linux驱动(续)
网络通信 --> IO多路复用之select、poll、epoll详解
IO多路复用之select、poll、epoll详解
select,pselect,poll,epoll,I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,pselect,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。一、使用场景
二、select、poll、epoll简介
其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现。1、select
其良好跨平台支持也是它的一个优点。select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。2、poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。原因是它是基于链表来存储的,但是同样有一个缺点:1)大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。2)poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。3、epoll
epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)。2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。3、内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。 LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的。 ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)。 ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。(此处去掉了遍历文件描述符,而是通过监听回调的的机制。这正是epoll的魅力所在。)三、select、poll、epoll区别
1、支持一个进程所能打开的最大连接数

2、FD剧增后带来的IO效率问题

3、消息传递方式

但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善。
详述socket编程之select()和poll()函数
select()函数和poll()函数均是主要用来处理多路I/O复用的情况。比如一个服务器既想等待输入终端到来,又想等待若干个套接字有客户请求到达,这时候就需要借助select或者poll函数了。
(一)select()函数
原型如下:
各个参数含义如下:
- int fdsp1:最大描述符值 + 1
- fd_set *readfds:对可读感兴趣的描述符集
- fd_set *writefds:对可写感兴趣的描述符集
- fd_set *errorfds:对出错感兴趣的描述符集
- struct timeval *timeout:超时时间(注意:对于linux系统,此参数没有const限制,每次select调用完毕timeout的值都被修改为剩余时间,而unix系统则不会改变timeout值)
select函数会在发生以下情况时返回:
- readfds集合中有描述符可读
- writefds集合中有描述符可写
- errorfds集合中有描述符遇到错误条件
- 指定的超时时间timeout到了
当select返回时,描述符集合将被修改以指示哪些个描述符正处于可读、可写或有错误状态。可以用FD_ISSET宏对描述符进行测试以找到状态变化的描述符。如果select因为超时而返回的话,所有的描述符集合都将被清空。
select函数返回状态发生变化的描述符总数。返回0意味着超时。失败则返回-1并设置errno。可能出现的错误有:EBADF(无效描述符)、EINTR(因终端而返回)、EINVAL(nfds或timeout取值错误)。
设置描述符集合通常用如下几个宏定义:
2 FD_SET(int fd, fd_set *fdset); /* turn on the bit for fd in fd_set */
3 FD_CLR(int fd, fd_set *fdset); /* turn off the bit for fd in fd_set */
4 int FD_ISSET(int fd, fd_set *fdset); /* is the bit for fd on in fdset? */
如:
2 FD_ZERO(&rset); /* initialize the set: all bits off */
3 FD_SET(1, &rset); /* turn on bit for fd 1 */
4 FD_SET(4, &rset); /* turn on bit for fd 4 */
5 FD_SET(5, &rset); /* turn on bit for fd 5 */
当select返回的时候,rset位都将被置0,除了那些有变化的fd位。
当发生如下情况时认为是可读的:
- socket的receive buffer中的字节数大于socket的receive buffer的low-water mark属性值。(low-water mark值类似于分水岭,当receive buffer中的字节数小于low-water mark值的时候,认为socket还不可读,只有当receive buffer中的字节数达到一定量的时候才认为socket可读)
- 连接半关闭(读关闭,即收到对端发来的FIN包)
- 发生变化的描述符是被动套接字,而连接的三路握手完成的数量大于0,即有新的TCP连接建立
- 描述符发生错误,如果调用read系统调用读套接字的话会返回-1。
当发生如下情况时认为是可写的:
- socket的send buffer中的字节数大于socket的send buffer的low-water mark属性值以及socket已经连接或者不需要连接(如UDP)。
- 写半连接关闭,调用write函数将产生SIGPIPE
- 描述符发生错误,如果调用write系统调用写套接字的话会返回-1。
注意:
select默认能处理的描述符数量是有上限的,为FD_SETSIZE的大小。
对于timeout参数,如果置为NULL,则表示wait forever;若timeout->tv_sec = timeout->tv_usec = 0,则表示do not wait at all;否则指定等待时间。
如果使用select处理多个套接字,那么需要使用一个数组(也可以是其他结构)来记录各个描述符的状态。而使用poll则不需要,下面看poll函数。
(二)poll()函数
原型如下:
各参数含义如下:
- struct pollfd *fdarray:一个结构体,用来保存各个描述符的相关状态。
- unsigned long nfds:fdarray数组的大小,即里面包含有效成员的数量。
- int timeout:设定的超时时间。(以毫秒为单位)
poll函数返回值及含义如下:
- -1:有错误产生
- 0:超时时间到,而且没有描述符有状态变化
- >0:有状态变化的描述符个数
着重讲fdarray数组,因为这是它和select()函数主要的不同的地方:
pollfd的结构如下:
2 int fd; /* descriptor to check */
3 short events; /* events of interest on fd */
4 short revents; /* events that occured on fd */
5 };
其实poll()和select()函数要处理的问题是相同的,只不过是不同组织在几乎相同时刻同时推出的,因此才同时保留了下来。select()函数把可读描述符、可写描述符、错误描述符分在了三个集合里,这三个集合都是用bit位来标记一个描述符,一旦有若干个描述符状态发生变化,那么它将被置位,而其他没有发生变化的描述符的bit位将被clear,也就是说select()的readset、writeset、errorset是一个value-result类型,通过它们传值,而也通过它们返回结果。这样的一个坏处是每次重新select
的时候对集合必须重新赋值。而poll()函数则与select()采用的方式不同,它通过一个结构数组保存各个描述符的状态,每个结构体第一项fd代表描述符,第二项代表要监听的事件,也就是感兴趣的事件,而第三项代表poll()返回时描述符的返回状态。合法状态如下:
- POLLIN: 有普通数据或者优先数据可读
- POLLRDNORM: 有普通数据可读
- POLLRDBAND: 有优先数据可读
- POLLPRI: 有紧急数据可读
- POLLOUT: 有普通数据可写
- POLLWRNORM: 有普通数据可写
- POLLWRBAND: 有紧急数据可写
- POLLERR: 有错误发生
- POLLHUP: 有描述符挂起事件发生
- POLLNVAL: 描述符非法
对于POLLIN | POLLPRI等价与select()的可读事件;POLLOUT |
POLLWRBAND等价与select()的可写事件;POLLIN 等价与POLLRDNORM |
POLLRDBAND,而POLLOUT等价于POLLWRBAND。如果你对一个描述符的可读事件和可写事件以及错误等事件均感兴趣那么你应该都进行相应的设置。
对于timeout的设置如下:
- INFTIM: wait forever
- 0: return immediately, do not block
- >0: wait specified number of milliseconds
Linux IO模式及 select、poll、epoll详解
同步IO和异步IO,阻塞IO和非阻塞IO分别是什么,到底有什么区别?不同的人在不同的上下文下给出的答案是不同的。所以先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
一 概念说明
在进行解释之前,首先要说明几个概念:
- 用户空间和内核空间
- 进程切换
- 进程的阻塞
- 文件描述符
- 缓存 I/O
用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6. 恢复处理机上下文。
注:总而言之就是很耗资源,具体的可以参考这篇文章:进程切换
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
二 IO模式
刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
阻塞 I/O(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
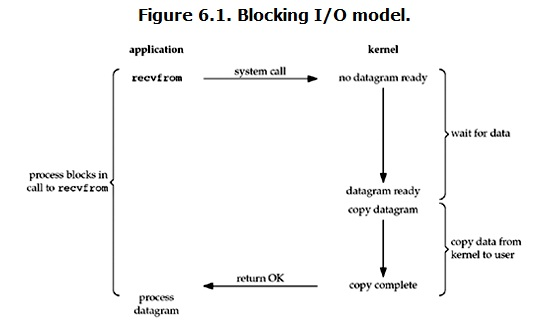
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
非阻塞 I/O(nonblocking IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
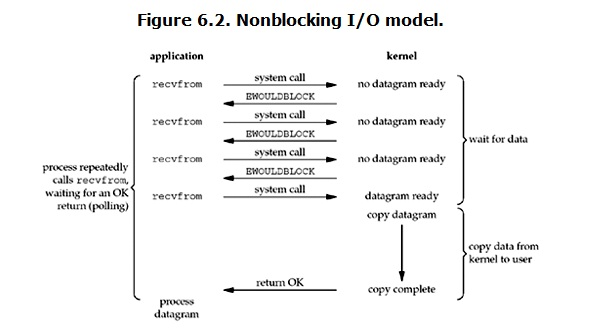
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
I/O 多路复用( IO multiplexing)
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
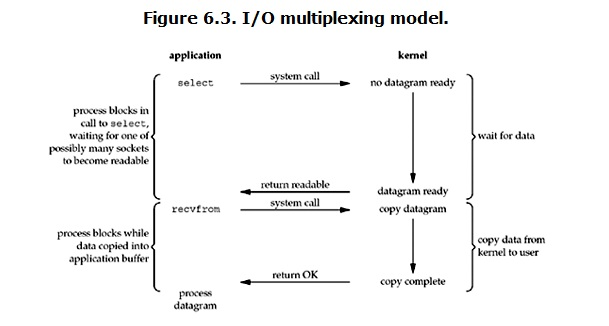
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
异步 I/O(asynchronous IO)
inux下的asynchronous IO其实用得很少。先看一下它的流程:
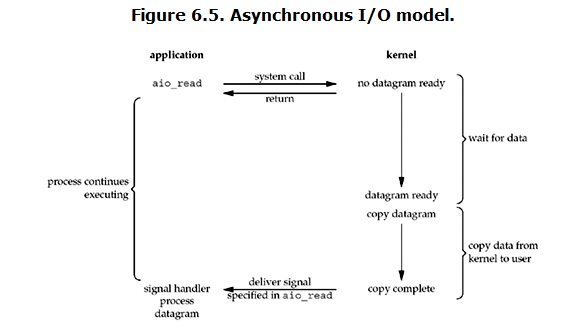
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
总结
blocking和non-blocking的区别
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
synchronous IO和asynchronous IO的区别
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。
有人会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。
而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

通过上面的图片,可以发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
三 I/O 多路复用之select、poll、epoll详解
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。(这里啰嗦下)
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
从上面看,select和poll都需要在返回后,
通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
一 epoll操作过程
epoll操作过程需要三个接口,分别如下:
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
- epfd:是epoll_create()的返回值。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事,struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
//events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
二 工作模式
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
1. LT模式
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的。
2. ET模式
ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
3. 总结
假如有这样一个例子:
1. 我们已经把一个用来从管道中读取数据的文件句柄(RFD)添加到epoll描述符
2. 这个时候从管道的另一端被写入了2KB的数据
3. 调用epoll_wait(2),并且它会返回RFD,说明它已经准备好读取操作
4. 然后我们读取了1KB的数据
5. 调用epoll_wait(2)......
LT模式:
如果是LT模式,那么在第5步调用epoll_wait(2)之后,仍然能受到通知。
ET模式:
如果我们在第1步将RFD添加到epoll描述符的时候使用了EPOLLET标志,那么在第5步调用epoll_wait(2)之后将有可能会挂起,因为剩余的数据还存在于文件的输入缓冲区内,而且数据发出端还在等待一个针对已经发出数据的反馈信息。只有在监视的文件句柄上发生了某个事件的时候
ET 工作模式才会汇报事件。因此在第5步的时候,调用者可能会放弃等待仍在存在于文件输入缓冲区内的剩余数据。
当使用epoll的ET模型来工作时,当产生了一个EPOLLIN事件后,
读数据的时候需要考虑的是当recv()返回的大小如果等于请求的大小,那么很有可能是缓冲区还有数据未读完,也意味着该次事件还没有处理完,所以还需要再次读取:
while(rs){
buflen = recv(activeevents[i].data.fd, buf, sizeof(buf), 0);
if(buflen < 0){
// 由于是非阻塞的模式,所以当errno为EAGAIN时,表示当前缓冲区已无数据可读
// 在这里就当作是该次事件已处理处.
if(errno == EAGAIN){
break;
}
else{
return;
}
}
else if(buflen == 0){
// 这里表示对端的socket已正常关闭.
}
if(buflen == sizeof(buf){
rs = 1; // 需要再次读取
}
else{
rs = 0;
}
}
Linux中的EAGAIN含义
Linux环境下开发经常会碰到很多错误(设置errno),其中EAGAIN是其中比较常见的一个错误(比如用在非阻塞操作中)。
从字面上来看,是提示再试一次。这个错误经常出现在当应用程序进行一些非阻塞(non-blocking)操作(对文件或socket)的时候。
例如,以 O_NONBLOCK的标志打开文件/socket/FIFO,如果你连续做read操作而没有数据可读。此时程序不会阻塞起来等待数据准备就绪返回,read函数会返回一个错误EAGAIN,提示你的应用程序现在没有数据可读请稍后再试。
又例如,当一个系统调用(比如fork)因为没有足够的资源(比如虚拟内存)而执行失败,返回EAGAIN提示其再调用一次(也许下次就能成功)。
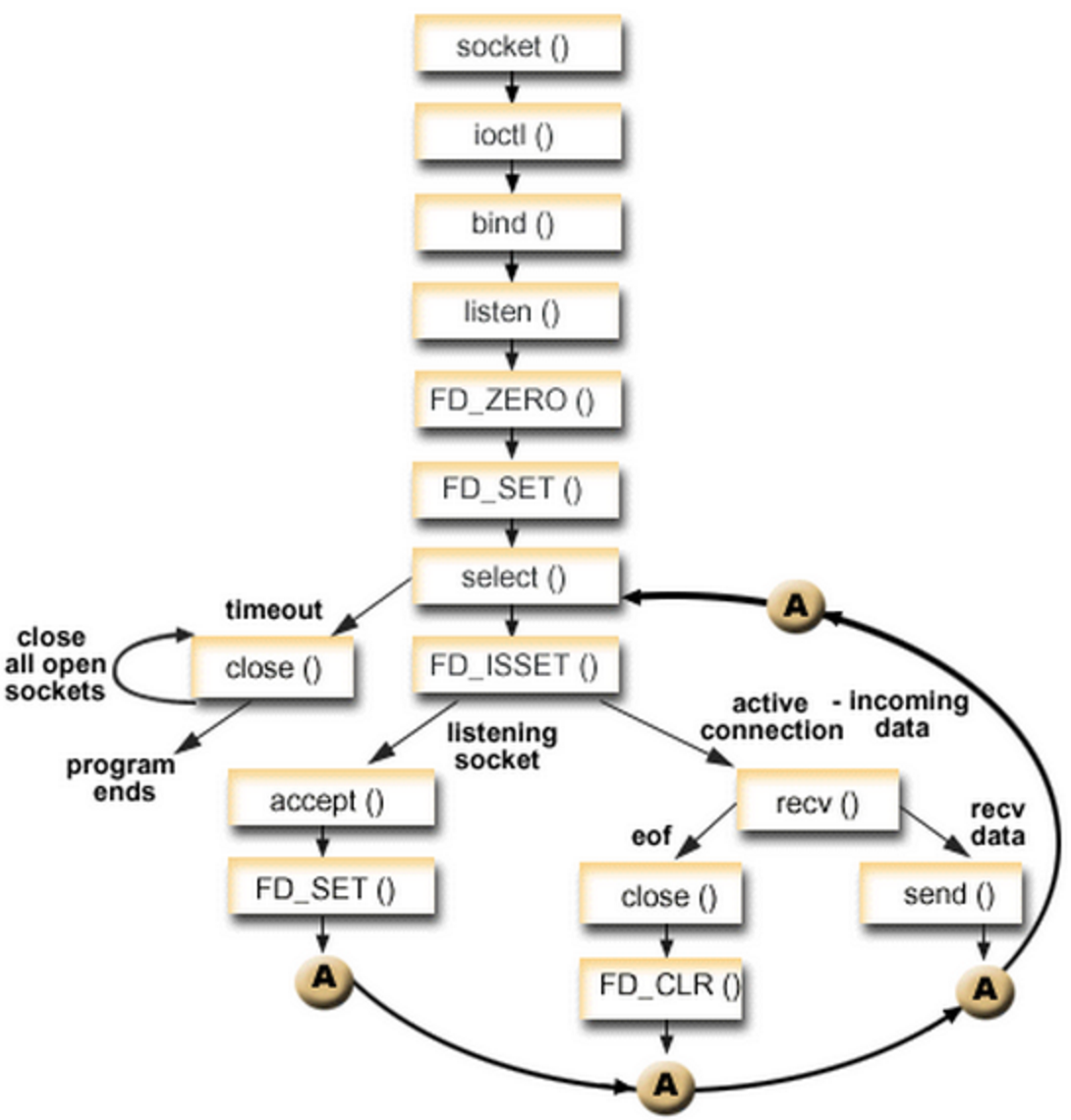
三 代码演示
下面是一段不完整的代码且格式不对,意在表述上面的过程,去掉了一些模板代码。
#define IPADDRESS "127.0.0.1"
#define PORT 8787
#define MAXSIZE 1024
#define LISTENQ 5
#define FDSIZE 1000
#define EPOLLEVENTS 100
listenfd = socket_bind(IPADDRESS,PORT);
struct epoll_event events[EPOLLEVENTS];
//创建一个描述符
epollfd = epoll_create(FDSIZE);
//添加监听描述符事件
add_event(epollfd,listenfd,EPOLLIN);
//循环等待
for ( ; ; ){
//该函数返回已经准备好的描述符事件数目
ret = epoll_wait(epollfd,events,EPOLLEVENTS,-1);
//处理接收到的连接
handle_events(epollfd,events,ret,listenfd,buf);
}
//事件处理函数
static void handle_events(int epollfd,struct epoll_event *events,int num,int listenfd,char *buf)
{
int i;
int fd;
//进行遍历;这里只要遍历已经准备好的io事件。num并不是当初epoll_create时的FDSIZE。
for (i = 0;i < num;i++)
{
fd = events[i].data.fd;
//根据描述符的类型和事件类型进行处理
if ((fd == listenfd) &&(events[i].events & EPOLLIN))
handle_accpet(epollfd,listenfd);
else if (events[i].events & EPOLLIN)
do_read(epollfd,fd,buf);
else if (events[i].events & EPOLLOUT)
do_write(epollfd,fd,buf);
}
}
//添加事件
static void add_event(int epollfd,int fd,int state){
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_ADD,fd,&ev);
}
//处理接收到的连接
static void handle_accpet(int epollfd,int listenfd){
int clifd;
struct sockaddr_in cliaddr;
socklen_t cliaddrlen;
clifd = accept(listenfd,(struct sockaddr*)&cliaddr,&cliaddrlen);
if (clifd == -1)
perror("accpet error:");
else {
printf("accept a new client: %s:%d\n",inet_ntoa(cliaddr.sin_addr),cliaddr.sin_port); //添加一个客户描述符和事件
add_event(epollfd,clifd,EPOLLIN);
}
}
//读处理
static void do_read(int epollfd,int fd,char *buf){
int nread;
nread = read(fd,buf,MAXSIZE);
if (nread == -1) {
perror("read error:");
close(fd); //记住close fd
delete_event(epollfd,fd,EPOLLIN); //删除监听
}
else if (nread == 0) {
fprintf(stderr,"client close.\n");
close(fd); //记住close fd
delete_event(epollfd,fd,EPOLLIN); //删除监听
}
else {
printf("read message is : %s",buf);
//修改描述符对应的事件,由读改为写
modify_event(epollfd,fd,EPOLLOUT);
}
}
//写处理
static void do_write(int epollfd,int fd,char *buf) {
int nwrite;
nwrite = write(fd,buf,strlen(buf));
if (nwrite == -1){
perror("write error:");
close(fd); //记住close fd
delete_event(epollfd,fd,EPOLLOUT); //删除监听
}else{
modify_event(epollfd,fd,EPOLLIN);
}
memset(buf,0,MAXSIZE);
}
//删除事件
static void delete_event(int epollfd,int fd,int state) {
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_DEL,fd,&ev);
}
//修改事件
static void modify_event(int epollfd,int fd,int state){
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_MOD,fd,&ev);
}
//注:另外一端我就省了
四 epoll总结
在 select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一 个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait() 时便得到通知。(此处去掉了遍历文件描述符,而是通过监听回调的的机制。这正是epoll的魅力所在。)
epoll的优点主要是一下几个方面:
1.
监视的描述符数量不受限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左
右,具体数目可以cat
/proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。select的最大缺点就是进程打开的fd是有数量限制的。这对
于连接数量比较大的服务器来说根本不能满足。虽然也可以选择多进程的解决方案(
Apache就是这样实现的),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。
- IO的效率不会随着监视fd的数量的增长而下降。epoll不同于select和poll轮询的方式,而是通过每个fd定义的回调函数来实现的。只有就绪的fd才会执行回调函数。
如果没有大量的idle -connection或者dead-connection,epoll的效率并不会比select/poll高很多,但是当遇到大量的idle- connection,就会发现epoll的效率大大高于select/poll。
参考
用户空间与内核空间,进程上下文与中断上下文[总结]
进程切换
维基百科-文件描述符
Linux 中直接 I/O 机制的介绍
IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
Linux中select poll和epoll的区别
IO多路复用之select总结
IO多路复用之poll总结
IO多路复用之epoll总结
select、poll、epoll之间的区别总结[整理]
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。关于这三种IO多路复用的用法,前面三篇总结写的很清楚,并用服务器回射echo程序进行了测试。连接如下所示:
select:http://www.cnblogs.com/Anker/archive/2013/08/14/3258674.html
poll:http://www.cnblogs.com/Anker/archive/2013/08/15/3261006.html
epoll:http://www.cnblogs.com/Anker/archive/2013/08/17/3263780.html
今天对这三种IO多路复用进行对比,参考网上和书上面的资料,整理如下:
1、select实现
select的调用过程如下所示:
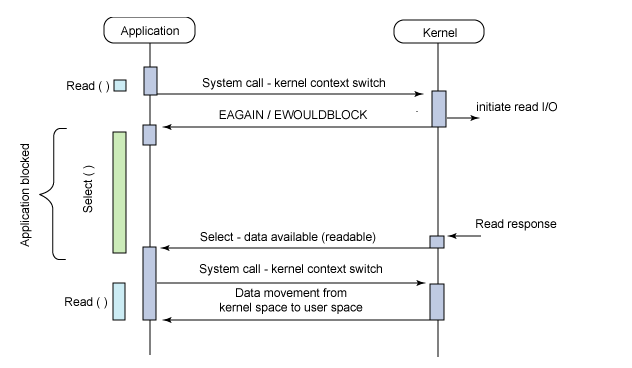
(1)使用copy_from_user从用户空间拷贝fd_set到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结:
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
2 poll实现
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多。
关于select和poll的实现分析,可以参考下面几篇博文:
http://blog.csdn.net/lizhiguo0532/article/details/6568964#comments
http://blog.csdn.net/lizhiguo0532/article/details/6568968
http://blog.csdn.net/lizhiguo0532/article/details/6568969
http://www.ibm.com/developerworks/cn/linux/l-cn-edntwk/index.html?ca=drs-
http://linux.chinaunix.net/techdoc/net/2009/05/03/1109887.shtml
3、epoll
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
参考资料:
http://www.cnblogs.com/apprentice89/archive/2013/05/09/3070051.html
http://www.linuxidc.com/Linux/2012-05/59873p3.htm
http://xingyunbaijunwei.blog.163.com/blog/static/76538067201241685556302/
http://blog.csdn.net/kkxgx/article/details/7717125
https://banu.com/blog/2/how-to-use-epoll-a-complete-example-in-c/epoll-example.c
Linux I/O复用中select poll epoll模型的介绍及其优缺点的比较
关于I/O多路复用:
I/O多路复用(又被称为“事件驱动”),首先要理解的是,操作系统为你提供了一个功能,当你的某个socket可读或者可写的时候,它可以给你一个通知。这样当配合非阻塞的socket使用时,只有当系统通知我哪个描述符可读了,我才去执行read操作,可以保证每次read都能读到有效数据而不做纯返回-1和EAGAIN的无用功。写操作类似。操作系统的这个功能通过select/poll/epoll之类的系统调用来实现,这些函数都可以同时监视多个描述符的读写就绪状况,这样,**多个描述符的I/O操作都能在一个线程内并发交替地顺序完成,这就叫I/O多路复用,这里的“复用”指的是复用同一个线程。
一、I/O复用之select
1、介绍:
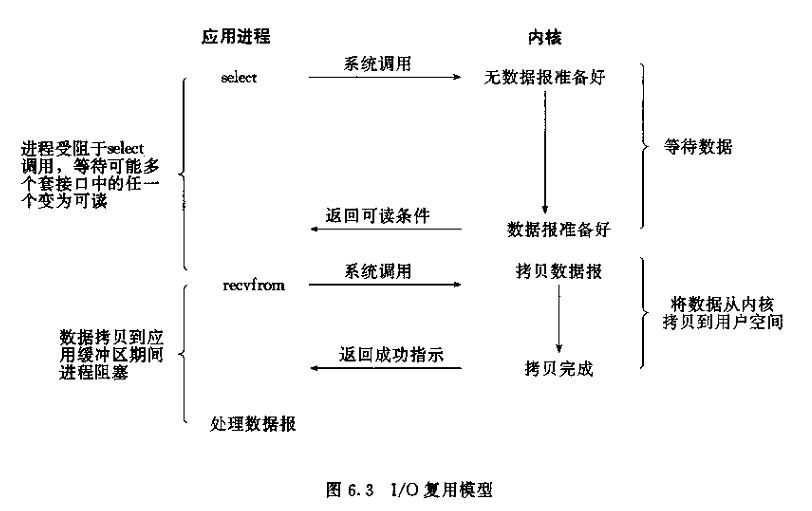
select系统调用的目的是:在一段指定时间内,监听用户感兴趣的文件描述符上的可读、可写和异常事件。poll和select应该被归类为这样的系统调用,它们可以阻塞地同时探测一组支持非阻塞的IO设备,直至某一个设备触发了事件或者超过了指定的等待时间——也就是说它们的职责不是做IO,而是帮助调用者寻找当前就绪的设备。
下面是select的原理图:
2、select系统调用API如下:
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
fd_set结构体是文件描述符集,该结构体实际上是一个整型数组,数组中的每个元素的每一位标记一个文件描述符。fd_set能容纳的文件描述符数量由FD_SETSIZE指定,一般情况下,FD_SETSIZE等于1024,这就限制了select能同时处理的文件描述符的总量。
3、下面介绍一下各个参数的含义:
1)nfds参数指定被监听的文件描述符的总数。通常被设置为select监听的所有文件描述符中最大值加1;
2)readfds、writefds、exceptfds分别指向可读、可写和异常等事件对应的文件描述符集合。这三个参数都是传入传出型参数,指的是在调用select之前,用户把关心的可读、可写、或异常的文件描述符通过FD_SET(下面介绍)函数分别添加进readfds、writefds、exceptfds文件描述符集,select将对这些文件描述符集中的文件描述符进行监听,如果有就绪文件描述符,select会重置readfds、writefds、exceptfds文件描述符集来通知应用程序哪些文件描述符就绪。这个特性将导致select函数返回后,再次调用select之前,必须重置我们关心的文件描述符,也就是三个文件描述符集已经不是我们之前传入 的了。
3)timeout参数用来指定select函数的超时时间(下面讲select返回值时还会谈及)。
struct timeval
{
long tv_sec; //秒数
long tv_usec; //微秒数
};
4、下面几个函数(宏实现)用来操纵文件描述符集:
void FD_SET(int fd, fd_set *set); //在set中设置文件描述符fd
void FD_CLR(int fd, fd_set *set); //清除set中的fd位
int FD_ISSET(int fd, fd_set *set); //判断set中是否设置了文件描述符fd
void FD_ZERO(fd_set *set); //清空set中的所有位(在使用文件描述符集前,应该先清空一下)
//(注意FD_CLR和FD_ZERO的区别,一个是清除某一位,一个是清除所有位)
5、select的返回情况:
1)如果指定timeout为NULL,select会永远等待下去,直到有一个文件描述符就绪,select返回;
2)如果timeout的指定时间为0,select根本不等待,立即返回;
3)如果指定一段固定时间,则在这一段时间内,如果有指定的文件描述符就绪,select函数返回,如果超过指定时间,select同样返回。
4)返回值情况:
a)超时时间内,如果文件描述符就绪,select返回就绪的文件描述符总数(包括可读、可写和异常),如果没有文件描述符就绪,select返回0;
b)select调用失败时,返回 -1并设置errno,如果收到信号,select返回 -1并设置errno为EINTR。
6、文件描述符的就绪条件:
在网络编程中,
1)下列情况下socket可读:
a) socket内核接收缓冲区的字节数大于或等于其低水位标记SO_RCVLOWAT;
b) socket通信的对方关闭连接,此时该socket可读,但是一旦读该socket,会立即返回0(可以用这个方法判断client端是否断开连接);
c) 监听socket上有新的连接请求;
d) socket上有未处理的错误。
2)下列情况下socket可写:
a) socket内核发送缓冲区的可用字节数大于或等于其低水位标记SO_SNDLOWAT;
b) socket的读端关闭,此时该socket可写,一旦对该socket进行操作,该进程会收到SIGPIPE信号;
c) socket使用connect连接成功之后;
d) socket上有未处理的错误。
二、I/O复用之poll
1、poll系统调用的原理与原型和select基本类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有就绪者。
2、poll系统调用API如下:
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
3、下面介绍一下各个参数的含义:
1)第一个参数是指向一个结构数组的第一个元素的指针,每个元素都是一个pollfd结构,用于指定测试某个给定描述符的条件。
struct pollfd
{
int fd; //指定要监听的文件描述符
short events; //指定监听fd上的什么事件
short revents; //fd上事件就绪后,用于保存实际发生的时间
};
待监听的事件由events成员指定,函数在相应的revents成员中返回该描述符的状态(每个文件描述符都有两个事件,一个是传入型的events,一个是传出型的revents,从而避免使用传入传出型参数,注意与select的区别),从而告知应用程序fd上实际发生了哪些事件。events和revents都可以是多个事件的按位或。
2)第二个参数是要监听的文件描述符的个数,也就是数组fds的元素个数;
3)第三个参数意义与select相同。
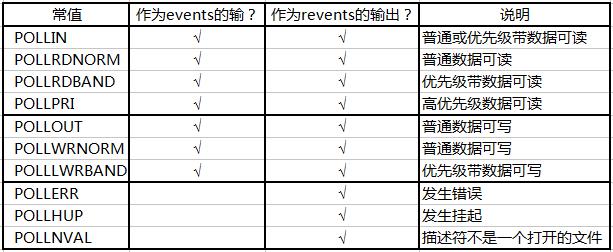
4、poll的事件类型:
在使用POLLRDHUP时,要在代码开始处定义_GNU_SOURCE
5、poll的返回情况:
与select相同。
三、I/O复用之epoll
1、介绍:
epoll
与select和poll在使用和实现上有很大区别。首先,epoll使用一组函数来完成,而不是单独的一个函数;其次,epoll把用户关心的文件描述符上的事件放在内核里的一个事件表中,无须向select和poll那样每次调用都要重复传入文件描述符集合事件集。
2、创建一个文件描述符,指定内核中的事件表:
#include<sys/epoll.h>
int epoll_create(int size);
//调用成功返回一个文件描述符,失败返回-1并设置errno。
size参数并不起作用,只是给内核一个提示,告诉它事件表需要多大。该函数返回的文件描述符指定要访问的内核事件表,是其他所有epoll系统调用的句柄。
3、操作内核事件表:
#include<sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
//调用成功返回0,调用失败返回-1并设置errno。
epfd是epoll_create返回的文件句柄,标识事件表,op指定操作类型。操作类型有以下3种:
a)EPOLL_CTL_ADD, 往事件表中注册fd上的事件;
b)EPOLL_CTL_MOD, 修改fd上注册的事件;
c)EPOLL_CTL_DEL, 删除fd上注册的事件。
event参数指定事件,epoll_event的定义如下:
struct epoll_event
{
__int32_t events; //epoll事件
epoll_data_t data; //用户数据
};
typedef union epoll_data
{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data;
在使用epoll_ctl时,是把fd添加、修改到内核事件表中,或从内核事件表中删除fd的事件。如果是添加事件到事件表中,可以往data中的fd上添加事件events,或者不用data中的fd,而把fd放到用户数据ptr所指的内存中(因为epoll_data是一个联合体,只能使用其中一个数据),再设置events。
3、epoll_wait函数
epoll系统调用的最关键的一个函数epoll_wait,它在一段时间内等待一个组文件描述符上的事件。
#include<sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
//函数调用成功返回就绪文件描述符个数,失败返回-1并设置errno。
timeout参数和select与poll相同,指定一个超时时间;maxevents指定最多监听多少个事件;events是一个传出型参数,epoll_wait函数如果检测到事件就绪,就将所有就绪的事件从内核事件表(epfd所指的文件)中复制到events指定的数组中。这个数组用来输出epoll_wait检测到的就绪事件,而不像select与poll那样,这也是epoll与前者最大的区别,下文在比较三者之间的区别时还会说到。
四、三组I/O复用函数的比较
相同点:
1)三者都需要在fd上注册用户关心的事件;
2)三者都要一个timeout参数指定超时时间;
不同点:
1)select:
a)select指定三个文件描述符集,分别是可读、可写和异常事件,所以不能更加细致地区分所有可能发生的事件;
b)select如果检测到就绪事件,会在原来的文件描述符上改动,以告知应用程序,文件描述符上发生了什么时间,所以再次调用select时,必须先重置文件描述符;
c)select采用对所有注册的文件描述符集轮询的方式,会返回整个用户注册的事件集合,所以应用程序索引就绪文件的时间复杂度为O(n);
d)select允许监听的最大文件描述符个数通常有限制,一般是1024,如果大于1024,select的性能会急剧下降;
e)只能工作在LT模式。
2)poll:
a)poll把文件描述符和事件绑定,事件不但可以单独指定,而且可以是多个事件的按位或,这样更加细化了事件的注册,而且poll单独采用一个元素用来保存就绪返回时的结果,这样在下次调用poll时,就不用重置之前注册的事件;
b)poll采用对所有注册的文件描述符集轮询的方式,会返回整个用户注册的事件集合,所以应用程序索引就绪文件的时间复杂度为O(n)。
c)poll用nfds参数指定最多监听多少个文件描述符和事件,这个数能达到系统允许打开的最大文件描述符数目,即65535。
d)只能工作在LT模式。
3)epoll:
a)epoll把用户注册的文件描述符和事件放到内核当中的事件表中,提供了一个独立的系统调用epoll_ctl来管理用户的事件,而且epoll采用回调的方式,一旦有注册的文件描述符就绪,讲触发回调函数,该回调函数将就绪的文件描述符和事件拷贝到用户空间events所管理的内存,这样应用程序索引就绪文件的时间复杂度达到O(1)。
b)epoll_wait使用maxevents来制定最多监听多少个文件描述符和事件,这个数能达到系统允许打开的最大文件描述符数目,即65535;
c)不仅能工作在LT模式,而且还支持ET高效模式(即EPOLLONESHOT事件,读者可以自己查一下这个事件类型,对于epoll的线程安全有很好的帮助)。
select/poll/epoll总结:
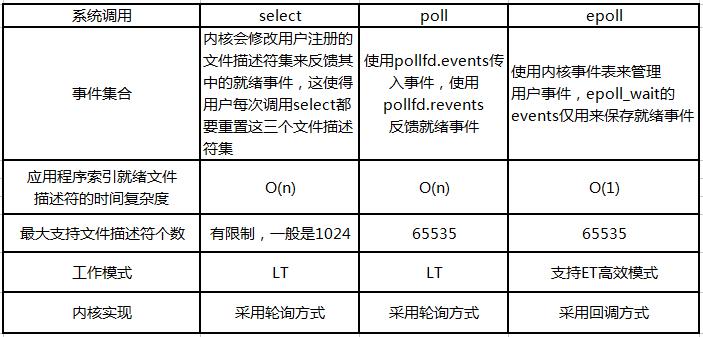
深度理解select、poll和epoll
在linux 没有实现epoll事件驱动机制之前,我们一般选择用select或者poll等IO多路复用的方法来实现并发服务程序。在大数据、高并发、集群等一些名词唱得火热之年代,select和poll的用武之地越来越有限,风头已经被epoll占尽。
本文便来介绍epoll的实现机制,并附带讲解一下select和poll。通过对比其不同的实现机制,真正理解为何epoll能实现高并发。
select()和poll() IO多路复用模型
select的缺点:
- 单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024)
- 内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
- select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
因此,该epoll上场了。
epoll IO多路复用模型实现机制
由于epoll的实现机制与select/poll机制完全不同,上面所说的 select的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
1)调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生的事件的连接
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
下面来看看Linux内核具体的epoll机制实现思路。
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
- struct eventpoll{
- ....
- /*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
- struct rb_root rbr;
- /*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
- struct list_head rdlist;
- ....
- };
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
- struct epitem{
- struct rb_node rbn;//红黑树节点
- struct list_head rdllink;//双向链表节点
- struct epoll_filefd ffd; //事件句柄信息
- struct eventpoll *ep; //指向其所属的eventpoll对象
- struct epoll_event event; //期待发生的事件类型
- }
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。

epoll数据结构示意图
从上面的讲解可知:通过红黑树和双链表数据结构,并结合回调机制,造就了epoll的高效。
OK,讲解完了Epoll的机理,我们便能很容易掌握epoll的用法了。一句话描述就是:三步曲。
第一步:epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
第二步:epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
第三部:epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
最后,附上一个epoll编程实例。(作者为sparkliang)
- //
- // a simple echo server using epoll in linux
- //
- // 2009-11-05
- // 2013-03-22:修改了几个问题,1是/n格式问题,2是去掉了原代码不小心加上的ET模式;
- // 本来只是简单的示意程序,决定还是加上 recv/send时的buffer偏移
- // by sparkling
- //
- #include <sys/socket.h>
- #include <sys/epoll.h>
- #include <netinet/in.h>
- #include <arpa/inet.h>
- #include <fcntl.h>
- #include <unistd.h>
- #include <stdio.h>
- #include <errno.h>
- #include <iostream>
- using namespace std;
- #define MAX_EVENTS 500
- struct myevent_s
- {
- int fd;
- void (*call_back)(int fd, int events, void *arg);
- int events;
- void *arg;
- int status; // 1: in epoll wait list, 0 not in
- char buff[128]; // recv data buffer
- int len, s_offset;
- long last_active; // last active time
- };
- // set event
- void EventSet(myevent_s *ev, int fd, void (*call_back)(int, int, void*), void *arg)
- {
- ev->fd = fd;
- ev->call_back = call_back;
- ev->events = 0;
- ev->arg = arg;
- ev->status = 0;
- bzero(ev->buff, sizeof(ev->buff));
- ev->s_offset = 0;
- ev->len = 0;
- ev->last_active = time(NULL);
- }
- // add/mod an event to epoll
- void EventAdd(int epollFd, int events, myevent_s *ev)
- {
- struct epoll_event epv = {0, {0}};
- int op;
- epv.data.ptr = ev;
- epv.events = ev->events = events;
- if(ev->status == 1){
- op = EPOLL_CTL_MOD;
- }
- else{
- op = EPOLL_CTL_ADD;
- ev->status = 1;
- }
- if(epoll_ctl(epollFd, op, ev->fd, &epv) < 0)
- printf("Event Add failed[fd=%d], evnets[%d]\n", ev->fd, events);
- else
- printf("Event Add OK[fd=%d], op=%d, evnets[%0X]\n", ev->fd, op, events);
- }
- // delete an event from epoll
- void EventDel(int epollFd, myevent_s *ev)
- {
- struct epoll_event epv = {0, {0}};
- if(ev->status != 1) return;
- epv.data.ptr = ev;
- ev->status = 0;
- epoll_ctl(epollFd, EPOLL_CTL_DEL, ev->fd, &epv);
- }
- int g_epollFd;
- myevent_s g_Events[MAX_EVENTS+1]; // g_Events[MAX_EVENTS] is used by listen fd
- void RecvData(int fd, int events, void *arg);
- void SendData(int fd, int events, void *arg);
- // accept new connections from clients
- void AcceptConn(int fd, int events, void *arg)
- {
- struct sockaddr_in sin;
- socklen_t len = sizeof(struct sockaddr_in);
- int nfd, i;
- // accept
- if((nfd = accept(fd, (struct sockaddr*)&sin, &len)) == -1)
- {
- if(errno != EAGAIN && errno != EINTR)
- {
- }
- printf("%s: accept, %d", __func__, errno);
- return;
- }
- do
- {
- for(i = 0; i < MAX_EVENTS; i++)
- {
- if(g_Events[i].status == 0)
- {
- break;
- }
- }
- if(i == MAX_EVENTS)
- {
- printf("%s:max connection limit[%d].", __func__, MAX_EVENTS);
- break;
- }
- // set nonblocking
- int iret = 0;
- if((iret = fcntl(nfd, F_SETFL, O_NONBLOCK)) < 0)
- {
- printf("%s: fcntl nonblocking failed:%d", __func__, iret);
- break;
- }
- // add a read event for receive data
- EventSet(&g_Events[i], nfd, RecvData, &g_Events[i]);
- EventAdd(g_epollFd, EPOLLIN, &g_Events[i]);
- }while(0);
- printf("new conn[%s:%d][time:%d], pos[%d]\n", inet_ntoa(sin.sin_addr),
- ntohs(sin.sin_port), g_Events[i].last_active, i);
- }
- // receive data
- void RecvData(int fd, int events, void *arg)
- {
- struct myevent_s *ev = (struct myevent_s*)arg;
- int len;
- // receive data
- len = recv(fd, ev->buff+ev->len, sizeof(ev->buff)-1-ev->len, 0);
- EventDel(g_epollFd, ev);
- if(len > 0)
- {
- ev->len += len;
- ev->buff[len] = '\0';
- printf("C[%d]:%s\n", fd, ev->buff);
- // change to send event
- EventSet(ev, fd, SendData, ev);
- EventAdd(g_epollFd, EPOLLOUT, ev);
- }
- else if(len == 0)
- {
- close(ev->fd);
- printf("[fd=%d] pos[%d], closed gracefully.\n", fd, ev-g_Events);
- }
- else
- {
- close(ev->fd);
- printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno));
- }
- }
- // send data
- void SendData(int fd, int events, void *arg)
- {
- struct myevent_s *ev = (struct myevent_s*)arg;
- int len;
- // send data
- len = send(fd, ev->buff + ev->s_offset, ev->len - ev->s_offset, 0);
- if(len > 0)
- {
- printf("send[fd=%d], [%d<->%d]%s\n", fd, len, ev->len, ev->buff);
- ev->s_offset += len;
- if(ev->s_offset == ev->len)
- {
- // change to receive event
- EventDel(g_epollFd, ev);
- EventSet(ev, fd, RecvData, ev);
- EventAdd(g_epollFd, EPOLLIN, ev);
- }
- }
- else
- {
- close(ev->fd);
- EventDel(g_epollFd, ev);
- printf("send[fd=%d] error[%d]\n", fd, errno);
- }
- }
- void InitListenSocket(int epollFd, short port)
- {
- int listenFd = socket(AF_INET, SOCK_STREAM, 0);
- fcntl(listenFd, F_SETFL, O_NONBLOCK); // set non-blocking
- printf("server listen fd=%d\n", listenFd);
- EventSet(&g_Events[MAX_EVENTS], listenFd, AcceptConn, &g_Events[MAX_EVENTS]);
- // add listen socket
- EventAdd(epollFd, EPOLLIN, &g_Events[MAX_EVENTS]);
- // bind & listen
- sockaddr_in sin;
- bzero(&sin, sizeof(sin));
- sin.sin_family = AF_INET;
- sin.sin_addr.s_addr = INADDR_ANY;
- sin.sin_port = htons(port);
- bind(listenFd, (const sockaddr*)&sin, sizeof(sin));
- listen(listenFd, 5);
- }
- int main(int argc, char **argv)
- {
- unsigned short port = 12345; // default port
- if(argc == 2){
- port = atoi(argv[1]);
- }
- // create epoll
- g_epollFd = epoll_create(MAX_EVENTS);
- if(g_epollFd <= 0) printf("create epoll failed.%d\n", g_epollFd);
- // create & bind listen socket, and add to epoll, set non-blocking
- InitListenSocket(g_epollFd, port);
- // event loop
- struct epoll_event events[MAX_EVENTS];
- printf("server running:port[%d]\n", port);
- int checkPos = 0;
- while(1){
- // a simple timeout check here, every time 100, better to use a mini-heap, and add timer event
- long now = time(NULL);
- for(int i = 0; i < 100; i++, checkPos++) // doesn't check listen fd
- {
- if(checkPos == MAX_EVENTS) checkPos = 0; // recycle
- if(g_Events[checkPos].status != 1) continue;
- long duration = now - g_Events[checkPos].last_active;
- if(duration >= 60) // 60s timeout
- {
- close(g_Events[checkPos].fd);
- printf("[fd=%d] timeout[%d--%d].\n", g_Events[checkPos].fd, g_Events[checkPos].last_active, now);
- EventDel(g_epollFd, &g_Events[checkPos]);
- }
- }
- // wait for events to happen
- int fds = epoll_wait(g_epollFd, events, MAX_EVENTS, 1000);
- if(fds < 0){
- printf("epoll_wait error, exit\n");
- break;
- }
- for(int i = 0; i < fds; i++){
- myevent_s *ev = (struct myevent_s*)events[i].data.ptr;
- if((events[i].events&EPOLLIN)&&(ev->events&EPOLLIN)) // read event
- {
- ev->call_back(ev->fd, events[i].events, ev->arg);
- }
- if((events[i].events&EPOLLOUT)&&(ev->events&EPOLLOUT)) // write event
- {
- ev->call_back(ev->fd, events[i].events, ev->arg);
- }
- }
- }
- // free resource
- return 0;
- }
Mmap的实现原理和应用
很多文章分析了mmap的实现原理。从代码的逻辑来分析,总是觉没有把mmap后读写映射区域和普通的read/write联系起来。不得不产生疑问:
1,普通的read/write和mmap后的映射区域的读写到底有什么区别。
2, 为什么有时候会选择mmap而放弃普通的read/write。
3,如果文章中的内容有不对是或者是不妥的地方,欢迎大家指正。
围绕着这两个问题分析一下,其实在考虑这些问题的同时不免和其他的很多系统机制产生交互。虽然是讲解mmap,但是很多知识还是为了阐明问题做必要的铺垫。这些知识也正是linux的繁琐所在。一个应用往往和系统中的多种机制交互。这篇文章中尽量减少对源代码的引用和分析。把这样的工作留到以后的细节分析中。但是很多分析的理论依据还是来自于源代码。可见源代码的重要地位。
基础知识:
1, 进程每次切换后,都会在tlb base寄存器中重新load属于每一个进程自己的地址转换基地址。在cpu当前运行的进程中都会有current宏来表示当前的进程的信息。应为这个代码实现涉及到硬件架构的问题,为了避免差异的存在在文章中用到硬件知识的时候还是指明是x86的架构,毕竟x86的资料和分析的研究人员也比较多。其实arm还有其他类似的RISC的芯片,只要有mmu支持的,都会有类似的基地址寄存器。
2, 在系统运行进程之前都会为每一个进程分配属于它自己的运行空间。并且这个空间的有效性依赖于tlb base中的内容。32位的系统中访问的空间大小为4G。在这个空间中进程是“自由”的。所谓“自由”不是说对于4G的任何一个地址或者一段空间都可以访问。如果要访问,还是要遵循地址有效性,就是tlb base中所指向的任何页表转换后的物理地址。其中的有效性有越界,权限等等检查。
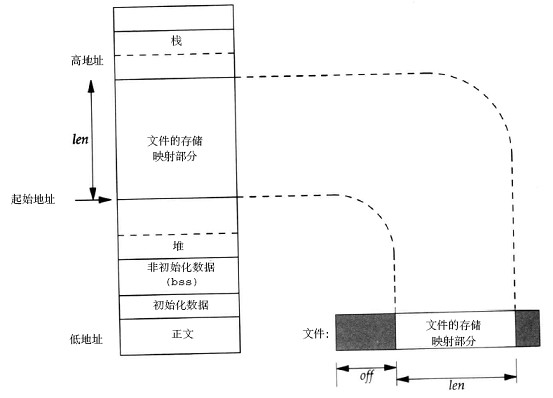
3, 任何一个用户进程的运行在系统分配的空间中。这个空间可以有
vma:struct vm_area_struct来表示。所有的运行空间可以有这个结构体描述。用户进程可以分为text data 段。这些段的具体在4G中的位置有不同的vma来描述。Vma的管理又有其他机制保证,这些机制涉及到了算法和物理内存管理等。请看一下两个图片:
图 一:

图 二:

系统调用中的write和read:
这里没有指定确切的文件系统类型作为分析的对象。找到系统调用号,然后确定具体的文件系统所带的file operation。在特定的file operation中有属于每一种文件系统自己的操作函数集合。其中就有read和write。
图 三:

在真正的把用户数据读写到磁盘或者是存储设备前,内核还会在page cache中管理这些数据。这些page的存在有效的管理了用户数据和读写的效率。用户数据不是直接来自于应用层,读(read)或者是写入(write)磁盘和存储介质,而是被一层一层的应用所划分,在每一层次中都会有不同的功能对应。最后发生交互时,在最恰当的时机触发磁盘的操作。通过IO驱动写入磁盘和存储介质。这里主要强调page cache的管理。应为page的管理设计到了缓存,这些缓存以page的单位管理。在没有IO操作之前,暂时存放在系统空间中,而并未直接写入磁盘或者存贮介质。
系统调用中的mmap:
当创建一个或者切换一个进程的同时,会把属于这个当前进程的系统信息载入。这些系统信息中包含了当前进程的运行空间。当用户程序调用mmap后。函数会在当前进程的空间中找到适合的vma来描述自己将要映射的区域。这个区域的作用就是将mmap函数中文件描述符所指向的具体文件中内容映射过来。
原理是:mmap的执行,仅仅是在内核中建立了文件与虚拟内存空间的对应关系。用户访问这些虚拟内存空间时,页面表里面是没有这些空间的表项的。当用户程序试图访问这些映射的空间时,于是产生缺页异常。内核捕捉这些异常,逐渐将文件载入。所谓的载入过程,具体的操作就是read和write在管理pagecache。Vma的结构体中有很文件操作集。vma操作集中会有自己关于page cache的操作集合。这样,虽然是两种不同的系统调用,由于操作和调用触发的路径不同。但是最后还是落实到了page cache的管理。实现了文件内容的操作。
Ps:
文件的page cache管理也是很好的内容。涉及到了address space的操作。其中很多的内容和文件操作相关。
效率对比:
这里应用了网上一篇文章。发现较好的分析,着这里引用一下。
Mmap:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <sys/mman.h>
void main()
{
int fd = open("test.file", 0);
struct stat statbuf;
char *start;
char buf[2] = {0};
int ret = 0;
fstat(fd, &statbuf);
start = mmap(NULL, statbuf.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
do {
*buf = start[ret++];
}while(ret < statbuf.st_size);
}
Read:
#include <stdio.h>
#include <stdlib.h>
void main()
{
FILE *pf = fopen("test.file", "r");
char buf[2] = {0};
int ret = 0;
do {
ret = fread(buf, 1, 1, pf);
}while(ret);
}
运行结果:
[xiangy@compiling-server test_read]$ time ./fread
real 0m0.901s
user 0m0.892s
sys 0m0.010s
[xiangy@compiling-server test_read]$ time ./mmap
real 0m0.112s
user 0m0.106s
sys 0m0.006s
[xiangy@compiling-server test_read]$ time ./read
real 0m15.549s
user 0m3.933s
sys 0m11.566s
[xiangy@compiling-server test_read]$ ll test.file
-rw-r--r-- 1 xiangy svx8004 23955531 Sep 24 17:17 test.file
可以看出使用mmap后发现,系统调用所消耗的时间远远比普通的read少很多。
共享内存:mmap函数实现
内存映射的应用:
- 以页面为单位,将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代I/O读写,以获得较高的性能;
- 将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间;
- 为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中。
相关API
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
void *mmap64(void *addr, size_t length, int prot, int flags,
int fd, off64_t offset);
int munmap(void *addr, size_t length);
int msync(void *addr, size_t length, int flags);mmap函数说明:
-
参数 addr 指明文件描述字fd指定的文件在进程地址空间内的映射区的开始地址,必须是页面对齐的地址,通常设为 NULL,让内核去选择开始地址。任何情况下,mmap 的返回值为内存映射区的开始地址。
-
参数 length 指明文件需要被映射的字节长度。off 指明文件的偏移量。通常 off 设为 0 。
- 如果 len 不是页面的倍数,它将被扩大为页面的倍数。扩充的部分通常被系统置为 0 ,而且对其修改并不影响到文件。
- off 同样必须是页面的倍数。通过 sysconf(_SC_PAGE_SIZE) 可以获得页面的大小。
-
参数 prot 指明映射区的保护权限。通常有以下 4 种。通常是 PROT_READ | PROT_WRITE 。
- PROT_READ 可读
- PROT_WRITE 可写
- PROT_EXEC 可执行
- PROT_NONE 不能被访问
-
参数 flag 指明映射区的属性。取值有以下几种。MAP_PRIVATE 与 MAP_SHARED 必选其一,MAP_FIXED 为可选项。
- MAP_PRIVATE 指明对映射区数据的修改不会影响到真正的文件。
- MAP_SHARED 指明对映射区数据的修改,多个共享该映射区的进程都可以看见,而且会反映到实际的文件。
- MAP_FIXED 要求 mmap 的返回值必须等于 addr 。如果不指定 MAP_FIXED 并且 addr 不为 NULL ,则对 addr 的处理取决于具体实现。考虑到可移植性,addr 通常设为 NULL ,不指定 MAP_FIXED。
-
当 mmap 成功返回时,fd 就可以关闭,这并不影响创建的映射区。
munmap函数说明:
进程退出的时候,映射区会自动删除。不过当不再需要映射区时,可以调用 munmap 显式删除。当映射区删除后,后续对映射区的引用会生成 SIGSEGV 信号。
msync函数说明:
文件一旦被映射后,调用mmap()的进程对返回地址的访问是对某一内存区域的访问,暂时脱离了磁盘上文件的影响。所有对mmap()返回地址空间的操作只在内存中有意义,只有在调用了munmap()后或者msync()时,才把内存中的相应内容写回磁盘文件。
代码实例:
两个进程通过映射普通文件实现共享内存通信
map_normalfile1.c及map_normalfile2.c。编译两个程序,可执行文件分别为map_normalfile1及map_normalfile2。两个程序通过命令行参数指定同一个文件来实现共享内存方式的进程间通信。map_normalfile2试图打开命令行参数指定的一个普通文件,把该文件映射到进程的地址空间,并对映射后的地址空间进行写操作。map_normalfile1把命令行参数指定的文件映射到进程地址空间,然后对映射后的地址空间执行读操作。这样,两个进程通过命令行参数指定同一个文件来实现共享内存方式的进程间通信。
/*-------------map_normalfile1.c-----------*/
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
typedef struct{
char name[4];
int age;
}people;
int main(int argc, char** argv) // map a normal file as shared mem:
{
int fd,i;
people *p_map;
char temp[2] = {'\0'};
fd=open(argv[1],O_CREAT|O_RDWR|O_TRUNC,00777);
lseek(fd,sizeof(people)*5-1,SEEK_SET);
write(fd,"",1);
p_map = (people*) mmap( NULL,sizeof(people)*10,PROT_READ|PROT_WRITE,
MAP_SHARED,fd,0 );
close( fd );
temp[0] = 'a';
for(i=0; i<15; i++)
{
temp[0] += 1;
memcpy( ( *(p_map+i) ).name, &temp[0],2 );
( *(p_map+i) ).age = 20+i;
}
printf("initialize over\n");
sleep(10);
munmap( p_map, sizeof(people)*10 );
printf( "umap ok \n" );
return 0;
}/*-------------map_normalfile2.c-----------*/
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
typedef struct{
char name[4];
int age;
}people;
int main(int argc, char** argv) // map a normal file as shared mem:
{
int fd,i;
people *p_map;
char temp[2] = {'\0'};
fd=open(argv[1],O_CREAT|O_RDWR|O_TRUNC,00777);
lseek(fd,sizeof(people)*5-1,SEEK_SET);
write(fd,"",1);
p_map = (people*) mmap( NULL,sizeof(people)*10,PROT_READ|PROT_WRITE,
MAP_SHARED,fd,0 );
close( fd );
temp[0] = 'a';
for(i=0; i<15; i++)
{
temp[0] += 1;
memcpy( ( *(p_map+i) ).name, &temp[0],2 );
( *(p_map+i) ).age = 20+i;
}
printf("initialize over\n");
sleep(10);
munmap( p_map, sizeof(people)*10 );
printf( "umap ok \n" );
return 0;
}map_normalfile1首先打开或创建一个文件,并把文件的长度设置为5个people结构大小.mmap映射10个people结构大小的内存,利用返回的地址开始设置15个people结构。然后睡眠10S,等待其他进程映射同一个文件,然后解除映射。
通过实验,在map_normalfile1输出initialize over 之后,输出umap ok之前,运行map_normalfile2 file,可以输出设置好的15个people结构
在map_normalfile1 输出umap ok后,运行map_normalfile2则输出结构,前5个people是已设置的,后10结构为0。
1) 最终被映射文件的内容的长度不会超过文件本身的初始大小,即映射不能改变文件的大小.
2) 可以用于进程通信的有效地址空间大小大体上受限于被映射文件的大小,但不完全受限于文件大小.打开文件的大小为5个people结构,映射长度为10个people结构长度,共享内存通信用15个people结构大小。
在linux中,内存的保护是以页为基本单位的,即使被映射文件只有一个字节大小,内核也会为映射分配一个页面大小的内存。当被映射文件小于一个页面大小时,进程可以对从mmap()返回地址开始的一个页面大小进行访问,而不会出错;但是,如果对一个页面以外的地址空间进行访问,则导致错误发生,后面将进一步描述。因此,可用于进程间通信的有效地址空间大小不会超过文件大小及一个页面大小的和。
3)
文件一旦被映射后,调用mmap()的进程对返回地址的访问是对某一内存区域的访问,暂时脱离了磁盘上文件的影响。所有对mmap()返回地址空间的操作只在内存中有意义,只有在调用了munmap()后或者msync()时,才把内存中的相应内容写回磁盘文件,所写内容仍然不能超过文件的大小
技巧:
生成固定大小的文件的两种方式:
/*第一种方法*/
fd = open(PATHNAME, O_RDWR | O_CREAT | O_TRUNC, FILE_MODE);
lseek(fd, filesize-1, SEEK_SET);
write(fd, "", 1);
/*第二种方法*/
ftruncate(fd, filesize);父子进程通过匿名映射实现共享内存
- 匿名内存映射 与 使用 /dev/zero 类型,都不需要真实的文件。要使用匿名映射之需要向 mmap 传入 MAP_ANON 标志,并且 fd 参数 置为 -1 。
- 所谓匿名,指的是映射区并没有通过 fd 与 文件路径名相关联。匿名内存映射用在有血缘关系的进程间。
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
typedef struct{
char name[4];
int age;
}people;
main(int argc, char** argv)
{
int i;
people *p_map;
char temp;
p_map=(people*)mmap(NULL,sizeof(people)*10,PROT_READ|PROT_WRITE,
MAP_SHARED|MAP_ANONYMOUS,-1,0);
if(fork() == 0)
{
sleep(2);
for(i = 0;i<5;i++)
printf("child read: the %d people's age is %d\n",i+1,(*(p_map+i)).age);
(*p_map).age = 100;
munmap(p_map,sizeof(people)*10); //实际上,进程终止时,会自动解除映射。
exit();
}
temp = 'a';
for(i = 0;i<5;i++)
{
temp += 1;
memcpy((*(p_map+i)).name, &temp,2);
(*(p_map+i)).age=20+i;
}
sleep(5);
printf( "parent read: the first people,s age is %d\n",(*p_map).age );
printf("umap\n");
munmap( p_map,sizeof(people)*10 );
printf( "umap ok\n" );
}参考:
man pthread_mutexattr_init查看信号量进程间同步实现实例- http://blog.csdn.net/nancygreen/article/details/6558039
- http://blog.chinaunix.net/uid-20564848-id-74123.html
- Linux环境进程间通信(五): 共享内存(上)
驱动总结之mmap函数实现
mmap作为struct file_operations的重要一个元素,mmap主要是实现物理内存到虚拟内存的映射关系,这样可以实现直接访问虚拟内存,而不用使用设备相关的read、write操作,mmap的基本过程是将文件映射到虚拟内存中。在之前的一篇博客中谈到了mmap实现文件复制的操作。

- /*主要是建立虚拟地址到物理地址的页表关系,其他的过程又内核自己完成*/
- static int mem_mmap(struct file* filp,struct
vm_area_struct *vma)
- {
- /*间接的控制设备*/
- struct mem_dev *dev = filp->private_data;
- /*标记这段虚拟内存映射为IO区域,并阻止系统将该区域包含在进程的存放转存中*/
- vma->vm_flags |= VM_IO;
- /*标记这段区域不能被换出*/
- vma->vm_flags |= VM_RESERVED;
- /**/
- if(remap_pfn_range(vma,/*虚拟内存区域*/
- vma->vm_start, /*虚拟地址的起始地址*/
- virt_to_phys(dev->data)>>PAGE_SHIFT, /*物理存储区的物理页号*/
- dev->size, /*映射区域大小*/
- vma->vm_page_prot /*虚拟区域保护属性*/
- ))
- return -EAGAIN;
- return 0;
- }
-
vma->vm_flags |= VM_IO;
- vma->vm_flags |= VM_RESERVED;
上面的两个保护机制就说明了被映射的这段区域具有映射IO的相似性,同时保证这段区域不能随便的换出。就是建立一个物理页与虚拟页之间的关联性。具体原理是虚拟页和物理页之间是以页表的方式关联起来,虚拟内存通常大于物理内存,在使用过程中虚拟页通过页表关联一切对应的物理页,当物理页不够时,会选择性的牺牲一些页,也就是将物理页与虚拟页之间切断,重现关联其他的虚拟页,保证物理内存够用。在设备驱动中应该具体的虚拟页和物理页之间的关系应该是长期的,应该保护起来,不能随便被别的虚拟页所替换。具体也可参看关于虚拟存储器的文章。
接下来就是建立物理页与虚拟页之间的关系,即采用函数remap_pfn_range(),具体的参数如下:
int remap_pfn_range(structvm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot)
1、struct vm_area_struct是一个虚拟内存区域结构体,表示虚拟存储器中的一个内存区域。其中的元素vm_start是指虚拟存储器中的起始地址。
2、addr也就是虚拟存储器中的起始地址,通常可以选择addr = vma->vm_start。
3、pfn是指物理存储器的具体页号,通常通过物理地址得到对应的物理页号,具体采用virt_to_phys(dev->data)>>PAGE_SHIFT.首先将虚拟内存转换到物理内存,然后得到页号。>>PAGE_SHIFT通常为12,这是因为每一页的大小刚好是4K,这样右移12相当于除以4096,得到页号。
4、size区域大小
5、区域保护机制。
返回值,如果成功返回0,否则正数。
测试代码可以直接通过对虚拟内存区域操作,实现不同的操作,如下:
- #include<fcntl.h>
- #include<unistd.h>
- #include<stdio.h>
- #include<stdlib.h>
- #include<sys/types.h>
- #include<sys/stat.h>
- #include<sys/mman.h>
- #include<string.h>
- int main()
- {
- int fd;
- char *start;
- char buf[2048];
- strcpy(buf,"This is a test!!!!");
- fd = open("/dev/memdev0",O_RDWR);
- if(fd == -1)
- {
- printf("Error!!\n");
- exit(-1);
- }
- /*创建映射*/
- start = mmap(NULL,2048,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
- /*必须检测是否成功*/
- if(start == -1)
- {
- printf("mmap error!!!\n");
- exit(-1);
- }
- strcpy(start,buf);
- printf("start = %s,buf = %s\n",start,buf);
- strcpy(start,"Test is Test!!!\n");
- printf("start = %s,buf = %s\n",start,buf);
- /**/
- strcpy(buf,start);
- printf("start = %s,buf=%s\n",start,buf);
- /*取消映射关系*/
- munmap(start,2048);
- /*关闭文件*/
- close(fd);
- exit(0);
- }
经过测试,成功得到了驱动。
Linux 内存映射函数 mmap()函数详解
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。
头文件 <sys/mman.h>
函数原型
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
int munmap(void* start,size_t length);
mmap()[1] 必须以PAGE_SIZE为单位进行映射,而内存也只能以页为单位进行映射,若要映射非PAGE_SIZE整数倍的地址范围,要先进行内存对齐,强行以PAGE_SIZE的倍数大小进行映射。
用法:
下面说一下内存映射的步骤:
用open系统调用打开文件, 并返回描述符fd.
用mmap建立内存映射, 并返回映射首地址指针start.
对映射(文件)进行各种操作, 显示(printf), 修改(sprintf).
用munmap(void *start, size_t lenght)关闭内存映射.
用close系统调用关闭文件fd.
UNIX网络编程第二卷进程间通信对mmap函数进行了说明。该函数主要用途有三个:
1、将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代I/O读写,以获得较高的性能;
2、将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间;
3、为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中。
函数:void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offsize);
参数start:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址,映射成功后返回该地址。
参数length:代表将文件中多大的部分映射到内存。
参数prot:映射区域的保护方式。可以为以下几种方式的组合:
PROT_EXEC 映射区域可被执行
PROT_READ 映射区域可被读取
PROT_WRITE 映射区域可被写入
PROT_NONE 映射区域不能存取
参数flags:影响映射区域的各种特性。在调用mmap()时必须要指定MAP_SHARED 或MAP_PRIVATE。
MAP_FIXED 如果参数start所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。通常不鼓励用此旗标。
MAP_SHARED对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
MAP_PRIVATE 对映射区域的写入操作会产生一个映射文件的复制,即私人的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。
MAP_ANONYMOUS建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。
MAP_DENYWRITE只允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝。
MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置换(swap)。
参数fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即flags中设置了MAP_ANONYMOUS,fd设为-1。有些系统不支持匿名内存映射,则可以使用fopen打开/dev/zero文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。
参数offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。
返回值:
若映射成功则返回映射区的内存起始地址,否则返回MAP_FAILED(-1),错误原因存于errno 中。
错误代码:
EBADF 参数fd 不是有效的文件描述词
EACCES 存取权限有误。如果是MAP_PRIVATE 情况下文件必须可读,使用MAP_SHARED则要有PROT_WRITE以及该文件要能写入。
EINVAL 参数start、length 或offset有一个不合法。
EAGAIN 文件被锁住,或是有太多内存被锁住。
ENOMEM 内存不足。
系统调用mmap()用于共享内存的两种方式:
(1)使用普通文件提供的内存映射:
适用于任何进程之间。此时,需要打开或创建一个文件,然后再调用mmap()
典型调用代码如下:
fd=open(name, flag, mode); if(fd<0) ...
ptr=mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0);
通过mmap()实现共享内存的通信方式有许多特点和要注意的地方,可以参看UNIX网络编程第二卷。
(2)使用特殊文件提供匿名内存映射:
适用于具有亲缘关系的进程之间。由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用
fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区
域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。
对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可。
一、概述
内存映射,简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间<---->用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
以下是一个把普遍文件映射到用户空间的内存区域的示意图。
图一:
二、基本函数
mmap函数是unix/linux下的系统调用,详细内容可参考《Unix Netword programming》卷二12.2节。
mmap系统调用并不是完全为了用于共享内存而设计的。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。而Posix或系统V的共享内存IPC则纯粹用于共享目的,当然mmap()实现共享内存也是其主要应用之一。
mmap系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。mmap并不分配空间,
只是将文件映射到调用进程的地址空间里(但是会占掉你的 virutal memory), 然后你就可以用memcpy等操作写文件,
而不用write()了.写完后,内存中的内容并不会立即更新到文件中,而是有一段时间的延迟,你可以调用msync()来显式同步一下,
这样你所写的内容就能立即保存到文件里了.这点应该和驱动相关。
不过通过mmap来写文件这种方式没办法增加文件的长度,
因为要映射的长度在调用mmap()的时候就决定了.如果想取消内存映射,可以调用munmap()来取消内存映射
- void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset)
mmap用于把文件映射到内存空间中,简单说mmap就是把一个文件的内容在内存里面做一个映像。映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间<---->用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
start:要映射到的内存区域的起始地址,通常都是用NULL(NULL即为0)。NULL表示由内核来指定该内存地址
length:要映射的内存区域的大小
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
PROT_EXEC //页内容可以被执行
PROT_READ //页内容可以被读取
PROT_WRITE //页可以被写入
PROT_NONE //页不可访问
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
MAP_FIXED :使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
MAP_SHARED :对映射区域的写入数据会复制回文件内, 而且允许其他映射该文件的进程共享。
MAP_PRIVATE :建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
MAP_DENYWRITE :这个标志被忽略。
MAP_EXECUTABLE :同上
MAP_NORESERVE :不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
MAP_LOCKED :锁定映射区的页面,从而防止页面被交换出内存。
MAP_GROWSDOWN :用于堆栈,告诉内核VM系统,映射区可以向下扩展。
MAP_ANONYMOUS :匿名映射,映射区不与任何文件关联。
MAP_ANON :MAP_ANONYMOUS的别称,不再被使用。
MAP_FILE :兼容标志,被忽略。
MAP_32BIT :将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。
MAP_POPULATE :为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。
MAP_NONBLOCK :仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。
fd:文件描述符(由open函数返回)
offset:表示被映射对象(即文件)从那里开始对映,通常都是用0。 该值应该为大小为PAGE_SIZE的整数倍
返回说明
成功执行时,mmap()返回被映射区的指针,munmap()返回0。失败时,mmap()返回MAP_FAILED[其值为(void *)-1],munmap返回-1。errno被设为以下的某个值
EACCES:访问出错
EAGAIN:文件已被锁定,或者太多的内存已被锁定
EBADF:fd不是有效的文件描述词
EINVAL:一个或者多个参数无效
ENFILE:已达到系统对打开文件的限制
ENODEV:指定文件所在的文件系统不支持内存映射
ENOMEM:内存不足,或者进程已超出最大内存映射数量
EPERM:权能不足,操作不允许
ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
SIGSEGV:试着向只读区写入
SIGBUS:试着访问不属于进程的内存区
- int munmap(void *start, size_t length)
start:要取消映射的内存区域的起始地址
length:要取消映射的内存区域的大小。
返回说明
成功执行时munmap()返回0。失败时munmap返回-1.
int msync(const void *start, size_t length, int flags);
对映射内存的内容的更改并不会立即更新到文件中,而是有一段时间的延迟,你可以调用msync()来显式同步一下, 这样你内存的更新就能立即保存到文件里
start:要进行同步的映射的内存区域的起始地址。
length:要同步的内存区域的大小
flag:flags可以为以下三个值之一:
MS_ASYNC : 请Kernel快将资料写入。
MS_SYNC : 在msync结束返回前,将资料写入。
MS_INVALIDATE : 让核心自行决定是否写入,仅在特殊状况下使用
三、用户空间和驱动程序的内存映射
3.1、基本过程
首先,驱动程序先分配好一段内存,接着用户进程通过库函数mmap()来告诉内核要将多大的内存映射到内核空间,内核经过一系列函数调用后调用对应的驱动程序的file_operation中指定的mmap函数,在该函数中调用remap_pfn_range()来建立映射关系。
3.2、映射的实现
首先在驱动程序分配一页大小的内存,然后用户进程通过mmap()将用户空间中大小也为一页的内存映射到内核空间这页内存上。映射完成后,驱动程序往这段内存写10个字节数据,用户进程将这些数据显示出来。
驱动程序:
- #include <linux/miscdevice.h>
- #include <linux/delay.h>
- #include <linux/kernel.h>
- #include <linux/module.h>
- #include <linux/init.h>
- #include <linux/mm.h>
- #include <linux/fs.h>
- #include <linux/types.h>
- #include <linux/delay.h>
- #include <linux/moduleparam.h>
- #include <linux/slab.h>
- #include <linux/errno.h>
- #include <linux/ioctl.h>
- #include <linux/cdev.h>
- #include <linux/string.h>
- #include <linux/list.h>
- #include <linux/pci.h>
- #include <linux/gpio.h>
- #define DEVICE_NAME "mymap"
- static unsigned char array[10]={0,1,2,3,4,5,6,7,8,9};
- static unsigned char *buffer;
- static int my_open(struct inode *inode, struct file *file)
- {
- return 0;
- }
- static int my_map(struct file *filp, struct vm_area_struct *vma)
- {
- unsigned long page;
- unsigned char i;
- unsigned long start = (unsigned long)vma->vm_start;
- //unsigned long end = (unsigned long)vma->vm_end;
- unsigned long size = (unsigned long)(vma->vm_end - vma->vm_start);
- //得到物理地址
- page = virt_to_phys(buffer);
- //将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上
- if(remap_pfn_range(vma,start,page>>PAGE_SHIFT,size,PAGE_SHARED))//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得到
- return -1;
- //往该内存写10字节数据
- for(i=0;i<10;i++)
- buffer[i] = array[i];
- return 0;
- }
- static struct file_operations dev_fops = {
- .owner = THIS_MODULE,
- .open = my_open,
- .mmap = my_map,
- };
- static struct miscdevice misc = {
- .minor = MISC_DYNAMIC_MINOR,
- .name = DEVICE_NAME,
- .fops = &dev_fops,
- };
- static int __init dev_init(void)
- {
- int ret;
- //注册混杂设备
- ret = misc_register(&misc);
- //内存分配
- buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL);
- //将该段内存设置为保留
- SetPageReserved(virt_to_page(buffer));
- return ret;
- }
- static void __exit dev_exit(void)
- {
- //注销设备
- misc_deregister(&misc);
- //清除保留
- ClearPageReserved(virt_to_page(buffer));
- //释放内存
- kfree(buffer);
- }
- module_init(dev_init);
- module_exit(dev_exit);
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("LKN@SCUT");
应用程序:
- #include <unistd.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <fcntl.h>
- #include <linux/fb.h>
- #include <sys/mman.h>
- #include <sys/ioctl.h>
- #define PAGE_SIZE 4096
- int main(int argc , char *argv[])
- {
- int fd;
- int i;
- unsigned char *p_map;
- //打开设备
- fd = open("/dev/mymap",O_RDWR);
- if(fd < 0)
- {
- printf("open fail\n");
- exit(1);
- }
- //内存映射
- p_map = (unsigned char *)mmap(0, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,fd, 0);
- if(p_map == MAP_FAILED)
- {
- printf("mmap fail\n");
- goto here;
- }
- //打印映射后的内存中的前10个字节内容
- for(i=0;i<10;i++)
- printf("%d\n",p_map[i]);
- here:
- munmap(p_map, PAGE_SIZE);
- return 0;
- }
先加载驱动后执行应用程序,用户空间打印如下:

linux内存映射mmap原理分析
一直都对内存映射文件这个概念很模糊,不知道它和虚拟内存有什么区别,而且映射这个词也很让人迷茫,今天终于搞清楚了。。。下面,我先解释一下我对映射这个词的理解,再区分一下几个容易混淆的概念,之后,什么是内存映射就很明朗了。
原理
首先,“映射”这个词,就和数学课上说的“一一映射”是一个意思,就是建立一种一一对应关系,在这里主要是只 硬盘上文件 的位置与进程 逻辑地址空间 中一块大小相同的区域之间的一一对应,如图1中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。
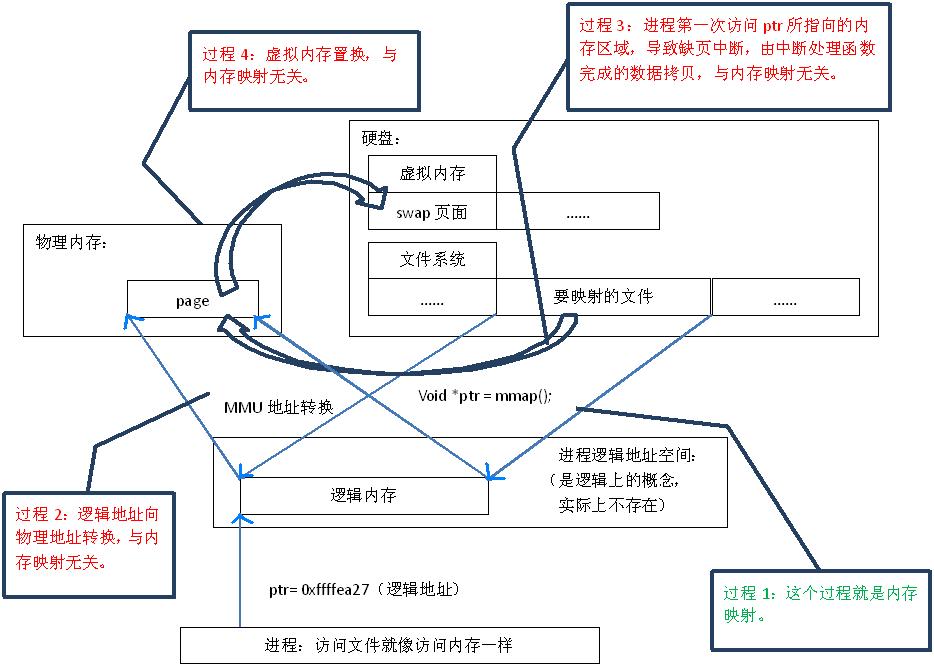
图1.内存映射原理
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?那就要看内存映射之后的几个相关的过程了。
mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。这个过程也与内存映射无关。
效率
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么呢?原因是read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
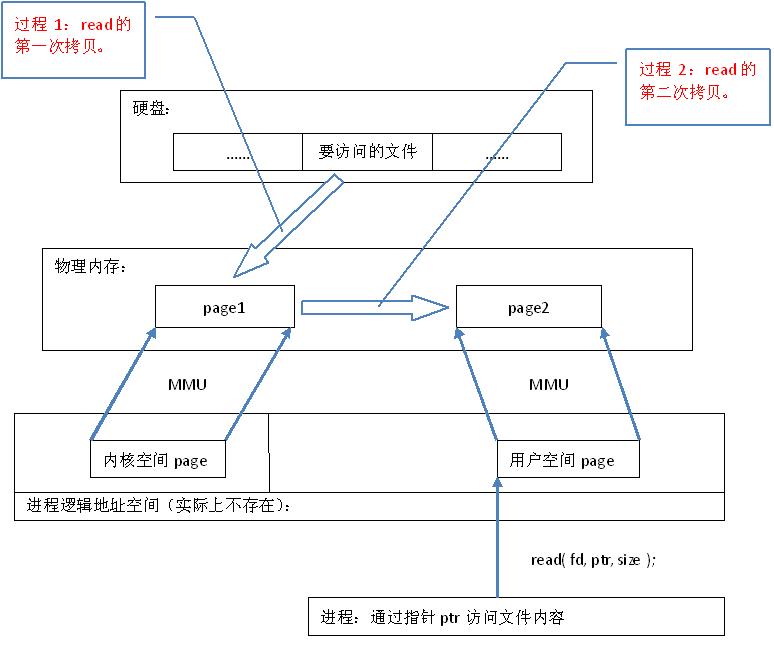
图2.read系统调用原理
下面这个程序,通过read和mmap两种方法分别对硬盘上一个名为“mmap_test”的文件进行操作,文件中存有10000个整数,程序两次使用不同的方法将它们读出,加1,再写回硬盘。通过对比可以看出,read消耗的时间将近是mmap的两到三倍。
- #include<unistd.h>
- #include<stdio.h>
- #include<stdlib.h>
- #include<string.h>
- #include<sys/types.h>
- #include<sys/stat.h>
- #include<sys/time.h>
- #include<fcntl.h>
- #include<sys/mman.h>
- #define MAX 10000
- int main()
- {
- int i=0;
- int count=0, fd=0;
- struct timeval tv1, tv2;
- int *array = (int *)malloc( sizeof(int)*MAX );
- /*read*/
- gettimeofday( &tv1, NULL );
- fd = open( "mmap_test", O_RDWR );
- if( sizeof(int)*MAX != read( fd, (void *)array, sizeof(int)*MAX ) )
- {
- printf( "Reading data failed.../n" );
- return -1;
- }
- for( i=0; i<MAX; ++i )
- ++array[ i ];
- if( sizeof(int)*MAX != write( fd, (void *)array, sizeof(int)*MAX ) )
- {
- printf( "Writing data failed.../n" );
- return -1;
- }
- free( array );
- close( fd );
- gettimeofday( &tv2, NULL );
- printf( "Time of read/write: %dms/n", tv2.tv_usec-tv1.tv_usec );
- /*mmap*/
- gettimeofday( &tv1, NULL );
- fd = open( "mmap_test", O_RDWR );
- array = mmap( NULL, sizeof(int)*MAX, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0 );
- for( i=0; i<MAX; ++i )
- ++array[ i ];
- munmap( array, sizeof(int)*MAX );
- msync( array, sizeof(int)*MAX, MS_SYNC );
- free( array );
- close( fd );
- gettimeofday( &tv2, NULL );
- printf( "Time of mmap: %dms/n", tv2.tv_usec-tv1.tv_usec );
- return 0;
- }
输出结果:
Time of read/write: 154ms
Time of mmap: 68ms
Linux的mmap内存映射机制解析
在讲述文件映射的概念时,不可避免的要牵涉到虚存(SVR 4的VM).实际上,文件映射是虚存的中心概念, 文件映射一方面给用户提供了一组措施,好似用户将文件映射到自己地址空间的某个部分,使用简单的内存访问指令读写文件;另一方面,它也可以用于内核的基本组织模式,在这种模式种,内核将整个地址空间视为诸如文件之类的一组不同对象的映射.中的传统文件访问方式是,首先用open系统调用打开文件,然后使用read, write以及lseek等调用进行顺序或者随即的I/O.这种方式是非常低效的,每一次I/O操作都需要一次系统调用.另外,如果若干个进程访问同一个文件,每个进程都要在自己的地址空间维护一个副本,浪费了内存空间.而如果能够通过一定的机制将页面映射到进程的地址空间中,也就是说首先通过简单的产生某些内存管理数据结构完成映射的创建.当进程访问页面时产生一个缺页中断,内核将页面读入内存并且更新页表指向该页面.而且这种方式非常方便于同一副本的共享.
VM是面向对象的方法设计的,这里的对象是指内存对象:内存对象是一个软件抽象的概念,它描述内存区与后备存储之间的映射.系统可以使用多种类型的后备存储,比如交换空间,本地或者远程文件以及帧缓存等等. VM系统对它们统一处理,采用同一操作集操作,比如读取页面或者回写页面等.每种不同的后备存储都可以用不同的方法实现这些操作.这样,系统定义了一套统一的接口,每种后备存储给出自己的实现方法.这样,进程的地址空间就被视为一组映射到不同数据对象上的的映射组成.所有的有效地址就是那些映射到数据对象上的地址.这些对象为映射它的页面提供了持久性的后备存储.映射使得用户可以直接寻址这些对象.
值得提出的是, VM体系结构独立于Unix系统,所有的Unix系统语义,如正文,数据及堆栈区都可以建构在基本VM系统之上.同时, VM体系结构也是独立于存储管理的,存储管理是由操作系统实施的,如:究竟采取什么样的对换和请求调页算法,究竟是采取分段还是分页机制进行存储管理,究竟是如何将虚拟地址转换成为物理地址等等(Linux中是一种叫Three Level Page Table的机制),这些都与内存对象的概念无关.
一、Linux中VM的实现.
一个进程应该包括一个mm_struct(memory manage struct), 该结构是进程虚拟地址空间的抽象描述,里面包括了进程虚拟空间的一些管理信息: start_code, end_code, start_data, end_data, start_brk, end_brk等等信息.另外,也有一个指向进程虚存区表(vm_area_struct: virtual memory area)的指针,该链是按照虚拟地址的增长顺序排列的.在Linux进程的地址空间被分作许多区(vma),每个区(vma)都对应虚拟地址空间上一段连续的区域, vma是可以被共享和保护的独立实体,这里的vma就是前面提到的内存对象.
下面是vm_area_struct的结构,其中,前半部分是公共的,与类型无关的一些数据成员,如:指向mm_struct的指针,地址范围等等,后半部分则是与类型相关的成员,其中最重要的是一个指向vm_operation_struct向量表的指针vm_ops, vm_pos向量表是一组虚函数,定义了与vma类型无关的接口.每一个特定的子类,即每种vma类型都必须在向量表中实现这些操作.这里包括了: open, close, unmap, protect, sync, nopage, wppage, swapout这些操作.
- struct vm_area_struct {
- /*公共的, 与vma类型无关的 */
- struct mm_struct * vm_mm;
- unsigned long vm_start;
- unsigned long vm_end;
- struct vm_area_struct *vm_next;
- pgprot_t vm_page_prot;
- unsigned long vm_flags;
- short vm_avl_height;
- struct vm_area_struct * vm_avl_left;
- struct vm_area_struct * vm_avl_right;
- struct vm_area_struct *vm_next_share;
- struct vm_area_struct **vm_pprev_share;
- /* 与类型相关的 */
- struct vm_operations_struct * vm_ops;
- unsigned long vm_pgoff;
- struct file * vm_file;
- unsigned long vm_raend;
- void * vm_private_data;
- };
vm_ops: open, close, no_page, swapin, swapout……
二、驱动中的mmap()函数解析
设备驱动的mmap实现主要是将一个物理设备的可操作区域(设备空间)映射到一个进程的虚拟地址空间。这样就可以直接采用指针的方式像访问内存的方式访问设备。在驱动中的mmap实现主要是完成一件事,就是实际物理设备的操作区域到进程虚拟空间地址的映射过程。同时也需要保证这段映射的虚拟存储器区域不会被进程当做一般的空间使用,因此需要添加一系列的保护方式。
- /*主要是建立虚拟地址到物理地址的页表关系,其他的过程又内核自己完成*/
- static int mem_mmap(struct file* filp,struct vm_area_struct *vma)
- {
- /*间接的控制设备*/
- struct mem_dev *dev = filp->private_data;
- /*标记这段虚拟内存映射为IO区域,并阻止系统将该区域包含在进程的存放转存中*/
- vma->vm_flags |= VM_IO;
- /*标记这段区域不能被换出*/
- vma->vm_flags |= VM_RESERVED;
- /**/
- if(remap_pfn_range(vma,/*虚拟内存区域*/
- vma->vm_start, /*虚拟地址的起始地址*/
- virt_to_phys(dev->data)>>PAGE_SHIFT, /*物理存储区的物理页号*/
- dev->size, /*映射区域大小*/
- vma->vm_page_prot /*虚拟区域保护属性*/
- ))
- return -EAGAIN;
- return 0;
- }
具体的实现分析如下:
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
上面的两个保护机制就说明了被映射的这段区域具有映射IO的相似性,同时保证这段区域不能随便的换出。就是建立一个物理页与虚拟页之间的关联性。具体原理是虚拟页和物理页之间是以页表的方式关联起来,虚拟内存通常大于物理内存,在使用过程中虚拟页通过页表关联一切对应的物理页,当物理页不够时,会选择性的牺牲一些页,也就是将物理页与虚拟页之间切断,重现关联其他的虚拟页,保证物理内存够用。在设备驱动中应该具体的虚拟页和物理页之间的关系应该是长期的,应该保护起来,不能随便被别的虚拟页所替换。具体也可参看关于虚拟存储器的文章。
接下来就是建立物理页与虚拟页之间的关系,即采用函数remap_pfn_range(),具体的参数如下:
int remap_pfn_range(structvm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot)
1、struct vm_area_struct是一个虚拟内存区域结构体,表示虚拟存储器中的一个内存区域。其中的元素vm_start是指虚拟存储器中的起始地址。
2、addr也就是虚拟存储器中的起始地址,通常可以选择addr = vma->vm_start。
3、pfn是指物理存储器的具体页号,通常通过物理地址得到对应的物理页号,具体采用virt_to_phys(dev->data)>>PAGE_SHIFT.首先将虚拟内存转换到物理内存,然后得到页号。>>PAGE_SHIFT通常为12,这是因为每一页的大小刚好是4K,这样右移12相当于除以4096,得到页号。
4、size区域大小
5、区域保护机制。
返回值,如果成功返回0,否则正数。
三、系统调用mmap函数解析
介绍完VM的基本概念后,我们可以讲述mmap和munmap系统调用了.mmap调用实际上就是一个内存对象vma的创建过程,
1、mmap函数
Linux提供了内存映射函数mmap,它把文件内容映射到一段内存上(准确说是虚拟内存上),通过对这段内存的读取和修改,实现对文件的读取和修改 。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
先来看一下mmap的函数声明:
- 头文件:
- <unistd.h>
- <sys/mman.h>
- 原型: void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offsize);
- /*
- 返回值: 成功则返回映射区起始地址, 失败则返回MAP_FAILED(-1).
- 参数:
- addr: 指定映射的起始地址, 通常设为NULL, 由系统指定.
- length: 将文件的多大长度映射到内存.
- prot: 映射区的保护方式, 可以是:
- PROT_EXEC: 映射区可被执行.
- PROT_READ: 映射区可被读取.
- PROT_WRITE: 映射区可被写入.
- PROT_NONE: 映射区不能存取.
- flags: 映射区的特性, 可以是:
- MAP_SHARED: 对映射区域的写入数据会复制回文件, 且允许其他映射该文件的进程共享.
- MAP_PRIVATE: 对映射区域的写入操作会产生一个映射的复制(copy-on-write), 对此区域所做的修改不会写回原文件.
- 此外还有其他几个flags不很常用, 具体查看linux C函数说明.
- fd: 由open返回的文件描述符, 代表要映射的文件.
- offset: 以文件开始处的偏移量, 必须是分页大小的整数倍, 通常为0, 表示从文件头开始映射.
- */
mmap的作用是映射文件描述符fd指定文件的 [off,off + len]区域至调用进程的[addr, addr + len]的内存区域, 如下图所示:
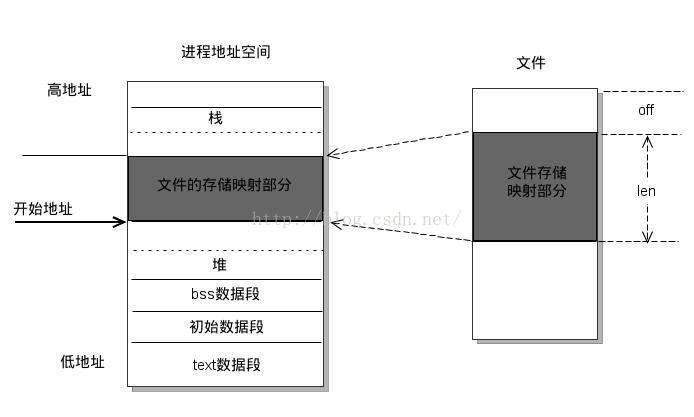
mmap系统调用的实现过程是
1.先通过文件系统定位要映射的文件;
2.权限检查,映射的权限不会超过文件打开的方式,也就是说如果文件是以只读方式打开,那么则不允许建立一个可写映射;
3.创建一个vma对象,并对之进行初始化;
4.调用映射文件的mmap函数,其主要工作是给vm_ops向量表赋值;
5.把该vma链入该进程的vma链表中,如果可以和前后的vma合并则合并;
6.如果是要求VM_LOCKED(映射区不被换出)方式映射,则发出缺页请求,把映射页面读入内存中.
2、munmap函数
munmap(void * start, size_t length):
该调用可以看作是mmap的一个逆过程.它将进程中从start开始length长度的一段区域的映射关闭,如果该区域不是恰好对应一个vma,则有可能会分割几个或几个vma.
msync(void * start, size_t length, int flags):
把映射区域的修改回写到后备存储中.因为munmap时并不保证页面回写,如果不调用msync,那么有可能在munmap后丢失对映射区的修改.其中flags可以是MS_SYNC, MS_ASYNC, MS_INVALIDATE, MS_SYNC要求回写完成后才返回, MS_ASYNC发出回写请求后立即返回, MS_INVALIDATE使用回写的内容更新该文件的其它映射.该系统调用是通过调用映射文件的sync函数来完成工作的.
brk(void * end_data_segement):
将进程的数据段扩展到end_data_segement指定的地址,该系统调用和mmap的实现方式十分相似,同样是产生一个vma,然后指定其属性.不过在此之前需要做一些合法性检查,比如该地址是否大于mm->end_code, end_data_segement和mm->brk之间是否还存在其它vma等等.通过brk产生的vma映射的文件为空,这和匿名映射产生的vma相似,关于匿名映射不做进一步介绍.库函数malloc就是通过brk实现的.
四、实例解析
下面这个例子显示了把文件映射到内存的方法,源代码是:
- /************关于本文 档********************************************
- *filename: mmap.c
- *purpose: 说明调用mmap把文件映射到内存的方法
- *wrote by: zhoulifa(zhoulifa@163.com) 周立发(http://zhoulifa.bokee.com)
- Linux爱好者 Linux知识传播者 SOHO族 开发者 最擅长C语言
- *date time:2008-01-27 18:59 上海大雪天,据说是多年不遇
- *Note: 任何人可以任意复制代码并运用这些文档,当然包括你的商业用途
- * 但请遵循GPL
- *Thanks to:
- * Ubuntu 本程序在Ubuntu 7.10系统上测试完全正常
- * Google.com 我通常通过google搜索发现许多有用的资料
- *Hope:希望越来越多的人贡献自己的力量,为科学技术发展出力
- * 科技站在巨人的肩膀上进步更快!感谢有开源前辈的贡献!
- *********************************************************************/
- #include <sys/mman.h> /* for mmap and munmap */
- #include <sys/types.h> /* for open */
- #include <sys/stat.h> /* for open */
- #include <fcntl.h> /* for open */
- #include <unistd.h> /* for lseek and write */
- #include <stdio.h>
- int main(int argc, char **argv)
- {
- int fd;
- char *mapped_mem, * p;
- int flength = 1024;
- void * start_addr = 0;
- fd = open(argv[1], O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
- flength = lseek(fd, 1, SEEK_END);
- write(fd, "\0", 1); /* 在文件最后添加一个空字符,以便下面printf正常工作 */
- lseek(fd, 0, SEEK_SET);
- mapped_mem = mmap(start_addr, flength, PROT_READ, //允许读
- MAP_PRIVATE, //不允许其它进程访问此内存区域
- fd, 0);
- /* 使用映射区域. */
- printf("%s\n", mapped_mem); /* 为了保证这里工作正常,参数传递的文件名最好是一个文本文件 */
- close(fd);
- munmap(mapped_mem, flength);
- return 0;
- }
编译运行此程序:
gcc -Wall mmap.c
./a.out text_filename
上面的方法因为用了PROT_READ,所以只能读取文件里的内容,不能修改,如果换成PROT_WRITE就可以修改文件的内容了。又由于 用了MAAP_PRIVATE所以只能此进程使用此内存区域,如果换成MAP_SHARED,则可以被其它进程访问,比如下面的
- #include <sys/mman.h> /* for mmap and munmap */
- #include <sys/types.h> /* for open */
- #include <sys/stat.h> /* for open */
- #include <fcntl.h> /* for open */
- #include <unistd.h> /* for lseek and write */
- #include <stdio.h>
- #include <string.h> /* for memcpy */
- int main(int argc, char **argv)
- {
- int fd;
- char *mapped_mem, * p;
- int flength = 1024;
- void * start_addr = 0;
- fd = open(argv[1], O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
- flength = lseek(fd, 1, SEEK_END);
- write(fd, "\0", 1); /* 在文件最后添加一个空字符,以便下面printf正常工作 */
- lseek(fd, 0, SEEK_SET);
- start_addr = 0x80000;
- mapped_mem = mmap(start_addr, flength, PROT_READ|PROT_WRITE, //允许写入
- MAP_SHARED, //允许其它进程访问此内存区域
- fd, 0);
- * 使用映射区域. */
- printf("%s\n", mapped_mem); /* 为了保证这里工作正常,参数传递的文件名最好是一个文本文 */
- while((p = strstr(mapped_mem, "Hello"))) { /* 此处来修改文件 内容 */
- memcpy(p, "Linux", 5);
- p += 5;
- }
- close(fd);
- munmap(mapped_mem, flength);
- return 0;
- }
五、mmap和共享内存对比
共享内存允许两个或多个进程共享一给定的存储区,因为数据不需要来回复制,所以是最快的一种进程间通信机制。共享内存可以通过mmap()映射普通文件(特殊情况下还可以采用匿名映射)机制实现,也可以通过系统V共享内存机制实现。应用接口和原理很简单,内部机制复杂。为了实现更安全通信,往往还与信号灯等同步机制共同使用。
对比如下:
mmap机制:就是在磁盘上建立一个文件,每个进程存储器里面,单独开辟一个空间来进行映射。如果多进程的话,那么不会对实际的物理存储器(主存)消耗太大。
shm机制:每个进程的共享内存都直接映射到实际物理存储器里面。
1、mmap保存到实际硬盘,实际存储并没有反映到主存上。优点:储存量可以很大(多于主存);缺点:进程间读取和写入速度要比主存的要慢。
2、shm保存到物理存储器(主存),实际的储存量直接反映到主存上。优点,进程间访问速度(读写)比磁盘要快;缺点,储存量不能非常大(多于主存)
使用上看:如果分配的存储量不大,那么使用shm;如果存储量大,那么使用mmap。
mmap - 用户空间与内核空间
mmap概述
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式, 因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据: 一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
传统文件访问
UNIX访问文件的传统方法是用open打开它们, 如果有多个进程访问同一个文件,
则每一个进程在自己的地址空间都包含有该文件的副本,这不必要地浪费了存储空间. 下图说明了两个进程同时读一个文件的同一页的情形.
系统要将该页从磁盘读到高速缓冲区中, 每个进程再执行一个存储器内的复制操作将数据从高速缓冲区读到自己的地址空间.
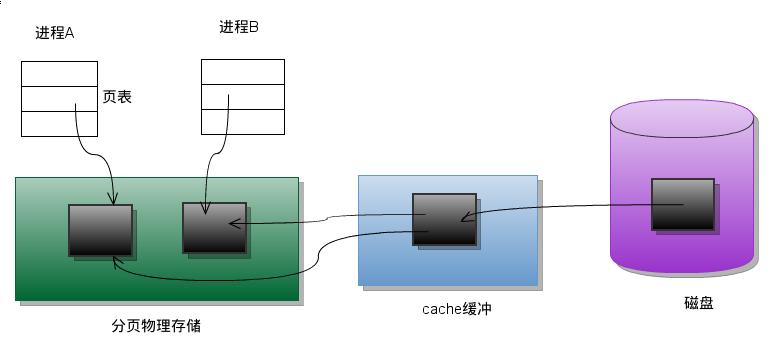
共享存储映射
现在考虑另一种处理方法: 进程A和进程B都将该页映射到自己的地址空间, 当进程A第一次访问该页中的数据时, 它生成一个缺页中断.
内核此时读入这一页到内存并更新页表使之指向它.以后, 当进程B访问同一页面而出现缺页中断时, 该页已经在内存,
内核只需要将进程B的页表登记项指向次页即可. 如下图所示:
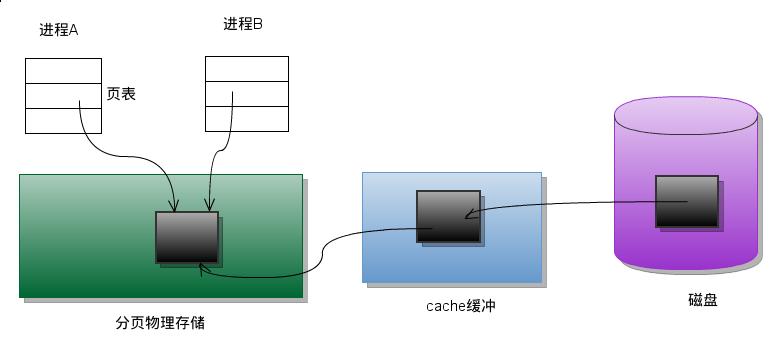
mmap系统调用使得进程之间通过映射同一个普通文件实现共享内存,普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read和write等。
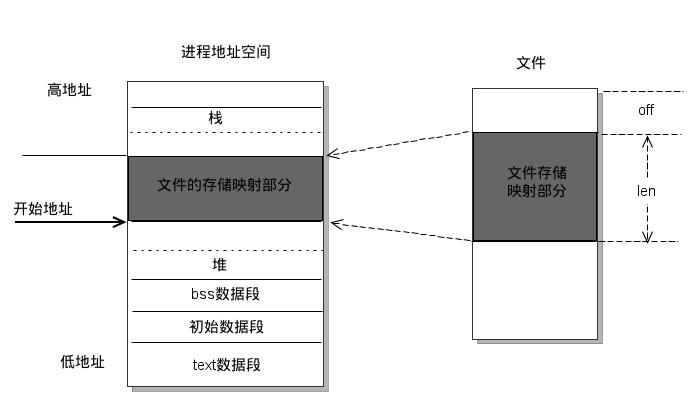
mmap用户空间
用户空间mmap函数原型
头文件 sys/mman.h
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
int msync ( void * addr , size_t len, int flags) 通过调用msync()实现磁盘上文件内容与共享内存区的内容一致
作用:
mmap将一个文件或者其他对象映射进内存,当文件映射到进程后,就可以直接操作这段虚拟地址进行文件的读写等操作。
参数说明:
start:映射区的开始地址
length:映射区的长度
prot:期望的内存保护标志
—-PROT_EXEC //页内容可以被执行
—-PROT_READ //页内容可以被读取
—-PROT_WRITE //页可以被写入
—-PROT_NONE //页不可访问
flags:指定映射对象的类型
—-MAP_FIXED
—-MAP_SHARED 与其它所有映射这个对象的进程共享映射空间
—-MAP_PRIVATE 建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件
—-MAP_ANONYMOUS 匿名映射,映射区不与任何文件关联
fd:如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1
offset:被映射对象内容的起点
通过共享映射的方式修改文件
系统调用mmap可以将文件映射至内存(进程空间),如此可以把对文件的操作转为对内存的操作,以此避免更多的lseek()、read()、write()等系统调用,这点对于大文件或者频繁访问的文件尤其有用,提高了I/O效率。
下面例子中测试所需的data.txt文件内容如下:
aaaaaaaaa
bbbbbbbbb
ccccccccc
ddddddddd
/*
* mmap file to memory
* ./mmap1 data.txt
*/
#include <stdio.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int fd = -1;
struct stat sb;
char *mmaped = NULL;
fd = open(argv[1], O_RDWR);
if (fd < 0) {
fprintf(stderr, "open %s fail\n", argv[1]);
exit(-1);
}
if (stat(argv[1], &sb) < 0) {
fprintf(stderr, "stat %s fail\n", argv[1]);
goto err;
}
/* 将文件映射至进程的地址空间 */
mmaped = (char *)mmap(NULL, sb.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (mmaped == (char *)-1) {
fprintf(stderr, "mmap fail\n");
goto err;
}
/* 映射完后, 关闭文件也可以操纵内存 */
close(fd);
printf("%s", mmaped);
mmaped[5] = '$';
if (msync(mmaped, sb.st_size, MS_SYNC) < 0) {
fprintf(stderr, "msync fail\n");
goto err;
}
return 0;
err:
if (fd > 0)
close(fd);
if (mmaped != (char *)-1)
munmap(mmaped, sb.st_size);
return -1;
}
通过共享映射实现两个进程之间的通信
两个程序映射同一个文件到自己的地址空间, 进程A先运行, 每隔两秒读取映射区域, 看是否发生变化.
进程B后运行, 它修改映射区域, 然后推出, 此时进程A能够观察到存储映射区的变化
进程A的代码:
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <error.h>
#define BUF_SIZE 100
int main(int argc, char **argv)
{
int fd, nread, i;
struct stat sb;
char *mapped, buf[BUF_SIZE];
for (i = 0; i < BUF_SIZE; i++) {
buf[i] = '#';
}
/* 打开文件 */
if ((fd = open(argv[1], O_RDWR)) < 0) {
perror("open");
}
/* 获取文件的属性 */
if ((fstat(fd, &sb)) == -1) {
perror("fstat");
}
/* 将文件映射至进程的地址空间 */
if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
PROT_WRITE, MAP_SHARED, fd, 0)) == (void *)-1) {
perror("mmap");
}
/* 文件已在内存, 关闭文件也可以操纵内存 */
close(fd);
/* 每隔两秒查看存储映射区是否被修改 */
while (1) {
printf("%s\n", mapped);
sleep(2);
}
return 0;
}
进程B的代码:
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <error.h>
#define BUF_SIZE 100
int main(int argc, char **argv)
{
int fd, nread, i;
struct stat sb;
char *mapped, buf[BUF_SIZE];
for (i = 0; i < BUF_SIZE; i++) {
buf[i] = '#';
}
/* 打开文件 */
if ((fd = open(argv[1], O_RDWR)) < 0) {
perror("open");
}
/* 获取文件的属性 */
if ((fstat(fd, &sb)) == -1) {
perror("fstat");
}
/* 私有文件映射将无法修改文件 */
if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
PROT_WRITE, MAP_PRIVATE, fd, 0)) == (void *)-1) {
perror("mmap");
}
/* 映射完后, 关闭文件也可以操纵内存 */
close(fd);
/* 修改一个字符 */
mapped[20] = '9';
return 0;
}
通过匿名映射实现父子进程通信
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define BUF_SIZE 100
int main(int argc, char** argv)
{
char *p_map;
/* 匿名映射,创建一块内存供父子进程通信 */
p_map = (char *)mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if(fork() == 0) {
sleep(1);
printf("child got a message: %s\n", p_map);
sprintf(p_map, "%s", "hi, dad, this is son");
munmap(p_map, BUF_SIZE); //实际上,进程终止时,会自动解除映射。
exit(0);
}
sprintf(p_map, "%s", "hi, this is father");
sleep(2);
printf("parent got a message: %s\n", p_map);
return 0;
}
对mmap返回地址的访问
linux采用的是页式管理机制。对于用mmap()映射普通文件来说,进程会在自己的地址空间新增一块空间,空间大
小由mmap()的len参数指定,注意,进程并不一定能够对全部新增空间都能进行有效访问。进程能够访问的有效地址大小取决于文件被映射部分的大小。简单的说,能够容纳文件被映射部分大小的最少页面个数决定了进程从mmap()返回的地址开始,能够有效访问的地址空间大小。超过这个空间大小,内核会根据超过的严重程度返回发送不同的信号给进程。可用如下图示说明:
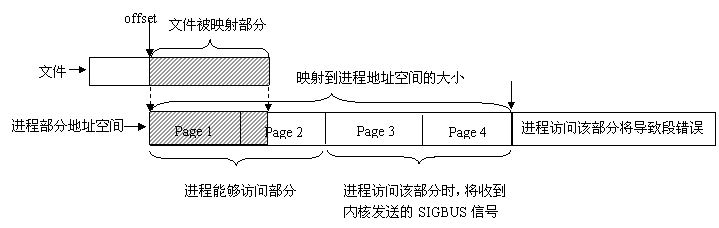
总结一下就是, 文件大小, mmap的参数 len 都不能决定进程能访问的大小, 而是容纳文件被映射部分的最小页面数决定进程能访问的大小. 下面看一个实例:
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main(int argc, char** argv)
{
int fd,i;
int pagesize,offset;
char *p_map;
struct stat sb;
/* 取得page size */
pagesize = sysconf(_SC_PAGESIZE);
printf("pagesize is %d\n",pagesize);
/* 打开文件 */
fd = open(argv[1], O_RDWR, 00777);
fstat(fd, &sb);
printf("file size is %zd\n", (size_t)sb.st_size);
offset = 0;
p_map = (char *)mmap(NULL, pagesize * 2, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, offset);
close(fd);
p_map[sb.st_size] = '9'; /* 导致总线错误 */
p_map[pagesize] = '9'; /* 导致段错误 */
munmap(p_map, pagesize * 2);
return 0;
}
mmap内核空间
内核空间mmap函数原型
内核空间的mmap函数原型为:int (*map)(struct file *filp, struct vm_area_struct *vma);
作用是实现用户进程中的地址与内核中物理页面的映射
mmap函数实现步骤
内核空间mmap函数具体实现步骤如下:
1. 通过kmalloc, get_free_pages, vmalloc等分配一段虚拟地址
2. 如果是使用kmalloc,
get_free_pages分配的虚拟地址,那么使用virt_to_phys()将其转化为物理地址,再将得到的物理地址通过”phys>>PAGE_SHIFT”获取其对应的物理页面帧号。或者直接使用virt_to_page从虚拟地址获取得到对应的物理页面帧号。
如果是使用vmalloc分配的虚拟地址,那么使用vmalloc_to_pfn获取虚拟地址对应的物理页面的帧号。
3. 对每个页面调用SetPageReserved()标记为保留才可以。
4. 通过remap_pfn_range为物理页面的帧号建立页表,并映射到用户空间。
说明:kmalloc, get_free_pages, vmalloc分配的物理内存页面最好还是不要用remap_pfn_range,建议使用VMA的nopage方法。
说明:
若共享小块连续内存,上面所说的get_free_pages就可以分配多达几M的连续空间,
若共享大块连续内存,就得靠uboot帮忙,给linux kernel传递参数的时候指定”mem=”,然后在内核中使用下面两个函数来预留和释放内存。
void *alloc_bootmem(unsigned long size);
void free_bootmem(unsigned long addr, unsigned long size);
mmap函数实现例子
在字符设备驱动中,有一个struct file_operation结构提,其中fops->mmap指向你自己的mmap钩子函数,用户空间对一个字符设备文件进行mmap系统调用后,最终会调用驱动模块里的mmap钩子函数。在mmap钩子函数中需要调用下面这个API:
int remap_pfn_range(struct vm_area_struct *vma, //这个结构很重要!!后面讲
unsigned long virt_addr, //要映射的范围的首地址
unsigned long pfn, //要映射的范围对应的物理内存的页帧号!!重要
unsigned long size, //要映射的范围的大小
pgprot_t prot); //PROTECT属性,mmap()中来的
在mmap钩子函数中,像下面这样就可以了
int my_mmap(struct file *filp, struct vm_area_struct *vma){
//......省略,page很重要,其他的参数一般照下面就可以了
remap_pfn_range(vma, vma->vm_start, page, (vma->vm_end - vma->vm_start), vma->vm_page_prot);
//......省略
}
来看一个例子:
内核空间代码mymap.c
#include <linux/miscdevice.h>
#include <linux/delay.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/types.h>
#include <linux/delay.h>
#include <linux/moduleparam.h>
#include <linux/slab.h>
#include <linux/errno.h>
#include <linux/ioctl.h>
#include <linux/cdev.h>
#include <linux/string.h>
#include <linux/list.h>
#include <linux/pci.h>
#include <linux/gpio.h>
#define DEVICE_NAME "mymap"
static unsigned char array[10]={0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
static unsigned char *buffer;
static int my_open(struct inode *inode, struct file *file)
{
return 0;
}
static int my_map(struct file *filp, struct vm_area_struct *vma)
{
unsigned long phys;
//得到物理地址
phys = virt_to_phys(buffer);
//将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上
if(remap_pfn_range(vma,
vma->vm_start,
phys >> PAGE_SHIFT,//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得>到
vma->vm_end - vma->vm_start,
vma->vm_page_prot))
return -1;
return 0;
}
static struct file_operations dev_fops = {
.owner = THIS_MODULE,
.open = my_open,
.mmap = my_map,
};
static struct miscdevice misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = DEVICE_NAME,
.fops = &dev_fops,
};
static ssize_t hwrng_attr_current_show(struct device *dev,
struct device_attribute *attr, char *buf)
{
int i;
for(i = 0; i < 10 ; i++){
printk("%d\n", buffer[i]);
}
return 0;
}
static DEVICE_ATTR(rng_current, S_IRUGO | S_IWUSR, hwrng_attr_current_show, NULL);
static int __init dev_init(void)
{
int ret;
unsigned char i;
//内存分配
buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL);
//driver起来时初始化内存前10个字节数据
for(i = 0;i < 10;i++)
buffer[i] = array[i];
//将该段内存设置为保留
SetPageReserved(virt_to_page(buffer));
//注册混杂设备
ret = misc_register(&misc);
ret = device_create_file(misc.this_device, &dev_attr_rng_current);
return ret;
}
static void __exit dev_exit(void)
{
device_remove_file(misc.this_device, &dev_attr_rng_current);
//注销设备
misc_deregister(&misc);
//清除保留
ClearPageReserved(virt_to_page(buffer));
//释放内存
kfree(buffer);
}
module_init(dev_init);
module_exit(dev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("LKN@SCUT");
用户空间代码mymap_app.c
/*
* /home/lei_wang/xxx/xxx_linux/toolchain/xxx/bin/xxx-linux-gcc mymap_app.c -o mymap_app
*/
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <errno.h>
#define PAGE_SIZE 4096
int main(int argc , char *argv[])
{
int fd;
int i;
unsigned char *p_map;
//打开设备
fd = open("/dev/mymap",O_RDWR);
if(fd < 0) {
printf("open fail\n");
exit(1);
}
//内存映射
p_map = (unsigned char *)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if(p_map == (void *)-1) {
printf("mmap fail\n");
goto here;
}
close(fd);
//打印映射后的内存中的前10个字节内容,
//并将前10个字节中的内容都加上10,写入内存中
//通过cat cat /sys/devices/virtual/misc/mymap/rng_current查看内存是否被修改
for(i = 0;i < 10;i++) {
printf("%d\n",p_map[i]);
p_map[i] = p_map[i] + 10;
}
here:
munmap(p_map, PAGE_SIZE);
return 0;
}

从上面这张图可以看出:
当系统开机,driver起来的时候会将内存前10个字节初始化,通过cat /sys/devices/virtual/misc/mymap/rng_current,可以看出此时内存中的值。
当执行mymap_app时会将前10个字节的内容加上10再写进内存,再通过cat /sys/devices/virtual/misc/mymap/rng_current,可以看出修改后的内存中的值。
参考文章
资源下载
Linux设备驱动之mmap设备操作
1.mmap系统调用
void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
功能:负责把文件内容映射到进程的虚拟地址空间,通过对这段内存的读取和修改来实现对文件的读取和修改,而不需要再调用read和write;
参数:addr:映射的起始地址,设为NULL由系统指定;
len:映射到内存的文件长度;
prot:期望的内存保护标志,不能与文件的打开模式冲突。PROT_EXEC,PROT_READ,PROT_WRITE等;
flags:指定映射对象的类型,映射选项和映射页是否可以共享。MAP_SHARED,MAP_PRIVATE等;
fd:由open返回的文件描述符,代表要映射的文件;
offset:开始映射的文件的偏移。
返回值:成功执行时,mmap()返回被映射区的指针。失败时,mmap()返回MAP_FAILED。
mmap映射图:

2.解除映射:
int munmap(void *start, size_t length);
3.虚拟内存区域:
虚拟内存区域是进程的虚拟地址空间中的一个同质区间,即具有同样特性的连续地址范围。一个进程的内存映象由下面几个部分组成:程序代码、数据、BSS和栈区域,以及内存映射的区域。
linux内核使用vm_area_struct结构来描述虚拟内存区。其主要成员:
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
unsigned long vm_flags; /* Flags, see mm.h. 该区域的标记。如VM_IO(该VMA标记为内存映射的IO区域,会阻止系统将该区域包含在进程的存放转存中)和VM_RESERVED(标志内存区域不能被换出)。*/
4.mmap设备操作:
映射一个设备是指把用户空间的一段地址(虚拟地址区间)关联到设备内存上,当程序读写这段用户空间的地址时,它实际上是在访问设备。
mmap方法是file_operations结构的成员,在mmap系统调用的发出时被调用。在此之前,内核已经完成了很多工作。
mmap设备方法所需要做的就是建立虚拟地址到物理地址的页表(虚拟地址和设备的物理地址的关联通过页表)。
static int mmap(struct file *file, struct vm_area_struct *vma);
mmap如何完成页表的建立?(两种方法)
(1)使用remap_pfn_range一次建立所有页表。

int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr, unsigned long pfn, unsigned long size, pgprot_t prot);
/**
* remap_pfn_range - remap kernel memory to userspace
* @vma: user vma to map to:内核找到的虚拟地址区间
* @addr: target user address to start at:要关联的虚拟地址
* @pfn: physical address of kernel memory:要关联的设备的物理地址,也即要映射的物理地址所在的物理帧号,可将物理地址>>PAGE_SHIFT
* @size: size of map area
* @prot: page protection flags for this mapping
*
* Note: this is only safe if the mm semaphore is held when called.
*/
(2)使用nopage VMA方法每次建立一个页表;
5.源码分析:
(1)memdev.h
 View
Code
View
Code/*mem设备描述结构体*/
struct mem_dev
{
char *data;
unsigned long size;
};
#endif /* _MEMDEV_H_ */
(2)memdev.c
View
Codestatic int mem_major = MEMDEV_MAJOR;
module_param(mem_major, int, S_IRUGO);
struct mem_dev *mem_devp; /*设备结构体指针*/
struct cdev cdev;
/*文件打开函数*/
int mem_open(struct inode *inode, struct file *filp)
{
struct mem_dev *dev;
/*获取次设备号*/
int num = MINOR(inode->i_rdev);
if (num >= MEMDEV_NR_DEVS)
return -ENODEV;
dev = &mem_devp[num];
/*将设备描述结构指针赋值给文件私有数据指针*/
filp->private_data = dev;
return 0;
}
/*文件释放函数*/
int mem_release(struct inode *inode, struct file *filp)
{
return 0;
}
static int memdev_mmap(struct file*filp, struct vm_area_struct *vma)
{
struct mem_dev *dev = filp->private_data; /*获得设备结构体指针*/
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
if (remap_pfn_range(vma,vma->vm_start,virt_to_phys(dev->data)>>PAGE_SHIFT, vma->vm_end - vma->vm_start, vma->vm_page_prot))
return -EAGAIN;
return 0;
}
/*文件操作结构体*/
static const struct file_operations mem_fops =
{
.owner = THIS_MODULE,
.open = mem_open,
.release = mem_release,
.mmap = memdev_mmap,
};
/*设备驱动模块加载函数*/
static int memdev_init(void)
{
int result;
int i;
dev_t devno = MKDEV(mem_major, 0);
/* 静态申请设备号*/
if (mem_major)
result = register_chrdev_region(devno, 2, "memdev");
else /* 动态分配设备号 */
{
result = alloc_chrdev_region(&devno, 0, 2, "memdev");
mem_major = MAJOR(devno);
}
if (result < 0)
return result;
/*初始化cdev结构*/
cdev_init(&cdev, &mem_fops);
cdev.owner = THIS_MODULE;
cdev.ops = &mem_fops;
/* 注册字符设备 */
cdev_add(&cdev, MKDEV(mem_major, 0), MEMDEV_NR_DEVS);
/* 为设备描述结构分配内存*/
mem_devp = kmalloc(MEMDEV_NR_DEVS * sizeof(struct mem_dev), GFP_KERNEL);
if (!mem_devp) /*申请失败*/
{
result = - ENOMEM;
goto fail_malloc;
}
memset(mem_devp, 0, sizeof(struct mem_dev));
/*为设备分配内存*/
for (i=0; i < MEMDEV_NR_DEVS; i++)
{
mem_devp[i].size = MEMDEV_SIZE;
mem_devp[i].data = kmalloc(MEMDEV_SIZE, GFP_KERNEL);
memset(mem_devp[i].data, 0, MEMDEV_SIZE);
}
return 0;
fail_malloc:
unregister_chrdev_region(devno, 1);
return result;
}
/*模块卸载函数*/
static void memdev_exit(void)
{
cdev_del(&cdev); /*注销设备*/
kfree(mem_devp); /*释放设备结构体内存*/
unregister_chrdev_region(MKDEV(mem_major, 0), 2); /*释放设备号*/
}
MODULE_AUTHOR("David Xie");
MODULE_LICENSE("GPL");
module_init(memdev_init);
module_exit(memdev_exit);
(3)app-mmap.c
#include <stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<sys/mman.h>
int main()
{
int fd;
char *start;
//char buf[100];
char *buf;
/*打开文件*/
fd = open("/dev/memdev0",O_RDWR);
buf = (char *)malloc(100);
memset(buf, 0, 100);
start=mmap(NULL,100,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
/* 读出数据 */
strcpy(buf,start);
sleep (1);
printf("buf 1 = %s\n",buf);
/* 写入数据 */
strcpy(start,"Buf Is Not Null!");
memset(buf, 0, 100);
strcpy(buf,start);
sleep (1);
printf("buf 2 = %s\n",buf);
munmap(start,100); /*解除映射*/
free(buf);
close(fd);
return 0;
}
测试步骤:
(1)编译安装内核模块:insmod memdev.ko
(2)查看设备名、主设备号:cat /proc/devices
(3)手工创建设备节点:mknod /dev/memdev0 c *** 0
查看设备文件是否存在:ls -l /dev/* | grep memdev
(4)编译下载运行应用程序:./app-mmap
结果:buf 1 =
buf 2 = Buf Is Not Null!
总结:mmap设备方法实现将用户空间的一段内存关联到设备内存上,对用户空间的读写就相当于对字符设备的读写;不是所有的设备都能进行mmap抽象,比如像串口和其他面向流的设备就不能做mmap抽象。
细说linux IPC(三):mmap系统调用共享内存
前面讲到socket的进程间通信方式,这种方式在进程间传递数据时首先需要从进程1地址空间中把数据拷贝到内核,内核再将数据拷贝到进程2的地址空间中,也就是数据传递需要经过内核传递。这样在处理较多数据时效率不是很高,而让多个进程共享一片内存区则解决了之前socket进程通信的问题。共享内存是最快的进程间通信 ,将一片内存映射到多个进程地址空间中,那么进程间的数据传递将不在涉及内核。
共享内存并不是从某一进程拥有的内存中划分出来的;进程的内存总是私有的。共享内存是从系统的空闲内存池中分配的,希望访问它的每个进程连接它。这个连接过程称为映射,它给共享内存段分配每个进程的地址空间中的本地地址。
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。函数原型为:
- #include <sys/mman.h>
- void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
其中参数addr为描述符fd应该被映射到进程空间的起始地址,当指定为NULL时内核将自己去选择起始地址,无论addr是为NULL,函数返回值都是fd所映射到内存的起始地址;
len是映射到调用进程地址空间的字节数,它 从被映射文件开头offset个字节开始算起,offset通常设置为0;
prot 参数指定共享内存的访问权限。可取如下几个值的或:PROT_READ(可读) , PROT_WRITE (可写),
PROT_EXEC (可执行), PROT_NONE(不可访问),该值常设置为PROT_READ | PROT_WRITE 。
flags由以下几个常值指定:MAP_SHARED , MAP_PRIVATE ,
MAP_FIXED,其中,MAP_SHARED(变动是共享的,对共享内存的修改所有进程可见) ,
MAP_PRIVATE(变动是私有的,对共享内存修改只对该进程可见) 必选其一,而MAP_FIXED则不推荐使用 。
munmp() 删除地址映射关系,函数原型如下:
- #include <sys/mman.h>
- int munmap(void *addr, size_t length);
参数addr是由mmap返回的地址,len是映射区大小。
进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,往往在调用munmap()后才执行该操作。可以通过调用msync()实现磁盘上文件内容与共享内存区的内容一致。 msync()函数原型为:
- #include <sys/mman.h>
- int msync(void *addr, size_t length, int flags);
参数addr和len代表内存区,flags有以下值指定,MS_ASYNC(执行异步写),
MS_SYNC(执行同步写),MS_INVALIDATE(使高速缓存失效)。其中MS_ASYNC和MS_SYNC两个值必须且只能指定一个,一旦写操作排入内核,MS_ASYNC立即返回,MS_SYNC要等到写操作完成后才返回。如果还指定了MS_INVALIDATE,那么与其最终拷贝不一致的文件数据的所有内存中拷贝都失效。
在使用open函数打开一个文件之后调用mmap把文件内容映射到调用进程的地址空间,这样我们操作文件内容只需要对映射的地址空间进行操作,而无需再使用open,write等函数。
使用共享内存的步骤基本是:
open()创建内存段;
用 ftruncate()设置它的大小;
用mmap() 把它映射到进程内存,执行其他参与者需要的操作;
当使用完时,原来的进程调用 munmap()然后退出。
下面来看一个实现:
server程序创建内存并向共享内存写入数据:
- int sln_shm_get(char *shm_file, void **shm, int mem_len)
- {
- int fd;
- fd = open(shm_file, O_RDWR | O_CREAT, 0644);//1. 创建内存段
- if (fd < 0) {
- printf("open <%s> failed: %s\n", shm_file, strerror(errno));
- return -1;
- }
- ftruncate(fd, mem_len);//2.设置共享内存大小
- *shm = mmap(NULL, mem_len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); //mmap映射系统内存池到进程内存
- if (MAP_FAILED == *shm) {
- printf("mmap: %s\n", strerror(errno));
- return -1;
- }
- close(fd);
- return 0;
- }
- int main(int argc, const char *argv[])
- {
- char *shm_buf = NULL;
- sln_shm_get(SHM_IPC_FILENAME, (void **)&shm_buf, SHM_IPC_MAX_LEN);
- snprintf(shm_buf, SHM_IPC_MAX_LEN, "hello share memory ipc! i'm server.");
- return 0;
- }
client程序映射共享内存并读取其中数据:
- int main(int argc, const char *argv[])
- {
- char *shm_buf = NULL;
- sln_shm_get(SHM_IPC_FILENAME, (void **)&shm_buf, SHM_IPC_MAX_LEN);
- printf("ipc client get: %s\n", shm_buf);
- munmap(shm_buf, SHM_IPC_MAX_LEN);
- return 0;
- }
先执行server程序向共享内存写入数据,再运行客户程序,运行结果如下:
- # ./server
- # ./client
- ipc client get: hello share memory ipc! i'm server.
- #
共享内存不像socket那样本身具有同步机制,它需要通过增加其他同步操作来实现同步,比如信号量等。同步相关操作在后面会有相关专栏详细叙述。
存储器结构、cache、DMA架构分析
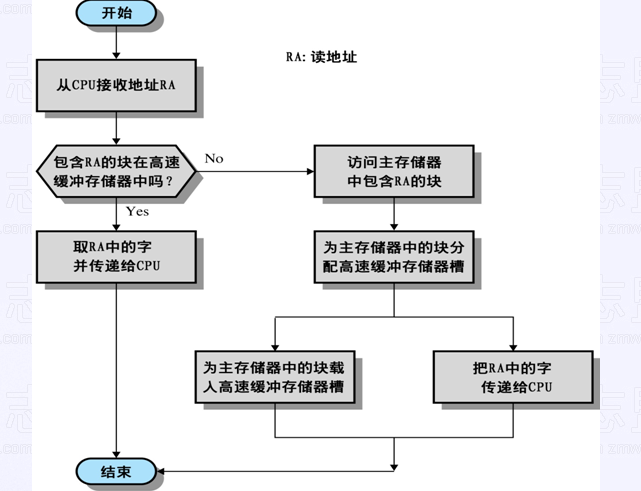

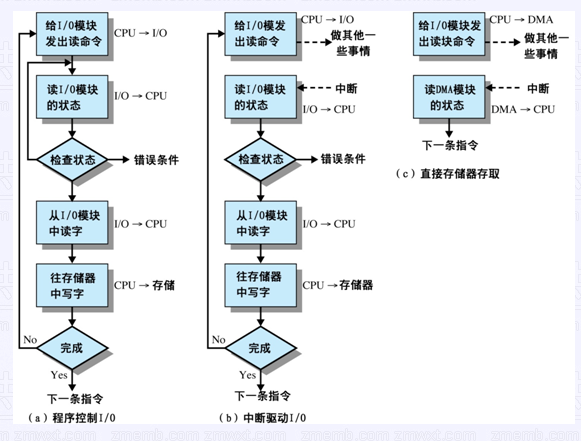
1. 什么是DMA
直接内存访问是一种硬件机制,它允许外围设备和主内存之间直接传输它们的I/O数据,而不需要系统处理器的参与。使用这种机制可以大大提高与设备通信的吞吐量。
2. DMA数据传输
有两种方式引发数据传输:
第一种情况:软件对数据的请求
1. 当进程调用read,驱动程序函数分配一个DMA缓冲区,并让硬件将数据传输到这个缓冲区中。进程处于睡眠状态。
2. 硬件将数据写入到DMA缓冲区中,当写入完毕,产生一个中断
3. 中断处理程序获取输入的数据,应答中断,并唤起进程,该进程现在即可读取数据
第二种情况发生在异步使用DMA时。
1. 硬件产生中断,宣告新数据的到来
2. 中断处理程序分配一个缓冲区,并且告诉硬件向哪里传输数据
3. 外围设备将数据写入数据区,完成后,产生另外一个中断
4.处理程序分发新数据,唤醒任何相关进程,然后执行清理工作
高效的DMA处理依赖于中断报告。
3. 分配DMA缓冲区
使用DMA缓冲区的主要问题是:当大于一页时,它们必须占据连续的物理页,因为设备使用ISA或PCI系统总线传输数据,而这两种方式使用的都是物理地址。
使用get_free_pasges可以分配多大几M字节的内存(MAX_ORDER是11),但是对于较大数量(即使是远小于128KB)的请求,通常会失败,这是因为系统内存充满了内存碎片。
解决方法之一就是在引导时分配内存,或者为缓冲区保留顶部物理内存。
例子:在系统引导时,向内核传递参数“mem=value”的方法保留顶部的RAM。比如系统有256内存,参数“mem=255M”,使内核不能使用顶部的1M字节。随后,模块可以使用下面代码获得该内存的访问权:
dmabuf=ioremap(0XFF00000/**255M/, 0X100000/*1M/*);
解决方法之二是使用GPF_NOFAIL分配标志为缓冲区分配内存,但是该方法为内存管理子系统带来了相当大的压力。
解决方法之三十设备支持分散/聚集I/O,这可以将缓冲区分配成多个小块,设备会很好地处理它们。
4. 通用DMA层
DMA操作最终会分配缓冲区,并将总线地址传递给设备。内核提高了一个与总线——体系结构无关的DMA层。强烈建议在编写驱动程序时,为DMA操作使用该层。使用这些函数的头文件是。
int dma_set_mask(struct device *dev, u64 mask);
该掩码显示该设备能寻址能力对应的位。比如说,设备受限于24位寻址,则mask应该是0x0FFFFFF。
5. DMA映射
IOMMU在设备可访问的地址范围内规划了物理内存,使得物理上分散的缓冲区对设备来说成连续的。对IOMMU的运用需要使用到通用DMA层,而vir_to_bus函数不能完成这个任务。但是,x86平台没有对IOMMU的支持。
解决之道就是建立回弹缓冲区,然后,必要时会将数据写入或者读出回弹缓冲区。缺点是降低系统性能。
根据DMA缓冲区期望保留的时间长短,PCI代码区分两种类型的DMA映射:
一是一致性DMA映射,存在于驱动程序生命周期中,一致性映射的缓冲区必须可同时被CPU和外围设备访问。一致性映射必须保存在一致性缓存中。建立和使用一致性映射的开销是很大的。
二是流式DMA映射,内核开发者建议尽量使用流式映射,原因:一是在支持映射寄存器的系统中,每个DMA映射使用总线上的一个或多个映射寄存器,而一致性映射生命周期很长,长时间占用这些这些寄存器,甚至在不使用他们的时候也不释放所有权;二是在一些硬件中,流式映射可以被优化,但优化的方法对一致性映射无效。
6. 建立一致性映射
驱动程序可调用pci_alloc_consistent函数建立一致性映射:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int falg);
该函数处理了缓冲区的分配和映射,前两个参数是device结构和所需的缓冲区的大小。函数在两处返回DMA映射的结果:函数的返回值是缓冲区的内核虚拟地址,可以被驱动程序使用;而与其相关的总线地址保存在dma_handle中。
当不再需要缓冲区时,调用下函数:
void dma_free_conherent(struct device *dev, size_t size, void *vaddr, dma_addr_t *dma_handle);
7. DMA池
DMA池是一个生成小型,一致性DMA映射的机制。调用dma_alloc_coherent函数获得的映射,可能其最小大小为单个页。如果设备需要的DMA区域比这还小,就是用DMA池。在中定义了DMA池函数:
struct dma_pool *dma_pool_create(const char *name, struct device *dev, size_t size, size_t align, size_t allocation);
void dma_pool_destroy(struct dma_pool *pool);
name是DMA池的名字,dev是device结构,size是从该池中分配的缓冲区的大小,align是该池分配操作所必须遵守的硬件对齐原则(用字节表示),如果allocation不为零,表示内存边界不能超越allocation。比如说传入的allocation是4K,表示从该池分配的缓冲区不能跨越4KB的界限。
在销毁之前必须向DMA池返回所有分配的内存。
void * dma_pool_alloc(sturct dma_pool *pool, int mem_flags, dma_addr_t *handle);
void dma_pool_free(struct dma_pool *pool, void *addr, dma_addr_t addr);
8. 建立流式DMA映射
在某些体系结构中,流式映射也能够拥有多个不连续的页和多个“分散/聚集”缓冲区。建立流式映射时,必须告诉内核数据流动的方向。
DMA_TO_DEVICE
DEVICE_TO_DMA
如果数据被发送到设备,使用DMA_TO_DEVICE;而如果数据被发送到CPU,则使用DEVICE_TO_DMA。
DMA_BIDIRECTTONAL
如果数据可双向移动,则使用该值
DMA_NONE
该符号只是出于调试目的。
当只有一个缓冲区要被传输的时候,使用下函数映射它:
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction);
返回值是总线地址,可以把它传递给设备;如果执行错误,返回NULL。
当传输完毕后,使用下函数删除映射:
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma-data_direction direction);
使用流式DMA的原则:
一是缓冲区只能用于这样的传送,即其传送方向匹配与映射时给定的方向值;
二是一旦缓冲区被映射,它将属于设备,不是处理器。直到缓冲区被撤销映射前,驱动程序不能以任何方式访问其中的内容。只用当dma_unmap_single函数被调用后,显示刷新处理器缓存中的数据,驱动程序才能安全访问其中的内容。
三是在DMA出于活动期间内,不能撤销对缓冲区的映射,否则会严重破坏系统的稳定性。
如果要映射的缓冲区位于设备不能访问的内存区段(高端内存),怎么办?一些体系结构只产生一个错误,但是其他一些系统结构件创建一个回弹缓冲区。回弹缓冲区就是内存中的独立区域,它可被设备访问。如果使用DMA_TO_DEVICE标志映射缓冲区,并且需要使用回弹缓冲区,则在最初缓冲区中的内容作为映射操作的一部分被拷贝。很明显,在拷贝后,最初缓冲区内容的改变对设备不可见。同样DEVICE_TO_DMA回弹缓冲区被dma_unmap_single函数拷贝回最初的缓冲区中,也就是说,直到拷贝操作完成,来自设备的数据才可用。
有时候,驱动程序需要不经过撤销映射就访问流式DMA缓冲区的内容,为此内核提供了如下调用:
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_directction direction);
应该在处理器访问流式DMA缓冲区前调用该函数。一旦调用了该函数,处理器将“拥有”DMA缓冲区,并可根据需要对它进行访问。然后在设备访问缓冲区前,应该调用下面的函数将所有权交还给设备:
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);
再次强调,处理器在调用该函数后,不能再访问DMA缓冲区了。
DMA原理
DMA原理:DMA 是所有现代电脑的重要特色,他允许不同速度的硬件装置来沟通,而不需要依于 CPU 的大量 中断 负载。否则,CPU 需要从 来源 把每一片段的资料复制到 暂存器,然后把他们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。 DMA 传输重要地将一个内存区从一个装置复制到另外一个。当 CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器 来实行和完成。典型的例子就是移动一个外部内存的区块到芯片内部更快的内存去。像是这样的操作并没有让处理器工作拖延,反而可以被重新排程去处理其他的工作。DMA 传输对于高效能 嵌入式系统 算法和网络是很重要的。
在实现DMA传输时,是由DMA控制器直接掌管总线,因此,存在着一个总线控制权转移问题。即DMA传输前,CPU要把总线控制权交给DMA控制器,而在结束DMA传输后,DMA控制器应立即把总线控制权再交回给CPU。

DMA
一个完整的DMA传输过程必须经过下面的4个步骤。
1.DMA请求
CPU对DMA控制器初始化,并向I/O接口发出操作命令,I/O接口提出DMA请求。
2.DMA响应
DMA控制器对DMA请求判别优先级及屏蔽,向总线裁决逻辑提出总线请求。当CPU执行完当前总线周期即可释放总线控制权。此时,总线裁决逻辑输出总线应答,表示DMA已经响应,通过DMA控制器通知I/O接口开始DMA传输。
3.DMA传输
DMA控制器获得总线控制权后,CPU即刻挂起或只执行内部操作,由DMA控制器输出读写命令,直接控制RAM与I/O接口进行DMA传输。
4.DMA结束
当完成规定的成批数据传送后,DMA控制器即释放总线控制权,并向I/O接口发出结束信号。当I/O接口收到结束信号后,一方面停
止I/O设备的工作,另一方面向CPU提出中断请求,使CPU从不介入的状态解脱,并执行一段检查本次DMA传输操作正确性的代码。最后,带着本次操作结果及状态继续执行原来的程序。
由此可见,DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件为RAM与I/O设备开辟一条直接传送数据的通路,使CPU的效率大为提高。
DMA操作模式
DMA用于无需CPU的介入而直接由专用控制器建立源与目的传输的应用,因此,在大量数据传输中解放了CPU。PIC32微控制器中的DMA可用于映射到内存空间中的不同外设,如从存储区到SPI,UART或I2C等设备。DMA特性详见器件参考手册,这里仅对一些基本原理与功能做一个简析。
PIC32中DMA的传输涉及到几个基本的术语。
Event:事件,触发控制器启动或停止DMA传输的操作;
Transaction:事务,单字传输(最多可以到4个字节),由读/写组成;
Cell transfer:元传输,单次共DCHXCSIZE个字节的数据传输。元传输由单个或多个事务组成。
Block transfer:块传输,块传输总的字节数由DCHXSSIZ或DCHXDSIZ决定。块传输由单个或多个元传输组成。
事件是触发DMA控制器产生动作的方式,分为,START EVENT->启动传输;ABORT EVENT->取消传输;STOP EVENT->停止传输;为了有一个完整的概念认识,可以把用户软件的操作,如置位启动传输位等也包含在事件范围内。由此,可以看出,任何一个DMA动作都是由事件触发完成的。用户在使用DMA控制器时只需设计好事件与DMA操作的关联即可。要充分的使用DMA控制器,熟悉DMA各种工作模式的原理是很有必要的。
传输模式二:字符匹配终止模式
字符匹配模式用于传输不定长字节,而又有传输终止标识字节的应用环境中,Uart是这种模式的应用案例。
DMA通道的自动使能模式
DMA每个通道在正常的块传输、终结字符匹配后或者因异常ABORT后,通道自动禁能。如果该通道有多次的块传输,需要手动的使能通道;为了省却该操作,DCHXCON寄存器提供了允许自动使能通道的位CHAEN(channel
auto enable)。通道使能位CHEN在取消传输或ABORT事件发生时会被置为0。
注:
1、通道起始/终止/停止中断事件独立于中断控制器,因此相应的中断无需使能,也无需在DMA传输后清除相应的位;
2、通道优先级和选择
DMA控制器每个通道有一个自然的优先级,CH0默认为最高,CH4默认为最低;通道寄存器DCHXCON中提供了修改优先级的控制位。优先级控制了通道的传输顺序。
3、DMA传输中的字节对齐
PIC32采用的数据总线是32位,4字节;无疑访问地址为4字节对齐的访问效率最高,但是,如果把所有的常量或变量存储地址都限制在4字节对齐显然是不可能的;DMA中在处理这个问题上采用的字节对齐方法(存储方式为LSB)。举例来说,如果当前物理地址与4的模为0,则取4字节;模为1,则取高3字节;模为2,则取高2字节;模为3,则取高1字节。
物理地址为0x1230,模为0,则取从0x1230处4字节数据;
物理地址为0x1231,模为1,则取从0x1231处3字节数据;
物理地址为0x1232,模为2,则取从0x1232处2字节数据;
物理地址为0x1233,模为3,则取从0x1233处1字节数据;
读/写过程均采取相同的字节对齐机制。DMA传输中的字节对齐过程如图2.
直接存储器存取(DMA)控制器是一种在系统内部转移数据的独特外设,可以将其视为一种能够通过一组专用总线将内部和外部存储器与每个具有DMA能力的外设连接起来的控制器。它之所以属于外设,是因为它是在处理器的编程控制下来执行传输的。值得注意的是,通常只有数据流量较大(kBps或者更高)的外设才需要支持DMA能力,这些应用方面典型的例子包括视频、音频和网络接口。
一般而言,DMA控制器将包括一条地址总线、一条数据总线和控制寄存器。高效率的DMA控制器将具有访问其所需要的任意资源的能力,而无须处理器本身的介入,它必须能产生中断。最后,它必须能在控制器内部计算出地址。
一个处理器可以包含多个DMA控制器。每个控制器有多个DMA通道,以及多条直接与存储器站(memory bank)和外设连接的总线,如图1所示。在很多高性能处理器中集成了两种类型的DMA控制器。第一类通常称为“系统DMA控制器”,可以实现对任何资源(外设和存储器)的访问,对于这种类型的控制器来说,信号周期数是以系统时钟(SCLK)来计数的,以ADI的Blackfin处理器为例,频率最高可达133MHz。第二类称为内部存储器DMA控制器(IMDMA),专门用于内部存储器所处位置之间的相互存取操作。因为存取都发生在内部(L1-L1、L1-L2,或者L2-L2),周期数的计数则以内核时钟(CCLK)为基准来进行,该时钟的速度可以超过600MHz。
每个DMA控制器有一组FIFO,起到DMA子系统和外设或存储器之间的缓冲器的作用。对于MemDMA(Memory DMA)来说,传输的源端和目标端都有一组FIFO存在。当资源紧张而不能完成数据传输的话,则FIFO可以提供数据的暂存区,从而提高性能。
因为通常会在代码初始化过程中对DMA控制器进行配置,内核就只需要在数据传输完成后对中断做出响应即可。你可以对DMA控制进行编程,让其与内核并行地移动数据,而同时让内核执行其基本的处理任务—那些应该让它专注完成的工作。

图1:系统和存储器DMA架构。
在一个优化的应用中,内核永远不用参与任何数据的移动,而仅仅对L1存储器中的数据进行读写。于是,内核不需要等待数据的到来,因为DMA引擎会在内核准备读取数据之前将数据准备好。图2给出了处理器和DMA控制器间的交互关系。由处理器完成的操作步骤包括:建立传输,启用中断,生成中断时执行代码。返回到处理器的中断输入可以用来指示“数据已经准备好,可进行处理”。

图2:DMA控制器。
数据除了往来外设之外,还需要从一个存储器空间转移到另一个空间中。例如,视频源可以从一个视频端口直接流入L3存储器,因为工作缓冲区规模太大,无法放入到存储器中。我们并不希望让处理器在每次需要执行计算时都从外部存储读取像素信息,因此为了提高存取的效率,可以用一个存储器到存储器的DMA(MemDMA)来将像素转移到L1或者L2存储器中。
到目前为之,我们还仅专注于数据的移动,但是DMA的传送能力并不总是用来移动数据。
在最简单的MemDMA情况中,我们需要告诉DMA控制器源端地址、目标端地址和待传送的字的个数。每次传输的字的大小可以是8、16或者12位。 我们只需要改变数据传输每次的数据大小,就可以简单地增加DMA的灵活性。例如,采用非单一大小的传输方式时,我们以传输数据块的大小的倍数来作为地址增量。也就是说,若规定32位的传输和4个采样的跨度,则每次传输结束后,地址的增量为16字节(4个32位字)。
DMA的设置
目前有两类主要的DMA传输结构:寄存器模式和描述符模式。无论属于哪一类DMA,表1所描述的几类信息都会在DMA控制器中出现。当DMA以寄存器模式工作时,DMA控制器只是简单地利用寄存器中所存储的参数值。在描述符模式中,DMA控制器在存储器中查找自己的配置参数。

表1:DMA寄存器
基于寄存器的DMA
在基于寄存器的DMA内部,处理器直接对DMA控制寄存器进行编程,来启动传输。基于寄存器的DMA提供了最佳的DMA控制器性能,因为寄存器并不需要不断地从存储器中的描述符上载入数据,而内核也不需要保持描述符。
基于寄存器的DMA由两种子模式组成:自动缓冲(Autobuffer)模式和停止模式。在自动缓冲DMA中,当一个传输块传输完毕,控制寄存器就自动重新载入其最初的设定值,同一个DMA进程重新启动,开销为零。
正如我们在图3中所看到的那样,如果将一个自动缓冲DMA设定为从外设传输一定数量的字到L1数据存储器的缓冲器上,则DMA控制器将会在最后一个字传输完成的时刻就迅速重新载入初始的参数。这构成了一个“循环缓冲器”,因为当一个量值被写入到缓冲器的最后一个位置上时,下一个值将被写入到缓冲器的第一个位置上。

图3:用DMA实现循环缓冲器。
自动缓冲DMA特别适合于对性能敏感的、存在持续数据流的应用。DMA控制器可以在独立于处理器其他活动的情况下读入数据流,然后在每次传输结束时,向内核发出中断。
停止模式的工作方式与自动缓冲DMA类似,区别在于各寄存器在DMA结束后不会重新载入,因此整个DMA传输只发生一次。停止模式对于基于某种事件的一次性传输来说十分有用。例如,非定期地将数据块从一个位置转移到另一个位置。当你需要对事件进行同步时,这种模式也非常有用。例如,如果一个任务必须在下一次传输前完成的话,则停止模式可以确保各事件发生的先后顺序。此外,停止模式对于缓冲器的初始化来说非常有用。
描述符模型
基于描述符(descriptor)的DMA要求在存储器中存入一组参数,以启动DMA的系列操作。该描述符所包含的参数与那些通常通过编程写入DMA控制寄存器组的所有参数相同。不过,描述符还可以容许多个DMA操作序列串在一起。在基于描述符的DMA操作中,我们可以对一个DMA通道进行编程,在当前的操作序列完成后,自动设置并启动另一次DMA传输。基于描述符的方式为管理系统中的DMA传输提供了最大的灵活性。
ADI 的Blackfin处理器上有两种主要的描述符方式—描述符阵列和描述符列表,这两种操作方式所要实现的目标是在灵活性和性能之间实现一种折中平衡。
DMA 方式, 即外设在专用的接口电路DMA 控制器的控制下直接和存储器进行高速数据传送。采用DMA 方式时,如外设
需要进行数据传输, 首先向DMA 控制器发出请求,DMA 再向CPU 发出总线请求,要求控制系统总线。CPU 响应DMA 控制器
的总线请求并把总线控制权交给DMA, 然后在DMA 的控制下开始利用系统总线进行数据传输。数据传输结束后,DMA 并回
总线控制权。DMA 操作步骤:
(1) DMA 控制器的初始化
(2) DMA 数据传送
(3) DMA 结束
DMA 初始化预置如下信息:一是指定I/O 设备对外设"读"还是"写",即指定其控制/状态寄存器中相应的控制位;二是数据应传送至何处,指定其地址的首地址;三是有多少数据字需要传送。
DMA原理解析
DMA概念
DMA(Direct Memory Access,直接内存存取) ,DMA 传输将数据从一个地址空间复制到另外一个地址空间。采用CPU来初始化这个传输动作,但是传输动作本身是由 DMA 控制器来实行和完成,不需要占用CPU。
DMA控制器(以2440为例)
2440芯片手册第8章为DMA控制器。
2440的DMA控制器支持4个通道。
请求源:
上图是2440中DMA控制器支持的请求源。
基本时序
在请求信号有效之后,经过2个周期DACK信号有效,再经过3个周期,DMA控制器才可获得总线的控制权,开始读写操作。
工作模式
Demond模式:
如果DMA完成一次请求后如果Request仍然有效,那么DMA就认为这是下一次DMA请求,并立即开始下一次的传输。
Handshake模式:
DMA完成一次请求后等待Request信号无效,如果Request 无效,DMA会无效ACK两个时钟周期,再等待下一次Request。
6410芯片的DMA控制器在芯片手册的第11章。
DMA程序设计(2440芯片)
char *buf = "Hello World!";
#define DISRC0 (*(volatile unsigned long*)0x4B000000)
#define DISRCC0 (*(volatile unsigned long*)0x4B000004)
#define DIDST0 (*(volatile unsigned long*)0x4B000008)
#define DIDSTC0 (*(volatile unsigned long*)0x4B00000C)
#define DCON0 (*(volatile unsigned long*)0x4B000010)
#define DMASKTRIG0 (*(volatile unsigned long*)0x4B000020)
#define UTXH0 (volatile unsigned long*)0x50000020
void dma_init()
{
//初始化源地址
DISRC0 = (unsigned int)buf; //向寄存器中填写源地址
DISRCC0 = (0<<1)| (0<<0); //内存使用的是AHB总线,源地址需要增长
//初始化目的地址
DIDST0 = UTXH0; //向串口中传送数据
DIDSTC0 = (1<<1)| (1<<0); //串口使用的是APB总线,目的地址总是一个寄存器不增长
DCON0 = (1<<24)| (1<<23)| (1<<22)| (12<<0);
//控制寄存器,选择DMA源,硬件,是否多次发送,数据个数
}
void dma_start()
{
DMASKTRIG0 = (1<<1);//启动传输
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
DMA程序设计(6410芯片)
/*
S3C6410中DMA操作步骤:
1、决定使用安全DMAC(SDMAC)还是通用DMAC(DMAC);
2、开启DMAC控制,设置DMAC_Configuration寄存器;
3、清除传输结束中断寄存器和错误中断寄存器;
4、选择合适的优先级通道;
5、设置通道的源数据地址和目的数据地址(设置DMACC_SrcAddr和DMACC_DestAddr);
6、设置通道控制寄存器0(设置DMACC_Control0);
7、设置通道控制寄存器1,(传输大小,设置DMACC_Control1);
8、设置通道配置寄存器;(设置DMACC_Configuration)
9、使能相应通道(设置DMACC_Configuratoin);
*/
#define SDMA_SEL (*((volatile unsigned long *)0x7E00F110))
#define DMACIntTCClear (*((volatile unsigned long *)0x7DB00008))
#define DMACIntErrClr (*((volatile unsigned long *)0x7DB00010))
#define DMACConfiguration (*((volatile unsigned long *)0x7DB00030))
#define DMACSync (*((volatile unsigned long *)0x7DB00034))
#define DMACC0SrcAddr (*((volatile unsigned long *)0x7DB00100))
#define DMACC0DestAddr (*((volatile unsigned long *)0x7DB00104))
#define DMACC0Control0 (*((volatile unsigned long *)0x7DB0010c))
#define DMACC0Control1 (*((volatile unsigned long *)0x7DB00110))
#define DMACC0Configuration (*((volatile unsigned long *)0x7DB00114))
#define UTXH0 (volatile unsigned long *)0x7F005020
char src[100] = "\n\rHello World-> This is a test!\n\r";
void dma_init()
{
//DMA控制器的选择(SDMAC0)
SDMA_SEL = 0;
//DMA控制器使能
DMACConfiguration = 1;
//初始化源地址
DMACC0SrcAddr = (unsigned int)src;
//初始化目的地址
DMACC0DestAddr = (unsigned int)UTXH0;
//对控制寄存器进行配置
/*
源地址自增
目的地址固定、
目标主机选择AHB主机2
源主机选择AHB主机1
*/
DMACC0Control0 =(1<<25) | (1 << 26)| (1<<31);
DMACC0Control1 = 0x64; //传输的大小
/*
流控制和传输类型:MTP 为 001
目标外设:DMA_UART0_1,源外设:DMA_MEM
通道有效: 1
*/
DMACC0Configuration = (1<<6) | (1<<11) | (1<<14) | (1<<15);
}
void dma_start()
{
//开启channel0 DMA
DMACC0Configuration = 1;
}
Linux内核DMA机制
DMA控制器硬件结构
DMA允许外围设备和主内存之间直接传输 I/O 数据, DMA 依赖于系统。每一种体系结构DMA传输不同,编程接口也不同。
数据传输可以以两种方式触发:一种软件请求数据,另一种由硬件异步传输。
在第一种情况下,调用的步骤可以概括如下(以read为例):
(1)在进程调用 read 时,驱动程序的方法分配一个 DMA 缓冲区,随后指示硬件传送它的数据。进程进入睡眠。
(2)硬件将数据写入 DMA 缓冲区并在完成时产生一个中断。
(3)中断处理程序获得输入数据,应答中断,最后唤醒进程,该进程现在可以读取数据了。
第二种情形是在 DMA 被异步使用时发生的。以数据采集设备为例:
(1)硬件发出中断来通知新的数据已经到达。
(2)中断处理程序分配一个DMA缓冲区。
(3)外围设备将数据写入缓冲区,然后在完成时发出另一个中断。
(4)处理程序利用DMA分发新的数据,唤醒任何相关进程。
网卡传输也是如此,网卡有一个循环缓冲区(通常叫做 DMA 环形缓冲区)建立在与处理器共享的内存中。每一个输入数据包被放置在环形缓冲区中下一个可用缓冲区,并且发出中断。然后驱动程序将网络数据包传给内核的其它部分处理,并在环形缓冲区中放置一个新的 DMA 缓冲区。
驱动程序在初始化时分配DMA缓冲区,并使用它们直到停止运行。
DMA控制器依赖于平台硬件,这里只对i386的8237 DMA控制器做简单的说明,它有两个控制器,8个通道,具体说明如下:
控制器1: 通道0-3,字节操作, 端口为 00-1F
控制器2: 通道 4-7, 字操作, 端口咪 C0-DF
- 所有寄存器是8 bit,与传输大小无关。
- 通道 4 被用来将控制器1与控制器2级联起来。
- 通道 0-3 是字节操作,地址/计数都是字节的。
- 通道 5-7 是字操作,地址/计数都是以字为单位的。
- 传输器对于(0-3通道)必须不超过64K的物理边界,对于5-7必须不超过128K边界。
- 对于5-7通道page registers 不用数据 bit 0, 代表128K页
- 对于0-3通道page registers 使用 bit 0, 表示 64K页
DMA 传输器限制在低于16M物理内存里。装入寄存器的地址必须是物理地址,而不是逻辑地址。
对于0-3通道来说地址对寄存器的映射如下:
A23 ... A16 A15 ... A8 A7 ... A0 (物理地址)
| ... | | ... | | ... |
| ... | | ... | | ... |
| ... | | ... | | ... |
P7 ... P0 A7 ... A0 A7 ... A0
| Page | Addr MSB | Addr LSB | (DMA 地址寄存器)
对于5-7通道来说地址对寄存器的映射如下:
A23 ... A17 A16 A15 ... A9 A8 A7 ... A1 A0 (物理地址)
| ... | \ \ ... \ \ \ ... \ \
| ... | \ \ ... \ \ \ ... \ (没用)
| ... | \ \ ... \ \ \ ... \
P7 ... P1 (0) A7 A6 ... A0 A7 A6 ... A0
| Page | Addr MSB | Addr LSB | (DMA 地址寄存器)
通道 5-7 传输以字为单位, 地址和计数都必须是以字对齐的。
在include/asm-i386/dma.h中有i386平台的8237 DMA控制器的各处寄存器的地址及寄存器的定义,这里只对控制寄存器加以说明:
DMA Channel Control/Status Register (DCSRX)
第31位 表明是否开始
第30位 选定Descriptor和Non-Descriptor模式
第29位 判断有无中断
第8位 请求处理 (Request Pending)
第3位 Channel是否运行
第2位 当前数据交换是否完成
第1位 是否由Descriptor产生中断
第0位 是否由总线错误引起中断
DMA通道使用的地址
DMA通道用dma_chan结构数组表示,这个结构在kernel/dma.c中,列出如下:struct dma_chan {
int lock;
const char *device_id;
};
static struct dma_chan dma_chan_busy[MAX_DMA_CHANNELS] = {
[4] = { 1, "cascade" },
};
如果dma_chan_busy[n].lock != 0表示忙,DMA0保留为DRAM更新用,DMA4用作级联。DMA 缓冲区的主要问题是,当它大于一页时,它必须占据物理内存中的连续页。
由于DMA需要连续的内存,因而在引导时分配内存或者为缓冲区保留物理 RAM 的顶部。在引导时给内核传递一个"mem="参数可以保留 RAM 的顶部。例如,如果系统有 32MB 内存,参数"mem=31M"阻止内核使用最顶部的一兆字节。稍后,模块可以使用下面的代码来访问这些保留的内存:
dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
分配 DMA 空间的方法,代码调用 kmalloc(GFP_ATOMIC) 直到失败为止,然后它等待内核释放若干页面,接下来再一次进行分配。最终会发现由连续页面组成的DMA 缓冲区的出现。
一个使用 DMA 的设备驱动程序通常会与连接到接口总线上的硬件通讯,这些硬件使用物理地址,而程序代码使用虚拟地址。基于 DMA 的硬件使用总线地址而不是物理地址,有时,接口总线是通过将 I/O 地址映射到不同物理地址的桥接电路连接的。甚至某些系统有一个页面映射方案,能够使任意页面在外围总线上表现为连续的。
当驱动程序需要向一个 I/O 设备(例如扩展板或者DMA控制器)发送地址信息时,必须使用 virt_to_bus 转换,在接受到来自连接到总线上硬件的地址信息时,必须使用 bus_to_virt 了。
DMA操作函数
因为 DMA 控制器是一个系统级的资源,所以内核协助处理这一资源。内核使用 DMA 注册表为 DMA 通道提供了请求/释放机制,并且提供了一组函数在 DMA 控制器中配置通道信息。
DMA 控制器使用函数request_dma和free_dma来获取和释放 DMA 通道的所有权,请求 DMA 通道应在请求了中断线之后,并且在释放中断线之前释放它。每一个使用 DMA 的设备也必须使用中断信号线,否则就无法发出数据传输完成的通知。这两个函数的声明列出如下(在kernel/dma.c中):int request_dma(unsigned int channel, const char *name);
void free_dma(unsigned int channel);
DMA 控制器被dma_spin_lock 的自旋锁所保护。使用函数claim_dma_lock和release_dma_lock对获得和释放自旋锁。这两个函数的声明列出如下(在kernel/dma.c中):
unsigned long claim_dma_lock(); 获取 DMA 自旋锁,该函数会阻塞本地处理器上的中断,因此,其返回值是"标志"值,在重新打开中断时必须使用该值。
void release_dma_lock(unsigned long flags); 释放 DMA 自旋锁,并且恢复以前的中断状态。
DMA 控制器的控制设置信息由RAM 地址、传输的数据(以字节或字为单位),以及传输的方向三部分组成。下面是i386平台的8237 DMA控制器的操作函数说明(在include/asm-i386/dma.h中),使用这些函数设置DMA控制器时,应该持有自旋锁。但在驱动程序做I/O 操作时,不能持有自旋锁。
void set_dma_mode(unsigned int channel, char mode); 该函数指出通道从设备读(DMA_MODE_WRITE)或写(DMA_MODE_READ)数据方式,当mode设置为 DMA_MODE_CASCADE时,表示释放对总线的控制。
void set_dma_addr(unsigned int channel, unsigned int addr); 函数给 DMA 缓冲区的地址赋值。该函数将 addr 的最低 24 位存储到控制器中。参数 addr 是总线地址。
void set_dma_count(unsigned int channel, unsigned int count);该函数对传输的字节数赋值。参数 count 也代表 16 位通道的字节数,在此情况下,这个数字必须是偶数。
除了这些操作函数外,还有些对DMA状态进行控制的工具函数:
void disable_dma(unsigned int channel); 该函数设置禁止使用DMA 通道。这应该在配置 DMA 控制器之前设置。
void enable_dma(unsigned int channel); 在DMA 通道中包含了合法的数据时,该函数激活DMA 控制器。
int get_dma_residue(unsigned int channel); 该函数查询一个 DMA 传输还有多少字节还没传输完。函数返回没传完的字节数。当传输成功时,函数返回值是0。
void clear_dma_ff(unsigned int channel) 该函数清除 DMA 触发器(flip-flop),该触发器用来控制对 16 位寄存器的访问。可以通过两个连续的 8 位操作来访问这些寄存器,触发器被清除时用来选择低字节,触发器被置位时用来选择高字节。在传输 8 位后,触发器会自动反转;在访问 DMA 寄存器之前,程序员必须清除触发器(将它设置为某个已知状态)。
DMA映射
一个DMA映射就是分配一个 DMA 缓冲区并为该缓冲区生成一个能够被设备访问的地址的组合操作。一般情况下,简单地调用函数virt_to_bus 就设备总线上的地址,但有些硬件映射寄存器也被设置在总线硬件中。映射寄存器(mapping register)是一个类似于外围设备的虚拟内存等价物。在使用这些寄存器的系统上,外围设备有一个相对较小的、专用的地址区段,可以在此区段执行 DMA。通过映射寄存器,这些地址被重映射到系统 RAM。映射寄存器具有一些好的特性,包括使分散的页面在设备地址空间看起来是连续的。但不是所有的体系结构都有映射寄存器,特别地,PC 平台没有映射寄存器。
在某些情况下,为设备设置有用的地址也意味着需要构造一个反弹(bounce)缓冲区。例如,当驱动程序试图在一个不能被外围设备访问的地址(一个高端内存地址)上执行 DMA 时,反弹缓冲区被创建。然后,按照需要,数据被复制到反弹缓冲区,或者从反弹缓冲区复制。
根据 DMA 缓冲区期望保留的时间长短,PCI 代码区分两种类型的 DMA 映射:
- 一致 DMA 映射 它们存在于驱动程序的生命周期内。一个被一致映射的缓冲区必须同时可被 CPU 和外围设备访问,这个缓冲区被处理器写时,可立即被设备读取而没有cache效应,反之亦然,使用函数pci_alloc_consistent建立一致映射。
- 流式 DMA映射 流式DMA映射是为单个操作进行的设置。它映射处理器虚拟空间的一块地址,以致它能被设备访问。应尽可能使用流式映射,而不是一致映射。这是因为在支持一致映射的系统上,每个 DMA 映射会使用总线上一个或多个映射寄存器。具有较长生命周期的一致映射,会独占这些寄存器很长时间――即使它们没有被使用。使用函数dma_map_single建立流式映射。
(1)建立一致 DMA 映射
函数pci_alloc_consistent处理缓冲区的分配和映射,函数分析如下(在include/asm-generic/pci-dma-compat.h中):static inline void *pci_alloc_consistent(struct pci_dev *hwdev,
size_t size, dma_addr_t *dma_handle)
{
return dma_alloc_coherent(hwdev == NULL ? NULL : &hwdev->dev,
size, dma_handle, GFP_ATOMIC);
}
结构dma_coherent_mem定义了DMA一致性映射的内存的地址、大小和标识等。结构dma_coherent_mem列出如下(在arch/i386/kernel/pci-dma.c中):
struct dma_coherent_mem {
void *virt_base; u32 device_base; int size; int flags; unsigned long *bitmap;
};函数dma_alloc_coherent分配size字节的区域的一致内存,得到的dma_handle是指向分配的区域的地址指针,这个地址作为区域的物理基地址。dma_handle是与总线一样的位宽的无符号整数。 函数dma_alloc_coherent分析如下(在arch/i386/kernel/pci-dma.c中):
void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, int gfp)
{
void *ret;
//若是设备,得到设备的dma内存区域,即mem= dev->dma_mem
struct dma_coherent_mem *mem = dev ? dev->dma_mem : NULL;
int order = get_order(size);//将size转换成order,即
//忽略特定的区域,因而忽略这两个标识
gfp &= ~(__GFP_DMA | __GFP_HIGHMEM);
if (mem) {//设备的DMA映射,mem= dev->dma_mem
//找到mem对应的页
int page = bitmap_find_free_region(mem->bitmap, mem->size,
order);
if (page >= 0) {
*dma_handle = mem->device_base + (page << PAGE_SHIFT);
ret = mem->virt_base + (page << PAGE_SHIFT);
memset(ret, 0, size);
return ret;
}
if (mem->flags & DMA_MEMORY_EXCLUSIVE)
return NULL;
}
//不是设备的DMA映射
if (dev == NULL || (dev->coherent_dma_mask < 0xffffffff))
gfp |= GFP_DMA;
//分配空闲页
ret = (void *)__get_free_pages(gfp, order);
if (ret != NULL) {
memset(ret, 0, size);//清0
*dma_handle = virt_to_phys(ret);//得到物理地址
}
return ret;
}
当不再需要缓冲区时(通常在模块卸载时),应该调用函数 pci_free_consitent 将它返还给系统。
(2)建立流式 DMA 映射
在流式 DMA 映射的操作中,缓冲区传送方向应匹配于映射时给定的方向值。缓冲区被映射后,它就属于设备而不再属于处理器了。在缓冲区调用函数pci_unmap_single撤销映射之前,驱动程序不应该触及其内容。
在缓冲区为 DMA 映射时,内核必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新。在刷新之后,由处理器写入缓冲区的数据对设备来说也许是不可见的。
如果欲映射的缓冲区位于设备不能访问的内存区段时,某些体系结构仅仅会操作失败,而其它的体系结构会创建一个反弹缓冲区。反弹缓冲区是被设备访问的独立内存区域,反弹缓冲区复制原始缓冲区的内容。
函数pci_map_single映射单个用于传送的缓冲区,返回值是可以传递给设备的总线地址,如果出错的话就为 NULL。一旦传送完成,应该使用函数pci_unmap_single 删除映射。其中,参数direction为传输的方向,取值如下:
PCI_DMA_TODEVICE 数据被发送到设备。
PCI_DMA_FROMDEVICE如果数据将发送到 CPU。
PCI_DMA_BIDIRECTIONAL数据进行两个方向的移动。
PCI_DMA_NONE 这个符号只是为帮助调试而提供。
函数pci_map_single分析如下(在arch/i386/kernel/pci-dma.c中):static inline dma_addr_t pci_map_single(struct pci_dev *hwdev,
void *ptr, size_t size, int direction)
{
return dma_map_single(hwdev == NULL ? NULL : &hwdev->dev, ptr, size,
(enum ma_data_direction)direction);
}
函数dma_map_single映射一块处理器虚拟内存,这块虚拟内存能被设备访问,返回内存的物理地址,函数dma_map_single分析如下(在include/asm-i386/dma-mapping.h中):
static inline dma_addr_t dma_map_single(struct device *dev, void *ptr,
size_t size, enum dma_data_direction direction)
{BUG_ON(direction == DMA_NONE); //可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新flush_write_buffers();return virt_to_phys(ptr); //虚拟地址转化为物理地址
}(3)分散/集中映射
分散/集中映射是流式 DMA 映射的一个特例。它将几个缓冲区集中到一起进行一次映射,并在一个 DMA 操作中传送所有数据。这些分散的缓冲区由分散表结构scatterlist来描述,多个分散的缓冲区的分散表结构组成缓冲区的struct scatterlist数组。
分散表结构列出如下(在include/asm-i386/scatterlist.h):struct scatterlist {
struct page *page;
unsigned int offset;
dma_addr_t dma_address; //用在分散/集中操作中的缓冲区地址
unsigned int length;//该缓冲区的长度
};
每一个缓冲区的地址和长度会被存储在 struct scatterlist 项中,但在不同的体系结构中它们在结构中的位置是不同的。下面的两个宏定义来解决平台移植性问题,这些宏定义应该在一个pci_map_sg 被调用后使用:
//从该分散表项中返回总线地址
#define sg_dma_address(sg) �sg)->dma_address) //返回该缓冲区的长度
#define sg_dma_len(sg) �sg)->length)函数pci_map_sg完成分散/集中映射,其返回值是要传送的 DMA 缓冲区数;它可能会小于 nents(也就是传入的分散表项的数量),因为可能有的缓冲区地址上是相邻的。一旦传输完成,分散/集中映射通过调用函数pci_unmap_sg 来撤销映射。 函数pci_map_sg分析如下(在include/asm-generic/pci-dma-compat.h中):
static inline int pci_map_sg(struct pci_dev *hwdev, struct scatterlist *sg,
int nents, int direction)
{
return dma_map_sg(hwdev == NULL ? NULL : &hwdev->dev, sg, nents,
(enum dma_data_direction)direction);
}
include/asm-i386/dma-mapping.h
static inline int dma_map_sg(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction)
{
int i;
BUG_ON(direction == DMA_NONE);
for (i = 0; i < nents; i++ ) {
BUG_ON(!sg[i].page);
//将页及页偏移地址转化为物理地址
sg[i].dma_address = page_to_phys(sg[i].page) + sg[i].offset;
}
//可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新
flush_write_buffers();
return nents;
}
DMA池
许多驱动程序需要又多又小的一致映射内存区域给DMA描述子或I/O缓存buffer,这使用DMA池比用dma_alloc_coherent分配的一页或多页内存区域好,DMA池用函数dma_pool_create创建,用函数dma_pool_alloc从DMA池中分配一块一致内存,用函数dmp_pool_free放内存回到DMA池中,使用函数dma_pool_destory释放DMA池的资源。
结构dma_pool是DMA池描述结构,列出如下:struct dma_pool { /* the pool */
struct list_head page_list;//页链表
spinlock_t lock;
size_t blocks_per_page; //每页的块数
size_t size; //DMA池里的一致内存块的大小
struct device *dev; //将做DMA的设备
size_t allocation; //分配的没有跨越边界的块数,是size的整数倍
char name [32]; //池的名字
wait_queue_head_t waitq; //等待队列
struct list_head pools;
};
函数dma_pool_create给DMA创建一个一致内存块池,其参数name是DMA池的名字,用于诊断用,参数dev是将做DMA的设备,参数size是DMA池里的块的大小,参数align是块的对齐要求,是2的幂,参数allocation返回没有跨越边界的块数(或0)。
函数dma_pool_create返回创建的带有要求字符串的DMA池,若创建失败返回null。对被给的DMA池,函数dma_pool_alloc被用来分配内存,这些内存都是一致DMA映射,可被设备访问,且没有使用缓存刷新机制,因为对齐原因,分配的块的实际尺寸比请求的大。如果分配非0的内存,从函数dma_pool_alloc返回的对象将不跨越size边界(如不跨越4K字节边界)。这对在个体的DMA传输上有地址限制的设备来说是有利的。
函数dma_pool_create分析如下(在drivers/base/dmapool.c中):struct dma_pool *dma_pool_create (const char *name, struct device *dev,
size_t size, size_t align, size_t allocation)
{
struct dma_pool *retval;
if (align == 0)
align = 1;
if (size == 0)
return NULL;
else if (size < align)
size = align;
else if ((size % align) != 0) {//对齐处理
size += align + 1;
size &= ~(align - 1);
}
//如果一致内存块比页大,是分配为一致内存块大小,否则,分配为页大小
if (allocation == 0) {
if (PAGE_SIZE < size)//页比一致内存块小
allocation = size;
else
allocation = PAGE_SIZE;//页大小
// FIXME: round up for less fragmentation
} else if (allocation < size)
return NULL;
//分配dma_pool结构对象空间
if (!(retval = kmalloc (sizeof *retval, SLAB_KERNEL)))
return retval;
strlcpy (retval->name, name, sizeof retval->name);
retval->dev = dev;
//初始化dma_pool结构对象retval
INIT_LIST_HEAD (&retval->page_list);//初始化页链表
spin_lock_init (&retval->lock);
retval->size = size;
retval->allocation = allocation;
retval->blocks_per_page = allocation / size;
init_waitqueue_head (&retval->waitq);//初始化等待队列
if (dev) {//设备存在时
down (&pools_lock);
if (list_empty (&dev->dma_pools))
//给设备创建sysfs文件系统属性文件
device_create_file (dev, &dev_attr_pools);
/* note: not currently insisting "name" be unique */
list_add (&retval->pools, &dev->dma_pools); //将DMA池加到dev中
up (&pools_lock);
} else
INIT_LIST_HEAD (&retval->pools);
return retval;
}
函数dma_pool_alloc从DMA池中分配一块一致内存,其参数pool是将产生块的DMA池,参数mem_flags是GFP_*位掩码,参数handle是指向块的DMA地址,函数dma_pool_alloc返回当前没用的块的内核虚拟地址,并通过handle给出它的DMA地址,如果内存块不能被分配,返回null。
函数dma_pool_alloc包裹了dma_alloc_coherent页分配器,这样小块更容易被总线的主控制器使用。这可能共享slab分配器的内容。
函数dma_pool_alloc分析如下(在drivers/base/dmapool.c中):void *dma_pool_alloc (struct dma_pool *pool, int mem_flags, dma_addr_t *handle)
{
unsigned long flags;
struct dma_page *page;
int map, block;
size_t offset;
void *retval;
restart:
spin_lock_irqsave (&pool->lock, flags);
list_for_each_entry(page, &pool->page_list, page_list) {
int i;
/* only cachable accesses here ... */
//遍历一页的每块,而每块又以32字节递增
for (map = 0, i = 0;
i < pool->blocks_per_page; //每页的块数
i += BITS_PER_LONG, map++) { // BITS_PER_LONG定义为32
if (page->bitmap [map] == 0)
continue;
block = ffz (~ page->bitmap [map]);//找出第一个0
if ((i + block) < pool->blocks_per_page) {
clear_bit (block, &page->bitmap [map]);
//得到相对于页边界的偏移
offset = (BITS_PER_LONG * map) + block;
offset *= pool->size;
goto ready;
}
}
}
//给DMA池分配dma_page结构空间,加入到pool->page_list链表,
//并作DMA一致映射,它包括分配给DMA池一页。
// SLAB_ATOMIC表示调用 kmalloc(GFP_ATOMIC) 直到失败为止,
//然后它等待内核释放若干页面,接下来再一次进行分配。
if (!(page = pool_alloc_page (pool, SLAB_ATOMIC))) {
if (mem_flags & __GFP_WAIT) {
DECLARE_WAITQUEUE (wait, current);
current->state = TASK_INTERRUPTIBLE;
add_wait_queue (&pool->waitq, &wait);
spin_unlock_irqrestore (&pool->lock, flags);
schedule_timeout (POOL_TIMEOUT_JIFFIES);
remove_wait_queue (&pool->waitq, &wait);
goto restart;
}
retval = NULL;
goto done;
}
clear_bit (0, &page->bitmap [0]);
offset = 0;
ready:
page->in_use++;
retval = offset + page->vaddr; //返回虚拟地址
*handle = offset + page->dma; //相对DMA地址
#ifdef CONFIG_DEBUG_SLAB
memset (retval, POOL_POISON_ALLOCATED, pool->size);
#endif
done:
spin_unlock_irqrestore (&pool->lock, flags);
return retval;
}
一个简单的使用DMA 例子
示例:下面是一个简单的使用DMA进行传输的驱动程序,它是一个假想的设备,只列出DMA相关的部分来说明驱动程序中如何使用DMA的。
函数dad_transfer是设置DMA对内存buffer的传输操作函数,它使用流式映射将buffer的虚拟地址转换到物理地址,设置好DMA控制器,然后开始传输数据。int dad_transfer(struct dad_dev *dev, int write, void *buffer,
size_t count)
{
dma_addr_t bus_addr;
unsigned long flags;
/* Map the buffer for DMA */
dev->dma_dir = (write ? PCI_DMA_TODEVICE : PCI_DMA_FROMDEVICE);
dev->dma_size = count;
//流式映射,将buffer的虚拟地址转化成物理地址
bus_addr = pci_map_single(dev->pci_dev, buffer, count,
dev->dma_dir);
dev->dma_addr = bus_addr; //DMA传送的buffer物理地址
//将操作控制写入到DMA控制器寄存器,从而建立起设备
writeb(dev->registers.command, DAD_CMD_DISABLEDMA);
//设置传输方向--读还是写
writeb(dev->registers.command, write ? DAD_CMD_WR : DAD_CMD_RD);
writel(dev->registers.addr, cpu_to_le32(bus_addr));//buffer物理地址
writel(dev->registers.len, cpu_to_le32(count)); //传输的字节数
//开始激活DMA进行数据传输操作
writeb(dev->registers.command, DAD_CMD_ENABLEDMA);
return 0;
}
函数dad_interrupt是中断处理函数,当DMA传输完时,调用这个中断函数来取消buffer上的DMA映射,从而让内核程序可以访问这个buffer。
void dad_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
struct dad_dev *dev = (struct dad_dev *) dev_id;
/* Make sure it's really our device interrupting */
/* Unmap the DMA buffer */
pci_unmap_single(dev->pci_dev, dev->dma_addr, dev->dma_size,
dev->dma_dir);
/* Only now is it safe to access the buffer, copy to user, etc. */
...
} 函数dad_open打开设备,此时应申请中断号及DMA通道。
int dad_open (struct inode *inode, struct file *filp)
{
struct dad_device *my_device;
// SA_INTERRUPT表示快速中断处理且不支持共享 IRQ 信号线
if ( (error = request_irq(my_device.irq, dad_interrupt,
SA_INTERRUPT, "dad", NULL)) )
return error; /* or implement blocking open */
if ( (error = request_dma(my_device.dma, "dad")) ) {
free_irq(my_device.irq, NULL);
return error; /* or implement blocking open */
}
return 0;
} 在与open 相对应的 close 函数中应该释放DMA及中断号。
void dad_close (struct inode *inode, struct file *filp)
{
struct dad_device *my_device;
free_dma(my_device.dma);
free_irq(my_device.irq, NULL);
……
} 函数dad_dma_prepare初始化DMA控制器,设置DMA控制器的寄存器的值,为 DMA 传输作准备。
int dad_dma_prepare(int channel, int mode, unsigned int buf,
unsigned int count)
{
unsigned long flags;
flags = claim_dma_lock();
disable_dma(channel);
clear_dma_ff(channel);
set_dma_mode(channel, mode);
set_dma_addr(channel, virt_to_bus(buf));
set_dma_count(channel, count);
enable_dma(channel);
release_dma_lock(flags);
return 0;
} 函数dad_dma_isdone用来检查 DMA 传输是否成功结束。
int dad_dma_isdone(int channel)
{
int residue;
unsigned long flags = claim_dma_lock ();
residue = get_dma_residue(channel);
release_dma_lock(flags);
return (residue == 0);
}
Linux 内核DMA机制
DMA控制器硬件结构
DMA允许外围设备和主内存之间直接传输 I/O 数据, DMA 依赖于系统。每一种体系结构DMA传输不同,编程接口也不同。
数据传输可以以两种方式触发:一种软件请求数据,另一种由硬件异步传输。
在第一种情况下,调用的步骤可以概括如下(以read为例):
(1)在进程调用 read 时,驱动程序的方法分配一个 DMA 缓冲区,随后指示硬件传送它的数据。进程进入睡眠。
(2)硬件将数据写入 DMA 缓冲区并在完成时产生一个中断。
(3)中断处理程序获得输入数据,应答中断,最后唤醒进程,该进程现在可以读取数据了。
第二种情形是在 DMA 被异步使用时发生的。以数据采集设备为例:
(1)硬件发出中断来通知新的数据已经到达。
(2)中断处理程序分配一个DMA缓冲区。
(3)外围设备将数据写入缓冲区,然后在完成时发出另一个中断。
(4)处理程序利用DMA分发新的数据,唤醒任何相关进程。
网卡传输也是如此,网卡有一个循环缓冲区(通常叫做 DMA
环形缓冲区)建立在与处理器共享的内存中。每一个输入数据包被放置在环形缓冲区中下一个可用缓冲区,并且发出中断。然后驱动程序将网络数据包传给内核的其它部分处理,并在环形缓冲区中放置一个新的
DMA 缓冲区。
驱动程序在初始化时分配DMA缓冲区,并使用它们直到停止运行。
DMA控制器依赖于平台硬件,这里只对i386的8237 DMA控制器做简单的说明,它有两个控制器,8个通道,具体说明如下:
控制器1: 通道0-3,字节操作, 端口为 00-1F
控制器2: 通道 4-7, 字操作, 端口咪 C0-DF
- 所有寄存器是8 bit,与传输大小无关。
- 通道 4 被用来将控制器1与控制器2级联起来。
- 通道 0-3 是字节操作,地址/计数都是字节的。
- 通道 5-7 是字操作,地址/计数都是以字为单位的。
- 传输器对于(0-3通道)必须不超过64K的物理边界,对于5-7必须不超过128K边界。
- 对于5-7通道page registers 不用数据 bit 0, 代表128K页
- 对于0-3通道page registers 使用 bit 0, 表示 64K页
DMA 传输器限制在低于16M物理内存里。装入寄存器的地址必须是物理地址,而不是逻辑地址。
在include/asm-i386/dma.h中有i386平台的8237 DMA控制器的各处寄存器的地址及寄存器的定义,这里只对控制寄存器加以说明:
DMA Channel Control/Status Register (DCSRX)
第31位 表明是否开始
第30位选定Descriptor和Non-Descriptor模式
第29位 判断有无中断
第8位 请求处理 (Request Pending)
第3位 Channel是否运行
第2位 当前数据交换是否完成
第1位是否由Descriptor产生中断
第0位 是否由总线错误引起中断
DMA通道使用的地址
DMA通道用dma_chan结构数组表示,这个结构在kernel/dma.c中,列出如下:
- struct dma_chan {
- int lock;
- const char *device_id;
- };
- static struct dma_chan dma_chan_busy[MAX_DMA_CHANNELS] = {
- [4] = { 1, "cascade" },
- };
如果dma_chan_busy[n].lock != 0表示忙,DMA0保留为DRAM更新用,DMA4用作级联。DMA 缓冲区的主要问题是,当它大于一页时,它必须占据物理内存中的连续页。
由于DMA需要连续的内存,因而在引导时分配内存或者为缓冲区保留物理 RAM 的顶部。在引导时给内核传递一个"mem="参数可以保留 RAM
的顶部。例如,如果系统有 32MB 内存,参数"mem=31M"阻止内核使用最顶部的一兆字节。稍后,模块可以使用下面的代码来访问这些保留的内存:
- dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
分配 DMA 空间的方法,代码调用 kmalloc(GFP_ATOMIC) 直到失败为止,然后它等待内核释放若干页面,接下来再一次进行分配。最终会发现由连续页面组成的DMA 缓冲区的出现。
一个使用 DMA 的设备驱动程序通常会与连接到接口总线上的硬件通讯,这些硬件使用物理地址,而程序代码使用虚拟地址。基于 DMA
的硬件使用总线地址而不是物理地址,有时,接口总线是通过将 I/O
地址映射到不同物理地址的桥接电路连接的。甚至某些系统有一个页面映射方案,能够使任意页面在外围总线上表现为连续的。
当驱动程序需要向一个 I/O 设备(例如扩展板或者DMA控制器)发送地址信息时,必须使用 virt_to_bus 转换,在接受到来自连接到总线上硬件的地址信息时,必须使用 bus_to_virt 了。
DMA操作函数
因为 DMA 控制器是一个系统级的资源,所以内核协助处理这一资源。内核使用 DMA 注册表为 DMA 通道提供了请求/释放机制,并且提供了一组函数在 DMA 控制器中配置通道信息。
DMA 控制器使用函数request_dma和free_dma来获取和释放 DMA 通道的所有权,请求 DMA
通道应在请求了中断线之后,并且在释放中断线之前释放它。每一个使用 DMA
的设备也必须使用中断信号线,否则就无法发出数据传输完成的通知。这两个函数的声明列出如下(在kernel/dma.c中):
- int request_dma(unsigned int channel, const char *name);
- void free_dma(unsigned int channel);
DMA 控制器被dma_spin_lock 的自旋锁所保护。使用函数claim_dma_lock和release_dma_lock对获得和释放自旋锁。这两个函数的声明列出如下(在kernel/dma.c中):
unsigned long claim_dma_lock(); 获取 DMA 自旋锁,该函数会阻塞本地处理器上的中断,因此,其返回值是"标志"值,在重新打开中断时必须使用该值。
void release_dma_lock(unsigned long flags); 释放 DMA 自旋锁,并且恢复以前的中断状态。
DMA 控制器的控制设置信息由RAM 地址、传输的数据(以字节或字为单位),以及传输的方向三部分组成。下面是i386平台的8237
DMA控制器的操作函数说明(在include/asm-i386/dma.h中),使用这些函数设置DMA控制器时,应该持有自旋锁。但在驱动程序做I/O
操作时,不能持有自旋锁。
void set_dma_mode(unsigned int channel, char mode);
该函数指出通道从设备读(DMA_MODE_WRITE)或写(DMA_MODE_READ)数据方式,当mode设置为
DMA_MODE_CASCADE时,表示释放对总线的控制。
void set_dma_addr(unsigned int channel, unsigned int addr); 函数给 DMA 缓冲区的地址赋值。该函数将 addr 的最低 24 位存储到控制器中。参数 addr 是总线地址。
void set_dma_count(unsigned int channel, unsigned int count);该函数对传输的字节数赋值。参数 count 也代表 16 位通道的字节数,在此情况下,这个数字必须是偶数。
除了这些操作函数外,还有些对DMA状态进行控制的工具函数:
void disable_dma(unsigned int channel); 该函数设置禁止使用DMA 通道。这应该在配置 DMA 控制器之前设置。
void enable_dma(unsigned int channel); 在DMA 通道中包含了合法的数据时,该函数激活DMA 控制器。
int get_dma_residue(unsigned int channel); 该函数查询一个 DMA 传输还有多少字节还没传输完。函数返回没传完的字节数。当传输成功时,函数返回值是0。
void clear_dma_ff(unsigned int channel) 该函数清除 DMA
触发器(flip-flop),该触发器用来控制对 16 位寄存器的访问。可以通过两个连续的 8
位操作来访问这些寄存器,触发器被清除时用来选择低字节,触发器被置位时用来选择高字节。在传输 8 位后,触发器会自动反转;在访问 DMA
寄存器之前,程序员必须清除触发器(将它设置为某个已知状态)。
DMA映射
一个DMA映射就是分配一个 DMA 缓冲区并为该缓冲区生成一个能够被设备访问的地址的组合操作。一般情况下,简单地调用函数virt_to_bus
就设备总线上的地址,但有些硬件映射寄存器也被设置在总线硬件中。映射寄存器(mapping
register)是一个类似于外围设备的虚拟内存等价物。在使用这些寄存器的系统上,外围设备有一个相对较小的、专用的地址区段,可以在此区段执行
DMA。通过映射寄存器,这些地址被重映射到系统
RAM。映射寄存器具有一些好的特性,包括使分散的页面在设备地址空间看起来是连续的。但不是所有的体系结构都有映射寄存器,特别地,PC
平台没有映射寄存器。
在某些情况下,为设备设置有用的地址也意味着需要构造一个反弹(bounce)缓冲区。例如,当驱动程序试图在一个不能被外围设备访问的地址(一个高端内存地址)上执行 DMA 时,反弹缓冲区被创建。然后,按照需要,数据被复制到反弹缓冲区,或者从反弹缓冲区复制。
根据 DMA 缓冲区期望保留的时间长短,PCI 代码区分两种类型的 DMA 映射:
一致 DMA 映射 它们存在于驱动程序的生命周期内。一个被一致映射的缓冲区必须同时可被 CPU 和外围设备访问,这个缓冲区被处理器写时,可立即被设备读取而没有cache效应,反之亦然,使用函数pci_alloc_consistent建立一致映射。
流式 DMA映射
流式DMA映射是为单个操作进行的设置。它映射处理器虚拟空间的一块地址,以致它能被设备访问。应尽可能使用流式映射,而不是一致映射。这是因为在支持一致映射的系统上,每个
DMA
映射会使用总线上一个或多个映射寄存器。具有较长生命周期的一致映射,会独占这些寄存器很长时间――即使它们没有被使用。使用函数dma_map_single建立流式映射。
(1)建立一致 DMA 映射
函数pci_alloc_consistent处理缓冲区的分配和映射,函数分析如下(在include/asm-generic/pci-dma-compat.h中):
- static inline void *pci_alloc_consistent(struct pci_dev *hwdev, size_t size, dma_addr_t *dma_handle)
- {
- return dma_alloc_coherent(hwdev == NULL ? NULL : &hwdev->dev, size, dma_handle, GFP_ATOMIC);
- }
结构dma_coherent_mem定义了DMA一致性映射的内存的地址、大小和标识等。结构dma_coherent_mem列出如下(在arch/i386/kernel/pci-dma.c中):
- struct dma_coherent_mem {
- void *virt_base;
- u32 device_base;
- int size;
- int flags;
- unsigned long *bitmap;
- };
函数dma_alloc_coherent分配size字节的区域的一致内存,得到的dma_handle是指向分配的区域的地址指针,这个地址作为区域的物理基地址。dma_handle是与总线一样的位宽的无符号整数。
函数dma_alloc_coherent分析如下(在arch/i386/kernel/pci-dma.c中):
- void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int gfp)
- {
- void *ret; //若是设备,得到设备的dma内存区域,即mem= dev->dma_mem
- struct dma_coherent_mem *mem = dev ? dev->dma_mem : NULL;
- int order = get_order(size);//将size转换成order,即忽略特定的区域,因而忽略这两个标识
- gfp &= ~(__GFP_DMA | __GFP_HIGHMEM);
- if (mem) { //设备的DMA映射,mem= dev->dma_mem
- //找到mem对应的页
- int page = bitmap_find_free_region(mem->bitmap, mem->size, order);
- if (page >= 0) {
- *dma_handle = mem->device_base + (page << PAGE_SHIFT);
- ret = mem->virt_base + (page << PAGE_SHIFT);
- memset(ret, 0, size);
- return ret;
- }
- if (mem->flags & DMA_MEMORY_EXCLUSIVE)
- return NULL;
- }
- //不是设备的DMA映射
- if (dev == NULL || (dev->coherent_dma_mask < 0xffffffff))
- gfp |= GFP_DMA;
- //分配空闲页
- ret = (void *)__get_free_pages(gfp, order);
- if (ret != NULL) {
- memset(ret, 0, size); //清0
- *dma_handle = virt_to_phys(ret); //得到物理地址
- }
- return ret;
- }
当不再需要缓冲区时(通常在模块卸载时),应该调用函数 pci_free_consitent 将它返还给系统。
(2)建立流式 DMA 映射
在流式 DMA 映射的操作中,缓冲区传送方向应匹配于映射时给定的方向值。缓冲区被映射后,它就属于设备而不再属于处理器了。在缓冲区调用函数pci_unmap_single撤销映射之前,驱动程序不应该触及其内容。
在缓冲区为 DMA 映射时,内核必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新。在刷新之后,由处理器写入缓冲区的数据对设备来说也许是不可见的。
如果欲映射的缓冲区位于设备不能访问的内存区段时,某些体系结构仅仅会操作失败,而其它的体系结构会创建一个反弹缓冲区。反弹缓冲区是被设备访问的独立内存区域,反弹缓冲区复制原始缓冲区的内容。
函数pci_map_single映射单个用于传送的缓冲区,返回值是可以传递给设备的总线地址,如果出错的话就为 NULL。一旦传送完成,应该使用函数pci_unmap_single 删除映射。其中,参数direction为传输的方向,取值如下:
PCI_DMA_TODEVICE 数据被发送到设备。
PCI_DMA_FROMDEVICE如果数据将发送到 CPU。
PCI_DMA_BIDIRECTIONAL数据进行两个方向的移动。
PCI_DMA_NONE 这个符号只是为帮助调试而提供。
函数pci_map_single分析如下(在arch/i386/kernel/pci-dma.c中):
- static inline dma_addr_t pci_map_single(struct pci_dev *hwdev, void *ptr, size_t size, int direction)
- {
- return dma_map_single(hwdev == NULL ? NULL : &hwdev->dev, ptr, size, (enum ma_data_direction)direction);
- }
函数dma_map_single映射一块处理器虚拟内存,这块虚拟内存能被设备访问,返回内存的物理地址,函数dma_map_single分析如下(在include/asm-i386/dma-mapping.h中):
- static inline dma_addr_t dma_map_single(struct device *dev, void *ptr, size_t size, enum dma_data_direction direction)
- {
- BUG_ON(direction == DMA_NONE);
- //可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新
- flush_write_buffers();
- return virt_to_phys(ptr);//虚拟地址转化为物理地址
- }
(3)分散/集中映射
分散/集中映射是流式 DMA 映射的一个特例。它将几个缓冲区集中到一起进行一次映射,并在一个 DMA
操作中传送所有数据。这些分散的缓冲区由分散表结构scatterlist来描述,多个分散的缓冲区的分散表结构组成缓冲区的struct
scatterlist数组。
分散表结构列出如下(在include/asm-i386/scatterlist.h):
- struct scatterlist {
- struct page *page;
- unsigned int offset;
- dma_addr_t dma_address; //用在分散/集中操作中的缓冲区地址
- unsigned int length;//该缓冲区的长度
- };
每一个缓冲区的地址和长度会被存储在 struct scatterlist 项中,但在不同的体系结构中它们在结构中的位置是不同的。下面的两个宏定义来解决平台移植性问题,这些宏定义应该在一个pci_map_sg 被调用后使用:
- #define sg_dma_address(sg) ((sg)->dma_address) //从该分散表项中返回总线地址
- #define sg_dma_len(sg) ((sg)->length) //返回该缓冲区的长度
函数pci_map_sg完成分散/集中映射,其返回值是要传送的 DMA 缓冲区数;它可能会小于
nents(也就是传入的分散表项的数量),因为可能有的缓冲区地址上是相邻的。一旦传输完成,分散/集中映射通过调用函数pci_unmap_sg
来撤销映射。 函数pci_map_sg分析如下(在include/asm-generic/pci-dma-compat.h中):
- static inline int pci_map_sg(struct pci_dev *hwdev, struct scatterlist *sg, int nents, int direction)
- {
- return dma_map_sg(hwdev == NULL ? NULL : &hwdev->dev, sg, nents, (enum dma_data_direction)direction);
- }
- //include/asm-i386/dma-mapping.h
- static inline int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction)
- {
- int i;
- BUG_ON(direction == DMA_NONE);
- for (i = 0; i < nents; i++ ) {
- BUG_ON(!sg[i].page);
- //将页及页偏移地址转化为物理地址
- sg[i].dma_address = page_to_phys(sg[i].page) + sg[i].offset;
- }
- //可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新
- flush_write_buffers();
- return nents;
- }
DMA池
许多驱动程序需要又多又小的一致映射内存区域给DMA描述子或I/O缓存buffer,这使用DMA池比用dma_alloc_coherent分配的一页或多页内存区域好,DMA池用函数dma_pool_create创建,用函数dma_pool_alloc从DMA池中分配一块一致内存,用函数dmp_pool_free放内存回到DMA池中,使用函数dma_pool_destory释放DMA池的资源。
结构dma_pool是DMA池描述结构,列出如下:
- struct dma_pool { /* the pool */
- struct list_head page_list;//页链表
- spinlock_t lock;
- size_t blocks_per_page;//每页的块数
- size_t size; //DMA池里的一致内存块的大小
- struct device *dev; //将做DMA的设备
- size_t allocation; //分配的没有跨越边界的块数,是size的整数倍
- char name [32];//池的名字
- wait_queue_head_t waitq; //等待队列
- struct list_head pools;
- };
函数dma_pool_create给DMA创建一个一致内存块池,其参数name是DMA池的名字,用于诊断用,参数dev是将做DMA的设备,参数size是DMA池里的块的大小,参数align是块的对齐要求,是2的幂,参数allocation返回没有跨越边界的块数(或0)。
函数dma_pool_create返回创建的带有要求字符串的DMA池,若创建失败返回null。对被给的DMA池,函数dma_pool_alloc被用来分配内存,这些内存都是一致DMA映射,可被设备访问,且没有使用缓存刷新机制,因为对齐原因,分配的块的实际尺寸比请求的大。如果分配非0的内存,从函数dma_pool_alloc返回的对象将不跨越size边界(如不跨越4K字节边界)。这对在个体的DMA传输上有地址限制的设备来说是有利的。
函数dma_pool_create分析如下(在drivers/base/dmapool.c中):
- struct dma_pool *dma_pool_create (const char *name, struct device *dev, size_t size, size_t align, size_t allocation)
- {
- struct dma_pool *retval;
- if (align == 0)
- align = 1;
- if (size == 0)
- return NULL;
- else if (size < align)
- size = align;
- else if ((size % align) != 0) {//对齐处理
- size += align + 1;
- size &= ~(align - 1);
- }
- //如果一致内存块比页大,是分配为一致内存块大小,否则,分配为页大小
- if (allocation == 0) {
- if (PAGE_SIZE < size)//页比一致内存块小
- allocation = size;
- else
- allocation = PAGE_SIZE;//页大小
- // FIXME: round up for less fragmentation
- } else if (allocation < size)
- return NULL;
- //分配dma_pool结构对象空间
- if (!(retval = kmalloc (sizeof *retval, SLAB_KERNEL)))
- return retval;
- strlcpy (retval->name, name, sizeof retval->name);
- retval->dev = dev;
- //初始化dma_pool结构对象retval
- INIT_LIST_HEAD (&retval->page_list);//初始化页链表
- spin_lock_init (&retval->lock);
- retval->size = size;
- retval->allocation = allocation;
- retval->blocks_per_page = allocation / size;
- init_waitqueue_head (&retval->waitq);//初始化等待队列
- if (dev) {
- down (&pools_lock);
- if (list_empty (&dev->dma_pools))
- //给设备创建sysfs文件系统属性文件
- device_create_file (dev, &dev_attr_pools);
- /* note: not currently insisting "name" be unique */
- list_add (&retval->pools, &dev->dma_pools);//将DMA池加到dev中
- up (&pools_lock);
- } else
- INIT_LIST_HEAD (&retval->pools);
- return retval;
- }
函数dma_pool_alloc从DMA池中分配一块一致内存,其参数pool是将产生块的DMA池,参数mem_flags是GFP_*位掩码,参数handle是指向块的DMA地址,函数dma_pool_alloc返回当前没用的块的内核虚拟地址,并通过handle给出它的DMA地址,如果内存块不能被分配,返回null。
函数dma_pool_alloc包裹了dma_alloc_coherent页分配器,这样小块更容易被总线的主控制器使用。这可能共享slab分配器的内容。
函数dma_pool_alloc分析如下(在drivers/base/dmapool.c中):
- void *dma_pool_alloc (struct dma_pool *pool, int mem_flags, dma_addr_t *handle)
- {
- unsigned long flags;
- struct dma_page *page;
- int map, block;
- size_t offset;
- void *retval;
- restart:
- spin_lock_irqsave (&pool->lock, flags);
- list_for_each_entry(page, &pool->page_list, page_list) {
- int i;
- /* only cachable accesses here ... */
- //遍历一页的每块,而每块又以32字节递增
- for (map = 0, i = 0; i < pool->blocks_per_page;/*每页的块数*/ i += BITS_PER_LONG, map++) {// BITS_PER_LONG定义为32
- if (page->bitmap [map] == 0)
- continue;
- block = ffz (~ page->bitmap [map]);//找出第一个0
- if ((i + block) < pool->blocks_per_page) {
- clear_bit (block, &page->bitmap [map]);
- //得到相对于页边界的偏移
- offset = (BITS_PER_LONG * map) + block;
- offset *= pool->size;
- goto ready;
- }
- }
- }
- //给DMA池分配dma_page结构空间,加入到pool->page_list链表,并作DMA一致映射,它包括分配给DMA池一页。
- //SLAB_ATOMIC表示调用 kmalloc(GFP_ATOMIC)直到失败为止,然后它等待内核释放若干页面,接下来再一次进行分配。
- if (!(page = pool_alloc_page (pool, SLAB_ATOMIC))) {
- if (mem_flags & __GFP_WAIT) {
- DECLARE_WAITQUEUE (wait, current);
- current->state = TASK_INTERRUPTIBLE;
- add_wait_queue (&pool->waitq, &wait);
- spin_unlock_irqrestore (&pool->lock, flags);
- schedule_timeout (POOL_TIMEOUT_JIFFIES);
- remove_wait_queue (&pool->waitq, &wait);
- goto restart;
- }
- retval = NULL;
- goto done;
- }
- clear_bit (0, &page->bitmap [0]);
- offset = 0;
- ready:
- page->in_use++;
- retval = offset + page->vaddr;//返回虚拟地址
- *handle = offset + page->dma;//相对DMA地址
- #ifdef CONFIG_DEBUG_SLAB
- memset (retval, POOL_POISON_ALLOCATED, pool->size);
- #endif
- done:
- spin_unlock_irqrestore (&pool->lock, flags);
- return retval;
- }
一个简单的使用DMA 例子
示例:下面是一个简单的使用DMA进行传输的驱动程序,它是一个假想的设备,只列出DMA相关的部分来说明驱动程序中如何使用DMA的。
函数dad_transfer是设置DMA对内存buffer的传输操作函数,它使用流式映射将buffer的虚拟地址转换到物理地址,设置好DMA控制器,然后开始传输数据。
- int dad_transfer(struct dad_dev *dev, int write, void *buffer, size_t count)
- {
- dma_addr_t bus_addr;
- unsigned long flags;
- /* Map the buffer for DMA */
- dev->dma_dir = (write ? PCI_DMA_TODEVICE : PCI_DMA_FROMDEVICE);
- dev->dma_size = count;
- //流式映射,将buffer的虚拟地址转化成物理地址
- bus_addr = pci_map_single(dev->pci_dev, buffer, count, dev->dma_dir);
- dev->dma_addr = bus_addr; //DMA传送的buffer物理地址
- //将操作控制写入到DMA控制器寄存器,从而建立起设备
- writeb(dev->registers.command, DAD_CMD_DISABLEDMA);
- //设置传输方向--读还是写
- writeb(dev->registers.command, write ? DAD_CMD_WR : DAD_CMD_RD);
- writel(dev->registers.addr, cpu_to_le32(bus_addr));//buffer物理地址
- writel(dev->registers.len, cpu_to_le32(count)); //传输的字节数
- //开始激活DMA进行数据传输操作
- writeb(dev->registers.command, DAD_CMD_ENABLEDMA);
- return 0;
- }
- //函数dad_interrupt是中断处理函数,当DMA传输完时,调用这个中断函数来取消buffer上的DMA映射,从而让内核程序可以访问这个buffer。
- void dad_interrupt(int irq, void *dev_id, struct pt_regs *regs)
- {
- struct dad_dev *dev = (struct dad_dev *) dev_id;
- /* Make sure it's really our device interrupting */
- /* Unmap the DMA buffer */
- pci_unmap_single(dev->pci_dev, dev->dma_addr, dev->dma_size, dev->dma_dir);
- /* Only now is it safe to access the buffer, copy to user, etc. */
- ...
- }
- //函数dad_open打开设备,此时应申请中断号及DMA通道。
- int dad_open (struct inode *inode, struct file *filp)
- {
- struct dad_device *my_device;
- // SA_INTERRUPT表示快速中断处理且不支持共享 IRQ 信号线
- if ( (error = request_irq(my_device.irq, dad_interrupt, SA_INTERRUPT, "dad", NULL)) )
- return error; /* or implement blocking open */
- if ( (error = request_dma(my_device.dma, "dad")) ) {
- free_irq(my_device.irq, NULL);
- return error; /* or implement blocking open */
- }
- return 0;
- }
- //在与open 相对应的 close 函数中应该释放DMA及中断号。
- void dad_close (struct inode *inode, struct file *filp)
- {
- struct dad_device *my_device;
- free_dma(my_device.dma);
- free_irq(my_device.irq, NULL);
- ……
- }
- //函数dad_dma_prepare初始化DMA控制器,设置DMA控制器的寄存器的值,为 DMA 传输作准备。
- int dad_dma_prepare(int channel, int mode, unsigned int buf, unsigned int count)
- {
- unsigned long flags;
- flags = claim_dma_lock();
- disable_dma(channel);
- clear_dma_ff(channel);
- set_dma_mode(channel, mode);
- set_dma_addr(channel, virt_to_bus(buf));
- set_dma_count(channel, count);
- enable_dma(channel);
- release_dma_lock(flags);
- return 0;
- }
- //函数dad_dma_isdone用来检查 DMA 传输是否成功结束。
- int dad_dma_isdone(int channel)
- {
- int residue;
- unsigned long flags = claim_dma_lock ();
- residue = get_dma_residue(channel);
- release_dma_lock(flags);
- return (residue == 0);
- }
Linux 中断详解 【转】
方法之三:以数据结构为基点,触类旁通
结构化程序设计思想认为:程序 =数据结构 +算法。数据结构体现了整个系统的构架,所以数据结构通常都是代码分析的很好的着手点,对Linux内核分析尤其如此。比如,把进程控制块结构分析清楚 了,就对进程有了基本的把握;再比如,把页目录结构和页表结构弄懂了,两级虚存映射和内存管理也就掌握得差不多了。为了体现循序渐进的思想,在这我就以 Linux对中断机制的处理来介绍这种方法。
首先,必须指出的是:在此处,中断指广义的中断概义,它指所有通过idt进行的控制转移的机制和处理;它覆盖以下几个常用的概义:中断、异常、可屏蔽中断、不可屏蔽中断、硬中断、软中断 … … …
I、硬件提供的中断机制和约定
一.中断向量寻址:
硬件提供可供256个服务程序中断进入的入口,即中断向量;
中断向量在保护模式下的实现机制是中断描述符表idt,idt的位置由idtr确定,idtr是个48位的寄存器,高32位是idt的基址,低16位为idt的界限(通常为2k=256*8);
idt中包含256个中断描述符,对应256个中断向量;每个中断描述符8位,其结构如图一:

中断进入过程如图二所示。
当中断是由低特权级转到高特权级(即当前特权级CPL>DPL)时,将进行堆栈的转移;内层堆栈的选择由当前tss的相应字段确定,而且内层堆栈将依次被压入如下数据:外层SS,外层ESP,EFLAGS,外层CS,外层EIP; 中断返回过程为一逆过程;

二.异常处理机制:
Intel公司保留0-31号中断向量用来处理异常事件:当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,异常的处理程序由操作系统提供,中断向量和异常事件对应如表一:
| 中断向量号 | 异常事件 | Linux的处理程序 |
| 0 | 除法错误 | Divide_error |
| 1 | 调试异常 | Debug |
| 2 | NMI中断 | Nmi |
| 3 | 单字节,int 3 | Int3 |
| 4 | 溢出 | Overflow |
| 5 | 边界监测中断 | Bounds |
| 6 | 无效操作码 | Invalid_op |
| 7 | 设备不可用 | Device_not_available |
| 8 | 双重故障 | Double_fault |
| 9 | 协处理器段溢出 | Coprocessor_segment_overrun |
| 10 | 无效TSS | Incalid_tss |
| 11 | 缺段中断 | Segment_not_present |
| 12 | 堆栈异常 | Stack_segment |
| 13 | 一般保护异常 | General_protection |
| 14 | 页异常 | Page_fault |
| 15 | Spurious_interrupt_bug | |
| 16 | 协处理器出错 | Coprocessor_error |
| 17 | 对齐检查中断 | Alignment_check |
三.可编程中断控制器8259A:
为更好的处理外部设备,x86微机提供了两片可编程中断控制器,用来辅助cpu接受外部的中断信号;对于中断,cpu只提供两个外接引线:NMI和INTR;
NMI只能通过端口操作来屏蔽,它通常用于:电源掉电和物理存储器奇偶验错;
INTR可通过直接设置中断屏蔽位来屏蔽,它可用来接受外部中断信号,但只有一个引线,不够用;所以它通过外接两片级链了的8259A,以接受更多的外部中断信号。8259A主要完成这样一些任务:
- 中断优先级排队管理,
- 接受外部中断请求
- 向cpu提供中断类型号
外部设备产生的中断信号在IRQ(中断请求)管脚上首先由中断控制器处理。中断控制器可 以响应多个中断输入,它的输出连接到 CPU 的 INT 管脚,信号可通过INT 管脚,通知处理器产生了中断。如果 CPU 这时可以处理中断,CPU 会通过 INTA(中断确认)管脚上的信号通知中断控制器已接受中断,这时,中断控制器可将一个 8 位数据放置在数据总线上,这一 8 位数据也称为中断向量号,CPU 依据中断向量号和中断描述符表(IDT)中的信息自动调用相应的中断服务程序。图三中,两个中断控制器级联了起来,从属中断控制器的输出连接到了主中断控 制器的第 3 个中断信号输入,这样,该系统可处理的外部中断数量最多可达 15 个,图的右边是 i386 PC 中各中断输入管脚的一般分配。可通过对8259A的初始化,使这15个外接引脚对应256个中断向量的任何15个连续的向量;由于intel公司保留0- 31号中断向量用来处理异常事件(而默认情况下,IBM bios把硬中断设在0x08-0x0f),所以,硬中断必须设在31以后,linux则在实模式下初始化时把其设在0x20-0x2F,对此下面还将具 体说明。
图三、i386 PC 可编程中断控制器8259A级链示意图

II、Linux的中断处理
硬件中断机制提供了256个入口,即idt中包含的256个中断描述符(对应256个中断向量)。
而0-31号中断向量被intel公司保留用来处理异常事件,不能另作它用。对这 0-31号中断向量,操作系统只需提供异常的处理程序,当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序;而事实 上,对于这32个处理异常的中断向量,此版本(2.2.5)的 Linux只提供了0-17号中断向量的处理程序,其对应处理程序参见表一、中断向量和异常事件对应表;也就是说,17-31号中断向量是空着未用的。
既然0-31号中断向量已被保留,那么,就是剩下32-255共224个中断向量可用。 这224个中断向量又是怎么分配的呢?在此版本(2.2.5)的Linux中,除了0x80 (SYSCALL_VECTOR)用作系统调用总入口之外,其他都用在外部硬件中断源上,其中包括可编程中断控制器8259A的15个irq;事实上,当 没有定义CONFIG_X86_IO_APIC时,其他223(除0x80外)个中断向量,只利用了从32号开始的15个,其它208个空着未用。
这些中断服务程序入口的设置将在下面有详细说明。
一.相关数据结构
- 中断描述符表idt: 也就是中断向量表,相当如一个数组,保存着各中断服务例程的入口。(详细描述参见图一、中断描述符格式)
- 与硬中断相关数据结构:
与硬中断相关数据结构主要有三个:
一:定义在/arch/i386/kernel/irq.h中的
struct hw_interrupt_type {
const char * typename;
void (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*handle)(unsigned int irq, struct pt_regs * regs);
void (*enable)(unsigned int irq);
void (*disable)(unsigned int irq);
};
二:定义在/arch/i386/kernel/irq.h中的
typedef struct {
unsigned int status; /* IRQ status - IRQ_INPROGRESS, IRQ_DISABLED */
struct hw_interrupt_type *handler; /* handle/enable/disable functions */
struct irqaction *action; /* IRQ action list */
unsigned int depth; /* Disable depth for nested irq disables */
} irq_desc_t;
三:定义在include/linux/ interrupt.h中的
struct irqaction {
void (*handler)(int, void *, struct pt_regs *);
unsigned long flags;
unsigned long mask;
const char *name;
void *dev_id;
struct irqaction *next;
};
三者关系如下:

图四、与硬中断相关的几个数据结构各关系
各结构成员详述如下:
- struct irqaction结构,它包含了内核接收到特定IRQ之后应该采取的操作,其成员如下:
- handler:是一指向某个函数的指针。该函数就是所在结构对相应中断的处理函数。
- flags:取值只有SA_INTERRUPT(中断可嵌套),SA_SAMPLE_RANDOM(这个中断是源于物理随机性的),和SA_SHIRQ(这个IRQ和其它struct irqaction共享)。
- mask:在x86或者体系结构无关的代码中不会使用(除非将其设置为0);只有在SPARC64的移植版本中要跟踪有关软盘的信息时才会使用它。
- name:产生中断的硬件设备的名字。因为不止一个硬件可以共享一个IRQ。
- dev_id:标识硬件类型的一个唯一的ID。Linux支持的所有硬件设备的每一种类型,都有一个由制造厂商定义的在此成员中记录的设备ID。
- next:如果IRQ是共享的,那么这就是指向队列中下一个struct irqaction结构的指针。通常情况下,IRQ不是共享的,因此这个成员就为空。
- struct hw_interrupt_type结构,它是一个抽象的中断控制器。这包含一系列的指向函数的指针,这些函数处理控制器特有的操作:
- typename:控制器的名字。
- startup:允许从给定的控制器的IRQ所产生的事件。
- shutdown:禁止从给定的控制器的IRQ所产生的事件。
- handle:根据提供给该函数的IRQ,处理唯一的中断。
- enable和disable:这两个函数基本上和startup和shutdown相同;
- 另外一个数据结构是irq_desc_t,它具有如下成员:
- status:一个整数。代表IRQ的状态:IRQ是否被禁止了,有关IRQ的设备当前是否正被自动检测,等等。
- handler:指向hw_interrupt_type的指针。
- action:指向irqaction结构组成的队列的头。正常情况下每个IRQ只有一个操作,因此链接列表的正常长度是1(或者0)。但是,如果IRQ被两个或者多个设备所共享,那么这个队列中就有多个操作。
- depth:irq_desc_t的当前用户的个数。主要是用来保证在中断处理过程中IRQ不会被禁止。
- irq_desc是irq_desc_t 类型的数组。对于每一个IRQ都有一个数组入口,即数组把每一个IRQ映射到和它相关的处理程序和irq_desc_t中的其它信息。
- 与Bottom_half相关的数据结构:
图五、底半处理数据结构示意图

- bh_mask_count:计数器。对每个enable/disable请求嵌套对进行计数。这些请求通过调用enable_bh和 disable_bh实现。每个禁止请求都增加计数器;每个使能请求都减小计数器。当计数器达到0时,所有未完成的禁止语句都已经被使能语句所匹配了,因 此下半部分最终被重新使能。(定义在kernel/softirq.c中)
- bh_mask和bh_active:它们共同决定下半部分是否运行。它们两个都有32位,而每一个下半部分都占用一位。当一个上半部 分(或者一些其它代码)决定其下半部分需要运行时,就通过设置bh_active中的一位来标记下半部分。不管是否做这样的标记,下半部分都可以通过清空 bh_mask中的相关位来使之失效。因此,对bh_mask和bh_active进行位AND运算就能够表明应该运行哪一个下半部分。特别是如果位与运 算的结果是0,就没有下半部分需要运行。
- bh_base:是一组简单的指向下半部分处理函数的指针。
bh_base代表的指针数组中可包含 32 个不同的底半处理程序。bh_mask 和 bh_active 的数据位分别代表对应的底半处理过程是否安装和激活。如果 bh_mask 的第 N 位为 1,则说明 bh_base 数组的第 N 个元素包含某个底半处理过程的地址;如果 bh_active 的第 N 位为 1,则说明必须由调度程序在适当的时候调用第 N 个底半处理过程。
二. 向量的设置和相关数据的初始化:
- 在实模式下的初始化过程中,通过对中断控制器8259A-1,9259A-2重新编程,把硬中断设到0x20-0x2F。即把IRQ0& #0;IRQ15分别与0x20-0x2F号中断向量对应起来;当对应的IRQ发生了时,处理机就会通过相应的中断向量,把控制转到对应的中断服务例 程。(源码在Arch/i386/boot/setup.S文件中;相关内容可参见 实模式下的初始化 部分)
- 在保护模式下的初始化过程中,设置并初始化idt,共256个入口,服务程序均为ignore_int, 该服务程序仅打印“Unknown interruptn”。(源码参见Arch/i386/KERNEL/head.S文件;相关内容可参见 保护模式下的初始化 部分)
- 在系统初始化完成后运行的第一个内核程序asmlinkage void __init start_kernel(void) (源码在文件init/main.c中) 中,通过调用void __init trap_init(void)函数,把各自陷和中断服务程序的入口地址设置到 idt 表中,即将表一中对应的处理程序入口设置到相应的中断向量表项中;在此版本(2.2.5)的Linux只设置0-17号中断向量。(trap_init (void)函数定义在arch/i386/kernel/traps.c 中; 相关内容可参见 详解系统调用 部分)
- 在同一个函数void __init trap_init(void)中,通过调用函数set_system_gate(SYSCALL_VECTOR,&system_call); 把系统调用总控程序的入口挂在中断0x80上。其中SYSCALL_VECTOR是定义在 linux/arch/i386/kernel/irq.h中的一个常量0x80; 而 system_call 即为中断总控程序的入口地址;中断总控程序用汇编语言定义在arch/i386/kernel/entry.S中。(相关内容可参见 详解系统调用 部分)
- 在系统初始化完成后运行的第一个内核程序asmlinkage void __init start_kernel(void) (源码在文件init/main.c中) 中,通过调用void init_IRQ(void)函数,把地址标号interrupt[i](i从1-223)设置到 idt 表中的的32-255号中断向量(0x80除外),外部硬件IRQ的触发,将通过这些地址标号最终进入到各自相应的处理程序。(init_IRQ (void)函数定义在arch/i386/kernel/IRQ.c 中;)
- interrupt[i](i从1-223),是在arch/i386/kernel/IRQ.c文件中,通过一系列嵌套的类似如 BUILD_16_IRQS(0x0)的宏,定义的一系列地址标号;(这些定义interrupt[i]的宏,全部定义在文件 arch/i386/kernel/IRQ.c和arch/i386/kernel/IRQ.H中。这些嵌套的宏的使用,原理很简单,但很烦,限于篇幅, 在此省略)
- 各以interrupt[i]为入口的代码,在进行一些简单的处理后,最后都会调用函数asmlinkage void do_IRQ(struct pt_regs regs),do_IRQ函数调用static void do_8259A_IRQ(unsigned int irq, struct pt_regs * regs) 而do_8259A_IRQ在进行必要的处理后,将调用已与此IRQ建立联系irqaction中的处理函数,以进行相应的中断处理。最后处理机将跳转到 ret_from_intr进行必要处理后,整个中断处理结束返回。(相关源码都在文件arch/i386/kernel/IRQ.c和 arch/i386/kernel/IRQ.H中。Irqaction结构参见上面的数据结构说明)
三. Bottom_half处理机制
在此版本(2.2.5)的Linux中,中断处理程序从概念上被分为上半部分(top half)和下半部分(bottom half);在中断发生时上半部分的处理过程立即执行,但是下半部分(如果有的话)却推迟执行。内核把上半部分和下半部分作为独立的函数来处理,上半部分 决定其相关的下半部分是否需要执行。必须立即执行的部分必须位于上半部分,而可以推迟的部分可能属于下半部分。
那么为什么这样划分成两个部分呢?
- 一个原因是要把中断的总延迟时间最小化。Linux内核定义了两种类型的中断,快速的和慢速的,这两者之间的一个区别是慢速中断自身还可以被中 断,而快速中断则不能。因此,当处理快速中断时,如果有其它中断到达;不管是快速中断还是慢速中断,它们都必须等待。为了尽可能快地处理这些其它的中断, 内核就需要尽可能地将处理延迟到下半部分执行。
- 另外一个原因是,当内核执行上半部分时,正在服务的这个特殊IRQ将会被可编程中断控制器禁止,于是,连接在同一个IRQ上的其它设备 就只有等到该该中断处理被处理完毕后果才能发出IRQ请求。而采用Bottom_half机制后,不需要立即处理的部分就可以放在下半部分处理,从而,加 快了处理机对外部设备的中断请求的响应速度。
- 还有一个原因就是,处理程序的下半部分还可以包含一些并非每次中断都必须处理的操作;对这些操作,内核可以在一系列设备中断之后集中处 理一次就可以了。即在这种情况下,每次都执行并非必要的操作完全是一种浪费,而采用Bottom_half机制后,可以稍稍延迟并在后来只执行一次就行 了。
由此可见,没有必要每次中断都调用下半部分;只有bh_mask 和 bh_active的对应位的与为1时,才必须执行下半部分(do_botoom_half)。所以,如果在上半部分中(也可能在其他地方)决定必须执行 对应的半部分,那么可以通过设置bh_active的对应位,来指明下半部分必须执行。当然,如果bh_active的对应位被置位,也不一定会马上执行 下半部分,因为还必须具备另外两个条件:首先是bh_mask的相应位也必须被置位,另外,就是处理的时机,如果下半部分已经标记过需要执行了,现在又再 次标记,那么内核就简单地保持这个标记;当情况允许的时候,内核就对它进行处理。如果在内核有机会运行其下半部分之前给定的设备就已经发生了100次中 断,那么内核的上半部分就运行100次,下半部分运行1次。
bh_base数组的索引是静态定义的,定时器底半处理过程的地址保存在第 0 个元素中,控制台底半处理过程的地址保存在第 1 个元素中,等等。当 bh_mask 和 bh_active 表明第 N 个底半处理过程已被安装且处于活动状态,则调度程序会调用第 N 个底半处理过程,该底半处理过程最终会处理与之相关的任务队列中的各个任务。因为调度程序从第 0 个元素开始依次检查每个底半处理过程,因此,第 0 个底半处理过程具有最高的优先级,第 31 个底半处理过程的优先级最低。
内核中的某些底半处理过程是和特定设备相关的,而其他一些则更一般一些。表二列出了内核中通用的底半处理过程。
表二、Linux 中通用的底半处理过程
| TIMER_BH(定时器) | 在每次系统的周期性定时器中断中,该底半处理过程被标记为活动状态,并用来驱动内核的定时器队列机制。 |
| CONSOLE_BH(控制台) | 该处理过程用来处理控制台消息。 |
| TQUEUE_BH(TTY 消息队列) | 该处理过程用来处理 tty 消息。 |
| NET_BH(网络) | 用于一般网络处理,作为网络层的一部分 |
| IMMEDIATE_BH(立即) | 这是一个一般性处理过程,许多设备驱动程序利用该过程对自己要在随后处理的任务进行排队。 |
当某个设备驱动程序,或内核的其他部分需要将任务排队进行处理时,它将任务添加到适当的 系统队列中(例如,添加到系统的定时器队列中),然后通知内核,表明需要进行底半处理。为了通知内核,只需将 bh_active 的相应数据位置为 1。例如,如果驱动程序在 immediate 队列中将某任务排队,并希望运行 IMMEDIATE 底半处理过程来处理排队任务,则只需将 bh_active 的第 8 位置为 1。在每个系统调用结束并返回调用进程之前,调度程序要检验 bh_active 中的每个位,如果有任何一位为 1,则相应的底半处理过程被调用。每个底半处理过程被调用时,bh_active 中的相应为被清除。bh_active 中的置位只是暂时的,在两次调用调度程序之间 bh_active 的值才有意义,如果 bh_active 中没有置位,则不需要调用任何底半处理过程。
四.中断处理全过程
由前面的分析可知,对于0-31号中断向量,被保留用来处理异常事件;0x80中断向量用来作为系统调用的总入口点;而其他中断向量,则用来处理外部设备中断;这三者的处理过程都是不一样的。
- 异常的处理全过程
对这0-31号中断向量,保留用来处理异常事件;操作系统提供相应的异常的处理程序,并在初 始化时把处理程序的入口等级在对应的中断向量表项中。当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序,进行相应 的处理后,返回原中断处。当然,在前面已经提到,此版本(2.2.5)的Linux只提供了0-17号中断向量的处理程序。
- 中断的处理全过程
对于0-31号和0x80之外的中断向量,主要用来处理外部设备中断;在系统完成初始化后,其中断处理过程如下:
当外部设备需要处理机进行中断服务时,它就会通过中断控制器要求处理机进行中断服务。如 果 CPU 这时可以处理中断,CPU将根据中断控制器提供的中断向量号和中断描述符表(IDT)中的登记的地址信息,自动跳转到相应的interrupt[i]地 址;在进行一些简单的但必要的处理后,最后都会调用函数do_IRQ , do_IRQ函数调用 do_8259A_IRQ 而do_8259A_IRQ在进行必要的处理后,将调用已与此IRQ建立联系irqaction中的处理函数,以进行相应的中断处理。最后处理机将跳转到 ret_from_intr进行必要处理后,整个中断处理结束返回。
从数据结构入手,应该说是分析操作系统源码最常用的和最主要的方法。因为操作系统的几大功能部件,如进程管理,设备管理,内存管理等等,都可以通过对其相应的数据结构的分析来弄懂其实现机制。很好的掌握这种方法,对分析Linux内核大有裨益。
方法之四:以功能为中心,各个击破
从功能上看,整个Linux系统可看作有一下几个部分组成:
- 进程管理机制部分;
- 内存管理机制部分;
- 文件系统部分;
- 硬件驱动部分;
- 系统调用部分等;
以功能为中心、各个击破,就是指从这五个功能入手,通过源码分析,找出Linux是怎样实现这些功能的。
在这五个功能部件中,系统调用是用户程序或操作调用核心所提供的功能的接口;也是分析 Linux内核源码几个很好的入口点之一。对于那些在dos或 Uinx、Linux下有过C编程经验的高手尤其如此。又由于系统调用相对其它功能而言,较为简单,所以,我就以它为例,希望通过对系统调用的分析,能使 读者体会到这一方法。
与系统调用相关的内容主要有:系统调用总控程序,系统调用向量表sys_call_table,以及各系统调用服务程序。下面将对此一一介绍:
- 保护模式下的初始化过程中,设置并初始化idt,共256个入口,服务程序均为ignore_int, 该服务程序仅打印“Unknown interruptn”。(源码参见/Arch/i386/KERNEL/head.S文件;相关内容可参见 保护模式下的初始化 部分)
- 在系统初始化完成后运行的第一个内核程序start_kernel中,通过调用 trap_init函数,把各自陷和中断服务程序的入口地址设置到 idt 表中;同时,此函数还通过调用函数set_system_gate 把系统调用总控程序的入口地址挂在中断0x80上。其中:
- start_kernel的原型为void __init start_kernel(void) ,其源码在文件 init/main.c中;
- trap_init函数的原型为void __init trap_init(void),定义在arch/i386/kernel/traps.c 中
- 函数set_system_gate同样定义在arch/i386/kernel/traps.c 中,调用原型为set_system_gate(SYSCALL_VECTOR,&system_call);
- 其中,SYSCALL_VECTOR是定义在 linux/arch/i386/kernel/irq.h中的一个常量0x80;
- 而 system_call 即为系统调用总控程序的入口地址;中断总控程序用汇编语言定义在arch/i386/kernel/entry.S中。
- 系统调用向量表sys_call_table, 是一个含有NR_syscalls=256个单元的数组。它的每个单元存放着一个系统调用服务程序的入口地址。该数组定义在 /arch/i386/kernel/entry.S中;而NR_syscalls则是一个等于256的宏,定义在 include/linux/sys.h中。
- 各系统调用服务程序则分别定义在各个模块的相应文件中;例如asmlinkage int sys_time(int * tloc)就定义在kerneltime.c中;另外,在kernelsys.c中也有不少服务程序;
II、系统调用过程
∥颐侵溃低车饔檬怯没С绦蚧虿僮鞯饔煤诵乃峁┑墓δ艿慕涌冢凰韵低车粲玫墓叹褪谴佑没С绦虻较低衬诤耍缓笥只氐接没С绦虻墓蹋辉贚inux中,此过程大体过程可描述如下:
系统调用过程示意图:
![Linux 中断详解 - 海飞丝 - 风十二的博客]()
整个系统调用进入过程客表示如下:
用户程序 系统调用总控程序(system_call) 各个服务程序
可见,系统调用的进入课分为“用户程序 系统调用总控程序”和“系统调用总控程序各个服务程序”两部分;下边将分别对这两个部分进行详细说明:
以程序流程为线索,适合于分析系统的初始化过程:系统引导、实模式下的初始化、保护模式下的初始化三个部分,和分析应用程序的执行流程:从程序的装载,到运行,一直到程序的退出。而流程图则是这种分析方法最合适的表达工具。- “用户程序 系统调用总控程序”的实现:在前面已经说过,Linux的系统调用使用第0x80号中断向量项作为总的入口,也即,系统调用总控程序的入口地址 system_call就挂在中断0x80上。也就是说,只要用户程序执行0x80中断 ( int 0x80 ),就可实现“用户程序 系统调用总控程序”的进入;事实上,在Linux中,也是这么做的。只是0x80中断的执行语句int 0x80 被封装在标准C库中,用户程序只需用标准系统调用函数就可以了,而不需要在用户程序中直接写0x80中断的执行语句int 0x80。至于中断的进入的详细过程可参见前面的“中断和中断处理”部分。
- “系统调用总控程序 各个服务程序” 的实现:在系统调用总控程序中通过语句“call * SYMBOL_NAME(sys_call_table)(,%eax,4)”来调用各个服务程序(SYMBOL_NAME是定义在 /include/linux/linkage.h中的宏:#define SYMBOL_NAME_LABEL(X) X),可以忽略)。当系统调用总控程序执行到此语句时,eax中的内容即是相应系统调用的编号,此编号即为相应服务程序在系统调用向量表 sys_call_table中的编号(关于系统调用的编号说明在/linux/include/asm/unistd.h中)。又因为系统调用向量表 sys_call_table每项占4个字节,所以由%eax 乘上4形成偏移地址,而sys_call_table则为基址;基址加上偏移所指向的内容就是相应系统调用服务程序的入口地址。所以此call语句就相当 于直接调用对应的系统调用服务程序。
- 参数传递的实现:在Linux中所有系统调用服务例程都使用了asmlinkage标志。此标志是一个定义在/include/linux/linkage.h 中的一个宏:
#if defined __i386__ && (__GNUC__ > 2 || __GNUC_MINOR__ > 7)
#define asmlinkage CPP_ASMLINKAGE__attribute__((regparm(0)))
#else
#define asmlinkage CPP_ASMLINKAGE
#endif
其中涉及到了gcc的一些约定,总之,这个标志它可以告诉编译器该函数不需要从寄存器中获得任何参数,而是从堆栈中取得参数;即参数在堆栈中传递,而不是直接通过寄存器;
堆栈参数如下:
EBX = 0x00
ECX = 0x04
EDX = 0x08
ESI = 0x0C
EDI = 0x10
EBP = 0x14
EAX = 0x18
DS = 0x1C
ES = 0x20
ORIG_EAX = 0x24
EIP = 0x28
CS = 0x2C
EFLAGS = 0x30
在进入系统调用总控程序前,用户按照以上的对应顺序将参数放到对应寄存器中,在系统调用 总控程序一开始就将这些寄存器压入堆栈;在退出总控程序前又按如上顺序堆栈;用户程序则可以直接从寄存器中复得被服务程序加工过了的参数。而对于系统调用 服务程序而言,参数就可以直接从总控程序压入的堆栈中复得;对参数的修改一可以直接在堆栈中进行;其实,这就是asmlinkage标志的作用。所以在进 入和退出系统调用总控程序时,“保护现场”和“恢复现场”的内容并不一定会相同。
- 特殊的服务程序:在此版本(2.2.5)的linux内核中,有好几个系统调用的服务程序都是定义在/usr/src/linux/kernel/sys.c 中的同一个函数:
asmlinkage int sys_ni_syscall(void)
{
return -ENOSYS;
}
此函数除了返回错误号之外,什么都没干。那他有什么作用呢?归结起来有如下三种可能:
1.处理边界错误,0号系统调用就是用的此特殊的服务程序;
2.用来替换旧的已淘汰了的系统调用,如: Nr 17, Nr 31, Nr 32, Nr 35, Nr 44, Nr 53, Nr 56, Nr58, Nr 98;
3. 用于将要扩展的系统调用,如: Nr 137, Nr 188, Nr 189;
III、系统调用总控程序(system_call)
系统调用总控程序(system_call)可参见arch/i386/kernel/entry.S其执行流程如下图:
![Linux 中断详解 - 海飞丝 - 风十二的博客]()
IV、实例:增加一个系统调用
由以上的分析可知,增加系统调用由于下两种方法:
i.编一个新的服务例程,将它的入口地址加入到sys_call_table的某一项,只要该项的原服务例程是sys_ni_syscall,并且是sys_ni_syscall的作用属于第三种的项,也即Nr 137, Nr 188, Nr 189。
ii.直接增加:
- 编一个新的服务例程;
- 在sys_call_table中添加一个新项, 并把的新增加的服务例程的入口地址加到sys_call_table表中的新项中;
- 把增加的 sys_call_table 表项所对应的向量, 在include/asm-386/unistd.h 中进行必要申明,以供用户进程和其他系统进程查询或调用。
- 由于在标准的c语言库中没有新系统调用的承接段,所以,在测试程序中,除了要#include ,还要申明如下 _syscall1(int,additionSysCall,int, num)。
下面将对第ii种情况列举一个我曾经实现过了的一个增加系统调用的实例:
1.)在kernel/sys.c中增加新的系统服务例程如下:
asmlinkage int sys_addtotal(int numdata)
{
int i=0,enddata=0;
while(i<=numdata)
enddata+=i++;
return enddata;
}
该函数有一个 int 型入口参数 numdata , 并返回从 0 到 numdata 的累加值; 当然也可以把系统服务例程放在一个自己定义的文件或其他文件中,只是要在相应文件中作必要的说明;
2.)把 asmlinkage int sys_addtotal( int) 的入口地址加到sys_call_table表中:
arch/i386/kernel/entry.S 中的最后几行源代码修改前为:
... ...
.long SYMBOL_NAME(sys_sendfile)
.long SYMBOL_NAME(sys_ni_syscall) /* streams1 */
.long SYMBOL_NAME(sys_ni_syscall) /* streams2 */
.long SYMBOL_NAME(sys_vfork) /* 190 */
.rept NR_syscalls-190
.long SYMBOL_NAME(sys_ni_syscall)
.endr
修改后为: ... ...
.long SYMBOL_NAME(sys_sendfile)
.long SYMBOL_NAME(sys_ni_syscall) /* streams1 */
.long SYMBOL_NAME(sys_ni_syscall) /* streams2 */
.long SYMBOL_NAME(sys_vfork) /* 190 */
/* add by I */
.long SYMBOL_NAME(sys_addtotal)
.rept NR_syscalls-191
.long SYMBOL_NAME(sys_ni_syscall)
.endr
3.) 把增加的 sys_call_table 表项所对应的向量,在include/asm-386/unistd.h 中进行必要申明,以供用户进程和其他系统进程查询或调用:
增加后的部分 /usr/src/linux/include/asm-386/unistd.h 文件如下:
... ...
#define __NR_sendfile 187
#define __NR_getpmsg 188
#define __NR_putpmsg 189
#define __NR_vfork 190
/* add by I */
#define __NR_addtotal 191
4.测试程序(test.c)如下:
#include
#include
_syscall1(int,addtotal,int, num)
main()
{
int i,j;
do
printf("Please input a numbern");
while(scanf("%d",&i)==EOF);
if((j=addtotal(i))==-1)
printf("Error occurred in syscall-addtotal();n");
printf("Total from 0 to %d is %d n",i,j);
}
对修改后的新的内核进行编译,并引导它作为新的操作系统,运行几个程序后可以发现一切正常;在新的系统下对测试程序进行编译(*注:由于原内核并未提供此系统调用,所以只有在编译后的新内核下,此测试程序才能可能被编译通过),运行情况如下:
$gcc �o test test.c
$./test
Please input a number
36
Total from 0 to 36 is 666
综述
可见,修改成功。
由于操作系统内核源码的特殊性:体系庞大,结构复杂,代码冗长,代码间联系错综复杂。所以要把内核源码分析清楚,也是一个很艰难,很需要毅力的事。尤其需要交流和讲究方法;只有方法正确,才能事半功倍。
在上面的论述中,一共列举了两个内核分析的入口、和三种分析源码的方法:以程序流程为线索,一线串珠;以数据结构为基点,触类旁通;以功能为中心,各个击破。三种方法各有特点,适合于分析不同部分的代码:
- 以数据结构为基点、触类旁通,这种方法是分析操作系统源码最常用的和最主要的方法。对分析进程管理,设备管理,内存管理等等都是很有效的。
- 以功能为中心、各个击破,是把整个系统分成几个相对独立的功能模块,然后分别对各个功能进行分析。这样带来的一个好处就是,每次只以一 个功能为中心,涉及到其他部分的内容,可以看作是其它功能提供的服务,而无需急着追究这种服务的实现细节;这样,在很大程度上减轻了分析的复杂度。
三种方法,各有其长,只要合理的综合运用这些方法,相信对减轻分析的复杂度还是有所帮组的。


LINUX中断机制
【主要内容】
Linux设备驱动编程中的中断与定时器处理
【正文】
一、基础知识
1、中断
所谓中断是指CPU在执行程序的过程中,出现了某些突发事件急待处理,CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回程序被中断的位置并继续执行。
2、中断的分类
1)根据中断来源分为:内部中断和外部中断。内部中断来源于CPU内部(软中断指令、溢出、语法错误等),外部中断来自CPU外部,由设备提出请求。
2)根据是否可被屏蔽分为:可屏蔽中断和不可屏蔽中断(NMI),被屏蔽的中断将不会得到响应。
3)根据中断入口跳转方法分为:向量中断和非向量中断。向量中断为不同的中断分配不同的中断号,非向量中断多个中断共享一个中断号,在软件中判断具体是哪个中断(非向量中断由软件提供中断服务程序入口地址)。
二、Linux中断处理程序架构
设备的中断会打断内核中正常调度和运行,系统对更高吞吐率的追求势必要求中断服务程序尽可能的短小(时间短),但是在大多数实际使用中,要完成的工作都是复杂的,它可能需要进行大量的耗时工作。
1、Linux中断处理中的顶半部和底半部机制
由于中断服务程序的执行并不存在于进程上下文,因此,要求中断服务程序的时间尽可能的短。 为了在中断执行事件尽可能短和中断处理需完成大量耗时工作之间找到一个平衡点,Linux将中断处理分为两个部分:顶半部(top half)和底半部(bottom half)。
 Linux中断处理机制
Linux中断处理机制
顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后进行“登记中断”的工作。“登记”意味着将底半部的处理程序挂载到该设备的底半部指向队列中去。底半部作为工作重心,完成中断事件的绝大多数任务。
a. 底半部可以被新的中断事件打断,这是和顶半部最大的不同,顶半部通常被设计成不可被打断
b. 底半部相对来说不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行。
c. 如果中断要处理的工作本身很少,所有的工作可在顶半部全部完成
三、中断编程
1、申请和释放中断
在Linux设备驱动中,使用中断的设备需要申请和释放相对应的中断,分别使用内核提供的 request_irq() 和 free_irq() 函数
a. 申请IRQ
typedef irqreturn_t (*irq_handler_t)(int irq, void *dev_id);

int request_irq(unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id)
/* 参数:
** irq:要申请的硬件中断号
** handler:中断处理函数(顶半部)
** irqflags:触发方式及工作方式
** 触发:IRQF_TRIGGER_RISING 上升沿触发
** IRQF_TRIGGER_FALLING 下降沿触发
** IRQF_TRIGGER_HIGH 高电平触发
** IRQF_TRIGGER_LOW 低电平触发
** 工作:不写:快速中断(一个设备占用,且中断例程回调过程中会屏蔽中断)
** IRQF_SHARED:共享中断
** dev_id:在共享中断时会用到(中断注销与中断注册的此参数应保持一致)
** 返回值:成功返回 - 0 失败返回 - 负值(绝对值为错误码)
*/
b. 释放IRQ
void free_irq(unsigned int irq, void *dev_id);
/* 参数参见申请IRQ */
2、屏蔽和使能中断
void disable_irq(int irq); //屏蔽中短、立即返回
void disable_irq_nosync(int irq); //屏蔽中断、等待当前中断处理结束后返回
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
void enable_irq(int irq); //使能中断
全局中断使能和屏蔽函数(或宏)
屏蔽:
#define local_irq_save(flags) ...
void local irq_disable(void );
使能:
#define local_irq_restore(flags) ...
void local_irq_enable(void);
3、底半部机制
Linux实现底半部机制的的主要方式有 Tasklet、工作队列和软中断
a. Tasklet
Tasklet使用简单,只需要定义tasklet及其处理函数并将二者关联即可,例如:
void my_tasklet_func(unsigned long); /* 定义一个处理函数 */
DECLARE_TASKLET(my_tasklet, my_tasklet_func, data);
/* 定义一个名为 my_tasklet 的 struct tasklet 并将其与 my_tasklet_func 绑定,data为传入 my_tasklet_func的参数 */
只需要在顶半部中电泳 tasklet_schedule()函数就能使系统在适当的时候进行调度运行
tasklet_schedule(struct tasklet *xxx_tasklet);
tasklet使用模版
/* 定义 tasklet 和底半部函数并关联 */
void xxx_do_tasklet(unsigned long data);
DECLARE_TASKLET(xxx_tasklet, xxx_tasklet_func, data);
/* 中断处理底半部 */
void xxx_tasklet_func()
{
/* 中断处理具体操作 */
}
/* 中断处理顶半部 */
irqreturn xxx_interrupt(int irq, void *dev_id)
{
//do something
task_schedule(&xxx_tasklet);
//do something
return IRQ_HANDLED;
}
/* 设备驱动模块 init */
int __init xxx_init(void)
{
...
/* 申请设备中断 */
result = request_irq(xxx_irq, xxx_interrupt, IRQF_DISABLED, "xxx", NULL);
...
return 0;
}
module_init(xxx_init);
/* 设备驱动模块exit */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, NULL);
}
module_exit(xxx_exit);
b. 工作队列 workqueue
工作队列与tasklet方法非常类似,使用一个结构体定义一个工作队列和一个底半部执行函数:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
struct work_struct my_wq; /* 定义一个工作队列 */
void my_wq_func(unsigned long); /*定义一个处理函数 */
通过INIT_WORK()可以初始化这个工作队列并将工作队列与处理函数绑定(一般在模块初始化中使用):
void INIT_WORK(struct work_struct *my_wq, work_func_t);
/* my_wq 工作队列地址
** work_func_t 处理函数
*/
与tasklet_schedule_work ()对应的用于调度工作队列执行的函数为schedule_work()
schedule_work(&my_wq);
工作队列使用模版
/* 定义工作队列和关联函数 */
struct work_struct xxx_wq;
void xxx_do_work(unsigned long);
/* 中断处理底半部 */
void xxx_work(unsigned long)
{
/* do something */
}
/* 中断处理顶半部 */
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
schedule_work(&xxx_wq);
...
return IRQ_HANDLED;
}
/* 设备驱动模块 init */
int __init xxx_init(void)
{
...
/* 申请设备中断 */
result = request_irq(xxx_irq, xxx_interrupt, IRQF_DISABLED, "xxx", NULL);
/* 初始化工作队列 */
INIT_WORK(&xxx_wq, xxx_do_work);
...
return 0;
}
module_init(xxx_init);
/* 设备驱动模块exit */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, NULL);
}
module_exit(xxx_exit);
c. 软中断
软中断(softirq)也是一种传统的底半部处理机制,它的执行时机通常是顶半部返回的时候,tasklet的基于软中断实现的,因此也运行于软中断上下文。
在Linux内核中,用softirq_action结构体表征一个软中断,这个结构体中包含软中断处理函数指针和传递给该函数的参数。使用open_softirq()函数可以注册软中断对应的处理函数,而raise_softirq()函数可以触发一个软中断。
struct softirq_action
{
void (*action)(struct softirq_action *);
};
void open_softirq(int nr, void (*action)(struct softirq_action *)); /* 注册软中断 */
void raise_softirq(unsigned int nr); /* 触发软中断 */
local_bh_disable() 和 local_bh_enable() 是内核中用于禁止和使能软中断和tasklet底半部机制的函数。
Tasklet作为一种新机制,显然可以承担更多的优点。正好这时候SMP越来越火了,因此又在tasklet中加入了SMP机制,保证同种中断只能在一个cpu上执行。在软中断时代,显然没有这种考虑。因此同一种中断可以在两个cpu上同时执行,很可能造成冲突。
Linux中断下半部处理有三种方式:软中断、tasklet、工作队列。
曾经有人问我为什么要分这几种,该怎么用。当时用书上的东西蒙混了过去,但是自己明白自己实际上是不懂的。最近有时间了,于是试着整理一下linux的中断处理机制,目的是起码从原理上能够说得通。
一、最简单的中断机制
最简单的中断机制就是像芯片手册上讲的那样,在中断向量表中填入跳转到对应处理函数的指令,然后在处理函数中实现需要的功能。类似下图:
这种方式在原来的单片机课程中常常用到,一些简单的单片机系统也是这样用。
它的好处很明显,简单,直接。
二、下半部
中断处理函数所作的第一件事情是什么?答案是屏蔽中断(或者是什么都不做,因为常常是如果不清除IF位,就等于屏蔽中断了),当然只屏蔽同一种中断。之所以要屏蔽中断,是因为新的中断会再次调用中断处理函数,导致原来中断处理现场的破坏。即,破坏了 interrupt context。
随着系统的不断复杂,中断处理函数要做的事情也越来越多,多到都来不及接收新的中断了。于是发生了中断丢失,这显然不行,于是产生了新的机制:分离中断接收与中断处理过程。中断接收在屏蔽中断的情况下完成;中断处理在时能中断的情况下完成,这部分被称为中断下半部。
从上图中看,只看int0的处理。Func0为中断接收函数。中断只能简单的触发func0,而func0则能做更多的事情,它与funcA之间可以使用队列等缓存机制。当又有中断发生时,func0被触发,然后发送一个中断请求到缓存队列,然后让funcA去处理。
由于func0做的事情是很简单的,所以不会影响int0的再次接收。而且在func0返回时就会使能int0,因此funcA执行时间再长也不会影响int0的接收。
三、软中断
下面看看linux中断处理。作为一个操作系统显然不能任由每个中断都各自为政,统一管理是必须的。
我们不可中断部分的共同部分放在函数do_IRQ中,需要添加中断处理函数时,通过request_irq实现。下半部放在do_softirq中,也就是软中断,通过open_softirq添加对应的处理函数。
四、tasklet
旧事物跟不上历史的发展时,总会有新事物出现。
随着中断数的不停增加,软中断不够用了,于是下半部又做了进化。
软中断用轮询的方式处理。假如正好是最后一种中断,则必须循环完所有的中断类型,才能最终执行对应的处理函数。显然当年开发人员为了保证轮询的效率,于是限制中断个数为32个。
为了提高中断处理数量,顺道改进处理效率,于是产生了tasklet机制。
Tasklet采用无差别的队列机制,有中断时才执行,免去了循环查表之苦。
总结下tasklet的优点:
(1)无类型数量限制;
(2)效率高,无需循环查表;
(3)支持SMP机制;
五、工作队列
前面的机制不论如何折腾,有一点是不会变的。它们都在中断上下文中。什么意思?说明它们不可挂起。而且由于是串行执行,因此只要有一个处理时间较长,则会导致其他中断响应的延迟。为了完成这些不可能完成的任务,于是出现了工作队列。工作队列说白了就是一组内核线程,作为中断守护线程来使用。多个中断可以放在一个线程中,也可以每个中断分配一个线程。
工作队列对线程作了封装,使用起来更方便。
因为工作队列是线程,所以我们可以使用所有可以在线程中使用的方法。
Tasklet其实也不一定是在中断上下文中执行,它也有可能在线程中执行。
假如中断数量很多,而且这些中断都是自启动型的(中断处理函数会导致新的中断产生),则有可能cpu一直在这里执行中断处理函数,会导致用户进程永远得不到调度时间。
为了避免这种情况,linux发现中断数量过多时,会把多余的中断处理放到一个单独的线程中去做,就是ksoftirqd线程。这样又保证了中断不多时的响应速度,又保证了中断过多时不会把用户进程饿死。
问题是我们不能保证我们的tasklet或软中断处理函数一定会在线程中执行,所以还是不能使用进程才能用的一些方法,如放弃调度、长延时等。
六、使用方式总结
Request_irq挂的中断函数要尽量简单,只做必须在屏蔽中断情况下要做的事情。
中断的其他部分都在下半部中完成。
软中断的使用原则很简单,永远不用。它甚至都不算是一种正是的中断处理机制,而只是tasklet的实现基础。
工作队列也要少用,如果不是必须要用到线程才能用的某些机制,就不要使用工作队列。其实对于中断来说,只是对中断进行简单的处理,大部分工作是在驱动程序中完成的。所以有什么必要非使用工作队列呢?
除了上述情况,就要使用tasklet。
即使是下半部,也只是作必须在中断中要做的事情,如保存数据等,其他都交给驱动程序去做。
linux 中断机制的处理过程
一、中断的概念
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)。
在实地址模式中,CPU把内存中从0开始的1KB空间作为一个中断向量表。表中的每一项占4个字节。但是在保护模式中,有这4个字节的表项构成的中断向量表不满足实际需求,于是根据反映模式切换的信息和偏移量的足够使得中断向量表的表项由8个字节组成,而中断向量表也叫做了中断描述符表(IDT)。在CPU中增加了一个用来描述中断描述符表寄存器(IDTR),用来保存中断描述符表的起始地址。
二、中断的请求过程
外部设备当需要操作系统做相关的事情的时候,会产生相应的中断。设备通过相应的中断线向中断控制器发送高电平以产生中断信号,而操作系统则会从中断控制器的状态位取得那根中断线上产生的中断。而且只有在设备在对某一条中断线拥有控制权,才可以向这条中断线上发送信号。也由于现在的外设越来越多,中断线又是很宝贵的资源不可能被一一对应。因此在使用中断线前,就得对相应的中断线进行申请。无论采用共享中断方式还是独占一个中断,申请过程都是先讲所有的中断线进行扫描,得出哪些没有别占用,从其中选择一个作为该设备的IRQ。其次,通过中断申请函数申请相应的IRQ。最后,根据申请结果查看中断是否能够被执行。
中断机制的核心数据结构是 irq_desc, 它完整地描述了一条中断线 (或称为 “中断通道” )。以下程序源码版本为linux-2.6.32.2。
其中irq_desc 结构在 include/linux/irq.h 中定义:
typedef void (*irq_flow_handler_t)(unsigned int irq,
struct irq_desc *desc);
struct irq_desc {
unsigned int irq;
struct timer_rand_state *timer_rand_state;
unsigned int *kstat_irqs;
#ifdef CONFIG_INTR_REMAP
struct irq_2_iommu *irq_2_iommu;
#endif
irq_flow_handler_t handle_irq; /* 高层次的中断事件处理函数 */
struct irq_chip *chip; /* 低层次的硬件操作 */
struct msi_desc *msi_desc;
void *handler_data; /* chip 方法使用的数据*/
void *chip_data; /* chip 私有数据 */
struct irqaction *action; /* 行为链表(action list) */
unsigned int status; /* 状态 */
unsigned int depth; /* 关中断次数 */
unsigned int wake_depth; /* 唤醒次数 */
unsigned int irq_count; /* 发生的中断次数 */
unsigned long last_unhandled; /*滞留时间 */
unsigned int irqs_unhandled;
spinlock_t lock; /*自选锁*/
#ifdef CONFIG_SMP
cpumask_var_t affinity;
unsigned int node;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir; /* 在 proc 文件系统中的目录 */
#endif
const char *name;/*名称*/
} ____cacheline_internodealigned_in_smp;
I、Linux中断的申请与释放:在<linux/interrupt.h>, , 实现中断申请接口:
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev);
函数参数说明
unsigned int irq:所要申请的硬件中断号
irq_handler_t handler:中断服务程序的入口地址,中断发生时,系统调用handler这个函数。irq_handler_t为自定义类型,其原型为:
typedef irqreturn_t (*irq_handler_t)(int, void *);
而irqreturn_t的原型为:typedef enum irqreturn irqreturn_t;
enum irqreturn {
IRQ_NONE,/*此设备没有产生中断*/
IRQ_HANDLED,/*中断被处理*/
IRQ_WAKE_THREAD,/*唤醒中断*/
};
在枚举类型irqreturn定义在include/linux/irqreturn.h文件中。
unsigned long flags:中断处理的属性,与中断管理有关的位掩码选项,有一下几组值:
#define IRQF_DISABLED 0x00000020 /*中断禁止*/
#define IRQF_SAMPLE_RANDOM 0x00000040 /*供系统产生随机数使用*/
#define IRQF_SHARED 0x00000080 /*在设备之间可共享*/
#define IRQF_PROBE_SHARED 0x00000100/*探测共享中断*/
#define IRQF_TIMER 0x00000200/*专用于时钟中断*/
#define IRQF_PERCPU 0x00000400/*每CPU周期执行中断*/
#define IRQF_NOBALANCING 0x00000800/*复位中断*/
#define IRQF_IRQPOLL 0x00001000/*共享中断中根据注册时间判断*/
#define IRQF_ONESHOT 0x00002000/*硬件中断处理完后触发*/
#define IRQF_TRIGGER_NONE 0x00000000/*无触发中断*/
#define IRQF_TRIGGER_RISING 0x00000001/*指定中断触发类型:上升沿有效*/
#define IRQF_TRIGGER_FALLING 0x00000002/*中断触发类型:下降沿有效*/
#define IRQF_TRIGGER_HIGH 0x00000004/*指定中断触发类型:高电平有效*/
#define IRQF_TRIGGER_LOW 0x00000008/*指定中断触发类型:低电平有效*/
#define IRQF_TRIGGER_MASK (IRQF_TRIGGER_HIGH | IRQF_TRIGGER_LOW | /
IRQF_TRIGGER_RISING | IRQF_TRIGGER_FALLING)
#define IRQF_TRIGGER_PROBE 0x00000010/*触发式检测中断*/
const char *dev_name:设备描述,表示那一个设备在使用这个中断。
void *dev_id:用作共享中断线的指针.。一般设置为这个设备的设备结构体或者NULL。它是一个独特的标识, 用在当释放中断线时以及可能还被驱动用来指向它自己的私有数据区,来标识哪个设备在中断 。这个参数在真正的驱动程序中一般是指向设备数据结构的指针.在调用中断处理程序的时候它就会传递给中断处理程序的void *dev_id。如果中断没有被共享, dev_id 可以设置为 NULL。
II、释放IRQ
void free_irq(unsigned int irq, void *dev_id);
III、中断线共享的数据结构
struct irqaction {
irq_handler_t handler; /* 具体的中断处理程序 */
unsigned long flags;/*中断处理属性*/
const char *name; /* 名称,会显示在/proc/interreupts 中 */
void *dev_id; /* 设备ID,用于区分共享一条中断线的多个处理程序 */
struct irqaction *next; /* 指向下一个irq_action 结构 */
int irq; /* 中断通道号 */
struct proc_dir_entry *dir; /* 指向proc/irq/NN/name 的入口*/
irq_handler_t thread_fn;/*线程中断处理函数*/
struct task_struct *thread;/*线程中断指针*/
unsigned long thread_flags;/*与线程有关的中断标记属性*/
};
thread_flags参见枚举型
enum {
IRQTF_RUNTHREAD,/*线程中断处理*/
IRQTF_DIED,/*线程中断死亡*/
IRQTF_WARNED,/*警告信息*/
IRQTF_AFFINITY,/*调整线程中断的关系*/
};
多个中断处理程序可以共享同一条中断线,irqaction 结构中的 next 成员用来把共享同一条中断线的所有中断处理程序组成一个单向链表,dev_id 成员用于区分各个中断处理程序。
根据以上内容可以得出中断机制各个数据结构之间的联系如下图所示:
三.中断的处理过程
Linux中断分为两个半部:上半部(tophalf)和下半部(bottom half)。上半部的功能是"登记中断",当一个中断发生时,它进行相应地硬件读写后就把中断例程的下半部挂到该设备的下半部执行队列中去。因此,上半部执行的速度就会很快,可以服务更多的中断请求。但是,仅有"登记中断"是远远不够的,因为中断的事件可能很复杂。因此,Linux引入了一个下半部,来完成中断事件的绝大多数使命。下半部和上半部最大的不同是下半部是可中断的,而上半部是不可中断的,下半部几乎做了中断处理程序所有的事情,而且可以被新的中断打断!下半部则相对来说并不是非常紧急的,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。
中断号的查看可以使用下面的命令:“cat /proc/interrupts”。
Linux实现下半部的机制主要有tasklet和工作队列。
小任务tasklet的实现
其数据结构为struct tasklet_struct,每一个结构体代表一个独立的小任务,定义如下
struct tasklet_struct
{
struct tasklet_struct *next;/*指向下一个链表结构*/
unsigned long state;/*小任务状态*/
atomic_t count;/*引用计数器*/
void (*func)(unsigned long);/*小任务的处理函数*/
unsigned long data;/*传递小任务函数的参数*/
};
state的取值参照下边的枚举型:
enum
{
TASKLET_STATE_SCHED, /* 小任务已被调用执行*/
TASKLET_STATE_RUN /*仅在多处理器上使用*/
};
count域是小任务的引用计数器。只有当它的值为0的时候才能被激活,并其被设置为挂起状态时,才能够被执行,否则为禁止状态。
I、声明和使用小任务tasklet
静态的创建一个小任务的宏有一下两个:
#define DECLARE_TASKLET(name, func, data) /
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) /
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
这两个宏的区别在于计数器设置的初始值不同,前者可以看出为0,后者为1。为0的表示激活状态,为1的表示禁止状态。其中ATOMIC_INIT宏为:
#define ATOMIC_INIT(i) { (i) }
即可看出就是设置的数字。此宏在include/asm-generic/atomic.h中定义。这样就创建了一个名为name的小任务,其处理函数为func。当该函数被调用的时候,data参数就被传递给它。
II、小任务处理函数程序
处理函数的的形式为:void my_tasklet_func(unsigned long data)。这样DECLARE_TASKLET(my_tasklet, my_tasklet_func, data)实现了小任务名和处理函数的绑定,而data就是函数参数。
III、调度编写的tasklet
调度小任务时引用tasklet_schedule(&my_tasklet)函数就能使系统在合适的时候进行调度。函数原型为:
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
这个调度函数放在中断处理的上半部处理函数中,这样中断申请的时候调用处理函数(即irq_handler_t handler)后,转去执行下半部的小任务。
如果希望使用DECLARE_TASKLET_DISABLED(name,function,data)创建小任务,那么在激活的时候也得调用相应的函数被使能
tasklet_enable(struct tasklet_struct *); //使能tasklet
tasklet_disble(struct tasklet_struct *); //禁用tasklet
tasklet_init(struct tasklet_struct *,void (*func)(unsigned long),unsigned long);
当然也可以调用tasklet_kill(struct tasklet_struct *)从挂起队列中删除一个小任务。清除指定tasklet的可调度位,即不允许调度该tasklet 。
使用tasklet作为下半部的处理中断的设备驱动程序模板如下:
/*定义tasklet和下半部函数并关联*/
void my_do_tasklet(unsigned long);
DECLARE_TASKLET(my_tasklet, my_tasklet_func, 0);
/*中断处理下半部*/
void my_do_tasklet(unsigned long)
{
……/*编写自己的处理事件内容*/
}
/*中断处理上半部*/
irpreturn_t my_interrupt(unsigned int irq,void *dev_id)
{
……
tasklet_schedule(&my_tasklet)/*调度my_tasklet函数,根据声明将去执行my_tasklet_func函数*/
……
}
/*设备驱动的加载函数*/
int __init xxx_init(void)
{
……
/*申请中断, 转去执行my_interrupt函数并传入参数*/
result=request_irq(my_irq,my_interrupt,IRQF_DISABLED,"xxx",NULL);
……
}
/*设备驱动模块的卸载函数*/
void __exit xxx_exit(void)
{
……
/*释放中断*/
free_irq(my_irq,my_interrupt);
……
}
工作队列的实现
工作队列work_struct结构体,位于/include/linux/workqueue.h
typedef void (*work_func_t)(struct work_struct *work);
struct work_struct {
atomic_long_t data; /*传递给处理函数的参数*/
#define WORK_STRUCT_PENDING 0/*这个工作是否正在等待处理标志*/
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; /* 连接所有工作的链表*/
work_func_t func; /* 要执行的函数*/
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
这些结构被连接成链表。当一个工作者线程被唤醒时,它会执行它的链表上的所有工作。工作被执行完毕,它就将相应的work_struct对象从链表上移去。当链表上不再有对象的时候,它就会继续休眠。可以通过DECLARE_WORK在编译时静态地创建该结构,以完成推后的工作。
#define DECLARE_WORK(n, f) /
struct work_struct n = __WORK_INITIALIZER(n, f)
而后边这个宏为一下内容:
#define __WORK_INITIALIZER(n, f) { /
.data = WORK_DATA_INIT(), /
.entry = { &(n).entry, &(n).entry }, /
.func = (f), /
__WORK_INIT_LOCKDEP_MAP(#n, &(n)) /
}
其为参数data赋值的宏定义为:
#define WORK_DATA_INIT() ATOMIC_LONG_INIT(0)
这样就会静态地创建一个名为n,待执行函数为f,参数为data的work_struct结构。同样,也可以在运行时通过指针创建一个工作:
INIT_WORK(struct work_struct *work, void(*func) (void *));
这会动态地初始化一个由work指向的工作队列,并将其与处理函数绑定。宏原型为:
#define INIT_WORK(_work, _func) /
do { /
static struct lock_class_key __key; /
/
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); /
lockdep_init_map(&(_work)->lockdep_map, #_work, &__key, 0);/
INIT_LIST_HEAD(&(_work)->entry); /
PREPARE_WORK((_work), (_func)); /
} while (0)
在需要调度的时候引用类似tasklet_schedule()函数的相应调度工作队列执行的函数schedule_work(),如:
schedule_work(&work);/*调度工作队列执行*/
如果有时候并不希望工作马上就被执行,而是希望它经过一段延迟以后再执行。在这种情况下,可以调度指定的时间后执行函数:
schedule_delayed_work(&work,delay);函数原型为:
int schedule_delayed_work(struct delayed_work *work, unsigned long delay);
其中是以delayed_work为结构体的指针,而这个结构体的定义是在work_struct结构体的基础上增加了一项timer_list结构体。
struct delayed_work {
struct work_struct work;
struct timer_list timer; /* 延迟的工作队列所用到的定时器,当不需要延迟时初始化为NULL*/
};
这样,便使预设的工作队列直到delay指定的时钟节拍用完以后才会执行。
使用工作队列处理中断下半部的设备驱动程序模板如下:
/*定义工作队列和下半部函数并关联*/
struct work_struct my_wq;
void my_do_work(unsigned long);
/*中断处理下半部*/
void my_do_work(unsigned long)
{
……/*编写自己的处理事件内容*/
}
/*中断处理上半部*/
irpreturn_t my_interrupt(unsigned int irq,void *dev_id)
{
……
schedule_work(&my_wq)/*调度my_wq函数,根据工作队列初始化函数将去执行my_do_work函数*/
……
}
/*设备驱动的加载函数*/
int __init xxx_init(void)
{
……
/*申请中断,转去执行my_interrupt函数并传入参数*/
result=request_irq(my_irq,my_interrupt,IRQF_DISABLED,"xxx",NULL);
……
/*初始化工作队列函数,并与自定义处理函数关联*/
INIT_WORK(&my_irq,(void (*)(void *))my_do_work);
……
}
/*设备驱动模块的卸载函数*/
void __exit xxx_exit(void)
{
……
/*释放中断*/
free_irq(my_irq,my_interrupt);
……
}
深入剖析Linux中断机制之三---Linux对异常和中断的处理
【摘要】本文详解了Linux内核的中断实现机制。首先介绍了中断的一些基本概念,然后分析了面向对象的Linux中断的组织形式、三种主要数据结构及其之间的关系。随后介绍了Linux处理异常和中断的基本流程,在此基础上分析了中断处理的详细流程,包括保存现场、中断处理、中断退出时的软中断执行及中断返回时的进程切换等问题。最后介绍了中断相关的API,包括中断注册和释放、中断关闭和使能、如何编写中断ISR、共享中断、中断上下文中断状态等。
【关键字】中断,异常,hw_interrupt_type,irq_desc_t,irqaction,asm_do_IRQ,软中断,进程切换,中断注册释放request_irq,free_irq,共享中断,可重入,中断上下文
1 Linux对异常和中断的处理
1.1 异常处理
Linux利用异常来达到两个截然不同的目的:
² 给进程发送一个信号以通报一个反常情况
² 管理硬件资源
对于第一种情况,例如,如果进程执行了一个被0除的操作,CPU则会产生一个“除法错误”异常,并由相应的异常处理程序向当前进程发送一个SIGFPE信号。当前进程接收到这个信号后,就要采取若干必要的步骤,或者从错误中恢复,或者终止执行(如果这个信号没有相应的信号处理程序)。
内核对异常处理程序的调用有一个标准的结构,它由以下三部分组成:
² 在内核栈中保存大多数寄存器的内容(由汇编语言实现)
² 调用C编写的异常处理函数
² 通过ret_from_exception()函数从异常退出。
1.2 中断处理
当一个中断发生时,并不是所有的操作都具有相同的急迫性。事实上,把所有的操作都放进中断处理程序本身并不合适。需要时间长的、非重要的操作应该推后,因为当一个中断处理程序正在运行时,相应的IRQ中断线上再发出的信号就会被忽略。另外中断处理程序不能执行任何阻塞过程,如I/O设备操作。因此,Linux把一个中断要执行的操作分为下面的三类:
² 紧急的(Critical)
这样的操作诸如:中断到来时中断控制器做出应答,对中断控制器或设备控制器重新编程,或者对设备和处理器同时访问的数据结构进行修改。这些操作都是紧急的,应该被很快地执行,也就是说,紧急操作应该在一个中断处理程序内立即执行,而且是在禁用中断的状态下。
² 非紧急的(Noncritical)
这样的操作如修改那些只有处理器才会访问的数据结构(例如,按下一个键后,读扫描码)。这些操作也要很快地完成,因此,它们由中断处理程序立即执行,但在启用中断的状态下。
² 非紧急可延迟的(Noncritical deferrable)
这样的操作如,把一个缓冲区的内容拷贝到一些进程的地址空间(例如,把键盘行缓冲区的内容发送到终端处理程序的进程)。这些操作可能被延迟较长的时间间隔而不影响内核操作,有兴趣的进程会等待需要的数据。
所有的中断处理程序都执行四个基本的操作:
² 在内核栈中保存IRQ的值和寄存器的内容。
² 给与IRQ中断线相连的中断控制器发送一个应答,这将允许在这条中断线上进一步发出中断请求。
² 执行共享这个IRQ的所有设备的中断服务例程(ISR)。
² 跳到ret_to_usr( )的地址后终止。
1.3 中断处理程序的执行流程
1.3.1 流程概述
现在,我们可以从中断请求的发生到CPU的响应,再到中断处理程序的调用和返回,沿着这一思路走一遍,以体会Linux内核对中断的响应及处理。
假定外设的驱动程序都已完成了初始化工作,并且已把相应的中断服务例程挂入到特定的中断请求队列。又假定当前进程正在用户空间运行(随时可以接受中断),且外设已产生了一次中断请求,CPU就在执行完当前指令后来响应该中断。
中断处理系统在Linux中的实现是非常依赖于体系结构的,实现依赖于处理器、所使用的中断控制器的类型、体系结构的设计及机器本身。
设备产生中断,通过总线把电信号发送给中断控制器。如果中断线是激活的,那么中断控制器就会把中断发往处理器。在大多数体系结构中,这个工作就是通过电信号给处理器的特定管脚发送一个信号。除非在处理器上禁止该中断,否则,处理器会立即停止它正在做的事,关闭中断系统,然后跳到内存中预定义的位置开始执行那里的代码。这个预定义的位置是由内核设置的,是中断处理程序的入口点。
对于ARM系统来说,有个专用的IRQ运行模式,有一个统一的入口地址。假定中断发生时CPU运行在用户空间,而中断处理程序属于内核空间,因此,要进行堆栈的切换。也就是说,CPU从TSS中取出内核栈指针,并切换到内核栈(此时栈还为空)。
若当前处于内核空间时,对于ARM系统来说是处于SVC模式,此时产生中断,中断处理完毕后,若是可剥夺内核,则检查是否需要进行进程调度,否则直接返回到被中断的内核空间;若需要进行进程调度,则svc_preempt,进程切换。
190 .align 5
191__irq_svc:
192 svc_entry
197#ifdef CONFIG_PREEMPT
198 get_thread_info tsk
199 ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
200 add r7, r8, #1 @ increment it
201 str r7, [tsk, #TI_PREEMPT]
202#endif
204 irq_handler
205#ifdef CONFIG_PREEMPT
206 ldr r0, [tsk, #TI_FLAGS] @ get flags
207 tst r0, #_TIF_NEED_RESCHED
208 blne svc_preempt
209preempt_return:
210 ldr r0, [tsk, #TI_PREEMPT] @ read preempt value
211 str r8, [tsk, #TI_PREEMPT] @ restore preempt count
212 teq r0, r7
213 strne r0, [r0, -r0] @ bug()
214#endif
215 ldr r0, [sp, #S_PSR] @ irqs are already disabled
216 msr spsr_cxsf, r0
221 ldmia sp, {r0 - pc}^ @ load r0 - pc, cpsr
223 .ltorg
当前处于用户空间时,对于ARM系统来说是处于USR模式,此时产生中断,中断处理完毕后,无论是否是可剥夺内核,都调转到统一的用户模式出口ret_to_user,其检查是否需要进行进程调度,若需要进行进程调度,则进程切换,否则直接返回到被中断的用户空间。
404 .align 5
405__irq_usr:
406 usr_entry
411 get_thread_info tsk
412#ifdef CONFIG_PREEMPT
413 ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
414 add r7, r8, #1 @ increment it
415 str r7, [tsk, #TI_PREEMPT]
416#endif
418 irq_handler
419#ifdef CONFIG_PREEMPT
420 ldr r0, [tsk, #TI_PREEMPT]
421 str r8, [tsk, #TI_PREEMPT]
422 teq r0, r7
423 strne r0, [r0, -r0] @ bug()
424#endif
429 mov why, #0
430 b ret_to_user
432 .ltorg
1.3.2 保存现场
105/*
106 * SVC mode handlers
107 */
115 .macro svc_entry
116 sub sp, sp, #S_FRAME_SIZE
117 SPFIX( tst sp, #4 )
118 SPFIX( bicne sp, sp, #4 )
119 stmib sp, {r1 - r12}
121 ldmia r0, {r1 - r3}
122 add r5, sp, #S_SP @ here for interlock avoidance
123 mov r4, #-1 @ "" "" "" ""
124 add r0, sp, #S_FRAME_SIZE @ "" "" "" ""
125 SPFIX( addne r0, r0, #4 )
126 str r1, [sp] @ save the "real" r0 copied
127 @ from the exception stack
129 mov r1, lr
131 @
132 @ We are now ready to fill in the remaining blanks on the stack:
133 @
134 @ r0 - sp_svc
135 @ r1 - lr_svc
136 @ r2 - lr_<exception>, already fixed up for correct return/restart
137 @ r3 - spsr_<exception>
138 @ r4 - orig_r0 (see pt_regs definition in ptrace.h)
139 @
140 stmia r5, {r0 - r4}
141 .endm
1.3.3 中断处理
因为C的调用惯例是要把函数参数放在栈的顶部,因此pt- regs结构包含原始寄存器的值,这些值是以前在汇编入口例程svc_entry中保存在栈中的。
linux+v2.6.19/include/asm-arm/arch-at91rm9200/entry-macro.S
18 .macro get_irqnr_and_base, irqnr, irqstat, base, tmp
19 ldr /base, =(AT91_VA_BASE_SYS) @ base virtual address of SYS peripherals
20 ldr /irqnr, [/base, #AT91_AIC_IVR] @ read IRQ vector register: de-asserts nIRQ to processor (and clears interrupt)
21 ldr /irqstat, [/base, #AT91_AIC_ISR] @ read interrupt source number
22 teq /irqstat, #0 @ ISR is 0 when no current interrupt, or spurious interrupt
23 streq /tmp, [/base, #AT91_AIC_EOICR] @ not going to be handled further, then ACK it now.
24 .endm
26/*
27 * Interrupt handling. Preserves r7, r8, r9
28 */
29 .macro irq_handler
301: get_irqnr_and_base r0, r6, r5, lr
31 movne r1, sp
32 @
33 @ routine called with r0 = irq number, r1 = struct pt_regs *
34 @
35 adrne lr, 1b
36 bne asm_do_IRQ
58 .endm
中断号的值也在irq_handler初期得以保存,所以,asm_do_IRQ可以将它提取出来。这个中断处理程序实际上要调用do_IRQ(),而do_IRQ()要调用handle_IRQ_event()函数,最后这个函数才真正地执行中断服务例程(ISR)。下图给出它们的调用关系:
|
|
|
|
|
|
|
|
|
|
中断处理函数的调用关系
1.3.3.1 asm_do_IRQ
112asmlinkage void asm_do_IRQ(unsigned int irq, struct pt_regs *regs)
113{
114 struct pt_regs *old_regs = set_irq_regs(regs);
115 struct irqdesc *desc = irq_desc + irq;
122 desc = &bad_irq_desc;
124 irq_enter(); //记录硬件中断状态,便于跟踪中断情况确定是否是中断上下文
126 desc_handle_irq(irq, desc);
///////////////////desc_handle_irq
33static inline void desc_handle_irq(unsigned int irq, struct irq_desc *desc)
34{
35 desc->handle_irq(irq, desc); //通常handle_irq指向__do_IRQ
36}
///////////////////desc_handle_irq
131 irq_exit(); //中断退出前执行可能的软中断,被中断前是在中断上下文中则直接退出,这保证了软中断不会嵌套
133}
1.3.3.2 __do_IRQ
157 * __do_IRQ - original all in one highlevel IRQ handler
167fastcall unsigned int __do_IRQ(unsigned int irq)
168{
169 struct irq_desc *desc = irq_desc + irq;
173 kstat_this_cpu.irqs[irq]++;
188 if (desc->chip->ack) //首先响应中断,通常实现为关闭本中断线
194 status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
195 status |= IRQ_PENDING; /* we _want_ to handle it */
202 if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
204 status &= ~IRQ_PENDING; /* we commit to handling */
205 status |= IRQ_INPROGRESS; /* we are handling it */
206 }
218 /*
219 * Edge triggered interrupts need to remember
220 * pending events.
227 */
228 for (;;) {
231 spin_unlock(&desc->lock);//解锁,中断处理期间可以响应其他中断,否则再次进入__do_IRQ时会死锁
233 action_ret = handle_IRQ_event(irq, action);
238 if (likely(!(desc->status & IRQ_PENDING)))
239 break;
240 desc->status &= ~IRQ_PENDING;
241 }
242 desc->status &= ~IRQ_INPROGRESS;
250 spin_unlock(&desc->lock);
252 return 1;
253}
该函数的实现用到中断线的状态,下面给予具体说明:
#define IRQ_INPROGRESS 1 /* 正在执行这个IRQ的一个处理程序*/
#define IRQ_DISABLED 2 /* 由设备驱动程序已经禁用了这条IRQ中断线 */
#define IRQ_PENDING 4 /* 一个IRQ已经出现在中断线上,且被应答,但还没有为它提供服务 */
#define IRQ_REPLAY 8 /* 当Linux重新发送一个已被删除的IRQ时 */
#define IRQ_WAITING 32 /*当对硬件设备进行探测时,设置这个状态以标记正在被测试的irq */
#define IRQ_LEVEL 64 /* IRQ level triggered */
#define IRQ_MASKED 128 /* IRQ masked - shouldn't be seen again */
#define IRQ_PER_CPU 256 /* IRQ is per CPU */
这8个状态的前5个状态比较常用,因此我们给出了具体解释。
经验表明,应该避免在同一条中断线上的中断嵌套,内核通过IRQ_PENDING标志位的应用保证了这一点。当do_IRQ()执行到for (;;)循环时,desc->status 中的IRQ_PENDING的标志位肯定为0。当CPU执行完handle_IRQ_event()函数返回时,如果这个标志位仍然为0,那么循环就此结束。如果这个标志位变为1,那就说明这条中断线上又有中断产生(对单CPU而言),所以循环又执行一次。通过这种循环方式,就把可能发生在同一中断线上的嵌套循环化解为“串行”。
在循环结束后调用desc->handler->end()函数,具体来说,如果没有设置IRQ_DISABLED标志位,就启用这条中断线。
1.3.3.3 handle_IRQ_event
当执行到for (;;)这个无限循环时,就准备对中断请求队列进行处理,这是由handle_IRQ_event()函数完成的。因为中断请求队列为一临界资源,因此在进入这个函数前要加锁。
handle_IRQ_event执行所有的irqaction链表:
130irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction *action)
131{
132 irqreturn_t ret, retval = IRQ_NONE;
135 handle_dynamic_tick(action);
136 // 如果没有设置IRQF_DISABLED,则中断处理过程中,打开中断
137 if (!(action->flags & IRQF_DISABLED))
138 local_irq_enable_in_hardirq();
140 do {
141 ret = action->handler(irq, action->dev_id);
142 if (ret == IRQ_HANDLED)
153}
这个循环依次调用请求队列中的每个中断服务例程。这里要说明的是,如果设置了IRQF_DISABLED,则中断服务例程在关中断的条件下进行(不包括非屏蔽中断),但通常CPU在穿过中断门时自动关闭中断。但是,关中断时间绝不能太长,否则就可能丢失其它重要的中断。也就是说,中断服务例程应该处理最紧急的事情,而把剩下的事情交给另外一部分来处理。即后半部分(bottom half)来处理,这一部分内容将在下一节进行讨论。
不同的CPU不允许并发地进入同一中断服务例程,否则,那就要求所有的中断服务例程必须是“可重入”的纯代码。可重入代码的设计和实现就复杂多了,因此,Linux在设计内核时巧妙地“避难就易”,以解决问题为主要目标。
1.3.3.4 irq_exit()
中断退出前执行可能的软中断,被中断前是在中断上下文中则直接退出,这保证了软中断不会嵌套
////////////////////////////////////////////////////////////
linux+v2.6.19/kernel/softirq.c
286{
287 account_system_vtime(current);
289 sub_preempt_count(IRQ_EXIT_OFFSET);
290 if (!in_interrupt() && local_softirq_pending())
////////////
276#ifdef __ARCH_IRQ_EXIT_IRQS_DISABLED
277# defineinvoke_softirq() __do_softirq()
278#else
279# defineinvoke_softirq() do_softirq()
280#endif
////////////
292 preempt_enable_no_resched();
293}
////////////////////////////////////////////////////////////
1.3.4 从中断返回
asm_do_IRQ()这个函数处理所有外设的中断请求后就要返回。返回情况取决于中断前程序是内核态还是用户态以及是否是可剥夺内核。
² 内核态可剥夺内核,只有在preempt_count为0时,schedule()才会被调用,其检查是否需要进行进程切换,需要的话就切换。在schedule()返回之后,或者如果没有挂起的工作,那么原来的寄存器被恢复,内核恢复到被中断的内核代码。
² 内核态不可剥夺内核,则直接返回至被中断的内核代码。
² 中断前处于用户态时,无论是否是可剥夺内核,统一跳转到ret_to_user。
虽然我们这里讨论的是中断的返回,但实际上中断、异常及系统调用的返回是放在一起实现的,因此,我们常常以函数的形式提到下面这三个入口点:
ret_to_user()
终止中断处理程序
ret_slow_syscall ( ) 或者ret_fast_syscall
终止系统调用,即由0x80引起的异常
ret_from_exception( )
终止除了0x80的所有异常
565/*
566 * This is the return code to user mode for abort handlers
567 */
568ENTRY(ret_from_exception)
569 get_thread_info tsk
570 mov why, #0
571 b ret_to_user
57ENTRY(ret_to_user)
58ret_slow_syscall:
由上可知,中断和异常需要返回用户空间时以及系统调用完毕后都需要经过统一的出口ret_slow_syscall,以此决定是否进行进程调度切换等。
linux+v2.6.19/arch/arm/kernel/entry-common.S
16 .align 5
17/*
18 * This is the fast syscall return path. We do as little as
19 * possible here, and this includes saving r0 back into the SVC
20 * stack.
21 */
22ret_fast_syscall:
23 disable_irq @ disable interrupts
24 ldr r1, [tsk, #TI_FLAGS]
25 tst r1, #_TIF_WORK_MASK
26 bne fast_work_pending
28 @ fast_restore_user_regs
29 ldr r1, [sp, #S_OFF + S_PSR] @ get calling cpsr
30 ldr lr, [sp, #S_OFF + S_PC]! @ get pc
31 msr spsr_cxsf, r1 @ save in spsr_svc
32 ldmdb sp, {r1 - lr}^ @ get calling r1 - lr
33 mov r0, r0
34 add sp, sp, #S_FRAME_SIZE - S_PC
35 movs pc, lr @ return & move spsr_svc into cpsr
37/*
38 * Ok, we need to do extra processing, enter the slow path.
39 */
40fast_work_pending:
41 str r0, [sp, #S_R0+S_OFF]! @ returned r0
42work_pending:
43 tst r1, #_TIF_NEED_RESCHED
44 bne work_resched
45 tst r1, #_TIF_NOTIFY_RESUME | _TIF_SIGPENDING
46 beq no_work_pending
47 mov r0, sp @ 'regs'
48 mov r2, why @ 'syscall'
49 bl do_notify_resume
50 b ret_slow_syscall @ Check work again
52work_resched:
53 bl schedule
54/*
55 * "slow" syscall return path. "why" tells us if this was a real syscall.
56 */
57ENTRY(ret_to_user)
58ret_slow_syscall:
59 disable_irq @ disable interrupts
60 ldr r1, [tsk, #TI_FLAGS]
61 tst r1, #_TIF_WORK_MASK
62 bne work_pending
63no_work_pending:
64 @ slow_restore_user_regs
65 ldr r1, [sp, #S_PSR] @ get calling cpsr
66 ldr lr, [sp, #S_PC]! @ get pc
67 msr spsr_cxsf, r1 @ save in spsr_svc
68 ldmdb sp, {r0 - lr}^ @ get calling r1 - lr
69 mov r0, r0
70 add sp, sp, #S_FRAME_SIZE - S_PC
71 movs pc, lr @ return & move spsr_svc into cpsr
进入ret_slow_syscall后,首先关中断,也就是说,执行这段代码时CPU不接受任何中断请求。然后,看调度标志是否为非0(tst r1, #_TIF_NEED_RESCHED),如果调度标志为非0,说明需要进行调度,则去调用schedule()函数进行进程调度。
【嵌入式Linux学习七步曲之第五篇 Linux内核及驱动编程】中断服务下半部之工作队列详解
【摘要】本文详解了中断服务下半部之工作队列实现机制。介绍了工作队列的特点、其与tasklet和softirq的区别以及其使用场合。接着分析了工作队列的三种数据结构的组织形式,在此基础之上分析了工作队列执行流程。最后介绍了工作队列相关的API,如何编写自己的工作队列处理程序及定义一个work对象并向内核提交等待调度运行。
【关键字】中断下半部,工作队列,workqueue_struct,work_struct,DECLARE_WORK,schedule_work,schedule_delayed_work ,flush_workqueue,create_workqueue,destroy_workqueue
1 工作队列概述
工作队列(work queue)是另外一种将工作推后执行的形式,它和我们前面讨论的所有其他形式都不相同。工作队列可以把工作推后,交由一个内核线程去执行—这个下半部分总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。最重要特点的就是工作队列允许重新调度甚至是睡眠。
通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则:
² 如果推后执行的任务需要睡眠,那么只能选择工作队列;
² 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时;
² 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程;
² 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
另外如果你需要用一个可以重新调度的实体来执行你的下半部处理,你应该使用工作队列。它是惟一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。这意味着在你需要获得大量的内存时、在你需要获取信号量时,在你需要执行阻塞式的I/O操作时,它都会非常有用。
实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
2 工作队列的实现
2.1 工作者线程
工作队列子系统是一个用于创建内核线程的接口,通过它创建的进程负责执行由内核其他部分排到队列里的任务。它创建的这些内核线程被称作工作者线程(worker thread)。工作队列可以让你的驱动程序创建一个专门的工作者线程来处理需要推后的工作。不过,工作队列子系统提供了一个默认的工作者线程来处理这些工作。因此,工作队列最基本的表现形式就转变成了一个把需要推后执行的任务交给特定的通用线程这样一种接口。
默认的工作者线程叫做events/n,这里n是处理器的编号,每个处理器对应一个线程。比如,单处理器的系统只有events/0这样一个线程。而双处理器的系统就会多一个events/1线程。
默认的工作者线程会从多个地方得到被推后的工作。许多内核驱动程序都把它们的下半部交给默认的工作者线程去做。除非一个驱动程序或者子系统必须建立一个属于它自己的内核线程,否则最好使用默认线程。不过并不存在什么东西能够阻止代码创建属于自己的工作者线程。如果你需要在工作者线程中执行大量的处理操作,这样做或许会带来好处。处理器密集型和性能要求严格的任务会因为拥有自己的工作者线程而获得好处。
2.2 工作队列的组织结构
2.2.1 工作队列workqueue_struct
外部可见的工作队列抽象,用户接口,是由每个CPU的工作队列组成的链表
64struct workqueue_struct {
65 struct cpu_workqueue_struct *cpu_wq;
67 struct list_head list; /* Empty if single thread */
68};
² cpu_wq:本队列包含的工作者线程;
² name:所有本队列包含的线程的公共名称部分,创建工作队列时的唯一用户标识;
² list:链接本队列的各个工作线程。
在早期的版本中,cpu_wq是用数组维护的,即对每个工作队列,每个CPU包含一个此线程。改成链表的优势在于,创建工作队列的时候可以指定只创建一个内核线程,这样消耗的资源较少。
在该结构体里面,给每个线程分配一个cpu_workqueue_struct,因而也就是给每个处理器分配一个,因为每个处理器都有一个该类型的工作者线程。
2.2.2 工作者线程cpu_workqueue_struct
这个结构是针对每个CPU的,属于内核维护的结构,用户不可见。
43struct cpu_workqueue_struct {
47 long remove_sequence; /* Least-recently added (next to run) */
48 long insert_sequence; /* Next to add */
51 wait_queue_head_t more_work;
52 wait_queue_head_t work_done;
54 struct workqueue_struct *wq;
55 struct task_struct *thread;
57 int run_depth; /* Detect run_workqueue() recursion depth */
² lock:操作该数据结构的互斥锁
² remove_sequence:下一个要执行的工作序号,用于flush
² insert_sequence:下一个要插入工作的序号
² worklist:待处理的工作的链表头
² more_work:标识有工作待处理的等待队列,插入新工作后唤醒对应的内核线程
² work_done:处理完的等待队列,没完成一个工作后,唤醒可能等待通知处理完成通知的线程
² wq:所属的工作队列节点
² thread:关联的内核线程指针
² run_depth:run_workqueue()循环深度,多处可能调用此函数
所有的工作者线程都是用普通的内核线程实现的,它们都要执行worker thread()函数。在它初始化完以后,这个函数执行一个死循环并开始休眠。当有操作被插入到队列里的时候,线程就会被唤醒,以便执行这些操作。当没有剩余的操作时,它又会继续休眠。
2.2.3 工作work_struct
工作用work_struct结构体表示:
linux+v2.6.19/include/linux/workqueue.h
14struct work_struct {
20 struct timer_list timer;
21};
² Pending:这个工作是否正在等待处理标志,加入到工作队列后置此标志
² Entry:该工作在链表中的入口点,连接所有工作
² Func:该工作执行的回调函数
² Data:传递给处理函数的参数
² wq_data:本工作所挂接的cpu_workqueue_struct;若需要使用定时器,则其为工作队列传递给timer
² timer:延迟的工作队列所用到的定时器,无需延迟是初始化为NULL
2.2.4 三者的关系
位于最高一层的是工作队列。系统允许有多种类型的工作队列存在。每一个工作队列具备一个workqueue_struct,而SMP机器上每个CPU都具备一个该类的工作者线程cpu_workqueue_struct,系统通过CPU号和workqueue_struct 的链表指针及第一个成员cpu_wq可以得到每个CPU的cpu_workqueue_struct结构。
而每个工作提交时,将链接在当前CPU的cpu_workqueue_struct结构的worklist链表中。通常情况下由当前所注册的CPU执行此工作,但在flush_work中可能由其他CPU来执行。或者CPU热插拔后也将进行工作的转移。
内核中有些部分可以根据需要来创建工作队列。而在默认情况下内核只有events这一种类型的工作队列。大部分驱动程序都使用的是现存的默认工作者线程。它们使用起来简单、方便。可是,在有些要求更严格的情况下,驱动程序需要自己的工作者线程。
2.3 工作队列执行的细节
工作结构体被连接成链表,对于某个工作队列,在每个处理器上都存在这样一个链表。当一个工作者线程被唤醒时,它会执行它的链表上的所有工作。工作被执行完毕,它就将相应的work_struct对象从链表上移去。当链表上不再有对象的时候,它就会继续休眠。
此为工作者线程的标准模板,所以工作者线程都使用此函数。对于用户自定义的内核线程可以参考此函数。
233static int worker_thread(void *__cwq)
234{
235 struct cpu_workqueue_struct *cwq = __cwq;
// 与该工作者线程关联的cpu_workqueue_struct结构
236 DECLARE_WAITQUEUE(wait, current);
// 声明一个等待节点,若无工作,则睡眠
237 struct k_sigaction sa;
240 current->flags |= PF_NOFREEZE;
242 set_user_nice(current, -5);
// 设定较低的进程优先级, 工作进程不是个很紧急的进程,不和其他进程抢占CPU,通常在系统空闲时运行
244 /* 禁止并清除所有信号 */
245 sigfillset(&blocked);
246 sigprocmask(SIG_BLOCK, &blocked, NULL);
255 /* SIG_IGN makes children autoreap: see do_notify_parent(). */
// 允许SIGCHLD信号,并设置处理函数
256 sa.sa.sa_handler = SIG_IGN;
258 siginitset(&sa.sa.sa_mask, sigmask(SIGCHLD));
259 do_sigaction(SIGCHLD, &sa, (struct k_sigaction *)0);
261 set_current_state(TASK_INTERRUPTIBLE);
// 可被信号中断,适当的时刻可被杀死,若收到停止命令则退出返回,否则进程就一直运行,无工作可执行时,主动休眠
262 while (!kthread_should_stop()) {
// 为了便于remove_wait_queue的统一处理,将当前内核线程添加到cpu_workqueue_struct的more_work等待队列中,当有新work结构链入队列中时会激活此等待队列
263 add_wait_queue(&cwq->more_work, &wait);
// 判断是否有工作需要作,无则调度让出CPU等待唤醒
264 if (list_empty(&cwq->worklist))
266 else
267 __set_current_state(TASK_RUNNING);
268 remove_wait_queue(&cwq->more_work, &wait);
// 至此,线程肯定处于TASK_RUNNING,从等待队列中移出
//需要再次判断是因为可能从schedule中被唤醒的。如果有工作做,则执行
270 if (!list_empty(&cwq->worklist))
// 无工作或者全部执行完毕了,循环整个过程,接着一般会休眠
272 set_current_state(TASK_INTERRUPTIBLE);
273 }
274 __set_current_state(TASK_RUNNING);
275 return 0;
276}
该函数在死循环中完成了以下功能:
² 线程将自己设置为休眠状态TASK_INTERRUPTIBLE并把自己加人到等待队列上。
² 如果工作链表是空的,线程调用schedule()函数进入睡眠状态。
² 如果链表中有对象,线程不会睡眠。相反,它将自己设置成TASK_RUNNING,脱离等待队列。
² 如果链表非空,调用run_workqueue函数执行被推后的工作。
run_workqueue执行具体的工作,多处会调用此函数。在调用Flush_work时为防止死锁,主动调用run_workqueue,此时可能导致多层次递归。
196static void run_workqueue(struct cpu_workqueue_struct *cwq)
197{
204 spin_lock_irqsave(&cwq->lock, flags);
// 统计已经递归调用了多少次了
207 /* morton gets to eat his hat */
208 printk("%s: recursion depth exceeded: %d/n",
209 __FUNCTION__, cwq->run_depth);
210 dump_stack();
211 }
212 while (!list_empty(&cwq->worklist)) {
213 struct work_struct *work = list_entry(cwq->worklist.next,
214 struct work_struct, entry);
215 void (*f) (void *) = work->func;
217 //将当前节点从链表中删除并初始化其entry
218 list_del_init(cwq->worklist.next);
219 spin_unlock_irqrestore(&cwq->lock, flags);
221 BUG_ON(work->wq_data != cwq);
222 clear_bit(0, &work->pending); //清除pengding位,标示已经执行
225 spin_lock_irqsave(&cwq->lock, flags);
226 cwq->remove_sequence++;
// // 唤醒可能等待的进程,通知其工作已经执行完毕
228 }
230 spin_unlock_irqrestore(&cwq->lock, flags);
231}
3 工作队列的API
3.1 API列表
|
功能描述 |
对应API函数 |
附注 |
|
静态定义一个工作 |
DECLARE_WORK(n, f, d) |
|
|
动态创建一个工作 |
INIT_WORK(_work, _func, _data) |
|
|
工作原型 |
void work_handler(void *data) |
|
|
将工作添加到指定的工作队列中 |
queue_work(struct workqueue_struct *wq, struct work_struct *work) |
|
|
将工作添加到keventd_wq队列中 |
schedule_work(struct work_struct *work) |
|
|
延迟delay个tick后将工作添加到指定的工作队列中 |
queue_delayed_work(struct workqueue_struct *wq, struct work_struct *work, unsigned long delay) |
|
|
延迟delay个tick后将工作添加到keventd_wq队列中 |
schedule_delayed_work(struct work_struct *work, unsigned long delay) |
|
|
刷新等待指定队列中的所有工作完成 |
flush_workqueue(struct workqueue_struct *wq) |
|
|
刷新等待keventd_wq中的所有工作完成 |
flush_scheduled_work(void) |
|
|
取消指定队列中所有延迟工作 |
cancel_delayed_work(struct work_struct *work) |
|
|
创建一个工作队列 |
create_workqueue(name) |
|
|
创建一个单线程的工作队列 |
create_singlethread_workqueue(name) |
|
|
销毁指定的工作队列 |
destroy_workqueue(struct workqueue_struct *wq) |
|
3.2 如何创建工作
首先要做的是实际创建一些需要推后完成的工作。可以通过DECLARE_WORK在编译时静态地创建该结构体:
27#define __WORK_INITIALIZER(n, f, d) { /
28 .entry = { &(n).entry, &(n).entry }, /
31 .timer = TIMER_INITIALIZER(NULL, 0, 0), /
32 }
34#define DECLARE_WORK(n, f, d) /
35 struct work_struct n = __WORK_INITIALIZER(n, f, d)
这样就会静态地创建一个名为name,处理函数为func,参数为data的work_struct结构体。
同样,也可以在运行时通过指针创建一个工作:
40#define PREPARE_WORK(_work, _func, _data) /
41 do { /
44 } while (0)
49#define INIT_WORK(_work, _func, _data) /
50 do { /
51 INIT_LIST_HEAD(&(_work)->entry); /
53 PREPARE_WORK((_work), (_func), (_data)); /
54 init_timer(&(_work)->timer); /
55 } while (0)
这会动态地初始化一个由work指向的工作,处理函数为func,参数为data。
无论是动态还是静态创建,默认定时器初始化为0,即不进行延时调度。
3.3 工作队列处理函数
工作队列处理函数的原型是:
void work_handler(void *data)
这个函数会由一个工作者线程执行,因此,函数会运行在进程上下文中。默认情况下,允许响应中断,并且不持有任何锁。如果需要,函数可以睡眠。需要注意的是,尽管操作处理函数运行在进程上下文中,但它不能访问用户空间,因为内核线程在用户空间没有相关的内存映射。通常在系统调用发生时,内核会代表用户空间的进程运行,此时它才能访问用户空间,也只有在此时它才会映射用户空间的内存。
在工作队列和内核其他部分之间使用锁机制就像在其他的进程上下文中使用锁机制一样方便。这使编写处理函数变得相对容易。
3.4 调度工作
3.4.1 queue_work
创建一个工作的时候无须考虑工作队列的类型。在创建之后,可以调用下面列举的函数。这些函数与schedule-work()以及schedule-delayed-Work()相近,惟一的区别就在于它们针对给定的工作队列而不是默认的event队列进行操作。
将工作添加到当前处理器对应的链表中,但并不能保证此工作由提交该工作的CPU执行。Flushwork时可能执行所有CPU上的工作或者CPU热插拔后将进行工作的转移
107int fastcall queue_work(struct workqueue_struct *wq, struct work_struct *work)
108{
109 int ret = 0, cpu = get_cpu();
// 工作结构还没在队列, 设置pending标志表示把工作结构挂接到队列中
111 if (!test_and_set_bit(0, &work->pending)) {
112 if (unlikely(is_single_threaded(wq)))
114 BUG_ON(!list_empty(&work->entry));
115 __queue_work(per_cpu_ptr(wq->cpu_wq, cpu), work);
////////////////////////////////
84static void __queue_work(struct cpu_workqueue_struct *cwq,
85 struct work_struct *work)
86{
89 spin_lock_irqsave(&cwq->lock, flags);
//// 指向CPU工作队列
// 加到队列尾部
91 list_add_tail(&work->entry, &cwq->worklist);
92 cwq->insert_sequence++;
// 唤醒工作队列的内核处理线程
94 spin_unlock_irqrestore(&cwq->lock, flags);
95}
////////////////////////////////////
117 }
120}
121EXPORT_SYMBOL_GPL(queue_work);
一旦其所在的处理器上的工作者线程被唤醒,它就会被执行。
3.4.2 schedule_work
在大多数情况下, 并不需要自己建立工作队列,而是只定义工作, 将工作结构挂接到内核预定义的事件工作队列中调度, 在kernel/workqueue.c中定义了一个静态全局量的工作队列static struct workqueue_struct *keventd_wq;
调度工作结构, 将工作结构添加到全局的事件工作队列keventd_wq,调用了queue_work通用模块。对外屏蔽了keventd_wq的接口,用户无需知道此参数,相当于使用了默认参数。keventd_wq由内核自己维护,创建,销毁。
455static struct workqueue_struct *keventd_wq;
463int fastcall schedule_work(struct work_struct *work)
464{
465 return queue_work(keventd_wq, work);
466}
467EXPORT_SYMBOL(schedule_work);
3.4.3 queue_delayed_work
有时候并不希望工作马上就被执行,而是希望它经过一段延迟以后再执行。在这种情况下,
同时也可以利用timer来进行延时调度,到期后才由默认的定时器回调函数进行工作注册。
延迟delay后,被定时器唤醒,将work添加到工作队列wq中。
143int fastcall queue_delayed_work(struct workqueue_struct *wq,
144 struct work_struct *work, unsigned long delay)
145{
147 struct timer_list *timer = &work->timer;
149 if (!test_and_set_bit(0, &work->pending)) {
150 BUG_ON(timer_pending(timer));
151 BUG_ON(!list_empty(&work->entry));
153 /* This stores wq for the moment, for the timer_fn */
155 timer->expires = jiffies + delay;
156 timer->data = (unsigned long)work;
157 timer->function = delayed_work_timer_fn;
////////////////////////////////////
定时器到期后执行的默认函数,其将某个work添加到一个工作队列中,需两个重要信息:
Work:__data定时器的唯一参数
123static void delayed_work_timer_fn(unsigned long __data)
124{
125 struct work_struct *work = (struct work_struct *)__data;
126 struct workqueue_struct *wq = work->wq_data;
127 int cpu = smp_processor_id();
129 if (unlikely(is_single_threaded(wq)))
132 __queue_work(per_cpu_ptr(wq->cpu_wq, cpu), work);
133}
////////////////////////////////////
160 }
162}
163EXPORT_SYMBOL_GPL(queue_delayed_work);
3.4.4 schedule_delayed_work
其利用queue_delayed_work实现了默认线程keventd_wq中工作的调度。
477int fastcall schedule_delayed_work(struct work_struct *work, unsigned long delay)
478{
479 return queue_delayed_work(keventd_wq, work, delay);
480}
481EXPORT_SYMBOL(schedule_delayed_work);
3.5 刷新工作
3.5.1 flush_workqueue
排入队列的工作会在工作者线程下一次被唤醒的时候执行。有时,在继续下一步工作之前,你必须保证一些操作已经执行完毕了。这一点对模块来说就很重要,在卸载之前,它就有可能需要调用下面的函数。而在内核的其他部分,为了防止竟争条件的出现,也可能需要确保不再有待处理的工作。
出于以上目的,内核准备了一个用于刷新指定工作队列的函数flush_workqueue。其确保所有已经调度的工作已经完成了,否则阻塞直到其执行完毕,通常用于驱动模块的关闭处理。其检查已经每个CPU上执行完的序号是否大于此时已经待插入的序号。对于新的以后插入的工作,其不受影响。
320void fastcall flush_workqueue(struct workqueue_struct *wq)
321{
322 might_sleep();
324 if (is_single_threaded(wq)) {
325 /* Always use first cpu's area. */
326 flush_cpu_workqueue(per_cpu_ptr(wq->cpu_wq, singlethread_cpu));
327 } else {
// 被保护的代码可能休眠,故此处使用内核互斥锁而非自旋锁
330 mutex_lock(&workqueue_mutex);
// 将同时调度其他CPU上的工作,这说明了工作并非在其注册的CPU上执行
332 flush_cpu_workqueue(per_cpu_ptr(wq->cpu_wq, cpu));
//////////////////////////
278static void flush_cpu_workqueue(struct cpu_workqueue_struct *cwq)
279{
280 if (cwq->thread == current) {
// keventd本身需要刷新所有工作时,手动调用run_workqueue,否则将造成死锁。
286 } else {
288 long sequence_needed;
290 spin_lock_irq(&cwq->lock);
// 保存队列中当前已有的工作所处的位置,不用等待新插入的工作执行完毕
291 sequence_needed = cwq->insert_sequence;
293 while (sequence_needed - cwq->remove_sequence > 0) {
// 如果队列中还有未执行完的工作,则休眠
294 prepare_to_wait(&cwq->work_done, &wait,
296 spin_unlock_irq(&cwq->lock);
298 spin_lock_irq(&cwq->lock);
299 }
300 finish_wait(&cwq->work_done, &wait);
301 spin_unlock_irq(&cwq->lock);
302 }
303}
//////////////////////////
333 mutex_unlock(&workqueue_mutex);
334 }
335}
336EXPORT_SYMBOL_GPL(flush_workqueue);
函数会一直等待,直到队列中所有对象都被执行以后才返回。在等待所有待处理的工作执行的时候,该函数会进入休眠状态,所以只能在进程上下文中使用它。
注意,该函数并不取消任何延迟执行的工作。就是说,任何通过schedule_delayed_work调度的工作,如果其延迟时间未结束,它并不会因为调用flush_scheduled_work()而被刷新掉。
3.5.2 flush_scheduled_work
刷新系统默认工作线程的函数为flush_scheduled_work,其调用了上面通用的函数
532void flush_scheduled_work(void)
533{
534 flush_workqueue(keventd_wq);
535}
536EXPORT_SYMBOL(flush_scheduled_work);
3.5.3 cancel_delayed_work
取消延迟执行的工作应该调用:
int cancel_delayed_work(struct work_struct *work);
这个函数可以取消任何与work_struct相关的挂起工作。
3.6 创建新的工作队列
如果默认的队列不能满足你的需要,你应该创建一个新的工作队列和与之相应的工作者线程。由于这么做会在每个处理器上都创建一个工作者线程,所以只有在你明确了必须要靠自己的一套线程来提高性能的情况下,再创建自己的工作队列。
创建一个新的任务队列和与之相关的工作者线程,只需调用一个简单的函数:create_workqueue。这个函数会创建所有的工作者线程(系统中的每个处理器都有一个)并且做好所有开始处理工作之前的准备工作。name参数用于该内核线程的命名。对于具体的线程会更加CPU号添加上序号。
create_workqueue和create_singlethread_workqueue都是创建一个工作队列,但是差别在于create_singlethread_workqueue可以指定为此工作队列只创建一个内核线程,这样可以节省资源,无需发挥SMP的并行处理优势。
create_singlethread_workqueue对外进行了封装,相当于使用了默认参数。二者同时调用了统一的处理函数__create_workqueue,其对外不可见。
59#define create_workqueue(name) __create_workqueue((name), 0)
60#define create_singlethread_workqueue(name) __create_workqueue((name), 1)
363struct workqueue_struct *__create_workqueue(const char *name,
364 int singlethread)
365{
367 struct workqueue_struct *wq;
368 struct task_struct *p;
370 wq = kzalloc(sizeof(*wq), GFP_KERNEL);
374 wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct);
378 }
381 mutex_lock(&workqueue_mutex);
382 if (singlethread) {
383 INIT_LIST_HEAD(&wq->list); //终止链表
384 p = create_workqueue_thread(wq, singlethread_cpu);
387 else
389 } else {
390 list_add(&wq->list, &workqueues);
391 for_each_online_cpu(cpu) {
392 p = create_workqueue_thread(wq, cpu);
/////////////////////////////////
338static struct task_struct *create_workqueue_thread(struct workqueue_struct *wq,
340{
341 struct cpu_workqueue_struct *cwq = per_cpu_ptr(wq->cpu_wq, cpu);
342 struct task_struct *p;
344 spin_lock_init(&cwq->lock);
347 cwq->insert_sequence = 0;
348 cwq->remove_sequence = 0;
349 INIT_LIST_HEAD(&cwq->worklist);
350 init_waitqueue_head(&cwq->more_work);
351 init_waitqueue_head(&cwq->work_done);
353 if (is_single_threaded(wq))
354 p = kthread_create(worker_thread, cwq, "%s", wq->name);
355 else
356 p = kthread_create(worker_thread, cwq, "%s/%d", wq->name, cpu);
361}
/////////////////////////////////
394 kthread_bind(p, cpu);
396 } else
398 }
399 }
400 mutex_unlock(&workqueue_mutex);
405 if (destroy) {//如果启动任意一个线程失败,则销毁整个工作队列
408 }
410}
411EXPORT_SYMBOL_GPL(__create_workqueue);
3.7 销毁工作队列
销毁一个工作队列,若有未完成的工作,则阻塞等待其完成。然后销毁对应的内核线程。
434void destroy_workqueue(struct workqueue_struct *wq)
435{
438 flush_workqueue(wq); //等待所有工作完成
439/// 利用全局的互斥锁锁定所有工作队列的操作
441 mutex_lock(&workqueue_mutex);
// 清除相关的内核线程
442 if (is_single_threaded(wq))
443 cleanup_workqueue_thread(wq, singlethread_cpu);
444 else {
446 cleanup_workqueue_thread(wq, cpu);
/////////////////////////////////
413static void cleanup_workqueue_thread(struct workqueue_struct *wq, int cpu)
414{
415 struct cpu_workqueue_struct *cwq;
417 struct task_struct *p;
419 cwq = per_cpu_ptr(wq->cpu_wq, cpu);
420 spin_lock_irqsave(&cwq->lock, flags);
423 spin_unlock_irqrestore(&cwq->lock, flags);
425 kthread_stop(p); //销毁该线程,此处可能休眠
426}
/////////////////////////////////
448 }
449 mutex_unlock(&workqueue_mutex);
450 free_percpu(wq->cpu_wq);
452}
453EXPORT_SYMBOL_GPL(destroy_workqueue);
【嵌入式Linux学习七步曲之第五篇 Linux内核及驱动编程】中断服务下半部之七姑八姨
【摘要】本文分析了中断服务下半部存在的必要性,接着介绍了上下半部的分配原则,最后分析了各种下半部机制的历史渊源,简单介绍了各种机制的特点。
【关键字】下半部,bottom half,BH,tasklet,softirq,工作队列,内核定时器
1 下半部,我思故我在
中断处理程序是内核中很有用的—实际上也是必不可少的—部分。但是,由于本身存在一些局限,所以它只能完成整个中断处理流程的上半部分。这些局限包括:
² 中断处理程序以异步方式执行并且它有可能会打断其他重要代码(甚至包括其他中断处理程序)的执行。因此,为了避免被打断的代码停止时间过长,中断处理程序应该执行得越快越好。
² 如果当前有一个中断处理程序正在执行,在最好的情况下与该中断同级的其他中断会被屏蔽,在最坏的情况下,当前处理器上所有其他中断都会被屏蔽。因此,仍应该让它们执行得越快越好。
² 由于中断处理程序往往需要对硬件进行操作,所以它们通常有很高的时限要求。
² 中断处理程序不在进程上下文中运行,所以它们不能阻塞。这限制了它们所做的事情。
现在,为什么中断处理程序只能作为整个硬件中断处理流程一部分的原因就很明显了。我们必须有一个快速、异步、简单的处理程序负责对硬件做出迅速响应并完成那些时间要求很严格的操作。中断处理程序很适合于实现这些功能,可是,对于那些其他的、对时间要求相对宽松的任务,就应该推后到中断被激活以后再去运行。
这样,整个中断处理流程就被分为了两个部分,或叫两半。第一个部分是中断处理程序(上半部),内核通过对它的异步执行完成对硬件中断的即时响应。下半部(bottom half)负责其他响应。
2 上下半部分家产的原则
下半部的任务就是执行与中断处理密切相关但中断处理程序本身不执行的工作。在理想的情况下,最好是中断处理程序将所有工作都交给下半部分执行,因为我们希望在中断处理程序中完成的工作越少越好(也就是越快越好)。我们期望中断处理程序能够尽可能快地返回。
但是,中断处理程序注定要完成一部分工作。例如,中断处理程序几乎都需要通过操作硬件对中断的到达进行确认。有时它还会从硬件拷贝数据。因为这些工作对时间非常敏感,所以只能靠中断处理程序自己去完成。
剩下的几乎所有其他工作都是下半部执行的目标。例如,如果你在上半部中把数据从硬件拷贝到了内存,那么当然应该在下半部中处理它们。遗憾的是,并不存在严格明确的规定来说明到底什么任务应该在哪个部分中完成—如何做决定完全取决于驱动程序开发者自己的判断。记住,中断处理程序会异步执行,并且即使在最好的情况下它也会锁定当前的中断线。因此将中断处理程序持续执行的时间缩短到最小非常重要。上半部和下半部之间划分应大致遵循以下规则:
² 如果一个任务对时间非常敏感,将其放在中断处理程序中执行;
² 如果一个任务和硬件相关,将其放在中断处理程序中执行;
² 如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行;
² 其他所有任务,考虑放置在下半部执行。
在决定怎样把你的中断处理流程中的工作划分到上半部和下半部中去的时候,问问自己什么必须放进上半部而什么可以放进下半部。通常,中断处理程序要执行得越快越好。
理解为什么要让工作推后执行以及在什么时候推后执行非常关键。我们希望尽量减少中断处理程序中需要完成的工作量,因为在它运行的时候当前的中断线在所有处理器上都会被屏蔽。更糟糕的是如果一个处理程序是SA_ INTERRUPT类型,它执行的时候会禁止所有本地中断。而缩短中断被屏蔽的时间对系统的响应能力和性能都至关重要。解决的方法就是把一些工作放到以后去做。
但具体放到以后的什么时候去做呢?在这里,以后仅仅用来强调不是马上而已,理解这一点相当重要。下半部并不需要指明一个确切时间,只要把这些任务推迟一点,让它们在系统不太繁忙并且中断恢复后执行就可以了。通常下半部在中断处理程序一返回就会马上运行。下半部执行的关键在于当它们运行的时候,允许响应所有的中断。
不仅仅是Linux,许多操作系统也把处理硬件中断的过程分为两个部分。上半部分简单快速,执行的时候禁止一些或者全部中断。下半部分稍后执行,而且执行期间可以响应所有的中断。这种设计可使系统处干中断屏蔽状态的时间尽可能的短,以此来提高系统的响应能力。
3 下半部之七姑八姨
和上半部分只能通过中断处理程序实现不同,下半部可以通过多种机制实现。这些用来实现下半部的机制分别由不同的接口和子系统组成。实际上,在Linux发展的过程中曾经出现过多种下半部机制。让人倍受困扰的是,其中不少机制名字起得很相像,甚至还有一些机制名字起得辞不达意。
最早的Linux只提供“bottom half”这种机制用于实现下半部。这个名字在那个时候毫无异义,因为当时它是将工作推后的惟一方法。这种机制也被称为“BH",我们现在也这么叫它,以避免和“下半部”这个通用词汇混淆。
BH接口也非常简单。它提供了一个静态创建、由32个bottom half组成的数组。上半部通过一个32位整数中的一位来标识出哪个bottom half可以执行。每个BH都在全局范围内进行同步。对于本地CPU,严格的串行执行,当被中断重入后,若发现中断前已经在执行BH则退出。即使分属于不同的处理器,也不允许任何两个bottom half同时执行。若发现另一CPU正在执行,则退出。这种机制使用方便却不够灵活,简单却有性能瓶颈。
不久,内核开发者们就引入了任务队列(task queue)机制来实现工作的推后执行,并用它来代替BH机制。内核为此定义了一组队列,其中每个队列都包含一个由等待调用的函数组成链表,这样就相当于实现了二级链表,扩展了BH32个的限制。根据其所处队列的位置,这些函数会在某个时刻被执行。驱动程序可以把它们自己的下半部注册到合适的队列上去。这种机制表现得还不错,但仍不够灵活,没法代替整个BH接口。对于一些性能要求较高的子系统,像网络部分,它也不能胜任。
在2.3这个开发版本中,内核开发者引入了tasklet和软中断softirq。如果无须考虑和过去开发的驱动程序兼容的话,软中断和tasklet可以完全代替BH接口。
软中断是一组静态定义的下半部接口,有32个,可以在所有处理器上同时执行—即使两个类型相同也可以。
tasklet是一种基于软中断实现的灵活性强、动态创建的下半部实现机制。两个不同类型的tasklet可以在不同的处理器上同时执行,但类型相同的tasklet不能同时执行。tasklet其实是一种在性能和易用性之间寻求平衡的产物。对于大部分下半部处理来说,用tasklet就足够了。像网络这样对性能要求非常高的情况才需要使用软中断。可是,使用软中断需要特别小心,因为两个相同的软中断在SMP上有可能同时被执行。此外,软中断由数组组织,还必须在编译期间就进行静态注册,即与某个软中断号关联。与此相反,tasklet为某个固定的软中断号,经过二级扩展,维护了一个链表,因此可以动态注册删除。
在开发2.5版本的内核时,BH接口最终被弃置了,所有的BH使用者必须转而使用其他下半部接口。此外,任务队列接口也被工作队列接口取代了。工作队列是一种简单但很有用的方法,它们先对要推后执行的工作排队,稍后在进程上下文中执行它们。
另外一个可以用于将工作推后执行的机制是内核定时器。不像其他下半部机制,内核定时器把操作推迟到某个确定的时间段之后执行。也就是说,尽管本章讨论的其他机制可以把操作推后到除了现在以外的任何时间进行,但是当你必须保证在一个确定的时间段过去以后再运行时,你应该使用内核定时器。但是执行定时器注册的函数时,仍然需要使用软中断机制,即定时器引入了一个固定延时和一个软中断的可变延时。
把BH转换为软中断或者tasklet并不是轻而易举的事,因为BH是全局同步的,因此,在其执行期间假定没有其他BH在执行。但是,这种转换最终还是在内核2.5中实现了。
“下半部(bottom half)”是一个操作系统通用词汇,用于指代中断处理流程中推后执行的那一部分,之所以这样命名是因为它表示中断处理方案一半的第二部分或者下半部。所有用于实现将工作推后执行的内核机制都被称为“下半部机制”。
综上所述,在2.6这个当前版本中,内核提供了三种不同形式的下半部实现机制:软中断、tasklet和工作队列。tasklet通过软中断实现,而工作队列与它们完全不同。下半部机制的演化历程如下:
【嵌入式Linux学习七步曲之第五篇 Linux内核及驱动编程】中断服务下半部之老大-软中断softirq
【摘要】本文详解了中断服务下半部机制的基础softirq。首先介绍了其数据结构,分析了softirq的执行时机及流程。接着介绍了软中断的API及如何添加自己的软中断程序,注册及其触发。最后了介绍了用于处理过多软中断的内核线程ksoftirqd,分析了触发ksoftirqd的原则及其执行流程。
【关键字】中断服务下半部,软中断softirq,softirq_action,open_softirq(),raise_softirq,ksoftirqd
1 软中断结构softirq_action
2 执行软中断
3 软中断的API
3.1 分配索引号
3.2 软中断处理程序
3.3 注册软中断处理程序
3.4 触发软中断
4 ksoftirqd
4.1 Ksoftirqd的诞生
4.2 启用Ksoftirqd的准则
4.3 Ksoftirqd的实现
1 软中断结构softirq_action
软中断使用得比较少,但其是tasklet实现的基础。而tasklet是下半部更常用的一种形式。软中断是在编译期间静态分配的。它不像tasklet那样能被动态地注册或去除。软中断由softirq_action结构表示,它定义在<linux/interrupt.h>中:
246struct softirq_action
247{
248 void (*action)(struct softirq_action *);
250};
Action: 待执行的函数;
Data: 传给函数的参数,任意类型的指针,在action内部转化
kernel/softirq.c中定义了一个包含有32个该结构体的数组。
static struct softirq_actionsoftirq_vec[32] __cacheline_aligned_in_smp;
每个被注册的软中断都占据该数组的一项。因此最多可能有32个软中断,因为系统靠一个32位字的各个位来标识是否需要执行某个软中断。注意,这是注册的软中断数目的最大值没法动态改变。在当前版本的内核中,这个项中只用到6个。。
2 执行软中断
一个注册的软中断必须在被标记后才会执行。这被称作触发软中断(raising the softirq )。通常,中断处理程序会在返回前标记它的软中断,使其在稍后被执行。于是,在合适的时刻,该软中断就会运行。在下列地方,待处理的软中断会被检查和执行:
² 从一个硬件中断代码处返回时。
² 在ksoftirqd内核线程中。
² 在那些显式检查和执行待处理的软中断的代码中,如网络子系统中。
不管是用什么办法唤起,软中断都要在do_softirq()中执行。如果有待处理的软中断,do_softirq()会循环遍历每一个,调用它们的处理程序。
252#ifndef __ARCH_HAS_DO_SOFTIRQ
254asmlinkage void do_softirq(void)
255{
259 if (in_interrupt()) //中断函数中不能执行软中断
260 return;
264 pending = local_softirq_pending();
266 if (pending) //只有有软中断需要处理时才进入__do_softirq
267 __do_softirq();
/////////////////////////
195/*
196 * 最多循环执行MAX_SOFTIRQ_RESTART 次若中断,若仍然有未处理完的,则交由softirqd 在适当的时机处理。需要协调的是延迟和公平性。尽快处理完软中断,但不能过渡影响用户进程的运行。
203 */
204#define MAX_SOFTIRQ_RESTART 10
206asmlinkage void __do_softirq(void)
207{
208 struct softirq_action *h;
210 int max_restart = MAX_SOFTIRQ_RESTART;
213 pending = local_softirq_pending();
214 account_system_vtime(current);
216 __local_bh_disable((unsigned long)__builtin_return_address(0));
219 cpu = smp_processor_id();
221 /* Reset the pending bitmask before enabling irqs */
226 h = softirq_vec;
228 do {
232 }
239 pending = local_softirq_pending();
240 if (pending && --max_restart)
248 account_system_vtime(current);
250}
//////////////////////////
270}
do_softirq检查并执行所有待处理的软中断,具体要做的包括:
1) 用局部变量pending保存softirq_pending()宏的返回值。它是待处理的软中断的32位位图—如果第n位被设置为1,那么第n位对应类型的软中断等待处理。
2) 现在待处理的软中断位图已经被保存,可以将实际的软中断位图清零了
3) 将指针h指向softirq_vec的第一项。
4) 如果pending的第一位被置为1, h->action(h)被调用。
5) 指针加1,所以现在它指向softirq_vec数组的第二项。
6) 位掩码pending右移一位。这样会丢弃第一位,然后让其他各位依次向右移动一个位置。于是,原来的第二位现在就在第一位的位置上了(依次类推)。现在指针h指向数组的第二项,pending位掩码的第二位现在也到了第一位上。重复执行上面的步骤。
一直重复下去,直到pending变为0,这表明已经没有待处理的软中断了,我们的任务也就完成了。注意,这种检查足以保证h总指向softirq_vec的有效项,因为pending最多只可能设置32位,循环最多也只能执行32次。
一个软中断不会抢占另外一个软中断。实际上,唯一可以抢占软中断的是中断处理程序。不过,其他的软中断—甚至是相同类型的软中断—可以在其他处理器上同时执行。因此对于SMP,软中断处理函数需要考虑多处理器的竞争。
实际上在执行此步操作时需要禁止本地中断。如果中断不被屏蔽,在保存位图和清除它的间隙,可能会有一个新的软中断被唤醒,这可能会造成对此待处理的位进行不应该的清除。
3 软中断的API
软中断保留给系统中对时间要求最严格以及最重要的下半部使用。目前,只有两个子系统—网络和SCSI—直接使用软中断。此外,内核定时器和tasklet都是建立在软中断上的。如果你想加入一个新的软中断,首先应该问问自己为什么用tasklet实现不了。tasklet可以动态生成,由于它们对加锁的要求不高,所以使用起来也很方便,而且它们的性能也非常不错。当然,对于时间要求严格并能自己高效地完成加锁工作的应用,软中断会是正确的选择。
3.1 分配索引号
在编译期间,可以通过<linux/interrupt.h>中定义的一个枚举类型来静态地声明软中断。
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
TASKLET_SOFTIRQ
};
内核用这些从0开始的索引来表示一种相对优先级。索引号小的软中断在索引号大的软中断之前执行。
tasklet类型列表
建立一个新的软中断必须在此枚举类型中加入新的项。而加入时不能像在其他地方一样,简单地把新项加到列表的末尾。相反,必须根据希望赋予它的优先级来决定加入的位置。习惯上,HI_ SOFTIRQ通常作为第一项,而TASKLET_ SOFTIRQ作为最后一项。新项可能插在网络相关的那些项之后、TASKLET_SOFTIRQ之前。
3.2 软中断处理程序
软中断处理程序action的函数原型如下:
void softirq_handler(struct softirq_action*)
当内核运行一个软中断处理程序的时候,它就会执行这个action函数,其惟一的参数为指向相应softirq_action结构体的指针。例如,如果my_softirq指向softirq_vec数组的某项,那么内核会用如下的方式调用软中断处理程序中的函数:
My_softirq->action(my_softirq)
当你看到内核把整个结构体都传递给软中断处理程序而不仅仅是传递数据值的时候,你可能会很吃惊。这个小技巧可以保证将来在结构体中加入新的域时,无须对所有的软中断处理程序都进行变动。如果需要,软中断处理程序可以方便地解析它的参数,从数据成员中提取数值。
同一个软中断可以同时在多个CPU上运行,而同一CPU上可以同时运行多个软中断,因此软中断处理程序在访问共享资源时应该实现各种互斥机制。
软中断处理程序执行的时候,允许响应中断,但它自己不能休眠。在一个软中断处理程序运行的时候,当前处理器上的软中断被禁止,但其他的处理器仍可以执行别的软中断。实际上,如果同一个软中断在它被执行的同时再次被触发了,那么另外一个处理器可以同时运行其处理程序。这意味着任何共享数据—甚至是仅在软中断处理程序内部使用的全局变量—都需要严格的锁保护。这点很重要,它也是为什么tasklet更受青睐的原因。单纯地禁止你的软中断处理程序同时执行不是很理想。如果仅仅通过互斥的加锁方式来防止它自身的并发执行,那么使用软中断就没有任何意义。因此,大部分软中断处理程序都通过采取单处理器数据(仅属于某一个处理器的数据,因此根本不需要加锁)或其他一些技巧来避免显式地加锁,从而提供更出色的性能。
引入软中断的主要原因是其可扩展性。如果不需要扩展到多个处理器,那么,就使用tasklet吧。tasklet本质上也是软中断,只不过同一个处理程序的多个实例不能在多个处理器上同时运行。
3.3 注册软中断处理程序
接着,在运行时通过调用open_softirq()注册软中断处理程序。
326void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
327{
328 softirq_vec[nr].data = data;
329 softirq_vec[nr].action = action;
330}
该函数有三个参数:软中断的索引号、处理函数和data域存放的数值。例如网络子系统,通过以下方式注册自己的软中断:
open_softirq(NET_TX_ SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_ SOFTIRQ, net_rx_action, NULL);
3.4 触发软中断
通过在枚举类型的列表中添加新项以及调用open_softirq进行注册以后,新的软中断处理程序就能够运行。raise_softirq()函数可以将一个软中断设置为挂起状态,让它在下次调用do softirq()函数时投入运行。
317void fastcall raise_softirq(unsigned int nr)
318{
//////////////////////////////////////////////raise_softirq_irqoff
298inline fastcall void raise_softirq_irqoff(unsigned int nr)
299{
300 __raise_softirq_irqoff(nr);
//////////////////////////////__raise_softirq_irqoff
255#define __raise_softirq_irqoff(nr) do { or_softirq_pending(1UL << (nr)); } while (0)
187#define set_softirq_pending(x) (local_softirq_pending() = (x))
188#define or_softirq_pending(x) (local_softirq_pending() |= (x))
///////////////////////////__raise_softirq_irqoff
302 /*
303 * 如果当前在中断或者软中断中,直接返回,否则唤醒ksoftirqd
304 */
311 if (!in_interrupt())
///////////////////////////wakeup_softirqd
55static inline void wakeup_softirqd(void)
56{
57 /* Interrupts are disabled: no need to stop preemption */
58 struct task_struct *tsk = __get_cpu_var(ksoftirqd);
60 if (tsk && tsk->state != TASK_RUNNING)
61 wake_up_process(tsk); //唤醒ksoftirqd内核线程
62}
//////////////////////////wakeup_softirqd
313}
315EXPORT_SYMBOL(raise_softirq_irqoff);
//////////////////////////////////////////////raise_softirq_irqoff
324}
该函数在触发一个软中断之前先要禁止中断,触发后再恢复回原来的状态。如果中断本来就已经被禁止了,那么可以调用另一函数raise_softirq_irqoff,这会带来一些优化效果。
在中断处理程序中触发软中断是最常见的形式。在这种情况下,中断处理程序执行硬件设备的相关操作,然后触发相应的软中断,最后退出。内核在执行完中断处理程序以后,马上就会调用do_softirq()函数。于是软中断开始执行中断处理程序留给它去完成的剩余任务。
4 ksoftirqd
4.1 Ksoftirqd的诞生
每个处理器都有一组辅助处理软中断(和tasklet)的内核线程。当内核中出现大量软中断的时候,这些内核进程就会辅助处理它们。
对于软中断,内核会选择在几个特殊时机进行处理。而在中断处理程序返回时处理是最常见的。软中断被触发的频率有时可能很高(像在进行大流量的网络通信期间)。更不利的是,处理函数有时还会自行重复触发。也就是说,当一个软中断执行的时候,它可以重新触发自己以便再次得到执行(事实上,网络子系统就会这么做)。如果软中断本身出现的频率就高,再加上它们又有将自己重新设置为可执行状态的能力,那么就会导致用户空间进程无法获得足够的处理器时间,因而处于饥饿状态。而且,单纯的对重新触发的软中断采取不立即处理的策略,也无法让人接受。当软中断最初提出时,就是一个让人进退维谷的问题,巫待解决,而直观的解决方案都不理想。首先,就让我们看看两种最容易想到的直观的方案。
第一种方案是只要还有被触发并等待处理的软中断,本次执行就要负责处理,重新触发的软中断也在本次执行返回前被处理。这样做可以保证对内核的软中断采取即时处理的方式,关键在于,对重新触发的软中断也会立即处理。当负载很高的时候这样做就会出问题,此时会有大量被触发的软中断,而它们本身又会重复触发。系统可能会一直处理软中断,根本不能完成其他任务。用户空间的任务被忽略了—实际上,只有软中断和中断处理程序轮流执行,而系统的用户只能等待。只有在系统永远处于低负载的情况下,这种方案才会有理想的运行效果;只要系统有哪怕是中等程度的负载量,这种方案就无法让人满意。用户空间根本不能容忍有明显的停顿出现。
第二种方案选择不处理重新触发的软中断。在从中断返回的时候,内核和平常一样,也会检查所有挂起的软中断并处理它们。但是,任何自行重新触发的软中断都不会马上处理,它们被放到下一个软中断执行时机去处理。而这个时机通常也就是下一次中断返回的时候,这等于是说,一定得等一段时间,新的(或者重新触发的)软中断才能被执行。可是,在比较空闲的系统中,立即处理软中断才是比较好的做法。很不幸,这个方案显然又是一个时好时坏的选择。尽管它能保证用户空间不处于饥饿状态,但它却让软中断忍受饥饿的痛苦,而根本没有好好利用闲置的系统资源。
在设计软中断时,开发者要意识到需要一些折中。最终在内核中实现的方案是不会立即处理重新触发的软中断。而作为改进,当大量软中断出现的时候,内核会唤醒一组内核线程来处理这些负载。这些线程在最低的优先级上运行(nice值是19),这能避免它们跟其他重要的任务抢夺资源。但它们最终肯定会被执行,所以,这个折中方案能够保证在软中断负担很重的时候用户程序不会因为得不到处理时间而处于饥饿状态。相应的,也能保证“过量”的软中断终究会得到处理。最后,在空闲系统上,这个方案同样表现良好,软中断处理得非常迅速(因为仅存的内核线程肯定会马上调度)。
4.2 启用Ksoftirqd的准则
__do_softirq中若经过MAX_SOFTIRQ_RESTART次循环后,仍然有新的软中断需要执行,则激活ksoftirqd软中断内核线程,将其余的软中断交由ksoftirqd处理。这样可以防止用户进程常时间得不到执行。但是若不处理这些软中断的话,最长到下次tick中断才能执行这些软中断,即最大延时达到1/HZ。这样内核可以在无其他用户进程需要运行的时候调度ksoftirqd线程。
55static inline void wakeup_softirqd(void)
56{
57 /* Interrupts are disabled: no need to stop preemption */
58 struct task_struct *tsk = __get_cpu_var(ksoftirqd);
59 //若当前ksoftirqd已经是TASK_RUNNING,则返回,ksoftirqd适当时刻会被调度
60 if (tsk && tsk->state != TASK_RUNNING)
62}
每个处理器都有一个这样的线程。所有线程的名字都叫做ksoftirqd/n,区别在于n,它对应的是处理器的编号。在一个双CPU的机器上就有两个这样的线程,分别叫ksoftirad/0和ksoftirad/l。
4.3 Ksoftirqd的实现
为了保证只要有空闲的处理器,它们就会处理软中断,所以给每个处理器都分配一个这样的线程。这样可以充分利用SMP机器的性能。一旦该线程被初始化,它就会死循环等待处理过剩的软中断。
470static int ksoftirqd(void * __bind_cpu)
471{
472 set_user_nice(current, 19);
473 current->flags |= PF_NOFREEZE;
475 set_current_state(TASK_INTERRUPTIBLE);
477 while (!kthread_should_stop()) {
479 if (!local_softirq_pending()) {
480 preempt_enable_no_resched();
481 schedule(); //没有待处理软中断,让出CPU
483 }
484 //确保ksoftirqd为TASK_RUNNING状态
485 __set_current_state(TASK_RUNNING);
487 while (local_softirq_pending()) {
488 /* Preempt disable stops cpu going offline.
489 If already offline, we'll be on wrong CPU:
490 don't process */
491 if (cpu_is_offline((long)__bind_cpu))
492 goto wait_to_die;
493 do_softirq();
494 preempt_enable_no_resched();
495 cond_resched();
497 }
499 set_current_state(TASK_INTERRUPTIBLE);
500 }
501 __set_current_state(TASK_RUNNING);
502 return 0;
506 /* Wait for kthread_stop */
507 set_current_state(TASK_INTERRUPTIBLE);
508 while (!kthread_should_stop()) {
510 set_current_state(TASK_INTERRUPTIBLE);
511 }
512 __set_current_state(TASK_RUNNING);
513 return 0;
514}
只要有待处理的软中断(由soflirq_pending()函数负责发现),ksoftirq就会调用do_softirq去处理它们。通过重复执行这样的操作,重新触发的软中断也会被执行。如果有必要的话,每次迭代后都会调用schedule()以便让更重要的进程得到处理机会。当所有需要执行的操作都完成以后,该内核线程将自己设置为TASK_INTERRUPTIBLE状态,唤起调度程序选择其他可执行进程投入运行。
只要do_softirqQ函数发现已经执行过的内核线程重新触发了它自己,软中断内核线程就会被唤醒。
linux 中断机制浅析

一、中断相关结构体
1.irq_desc中断描述符
- struct irq_desc {
- #ifdef CONFIG_GENERIC_HARDIRQS_NO_DEPRECATED
- struct irq_data irq_data;
- #else
- union {
- struct irq_data irq_data; //中断数据
- struct {
- unsigned int irq; //中断号
- unsigned int node; //节点号
- struct irq_chip *chip; //irq_chip
- void *handler_data;
- void *chip_data;
- struct msi_desc *msi_desc;
- #ifdef CONFIG_SMP
- cpumask_var_t affinity;
- #endif
- };
- };
- #endif
- struct timer_rand_state *timer_rand_state;
- unsigned int *kstat_irqs;
- irq_flow_handler_t handle_irq; //中断处理句柄
- struct irqaction *action; /* 中断动作列表 */
- unsigned int status; /* 中断状态 */
- unsigned int depth; /* nested irq disables */
- unsigned int wake_depth; /* nested wake enables */
- unsigned int irq_count; /* For detecting broken IRQs */
- unsigned long last_unhandled; /* Aging timer for unhandled count */
- unsigned int irqs_unhandled;
- raw_spinlock_t lock;
- #ifdef CONFIG_SMP
- const struct cpumask *affinity_hint;
- #ifdef CONFIG_GENERIC_PENDING_IRQ
- cpumask_var_t pending_mask;
- #endif
- #endif
- atomic_t threads_active;
- wait_queue_head_t wait_for_threads;
- #ifdef CONFIG_PROC_FS
- struct proc_dir_entry *dir; //proc接口目录
- #endif
- const char *name; //名字
- } ____cacheline_internodealigned_in_smp;
2.irq_chip 芯片相关的处理函数集合
- struct irq_chip { //芯片相关的处理函数集合
- const char *name; //"proc/interrupts/name"
- #ifndef CONFIG_GENERIC_HARDIRQS_NO_DEPRECATED
- unsigned int (*startup)(unsigned int irq);
- void (*shutdown)(unsigned int irq);
- void (*enable)(unsigned int irq);
- void (*disable)(unsigned int irq);
- void (*ack)(unsigned int irq);
- void (*mask)(unsigned int irq);
- void (*mask_ack)(unsigned int irq);
- void (*unmask)(unsigned int irq);
- void (*eoi)(unsigned int irq);
- void (*end)(unsigned int irq);
- int (*set_affinity)(unsigned int irq,const struct cpumask *dest);
- int (*retrigger)(unsigned int irq);
- int (*set_type)(unsigned int irq, unsigned int flow_type);
- int (*set_wake)(unsigned int irq, unsigned int on);
- void (*bus_lock)(unsigned int irq);
- void (*bus_sync_unlock)(unsigned int irq);
- #endif
- unsigned int (*irq_startup)(struct irq_data *data); //中断开始
- void (*irq_shutdown)(struct irq_data *data); //中断关闭
- void (*irq_enable)(struct irq_data *data); //中断使能
- void (*irq_disable)(struct irq_data *data); //中断禁用
- void (*irq_ack)(struct irq_data *data);
- void (*irq_mask)(struct irq_data *data);
- void (*irq_mask_ack)(struct irq_data *data);
- void (*irq_unmask)(struct irq_data *data);
- void (*irq_eoi)(struct irq_data *data);
- int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);
- int (*irq_retrigger)(struct irq_data *data);
- int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);
- int (*irq_set_wake)(struct irq_data *data, unsigned int on);
- void (*irq_bus_lock)(struct irq_data *data);
- void (*irq_bus_sync_unlock)(struct irq_data *data);
- #ifdef CONFIG_IRQ_RELEASE_METHOD
- void (*release)(unsigned int irq, void *dev_id);
- #endif
- };
3.irqaction中断行动结构体
- struct irqaction {
- irq_handler_t handler; //中断处理函数
- unsigned long flags; //中断标志
- const char *name; //中断名
- void *dev_id; //设备id号,共享中断用
- struct irqaction *next; //共享中断类型指向下一个irqaction
- int irq; //中断号
- struct proc_dir_entry *dir; //proc接口目录
- irq_handler_t thread_fn; //中断处理函数(线程)
- struct task_struct *thread; //线程任务
- unsigned long thread_flags; //线程标志
- };
在整个中断系统中将勾勒出以下的关系框图

二、中断初始化工作
从start_kernel看起,大致按以下的分支顺序初始化
- start_kernel
- setup_arch //设置全局init_arch_irq函数
- early_trap_init //搬移向量表
- early_irq_init(); //初始化全局irq_desc数组
- init_IRQ(); //调用init_arch_irq函数
- [ //板级中断初始化常用到的API
- set_irq_chip
- set_irq_handler
- set_irq_chained_handler
- set_irq_flags
- set_irq_type
- set_irq_chip_data
- set_irq_data
- ]
1.在setup_arch中主要是设置全局init_arch_irq函数
- void __init setup_arch(char **cmdline_p)
- {
- struct tag *tags = (struct tag *)&init_tags;
- struct machine_desc *mdesc;
- char *from = default_command_line;
- init_tags.mem.start = PHYS_OFFSET;
- unwind_init();
- setup_processor();
- mdesc = setup_machine(machine_arch_type);
- machine_name = mdesc->name;
- if (mdesc->soft_reboot)
- reboot_setup("s");
- if (__atags_pointer)
- tags = phys_to_virt(__atags_pointer);
- else if (mdesc->boot_params) {
- #ifdef CONFIG_MMU
- if (mdesc->boot_params < PHYS_OFFSET ||mdesc->boot_params >= PHYS_OFFSET + SZ_1M) {
- printk(KERN_WARNING"Default boot params at physical 0x%08lx out of reach\n",mdesc->boot_params);
- }
- else
- #endif
- {
- tags = phys_to_virt(mdesc->boot_params);
- }
- }
- #if defined(CONFIG_DEPRECATED_PARAM_STRUCT)
- if (tags->hdr.tag != ATAG_CORE)
- convert_to_tag_list(tags);
- #endif
- if (tags->hdr.tag != ATAG_CORE)
- tags = (struct tag *)&init_tags;
- if (mdesc->fixup)
- mdesc->fixup(mdesc, tags, &from, &meminfo);
- if (tags->hdr.tag == ATAG_CORE) {
- if (meminfo.nr_banks != 0)
- squash_mem_tags(tags);
- save_atags(tags);
- parse_tags(tags);
- }
- init_mm.start_code = (unsigned long) _text;
- init_mm.end_code = (unsigned long) _etext;
- init_mm.end_data = (unsigned long) _edata;
- init_mm.brk = (unsigned long) _end;
- strlcpy(boot_command_line, from, COMMAND_LINE_SIZE);
- strlcpy(cmd_line, boot_command_line, COMMAND_LINE_SIZE);
- *cmdline_p = cmd_line;
- parse_early_param();
- arm_memblock_init(&meminfo, mdesc);
- paging_init(mdesc);
- request_standard_resources(&meminfo, mdesc);
- #ifdef CONFIG_SMP
- if (is_smp())
- smp_init_cpus();
- #endif
- reserve_crashkernel();
- cpu_init();
- tcm_init();
- arch_nr_irqs = mdesc->nr_irqs;
- init_arch_irq = mdesc->init_irq; //设置全局init_arch_irq函数
- //void (*init_arch_irq)(void) __initdata = NULL;
- system_timer = mdesc->timer;
- init_machine = mdesc->init_machine;
- #ifdef CONFIG_VT
- #if defined(CONFIG_VGA_CONSOLE)
- conswitchp = &vga_con;
- #elif defined(CONFIG_DUMMY_CONSOLE)
- conswitchp = &dummy_con;
- #endif
- #endif
- early_trap_init();//调用early_trap_init函数
- }
1.1.early_trap_init主要挪移了中断向量表到特定位置
- void __init early_trap_init(void)
- {
- unsigned long vectors = CONFIG_VECTORS_BASE; //0xffff0000
- extern char __stubs_start[], __stubs_end[];
- extern char __vectors_start[], __vectors_end[];
- extern char __kuser_helper_start[], __kuser_helper_end[];
- int kuser_sz = __kuser_helper_end - __kuser_helper_start;
- memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start); //移动中断向量表
- memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start); //移动__stubs_start段
- memcpy((void *)vectors + 0x1000 - kuser_sz, __kuser_helper_start, kuser_sz);
- kuser_get_tls_init(vectors);
- memcpy((void *)KERN_SIGRETURN_CODE, sigreturn_codes,sizeof(sigreturn_codes));
- memcpy((void *)KERN_RESTART_CODE, syscall_restart_code,sizeof(syscall_restart_code));
- flush_icache_range(vectors, vectors + PAGE_SIZE);
- modify_domain(DOMAIN_USER, DOMAIN_CLIENT);
- }
2.early_irq_init 初始化全局irq_desc数组
在(kernel/irqs/irqdesc.c)中定义了全局irq_desc数组

- struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
- [0 ... NR_IRQS-1] = {
- .status = IRQ_DEFAULT_INIT_FLAGS,
- .handle_irq = handle_bad_irq,
- .depth = 1,
- .lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
- }
- };
获取irq_desc数组项的宏
- #define irq_to_desc(irq) (&irq_desc[irq])
early_irq_init函数
- int __init early_irq_init(void) //初始化全局irq_desc数组
- {
- int count, i, node = first_online_node;
- struct irq_desc *desc;
- init_irq_default_affinity();
- printk(KERN_INFO "NR_IRQS:%d\n", NR_IRQS);
- desc = irq_desc; //获取全局irq_desc数组
- count = ARRAY_SIZE(irq_desc); //获取全局irq_desc数组项个数
- for (i = 0; i < count; i++) { //初始化全局irq_desc数组
- desc[i].irq_data.irq = i;
- desc[i].irq_data.chip = &no_irq_chip;
- desc[i].kstat_irqs = kstat_irqs_all[i];
- alloc_masks(desc + i, GFP_KERNEL, node);
- desc_smp_init(desc + i, node);
- lockdep_set_class(&desc[i].lock, &irq_desc_lock_class);
- }
- return arch_early_irq_init();
- }

3.init_IRQ函数调用全局init_arch_irq函数,进入板级初始化
- void __init init_IRQ(void)
- {
- init_arch_irq(); //调用板级驱动的中断初始化函数
- }
4.板级中断初始化常用到的API
1.set_irq_chip 通过irq中断号获取对应全局irq_desc数组项,并设置其irq_data.chip指向传递进去的irq_chip指针
- int set_irq_chip(unsigned int irq, struct irq_chip *chip)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- unsigned long flags;
- if (!desc) {
- WARN(1, KERN_ERR "Trying to install chip for IRQ%d\n", irq);
- return -EINVAL;
- }
- if (!chip) //若irq_chip不存在
- chip = &no_irq_chip; //设置为no_irq_chip
- raw_spin_lock_irqsave(&desc->lock, flags);
- irq_chip_set_defaults(chip); //初始化irq_chip
- desc->irq_data.chip = chip; //设置irq_desc->irq_data.chip
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- return 0;
- }
- EXPORT_SYMBOL(set_irq_chip);

1.1 irq_chip_set_defaults 根据irq_chip的实际情况初始化默认方法
- void irq_chip_set_defaults(struct irq_chip *chip) //根据irq_chip的实际情况初始化默认方法
- {
- #ifndef CONFIG_GENERIC_HARDIRQS_NO_DEPRECATED
- if (chip->enable)
- chip->irq_enable = compat_irq_enable;
- if (chip->disable)
- chip->irq_disable = compat_irq_disable;
- if (chip->shutdown)
- chip->irq_shutdown = compat_irq_shutdown;
- if (chip->startup)
- chip->irq_startup = compat_irq_startup;
- #endif
- if (!chip->irq_enable) //使能中断
- chip->irq_enable = default_enable;
- if (!chip->irq_disable) //禁用中断
- chip->irq_disable = default_disable;
- if (!chip->irq_startup) //中断开始
- chip->irq_startup = default_startup;
- if (!chip->irq_shutdown) //关闭中断
- chip->irq_shutdown = chip->irq_disable != default_disable ? chip->irq_disable : default_shutdown;
- #ifndef CONFIG_GENERIC_HARDIRQS_NO_DEPRECATED
- if (!chip->end)
- chip->end = dummy_irq_chip.end;
- if (chip->bus_lock)
- chip->irq_bus_lock = compat_bus_lock;
- if (chip->bus_sync_unlock)
- chip->irq_bus_sync_unlock = compat_bus_sync_unlock;
- if (chip->mask)
- chip->irq_mask = compat_irq_mask;
- if (chip->unmask)
- chip->irq_unmask = compat_irq_unmask;
- if (chip->ack)
- chip->irq_ack = compat_irq_ack;
- if (chip->mask_ack)
- chip->irq_mask_ack = compat_irq_mask_ack;
- if (chip->eoi)
- chip->irq_eoi = compat_irq_eoi;
- if (chip->set_affinity)
- chip->irq_set_affinity = compat_irq_set_affinity;
- if (chip->set_type)
- chip->irq_set_type = compat_irq_set_type;
- if (chip->set_wake)
- chip->irq_set_wake = compat_irq_set_wake;
- if (chip->retrigger)
- chip->irq_retrigger = compat_irq_retrigger;
- #endif
- }
2.set_irq_handler和set_irq_chained_handler
这两个函数的功能是:根据irq中断号,获取对应全局irq_desc数组项,并将数组项描述符的handle_irq中断处理函数指针指向handle
如果是chain类型则添加数组项的status状态IRQ_NOREQUEST和IRQ_NOPROBE属性
- static inline void set_irq_handler(unsigned int irq, irq_flow_handler_t handle)
- {
- __set_irq_handler(irq, handle, 0, NULL); //调用__set_irq_handler
- }
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
- static inline void set_irq_chained_handler(unsigned int irq,irq_flow_handler_t handle)
- {
- __set_irq_handler(irq, handle, 1, NULL); //调用__set_irq_handler
- }
2.1 __set_irq_handler函数
- void __set_irq_handler(unsigned int irq, irq_flow_handler_t handle, int is_chained,const char *name)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- unsigned long flags;
- if (!desc) {
- printk(KERN_ERR"Trying to install type control for IRQ%d\n", irq);
- return;
- }
- if (!handle) //若没指定handle
- handle = handle_bad_irq; //则设置为handle_bad_irq
- else if (desc->irq_data.chip == &no_irq_chip) {
- printk(KERN_WARNING "Trying to install %sinterrupt handler for IRQ%d\n", is_chained ? "chained " : "", irq);
- desc->irq_data.chip = &dummy_irq_chip; //设置desc->irq_data.chip为dummy_irq_chip(空操作的irq_chip)
- }
- chip_bus_lock(desc);
- raw_spin_lock_irqsave(&desc->lock, flags);
- if (handle == handle_bad_irq) {
- if (desc->irq_data.chip != &no_irq_chip)
- mask_ack_irq(desc);
- desc->status |= IRQ_DISABLED;
- desc->depth = 1;
- }
- desc->handle_irq = handle; //高级中断处理句柄
- desc->name = name;
- if (handle != handle_bad_irq && is_chained) { //链接
- desc->status &= ~IRQ_DISABLED;
- desc->status |= IRQ_NOREQUEST | IRQ_NOPROBE;
- desc->depth = 0;
- desc->irq_data.chip->irq_startup(&desc->irq_data);
- }
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- chip_bus_sync_unlock(desc);
- }
- EXPORT_SYMBOL_GPL(__set_irq_handler);
3.set_irq_flags 根据irq号获取全局irq_desc数组项,并设置其status标志(中断标志)
- void set_irq_flags(unsigned int irq, unsigned int iflags)
- {
- struct irq_desc *desc;
- unsigned long flags;
- if (irq >= nr_irqs) {
- printk(KERN_ERR "Trying to set irq flags for IRQ%d\n", irq);
- return;
- }
- desc = irq_to_desc(irq); //获取全局irq_desc数组项
- raw_spin_lock_irqsave(&desc->lock, flags);
- desc->status |= IRQ_NOREQUEST | IRQ_NOPROBE | IRQ_NOAUTOEN;
- if (iflags & IRQF_VALID)
- desc->status &= ~IRQ_NOREQUEST;
- if (iflags & IRQF_PROBE)
- desc->status &= ~IRQ_NOPROBE;
- if (!(iflags & IRQF_NOAUTOEN))
- desc->status &= ~IRQ_NOAUTOEN;
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- }
4.set_irq_type根据irq号获取全局irq_desc数组项,并设置其status标志(中断触发类型)
- int set_irq_type(unsigned int irq, unsigned int type)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- unsigned long flags;
- int ret = -ENXIO;
- if (!desc) {
- printk(KERN_ERR "Trying to set irq type for IRQ%d\n", irq);
- return -ENODEV;
- }
- type &= IRQ_TYPE_SENSE_MASK;
- if (type == IRQ_TYPE_NONE)
- return 0;
- raw_spin_lock_irqsave(&desc->lock, flags);
- ret = __irq_set_trigger(desc, irq, type); //调用__irq_set_trigger
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- return ret;
- }
- EXPORT_SYMBOL(set_irq_type);
4.1 __irq_set_trigger函数
- int __irq_set_trigger(struct irq_desc *desc, unsigned int irq,unsigned long flags)
- {
- int ret;
- struct irq_chip *chip = desc->irq_data.chip;
- if (!chip || !chip->irq_set_type) {
- pr_debug("No set_type function for IRQ %d (%s)\n", irq,chip ? (chip->name ? : "unknown") : "unknown");
- return 0;
- }
- ret = chip->irq_set_type(&desc->irq_data, flags);
- if (ret)
- pr_err("setting trigger mode %lu for irq %u failed (%pF)\n",flags, irq, chip->irq_set_type);
- else {
- if (flags & (IRQ_TYPE_LEVEL_LOW | IRQ_TYPE_LEVEL_HIGH))
- flags |= IRQ_LEVEL;
- /* note that IRQF_TRIGGER_MASK == IRQ_TYPE_SENSE_MASK */
- desc->status &= ~(IRQ_LEVEL | IRQ_TYPE_SENSE_MASK);
- desc->status |= flags;
- if (chip != desc->irq_data.chip)
- irq_chip_set_defaults(desc->irq_data.chip);
- }
- return ret;
- }
5.set_irq_chip_data 根据irq号获取全局irq_desc数组项,并设置其irq_data的chip_data
- int set_irq_chip_data(unsigned int irq, void *data)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- unsigned long flags;
- if (!desc) {
- printk(KERN_ERR"Trying to install chip data for IRQ%d\n", irq);
- return -EINVAL;
- }
- if (!desc->irq_data.chip) {
- printk(KERN_ERR "BUG: bad set_irq_chip_data(IRQ#%d)\n", irq);
- return -EINVAL;
- }
- raw_spin_lock_irqsave(&desc->lock, flags);
- desc->irq_data.chip_data = data;
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- return 0;
- }
- EXPORT_SYMBOL(set_irq_chip_data);
6.set_irq_data
- int set_irq_data(unsigned int irq, void *data)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- unsigned long flags;
- if (!desc) {
- printk(KERN_ERR"Trying to install controller data for IRQ%d\n", irq);
- return -EINVAL;
- }
- raw_spin_lock_irqsave(&desc->lock, flags);
- desc->irq_data.handler_data = data;
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- return 0;
- }
- EXPORT_SYMBOL(set_irq_data);
三、中断的申请与释放request_irq
1.申请中断(主要是分配设置irqaction结构体)
- static inline int __must_check request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev)
- {
- return request_threaded_irq(irq, handler, NULL, flags, name, dev);
- }
1.1 request_threaded_irq函数
- int request_threaded_irq(unsigned int irq, irq_handler_t handler,irq_handler_t thread_fn, unsigned long irqflags,const char *devname, void *dev_id)
- {
- struct irqaction *action;
- struct irq_desc *desc;
- int retval;
- if ((irqflags & IRQF_SHARED) && !dev_id) //共享中断但没指定中断id
- return -EINVAL;
- desc = irq_to_desc(irq); //获取全局irq_desc数组项
- if (!desc)
- return -EINVAL;
- if (desc->status & IRQ_NOREQUEST) //中断不能被请求
- return -EINVAL;
- if (!handler) { //没指定handler
- if (!thread_fn) //但存在thread_fn
- return -EINVAL;
- handler = irq_default_primary_handler; //则设置irq_default_primary_handler
- }
- action = kzalloc(sizeof(struct irqaction), GFP_KERNEL); //分配irqaction内存
- if (!action)
- return -ENOMEM;
- action->handler = handler; //设置处理句柄
- action->thread_fn = thread_fn; //设置线程函数NULL
- action->flags = irqflags; //设置中断标志
- action->name = devname; //设置设备名
- action->dev_id = dev_id; //设置设备id
- chip_bus_lock(desc);
- retval = __setup_irq(irq, desc, action); //-->__setup_irq
- chip_bus_sync_unlock(desc);
- if (retval)
- kfree(action);
- #ifdef CONFIG_DEBUG_SHIRQ
- if (!retval && (irqflags & IRQF_SHARED)) {
- unsigned long flags;
- disable_irq(irq);
- local_irq_save(flags);
- handler(irq, dev_id);
- local_irq_restore(flags);
- enable_irq(irq);
- }
- #endif
- return retval;
- }
- EXPORT_SYMBOL(request_threaded_irq);

1.2 __setup_irq函数
- static int __setup_irq(unsigned int irq, struct irq_desc *desc, struct irqaction *new)
- {
- struct irqaction *old, **old_ptr;
- const char *old_name = NULL;
- unsigned long flags;
- int nested, shared = 0;
- int ret;
- if (!desc)
- return -EINVAL;
- if (desc->irq_data.chip == &no_irq_chip)
- return -ENOSYS;
- if (new->flags & IRQF_SAMPLE_RANDOM) {
- rand_initialize_irq(irq);
- }
- if ((new->flags & IRQF_ONESHOT) && (new->flags & IRQF_SHARED))
- return -EINVAL;
- nested = desc->status & IRQ_NESTED_THREAD; //嵌套标志
- if (nested) { //嵌套
- if (!new->thread_fn) //且存在线程处理句柄
- return -EINVAL;
- new->handler = irq_nested_primary_handler; //嵌套处理的句柄
- }
- if (new->thread_fn && !nested) { //非嵌套且存在线程函数
- struct task_struct *t;
- t = kthread_create(irq_thread, new, "irq/%d-%s", irq,new->name); //创建线程
- if (IS_ERR(t))
- return PTR_ERR(t);
- get_task_struct(t);
- new->thread = t; //设置线程任务结构体
- }
- raw_spin_lock_irqsave(&desc->lock, flags);
- old_ptr = &desc->action;
- old = *old_ptr;
- if (old) {
- if (!((old->flags & new->flags) & IRQF_SHARED) || ((old->flags ^ new->flags) & IRQF_TRIGGER_MASK)) {
- old_name = old->name;
- goto mismatch;
- }
- #if defined(CONFIG_IRQ_PER_CPU)
- if ((old->flags & IRQF_PERCPU) != (new->flags & IRQF_PERCPU))
- goto mismatch;
- #endif
- do {
- old_ptr = &old->next;
- old = *old_ptr;
- } while (old);
- shared = 1; //共享中断标志
- }
- if (!shared) { //非共享中断
- irq_chip_set_defaults(desc->irq_data.chip); //设置默认的芯片处理函数
- init_waitqueue_head(&desc->wait_for_threads);
- if (new->flags & IRQF_TRIGGER_MASK) { //设置触发方式
- ret = __irq_set_trigger(desc, irq,new->flags & IRQF_TRIGGER_MASK);
- if (ret)
- goto out_thread;
- }
- else
- compat_irq_chip_set_default_handler(desc);
- #if defined(CONFIG_IRQ_PER_CPU)
- if (new->flags & IRQF_PERCPU)
- desc->status |= IRQ_PER_CPU;
- #endif
- desc->status &= ~(IRQ_AUTODETECT | IRQ_WAITING | IRQ_ONESHOT |IRQ_INPROGRESS | IRQ_SPURIOUS_DISABLED);
- if (new->flags & IRQF_ONESHOT)
- desc->status |= IRQ_ONESHOT;
- if (!(desc->status & IRQ_NOAUTOEN)) {
- desc->depth = 0;
- desc->status &= ~IRQ_DISABLED;
- desc->irq_data.chip->irq_startup(&desc->irq_data);
- }
- else
- desc->depth = 1;
- if (new->flags & IRQF_NOBALANCING)
- desc->status |= IRQ_NO_BALANCING;
- setup_affinity(irq, desc);
- }
- else if ((new->flags & IRQF_TRIGGER_MASK)&& (new->flags & IRQF_TRIGGER_MASK)!= (desc->status & IRQ_TYPE_SENSE_MASK)) {
- pr_warning("IRQ %d uses trigger mode %d; requested %d\n",
- irq, (int)(desc->status & IRQ_TYPE_SENSE_MASK),(int)(new->flags & IRQF_TRIGGER_MASK));
- }
- new->irq = irq; //设置中断号
- *old_ptr = new;
- desc->irq_count = 0;
- desc->irqs_unhandled = 0;
- if (shared && (desc->status & IRQ_SPURIOUS_DISABLED)) { //共享中断
- desc->status &= ~IRQ_SPURIOUS_DISABLED;
- __enable_irq(desc, irq, false);
- }
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- if (new->thread)
- wake_up_process(new->thread);
- register_irq_proc(irq, desc); //注册proc irq接口
- new->dir = NULL;
- register_handler_proc(irq, new); //注册proc handler接口
- return 0;
- mismatch:
- #ifdef CONFIG_DEBUG_SHIRQ
- if (!(new->flags & IRQF_PROBE_SHARED)) {
- printk(KERN_ERR "IRQ handler type mismatch for IRQ %d\n", irq);
- if (old_name)
- printk(KERN_ERR "current handler: %s\n", old_name);
- dump_stack();
- }
- #endif
- ret = -EBUSY;
- out_thread:
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- if (new->thread) {
- struct task_struct *t = new->thread;
- new->thread = NULL;
- if (likely(!test_bit(IRQTF_DIED, &new->thread_flags)))
- kthread_stop(t);
- put_task_struct(t);
- }
- return ret;
- }
代码可以去细究,主要功能是填充irqaction
在设备驱动程序中申请中断可以这么申请
(eg:request_irq(1, &XXX_interrupt,IRQF_TRIGGER_RISING,"nameXXX", (void*)0))
第一个参数是中断号,第二个参数是中断处理函数,第三个参数是中断标志(上升沿),第四个是名字,第五个是设备id(非共享中断设置成(void*)0)即可
共享中断情况下要将第三个参数添加IRQF_SHARED标志,同时要给他制定第五个参数设备id
触发方式宏
- #define IRQ_TYPE_NONE 0x00000000 /* Default, unspecified type */
- #define IRQ_TYPE_EDGE_RISING 0x00000001 //上升沿触发
- #define IRQ_TYPE_EDGE_FALLING 0x00000002 //下降沿触发
- #define IRQ_TYPE_EDGE_BOTH (IRQ_TYPE_EDGE_FALLING | IRQ_TYPE_EDGE_RISING) //双边沿触发
- #define IRQ_TYPE_LEVEL_HIGH 0x00000004 //高电平有效
- #define IRQ_TYPE_LEVEL_LOW 0x00000008 //低电平有效
- #define IRQ_TYPE_SENSE_MASK 0x0000000f /* Mask of the above */
- #define IRQ_TYPE_PROBE 0x00000010 /* Probing in progress */
然后设计中断函数
static irqreturn_t XXX_interrupt(int irq, void *arg){
......
return IRQ_HANDLED;
}
2.释放中断
- void free_irq(unsigned int irq, void *dev_id)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- if (!desc)
- return;
- chip_bus_lock(desc);
- kfree(__free_irq(irq, dev_id));
- chip_bus_sync_unlock(desc);
- }
- EXPORT_SYMBOL(free_irq);
2.1 __free_irq
- static struct irqaction *__free_irq(unsigned int irq, void *dev_id)
- {
- struct irq_desc *desc = irq_to_desc(irq); //获取全局irq_desc数组项
- struct irqaction *action, **action_ptr;
- unsigned long flags;
- WARN(in_interrupt(), "Trying to free IRQ %d from IRQ context!\n", irq);
- if (!desc)
- return NULL;
- raw_spin_lock_irqsave(&desc->lock, flags);
- action_ptr = &desc->action;
- for (;;) {
- action = *action_ptr;
- if (!action) {
- WARN(1, "Trying to free already-free IRQ %d\n", irq);
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- return NULL;
- }
- if (action->dev_id == dev_id) //找到匹配的id项
- break;
- action_ptr = &action->next;
- }
- *action_ptr = action->next;
- #ifdef CONFIG_IRQ_RELEASE_METHOD
- if (desc->irq_data.chip->release)
- desc->irq_data.chip->release(irq, dev_id);
- #endif
- if (!desc->action) {
- desc->status |= IRQ_DISABLED;
- if (desc->irq_data.chip->irq_shutdown)
- desc->irq_data.chip->irq_shutdown(&desc->irq_data);
- else
- desc->irq_data.chip->irq_disable(&desc->irq_data);
- }
- #ifdef CONFIG_SMP
- if (WARN_ON_ONCE(desc->affinity_hint))
- desc->affinity_hint = NULL;
- #endif
- raw_spin_unlock_irqrestore(&desc->lock, flags);
- unregister_handler_proc(irq, action);
- synchronize_irq(irq);
- #ifdef CONFIG_DEBUG_SHIRQ
- if (action->flags & IRQF_SHARED) {
- local_irq_save(flags);
- action->handler(irq, dev_id);
- local_irq_restore(flags);
- }
- #endif
- if (action->thread) {
- if (!test_bit(IRQTF_DIED, &action->thread_flags))
- kthread_stop(action->thread);
- put_task_struct(action->thread);
- }
- return action;
- }
四、中断处理过程
1.当有中断发生时,程序会到__vectors_star去查找向量表(arch/arm/kernel/entry-armv.S)
- .globl __vectors_start
- _vectors_start:
- ARM( swi SYS_ERROR0 ) /* swi指令 */
- THUMB( svc #0 )
- THUMB( nop )
- W(b) vector_und + stubs_offset
- W(ldr) pc, .LCvswi + stubs_offset
- W(b) vector_pabt + stubs_offset
- W(b) vector_dabt + stubs_offset
- W(b) vector_addrexcptn + stubs_offset
- W(b) vector_irq + stubs_offset /* 中断向量表 */
- W(b) vector_fiq + stubs_offset
- .globl __vectors_end
- _vectors_end:
2.vector_irq的定义声明
- .globl __stubs_start
- __stubs_start:
- /*
- * Interrupt dispatcher
- */
- vector_stub irq, IRQ_MODE, 4 /*参看下面vector_stub宏的定义*/
- .long __irq_usr @ 0 (USR_26 / USR_32) /*usr模式下中断处理(见下面)*/
- .long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
- .long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
- .long __irq_svc @ 3 (SVC_26 / SVC_32) /*svc模式下中断处理(见下面)*/
- .long __irq_invalid @ 4
- .long __irq_invalid @ 5
- .long __irq_invalid @ 6
- .long __irq_invalid @ 7
- .long __irq_invalid @ 8
- .long __irq_invalid @ 9
- .long __irq_invalid @ a
- .long __irq_invalid @ b
- .long __irq_invalid @ c
- .long __irq_invalid @ d
- .long __irq_invalid @ e
- .long __irq_invalid @ f
3.vector_stub宏的定义
- /*vector_stub irq, IRQ_MODE, 4*/
- .macro vector_stub, name, mode, correction=0
- .align 5
- vector_\name: /*构造了vector_irq*/
- .if \correction /*if 4*/
- sub lr, lr, #\correction
- .endif
- @
- @ Save r0, lr_<exception> (parent PC) and spsr_<exception>
- @ (parent CPSR)
- @
- stmia sp, {r0, lr} @ save r0, lr
- mrs lr, spsr
- str lr, [sp, #8] @ save spsr
- @
- @ Prepare for SVC32 mode. IRQs remain disabled. 准备切到svc模式
- @
- mrs r0, cpsr
- eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE)
- msr spsr_cxsf, r0
- @ /*分支表必须紧接着这段代码*/
- @ the branch table must immediately follow this code
- @
- and lr, lr, #0x0f
- THUMB( adr r0, 1f )
- THUMB( ldr lr, [r0, lr, lsl #2] )
- mov r0, sp
- ARM( ldr lr, [pc, lr, lsl #2] )
- movs pc, lr @ branch to handler in SVC mode 跳到分支表处
- ENDPROC(vector_\name)
- .align 2
- @ handler addresses follow this label
- 1:
- .endm
这几段汇编的大致意思是中断发生会跳到vector_irq去执行,vector_irq根据情况会跳到__irq_usr或__irq_svc执行
4.__irq_usr
- __irq_usr:
- usr_entry
- kuser_cmpxchg_check
- get_thread_info tsk
- #ifdef CONFIG_PREEMPT
- ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
- add r7, r8, #1 @ increment it
- str r7, [tsk, #TI_PREEMPT]
- #endif
- irq_handler /*跳转到irq_handler处理*/
- #ifdef CONFIG_PREEMPT
- ldr r0, [tsk, #TI_PREEMPT]
- str r8, [tsk, #TI_PREEMPT]
- teq r0, r7
- ARM( strne r0, [r0, -r0] )
- THUMB( movne r0, #0 )
- THUMB( strne r0, [r0] )
- #endif
- mov why, #0
- b ret_to_user
- UNWIND(.fnend )
- ENDPROC(__irq_usr)
5.__irq_svc
- __irq_svc:
- svc_entry
- #ifdef CONFIG_TRACE_IRQFLAGS
- bl trace_hardirqs_off
- #endif
- #ifdef CONFIG_PREEMPT
- get_thread_info tsk
- ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
- add r7, r8, #1 @ increment it
- str r7, [tsk, #TI_PREEMPT]
- #endif
- irq_handler /*跳转到irq_handler处理*/
- #ifdef CONFIG_PREEMPT
- str r8, [tsk, #TI_PREEMPT] @ restore preempt count
- ldr r0, [tsk, #TI_FLAGS] @ get flags
- teq r8, #0 @ if preempt count != 0
- movne r0, #0 @ force flags to 0
- tst r0, #_TIF_NEED_RESCHED
- blne svc_preempt
- #endif
- ldr r4, [sp, #S_PSR] @ irqs are already disabled
- #ifdef CONFIG_TRACE_IRQFLAGS
- tst r4, #PSR_I_BIT
- bleq trace_hardirqs_on
- #endif
- svc_exit r4 @ return from exception
- UNWIND(.fnend )
- ENDPROC(__irq_svc)
6.不管是__irq_svc或是__irq_usr都会调用到irqhandler
- .macro irq_handler
- get_irqnr_preamble r5, lr
- 1: get_irqnr_and_base r0, r6, r5, lr
- movne r1, sp
- @ r0保存了中断号,r1保存了保留现场的寄存器指针
- @ routine called with r0 = irq number, r1 = struct pt_regs *
- @
- adrne lr, BSYM(1b)
- bne asm_do_IRQ /*********************跳转到asm_do_IRQ函数处理*/
- #ifdef CONFIG_SMP
- /*
- * XXX
- *
- * this macro assumes that irqstat (r6) and base (r5) are
- * preserved from get_irqnr_and_base above
- */
- ALT_SMP(test_for_ipi r0, r6, r5, lr)
- ALT_UP_B(9997f)
- movne r0, sp
- adrne lr, BSYM(1b)
- bne do_IPI
- #ifdef CONFIG_LOCAL_TIMERS
- test_for_ltirq r0, r6, r5, lr
- movne r0, sp
- adrne lr, BSYM(1b)
- bne do_local_timer
- #endif
- 9997:
- #endif
- .endm
7.就这样进入了c处理的阶段asm_do_IRQ
- asmlinkage void __exception asm_do_IRQ(unsigned int irq, struct pt_regs *regs)
- {
- struct pt_regs *old_regs = set_irq_regs(regs);
- irq_enter();
- /*
- * Some hardware gives randomly wrong interrupts. Rather
- * than crashing, do something sensible.
- */
- if (unlikely(irq >= nr_irqs)) { //中断号大于中断的个数
- if (printk_ratelimit())
- printk(KERN_WARNING "Bad IRQ%u\n", irq);
- ack_bad_irq(irq);
- }
- else {
- generic_handle_irq(irq); //通用中断处理函数
- }
- /* AT91 specific workaround */
- irq_finish(irq);
- irq_exit();
- set_irq_regs(old_regs);
- }
8.generic_handle_irq函数
- static inline void generic_handle_irq(unsigned int irq)
- {
- generic_handle_irq_desc(irq, irq_to_desc(irq)); //调用了irq_to_desc获取全局irq_desc[irq]项
- }
9.generic_handle_irq_desc函数
- static inline void generic_handle_irq_desc(unsigned int irq, struct irq_desc *desc)
- {
- #ifdef CONFIG_GENERIC_HARDIRQS_NO__DO_IRQ //根据板级配置的设置若定义了
- desc->handle_irq(irq, desc); //则只能用指定的handle_irq方法
- #else
- if (likely(desc->handle_irq)) //若中断处理函数存在
- desc->handle_irq(irq, desc); //则调用注册的中断处理函数(irq_desc[irq]->handle_irq(irq,desc))
- else
- __do_IRQ(irq); //没指定中断处理函数的处理分支
- #endif
- }
这里有了分支关键看CONFIG_GENERIC_HARDIRQS_NO__DO_IRQ的设置
如果设置为1,则只调用中断描述符的handle_irq方法
如果设置为0,则如果中断描述符存在handle_irq方法则调用该方法,如果没有则调用__do_IRQ()
中断描述符handle_irq方法,一般是芯片厂商写好的,先看看__do_IRQ()吧
10.__do_IRQ函数
- unsigned int __do_IRQ(unsigned int irq)
- {
- struct irq_desc *desc = irq_to_desc(irq);
- struct irqaction *action;
- unsigned int status;
- kstat_incr_irqs_this_cpu(irq, desc);
- if (CHECK_IRQ_PER_CPU(desc->status)) {
- irqreturn_t action_ret;
- if (desc->irq_data.chip->ack)
- desc->irq_data.chip->ack(irq);
- if (likely(!(desc->status & IRQ_DISABLED))) {
- action_ret = handle_IRQ_event(irq, desc->action);//调用handle_IRQ_event函数
- if (!noirqdebug)
- note_interrupt(irq, desc, action_ret);
- }
- desc->irq_data.chip->end(irq);
- return 1;
- }
- raw_spin_lock(&desc->lock);
- if (desc->irq_data.chip->ack)
- desc->irq_data.chip->ack(irq);
- status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
- status |= IRQ_PENDING; /* we _want_ to handle it */
- action = NULL;
- if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
- action = desc->action;
- status &= ~IRQ_PENDING; /* we commit to handling */
- status |= IRQ_INPROGRESS; /* we are handling it */
- }
- desc->status = status;
- if (unlikely(!action))
- goto out;
- for (;;) {
- irqreturn_t action_ret;
- raw_spin_unlock(&desc->lock);
- action_ret = handle_IRQ_event(irq, action);//调用handle_IRQ_event函数
- if (!noirqdebug)
- note_interrupt(irq, desc, action_ret);
- raw_spin_lock(&desc->lock);
- if (likely(!(desc->status & IRQ_PENDING)))
- break;
- desc->status &= ~IRQ_PENDING;
- }
- desc->status &= ~IRQ_INPROGRESS;
- out:
- desc->irq_data.chip->end(irq);
- raw_spin_unlock(&desc->lock);
- return 1;
- }
.__do_IRQ函数主要是调用handle_IRQ_event来处理中断
11.handle_IRQ_event函数
- irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction *action)
- {
- irqreturn_t ret, retval = IRQ_NONE;
- unsigned int status = 0;
- do {
- trace_irq_handler_entry(irq, action);
- ret = action->handler(irq, action->dev_id);//调用了irqaction的handler方法
- trace_irq_handler_exit(irq, action, ret);
- switch (ret) {
- case IRQ_WAKE_THREAD:
- ret = IRQ_HANDLED;
- if (unlikely(!action->thread_fn)) {
- warn_no_thread(irq, action);
- break;
- }
- if (likely(!test_bit(IRQTF_DIED,
- &action->thread_flags))) {
- set_bit(IRQTF_RUNTHREAD, &action->thread_flags);
- wake_up_process(action->thread);
- }
- case IRQ_HANDLED:
- status |= action->flags;
- break;
- default:
- break;
- }
- retval |= ret;
- action = action->next;
- } while (action);
- if (status & IRQF_SAMPLE_RANDOM)
- add_interrupt_randomness(irq);
- local_irq_disable();
- return retval;
- }
这里调用的irqaction的handler方法就是调用了之前设备驱动中用request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev)
申请中断时传递进来的第二个参数的函数
其实很多芯片厂商在编写中断描述符handle_irq方法的时候也会调用到handle_IRQ_event函数
整个中断的处理过程就是

linux中断机制的处理过程
一、中断的概念
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)。
在实地址模式中,CPU把内存中从0开始的1KB空间作为一个中断向量表。表中的每一项占4个字节。但是在保护模式中,有这4个字节的表项构成的中断向量表不满足实际需求,于是根据反映模式切换的信息和偏移量的足够使得中断向量表的表项由8个字节组成,而中断向量表也叫做了中断描述符表(IDT)。在CPU中增加了一个用来描述中断描述符表寄存器(IDTR),用来保存中断描述符表的起始地址。
二、中断的请求过程
外部设备当需要操作系统做相关的事情的时候,会产生相应的中断。设备通过相应的中断线向中断控制器发送高电平以产生中断信号,而操作系统则会从中断控制器的状态位取得那根中断线上产生的中断。而且只有在设备在对某一条中断线拥有控制权,才可以向这条中断线上发送信号。也由于现在的外设越来越多,中断线又是很宝贵的资源不可能被一一对应。因此在使用中断线前,就得对相应的中断线进行申请。无论采用共享中断方式还是独占一个中断,申请过程都是先讲所有的中断线进行扫描,得出哪些没有别占用,从其中选择一个作为该设备的IRQ。其次,通过中断申请函数申请相应的IRQ。最后,根据申请结果查看中断是否能够被执行。
中断机制的核心数据结构是 irq_desc, 它完整地描述了一条中断线 (或称为 “中断通道” )。以下程序源码版本为linux-2.6.32.2。
其中irq_desc 结构在 include/linux/irq.h 中定义:
typedef void (*irq_flow_handler_t)(unsigned int irq,
struct irq_desc *desc);
struct irq_desc {
unsigned int irq;
struct timer_rand_state *timer_rand_state;
unsigned int *kstat_irqs;
#ifdef CONFIG_INTR_REMAP
struct irq_2_iommu *irq_2_iommu;
#endif
irq_flow_handler_t handle_irq; /* 高层次的中断事件处理函数 */
struct irq_chip *chip; /* 低层次的硬件操作 */
struct msi_desc *msi_desc;
void *handler_data; /* chip 方法使用的数据*/
void *chip_data; /* chip 私有数据 */
struct irqaction *action; /* 行为链表(action list) */
unsigned int status; /* 状态 */
unsigned int depth; /* 关中断次数 */
unsigned int wake_depth; /* 唤醒次数 */
unsigned int irq_count; /* 发生的中断次数 */
unsigned long last_unhandled; /*滞留时间 */
unsigned int irqs_unhandled;
spinlock_t lock; /*自选锁*/
#ifdef CONFIG_SMP
cpumask_var_t affinity;
unsigned int node;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir; /* 在 proc 文件系统中的目录 */
#endif
const char *name;/*名称*/
} ____cacheline_internodealigned_in_smp;
I、Linux中断的申请与释放:在<linux/interrupt.h>, , 实现中断申请接口:
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev);
函数参数说明
unsigned int irq:所要申请的硬件中断号
irq_handler_t handler:中断服务程序的入口地址,中断发生时,系统调用handler这个函数。irq_handler_t为自定义类型,其原型为:
typedef irqreturn_t (*irq_handler_t)(int, void *);
而irqreturn_t的原型为:typedef enum irqreturn irqreturn_t;
enum irqreturn {
IRQ_NONE,/*此设备没有产生中断*/
IRQ_HANDLED,/*中断被处理*/
IRQ_WAKE_THREAD,/*唤醒中断*/
};
在枚举类型irqreturn定义在include/linux/irqreturn.h文件中。
unsigned long flags:中断处理的属性,与中断管理有关的位掩码选项,有一下几组值:
#define IRQF_DISABLED 0x00000020 /*中断禁止*/
#define IRQF_SAMPLE_RANDOM 0x00000040 /*供系统产生随机数使用*/
#define IRQF_SHARED 0x00000080 /*在设备之间可共享*/
#define IRQF_PROBE_SHARED 0x00000100/*探测共享中断*/
#define IRQF_TIMER 0x00000200/*专用于时钟中断*/
#define IRQF_PERCPU 0x00000400/*每CPU周期执行中断*/
#define IRQF_NOBALANCING 0x00000800/*复位中断*/
#define IRQF_IRQPOLL 0x00001000/*共享中断中根据注册时间判断*/
#define IRQF_ONESHOT 0x00002000/*硬件中断处理完后触发*/
#define IRQF_TRIGGER_NONE 0x00000000/*无触发中断*/
#define IRQF_TRIGGER_RISING 0x00000001/*指定中断触发类型:上升沿有效*/
#define IRQF_TRIGGER_FALLING 0x00000002/*中断触发类型:下降沿有效*/
#define IRQF_TRIGGER_HIGH 0x00000004/*指定中断触发类型:高电平有效*/
#define IRQF_TRIGGER_LOW 0x00000008/*指定中断触发类型:低电平有效*/
#define IRQF_TRIGGER_MASK (IRQF_TRIGGER_HIGH | IRQF_TRIGGER_LOW | \
IRQF_TRIGGER_RISING | IRQF_TRIGGER_FALLING)
#define IRQF_TRIGGER_PROBE 0x00000010/*触发式检测中断*/
const char *dev_name:设备描述,表示那一个设备在使用这个中断。
void *dev_id:用作共享中断线的指针.。一般设置为这个设备的设备结构体或者NULL。它是一个独特的标识, 用在当释放中断线时以及可能还被驱动用来指向它自己的私有数据区,来标识哪个设备在中断 。这个参数在真正的驱动程序中一般是指向设备数据结构的指针.在调用中断处理程序的时候它就会传递给中断处理程序的void *dev_id。如果中断没有被共享, dev_id 可以设置为 NULL。
II、释放IRQ
void free_irq(unsigned int irq, void *dev_id);
III、中断线共享的数据结构
struct irqaction {
irq_handler_t handler; /* 具体的中断处理程序 */
unsigned long flags;/*中断处理属性*/
const char *name; /* 名称,会显示在/proc/interreupts 中 */
void *dev_id; /* 设备ID,用于区分共享一条中断线的多个处理程序 */
struct irqaction *next; /* 指向下一个irq_action 结构 */
int irq; /* 中断通道号 */
struct proc_dir_entry *dir; /* 指向proc/irq/NN/name 的入口*/
irq_handler_t thread_fn;/*线程中断处理函数*/
struct task_struct *thread;/*线程中断指针*/
unsigned long thread_flags;/*与线程有关的中断标记属性*/
};
thread_flags参见枚举型
enum {
IRQTF_RUNTHREAD,/*线程中断处理*/
IRQTF_DIED,/*线程中断死亡*/
IRQTF_WARNED,/*警告信息*/
IRQTF_AFFINITY,/*调整线程中断的关系*/
};
多个中断处理程序可以共享同一条中断线,irqaction 结构中的 next 成员用来把共享同一条中断线的所有中断处理程序组成一个单向链表,dev_id 成员用于区分各个中断处理程序。
根据以上内容可以得出中断机制各个数据结构之间的联系如下图所示:
三.中断的处理过程
Linux中断分为两个半部:上半部(tophalf)和下半部(bottom half)。上半部的功能是"登记中断",当一个中断发生时,它进行相应地硬件读写后就把中断例程的下半部挂到该设备的下半部执行队列中去。因此,上半部执行的速度就会很快,可以服务更多的中断请求。但是,仅有"登记中断"是远远不够的,因为中断的事件可能很复杂。因此,Linux引入了一个下半部,来完成中断事件的绝大多数使命。下半部和上半部最大的不同是下半部是可中断的,而上半部是不可中断的,下半部几乎做了中断处理程序所有的事情,而且可以被新的中断打断!下半部则相对来说并不是非常紧急的,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。
中断号的查看可以使用下面的命令:“cat /proc/interrupts”。
Linux实现下半部的机制主要有tasklet和工作队列。
小任务tasklet的实现
其数据结构为struct tasklet_struct,每一个结构体代表一个独立的小任务,定义如下
struct tasklet_struct
{
struct tasklet_struct *next;/*指向下一个链表结构*/
unsigned long state;/*小任务状态*/
atomic_t count;/*引用计数器*/
void (*func)(unsigned long);/*小任务的处理函数*/
unsigned long data;/*传递小任务函数的参数*/
};
state的取值参照下边的枚举型:
enum
{
TASKLET_STATE_SCHED, /* 小任务已被调用执行*/
TASKLET_STATE_RUN /*仅在多处理器上使用*/
};
count域是小任务的引用计数器。只有当它的值为0的时候才能被激活,并其被设置为挂起状态时,才能够被执行,否则为禁止状态。
I、声明和使用小任务tasklet
静态的创建一个小任务的宏有一下两个:
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
这两个宏的区别在于计数器设置的初始值不同,前者可以看出为0,后者为1。为0的表示激活状态,为1的表示禁止状态。其中ATOMIC_INIT宏为:
#define ATOMIC_INIT(i) { (i) }
即可看出就是设置的数字。此宏在include/asm-generic/atomic.h中定义。这样就创建了一个名为name的小任务,其处理函数为func。当该函数被调用的时候,data参数就被传递给它。
II、小任务处理函数程序
处理函数的的形式为:void my_tasklet_func(unsigned long data)。这样DECLARE_TASKLET(my_tasklet, my_tasklet_func, data)实现了小任务名和处理函数的绑定,而data就是函数参数。
III、调度编写的tasklet
调度小任务时引用tasklet_schedule(&my_tasklet)函数就能使系统在合适的时候进行调度。函数原型为:
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
这个调度函数放在中断处理的上半部处理函数中,这样中断申请的时候调用处理函数(即irq_handler_t handler)后,转去执行下半部的小任务。
如果希望使用DECLARE_TASKLET_DISABLED(name,function,data)创建小任务,那么在激活的时候也得调用相应的函数被使能
tasklet_enable(struct tasklet_struct *); //使能tasklet
tasklet_disble(struct tasklet_struct *); //禁用tasklet
tasklet_init(struct tasklet_struct *,void (*func)(unsigned long),unsigned long);
当然也可以调用tasklet_kill(struct tasklet_struct *)从挂起队列中删除一个小任务。清除指定tasklet的可调度位,即不允许调度该tasklet 。
使用tasklet作为下半部的处理中断的设备驱动程序模板如下:
/*定义tasklet和下半部函数并关联*/
void my_do_tasklet(unsigned long);
DECLARE_TASKLET(my_tasklet, my_tasklet_func, 0);
/*中断处理下半部*/
void my_do_tasklet(unsigned long)
{
……/*编写自己的处理事件内容*/
}
/*中断处理上半部*/
irpreturn_t my_interrupt(unsigned int irq,void *dev_id)
{
……
tasklet_schedule(&my_tasklet)/*调度my_tasklet函数,根据声明将去执行my_tasklet_func函数*/
……
}
/*设备驱动的加载函数*/
int __init xxx_init(void)
{
……
/*申请中断, 转去执行my_interrupt函数并传入参数*/
result=request_irq(my_irq,my_interrupt,IRQF_DISABLED,"xxx",NULL);
……
}
/*设备驱动模块的卸载函数*/
void __exit xxx_exit(void)
{
……
/*释放中断*/
free_irq(my_irq,my_interrupt);
……
}
工作队列的实现
工作队列work_struct结构体,位于/include/linux/workqueue.h
typedef void (*work_func_t)(struct work_struct *work);
struct work_struct {
atomic_long_t data; /*传递给处理函数的参数*/
#define WORK_STRUCT_PENDING 0/*这个工作是否正在等待处理标志*/
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; /* 连接所有工作的链表*/
work_func_t func; /* 要执行的函数*/
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
这些结构被连接成链表。当一个工作者线程被唤醒时,它会执行它的链表上的所有工作。工作被执行完毕,它就将相应的work_struct对象从链表上移去。当链表上不再有对象的时候,它就会继续休眠。可以通过DECLARE_WORK在编译时静态地创建该结构,以完成推后的工作。
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
而后边这个宏为一下内容:
#define __WORK_INITIALIZER(n, f) { \
.data = WORK_DATA_INIT(), \
.entry = { &(n).entry, &(n).entry }, \
.func = (f), \
__WORK_INIT_LOCKDEP_MAP(#n, &(n)) \
}
其为参数data赋值的宏定义为:
#define WORK_DATA_INIT() ATOMIC_LONG_INIT(0)
这样就会静态地创建一个名为n,待执行函数为f,参数为data的work_struct结构。同样,也可以在运行时通过指针创建一个工作:
INIT_WORK(struct work_struct *work, void(*func) (void *));
这会动态地初始化一个由work指向的工作队列,并将其与处理函数绑定。宏原型为:
#define INIT_WORK(_work, _func) \
do { \
static struct lock_class_key __key; \
\
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
lockdep_init_map(&(_work)->lockdep_map, #_work, &__key, 0);\
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
在需要调度的时候引用类似tasklet_schedule()函数的相应调度工作队列执行的函数schedule_work(),如:
schedule_work(&work);/*调度工作队列执行*/
如果有时候并不希望工作马上就被执行,而是希望它经过一段延迟以后再执行。在这种情况下,可以调度指定的时间后执行函数:
schedule_delayed_work(&work,delay);函数原型为:
int schedule_delayed_work(struct delayed_work *work, unsigned long delay);
其中是以delayed_work为结构体的指针,而这个结构体的定义是在work_struct结构体的基础上增加了一项timer_list结构体。
struct delayed_work {
struct work_struct work;
struct timer_list timer; /* 延迟的工作队列所用到的定时器,当不需要延迟时初始化为NULL*/
};
这样,便使预设的工作队列直到delay指定的时钟节拍用完以后才会执行。
使用工作队列处理中断下半部的设备驱动程序模板如下:
/*定义工作队列和下半部函数并关联*/
struct work_struct my_wq;
void my_do_work(unsigned long);
/*中断处理下半部*/
void my_do_work(unsigned long)
{
……/*编写自己的处理事件内容*/
}
/*中断处理上半部*/
irpreturn_t my_interrupt(unsigned int irq,void *dev_id)
{
……
schedule_work(&my_wq)/*调度my_wq函数,根据工作队列初始化函数将去执行my_do_work函数*/
……
}
/*设备驱动的加载函数*/
int __init xxx_init(void)
{
……
/*申请中断,转去执行my_interrupt函数并传入参数*/
result=request_irq(my_irq,my_interrupt,IRQF_DISABLED,"xxx",NULL);
……
/*初始化工作队列函数,并与自定义处理函数关联*/
INIT_WORK(&my_irq,(void (*)(void *))my_do_work);
……
}
/*设备驱动模块的卸载函数*/
void __exit xxx_exit(void)
{
……
/*释放中断*/
free_irq(my_irq,my_interrupt);
……
}
Linux中断机制(1)
1、基本输入输出方式
现代体系结构的基本输入输出方式有三种:
(1)程序查询:
CPU周期性询问外部设备是否准备就绪。该方式的明显的缺点就是浪费CPU资源,效率低下。
但是,不要轻易的就认为该方式是一种不好的方式,通常效率低下是由于CPU在大部分时间没事可做造成的,这种轮询方式自有应用它的地方。例如,在网络驱动中,通常接口(Interface)每接收一个报文,就发出一个中断。而对于高速网络,每秒就能接收几千个报文,在这样的负载下,系统性能会受到极大的损害。
为了提高系统性能,内核开发者已经为网络子系统开发了一种可选的基于查询的接口NAPI(代表new API)。当系统拥有一个高流量的高速接口时,系统通常会收集足够多的报文,而不是马上中断CPU。
(2)中断方式
这是现代CPU最常用的与外围设备通信方式。相对于轮询,该方式不用浪费稀缺的CPU资源,所以高效而灵活。中断处理方式的缺点是每传送一个字符都要进行中断,启动中断控制器,还要保留和恢复现场以便能继续原程序的执行,花费的工作量很大,这样如果需要大量数据交换,系统的性能会很低。
(3)DMA方式
通常用于高速设备,设备请求直接访问内存,不用CPU干涉。但是这种方式需要DMA控制器,增加了硬件成本。在进行DMA数据传送之前,DMA控制器会向CPU申请总线控制 权,CPU如果允许,则将控制权交出,因此,在数据交换时,总线控制权由DMA控制器掌握,在传输结束后,DMA控制器将总线控制权交还给CPU。
2、中断概述
2.1、中断向量
X86支持256个中断向量,依次编号为0~255。它们分为两类:
(1)异常,由CPU内部引起的,所以也叫同步中断,不能被CPU屏蔽;它又分为Faults(可更正异常,恢复后重新执行),Traps(返回后执行发生trap指令的后一条指令)和Aborts(无法恢复,系统只能停机);
(2)中断,由外部设备引起的。它又分为可屏蔽中断(INTR)和非可屏蔽中断(NMI)。
Linux对256个中断向量分配如下:
(1)0~31为异常和非屏蔽中断,它实际上被Intel保留。
(2)32~47为可屏蔽中断。
(3)余下的48~255用来标识软中断;Linux只用了其中一个,即128(0x80),用来实现系统调用。当用户程序执行一条int 0x80时,就会陷入内核态,并执行内核函数system_call(),该函数与具体的架构相关。
2.2、可屏蔽中断
X86通过两个级连的8259A中断控制器芯片来管理15个外部中断源,如图所示:
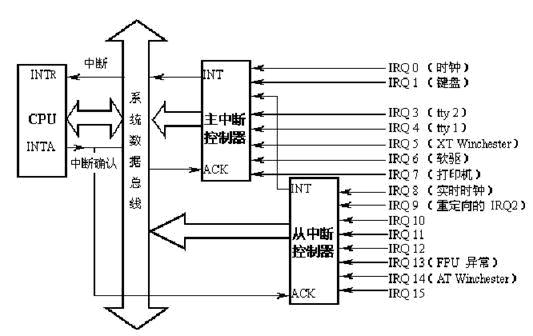
外部设备要使用中断线,首先要申请中断号(IRQ),每条中断线的中断号IRQn对应的中断向量为n+32,IRQ和向量之间的映射可以通过中断控制器商端口来修改。X86下8259A的初始化工作及IRQ与向量的映射是在函数init_8259A()(位于arch/i386/kernel/i8259.c)完成的。
CPU通过INTR引脚来接收8259A发出的中断请求,而且CPU可以通过清除EFLAG的中断标志位(IF)来屏蔽外部中断。当IF=0时,禁止任何外部I/O请求,即关中断(对应指令cli)。另外,中断控制器有一个8位的中断屏蔽寄存器(IMR),每位对应8259A中的一条中断线,如果要禁用某条中断线,相应的位置1即可,要启用,则置0。
IF标志位可以使用指令STI和CLI来设置或清除。并且只有当程序的CPL<=IOPL时才可执行这两条指令,否则将引起一般保护性异常(通常来说,in,ins,out,outs,cli,sti只有在CPL<=IOPL时才能执行,这些指令称为I/O敏感指令)。
以下一些操作也会影响IF标志位:
(1)PUSHF指令将EFLAGS内容存入堆栈,且可以在那里修改。POPF可将已经修改过的内容写入EFLAGS寄存器。
(2)任务切换和IRET指令会加载EFLAGS寄存器。因此,可修改IF标志。
(3)通过中断门处理一个中断时,IF标志位被自动清除,从而禁止可尽屏蔽中断。但是,陷阱门不会复位IF。
2.3、异常及非屏蔽中断
异常就是CPU内部出现的中断,也就是说,在CPU执行特定指令时出现的非法情况。非屏蔽中断就是计算机内部硬件出错时引起的异常情况。从上图可以看出,二者与外部I/O接口没有任何关系。Intel把非屏蔽中断作为异常的一种来处理,因此,后面所提到的异常也包括了非屏蔽中断。在CPU执行一个异常处理程序时,就不再为其他异常或可屏蔽中断请求服务,也就是说,当某个异常被响应后,CPU清除EFLAG的中IF位,禁止任何可屏蔽中断(IF不能禁止异常和非可屏蔽中断)。但如果又有异常产生,则由CPU锁存(CPU具有缓冲异常的能力),待这个异常处理完后,才响应被锁存的异常。我们这里讨论的异常中断向量在0~31之间,不包括系统调用(中断向量为0x80)。
2.4、中断描述符表
2.4.1、中断描述符
在实地址模式中,CPU把内存中从0开始的1K字节作为一个中断向量表。表中的每个表项占四个字节,由两个字节的段地址和两个字节的偏移量组成,这样构成的地址便是相应中断处理程序的入口地址。但是,在保护模式下,由四字节的表项构成的中断向量表显然满足不了要求。这是因为,除了两个字节的段描述符,偏移量必用四字节来表示;要有反映模式切换的信息。因此,在保护模式下,中断向量表中的表项由8个字节组成,中断向量表也改叫做中断描述符表IDT(Interrupt Descriptor Table)。其中的每个表项叫做一个门描述符(gate descriptor),“门”的含义是当中断发生时必须先通过这些门,然后才能进入相应的处理程序。门描述符的一般格式如下:

中断描述符表中可放三类门描述符:
(1)中断门(Interrupt gate)
其类型码为110,它包含一个中断或异常处理程序所在的段选择符和段内偏移。控制权通过中断门进入中断处理程序时,处理器清IF标志,即关中断,以避免嵌套中断的发生。中断门中的DPL(Descriptor Privilege Level)为0,因此,用户态的进程不能访问Intel的中断门。所有的中断处理程序都由中断门激活,并全部限制在内核态。设置中断门的代码如下:
void set_intr_gate(unsigned int n, void *addr)
{ //type=14,dpl=0,selector=__KERNEL_CS
_set_gate(idt_table+n,14,0,addr,__KERNEL_CS);
}
struct desc_struct idt_table[256] __attribute__((__section__(".data.idt"))) = { {0, 0}, };
//描述符结构
struct desc_struct {
unsigned long a,b;
};
其类型码为111,与中断门类似,其唯一的区别是,控制权通过陷阱门进入处理程序时维持IF标志位不变,也就是说,不关中断。其设置代码如下:
{
_set_gate(idt_table+n,15,0,addr,__KERNEL_CS);
}
IDT中的任务门描述符格式与GDT和LDT中的任务门格式相同,含有一个任务TSS段的选择符,该任务用于处理异常或中断,Linux用于处理Double fault。其设置代码如下:
{
_set_gate(idt_table+n,5,0,0,(gdt_entry<<3));
}
此外,在Linux中还有系统门(System gate),用于处理用户态下的异常overflow,bound以及系统调用int 0x80;以及系统中断门(system interrupt gate),用来处理int3,这样汇编指令int3就能在用户态下调用。
{
_set_gate(idt_table+n,15,3,addr,__KERNEL_CS);
}
//设置系统调用门描述符,在trap.c中被trap_init()调用
set_system_gate(SYSCALL_VECTOR,&system_call);
//设置系统中断门
static inline void set_system_intr_gate(unsigned int n, void *addr)
{
_set_gate(idt_table+n, 14, 3, addr, __KERNEL_CS);
}
//位于arch/i386/kernel/traps.c
void __init trap_init(void)
{
set_trap_gate(0,÷_error);
set_intr_gate(1,&debug);
set_intr_gate(2,&nmi);
//系统中断门
set_system_intr_gate(3, &int3); /* int3-5 can be called from all */
//系统门
set_system_gate(4,&overflow);
set_system_gate(5,&bounds);
set_trap_gate(6,&invalid_op);
set_trap_gate(7,&device_not_available);
set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
set_trap_gate(9,&coprocessor_segment_overrun);
set_trap_gate(10,&invalid_TSS);
set_trap_gate(11,&segment_not_present);
set_trap_gate(12,&stack_segment);
set_trap_gate(13,&general_protection);
set_intr_gate(14,&page_fault);
set_trap_gate(15,&spurious_interrupt_bug);
set_trap_gate(16,&coprocessor_error);
set_trap_gate(17,&alignment_check);
#ifdef CONFIG_X86_MCE
set_trap_gate(18,&machine_check);
#endif
set_trap_gate(19,&simd_coprocessor_error);
set_system_gate(SYSCALL_VECTOR,&system_call);
}
中断描述表的最终初始化是init/main.c中的start_kernel()中完成的
{
//陷阱门初始化
trap_init();
//中断门初始化
init_IRQ();
//软中断初始化
softirq_init();
}
void __init init_IRQ(void)
{
//调用init_ISA_irqs
pre_intr_init_hook();
//设置中断门
for (i = 0; i < (NR_VECTORS - FIRST_EXTERNAL_VECTOR); i++) {
int vector = FIRST_EXTERNAL_VECTOR + i;
if (i >= NR_IRQS)
break;
//跳过系统调用的向量
if (vector != SYSCALL_VECTOR)
set_intr_gate(vector, interrupt[i]);
}
}
Linux中断机制(2)
3.1、中断处理入口
由上节可知,中断向量的对应的处理程序位于interrupt数组中,下面来看看interrupt:
342 ENTRY(interrupt)
343 .text
344
345 vector=0
346 ENTRY(irq_entries_start)
347 .rept NR_IRQS #348-354行重复NR_IRQS次
348 ALIGN
349 1: pushl $vector-256 #vector在354行递增
350 jmp common_interrupt #所有的外部中断处理函数的统一部分,以后再讲述
351 .data
352 .long 1b #存储着指向349行的地址,但是随着348行-354被gcc展开,每次的值都不同
353 .text
354 vector=vector+1
355 .endr #与347行呼应
356
357 ALIGN
#公共处理函数
common_interrupt:
SAVE_ALL /*寄存器值入栈*/
movl %esp,%eax /*栈顶指针保存到eax*/
call do_IRQ /*处理中断*/
jmp ret_from_intr /*从中断返回*/
首先342行和352行都处于.data段,虽然看起来它们是隔开的,但实际上被gcc安排在了连续的数据段内存 中,同理在代码段内存中,354行与350行的指令序列也是连续存储的。另外,348-354行会被gcc展开NR_IRQS次,因此每次352行都会存 储一个新的指针,该指针指向每个349行展开的新对象。最后在代码段内存中连续存储了NR_IRQS个代码片断,首地址由 irq_entries_start指向。而在数据段内存中连续存储了NR_IRQS个指针,首址存储在interrupt这个全局变量中。这样,例如 IRQ号是0 (从init_IRQ()调用,它对应的中断向量是FIRST_EXTERNAL_VECTOR)的中断通过中断门后会触发 interrput[0],从而执行:
pushl 0-256
jmp common_interrupt
的代码片断,进入到Linux内核安排好的中断入口路径。
3.2、数据结构
3.2.1、IRQ描述符
Linux支持多个外设共享一个IRQ,同时,为了维护中断向量和中断服务例程(ISR)之间的映射关系,Linux用一个irq_desc_t数据结构来描述,叫做IRQ描述符。除了分配给异常的
32个向量外,其余224(NR_IRQS)个中断向量对应的IRQ构成一个数组irq_desc[],定义如下:
typedef struct irq_desc {
unsigned int status; /* IRQ status */
hw_irq_controller *handler;
struct irqaction *action; /* IRQ action list */
unsigned int depth; /* nested irq disables */
unsigned int irq_count; /* For detecting broken interrupts */
unsigned int irqs_unhandled;
spinlock_t lock;
} ____cacheline_aligned irq_desc_t;
//IRQ描述符表
extern irq_desc_t irq_desc [NR_IRQS];
status:描述IRQ中断线状态,在irq.h中定义。如下:
#define IRQ_DISABLED 2 /* 由设备驱动程序已经禁用了这条IRQ中断线 */
#define IRQ_PENDING 4 /* 一个IRQ已经出现在中断线上,且被应答,但还没有为它提供服务 */
#define IRQ_REPLAY 8 /* 当Linux重新发送一个已被删除的IRQ时 */
#define IRQ_AUTODETECT 16 /* 当进行硬件设备探测时,内核使用这条IRQ中断线 */
#define IRQ_WAITING 32 /*当对硬件设备进行探测时,设置这个状态以标记正在被测试的irq */
#define IRQ_LEVEL 64 /* IRQ level triggered */
#define IRQ_MASKED 128 /* IRQ masked - shouldn't be seen again */
#define IRQ_PER_CPU 256 /* IRQ is per CPU */
action:指向一个单向链表的指针,这个链表就是对中断服务例程进行描述的irqaction结构。下面有描述。
depth:如果启用这条IRQ中断线,depth则为0,如果禁用这条IRQ中断线不止一次,则为一个正数。每当调用一次disable_irq(),该函数就对这个域的值加1;如果depth等于0,该函数就禁用这条IRQ中断线。相反,每当调用enable_irq()函数时,该函数就对这个域的值减1;如果depth变为0,该函数就启用这条IRQ中断线。
lock:保护该数据结构的自旋锁。
IRQ描述符的初始化:
void __init init_ISA_irqs (void)
{
int i;
#ifdef CONFIG_X86_LOCAL_APIC
init_bsp_APIC();
#endif
//初始化8259A
init_8259A(0);
//IRQ描述符的初始化
for (i = 0; i < NR_IRQS; i++) {
irq_desc[i].status = IRQ_DISABLED;
irq_desc[i].action = NULL;
irq_desc[i].depth = 1;
if (i < 16) {
/*
* 16 old-style INTA-cycle interrupts:
*/
irq_desc[i].handler = &i8259A_irq_type;
} else {
/*
* 'high' PCI IRQs filled in on demand
*/
irq_desc[i].handler = &no_irq_type;
}
}
}
3.2.2、中断控制器描述符hw_interrupt_type
这个描述符包含一组指针,指向与特定的可编程中断控制器电路(PIC)打交道的低级I/O例程,定义如下:
struct hw_interrupt_type {
const char * typename;
unsigned int (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*enable)(unsigned int irq);
void (*disable)(unsigned int irq);
void (*ack)(unsigned int irq);
void (*end)(unsigned int irq);
void (*set_affinity)(unsigned int irq, cpumask_t dest);
};
typedef struct hw_interrupt_type hw_irq_controller;
static struct hw_interrupt_type i8259A_irq_type = {
"XT-PIC",
startup_8259A_irq,
shutdown_8259A_irq,
enable_8259A_irq,
disable_8259A_irq,
mask_and_ack_8259A,
end_8259A_irq,
NULL
};
3.2.3、中断服务例程描述符irqaction
为了处理多个设备共享一个IRQ,Linux中引入了irqaction数据结构。定义如下:
struct irqaction {
irqreturn_t (*handler)(int, void *, struct pt_regs *);
unsigned long flags;
cpumask_t mask;
const char *name;
void *dev_id;
struct irqaction *next;
int irq;
struct proc_dir_entry *dir;
};
flags:用一组标志描述中断线与I/O设备之间的关系。
SA_INTERRUPT
中断处理程序必须以禁用中断来执行
SA_SHIRQ
该设备允许其中断线与其他设备共享。
SA_SAMPLE_RANDOM
可以把这个设备看作是随机事件发生源;因此,内核可以用它做随机数产生器。(用户可以从/dev/random 和/dev/urandom设备文件中取得随机数而访问这种特征)
SA_PROBE
内核在执行硬件设备探测时正在使用这条中断线。
name:I/O设备名(通过读取/proc/interrupts文件,可以看到,在列出中断号时也显示设备名。)
dev_id:指定I/O设备的主设备号和次设备号。
next:指向irqaction描述符链表的下一个元素。共享同一中断线的每个硬件设备都有其对应的中断服务例程,链表中的每个元素就是对相应设备及中断服务例程的描述。
irq:IRQ线。
3.2.4、中断服务例程(Interrupt Service Routine)
在Linux中,中断服务例程和中断处理程序(Interrupt Handler)是两个不同的概念。可以这样认为,中断处理程序相当于某个中断向量的总处理程序,它与中断描述表(IDT)相关;中断服务例程(ISR)在中断处理过程被调用,它与IRQ描述符相关,一般来说,它是设备驱动的一部分。
(1) 注册中断服务例程
中断服务例程是硬件驱动的组成部分,如果设备要使用中断,相应的驱动程序在初始化的过程中可以通过调用request_irq函数注册中断服务例程。
/*irq:IRQ号
**handler:中断服务例程
**irqflags:SA_SHIRQ,SA_INTERRUPT或SA_SAMPLE_RANDOM
**devname:设备名称,这些名称会被/proc/irq和/proc/interrupt使用
**dev_id:主要用于设备共享
*/
int request_irq(unsigned int irq,
irqreturn_t (*handler)(int, void *, struct pt_regs *),
unsigned long irqflags, const char * devname, void *dev_id)
{
struct irqaction * action;
int retval;
/*
* Sanity-check: shared interrupts must pass in a real dev-ID,
* otherwise we'll have trouble later trying to figure out
* which interrupt is which (messes up the interrupt freeing
* logic etc).
*/
if ((irqflags & SA_SHIRQ) && !dev_id)
return -EINVAL;
if (irq >= NR_IRQS)
return -EINVAL;
if (!handler)
return -EINVAL;
//分配数据结构空间
action = kmalloc(sizeof(struct irqaction), GFP_ATOMIC);
if (!action)
return -ENOMEM;
action->handler = handler;
action->flags = irqflags;
cpus_clear(action->mask);
action->name = devname;
action->next = NULL;
action->dev_id = dev_id;
//调用setup_irq完成真正的注册,驱动程序也可以调用它来完成注册
retval = setup_irq(irq, action);
if (retval)
kfree(action);
return retval;
}
static int __init rtc_init(void)
{
request_irq(RTC_IRQ, rtc_int_handler_ptr, SA_INTERRUPT, "rtc", NULL);
}
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, CPU_MASK_NONE, "timer", NULL, NULL};
//由time_init()调用
void __init time_init_hook(void)
{
setup_irq(0, &irq0);
}
整个流程如下:
所有I/O中断处理函数的过程如下:
(1)把IRQ值和所有寄存器值压入内核栈;
(2) 给与IRQ中断线相连的中断控制器发送一个应答,这将允许在这条中断线上进一步发出中断请求;
(3)执行共享这个IRQ的所有设备的中断服务例程(ISR);
(4)跳到ret_from_intr()处结束。
3.3.1、保存现场与恢复现场
中断处理程序做的第一件事就是保存现场,由宏SAVE_ALL(位于entry.S中)完成:
cld; \
pushl %es; \
pushl %ds; \
pushl %eax; \
pushl %ebp; \
pushl %edi; \
pushl %esi; \
pushl %edx; \
pushl %ecx; \
pushl %ebx; \
movl $(__USER_DS), %edx; \
movl %edx, %ds; \
movl %edx, %es;
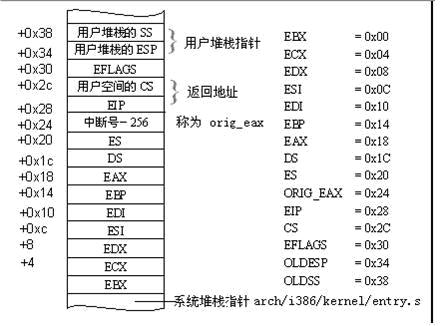
恢复现场由宏RESTORE_ALL完成
RESTORE_REGS \
addl $4, %esp; \
1: iret; \
.section .fixup,"ax"; \
2: sti; \
movl $(__USER_DS), %edx; \
movl %edx, %ds; \
movl %edx, %es; \
movl $11,%eax; \
call do_exit; \
.previous; \
.section __ex_table,"a";\
.align 4; \
.long 1b,2b; \
.previous
该函数的大致内容如下:
fastcall unsigned int do_IRQ(struct pt_regs *regs)
{
/* high bits used in ret_from_ code */
//取得中断号
int irq = regs->orig_eax & 0xff;
//增加代表嵌套中断数量的计数器的值,该值保存在current->thread_info->preempt_count
irq_enter();
__do_IRQ(irq, regs);
//减中断计数器preempt_count的值,检查是否有软中断要处理
irq_exit();
}
long ebx;
long ecx;
long edx;
long esi;
long edi;
long ebp;
long eax;
int xds;
int xes;
long orig_eax;
long eip;
int xcs;
long eflags;
long esp;
int xss;
};
3.3.3、__do_IRQ()函数
该函数的内容如下:
fastcall unsigned int __do_IRQ(unsigned int irq, struct pt_regs *regs)
{
irq_desc_t *desc = irq_desc + irq;
struct irqaction * action;
unsigned int status;
kstat_this_cpu.irqs[irq]++;
if (desc->status & IRQ_PER_CPU) {
irqreturn_t action_ret;
/*
* No locking required for CPU-local interrupts:
*/
//确认中断
desc->handler->ack(irq);
action_ret = handle_IRQ_event(irq, regs, desc->action);
if (!noirqdebug)
note_interrupt(irq, desc, action_ret);
desc->handler->end(irq);
return 1;
}
/*加自旋锁.对于多CPU系统,这是必须的,因为同类型的其它中断可能产生,并被其它的CPU处理,
**没有自旋锁,IRQ描述符将被多个CPU同时访问.
*/
spin_lock(&desc->lock);
/*确认中断.对于8259A PIC,由mask_and_ack_8259A()完成确认,并禁用当前IRQ线.
**屏蔽中断是为了确保该中断处理程序结束前,CPU不会又接受这种中断.虽然,CPU在处理中断会自动
**清除eflags中的IF标志,但是在执行中断服务例程前,可能重新激活本地中断.见handle_IRQ_event.
*/
/*在多处理器上,应答中断依赖于具体的中断类型.可能由ack方法做,也可能由end方法做.不管怎样,在中断处理结束
*前,本地APIC不再接收同样的中断,尽管这种中断可以被其它CPU接收.
*/
desc->handler->ack(irq);
/*
* REPLAY is when Linux resends an IRQ that was dropped earlier
* WAITING is used by probe to mark irqs that are being tested
*/
//清除IRQ_REPLAY和IRQ_WAITING标志
status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
/* IRQ_PENDING表示一个IRQ已经出现在中断线上,且被应答,但还没有为它提供服务 */
status |= IRQ_PENDING; /* we _want_ to handle it */
/*
* If the IRQ is disabled for whatever reason, we cannot
* use the action we have.
*/
action = NULL;
/*现在开始检查是否真的需要处理中断.在三种情况下什么也不做.
*(1)IRQ_DISABLED被设置.即使在相应的IRQ线被禁止的情况下,do_IRQ()也可能执行.
*(2)IRQ_INPROGRESS被设置时,在多CPU系统中,表示其它CPU正在处理同样中断的前一次发生.Linux中,同类型
*中断的中断服务例程由同一个CPU处理.这样使得中断服务例程不必是可重入的(在同一CPU上串行执行).
*
*(3)action==NULL.此时,直接跳到out处执行.
*/
if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
action = desc->action;
//清除IRQ_PENDING标志
status &= ~IRQ_PENDING; /* we commit to handling */
/*表示当前CPU正在处理该中断,其它CPU不应该处理同样的中断,而应该让给本CPU处理.一旦设置
*IRQ_INPROGRESS,其它CPU即使进行do_IRQ,也不会执行该程序段,则action==NULL,则其它CPU什么也不做.
*当调用handle_IRQ_event执行中断服务例程时,由于释放了自旋锁,其它CPU可能接受到同类型的中断(本CPU
*不会接受同类型中断),而进入do_IRQ(),并设置IRQ_PENDING.
*/
status |= IRQ_INPROGRESS; /* we are handling it */
}
desc->status = status;
/*
* If there is no IRQ handler or it was disabled, exit early.
* Since we set PENDING, if another processor is handling
* a different instance of this same irq, the other processor
* will take care of it.
*/
if (unlikely(!action))
goto out;
/*
* Edge triggered interrupts need to remember
* pending events.
* This applies to any hw interrupts that allow a second
* instance of the same irq to arrive while we are in do_IRQ
* or in the handler. But the code here only handles the _second_
* instance of the irq, not the third or fourth. So it is mostly
* useful for irq hardware that does not mask cleanly in an
* SMP environment.
*/
for (;;) {
irqreturn_t action_ret;
//释放自旋锁
spin_unlock(&desc->lock);
action_ret = handle_IRQ_event(irq, regs, action);
//加自旋锁
spin_lock(&desc->lock);
if (!noirqdebug)
note_interrupt(irq, desc, action_ret);
/*如果此时IRQ_PENDING处于清除状态,说明中断服务例程已经执行完毕,退出循环.反之,说明在执行中断服务例程时,
*其它CPU进入过do_IRQ,并设置了IRQ_PENDING.也就是说其它CPU收到了同类型的中断.此时,应该清除
*IRQ_INPROGRESS,并重新循环,执行中断服务例程,处理其它CPU收到的中断.
*/
if (likely(!(desc->status & IRQ_PENDING)))
break;
desc->status &= ~IRQ_PENDING;
}
/*所有中断处理完毕,则清除IRQ_INPROGRESS*/
desc->status &= ~IRQ_INPROGRESS;
out:
/*
* The ->end() handler has to deal with interrupts which got
* disabled while the handler was running.
*/
//结束中断处理.对end_8259A_irq()仅仅是重新激活中断线.
/*对于多处器,end应答中断(如果ack方法还没有做的话)
*/
desc->handler->end(irq);
//最后,释放自旋锁,
spin_unlock(&desc->lock);
return 1;
}
//kernel/irq/handle.c
fastcall int handle_IRQ_event(unsigned int irq, struct pt_regs *regs,
struct irqaction *action)
{
int ret, retval = 0, status = 0;
//开启本地中断,对于单CPU,仅仅是sti指令
if (!(action->flags & SA_INTERRUPT))
local_irq_enable();
//依次调用共享该中断向量的服务例程
do {
//调用中断服务例程
ret = action->handler(irq, action->dev_id, regs);
if (ret == IRQ_HANDLED)
status |= action->flags;
retval |= ret;
action = action->next;
} while (action);
if (status & SA_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
//关本地中断,对于单CPU,为cli指令
local_irq_disable();
return retval;
}
Linux中断机制(3)
在中断处理过程中,不能睡眠。另外,它运行的时候,会把当前中断线在所有处理器上都屏蔽(在ack中完成屏蔽);更糟糕的情况是,如果一个处理程序是SA_INTERRUPT类型,它执行的时候会禁上所有本地中断(通过cli指令完成),所以,中断处理应该尽可能快的完成。所以Linux把中断处理分为上半部和下半部。
上半部由中断处理程序完成,它通常完成一些和硬件相关的操作,比如对中断的到达的确认。有时它还会从硬件拷贝数据,这些工作对时间非常敏感,只能靠中断处理程序自己完成。而把其它工作放到下半部实现。
下半部的执行不需要一个确切的时间,它会在稍后系统不太繁忙时执行。下半部执行的关键在于运行的时候允许响应所有的中断。最早,Linux用”bottom half”实现下半部,这种机制简称BH,但是即使属于不同的处理器,也不允许任何两个bottom half同时执行,这种机制简单,但是却有性能瓶颈。不久,又引入任务队列(task queue)机制来实现下半部,但该机制仍不够灵活,没法代替整个BH接口。
从2.3开始,内核引入软中断(softirqs)和tasklet,并完全取代了BH。2.5中,BH最终舍去,在2.6中,内核用有三种机制实现下半部:软中断,tasklet和工作队列。Tasklet是基于软中断实现的。软中断可以在多个CPU上同时执行,即使它们是同一类型的,所以,软中断处理程序必须是可重入的,或者显示的用自旋锁保护相应的数据结构。而相同的tasklet不能同时在多个CPU上执行,所以tasklet不必是可重入的;但是,不同类型的tasklet可以在多个CPU上同时执行。一般来说,tasklet比较常用,它可以处理绝大部分的问题;而软中断用得比较少,但是对于时间要求较高的地方,比如网络子系统,常用软中断处理下半部工作。
4.1、软中断
内核2.6中定义了6种软中断:

下标越低,优先级越高。
4.1.1、数据结构
(1)软中断向量
struct softirq_action
{
void (*action)(struct softirq_action *); //待执行的函数
void *data; //传给函数的参数
};
//kernel/softirq.c
//软中断向量数组
static struct softirq_action softirq_vec[32] __cacheline_aligned_in_smp;
(2) preempt_count字段
位于任务描述符的preempt_count是用来跟踪内核抢占和内核控制路径嵌套关键数据。其各个位的含义如下:
位 描述
0——7 preemption counter,内核抢占计数器(最大值255)
8——15 softirq counter,软中断计数器(最大值255)
16——27 hardirq counter,硬件中断计数器(最大值4096)
28 PREEMPT_ACTIVE标志
第一个计数用来表示内核抢占被关闭的次数,0表示可以抢占。第二个计数器表示推迟函数(下半部)被关闭的次数,0表示推迟函数打开。第三个计数器表示本地CPU中断嵌套的层数,irq_enter()增加该值,irq_exit减该值。
宏in_interrupt()检查current_thread_info->preempt_count的hardirq和softirq来断定是否处于中断上下文。如果这两个计数器之一为正,则返回非零。
(3) 软中断控制/状态结构
softirq_vec是个全局量,系统中每个CPU所看到的是同一个数组。但是,每个CPU各有其自己的“软中断控制/状态”结构,这些数据结构形成一个以CPU编号为下标的数组irq_stat[](定义在include/asm-i386/hardirq.h中)
unsigned int __softirq_pending;
unsigned long idle_timestamp;
unsigned int __nmi_count; /* arch dependent */
unsigned int apic_timer_irqs; /* arch dependent */
} ____cacheline_aligned irq_cpustat_t;
//位于kernel/softirq.c
irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
可以通过open_softirq注册软中断处理程序:
//nr:软中断的索引号
// softirq_action:处理函数
//data:传递给处理函数的参数值
void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
{
softirq_vec[nr].data = data;
softirq_vec[nr].action = action;
}
//软中断初始化
void __init softirq_init(void)
{
open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
}
4.1.3、触发软中断
raise_softirq会将软中断设置为挂起状态,并在下一次运行do_softirq中投入运行。
void fastcall raise_softirq(unsigned int nr)
{
unsigned long flags;
//保存IF值,并关中断
local_irq_save(flags);
//调用wakeup_softirqd()
raise_softirq_irqoff(nr);
//恢复IF值
local_irq_restore(flags);
}
inline fastcall void raise_softirq_irqoff(unsigned int nr)
{
//把软中断设置为挂起状态
__raise_softirq_irqoff(nr);
//唤醒内核线程
if (!in_interrupt())
wakeup_softirqd();
}
在中断服务例程中触发软中断是最常见的形式。而中断服务例程通常作为设备驱动的一部分。例如,对于网络设备,当接口收到数据时,会产生一个中断,在中断服务例程中,最终会调用netif_rx函数处理接到的数据,而netif_rx作相应处理,最终以触发一个软中断结束处理。之后,内核在执行中断处理任务后,会调用do_softirq()。于是软中断就通过软中断处理函数去处理留给它的任务。
4.1.4、软中断执行
(1) do_softirq()函数
asmlinkage void do_softirq(void)
{
//处于中断上下文,表明软中断是在中断上下文中触发的,或者软中断被关闭
/*这个宏限制了软中断服务例程既不能在一个硬中断服务例程内部执行,
*也不能在一个软中断服务例程内部执行(即嵌套)。但这个函数并没有对中断服务例程的执行
*进行“串行化”限制。这也就是说,不同的CPU可以同时进入对软中断服务例程的执行,每个CPU
*分别执行各自所请求的软中断服务。从这个意义上说,软中断服务例程的执行是“并发的”、多序的。
*但是,这些软中断服务例程的设计和实现必须十分小心,不能让它们相互干扰(例如通过共享的全局变量)。
*/
if (in_interrupt())
return;
//保存IF值,并关中断
local_irq_save(flags);
//调用__do_softirq
asm volatile(
" xchgl %%ebx,%%esp \n"
" call __do_softirq \n"
" movl %%ebx,%%esp \n"
: "=b"(isp)
: "0"(isp)
: "memory", "cc", "edx", "ecx", "eax"
);
//恢复IF值
local_irq_restore(flags);
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
/*最多迭代执行10次.在执行软中断的过程中,由于允许中断,所以新的软中断可能产生.为了使推迟函数能够在
*较短的时间延迟内执行,__do_softirq会执行所有挂起的软中断,这可能会执行太长的时间而大大延迟返回用户
*空间的时间.所以,__do_softirq最多允许10次迭代.剩下的软中断在软中断内核线程ksoftirqd中处理.
*/
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
//用局部变量保存软件中断位图
pending = local_softirq_pending();
/*增加softirq计数器的值.由于执行软中断时允许中断,当do_IRQ调用irq_exit时,另一个__do_softirq实例可能
*开始执行.这是不允许的,推迟函数必须在CPU上串行执行.
*/
local_bh_disable();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
//重置软中断位图,使得新的软中断可以发生
local_softirq_pending() = 0;
//开启本地中断,执行软中断时,允许中断的发生
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
//执行软中断处理函数
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
pending >>= 1;
} while (pending);
//关闭中断
local_irq_disable();
//再一次检查软中断位图,因为在执行软中断处理函数时,新的软中断可能产生.
pending = local_softirq_pending();
if (pending && --max_restart)
goto restart;
/*如果还有多的软中断没有处理,通过wakeup_softirqd唤醒内核线程处理本地CPU余下的软中断.
*/
if (pending)
wakeup_softirqd();
//减softirq counter的值
__local_bh_enable();
}
内核会周期性的检查是否有挂起的软中断,它们位于内核代码的以下几个点:
(1)内核调用local_bh_enable()函数打开本地CPU的软中断:
void local_bh_enable(void)
{
preempt_count() -= SOFTIRQ_OFFSET - 1;
if (unlikely(!in_interrupt() && local_softirq_pending()))
do_softirq(); //软中断处理
//……
}
(3)内核线程ksoftirqd被唤醒。
(4) smp_apic_timer_interrupt()完成处理本地时钟中断。
Linux内核抢占与中断返回
一般来说,CPU在任何时刻都处于以下三种情况之一:
(1)运行于用户空间,执行用户进程;
(2)运行于内核空间,处于进程上下文;
(3)运行于内核空间,处于中断上下文。
应用程序通过系统调用陷入内核,此时处于进程上下文。现代几乎所有的CPU体系结构都支持中断。当外部设备产生中断,向CPU发送一个异步信号,CPU调用相应的中断处理程序来处理该中断,此时CPU处于中断上下文。
在进程上下文中,可以通过current关联相应的任务。进程以进程上下文的形式运行在内核空间,可以发生睡眠,所以在进程上下文中,可以使作信号量(semaphore)。实际上,内核经常在进程上下文中使用信号量来完成任务之间的同步,当然也可以使用锁。
中断上下文不属于任何进程,它与current没有任何关系(尽管此时current指向被中断的进程)。由于没有进程背景,在中断上下文中不能发生睡眠,否则又如何对它进行调度。所以在中断上下文中只能使用锁进行同步,正是因为这个原因,中断上下文也叫做原子上下文(atomic context)(关于同步以后再详细讨论)。在中断处理程序中,通常会禁止同一中断,甚至会禁止整个本地中断,所以中断处理程序应该尽可能迅速,所以又把中断处理分成上部和下部(关于中断以后再详细讨论)。
2、上下文切换
上下文切换,也就是从一个可执行进程切换到另一个可执行进程。上下文切换由函数context_switch()函数完成,该函数位于kernel/sched.c中,它由进程调度函数schedule()调用。
task_t * context_switch(runqueue_t *rq, task_t *prev, task_t *next)
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (unlikely(!mm)) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
if (unlikely(!prev->mm)) {
prev->active_mm = NULL;
WARN_ON(rq->prev_mm);
rq->prev_mm = oldmm;
}
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
return prev;
}
2.2、用户抢占
当内核即将返回用户空间时,内核会检查need_resched是否设置,如果设置,则调用schedule(),此时,发生用户抢占。一般来说,用户抢占发生几下情况:
(1)从系统调用返回用户空间;
(2)从中断(异常)处理程序返回用户空间。
2.3、内核抢占
内核从2.6开始就支持内核抢占,对于非内核抢占系统,内核代码可以一直执行,直到完成,也就是说当进程处于内核态时,是不能被抢占的(当然,运行于内核态的进程可以主动放弃CPU,比如,在系统调用服务例程中,由于内核代码由于等待资源而放弃CPU,这种情况叫做计划性进程切换(planned process switch))。但是,对于由异步事件(比如中断)引起的进程切换,抢占式内核与非抢占式是有区别的,对于前者叫做强制性进程切换(forced process switch)。
为了支持内核抢占,内核引入了preempt_count字段,该计数初始值为0,每当使用锁时加1,释放锁时减1。当preempt_count为0时,表示内核可以被安全的抢占,大于0时,则禁止内核抢占。该字段对应三个不同的计数器(见软中断一节),也就是说在以下三种任何一种情况,该字段的值都会大于0。
(1) 内核执行中断处理程序时,通过irq_enter增加中断计数器的值;
#define irq_enter() (preempt_count() += HARDIRQ_OFFSET)
(2) 可延迟函数被禁止(执行软中断和tasklet时经常如此,由local_bh_disable完成;
(3) 通过把抢占计数器设置为正而显式禁止内核抢占,由preempt_disable完成。
当从中断返回内核空间时,内核会检preempt_count和need_resched的值(返回用户空间时只需要检查need_resched),如查preempt_count为0且need_resched设置,则调用schedule(),完成任务抢占。一般来说,内核抢占发生以下情况:
(1) 从中断(异常)返回时,preempt_count为0且need_resched置位(见从中断返回);
(2) 在异常处理程序中(特别是系统调用)调用preempt_enable()来允许内核抢占发生;
#define preempt_enable() \
do { \
//抢占计数器值减1
preempt_enable_no_resched(); \
//检查是否需要进行内核抢占调度,见(3)
preempt_check_resched(); \
} while (0)
void local_bh_enable(void)
{
WARN_ON(irqs_disabled());
/*
* Keep preemption disabled until we are done with
* softirq processing:
*/
//软中断计数器值减1
preempt_count() -= SOFTIRQ_OFFSET - 1;
if (unlikely(!in_interrupt() && local_softirq_pending()))
do_softirq(); //软中断处理
//抢占计数据器值减1
dec_preempt_count();
//检查是否需要进行内核抢占调度
preempt_check_resched();
}
//include/linux/preempt.h
#define preempt_check_resched() \
do { \
//检查need_resched
if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) \
//抢占调度
preempt_schedule(); \
} while (0)
//kernel/sched.c
asmlinkage void __sched preempt_schedule(void)
{
struct thread_info *ti = current_thread_info();
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
//检查是否允许抢占,本地中断关闭,或者抢占计数器值不为0时不允许抢占
if (unlikely(ti->preempt_count || irqs_disabled()))
return;
need_resched:
ti->preempt_count = PREEMPT_ACTIVE;
//发生调度
schedule();
ti->preempt_count = 0;
/* we could miss a preemption opportunity between schedule and now */
barrier();
if (unlikely(test_thread_flag(TIF_NEED_RESCHED)))
goto need_resched;
}
5、从中断返回
当内核从中断返回时,应当考虑以下几种情况:
(1) 内核控制路径并发执行的数量:如果为1,则CPU返回用户态。
(2) 挂起进程的切换请求:如果有挂起请求,则进行进程调度;否则,返回被中断的进程。
(3) 待处理信号:如果有信号发送给当前进程,则必须进行信号处理。
(4) 单步调试模式:如果调试器正在跟踪当前进程,在返回用户态时必须恢复单步模式。
(5) Virtual-8086模式:如果中断时CPU处于虚拟8086模式,则进行特殊的处理。
4.1从中断返回
中断返回点为ret_from-intr:
ret_from_intr:
GET_THREAD_INFO(%ebp)
movl EFLAGS(%esp), %eax # mix EFLAGS and CS
movb CS(%esp), %al
testl $(VM_MASK | 3), %eax #是否运行在VM86模式或者用户态
/*中断或异常发生时,处于内核空间,则返回内核空间;否则返回用户空间*/
jz resume_kernel # returning to kernel or vm86-space
5.1.1、返回内核态
/*返回内核空间,先检查preempt_count,再检查need_resched*/
ENTRY(resume_kernel)
/*是否可以抢占,即preempt_count是否为0*/
cmpl $0,TI_preempt_count(%ebp) # non-zero preempt_count ?
jnz restore_all #不能抢占,则恢复被中断时处理器状态
need_resched:
movl TI_flags(%ebp), %ecx # need_resched set ?
testb $_TIF_NEED_RESCHED, %cl #是否需要重新调度
jz restore_all #不需要重新调度
testl $IF_MASK,EFLAGS(%esp) # 发生异常则不调度
jz restore_all
#将最大值赋值给preempt_count,表示不允许再次被抢占
movl $PREEMPT_ACTIVE,TI_preempt_count(%ebp)
sti
call schedule #调度函数
cli
movl $0,TI_preempt_count(%ebp) #preempt_count还原为0
#跳转到need_resched,判断是否又需要发生被调度
jmp need_resched
#endif
ENTRY(resume_userspace) #返回用户空间,中断或异常发生时,任务处于用户空间
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx # is there any work to be done on
# int/exception return?
jne work_pending #还有其它工作要做
jmp restore_all #所有工作都做完,则恢复处理器状态
#恢复处理器状态
restore_all:
RESTORE_ALL
# perform work that needs to be done immediately before resumption
ALIGN
#完成其它工作
work_pending:
testb $_TIF_NEED_RESCHED, %cl #检查是否需要重新调度
jz work_notifysig #不需要重新调度
#需要重新调度
work_resched:
call schedule #调度进程
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
/*检查是否还有其它的事要做*/
andl $_TIF_WORK_MASK, %ecx # is there any work to be done other
# than syscall tracing?
jz restore_all #没有其它的事,则恢复处理器状态
testb $_TIF_NEED_RESCHED, %cl
jnz work_resched #如果need_resched再次置位,则继续调度
#VM和信号检测
work_notifysig: # deal with pending signals and
# notify-resume requests
testl $VM_MASK, EFLAGS(%esp) #检查是否是VM模式
movl %esp, %eax
jne work_notifysig_v86 # returning to kernel-space or
# vm86-space
xorl %edx, %edx
#进行信号处理
call do_notify_resume
jmp restore_all
ALIGN
work_notifysig_v86:
pushl %ecx # save ti_flags for do_notify_resume
call save_v86_state # %eax contains pt_regs pointer
popl %ecx
movl %eax, %esp
xorl %edx, %edx
call do_notify_resume #信号处理
jmp restore_all
异常返回点为ret_from_exception:
ALIGN
ret_from_exception:
preempt_stop /*相当于cli,从中断返回时,在handle_IRQ_event已经关中断,不需要这步*/
6、从系统调用返回
ENTRY(system_call)
pushl %eax # save orig_eax
SAVE_ALL
GET_THREAD_INFO(%ebp)
# system call tracing in operation
testb $(_TIF_SYSCALL_TRACE|_TIF_SYSCALL_AUDIT),TI_flags(%ebp)
jnz syscall_trace_entry
cmpl $(nr_syscalls), %eax
jae syscall_badsys
syscall_call:
#调用相应的函数
call *sys_call_table(,%eax,4)
movl %eax,EAX(%esp) # store the return value,返回值保存到eax
#系统调用返回
syscall_exit:
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
testw $_TIF_ALLWORK_MASK, %cx # current->work,检查是否还有其它工作要完成
jne syscall_exit_work
#恢复处理器状态
restore_all:
RESTORE_ALL
#做其它工作
syscall_exit_work:
#检查是否系统调用跟踪,审计,单步执行,不需要则跳到work_pending(进行调度,信号处理)
testb $(_TIF_SYSCALL_TRACE|_TIF_SYSCALL_AUDIT|_TIF_SINGLESTEP), %cl
jz work_pending
sti # could let do_syscall_trace() call
# schedule() instead
movl %esp, %eax
movl $1, %edx
#系统调用跟踪
call do_syscall_trace
#返回用户空间
jmp resume_userspace
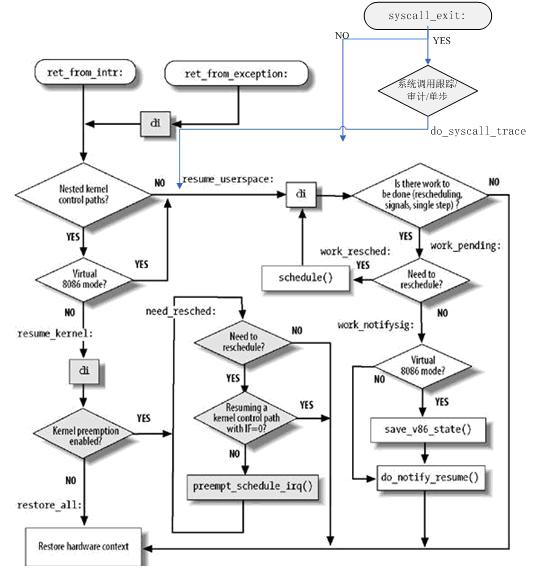
Linux内核中常见内存分配函数
1. 原理说明
Linux内核中采用了一种同时适用于32位和64位系统的内存分页模型,对于32位系统来说,两级页表足够用了,而在x86_64系统中,用到了四级页表,如图2-1所示。四级页表分别为:
l 页全局目录(Page Global Directory)
l 页上级目录(Page Upper Directory)
l 页中间目录(Page Middle Directory)
l 页表(Page Table)
页全局目录包含若干页上级目录的地址,页上级目录又依次包含若干页中间目录的地址,而页中间目录又包含若干页表的地址,每一个页表项指向一个页框。Linux中采用4KB大小的页框作为标准的内存分配单元。
多级分页目录结构
1.1. 伙伴系统算法
在实际应用中,经常需要分配一组连续的页框,而频繁地申请和释放不同大小的连续页框,必然导致在已分配页框的内存块中分散了许多小块的空闲页框。这样,即使这些页框是空闲的,其他需要分配连续页框的应用也很难得到满足。
为了避免出现这种情况,Linux内核中引入了伙伴系统算法(buddy system)。把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍。
假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找,如果仍然没有,则返回错误。
页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
1.2. slab分配器
slab分配器源于 Solaris 2.4 的分配算法,工作于物理内存页框分配器之上,管理特定大小对象的缓存,进行快速而高效的内存分配。
slab分配器为每种使用的内核对象建立单独的缓冲区。Linux 内核已经采用了伙伴系统管理物理内存页框,因此 slab分配器直接工作于伙伴系统之上。每种缓冲区由多个 slab 组成,每个 slab就是一组连续的物理内存页框,被划分成了固定数目的对象。根据对象大小的不同,缺省情况下一个 slab 最多可以由 1024个页框构成。出于对齐等其它方面的要求,slab 中分配给对象的内存可能大于用户要求的对象实际大小,这会造成一定的内存浪费。
2. 常用内存分配函数
2.1. __get_free_pages
unsigned long __get_free_pages(gfp_tgfp_mask, unsigned int order)
__get_free_pages函数是最原始的内存分配方式,直接从伙伴系统中获取原始页框,返回值为第一个页框的起始地址。__get_free_pages在实现上只是封装了alloc_pages函数,从代码分析,alloc_pages函数会分配长度为1<<order的连续页框块。order参数的最大值由include/linux/Mmzone.h文件中的MAX_ORDER宏决定,在默认的2.6.18内核版本中,该宏定义为10。也就是说在理论上__get_free_pages函数一次最多能申请1<<10 * 4KB也就是4MB的连续物理内存。但是在实际应用中,很可能因为不存在这么大量的连续空闲页框而导致分配失败。在测试中,order为10时分配成功,order为11则返回错误。
2.2. kmem_cache_alloc
struct kmem_cache *kmem_cache_create(constchar *name, size_t size,
size_talign, unsigned long flags,
void(*ctor)(void*, struct kmem_cache *, unsigned long),
void(*dtor)(void*, struct kmem_cache *, unsigned long))
void *kmem_cache_alloc(struct kmem_cache *c,gfp_t flags)
kmem_cache_create/ kmem_cache_alloc是基于slab分配器的一种内存分配方式,适用于反复分配释放同一大小内存块的场合。首先用kmem_cache_create创建一个高速缓存区域,然后用kmem_cache_alloc从该高速缓存区域中获取新的内存块。 kmem_cache_alloc一次能分配的最大内存由mm/slab.c文件中的MAX_OBJ_ORDER宏定义,在默认的2.6.18内核版本中,该宏定义为5,于是一次最多能申请1<<5 * 4KB也就是128KB的连续物理内存。分析内核源码发现,kmem_cache_create函数的size参数大于128KB时会调用BUG()。测试结果验证了分析结果,用kmem_cache_create分配超过128KB的内存时使内核崩溃。
2.3. kmalloc
void *kmalloc(size_t size, gfp_t flags)
kmalloc是内核中最常用的一种内存分配方式,它通过调用kmem_cache_alloc函数来实现。kmalloc一次最多能申请的内存大小由include/linux/Kmalloc_size.h的内容来决定,在默认的2.6.18内核版本中,kmalloc一次最多能申请大小为131702B也就是128KB字节的连续物理内存。测试结果表明,如果试图用kmalloc函数分配大于128KB的内存,编译不能通过。
2.4. vmalloc
void *vmalloc(unsigned long size)
前面几种内存分配方式都是物理连续的,能保证较低的平均访问时间。但是在某些场合中,对内存区的请求不是很频繁,较高的内存访问时间也可以接受,这是就可以分配一段线性连续,物理不连续的地址,带来的好处是一次可以分配较大块的内存。图3-1表示的是vmalloc分配的内存使用的地址范围。vmalloc对一次能分配的内存大小没有明确限制。出于性能考虑,应谨慎使用vmalloc函数。在测试过程中,最大能一次分配1GB的空间。
Linux内核部分内存分布
2.5. dma_alloc_coherent
void *dma_alloc_coherent(struct device *dev,size_t size,
ma_addr_t*dma_handle, gfp_t gfp)
DMA是一种硬件机制,允许外围设备和主存之间直接传输IO数据,而不需要CPU的参与,使用DMA机制能大幅提高与设备通信的吞吐量。DMA操作中,涉及到CPU高速缓存和对应的内存数据一致性的问题,必须保证两者的数据一致,在x86_64体系结构中,硬件已经很好的解决了这个问题,dma_alloc_coherent和__get_free_pages函数实现差别不大,前者实际是调用__alloc_pages函数来分配内存,因此一次分配内存的大小限制和后者一样。__get_free_pages分配的内存同样可以用于DMA操作。测试结果证明,dma_alloc_coherent函数一次能分配的最大内存也为4M。
2.6. ioremap
void * ioremap (unsigned long offset,unsigned long size)
ioremap是一种更直接的内存“分配”方式,使用时直接指定物理起始地址和需要分配内存的大小,然后将该段物理地址映射到内核地址空间。ioremap用到的物理地址空间都是事先确定的,和上面的几种内存分配方式并不太一样,并不是分配一段新的物理内存。ioremap多用于设备驱动,可以让CPU直接访问外部设备的IO空间。ioremap能映射的内存由原有的物理内存空间决定,所以没有进行测试。
2.7. Boot Memory
如果要分配大量的连续物理内存,上述的分配函数都不能满足,就只能用比较特殊的方式,在Linux内核引导阶段来预留部分内存。
2.7.1. 在内核引导时分配内存
void* alloc_bootmem(unsigned long size)
可以在Linux内核引导过程中绕过伙伴系统来分配大块内存。使用方法是在Linux内核引导时,调用mem_init函数之前用alloc_bootmem函数申请指定大小的内存。如果需要在其他地方调用这块内存,可以将alloc_bootmem返回的内存首地址通过EXPORT_SYMBOL导出,然后就可以使用这块内存了。这种内存分配方式的缺点是,申请内存的代码必须在链接到内核中的代码里才能使用,因此必须重新编译内核,而且内存管理系统看不到这部分内存,需要用户自行管理。测试结果表明,重新编译内核后重启,能够访问引导时分配的内存块。
2.7.2. 通过内核引导参数预留顶部内存
在Linux内核引导时,传入参数“mem=size”保留顶部的内存区间。比如系统有256MB内存,参数“mem=248M”会预留顶部的8MB内存,进入系统后可以调用ioremap(0xF800000,0x800000)来申请这段内存。
3. 几种分配函数的比较
|
|
分配原理 |
最大内存 |
其他 |
|
__get_free_pages |
直接对页框进行操作 |
4MB |
适用于分配较大量的连续物理内存 |
|
kmem_cache_alloc |
基于slab机制实现 |
128KB |
适合需要频繁申请释放相同大小内存块时使用 |
|
kmalloc |
基于kmem_cache_alloc实现 |
128KB |
最常见的分配方式,需要小于页框大小的内存时可以使用 |
|
vmalloc |
建立非连续物理内存到虚拟地址的映射 |
|
物理不连续,适合需要大内存,但是对地址连续性没有要求的场合 |
|
dma_alloc_coherent |
基于__alloc_pages实现 |
4MB |
适用于DMA操作 |
|
ioremap |
实现已知物理地址到虚拟地址的映射 |
|
适用于物理地址已知的场合,如设备驱动 |
|
alloc_bootmem |
在启动kernel时,预留一段内存,内核看不见 |
|
小于物理内存大小,内存管理要求较高 |
注:表中提到的最大内存数据来自CentOS5.3 x86_64系统,其他系统和体系结构会有不同
Linux中断(interrupt)子系统之一:中断系统基本原理
这个中断系列文章主要针对移动设备中的Linux进行讨论,文中的例子基本都是基于ARM这一体系架构,其他架构的原理其实也差不多,区别只是其中的硬件抽象层。内核版本基于3.3。虽然内核的版本不断地提升,不过自从上一次变更到当前的通用中断子系统后,大的框架性的东西并没有太大的改变。
/*****************************************************************************************************/
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
1. 设备、中断控制器和CPU
一个完整的设备中,与中断相关的硬件可以划分为3类,它们分别是:设备、中断控制器和CPU本身,下图展示了一个smp系统中的中断硬件的组成结构:

图 1.1 中断系统的硬件组成
设备 设备是发起中断的源,当设备需要请求某种服务的时候,它会发起一个硬件中断信号,通常,该信号会连接至中断控制器,由中断控制器做进一步的处理。在现代的移动设备中,发起中断的设备可以位于soc(system-on-chip)芯片的外部,也可以位于soc的内部,因为目前大多数soc都集成了大量的硬件IP,例如I2C、SPI、Display Controller等等。
中断控制器 中断控制器负责收集所有中断源发起的中断,现有的中断控制器几乎都是可编程的,通过对中断控制器的编程,我们可以控制每个中断源的优先级、中断的电器类型,还可以打开和关闭某一个中断源,在smp系统中,甚至可以控制某个中断源发往哪一个CPU进行处理。对于ARM架构的soc,使用较多的中断控制器是VIC(Vector Interrupt Controller),进入多核时代以后,GIC(General Interrupt Controller)的应用也开始逐渐变多。
CPU cpu是最终响应中断的部件,它通过对可编程中断控制器的编程操作,控制和管理者系统中的每个中断,当中断控制器最终判定一个中断可以被处理时,他会根据事先的设定,通知其中一个或者是某几个cpu对该中断进行处理,虽然中断控制器可以同时通知数个cpu对某一个中断进行处理,实际上,最后只会有一个cpu相应这个中断请求,但具体是哪个cpu进行响应是可能是随机的,中断控制器在硬件上对这一特性进行了保证,不过这也依赖于操作系统对中断系统的软件实现。在smp系统中,cpu之间也通过IPI(inter processor interrupt)中断进行通信。
2. IRQ编号
系统中每一个注册的中断源,都会分配一个唯一的编号用于识别该中断,我们称之为IRQ编号。IRQ编号贯穿在整个Linux的通用中断子系统中。在移动设备中,每个中断源的IRQ编号都会在arch相关的一些头文件中,例如arch/xxx/mach-xxx/include/irqs.h。驱动程序在请求中断服务时,它会使用IRQ编号注册该中断,中断发生时,cpu通常会从中断控制器中获取相关信息,然后计算出相应的IRQ编号,然后把该IRQ编号传递到相应的驱动程序中。
3. 在驱动程序中申请中断
Linux中断子系统向驱动程序提供了一系列的API,其中的一个用于向系统申请中断:
- int request_threaded_irq(unsigned int irq, irq_handler_t handler,
- irq_handler_t thread_fn, unsigned long irqflags,
- const char *devname, void *dev_id)
其中,
- irq是要申请的IRQ编号,
- handler是中断处理服务函数,该函数工作在中断上下文中,如果不需要,可以传入NULL,但是不可以和thread_fn同时为NULL;
- thread_fn是中断线程的回调函数,工作在内核进程上下文中,如果不需要,可以传入NULL,但是不可以和handler同时为NULL;
- irqflags是该中断的一些标志,可以指定该中断的电气类型,是否共享等信息;
- devname指定该中断的名称;
- dev_id用于共享中断时的cookie data,通常用于区分共享中断具体由哪个设备发起;
关于该API的详细工作机理我们后面再讨论。
4. 通用中断子系统(Generic irq)的软件抽象
在通用中断子系统(generic irq)出现之前,内核使用__do_IRQ处理所有的中断,这意味着__do_IRQ中要处理各种类型的中断,这会导致软件的复杂性增加,层次不分明,而且代码的可重用性也不好。事实上,到了内核版本2.6.38,__do_IRQ这种方式已经彻底在内核的代码中消失了。通用中断子系统的原型最初出现于ARM体系中,一开始内核的开发者们把3种中断类型区分出来,他们是:
- 电平触发中断(level type)
- 边缘触发中断(edge type)
- 简易的中断(simple type)

图 4.1 通用中断子系统的层次结构
硬件封装层 它包含了体系架构相关的所有代码,包括中断控制器的抽象封装,arch相关的中断初始化,以及各个IRQ的相关数据结构的初始化工作,cpu的中断入口也会在arch相关的代码中实现。中断通用逻辑层通过标准的封装接口(实际上就是struct irq_chip定义的接口)访问并控制中断控制器的行为,体系相关的中断入口函数在获取IRQ编号后,通过中断通用逻辑层提供的标准函数,把中断调用传递到中断流控层中。我们看看irq_chip的部分定义:
- struct irq_chip {
- const char *name;
- unsigned int (*irq_startup)(struct irq_data *data);
- void (*irq_shutdown)(struct irq_data *data);
- void (*irq_enable)(struct irq_data *data);
- void (*irq_disable)(struct irq_data *data);
- void (*irq_ack)(struct irq_data *data);
- void (*irq_mask)(struct irq_data *data);
- void (*irq_mask_ack)(struct irq_data *data);
- void (*irq_unmask)(struct irq_data *data);
- void (*irq_eoi)(struct irq_data *data);
- int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);
- int (*irq_retrigger)(struct irq_data *data);
- int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);
- int (*irq_set_wake)(struct irq_data *data, unsigned int on);
- ......
- };
中断流控层 所谓中断流控是指合理并正确地处理连续发生的中断,比如一个中断在处理中,同一个中断再次到达时如何处理,何时应该屏蔽中断,何时打开中断,何时回应中断控制器等一系列的操作。该层实现了与体系和硬件无关的中断流控处理操作,它针对不同的中断电气类型(level,edge......),实现了对应的标准中断流控处理函数,在这些处理函数中,最终会把中断控制权传递到驱动程序注册中断时传入的处理函数或者是中断线程中。目前内核提供了以下几个主要的中断流控函数的实现(只列出部分):
- handle_simple_irq();
- handle_level_irq(); 电平中断流控处理程序
- handle_edge_irq(); 边沿触发中断流控处理程序
- handle_fasteoi_irq(); 需要eoi的中断处理器使用的中断流控处理程序
- handle_percpu_irq(); 该irq只有单个cpu响应时使用的流控处理程序
中断通用逻辑层 该层实现了对中断系统几个重要数据的管理,并提供了一系列的辅助管理函数。同时,该层还实现了中断线程的实现和管理,共享中断和嵌套中断的实现和管理,另外它还提供了一些接口函数,它们将作为硬件封装层和中断流控层以及驱动程序API层之间的桥梁,例如以下API:
- generic_handle_irq();
- irq_to_desc();
- irq_set_chip();
- irq_set_chained_handler();
驱动程序API 该部分向驱动程序提供了一系列的API,用于向系统申请/释放中断,打开/关闭中断,设置中断类型和中断唤醒系统的特性等操作。驱动程序的开发者通常只会使用到这一层提供的这些API即可完成驱动程序的开发工作,其他的细节都由另外几个软件层较好地“隐藏”起来了,驱动程序开发者无需再关注底层的实现,这看起来确实是一件美妙的事情,不过我认为,要想写出好的中断代码,还是花点时间了解一下其他几层的实现吧。其中的一些API如下:
- enable_irq();
- disable_irq();
- disable_irq_nosync();
- request_threaded_irq();
- irq_set_affinity();
这里不再对每一层做详细的介绍,我将会在本系列的其他几篇文章中做深入的探讨。
5. irq描述结构:struct irq_desc
整个通用中断子系统几乎都是围绕着irq_desc结构进行,系统中每一个irq都对应着一个irq_desc结构,所有的irq_desc结构的组织方式有两种:
基于数组方式 平台相关板级代码事先根据系统中的IRQ数量,定义常量:NR_IRQS,在kernel/irq/irqdesc.c中使用该常量定义irq_desc结构数组:
- struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
- [0 ... NR_IRQS-1] = {
- .handle_irq = handle_bad_irq,
- .depth = 1,
- .lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
- }
- };
基于基数树方式 当内核的配置项CONFIG_SPARSE_IRQ被选中时,内核使用基数树(radix tree)来管理irq_desc结构,这一方式可以动态地分配irq_desc结构,对于那些具备大量IRQ数量或者IRQ编号不连续的系统,使用该方式管理irq_desc对内存的节省有好处,而且对那些自带中断控制器管理设备自身多个中断源的外部设备,它们可以在驱动程序中动态地申请这些中断源所对应的irq_desc结构,而不必在系统的编译阶段保留irq_desc结构所需的内存。
下面我们看一看irq_desc的部分定义:
- struct irq_data {
- unsigned int irq;
- unsigned long hwirq;
- unsigned int node;
- unsigned int state_use_accessors;
- struct irq_chip *chip;
- struct irq_domain *domain;
- void *handler_data;
- void *chip_data;
- struct msi_desc *msi_desc;
- #ifdef CONFIG_SMP
- cpumask_var_t affinity;
- #endif
- };
- struct irq_desc {
- struct irq_data irq_data;
- unsigned int __percpu *kstat_irqs;
- irq_flow_handler_t handle_irq;
- #ifdef CONFIG_IRQ_PREFLOW_FASTEOI
- irq_preflow_handler_t preflow_handler;
- #endif
- struct irqaction *action; /* IRQ action list */
- unsigned int status_use_accessors;
- unsigned int depth; /* nested irq disables */
- unsigned int wake_depth; /* nested wake enables */
- unsigned int irq_count; /* For detecting broken IRQs */
- raw_spinlock_t lock;
- struct cpumask *percpu_enabled;
- #ifdef CONFIG_SMP
- const struct cpumask *affinity_hint;
- struct irq_affinity_notify *affinity_notify;
- #ifdef CONFIG_GENERIC_PENDING_IRQ
- cpumask_var_t pending_mask;
- #endif
- #endif
- wait_queue_head_t wait_for_threads;
- const char *name;
- } ____cacheline_internodealigned_in_smp;
irq_data 这个内嵌结构在2.6.37版本引入,之前的内核版本的做法是直接把这个结构中的字段直接放置在irq_desc结构体中,然后在调用硬件封装层的chip->xxx()回调中传入IRQ编号作为参数,但是底层的函数经常需要访问->handler_data,->chip_data,->msi_desc等字段,这需要利用irq_to_desc(irq)来获得irq_desc结构的指针,然后才能访问上述字段,者带来了性能的降低,尤其在配置为sparse irq的系统中更是如此,因为这意味着基数树的搜索操作。为了解决这一问题,内核开发者把几个低层函数需要使用的字段单独封装为一个结构,调用时的参数则改为传入该结构的指针。实现同样的目的,那为什么不直接传入irq_desc结构指针?因为这会破坏层次的封装性,我们不希望低层代码可以看到不应该看到的部分,仅此而已。
kstat_irqs 用于irq的一些统计信息,这些统计信息可以从proc文件系统中查询。
action 中断响应链表,当一个irq被触发时,内核会遍历该链表,调用action结构中的回调handler或者激活其中的中断线程,之所以实现为一个链表,是为了实现中断的共享,多个设备共享同一个irq,这在外围设备中是普遍存在的。
status_use_accessors 记录该irq的状态信息,内核提供了一系列irq_settings_xxx的辅助函数访问该字段,详细请查看kernel/irq/settings.h
depth 用于管理enable_irq()/disable_irq()这两个API的嵌套深度管理,每次enable_irq时该值减去1,每次disable_irq时该值加1,只有depth==0时才真正向硬件封装层发出关闭irq的调用,只有depth==1时才会向硬件封装层发出打开irq的调用。disable的嵌套次数可以比enable的次数多,此时depth的值大于1,随着enable的不断调用,当depth的值为1时,在向硬件封装层发出打开irq的调用后,depth减去1后,此时depth为0,此时处于一个平衡状态,我们只能调用disable_irq,如果此时enable_irq被调用,内核会报告一个irq失衡的警告,提醒驱动程序的开发人员检查自己的代码。
lock 用于保护irq_desc结构本身的自旋锁。
affinity_hit 用于提示用户空间,作为优化irq和cpu之间的亲缘关系的依据。
pending_mask 用于调整irq在各个cpu之间的平衡。
wait_for_threads 用于synchronize_irq(),等待该irq所有线程完成。
irq_data结构中的各字段:
irq 该结构所对应的IRQ编号。
hwirq 硬件irq编号,它不同于上面的irq;
node 通常用于hwirq和irq之间的映射操作;
state_use_accessors 硬件封装层需要使用的状态信息,不要直接访问该字段,内核定义了一组函数用于访问该字段:irqd_xxxx(),参见include/linux/irq.h。
chip 指向该irq所属的中断控制器的irq_chip结构指针
handler_data 每个irq的私有数据指针,该字段由硬件封转层使用,例如用作底层硬件的多路复用中断。
chip_data 中断控制器的私有数据,该字段由硬件封转层使用。
msi_desc 用于PCIe总线的MSI或MSI-X中断机制。
affinity 记录该irq与cpu之间的亲缘关系,它其实是一个bit-mask,每一个bit代表一个cpu,置位后代表该cpu可能处理该irq。
这是通用中断子系统系列文章的第一篇,这里不会详细介绍各个软件层次的实现原理,但是有必要对整个架构做简要的介绍:
- 系统启动阶段,取决于内核的配置,内核会通过数组或基数树分配好足够多的irq_desc结构;
- 根据不同的体系结构,初始化中断相关的硬件,尤其是中断控制器;
- 为每个必要irq的irq_desc结构填充默认的字段,例如irq编号,irq_chip指针,根据不同的中断类型配置流控handler;
- 设备驱动程序在初始化阶段,利用request_threaded_irq() api申请中断服务,两个重要的参数是handler和thread_fn;
- 当设备触发一个中断后,cpu会进入事先设定好的中断入口,它属于底层体系相关的代码,它通过中断控制器获得irq编号,在对irq_data结构中的某些字段进行处理后,会将控制权传递到中断流控层(通过irq_desc->handle_irq);
- 中断流控处理代码在作出必要的流控处理后,通过irq_desc->action链表,取出驱动程序申请中断时注册的handler和thread_fn,根据它们的赋值情况,或者只是调用handler回调,或者启动一个线程执行thread_fn,又或者两者都执行;
- 至此,中断最终由驱动程序进行了响应和处理。
6. 中断子系统的proc文件接口
在/proc目录下面,有两个与中断子系统相关的文件和子目录,它们是:
- /proc/interrupts:文件
- /proc/irq:子目录
/proc/irq目录下面会为每个注册的irq创建一个以irq编号为名字的子目录,每个子目录下分别有以下条目:
- smp_affinity irq和cpu之间的亲缘绑定关系;
- smp_affinity_hint 只读条目,用于用户空间做irq平衡只用;
- spurious 可以获得该irq被处理和未被处理的次数的统计信息;
- handler_name 驱动程序注册该irq时传入的处理程序的名字;
# cd /proc/irq
# ls
ls
332
248
......
......
12
11
default_smp_affinity
# ls 332
bcmsdh_sdmmc
spurious
node
affinity_hint
smp_affinity
# cat 332/smp_affinity
3
可见,以上设备是一个使用双核cpu的设备,因为smp_affinity的值是3,系统默认每个中断可以由两个cpu进行处理。
Linux中断(interrupt)子系统之二:arch相关的硬件封装层
Linux的通用中断子系统的一个设计原则就是把底层的硬件实现尽可能地隐藏起来,使得驱动程序的开发人员不用关注底层的实现,要实现这个目标,内核的开发者们必须把硬件相关的内容剥离出来,然后定义一些列标准的接口供上层访问,上层的开发人员只要知道这些接口即可完成对中断的进一步处理和控制。对底层的封装主要包括两部分:
- 实现不同体系结构中断入口,这部分代码通常用asm实现;
- 中断控制器进行封装和实现;
本文的内容正是要讨论硬件封装层的实现细节。我将以ARM体系进行介绍,大部分的代码位于内核代码树的arch/arm/目录内。
/*****************************************************************************************************/
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
1. CPU的中断入口
我们知道,arm的异常和复位向量表有两种选择,一种是低端向量,向量地址位于0x00000000,另一种是高端向量,向量地址位于0xffff0000,Linux选择使用高端向量模式,也就是说,当异常发生时,CPU会把PC指针自动跳转到始于0xffff0000开始的某一个地址上:
| 地址 | 异常种类 |
|---|---|
| FFFF0000 | 复位 |
| FFFF0004 | 未定义指令 |
| FFFF0008 | 软中断(swi) |
| FFFF000C | Prefetch abort |
| FFFF0010 | Data abort |
| FFFF0014 | 保留 |
| FFFF0018 | IRQ |
| FFFF001C | FIQ |
中断向量表在arch/arm/kernel/entry_armv.S中定义,为了方便讨论,下面只列出部分关键的代码:
- .globl __stubs_start
- __stubs_start:
- vector_stub irq, IRQ_MODE, 4
- .long __irq_usr @ 0 (USR_26 / USR_32)
- .long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
- .long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
- .long __irq_svc @ 3 (SVC_26 / SVC_32)
- vector_stub dabt, ABT_MODE, 8
- .long __dabt_usr @ 0 (USR_26 / USR_32)
- .long __dabt_invalid @ 1 (FIQ_26 / FIQ_32)
- .long __dabt_invalid @ 2 (IRQ_26 / IRQ_32)
- .long __dabt_svc @ 3 (SVC_26 / SVC_32)
- vector_fiq:
- disable_fiq
- subs pc, lr, #4
- ......
- .globl __stubs_end
- __stubs_end:
- .equ stubs_offset, __vectors_start + 0x200 - __stubs_start
- .globl __vectors_start
- __vectors_start:
- ARM( swi SYS_ERROR0 )
- THUMB( svc #0 )
- THUMB( nop )
- W(b) vector_und + stubs_offset
- W(ldr) pc, .LCvswi + stubs_offset
- W(b) vector_pabt + stubs_offset
- W(b) vector_dabt + stubs_offset
- W(b) vector_addrexcptn + stubs_offset
- W(b) vector_irq + stubs_offset
- W(b) vector_fiq + stubs_offset
- .globl __vectors_end
- __vectors_end:
- 第一部分是真正的向量跳转表,位于__vectors_start和__vectors_end之间;
- 第二部分是处理跳转的部分,位于__stubs_start和__stubs_end之间;
- vector_stub irq, IRQ_MODE, 4
以上这一句把宏展开后实际上就是定义了vector_irq,根据进入中断前的cpu模式,分别跳转到__irq_usr或__irq_svc。
- vector_stub dabt, ABT_MODE, 8
系统启动阶段,位于arch/arm/kernel/traps.c中的early_trap_init()被调用:
- void __init early_trap_init(void)
- {
- ......
- /*
- * Copy the vectors, stubs and kuser helpers (in entry-armv.S)
- * into the vector page, mapped at 0xffff0000, and ensure these
- * are visible to the instruction stream.
- */
- memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
- memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start);
- ......
- }
图1.1 Linux中ARM体系的中断向量拷贝过程
对于系统的外部设备来说,通常都是使用IRQ中断,所以我们只关注__irq_usr和__irq_svc,两者的区别是进入和退出中断时是否进行用户栈和内核栈之间的切换,还有进程调度和抢占的处理等,这些细节不在这里讨论。两个函数最终都会进入irq_handler这个宏:
- .macro irq_handler
- #ifdef CONFIG_MULTI_IRQ_HANDLER
- ldr r1, =handle_arch_irq
- mov r0, sp
- adr lr, BSYM(9997f)
- ldr pc, [r1]
- #else
- arch_irq_handler_default
- #endif
- 9997:
- .endm
- .macro arch_irq_handler_default
- get_irqnr_preamble r6, lr
- 1: get_irqnr_and_base r0, r2, r6, lr
- movne r1, sp
- @
- @ routine called with r0 = irq number, r1 = struct pt_regs *
- @
- adrne lr, BSYM(1b)
- bne asm_do_IRQ
- ......
get_irqnr_preamble和get_irqnr_and_base两个宏由machine级的代码定义,目的就是从中断控制器中获得IRQ编号,紧接着就调用asm_do_IRQ,从这个函数开始,中断程序进入C代码中,传入的参数是IRQ编号和寄存器结构指针,这个函数在arch/arm/kernel/irq.c中实现:
- /*
- * asm_do_IRQ is the interface to be used from assembly code.
- */
- asmlinkage void __exception_irq_entry
- asm_do_IRQ(unsigned int irq, struct pt_regs *regs)
- {
- handle_IRQ(irq, regs);
- }
2. 初始化

- 首先,在setup_arch函数中,early_trap_init被调用,其中完成了第1节所说的中断向量的拷贝和重定位工作。
- 然后,start_kernel发出early_irq_init调用,early_irq_init属于与硬件和平台无关的通用逻辑层,它完成irq_desc结构的内存申请,为它们其中某些字段填充默认值,完成后调用体系相关的arch_early_irq_init函数完成进一步的初始化工作,不过ARM体系没有实现arch_early_irq_init。
- 接着,start_kernel发出init_IRQ调用,它会直接调用所属板子machine_desc结构体中的init_irq回调。machine_desc通常在板子的特定代码中,使用MACHINE_START和MACHINE_END宏进行定义。
- machine_desc->init_irq()完成对中断控制器的初始化,为每个irq_desc结构安装合适的流控handler,为每个irq_desc结构安装irq_chip指针,使他指向正确的中断控制器所对应的irq_chip结构的实例,同时,如果该平台中的中断线有多路复用(多个中断公用一个irq中断线)的情况,还应该初始化irq_desc中相应的字段和标志,以便实现中断控制器的级联。
3. 中断控制器的软件抽象:struct irq_chip
正如上一篇文章Linux中断(interrupt)子系统之一:中断系统基本原理所述,所有的硬件中断在到达CPU之前,都要先经过中断控制器进行汇集,合乎要求的中断请求才会通知cpu进行处理,中断控制器主要完成以下这些功能:
- 对各个irq的优先级进行控制;
- 向CPU发出中断请求后,提供某种机制让CPU获得实际的中断源(irq编号);
- 控制各个irq的电气触发条件,例如边缘触发或者是电平触发;
- 使能(enable)或者屏蔽(mask)某一个irq;
- 提供嵌套中断请求的能力;
- 提供清除中断请求的机制(ack);
- 有些控制器还需要CPU在处理完irq后对控制器发出eoi指令(end of interrupt);
- 在smp系统中,控制各个irq与cpu之间的亲缘关系(affinity);
通用中断子系统把中断控制器抽象为一个数据结构:struct irq_chip,其中定义了一系列的操作函数,大部分多对应于上面所列的某个功能:
- struct irq_chip {
- const char *name;
- unsigned int (*irq_startup)(struct irq_data *data);
- void (*irq_shutdown)(struct irq_data *data);
- void (*irq_enable)(struct irq_data *data);
- void (*irq_disable)(struct irq_data *data);
- void (*irq_ack)(struct irq_data *data);
- void (*irq_mask)(struct irq_data *data);
- void (*irq_mask_ack)(struct irq_data *data);
- void (*irq_unmask)(struct irq_data *data);
- void (*irq_eoi)(struct irq_data *data);
- int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);
- int (*irq_retrigger)(struct irq_data *data);
- int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);
- int (*irq_set_wake)(struct irq_data *data, unsigned int on);
- void (*irq_bus_lock)(struct irq_data *data);
- void (*irq_bus_sync_unlock)(struct irq_data *data);
- void (*irq_cpu_online)(struct irq_data *data);
- void (*irq_cpu_offline)(struct irq_data *data);
- void (*irq_suspend)(struct irq_data *data);
- void (*irq_resume)(struct irq_data *data);
- void (*irq_pm_shutdown)(struct irq_data *data);
- void (*irq_print_chip)(struct irq_data *data, struct seq_file *p);
- unsigned long flags;
- /* Currently used only by UML, might disappear one day.*/
- #ifdef CONFIG_IRQ_RELEASE_METHOD
- void (*release)(unsigned int irq, void *dev_id);
- #endif
- };
各个字段解释如下:
name 中断控制器的名字,会出现在 /proc/interrupts中。irq_startup 第一次开启一个irq时使用。
irq_shutdown 与irq_starup相对应。
irq_enable 使能该irq,通常是直接调用irq_unmask()。
irq_disable 禁止该irq,通常是直接调用irq_mask,严格意义上,他俩其实代表不同的意义,disable表示中断控制器根本就不响应该irq,而mask时,中断控制器可能响应该irq,只是不通知CPU,这时,该irq处于pending状态。类似的区别也适用于enable和unmask。
irq_ack 用于CPU对该irq的回应,通常表示cpu希望要清除该irq的pending状态,准备接受下一个irq请求。
irq_mask 屏蔽该irq。
irq_unmask 取消屏蔽该irq。
irq_mask_ack 相当于irq_mask + irq_ack。
irq_eoi 有些中断控制器需要在cpu处理完该irq后发出eoi信号,该回调就是用于这个目的。
irq_set_affinity 用于设置该irq和cpu之间的亲缘关系,就是通知中断控制器,该irq发生时,那些cpu有权响应该irq。当然,中断控制器会在软件的配合下,最终只会让一个cpu处理本次请求。
irq_set_type 设置irq的电气触发条件,例如IRQ_TYPE_LEVEL_HIGH或IRQ_TYPE_EDGE_RISING。
irq_set_wake 通知电源管理子系统,该irq是否可以用作系统的唤醒源。
以上大部分的函数接口的参数都是irq_data结构指针,irq_data结构的由来在上一篇文章已经说过,这里仅贴出它的定义,各字段的意义请参考注释:
- /**
- * struct irq_data - per irq and irq chip data passed down to chip functions
- * @irq: interrupt number
- * @hwirq: hardware interrupt number, local to the interrupt domain
- * @node: node index useful for balancing
- * @state_use_accessors: status information for irq chip functions.
- * Use accessor functions to deal with it
- * @chip: low level interrupt hardware access
- * @domain: Interrupt translation domain; responsible for mapping
- * between hwirq number and linux irq number.
- * @handler_data: per-IRQ data for the irq_chip methods
- * @chip_data: platform-specific per-chip private data for the chip
- * methods, to allow shared chip implementations
- * @msi_desc: MSI descriptor
- * @affinity: IRQ affinity on SMP
- *
- * The fields here need to overlay the ones in irq_desc until we
- * cleaned up the direct references and switched everything over to
- * irq_data.
- */
- struct irq_data {
- unsigned int irq;
- unsigned long hwirq;
- unsigned int node;
- unsigned int state_use_accessors;
- struct irq_chip *chip;
- struct irq_domain *domain;
- void *handler_data;
- void *chip_data;
- struct msi_desc *msi_desc;
- #ifdef CONFIG_SMP
- cpumask_var_t affinity;
- #endif
- };
根据设备使用的中断控制器的类型,体系架构的底层的开发只要实现上述接口中的各个回调函数,然后把它们填充到irq_chip结构的实例中,最终把该irq_chip实例注册到irq_desc.irq_data.chip字段中,这样各个irq和中断控制器就进行了关联,只要知道irq编号,即可得到对应到irq_desc结构,进而可以通过chip指针访问中断控制器。
4. 进入流控处理层
进入C代码的第一个函数是asm_do_IRQ,在ARM体系中,这个函数只是简单地调用handle_IRQ:
- /*
- * asm_do_IRQ is the interface to be used from assembly code.
- */
- asmlinkage void __exception_irq_entry
- asm_do_IRQ(unsigned int irq, struct pt_regs *regs)
- {
- handle_IRQ(irq, regs);
- }
- void handle_IRQ(unsigned int irq, struct pt_regs *regs)
- {
- struct pt_regs *old_regs = set_irq_regs(regs);
- irq_enter();
- /*
- * Some hardware gives randomly wrong interrupts. Rather
- * than crashing, do something sensible.
- */
- if (unlikely(irq >= nr_irqs)) {
- if (printk_ratelimit())
- printk(KERN_WARNING "Bad IRQ%u\n", irq);
- ack_bad_irq(irq);
- } else {
- generic_handle_irq(irq);
- }
- /* AT91 specific workaround */
- irq_finish(irq);
- irq_exit();
- set_irq_regs(old_regs);
- }
- #define __irq_enter() \
- do { \
- account_system_vtime(current); \
- add_preempt_count(HARDIRQ_OFFSET); \
- trace_hardirq_enter(); \
- } while (0)
下一步,generic_handle_irq被调用,generic_handle_irq是通用逻辑层提供的API,通过该API,中断的控制被传递到了与体系结构无关的中断流控层:
- int generic_handle_irq(unsigned int irq)
- {
- struct irq_desc *desc = irq_to_desc(irq);
- if (!desc)
- return -EINVAL;
- generic_handle_irq_desc(irq, desc);
- return 0;
- }
- static inline void generic_handle_irq_desc(unsigned int irq, struct irq_desc *desc)
- {
- desc->handle_irq(irq, desc);
- }
5. 中断控制器的级联
- 机器级别的级联 子控制器位于SOC内部,或者子控制器在SOC的外部,但是是某个板子系列的标准配置,如图5.1的左边所示;
- 设备级别的级联 子控制器位于某个外部设备中,用于汇集该设备发出的多个中断,如图5.1的右边所示;
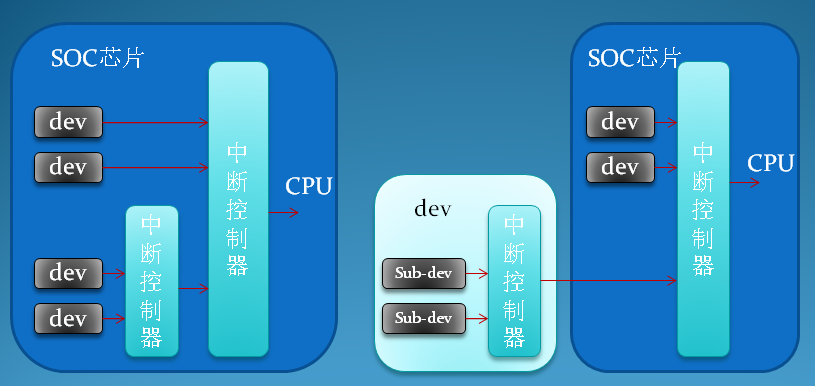
图5.1 中断控制器的级联类型
对于机器级别的级联,级联的初始化代码理所当然地位于板子的初始化代码中(arch/xxx/mach-xxx),因为只要是使用这个板子或SOC的设备,必然要使用这个子控制器。而对于设备级别的级联,因为该设备并不一定是系统的标配设备,所以中断控制器的级联操作应该在该设备的驱动程序中实现。机器设备的级联,因为得益于事先已经知道子控制器的硬件连接信息,内核可以方便地为子控制器保留相应的irq_desc结构和irq编号,处理起来相对简单。设备级别的级联则不一样,驱动程序必须动态地决定组合设备中各个子设备的irq编号和irq_desc结构。本章我只讨论机器级别的级联,设备级别的关联可以使用同样的原理,也可以实现为共享中断,我会在本系列接下来的文章中讨论。
要实现中断控制器的级联,要使用以下几个的关键数据结构字段和通用中断逻辑层的API:
irq_desc.handle_irq irq的流控处理回调函数,子控制器在把多个irq汇集起来后,输出端连接到根控制器的其中一个irq中断线输入脚,这意味着,每个子控制器的中断发生时,CPU一开始只会得到根控制器的irq编号,然后进入该irq编号对应的irq_desc.handle_irq回调,该回调我们不能使用流控层定义好的几个流控函数,而是要自己实现一个函数,该函数负责从子控制器中获得irq的中断源,并计算出对应新的irq编号,然后调用新irq所对应的irq_desc.handle_irq回调,这个回调使用流控层的标准实现。
irq_set_chained_handler() 该API用于设置根控制器与子控制器相连的irq所对应的irq_desc.handle_irq回调函数,并且设置IRQ_NOPROBE和IRQ_NOTHREAD以及IRQ_NOREQUEST标志,这几个标志保证驱动程序不会错误地申请该irq,因为该irq已经被作为级联irq使用。
irq_set_chip_and_handler() 该API同时设置irq_desc中的handle_irq回调和irq_chip指针。
以下例子代码位于:/arch/arm/plat-s5p/irq-eint.c:
- int __init s5p_init_irq_eint(void)
- {
- int irq;
- for (irq = IRQ_EINT(0); irq <= IRQ_EINT(15); irq++)
- irq_set_chip(irq, &s5p_irq_vic_eint);
- for (irq = IRQ_EINT(16); irq <= IRQ_EINT(31); irq++) {
- irq_set_chip_and_handler(irq, &s5p_irq_eint, handle_level_irq);
- set_irq_flags(irq, IRQF_VALID);
- }
- irq_set_chained_handler(IRQ_EINT16_31, s5p_irq_demux_eint16_31);
- return 0;
- }
该SOC芯片的外部中断:IRQ_EINT(0)到IRQ_EINT(15),每个引脚对应一个根控制器的irq中断线,它们是正常的irq,无需级联。IRQ_EINT(16)到IRQ_EINT(31)经过子控制器汇集后,统一连接到根控制器编号为IRQ_EINT16_31这个中断线上。可以看到,子控制器对应的irq_chip是s5p_irq_eint,子控制器的irq默认设置为电平中断的流控处理函数handle_level_irq,它们通过API:irq_set_chained_handler进行设置。如果根控制器有128个中断线,IRQ_EINT0--IRQ_EINT15通常占据128内的某段连续范围,这取决于实际的物理连接。IRQ_EINT16_31因为也属于跟控制器,所以它的值也会位于128以内,但是IRQ_EINT16--IRQ_EINT31通常会在128以外的某段范围,这时,代表irq数量的常量NR_IRQS,必须考虑这种情况,定义出超过128的某个足够的数值。级联的实现主要依靠编号为IRQ_EINT16_31的流控处理程序:s5p_irq_demux_eint16_31,它的最终实现类似于以下代码:
- static inline void s5p_irq_demux_eint(unsigned int start)
- {
- u32 status = __raw_readl(S5P_EINT_PEND(EINT_REG_NR(start)));
- u32 mask = __raw_readl(S5P_EINT_MASK(EINT_REG_NR(start)));
- unsigned int irq;
- status &= ~mask;
- status &= 0xff;
- while (status) {
- irq = fls(status) - 1;
- generic_handle_irq(irq + start);
- status &= ~(1 << irq);
- }
- }
在获得新的irq编号后,它的最关键的一句是调用了通用中断逻辑层的API:generic_handle_irq,这时它才真正地把中断控制权传递到中断流控层中来。
Linux中断(interrupt)子系统之三:中断流控处理层
1. 中断流控层简介
早期的内核版本中,几乎所有的中断都是由__do_IRQ函数进行处理,但是,因为各种中断请求的电气特性会有所不同,又或者中断控制器的特性也不同,这会导致以下这些处理也会有所不同:
- 何时对中断控制器发出ack回应;
- mask_irq和unmask_irq的处理;
- 中断控制器是否需要eoi回应?
- 何时打开cpu的本地irq中断?以便允许irq的嵌套;
- 中断数据结构的同步和保护;
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
为此,通用中断子系统把几种常用的流控类型进行了抽象,并为它们实现了相应的标准函数,我们只要选择相应的函数,赋值给irq所对应的irq_desc结构的handle_irq字段中即可。这些标准的回调函数都是irq_flow_handler_t类型:
- typedef void (*irq_flow_handler_t)(unsigned int irq,
- struct irq_desc *desc);
- handle_simple_irq 用于简易流控处理;
- handle_level_irq 用于电平触发中断的流控处理;
- handle_edge_irq 用于边沿触发中断的流控处理;
- handle_fasteoi_irq 用于需要响应eoi的中断控制器;
- handle_percpu_irq 用于只在单一cpu响应的中断;
- handle_nested_irq 用于处理使用线程的嵌套中断;
驱动程序和板级代码可以通过以下几个API设置irq的流控函数:
- irq_set_handler();
- irq_set_chip_and_handler();
- irq_set_chip_and_handler_name();
以下这个序列图展示了整个通用中断子系统的中断响应过程,flow_handle一栏就是中断流控层的生命周期:
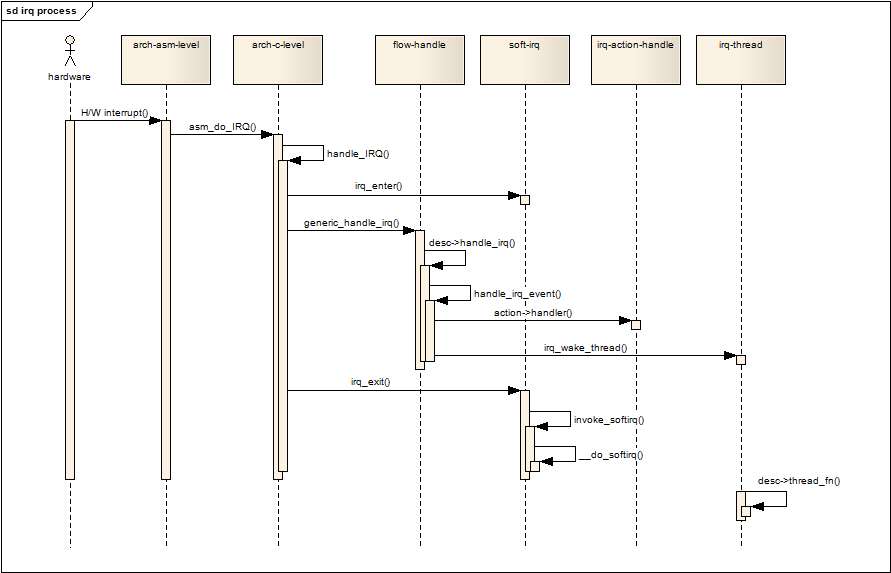
图1.1 通用中断子系统的中断响应过程
2. handle_simple_irq
该函数没有实现任何实质性的流控操作,在把irq_desc结构锁住后,直接调用handle_irq_event处理irq_desc中的action链表,它通常用于多路复用(类似于中断控制器级联)中的子中断,由父中断的流控回调中调用。或者用于无需进行硬件控制的中断中。以下是它的经过简化的代码:
- void
- handle_simple_irq(unsigned int irq, struct irq_desc *desc)
- {
- raw_spin_lock(&desc->lock);
- ......
- handle_irq_event(desc);
- out_unlock:
- raw_spin_unlock(&desc->lock);
- }
3. handle_level_irq
- void
- handle_level_irq(unsigned int irq, struct irq_desc *desc)
- {
- raw_spin_lock(&desc->lock);
- mask_ack_irq(desc);
- if (unlikely(irqd_irq_inprogress(&desc->irq_data)))
- goto out_unlock;
- ......
- if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data)))
- goto out_unlock;
- handle_irq_event(desc);
- if (!irqd_irq_disabled(&desc->irq_data) && !(desc->istate & IRQS_ONESHOT))
- unmask_irq(desc);
- out_unlock:
- raw_spin_unlock(&desc->lock);
- }
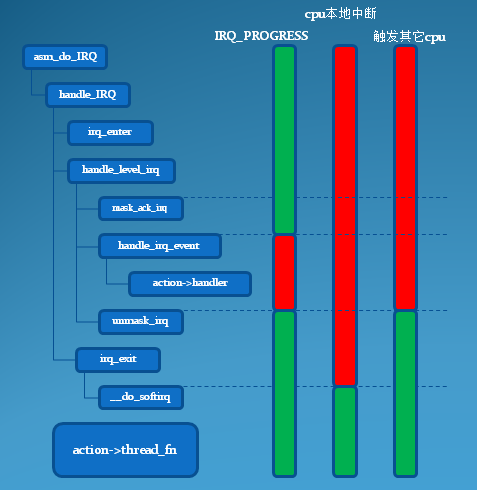
| 状态 | 红色 | 绿色 |
|---|---|---|
| IRQ_PROGRESS | TRUE | FALSE |
| 是否允许本地cpu中断 | 禁止 | 允许 |
| 是否允许该设备再次触发中断(可能由其它cpu响应) | 禁止 | 允许 |
4. handle_edge_irq
- if (unlikely(irqd_irq_disabled(&desc->irq_data) ||
- irqd_irq_inprogress(&desc->irq_data) || !desc->action)) {
- if (!irq_check_poll(desc)) {
- desc->istate |= IRQS_PENDING;
- mask_ack_irq(desc);
- goto out_unlock;
- }
- }
- desc->irq_data.chip->irq_ack(&desc->irq_data);
- do {
- ......
- if (unlikely(desc->istate & IRQS_PENDING)) {
- if (!irqd_irq_disabled(&desc->irq_data) &&
- irqd_irq_masked(&desc->irq_data))
- unmask_irq(desc);
- }
- handle_irq_event(desc);
- } while ((desc->istate & IRQS_PENDING) &&
- !irqd_irq_disabled(&desc->irq_data));
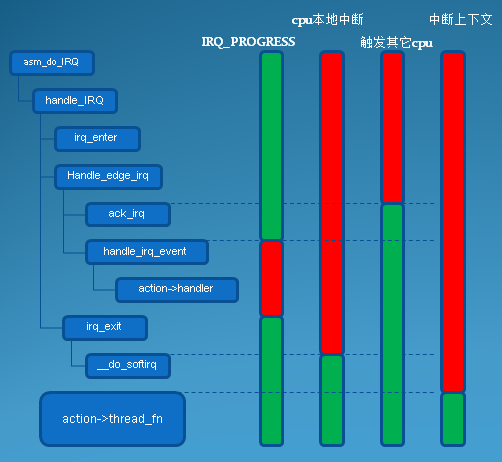
| 状态 | 红色 | 绿色 |
| IRQ_PROGRESS | TRUE | FALSE |
| 是否允许本地cpu中断 | 禁止 | 允许 |
| 是否允许该设备再次触发中断(可能由其它cpu响应) | 禁止 | 允许 |
| 是否处于中断上下文 | 处于中断上下文 | 处于进程上下文 |
由图4.1也可以看出,在处理软件中断(softirq)期间,此时仍然处于中断上下文中,但是cpu的本地中断是处于打开状态的,这表明此时嵌套中断允许发生,不过这不要紧,因为重要的处理已经完成,被嵌套的也只是软件中断部分而已。这个也就是内核区分top和bottom两个部分的初衷吧。
5. handle_fasteoi_irq
- void
- handle_fasteoi_irq(unsigned int irq, struct irq_desc *desc)
- {
- raw_spin_lock(&desc->lock);
- if (unlikely(irqd_irq_inprogress(&desc->irq_data)))
- if (!irq_check_poll(desc))
- goto out;
- ......
- if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data))) {
- desc->istate |= IRQS_PENDING;
- mask_irq(desc);
- goto out;
- }
- if (desc->istate & IRQS_ONESHOT)
- mask_irq(desc);
- preflow_handler(desc);
- handle_irq_event(desc);
- out_eoi:
- desc->irq_data.chip->irq_eoi(&desc->irq_data);
- out_unlock:
- raw_spin_unlock(&desc->lock);
- return;
- ......
- }
6. handle_percpu_irq
- void
- handle_percpu_irq(unsigned int irq, struct irq_desc *desc)
- {
- struct irq_chip *chip = irq_desc_get_chip(desc);
- kstat_incr_irqs_this_cpu(irq, desc);
- if (chip->irq_ack)
- chip->irq_ack(&desc->irq_data);
- handle_irq_event_percpu(desc, desc->action);
- if (chip->irq_eoi)
- chip->irq_eoi(&desc->irq_data);
- }
7. handle_nested_irq
该函数用于实现其中一种中断共享机制,当多个中断共享某一根中断线时,我们可以把这个中断线作为父中断,共享该中断的各个设备作为子中断,在父中断的中断线程中决定和分发响应哪个设备的请求,在得出真正发出请求的子设备后,调用handle_nested_irq来响应中断。所以,该函数是在进程上下文执行的,我们也无需扫描和执行irq_desc结构中的action链表。父中断在初始化时必须通过irq_set_nested_thread函数明确告知中断子系统:这些子中断属于线程嵌套中断类型,这样驱动程序在申请这些子中断时,内核不会为它们建立自己的中断线程,所有的子中断共享父中断的中断线程。
- void handle_nested_irq(unsigned int irq)
- {
- ......
- might_sleep();
- raw_spin_lock_irq(&desc->lock);
- ......
- action = desc->action;
- if (unlikely(!action || irqd_irq_disabled(&desc->irq_data)))
- goto out_unlock;
- irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);
- raw_spin_unlock_irq(&desc->lock);
- action_ret = action->thread_fn(action->irq, action->dev_id);
- raw_spin_lock_irq(&desc->lock);
- irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
- out_unlock:
- raw_spin_unlock_irq(&desc->lock);
- }
Linux中断(interrupt)子系统之四:驱动程序接口层 & 中断通用逻辑层
本章我将会讨论这两层对外提供的标准接口和内部实现机制,几乎所有的接口都是围绕着irq_desc和irq_chip这两个结构体进行的,对这两个结构体不熟悉的读者可以现读一下前面几篇文章。
/*****************************************************************************************************/
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
1. irq的打开和关闭
中断子系统为我们提供了一系列用于irq的打开和关闭的函数接口,其中最基本的一对是:
- disable_irq(unsigned int irq);
- enable_irq(unsigned int irq);

图1.1 disable_irq的调用过程
函数的开始使用异步方式的内部函数__disable_irq_nosync(),所谓异步方式就是不理会当前该irq是否正在被处理(有handler在运行或者有中断线程尚未结束)。有些中断控制器可能挂在某个慢速的总线上,所以在进一步处理前,先通过irq_get_desc_buslock获得总线锁(最终会调用chip->irq_bus_lock),然后进入内部函数__disable_irq:
- void __disable_irq(struct irq_desc *desc, unsigned int irq, bool suspend)
- {
- if (suspend) {
- if (!desc->action || (desc->action->flags & IRQF_NO_SUSPEND))
- return;
- desc->istate |= IRQS_SUSPENDED;
- }
- if (!desc->depth++)
- irq_disable(desc);
- }
disable_irq的最后,调用了synchronize_irq,该函数通过IRQ_INPROGRESS标志,确保action链表中所有的handler都已经处理完毕,然后还要通过wait_event等待该irq所有的中断线程退出。正因为这样,在中断上下文中,不应该使用该API来关闭irq,同时要确保调用该API的函数不能拥有该irq处理函数或线程的资源,否则就会发生死锁!!如果一定要在这两种情况下关闭irq,中断子系统为我们提供了另外一个API,它不会做出任何等待动作:
- disable_irq_nosync();
- enable_irq();
- void __enable_irq(struct irq_desc *desc, unsigned int irq, bool resume)
- {
- if (resume) {
- ......
- }
- switch (desc->depth) {
- case 0:
- err_out:
- WARN(1, KERN_WARNING "Unbalanced enable for IRQ %d\n", irq);
- break;
- case 1: {
- ......
- irq_enable(desc);
- ......
- }
- default:
- desc->depth--;
- }
- }
2. 中断子系统内部数据结构访问接口
我们知道,中断子系统内部定义了几个重要的数据结构,例如:irq_desc,irq_chip,irq_data等等,这些数据结构的各个字段控制或影响着中断子系统和各个irq的行为和实现方式。通常,驱动程序不应该直接访问这些数据结构,直接访问会破会中断子系统的封装性,为此,中断子系统为我们提供了一系列的访问接口函数,用于访问这些数据结构。
存取irq_data结构相关字段的API:
irq_set_chip(irq, *chip) / irq_get_chip(irq) 通过irq编号,设置、获取irq_cip结构指针;
irq_set_handler_data(irq, *data) / irq_get_handler_data(irq) 通过irq编号,设置、获取irq_desc.irq_data.handler_data字段,该字段是每个irq的私有数据,通常用于硬件封装层,例如中断控制器级联时,父irq用该字段保存子irq的起始编号。
irq_set_chip_data(irq, *data) / irq_get_chip_data(irq) 通过irq编号,设置、获取irq_desc.irq_data.chip_data字段,该字段是每个中断控制器的私有数据,通常用于硬件封装层。
irq_set_irq_type(irq, type) 用于设置中断的电气类型,可选的类型有:
- IRQ_TYPE_EDGE_RISING
- IRQ_TYPE_EDGE_FALLING
- IRQ_TYPE_EDGE_BOTH
- IRQ_TYPE_LEVEL_HIGH
- IRQ_TYPE_LEVEL_LOW
irq_get_irq_data(irq) 通过irq编号,获取irq_data结构指针;
irq_data_get_irq_chip(irq_data *d) 通过irq_data指针,获取irq_chip字段;
irq_data_get_irq_chip_data(irq_data *d) 通过irq_data指针,获取chip_data字段;
irq_data_get_irq_handler_data(irq_data *d) 通过irq_data指针,获取handler_data字段;
设置中断流控处理回调API:
irq_set_handler(irq, handle) 设置中断流控回调字段:irq_desc.handle_irq,参数handle的类型是irq_flow_handler_t。
irq_set_chip_and_handler(irq, *chip, handle) 同时设置中断流控回调字段和irq_chip指针:irq_desc.handle_irq和irq_desc.irq_data.chip。
irq_set_chip_and_handler_name(irq, *chip, handle, *name) 同时设置中断流控回调字段和irq_chip指针以及irq名字:irq_desc.handle_irq、irq_desc.irq_data.chip、irq_desc.name。
irq_set_chained_handler(irq, *chip, handle) 设置中断流控回调字段:irq_desc.handle_irq,同时设置标志:IRQ_NOREQUEST、IRQ_NOPROBE、IRQ_NOTHREAD,该api通常用于中断控制器的级联,父控制器通过该api设置流控回调后,同时设置上述三个标志位,使得父控制器的中断线不允许被驱动程序申请。
3. 在驱动程序中申请中断
系统启动阶段,中断子系统完成了必要的初始化工作,为驱动程序申请中断服务做好了准备,通常,我们用一下API申请中断服务:
- request_threaded_irq(unsigned int irq, irq_handler_t handler,
- irq_handler_t thread_fn,
- unsigned long flags, const char *name, void *dev);
handler 中断服务回调函数,该回调运行在中断上下文中,并且cpu的本地中断处于关闭状态,所以该回调函数应该只是执行需要快速响应的操作,执行时间应该尽可能短小,耗时的工作最好留给下面的thread_fn回调处理。
thread_fn 如果该参数不为NULL,内核会为该irq创建一个内核线程,当中断发生时,如果handler回调返回值是IRQ_WAKE_THREAD,内核将会激活中断线程,在中断线程中,该回调函数将被调用,所以,该回调函数运行在进程上下文中,允许进行阻塞操作。
flags 控制中断行为的位标志,IRQF_XXXX,例如:IRQF_TRIGGER_RISING,IRQF_TRIGGER_LOW,IRQF_SHARED等,在include/linux/interrupt.h中定义。
name 申请本中断服务的设备名称,同时也作为中断线程的名称,该名称可以在/proc/interrupts文件中显示。
dev 当多个设备的中断线共享同一个irq时,它会作为handler的参数,用于区分不同的设备。
下面我们分析一下request_threaded_irq的工作流程。函数先是根据irq编号取出对应的irq_desc实例的指针,然后分配了一个irqaction结构,用参数handler,thread_fn,irqflags,devname,dev_id初始化irqaction结构的各字段,同时做了一些必要的条件判断:该irq是否禁止申请?handler和thread_fn不允许同时为NULL,最后把大部分工作委托给__setup_irq函数:
- desc = irq_to_desc(irq);
- if (!desc)
- return -EINVAL;
- if (!irq_settings_can_request(desc) ||
- WARN_ON(irq_settings_is_per_cpu_devid(desc)))
- return -EINVAL;
- if (!handler) {
- if (!thread_fn)
- return -EINVAL;
- handler = irq_default_primary_handler;
- }
- action = kzalloc(sizeof(struct irqaction), GFP_KERNEL);
- if (!action)
- return -ENOMEM;
- action->handler = handler;
- action->thread_fn = thread_fn;
- action->flags = irqflags;
- action->name = devname;
- action->dev_id = dev_id;
- chip_bus_lock(desc);
- retval = __setup_irq(irq, desc, action);
- chip_bus_sync_unlock(desc);
- if (new->thread_fn && !nested) {
- struct task_struct *t;
- t = kthread_create(irq_thread, new, "irq/%d-%s", irq,
- new->name);
- if (IS_ERR(t)) {
- ret = PTR_ERR(t);
- goto out_mput;
- }
- /*
- * We keep the reference to the task struct even if
- * the thread dies to avoid that the interrupt code
- * references an already freed task_struct.
- */
- get_task_struct(t);
- new->thread = t;
- }
- 一定要设置了IRQF_SHARED标志
- 电气触发方式要完全一样(IRQF_TRIGGER_XXXX)
- IRQF_PERCPU要一致
- IRQF_ONESHOT要一致
- /* add new interrupt at end of irq queue */
- do {
- thread_mask |= old->thread_mask;
- old_ptr = &old->next;
- old = *old_ptr;
- } while (old);
- shared = 1;
- if (irq_settings_can_autoenable(desc))
- irq_startup(desc);
- else
- /* Undo nested disables: */
- desc->depth = 1;
- /* Set default affinity mask once everything is setup */
- setup_affinity(irq, desc, mask);
- new->irq = irq;
- *old_ptr = new;
- if (new->thread)
- wake_up_process(new->thread);
- register_irq_proc(irq, desc);
- new->dir = NULL;
- register_handler_proc(irq, new);
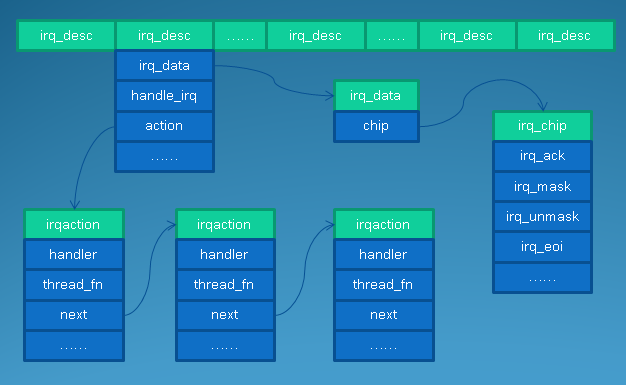
图3.1 irq各个数据结构之间的关系
4. 动态扩展irq编号
- 配置了CONFIG_SPARSE_IRQ内核配置项,使用基数树动态管理irq_desc结构。
- 针对多功能复合设备,内部具备多个中断源,但中断触发引脚只有一个,为了实现驱动程序的跨平台,不希望这些中断源的irq被硬编码在板级代码中。
- irq_set_chip_and_handler_name
- irq_set_handler_data
- irq_set_chip_data
5. 多功能复合设备的中断处理
在移动设备系统中,存在着大量的多功能复合设备,最常见的是一个芯片中,内部集成了多个功能部件,或者是一个模块单元内部集成了功能部件,这些内部功能部件可以各自产生中断请求,但是芯片或者硬件模块对外只有一个中断请求引脚,我们可以使用多种方式处理这些设备的中断请求,以下我们逐一讨论这些方法。
对于这种复合设备,通常设备中会提供某种方式,以便让CPU获取真正的中断来源, 方式可以是一个内部寄存器,gpio的状态等等。单一中断模式是指驱动程序只申请一个irq,然后在中断处理程序中通过读取设备的内部寄存器,获取中断源,然后根据不同的中断源做出不同的处理,以下是一个简化后的代码:
- static int xxx_probe(device *dev)
- {
- ......
- irq = get_irq_from_dev(dev);
- ret = request_threaded_irq(irq, NULL, xxx_irq_thread,
- IRQF_TRIGGER_RISING,
- "xxx_dev", NULL);
- ......
- return 0;
- }
- static irqreturn_t xxx_irq_thread(int irq, void *data)
- {
- ......
- irq_src = read_device_irq();
- switch (irq_src) {
- case IRQ_SUB_DEV0:
- ret = handle_sub_dev0_irq();
- break;
- case IRQ_SUB_DEV1:
- ret = handle_sub_dev1_irq();
- break;
- ......
- default:
- ret = IRQ_NONE;
- break;
- }
- ......
- return ret;
- }
5.2 共享中断模式
共享中断模式充分利用了通用中断子系统的特性,经过前面的讨论,我们知道,irq对应的irq_desc结构中的action字段,本质上是一个链表,这给我们实现中断共享提供了必要的基础,只要我们以相同的irq编号多次申请中断服务,那么,action链表上就会有多个irqaction实例,当中断发生时,中断子系统会遍历action链表,逐个执行irqaction实例中的handler回调,根据handler回调的返回值不同,决定是否唤醒中断线程。需要注意到是,申请多个中断时,irq编号要保持一致,flag参数最好也能保持一致,并且都要设上IRQF_SHARED标志。在使用共享中断时,最好handler和thread_fn都要提供,在各自的中断处理回调handler中,做出以下处理:
- 判断中断是否来自本设备;
- 如果不是来自本设备:
- 直接返回IRQ_NONE;
- 如果是来自本设备:
- 关闭irq;
- 返回IRQ_WAKE_THREAD,唤醒中断线程,thread_fn将会被执行;
5.3 中断控制器级联模式
- 首先,父中断的irq编号可以从板级代码的预定义中获得,或者通过device的platform_data字段获得;
- 使用父中断的irq编号,利用irq_set_chained_handler函数修改父中断的流控函数;
- 使用父中断的irq编号,利用irq_set_handler_data设置流控函数的参数,该参数要能够用于判别子控制器的中断来源;
- 实现父中断的流控函数,其中只需获得并计算子设备的irq编号,然后调用generic_handle_irq即可;
- 为设备内的中断控制器实现一个irq_chip结构,实现其中必要的回调,例如irq_mask,irq_unmask,irq_ack等;
- 循环每一个子设备,做以下动作:
- 为每个子设备,使用irq_alloc_descs函数申请irq编号;
- 使用irq_set_chip_data设置必要的cookie数据;
- 使用irq_set_chip_and_handler设置子控制器的irq_chip实例和子irq的流控处理程序,通常使用标准的流控函数,例如handle_edge_irq;
- 子设备的驱动程序使用自身申请到的irq编号,按照正常流程申请中断服务即可。
5.4 中断线程嵌套模式
- 首先,父中断的irq编号可以从板级代码的预定义中获得,或者通过device的platform_data字段获得;
- 使用父中断的irq编号,利用request_threaded_irq函数申请中断服务,需要提供thread_fn参数和dev_id参数;
- dev_id参数要能够用于判别子控制器的中断来源;
- 实现父中断的thread_fn函数,其中只需获得并计算子设备的irq编号,然后调用handle_nested_irq即可;
- 为设备内的中断控制器实现一个irq_chip结构,实现其中必要的回调,例如irq_mask,irq_unmask,irq_ack等;
- 循环每一个子设备,做以下动作:
- 为每个子设备,使用irq_alloc_descs函数申请irq编号;
- 使用irq_set_chip_data设置必要的cookie数据;
- 使用irq_set_chip_and_handler设置子控制器的irq_chip实例和子irq的流控处理程序,通常使用标准的流控函数,例如handle_edge_irq;
- 使用irq_set_nested_thread函数,把子设备irq的线程嵌套特性打开;
- 子设备的驱动程序使用自身申请到的irq编号,按照正常流程申请中断服务即可。
Linux中断(interrupt)子系统之五:软件中断(softIRQ)
软件中断(softIRQ)是内核提供的一种延迟执行机制,它完全由软件触发,虽然说是延迟机制,实际上,在大多数情况下,它与普通进程相比,能得到更快的响应时间。软中断也是其他一些内核机制的基础,比如tasklet,高分辨率timer等。
/*****************************************************************************************************/
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
1. 软件中断的数据结构
1.1 struct softirq_action
- struct softirq_action
- {
- void (*action)(struct softirq_action *);
- };
- enum
- {
- HI_SOFTIRQ=0,
- TIMER_SOFTIRQ,
- NET_TX_SOFTIRQ,
- NET_RX_SOFTIRQ,
- BLOCK_SOFTIRQ,
- BLOCK_IOPOLL_SOFTIRQ,
- TASKLET_SOFTIRQ,
- SCHED_SOFTIRQ,
- HRTIMER_SOFTIRQ,
- RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
- NR_SOFTIRQS
- };
- typedef struct {
- unsigned int __softirq_pending;
- } ____cacheline_aligned irq_cpustat_t;
- irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
1.3 软中断的守护进程ksoftirqd
- DEFINE_PER_CPU(struct task_struct *, ksoftirqd);
2. 触发软中断
- void raise_softirq(unsigned int nr)
- {
- unsigned long flags;
- local_irq_save(flags);
- raise_softirq_irqoff(nr);
- local_irq_restore(flags);
- }
- inline void raise_softirq_irqoff(unsigned int nr)
- {
- __raise_softirq_irqoff(nr);
- ......
- if (!in_interrupt())
- wakeup_softirqd();
- }
3. 软中断的执行
3.1 在irq_exit中执行
- void irq_exit(void)
- {
- ......
- sub_preempt_count(IRQ_EXIT_OFFSET);
- if (!in_interrupt() && local_softirq_pending())
- invoke_softirq();
- ......
- }
- asmlinkage void __do_softirq(void)
- {
- ......
- pending = local_softirq_pending();
- __local_bh_disable((unsigned long)__builtin_return_address(0),
- SOFTIRQ_OFFSET);
- restart:
- /* Reset the pending bitmask before enabling irqs */
- set_softirq_pending(0);
- local_irq_enable();
- h = softirq_vec;
- do {
- if (pending & 1) {
- ......
- trace_softirq_entry(vec_nr);
- h->action(h);
- trace_softirq_exit(vec_nr);
- ......
- }
- h++;
- pending >>= 1;
- } while (pending);
- local_irq_disable();
- pending = local_softirq_pending();
- if (pending && --max_restart)
- goto restart;
- if (pending)
- wakeup_softirqd();
- lockdep_softirq_exit();
- __local_bh_enable(SOFTIRQ_OFFSET);
- }
- 首先取出pending的状态;
- 禁止软中断,主要是为了防止和软中断守护进程发生竞争;
- 清除所有的软中断待决标志;
- 打开本地cpu中断;
- 循环执行待决软中断的回调函数;
- 如果循环完毕,发现新的软中断被触发,则重新启动循环,直到以下条件满足,才退出:
- 没有新的软中断等待执行;
- 循环已经达到最大的循环次数MAX_SOFTIRQ_RESTART,目前的设定值时10次;
- 如果经过MAX_SOFTIRQ_RESTART次循环后还未处理完,则激活守护进程,处理剩下的软中断;
- 推出前恢复软中断;
3.2 在ksoftirqd进程中执行
- 在irq_exit中执行软中断,但是在经过MAX_SOFTIRQ_RESTART次循环后,软中断还未处理完,这种情况虽然极少发生,但毕竟有可能;
- 内核的其它代码主动调用raise_softirq,而这时正好不是在中断上下文中,守护进程将被唤醒;
4. tasklet
4.1 tasklet_struct
- void __init softirq_init(void)
- {
- ......
- open_softirq(TASKLET_SOFTIRQ, tasklet_action);
- open_softirq(HI_SOFTIRQ, tasklet_hi_action);
- }
- struct tasklet_struct
- {
- struct tasklet_struct *next;
- unsigned long state;
- atomic_t count;
- void (*func)(unsigned long);
- unsigned long data;
- };
- enum
- {
- TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */
- TASKLET_STATE_RUN /* Tasklet is running (SMP only) */
- };
4.2 初始化一个tasklet
- DECLARE_TASKLET(name, func, data);定义名字为name的tasklet,默认为enable状态,也就是count字段等于0。
- DECLARE_TASKLET_DISABLED(name, func, data);定义名字为name的tasklet,默认为enable状态,也就是count字段等于1。
- tasklet_disable() 通过给count字段加1来禁止一个tasklet,如果tasklet正在运行中,则等待运行完毕才返回(通过TASKLET_STATE_RUN标志)。
- tasklet_disable_nosync() tasklet_disable的异步版本,它不会等待tasklet运行完毕。
- tasklet_enable() 使能tasklet,只是简单地给count字段减1。
- tasklet_schedule(struct tasklet_struct *t) 如果TASKLET_STATE_SCHED标志为0,则置位TASKLET_STATE_SCHED,然后把tasklet挂到该cpu等待执行的tasklet链表上,接着发出TASKLET_SOFTIRQ软件中断请求。
- tasklet_hi_schedule(struct tasklet_struct *t) 效果同上,区别是它发出的是HI_SOFTIRQ软件中断请求。
- tasklet_kill(struct tasklet_struct *t) 如果tasklet处于TASKLET_STATE_SCHED状态,或者tasklet正在执行,则会等待tasklet执行完毕,然后清除TASKLET_STATE_SCHED状态。
4.4 tasklet的内部执行机制
- struct tasklet_head
- {
- struct tasklet_struct *head;
- struct tasklet_struct **tail;
- };
- static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
- static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
- static void tasklet_action(struct softirq_action *a)
- {
- struct tasklet_struct *list;
- local_irq_disable();
- list = __this_cpu_read(tasklet_vec.head);
- __this_cpu_write(tasklet_vec.head, NULL);
- __this_cpu_write(tasklet_vec.tail, &__get_cpu_var(tasklet_vec).head);
- local_irq_enable();
- while (list) {
- struct tasklet_struct *t = list;
- list = list->next;
- if (tasklet_trylock(t)) {
- if (!atomic_read(&t->count)) {
- if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
- BUG();
- t->func(t->data);
- tasklet_unlock(t);
- continue;
- }
- tasklet_unlock(t);
- }
- local_irq_disable();
- t->next = NULL;
- *__this_cpu_read(tasklet_vec.tail) = t;
- __this_cpu_write(tasklet_vec.tail, &(t->next));
- __raise_softirq_irqoff(TASKLET_SOFTIRQ);
- local_irq_enable();
- }
- }
- 关闭本地中断的前提下,移出当前cpu的待处理tasklet链表到一个临时链表后,清除当前cpu的tasklet链表,之所以这样处理,是为了处理当前tasklet链表的时候,允许新的tasklet被调度进待处理链表中。
- 遍历临时链表,用tasklet_trylock判断当前tasklet是否已经在其他cpu上运行,而且tasklet没有被禁止:
- 如果没有运行,也没有禁止,则清除TASKLET_STATE_SCHED状态位,执行tasklet的回调函数。
- 如果已经在运行,或者被禁止,则把该tasklet重新添加会当前cpu的待处理tasklet链表上,然后触发TASKLET_SOFTIRQ软中断,等待下一次软中断时再次执行。
- 同一个tasklet只能同时在一个cpu上执行,但不同的tasklet可以同时在不同的cpu上执行;
- 一旦tasklet_schedule被调用,内核会保证tasklet一定会在某个cpu上执行一次;
- 如果tasklet_schedule被调用时,tasklet不是出于正在执行状态,则它只会执行一次;
- 如果tasklet_schedule被调用时,tasklet已经正在执行,则它会在稍后被调度再次被执行;
- 两个tasklet之间如果有资源冲突,应该要用自旋锁进行同步保护;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号