内核控制路径)在临界区的访问行为,我们发现有些线程只是简单地读取信息,并不修改任何东西,那么允许它们同时进入临界区不会有任何危险,反而能大大提高系统的并发性。这种将线程区分为读者和写者、多个读者允许同时访问共享资源、申请线程在等待期内依然使用忙等待方式的锁,我们称之为读写自旋锁(Reader-Writer Spinlock)。
读写自旋锁同样是在保护SMP体系下的共享数据结构而引入的,它的引入是为了增加内核的并发能力。只要内核控制路径没有对数据结构进行修改,读/写自旋锁就允许多个内核控制路径同时读同一数据结构。如果一个内核控制路径想对这个结构进行写操作,那么它必须首先获取读/写锁的写锁,写锁授权独占访问这个资源。这样设计的目的,即允许对数据结构并发读可以提高系统性能。
下图显示有两个受读写自旋锁保护的临界区。内核控制路径R0和R1正在同时读取C1中的数据结构,而W0正在等待获取写锁。内核控制路径W1正对C2中的数据进行写操作,而R2和W1分别等待获取读锁和写锁。
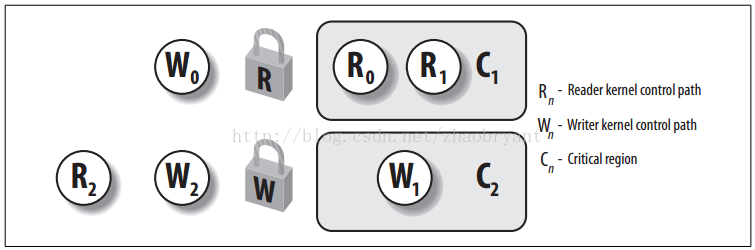
每个读/写自旋锁都是一个rwlock_t结构:
typedef struct { raw_rwlock_t raw_lock;#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP) unsigned int break_lock;#endif#ifdef CONFIG_DEBUG_SPINLOCK unsigned int magic, owner_cpu; void *owner;#endif#ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map;#endif} rwlock_t;typedef struct { volatile unsigned int lock;} raw_rwlock_t;其lock字段(raw_lock)是一个32位的字段,分为两个不同的部分:
a、24位计数器,表示对受保护的数据结构并发地进行读操作的内核控制路径的数目。这个计数器的二进制补码存放在这个字段的0~23位。(为什么不保存尽心写操作的内核控制路径呢?原因在于:最多只能有一个写者访问受保护的数据结构,只存在0与1两种情况。lock字段完全可以实现,见下文。)
b、“未锁”标志字段,当没有内核控制路径在读或写时设置该位(为1),否则清0。这个“未锁”标志存放在lock字段的第24位。
注意,如果自旋锁为空(设置了“未锁”标志且无读者),那么lock字段的值为0x01000000;如果写者已经获得自旋锁(“未锁”标志清0且无读者),那么lock字段的值为0x00000000;如果一个、两个或多个进程因为读获取了自旋锁,那么,lock字段的值为Ox00ffffff,Ox00fffffe等(“未锁”标志清0表示写锁定,不允许写该数据结构的进程,读者个数的二进制补码在0~23位上;如果全为0,则表示有一个写进程在操作此数据结构)。
与spinlock_t结构一样,rwlock_t结构也包括break_lock字段。
rwlock_init()宏把读/写自旋锁的lock字段初始化为0x01000000(“未锁”),把break_lock初始化为0,算法类似spin_lock_init。
2、读写自旋锁的属性
上面提及的共享资源可以是简单的单一变量或多个变量,也可以是像文件这样的复杂数据结构。为了防止错误地使用读写自旋锁而引发的bug,我们假定每个共享资源关联一把唯一的读写自旋锁,线程只允许按照类似大象装冰箱的方式访问共享资源:
申请锁 ==>> 获得锁后,读写共享资源 ==>> 释放锁。
对于线程(内核控制路径)的执行,我们假设:
a、系统存在一个全局时钟,我们讨论的时间是离散的,不是连续的、数学意义上的时间。
b、任意时刻,系统中活跃线程的总数目是有限的。
c、线程的执行不会因为调度、缺页异常等原因无限期地被延迟。理论上,线程的执行可以被系统无限期地延迟,因此任何互斥算法都有死锁的危险。我们希望排除系统的干扰,集中关注算法及具体实现本身。
d、线程对共享资源的访问在有限步骤内结束。
e、当线程释放锁时,我们希望:线程在有限步骤内释放锁。
因为每个程序步骤花费有限时间,所以如果满足上述 5 个条件,那么:获得锁的线程必然在有限时间内将锁释放掉。
我们说某个读写自旋锁算法是正确的,是指该锁满足如下三个属性:
a、互斥。任意时刻读者和写者不能同时访问共享资源(即获得锁);任意时刻只能有至多一个写者访问共享资源。
b、读者并发。在满足“互斥”的前提下,多个读者可以同时访问共享资源。
c、无死锁(Freedom from Deadlock)。如果线程A试图获取锁,那么某个线程必将获得锁,这个线程可能是A自己;如果线程A试图但是却永远没有获得锁,那么某个或某些线程必定无限次地获得锁。
读写自旋锁主要用于比较短小的代码片段,线程等待期间不应该进入睡眠状态,因为睡眠 / 唤醒操作相当耗时,大大延长了获得锁的等待时间,所以我们要求:
d. 忙等待。申请锁的线程必须不断地查询是否发生退出等待的事件,不能进入睡眠状态。这个要求只是描述线程执行锁申请操作未成功时的行为,并不涉及锁自身的正确性。
“无死锁”属性告诉我们,从全局来看一定会有申请线程获得锁,但对于某个或某些申请线程而言,它们可能永远无法获得锁,这种现象称为饥饿(Starvation)。一种原因源于计算机体系结构的特点:例如在使用基于单一共享变量的读写自旋锁的多核系统中,如果锁的持有者A所处的处理器和等待者B所处的处理器相邻(也许还能共享二级缓存),B更容易获知锁被释放,增大获得锁的几率,而距离较远的处理器上的线程则难与之PK,导致饥饿的发生。还有一种原因源于设计策略,即读写自旋锁刻意偏好某类角色的线程。
为了提高并发性,读写自旋锁可以选择偏好读者,即读者能够优先获得锁:
a、读者优先(Reader Preference)。如果锁被读者持有,那么新来的读者可以立即获得锁,无需忙等待。至于当锁被“写者持有”或“未被持有”时,新来的读者是否可以“阻塞”到正在等待的写者之前,依赖于具体实现。
如果读者持续不断地到来,等待的写者很可能永远无法获得锁,导致饥饿。在现实中,写者的数目一般较读者少许多,而且到来的频率很低,因此读写自旋锁可以选择偏好写者来有效地缓解饥饿现象:
b、写者优先(Writer Preference)。写者必须在后到的读者 / 写者之前获得锁。因为在写者之前到来的等待线程数目是有限的,所以可以保证写者的等待时间有个合理的上界。但是多个读者之间获得锁的顺序不确定,且先到的读者不一定能在后到的写者之前获得锁。可见,如果写者持续到来,读者仍然可能产生饥饿。
为了彻底消除饥饿现象,完美的读写自旋锁还需满足下面任一属性:
c、无饥饿(Freedom from Starvation)。如果线程A试图获取锁,那么A必定能在有限时间内获得锁。当然,这个“有限时间”也许相当漫长。
d、公平(Fairness)。我们把“锁申请”操作的执行分为两个阶段:准备阶段(Doorway Section),能在有限程序步骤结束;等待阶段(Waiting Section),也许永远无法结束等待阶段一旦结束,线程即获得读写自旋锁。如果线程A和B同时申请锁,但是A的等待阶段完成于B之前,那么公平读写自旋锁保证A在B之前获得锁。如果A和B的等待阶段在时间上有重叠,那么它们获得锁的顺序是不确定的。
“公平”意味着申请锁的线程必定在有限时间内获得锁。若不然,假设A申请一个公平读写自旋锁但是永远不能获得,那么在A之后完成准备阶段的线程显然也永远不能获得锁。而在A之前或“重叠”地完成等待阶段的申请线程数目是 有限的,可见必然发生了“死锁”,矛盾。同时这也说明释放锁的时间也是有限的。使用公平读写自旋锁杜绝了饥饿现象的发生,如果假定线程访问共享资源和释放锁的时间有一个合理的上界,那么锁申请线程的等待时间只与前面等待的线程数目有关,不依赖其它因素。
P.S. 我们也可以自己去进行相关算法的设计与实现,比如说从博弈论和统计学的方向来思考(如利用概率进行读写者优先权分配等)。
3、以自动机的观点看读写自旋锁
前面关于读写自旋锁的定义和描述虽然通俗易懂,但是并不精确,很多细节比较含糊。例如,读者和写者这种角色到底是什么含义?“先来”,“后到”,“新来”以及“同时到来”如何界定?申请和释放锁的过程到底是怎样的?
现在,我们集中精力思考一下读写自旋锁到底是什么东西?读写自旋锁其实就是一个有限状态自动机(Finite State Machine)。自动机模型是一种强大的武器,可以帮助我们精确描述和理解各种算法。在给出严格定义之前,我们先规范一下上节中出现的各种概念:
a、首先,我们把读写自旋锁看成一个独立的串行系统,线程对锁函数的调用本质上是向其独立地提交操作(Operation)。操作必须是基本的,语义清晰的。所谓“基本”,是指任一种类操作的执行效果都不能由其它一种或多种操作的执行累积而成。
b、读写自旋锁的函数调用的全过程现在可以建模为:
线程提交了一个操作,然后等待读写自旋锁在某个时刻选择并执行该操作。我们举个读者申请锁的例子来具体说明。前面提到申请锁分成两个阶段,其中准备阶段我们认为线程向读写自旋锁提交了一个“读者申请”的操作。读者在等待阶段不停地测试锁的最新状态,其实就是在等待读写自旋锁的选择。最终读者在被许可的情况下“原子地”更新锁的状态,从而获得锁,说明读写自旋锁在某个合适的时刻选择并执行了该“读者申请”的操作。一旦某个操作被选中,它将不受干扰地在有限时间内成功完成并且在执行过程中读写自旋锁不能选择其它的操作。读者可能会有些奇怪,直观上锁的释放操作似乎是立即执行,难道也需要“等待”么?为了保证锁状态的一致性(Consistency),某些实现的释放函数使用了忙等待方式(参见本文的第一个实现),亦或由于调度、处理器相对速度等原因,总之锁的释放操作同样有一个不确定的等待执行的延时,因此可以和其它操作统一到相同的执行模型中。在操作成功提交至执行完毕这段时间内,线程不能睡眠。
c、某个线程对锁的一次使用既可以用读者身份申请,也可以用写者身份申请,但是不能以两种身份同时申请。可见“角色”实质上是线程分别提交了“读者申请”或“写者申请”的操作,而不能提交类似“读者写者同时申请”的操作。
d、读者 / 写者可以不停地到来 / 离去,这意味着线程能够持续地向读写自旋锁提交各种操作,但是每次只能提交一个。只有当上次提交的操作被执行后,线程才被允许提交新操作。读写自旋锁有能力知道某个操作是哪个线程提交的。
e、线程对锁的使用必须采用前面提及的规范化流程,这是指线程必须提交配对的“申请”/“释放”操作,即“申请”操作成功执行后,线程应当在有限时间内提交相应的“释放”操作,且在此之前不准提交其它操作。
f、关于读者 / 写者先来后到的顺序问题,我们转换成确定操作的提交顺序。我们认为操作的提交效果是“瞬间”产生的,即使多个线程在所谓的“同一时刻”提交操作,这些操作彼此之间也有严格的先后顺序,不存在两个或多个操作是“同时”提交成功的。在现实中,提交显然是需要一定时间的,不同线程的提交过程可能在时间上重叠,但是我们认为总可以按照一种策略规定它们的提交顺序,虽然这可能影响锁的实际执行过程,但并不影响正确性;对于同一线程提交的各个操作,它们彼此之间显然有着严格的时序关系,当然能够确定提交顺序。在此,我们彻底取消同时性的概念。
令 A(t) 为在时间段 (0, t] 内所有提交的操作构成的集合,A(t) 中的任两个操作 o1和 o2,要么 o1在 o2之前提交,要么 o1在 o2之后提交,这种提交顺序是一种全序关系(Total Order)。
读写自旋锁的形式化定义是一个 6 元组(Q,O,T,S,q0,qf),其中:
Q = {q0,q1,…,qn},是一个有限集合,称为状态集。状态 qi描述了读写自旋锁在某时刻t0所处于的一种真实状况。
O = {o0,o1,…,om},是一个有限集合,称为操作种类集。
T:Q x O -> Q 是转移函数。T 是一个偏函数(Partial Function),即 T 的定义域是 Q x O 的子集。如果 T 在 (q, o) 有定义,即存在 q’ = T(q, o),我们称状态 q 允许操作 o,在状态 q 可以执行操作 o,成功完成后读写自旋锁转换到状态 q ’;反之,如果 T 在 (q, o) 没有定义,我们称状态 q 不允许操作 o,说明在状态 q 不能执行操作 o,例如在锁被写者持有时,不能选择 “读者申请获取锁”的操作。
S 是选择函数,从已提交但未执行的操作实例集合中选择一个让读写自旋锁执行,后文详细讨论。由于任意时刻活跃线程的总数目是有限的,这个集合必然是有限集,因此我们认为 S 的每一次选择能在有限步骤内结束。
q0是初始状态。
qf是结束状态,对于任一种操作 o,T 在 (qf, o) 无定义。也就是说到达该状态后,读写自旋锁不再执行任何操作。
我们先画出与定义等价的状态图,然后描述 6 元组具体是什么。
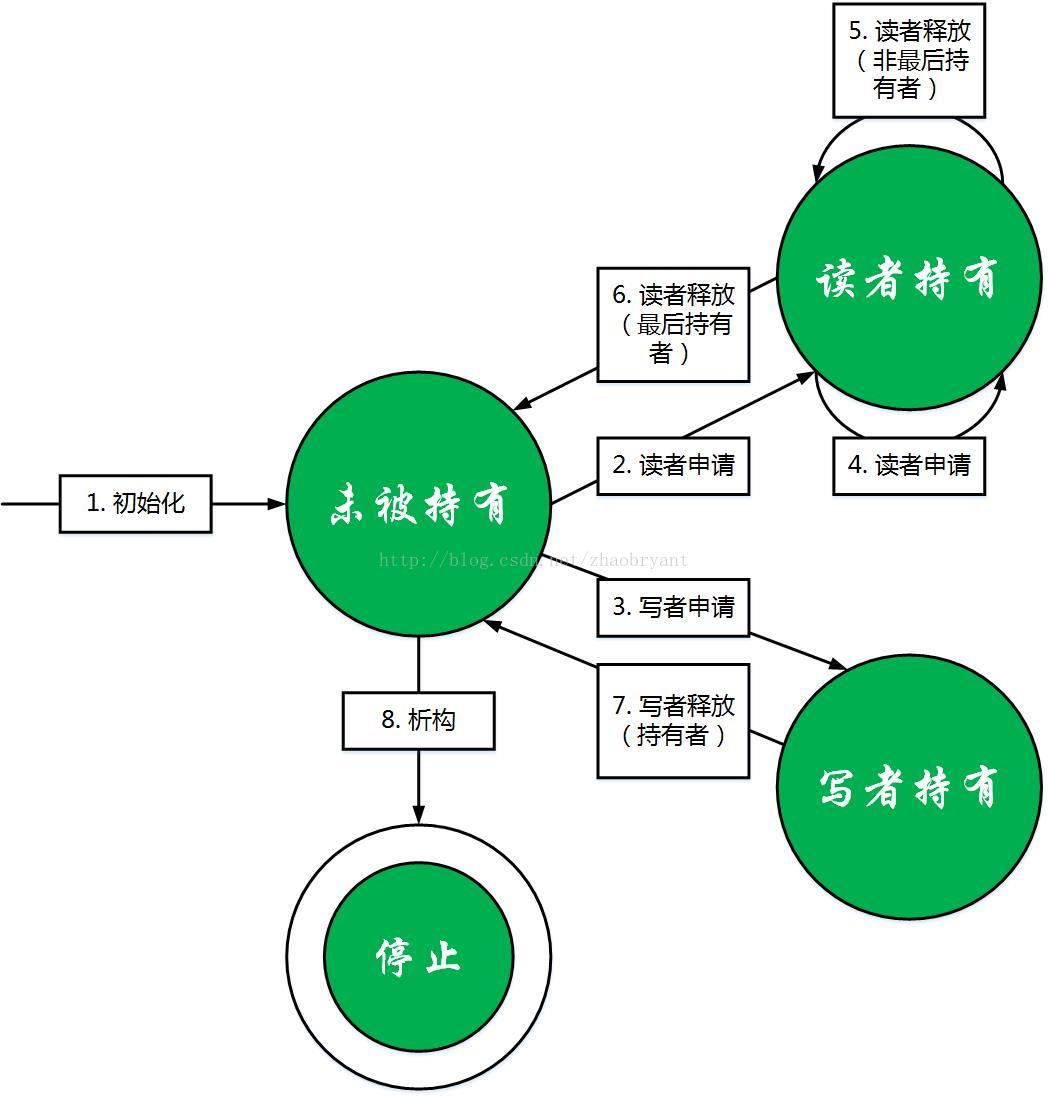
a、状态图中的每个圆圈代表一个状态。状态集合Q至少应该有3个状态:“未被持有”,“读者持有”和“写者持有”。因为可能执行“析构”操作,所以还需要增加一个结束状态“停止”。除此之外不需要新的状态。
b、有向边上的文字代表了一种操作。读写自旋锁需要 6 种操作: “初始化”、“析构”、“读者申请”、 “读者释放”、 “写者申请”和“写者释放”。操作后面括号内的文字,例如“最后持有者”,只是辅助理解,并不表示一种新的操作。
c、有向边及其上的操作定义了转移函数。如果一条有向边从状态q指向q’,且标注的操作是 o,那么表明状态q允许操作o,且 q’ = T(q, o)。
d、初始状态是“未被持有”。
e、结束状态是“停止”,双圆圈表示,该状态不射出任何有向边,表明此后锁停止执行任何操作。
结合状态图,我们描述读写自旋锁的工作原理:
a、我们规定在时刻 0 执行全局唯一一次的“初始化”操作,将锁置为初始状态“未被持有”,图中即为那条没有起点、标注“初始化“操作的有向边。如果决定停止使用读写自旋锁,则执行全局唯一一次的“析构”操作,将锁置为结束状态“停止”。
b、读写自旋锁可以被看成一个从初始状态“未被持有”开始依次“吃”操作、不断转换状态的串行机器。令 W(t) 为时间段 (0, t] 内已提交但未执行的操作构成的集合,W(t) 是所有提交的操作集合 A(t) 的子集。在时刻t,如果锁准备执行新的操作,假设当前处于状态q,W(t)不是空集且存在状态q允许的操作,那么读写自旋锁使用选择函数S在W(t)集合中选出一个来执行,执行完成后将自身状态置为 q’ = T(q, o)。
c、我们称序列 < qI1,oI1,qI2,oI2,…,oIn,qI(n+1)> 是读写自旋锁在 t 时刻的执行序列,如果:
①. oIk是操作,1 <= k <= (n + 1) 且 oI1,oI2,…,oIn属于集合 A(t)。
②. qIk是状态,1 <= k <= (n + 1)。
③. 读写自旋锁在 t 时刻的状态是 qI(n+1)。
④. qI1= q0。
⑤. T 在 (qIk, oIk) 有定义,且 qI(k+1)= T(qIk, oIk)(1 <= k <= n)。
c、假如执行序列的最后一个状态 qI(n+1)不是结束状态 qf,且在时刻 t0,W(t0) 为空或者 qI(n+1)不允许 W(t0) 中的任一个操作 o,我们称读写自旋锁在时刻t0处于潜在死锁状态。这并不表明读写自旋锁真的死锁了,因为随后线程可以提交新的操作,使其继续工作下去。例如 qI(n+1)是“写者持有”状态,而 W(t0) 中全是“读者申请”的操作。但是我们知道锁的持有者一会定在 t0之后的有限时间内提交“写者释放”操作,届时读写自旋锁可以选择执行它,将状态置为“未被持有”,而现存的“读者申请”的操作随后也可被执行了。
d、如果存在t0 > 0,且对于任意 t >= t0,读写自旋锁在时刻t都处于潜在死锁状态,我们称读写自旋锁从时刻t0开始“死锁”。
以下是状态图正确性的证明概要:
a、互斥。从图可知,状态“读者持有”只能转换到自身和“未被持有”,不能转换到“写者持有”,同时状态“写者持有”只能转换到“未被持有”,不能转换到“读者持有”,所以锁一旦被持有,另一种角色的线程只有等到“未被持有”的状态才有机会获得锁,因此读者和写者不可能同时获得锁。状态“写者持有”不允许“写者申请”操作,故而任何时刻只有至多一个写者获得锁。
b、读者并发。状态“读者持有”允许“读者申请”操作,因此可以有多个读者同时持有锁。
c、无死锁。证明关于线程执行的 3 个假设。反证法,假设对任意t >= t0,锁在时刻t都处于潜在死锁状态。令q为t0时刻锁的状态,分 3 种情况讨论:
“未被持有”。如果线程A在 t1 > t0 的时刻提交“读者申请”或“写者申请”的操作,那么锁在t1时刻并不处于潜在死锁状态。
“读者持有”。持有者必须在某个 t1 > t0 的时刻提交“读者释放”的操作,那么锁在t1时刻并不处于潜在死锁状态。
“写者持有”。持有者必须在某个 t1 > t0 的时刻提交“写者释放”的操作,那么锁在t1时刻并不处于潜在死锁状态。
从线程 A 申请锁的角度来看,由状态图知对于任意时刻 t0,不论锁在 t0的状态如何,总存在 t1> t0,锁在时刻 t1必定处于“未被持有”的状态,那么在时刻 t1允许锁申请操作,不是 A 就是别的线程获得锁。如果 A 永远不能获得锁,说明锁一旦处于“未被持有”的状态,就选择了别的线程提交的锁申请操作,那么某个或某些线程必然无限次地获得锁。
上面提到读写自旋锁有一种选择未执行的操作的能力,即选择函数 S,正是这个函数的差异,导致锁展现不同属性:
a、读者优先。在任意时刻 t,如果锁处于状态“读者持有”,S 以大于 0 的概率选择一个尚未执行的“读者申请”操作。这意味着:首先,即使有先提交但尚未执行的“写者申请”操作,“读者申请”操作可以被优先执行;其次,没有刻意规定如何选“读者申请”操作,因此多个“读者申请”操作间的执行顺序是不确定的;最后,不排除连续选择“读者释放”操作,使得锁状态迅速变为“未被持有”,只不过这种几率很小。
b、写者优先。在任意时刻 t,如果 o1是尚未执行的“写者申请”操作,o2是尚未执行的“读者申请”或“写者申请”操作,且 o1在 o2之前提交,那么 S 保证一定在 o2之前选择 o1。
c、无饥饿。如果线程提交了操作 o,那么 S 必定在有限时间内选择 o。即存在时刻 t,读写自旋锁在 t 的执行序列 < qI1,oI1,qI2,oI2,…,oIn,qI(n+1)> 满足 o = oIn。狭义上, o 限定为“读者申请”或“写者申请”操作。
d、公平。如果操作 o1在 o2之前提交,那么 S 保证一定在在 o2之前选择执行 o1。狭义上,o1和 o2限定为“读者申请”或“写者申请”操作。
4、读写自旋锁的实现细节
上文阐述的自动机模型是个抽象的机器,用于帮助我们理解读写自旋锁的工作原理,但是忽略了很多实现的关键细节:
a、操作的执行者。如果按照前面的描述,为读写自旋锁创建专门的操作执行线程,那么锁的实际性能将会比较低下,因此我们要求申请线程自己执行提交的操作。
b、操作类别的区分。可以提供多个调用接口来区分不同种类的操作,避免使用额外变量存放类别信息。
c、确定操作的提交顺序,即线程的到来的先后关系。写者优先和公平读写自旋锁需要这个信息。可以有 3 种方法:
①、假定系统有一个非常精确的实时时钟,线程到来的时刻用于确定顺序。但是寻找直接后继者比较困难,因为事先无法预知线程到来的精确时间。
②、参考银行的做法,即每个到来的线程领取一张号码牌,号码的大小决定先后关系。
③、将线程组织成一个先进先出(FIFO)的队列,具体实现可以使用单向链表,双向链表等。
d、在状态 q,确定操作(线程)是否被允许执行。这有 2 个条件:首先 q 必须允许该操作;其次对于写者优先和公平读写自旋锁,不存在先提交但尚未执行的写者(读者 / 写者)申请操作。可以有 3 种方法:
①、不停地主动查询这 2 个条件。
②、被动等待前一个执行线程通知。
③、主动/被动相结合。
e、选择执行的线程。在状态 q,如果存在多个被允许执行的线程,那么它们必须达成一致(Consensus),保证只有一个线程执行成功,否则会破坏锁状态的一致性。有 2 种简单方法:
①、互斥执行。原子指令(总线级别的互斥),或使用锁(高级互斥原语)。
②、投机执行。线程不管三七二十一先执行再说,然后检查是否成功。如果不成功,可能需要执行回滚操作。
f、因为多个读者可以同时持有锁,那么读者释放锁时,有可能需要知道自己是不是最后一个持有者(例如通知后面的写者)。一个简单的方法是用共享计数器保存当前持有锁的读者数目。如果我们对具体数目并不关心,只是想知道计数器是大于 0 还是等于 0,那么用一种称为“非零指示器”(Non-Zero Indicator)的数据结构效果更好。还可以使用双向链表等特殊数据结构。
5、为读获取和释放一个锁
read_lock宏,作用于读/写自旋锁的地址*lock,与前面所描述的spin_lock宏非常相似。如果编译内核时选择了内核抢占选项,read_lock宏执行与spin_lock()非常相似的操作,只有一点不同:该宏执行_raw_read_trylock( )函数以在第2步有效地获取读/写自旋锁。
void __lockfunc _read_lock(rwlock_t *lock){ preempt_disable(); rwlock_acquire_read(&lock->dep_map, 0, 0, _RET_IP_); LOCK_CONTENDED(lock, _raw_read_trylock, _raw_read_lock);}在没有定义调试自旋锁操作时rwlock_acquire_read为空函数,我们不去管它。所以_read_lock的实务函数是_raw_read_trylock:
# define _raw_read_trylock(rwlock) __raw_read_trylock(&(rwlock)->raw_lock)static inline int __raw_read_trylock(raw_rwlock_t *lock){ atomic_t *count = (atomic_t *)lock; atomic_dec(count); if (atomic_read(count) >= 0) return 1; atomic_inc(count); return 0;}读/写锁计数器lock字段是通过原子操作来访问的。注意,尽管如此,但整个函数对计数器的操作并不是原子性的,利用原子操作主要目的是禁止内核抢占。例如,在用if语句完成对计数器值的测试之后并返回1之前,计数器的值可能发生变化。不过,函数能够正常工作:实际上,只有在递减之前计数器的值不为0或负数的情况下,函数才返回1,因为计数器等于0x01000000表示没有任何进程占用锁,等于Ox00ffffff表示有一个读者,等于0x00000000表示有一个写者(因为只可能有一个写者)。
如果编译内核时没有选择内核抢占选项,read_lock宏产生下面的汇编语言代码:
movl $rwlp->lock,%eax lock; subl $1,(%eax) jns 1f call _ _read_lock_failed 1:这里,__read_lock_failed()是下列汇编语言函数:
_ _read_lock_failed: lock; incl (%eax) 1: pause cmpl $1,(%eax) js 1b lock; decl (%eax) js _ _read_lock_failed retread_lock宏原子地把自旋锁的值减1,由此增加读者的个数。如果递减操作产生一个非负值,就获得自旋锁;否则就算作失败。我们看到lock字段的值由Ox00ffffff到0x00000000要减多少次才可能出现负值,所以几乎很难出现调用__read_lock_failed()函数的情况。该函数原子地增加lock字段以取消由read_lock宏执行的递减操作,然后循环,直到lock字段变为正数(大于或等于0)。接下来,__read_lock_failed()又试图获取自旋锁(正好在cmpl指令之后,另一个内核控制路径可能为写获取自旋锁)。
释放读自旋锁是相当简单的,因为read_unlock宏只需要使用汇编语言指令简单地增加lock字段的计数器:
lock; incl rwlp->lock以减少读者的计数,然后调用preempt_enable()重新启用内核抢占。
6、为写获取或释放一个锁
write_lock宏实现的方式与spin_lock()和read_lock()相似。例如,如果支持内核抢占,则该函数禁用内核抢占并通过调用_raw_write_trylock()立即获得锁。如果该函数返回0,说明锁已经被占用,因此,该宏像前面博文描述的那样重新启用内核抢占并开始忙等待循环。
#define write_lock(lock) _write_lock(lock)void __lockfunc _write_lock(rwlock_t *lock){ preempt_disable(); rwlock_acquire(&lock->dep_map, 0, 0, _RET_IP_); LOCK_CONTENDED(lock, _raw_write_trylock, _raw_write_lock);} _raw_write_trylock()函数描述如下:
{ atomic_t *count = (atomic_t *)lock->lock; if (atomic_sub_and_test(0x01000000, count)) return 1; atomic_add(0x01000000, count); return 0;}static __inline__ int atomic_sub_and_test(int i, atomic_t *v){ unsigned char c; __asm__ __volatile__( LOCK "subl %2,%0; sete %1" :"=m" (v->counter), "=qm" (c) :"ir" (i), "m" (v->counter) : "memory"); return c;}函数_raw_write_trylock()调用tomic_sub_and_test(0x01000000, count)从读/写自旋锁lock->lock的值中减去0x01000000,从而清除未上锁标志(看见没有?正好是第24位)。如果减操作产生0值(没有读者),则获取锁并返回1;否则,函数原子地在自旋锁的值上加0x01000000,以取消减操作。
释放写锁同样非常简单,因为write_unlock宏只需使用汇编语言指令:
lock; addl $0x01000000,rwlp把lock字段中的“未锁”标识置位,然后再调用preempt_enable()。
参考:
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock1/#ibm-pcon
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock2/index.html
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock3/index.html
顺序锁
当使用读写自旋锁时,内核控制路径发出的执行read_lock或write_lock操作的请求具有相同的优先级:读者必须等待,直到写操作完成。同样的,写者也必须等待,直到读操作完成。
Linux2.6中引入了顺序锁(seqlock),它与读写自旋锁非常相似,只是它为写者赋予了更高的优先级:事实上,即使在读者正在读的时候也允许写者继续运行。这种策略的好处是写者永远不会等待(除非另一个写者正在写),缺点就是有些时候读者不得不反复多次读相同的数据直到它获得有效的副本。
顺序锁是对读写锁的一种优化,对于顺序锁,读者绝不会被写者阻塞,也就说,读者可以在写者对被顺序锁保护的共享资源进行写操作时仍然可以继续读,而不必等待写者完成写操作,写者也不需要等待所有读者完成读操作才去进行写操作。但是,写者与写者之间仍然是互斥的,即如果有写者在进行写操作,其他写者必须自旋在那里,直到写者释放了顺序锁。
这种锁有一个限制,它必须要求被保护的共享资源不含有指针,因为写者可能使得指针失效,但读者如果正要访问该指针,将导致致命错误。
如果读者在读操作期间,写者已经发生了写操作,那么,读者必须重新读取数据,以便确保得到的数据是完整的。
这种锁对于读写同时进行的概率比较小的情况,性能是非常好的,而且它允许读写同时进行,因而更大地提高了并发性。
顺序锁的结构如下:
typedef struct{ unsigned int sequence; spinlock_t lock;} seqlock_t;其中包含一个类型为spinlock_t的lock字段和一个整型的sequence字段,第二个字段是一个顺序计数器。每个读者都必须在读数据前后两次读顺序计数器,并检查两次读到的数据是否相同,如果不相同,说明新的写者已经开始写并增加了顺序计数器,因此暗示读者刚读到的数据是无效的。
注意,并不是每一种资源都可以使用顺序锁来保护,一般来说,必须满足下述条件时才能使用顺序锁:
* 被保护的数据结构不包括被写者修改和被读者间接引用的指针(否则,写者可能在读者访问时修改指针而不被发现);
* 读者的临界区代码没有副作用(否则,多个读者的操作会与单独的读操作有着不同的结果)。
顺序锁的API如下:
void write_seqlock(seqlock_t *sl);写者在访问被顺序锁s1保护的共享资源前需要调用该函数来获得顺序锁s1。它实际功能上等同于spin_lock,只是增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
void write_sequnlock(seqlock_t *sl);写者在访问完被顺序锁s1保护的共享资源后需要调用该函数来释放顺序锁s1。它实际功能上等同于spin_unlock,只是增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
写者使用顺序锁的模式如下:
write_seqlock(&seqlock_a);//写操作代码块…write_sequnlock(&seqlock_a);因此,对写者而言,它的使用与spinlock相同。
int write_tryseqlock(seqlock_t *sl);写者在访问被顺序锁s1保护的共享资源前也可以调用该函数来获得顺序锁s1。它实际功能上等同于spin_trylock,只是如果成功获得锁后,该函数增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
unsigned read_seqbegin(const seqlock_t *sl);读者在对被顺序锁s1保护的共享资源进行访问前需要调用该函数。读者实际没有任何得到锁和释放锁的开销,该函数只是返回顺序锁s1的当前顺序号。
int read_seqretry(const seqlock_t *sl, unsigned iv); 读者在访问完被顺序锁s1保护的共享资源后需要调用该函数来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。
因此,读者使用顺序锁的模式如下:
do { seqnum = read_seqbegin(&seqlock_a);//读操作代码块...} while (read_seqretry(&seqlock_a, seqnum));write_seqlock_irqsave(lock, flags)写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还把标志寄存器的值保存到变量flags中,并且失效了本地中断。
write_seqlock_irq(lock)写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还失效了本地中断。与write_seqlock_irqsave不同的是,该宏不保存标志寄存器。
write_seqlock_bh(lock)写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还失效了本地软中断。
write_sequnlock_irqrestore(lock, flags)写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还把标志寄存器的值恢复为变量flags的值。它必须与write_seqlock_irqsave配对使用。
write_sequnlock_irq(lock)写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还使能本地中断。它必须与write_seqlock_irq配对使用。
write_sequnlock_bh(lock)写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还使能本地软中断。它必须与write_seqlock_bh配对使用。
read_seqbegin_irqsave(lock, flags)读者在对被顺序锁lock保护的共享资源进行访问前也可以使用该宏来获得顺序锁lock的当前顺序号,与read_seqbegin不同的是,它同时还把标志寄存器的值保存到变量flags中,并且失效了本地中断。注意,它必须与read_seqretry_irqrestore配对使用。
read_seqretry_irqrestore(lock, iv, flags)读者在访问完被顺序锁lock保护的共享资源进行访问后也可以使用该宏来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。它与read_seqretry不同的是,该宏同时还把标志寄存器的值恢复为变量flags的值。注意,它必须与read_seqbegin_irqsave配对使用。
因此,读者使用顺序锁的模式也可以为:
do { seqnum = read_seqbegin_irqsave(&seqlock_a, flags);//读操作代码块...} while (read_seqretry_irqrestore(&seqlock_a, seqnum, flags));读者和写者所使用的API的几个版本应该如何使用与自旋锁的类似。
如果写者在操作被顺序锁保护的共享资源时已经保持了互斥锁保护对共享数据的写操作,即写者与写者之间已经是互斥的,但读者仍然可以与写者同时访问,那么这种情况仅需要使用顺序计数(seqcount),而不必要spinlock。
顺序计数的API如下:
unsigned read_seqcount_begin(const seqcount_t *s);读者在对被顺序计数保护的共享资源进行读访问前需要使用该函数来获得当前的顺序号。
int read_seqcount_retry(const seqcount_t *s, unsigned iv);读者在访问完被顺序计数s保护的共享资源后需要调用该函数来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。
因此,读者使用顺序计数的模式如下:
do { seqnum = read_seqbegin_count(&seqcount_a);//读操作代码块...} while (read_seqretry(&seqcount_a, seqnum));void write_seqcount_begin(seqcount_t *s);写者在访问被顺序计数保护的共享资源前需要调用该函数来对顺序计数的顺序号加1,以便读者能够检查出是否在读期间有写者访问过。
void write_seqcount_end(seqcount_t *s);写者在访问完被顺序计数保护的共享资源后需要调用该函数来对顺序计数的顺序号加1,以便读者能够检查出是否在读期间有写者访问过。
写者使用顺序计数的模式为:
write_seqcount_begin(&seqcount_a);//写操作代码块…write_seqcount_end(&seqcount_a);需要特别提醒,顺序计数的使用必须非常谨慎,只有确定在访问共享数据时已经保持了互斥锁才可以使用。
读-拷贝-更新(RCU)
读-拷贝-更新(RCU)是为了保护在多数情况下被多个CPU读的数据结构而设计的另一种同步技术。RCU允许多个读者和写者并发执行(相对于只允许一个写者执行的顺序锁有了改进)。而且,RCU是不是用锁的,就是说,它不使用被所有CPU共享的锁或计数器,在这一点上与读写自旋锁和顺序锁相比,RCU具有更大的优势。
RCU是如何不使用共享数据结构而实现多个CPU同步呢?其关键思想如下所示:
* RCU只保护被动态分配并通过指针引用的数据结构;
* 在被RCU保护的临界区中,任何内核控制路径都不能睡眠。
当内核控制路径要读取被RCU保护的数据结构时,执行宏rcu_read_lock(),它等同于preempt_disable()。接下来,读者间接引用该数据结构所对应的内存单元并开始读这个数据结构。读者在完成对数据结构的读操作之前,是不能睡眠的。用等同于preempt_enable()的宏rcu_read_unlock()标记临界区的结束。
由于读者几乎不做任何事情来防止竞争条件的出现,所以写者不得不做得更多一些。事实上,当写者要更新数据结构是,它间接引用指针并生成整个数据结构的副本。接下来,写者修改这个副本。由于修改指针值的操作是一个原子操作,所以旧副本和新副本对每个读者和写者是可见的,在数据结构中不会出现数据崩溃。尽管如此,还需要内存屏障来保证:只有在数据结构被修改之后,已更新的指针对其他CPU才是可见的。如果把自旋锁与RCU结合起来以禁止写者的并发执行,就隐含地引入了这样的内存屏障。
然而,使用RCU的真正困难在于:写者修改指针时不能立即释放数据结构的旧副本。实际上,写者开始修改时,正在访问数据结构的读者可能还在读旧副本。只有在CPU上的所有读者都执行完宏rcu_read_unlock()之后,才可以释放旧副本。内核要求每个潜在的读者在下面的操作之前执行rcu_read_unlock()宏:
* CPU执行进程切换;
* CPU开始在用户态执行;
* CPU执行空循环。
对于上述每种情况,我们说CPU已经过了静止状态(quiescent state)。
写者调用call_rcu()来释放数据结构的旧副本。该函数把回调函数和其参数的地址存放在rcu_head描述符中,然后把描述符插入回调函数的每个CPU链表中。内核没经过一个时钟滴答就周期性的检查本地CPU是否经过了一个静止状态。如果所有CPU都经过了静止状态,本地tasklet就执行链表中的所有回调函数。
RCU是Linux 2.6中新加的功能,常用在网络层和虚拟文件系统中。
信号量
信号量,从本质上说,它实现了一个加锁原语,即让等待者睡眠,直到等待的资源变为空闲。
实际上,Linux提供两种信号量:
* 内核信号量,由内核控制路径使用。
* System V IPC信号量,由用户态进程使用。
内核信号量类似于自旋锁,因为当锁关闭着时,它不允许内核控制路径继续进行。然而,当内核控制路径试图获取内核信号量所保护的忙资源时,相应的进程被挂起。只有在资源被释放时,相应的进程才再次变为可运行的。因此,只有可以睡眠的函数才能获取信号量:中断处理程序和可延迟函数都不能使用内核信号量。
信号量由结构semaphore描述,它基于自旋锁改进而成,其包括一个自旋锁、信号量计数器和一个等待队列。用户程序只能调用信号量API函数,而不能直接访问semaphore结构。其结构定义如下(include/asm-i386/semaphore.h)
struct semaphore { atomic_t count; int sleepers; wait_queue_head_t wait;};struct semaphore{ spinlock_t lock; unsigned int count; struct list_head wait_list;};在这里,我们主要关注linux 2.6版本中的信号量机制。
现对linux 2.6版本中的信号量结构体字段进行详细说明:
## count字段:存放atomic_t类型的一个值,如果该值大于0,那么资源就是空闲的,也就是说,该资源现在可以使用。相反,如果count等于0,那么信号量是忙的,但没有进程等待这个被保护的资源。最后,如果count为负数,那么资源是不可用的,并至少一个进程在等待该资源。
## wait字段:存放等待队列链表的地址,当前等待资源的所有睡眠进程都放在这个链表中。当然,如果count大于或等于0,等待队列就为空。
注:wait_queue_head_t结构体:
struct __wait_queue_head { wq_lock_t lock; struct list_head task_list;#if WAITQUEUE_DEBUG long __magic; long __creator;#endif}; typedef struct __wait_queue_head wait_queue_head_t;## sleepers字段:存放一个标志,表示是否有一些进程在信号量上睡眠。
在具体的操作中,信号量提供了许多的API供程序调用:
可以用init_MUTEX()和init_MUTEX_LOCKED()函数来初始化互斥访问所需的信号量:这两个函数分别把count字段设置成1(互斥资源访问的资源空闲)和0(对信号量进行初始化的进程当前互斥访问的资源忙)。
static inline void sema_init (struct semaphore *sem, int val){/* * *sem = (struct semaphore)__SEMAPHORE_INITIALIZER((*sem),val); * * i'd rather use the more flexible initialization above, but sadly * GCC 2.7.2.3 emits a bogus warning. EGCS doesn't. Oh well. */ atomic_set(&sem->count, val); sem->sleepers = 0; init_waitqueue_head(&sem->wait);} static inline void init_MUTEX (struct semaphore *sem){ sema_init(sem, 1);} static inline void init_MUTEX_LOCKED (struct semaphore *sem){ sema_init(sem, 0);}宏DECLARE_MUTEX和DECLARE_MUTEX_LOCKED完成同上的同样的功能,但它们也静态分配semaphore结构的变量。当然,也可以把信号量中的count字段初始化为任意的正整数n,在这种情况下,最多有n个进程可以并发地访问这个资源。
#define __SEMAPHORE_INITIALIZER(name, n) \{ \ .count = ATOMIC_INIT(n), \ .sleepers = 0, \ .wait = __WAIT_QUEUE_HEAD_INITIALIZER((name).wait) \} #define __MUTEX_INITIALIZER(name) \ __SEMAPHORE_INITIALIZER(name,1) #define __DECLARE_SEMAPHORE_GENERIC(name,count) \ struct semaphore name = __SEMAPHORE_INITIALIZER(name,count) #define DECLARE_MUTEX(name) __DECLARE_SEMAPHORE_GENERIC(name,1)#define DECLARE_MUTEX_LOCKED(name) __DECLARE_SEMAPHORE_GENERIC(name,0)&*& 获取和释放信号量
获取信号量函数:static inline void down(struct semaphore * sem);
释放信号量函数:static inline void up(struct semaphore * sem);
首先,从如何释放信号量开始讨论,up()函数本质上等价于下面的汇编语言片段:
movl $sem->count, %ecx lock; incl (%ecx) jg lf # 大于0跳转至1标记处 lea %ecx, %eax # lea(Load effect address): 取有效地址,也就是取偏移地址---- lea 目的 源:即将源中的地址传给目的. pushl %edx # 保存现场 pushl %ecx call __up # 队列释放(唤醒队列中的睡眠进程) popl %ecx popl %edx1:fastcall void __up(struct semaphore *sem){ wake_up(&sem->wait);}up()函数增加*sem信号量count字段的值,然后,检查它的值是否大于0。count的增加及其后所测试的标志的设置都必须原子地执行;否则,另一个内核控制路径有可能同时访问这个字段的值,这会导致灾难性的后果。如果count大于0,说明没有进程在等待队列上睡眠,因此,就什么事都不做。否则,调用__up()函数以唤醒一个睡眠进程。
相反,当进程希望获取内核信号量锁时,就调用down()函数。down()的实现相当棘手,但本质上等价于下面代码:
down: movl $sem->count, %ecx lock; decl (%ecx) jns 1f #JNS(jump if not sign),汇编语言中的条件转移指令.结果为正则转移. lea %ecx, %eax pushl %edx pushl %ecx call __down popl %ecx popl %edx1:fastcall void __sched __down(struct semaphore * sem){ struct task_struct *tsk = current; DECLARE_WAITQUEUE(wait, tsk); unsigned long flags; tsk->state = TASK_UNINTERRUPTIBLE; spin_lock_irqsave(&sem->wait.lock, flags); add_wait_queue_exclusive_locked(&sem->wait, &wait); sem->sleepers++; for (;;) { int sleepers = sem->sleepers; /* * Add "everybody else" into it. They aren't * playing, because we own the spinlock in * the wait_queue_head. */ if (!atomic_add_negative(sleepers - 1, &sem->count)) // atomic_add_negative(i,v):把i加到*v,如果结果为负,返回1,如果结果为0或正数,返回0. // 同时注意该函数会将sleepers-1加到sem->count并保存该值至sem->count,这就会有这样一个细节: // 如果有睡眠进程,sleepers=1, sleepers++;=>>2, 这样sleepers-1+sem->count就相当于恢复了前面的sem->count // (注意刚开始时由汇编语言导致sem->count--,现在通过+1即保证了count的取值范围即为1/0/-1). { sem->sleepers = 0; break; } sem->sleepers = 1; /* us - see -1 above */ spin_unlock_irqrestore(&sem->wait.lock, flags); schedule(); spin_lock_irqsave(&sem->wait.lock, flags); tsk->state = TASK_UNINTERRUPTIBLE; } remove_wait_queue_locked(&sem->wait, &wait); wake_up_locked(&sem->wait); spin_unlock_irqrestore(&sem->wait.lock, flags); tsk->state = TASK_RUNNING;}down()函数减少*sem信号量的count字段的值,然后检查该值是否为负。该值的减少和检查过程都必须是原子的。如果count大于等于0,当前进程获得资源并继续正常执行。否则,count为负,当前进程必须挂起。把一些寄存器的内容保存在栈中,然后调用__down()。
从本质上说,__down()函数把当前进程的状态从TASK_RUNNING变为TASK_UNINTERRUPTIBLE,并把进程放在信号量的等待队列。该函数在访问信号量结构的字段之前,要获得用来保护信号量等待队列的sem->wait.lock自旋锁,并禁止本地中断。通常当插入和删除元素时,等待队列函数根据需要获取和释放等待队列的自旋锁。函数__down()也用等待队列自旋锁来保护信号量数据结构的其他字段,以使在其他CPU上运行的进程不能读或修改这些字段。最后,__down()使用等待队列函数的"lock"版本,它假设在调用等待队列函数之前已经获得了自旋锁。
__down()函数的主要任务是挂起当前进程,直到信号量被释放。然而,要实现这种想法并不容易。为了更容易地理解代码,要牢记如果没有进程在信号量等待队列上睡眠,则信号量sleepers字段通常被置为0,否则被置为1。
考虑以下几种典型的情况:
* MUTEX信号量打开(count=1,sleepers=0)
down宏仅仅把count字段置为0,并跳到主程序的下一条指令;因此,__down()函数根本不执行。
* MUTEX信号量关闭,没有睡眠进程(count=0,sleepers=0)
down宏减count并将count字段置为-1 且sleepers字段置为0来调用__down()函数。在循环体的每次循环中,该函数检查count字段是否为负。
# 如果count字段为负,__down()就调用schedule()挂起当前进程。count字段仍然设置为-1,而sleepers字段置为1,。随后,进程在这个循环内核恢复自己的运行并又进行测试。
# 如果count字段不为负,则把sleepers置为0,并从循环退出。__down()试图唤醒信号量等待队列中的另一个进程,并终止保持的信号量。在退出时,count字段和sleepers字段都置为0,这表示信号量关闭且没有进程等待信号量。
* MUTEX信号量关闭,有其他睡眠进程(count=-1,sleepers=1)
down宏减count并将count字段置为-2且sleepers字段置为1来调用__down()函数。该函数暂时把sleepers置为2,然后通过把sleepers
- 1 加到count来取消down宏执行的减操作。同时,该函数检查count是否依然为负。
# 如果count字段为负,__down()函数把sleepers重新设置为1,并调用schedule()函数挂起当前进程。count字段还是置为-1,而sleepers字段置为1.
# 如果count字段不为负,__down()函数吧sleepers置为0,试图唤醒信号量等待队列上的另一个进程,并退出持有的信号量。在退出时,count字段置为0且sleepers字段置为0。
其他函数:
down_trylock()函数:适用于异步处理程序。该函数和down()函数除了对资源繁忙情况的处理有所不同之外,其他都是相同的。在资源繁忙时,该函数会立即返回,而不是让进程去睡眠。
down_interruptible函数:该函数广泛使用在设备驱动程序中,因为如果进程接收了一个信号但在信号量上被阻塞,就允许进程放弃“down”操作。
另外,因为进程通常发现信号量处于打开状态,因此,就可以优化信号量函数。尤其是,如果信号量等待队列为空,up()函数就不执行跳转指令。同样,如果信号量是打开的,down()函数就不执行跳转指令。信号量实现的复杂性是由于极力在执行流的主分支上避免费时的指令而造成的。
读写信号量
读写信号量类似于前面的“读写自旋锁”,但不同的是:在信号量再次变为打开之前,等待进程挂起而不是自旋。很多内核控制路径为读可以并发地获取读写信号量,但是,任何写者内核控制路径必须有对被保护资源的互斥访问。因此,只有在没有内核控制路径为读访问或写访问持有信号量时,才可以为写获取信号量。读写信号量可以提高内核中的并发度,并改善了整个系统的性能。
内核以严格的FIFO顺序处理等待读写信号量的所有进程。如果读者或写者进程发现信号量关闭,这些进程就被插入到信号量等待队列链表的末尾。当信号量被释放时,就检查处于等待队列链表第一个位置的进程。第一个进程常被唤醒。如果是一个写者进程,等待队列上其他的进程就继续睡眠。如果是一个读者进程,那么紧跟第一个进程的其他所有读者进程也被唤醒并获得锁。不过,在写者进程之后排队的读者进程继续睡眠。
每个读写信号量都是由rw_semaphore结构描述的,它包含下列字段:
/* * the semaphore definition */struct rw_semaphore { signed long count;#define RWSEM_UNLOCKED_VALUE 0x00000000#define RWSEM_ACTIVE_BIAS 0x00000001#define RWSEM_ACTIVE_MASK 0x0000ffff#define RWSEM_WAITING_BIAS (-0x00010000)#define RWSEM_ACTIVE_READ_BIAS RWSEM_ACTIVE_BIAS#define RWSEM_ACTIVE_WRITE_BIAS (RWSEM_WAITING_BIAS + RWSEM_ACTIVE_BIAS) spinlock_t wait_lock; struct list_head wait_list;#if RWSEM_DEBUG int debug;#endif};## count字段:存放两个16位计数器。其中,最高16位计数器以二进制补码形式存放非等待写者进程的总数(0或1)和等待的写内核控制路径数。最低16位计数器存放非等待的读者和写者进程的总数。
## wait_list字段:指向等待进程的链表。链表中的每个元素都是一个rwsem_waiter结构,该结构包含一个指针和一个标志,指针指向睡眠进程的描述符,标志表示进程是为读需要信号量还是为写需要信号量。
## wait_lock字段:一个自旋锁,用于保护等待队列链表和rw_semaphore结构本身。
init_rwsem()函数初始化rw_semaphore结构,即把count字段置为0,wait_lock自旋锁置为未锁,而把wait_list置为空链表。
down_read()和down_write()函数分别为读或写获取信号量。同样,up_read()和up_write()函数为读或写释放以前获取的读写信号量。down_read_trylock()和down_write_trylock()函数分别类似于down_read()和down_write()函数,但是,在信号量忙的情况下,它们不阻塞进程。最后,函数downgrade_write()自动把写锁转换成读锁。
对于前面提及的5个函数,其实现思想同信号量有着相同的设计思想。
禁止本地中断
确保一组内核语句被当做一个临界区处理的主要机制之一就是中断禁止。即使当硬件设备产生了一个IRQ信号时,中断禁止也让内核控制路径继续执行。因此,这就提供了一种有效的方式,确保中断处理程序访问的数据结构也受到保护。然而,禁止本地中断并不保护运行在另一个CPU上的中断处理程序对数据结构的并发访问,因此,在多处理器系统上,禁止本地中断通常与自旋锁结合使用。
宏local_irq_disable()使用cli汇编语言指令关闭本地CPU上的中断,宏local_irq_enable()函数使用sti汇编语言指令打开被关闭的中断。汇编语言指令cli和sti分别清除和设置eflags控制寄存器的IF标志。如果eflags寄存器的IF标志被清零,宏irqs_disabled()产生等于1的值;如果IF标志被设置,该宏也产生为1的值。
保存和恢复eflags的内容是分别通过宏local_irq_save()和local_irq_restore()宏来实现的。local_irq_save宏把eflags寄存器的内容拷贝到一个局部变量中,随后用cli汇编语言指令把IF标志清零。在临界区的末尾,宏local_irq_restore恢复eflags原来的内容。因此,只有在这个控制路径发出cli汇编指令之前,中断被激活的情况下,中断才处于打开状态。
/* interrupt control.. */#define local_save_flags(x) do { typecheck(unsigned long,x); __asm__ __volatile__("pushfl ; popl %0":"=g" (x): /* no input */); } while (0)#define local_irq_restore(x) do { typecheck(unsigned long,x); __asm__ __volatile__("pushl %0 ; popfl": /* no output */ :"g" (x):"memory", "cc"); } while (0)#define local_irq_disable() __asm__ __volatile__("cli": : :"memory")#define local_irq_enable() __asm__ __volatile__("sti": : :"memory")/* For spinlocks etc */#define local_irq_save(x) __asm__ __volatile__("pushfl ; popl %0 ; cli":"=g" (x): /* no input */ :"memory")禁止和激活可延迟函数
可延迟函数可能在不可预知的时间执行(实际上是在硬件中断程序结束时)。因此,必须保护可延迟函数访问的数据结构使其避免竞争条件。
我们前面在”中断处理”提到,在由内核执行的几个任务之间有些不是紧急的的;在必要情况下它们可以延迟一段时间。一个中断处理程序的几个中断服务例程之间是串行执行的,并且通常在一个中断的处理程序结束前,不应该再次出现此中断。相反,可延迟函数可以在开中断的情况下执行。把可延迟函数从中断处理程序中抽出来有助于使内核保持较短的响应时间。这对于那些期望它们的中断能在几毫秒内得到处理的”急迫”应用来说是非常重要的。
Linux2.6是通过两种非紧迫、可中断内核函数来实现这种机制的:可延迟函数和工作队列。
软中断和tasklet有密切的关系,tasklet是在软中断之上实现。事实上,出现在内核代码中的术语”软中断”常常表示可延迟函数的所有种类。另外一种被广泛使用的术语是”中断上下文”:表示内核当前正执行一个中断处理程序或一个可延迟函数。
软中断的分配是静态的,而tasklet的分配和初始化可以在运行是进行。软中断可以并发地运行在多个CPU上。因此,软中断是可重入函数而且必须明确地使用自旋锁保护其数据结构。tasklet不必担心这些问题,因为内核对tasklet的执行了更加严格的控制。相同类型的tasklet总是被串行地执行,换句话说就是:不能在两个CPU上同时运行相同类型的tasklet。但是,类型不同的tasklet可以在几个CPU上并发执行。tasklet的串行化使tasklet函数不必是可重入的,因此简化了设备驱动程序开发者的工作。
可延迟函数实现见实时测量一节。
一般而言,在可延迟函数上可以执行四种操作:
初始化
定义一个新的可延迟函数,这个操作通常在内核自身初始化或加载模块时进行。
激活
标记一个可延迟函数为”挂起”,激活可以在任何时候进行。
屏蔽
有选择地屏蔽一个可延迟函数,这样,即使它被激活,内核也不执行它。禁止可延迟函数有时是必要的。
执行
执行一个挂起的可延迟函数和同类型的其它所有挂起的可延迟函数,执行是在特定的时间进行的。
激活和执行总是捆绑在一起,由给定CPU激活的一个可延迟函数必须在同一个CPU上执行。把可延迟函数绑定在激活CPU上从理论上说可以充分利用CPU的硬件高速缓存。毕竟,可以想象,激活的内核线程访问的一些数据结构,可延迟函数也可能会使用。然后,当可延迟函数运行时,因为它的执行可以延迟一段时间,因此相关高速缓存行很可能就不再在高速缓存中了。此外,把一个函数绑定在一个CPU上总是有潜在”危险的”操作,因为一个CPU可能忙死而其它CPU又无所事事。
禁止可延迟函数在一个CPU上执行的一种简单方式就是禁止在那个CPU上的中断。因为没有中断处理程序被激活,因此,软中断操作就不能异步地开始。
然而,内核有时需要只禁止可延迟函数而不禁止中断。通过操纵当前thread_info描述符preempt_count字段中存放的软中断计数器,可以在本地CPU上激活或禁止可延迟函数。如果软中断计数器是正数,do_softirq()函数就不会执行软中断,而且,因为tasklet在软中断之前被执行,把这个计数器设置为大于0的值,由此禁止了在给定CPU上的所有可延迟函数和软中断的执行。
宏local_bh_disable()给本地CPU的软中断计数器加1,而函数local_bh_enable()从本地CPU的软中断计数器中减掉1。内核因此能使用几个嵌套的local_bh_disable调用,只有宏local_bh_enable与第一个local_bh_disable调用相匹配,可延迟函数才再次被激活。
递减软中断计数器后,local_bh_enable()执行两个重要的操作以有助于保证适时地执行长时间等待的线程:
1、检查本地CPU的preempt_count字段中硬中断计数器和软中断计数器,如果这两个计数器的值都等于0而且有挂起的软中断要执行,就调用do_softirq()来激活这些软中断。
2、检查本地CPU的TIF_NEED_RESCHED标志是否被设置,如果是,说明进程切换请求是挂起的,因此调用preempt_schedule()函数。
对内核数据结构的同步访问
在前文,我们详细介绍了内核所提供的几种同步原语以保护共享数据结构避免竞争条件。系统性能可能随所选择的同步原语种类的不同而有很大变化。通常情况下,内核开发者采用下述由经验得到的法则:把系统中的并发度保持在尽可能高的程度。
系统中的并发度取决于两个主要因素:
* 同时运转的I/O设备数;
* 进行有效工作的CPU数。
为了使I/O吞吐量最大化,应该使中断禁止保持在很短的时间。当中断被禁止时,由I/O设备产生的IRQ被PIC暂时忽略,因此,就没有新的活动在这种设备上开始。
为了有效地利用CPU,应该尽可能避免使用基于自旋锁的同步原语。当一个CPU执行紧指令循环等待自旋锁打开时,是在浪费宝贵的机器周期。同时,由于自旋锁对硬件高速缓存的影响而使其对系统的整体性能产生不利影响。
在下列两个例子所展示的情况下,即可以保持较高的并发度,同时也能够达到同步:
* 共享的数据结构是一个单独的整数值,可以把它声明为atomic_t类型并使用原子操作对其更新。原子操作比自旋锁和中断禁止操作都快,只有在几个内核控制路径同时访问这个数据结构时速度才会慢下来。
* 把一个元素插入到共享链表的操作绝不是原子的,因为这至少涉及两个指针赋值。不过,内核有时并不用锁或禁止中断就可以执行这种插入操作。考虑这样一种情况,系统调用服务例程把新元素插入到一个简单链表中,而中断处理程序或可延迟函数异步地查看该链表。
在C语言中,插入是通过下面的指针赋值来实现的:
new->next = list_element->next;list_element->next = new;在汇编语言中,插入简化为两个连续的原子指令。第一条指令建立new元素的next指针,但不修改链表。因此,如果中断处理程序在第一条指令和第二条指令执行的中间查看这个链表,看到的就是没有新元素的链表。如果该处理程序在第二条指令执行之后查看链表,就会看到有新元素的链表。关键是,在任一种情况下,链表都是一致的且处于未损坏状态。然而,只有在中断处理程序不修改链表的情况下才能确保这种完整性。如果修改了链表,那么在new元素内刚刚设置的next指针就可能变为无效。
然而,上面的两个赋值操作的顺序不能被编译器或CPU控制器改变,所以可以添加内存屏障来实现写顺序控制:
new->next = list_element->next;wmb();list_element->next = new;在自旋锁、信号量及中断禁止之间选择
前面我们介绍了两个例子,这两个例子实现了高并发高同步,但是,实际遇到的问题往往复杂许多,这个时候,我们就必须使用信号量、自旋锁、中断禁止和软中断禁止来实现并发同步。一般来说,同步原语的选择取决于访问数据结构的内核控制路径的种类。
| 访问数据结构的内核控制路径 | 单处理器保护 | 多处理器进一步保护 |
| 异常 | 信号量 | 无 |
| 中断 | 本地中断禁止 | 自旋锁 |
| 可延迟函数 | 无 | 无或自旋锁(见下表) |
| 异常与中断 | 本地中断禁止 | 自旋锁 |
| 异常与可延迟函数 | 本地软中断禁止 | 自旋锁 |
| 中断与可延迟函数 | 本地中断禁止 | 自旋锁 |
| 异常、中断与可延迟函数 | 本地中断禁止 | 自旋锁 |
1、保护异常所访问的数据结构
当一个数据结构仅由异常处理程序访问时,竞争条件通常是易于理解也易于避免的。最常见的产生同步问题的异常就是系统调用服务例程。在这种情况下,CPU运行在内核态而为用户态程序提供服务。因此,仅由异常访问的数据结构通常表示一种资源,可以分配给一个或多个进程。
竞争条件可以通过信号量避免,因为信号量原语允许进程睡眠到资源变为可用。注意,信号量工作方式在单处理器系统和多处理器系统上完全相同。
内核抢占不会引起太大的问题。如果一个拥有信号量的进程是可以被抢占的,运行在同一个CPU上的新进程就可能试图获得这个信号量。在这种情况下,让新进程处于睡眠状态,而且原来拥有信号量的进程最终会释放信号量。只有在访问每CPU变量的情况下,必须显式地禁用内核抢占。
2、保护中断所访问的数据结构
假定一个数据结构仅被中断处理程序的“上半部”访问,那么,每个中断处理程序都相对自己串行地执行,也就是说,中断服务例程本身不能同时多次运行,因此,访问数据结构就无需任何同步原语。
但是,如果多个中断处理程序访问一个数据结构,情况就有所不同了。一个处理程序可以中断另一个处理程序,不同的中断处理程序可以在多处理器系统上同时运行。没有同步,共享的数据结构就很容易被破坏。
在单处理器系统上,必须通过在中断处理程序的所有临界区上禁止中断来避免竞争条件。只能用这种方式进行同步,因为其他的同步原语都不能完成这件事。信号量能够阻塞进程,因此,不能用在中断处理程序上。另一方面,自旋锁可能使系统冻结:如果访问数据结构的处理程序被中断,它就不能释放锁,因此,新的中断处理程序在自旋锁的紧循环上保持等待。
在多处理器系统上,其要求更加苛刻。不能简单地通过禁止本地中断来避免竞争条件。事实上,即使在一个CPU上禁止了中断,中断处理程序还可以在其他CPU上执行。避免竞争条件的最简单的方法是禁止本地中断,并获取保护数据结构的自旋锁或读写自旋锁。注意,这些附加的自旋锁不能冻结系统,因为即使中断处理程序发现锁关闭,在另一个CPU上拥有锁的中断处理程序最终也会释放这个锁。
Linux使用了几个宏,把本地中断禁止与激活同自旋锁结合起来。

3、保护由可延迟函数访问的数据结构
只被可延迟函数访问的数据结构的保护主要取决于可延迟函数的种类。
在单处理器系统上,不存在竞争条件,这是因为可延迟函数的执行总是在一个CPU上串行执行,也就是说,一个可延迟函数不会被另一个可延迟函数中断。因此,不需要同步原语。
在多处理器系统上,几个可延迟函数的并发运行导致了竞争的存在。
表:在SMP上可延迟函数访问的数据结构所需的保护
| 访问数据结构的可延迟函数 | 保护 |
| 软中断 | 自旋锁 |
| 一个tasklet | 无 |
| 多个tasklet | 自旋锁 |
由软中断访问的数据结构必须受到保护,通常使用自旋锁进行保护,因为一个软中断可以在两个或多个CPU上并发运行。相反,仅由一个tasklet访问的数据结构不需要保护,因为同种tasklet不能并发运行,但是,如果数据结构被几种tasklet访问,那么,就必须对数据结构进行保护。
为什么要使用软中断?
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。它的特性包括:
a)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
b)可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
为什么要使用tasklet?(tasklet和软中断的区别)
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
a)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
b)多个不同类型的tasklet可以并行在多个CPU上。
c)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。
4、保护由异常和中断访问的数据结构
对于由异常处理程序(如系统调用服务例程)和中断处理程序访问的数据结构,通常采用如下策略:
在单处理器系统上,竞争条件的防止是相当简单的,因为中断处理程序不是可重入的且不能被异常中断。只要内核以本地中断禁止访问数据结构,内核在访问数据结构的过程中就不会被中断。不过,如果数据结构正好是被一种中断处理程序访问,那么,中断处理程序不用禁止本地中断就可以自由访问数据结构。
在多处理器系统上,必须关注异常和中断在其他CPU上的并发执行。本地中断禁止外还必须外加自旋锁,强制并发的内核控制路径进行等待,直到访问数据结构的处理程序完成自己的工作。
有时,用信号量代替自旋锁可能更好。因为中断处理程序不能被挂起,它们必须用紧循环和down_trylock()函数获得信号量;对于中断处理程序来说,信号量起的作用本质上与自旋锁一样。另一方面,系统调用服务例程可以在信号量忙是挂起调用进程。
5、保护由异常和可延迟函数访问的数据结构
异常和可延迟函数都访问的数据结构与异常和中断访问的数据结构处理方式类似。事实上,可延迟函数本质上是由中断的出现激活的,而可延迟函数执行时不可能产生异常。因此,把本地中断禁止与自旋锁结合起来就可以了。
异常处理程序可以调用local_bh_disable()宏简单地禁止可延迟函数,而不禁止本地中断。仅禁止可延迟函数比禁止中断更可取,因为中断还可以继续在CPU上得到服务。在每个CPU上可延迟函数的执行被串行化,不存在竞争条件。
同样,在多处理器系统上,要用自旋锁确保在任何时候只有一个内核控制路径访问数据结构。
6、保护由中断和可延迟函数访问的数据结构
这种情况类似于中断和异常处理程序访问的数据结构。当可延迟函数运行时可能产生中断,但是,可延迟函数不能阻止中断处理程序。因此,必须通过在可延迟函数执行期间禁用本地中断来避免竞争条件。不过,中断处理程序可以随意访问被可延迟函数访问的数据结构而不用关中断,前提是没有其他的中断处理程序访问这个数据结构。
在多处理器系统上,还是需要自旋锁禁止对多个CPU上数据结构的并发访问。
7、保护由异常、中断和可延迟函数访问的数据结构
类似前面的情况,禁止本地中断和获取自旋锁几乎总是避免竞争条件所必需的。但是,没有必要显式地禁止可延迟函数,因为当中断处理程序终止执行时,可延迟函数才能被实质激活,因此,禁止本地中断就可以了。
避免竞争条件的实例
人们总是期望内核开发者确定和解决由内核控制路径的交错执行所引起的同步问题。但是,避免竞争条件是一项艰巨的任务,因为这需要对内核的各个成分如何相互作用有一个清楚的理解。
引用计数器
引用计数器广泛地用在内核中以避免由于资源的并发分配和释放而产生的竞争条件。引用计数器(reference counter)只不过是一个atomic_t计数器,与特定的资源,如内存页、模块或文件相关。当内核控制路径开始使用资源时就原子地减少计数器的值,当内核控制路径使用完资源时就原子地增加计数器的值。当引用计数器变为0时,说明该资源未被使用,如有必要,就释放该资源。
大内核锁
大内核锁(Big Kernel Lock)也叫全局内核锁或BKL。其用一个kernel_sem的信号量来实现,但是,其比简单的信号量要复杂一些。
每个进程描述符都含有lock_depth字段,这个字段允许同一进程几次获取大内核锁。因此,对大内核锁两次连续的请求不挂起处理器(相对于普通自旋锁)。如果进程未获得过锁,则这个字段的值为-1;否则,这个字段的值加1,表示已经请求了多少次锁。lock_depth字段对中断处理程序、异常处理程序及可延迟函数获取大内核锁都是至关重要的。如果没有这个字段,那么,在当前进程已经拥有大内核锁的请况下,任何试图获得这个锁的异步函数都可能产生死锁。
lock_kernel()和unlock_kernel()内核函数用来获得和释放大内核锁。
lock_kernel()等价于:
depth = current->lock_depth + 1;if(depth == 0) down(&kernel_sem);current->lock_depth = depth;unlock_kernel()等价于:
if(--current->lock_depth < 0) up(&kernel_sem);BKL(大内核锁)是一个全局自旋锁,使用它主要是为了方便实现从Linux最初的SMP过度到细粒度加锁机制。
BKL的特性:
* 持有BKL的任务仍然可以睡眠 。因为当任务无法调度时,所加的锁会自动被抛弃;当任务被调度时,锁又会被重新获得。当然,并不是说,当任务持有BKL时,睡眠是安全的,紧急是可以这样做,因为睡眠不会造成任务死锁。
* BKL是一种递归锁。一个进程可以多次请求一个锁,并不会像自旋锁那么产生死锁。
* BKL可以在进程上下文中。
* BKL是有害的。
在内核中不鼓励使用BKL。一个执行线程可以递归的请求锁lock_kernel(),但是释放锁时也必须调用同样次数的unlock_kernel()操作,在最后一个解锁操作完成之后,锁才会被释放。
内存描述符读写信号量
mm_struct类型的每个内存描述符在mmap_sem字段中都包含了自己的信号量。由于几个轻量级进程之间可以共享一个内存描述符,因此,信号量保护这个描述符以避免可能产生的竞争条件。
例如,让我们假设内核必须为某个进程创建或扩展一个内存区。为了做到这一点,内核调用do_mmap()函数分配一个新的vm_area_struct数据结构。在分配的过程中,如果没有可用的空闲内存,而共享同一内存描述符的另一个进程可能在运行,那么当前进程可能被挂起。如果没有信号量,那么需要访问内存描述符的第二个进程的任何操作都可能会导致严重的数据崩溃。
这种信号量是作为读写信号量来实现的,因为一些内核函数,如缺页异常处理程序只需要描述内存描述符。
slab高速缓存链表的信号量
slab高速缓存描述符链表是通过cache_chain_sem信号量保护的,这个信号量允许互斥地访问和修改链表。
当kmem_cache_create()在链表中增加一个新元素,而kmem_cache_shrink()和kmem_cache_reap()顺序地扫描整个链表时,可能产生竞争条件。然而,在处理中断时,这些函数从不被调用,在访问链表时它们也从不阻塞。由于内核是支持抢占的,因此这种信号量在多处理器系统和单处理器系统中都会起作用。
索引节点的信号量
Linux把磁盘文件的信息存放在一种叫做索引节点(inode)的内存对象中。相应的数据结构也包括自己的信号量,存放在l_sem字段中。
在文件系统的处理过程中会出现很多竞争条件。实际上,磁盘上的每个文件都是所有用户共有的资源,因为所有进程可能会存取文件的内容、修改文件名或文件位置、删除或复制文件等。例如,让我们假设一个进程在显示某个目录所包含的文件。由于每个磁盘操作都可能会阻塞,因此即使在单处理器系统中,当第一个进程正在执行显示操作的过程中,其他进程也可能存取同一目录并修改它的内容。或者,两个不同的进程可能同时修改同一目录。所有这些竞争条件都可以通过用索引节点信号量保护目录文件来避免。
只要一个程序使用了两个或多个信号量,就存在死锁的可能,因为两个不同的控制路径可能互相死等着释放信号量。一般来说,Linux在信号量请求上很少会发生死锁问题,因为每个内核控制路径通常一次只需要获得一个信号量。然而,在有些情况下,内核必须获得两个或多个信号量锁。索引节点信号量倾向于这种情况,例如,在rename()系统调用的服务例程中就会发生上述情况。在这种情况下,操作涉及两个不同的索引节点,因此,必须采用两个信号量。为了避免这样的死锁,信号量的请求按预先确定的地址顺序进行。
浅析Linux内核同步机制
很早之前就接触过同步这个概念了,但是一直都很模糊,没有深入地学习了解过,近期有时间了,就花时间研习了一下《linux内核标准教程》和《深入linux设备驱动程序内核机制》这两本书的相关章节。趁刚看完,就把相关的内容总结一下。为了弄清楚什么事同步机制,必须要弄明白以下三个问题:
- 什么是互斥与同步?
- 为什么需要同步机制?
- Linux内核提供哪些方法用于实现互斥与同步的机制?
1、什么是互斥与同步?(通俗理解)
- 互斥与同步机制是计算机系统中,用于控制进程对某些特定资源的访问的机制。
- 同步是指用于实现控制多个进程按照一定的规则或顺序访问某些系统资源的机制。
- 互斥是指用于实现控制某些系统资源在任意时刻只能允许一个进程访问的机制。互斥是同步机制中的一种特殊情况。
- 同步机制是linux操作系统可以高效稳定运行的重要机制。
2、Linux为什么需要同步机制?
在操作系统引入了进程概念,进程成为调度实体后,系统就具备了并发执行多个进程的能力,但也导致了系统中各个进程之间的资源竞争和共享。另外,由于中断、异常机制的引入,以及内核态抢占都导致了这些内核执行路径(进程)以交错的方式运行。对于这些交错路径执行的内核路径,如不采取必要的同步措施,将会对一些关键数据结构进行交错访问和修改,从而导致这些数据结构状态的不一致,进而导致系统崩溃。因此,为了确保系统高效稳定有序地运行,linux必须要采用同步机制。
3、Linux内核提供了哪些同步机制?
在学习linux内核同步机制之前,先要了解以下预备知识:(临界资源与并发源)
在linux系统中,我们把对共享的资源进行访问的代码片段称为临界区。把导致出现多个进程对同一共享资源进行访问的原因称为并发源。
Linux系统下并发的主要来源有:
- 中断处理:例如,当进程在访问某个临界资源的时候发生了中断,随后进入中断处理程序,如果在中断处理程序中,也访问了该临界资源。虽然不是严格意义上的并发,但是也会造成了对该资源的竞态。
- 内核态抢占:例如,当进程在访问某个临界资源的时候发生内核态抢占,随后进入了高优先级的进程,如果该进程也访问了同一临界资源,那么就会造成进程与进程之间的并发。
- 多处理器的并发:多处理器系统上的进程与进程之间是严格意义上的并发,每个处理器都可以独自调度运行一个进程,在同一时刻有多个进程在同时运行 。
如前所述可知:采用同步机制的目的就是避免多个进程并发并发访问同一临界资源。
4、Linux内核同步机制:
(1)禁用中断 (单处理器不可抢占系统)
由前面可以知道,对于单处理器不可抢占系统来说,系统并发源主要是中断处理。因此在进行临界资源访问时,进行禁用/使能中断即可以达到消除异步并发源的目的。Linux系统中提供了两个宏local_irq_enable与 local_irq_disable来使能和禁用中断。在linux系统中,使用这两个宏来开关中断的方式进行保护时,要确保处于两者之间的代码执行时间不能太长,否则将影响到系统的性能。(不能及时响应外部中断)
问题:对于不可抢占单核的系统来说,如果一块临界区代码正访问一半,出现时间片轮转,时间片再次转回来,是否存在临界资源访问问题?
(2)自旋锁
应用背景:自旋锁的最初设计目的是在多处理器系统中提供对共享数据的保护。
自旋锁的设计思想:在多处理器之间设置一个全局变量V,表示锁。并定义当V=1时为锁定状态,V=0时为解锁状态。自旋锁同步机制是针对多处理器设计的,属于忙等机制。自旋锁机制只允许唯一的一个执行路径持有自旋锁。如果处理器A上的代码要进入临界区,就先读取V的值。如果V!=0说明是锁定状态,表明有其他处理器的代码正在对共享数据进行访问,那么此时处理器A进入忙等状态(自旋);如果V=0,表明当前没有其他处理器上的代码进入临界区,此时处理器A可以访问该临界资源。然后把V设置为1,再进入临界区,访问完毕后离开临界区时将V设置为0。
为什么叫自旋,因为忙等,一直在询问锁的情况。
注意:必须要确保处理器A“读取V,半段V的值与更新V”这一操作是一个原子操作。所谓的原子操作是指,一旦开始执行,就不可中断直至执行结束。
自旋锁的分类:
2.1、普通自旋锁
普通自旋锁由数据结构spinlock_t来表示,该数据结构在文件src/include/linux/spinlock_types.h中定义。定义如下:
1 typedef struct {
2 raw_spinklock_t raw_lock;
3 #ifdefined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
4 unsigned int break_lock;
5 #endif
6 } spinlock_t;
成员raw_lock:该成员变量是自旋锁数据类型的核心,它展开后实质上是一个Volatile unsigned类型的变量。具体的锁定过程与它密切相关,该变量依赖于内核选项CONFIG_SMP。(是否支持多对称处理器)
成员break_lock:同时依赖于内核选项CONFIG_SMP和CONFIG_PREEMPT(是否支持内核态抢占),该成员变量用于指示当前自旋锁是否被多个内核执行路径同时竞争、访问。
在单处理器系统下:CONFIG_SMP没有选中时,变量类型raw_spinlock_t退化为一个空结构体。相应的接口函数也发生了退化。相应的加锁函数spin_lock()和解锁函数spin_unlock()退化为只完成禁止内核态抢占、使能内核态抢占。
在多处理器系统下:选中CONFIG_SMP时,核心变量raw_lock的数据类型raw_lock_t在文件中src/include/asm-i386/spinlock_types.h中定义如下:
typedef struct { volatileunsigned int slock;} raw_spinklock_t;
从定义中可以看出该数据结构定义了一个内核变量,用于计数工作。当结构中成员变量slock的数值为1时,表示自旋锁处于非锁定状态,可以使用。否则,表示处于锁定状态,不可以使用。
普通自旋锁的接口函数:

1 spin_lock_init(lock) //声明自旋锁是,初始化为锁定状态
2 spin_lock(lock)//锁定自旋锁,成功则返回,否则循环等待自旋锁变为空闲
3 spin_unlock(lock) //释放自旋锁,重新设置为未锁定状态
4 spin_is_locked(lock) //判断当前锁是否处于锁定状态。若是,返回1.
5 spin_trylock(lock) //尝试锁定自旋锁lock,不成功则返回0,否则返回1
6 spin_unlock_wait(lock) //循环等待,直到自旋锁lock变为可用状态。
7 spin_can_lock(lock) //判断该自旋锁是否处于空闲状态。
普通自旋锁总结:自旋锁设计用于多处理器系统。当系统是单处理器系统时,自旋锁的加锁、解锁过程分为别退化为禁止内核态抢占、使能内核态抢占。在多处理器系统中,当锁定一个自旋锁时,需要首先禁止内核态抢占,然后尝试锁定自旋锁,在锁定失败时执行一个死循环等待自旋锁被释放;当解锁一个自旋锁时,首先释放当前自旋锁,然后使能内核态抢占。
2.2、自旋锁的变种
在前面讨论spin_lock很好的解决了多处理器之间的并发问题。但是如果考虑如下一个应用场景:处理器上的当前进程A要对某一全局性链表g_list进行操作,所以在操作前调用了spin_lock获取锁,然后再进入临界区。如果在临界区代码当中,进程A所在的处理器上发生了一个外部硬件中断,那么这个时候系统必须暂停当前进程A的执行转入到中断处理程序当中。假如中断处理程序当中也要操作g_list,由于它是共享资源,在操作前必须要获取到锁才能进行访问。因此当中断处理程序试图调用spin_lock获取锁时,由于该锁已经被进程A持有,中断处理程序将会进入忙等状态(自旋)。从而就会出现大问题了:中断程序由于无法获得锁,处于忙等(自旋)状态无法返回;由于中断处理程序无法返回,进程A也处于没有执行完的状态,不会释放锁。因此这样导致了系统的死锁。即spin_lock对存在中断源的情况是存在缺陷的,因此引入了它的变种。
spin_lock_irq(lock)
spin_unlock_irq(lock)
相比于前面的普通自旋锁,它在上锁前增加了禁用中断的功能,在解锁后,使能了中断。
2.3、读写自旋锁rwlock
应用背景:前面说的普通自旋锁spin_lock类的函数在进入临界区时,对临界区中的操作行为不细分。只要是访问共享资源,就执行加锁操作。但是有时候,比如某些临界区的代码只是去读这些共享的数据,并不会改写,如果采用spin_lock()函数,就意味着,任意时刻只能有一个进程可以读取这些共享数据。如果系统中有大量对这些共享资源的读操作,很明显spin_lock将会降低系统的性能。因此提出了读写自旋锁rwlock的概念。对照普通自旋锁,读写自旋锁允许多个读者进程同时进入临界区,交错访问同一个临界资源,提高了系统的并发能力,提升了系统的吞吐量。
读写自旋锁有数据结构rwlock_t来表示。定义在…/spinlock_types.h中
读写自旋锁的接口函数:
1 DEFINE_RWLOCK(lock) //声明读写自旋锁lock,并初始化为未锁定状态
2 write_lock(lock) //以写方式锁定,若成功则返回,否则循环等待
3 write_unlock(lock) //解除写方式的锁定,重设为未锁定状态
4 read_lock(lock) //以读方式锁定,若成功则返回,否则循环等待
5 read_unlock(lock) //解除读方式的锁定,重设为未锁定状态
读写自旋锁的工作原理:
对于读写自旋锁rwlock,它允许任意数量的读取者同时进入临界区,但写入者必须进行互斥访问。一个进程要进行读,必须要先检查是否有进程正在写入,如果有,则自旋(忙等),否则获得锁。一个进程要进程写,必须要先检查是否有进程正在读取或者写入,如果有,则自旋(忙等)否则获得锁。即读写自旋锁的应用规则如下:
(1)如果当前有进程正在写,那么其他进程就不能读也不能写。
(2)如果当前有进程正在读,那么其他程序可以读,但是不能写。
2.4、顺序自旋锁seqlock
应用背景:顺序自旋锁主要用于解决自旋锁同步机制中,在拥有大量读者进程时,写进程由于长时间无法持有锁而被饿死的情况,其主要思想是:为写进程提高更高的优先级,在写锁定请求出现时,立即满足写锁定的请求,无论此时是否有读进程正在访问临界资源。但是新的写锁定请求不会,也不能抢占已有写进程的写锁定。
顺序锁的设计思想:对某一共享数据读取时不加锁,写的时候加锁。为了保证读取的过程中不会因为写入者的出现导致该共享数据的更新,需要在读取者和写入者之间引入一个整形变量,称为顺序值sequence。读取者在开始读取前读取该sequence,在读取后再重新读取该值,如果与之前读取到的值不一致,则说明本次读取操作过程中发生了数据更新,读取操作无效。因此要求写入者在开始写入的时候更新。
顺序自旋锁由数据结构seqlock_t表示,定义在src/include/linux/seqlcok.h
顺序自旋锁访问接口函数:
1 seqlock_init(seqlock) //初始化为未锁定状态
2 read_seqbgin()、read_seqretry() //保证数据的一致性
3 write_seqlock(lock) //尝试以写锁定方式锁定顺序锁
4 write_sequnlock(lock) //解除对顺序锁的写方式锁定,重设为未锁定状态。
顺序自旋锁的工作原理:写进程不会被读进程阻塞,也就是,写进程对被顺序自旋锁保护的临界资源进行访问时,立即锁定并完成更新工作,而不必等待读进程完成读访问。但是写进程与写进程之间仍是互斥的,如果有写进程在进行写操作,其他写进程必须循环等待,直到前一个写进程释放了自旋锁。顺序自旋锁要求被保护的共享资源不包含有指针,因为写进程可能使得指针失效,如果读进程正要访问该指针,将会出错。同时,如果读者在读操作期间,写进程已经发生了写操作,那么读者必须重新读取数据,以便确保得到的数据是完整的。
(3)信号量机制(semaphore)
应用背景:前面介绍的自旋锁同步机制是一种“忙等”机制,在临界资源被锁定的时间很短的情况下很有效。但是在临界资源被持有时间很长或者不确定的情况下,忙等机制则会浪费很多宝贵的处理器时间。针对这种情况,linux内核中提供了信号量机制,此类型的同步机制在进程无法获取到临界资源的情况下,立即释放处理器的使用权,并睡眠在所访问的临界资源上对应的等待队列上;在临界资源被释放时,再唤醒阻塞在该临界资源上的进程。另外,信号量机制不会禁用内核态抢占,所以持有信号量的进程一样可以被抢占,这意味着信号量机制不会给系统的响应能力,实时能力带来负面的影响。
信号量设计思想:除了初始化之外,信号量只能通过两个原子操作P()和V()访问,也称为down()和up()。down()原子操作通过对信号量的计数器减1,来请求获得一个信号量。如果操作后结果是0或者大于0,获得信号量锁,任务就可以进入临界区。如果操作后结果是负数,任务会放入等待队列,处理器执行其他任务;对临界资源访问完毕后,可以调用原子操作up()来释放信号量,该操作会增加信号量的计数器。如果该信号量上的等待队列不为空,则唤醒阻塞在该信号量上的进程。
信号量的分类:
3.1、普通信号量
普通信号量由数据结构struct semaphore来表示,定义在src/inlcude/ asm-i386/semaphore.h中.
信号量(semaphore)定义如下:
1 <include/linux/semaphore.h>
2 struct semaphore{
3 spinlock_t lock; //自旋锁,用于实现对count的原子操作
4 unsigned int count; //表示通过该信号量允许进入临界区的执行路径的个数
5 struct list_head wait_list; //用于管理睡眠在该信号量上的进程
6 };
普通信号量的接口函数:
1 sema_init(sem,val) //初始化信号量计数器的值为val
2 int_MUTEX(sem) //初始化信号量为一个互斥信号量
3 down(sem) //锁定信号量,若不成功,则睡眠在等待队列上
4 up(sem) //释放信号量,并唤醒等待队列上的进程
DOWN操作:linux内核中,对信号量的DOWN操作有如下几种:
1 void down(struct semaphore *sem); //不可中断
2 int down_interruptible(struct semaphore *sem);//可中断
3 int down_killable(struct semaphore *sem);//睡眠的进程可以因为受到致命信号而被唤醒,中断获取信号量的操作。
4 int down_trylock(struct semaphore *sem);//试图获取信号量,若无法获得则直接返回1而不睡眠。返回0则 表示获取到了信号量
5 int down_timeout(struct semaphore *sem,long jiffies);//表示睡眠时间是有限制的,如果在jiffies指明的时间到期时仍然无法获得信号量,则将返回错误码。
在以上四种函数中,驱动程序使用的最频繁的就是down_interruptible函数
UP操作:LINUX内核只提供了一个up函数
void up(struct semaphore *sem)
加锁处理过程:加锁过程由函数down()完成,该函数负责测试信号量的状态,在信号量可用的情况下,获取该信号量的使用权,否则将当前进程插入到当前信号量对应的等待队列中。函数调用关系如下:down()->__down_failed()->__down.函数说明如下:
down()功能介绍:该函数用于对信号量sem进行加锁,在加锁成功即获得信号的使用权是,直接退出,否则,调用函数__down_failed()睡眠到信号量sem的等待队列上。__down()功能介绍:该函数在加锁失败时被调用,负责将进程插入到信号量 sem的等待队列中,然后调用调度器,释放处理器的使用权。
解锁处理过程:普通信号量的解锁过程由函数up()完成,该函数负责将信号计数器count的值增加1,表示信号量被释放,在有进程阻塞在该信号量的情况下,唤醒等待队列中的睡眠进程。
3.2读写信号量(rwsem)
应用背景:为了提高内核并发执行能力,内核提供了读入者信号量和写入者信号量。它们的概念和实现机制类似于读写自旋锁。
工作原理:该信号量机制使得所有的读进程可以同时访问信号量保护的临界资源。当进程尝试锁定读写信号量不成功时,则这些进程被插入到一个先进先出的队列中;当一个进程访问完临界资源,释放对应的读写信号量是,该进程负责将该队列中的进程按一定的规则唤醒。
唤醒规则:唤醒排在该先进先出队列中队首的进程,在被唤醒进程为写进程的情况下,不再唤醒其他进程;在唤醒进程为读进程的情况下,唤醒其他的读进程,直到遇到一个写进程(该写进程不被唤醒)
读写信号量的定义如下:
1 <include/linux/rwsem-spinlock.h>
2 sturct rw_semaphore{
3 __s32 activity; //用于表示读者或写者的数量
4 spinlock_t wait_lock;
5 struct list_head wait_list;
6 };
读写信号量相应的接口函数
读者up、down操作函数:
1 void up_read(Sturct rw_semaphore *sem);
2 void __sched down_read(Sturct rw_semaphore *sem);
3 Int down_read_trylock(Sturct rw_semaphore *sem);
写入者up、down操作函数:
1 void up_write(Sturct rw_semaphore *sem);
2 void __sched down_write(Sturct rw_semaphore *sem);
3 int down_write_trylock(Sturct rw_semaphore *sem);
3.3、互斥信号量
在linux系统中,信号量的一个常见的用途是实现互斥机制,这种情况下,信号量的count值为1,也就是任意时刻只允许一个进程进入临界区。为此,linux内核源码提供了一个宏DECLARE_MUTEX,专门用于这种用途的信号量定义和初始化
1 <include/linux/semaphore.h>
2 #define DECLARE_MUTEX(name) \
3 structsemaphore name=__SEMAPHORE_INITIALIZER(name,1)
(4)互斥锁mutex
Linux内核针对count=1的信号量重新定义了一个新的数据结构struct mutex,一般都称为互斥锁。内核根据使用场景的不同,把用于信号量的down和up操作在struct mutex上做了优化与扩展,专门用于这种新的数据类型。
(5)RCU
RCU概念:RCU全称是Read-Copy-Update(读/写-复制-更新),是linux内核中提供的一种免锁的同步机制。RCU与前面讨论过的读写自旋锁rwlock,读写信号量rwsem,顺序锁一样,它也适用于读取者、写入者共存的系统。但是不同的是,RCU中的读取和写入操作无须考虑两者之间的互斥问题。但是写入者之间的互斥还是要考虑的。
RCU原理:简单地说,是将读取者和写入者要访问的共享数据放在一个指针p中,读取者通过p来访问其中的数据,而读取者则通过修改p来更新数据。要实现免锁,读写双方必须要遵守一定的规则。
读取者的操作(RCU临界区)
对于读取者来说,如果要访问共享数据。首先要调用rcu_read_lock和rcu_read_unlock函数构建读者侧的临界区(read-side critical section),然后再临界区中获得指向共享数据区的指针,实际的读取操作就是对该指针的引用。
读取者要遵守的规则是:(1)对指针的引用必须要在临界区中完成,离开临界区之后不应该出现任何形式的对该指针的引用。(2)在临界区内的代码不应该导致任何形式的进程切换(一般要关掉内核抢占,中断可以不关)。
写入者的操作
对于写入者来说,要写入数据,首先要重新分配一个新的内存空间做作为共享数据区。然后将老数据区内的数据复制到新数据区,并根据需要修改新数据区,最后用新数据区指针替换掉老数据区的指针。写入者在替换掉共享区的指针后,老指针指向的共享数据区所在的空间还不能马上释放(原因后面再说明)。写入者需要和内核共同协作,在确定所有对老指针的引用都结束后才可以释放老指针指向的内存空间。为此,写入者要做的操作是调用call_rcu函数向内核注册一个回调函数,内核在确定所有对老指针的引用都结束时会调用该回调函数,回调函数的功能主要是释放老指针指向的内存空间。Call_rcu函数的原型如下:
Void call_rcu(struct rcu_head *head,void (*func)(struct rcu_head *rcu));
内核确定没有读取者对老指针的引用是基于以下条件的:系统中所有处理器上都至少发生了一次进程切换。因为所有可能对共享数据区指针的不一致引用一定是发生在读取者的RCU临界区,而且临界区一定不能发生进程切换。所以如果在CPU上发生了一次进程切换切换,那么所有对老指针的引用都会结束,之后读取者再进入RCU临界区看到的都将是新指针。
老指针不能马上释放的原因:这是因为系统中爱可能存在对老指针的引用,者主要发生在以下两种情况:(1)一是在单处理器范围看,假设读取者在进入RCU临界区后,刚获得共享区的指针之后发生了一个中断,如果写入者恰好是中断处理函数中的行为,那么当中断返回后,被中断进程RCU临界区中继续执行时,将会继续引用老指针。(2)另一个可能是在多处理器系统,当处理器A上的一个读取者进入RCU临界区并获得共享数据区中的指针后,在其还没来得及引用该指针时,处理器B上的一个写入者更新了指向共享数据区的指针,这样处理器A上的读取者也饿将引用到老指针。
RCU特点:由前面的讨论可以知道,RCU实质上是对读取者与写入者自旋锁rwlock的一种优化。RCU的可以让多个读取者和写入者同时工作。但是RCU的写入者操作开销就比较大。在驱动程序中一般比较少用。
为了在代码中使用RCU,所有RCU相关的操作都应该使用内核提供的RCU API函数,以确保RCU机制的正确使用,这些API主要集中在指针和链表的操作。
下面是一个RCU的典型用法范例:
1 假设struct shared_data是一个在读取者和写入者之间共享的受保护数据
2 Struct shared_data{
3 Int a;
4 Int b;
5 Struct rcu_head rcu;
6 };
7
8 //读取者侧的代码
9
10 Static void demo_reader(struct shared_data *ptr)
11 {
12 Struct shared_data *p=NULL;
13 Rcu_read_lock();
14 P=rcu_dereference(ptr);
15 If(p)
16 Do_something_withp(p);
17 Rcu_read_unlock();
18 }
19
20 //写入者侧的代码
21 Static void demo_del_oldptr(struct rcu_head *rh) //回调函数
22 {
23 Struct shared_data *p=container_of(rh,struct shared_data,rcu);
24 Kfree(p);
25 }
26
27 Static void demo_writer(struct shared_data *ptr)
28 {
29 Struct shared_data *new_ptr=kmalloc(…);
30 …
31 New_ptr->a=10;
32 New_ptr->b=20;
33 Rcu_assign_pointer(ptr,new_ptr);//用新指针更新老指针
34 Call_rcu(ptr->rcu,demo_del_oldptr); 向内核注册回调函数,用于删除老指针指向的内存空间
35 }
(6)完成接口completion
Linux内核还提供了一个被称为“完成接口completion”的同步机制,该机制被用来在多个执行路径间作同步使用,也即协调多个执行路径的执行顺序。在此就不展开了。----见分享的另外一篇关于completion的文章
linux内核同步机制中的概念介绍和方法
Linux设备驱动中必须解决的一个问题是多个进程对共享资源的并发访问,并发访问会导致竞态,linux提供了多种解决竞态问题的方式,这些方式适合不同的应用场景。
Linux内核是多进程、多线程的操作系统,它提供了相当完整的内核同步方法。内核同步方法列表如下:
=========================
内核中采用的同步技术:
中断屏蔽
原子操作 (分为整数原子操作和位 原子操作)
信号量 (semaphore)
RCU (read-copy-update)
SMP系统中的同步机制 :
自旋锁 (spin lock)
读写自旋锁
顺序锁 (seqlock 只包含在2.6内核中)
读写信号量 (rw_semaphore)
大内核锁BKL(Big Kernel Lock)
Seq锁()。
==========================
一、概念介绍
并发与竞态:
并发(concurrency)指的是多个执行单元同时、并行被执行,而并发的执行单元对共享资源(硬件资源和软件上的全局变量、静态变量等)的访问则很容易导致竞态(race conditions)。
在linux中,主要的竞态发生在如下几种情况:
1、对称多处理器(SMP)多个CPU 特点是多个CPU使用共同的系统总线,因此可访问共同的外设和存储器。
2、单CPU内进程与抢占它的进程
3、中断(硬中断、软中断、Tasklet、底半部)与进程之间
只要并发的多个执行单元存在对共享资源的访问,竞态就有可能发生。
如果中断处理程序访问进程正在访问的资源,则竞态也会会发生。
多个中断之间本身也可能引起并发而导致竞态(中断被更高优先级的中断打断)。
解决竞态问题的途径是保证对共享资源的互斥访问,所谓互斥访问就是指一个执行单元在访问共享资源的时候,其他的执行单元都被禁止访问。
访问共享资源的代码区域被称为临界区,临界区需要以某种互斥机制加以保护,如:中断屏蔽,原子操作,自旋锁,和信号量都是linux设备驱动中可采用的互斥途径。
临界区和竞争条件:
所谓临界区(critical regions)就是访问和操作共享数据的代码段,为了避免在临界区中并发访问,编程者必须保证这些代码原子地执行——也就是说,代码在执行结束前不可被打断,就如同整个临界区是一个不可分割的指令一样,如果两个执行线程有可能处于同一个临界区中,那么就是程序包含一个bug,如果这种情况发生了,我们就称之为竞争条件(race conditions),避免并发和防止竞争条件被称为同步。
死锁:
死锁的产生需要一定条件:要有一个或多个执行线程和一个或多个资源,每个线程都在等待其中的一个资源,但所有的资源都已经被占用了,所有线程都在相互等待,但它们永远不会释放已经占有的资源,于是任何线程都无法继续,这便意味着死锁的发生。
=========================================================================================================================
详细的同步方法如下:
一、中断屏蔽
在单CPU范围内避免竞态的一种简单方法是在进入临界区之前屏蔽系统的中断。由于linux内核的进程调度等操作都依赖中断来实现,内核抢占进程之间的并发也就得以避免了。
中断屏蔽的使用方法:
- local_irq_disable()//屏蔽中断
- //临界区
- local_irq_enable()//开中断
- 特点:由于<span style="font-family:'Times New Roman';">linux</span>系统的异步<span style="font-family:'Times New Roman';">IO</span>,进程调度等很多重要操作都依赖于中断,在屏蔽中断期间所有的中断都无法得到处理,因此<strong>长时间的屏蔽是很危险</strong>的,有可能造成数据丢失甚至系统崩溃,这就要求在屏蔽中断之后,当前的内核执行路径应当尽快地执行完临界区的代码。
中断屏蔽只能禁止本CPU内的中断,因此,并不能解决多CPU引发的竞态,所以单独使用中断屏蔽并不是一个值得推荐的避免竞态的方法,它一般和自旋锁配合使用。
二、原子操作
定义:原子操作指的是在执行过程中不会被别的代码路径所中断的操作。(原子原本指的是不可分割的微粒,所以原子操作也就是不能够被分割的指令)
(它保证指令以“原子”的方式执行而不能被打断)
原子操作是不可分割的,在执行完毕不会被任何其它任务或事件中断。在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是"原子操作",因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。但是,在对称多处理器(Symmetric Multi-Processor)结构中就不同了,由于系统中有多个处理器在独立地运行,即使能在单条指令中完成的操作也有可能受到干扰。我们以decl (递减指令)为例,这是一个典型的"读-改-写"过程,涉及两次内存访问。
通俗理解:
原子操作,顾名思义,就是说像原子一样不可再细分。一个操作是原子操作,意思就是说这个操作是以原子的方式被执行,要一口气执行完,执行过程不能够被OS的其他行为打断,是一个整体的过程,在其执行过程中,OS的其它行为是插不进来的。
分类:linux内核提供了一系列函数来实现内核中的原子操作,分为整型原子操作和位原子操作,共同点是:在任何情况下操作都是原子的,内核代码可以安全的调用它们而不被打断。
原子整数操作:
针对整数的原子操作只能对atomic_t类型的数据进行处理,在这里之所以引入了一个特殊的数据类型,而没有直接使用C语言的int型,主要是出于两个原因:
第一、让原子函数只接受atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用,同时,这也确保了该类型的数据不会被传递给其它任何非原子函数;
第二、使用atomic_t类型确保编译器不对相应的值进行访问优化——这点使得原子操作最终接收到正确的内存地址,而不是一个别名,最后就是在不同体系结构上实现原子操作的时候,使用atomic_t可以屏蔽其间的差异。
原子整数操作最常见的用途就是实现计数器。
另一点需要说明原子操作只能保证操作是原子的,要么完成,要么不完成,不会有操作一半的可能,但原子操作并不能保证操作的顺序性,即它不能保证两个操作是按某个顺序完成的。如果要保证原子操作的顺序性,请使用内存屏障指令。
atomic_t和ATOMIC_INIT(i)定义如下:
- typedef struct { volatile int counter; } atomic_t;
- #define ATOMIC_INIT(i) { (i) }
=========================整数相关函数: ===========================================
- ATOMIC_INIT(int i) //声明一个atomic_t变量并且初始化为i
- int atomic_read(atomic_t *v) //原子地读取整数变量v
- void atomic_set(atomic_t *v, int i) //原子地设置v为i
- void atomic_add(int i, atomic_t *v) //v+i
- void atomic_sub(int i, atomic_t *v) //v-i
- void atomic_inc(atomic_t *v) //v+1
- void atomic_dec(atomic_t *v) //v-1
- int atomic_sub_and_test(int i, atomic_t *v) //v-i, 结果等于0,返回真,否则返回假
- int atomic_add_negative(int i, atomic_t *v) //原子地给v+i,结果是负数,返回真,否则返回假
- int atomic_dec_and_test(atomic_t *v) //v-1, 结果是0,返回真,否则返回假
- int atomic_inc_and_test(atomic_t *v) //v+1,如果是0,返回真,否则返回假
在你编写代码的时候,能使用原子操作的时候,就尽量不要使用复杂的加锁机制,对多数体系结构来讲,原子操作与更复杂的同步方法相比较,给系统带来的开销小,对高速缓存行的影响也小,但是,对于那些有高性能要求的代码,对多种同步方法进行测试比较,不失为一种明智的作法。
原子位操作:
针对位这一级数据进行操作的函数,是对普通的内存地址进行操作的。它的参数是一个指针和一个位号。
=================================位操作相关函数:====================================
- void set_bit(int nr, void *addr) //原子地设置addr所指对象的第nr位
- void clear_bit(int nr, void *addr) //清空addr第nr位
- void change_bit(int nr, void *addr) //反转addr第nr位
- int test_and _set_bit(int nr, void *addr) //设置addr第nr位,并返回原先的位的值
- int test_and_clear_bit(int nr, void *addr) //清除addr第nr位,并返回原先的值
- int test_and_change_bit(int nr, void *addr) //反转addr第nr,并返回原先的值
- int test_bit(int nr, void *addr) //原子地返回addr的第nr位
为方便其间,内核还提供了一组与上述操作对应的非原子位函数,非原子位函数与原子位函数的操作完全相同,但是,非原子位函数不保证原子性,且其名字前缀多两个下划线。例如,与test_bit()对应的非原子形式是_test_bit(),如果你不需要原子性操作(比如,如果你已经用锁保护了自己的数据),那么这些非原子的位函数相比原子的位函数可能会执行得更快些。
使用示例:
创建和初始化原子变量
atomic_t my_counter ATOMIC_INIT(0); //声明一个atomic_t类型的变量my_counter 并且初始化为0
或者
atomic_set( &my_counter, 0 );
- <span style="font-size:12px;color:#000000;">简单的算术原子函数
- val = atomic_read( &my_counter );
- atomic_add( 1, &my_counter );
- atomic_inc( &my_counter );
- atomic_sub( 1, &my_counter );
- atomic_dec( &my_counter );
- </span>
三、自旋锁(spin lock)
自旋锁的引入:
如果每个临界区都能像增加变量这样简单就好了,可惜现实不是这样,而是临界区可以跨越多个函数,例如:先得从一个数据结果中移出数据,对其进行格式转换和解析,最后再把它加入到另一个数据结构中,整个执行过程必须是原子的,在数据被更新完毕之前,不能有其他代码读取这些数据,显然,简单的原子操作是无能为力的(在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是"原子操作",因为中断只能发生于指令之间),这就需要使用更为复杂的同步方法——锁来提供保护。
自旋锁的介绍:
Linux内核中最常见的锁是自旋锁(spin lock),自旋锁最多只能被一个可执行线程持有,如果一个执行线程试图获得一个被争用(已经被持有)的自旋锁,那么该线程就会一直进行忙循环—旋转—等待锁重新可用,要是锁未被争用,请求锁的执行线程便能立刻得到它,继续执行,在任意时间,自旋锁都可以防止多于一个的执行线程同时进入理解区,注意同一个锁可以用在多个位置—例如,对于给定数据的所有访问都可以得到保护和同步。
一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋(特别浪费处理器时间),所以自旋锁不应该被长时间持有,事实上,这点正是使用自旋锁的初衷,在短期间内进行轻量级加锁,还可以采取另外的方式来处理对锁的争用:让请求线程睡眠,直到锁重新可用时再唤醒它,这样处理器就不必循环等待,可以去执行其他代码,这也会带来一定的开销——这里有两次明显的上下文切换,被阻塞的线程要换出和换入。因此,持有自旋锁的时间最好小于完成两次上下文切换的耗时,当然我们大多数人不会无聊到去测量上下文切换的耗时,所以我们让持有自旋锁的时间应尽可能的短就可以了,信号量可以提供上述第二种机制,它使得在发生争用时,等待的线程能投入睡眠,而不是旋转。
自旋锁可以使用在中断处理程序中(此处不能使用信号量,因为它们会导致睡眠),在中断处理程序中使用自旋锁时,一定要在获取锁之前,首先禁止本地中断(在当前处理器上的中断请求),否则,中断处理程序就会打断正持有锁的内核代码,有可能会试图去争用这个已经持有的自旋锁,这样以来,中断处理程序就会自旋,等待该锁重新可用,但是锁的持有者在这个中断处理程序执行完毕前不可能运行,这正是我们在前一章节中提到的双重请求死锁,注意,需要关闭的只是当前处理器上的中断,如果中断发生在不同的处理器上,即使中断处理程序在同一锁上自旋,也不会妨碍锁的持有者(在不同处理器上)最终释放锁。
自旋锁的简单理解:
理解自旋锁最简单的方法是把它作为一个变量看待,该变量把一个临界区或者标记为“我当前正在运行,请稍等一会”或者标记为“我当前不在运行,可以被使用”。如果A执行单元首先进入例程,它将持有自旋锁,当B执行单元试图进入同一个例程时,将获知自旋锁已被持有,需等到A执行单元释放后才能进入。
自旋锁的API函数:
其实介绍的几种信号量和互斥机制,其底层源码都是使用自旋锁,可以理解为自旋锁的再包装。所以从这里就可以理解为什么自旋锁通常可以提供比信号量更高的性能。
自旋锁是一个互斥设备,他只能会两个值:“锁定”和“解锁”。它通常实现为某个整数之中的单个位。
“测试并设置”的操作必须以原子方式完成。
任何时候,只要内核代码拥有自旋锁,在相关CPU上的抢占就会被禁止。
适用于自旋锁的核心规则:
(1)任何拥有自旋锁的代码都必须使原子的,除服务中断外(某些情况下也不能放弃CPU,如中断服务也要获得自旋锁。为了避免这种锁陷阱,需要在拥有自旋锁时禁止中断),不能放弃CPU(如休眠,休眠可发生在许多无法预期的地方)。否则CPU将有可能永远自旋下去(死机)。
(2)拥有自旋锁的时间越短越好。
需要强调的是,自旋锁设计用于多处理器的同步机制,对于单处理器(对于单处理器并且不可抢占的内核来说,自旋锁什么也不作),内核在编译时不会引入自旋锁机制,对于可抢占的内核,它仅仅被用于设置内核的抢占机制是否开启的一个开关,也就是说加锁和解锁实际变成了禁止或开启内核抢占功能。如果内核不支持抢占,那么自旋锁根本就不会编译到内核中。
内核中使用spinlock_t类型来表示自旋锁,它定义在<linux/spinlock_types.h>:
- typedef struct {
- raw_spinlock_t raw_lock;
- #if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
- unsigned int break_lock;
- #endif
- } spinlock_t;
对于不支持SMP的内核来说,struct raw_spinlock_t什么也没有,是一个空结构。对于支持多处理器的内核来说,struct raw_spinlock_t定义为
- typedef struct {
- unsigned int slock;
- } raw_spinlock_t;<span style="color:#2a2a2a;"><span style="font-family:'Times New Roman';"> </span></span>
slock表示了自旋锁的状态,“1”表示自旋锁处于解锁状态(UNLOCK),“0”表示自旋锁处于上锁状态(LOCKED)。
break_lock表示当前是否由进程在等待自旋锁,显然,它只有在支持抢占的SMP内核上才起作用。
自旋锁的实现是一个复杂的过程,说它复杂不是因为需要多少代码或逻辑来实现它,其实它的实现代码很少。自旋锁的实现跟体系结构关系密切,核心代码基本也是由汇编语言写成,与体协结构相关的核心代码都放在相关的<asm/>目录下,比如<asm/spinlock.h>。对于我们驱动程序开发人员来说,我们没有必要了解这么spinlock的内部细节,如果你对它感兴趣,请参考阅读Linux内核源代码。对于我们驱动的spinlock接口,我们只需包括<linux/spinlock.h>头文件。在我们详细的介绍spinlock的API之前,我们先来看看自旋锁的一个基本使用格式:
使用示例:
- #include <linux/spinlock.h>
- spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;
- spin_lock(&mr_lock);
- /*
- 临界区
- */
- spin_unlock(&mr_lock);
从使用上来说,spinlock的API还很简单的,一般我们会用的的API如下表,其实它们都是定义在<linux/spinlock.h>中的宏接口,真正的实现在<asm/spinlock.h>中
-
#include <linux/spinlock.h>
SPIN_LOCK_UNLOCKED
DEFINE_SPINLOCK
spin_lock_init( spinlock_t *)
spin_lock(spinlock_t *)
spin_unlock(spinlock_t *)
spin_lock_irq(spinlock_t *)
spin_unlock_irq(spinlock_t *)
spin_lock_irqsace(spinlock_t *,unsigned long flags)
spin_unlock_irqsace(spinlock_t *, unsigned long flags)
spin_trylock(spinlock_t *)
spin_is_locked(spinlock_t *)
初始化
spinlock有两种初始化形式,一种是静态初始化,一种是动态初始化。对于静态的spinlock对象,我们用 SPIN_LOCK_UNLOCKED来初始化,它是一个宏。当然,我们也可以把声明spinlock和初始化它放在一起做,这就是 DEFINE_SPINLOCK宏的工作,因此,下面的两行代码是等价的。
- DEFINE_SPINLOCK (lock);
- spinlock_t lock = SPIN_LOCK_UNLOCKED;
spin_lock_init函数一般用来初始化动态创建的spinlock_t对象,它的参数是一个指向spinlock_t对象的指针。当然,它也可以初始化一个静态的没有初始化的spinlock_t对象。
- spinlock_t *lock
- ......
- spin_lock_init(lock);
获取锁
内核提供了多个函数用于获取一个自旋锁。
- spin_try_lock() 试图获得某个特定的自旋锁,如果该锁已经被争用,该方法会立刻返回一个非0值,而不会自旋等待锁被释放,如果成果获得了这个锁,那么就返回0.
- spin_is_locked() //方法和spin_try_lock()是一样的功效,该方法只做判断,并不生效.<span style="color:#2a2a2a;">如果是则返回非<span style="font-family:'Times New Roman';">0</span>,否则,返回<span style="font-family:'Times New Roman';">0</span>。</span>
- spin_lock(); //获取指定的自旋锁
- spin_lock_irq(); //禁止本地中断获取指定的锁
- spin_lock_irqsave(); //保存本地中断的状态,禁止本地中断,并获取指定的锁
自旋锁是可以使用在中断处理程序中的,这时需要使用具有关闭本地中断功能的函数,我们推荐使用 spin_lock_irqsave,因为它会保存加锁前的中断标志,这样就会正确恢复解锁时的中断标志。如果spin_lock_irq在加锁时中断是关闭的,那么在解锁时就会错误的开启中断。
释放锁
同获取锁相对应,内核提供了三个相对的函数来释放自旋锁。
- <span style="color:#000000;">spin_unlock:释放指定的自旋锁。
- spin_unlock_irq:释放自旋锁并激活本地中断。
- spin_unlock_irqsave:释放自旋锁,并恢复保存的本地中断状态。</span>
四、读写自旋锁
如果临界区保护的数据是可读可写的,那么只要没有写操作,对于读是可以支持并发操作的。对于这种只要求写操作是互斥的需求,如果还是使用自旋锁显然是无法满足这个要求(对于读操作实在是太浪费了)。为此内核提供了另一种锁-读写自旋锁,读自旋锁也叫共享自旋锁,写自旋锁也叫排他自旋锁。
读写自旋锁是一种比自旋锁粒度更小的锁机制,它保留了“自旋”的概念,但是在写操作方面,只能最多有一个写进程,在读操作方面,同时可以有多个读执行单元,当然,读和写也不能同时进行。
读写自旋锁的使用也普通自旋锁的使用很类似,首先要初始化读写自旋锁对象:
- //静态初始化
- rwlock_t rwlock = RW_LOCK_UNLOCKED;
- //动态初始化
- rwlock_t *rwlock;
- ...
- rw_lock_init(rwlock);
在读操作代码里对共享数据获取读自旋锁:
- read_lock(&rwlock);
- ...
- read_unlock(&rwlock);
在写操作代码里为共享数据获取写自旋锁:
- write_lock(&rwlock);
- ...
- write_unlock(&rwlock);
需要注意的是,如果有大量的写操作,会使写操作自旋在写自旋锁上而处于写饥饿状态(等待读自旋锁的全部释放),因为读自旋锁会自由的获取读自旋锁。
读写自旋锁的函数类似于普通自旋锁,这里就不一一介绍了,我们把它列在下面的表中。
- RW_LOCK_UNLOCKED
- rw_lock_init(rwlock_t *)
- read_lock(rwlock_t *)
- read_unlock(rwlock_t *)
- read_lock_irq(rwlock_t *)
- read_unlock_irq(rwlock_t *)
- read_lock_irqsave(rwlock_t *, unsigned long)
- read_unlock_irqsave(rwlock_t *, unsigned long)
- write_lock(rwlock_t *)
- write_unlock(rwlock_t *)
- write_lock_irq(rwlock_t *)
- write_unlock_irq(rwlock_t *)
- write_lock_irqsave(rwlock_t *, unsigned long)
- write_unlock_irqsave(rwlock_t *, unsigned long)
- rw_is_locked(rwlock_t *)
五、顺序琐
顺序琐(seqlock)是对读写锁的一种优化,若使用顺序琐,读执行单元绝不会被写执行单元阻塞,也就是说,读执行单元可以在写执行单元对被顺序琐保护的共享资源进行写操作时仍然可以继续读,而不必等待写执行单元完成写操作,写执行单元也不需要等待所有读执行单元完成读操作才去进行写操作。但是,写执行单元与写执行单元之间仍然是互斥的,即如果有写执行单元在进行写操作,其它写执行单元必须自旋在哪里,直到写执行单元释放了顺序琐。
如果读执行单元在读操作期间,写执行单元已经发生了写操作,那么,读执行单元必须重新读取数据,以便确保得到的数据是完整的,这种锁在读写同时进行的概率比较小时,性能是非常好的,而且它允许读写同时进行,因而更大的提高了并发性,
注意,顺序琐由一个限制,就是它必须被保护的共享资源不含有指针,因为写执行单元可能使得指针失效,但读执行单元如果正要访问该指针,将导致Oops。
六、信号量
Linux中的信号量是一种睡眠锁,如果有一个任务试图获得一个已经被占用的信号量时,信号量会将其推进一个等待队列,然后让其睡眠,这时处理器能重获自由,从而去执行其它代码,当持有信号量的进程将信号量释放后,处于等待队列中的哪个任务被唤醒,并获得该信号量。
信号量,或旗标,就是我们在操作系统里学习的经典的P/V原语操作。
P:如果信号量值大于0,则递减信号量的值,程序继续执行,否则,睡眠等待信号量大于0。
V:递增信号量的值,如果递增的信号量的值大于0,则唤醒等待的进程。
信号量的值确定了同时可以有多少个进程可以同时进入临界区,如果信号量的初始值始1,这信号量就是互斥信号量(MUTEX)。对于大于1的非0值信号量,也可称为计数信号量(counting
semaphore)。对于一般的驱动程序使用的信号量都是互斥信号量。
类似于自旋锁,信号量的实现也与体系结构密切相关,具体的实现定义在<asm/semaphore.h>头文件中,对于x86_32系统来说,它的定义如下:
- struct semaphore {
- <span style="color:#ff9900;">atomic_t</span> count;
- int sleepers;
- wait_queue_head_t wait;
- };
信号量的初始值count是atomic_t类型的,这是一个原子操作类型,它也是一个内核同步技术,可见信号量是基于原子操作的。我们会在后面原子操作部分对原子操作做详细介绍。
信号量的使用类似于自旋锁,包括创建、获取和释放。我们还是来先展示信号量的基本使用形式:
- static DECLARE_MUTEX(my_sem);
- ......
- if (down_interruptible(&my_sem))
- {
- return -ERESTARTSYS;
- }
- ......
- up(&my_sem);
Linux内核中的信号量函数接口如下:
|
static DECLARE_SEMAPHORE_GENERIC(name, count); |
初始化信号量
信号量的初始化包括静态初始化和动态初始化。静态初始化用于静态的声明并初始化信号量。
|
static DECLARE_SEMAPHORE_GENERIC(name, count); |
对于动态声明或创建的信号量,可以使用如下函数进行初始化:
|
seam_init(sem, count); |
显然,带有MUTEX的函数始初始化互斥信号量。LOCKED则初始化信号量为锁状态。
使用信号量
- down_interruptible(struct semaphore *);
- <span style="color:#3366ff;">使进程进入可中断的睡眠状态。关于进程状态的详细细节,我们在内核的进程管理里在做详细介绍。
- </span>down(struct semaphore *) 尝试获取指定的信号量,如果信号量已经被使用了,则进程进入不可中断的睡眠状态。
- down_trylock(struct semaphore *) 尝试获取信号量,如果获取成功则返回0,失败则会立即返回非0。
- up(struct semaphore *) 释放信号量,如果信号量上的睡眠队列不为空,则唤醒其中一个等待进程。
七、读写信号量
类似于自旋锁,信号量也有读写信号量。读写信号量API定义在<linux/rwsem.h>头文件中,它的定义其实也是体系结构相关的,因此具体实现定义在<asm/rwsem.h>头文件中,以下是x86的例子:
|
struct rw_semaphore { |
首先要说明的是所有的读写信号量都是互斥信号量。读锁是共享锁,就是同时允许多个读进程持有该信号量,但写锁是独占锁,同时只能有一个写锁持有该互斥信号量。显然,写锁是排他的,包括排斥读锁。由于写锁是共享锁,它允许多个读进程持有该锁,只要没有进程持有写锁,它就始终会成功持有该锁,因此这会造成写进程写饥饿状态。
在使用读写信号量前先要初始化,就像你所想到的,它在使用上几乎与读写自旋锁一致。先来看看读写信号量的创建和初始化:
|
//静态初始化 |
读进程获取信号量保护临界区数据:
|
down_read(&rw_sem); |
写进程获取信号量保护临界区数据:
|
down_write(&rw_sem); |
更多的读写信号量API请参考下表:
|
#include <linux/rwsem.h> |
同自旋锁一样,down_read_trylock和down_write_trylock会尝试着获取信号量,如果获取成功则返回1,否则返回0。奇怪为什么返回值与信号量的对应函数相反,使用是一定要小心这点。
九、自旋锁和信号量区别
在驱动程序中,当多个线程同时访问相同的资源时(驱动程序中的全局变量是一种典型的共享资源),可能会引发"竞态",因此我们必须对共享资源进行并发控制。Linux内核中解决并发控制的最常用方法是自旋锁与信号量(绝大多数时候作为互斥锁使用)。
自旋锁与信号量"类似而不类",类似说的是它们功能上的相似性,"不类"指代它们在本质和实现机理上完全不一样,不属于一类。
自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环查看是否该自旋锁的保持者已经释放了锁,"自旋"就是"在原地打转"。而信号量则引起调用者睡眠,它把进程从运行队列上拖出去,除非获得锁。这就是它们的"不类"。
但是,无论是信号量,还是自旋锁,在任何时刻,最多只能有一个保持者,即在任何时刻最多只能有一个执行单元获得锁。这就是它们的"类似"。
鉴于自旋锁与信号量的上述特点,一般而言,自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用;信号量适合于保持时间较长的情况,会只能在进程上下文使用。如果被保护的共享资源只在进程上下文访问,则可以以信号量来保护该共享资源,如果对共享资源的访问时间非常短,自旋锁也是好的选择。但是,如果被保护的共享资源需要在中断上下文访问(包括底半部即中断处理句柄和顶半部即软中断),就必须使用自旋锁。
区别总结如下:
1、由于争用信号量的进程在等待锁重新变为可用时会睡眠,所以信号量适用于锁会被长时间持有的情况。
2、相反,锁被短时间持有时,使用信号量就不太适宜了,因为睡眠引起的耗时可能比锁被占用的全部时间还要长。
3、由于执行线程在锁被争用时会睡眠,所以只能在进程上下文中才能获取信号量锁,因为在中断上下文中(使用自旋锁)是不能进行调度的。
4、你可以在持有信号量时去睡眠(当然你也可能并不需要睡眠),因为当其它进程试图获得同一信号量时不会因此而死锁,(因为该进程也只是去睡眠而已,而你最终会继续执行的)。
5、在你占用信号量的同时不能占用自旋锁,因为在你等待信号量时可能会睡眠,而在持有自旋锁时是不允许睡眠的。
6、信号量锁保护的临界区可包含可能引起阻塞的代码,而自旋锁则绝对要避免用来保护包含这样代码的临界区,因为阻塞意味着要进行进程的切换,如果进程被切换出去后,另一进程企图获取本自旋锁,死锁就会发生。
7、信号量不同于自旋锁,它不会禁止内核抢占(自旋锁被持有时,内核不能被抢占),所以持有信号量的代码可以被抢占,这意味着信号量不会对调度的等待时间带来负面影响。
除了以上介绍的同步机制方法以外,还有BKL(大内核锁),Seq锁等。
BKL是一个全局自旋锁,使用它主要是为了方便实现从Linux最初的SMP过度到细粒度加锁机制。
Seq锁用于读写共享数据,实现这样锁只要依靠一个序列计数器。
linux内核开发总结----内核同步与异步
杂项:
gcc编译器内置宏变量:
__FILE__ :当前文件名
__FUNCTION__ :当前函数名;
__LINE__ :的文件中的行数
__DATA__ :编译时的日期
__TIME__ :编译时间
gcc -E 预处理
-S 汇编
-c 编译
as 汇编器
ld 链接器
1.属性声名:指定一个属性只需在其声明后添加__attribute__((ATTRIBUTE));
例如:void do_exit(int n)__attribute((noreturn));
属性:
noreturn:表示函数从不返回任何值。
format:表示函数使用printf,scanf或strftime风格的参数,根据格式串检查参数类型。
unused:表示该函数或变量可能不会被用到。
aligned(n):指定变量,结构体或联合体的对齐方式,以字节为单位。
packed:作用于变量或结构体成员使用最小可能的对齐。
2.内核模块参数:
MODULE_LICENSE("Dual BSD/GPL"); //声明模块采用BSD/GPL双license
参数类型 参数名;(定义一个参数)
module_parma(参数名,参数类型,参数读/写权限(/sys/module/xxx/parameters));
insmod 模块名 参数名=参数值
参数类型:byte,short,ushort,int,uint,long,ulong,bool,charp(字符指针)
读写权限:S_IRWXU,S_IRUSR
EXPORT_SYMBOL(符号名);
EXPORT_SYMBOL_GPL(符号名);
/proc/kallsyms 内核符号表
可选:
MODULE_AUTHOR();作者
MODULE_DESCRIPTION();描述
MODULE_VERSION();版本
MODULE_DEVICE_TABLE();设备表
MODULE_ALIAS();别名
3.内核空间与用户空间传递数据
用户空间--》内核空间
unsigned long copy_from_user(void*to,const void*from,unsigned long n);
to:内核目标地址
from:用户空间源地址
n:要拷贝的字节数
返回:成功返回0,失败返回没有拷贝成功的字节数。
int get_user(data,ptr);
data:可以是字节,半字,字,双字类型的内核变量。
ptr:用户空间内存指针。
返回:成功返回0,失败返回非0.
内核空间--》用户空间
unsigned long copt_to_user(void*to,const void*from,unsigned long n);
to:用户空间目标地址
from:内核空间源地址
n:要拷贝的字节数。
返回:成功返回0,失败返回没有拷贝成功的字节数。
int put_user(data,ptr);
data:可以是字节,半字,字,双字类型的内核变量。
ptr:用户空间内存指针。
返回:成功返回0,失败返回非0
用户空间内存可访问性验证:
int access_ok(int type,const void*addr,unsigned long size);
type:取值为VERIFY_READ 或VERIFY_WRITE
addr:待验证的用户内存地址
size:待验证的用户内存长度
返回值:返回非0代表用户内存可访问 ,返回0代表失败
调度:SCHED_NORMAL,SCHED_FIFO,SCHED_RR,SCHED_BATCH,SCHED_IDLE
主动调度:
current->state=TASK_INTERRUPTIBLE;
schedule();
schedule_timeout();
被动调度:中断,时间片
4.procfs:
struct proc_dir_entry{
mode_t mode;文件权限保护位
struct module *owner;当前拥有者
read_proc_t *read_proc;读函数
write_proc_t *write_proc;写函数
}
typedef int(read_proc_t)(char*page,char**start,off_t off,int count,int *eof,void*data)
page:要返回给用户的信息存放页面,最多一个PAGE_SIZE.
start:一般不使用 data:一般不使有
off:读数据偏移
count:用户要读取的数据长度
eof:读到文件结尾时,需要把*eof设为1
typedef int(write_proc_t)(struct file*file,const char __user*buffer,unsigned long count,void*data)
file:该procfs文件对应的内核struct file结构。
buffer:用户要写入的数据在用户空间的指针
count:用户要写入的数据大小
data:一般不使用
创建目录:
struct proc_dir_entry*proc_mkdir(char*name,struct proc_dir_entry*parent);
创建文件:
struct proc_dir_entry*create_proc_entry(char*name,mode_t mode,struct proc_dir_entry*parent);
删除文件:
void remove_proc_entry(char*name,struct proc_dir_entry*parent);
5,内核线程:
内核线程: 内核支持,多线程内核。
轻量级进程(LWP): 由内核支持的用户线程(各种系统调用)。是基于内核线程的抽象。
用户线程: 基于用户空间的线程库。用户线程的建立,同步,销毁,调度完全在用户空间完成。
创建内核线程:
linux/sched.h
pid_t kernel_thread(int(*fn)(void*),void*arg,unsigned long flags);//fork实现原理
创建线程:
linux/kthread.h
struct task_struct*kthread_creat(int(*threadfn)(void*data),void*data,char namefmt[],...);
wake_up_process(struct task_struct*p);//唤醒指定的线程
创建并立即唤醒线程:
#definekthead_run(threadfn,data,namefmt,...) \
{ struct task_struct *__k=kthread_create(threadfn,data,namefmt,##__VA_ARGS__); \
if(!IS_ERR(__k))\
wake_up_process(__k); \
k; \
}
绑定到指定的CPU核:
voidkthread_bind(struct task_struct*k,unsigned int cpu);
int kthread_stop(struct task_struct*k);结束指定的线程
线程函数内API:
int kthread_should_stop(void);//线程函数内判断是否收到结束信号
set_current_state(TASK_INTERRUPTIBLE);//设置进程当前状态
schedule();调度
schedule_timeout();//定时调度
一,Linux 内核同步方法
竞态条件 两个或更多线程同时操作资源时将会导致不一致的结果。
临界段 用于协调对共享资源的访问的代码段。
互斥锁 确保对共享资源进行排他访问的软件特性。
死锁 由两个或更多进程和资源锁导致的一种特殊情形,将会降低进程的工作效率。
中断屏蔽:
屏蔽本CPU中断: local_irq_disable();local_irq_save();
critical section //临界区
开本CPU中断: local_irq_enable();local_irq_restore();
屏蔽本CPU中断下半部:local_bh_disable();
使能本CPU中断下半部:local_bh_enable();
1.原子操作:
typedef struct {
int counter;
} atomic_t;
定义一个原子变量: atomic_t my_counter;
定义并初始化原子变量: atomic_t my_counter=ATOMIC_INIT(0);
设置原子变量: atomic_set( &my_counter, n );
读原子变量的值:val = atomic_read( &my_counter );
原子变量+n: atomic_add( 1, &my_counter ); val=atomic_add_return(value,&atomic)
原子变量+1: atomic_inc( &my_counter );val=atomic_inc_return(atomic_t*v);
原子变量-n:atomic_sub( 1, &my_counter );val=atomic_sub_return(value,&atomic)
原子变量-1:atomic_dec( &my_counter );var=atomic_dec_return(atomic_t*v);
改变原子变量的值并且测试是否为0
atomic_sub_and_test( 1, &my_counter )
atomic_dec_and_test( &my_counter )
atomic_inc_and_test( &my_counter )
atomic_add_negative( 1, &my_counter )
位原子操作:
设置位:set_bit(nr,void*addr);//设置addr地址的第nr位为1.
清除位:clear_bit(nr,void*addr);//设置addr地址的第nr位为0.
改变位:change_bit(nr,void*addr);//对addr地址的第nr位进行反置。
测试位:test_bit(nr,void*addr);//返回addr地址的第nr位。
测试并操作位:
int test_and_set_bit(nr,void*addr);
int test_and_clear_bit(nr,void*addr);
int test_and_change_bit(nr,void*addr);
位掩码
unsigned long my_bitmask;
atomic_clear_mask( 0, &my_bitmask );
atomic_set_mask( (1<<24), &my_bitmask );
2.自旋锁(用于SMP,单CPU时禁止内核抢占)
定义自旋锁:spinlock_t my_spinlock = SPIN_LOCK_UNLOCKED;
DEFINE_SPINLOCK( my_spinlock );
初始化自旋锁:spin_lock_init( &my_spinlock );
加锁:spin_lock( &my_spinlock );spin_trylock(lock);
临界区...
解锁:spin_unlock( &my_spinlock );
(为了避免在临界区中还受到中断和底半部bh的影响)
加锁并关本地CPU中断:spin_lock_irqsave( &my_spinlock, flags );
//critical section
解锁并恢复本地CPU中断:spin_unlock_irqrestore( &my_spinlock, flags );
加锁并关本地CPU软中断:spin_lock_bh( &my_spinlock );
// critical section
加锁并恢复本地CPU软中断:spin_unlock_bh( &my_spinlock );
3.读写(自旋)锁-->RCU(读拷贝更新):可以看作读写锁的高性能版。
读写锁变量:rwlock_t my_rwlock=RW_LOCK_LOCKED;//静态初始化
读写锁初始化:rwlock_init( &my_rwlock );
写锁加锁:write_lock( &my_rwlock );
write_lock_irq(lock);
write_lock_irqsave(lock,flags);
write_lock_bh(lock);
write_trylock(lock);
//critical section -- can read and write
写锁解锁:write_unlock( &my_rwlock );
write_unlock_irq(lock);
write_unlock_irqrestore(lock,flags);
write_unlock_bh(lock);
write_unlock_irq(lock);
write_unlock_irqrestore(lock,flags);
write_unlock_bh(lock);
读锁加锁: read_lock( &my_rwlock );
read_lock_irq(lock);
read_lock_irqsave(lock,unsigned long flags);
read_lock_bh(lock);
//critical section -- can read only
读锁解锁:read_unlock( &my_rwlock );
read_unlock_irq(lock);
read_unlock_irqrestore(lock,flags);
read_unlock_bh(lock);
4.顺序锁:seqlock是对读写锁的一种优化。要求被保护的共享资源不含有指针。
定义: seqlock_t sl;
初始化: seqlock_init(&sl);
读顺序锁: unsigned rsl=read_seqbegin(seqlock_t &sl);
读顺序锁检查: int read_seqretry(seqlock_t*sl,unsigned start);//对共享资源访问完后,检查在读访问期间是否有写操作发生。
使用模型:
do{
sequnum=read_seqbegin(&sl);
......
critical section;临界区
.....
}while(read_seqretry(&sl,seqnum));
写顺序锁锁定:write_seqlock(seqlock_t*sl);
write_tryseqlock(seqlock_t*sl);
write_seqlock_irq(seqlock_t*sl);
write_seqlock_irqsave(seqlock_t*lock,unsigned long flags);
write_seqlock_bh(seqlock_t*lock);
......critical section;//临界区
写顺序锁解锁:
write_sequnlock(seqlock_t*sl);
write_sequnlock_irq(seqlock_t*sl);
write_sequnlock_irqrestore(seqlock_t*lock,unsigned long flags);
write_sequnlock_bh(seqlock_t*lock);
5.互斥体(锁)(信号量为1的特例)
声明一个互斥体:
struct mutex my_mutex;
初始化互斥体: mutex_init(&my_mutex);
定义一个互斥锁:DEFINE_MUTEX(my_mutex);
非阻塞加锁: void fastcall mutex_trylock(&my_mutex);
阻塞加锁: void fastcall mutex_lock(&my_mutex);
可中断阻塞加锁:void fastcall mutex_lock_interruptible(&my_mutex);
...critical section;临界区
解锁:void fastcall mutex_unlock( &my_mutex );
检查锁状态:mutex_is_locked( &my_mutex );
6.信号量(初始化为0时,用于同步)
struct semaphore {
raw_spinlock_tlock;
unsigned int count;
struct list_headwait_list;
};
定义信号量:struct semaphore sem;
初始化信号量:sema_init(struct semaphore*sem,int val);//初始化信号量sem,并设置count=val;
init_MUTEX(struct semaphore*sem);//初始化信号量sem,并设置count=1;
init_MUTEX_LOCKED(struct semaphore*sem);
//初始化信号量,并将count=0。也就是创建时就处于锁定状态。
获取信号量:
void down(struct semaphore*sem);//获取信号量,可能睡眠,不能用于中断上下文
int down_interruptible(struct semaphore*sem);//获取信号量,信号量不可用时,
把进程设置为TASK_INTERRUPTIBLE的睡眠状态,
返回值0代表获取信号量正常返回,非0代表被信号打断返回。
int down_killable(struct semaphore*sem);//获取信号量,当信号量不可用时,把进程设置为TASK_KILLABLE的睡眠状态。
int down_trylock(struct semaphore*sem);//不会引起睡眠,可在中断上下文中使用。
......critical section临界区
释放信号量:
void up(struct semaphore*sem);//释放信号量sem,实质上把sem的值加1,
如果sem的值为非正数,表明有任务在等待,因此需要唤醒等待者。
7.完成变量completion;
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
定义完成变量:
struct completion my_completion;
初始化完成变量:
init_completion(&my_completion);
DECLARE_COMPLETION(my_completion);
DECLARE_COMPLETION_ONSTACK(work);
等待完成变量:
void wait_for_completion(struct completion *c);
唤醒完成变量:
void complete(struct completion*c);
void complete_all(struct completion*c);
8,大内核锁BLK(越来越少用)
lock_kernel();
unlock_kernel();
二,内核异步方法(API)
1.linux中断
中断请求号IRQ->中断向量-> 224:irq_desc_t irq_desc[NR_IRQ](前32个为异常和NMI,32~48为INTR,48~255为软中断)
中断线->中断处理程序---------->中断服务程序(ISR)
中断上半部(Tob Half) 中断下半部(Bottom Half)
软中断(softirq,tasklet,work queue)
中断申请:
int request_irq(unsigned int irq,irq_handler_t handler,unsigned long irqflags,const char*name,void*dev_id);
irq:想要申请的中断号
handler:想要注册的中断处理函数(返回:IRQ_NONE:未做处理,IRQ_HANDLED:正常处理后返回该值)
static irqreturn_t (*irq_handler_t)(int irq,void*dev_id);
irqflags:中断标志
IRQF_SHARED:表示多个设备共享中断
IRQF_SAMPLE_RANDOM:用于随机数种子的随机采样
IRQF_TRIGGER_RISING:上升沿触发中断
IRQF_TRIGGER_FALLING:下降沿触发中断
IRQF_TRIGGER_HIGH:高电平触发中断
IRQF_TRIGGER_LOW:低电平触发中断
name:中断设备的名称
dev_id:传递给中断处理函数的指针,通常用于共享中断时传递设备结构体指针
成功返回0,失败返回负值。
-EINVAL:表示申请的中断号无效或中断处理函数指针为空
-EBUSY:表示中断已经被占用并且不能共享
中断释放:
void free_irq(unsigned int irq,void *dev_id);
使能和屏蔽中断:
void disable_irq(unsigned int irq);屏蔽指定的中断 void disable_irq_nosync(unsigned int irq);屏蔽指定的中断,立即返回,不等待可能正在执行的中断处理程序。 void enable_irq(unsigned int irq);使能指定的中断
本CPU全部中断:
local_irq_disable();local_irq_save();......local_irq_enable();local_irq_restore();
软中断和tasklet:
local_bh_disable();local_bh_enable();
2.中断下半部:(软中断,tasklet仍然运行于中断上下文,工作队列是进程上下文) 2.1.软中断;用软件方式模拟硬件中断,来实现异步执行。 声明软中断:<linux/interrupt.h>中定义一个枚举类型来静态声明软中断。HI_SOFTIRQ 0TIMER_SOFTIRQ 1NET_TX_SOFTIRQ2NET_RX_SOFTIRQ3......RCU_SOFTIRQ //建立一个新的软中断在此之前添加一项NR_SOFTIRQS 注册软中断: open_softirq(int nr,void(*action)(struct softirq_action*)); 触发软中断: raise_softirq(int nr);raise_softirq_irqoff(int nr); 唤醒软中断处理线程ksoftirqd:void wakeup_softirqd(void); 2.2.tasklet:基于软中断 tasklet定义并初始化:DECLARE_TASKLET(taskletname,task_func,data);DECLARE_TASKLET_DISABLED(name,func,data);tasklet_init(taskletname,task_func,data); tasklet处理函数:void tasklet_func(unsigned long data); tasklet调用:void tasklet_schedule(struct tasklet_struct*taskletname);void tasklet_hi_schedule(struct tasklet_struct*d); tasklet禁止:void tasklet_disable_nosync( struct tasklet_struct * );void tasklet_disable( struct tasklet_struct * ); tasklet使能:void tasklet_enable( struct tasklet_struct * );void tasklet_hi_enable( struct tasklet_struct * ); tasklet关闭:void tasklet_kill( struct tasklet_struct * );void tasklet_kill_immediate( struct tasklet_struct *, unsigned int cpu ); 2.3.工作队列:把推后的工作交由内核线程去执行。允许重新调度或睡眠。 #include <linux/workqueu.h> #include <linux/kthread.h> #include <linux/sched.h> 工作数据类型定义(2.6.20后分成两部分):struct work_struct { atomic_long_t data;struct list_head entry;工作数据链成员work_func_t func;工作处理函数,由用户实现 };struct delayed_work { struct work_struct work;工作结构体struct timer_list timer;推后执行的定时器/* target workqueue and CPU ->timer uses to queue ->work */struct workqueue_struct *wq;int cpu; }; 2.3.1,工作 初始化工作:(使用默认的工作者线程) 声明并初始化工作: DECLARE_WORK(name,func,data); 初始化工作队列: INIT_WORK(struct work_struct*work,work_func_t func); 初始化廷迟工作队列: INIT_DELAYED_WORK(struct delayed_work*work,wrok_func_t func); 调度工作:int schedule_work(struct work_struct*work);//把工作提交给缺省的工作者线程处理;内部是queue_work(system_wq, work);int schedule_delayed_work(struct delayed_work*work,unsigned long delay);把工作提交给缺省的工作者线程处理,并指定延迟时间。 刷新工作队列:(唤配工作线程)void flush_scheduled_work(void); //刷新缺省的工作队列,此函数一直等待,直到队列中的所有工作完成。bool flush_delayed_work(struc delayed_work*dwork);bool flush_work(struct work_struct*work); 取消延迟工作:int cancel_delayed_work(struct delayed_work*work); //取消缺省工作队列中处于等待状态的延迟工作。bool cancel_delayed_work_sync(struct delayed_work*work); 取消工作:int cancel_work_sync(struct work_struct*work); //取消缺省工作队列中处于等待状态的工作,如果工作已经开始执行,该函数会阻塞直到工作处理函数完成。 2.3.2,工作者线程:默认情况下,每个CPU均有一个events/n的工作者线程,当调用schedule_work()时,这个工作者线会被唤醒去执行工作链表上的所有工作。 工作队列数据类型: struct workqueue_struct{ ......const char*name;struct list_head list;...... } 创建工作队列:struct workqueue_struct*create_workqueue(const char*name); stuct workqueue_struct *create_singlethread_workqueue(const char* name); (3.x内核API) struct workqueue_struct *alloc_workqueue(fmt, flags, max_active,args...); //3.9内核中工作队列使用线程池,全部由kworker/n 执行 //创建新的工作队列和相应的工作者线程, 调度工作:int queue_work(struct workqueue_struct*wq,struct work_struct*work);//调度工作,类似于schedule_work()函数,将指定的工作work加入到工作队列wq. 调度延迟工作:int queue_delayed_work(struct workqueue_struct*wq,struct delayed_work*dwork,unsigned long delay);//调度工作,类似于schedule_work()函数,将延迟工作work提交给工作队列wq,并指定延迟时间. 刷新工作队列:void flush_workqueue(struct workqueue_struct*wq);//刷新工作队列wq,此函数一直等待,直到队列中的所有工作完成。 销毁工作队列:void destroy_workqueue(struct workqueue_struct*wq);//销毁工作队列wq 3,内核定时器 struct timer_list { struct list_head entry;链表接入件unsigned long expires;到期时间struct tvec_base *base;void (*function)(unsigned long);超时处理函数unsigned long data;超时处理函数参数int slack; } struct timer_list mytimer; DEFINE_TIMER(name,function,expires,data); TIMER_INITIALIZER(function,expires,data); 初始化计时器: void init_timer(struct timer_list *timer); 安装计时器: setup_timer(timer, fn, data) 添加定时器: add_timer(timer);//修改expieres+n*jiffies,再次添加。 修改计时器: mod_timer(struct timer_list*timer,unsigned long expires); 删除计时器: del_timer(struct timer_list*timer); 检测计时器是否在等待(还没发出):int timer_pending(struct timer_list*timer); 4,高精度计时器hrtimer-->基于ktime_t void hrtimer_init(struct hrtimer *timer, clockid_t clock_id,enum hrtimer_mode mode); int hrtimer_start(struct hrtimer *timer, ktime_t tim, const enum hrtimer_mode mode); int hrtimer_cancel(struct hrtimer *timer); int hrtimer_try_to_cancel(struct hrtimer *timer) 5,等待队列wait queue 定义等待队列头:wait_queue_head_t wqh; 初始化等待队列头:init_waitqueue_head(wait_queue_head_t*wqh); 定义并初始化等待队列头: DECLARE_WAIT_QUEUE_HEAD(name); 定义等待队列: wait_queue_t name; 初始化等待队列: init_wait(name); 定义并初始化等待队列:DECLARE_WAITQUEUE(name, tsk); 添加等待队列:add_wait_queue(wait_queue_head_t*q,wait_queue_t*wait);//将等待队列wait加入到等待队列头q执行的等待队列链表中去。或者从中删除。 移除等待队列:remove_wait_queue(wait_queue_head_t*q,wait_queue_t*wait); 等待事情: wait_event(qhead,condition);//当条件为真时,立即返回, 否则进入TASK_UNINTERRUPTIBLE的睡眠状态,并挂在queue指定的等待队列上。 wait_event_interruptible(qhead,condition); add_wait_queue(qhead,condition);//当条件为真时,立即返回, 否则进入TASK_INTERRUPTIBLE的睡眠状态,并挂在queue指定的等待队列上。 wait_event_killable(qhead,condition);//当条件为真时,立即返回, 否则进入TASK_KILLABLE的睡眠状态,并挂在queue指定的等待队列上。 wait_event_timeout(qhead,condition,timeout);//当条件为真时,立即返回, 否则进入TASK_UNINTERRUPTIBLE的睡眠状态,并挂在queue指定的等待队列上,当阻塞时间timeout超时后,立即返回。wait_event_interruptible_timeout(qhead,condition,timeout);//当条件为真时,立即返回, 否则进入TASK_INTERRUPTIBLE的睡眠状态,并挂在queue指定的等待队列上,当阻塞时间timeout超时后,立即返回。 唤醒队列: wake_up(wait_queue_head_t*queue); wake_up_interruptible(wait_queue_head_t*queue); //唤醒由queue指向的等待队列头链表中所有等待队列对应的进程。 在等待队列中睡眠: sleep_on(wait_queue_head_t*q);//让进程进入不可中断的睡眠,并将它放入等待队列。 interruptible_sleep_on(wait_queue_head_t*q);//让进程进入可中断的睡眠,并将它放入等待队列。 等待队列头使用: init_waitqueue_head(wait_queue_head_t*wqh);wait_event_interruptible(qhead,condition);wake_up_interruptible(wait_queue_head_t*queue); 等待队列使用: init_waitqueue_head(wait_queue_head_t*qhead);DECLARE_WAITQUEUE(name, current);add_wait_queue(&qhead,&name);set_current_state(TASK_INTERRUPTIBLE);schedule();wake_up_interruptible(*qhead);remove_wait_queue(&qhead,&name);set_current_state(TASK_RUNNING); 内核等待队列一般使用方法:1.定义和初始化等待队列,将进程状态改变,并将等待队列放入等待队列数据链中2.改变进程状态a>,set_current_state(state_value);b>,set_task_state(task,state_value);c>,current->state=TASK_INTERRUPTIBLE;3.放弃CPU,调度其它进程执行:schedule();//schedule_timeout();4.进程被其它地方唤醒,将等待队列移出等待队列头指向的数据链。 6,内核链表 struct mydata{ ... struct list_head list } struct list_head*pos,*q; struct mydata*obj; 创建并初始化链表头:LIST_HEAD(myhead); 初始化链表头: struct list_head myhead = LIST_HEAD_INIT(myhead);obj=kmalloc(sizeof(struct mydata),GFP_KERNEL);obj->...对象成员操作list_add(&obj->list,&myhead) 插入链表前面:list_add(struct list_head*new,struct list_head*head); 插入链表后面:list_add_tail(struct list_head*new,struct list_head*head); for循环获取链表中的链入件: list_for_each(pos,&myhead){ 从链入件得到对象:list_entry(pos,struct mydata,list); //list_entry(ptr,type,member)=container_of(ptr, type, member) } for循环获取链表中的对象:list_for_each_entry(obj,&myhead,list){};//list_for_each_entry(pos,head,member){} (删除时)for循环取链表中的链入件:list_for_each_safe(pos,q,&myhead){struct mydata*tmp;tmp=list_entry(pos,struct mydata,list); 删除一个链接件: list_del(pos);kfree(tmp);} 把一个链表插入一个链表前:list_splice(struct list_head*list,struct list_head*head);list_splice_tail(list,head); 判断链表是否为空:list_empty(struct list_head*head); 7,轮询:(字符轮询 驱动实现) pull_wait(); 8,异步通知队列:(支持异步通知机制设备驱动实现) struct fasync_struct { spinlock_t fa_lock;int magic;int fa_fd;struct fasync_struct*fa_next; /* singly linked list */struct file *fa_file;struct rcu_headfa_rcu; }; 常见用法: 设备驱动中声明一个该类型变量:struct xxx_cdev{struct cdev chrdev;...struct fasync_struct *async_queue;} 设备驱动中实现fasync():static int xxx_fasync(){struct xxx_cdev*dev=filep->private_data;return fasync_helper(fd,filp,mode,&dev->async_queue);} fasync_helper()函数;初始化异步事件通知队列,包括分配内存和设置属性;释放初始化时分配的内存。 kill_fasync(struct fasync_struct**fp,int sig,int band)函数; 在设备资源可以获得时,应该调用此函数释放SIGIO信号,(band)可读时为POLL_IN,可写时为POLL_OUT;
linux环境内存分配原理
Linux的虚拟内存管理有几个关键概念:
Linux 虚拟地址空间如何分布?malloc和free是如何分配和释放内存?如何查看堆内内存的碎片情况?既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢 ?
Linux 的虚拟内存管理有几个关键概念:
1、每个进程都有独立的虚拟地址空间,进程访问的虚拟地址并不是真正的物理地址;
2、虚拟地址可通过每个进程上的页表(在每个进程的内核虚拟地址空间)与物理地址进行映射,获得真正物理地址;
3、如果虚拟地址对应物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
一、Linux 虚拟地址空间如何分布?
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别为:
1、只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
2、数据段:保存全局变量、静态变量的空间;
3、堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
4、文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
5、栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
6、内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
下图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。

32 位系统有4G 的地址空间::
其中 0x08048000~0xbfffffff 是用户空间,0xc0000000~0xffffffff 是内核空间,包括内核代码和数据、与进程相关的数据结构(如页表、内核栈)等。另外,%esp 执行栈顶,往低地址方向变化;brk/sbrk 函数控制堆顶_edata往高地址方向变化。
64位系统结果怎样呢? 64 位系统是否拥有 2^64 的地址空间吗?
事实上, 64 位系统的虚拟地址空间划分发生了改变:
1、地址空间大小不是2^32,也不是2^64,而一般是2^48。
因为并不需要 2^64 这么大的寻址空间,过大空间只会导致资源的浪费。64位Linux一般使用48位来表示虚拟地址空间,40位表示物理地址,
这可通过#cat /proc/cpuinfo 来查看:
2、其中,0x0000000000000000~0x00007fffffffffff 表示用户空间, 0xFFFF800000000000~ 0xFFFFFFFFFFFFFFFF 表示内核空间,共提供 256TB(2^48) 的寻址空间。
这两个区间的特点是,第 47 位与 48~63 位相同,若这些位为 0 表示用户空间,否则表示内核空间。
3、用户空间由低地址到高地址仍然是只读段、数据段、堆、文件映射区域和栈;

二、malloc和free是如何分配和释放内存?
如何查看进程发生缺页中断的次数?
用# ps -o majflt,minflt -C program 命令查看

majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
可以用命令ps -o majflt minflt -C program来查看进程的majflt, minflt的值,这两个值都是累加值,从进程启动开始累加。在对高性能要求的程序做压力测试的时候,我们可以多关注一下这两个值。
如果一个进程使用了mmap将很大的数据文件映射到进程的虚拟地址空间,我们需要重点关注majflt的值,因为相比minflt,majflt对于性能的损害是致命的,随机读一次磁盘的耗时数量级在几个毫秒,而minflt只有在大量的时候才会对性能产生影响。
发成缺页中断后,执行了那些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
1、检查要访问的虚拟地址是否合法
2、查找/分配一个物理页
3、填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
4、建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
内存分配的原理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
下面以一个例子来说明内存分配的原理:
情况一、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:

2、进程调用A=malloc(30K)以后,内存空间如图2:
3、进程调用B=malloc(40K)以后,内存空间如图3。
情况二、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:

5、进程调用D=malloc(100K)以后,内存空间如图5;
6、进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。

8、进程调用free(D)以后,如图8所示:
真相大白
说完内存分配的原理,那么被测模块在内核态cpu消耗高的原因就很清楚了:每次请求来都malloc一块2M的内存,默认情况下,malloc调用mmap分配内存,请求结束的时候,调用munmap释放内存。假设每个请求需要6个物理页,那么每个请求就会产生6个缺页中断,在2000的压力下,每秒就产生了10000多次缺页中断,这些缺页中断不需要读取磁盘解决,所以叫做minflt;缺页中断在内核态执行,因此进程的内核态cpu消耗很大。缺页中断分散在整个请求的处理过程中,所以表现为分配语句耗时(10us)相对于整条请求的处理时间(1000us)比重很小。
解决办法
将动态内存改为静态分配,或者启动的时候,用malloc为每个线程分配,然后保存在threaddata里面。但是,由于这个模块的特殊性,静态分配,或者启动时候分配都不可行。另外,Linux下默认栈的大小限制是10M,如果在栈上分配几M的内存,有风险。
禁止malloc调用mmap分配内存,禁止内存紧缩。
在进程启动时候,加入以下两行代码:
mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存
mallopt(M_TRIM_THRESHOLD, -1); // 禁止内存紧缩
效果:加入这两行代码以后,用ps命令观察,压力稳定以后,majlt和minflt都为0。进程的系统态cpu从20降到10。
三、如何查看堆内内存的碎片情况 ?
glibc 提供了以下结构和接口来查看堆内内存和 mmap 的使用情况。
struct mallinfo {
int arena; /* non-mmapped space allocated from system */
int ordblks; /* number of free chunks */
int smblks; /* number of fastbin blocks */
int hblks; /* number of mmapped regions */
int hblkhd; /* space in mmapped regions */
int usmblks; /* maximum total allocated space */
int fsmblks; /* space available in freed fastbin blocks */
int uordblks; /* total allocated space */
int fordblks; /* total free space */
int keepcost; /* top-most, releasable (via malloc_trim) space */
};
/*返回heap(main_arena)的内存使用情况,以 mallinfo 结构返回 */
struct mallinfo mallinfo();
/* 将heap和mmap的使用情况输出到stderr*/
void malloc_stats();
可通过以下例子来验证mallinfo和malloc_stats输出结果。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/mman.h>
#include <malloc.h>
size_t heap_malloc_total, heap_free_total,mmap_total, mmap_count;
void print_info()
{
struct mallinfo mi = mallinfo();
printf("count by itself:\n");
printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\tmmap_total=%lu mmap_count=%lu\n",
heap_malloc_total*1024, heap_free_total*1024, heap_malloc_total*1024-heap_free_total*1024,
mmap_total*1024, mmap_count);
printf("count by mallinfo:\n");
printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\tmmap_total=%lu mmap_count=%lu\n",
mi.arena, mi.fordblks, mi.uordblks,
mi.hblkhd, mi.hblks);
printf("from malloc_stats:\n");
malloc_stats();
}
#define ARRAY_SIZE 200
int main(int argc, char** argv)
{
char** ptr_arr[ARRAY_SIZE];
int i;
for( i = 0; i < ARRAY_SIZE; i++)
{
ptr_arr[i] = malloc(i * 1024);
if ( i < 128) //glibc默认128k以上使用mmap
{
heap_malloc_total += i;
}
else
{
mmap_total += i;
mmap_count++;
}
}
print_info();
for( i = 0; i < ARRAY_SIZE; i++)
{
if ( i % 2 == 0)
continue;
free(ptr_arr[i]);
if ( i < 128)
{
heap_free_total += i;
}
else
{
mmap_total -= i;
mmap_count--;
}
}
printf("\nafter free\n");
print_info();
return 1;
}
该例子第一个循环为指针数组每个成员分配索引位置 (KB) 大小的内存块,并通过 128 为分界分别对 heap 和 mmap 内存分配情况进行计数;
第二个循环是 free 索引下标为奇数的项,同时更新计数情况。通过程序的计数与mallinfo/malloc_stats 接口得到结果进行对比,并通过 print_info打印到终端。
下面是一个执行结果:
count by itself:
heap_malloc_total=8323072 heap_free_total=0 heap_in_use=8323072
mmap_total=12054528 mmap_count=72
count by mallinfo:
heap_malloc_total=8327168 heap_free_total=2032 heap_in_use=8325136
mmap_total=12238848 mmap_count=72
from malloc_stats:
Arena 0:
system bytes = 8327168
in use bytes = 8325136
Total (incl. mmap):
system bytes = 20566016
in use bytes = 20563984
max mmap regions = 72
max mmap bytes = 12238848
after free
count by itself:
heap_malloc_total=8323072 heap_free_total=4194304 heap_in_use=4128768
mmap_total=6008832 mmap_count=36
count by mallinfo:
heap_malloc_total=8327168 heap_free_total=4197360 heap_in_use=4129808
mmap_total=6119424 mmap_count=36
from malloc_stats:
Arena 0:
system bytes = 8327168
in use bytes = 4129808
Total (incl. mmap):
system bytes = 14446592
in use bytes = 10249232
max mmap regions = 72
max mmap bytes = 12238848
由上可知,程序统计和mallinfo 得到的信息基本吻合,其中 heap_free_total 表示堆内已释放的内存碎片总和。
如果想知道堆内究竟有多少碎片,可通过 mallinfo 结构中的 fsmblks 、smblks 、ordblks 值得到,这些值表示不同大小区间的碎片总个数,这些区间分别是 0~80 字节,80~512 字节,512~128k。如果
fsmblks 、 smblks 的值过大,那碎片问题可能比较严重了。
不过, mallinfo 结构有一个很致命的问题,就是其成员定义全部都是 int ,在 64 位环境中,其结构中的 uordblks/fordblks/arena/usmblks 很容易就会导致溢出,应该是历史遗留问题,使用时要注意!
四、既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢?
既然堆内碎片不能直接释放,导致疑似“内存泄露”问题,为什么
malloc 不全部使用 mmap 来实现呢(mmap分配的内存可以会通过 munmap 进行 free ,实现真正释放)?而是仅仅对于大于
128k 的大块内存才使用 mmap ?
其实,进程向 OS 申请和释放地址空间的接口
sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap
后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap
后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用
mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。
因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用
mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, <SIZE>)
来修改这个临界值。
五、如何查看进程的缺页中断信息?
可通过以下命令查看缺页中断信息
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中:: majflt 代表 major fault ,指大错误;
minflt 代表 minor fault ,指小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
其中 majflt 与 minflt 的不同是::
majflt 表示需要读写磁盘,可能是内存对应页面在磁盘中需要load 到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。
参看:: http://blog.163.com/xychenbaihu@yeah/blog/static/132229655201210975312473/
六、除了 glibc 的 malloc/free ,还有其他第三方实现吗?
其实,很多人开始诟病 glibc
内存管理的实现,特别是高并发性能低下和内存碎片化问题都比较严重,因此,陆续出现一些第三方工具来替换 glibc 的实现,最著名的当属
google 的tcmalloc和facebook 的jemalloc 。
网上有很多资源,可以自己查(只用使用第三方库,代码不用修改,就可以使用第三方库中的malloc)。
参考资料:
《深入理解计算机系统》第 10 章
http://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt
https://www.ibm.com/developerworks/cn/linux/l-lvm64/
http://www.kerneltravel.net/journal/v/mem.htm
http://blog.csdn.net/baiduforum/article/details/6126337
http://www.nosqlnotes.net/archives/105
Linux的内存管理(free 详解)
Linux的内存管理,实际上跟windows的内存管理有很相像的地方,都是用虚拟内存这个的概念,说到这里不得不骂MS,为什么在很多时候还有很大的物理内存的时候,却还是用到了pagefile. 所以才经常要跟一帮人吵着说Pagefile的大小,以及如何分配这个问题,在Linux大家就不用再吵什么swap大小的问题,我个人认为,swap设个512M已经足够了,如果你问说512M的SWAP不够用怎么办?只能说大哥你还是加内存吧,要不就检查你的应用,是不是真的出现了memory leak.
夜也深了,就不再说废话了。
在Linux下查看内存我们一般用command free
[root@nonamelinux ~]# free
total used free shared buffers cached
Mem: 386024 377116 8908 0 21280 155468
-/+ buffers/cache: 200368 185656
Swap: 393552 0 393552
下面是对这些数值的解释:
第二行(mem):
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行就不多解释了。
区别:
第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。
这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是8908KB,已用内存是377116KB,其中包括,内核(OS)使用+Application(X,oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached.
如上例:
185656=8908+21280+155468
接下来解释什么时候内存会被交换,以及按什么方交换。
当可用内存少于额定值的时候,就会开会进行交换.
如何看额定值(RHEL4.0):
#cat /proc/meminfo
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小,
2.将系统V类型的内存页面交换出去,
3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
事实上,少量地使用swap是不是影响到系统性能的。
Linux设备驱动之内存管理
对于包含 MMU 的处理器而言, Linux 系统提供了复杂的存储管理系统,使得进程所能访问的内存达到 4GB。进程的 4GB 内存空间被分为两个部分—用户空间与内核空间。用户空间地址一般分布为 0~3GB(即 PAGE_OFFSET),这样,剩下的 3~4GB 为内核空间。
内核空间申请内存涉及的函数主要包括 kmalloc()、__get_free_pages()和 vmalloc()等。
通过内存映射,用户进程可以在用户空间直接访问设备。
内核地址空间
每个进程的用户空间都是完全独立、互不相干的,用户进程各自有不同的页表。而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。内核空间地址有自己对应的页表,内核的虚拟空间独立于其他程序。用户进程只有通过系统调用(代表用户进程在内核态执行)等方式才可以访问到内核空间。
Linux 中 1GB 的内核地址空间又被划分为物理内存映射区、虚拟内存分配区、高端页面映射区、专用页面映射区和系统保留映射区这几个区域,如图所示。
-
保留区
Linux 保留内核空间最顶部 FIXADDR_TOP~4GB 的区域作为保留区。 -
专用页面映射区
紧接着最顶端的保留区以下的一段区域为专用页面映射区(FIXADDR_START~FIXADDR_TOP),它的总尺寸和每一页的用途由 fixed_address 枚举结构在编译时预定义,用__fix_to_virt(index)可获取专用区内预定义页面的逻辑地址。 -
高端内存映射区
当系统物理内存大于 896MB 时,超过物理内存映射区的那部分内存称为高端内存(而未超过物理内存映射区的内存通常被称为常规内存),内核在存取高端内存时必须将它们映射到高端页面映射区。 -
虚存内存分配区
用于 vmalloc()函数,它的前部与物理内存映射区有一个隔离带,后部与高端映射区也有一个隔离带。 -
物理内存映射区
一般情况下,物理内存映射区最大长度为 896MB,系统的物理内存被顺序映射在内核空间的这个区域中。
虚拟地址与物理地址关系
对于内核物理内存映射区的虚拟内存,使用 virt_to_phys()可以实现内核虚拟地址转化为物理地址, virt_to_phys()的实现是体系结构相关的,对于 ARM 而言, virt_to_phys()的定义如代码:
static inline unsigned long virt_to_phys(void *x)
{
return __virt_to_phys((unsigned long)(x));
}
/* PAGE_OFFSET 通常为 3GB,而 PHYS_OFFSET 则定于为系统 DRAM 内存的基地址 */
#define __virt_to_phys(x) ((x) - PAGE_OFFSET + PHYS_OFFSET)内存分配
在 Linux 内核空间申请内存涉及的函数主要包括 kmalloc()、__get_free_pages()和 vmalloc()等。kmalloc()和__get_free_pages()( 及其类似函数) 申请的内存位于物理内存映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系。而vmalloc()在虚拟内存空间给出一块连续的内存区,实质上,这片连续的虚拟内存在物理内存中并不一定连续,而 vmalloc()申请的虚拟内存和物理内存之间也没有简单的换算关系。
kmalloc()
void *kmalloc(size_t size, int flags);给 kmalloc()的第一个参数是要分配的块的大小,第二个参数为分配标志,用于控制 kmalloc()的行为。
flags
- 最常用的分配标志是 GFP_KERNEL,其含义是在内核空间的进程中申请内存。 kmalloc()的底层依赖__get_free_pages()实现,分配标志的前缀 GFP 正好是这个底层函数的缩写。使用 GFP_KERNEL 标志申请内存时,若暂时不能满足,则进程会睡眠等待页,即会引起阻塞,因此不能在中断上下文或持有自旋锁的时候使用 GFP_KERNEL 申请内存。
- 在中断处理函数、 tasklet 和内核定时器等非进程上下文中不能阻塞,此时驱动应当使用GFP_ATOMIC 标志来申请内存。当使用 GFP_ATOMIC 标志申请内存时,若不存在空闲页,则不等待,直接返回。
- 其他的相对不常用的申请标志还包括 GFP_USER(用来为用户空间页分配内存,可能阻塞)、GFP_HIGHUSER(类似 GFP_USER,但是从高端内存分配)、 GFP_NOIO(不允许任何 I/O 初始化)、 GFP_NOFS(不允许进行任何文件系统调用)、 __GFP_DMA(要求分配在能够 DMA 的内存区)、 __GFP_HIGHMEM(指示分配的内存可以位于高端内存)、 __GFP_COLD(请求一个较长时间不访问的页)、 __GFP_NOWARN(当一个分配无法满足时,阻止内核发出警告)、 __GFP_HIGH(高优先级请求,允许获得被内核保留给紧急状况使用的最后的内存页)、 __GFP_REPEAT(分配失败则尽力重复尝试)、 __GFP_NOFAIL(标志只许申请成功,不推荐)和__GFP_NORETRY(若申请不到,则立即放弃)。
使用 kmalloc()申请的内存应使用 kfree()释放,这个函数的用法和用户空间的 free()类似。
__get_free_pages ()
__get_free_pages()系列函数/宏是 Linux 内核本质上最底层的用于获取空闲内存的方法,因为底层的伙伴算法以 page 的 2 的 n 次幂为单位管理空闲内存,所以最底层的内存申请总是以页为单位的。
__get_free_pages()系列函数/宏包括 get_zeroed_page()、 __get_free_page()和__get_free_pages()。
/* 该函数返回一个指向新页的指针并且将该页清零 */
get_zeroed_page(unsigned int flags);
/* 该宏返回一个指向新页的指针但是该页不清零 */
__get_free_page(unsigned int flags);
/* 该函数可分配多个页并返回分配内存的首地址,分配的页数为 2^order,分配的页也不清零 */
__get_free_pages(unsigned int flags, unsigned int order);
/* 释放 */
void free_page(unsigned long addr);
void free_pages(unsigned long addr, unsigned long order);__get_free_pages 等函数在使用时,其申请标志的值与 kmalloc()完全一样,各标志的含义也与kmalloc()完全一致,最常用的是 GFP_KERNEL 和 GFP_ATOMIC。
vmalloc()
vmalloc()一般用在为只存在于软件中(没有对应的硬件意义)的较大的顺序缓冲区分配内存,vmalloc()远大于__get_free_pages()的开销,为了完成 vmalloc(),新的页表需要被建立。因此,只是调用 vmalloc()来分配少量的内存(如 1 页)是不妥的。
vmalloc()申请的内存应使用 vfree()释放, vmalloc()和 vfree()的函数原型如下:
void *vmalloc(unsigned long size);
void vfree(void * addr);vmalloc()不能用在原子上下文中,因为它的内部实现使用了标志为 GFP_KERNEL 的 kmalloc()。
slab
一方面,完全使用页为单元申请和释放内存容易导致浪费(如果要申请少量字节也需要 1 页);另一方面,在操作系统的运作过程中,经常会涉及大量对象的重复生成、使用和释放内存问题。在Linux 系统中所用到的对象,比较典型的例子是 inode、 task_struct 等。如果我们能够用合适的方法使得在对象前后两次被使用时分配在同一块内存或同一类内存空间且保留了基本的数据结构,就可以大大提高效率。 内核的确实现了这种类型的内存池,通常称为后备高速缓存(lookaside cache)。内核对高速缓存的管理称为slab分配器。实际上 kmalloc()即是使用 slab 机制实现的。
注意, slab
不是要代替__get_free_pages(),其在最底层仍然依赖于__get_free_pages(), slab在底层每次申请 1
页或多页,之后再分隔这些页为更小的单元进行管理,从而节省了内存,也提高了 slab 缓冲对象的访问效率。
#include <linux/slab.h>
/* 创建一个新的高速缓存对象,其中可容纳任意数目大小相同的内存区域 */
struct kmem_cache *kmem_cache_create(const char *name, /* 一般为将要高速缓存的结构类型的名字 */
size_t size, /* 每个内存区域的大小 */
size_t offset, /* 第一个对象的偏移量,一般为0 */
unsigned long flags, /* 一个位掩码:
SLAB_NO_REAP 即使内存紧缩也不自动收缩这块缓存,不建议使用
SLAB_HWCACHE_ALIGN 每个数据对象被对齐到一个缓存行
SLAB_CACHE_DMA 要求数据对象在DMA内存区分配
*/
/* 可选参数,用于初始化新分配的对象,多用于一组对象的内存分配时使用 */
void (*constructor)(void*, struct kmem_cache *, unsigned long),
void (*destructor)(void*, struct kmem_cache *, unsigned long)
);
/* 在 kmem_cache_create()创建的 slab 后备缓冲中分配一块并返回首地址指针 */
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
/* 释放 slab 缓存 */
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
/* 收回 slab 缓存,如果失败则说明内存泄漏 */
int kmem_cache_destroy(struct kmem_cache *cachep);Tip: 高速缓存的使用统计情况可以从/proc/slabinfo获得。
内存池(mempool)
内核中有些地方的内存分配是不允许失败的,内核开发者建立了一种称为内存池的抽象。内存池其实就是某种形式的高速后备缓存,它试图始终保持空闲的内存以便在紧急状态下使用。mempool很容易浪费大量内存,应尽量避免使用。
#include <linux/mempool.h>
/* 创建 */
mempool_t *mempool_create(int min_nr, /* 需要预分配对象的数目 */
mempool_alloc_t *alloc_fn, /* 分配函数,一般直接使用内核提供的mempool_alloc_slab */
mempool_free_t *free_fn, /* 释放函数,一般直接使用内核提供的mempool_free_slab */
void *pool_data); /* 传给alloc_fn/free_fn的参数,一般为kmem_cache_create创建的cache */
/* 分配释放 */
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);
/* 回收 */
void mempool_destroy(mempool_t *pool);内存映射
一般情况下,用户空间是不可能也不应该直接访问设备的,但是,设备驱动程序中可实现mmap()函数,这个函数可使得用户空间直能接访问设备的物理地址。
这种能力对于显示适配器一类的设备非常有意义,如果用户空间可直接通过内存映射访问显存的话,屏幕帧的各点的像素将不再需要一个从用户空间到内核空间的复制的过程。
从 file_operations 文件操作结构体可以看出,驱动中 mmap()函数的原型如下:
int(*mmap)(struct file *, struct vm_area_struct*);驱动程序中 mmap()的实现机制是建立页表,并填充 VMA 结构体中 vm_operations_struct 指针。VMA 即 vm_area_struct,用于描述一个虚拟内存区域:
struct vm_area_struct {
unsigned long vm_start; /* 开始虚拟地址 */
unsigned long vm_end; /* 结束虚拟地址 */
unsigned long vm_flags; /* VM_IO 设置一个内存映射I/O区域;
VM_RESERVED 告诉内存管理系统不要将VMA交换出去 */
struct vm_operations_struct *vm_ops; /* 操作 VMA 的函数集指针 */
unsigned long vm_pgoff; /* 偏移(页帧号) */
void *vm_private_data;
...
}
struct vm_operations_struct {
void(*open)(struct vm_area_struct *area); /*打开 VMA 的函数*/
void(*close)(struct vm_area_struct *area); /*关闭 VMA 的函数*/
struct page *(*nopage)(struct vm_area_struct *area, unsigned long address, int *type); /*访问的页不在内存时调用*/
/* 当用户访问页前,该函数允许内核将这些页预先装入内存。驱动程序一般不必实现 */
int(*populate)(struct vm_area_struct *area, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);
...建立页表的方法有两种:使用remap_pfn_range函数一次全部建立或者通过nopage VMA方法每次建立一个页表。
-
remap_pfn_range
remap_pfn_range负责为一段物理地址建立新的页表,原型如下:int remap_pfn_range(struct vm_area_struct *vma, /* 虚拟内存区域,一定范围的页将被映射到该区域 */ unsigned long addr, /* 重新映射时的起始用户虚拟地址。该函数为处于addr和addr+size之间的虚拟地址建立页表 */ unsigned long pfn, /* 与物理内存对应的页帧号,实际上就是物理地址右移 PAGE_SHIFT 位 */ unsigned long size, /* 被重新映射的区域大小,以字节为单位 */ pgprot_t prot); /* 新页所要求的保护属性 */demo:
static int xxx_mmap(struct file *filp, struct vm_area_struct *vma) { if (remap_pfn_range(vma, vma->vm_start, vm->vm_pgoff, vma->vm_end - vma->vm_start, vma->vm_page_prot)) /* 建立页表 */ return - EAGAIN; vma->vm_ops = &xxx_remap_vm_ops; xxx_vma_open(vma); return 0; } /* VMA 打开函数 */ void xxx_vma_open(struct vm_area_struct *vma) { ... printk(KERN_NOTICE "xxx VMA open, virt %lx, phys %lx\n", vma->vm_start, vma->vm_pgoff << PAGE_SHIFT); } /* VMA 关闭函数 */ void xxx_vma_close(struct vm_area_struct *vma) { ... printk(KERN_NOTICE "xxx VMA close.\n"); } static struct vm_operations_struct xxx_remap_vm_ops = { /* VMA 操作结构体 */ .open = xxx_vma_open, .close = xxx_vma_close, ... }; -
nopage
除了 remap_pfn_range()以外,在驱动程序中实现 VMA 的 nopage()函数通常可以为设备提供更加灵活的内存映射途径。当访问的页不在内存,即发生缺页异常时, nopage()会被内核自动调用。static int xxx_mmap(struct file *filp, struct vm_area_struct *vma) { unsigned long offset = vma->vm_pgoff << PAGE_SHIFT; if (offset >= _ _pa(high_memory) || (filp->f_flags &O_SYNC)) vma->vm_flags |= VM_IO; vma->vm_flags |= VM_RESERVED; /* 预留 */ vma->vm_ops = &xxx_nopage_vm_ops; xxx_vma_open(vma); return 0; } struct page *xxx_vma_nopage(struct vm_area_struct *vma, unsigned long address, int *type) { struct page *pageptr; unsigned long offset = vma->vm_pgoff << PAGE_SHIFT; unsigned long physaddr = address - vma->vm_start + offset; /* 物理地址 */ unsigned long pageframe = physaddr >> PAGE_SHIFT; /* 页帧号 */ if (!pfn_valid(pageframe)) /* 页帧号有效? */ return NOPAGE_SIGBUS; pageptr = pfn_to_page(pageframe); /* 页帧号->页描述符 */ get_page(pageptr); /* 获得页,增加页的使用计数 */ if (type) *type = VM_FAULT_MINOR; return pageptr; /*返回页描述符 */ }上述函数对常规内存进行映射, 返回一个页描述符,可用于扩大或缩小映射的内存区域。
由此可见, nopage()与 remap_pfn_range()的一个较大区别在于 remap_pfn_range()一般用于设备内存映射,而 nopage()还可用于 RAM 映射,其调用发生在缺页异常时。
Linux设备驱动之中断处理
中断(interrupt)是指CPU在执行程序的过程中,出现了某些突发事件急待处理,CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回原程序被中断的位置并继续执行。
中断服务程序的执行并不存在于进程上下文,因此,要求中断服务程序的时间尽可能地短。因此,Linux在中断处理中引入了顶半部和底半部分离的机制。顶半部处理紧急的硬件操作,底半部处理不紧急的耗时操作。
tasklet和工作队列都是调度中断底半部的良好机制,tasklet基于软中断实现,原子操作,速度快,常用,但不可阻塞或睡眠。
中断分类
-
根据中断的来源,可分为内部中断和外部中断
内部中断的中断源来自CPU内部(软件中断指令、溢出、除法错误等,例如,操作系统从用户态切换到内核态需借助CPU内部的软件中断),外部中断的中断源来自CPU外部,由外设提出请求。 -
根据中断是否可以屏蔽分为可屏蔽中断与不屏蔽中断(NMI)
可屏蔽中断可以通过屏蔽字(MASK)被屏蔽,屏蔽后,该中断不再得到响应,而不屏蔽中断不能被屏蔽。 -
根据中断入口跳转方法的不同,分为向量中断和非向量中断
采用向量中断的CPU通常为不同的中断分配不同的中断号,当检测到某中断号的中断到来后,就自动跳转到与该中断号对应的地址执行。不同中断号的中断有不同的入口地址。非向量中断的多个中断共享一个入口地址,进入该入口地址后再通过软件判断中断标志来识别具体是哪个中断。也就是说,向量中断由硬件提供中断服务程序入口地址,非向量中断由软件提供中断服务程序入口地址。
Linux中断处理(Interrupt Handling)架构
设备的中断会打断内核中进程的正常调度和运行,系统对更高吞吐率的追求势必要求中断服务程序尽可能的短小精悍。为了在中断执行时间尽可能短和中断处理需完成大量工作之间找到一个平衡点, Linux 将中断处理程序分解为两个半部:顶半部(top half)和底半部(bottom half)。
-
top half
顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作。“登记中断”意味着将底半部处理程序挂到该设备的底半部执行队列中去。这样,顶半部执行的速度就会很快,可以服务更多的中断请求。软件上一般采用handler中断响应程序实现。 -
bottom half
底半部由顶半部调度而来进行延后处理,几乎做了中断处理程序所有的事情,而且可以被新的中断打断,这也是底半部和顶半部的最大不同,因为顶半部往往被设计成不可中断。底半部则相对来说并不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行。软件上一般采用tasklet或工作队列机制。
Tip:尽管顶半部、底半部的结合能够改善系统的响应能力,但是,僵化地认为 Linux 设备驱动中的中断处理一定要分两个半部则是不对的。如果中断要处理的工作本身很少,则完全可以直接在顶半部全部完成。
Linux中断编程
申请和释放(Installing an Interrupt Handler)
#include <linux/interrupt.h>
int /* 返回 0 -- OK, -EINVAL -- irq/handler invalid, -EBUSY -- 中断被占用不能共享 */
request_irq(
unsigned int irq, /* 要申请的硬件中断号 */
irq_handler_t handler, /* 向系统登记的中断处理函数(顶半部)*/
unsigned long flags, /* 中断处理的属性,可以指定中断的触发方式以及处理方式等 */
const char *devname, /* used in /proc/interrupts */
void *dev_id /* 传递给handler的参数 */
);
void free_irq(unsigned int irq,void *dev_id);Tip: 如果中断确定不被共享可将其安装在初始化中,否则应安装在打开函数中。interrupt.h有irq_handler_t的定义及flags的详细注释
使能和屏蔽 (Enabling and Disabling Interrupts)
-
Disabling a single interrupt
#include <asm/irq.h> /* disable并等待指定的中断被处理完,如果调用线程占有interrupt handler需要的资源如spinlock那么就会死锁 */ void disable_irq(int irq); /* disable并立即返回,有可能产生竞态 */ void disable_irq_nosync(int irq); void enable_irq(int irq); -
Disabling all interrupts
#include <asm/system.h> void local_irq_save(unsigned long flags); /* save flags then disable local all */ void local_irq_disable(void); /* disable local all directly */ void local_irq_restore(unsigned long flags); void local_irq_enable(void);
底半部机制
-
tasklet
void my_tasklet_func(unsigned long); /*定义一个处理函数*/ /* 定义一个tasklet结构my_tasklet,并与my_tasklet_func(data)处理函数相关联 */ DECLARE_TASKLET(my_tasklet, my_tasklet_func, data); /* 在需要调度tasklet的时候引用一个tasklet_schedule()函数就能使系统在适当的时候进行调度运行 一般在top half即中断响应函数中调用 */ tasklet_schedule(&my_tasklet); -
工作队列(workqueues)
与tasklet类似:void my_wq_func(unsigned long); /*定义一个处理函数*/ struct work_struct my_wq; /*定义一个工作队列*/ /* 初始化工作队列并将其与处理函数绑定 */ INIT_WORK(&my_wq, (void (*)(void *)) my_wq_func, NULL); schedule_work(&my_wq);/*调度工作队列执行*/
Tip: tasklet在中断上下文中执行,不可阻塞或睡眠;而workqueues由内核线程去执行,属进程上下文,可阻塞和睡眠。
Linux设备驱动之字符设备
字符设备是3大类设备(字符设备、块设备和网络设备)中较简单的一类设备,其驱动程序中完成的主要工作是初始化、添加和删除cdev结构体,申请和释放设备号,以及填充 file_operations结构体中的操作函数,实现file_operations结构体中的read()、write()和ioctl()等函数是驱动设计的主体工作。
参考例程
源码
/*
* 虚拟字符设备globalmem实例:
* 在globalmem字符设备驱动中会分配一片大小为 GLOBALMEM_SIZE(4KB)
* 的内存空间,并在驱动中提供针对该片内存的读写、控制和定位函数,以供用户空间的进程能通过
* Linux系统调用访问这片内存。
*/
#include <linux/module.h>
#include <linux/types.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/sched.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <asm/io.h>
#include <asm/system.h>
#include <asm/uaccess.h>
#define DEV_NAME "globalmem" /* /dev中显示的设备名 */
#define DEV_MAJOR 0 /* 指定主设备号,为0则动态获取 */
/* ioctl用的控制字 */
#define GLOBALMEM_MAGIC 'M'
#define MEM_CLEAR _IO(GLOBALMEM_MAGIC, 0)
/*--------------------------------------------------------------------- local vars */
/*globalmem设备结构体*/
typedef struct {
struct cdev cdev; /* 字符设备cdev结构体*/
#define MEM_SIZE 0x1000 /*全局内存最大4K字节*/
unsigned char mem[MEM_SIZE]; /*全局内存*/
struct semaphore sem; /*并发控制用的信号量*/
} globalmem_dev_t;
static int globalmem_major = DEV_MAJOR;
static globalmem_dev_t *globalmem_devp; /*设备结构体指针*/
/*--------------------------------------------------------------------- file operations */
/*文件打开函数*/
static int globalmem_open(struct inode *inodep, struct file *filep)
{
/* 获取dev指针 */
globalmem_dev_t *dev = container_of(inodep->i_cdev, globalmem_dev_t, cdev);
filep->private_data = dev;
return 0;
}
/*文件释放函数*/
static int globalmem_release(struct inode *inodep, struct file *filep)
{
return 0;
}
/*读函数*/
static ssize_t globalmem_read(struct file *filep, char __user *buf, size_t len, loff_t *ppos)
{
globalmem_dev_t *dev = filep->private_data;
unsigned long p = *ppos;
int ret = 0;
/*分析和获取有效的长度*/
if (p > MEM_SIZE) {
printk(KERN_EMERG "%s: overflow!\n", __func__);
return - ENOMEM;
}
if (len > MEM_SIZE - p) {
len = MEM_SIZE - p;
}
if (down_interruptible(&dev->sem)) /* 获得信号量*/
return - ERESTARTSYS;
/*内核空间->用户空间*/
if (copy_to_user(buf, (void*)(dev->mem + p), len)) {
ret = - EFAULT;
}else{
*ppos += len;
printk(KERN_INFO "%s: read %d bytes from %d\n", DEV_NAME, (int)len, (int)p);
ret = len;
}
up(&dev->sem); /* 释放信号量*/
return ret;
}
/*写函数*/
static ssize_t globalmem_write(struct file *filep, const char __user *buf, size_t len, loff_t *ppos)
{
globalmem_dev_t *dev = filep->private_data;
int ret = 0;
unsigned long p = *ppos;
if (p > MEM_SIZE) {
printk(KERN_EMERG "%s: overflow!\n", __func__);
return - ENOMEM;
}
if (len > MEM_SIZE - p) {
len = MEM_SIZE - p;
}
if (down_interruptible(&dev->sem)) /* 获得信号量*/
return - ERESTARTSYS;
/*用户空间->内核空间*/
if (copy_from_user(dev->mem + p, buf, len)) {
ret = - EFAULT;
}else{
*ppos += len;
printk(KERN_INFO "%s: written %d bytes from %d\n", DEV_NAME, (int)len, (int)p);
ret = len;
}
up(&dev->sem); /* 释放信号量*/
return ret;
}
/* seek文件定位函数 */
static loff_t globalmem_llseek(struct file *filep, loff_t offset, int start)
{
globalmem_dev_t *dev = filep->private_data;
int ret = 0;
if (down_interruptible(&dev->sem)) /* 获得信号量*/
return - ERESTARTSYS;
switch (start) {
case SEEK_SET:
if (offset < 0 || offset > MEM_SIZE) {
printk(KERN_EMERG "%s: overflow!\n", __func__);
return - ENOMEM;
}
ret = filep->f_pos = offset;
break;
case SEEK_CUR:
if ((filep->f_pos + offset) < 0 || (filep->f_pos + offset) > MEM_SIZE) {
printk(KERN_EMERG "%s: overflow!\n", __func__);
return - ENOMEM;
}
ret = filep->f_pos += offset;
break;
default:
return - EINVAL;
break;
}
up(&dev->sem); /* 释放信号量*/
printk(KERN_INFO "%s: set cur to %d.\n", DEV_NAME, ret);
return ret;
}
/* ioctl设备控制函数 */
static long globalmem_ioctl(struct file *filep, unsigned int cmd, unsigned long arg)
{
globalmem_dev_t *dev = filep->private_data;
switch (cmd) {
case MEM_CLEAR:
if (down_interruptible(&dev->sem)) /* 获得信号量*/
return - ERESTARTSYS;
memset(dev->mem, 0, MEM_SIZE);
up(&dev->sem); /* 释放信号量*/
printk(KERN_INFO "%s: clear.\n", DEV_NAME);
break;
default:
return - EINVAL;
}
return 0;
}
/*文件操作结构体*/
static const struct file_operations globalmem_fops = {
.owner = THIS_MODULE,
.open = globalmem_open,
.release = globalmem_release,
.read = globalmem_read,
.write = globalmem_write,
.llseek = globalmem_llseek,
.compat_ioctl = globalmem_ioctl
};
/*---------------------------------------------------------------------*/
/*初始化并注册cdev*/
static int globalmem_setup(globalmem_dev_t *dev, int minor)
{
int ret = 0;
dev_t devno = MKDEV(globalmem_major, minor);
cdev_init(&dev->cdev, &globalmem_fops);
dev->cdev.owner = THIS_MODULE;
ret = cdev_add(&dev->cdev, devno, 1);
if (ret) {
printk(KERN_NOTICE "%s: Error %d dev %d.\n", DEV_NAME, ret, minor);
}
return ret;
}
/*设备驱动模块加载函数*/
static int __init globalmem_init(void)
{
int ret = 0;
dev_t devno;
/* 申请设备号*/
if(globalmem_major){
devno = MKDEV(globalmem_major, 0);
ret = register_chrdev_region(devno, 2, DEV_NAME);
}else{ /* 动态申请设备号 */
ret = alloc_chrdev_region(&devno, 0, 2, DEV_NAME);
globalmem_major = MAJOR(devno);
}
if (ret < 0) {
return ret;
}
/* 动态申请设备结构体的内存,创建两个设备 */
globalmem_devp = kmalloc(2*sizeof(globalmem_dev_t), GFP_KERNEL);
if (!globalmem_devp) {
unregister_chrdev_region(devno, 2);
return - ENOMEM;
}
ret |= globalmem_setup(&globalmem_devp[0], 0); /* globalmem0 */
ret |= globalmem_setup(&globalmem_devp[1], 1); /* globalmem1 */
if(ret)
return ret;
init_MUTEX(&globalmem_devp[0].sem); /*初始化信号量*/
init_MUTEX(&globalmem_devp[1].sem);
printk(KERN_INFO "globalmem: up %d,%d.\n", MAJOR(devno), MINOR(devno));
return 0;
}
/*模块卸载函数*/
static void __exit globalmem_exit(void)
{
cdev_del(&globalmem_devp[0].cdev);
cdev_del(&globalmem_devp[1].cdev);
kfree(globalmem_devp);
unregister_chrdev_region(MKDEV(globalmem_major, 0), 2);
printk(KERN_INFO "globalmem: down.\n");
}
/* 定义参数 */
module_param(globalmem_major, int, S_IRUGO);
module_init(globalmem_init);
module_exit(globalmem_exit);
/* 模块描述及声明 */
MODULE_AUTHOR("Archie Xie <archixie@cnblogs.com>");
MODULE_LICENSE("Dual BSD/GPL");
MODULE_DESCRIPTION("A char device module just for demo.");
MODULE_ALIAS("cdev gmem");
MODULE_VERSION("1.0");用户空间验证
- 切换到root用户
-
插入模块
insmod globalmem.ko -
创建设备节点(后续例程会展示自动创建节点的方法)
cat /proc/devices 找到主设备号major mknod /dev/globalmem0 c major 0 和 /dev/globalmem1 c major 1 -
读写测试
echo "hello world" > /dev/globalmem cat /dev/globalmem
Linux设备驱动之platform
根据Linux设备模型可知,一个现实的Linux设备和驱动通常都需要挂接在一种总线上,对于本身依附于PCI、USB等的设备而言,这自然不是问题,但是在嵌入式系统里面,SoC系统中集成的独立的外设控制器、挂接在 SoC 内存空间的外设等却不依附于此类总线。基于这一背景,Linux设计了一种虚拟的总线,称为platform总线,相应的设备称为platform_device,而驱动称为platform_driver。
设计目的
-
兼容设备模型
使得设备被挂接在一个总线上,因此,符合 Linux 2.6 的设备模型。其结果是,配套的sysfs结点、设备电源管理都成为可能。 -
BSP和驱动隔离
在BSP中定义platform设备和设备使用的资源、设备的具体配置信息。而在驱动中,只需要通过通用API去获取资源和数据,做到了板相关代码和驱动代码的分离,使得驱动具有更好的可扩展性和跨平台性。
软件架构
内核中Platform设备有关的实现位于include/linux/platform_device.h和drivers/base/platform.c两个文件中,它的软件架构如下:
由图片可知,Platform设备在内核中的实现主要包括三个部分:
- Platform Bus,基于底层bus模块,抽象出一个虚拟的Platform bus,用于挂载Platform设备;
- Platform Device,基于底层device模块,抽象出Platform Device,用于表示Platform设备;
- Platform Driver,基于底层device_driver模块,抽象出Platform Driver,用于驱动Platform设备。
platform_device
注意,所谓的platform_device并不是与字符设备、块设备和网络设备并列的概念,而是Linux系统提供的一种附加手段,例如,在S3C2440处理器中,把内部集成的I2C、RTC、SPI、LCD、看门狗等控制器都归纳为platform_device,而它们本身就是字符设备。
/* defined in <linux/platform_device.h> */
struct platform_device {
const char * name; / * 设备名 */
u32 id; /* 用于标识该设备的ID */
struct device dev; /* 真正的设备(Platform设备只是一个特殊的设备,因此其核心逻辑还是由底层的模块实现)*/
u32 num_resources; / * 设备所使用各类资源数量 */
struct resource * resource; / * 资源 */
};
/* defined in <linux/ioport.h> */
struct resource {
resource_size_t start; /* 资源起始 */
resource_size_t end; /* 结束 */
const char *name;
unsigned long flags; /* 类型 */
struct resource *parent, *sibling, *child;
};
/* 设备驱动获取BSP定义的resource */
struct resource *platform_get_resource(struct platform_device *, unsigned int flags, unsigned int num);
#include <linux/platform_device.h>
int platform_device_register(struct platform_device *);
void platform_device_unregister(struct platform_device *);Tip: 和板级紧密相关的资源描述放在dev.paltform_data中。
paltform_driver
platform_driver这个结构体中包含probe()、remove()、shutdown()、suspend()、resume()函数,通常也需要由驱动实现:
struct platform_driver {
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
#include <linux/platform_device.h>
int platform_driver_register(struct platform_driver *);
void platform_driver_unregister(struct platform_driver *);platform_bus
系统中为platform总线定义了一个bus_type的实例platform_bus_type:
struct bus_type platform_bus_type = {
.name = "platform",
.dev_attrs = platform_dev_attrs,
.match = platform_match,
.uevent = platform_uevent,
.pm = PLATFORM_PM_OPS_PTR,
};
EXPORT_SYMBOL_GPL(platform_bus_type);这里要重点关注其 match()成员函数,正是此成员函数确定了 platform_device 和 platform_driver之间如何匹配:
static int platform_match(struct device *dev, struct device_driver *drv)
{
struct platform_device *pdev;
pdev = container_of(dev, struct platform_device, dev);
return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
}
Linux设备驱动之devicetree
Devicetree(设备树)是用来描述系统硬件信息的树模型,其旨在unify内核。通过bootloader将devicetree的信息传给kernel,然后kernel根据这些设备描述初始化相应的板级驱动,达到一个内核多个平台共享的目的。
Overview
Devicetree主要为描述不可插拔(非动态)设备的板级硬件信息而设计的。它由分层的描述设备信息的节点(node)组成树结构。每个node包含的内容通过property/value对来表示。除root节点外,每个节点都有parent。如图所示:
Node Names
除root节点名用'/'表示外,其余节点都由node-name@unit-address来命名,且同一层级必须是唯一的。
-
node-name
表示节点名,由1-31个字符组成。如非必须,推荐使用以下通用的node-name: cpu、memory、memory-controller、gpio、serial、watchdog、flash、compact-flash、rtc、interrupt-controller、dma-controller、ethernet、ethernet-phy、timer、mdio、spi、i2c、usb、can、keyboard、ide、disk、display、sound、atm、cache-controller、crypto、fdc、isa、mouse、nvram、parallel、pc-card、pci、pcie、sata、scsi、vme。 -
unit-address
表示这个节点所在的bus类型。它必须和节点中reg属性的第一个地址一致。如果这个节点没有reg属性,则不需“@unit-address”。
Path Names
表示一个节点的完整路径(full path)。型如:
/node-name-1/node-name-2/node-name-NProperties
每个节点包含的主要内容就是这个所描述的设备的属性信息,由name和value组成:
-
Property Names
1-31个字符,可包含字母、数字、及‘,’,‘.’,‘_’,‘+’,‘?’,‘#’。 -
Property Values
| Value | Description |
|---|---|
| empty | 属性值为空,用来表示true-false信息 |
| u32/u64 | 32/64位大端字节序的无符号整形,表示时需加<> |
| string,stringlist | null-terminated字符串或其组成的列表 |
Standard Properties
-
compatible
Value type: <stringlist> Description: 表示兼容的设备类型,内核据此选择合适的驱动程序。由多个字符串组成,从左到由列出这个设备兼容的驱动(from most specific to most general)。 推荐的格式为:“制造商名,具体型号”。 Example: compatible = "fsl,mpc8641-uart", "ns16550"; 内核先搜索支持“fsl,mpc8641-uart”的驱动,如未找到,则搜索支持更通用的“ns16550”设备类型的驱动。 -
model
Value type: <stringlist> Description: 表明设备型号。 推荐的格式为:“制造商名,具体型号”。 Example: model = "fsl,MPC8349EMITX"; -
phandle
Value type: <u32> Description: 用一个树内唯一的数字标识所在的这个节点,其他节点可以直接通过这个数字标识来引用这个节点。 Example: pic@10000000 { phandle = <1>; interrupt-controller; }; interrupt-parent = <1>; -
status
Value type: <string> Description: 表示设备的可用状态: "okay" -> 设备可用 "disabled" -> 目前不可用,但以后可能会可用 "fail" -> 不可用。出现严重问题,得修一下 "fail-sss" -> 不可用。出现严重问题,得修一下。sss指明错误类型。 -
#address-cells and #size-cells
Value type: <u32> Description: 在拥有子节点的节点中使用,来描述它的字节点的地址分配问题。即分别表示子节点中使用多少个u32大小的cell来编码reg属性中的address域和size域。 这两个属性不会继承,必须明确指出。如未指出,默认#address-cells=2,#size-cells=1。 Example: soc { #address-cells = <1>; #size-cells = <1>; serial { reg = <0x4600 0x100>; }; }; -
reg
Value type: <prop-encoded-array> encoded as an arbitraty number of (address, length) pairs. Description: 描述该设备在parent bus定义的地址空间中的地址资源分配。 Example: reg = <0x3000 0x20 0xFE00 0x100>; a 32-byte block at offset 0x3000 and a 256-byte block at offset 0xFE00。 -
virtual-reg
Value type: <stringlist> Description: 表示映射到reg第一个物理地址对应的effective address。使bootloader能够提供给内核它所建立的virtual-to-physical mappings。 -
ranges
Value type: <empty> or <prop-encoded-array> encoded as an arbitrary number of (child-bus-address,parent-bus-address, length) triplets. Description: 提供了子地址空间与父地址空间的映射关系,如果值为空则父子地址相等,无需转换。 Example: soc { compatible = "simple-bus"; #address-cells = <1>; #size-cells = <1>; ranges = <0x0 0xe0000000 0x00100000>; serial { compatible = "ns16550"; reg = <0x4600 0x100>; }; }; 将子节点serial的0x0地址映射到父节点soc的0xe0000000,映射长度为0x100000。此时reg的实际物理地址就为0xe0004600。 -
dma-ranges
Value type: <empty> or <prop-encoded-array> encoded as an arbitrary number of (child-bus-address,parent-bus-address, length) triplets. Description: 提供了dma地址的映射方法。
Interrupts
描述中断的属性有4个:
-
interrupt-controller
一个空的属性用来指示这个节点设备是接收中断信号的控制器。 -
#interrupt-cells
这是上面所说中断控制器中的一个属性,用来描述需要用多少个cell来描述这个中断控制器的interrupt specifier(类似#address-cells和#size-cells)。 -
interrupt-parent
常出现在根节点的一个属性,它的属性值是指向interrupt-controller的一个phandle。可从parent继承。 -
interrupts
包含interrupt specifiers列表,每一个specifier表示一个中断输出信号。
Example
/ {
interrupt-parent = <&intc>;
intc: interrupt-controller@10140000 {
compatible = "arm,pl190";
reg = <0x10140000 0x1000 >;
interrupt-controller;
#interrupt-cells = <2>;
};
serial@101f0000 {
interrupts = < 1 0 >;
};
};Base Device Node Types
所有的设备树都必须有一个root节点,且root节点下必须包含一个cpus节点和至少一个memory节点。
-
root node
root节点须包含 #address-cells、#size-cells、model、compatible等属性。 -
/cpus node
是cpu子节点的父节点容器。须包含 #address-cells、#size-cells属性。 -
/cpus/cpu* node
是描述系统cpu的节点。 -
/memory node
描述系统物理内存的layout。须包含reg节点。 Example: 假如一个64位系统有如下两块物理内存: - RAM: starting address 0x0, length 0x80000000 (2GB) - RAM: starting address 0x100000000, length 0x100000000 (4GB) 则我们可以有下面两种描述方法(#address-cells = <2> and #size-cells =<2>): Example #1 memory@0 { reg = <0x000000000 0x00000000 0x00000000 0x80000000 0x000000001 0x00000000 0x00000001 0x00000000>; }; Example #2 memory@0 { reg = <0x000000000 0x00000000 0x00000000 0x80000000>; }; memory@100000000 { reg = <0x000000001 0x00000000 0x00000001 0x00000000>; }; -
/chosen node
根节点下的一个子节点,不是描述设备而是描述运行时参数。常用来给内核传递bootargs: chosen { bootargs = "root=/dev/nfs rw nfsroot=192.168.1.1 console=ttyS0,115200"; }; -
/aliases node
由1-31个字母、数字或下划线组成的设备节点full path的别名。它的值是节点的全路径,因此最终会被编码成字符串。 aliases { serial0 = "/simple-bus@fe000000/serial@llc500"; }
Device Bindings
更多具体设备具体类别的描述信息:内核源代码/Documentation/devicetree/bindings。
DTS是描述devicetree的源文本文件,它通过内核中的DTC(Devicetree Compiler)编译后生成相应平台可烧写的二进制DTB。
Devicetree Blob (DTB) Structure
DTB又称Flattened Devicetree(FDT),在内存中的结构如下图所示:
Header
大端字节序结构体:
struct fdt_header {
uint32_t magic; /* contain the value 0xd00dfeed (big-endian) */
uint32_t totalsize; /* the total size of the devicetree data structure */
uint32_t off_dt_struct; /* offset in bytes of the structure block */
uint32_t off_dt_strings; /* offset in bytes of the strings block */
uint32_t off_mem_rsvmap; /* offset in bytes of the memory reservation block */
uint32_t version; /* the version of the devicetree data structure */
uint32_t last_comp_version; /* the lowest version used is backwards compatible */
uint32_t boot_cpuid_phys; /* the physical ID of the system’s boot CPU */
uint32_t size_dt_strings; /* the length in bytes of the strings block */
uint32_t size_dt_struct; /* the length in bytes of the structure block */
};Memory Reservation Block
-
Purpose
为系统保留一些特殊用途的memory。这些保留内存不会进入内存管理系统。 -
Format
struct fdt_reserve_entry { uint64_t address; uint64_t size; };
Structure Block
Devicetree结构体存放的位置。由一行行“token+内容”片段线性组成。
- token
每一行内容都由一个32位的整形token起始。token指明了其后内容的属性及格式。共有以下5种token:
| token | Description |
|---|---|
| FDT_BEGIN_NODE (0x00000001) | 节点起始,其后内容为节点名 |
| FDT_END_NODE (0x00000002) | 节点结束 |
| FDT_PROP (0x00000003) | 描述属性 |
| FDT_NOP (0x00000004) | nothing,devicetree解析器忽略它 |
| FDT_END (0x00000009) | block结束 |
- tree structure
- (optionally) any number of FDT_NOP tokens
- FDT_BEGIN_NODE
- The node’s name as a null-terminated string
- [zeroed padding bytes to align to a 4-byte boundary]
- For each property of the node:
- (optionally) any number of FDT_NOP tokens
- FDT_PROP token
- property information
- [zeroed padding bytes to align to a 4-byte boundary]
- Representations of all child nodes in this format
- (optionally) any number of FDT_NOP tokens
- FDT_END_NODE token
Devicetree Source (DTS) Format
Node and property definitions
[label:] node-name[@unit-address] {
[properties definitions]
[child nodes]
};File layout
Version 1 DTS files have the overall layout:
/dts-v1/; /* dts 版本1 */
[memory reservations] /* DTB中内存保留表的入口 */
/ {
[property definitions]
[child nodes]
};
Linux设备驱动之定时与延时
Linux通过系统硬件定时器以规律的间隔(由HZ度量)产生定时器中断,每次中断使得一个内核计数器的值jiffies累加,因此这个jiffies就记录了系统启动开始的时间流逝,然后内核据此实现软件定时器和延时。
Demo for jiffies and HZ
#include <linux/jiffies.h>
unsigned long j, stamp_1, stamp_half, stamp_n;
j = jiffies; /* read the current value */
stamp_1 = j + HZ; /* 1 second in the future */
stamp_half = j + HZ/2; /* half a second */
stamp_n = j + n * HZ / 1000; /* n milliseconds */内核定时器
硬件时钟中断处理程序会唤起 TIMER_SOFTIRQ 软中断,运行当前处理器上到期的所有内核定时器。
定时器定义/初始化
在Linux内核中,timer_list结构体的一个实例对应一个定时器:
/* 当expires指定的定时器到期时间期满后,将执行function(data) */
struct timer_list {
unsigned long expires; /*定时器到期时间*/
void (*function)(unsigned long); /* 定时器处理函数 */
unsigned long data; /* function的参数 */
...
};
/* 定义 */
struct timer_list my_timer;
/* 初始化函数 */
void init_timer(struct timer_list * timer);
/* 初始化宏 */
TIMER_INITIALIZER(_function, _expires, _data)
/* 定义并初始化宏 */
DEFINE_TIMER(_name, _function, _expires, _data)定时器添加/移除
/* 注册内核定时器,将定时器加入到内核动态定时器链表中 */
void add_timer(struct timer_list * timer);
/* del_timer_sync()是 del_timer()的同步版,在删除一个定时器时需等待其被处理完,
因此该函数的调用不能发生在中断上下文 */
void del_timer(struct timer_list * timer);
void del_timer_sync(struct timer_list * timer);定时时间修改
int mod_timer(struct timer_list *timer, unsigned long expires);延时
短延时
void ndelay(unsigned long nsecs);
void udelay(unsigned long usecs);
void mdelay(unsigned long msecs);内核在启动时,会运行一个延迟测试程序(delay loop calibration),计算出lpj(loops per jiffy),根据lpj就实现了这几个函数,属忙等待。
长延时
-
一个很直观的方法是比较当前的 jiffies 和目标 jiffies:
int time_after(unsigned long a, unsigned long b); /* a after b, true */ int time_before(unsigned long a, unsigned long b); /* a before b */ int time_after_eq(unsigned long a, unsigned long b); /* a after or equal b */ int time_before_eq(unsigned long a, unsigned long b);/* a before or equal b */ -
睡着延时
void msleep(unsigned int millisecs); unsigned long msleep_interruptible(unsigned int millisecs); void ssleep(unsigned int seconds);Tip: msleep()、 ssleep()不能被打断。
Linux设备驱动之设备模型
Linux设备模型是对系统设备组织架构进行抽象的一个数据结构,旨在为设备驱动进行分层、分类、组织。降低设备多样性带来的Linux驱动开发的复杂度,以及设备热拔插处理、电源管理等。
Overview
设计目的
-
电源管理和系统关机(Power management and system shutdown)
设备之间大多情况下有依赖、耦合,因此要实现电源管理就必须对系统的设备结构有清楚的理解,应知道先关哪个然后才能再关哪个。设计设备模型就是为了使系统可以按照正确顺序进行硬件的遍历。 -
与用户空间的交互(Communications with user space)
实现了sysfs虚拟文件系统。它可以将设备模型中定义的设备属性信息等导出到用户空间,使得在用户空间可以实现对设备属性的访问及参数的更改。详见Documentation/filesystems/sysfs.txt。 -
可热插拔设备(Hotpluggable devices)
设备模型管理内核所使用的处理用户空间热插拔的机制,支持设备的动态添加与移除。 -
设备类别(Device classes)
系统的许多部分对设备如何连接没有兴趣, 但是它们需要知道什么类型的设备可用。设备模型也实现了一个给设备分类的机制, 它在一个更高的功能性级别描述了这些设备。 -
对象生命期(Object lifecycles)
设备模型的实现一套机制来处理对象生命期。
设备模型框图
Linux 设备模型是一个复杂的数据结构。如图所示为和USB鼠标相关联的设备模型的一小部分:
这个框图展示了设备模型最重要的四个部分的组织关系(在顶层容器中详解):
-
Devices
描述了设备如何连接到系统。 -
Drivers
系统中可用的驱动。 -
Buses
跟踪什么连接到每个总线,负责匹配设备与驱动。 -
classes
设备底层细节的抽象,描述了设备所提供的功能。
底层实现
kobject
作用与目的
Kobject是将整个设备模型连接在一起的基础。主要用来实现以下功能:
-
对象的引用计数(Reference counting of objects)
通常, 当一个内核对象被创建, 没有方法知道它会存在多长时间。 一种跟踪这种对象生命周期的方法是通过引用计数。 当没有内核代码持有对给定对象的引用, 那个对象已经完成了它的有用寿命并且可以被删除。 -
sysfs 表示(Sysfs representation)
在sysfs中显示的每一个项目都是通过一个与内核交互的kobject实现的。 -
数据结构粘和(Data structure glue)
设备模型整体来看是一个极端复杂的由多级组成的数据结构, kobject实现各级之间的连接粘和。 -
热插拔事件处理(Hotplug event handling)
kobject处理热插拔事件并通知用户空间。
数据结构
/* include in <linux/kobject.h> */
struct kobject {
const char *name; /* 该kobject的名称,同时也是sysfs中的目录名称 */
struct list_head entry; /* kobjetct双向链表 */
struct kobject *parent; /* 指向kset中的kobject,相当于指向父目录 */
struct kset *kset; /*指向所属的kset*/
struct kobj_type *ktype; /*负责对kobject结构跟踪*/
...
};
/* 定义kobject的类型及释放回调 */
struct kobj_type {
void (*release)(struct kobject *); /* kobject释放函数指针 */
struct sysfs_ops *sysfs_ops; /* 默认属性操作方法 */
struct attribute **default_attrs; /* 默认属性 */
};
/* kobject上层容器 */
struct kset {
struct list_head list; /* 用于连接kset中所有kobject的链表头 */
spinlock_t list_lock; /* 扫描kobject组成的链表时使用的锁 */
struct kobject kobj; /* 嵌入的kobject */
const struct kset_uevent_ops *uevent_ops; /* kset的uevent操作 */
};
/* 包含kset的更高级抽象 */
struct subsystem {
struct kset kset; /* 定义一个kset */
struct rw_semaphore rwsem; /* 用于串行访问kset内部链表的读写信号量 */
};kobject和kset关系:
如图所示,kset将它的children(kobjects)组成一个标准的内核链表。所以说kset是一个包含嵌入在同种类型结构中的kobject的集合。它自身也内嵌一个kobject,所以也是一个特殊的kobject。设计kset的主要目的是容纳,可以说是kobject的顶层容器。kset总是会在sysfs中以目录的形式呈现。需要注意的是图中所示的kobject其实是嵌入在其他类型中(很少单独使用),也可能是其他kset中。
kset和subsystem关系:
一个子系统subsystem, 其实只是一个附加了个读写信号量的kset的包装,反过来就是说每个 kset 必须属于一个子系统。根据subsystem之间的成员关系建立kset在整个层级中的位置。
子系统常常使用宏直接静态定义:
/* 定义一个struct subsystem name_subsys 并初始化kset的type及hotplug_ops */
decl_subsys(name, struct kobj_type *type,struct kset_hotplug_ops *hotplug_ops);操作函数
- 初始化
/* 初始化kobject内部结构 */
void kobject_init(struct kobject *kobj);
/* 设置name */
int kobject_set_name(struct kobject *kobj, const char *format, ...);
/* 先将kobj->kset指向要添加的kset中,然后调用会将kobject加入到指定的kset中 */
int kobject_add(struct kobject *kobj);
/* kobject_register = kobject_init + kobject_add */
extern int kobject_register(struct kobject *kobj);
/* 对应的Kobject删除函数 */
void kobject_del(struct kobject *kobj);
void kobject_unregister(struct kobject *kobj);
/* 与kobject类似的kset操作函数 */
void kset_init(struct kset *kset);
kobject_set_name(&my_set->kobj, "The name");
int kset_add(struct kset *kset);
int kset_register(struct kset *kset);
void kset_unregister(struct kset *kset);Tip: 初始化前应先使用memset将kobj清零;初始化完成后引用计数为1
- 引用计数管理
/* 引用计数加1并返回指向kobject的指针 */
struct kobject *kobject_get(struct kobject *kobj);
/* 当一个引用被释放, 调用kobject_put递减引用计数,当引用为0时free这个object */
void kobject_put(struct kobject *kobj);
/* 与kobject类似的kset操作函数 */
struct kset *kset_get(struct kset *kset);
void kset_put(struct kset *kset);- 释放
当引用计数为0时,会调用ktype中的release,因此可以这样定义release回调函数:
void my_object_release(struct kobject *kobj)
{
struct my_object *mine = container_of(kobj, struct my_object, kobj);
/* Perform any additional cleanup on this object, then... */
kfree(mine);
}
/* 查找ktype */
struct kobj_type *get_ktype(struct kobject *kobj);- subsystem相关
decl_subsys(name, type, hotplug_ops);
void subsystem_init(struct subsystem *subsys);
int subsystem_register(struct subsystem *subsys);
void subsystem_unregister(struct subsystem *subsys);
struct subsystem *subsys_get(struct subsystem *subsys);
void subsys_put(struct subsystem *subsys);Low-Level Sysfs Operations
kobject和sysfs关系
kobject是实现sysfs虚拟文件系统背后的机制。sysfs中的每一个目录都对应内核中的一个kobject。将kobject的属性(atrributes)导出就会在sysfs对应的目录下产生由内核自动生成的包含这些属性信息的文件。只需简单的调用前面所提到的kobject_add就会在sysfs中生成一个对应kobject的入口,但值得注意的是:
- 这个入口总会以目录呈现, 也就是说生成一个入口就是创建一个目录。通常这个目录会包含一个或多个属性文件(见下文)。
- 分配给kobject的名字(用kobject_set_name)就是给 sysfs 目录使用的名字,因此在sysfs层级中相同部分的kobject命名必须唯一,不能包含下划线,避免使用空格。
- 这个入口所处的目录表示kobject的parent指针,如果parent为NULL,则指向的是它的kset,因此可以说sysfs的层级其实对应的就是kset的层级。但当kset也为NULL时,这个入口就会创建在sysfs的top level,不过实际中很少出现这种情况。
属性(atrributes)
属性即为上面所提到的一旦导出就会由内核自动生成的包含kobject内核信息的文件。结构如下:
struct attribute {
char *name; /* 属性名,也是sysfs对应entry下的文件名 */
struct module *owner; /* 指向负责实现这个属性的模块 */
mode_t mode; /* 权限位,在<linux/stat.h>中定义 */
};
属性的导出显示及导入存储函数:
/* kobj: 需要处理的kobject
attr: 需要处理的属性
buffer: 存储编码后的属性信息,大小为PAGE_SIZE
return: 实际编码的属性信息长度
*/
struct sysfs_ops {
ssize_t (*show)(struct kobject *kobj, struct attribute *attr,char *buffer); /* 导出到用户空间 */
ssize_t (*store)(struct kobject *kobj, struct attribute *attr,const char *buffer, size_t size); /* 存储进内核空间 */
};需要注意的是:
- 每个属性都是用name=value表示,name即使属性的文件名,value即文件内容,如果value超过PAGE_SIZE,则应分为多个属性来处理;
- 上述函数可以处理不同的属性。可以在内部实现时同过属性名进行区分来实现;
- 由于store是从用户空间到内核,所以实现时首先要检查参数的合法行,以免内核崩溃及其他问题。
缺省属性(Default Attributes)
在kobject创建时都会赋予一些缺省的默认属性,即上面所提到的kobj_type中的default_attrs数组,这个数组的最后一个成员须设置成NULL,以表示数组大小。所有使用这个kobj_type的kobject都是通过kobj_type中的sfsfs_ops回调函数入口实现对缺省属性的定义。
非缺省属性(Nondefault Attributes)
一般来说,定义时就可以通过default_attrs完成所有的属性,但这里也提供了后续动态添加和删除属性的方法:
int sysfs_create_file(struct kobject *kobj, struct attribute *attr);
int sysfs_remove_file(struct kobject *kobj, struct attribute *attr);二进制属性(Binary Attributes)
上述属性包含的可读的文本值,二进制属性很少使用,大多用在从用户空间传递一些不改动的文件如firmware给设备的情况下。
struct bin_attribute {
struct attribute attr; /* 定义name,owner,mode */
size_t size; /* 属性最大长度,如没有最大长度则设为0 */
ssize_t (*read)(struct kobject *kobj, char *buffer,loff_t pos, size_t size);
ssize_t (*write)(struct kobject *kobj, char *buffer,loff_t pos, size_t size);
};read/write一次加载多次调用,每次最多PAGE_SIZE大小。注意write无法指示最后一个写操作,得通过其他方式判断操作的结束。
二进制属性不能定义为缺省值,因此需明确的创建与删除:
int sysfs_create_bin_file(struct kobject *kobj,struct bin_attribute *attr);
int sysfs_remove_bin_file(struct kobject *kobj,struct bin_attribute *attr);符号连接(Symbolic Links)
方法:
int sysfs_create_link(struct kobject *kobj, struct kobject *target,char *name);
void sysfs_remove_link(struct kobject *kobj, char *name);热插拔事件生成(Hotplug Event Generation)
热插拔事件即当系统配置发生改变是内核向用户空间的通知。然后用户空间会调用/sbin/hotplug通过创建节点、加载驱动等动作进行响应。这个热插拔事件的产生是在kobject_add和kobject_del时。我们可以通过上面kset中定义的uevent_ops对热插拔事件产生进行配置:
struct kset_uevent_ops {
/* 实现事件的过滤,其返回值为0时不产生事件 */
int (* const filter)(struct kset *kset, struct kobject *kobj);
/* 生成传递给/sbin/hotplug的name参数 */
const char *(* const name)(struct kset *kset, struct kobject *kobj);
/* 其他传递给/sbin/hotplug的参数通过这种设置环境变量的方式传递 */
int (* const uevent)(struct kset *kset, struct kobject *kobj,
struct kobj_uevent_env *env);
};顶层容器
Buses, Devices, Drivers and Classes
Buses
总线Buses是处理器和设备的通道。在设备模型中,所有设备都是通过总线连接在一起的,哪怕是一个内部虚拟的platform总线。
/* defined in <linux/device.h> */
struct bus_type {
const char *name; /* 总线类型名 */
struct bus_attribute *bus_attrs; /* 总线的属性 */
struct device_attribute *dev_attrs; /* 设备属性,为每个加入总线的设备建立属性链表 */
struct driver_attribute *drv_attrs; /* 驱动属性,为每个加入总线的驱动建立属性链表 */
/* 驱动与设备匹配函数:当一个新设备或者驱动被添加到这个总线时,
这个方法会被调用一次或多次,若指定的驱动程序能够处理指定的设备,则返回非零值。
必须在总线层使用这个函数, 因为那里存在正确的逻辑,核心内核不知道如何为每个总线类型匹配设备和驱动程序 */
int (*match)(struct device *dev, struct device_driver *drv);
/*在为用户空间产生热插拔事件之前,这个方法允许总线添加环境变量(参数和 kset 的uevent方法相同)*/
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
...
struct subsys_private *p; /* 一个很重要的域,包含了device链表和drivers链表 */
}
/* 定义bus_attrs的快捷方式 */
BUS_ATTR(name, mode, show, store);
/* bus属性文件的创建移除 */
int bus_create_file(struct bus_type *bus, struct bus_attribute *attr);
void bus_remove_file(struct bus_type *bus, struct bus_attribute *attr);
/* 总线注册 */
int bus_register(struct bus_type *bus);
void bus_unregister(struct bus_type *bus);
/* 遍历总线上的设备与驱动 */
int bus_for_each_dev(struct bus_type *bus, struct device *start, void *data, int(*fn)(struct device *, void *));
int bus_for_each_drv(struct bus_type *bus, struct device_driver *start, void *data, int(*fn)(struct device_driver *, void *));Devices
Linux中,每一个底层设备都是structure device的一个实例:
struct device {
struct device *parent; /* 父设备,总线设备指定为NULL */
struct device_private *p; /* 包含设备链表,driver_data(驱动程序要使用数据)等信息 */
struct kobject kobj;
const char *init_name; /* 初始默认的设备名 */
struct bus_type *bus; /* type of bus device is on */
struct device_driver *driver; /* which driver has allocated this device */
...
void (*release)(struct device *dev);
};
int device_register(struct device *dev);
void device_unregister(struct device *dev);
DEVICE_ATTR(name, mode, show, store);
int device_create_file(struct device *device,struct device_attribute *entry);
void device_remove_file(struct device *dev,struct device_attribute *attr);Drivers
设备模型跟踪所有系统已知的驱动。
struct device_driver {
const char *name; /* 驱动名称,在sysfs中以文件夹名出现 */
struct bus_type *bus; /* 驱动关联的总线类型 */
int (*probe) (struct device *dev); /* 查询设备的存在 */
int (*remove) (struct device *dev); /* 设备移除回调 */
void (*shutdown) (struct device *dev);
...
}
int driver_register(struct device_driver *drv);
void driver_unregister(struct device_driver *drv);
DRIVER_ATTR(name, mode, show, store);
int driver_create_file(struct device_driver *drv,struct driver_attribute *attr);
void driver_remove_file(struct device_driver *drv,struct driver_attribute *attr);Classes
类是设备的一个高级视图,实现了底层细节。通过对设备进行分类,同类代码可共享,减少了内核代码的冗余。
struct class {
const char *name; /* class的名称,会在“/sys/class/”目录下体现 */
struct class_attribute *class_attrs;
struct device_attribute *dev_attrs; /* 该class下每个设备的attribute */
struct kobject *dev_kobj;
/* 当该class下有设备发生变化时,会调用class的uevent回调函数 */
int (*dev_uevent)(struct device *dev, struct kobj_uevent_env *env);
char *(*devnode)(struct device *dev, mode_t *mode);
void (*class_release)(struct class *class);
void (*dev_release)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
struct class_private *p;
};
int class_register(struct class *cls);
void class_unregister(struct class *cls);
CLASS_ATTR(name, mode, show, store);
int class_create_file(struct class *cls,const struct class_attribute *attr);
void class_remove_file(struct class *cls,const struct class_attribute *attr);Putting It All Together



 浙公网安备 33010602011771号
浙公网安备 33010602011771号