linux 设备驱动概述
linux 设备驱动概述
(1)Linux应用软件工程师(Application Software Engineer):
主要利用C库函数和Linux API进行应用软件的编写;
从事这方面的开发工作,主要需要学习:符合linux posix标准的API函数及系统调用,linux的多任务编程技巧:多进程、多线程、进程间通信、多任务之间的同步互斥等,嵌入式数据库的学习,UI编程:QT、miniGUI等。
(2)Linux固件工程师(Firmware Engineer):
主要进行Bootloader、Linux的移植及Linux设备驱动程序的设计工作。
本系列文章我们将一步步、深入浅出的介绍linux设备驱动编程中设计的一些问题及学习方法,希望对大家学习linux设备驱动有所帮助。
在任何一个计算机系统中,大至服务器、PC机、小至手机、mp3/mp4播放器,无论是复杂的大型服务器系统还是一个简单的流水灯单片机系统,都离不开驱动程序的身影,没有硬件的软件是空中楼阁,没有软件的硬件只是一堆废铁,硬件是底层的基础,是所有软件得以运行的平台,代码最终会落实到硬件上的逻辑组合。
但是硬件与软件之间存在一个驳论:为了快速、优质的完成软件功能设计,应用程序工程师不想也不愿关心硬件,而硬件工程师也很难有功夫去处理软件开发中的一些应用。例如软件工程师在调用printf的时候,不许也不用关心信息到底是通过什么样的处理,走过哪些通路显示在该显示的地方,硬件工程师在写完了一个4*4键盘驱动后,无需也不必管应用程序在获得键值后做哪些处理及操作。
也就是说软件工程师需要看到一个没有硬件的纯软件世界,硬件必须透明的提供给他,谁来实现这一任务?答案是驱动程序,驱动程序从字面解释就是:“驱使硬件设备行动”。驱动程序直接与硬件打交道,按照硬件设备的具体形式,驱动设备的寄存器,完成设备的轮询、中断处理、DMA通信,最终让通信设备可以收发数据,让显示设备能够显示文字和画面,让音频设备可以完成声音的存储和播放。
可见,设备驱动程序充当了硬件和软件之间的枢纽,因此驱动程序的表现形式可能就是一些标准的、事先协定好的API函数,驱动工程师只需要去完成相应函数的填充,应用工程师只需要调用相应的接口完成相应的功能。无论有没有操作系统,驱动程序都有其存在价值,只是在裸机情况下,工作环境比较简单、完成的工作较单一,驱动程序完成的功能也就比较简单,同时接口只要在小范围内符合统一的标准即可。但是在有操作系统的情况下,此问题就会被放大:硬件来自不同的公司、千变万化,全世界每天都会有大量的新芯片被生产,大量的电路板被设计出来,如果没有一个很好的统一标准去规范这一程序,操作系统就会被设计的非常冗余,效率会非常低。
所以无论任何操作系统都会制定一套标准的架构去管理这些驱动程序:linux作为嵌入式操作系统的典范,其驱动架构具有很高的规范性与聚合性,不但把不同的硬件设备分门别类、综合管理,并且针对不同硬件的共性进行了统一抽象,将其硬件相关性降到最低,大大简化了驱动程序的编写,形成了具有其特色的驱动组织架构。
下图反映了应用程序、linux内核、驱动程序、硬件的关系。
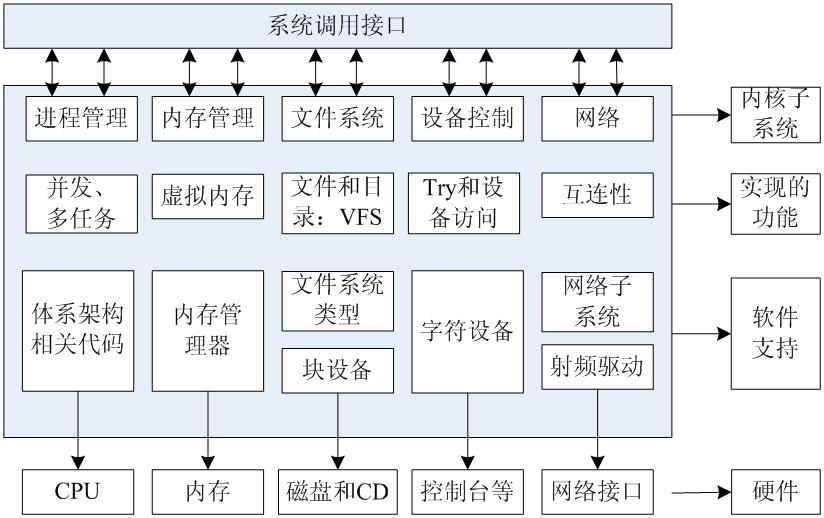
linux 设备驱动基本概念
- 应用程序、库、内核、驱动程序的关系
- 设备类型
- 设备文件、主设备号与从设备号
- 驱动程序与应用程序的区别
- 用户态与内核态
- Linux驱动程序功能
1)应用程序调用一系列函数库,通过对文件的操作完成一系列功能:
应用程序以文件形式访问各种硬件设备(linux特有的抽象方式,把所有的硬件访问抽象为对文件的读写、设置)
函数库:
部分函数无需内核的支持,由库函数内部通过代码实现,直接完成功能
部分函数涉及到硬件操作或内核的支持,由内核完成对应功能,我们称其为系统调用
2)内核处理系统调用,根据设备文件类型、主设备号、从设备号(后面会讲解),调用设备驱动程序;
3)设备驱动直接与硬件通信;
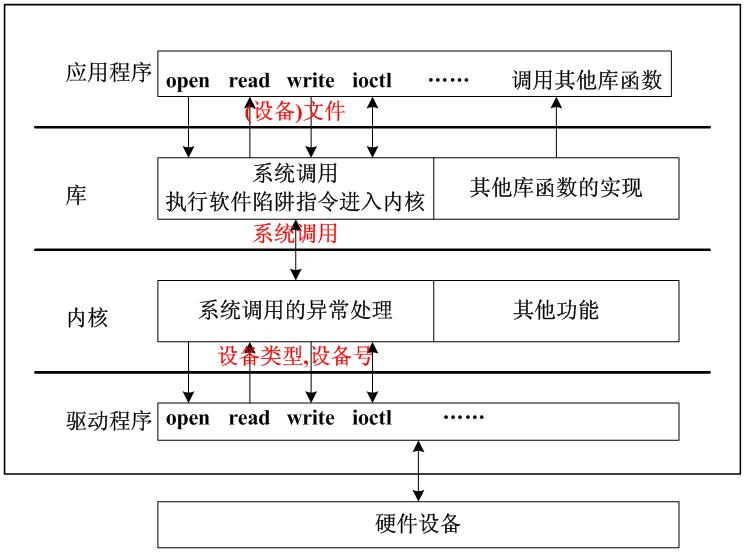
二、设备类型
硬件是千变万化的,没有八千也有一万了,就像世界上有三种人:男人、女人、女博士一样,linux做了一个很伟大也很艰难的分类:把所有的硬件设备分为三大类:字符设备、块设备、网络设备。
1)字符设备:字符(char)设备是个能够像字节流(类似文件)一样被访问的设备。
对字符设备发出读/写请求时,实际的硬件I/O操作一般紧接着发生;
字符设备驱动程序通常至少要实现open、close、read和write系统调用。
比如我们常见的lcd、触摸屏、键盘、led、串口等等,就像男人是用来干活的一样,他们一般对应具体的硬件都是进行出具的采集、处理、传输。
2)块设备:一个块设备驱动程序主要通过传输固定大小的数据(一般为512或1k)来访问设备。
块设备通过buffer cache(内存缓冲区)访问,可以随机存取,即:任何块都可以读写,不必考虑它在设备的什么地方。
块设备可以通过它们的设备特殊文件访问,但是更常见的是通过文件系统进行访问。
只有一个块设备可以支持一个安装的文件系统。
比如我们常见的电脑硬盘、SD卡、U盘、光盘等,就像女人一样是用来存储信息的。
3)网络接口:任何网络事务都经过一个网络接口形成,即一个能够和其他主机交换数据的设备。
访问网络接口的方法仍然是给它们分配一个唯一的名字(比如eth0),但这个名字在文件系统中不存在对应的节点。
内核和网络设备驱动程序间的通信,完全不同于内核和字符以及块驱动程序之间的通信,内核调用一套和数据包传输相关的函数(socket函数)而不是read、write等。
比如我们常见的网卡设备、蓝牙设备,就像女博士一样,数量稀少但又不可或缺。
linux中所有的驱动程序最终都能归到这三种设备中,当然他们之间也没有非常严格的界限,这些都是程序中对他们的划分而已,比如一个sd卡,我们也可以把它封装成字符设备去操作也是没有问题的。就像。。。
三、设备文件、主设备号、从设备号
有了设备类型的划分,那么应用程序应该怎样访问具体的硬件设备呢?
或者说已经确定他是一个男人了,那么怎么从万千世界中区分他与他的不同呢?
答案是:姓名,在linux驱动中也就是设备文件名。
那么重名怎么办?
答案是:身份证号,在linux驱动中也就是设备号(主、从)。
设备文件:
在linux
系统
中有一个约定俗成的说法:“一切皆文件”,
应用程序使用设备文件节点访问对应设备,
主设备号、从设备号
在设备管理中,除了设备类型外,内核还需要一对被称为主从设备号的参数,才能唯一标识一个设备,类似人的身份证号
主设备号:
用于标识驱动程序,相同的主设备号使用相同的驱动程序,例如:S3C2440 有串口、LCD、触摸屏三种设备,他们的主设备号各不相同;
从设备号:
用于标识同一驱动程序的不同硬件
例:PC的IDE设备,主设备号用于标识该硬盘,从设备号用于标识每个分区,2440有三个串口,每个串口的主设备号相同,从设备号用于区分具体属于那一个串口。
应用程序以main开始
驱动程序没有main,它以一个模块初始化函数作为入口
应用程序从头到尾执行一个任务
驱动程序完成初始化之后不再运行,等待系统调用
应用程序可以使用glibc等标准C函数库
驱动程序不能使用标准C库
五、用户态与内核态的区分
驱动程序是内核的一部分,工作在内核态
应用程序工作在用户态
数据空间访问问题
无法通过指针直接将二者的数据地址进行传递
系统提供一系列函数帮助完成数据空间转换
get_user
put_user
copy_from_user
copy_to_user
对设备初始化和释放资源
把数据从内核传送到硬件和从硬件读取数据
读取应用程序传送给设备文件的数据和回送应用程序请求的数据
检测和处理设备出现的错误(底层协议)
用于区分具体设备的实例
linux 驱动开发前奏(模块编程)
一、linux内核模块简介
linux内核整体结构非常庞大,其包含的组件也非常多。我们怎么把需要的部分都包含在内核中呢?
一种办法是把所有的需要的功能都编译到内核中。这会导致两个问题,一是生成的内核会很大,二是如果我们要在现有的内核中新增或删除功能,不得不重新编译内核,工作效率会非常的低,同时如果编译的模块不是很完善,很有可能会造成内核崩溃。
linux提供了另一种机制来解决这个问题,这种集中被称为模块,可以实现编译出的内核本身并不含有所有功能,而在这些功能需要被使用的时候,其对应的代码可以被动态的加载到内核中。
二、模块特点:
1)模块本身并不被编译入内核,从而控制了内核的大小。
2)模块一旦被加载,他就和内核中的其他部分完全一样。
注意:模块并不是驱动的必要形式:即:驱动不一定必须是模块,有些驱动是直接编译进内核的;同时模块也不全是驱动,例如我们写的一些很小的算法可以作为模块编译进内核,但它并不是驱动。就像烧饼不一定是圆的,圆的也不都是烧饼一样。
三、最简单的模块分析
1)以下是一个最简单的模块例子
- #include <linux/init.h> /* printk() */
- #include <linux/module.h> /* __init __exit */
- static int __init hello_init(void) /*模块加载函数,通过insmod命令加载模块时,被自动执行*/
- {
- printk(KERN_INFO " Hello World enter\n");
- return 0;
- }
- static void __exit hello_exit(void) /*模块卸载函数,当通过rmmod命令卸载时,会被自动执行*/
- {
- printk(KERN_INFO " Hello World exit\n ");
- }
- module_init(hello_init);
- module_exit(hello_exit);
- MODULE_AUTHOR("dengwei"); /*模块作者,可选*/
- MODULE_LICENSE("Dual BSD/GPL"); /*模块许可证明,描述内核模块的许可权限,必须*/
- MODULE_DESCRIPTION("A simple Hello World Module"); /*模块说明,可选*/
- MODULE_ALIAS("a simplest module"); /*模块说明,可选*/<span style="font-family:SimSun;font-size:18px;color:#FF0000;"><strong>
- </strong></span>
2) 以下是编译上述模块所需的编写的makefile
- obj-m :=hello.o //目标文件
- #module-objs := file1.o file.o //当模块有多个文件组成时,添加本句
- KDIR :=/usr/src/linux //内核路径,根据实际情况换成自己的内核路径,嵌入式的换成嵌入式,PC机的指定PC机路径
- PWD := $(shell pwd) //模块源文件路径
- all:
- $(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
- @rm -rf *.mod.*
- @rm -rf .*.cmd
- @rm -rf *.o
- @rm -rf Module.*
- clean:
- rm -rf *.ko
最终会编译得到:hello.ko文件
使用insmodhello.ko将模块插入内核,然后使用dmesg即可看到输出提示信息。
常用的几种模块操作:
3)linux内核模块的程序结构
1.模块加载函数:
Linux内核模块一般以__init标示声明,典型的模块加载函数的形式如下:
- static int __init myModule_init(void)
- {
- /* Module init code */
- PRINTK("myModule_init\n");
- return 0;
- }
- module_init(myModule_init);
模块加载函数的名字可以随便取,但必须以“module_init(函数名)”的形式被指定;
执行insmod命令时被执行,用于初始化模块所必需资源,比如内存空间、硬件设备等;
它返回整形值,若初始化成功,应返回0,初始化失败返回负数。
2.模块卸载函数
典型的模块卸载函数形式如下:
- static void __exit myModule_exit(void)
- {
- /* Module exit code */
- PRINTK("myModule_exit\n");
- return;
- }
- module_exit(myModule_exit);
模块卸载函数在模块卸载的时候执行,不返回任何值,需用”module_exit(函数名)”的形式被指定。
卸载模块完成与加载函数相反的功能:
若加载函数注册了XXX,则卸载函数应当注销XXX
若加载函数申请了内存空间,则卸载函数应当释放相应的内存空间
若加载函数申请了某些硬件资源(中断、DMA、I/0端口、I/O内存等),则卸载函数应当释放相应的硬件资源
若加载函数开启了硬件,则卸载函数应当关闭硬件。
其中__init 、__exit 为系统提供的两种宏,表示其所修饰的函数在调用完成后会自动回收内存,即内核认为这种函数只会被执行1次,然后他所占用的资源就会被释放。
3.模块声明与描述
在linux内核模块中,我们可以用MODULE_AUTHOR、MODULE_DESCRIPTION、MODULE_VERSION、MODULE_TABLE、MODULE_ALIA,分别描述模块的作者、描述、版本、设备表号、别名等。
- MODULE_AUTHOR("dengwei");
- MODULE_LICENSE("Dual BSD/GPL");
- MODULE_DESCRIPTION("A simple Hello World Module");
- MODULE_ALIAS("a simplest module");
四、有关模块的其它特性
1)模块参数:
我们可以利用module_param(参数名、参数类型、参数读写属性) 为模块定义一个参数,例如:
- static char *string_test = “this is a test”;
- static num_test = 1000;
- module_param (num_test,int,S_IRUGO);
- module_param (steing_test,charp,S_ITUGO);
在装载模块时,用户可以给模块传递参数,形式为:”insmod 模块名 参数名=参数值”,如果不传递,则参数使用默认的参数值
参数的类型可以是:byte,short,ushort,int,uint,long,ulong,charp,bool;
权限:定义在linux/stat.h中,控制存取权限,S_IRUGO表示所有用户只读;
模块被加载后,在sys/module/下会出现以此模块命名的目录,当读写权限为零时:表示此参数不存在sysfs文件系统下的文件节点,当读写权限不为零时:此模块的目录下会存在parameters目录,包含一系列以参数名命名的文件节点,这些文件节点的权限值就是传入module_param()的“参数读/写权限“,而该文件的内容为参数的值。
除此之外,模块也可以拥有参数数组,形式为:”module_param_array(数组名、数组类型、数组长、参数读写权限等)”,当不需要保存实际的输入的数组元素的个数时,可以设置“数组长“为0。
运行insmod时,使用逗号分隔输入的数组元素。
下面是一个实际的例子,来说明模块传参的过程。
- #include <linux/module.h> /*module_init()*/
- #include <linux/kernel.h> /* printk() */
- #include <linux/init.h> /* __init __exit */
- #define DEBUG //open debug message
- #ifdef DEBUG
- #define PRINTK(fmt, arg...) printk(KERN_WARNING fmt, ##arg)
- #else
- #define PRINTK(fmt, arg...) printk(KERN_DEBUG fmt, ##arg)
- #endif
- static char *string_test="default paramater";
- static int num_test=1000;
- static int __init hello_init(void)
- {
- PRINTK("\nthe string_test is : %s\n",string_test);
- PRINTK("the num_test is : %d\n",num_test);
- return 0;
- }
- static void __exit hello_exit(void)
- {
- PRINTK(" input paramater module exit\n ");
- }
- module_init(hello_init);
- module_exit(hello_exit);
- module_param(num_test,int,S_IRUGO);
- module_param(string_test,charp,S_IRUGO);
- MODULE_AUTHOR("dengwei");
- MODULE_LICENSE("GPL");
当执行 insmod hello_param.ko时,执行dmesg 查看内核输出信息:
- Hello World enter
- the test string is: this is a test
- the test num is :1000
当执行insmod hello_param.ko num_test=2000 string_test=“edit by dengwei”,执行dmesg查看内核输出信息:
- Hello World enter
- the test string is: edit by dengwei
- the test num is :2000
2)导出模块及符号的相互引用
Linux2.6内核的“/proc/kallsyms“文件对应内核符号表,它记录了符号以及符号所在的内存地址,模块可以使用下列宏导到内核符号表中。
EXPORT_SYMBOL(符号名); 任意模块均可
EXPORT_SYMBOL_GPL(符号名); 只使用于包含GPL许可权的模块
导出的符号可以被其它模块使用,使用前声明一下即可。
下面给出一个简单的例子:将add sub符号导出到内核符号表中,这样其它的模块就可以利用其中的函数
- #include <linux/module.h> /*module_init()*/
- #include <linux/kernel.h> /* printk() */
- #include <linux/init.h> /* __init __exit */
- int add_test(int a ,int b)
- {
- return a + b;
- }
- int sub_test(int a,int b)
- {
- return a - b;
- }
- EXPORT_SYMBOL(add_test);
- EXPORT_SYMBOL(sub_test);
- MODULE_AUTHOR("dengwei");
- MODULE_LICENSE("GPL");
执行 cat/proc/kallsyms | grep test 即可找到以下信息,表示模块确实被加载到内核表中。
- f88c9008 r __ksymtab_sub_integar [export_symb]
- f88c9020 r __kstrtab_sub_integar [export_symb]
- f88c9018 r __kcrctab_sub_integar [export_symb]
- f88c9010 r __ksymtab_add_integar [export_symb]
- f88c902c r __kstrtab_add_integar [export_symb]
- f88c901c r __kcrctab_add_integar [export_symb]
- f88c9000 T add_tes [export_symb]
- f88c9004 T sub_tes [export_symb]
- 13db98c9 a __crc_sub_integar [export_symb]
- e1626dee a __crc_add_integar [export_symb]
在其它模块中可以引用此符号
- #include <linux/module.h> /*module_init()*/
- #include <linux/kernel.h> /* printk() */
- #include <linux/init.h> /* __init __exit */
- #define DEBUG //open debug message
- #ifdef DEBUG
- #define PRINTK(fmt, arg...) printk(KERN_WARNING fmt, ##arg)
- #else
- #define PRINTK(fmt, arg...) printk(KERN_DEBUG fmt, ##arg)
- #endif
- extern int add_test(int a ,int b);
- extern int sub_test(int a,int b);
- static int __init hello_init(void)
- {
- int a,b;
- a = add_test(10,20);
- b = sub_test(30,20);
- PRINTK("the add test result is %d",a);
- PRINTK("the sub test result is %d\n",b);
- return 0;
- }
- static void __exit hello_exit(void)
- {
- PRINTK(" Hello World exit\n ");
- }
- module_init(hello_init);
- module_exit(hello_exit);
- MODULE_AUTHOR("dengwei");
- MODULE_LICENSE("GPL");
linux 内核配置机制(make menuconfig、Kconfig、makefile)讲解
前面我们介绍模块编程的时候介绍了驱动进入内核有两种方式:模块和直接编译进内核,并介绍了模块的一种编译方式——在一个独立的文件夹通过makefile配合内核源码路径完成
那么如何将驱动直接编译进内核呢?
在我们实际内核的移植配置过程中经常听说的内核裁剪又是怎么麽回事呢?
我们在进行linux内核配置的时候经常会执行make menuconfig这个命令,然后屏幕上会出现以下界面:
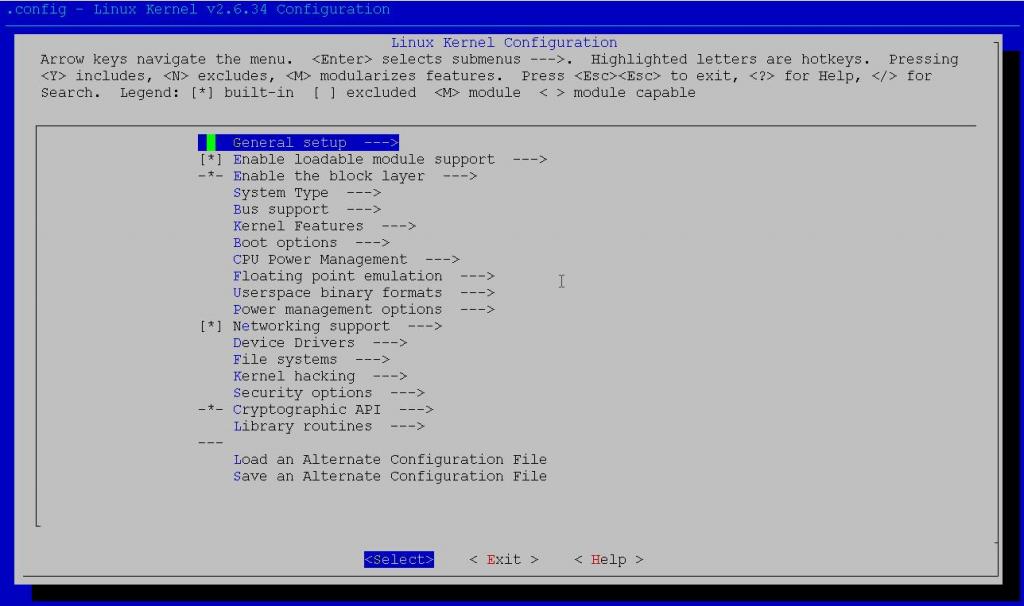
这个界面是怎么生成的呢?
跟我们经常说的内核配置与与编译又有什么关系呢?
下面我们借此来讲解一下linux内核的配置机制及其编译过程。
Linux内核的配置系统由三个部分组成,分别是:
1、Makefile:分布在 Linux 内核源代码根目录及各层目录中,定义 Linux 内核的编译规则;
2、配置文件(config.in(2.4内核,2.6内核)):给用户提供配置选择的功能;
3、配置工具:包括配置命令解释器(对配置脚本中使用的配置命令进行解释)和配置用户界面(提供基于字符界面、基于 Ncurses 图形界面以及基于 Xwindows 图形界面的用户配置界面,各自对应于 Make config、Make menuconfig 和 make xconfig)。
这些配置工具都是使用脚本语言,如 Tcl/TK、Perl 编写的(也包含一些用 C 编写的代码)。本文并不是对配置系统本身进行分析,而是介绍如何使用配置系统。所以,除非是配置系统的维护者,一般的内核开发者无须了解它们的原理,只需要知道如何编写 Makefile 和配置文件就可以。
二、makefile menuconfig过程讲解
当我们在执行make menuconfig这个命令时,系统到底帮我们做了哪些工作呢?
这里面一共涉及到了一下几个文件我们来一一讲解
Linux内核根目录下的scripts文件夹
arch/$ARCH/Kconfig文件、各层目录下的Kconfig文件
Linux内核根目录下的makefile文件、各层目录下的makefile文件
Linux内核根目录下的的.config文件、arm/$ARCH/下的config文件
Linux内核根目录下的 include/generated/autoconf.h文件
1)scripts文件夹存放的是跟make menuconfig配置界面的图形绘制相关的文件,我们作为使用者无需关心这个文件夹的内容
2)当我们执行make menuconfig命令出现上述蓝色配置界面以前,系统帮我们做了以下工作:
首先系统会读取arch/$ARCH/目录下的Kconfig文件生成整个配置界面选项(Kconfig是整个linux配置机制的核心),那么ARCH环境变量的值等于多少呢?
它是由linux内核根目录下的makefile文件决定的,在makefile下有此环境变量的定义:

或者通过 make ARCH=arm menuconfig命令来生成配置界面,默认生成的界面是所有参数都是没有值的
比如教务处进行考试,考试科数可能有外语、语文、数学等科,这里相当于我们选择了arm科可进行考试,系统就会读取arm/arm/kconfig文件生成配置选项(选择了arm科的卷子),系统还提供了x86科、milps科等10几门功课的考试题
3)假设教务处比较“仁慈”,为了怕某些同学做不错试题,还给我们准备了一份参考答案(默认配置选项),存放在arch/$ARCH/configs下,对于arm科来说就是arch/arm/configs文件夹:

此文件夹中有许多选项,系统会读取哪个呢?内核默认会读取linux内核根目录下.config文件作为内核的默认选项(试题的参考答案),我们一般会根据开发板的类型从中选取一个与我们开发板最接近的系列到Linux内核根目录下(选择一个最接近的参考答案)
#cp arch/arm/configs/s3c2410_defconfig .config
4).config
假设教务处留了一个心眼,他提供的参考答案并不完全正确(.config文件与我们的板子并不是完全匹配),这时我们可以选择直接修改.config文件然后执行make menuconfig命令读取新的选项
但是一般我们不采取这个方案,我们选择在配置界面中通过空格、esc、回车选择某些选项选中或者不选中,最后保存退出的时候,Linux内核会把新的选项(正确的参考答案)更新到.config中,此时我们可以把.config重命名为其它文件保存起来(当你执行make distclean时系统会把.config文件删除),以后我们再配置内核时就不需要再去arch/arm/configs下考取相应的文件了,省去了重新配置的麻烦,直接将保存的.config文件复制为.config即可.
5)经过以上两步,我们可以正确的读取、配置我们需要的界面了
那么他们如何跟makefile文件建立编译关系呢?
当你保存make menuconfig选项时,系统会除了会自动更新.config外,还会将所有的选项以宏的形式保存在
Linux内核根目录下的 include/generated/autoconf.h文件下

内核中的源代码就都会包含以上.h文件,跟宏的定义情况进行条件编译。
当我们需要对一个文件整体选择如是否编译时,还需要修改对应的makefile文件,例如:

我们选择是否要编译s3c2410_ts.c这个文件时,makefile会根据CONFIG_TOUCHSCREEN_S3C2410来决定是编译此文件,此宏是在Kconfig文件中定义,当我们配置完成后,会出现在.config及autconf中,至此,我们就完成了整个linux内核的编译过程。
最后我们会发现,整个linux内核配置过程中,留给用户的接口其实只有各层Kconfig、makefile文件以及对应的源文件。
比如我们如果想要给内核增加一个功能,并且通过make menuconfig控制其声称过程
首先需要做的工作是:修改对应目录下的Kconfig文件,按照Kconfig语法增加对应的选项;
其次执行make menuconfig选择编译进内核或者不编译进内核,或者编译为模块,.config文件和autoconf.h文件会自动生成;
最后修改对应目录下的makefile文件完成编译选项的添加;
最后的最后执行make zImage命令进行编译。
三、具体实例
下面我们以前面做过的模块实验为例,讲解如何通过make menuconfig机制将前面单独编译的模块编译进内核或编译为模块
假设我已经有了这么一个驱动:
modules.c
- #include <linux/module.h> /*module_init()*/
- #include <linux/kernel.h> /* printk() */
- #include <linux/init.h> /* __init __exit */
- #define DEBUG //open debug message
- #ifdef DEBUG
- #define PRINTK(fmt, arg...) printk(KERN_WARNING fmt, ##arg)
- #else
- #define PRINTK(fmt, arg...) printk(KERN_DEBUG fmt, ##arg)
- #endif
- /* Module Init & Exit function */
- static int __init myModule_init(void)
- {
- /* Module init code */
- PRINTK("myModule_init\n");
- return 0;
- }
- static void __exit myModule_exit(void)
- {
- /* Module exit code */
- PRINTK("myModule_exit\n");
- return;
- }
- module_init(myModule_init);
- module_exit(myModule_exit);
- MODULE_AUTHOR("dengwei"); /*模块作者,可选*/
- MODULE_LICENSE("GPL"); /*模块许可证明,描述内核模块的许可权限,必须*/
- MODULE_DESCRIPTION("A simple Hello World Module"); /*模块说明,可选*/
tristate "modules device support"
default y
help
Say Y here,the modules will be build in kernel.
Say M here,the modules willbe build to modules.
Say N here,there will be nothing to be do.
CONFIG_MODULES 必须跟上面的Kconfig中保持一致,系统会自动添加CONFIG_前缀
modules.o必须跟你加入的.c文件名一致
最后执行:make zImage modules就会被编译进内核中
第三步:
把星号在配置界面通过空格改为M,最后执行make modules,在driver/char/目录下会生成一个modules.ko文件
跟我们前面讲的单独编译模块效果一样,也会生成一个模块,将它考入开发板执行insmod moudles.ko,即可将生成的模块插入内核使用
linux platfoem总线机制讲解与实例开发
1、概述:
通常在Linux中,把SoC系统中集成的独立外设单元(如:I2C、IIS、RTC、看门狗等)都被当作平台设备来处理。
从Linux2.6起,引入了一套新的驱动管理和注册机制:Platform_device和Platform_driver,来管理相应设备。
Linux中大部分的设备驱动,都可以使用这套机制,设备用platform_device表示,驱动用platform_driver进行注册。
Linux platform driver机制和传统的device_driver机制相比,一个十分明显的优势在于platform机制将本身的资源注册进内核,由内核统一管理,在驱动程序中使用这些资源时通过platform_device提供的标准接口进行申请并使用。
这样提高了驱动和资源管理的独立性,并且拥有较好的可移植性和安全性。
对在每个挂在虚拟的platform bus的设备作__driver_attach() ->driver_probe_device()
开始真正的探测,如果probe成功,则绑定设备到该驱动。
定义 platform_device
struct platform_device
{
const char * name;
u32 id;
struct device dev;
u32 num_resources;
struct resource * resource;
};
每个具体的驱动都对应一个这样的结构体。
(注意,这个名字一定要和后面platform_driver.driver->name相同,因为在注册具体的设备驱动时会遍历这个结构体查找相应的数据结构,后面会详细讲解)
struct resource
{
resource_size_t start; //定义资源的起始地址
resource_size_t end; //定义资源的结束地址
const char *name; //定义资源的名称
unsigned long flags; //定义资源的类型,比如MEM,IO,IRQ,DMA类型
struct resource *parent, *sibling, *child; //资源链表指针
};
主要用于定义具体设备占用的硬件资源(如:地址空间、中断号等;
static void __init smdk2440_machine_init(void)
{
s3c24xx_fb_set_platdata(&smdk2440_fb_info);
s3c_i2c0_set_platdata(NULL);
platform_add_devices(smdk2440_devices, ARRAY_SIZE(smdk2440_devices));
smdk_machine_init();
}
此函数中调用了platform_add_devices() -> platform_device_register()注册platform设备
注册顺序根据同文件夹下的
{
&s3c_device_ohci,
&s3c_device_lcd,
&s3c_device_wdt,
&s3c_device_i2c0,
&s3c_device_iis,
&s3c_device_dm9k,
&s3c24xx_uda134x,
&s3c_device_sdi,
};
结构体进行
这些设备的初始化一般都在arch/arm/plat-s3c24xx/devs.c下
我们以s3c_device_wdt为例进行观察:
/* Watchdog */
//看门狗资源结构体
static struct resource s3c_wdt_resource[] = {
[0] = {
.start = S3C24XX_PA_WATCHDOG,
.end = S3C24XX_PA_WATCHDOG + S3C24XX_SZ_WATCHDOG - 1,
.flags = IORESOURCE_MEM, //看门狗所使用的IO口范围
},
[1] = {
.start = IRQ_WDT,
.end = IRQ_WDT,
.flags = IORESOURCE_IRQ, //看门狗所使用的中断资源
}
};
//定义了一个看门狗结构体
struct platform_device s3c_device_wdt = {
.name = "s3c2410-wdt", //驱动名称
.id = -1, //id号,-1代表自动分配
.num_resources = ARRAY_SIZE(s3c_wdt_resource),
//指定资源数量
.resource = s3c_wdt_resource, //指定资源结构体
};
platform_driver在具体的硬件设备驱动编写中完成:
同plartform_device相似,需要定义并实现以下结构体
{
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
其中除了一些函数指针外,还有一个一般驱动的device_driver结构。
/*Watchdog平台驱动结构体,平台驱动结构体定义在platform_device.h中,该结构体内的接口函数需要单独实现*/
static struct platform_driver watchdog_driver =
{
.probe = watchdog_probe, /*Watchdog探测函数*/
.remove = __devexit_p(watchdog_remove),/*Watchdog移除函数*/
.shutdown = watchdog_shutdown, /*Watchdog关闭函数*/
.suspend = watchdog_suspend, /*Watchdog挂起函数*/
.resume = watchdog_resume, /*Watchdog恢复函数*/
.driver =
{
/*注意这里的名称一定要和系统中定义平台设备的地方一致,这样才能把平台设备与该平台设备的驱动关联起来*/
.name = "s3c2410-wdt",
.owner = THIS_MODULE,
},
};
static int __init watchdog_init(void)
{
/*将Watchdog注册成平台设备驱动*/
return platform_driver_register(&watchdog_driver);
}
static void __exit watchdog_exit(void)
{
/*注销Watchdog平台设备驱动*/
platform_driver_unregister(&watchdog_driver);
}
module_init(watchdog_init);
module_exit(watchdog_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("linux");
MODULE_DESCRIPTION("S3C2440 Watchdog Driver");
static int __devinit watchdog_probe(struct platform_device *pdev)
{
int ret;
int started = 0;
struct resource *res;/*定义一个资源,用来保存获取的watchdog的IO资源*/
wdt_irqno = platform_get_irq(pdev, 0);
/*申请Watchdog中断服务,这里使用的是快速中断:IRQF_DISABLED。中断服务程序为:wdt_irq,将Watchdog平台设备pdev做参数传递过去了*/
ret = request_irq(wdt_irqno, wdt_irq, IRQF_DISABLED, pdev->name, pdev);
/*获取watchdog平台设备所使用的IO端口资源,注意这个IORESOURCE_MEM标志和watchdog平台设备定义中的一致*/
res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
/*申请watchdog的IO端口资源所占用的IO空间(要注意理解IO空间和内存空间的区别),request_mem_region定义在ioport.h中*/
wdt_mem = request_mem_region(res->start, res->end - res->start + 1, pdev->name);
/*将watchdog的IO端口占用的这段IO空间映射到内存的虚拟地址,ioremap定义在io.h中。
注意:IO空间要映射后才能使用,以后对虚拟地址的操作就是对IO空间的操作,*/
wdt_base = ioremap(res->start, res->end - res->start + 1);
return ret;
}
/*Watchdog平台驱动的设备移除接口函数的实现*/
static int __devexit wdt_remove(struct platform_device *dev)
{
/*释放获取的Watchdog平台设备的IO资源*/
release_resource(wdt_mem);
kfree(wdt_mem);
wdt_mem = NULL;
/*同watchdog_probe中中断的申请相对应,在那里申请中断,这里就释放中断*/
free_irq(wdt_irqno, dev);
wdt_irq = NULL;
/*释放获取的Watchdog平台设备的时钟*/
clk_disable(wdt_clock);
clk_put(wdt_clock);
wdt_clock = NULL;
/*释放Watchdog设备虚拟地址映射空间*/
iounmap(wdt_base);
return 0;
}
#ifdef CONFIG_PM
/*定义两个变量来分别保存挂起时的WTCON和WTDAT值,到恢复的时候使用*/
static unsigned long wtcon_save;
static unsigned long wtdat_save;
/*Watchdog平台驱动的设备挂起接口函数的实现*/
static int wdt_suspend(struct platform_device *dev, pm_message_t state)
{
/*保存挂起时的WTCON和WTDAT值*/
wtcon_save = readl(wdt_base + S3C2410_WTCON);
wtdat_save = readl(wdt_base + S3C2410_WTDAT);
/*停止看门狗定时器*/
wdt_start_or_stop(0);
return 0;
}
/*Watchdog平台驱动的设备恢复接口函数的实现*/
static int wdt_resume(struct platform_device *dev)
{
/*恢复挂起时的WTCON和WTDAT值,注意这个顺序*/
writel(wtdat_save, wdt_base + S3C2410_WTDAT);
writel(wtdat_save, wdt_base + S3C2410_WTCNT);
writel(wtcon_save, wdt_base + S3C2410_WTCON);
return 0;
}
#else /*配置内核时没选上电源管理,Watchdog平台驱动的设备挂起和恢复功能均无效,这两个函数也就无需实现了*/
#define wdt_suspend NULL
#define wdt_resume NULL
#endif
mknod利用udev、sys动态创建linux设备结点 --步骤
在Linux 2.6内核中,devfs被认为是过时的方法,并最终被抛弃,udev取代了它。Devfs的一个很重要的特点就是可以动态创建设备结点。那我们现在如何通过udev和sys文件系统动态创建设备结点呢?
用udev在/dev/下动态生成设备文件,这样用户就不用手工调用mknod了。
利用的kernel API:
class_create : 创建class
class_destroy : 销毁class
class_device_create : 创建device
class_device_destroy : 销毁device
注意,这些API是2.6.13开始有的,在2.6.13之前,应当使用
class_simple_create
class_simple_destroy
class_simple_device_add
class_simple_device_remove
这一系列,也就是ldd3第14章描述的。 详见:
https:/ n.net/Articles/128644/
Output:
===========================================
[root@localhost dynamic_dev_node]# insmod ./dummy_dev.ko
[root@localhost dynamic_dev_node]# file /dev/dummy_dev0
/dev/dummy_dev0: character special (250/0)
[root@localhost dynamic_dev_node]# rmmod dummy_dev.ko
[root@localhost dynamic_dev_node]# file /dev/dummy_dev0
/dev/dummy_dev0: ERROR: cannot open `/dev/dummy_dev0' (No such file or directory)
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux pes.h>
#include <linux/delay.h>
#include <linux/moduleparam.h>
#include <linux/slab.h>
#include <linux/errno.h>
#include <linux/ioctl.h>
#include <linux ev.h>
#include <linux/string.h>
#include <linux st.h>
#include <linux/pci.h>
#include <asm/uaccess.h>
#include <asm/atomic.h>
#include <asm/unistd.h>
#define THIS_DESCRIPTION "\
This module is a dummy device driver, it register\n\
\t\ta char device, and utilize udev to create/destroy \n\
\t\tdevice node under /dev/ dynamicallly."
MODULE_LICENSE("GPL");
MODULE_AUTHOR("albcamus <albcamus@gmail.com>");
MODULE_DESCRIPTION(THIS_DESCRIPTION);
#define DUMMY_MAJOR 250
#define DUMMY_MINOR 0
#define DUMMY_NAME "dummy_dev"
/**
* the open routine of 'dummy_dev'
*/
static int dummy_open(struct inode *inode, struct file *file)
{
printk("Open OK\n");
return 0;
}
/**
* the write routine of 'dummy_dev'
*/
static ssize_t dummy_write(struct file *filp, const char *bp, size_t count, loff_t *ppos)
{
printk("Don't Write!\n");
return 0;
}
/**
* the read routine of 'dummy_dev'
*/
static ssize_t dummy_read(struct file *filp, char *bp, size_t count, loff_t *ppos)
{
return 0;
}
/**
* the ioctl routine of 'dummy_dev'
*/
static int dummy_ioctl(struct inode *inode, struct file *filep,
unsigned int cmd, unsigned long arg)
{
return 0;
}
/**
* file_operations of 'dummy_dev'
*/
static struct file_operations dummy_dev_ops = {
.owner = THIS_MODULE,
.open = dummy_open,
.read = dummy_read,
.write = dummy_write,
.ioctl = dummy_ioctl,
};
/**
* struct cdev of 'dummy_dev'
*/
struct cdev *my_cdev;
struct class *my_class;
static int __init my_init(void)
{
int err, devno = MKDEV(DUMMY_MAJOR, DUMMY_MINOR);
/* register the 'dummy_dev' char device */
my_cdev = cdev_alloc();
cdev_init(my_cdev, &dummy_dev_ops);
my_cdev->owner = THIS_MODULE;
err = cdev_add(my_cdev, devno, 1);
if (err != 0)
printk("dummy pci device register failed!\n");
/* creating your own class */
my_class = class_create(THIS_MODULE, "dummy_class");
if(IS_ERR(my_class)) {
printk("Err: failed in creating class.\n");
return -1;
}
/* register your own device in sysfs, and this will cause udevd to create corresponding device node */
class_device_create(my_class, NULL, MKDEV(DUMMY_MAJOR, DUMMY_MINOR), NULL, DUMMY_NAME "%d", DUMMY_MINOR );
return 0;
}
static void __exit my_fini(void)
{
printk("bye\n");
cdev_del(my_cdev);
/ ree(my_cdev); no use. because that cdev_del() will call kfree if neccessary.
class_device_destroy(my_class, MKDEV(DUMMY_MAJOR, DUMMY_MINOR));
class_destroy(my_class);
}
module_init(my_init);
module_exit(my_fini);
原来2.6.15中的函数:
class_device_create();
class_device_destroy();
在2.6.27中变为:
device_create()
device_destroy()
第一、什么是udev?
这篇文章UDEV Primer给我们娓娓道来,花点时间预习一下是值得的。当然,不知道udev是什么也没关系,
把它当个助记符好了,有了下面的上路指南,可以节省很多时间。我们只需要树立一个信念:udev很简单!
嵌入式的udev应用尤其简单。
第二、为什么udev要取代devfs?
这是生产关系适应生产力的需要,udev好,devfs坏,用好的不用坏的。
udev是硬件平台无关的,属于user space的进程,它脱离驱动层的关联而建立在操作系统之上,基于这种设
计实现,我们可以随时修改及删除/dev下的设备文件名称和指向,随心所欲地按照我们的愿望安排和管理设
备文件系统,而完成如此灵活的功能只需要简单地修改udev的配置文件即可,无需重新启动操作系统。udev
已经使得我们对设备的管理如探囊取物般轻松自如。
第三、如何得到udev?
udev的主页在这里:http://www.kernel.org/pub/linux/utils/kernel/hotplug/udev.html
我们按照下面的步骤来生成udev的工具程序,以arm-linux为例:
1、wget http://www.us.kernel.org/pub/linux/utils/kernel/hotplug/udev-100.tar.bz2
2、tar xjf udev-100.tar.bz2
3、cd udev-100 编辑Makefile,查找CROSS_COMPILE,修改CROSS_COMPILE ?= arm-linux-
4、make
没有什么意外的话当前目录下生成udev,udevcontrol,udevd,udevinfo,udevmonitor,udevsettle,udevstart,
udevtest,udevtrigger九个工具程序,在嵌入式系统里,我们只需要udevd和udevstart就能使udev工作得很好,
其他工具则帮助我们完成udev的信息察看、事件捕捉或者更高级的操作。
另外一个方法是直接使用debian提供的已编译好的二进制包,美中不足的是版本老了一些。
1、wget http://ftp.us.debian.org/debian/pool/main/u/udev/udev_0.056-3_arm.deb
2、ar -xf udev_0.056-3_arm.deb
3、tar xzf data.tar.gz
在sbin目录里就有我们需要的udevd和udevstart工具程序。
建议大家采用第一种方式生成的udevd和udevstart。为什么要用最新udev呢?新的强,旧的弱,用强的不用弱的。
第四、如何配置udev?
首先,udev需要内核sysfs和tmpfs的支持,sysfs为udev提供设备入口和uevent通道,tmpfs为udev设备文件提供存放空间,也就是说,在上电之前系统上是没有足够的设备文件可用的,我们需要一些技巧让kernel先引导起来。
由于在kernel启动未完成以前我们的设备文件不可用,如果使用mtd设备作为rootfs的挂载点,这个时候/dev/mtdblock这个设备目录是不存在的,我们无法让kernel通过/dev/mtdblock/X这样的设备找到rootfs,kernel只好停在那里惊慌。这个问题我们可以通过给kernel传递设备号的方式来解决,在linux系统中,mtdblock的主设备号是31,part号从0开始,那么以前的/dev/mtdblock/3就等同于31:03,以次类推,所以我们只需要修改bootloader传给kernel的cmd
line参数,使root=31:03,就可以让kernel在udevd未起来之前成功的找到rootfs。
另外一种方法就是给kernel传递未经归类的设备文件名,在udev未创建之前,所有的设备实际上已经通过sysfs建立,mtdblockX的位置相对于/sys/block/mtdblockX/dev,这个文件里存放着mtdblockX的设备号,形式与上一种方式相同。这时由于没有相应的udev规则,所有的设备都被隐含地映射到/dev目录下,mtdblockX对应于/dev/mtdbockX,这样我们给kernel传递root=/dev/mtdblock3,kernel发现/dev没有被建立,就自动从映射表里查找对应关系,最后取出/sys/block/mtdblockX/dev里的设备号,完成rootfs的挂载。
其次,需要做的工作就是重新生成rootfs,把udevd和udevstart复制到/sbin目录。然后我们需要在/etc/下为udev建立设备规则,这可以说是udev最为复杂的一步。这篇文章提供了最完整的指导:Writing
udev
rules文中描述的复杂规则我们可以暂时不用去理会,上路指南将带领我们轻松穿过这片迷雾。这里提供一个由简入繁的方法,对于嵌入式系统,这样做可以一劳永逸。
1、在前面用到的udev-100目录里,有一个etc目录,里面放着的udev目录包含了udev设备规则的详细样例文本。为了简单而又简洁,我们只需要用到etc/udev/udev.conf这个文件,在我们的rootfs/etc下建立一个udev目录,把它复制过去,这个文件很简单,除了注释只有一行,是用来配置日志信息的,嵌入式系统也许用不上日志,但是udevd需要检查这个文件。
2、在rootfs/etc/udev下建立一个rules.d目录,生成一个空的配置文件touch etc/udev/rules.d/udev.conf。然后
我们来编辑这个文件并向它写入以下配置项:
###############################################
# vc devices
KERNEL=="tty[0-9]*", NAME="vc/%n"
# block devices
KERNEL=="loop[0-9]*", NAME="loop/%n"
# mtd devices
KERNEL=="mtd[0-9]*", NAME="mtd/%n"
KERNEL=="mtdblock*", NAME="mtdblock/%n"
# input devices
KERNEL=="mice" NAME="input/%k"
KERNEL=="mouse[0-9]*", NAME="input/%k"
KERNEL=="ts[0-9]*", NAME="input/%k"
KERNEL=="event[0-9]*", NAME="input/%k"
# misc devices
KERNEL=="apm_bios", NAME="misc/%k"
KERNEL=="rtc", NAME="misc/%k"
################################################
保存它,我们的设备文件系统基本上就可以了,udevd和udevstart会自动分析这个文件。
3、为了使udevd在kernel起来后能够自动运行,我们在rootfs/etc/init.d/rcS中增加以下几行:
##################################
/bin/mount -t tmpfs tmpfs /dev
echo "Starting udevd..."
/sbin/udevd --daemon
/sbin/udevstart
##################################
4、重新生成rootfs,烧写到flash指定的rootfs part中。
5、如果需要动态改变设备规则,可以把etc/udev放到jffs或yaffs part,以备修改,根据需求而定,可以随时扩充udev.conf中的配置项。
Linux下mknod的作用
1. mknod命令用于创建一个设备文件,即特殊文件
2. 首先要明白什么是设备文件,简单的我们说 操作系统与外部设备(入磁盘驱动器,打印机,modern,终端 等等)都是通过设备文件来进行通信 的,在Unix/Linux系统与外部设备通讯之前,这个设备必须首先要有一个设备文件,设备文件均放在/dev目录下。一般情况下在安装系统的时候系统自动创建了很多已检测到的设备的设备文件,但有时候我们也需要自己手动创建,命令行生成设备文件的方式有 insf,mksf,mknod等等
3. 根据mknod命令的使用参数来看【mknod Name { b | c } Major Minor 】,使用mknod之前,至少要明白以下几点:
设备文件类型:分为块设备和字符设备。ls -l /dev 结果显示第一个字段有b*** 和 c****,这里即标识了块设备和字符设备。
字符设备文件----字符设备文件传送数据给设备的时候,一次传送一个字符,终端,打印机,绘图仪,modern等设备都经过字符设备文件传送数据
块设备---系统通过块设备文件存取一个设备的时候,先从内存中的buffer中读或写数据,而不是直接传送数据到物理磁盘,这种方式能有效的提高磁盘和CD-ROMS的I/O性能。磁盘和CD-ROMS即可以使用字符设备文件也可使用块设备文件。
4. 来看看mknod 命令,如果该设备文件你想放在一个特定的文件夹下当然就先创建文件夹
mknod 设备文件名[/dev/xyz] b/c 主号 次号
Linux 字符设备驱动结构(一)—— cdev 结构体、设备号相关知识解析
一、字符设备基础知识
1、设备驱动分类
linux系统将设备分为3类:字符设备、块设备、网络设备。使用驱动程序:
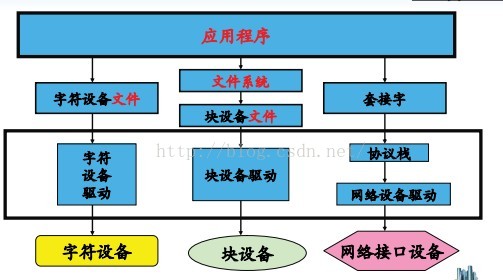
字符设备:是指只能一个字节一个字节读写的设备,不能随机读取设备内存中的某一数据,读取数据需要按照先后数据。字符设备是面向流的设备,常见的字符设备有鼠标、键盘、串口、控制台和LED设备等。
块设备:是指可以从设备的任意位置读取一定长度数据的设备。块设备包括硬盘、磁盘、U盘和SD卡等。
每一个字符设备或块设备都在/dev目录下对应一个设备文件。linux用户程序通过设备文件(或称设备节点)来使用驱动程序操作字符设备和块设备。
2、字符设备、字符设备驱动与用户空间访问该设备的程序三者之间的关系
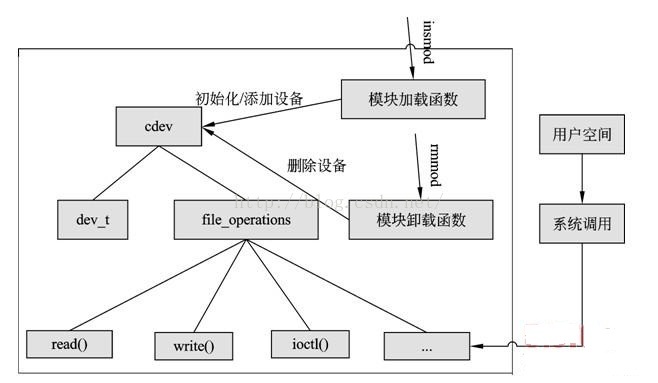
如图,在Linux内核中:
a -- 使用cdev结构体来描述字符设备;
b -- 通过其成员dev_t来定义设备号(分为主、次设备号)以确定字符设备的唯一性;
c -- 通过其成员file_operations来定义字符设备驱动提供给VFS的接口函数,如常见的open()、read()、write()等;
在Linux字符设备驱动中:
a -- 模块加载函数通过 register_chrdev_region( ) 或 alloc_chrdev_region( )来静态或者动态获取设备号;
b -- 通过 cdev_init( ) 建立cdev与 file_operations之间的连接,通过 cdev_add( ) 向系统添加一个cdev以完成注册;
c -- 模块卸载函数通过cdev_del( )来注销cdev,通过 unregister_chrdev_region( )来释放设备号;
用户空间访问该设备的程序:
a -- 通过Linux系统调用,如open( )、read( )、write( ),来“调用”file_operations来定义字符设备驱动提供给VFS的接口函数;
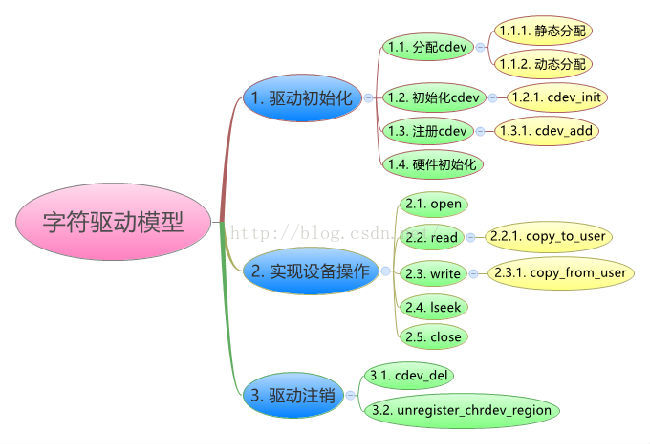
3、字符设备驱动模型
二、cdev 结构体解析
在Linux内核中,使用cdev结构体来描述一个字符设备,cdev结构体的定义如下:
- <include/linux/cdev.h>
- struct cdev {
- struct kobject kobj; //内嵌的内核对象.
- struct module *owner; //该字符设备所在的内核模块的对象指针.
- const struct file_operations *ops; //该结构描述了字符设备所能实现的方法,是极为关键的一个结构体.
- struct list_head list; //用来将已经向内核注册的所有字符设备形成链表.
- dev_t dev; //字符设备的设备号,由主设备号和次设备号构成.
- unsigned int count; //隶属于同一主设备号的次设备号的个数.
- };
内核给出的操作struct cdev结构的接口主要有以下几个:
a -- void cdev_init(struct cdev *, const struct file_operations *);
其源代码如代码清单如下:
- void cdev_init(struct cdev *cdev, const struct file_operations *fops)
- {
- memset(cdev, 0, sizeof *cdev);
- INIT_LIST_HEAD(&cdev->list);
- kobject_init(&cdev->kobj, &ktype_cdev_default);
- cdev->ops = fops;
- }
该函数主要对struct cdev结构体做初始化,最重要的就是建立cdev 和 file_operations之间的连接:
(1) 将整个结构体清零;
(2) 初始化list成员使其指向自身;
(3) 初始化kobj成员;
(4) 初始化ops成员;
b --struct cdev *cdev_alloc(void);
该函数主要分配一个struct cdev结构,动态申请一个cdev内存,并做了cdev_init中所做的前面3步初始化工作(第四步初始化工作需要在调用cdev_alloc后,显式的做初始化即: .ops=xxx_ops).
其源代码清单如下:
- struct cdev *cdev_alloc(void)
- {
- struct cdev *p = kzalloc(sizeof(struct cdev), GFP_KERNEL);
- if (p) {
- INIT_LIST_HEAD(&p->list);
- kobject_init(&p->kobj, &ktype_cdev_dynamic);
- }
- return p;
- }
在上面的两个初始化的函数中,我们没有看到关于owner成员、dev成员、count成员的初始化;其实,owner成员的存在体现了驱动程序与内核模块间的亲密关系,struct module是内核对于一个模块的抽象,该成员在字符设备中可以体现该设备隶属于哪个模块,在驱动程序的编写中一般由用户显式的初始化 .owner = THIS_MODULE, 该成员可以防止设备的方法正在被使用时,设备所在模块被卸载。而dev成员和count成员则在cdev_add中才会赋上有效的值。
c -- int cdev_add(struct cdev *p, dev_t dev, unsigned count);
该函数向内核注册一个struct cdev结构,即正式通知内核由struct cdev *p代表的字符设备已经可以使用了。
当然这里还需提供两个参数:
(1)第一个设备号 dev,
(2)和该设备关联的设备编号的数量。
这两个参数直接赋值给struct cdev 的dev成员和count成员。
d -- void cdev_del(struct cdev *p);
该函数向内核注销一个struct cdev结构,即正式通知内核由struct cdev *p代表的字符设备已经不可以使用了。
从上述的接口讨论中,我们发现对于struct cdev的初始化和注册的过程中,我们需要提供几个东西
(1) struct file_operations结构指针;
(2) dev设备号;
(3) count次设备号个数。
但是我们依旧不明白这几个值到底代表着什么,而我们又该如何去构造这些值!
三、设备号相应操作
1 -- 主设备号和次设备号(二者一起为设备号):
一个字符设备或块设备都有一个主设备号和一个次设备号。主设备号用来标识与设备文件相连的驱动程序,用来反映设备类型。次设备号被驱动程序用来辨别操作的是哪个设备,用来区分同类型的设备。
linux内核中,设备号用dev_t来描述,2.6.28中定义如下:
typedef u_long dev_t;
在32位机中是4个字节,高12位表示主设备号,低20位表示次设备号。
内核也为我们提供了几个方便操作的宏实现dev_t:
1) -- 从设备号中提取major和minor
MAJOR(dev_t dev);
MINOR(dev_t dev);
2) -- 通过major和minor构建设备号
MKDEV(int major,int minor);
注:这只是构建设备号。并未注册,需要调用 register_chrdev_region 静态申请;
- //宏定义:
- #define MINORBITS 20
- #define MINORMASK ((1U << MINORBITS) - 1)
- #define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS))
- #define MINOR(dev) ((unsigned int) ((dev) & MINORMASK))
- #define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))</span>
2、分配设备号(两种方法):
a -- 静态申请:
int register_chrdev_region(dev_t from, unsigned count, const char *name);
其源代码清单如下:
- int register_chrdev_region(dev_t from, unsigned count, const char *name)
- {
- struct char_device_struct *cd;
- dev_t to = from + count;
- dev_t n, next;
- for (n = from; n < to; n = next) {
- next = MKDEV(MAJOR(n)+1, 0);
- if (next > to)
- next = to;
- cd = __register_chrdev_region(MAJOR(n), MINOR(n),
- next - n, name);
- if (IS_ERR(cd))
- goto fail;
- }
- return 0;
- fail:
- to = n;
- for (n = from; n < to; n = next) {
- next = MKDEV(MAJOR(n)+1, 0);
- kfree(__unregister_chrdev_region(MAJOR(n), MINOR(n), next - n));
- }
- return PTR_ERR(cd);
- }
b -- 动态分配:
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, const char *name);
其源代码清单如下:
- int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count,
- const char *name)
- {
- struct char_device_struct *cd;
- cd = __register_chrdev_region(0, baseminor, count, name);
- if (IS_ERR(cd))
- return PTR_ERR(cd);
- *dev = MKDEV(cd->major, cd->baseminor);
- return 0;
- }
可以看到二者都是调用了__register_chrdev_region 函数,其源代码如下:
- static struct char_device_struct *
- __register_chrdev_region(unsigned int major, unsigned int baseminor,
- int minorct, const char *name)
- {
- struct char_device_struct *cd, **cp;
- int ret = 0;
- int i;
- cd = kzalloc(sizeof(struct char_device_struct), GFP_KERNEL);
- if (cd == NULL)
- return ERR_PTR(-ENOMEM);
- mutex_lock(&chrdevs_lock);
- /* temporary */
- if (major == 0) {
- for (i = ARRAY_SIZE(chrdevs)-1; i > 0; i--) {
- if (chrdevs[i] == NULL)
- break;
- }
- if (i == 0) {
- ret = -EBUSY;
- goto out;
- }
- major = i;
- ret = major;
- }
- cd->major = major;
- cd->baseminor = baseminor;
- cd->minorct = minorct;
- strlcpy(cd->name, name, sizeof(cd->name));
- i = major_to_index(major);
- for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
- if ((*cp)->major > major ||
- ((*cp)->major == major &&
- (((*cp)->baseminor >= baseminor) ||
- ((*cp)->baseminor + (*cp)->minorct > baseminor))))
- break;
- /* Check for overlapping minor ranges. */
- if (*cp && (*cp)->major == major) {
- int old_min = (*cp)->baseminor;
- int old_max = (*cp)->baseminor + (*cp)->minorct - 1;
- int new_min = baseminor;
- int new_max = baseminor + minorct - 1;
- /* New driver overlaps from the left. */
- if (new_max >= old_min && new_max <= old_max) {
- ret = -EBUSY;
- goto out;
- }
- /* New driver overlaps from the right. */
- if (new_min <= old_max && new_min >= old_min) {
- ret = -EBUSY;
- goto out;
- }
- }
- cd->next = *cp;
- *cp = cd;
- mutex_unlock(&chrdevs_lock);
- return cd;
- out:
- mutex_unlock(&chrdevs_lock);
- kfree(cd);
- return ERR_PTR(ret);
- }
通过这个函数可以看出 register_chrdev_region和 alloc_chrdev_region 的区别,register_chrdev_region直接将Major 注册进入,而 alloc_chrdev_region从Major = 0 开始,逐个查找设备号,直到找到一个闲置的设备号,并将其注册进去;
二者应用可以简单总结如下:
register_chrdev_region alloc_chrdev_region
|
devno = MKDEV(major,minor);
ret = register_chrdev_region(devno, 1, "hello");
cdev_init(&cdev,&hello_ops);
ret = cdev_add(&cdev,devno,1);
|
alloc_chrdev_region(&devno, minor, 1, "hello");
major = MAJOR(devno);
cdev_init(&cdev,&hello_ops);
ret = cdev_add(&cdev,devno,1)
|
register_chrdev(major,"hello",&hello |
可以看到,除了前面两个函数,还加了一个register_chrdev 函数,可以发现这个函数的应用非常简单,只要一句就可以搞定前面函数所做之事;
下面分析一下register_chrdev 函数,其源代码定义如下:
- static inline int register_chrdev(unsigned int major, const char *name,
- const struct file_operations *fops)
- {
- return __register_chrdev(major, 0, 256, name, fops);
- }
调用了 __register_chrdev(major, 0, 256, name, fops) 函数:
- int __register_chrdev(unsigned int major, unsigned int baseminor,
- unsigned int count, const char *name,
- const struct file_operations *fops)
- {
- struct char_device_struct *cd;
- struct cdev *cdev;
- int err = -ENOMEM;
- cd = __register_chrdev_region(major, baseminor, count, name);
- if (IS_ERR(cd))
- return PTR_ERR(cd);
- cdev = cdev_alloc();
- if (!cdev)
- goto out2;
- cdev->owner = fops->owner;
- cdev->ops = fops;
- kobject_set_name(&cdev->kobj, "%s", name);
- err = cdev_add(cdev, MKDEV(cd->major, baseminor), count);
- if (err)
- goto out;
- cd->cdev = cdev;
- return major ? 0 : cd->major;
- out:
- kobject_put(&cdev->kobj);
- out2:
- kfree(__unregister_chrdev_region(cd->major, baseminor, count));
- return err;
- }
可以看到这个函数不只帮我们注册了设备号,还帮我们做了cdev 的初始化以及cdev 的注册;
3、注销设备号:
void unregister_chrdev_region(dev_t from, unsigned count);
4、创建设备文件:
利用cat /proc/devices查看申请到的设备名,设备号。
1)使用mknod手工创建:mknod filename type major minor
2)自动创建设备节点:
利用udev(mdev)来实现设备文件的自动创建,首先应保证支持udev(mdev),由busybox配置。在驱动初始化代码里调用class_create为该设备创建一个class,再为每个设备调用device_create创建对应的设备。
详细解析见:Linux 字符设备驱动开发 (二)—— 自动创建设备节点
下面看一个实例,练习一下上面的操作:
hello.c
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- static int major = 250;
- static int minor = 0;
- static dev_t devno;
- static struct cdev cdev;
- static int hello_open (struct inode *inode, struct file *filep)
- {
- printk("hello_open \n");
- return 0;
- }
- static struct file_operations hello_ops=
- {
- .open = hello_open,
- };
- static int hello_init(void)
- {
- int ret;
- printk("hello_init");
- devno = MKDEV(major,minor);
- ret = register_chrdev_region(devno, 1, "hello");
- if(ret < 0)
- {
- printk("register_chrdev_region fail \n");
- return ret;
- }
- cdev_init(&cdev,&hello_ops);
- ret = cdev_add(&cdev,devno,1);
- if(ret < 0)
- {
- printk("cdev_add fail \n");
- return ret;
- }
- return 0;
- }
- static void hello_exit(void)
- {
- cdev_del(&cdev);
- unregister_chrdev_region(devno,1);
- printk("hello_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(hello_init);
- module_exit(hello_exit);
测试程序 test.c
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- main()
- {
- int fd;
- fd = open("/dev/hello",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- close(fd);
- }
makefile:
- ifneq ($(KERNELRELEASE),)
- obj-m:=hello.o
- $(info "2nd")
- else
- KDIR := /lib/modules/$(shell uname -r)/build
- PWD:=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- clean:
- rm -f *.ko *.o *.symvers *.mod.c *.mod.o *.order
- endif
编译成功后,使用 insmod 命令加载:
然后用cat /proc/devices 查看,会发现设备号已经申请成功;
Linux 字符设备驱动结构(二)—— 自动创建设备节点
上一篇我们介绍到创建设备文件的方法,利用cat /proc/devices查看申请到的设备名,设备号。
第一种是使用mknod手工创建:mknod filename type major minor
第二种是自动创建设备节点:利用udev(mdev)来实现设备文件的自动创建,首先应保证支持udev(mdev),由busybox配置。
具体udev相关知识这里不详细阐述,可以移步Linux 文件系统与设备文件系统 —— udev 设备文件系统,这里主要讲使用方法。
在驱动用加入对udev 的支持主要做的就是:在驱动初始化的代码里调用class_create(...)为该设备创建一个class,再为每个设备调用device_create(...)创建对应的设备。
内核中定义的struct class结构体,顾名思义,一个struct class结构体类型变量对应一个类,内核同时提供了class_create(…)函数,可以用它来创建一个类,这个类存放于sysfs下面,一旦创建好了这个类,再调用 device_create(…)函数来在/dev目录下创建相应的设备节点。
这样,加载模块的时候,用户空间中的udev会自动响应 device_create()函数,去/sysfs下寻找对应的类从而创建设备节点。
下面是两个函数的解析:
1、class_create(...) 函数
功能:创建一个类;
下面是具体定义:
- #define class_create(owner, name) \
- ({ \
- static struct lock_class_key __key; \
- __class_create(owner, name, &__key); \
- })
owner:THIS_MODULE
name : 名字
__class_create(owner, name, &__key)源代码如下:
- struct class *__class_create(struct module *owner, const char *name,
- struct lock_class_key *key)
- {
- struct class *cls;
- int retval;
- cls = kzalloc(sizeof(*cls), GFP_KERNEL);
- if (!cls) {
- retval = -ENOMEM;
- goto error;
- }
- cls->name = name;
- cls->owner = owner;
- cls->class_release = class_create_release;
- retval = __class_register(cls, key);
- if (retval)
- goto error;
- return cls;
- error:
- kfree(cls);
- return ERR_PTR(retval);
- }
- EXPORT_SYMBOL_GPL(__class_create);
销毁函数:void class_destroy(struct class *cls)
- void class_destroy(struct class *cls)
- {
- if ((cls == NULL) || (IS_ERR(cls)))
- return;
- class_unregister(cls);
- }
2、device_create(...) 函数
struct device *device_create(struct class *class, struct device *parent,
dev_t devt, void *drvdata, const char *fmt, ...)
功能:创建一个字符设备文件
参数:
struct class *class :类
struct device *parent:NULL
dev_t devt :设备号
void *drvdata :null、
const char *fmt :名字
返回:
struct device *
下面是源码解析:
- struct device *device_create(struct class *class, struct device *parent,
- dev_t devt, void *drvdata, const char *fmt, ...)
- {
- va_list vargs;
- struct device *dev;
- va_start(vargs, fmt);
- dev = device_create_vargs(class, parent, devt, drvdata, fmt, vargs);
- va_end(vargs);
- return dev;
- }
device_create_vargs(class, parent, devt, drvdata, fmt, vargs)解析如下:
- struct device *device_create_vargs(struct class *class, struct device *parent,
- dev_t devt, void *drvdata, const char *fmt,
- va_list args)
- {
- return device_create_groups_vargs(class, parent, devt, drvdata, NULL,
- fmt, args);
- }
现在就不继续往下跟了,大家可以继续往下跟;
下面是一个实例:
hello.c
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- #include <linux/device.h>
- static int major = 250;
- static int minor=0;
- static dev_t devno;
- static struct class *cls;
- static struct device *test_device;
- static int hello_open (struct inode *inode, struct file *filep)
- {
- printk("hello_open \n");
- return 0;
- }
- static struct file_operations hello_ops=
- {
- .open = hello_open,
- };
- static int hello_init(void)
- {
- int ret;
- printk("hello_init \n");
- devno = MKDEV(major,minor);
- ret = register_chrdev(major,"hello",&hello_ops);
- cls = class_create(THIS_MODULE, "myclass");
- if(IS_ERR(cls))
- {
- unregister_chrdev(major,"hello");
- return -EBUSY;
- }
- test_device = device_create(cls,NULL,devno,NULL,"hello");//mknod /dev/hello
- if(IS_ERR(test_device))
- {
- class_destroy(cls);
- unregister_chrdev(major,"hello");
- return -EBUSY;
- }
- return 0;
- }
- static void hello_exit(void)
- {
- device_destroy(cls,devno);
- class_destroy(cls);
- unregister_chrdev(major,"hello");
- printk("hello_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(hello_init);
- module_exit(hello_exit);
test.c
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- main()
- {
- int fd;
- fd = open("/dev/hello",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- close(fd);
- }
makefile
- ifneq ($(KERNELRELEASE),)
- obj-m:=hello.o
- $(info "2nd")
- else
- KDIR := /lib/modules/$(shell uname -r)/build
- PWD:=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- clean:
- rm -f *.ko *.o *.symvers *.mod.c *.mod.o *.order
- endif
下面可以看几个class几个名字的对应关系:
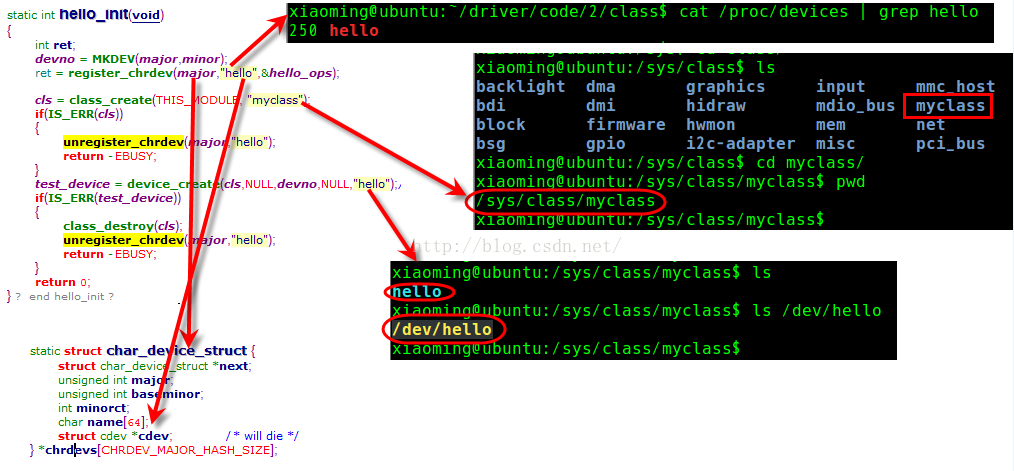
Linux 字符设备驱动结构(三)—— file、inode结构体及chardevs数组等相关知识解析
前面我们学习了字符设备结构体cdev Linux 字符设备驱动开发 (一)—— 字符设备驱动结构(上) 下面继续学习字符设备另外几个重要的数据结构。
先看下面这张图,这是Linux 中虚拟文件系统、一般的设备文件与设备驱动程序值间的函数调用关系;
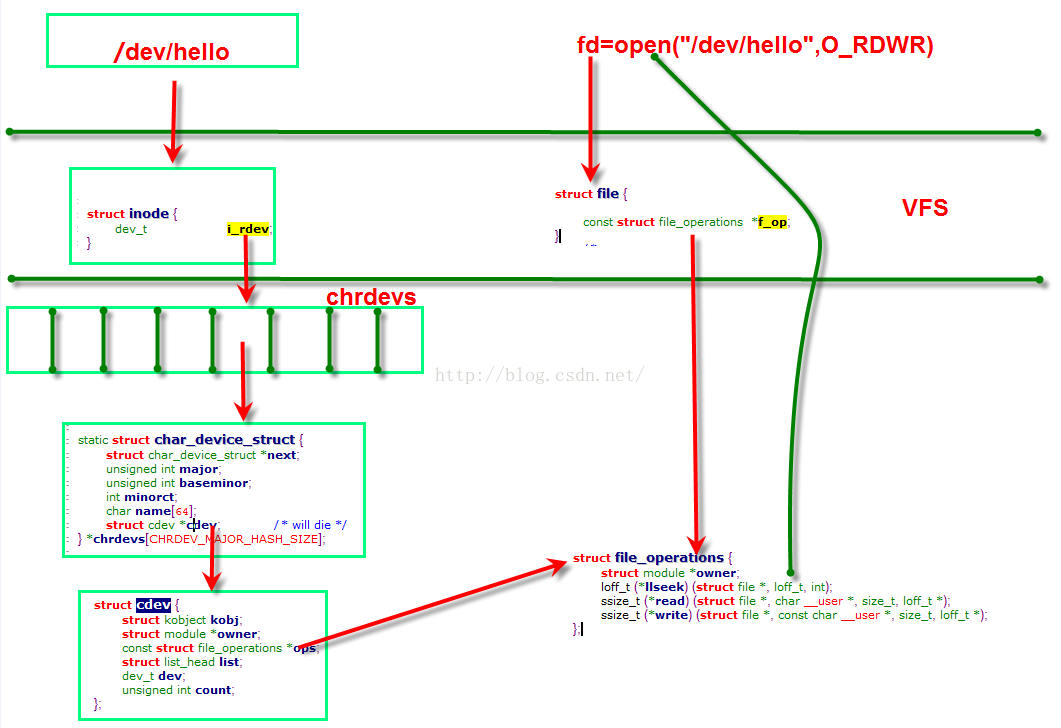
上面这张图展现了一个应用程序调用字符设备驱动的过程, 在设备驱动程序的设计中,一般而言,会关心 file 和 inode 这两个结构体
用户空间使用 open() 函数打开一个字符设备 fd = open("/dev/hello",O_RDWR) , 这一函数会调用两个数据结构 struct inode{...}与struct file{...} ,二者均在虚拟文件系统VFS处,下面对两个数据结构进行解析:
一、file 文件结构体
在设备驱动中,这也是个非常重要的数据结构,必须要注意一点,这里的file与用户空间程序中的FILE指针是不同的,用户空间FILE是定义在C库中,从来不会出现在内核中。而struct file,却是内核当中的数据结构,因此,它也不会出现在用户层程序中。
file结构体指示一个已经打开的文件(设备对应于设备文件),其实系统中的每个打开的文件在内核空间都有一个相应的struct file结构体,它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数,直至文件被关闭。如果文件被关闭,内核就会释放相应的数据结构。
在内核源码中,struct file要么表示为file,或者为filp(意指“file pointer”), 注意区分一点,file指的是struct file本身,而filp是指向这个结构体的指针。
下面是几个重要成员:
a -- fmode_t f_mode;
此文件模式通过FMODE_READ, FMODE_WRITE识别了文件为可读的,可写的,或者是二者。在open或ioctl函数中可能需要检查此域以确认文件的读/写权限,你不必直接去检测读或写权限,因为在进行octl等操作时内核本身就需要对其权限进行检测。
b -- loff_t f_pos;
当前读写文件的位置。为64位。如果想知道当前文件当前位置在哪,驱动可以读取这个值而不会改变其位置。对read,write来说,当其接收到一个loff_t型指针作为其最后一个参数时,他们的读写操作便作更新文件的位置,而不需要直接执行filp ->f_pos操作。而llseek方法的目的就是用于改变文件的位置。
c -- unsigned int f_flags;
文件标志,如O_RDONLY, O_NONBLOCK以及O_SYNC。在驱动中还可以检查O_NONBLOCK标志查看是否有非阻塞请求。其它的标志较少使用。特别地注意的是,读写权限的检查是使用f_mode而不是f_flog。所有的标量定义在头文件中
d -- struct file_operations *f_op;
与文件相关的各种操作。当文件需要迅速进行各种操作时,内核分配这个指针作为它实现文件打开,读,写等功能的一部分。filp->f_op 其值从未被内核保存作为下次的引用,即你可以改变与文件相关的各种操作,这种方式效率非常高。
file_operation 结构体解析如下:Linux 字符设备驱动结构(四)—— file_operations 结构体知识解析
e -- void *private_data;
在驱动调用open方法之前,open系统调用设置此指针为NULL值。你可以很自由的将其做为你自己需要的一些数据域或者不管它,如,你可以将其指向一个分配好的数据,但是你必须记得在file struct被内核销毁之前在release方法中释放这些数据的内存空间。private_data用于在系统调用期间保存各种状态信息是非常有用的。
二、 inode结构体
VFS inode 包含文件访问权限、属主、组、大小、生成时间、访问时间、最后修改时间等信息。它是Linux 管理文件系统的最基本单位,也是文件系统连接任何子目录、文件的桥梁。
内核使用inode结构体在内核内部表示一个文件。因此,它与表示一个已经打开的文件描述符的结构体(即file 文件结构)是不同的,我们可以使用多个file 文件结构表示同一个文件的多个文件描述符,但此时,所有的这些file文件结构全部都必须只能指向一个inode结构体。
inode结构体包含了一大堆文件相关的信息,但是就针对驱动代码来说,我们只要关心其中的两个域即可:
(1) dev_t i_rdev;
表示设备文件的结点,这个域实际上包含了设备号。
(2) struct cdev *i_cdev;
struct cdev是内核的一个内部结构,它是用来表示字符设备的,当inode结点指向一个字符设备文件时,此域为一个指向inode结构的指针。
下面是源代码:
- struct inode {
- struct hlist_node i_hash;
- struct list_head i_list;
- struct list_head i_sb_list;
- struct list_head i_dentry;
- unsigned long i_ino;
- atomic_t i_count;
- unsigned int i_nlink;
- uid_t i_uid;//inode拥有者id
- gid_t i_gid;//inode所属群组id
- dev_t i_rdev;//若是设备文件,表示记录设备的设备号
- u64 i_version;
- loff_t i_size;//inode所代表大少
- #ifdef __NEED_I_SIZE_ORDERED
- seqcount_t i_size_seqcount;
- #endif
- struct timespec i_atime;//inode最近一次的存取时间
- struct timespec i_mtime;//inode最近一次修改时间
- struct timespec i_ctime;//inode的生成时间
- unsigned int i_blkbits;
- blkcnt_t i_blocks;
- unsigned short i_bytes;
- umode_t i_mode;
- spinlock_t i_lock;
- struct mutex i_mutex;
- struct rw_semaphore i_alloc_sem;
- const struct inode_operations *i_op;
- const struct file_operations *i_fop;
- struct super_block *i_sb;
- struct file_lock *i_flock;
- struct address_space *i_mapping;
- struct address_space i_data;
- #ifdef CONFIG_QUOTA
- struct dquot *i_dquot[MAXQUOTAS];
- #endif
- struct list_head i_devices;
- union {
- struct pipe_inode_info *i_pipe;
- struct block_device *i_bdev;
- struct cdev *i_cdev;//若是字符设备,对应的为cdev结构体
- };
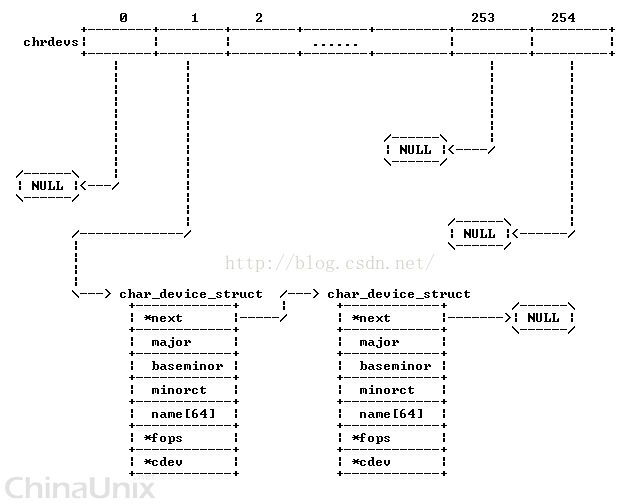
三、chardevs 数组
从图中可以看出,通过数据结构 struct inode{...} 中的 i_cdev 成员可以找到cdev,而所有的字符设备都在 chrdevs 数组中
下面先看一下 chrdevs 的定义:
- #define CHRDEV_MAJOR_HASH_SIZE 255
- static DEFINE_MUTEX(chrdevs_lock);
- static struct char_device_struct {
- struct char_device_struct *next; // 结构体指针
- unsigned int major; // 主设备号
- unsigned int baseminor; // 次设备起始号
- int minorct; // 次备号个数
- char name[64];
- struct cdev *cdev; /* will die */
- } *chrdevs[CHRDEV_MAJOR_HASH_SIZE]; // 只能挂255个字符主设备<span style="font-family: Arial, Helvetica, sans-serif; rgb(255, 255, 255);"> </span>
可以看到全局数组 chrdevs 包含了255(CHRDEV_MAJOR_HASH_SIZE 的值)个 struct char_device_struct的元素,每一个对应一个相应的主设备号。
如果分配了一个设备号,就会创建一个 struct char_device_struct 的对象,并将其添加到 chrdevs 中;这样,通过chrdevs数组,我们就可以知道分配了哪些设备号。
相关函数,(这些函数在上篇已经介绍过,现在回顾一下:
register_chrdev_region( ) 分配指定的设备号范围
alloc_chrdev_region( ) 动态分配设备范围
他们都主要是通过调用函数 __register_chrdev_region() 来实现的;要注意,这两个函数仅仅是注册设备号!如果要和cdev关联起来,还要调用cdev_add()。
register_chrdev( )申请指定的设备号,并且将其注册到字符设备驱动模型中.
它所做的事情为:
a -- 注册设备号, 通过调用 __register_chrdev_region() 来实现
b -- 分配一个cdev, 通过调用 cdev_alloc() 来实现
c -- 将cdev添加到驱动模型中, 这一步将设备号和驱动关联了起来. 通过调用 cdev_add() 来实现
d -- 将第一步中创建的 struct char_device_struct 对象的 cdev 指向第二步中分配的cdev. 由于register_chrdev()是老的接口,这一步在新的接口中并不需要。
四、cdev 结构体
在 Linux 字符设备驱动开发 (一)—— 字符设备驱动结构(上) 有解析。
五、文件系统中对字符设备文件的访问
下面看一下上层应用open() 调用系统调用函数的过程
对于一个字符设备文件, 其inode->i_cdev 指向字符驱动对象cdev, 如果i_cdev为 NULL ,则说明该设备文件没有被打开.
由于多个设备可以共用同一个驱动程序.所以,通过字符设备的inode 中的i_devices 和 cdev中的list组成一个链表
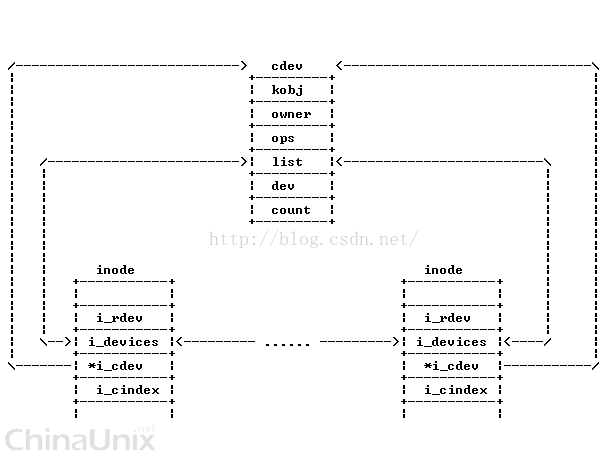
首先,系统调用open打开一个字符设备的时候, 通过一系列调用,最终会执行到 chrdev_open
(最终是通过调用到def_chr_fops中的.open, 而def_chr_fops.open = chrdev_open. 这一系列的调用过程,本文暂不讨论)
int chrdev_open(struct inode * inode, struct file * filp)
chrdev_open()所做的事情可以概括如下:
1. 根据设备号(inode->i_rdev), 在字符设备驱动模型中查找对应的驱动程序, 这通过kobj_lookup() 来实现, kobj_lookup()会返回对应驱动程序cdev的kobject.
2. 设置inode->i_cdev , 指向找到的cdev.
3. 将inode添加到cdev->list 的链表中.
4. 使用cdev的ops 设置file对象的f_op
5. 如果ops中定义了open方法,则调用该open方法
6. 返回
执行完 chrdev_open()之后,file对象的f_op指向cdev的ops,因而之后对设备进行的read, write等操作,就会执行cdev的相应操作。
Linux 字符设备驱动结构(四)—— file_operations 结构体知识解析
前面在 Linux 字符设备驱动开发基础 (三)—— 字符设备驱动结构(中) ,我们已经介绍了两种重要的数据结构 struct inode{...}与 struct file{...} ,下面来介绍另一个比较重要数据结构
struct _file_operations
struct _file_operations在Fs.h这个文件里面被定义的,如下所示:
- struct file_operations {
- struct module *owner;//拥有该结构的模块的指针,一般为THIS_MODULES
- loff_t (*llseek) (struct file *, loff_t, int);//用来修改文件当前的读写位置
- ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);//从设备中同步读取数据
- ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);//向设备发送数据
- ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);//初始化一个异步的读取操作
- ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);//初始化一个异步的写入操作
- int (*readdir) (struct file *, void *, filldir_t);//仅用于读取目录,对于设备文件,该字段为NULL
- unsigned int (*poll) (struct file *, struct poll_table_struct *); //轮询函数,判断目前是否可以进行非阻塞的读写或写入
- int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long); //执行设备I/O控制命令
- long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); //不使用BLK文件系统,将使用此种函数指针代替ioctl
- long (*compat_ioctl) (struct file *, unsigned int, unsigned long); //在64位系统上,32位的ioctl调用将使用此函数指针代替
- int (*mmap) (struct file *, struct vm_area_struct *); //用于请求将设备内存映射到进程地址空间
- int (*open) (struct inode *, struct file *); //打开
- int (*flush) (struct file *, fl_owner_t id);
- int (*release) (struct inode *, struct file *); //关闭
- int (*fsync) (struct file *, struct dentry *, int datasync); //刷新待处理的数据
- int (*aio_fsync) (struct kiocb *, int datasync); //异步刷新待处理的数据
- int (*fasync) (int, struct file *, int); //通知设备FASYNC标志发生变化
- int (*lock) (struct file *, int, struct file_lock *);
- ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
- unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
- int (*check_flags)(int);
- int (*flock) (struct file *, int, struct file_lock *);
- ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
- ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
- int (*setlease)(struct file *, long, struct file_lock **);
- };
Linux使用file_operations结构访问驱动程序的函数,这个结构的每一个成员的名字都对应着一个调用。
用户进程利用在对设备文件进行诸如read/write操作的时候,系统调用通过设备文件的主设备号找到相应的设备驱动程序,然后读取这个数据结构相应的函数指针,接着把控制权交给该函数,这是Linux的设备驱动程序工作的基本原理。
下面是各成员解析:
1、struct module *owner
第一个 file_operations 成员根本不是一个操作,它是一个指向拥有这个结构的模块的指针。
这个成员用来在它的操作还在被使用时阻止模块被卸载. 几乎所有时间中, 它被简单初始化为 THIS_MODULE, 一个在 <linux/module.h> 中定义的宏.这个宏比较复杂,在进行简单学习操作的时候,一般初始化为THIS_MODULE。
2、loff_t (*llseek) (struct file * filp , loff_t p, int orig);
(指针参数filp为进行读取信息的目标文件结构体指针;参数 p 为文件定位的目标偏移量;参数orig为对文件定位的起始地址,这个值可以为文件开头(SEEK_SET,0,当前位置(SEEK_CUR,1),文件末尾(SEEK_END,2))
llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值.
loff_t 参数是一个"long offset", 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示;如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在"file 结构" 一节中描述).
3、ssize_t (*read) (struct file * filp, char __user * buffer, size_t size , loff_t * p);
(指针参数 filp 为进行读取信息的目标文件,指针参数buffer 为对应放置信息的缓冲区(即用户空间内存地址),参数size为要读取的信息长度,参数 p 为读的位置相对于文件开头的偏移,在读取信息后,这个指针一般都会移动,移动的值为要读取信息的长度值)
这个函数用来从设备中获取数据。在这个位置的一个空指针导致 read 系统调用以 -EINVAL("Invalid argument") 失败。一个非负返回值代表了成功读取的字节数( 返回值是一个 "signed size" 类型, 常常是目标平台本地的整数类型).
4、ssize_t (*aio_read)(struct kiocb * , char __user * buffer, size_t size , loff_t p);
可以看出,这个函数的第一、三个参数和本结构体中的read()函数的第一、三个参数是不同 的,异步读写的第三个参数直接传递值,而同步读写的第三个参数传递的是指针,因为AIO从来不需要改变文件的位置。异步读写的第一个参数为指向kiocb结构体的指针,而同步读写的第一参数为指向file结构体的指针,每一个I/O请求都对应一个kiocb结构体);初始化一个异步读 -- 可能在函数返回前不结束的读操作.如果这个方法是 NULL, 所有的操作会由 read 代替进行(同步地).(有关linux异步I/O,可以参考有关的资料,《linux设备驱动开发详解》中给出了详细的解答)
5、ssize_t (*write) (struct file * filp, const char __user * buffer, size_t count, loff_t * ppos);
(参数filp为目标文件结构体指针,buffer为要写入文件的信息缓冲区,count为要写入信息的长度,ppos为当前的偏移位置,这个值通常是用来判断写文件是否越界)
发送数据给设备.。如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数。
(注:这个操作和上面的对文件进行读的操作均为阻塞操作)
6、ssize_t (*aio_write)(struct kiocb *, const char __user * buffer, size_t count, loff_t * ppos);
初始化设备上的一个异步写.参数类型同aio_read()函数;
7、int (*readdir) (struct file * filp, void *, filldir_t);
对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用.
8、unsigned int (*poll) (struct file *, struct poll_table_struct *);
(这是一个设备驱动中的轮询函数,第一个参数为file结构指针,第二个为轮询表指针)
这个函数返回设备资源的可获取状态,即POLLIN,POLLOUT,POLLPRI,POLLERR,POLLNVAL等宏的位“或”结果。每个宏都表明设备的一种状态,如:POLLIN(定义为0x0001)意味着设备可以无阻塞的读,POLLOUT(定义为0x0004)意味着设备可以无阻塞的写。
(poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞.poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到 I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
(这里通常将设备看作一个文件进行相关的操作,而轮询操作的取值直接关系到设备的响应情况,可以是阻塞操作结果,同时也可以是非阻塞操作结果)
9、int (*ioctl) (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg);
(inode 和 filp 指针是对应应用程序传递的文件描述符 fd 的值, 和传递给 open 方法的相同参数.cmd 参数从用户那里不改变地传下来, 并且可选的参数 arg 参数以一个 unsigned long 的形式传递, 不管它是否由用户给定为一个整数或一个指针.如果调用程序不传递第 3 个参数, 被驱动操作收到的 arg 值是无定义的.因为类型检查在这个额外参数上被关闭, 编译器不能警告你如果一个无效的参数被传递给 ioctl, 并且任何关联的错误将难以查找.)
ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表.如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, "设备无这样的 ioctl"), 系统调用返回一个错误.
10、int (*mmap) (struct file *, struct vm_area_struct *);
mmap 用来请求将设备内存映射到进程的地址空间。 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.
(如果想对这个函数有个彻底的了解,那么请看有关“进程地址空间”介绍的书籍)
11、int (*open) (struct inode * inode , struct file * filp ) ;
(inode 为文件节点,这个节点只有一个,无论用户打开多少个文件,都只是对应着一个inode结构;但是filp就不同,只要打开一个文件,就对应着一个file结构体,file结构体通常用来追踪文件在运行时的状态信息)
尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法.
如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.与open()函数对应的是release()函数。
12、int (*flush) (struct file *);
flush 操作在进程关闭它的设备文件描述符的拷贝时调用;
它应当执行(并且等待)设备的任何未完成的操作.这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush
在很少驱动中使用;SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL,
内核简单地忽略用户应用程序的请求.
13、int (*release) (struct inode *, struct file *);
release ()函数当最后一个打开设备的用户进程执行close()系统调用的时候,内核将调用驱动程序release()函数:
void release(struct inode inode,struct file *file),release函数的主要任务是清理未结束的输入输出操作,释放资源,用户自定义排他标志的复位等。在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
14、int(*synch)(struct file *,struct dentry *,int datasync);
刷新待处理的数据,允许进程把所有的脏缓冲区刷新到磁盘。
15、int (*aio_fsync)(struct kiocb *, int);
这是 fsync 方法的异步版本.所谓的fsync方法是一个系统调用函数。系统调用fsync把文件所指定的文件的所有脏缓冲区写到磁盘中(如果需要,还包括存有索引节点的缓冲区)。相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常这个方法以调用函数__writeback_single_inode()结束,这个函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘
16、int (*fasync) (int, struct file *, int);
这个函数是系统支持异步通知的设备驱动,下面是这个函数的模板:
- static int ***_fasync(int fd,struct file *filp,int mode)
- {
- struct ***_dev * dev=filp->private_data;
- return fasync_helper(fd,filp,mode,&dev->async_queue);//第四个参数为 fasync_struct结构体指针的指针。
- //这个函数是用来处理FASYNC标志的函数。(FASYNC:表示兼容BSD的fcntl同步操作)当这个标志改变时,驱动程序中的fasync()函数将得到执行。 (注:感觉这个‘标志'词用的并不恰当)
- }
此操作用来通知设备它的 FASYNC 标志的改变. 异步通知是一个高级的主题, 在第 6 章中描述.这个成员可以是NULL 如果驱动不支持异步通知.
17、int (*lock) (struct file *, int, struct file_lock *);
lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.
18、ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作;这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
19、ssize_t (*sendfile)(struct file *, loff_t *, size_t, read_actor_t, void *);
这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个.
例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用. 设备驱动常常使 sendfile 为 NULL.
20、ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.
21、unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中。这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.[10]
22、int (*check_flags)(int)
这个方法允许模块检查传递给 fnctl(F_SETFL...) 调用的标志.
23、int (*dir_notify)(struct file *, unsigned long);
这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用; 驱动不需要实现 dir_notify.
Linux 字符设备驱动开发基础(一)—— 编写简单 LED 设备驱动
现在,我们来编写自己第一个字符设备驱动 —— 点亮LED。(不完善,后面再完善)
硬件平台:Exynos4412(FS4412)
编写驱动分下面几步:
a -- 查看原理图、数据手册,了解设备的操作方法;
b -- 在内核中找到相近的驱动程序,以它为模板进行开发,有时候需要从零开始;
c -- 实现驱动程序的初始化:比如向内核注册这个驱动程序,这样应用程序传入文件名,内核才能找到相应的驱动程序;
d -- 设计所要实现的操作,比如 open、close、read、write 等函数;
e -- 实现中断服务(中断不是每个设备驱动所必须的);
f -- 编译该驱动程序到内核中,或者用 insmod 命令加载;
g-- 测试驱动程序;
下面是一个点亮LED 的驱动:
第一步,当然是查看手册,查看原理图,找到相应寄存器;
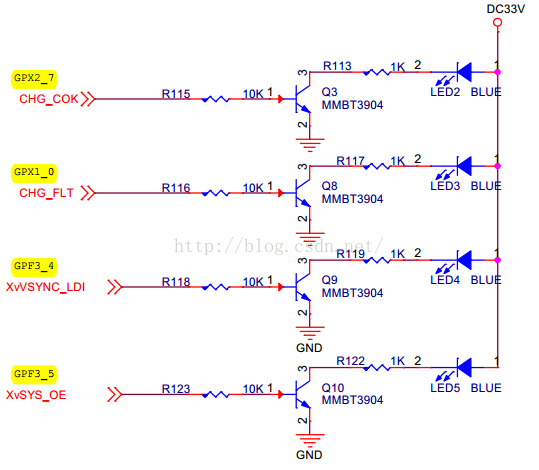
查看手册,四个LED 所用寄存器为:
led2
GPX2CON 0x11000c40
GPX2DAT 0x11000c44
led3
GPX1CON 0x11000c20
GPX1DAT 0x11000c24
led4 3-4 3-5
GPF3CON 0x114001e0
GPF3DAT 0x114001e4
这里要注意:arm体系架构是io内存,必须要映射 ioremap( ); 其作用是物理内存向虚拟内存的映射。 用到 writel readl这两个函数,详细解释会在后面不上,先看一下简单用法:
以LED2为例,下面是地址映射及读写:
- int *pgpx2con ;
- int *pgpx2dat;
- pgpx2con = ioremap( GPX2CON, 4);
- pgpx2dat = ioremap(GPX2DAT,4);
- readl(pgpx2con);
- writel(0x01, pgpx2dat );
下面是驱动程序,后面会更完善
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- #include <linux/device.h>
- #include <asm/io.h>
- #include <asm/uaccess.h>
- static int major = 250;
- static int minor=0;
- static dev_t devno;
- static struct class *cls;
- static struct device *test_device;
- #define GPX2CON 0x11000c40
- #define GPX2DAT 0x11000c44
- #define GPX1CON 0x11000c20
- #define GPX1DAT 0x11000c24
- #define GPF3CON 0x114001e0
- #define GPF3DAT 0x114001e4
- static int *pgpx2con ;
- static int *pgpx2dat;
- static int *pgpx1con ;
- static int *pgpx1dat;
- static int *pgpf3con ;
- static int *pgpf3dat;
- void fs4412_led_off(int num);
- void fs4412_led_on(int num)
- {
- switch(num)
- {
- case 1:
- writel(readl(pgpx2dat) |(0x1<<7), pgpx2dat);
- break;
- case 2:
- writel(readl(pgpx1dat) |(0x1<<0), pgpx1dat);
- break;
- case 3:
- writel(readl(pgpf3dat) |(0x1<<4), pgpf3dat);
- break;
- case 4:
- writel(readl(pgpf3dat) |(0x1<<5), pgpf3dat);
- break;
- default:
- fs4412_led_off(1);
- fs4412_led_off(2);
- fs4412_led_off(3);
- fs4412_led_off(4);
- break;
- }
- }
- void fs4412_led_off(int num)
- {
- switch(num)
- {
- case 1:
- writel(readl(pgpx2dat) &(~(0x1<<7)), pgpx2dat);
- break;
- case 2:
- writel(readl(pgpx1dat)&(~(0x1<<0)), pgpx1dat);
- break;
- case 3:
- writel(readl(pgpf3dat) &(~(0x1<<4)), pgpf3dat);
- break;
- case 4:
- writel(readl(pgpf3dat) &(~(0x1<<5)), pgpf3dat);
- break;
- }
- }
- static int led_open (struct inode *inode, struct file *filep)
- {//open
- fs4412_led_off(1);
- fs4412_led_off(2);
- fs4412_led_off(3);
- fs4412_led_off(4);
- return 0;
- }
- static int led_release(struct inode *inode, struct file *filep)
- {//close
- fs4412_led_off(1);
- fs4412_led_off(2);
- fs4412_led_off(3);
- fs4412_led_off(4);
- return 0;
- }
- static ssize_t led_read(struct file *filep, char __user *buf, size_t len, loff_t *pos)
- {
- return 0;
- }
- static ssize_t led_write(struct file *filep, const char __user *buf, size_t len, loff_t *pos)
- {
- int led_num;
- if(len !=4)
- {
- return -EINVAL;
- }
- if(copy_from_user(&led_num,buf,len))
- {
- return -EFAULT;
- }
- fs4412_led_on(led_num);
- printk("led_num =%d \n",led_num);
- return 0;
- }
- static struct file_operations hello_ops=
- {
- .open = led_open,
- .release = led_release,
- .read = led_read,
- .write = led_write,
- };
- static void fs4412_led_init(void)
- {
- pgpx2con = ioremap(GPX2CON,4);
- pgpx2dat = ioremap(GPX2DAT,4);
- pgpx1con = ioremap(GPX1CON,4);
- pgpx1dat =ioremap(GPX1DAT,4);
- pgpf3con = ioremap(GPF3CON,4);
- pgpf3dat =ioremap(GPF3DAT,4);
- writel((readl(pgpx2con)& ~(0xf<<28)) |(0x1<<28),pgpx2con) ;
- writel((readl(pgpx1con)& ~(0xf<<0)) |(0x1<<0),pgpx1con) ;
- writel((readl(pgpf3con)& ~(0xff<<16)) |(0x11<<16),pgpf3con) ;
- }
- static int led_init(void)
- {
- int ret;
- devno = MKDEV(major,minor);
- ret = register_chrdev(major,"led",&hello_ops);
- cls = class_create(THIS_MODULE, "myclass");
- if(IS_ERR(cls))
- {
- unregister_chrdev(major,"led");
- return -EBUSY;
- }
- test_device = device_create(cls,NULL,devno,NULL,"led");//mknod /dev/hello
- if(IS_ERR(test_device))
- {
- class_destroy(cls);
- unregister_chrdev(major,"led");
- return -EBUSY;
- }
- fs4412_led_init();
- return 0;
- }
- void fs4412_led_unmap(void)
- {
- iounmap(pgpx2con);
- iounmap(pgpx2dat );
- iounmap(pgpx1con);
- iounmap(pgpx1dat );
- iounmap(pgpf3con );
- iounmap(pgpf3dat );
- }
- static void led_exit(void)
- {
- fs4412_led_unmap();
- device_destroy(cls,devno);
- class_destroy(cls);
- unregister_chrdev(major,"led");
- printk("led_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(led_init);
- module_exit(led_exit);
测试程序:
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- main()
- {
- int fd,i,lednum;
- fd = open("/dev/led",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- for(i=0;i<100;i++)
- {
- lednum=0;
- write(fd,&lednum,sizeof(int));
- lednum = i%4+1;
- write(fd,&lednum,sizeof(int));
- sleep(1);
- }
- close(fd);
- }
makefile:
- ifneq ($(KERNELRELEASE),)
- obj-m:=hello.o
- $(info "2nd")
- else
- #KDIR := /lib/modules/$(shell uname -r)/build
- KDIR := /home/xiaoming/linux-3.14-fs4412
- PWD:=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- arm-none-linux-gnueabi-gcc test.c
- sudo cp hello.ko a.out /rootfs/test/
- clean:
- rm -f *.ko *.o *.symvers *.mod.c *.mod.o *.order
- endif
编译结束后,将a.out 和 hello.ko 拷贝到开发板中:
# insmod hello.ko
#mknod /dev/hello c 250 0
#./a.out
会看到跑马灯效果。
后面会对该驱动完善。
Linux 字符设备驱动开发基础(二)—— 编写简单 PWM 设备驱动
编写驱动的第一步仍是看原理图:
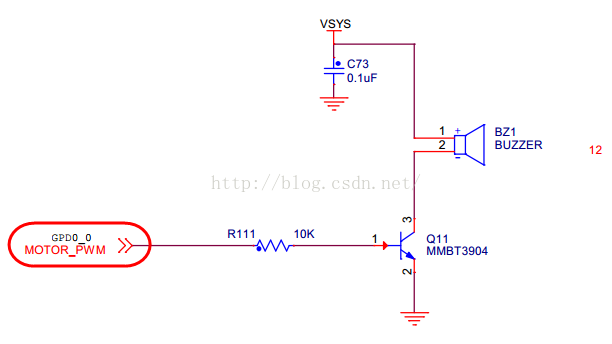
可以看到,该蜂鸣器由 GPD0_0 来控制 ,查手册可知该I/O口由Time0 来控制,找到相应的寄存器:
a -- I/O口寄存器及地址
GPD0CON 0x114000a0
b -- Time0 寄存器及地址
基地址为:TIMER_BASE 0x139D0000
这些物理寄存器地址都是相邻的,我们这里用偏移量来表示:
寄存器名 地址偏移量 所需配置
TCFG0 0x0000 [7-0] 0XFF
TCFG1 0x0004 [3-0] 0X2
TCON 0x0008 [3-0] 0X2 0X9 0X0
TCNTB0 0x000C 500
TCMPB0 0x0010 250
前面已经知道,驱动是无法直接操纵物理地址的,所以这里仍需物理地址向虚拟地址的转换,用到 ioremap() 函数、writel()函数、readl()函数:
1、地址映射操作
- unsigned int *gpd0con;
- void *timer_base;<span style="white-space:pre"> </span>//之所以是void类型,偏移量为4时,只是移动4个字节,方便理解
- gpd0con = ioremap(GPD0CON,4);
- timer_base = ioremap(TIMER_BASE , 0x14);
2、Time0初始化操作(这里使用的已经是虚拟地址)
这里现将数据从寄存器中读出,修改后再写回寄存器,具体寄存器操作可以移步Exynos4412裸机开发——PWM定时器:
- writel((readl(gpd0con)&~(0xf<<0)) | (0x2<<0),gpd0con);
- writel ((readl(timer_base +TCFG0 )&~(0xff<<0)) | (0xff <<0),timer_base +TCFG0);
- writel ((readl(timer_base +TCFG1 )&~(0xf<<0)) | (0x2 <<0),timer_base +TCFG1 );
3、装载数据,配置占空比
- writel(500, timer_base +TCNTB0 );
- writel(250, timer_base +TCMPB0 );
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x2 <<0),timer_base +TCON );
4、相关控制函数
- void beep_on(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x9 <<0),timer_base +TCON );
- }
- void beep_off(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x0 <<0),timer_base +TCON );
- }
下面是驱动程序,这里我们用到了 write() read() ioctl() 函数,具体解析移步:
驱动程序:beep.c
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- #include <linux/device.h>
- #include <asm/io.h>
- #include <asm/uaccess.h>
- static int major = 250;
- static int minor=0;
- static dev_t devno;
- static struct class *cls;
- static struct device *test_device;
- #define GPD0CON 0x114000a0
- #define TIMER_BASE 0x139D0000
- #define TCFG0 0x0000
- #define TCFG1 0x0004
- #define TCON 0x0008
- #define TCNTB0 0x000C
- #define TCMPB0 0x0010
- static unsigned int *gpd0con;
- static void *timer_base;
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
- static void fs4412_beep_init(void)
- {
- gpd0con = ioremap(GPD0CON,4);
- timer_base = ioremap(TIMER_BASE,0x14);
- writel ((readl(gpd0con)&~(0xf<<0)) | (0x2<<0),gpd0con);
- writel ((readl(timer_base +TCFG0 )&~(0xff<<0)) | (0xff <<0),timer_base +TCFG0);
- writel ((readl(timer_base +TCFG1 )&~(0xf<<0)) | (0x2 <<0),timer_base +TCFG1 );
- writel (500, timer_base +TCNTB0 );
- writel (250, timer_base +TCMPB0 );
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x2 <<0),timer_base +TCON );
- }
- void fs4412_beep_on(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x9 <<0),timer_base +TCON );
- }
- void fs4412_beep_off(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x0 <<0),timer_base +TCON );
- }
- static int beep_open (struct inode *inode, struct file *filep)
- {
- // fs4412_beep_on();
- return 0;
- }
- static int beep_release(struct inode *inode, struct file *filep)
- {
- fs4412_beep_off();
- return 0;
- }
- #define BEPP_IN_FREQ 100000
- static void beep_freq(unsigned long arg)
- {
- writel(BEPP_IN_FREQ/arg, timer_base +TCNTB0 );
- writel(BEPP_IN_FREQ/(2*arg), timer_base +TCMPB0 );
- }
- static long beep_ioctl(struct file *filep, unsigned int cmd, unsigned long arg)
- {
- switch(cmd)
- {
- case BEEP_ON:
- fs4412_beep_on();
- break;
- case BEEP_OFF:
- fs4412_beep_off();
- break;
- case BEEP_FREQ:
- beep_freq( arg );
- break;
- default :
- return -EINVAL;
- }
- }
- static struct file_operations beep_ops=
- {
- .open = beep_open,
- .release = beep_release,
- .unlocked_ioctl = beep_ioctl,
- };
- static int beep_init(void)
- {
- int ret;
- devno = MKDEV(major,minor);
- ret = register_chrdev(major,"beep",&beep_ops);
- cls = class_create(THIS_MODULE, "myclass");
- if(IS_ERR(cls))
- {
- unregister_chrdev(major,"beep");
- return -EBUSY;
- }
- test_device = device_create(cls,NULL,devno,NULL,"beep");//mknod /dev/hello
- if(IS_ERR(test_device))
- {
- class_destroy(cls);
- unregister_chrdev(major,"beep");
- return -EBUSY;
- }
- fs4412_beep_init();
- return 0;
- }
- void fs4412_beep_unmap(void)
- {
- iounmap(gpd0con);
- iounmap(timer_base);
- }
- static void beep_exit(void)
- {
- fs4412_beep_unmap();
- device_destroy(cls,devno);
- class_destroy(cls);
- unregister_chrdev(major,"beep");
- printk("beep_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(beep_init);
- module_exit(beep_exit);
makefile:
- ifneq ($(KERNELRELEASE),)
- obj-m:=beep.o
- $(info "2nd")
- else
- #KDIR := /lib/modules/$(shell uname -r)/build
- KDIR := /home/fs/linux/linux-3.14-fs4412
- PWD:=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- arm-none-linux-gnueabi-gcc test.c -o beeptest
- sudo cp beep.ko beeptest /tftpboot
- clean:
- rm -f *.ko *.o *.symvers *.mod.c *.mod.o *.order
- endif
下面是是个简单的测试程序test.c,仅实现蜂鸣器响6秒的功能:
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <sys/ioctl.h>
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
- main()
- {
- int fd;
- fd = open("/dev/beep",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- ioctl(fd,BEEP_ON);
- sleep(6);
- ioctl(fd,BEEP_OFF);
- close(fd);
- }
这是个音乐播放测试程序,慎听!!分别为《大长今》、《世上只有妈妈好》、《渔船》,这个单独编译一下
- /*
- * main.c : test demo driver
- */
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <fcntl.h>
- #include <string.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <sys/ioctl.h>
- #include "pwm_music.h"
- /*ioctl 鍛戒护*/
- #define magic_number 'k'
- #define BEEP_ON _IO(magic_number,0)
- #define BEEP_OFF _IO(magic_number,1)
- #define SET_FRE _IO(magic_number,2)
- int main(void)
- {
- int i = 0;
- int n = 2;
- int dev_fd;
- int div;
- dev_fd = open("/dev/beep",O_RDWR | O_NONBLOCK);
- if ( dev_fd == -1 ) {
- perror("open");
- exit(1);
- }
- for(i = 0;i<sizeof(GreatlyLongNow)/sizeof(Note);i++ )
- {
- div = (GreatlyLongNow[i].pitch);
- ioctl(dev_fd, SET_FRE, div);
- ioctl(dev_fd, BEEP_ON);
- usleep(GreatlyLongNow[i].dimation * 100);
- ioctl(dev_fd, BEEP_OFF);
- }
- for(i = 0;i<sizeof(MumIsTheBestInTheWorld)/sizeof(Note);i++ )
- {
- div = (MumIsTheBestInTheWorld[i].pitch);
- ioctl(dev_fd, SET_FRE, div);
- ioctl(dev_fd, BEEP_ON);
- usleep(MumIsTheBestInTheWorld[i].dimation * 100);
- ioctl(dev_fd, BEEP_OFF);
- }
- for(i = 0;i<sizeof(FishBoat)/sizeof(Note);i++ )
- {
- div = (FishBoat[i].pitch);
- ioctl(dev_fd, SET_FRE, div);
- ioctl(dev_fd, BEEP_ON);
- usleep(FishBoat[i].dimation * 100);
- ioctl(dev_fd, BEEP_OFF);
- }
- return 0;
- }
附所用头文件:
- #ifndef __PWM_MUSIC_H
- #define __PWM_MUSIC_H
- #define BIG_D
- #define PCLK (202800000/4)
- typedef struct
- {
- int pitch;
- int dimation;
- }Note;
- // 1 2 3 4 5 6 7
- // C D E F G A B
- //261.6256 293.6648 329.6276 349.2282 391.9954 440 493.8833
- //C澶ц皟
- #ifdef BIG_C
- #define DO 262
- #define RE 294
- #define MI 330
- #define FA 349
- #define SOL 392
- #define LA 440
- #define SI 494
- #define TIME 6000
- #endif
- //D澶ц皟
- #ifdef BIG_D
- #define DO 293
- #define RE 330
- #define MI 370
- #define FA 349
- #define SOL 440
- #define LA 494
- #define SI 554
- #define TIME 6000
- #endif
- Note MumIsTheBestInTheWorld[]={
- //6. //_5 //3 //5
- {LA,TIME+TIME/2}, {SOL,TIME/2},{MI,TIME},{SOL,TIME},
- //1^ //6_ //_5 //6-
- {DO*2,TIME},{LA,TIME/2},{SOL,TIME/2} ,{LA,2*TIME},
- // 3 //5_ //_6 //5
- {MI,TIME},{SOL,TIME/2},{LA,TIME/2},{SOL,TIME},
- // 3 //1_ //_6,
- {MI,TIME},{DO,TIME/2},{LA/2,TIME/2},
- //5_ //_3 //2- //2.
- {SOL,TIME/2},{MI,TIME/2},{RE,TIME*2},{RE,TIME+TIME/2},
- //_3 //5 //5_ //_6
- {MI,TIME/2},{SOL,TIME},{SOL,TIME/2},{LA,TIME/2},
- // 3 //2 //1- //5.
- {MI,TIME},{RE,TIME},{DO,TIME*2},{SOL,TIME+TIME/2},
- //_3 //2_ //_1 //6,_
- {MI,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME/2},
- //_1 //5,--
- {DO,TIME/2},{SOL/2,TIME*3}
- };
- Note GreatlyLongNow[]={
- // 2 3 3 3. _2 1
- {RE,TIME}, {MI,TIME},{MI,TIME},{MI,TIME+TIME/2},{RE,TIME/2},{DO,TIME},
- //6, 1 2 1-- 2 3 3
- {LA/2,TIME},{DO,TIME},{RE,TIME},{DO,TIME*3},{RE,TIME},{MI,TIME},{MI,TIME},
- //3. _5 3 3 2 3
- {MI,TIME+TIME/2},{SOL,TIME/2},{MI,TIME},{MI,TIME},{RE,TIME},{MI,TIME},
- //3-- 5 6 6 6. _5
- {MI,TIME*3},{SOL,TIME},{LA,TIME},{LA,TIME},{LA,TIME+TIME/2},{SOL,TIME/2},
- // 3 3 5 6 5--- 2 3
- {MI,TIME},{MI,TIME},{SOL,TIME},{LA,TIME},{SOL,TIME*3},{RE,TIME},{MI,TIME},
- // 3 2. _3 3 2 3
- {MI,TIME},{RE,TIME+TIME/2},{MI,TIME/2},{MI,TIME},{RE,TIME},{MI,TIME},
- //6, 1_ _6, 6,-
- {LA/2,TIME},{DO,TIME/2},{LA/2,TIME/2},{LA/2,TIME*2},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- // 2 3 1 2. _3 5
- {RE,TIME},{MI,TIME},{DO,TIME},{RE,TIME+TIME/2},{MI,TIME/2},{SOL,TIME},
- //6_ _6 6_ _5 3
- {LA,TIME/2},{LA,TIME/2},{LA,TIME/2},{SOL,TIME/2},{MI,TIME},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- //6, 5,. _6, 6,--
- {LA/2,TIME},{SOL/2,TIME+TIME/2},{LA/2,TIME/2},{LA/2,TIME*3},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- // 2 3 1 2. _3 5
- {RE,TIME},{MI,TIME},{DO,TIME},{RE,TIME+TIME/2},{MI,TIME/2},{SOL,TIME},
- //6_ _6 6_ _5 3
- {LA,TIME/2},{LA,TIME/2},{LA,TIME/2},{SOL,TIME/2},{MI,TIME},
- //2_ _2 2_ _1 6,
- {RE,TIME/2},{RE,TIME/2},{RE,TIME/2},{DO,TIME/2},{LA/2,TIME},
- //6, 5,. _6, 6,--
- {LA/2,TIME},{SOL/2,TIME+TIME/2},{LA/2,TIME/2},{LA/2,TIME*3}
- };
- Note FishBoat[]={ //3. _5 6._ =1^ 6_
- {MI,TIME+TIME/2},{SOL,TIME/2},{LA,TIME/2+TIME/4},{DO*2,TIME/4},{LA,TIME/2},
- //_5 3 -. 2 1. _3 2._
- {SOL,TIME/2},{MI,TIME*3},{RE,TIME},{DO,TIME+TIME/2},{MI,TIME/2},{RE,TIME/2+TIME/4},
- //=3 2_ _1 2-- 3. _5
- {MI,TIME/4},{RE,TIME/2},{DO,TIME/2},{RE,TIME*4},{MI,TIME+TIME/2},{SOL,TIME/2},
- // 2 1 6._ =1^ 6_ _5
- {RE,TIME},{DO,TIME},{LA,TIME/2+TIME/4},{DO*2,TIME/4},{LA,TIME/2},{SOL,TIME/2},
- //6- 5,. _6, 1._ =3
- {LA,TIME*2},{SOL/2,TIME+TIME/2},{LA/2,TIME/2},{DO,TIME/2+TIME/4},{MI,TIME/4},
- //2_ _1 5,--
- {RE,TIME/2},{DO,TIME/2},{SOL/2,TIME*4},
- //3. _5 6._ =1^ 6_
- {MI,TIME+TIME/2},{SOL,TIME/2},{LA,TIME/2+TIME/4},{DO*2,TIME/4},{LA,TIME/2},
- //_5 3-. 5_ _6 1^_ _6
- {SOL,TIME/2},{MI,TIME*3},{SOL,TIME/2},{LA,TIME/2},{DO*2,TIME+TIME/2},{LA,TIME/2},
- //5._ =6 5_ _3 2--
- {SOL,TIME/2+TIME/4},{LA,TIME/4},{SOL,TIME/2},{MI,TIME/2},{RE,TIME*4},
- //3. _5 2._ =3 2_ _1
- {MI,TIME+TIME/2},{SOL,TIME/2},{RE,TIME/2+TIME/4},{MI,TIME/4},{RE,TIME/2},{DO,TIME/2},
- //6._ =1^ 6_ _5 6- 1.
- {LA,TIME/2+TIME/4},{DO*2,TIME/4},{LA,TIME/2},{SOL,TIME/2},{LA,TIME*2},{DO,TIME+TIME/2},
- //_2 3_ _5 2_ _3 1--
- {RE,TIME/2},{MI,TIME/2},{SOL,TIME/2},{RE,TIME/2},{MI,TIME/2},{DO,TIME*4}
- };
- #endif
编译好程序后
# insmod beep.ko
#mknod /dev/beep c 250 0
#./music
便会听到悦耳的音乐了!
Linux 字符设备驱动开发基础(三)—— read()、write() 相关函数解析
我们在前面讲到了file_operations,其是一个函数指针的集合,用于存放我们定义的用于操作设备的函数的指针,如果我们不定义,它默认保留为NULL。其中有最重要的几个函数,分别是open()、read()、write()、ioctl(),下面分别对其进行解析
一、 打开和关闭设备函数
a -- 打开设备
int (*open) (struct inode *, struct file *);
在操作设备前必须先调用open函数打开文件,可以干一些需要的初始化操作。当然,如果不实现这个函数的话,驱动会默认设备的打开永远成功。打开成功时open返回0。
b -- 关闭设备
int (*release) (struct inode *, struct file *);
当设备文件被关闭时内核会调用这个操作,当然这也可以不实现,函数默认为NULL。关闭设备永远成功。
这两个函数已经讲过,这里不再赘述,主要看下面几个函数
二、read()、write() 函数
现在把 read()、write() 两个函数放一起讲,因为两个函数非密不可分的,先看一下两个函数的定义
a -- read() 函数
| 函数原型 | ssize_t (*read) (struct file * filp, char __user * buffer, size_t size , loff_t * p); |
| 参数含义 |
filp :为进行读取信息的目标文件, buffer :为对应放置信息的缓冲区(即用户空间内存地址); size :为要读取的信息长度; p :为读的位置相对于文件开头的偏移,在读取信息后,这个指针一般都会移动, 移动的值为要读取信息的长度值 |
b -- write() 函数
| 函数原型 | ssize_t (*write) (struct file * filp, const char __user * buffer, size_t count, loff_t * ppos); |
| 参数含义 |
filp :为目标文件结构体指针; buffer :为要写入文件的信息缓冲区; count :为要写入信息的长度; ppos :为当前的偏移位置,这个值通常是用来判断写文件是否越界 |
两个函数的作用分别是 从设备中获取数据及发送数据给设备,应用程序中与之对应的也有 write() 函数及 read() 函数:
|
len = read(fd,buf,len)
len = write(fd,buf,size)
|
static ssize_t hello_read(struct file *filep, char __user *buf, size_t len, loff_t *pos)
static ssize_t hello_write(struct file *filep, const char __user *buf, size_t len, loff_t *pos)
|
我们知道,应用程序工作在用户空间,而驱动工作在内核空间,二者不能直接通信的,那我们用何种方法进行通信呢?下面介绍一下内核中的memcpy---copy_from_user和copy_to_user,虽然说内核中不能使用C库提供的函数,但是内核也有一个memcpy的函数,用法跟C库中的一样。
下面看一下copy_from_user() 及 copy_to_user() 函数的定义:
- static inline int copy_from_user(void *to, const void __user volatile *from,
- unsigned long n)
- {
- __chk_user_ptr(from, n);
- volatile_memcpy(to, from, n);
- return 0;
- }
- static inline int copy_to_user(void __user volatile *to, const void *from,
- unsigned long n)
- {
- __chk_user_ptr(to, n);
- volatile_memcpy(to, from, n);
- return 0;
- }
可以看到两个函数均是调用了_memcpy() 函数:
- static void volatile_memcpy(volatile char *to, const volatile char *from,
- unsigned long n)
- {
- while (n--)
- *(to++) = *(from++);
- }
其实在这里,我们可以思考,既然拷贝的功能上面的_memcpy() 函数就可以实现,为什么还要封装成 copy_to_user()和copy_from_user()呢?答案是_memcpy() 函数是有缺陷的,譬如我们在用户层调用函数时传入的不是字符串,而是一个不能访问或修改的地址,那样就会造成系统崩溃。
出于上面的原因,内核和用户态之间交互的数据时必须要先对数据进行检测,如果数据是安全的,才可以进行数据交互。上面的函数就是memcpy的改进版,在memcpy功能的基础上加上的检查传入参数的功能,防止有些人有意或者无意的传入无效的参数。
现在我们可以审视一下这两个函数了:
- static inline unsigned long __must_check copy_to_user(void __user *to, const void *from, unsigned long n)
- static inline unsigned long __must_check copy_from_user(void *to, const void __user *from, unsigned long n)
用法:
和memcpy的参数一样,但它根据传参方向的不同分开了两个函数。
"to"是相对于内核态来说的。所以,to函数的意思是从from指针指向的数据将n个字节的数据传到to指针指向的数据。
"from"也是相对于内核来说的。所以,from函数的意思是从from指针指向的数据将n个字节的数据传到to指针指向的数据。
返回值:函数的返回值是指定要读取的n个字节中还剩下多少字节还没有被拷贝。
注意:
一般的,如果返回值不为0时,调用copy_to_user的函数会返回错误号-EFAULT表示操作出错。当然也可以自己决定。
又到了摆实例的时候了,这里只列出部分代码,看看这两个函数的用法:
- static ssize_t hello_read(struct file *filep, char __user *buf, size_t len, loff_t *pos)
- {
- if(len>64)
- {
- len =64;
- }
- if(copy_to_user(buf,temp,len))
- {
- return -EFAULT;
- }
- return len;
- }
- static ssize_t hello_write(struct file *filep, const char __user *buf, size_t len, loff_t *pos)
- {
- if(len>64)
- {
- len = 64;
- }
- if(copy_from_user(temp,buf,len))
- {
- return -EFAULT;
- }
- printk("write %s\n",temp);
- return len;
- }
测试程序:
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- char buf[]="111232342342342";
- char temp[64]={0};
- main()
- {
- int fd,len;
- fd = open("/dev/hello",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- write(fd,buf,strlen(buf));
- len=read(fd,temp,sizeof(temp));
- printf("len=%d,%s \n",len,temp);
- close(fd);
- }
到这里open、close、read、write四个函数已经学完,下面我们来看一下四个函数使用时,到底经历了一个怎样的过程:
注:箭头方向是从调用的一方指向受作用的一方
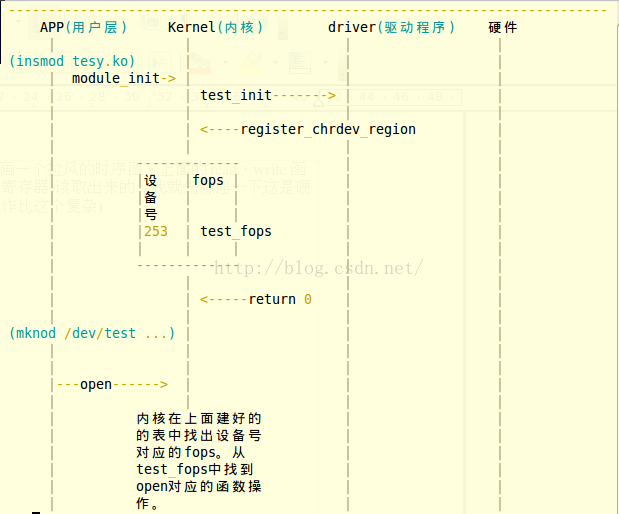
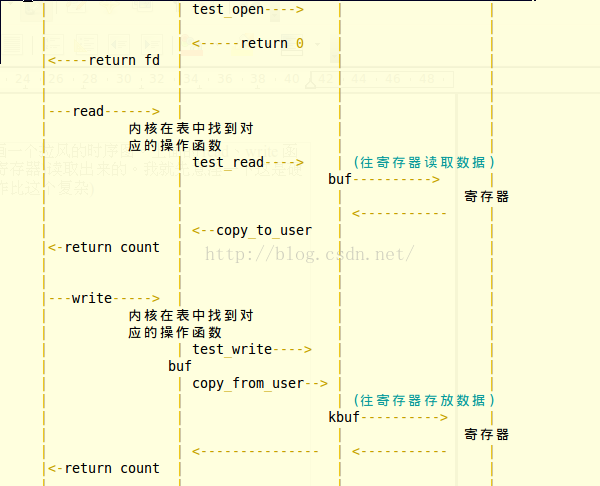
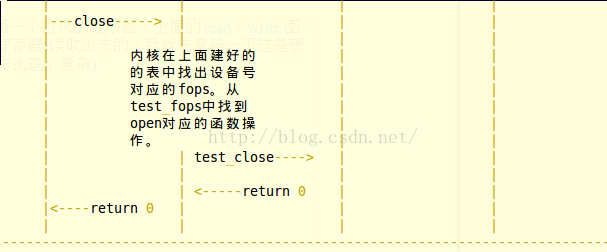
Linux 字符设备驱动开发基础(四)—— ioctl() 函数解析
解析完 open、close、read、write 四个函数后,终于到我们的 ioctl() 函数了
一、 什么是ioctl
ioctl是设备驱动程序中对设备的I/O通道进行管理的函数。所谓对I/O通道进行管理,就是对设备的一些特性进行控制,例如串口的传输波特率、马达的转速等等。下面是其源代码定义:
函数名: ioctl
功 能: 控制I/O设备
用 法: int ioctl(int handle, int cmd,[int *argdx, int argcx]);
参数:fd是用户程序打开设备时使用open函数返回的文件标示符,cmd是用户程序对设备的控制命令,后面是一些补充参数,一般最多一个,这个参数的有无和cmd的意义相关。
include/asm/ioctl.h中定义的宏的注释:
- #define _IOC_NRBITS 8 //序数(number)字段的字位宽度,8bits
- #define _IOC_TYPEBITS 8 //幻数(type)字段的字位宽度,8bits
- #define _IOC_SIZEBITS 14 //大小(size)字段的字位宽度,14bits
- #define _IOC_DIRBITS 2 //方向(direction)字段的字位宽度,2bits
- #define _IOC_NRMASK ((1 << _IOC_NRBITS)-1) //序数字段的掩码,0x000000FF
- #define _IOC_TYPEMASK ((1 << _IOC_TYPEBITS)-1) //幻数字段的掩码,0x000000FF
- #define _IOC_SIZEMASK ((1 << _IOC_SIZEBITS)-1) //大小字段的掩码,0x00003FFF
- #define _IOC_DIRMASK ((1 << _IOC_DIRBITS)-1) //方向字段的掩码,0x00000003
- #define _IOC_NRSHIFT 0 //序数字段在整个字段中的位移,0
- #define _IOC_TYPESHIFT (_IOC_NRSHIFT+_IOC_NRBITS) //幻数字段的位移,8
- #define _IOC_SIZESHIFT (_IOC_TYPESHIFT+_IOC_TYPEBITS) //大小字段的位移,16
- #define _IOC_DIRSHIFT (_IOC_SIZESHIFT+_IOC_SIZEBITS) //方向字段的位移,30
- #define _IOC_NONE 0U //没有数据传输
- #define _IOC_WRITE 1U //向设备写入数据,驱动程序必须从用户空间读入数据
- #define _IOC_READ 2U //从设备中读取数据,驱动程序必须向用户空间写入数据
- #define _IOC(dir,type,nr,size) \
- (((dir) << _IOC_DIRSHIFT) | \
- ((type) << _IOC_TYPESHIFT) | \
- ((nr) << _IOC_NRSHIFT) | \
- ((size) << _IOC_SIZESHIFT))
- //构造无参数的命令编号
- #define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
- //构造从驱动程序中读取数据的命令编号
- #define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),sizeof(size))
- //用于向驱动程序写入数据命令
- #define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),sizeof(size))
- //用于双向传输
- #define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),sizeof(size))
- //从命令参数中解析出数据方向,即写进还是读出
- #define _IOC_DIR(nr) (((nr) >> _IOC_DIRSHIFT) & _IOC_DIRMASK)
- //从命令参数中解析出幻数type
- #define _IOC_TYPE(nr) (((nr) >> _IOC_TYPESHIFT) & _IOC_TYPEMASK)
- //从命令参数中解析出序数number
- #define _IOC_NR(nr) (((nr) >> _IOC_NRSHIFT) & _IOC_NRMASK)
- //从命令参数中解析出用户数据大小
- #define _IOC_SIZE(nr) (((nr) >> _IOC_SIZESHIFT) & _IOC_SIZEMASK)
- #define IOC_IN (_IOC_WRITE << _IOC_DIRSHIFT)
- #define IOC_OUT (_IOC_READ << _IOC_DIRSHIFT)
- #define IOC_INOUT ((_IOC_WRITE|_IOC_READ) << _IOC_DIRSHIFT)
- #define IOCSIZE_MASK (_IOC_SIZEMASK << _IOC_SIZESHIFT)
- #define IOCSIZE_SHIFT (_IOC_SIZESHIFT)
二、ioctl的必要性
如果不用ioctl的话,也可以实现对设备I/O通道的控制。例如,我们可以在驱动程序中实现write的时候检查一下是否有特殊约定的数据流通过,如果有的话,那么后面就跟着控制命令(一般在socket编程中常常这样做)。但是如果这样做的话,会导致代码分工不明,程序结构混乱,程序员自己也会头昏眼花的。所以,我们就使用ioctl来实现控制的功能。要记住,用户程序所作的只是通过命令码(cmd)告诉驱动程序它想做什么,至于怎么解释这些命令和怎么实现这些命令,这都是驱动程序要做的事情。
三、 ioctl如何实现
在驱动程序中实现的ioctl函数体内,实际上是有一个switch{case}结构,每一个case对应一个命令码,做出一些相应的操作。怎么实现这些操作,这是每一个程序员自己的事情。因为设备都是特定的,这里也没法说。关键在于怎样组织命令码,因为在ioctl中命令码是唯一联系用户程序命令和驱动程序支持的途径。
命令码的组织是有一些讲究的,因为我们一定要做到命令和设备是一一对应的,这样才不会将正确的命令发给错误的设备,或者是把错误的命令发给正确的设备,或者是把错误的命令发给错误的设备。这些错误都会导致不可预料的事情发生,而当程序员发现了这些奇怪的事情的时候,再来调试程序查找错误,那将是非常困难的事情。所以在Linux核心中是这样定义一个命令码的:
| 设备类型 | 序列号 | 方向 |数据尺寸|
|-------------|----------|-------|------------|
| 8 bit | 8 bit | 2 bit | 8~14 bit |
|-------------|----------|-------|-------------|
这样一来,一个命令就变成了一个整数形式的命令码;但是命令码非常的不直观,所以Linux Kernel中提供了一些宏。这些宏可根据便于理解的字符串生成命令码,或者是从命令码得到一些用户可以理解的字符串以标明这个命令对应的设备类型、设备序列号、数据传送方向和数据传输尺寸。
比如上面展现的:
- //构造无参数的命令编号
- #define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
- //构造从驱动程序中读取数据的命令编号
- #define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),sizeof(size))
- //用于向驱动程序写入数据命令
- #define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),sizeof(size))
- //用于双向传输
- #define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),sizeof(size))
我们在前面PWM驱动程序中也定义了命令宏:
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
这里必须要提一下的,就是"幻数"MAGIC_NUMBER, "幻数"是一个字母,数据长度也是8,用一个特定的字母来标明设备类型,这和用一个数字是一样的,只是更加利于记忆和理解。
四、 cmd参数如何得出
这里确实要说一说,cmd参数在用户程序端由一些宏根据设备类型、序列号、传送方向、数据尺寸等生成,这个整数通过系统调用传递到内核中的驱动程序,再由驱动程序使用解码宏从这个整数中得到设备的类型、序列号、传送方向、数据尺寸等信息,然后通过switch{case}结构进行相应的操作。
实例时刻,当然只是部分代码:
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
- #define BEPP_IN_FREQ 100000
- static void beep_freq(unsigned long arg)
- {
- writel(BEPP_IN_FREQ/arg, timer_base +TCNTB0 );
- writel(BEPP_IN_FREQ/(2*arg), timer_base +TCMPB0 );
- }
- static long beep_ioctl(struct file *filep, unsigned int cmd, unsigned long arg)
- {
- switch(cmd)
- {
- case BEEP_ON:
- fs4412_beep_on();
- break;
- case BEEP_OFF:
- fs4412_beep_off();
- break;
- case BEEP_FREQ:
- beep_freq( arg );
- break;
- default :
- return -EINVAL;
- }
- }
测试代码如下:
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <sys/ioctl.h>
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
- main()
- {
- int fd;
- fd = open("/dev/beep",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- ioctl(fd,BEEP_ON);
- sleep(6);
- ioctl(fd,BEEP_OFF);
- close(fd);
- }
Linux 字符设备驱动开发基础(五)—— ioremap() 函数解析
一、 ioremap() 函数基础概念
几乎每一种外设都是通过读写设备上的寄存器来进行的,通常包括控制寄存器、状态寄存器和数据寄存器三大类,外设的寄存器通常被连续地编址。根据CPU体系结构的不同,CPU对IO端口的编址方式有两种:
a -- I/O 映射方式(I/O-mapped)
典型地,如X86处理器为外设专门实现了一个单独的地址空间,称为"I/O地址空间"或者"I/O端口空间",CPU通过专门的I/O指令(如X86的IN和OUT指令)来访问这一空间中的地址单元。
b -- 内存映射方式(Memory-mapped)
RISC指令系统的CPU(如ARM、PowerPC等)通常只实现一个物理地址空间,外设I/O端口成为内存的一部分。此时,CPU可以象访问一个内存单元那样访问外设I/O端口,而不需要设立专门的外设I/O指令。
但是,这两者在硬件实现上的差异对于软件来说是完全透明的,驱动程序开发人员可以将内存映射方式的I/O端口和外设内存统一看作是"I/O内存"资源。
一般来说,在系统运行时,外设的I/O内存资源的物理地址是已知的,由硬件的设计决定。但是CPU通常并没有为这些已知的外设I/O内存资源的物理地址预定义虚拟地址范围,驱动程序并不能直接通过物理地址访问I/O内存资源,而必须将它们映射到核心虚地址空间内(通过页表),然后才能根据映射所得到的核心虚地址范围,通过访内指令访问这些I/O内存资源。
Linux在io.h头文件中声明了函数ioremap(),用来将I/O内存资源的物理地址映射到核心虚地址空间(3GB-4GB)中(这里是内核空间),原型如下:
1、ioremap函数
ioremap宏定义在asm/io.h内:
#define ioremap(cookie,size) __ioremap(cookie,size,0)
__ioremap函数原型为(arm/mm/ioremap.c):
void __iomem * __ioremap(unsigned long phys_addr, size_t size, unsigned long flags);
参数:
phys_addr:要映射的起始的IO地址
size:要映射的空间的大小
flags:要映射的IO空间和权限有关的标志
该函数返回映射后的内核虚拟地址(3G-4G). 接着便可以通过读写该返回的内核虚拟地址去访问之这段I/O内存资源。
2、iounmap函数
iounmap函数用于取消ioremap()所做的映射,原型如下:
void iounmap(void * addr);
二、 ioremap() 相关函数解析
在将I/O内存资源的物理地址映射成核心虚地址后,理论上讲我们就可以象读写RAM那样直接读写I/O内存资源了。为了保证驱动程序的跨平台的可移植性,我们应该使用Linux中特定的函数来访问I/O内存资源,而不应该通过指向核心虚地址的指针来访问。
读写I/O的函数如下所示:
a -- writel()
writel()往内存映射的 I/O 空间上写数据,wirtel() I/O 上写入 32 位数据 (4字节)。
原型:void writel (unsigned char data , unsigned short addr )
b -- readl()
readl() 从内存映射的 I/O 空间上读数据,readl 从 I/O 读取 32 位数据 ( 4 字节 )。
原型:unsigned char readl (unsigned int addr )
变量 addr 是 I/O 地址。
返回值 : 从 I/O 空间读取的数值。
具体定义如下:
- #define readb __raw_readb
- #define readw(addr) __le16_to_cpu(__raw_readw(addr))
- #define readl(addr) __le32_to_cpu(__raw_readl(addr))
- #ifndef __raw_readb
- static inline u8 __raw_readb(const volatile void __iomem *addr)
- {
- return *(const volatile u8 __force *) addr;
- }
- #endif
- #ifndef __raw_readw
- static inline u16 __raw_readw(const volatile void __iomem *addr)
- {
- return *(const volatile u16 __force *) addr;
- }
- #endif
- #ifndef __raw_readl
- static inline u32 __raw_readl(const volatile void __iomem *addr)
- {
- return *(const volatile u32 __force *) addr;
- }
- #endif
- #define writeb __raw_writeb
- #define writew(b,addr) __raw_writew(__cpu_to_le16(b),addr)
- #define writel(b,addr) __raw_writel(__cpu_to_le32(b),addr)
三、使用实例
还是拿我们写PWM驱动的实例来解析
1、这里我们先定义了一些寄存器,这里使用的地址均是物理地址:
- #define GPD0CON 0x114000a0
- #define TIMER_BASE 0x139D0000
- #define TCFG0 0x0000
- #define TCFG1 0x0004
- #define TCON 0x0008
- #define TCNTB0 0x000C
- #define TCMPB0 0x0010
2、为了使用内存映射,我们需先定义指针用来保存内存映射后的地址:
- static unsigned int *gpd0con;
- static void *timer_base;
注意:这里timer_base 指针指向的类型设为 void, 主要因为上面使用了地址偏移,使用void 更有利于我们使用;
3、使用ioremap() 函数进行内存映射,并将映射的地址赋给我们刚才定义的指针
- gpd0con = ioremap(GPD0CON,4);
- timer_base = ioremap(TIMER_BASE,0x14);
4、得到地址后,可以调用 writel() 、readl() 函数进行相应的操作
- writel ((readl(gpd0con)&~(0xf<<0)) | (0x2<<0),gpd0con);
- writel ((readl(timer_base +TCFG0 )&~(0xff<<0)) | (0xff <<0),timer_base +TCFG0);
- writel ((readl(timer_base +TCFG1 )&~(0xf<<0)) | (0x2 <<0),timer_base +TCFG1 );
- writel (500, timer_base +TCNTB0 );
- writel (250, timer_base +TCMPB0 );
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x2 <<0),timer_base +TCON );
可以看到,这里先从相应的地址中读取数据,修改完毕后,再利用writel函数进行数据写入。
Linux 字符设备驱动开发基础(六)—— VFS 虚拟文件系统解析
一、VFS 虚拟文件系统基础概念
Linux 允许众多不同的文件系统共存,并支持跨文件系统的文件操作,这是因为有虚拟文件系统的存在。虚拟文件系统,即VFS(Virtual File System)是 Linux 内核中的一个软件抽象层。它通过一些数据结构及其方法向实际的文件系统如 ext2,vfat 提供接口机制。
Linux 有两个特性:
a -- 跨文件系统的文件操作
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的操作可以跨文件系统而执行。如图 1 所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。
图 1. 跨文件系统的文件操作
b -- 一切皆是文件
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。
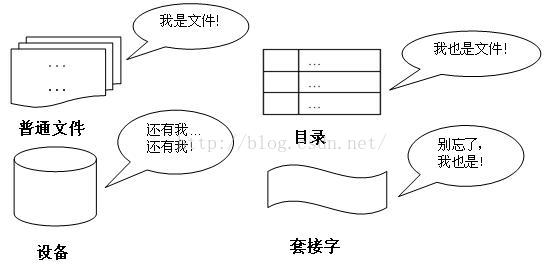
图 2. 一切皆是文件
而虚拟文件系统正是实现上述两点 Linux 特性的关键所在。虚拟文件系统(Virtual File System, 简称 VFS),是 Linux 内核中的一个软件层,用于给用户空间的程序提供文件系统接口;同时,它也提供了内核中的一个抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS 共存,而且也依靠 VFS 协同工作。
为了能够支持各种实际文件系统,VFS 定义了所有文件系统都支持的基本的、概念上的接口和数据结构;同时实际文件系统也提供 VFS 所期望的抽象接口和数据结构,将自身的诸如文件、目录等概念在形式上与VFS的定义保持一致。换句话说,一个实际的文件系统想要被 Linux 支持,就必须提供一个符合VFS标准的接口,才能与 VFS 协同工作。就像《老炮儿》里面的一样,“要有规矩”,想在Linux下混,就要按照Linux所定的规矩来办事。实际文件系统在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS 层和内核的其他部分看来,所有文件系统都是相同的。
图3显示了VFS在内核中与实际的文件系统的协同关系。
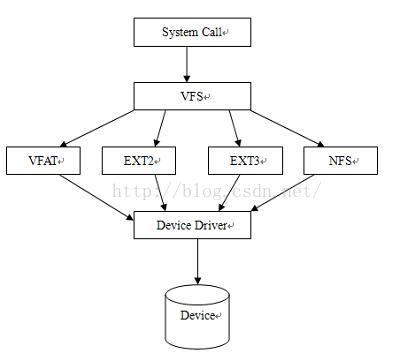
图3. VFS在内核中与其他的内核模块的协同关系
总结虚拟文件系统的作用:
虚拟文件系统(VFS)是linux内核和存储设备之间的抽象层,主要有以下好处。
- 简化了应用程序的开发:应用通过统一的系统调用访问各种存储介质
- 简化了新文件系统加入内核的过程:新文件系统只要实现VFS的各个接口即可,不需要修改内核部分
二、 VFS数据结构
1 、一些基本概念
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。
为了描述这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等也以文件被对待。总之,“一切皆文件”。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节点数等,存放于磁盘的特定扇区中。
如上的几个概念在磁盘中的位置关系如图4所示。
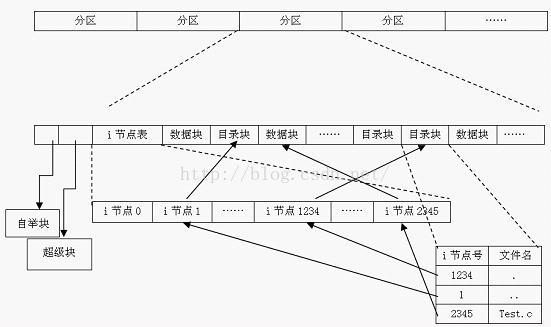
图4. 磁盘与文件系统
2、VFS数据结构
VFS依靠四个主要的数据结构和一些辅助的数据结构来描述其结构信息,这些数据结构表现得就像是对象;每个主要对象中都包含由操作函数表构成的操作对象,这些操作对象描述了内核针对这几个主要的对象可以进行的操作。
a -- 超级块对象
存储一个已安装的文件系统的控制信息,代表一个已安装的文件系统;每次一个实际的文件系统被安装时,内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应。超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
超级块的定义在:<linux/fs.h>
- /*
- * 超级块结构中定义的字段非常多,
- * 这里只介绍一些重要的属性
- */
- struct super_block {
- struct list_head s_list; /* 指向所有超级块的链表 */
- const struct super_operations *s_op; /* 超级块方法 */
- struct dentry *s_root; /* 目录挂载点 */
- struct mutex s_lock; /* 超级块信号量 */
- int s_count; /* 超级块引用计数 */
- struct list_head s_inodes; /* inode链表 */
- struct mtd_info *s_mtd; /* 存储磁盘信息 */
- fmode_t s_mode; /* 安装权限 */
- };
- /*
- * 其中的 s_op 中定义了超级块的操作方法
- * 这里只介绍一些相对重要的函数
- */
- struct super_operations {
- struct inode *(*alloc_inode)(struct super_block *sb); /* 创建和初始化一个索引节点对象 */
- void (*destroy_inode)(struct inode *); /* 释放给定的索引节点 */
- void (*dirty_inode) (struct inode *); /* VFS在索引节点被修改时会调用这个函数 */
- int (*write_inode) (struct inode *, int); /* 将索引节点写入磁盘,wait表示写操作是否需要同步 */
- void (*drop_inode) (struct inode *); /* 最后一个指向索引节点的引用被删除后,VFS会调用这个函数 */
- void (*delete_inode) (struct inode *); /* 从磁盘上删除指定的索引节点 */
- void (*put_super) (struct super_block *); /* 卸载文件系统时由VFS调用,用来释放超级块 */
- void (*write_super) (struct super_block *); /* 用给定的超级块更新磁盘上的超级块 */
- int (*sync_fs)(struct super_block *sb, int wait); /* 使文件系统中的数据与磁盘上的数据同步 */
- int (*statfs) (struct dentry *, struct kstatfs *); /* VFS调用该函数获取文件系统状态 */
- int (*remount_fs) (struct super_block *, int *, char *); /* 指定新的安装选项重新安装文件系统时,VFS会调用该函数 */
- void (*clear_inode) (struct inode *); /* VFS调用该函数释放索引节点,并清空包含相关数据的所有页面 */
- void (*umount_begin) (struct super_block *); /* VFS调用该函数中断安装操作 */
- };
b -- 索引节点对象
索引节点对象存储了文件的相关信息,代表了存储设备上的一个实际的物理文件。当一个文件首次被访问时,内核会在内存中组装相应的索引节点对象,以便向内核提供对一个文件进行操作时所必需的全部信息;这些信息一部分存储在磁盘特定位置,另外一部分是在加载时动态填充的。
索引节点定义在:<linux/fs.h>
- /*
- * 索引节点结构中定义的字段非常多,
- * 这里只介绍一些重要的属性
- */
- struct inode {
- struct hlist_node i_hash; /* 散列表,用于快速查找inode */
- struct list_head i_list; /* 索引节点链表 */
- struct list_head i_sb_list; /* 超级块链表超级块 */
- struct list_head i_dentry; /* 目录项链表 */
- unsigned long i_ino; /* 节点号 */
- atomic_t i_count; /* 引用计数 */
- unsigned int i_nlink; /* 硬链接数 */
- uid_t i_uid; /* 使用者id */
- gid_t i_gid; /* 使用组id */
- struct timespec i_atime; /* 最后访问时间 */
- struct timespec i_mtime; /* 最后修改时间 */
- struct timespec i_ctime; /* 最后改变时间 */
- const struct inode_operations *i_op; /* 索引节点操作函数 */
- const struct file_operations *i_fop; /* 缺省的索引节点操作 */
- struct super_block *i_sb; /* 相关的超级块 */
- struct address_space *i_mapping; /* 相关的地址映射 */
- struct address_space i_data; /* 设备地址映射 */
- unsigned int i_flags; /* 文件系统标志 */
- void *i_private; /* fs 私有指针 */
- };
- /*
- * 其中的 i_op 中定义了索引节点的操作方法
- * 这里只介绍一些相对重要的函数
- */
- struct inode_operations {
- /* 为dentry对象创造一个新的索引节点 */
- int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
- /* 在特定文件夹中寻找索引节点,该索引节点要对应于dentry中给出的文件名 */
- struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
- /* 创建硬链接 */
- int (*link) (struct dentry *,struct inode *,struct dentry *);
- /* 从一个符号链接查找它指向的索引节点 */
- void * (*follow_link) (struct dentry *, struct nameidata *);
- /* 在 follow_link调用之后,该函数由VFS调用进行清除工作 */
- void (*put_link) (struct dentry *, struct nameidata *, void *);
- /* 该函数由VFS调用,用于修改文件的大小 */
- void (*truncate) (struct inode *);
- };
c -- 目录项
和超级块和索引节点不同,目录项并不是实际存在于磁盘上的。在使用的时候在内存中创建目录项对象,其实通过索引节点已经可以定位到指定的文件,但是索引节点对象的属性非常多,在查找,比较文件时,直接用索引节点效率不高,所以引入了目录项的概念。这里可以看做又引入了一个抽象层,目录项是对索引节点的抽象!!!路径中的每个部分都是一个目录项,比如路径: /mnt/cdrom/foo/bar 其中包含5个目录项,/ mnt cdrom foo bar
每个目录项对象都有3种状态:被使用,未使用和负状态
- 被使用:对应一个有效的索引节点,并且该对象由一个或多个使用者
- 未使用:对应一个有效的索引节点,但是VFS当前并没有使用这个目录项
- 负状态:没有对应的有效索引节点(可能索引节点被删除或者路径不存在了)
目录项定义在:<linux/dcache.h>
- /* 目录项对象结构 */
- struct dentry {
- atomic_t d_count; /* 使用计数 */
- unsigned int d_flags; /* 目录项标识 */
- spinlock_t d_lock; /* 单目录项锁 */
- int d_mounted; /* 是否登录点的目录项 */
- struct inode *d_inode; /* 相关联的索引节点 */
- struct hlist_node d_hash; /* 散列表 */
- struct dentry *d_parent; /* 父目录的目录项对象 */
- struct qstr d_name; /* 目录项名称 */
- struct list_head d_lru; /* 未使用的链表 */
- /*
- * d_child and d_rcu can share memory
- */
- union {
- struct list_head d_child; /* child of parent list */
- struct rcu_head d_rcu;
- } d_u;
- struct list_head d_subdirs; /* 子目录链表 */
- struct list_head d_alias; /* 索引节点别名链表 */
- unsigned long d_time; /* 重置时间 */
- const struct dentry_operations *d_op; /* 目录项操作相关函数 */
- struct super_block *d_sb; /* 文件的超级块 */
- void *d_fsdata; /* 文件系统特有数据 */
- unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名 */
- };
- /* 目录项相关操作函数 */
- struct dentry_operations {
- /* 该函数判断目录项对象是否有效。VFS准备从dcache中使用一个目录项时会调用这个函数 */
- int (*d_revalidate)(struct dentry *, struct nameidata *);
- /* 为目录项对象生成hash值 */
- int (*d_hash) (struct dentry *, struct qstr *);
- /* 比较 qstr 类型的2个文件名 */
- int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
- /* 当目录项对象的 d_count 为0时,VFS调用这个函数 */
- int (*d_delete)(struct dentry *);
- /* 当目录项对象将要被释放时,VFS调用该函数 */
- void (*d_release)(struct dentry *);
- /* 当目录项对象丢失其索引节点时(也就是磁盘索引节点被删除了),VFS会调用该函数 */
- void (*d_iput)(struct dentry *, struct inode *);
- char *(*d_dname)(struct dentry *, char *, int);
- };
d -- 文件对象
文件对象是已打开的文件在内存中的表示,主要用于建立进程和磁盘上的文件的对应关系。
即文件对象并不是一个文件,只是抽象的表示一个打开的文件对。文件对象和物理文件的关系有点像进程和程序的关系一样。
它由sys_open() 现场创建,由sys_close()销毁。当我们站在用户空间来看待VFS,我们像是只需与文件对象打交道,而无须关心超级块,索引节点或目录项。因为多个进程可以同时打开和操作同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已经打开的文件,它反过来指向目录项对象(反过来指向索引节点)。
一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和目录项对象无疑是惟一的。
文件对象的定义在: <linux/fs.h>
- /*
- * 文件对象结构中定义的字段非常多,
- * 这里只介绍一些重要的属性
- */
- struct file {
- union {
- struct list_head fu_list; /* 文件对象链表 */
- struct rcu_head fu_rcuhead; /* 释放之后的RCU链表 */
- } f_u;
- struct path f_path; /* 包含的目录项 */
- const struct file_operations *f_op; /* 文件操作函数 */
- atomic_long_t f_count; /* 文件对象引用计数 */
- };
- /*
- * 其中的 f_op 中定义了文件对象的操作方法
- * 这里只介绍一些相对重要的函数
- */
- struct file_operations {
- /* 用于更新偏移量指针,由系统调用lleek()调用它 */
- loff_t (*llseek) (struct file *, loff_t, int);
- /* 由系统调用read()调用它 */
- ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
- /* 由系统调用write()调用它 */
- ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
- /* 由系统调用 aio_read() 调用它 */
- ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
- /* 由系统调用 aio_write() 调用它 */
- ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
- /* 将给定文件映射到指定的地址空间上,由系统调用 mmap 调用它 */
- int (*mmap) (struct file *, struct vm_area_struct *);
- /* 创建一个新的文件对象,并将它和相应的索引节点对象关联起来 */
- int (*open) (struct inode *, struct file *);
- /* 当已打开文件的引用计数减少时,VFS调用该函数 */
- int (*flush) (struct file *, fl_owner_t id);
- };
上面分别介绍了4种对象分别的属性和方法,下面用图来展示这4个对象的和VFS之间关系以及4个对象之间的关系。
VFS中4个主要对象
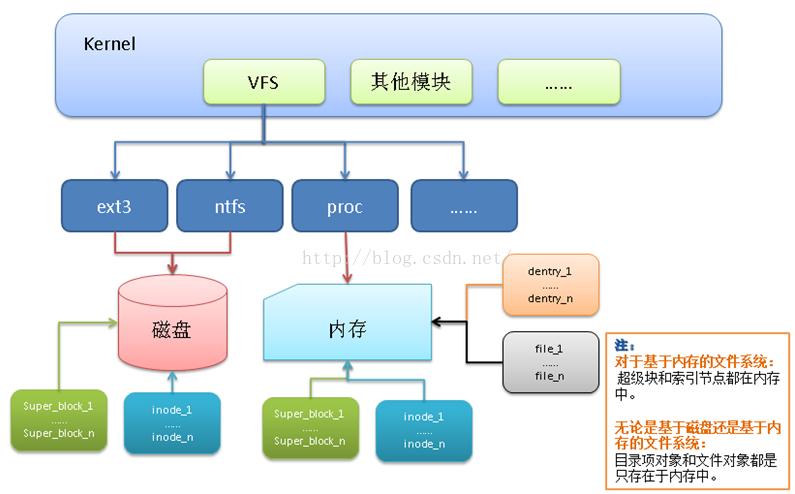
前面我们讲到,超级块和索引节点都是真实存在的,是一个实际的物理文件。即使基于内存的文件系统,也是一种抽象的实际物理文件;而目录项对象和文件对象是运行时才被创建的。
下面是VFS中4个主要对象之间的关系:
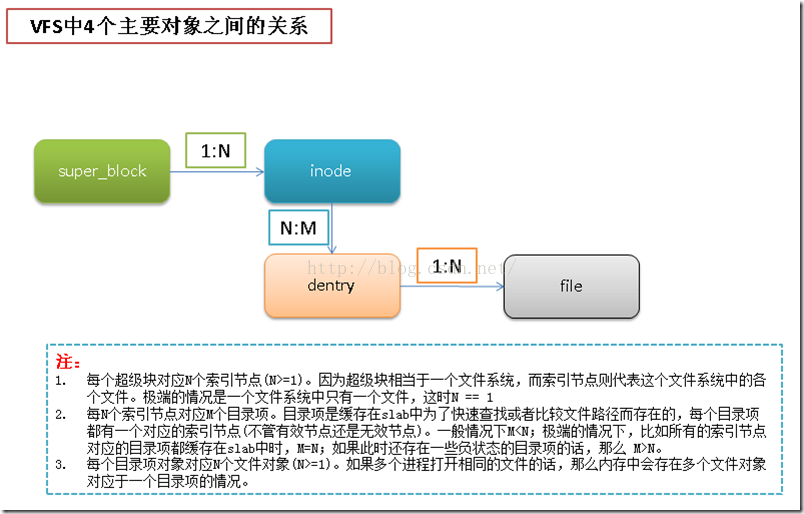
超级块是一个文件系统,一个文件系统中可以有多个索引节点;索引节点和目录的关系又是 N:M;一个目录中可以有多个文件对象,但一个文件对象却只能有一个目录;
三、基于VFS的文件I/O
到目前为止,文章主要都是从理论上来讲述VFS的运行机制;接下来我们将深入源代码层中,通过阐述两个具有代表性的系统调用sys_open()和sys_read()来更好地理解VFS 向具体文件系统提供的接口机制。由于本文更关注的是文件操作的整个流程体制,所以我们在追踪源代码时,对一些细节性的处理不予关心。又由于篇幅所限,只列出相关代码。本文中的源代码来自于linux-2.6.17内核版本。
在深入sys_open()和sys_read()之前,我们先概览下调用sys_read()的上下文。下图描述了从用户空间的read()调用到数据从磁盘读出的整个流程。
当在用户应用程序调用文件I/O read()操作时,系统调用sys_read()被激发,sys_read()找到文件所在的具体文件系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
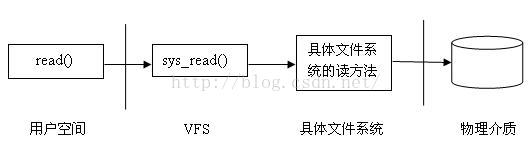
1、sys_open()
sys_open()系统调用打开或创建一个文件,成功返回该文件的文件描述符。图8是sys_open()实现代码中主要的函数调用关系图。

图8. sys_open函数调用关系图
由于sys_open()的代码量大,函数调用关系复杂,以下主要是对该函数做整体的解析;而对其中的一些关键点,则列出其关键代码。
a -- 从sys_open()的函数调用关系图可以看到,sys_open()在做了一些简单的参数检验后,就把接力棒传给do_sys_open():
1)、首先,get_unused_fd()得到一个可用的文件描述符;通过该函数,可知文件描述符实质是进程打开文件列表中对应某个文件对象的索引值;
2)、接着,do_filp_open()打开文件,返回一个file对象,代表由该进程打开的一个文件;进程通过这样的一个数据结构对物理文件进行读写操作。
3)、最后,fd_install()建立文件描述符与file对象的联系,以后进程对文件的读写都是通过操纵该文件描述符而进行。
b -- do_filp_open()用于打开文件,返回一个file对象;而打开之前需要先找到该文件:
1)、open_namei()用于根据文件路径名查找文件,借助一个持有路径信息的数据结构nameidata而进行;
2)、查找结束后将填充有路径信息的nameidata返回给接下来的函数nameidata_to_filp()从而得到最终的file对象;当达到目的后,nameidata这个数据结构将会马上被释放。
c -- open_namei()用于查找一个文件:
1)、path_lookup_open()实现文件的查找功能;要打开的文件若不存在,还需要有一个新建的过程,则调用path_lookup_create(),后者和前者封装的是同一个实际的路径查找函数,只是参数不一样,使它们在处理细节上有所偏差;
2)、当是以新建文件的方式打开文件时,即设置了O_CREAT标识时需要创建一个新的索引节点,代表创建一个文件。在vfs_create()里的一句核心语句dir->i_op->create(dir, dentry, mode, nd)可知它调用了具体的文件系统所提供的创建索引节点的方法。注意:这边的索引节点的概念,还只是位于内存之中,它和磁盘上的物理的索引节点的关系就像位于内存中和位于磁盘中的文件一样。此时新建的索引节点还不能完全标志一个物理文件的成功创建,只有当把索引节点回写到磁盘上才是一个物理文件的真正创建。想想我们以新建的方式打开一个文件,对其读写但最终没有保存而关闭,则位于内存中的索引节点会经历从新建到消失的过程,而磁盘却始终不知道有人曾经想过创建一个文件,这是因为索引节点没有回写的缘故。
3)、path_to_nameidata()填充nameidata数据结构;
4)、may_open()检查是否可以打开该文件;一些文件如链接文件和只有写权限的目录是不能被打开的,先检查nd->dentry->inode所指的文件是否是这一类文件,是的话则错误返回。还有一些文件是不能以TRUNC的方式打开的,若nd->dentry->inode所指的文件属于这一类,则显式地关闭TRUNC标志位。接着如果有以TRUNC方式打开文件的,则更新nd->dentry->inode的信息
d -- __path_lookup_intent_open()
不管是path_lookup_open()还是path_lookup_create()最终都是调用__path_lookup_intent_open()来实现查找文件的功能。查找时,在遍历路径的过程中,会逐层地将各个路径组成部分解析成目录项对象,如果此目录项对象在目录项缓存中,则直接从缓存中获得;如果该目录项在缓存中不存在,则进行一次实际的读盘操作,从磁盘中读取该目录项所对应的索引节点。得到索引节点后,则建立索引节点与该目录项的联系。如此循环,直到最终找到目标文件对应的目录项,也就找到了索引节点,而由索引节点找到对应的超级块对象就可知道该文件所在的文件系统的类型。从磁盘中读取该目录项所对应的索引节点;这将引发VFS和实际的文件系统的一次交互。从前面的VFS理论介绍可知,读索引节点方法是由超级块来提供的。而当安装一个实际的文件系统时,在内存中创建的超级块的信息是由一个实际文件系统的相关信息来填充的,这里的相关信息就包括了实际文件系统所定义的超级块的操作函数列表,当然也就包括了读索引节点的具体执行方式。当继续追踪一个实际文件系统ext3的ext3_read_inode()时,可发现这个函数很重要的一个工作就是为不同的文件类型设置不同的索引节点操作函数表和文件操作函数表。
清单8. ext3_read_inode
- void ext3_read_inode(struct inode * inode)
- {
- ……
- //是普通文件
- if (S_ISREG(inode->i_mode)) {
- inode->i_op = &ext3_file_inode_operations;
- inode->i_fop = &ext3_file_operations;
- ext3_set_aops(inode);
- } else if (S_ISDIR(inode->i_mode)) {
- //是目录文件
- inode->i_op = &ext3_dir_inode_operations;
- inode->i_fop = &ext3_dir_operations;
- } else if (S_ISLNK(inode->i_mode)) {
- // 是连接文件
- ……
- } else {
- // 如果以上三种情况都排除了,则是设备驱动
- //这里的设备还包括套结字、FIFO等伪设备
- ……
e -- nameidata_to_filp子函数:__dentry_open
这是VFS与实际的文件系统联系的一个关键点。从3.1.1小节分析中可知,调用实际文件系统读取索引节点的方法读取索引节点时,实际文件系统会根据文件的不同类型赋予索引节点不同的文件操作函数集,如普通文件有普通文件对应的一套操作函数,设备文件有设备文件对应的一套操作函数。这样当把对应的索引节点的文件操作函数集赋予文件对象,以后对该文件进行操作时,比如读操作,VFS虽然对各种不同文件都是执行同一个read()操作界面,但是真正读时,内核却知道怎么区分对待不同的文件类型。
清单9. __dentry_open
- static struct file *__dentry_open(struct dentry *dentry, struct vfsmount *mnt,
- int flags, struct file *f,
- int (*open)(struct inode *, struct file *))
- {
- struct inode *inode;
- ……
- //整个函数的工作在于填充一个file对象
- ……
- f->f_mapping = inode->i_mapping;
- f->f_dentry = dentry;
- f->f_vfsmnt = mnt;
- f->f_pos = 0;
- //将对应的索引节点的文件操作函数集赋予文件对象的操作列表
- f->f_op = fops_get(inode->i_fop);
- ……
- //若文件自己定义了open操作,则执行这个特定的open操作。
- if (!open && f->f_op)
- open = f->f_op->open;
- if (open) {
- error = open(inode, f);
- if (error)
- goto cleanup_all;
- ……
- return f;
- }
2、 sys_read()
sys_read()系统调用用于从已打开的文件读取数据。如read成功,则返回读到的字节数。如已到达文件的尾端,则返回0。图9是sys_read()实现代码中的函数调用关系图。

对文件进行读操作时,需要先打开它。从3.1小结可知,打开一个文件时,会在内存组装一个文件对象,希望对该文件执行的操作方法已在文件对象设置好。所以对文件进行读操作时,VFS在做了一些简单的转换后(由文件描述符得到其对应的文件对象;其核心思想是返回current->files->fd[fd]所指向的文件对象),就可以通过语句file->f_op->read(file,
buf, count, pos)轻松调用实际文件系统的相应方法对文件进行读操作了。
四、解决问题
1、 跨文件系统的文件操作的基本原理
到此,我们也就能够解释在Linux中为什么能够跨文件系统地操作文件了。举个例子,将vfat格式的磁盘上的一个文件a.txt拷贝到ext3格式的磁盘上,命名为b.txt。这包含两个过程,对a.txt进行读操作,对b.txt进行写操作。读写操作前,需要先打开文件。由前面的分析可知,打开文件时,VFS会知道该文件对应的文件系统格式,以后操作该文件时,VFS会调用其对应的实际文件系统的操作方法。
所以,VFS调用vfat的读文件方法将a.txt的数据读入内存;在将a.txt在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而实现了最终的跨文件系统的复制操作。
2、“一切皆是文件”的实现根本
不论是普通的文件,还是特殊的目录、设备等,VFS都将它们同等看待成文件,通过同一套文件操作界面来对它们进行操作。操作文件时需先打开;打开文件时,VFS会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这也就是“一切皆是文件”的根本所在。
五、总结
VFS即虚拟文件系统是Linux文件系统中的一个抽象软件层;因为它的支持,众多不同的实际文件系统才能在Linux中共存,跨文件系统操作才能实现。
VFS借助它四个主要的数据结构即超级块、索引节点、目录项和文件对象以及一些辅助的数据结构,向Linux中不管是普通的文件还是目录、设备、套接字等都提供同样的操作界面,如打开、读写、关闭等。只有当把控制权传给实际的文件系统时,实际的文件系统才会做出区分,对不同的文件类型执行不同的操作。由此可见,正是有了VFS的存在,跨文件系统操作才能执行,Unix/Linux中的“一切皆是文件”的口号才能够得以实现。
Linux 文件系统与设备文件系统 (一)—— udev 设备文件系统
一、什么是Linux设备文件系统
首先我们不看定义,定义总是太抽象很难理解,我们先看现象。当我们往开发板上移植了一个新的文件系统之后(假如各种设备驱动也移植好了),启动开发板,我们用串口工具进入开发板,查看系统/dev目录,往往里面没有或者就只有null、console等几个系统必须的设备文件在这儿外,没有任何设备文件了。那我们移植好的各种设备驱动的设备文件怎么没有啊?如果要使用这些设备,那不是要一个一个的去手动的创建这些设备的设备文件节点,这给我们使用设备带来了极为的不便(在之前篇幅中讲的各种设备驱动的移植都是这样)。
设备文件系统就是给我们解决这一问题的关键,他能够在系统设备初始化时动态的在/dev目录下创建好各种设备的设备文件节点(也就是说,系统启动后/dev目录下就有了各种设备的设备文件,直接就可使用了)。除此之外,他还可以在设备卸载后自动的删除/dev下对应的设备文件节点(这对于一些热插拔设备很有用,插上的时候自动创建,拔掉的时候又自动删除)。还有一个好处就是,在我们编写设备驱动的时候,不必再去为设备指定主设备号,在设备注册时用0来动态的获取可用的主设备号,然后在驱动中来实现创建和销毁设备文件(一般在驱动模块加载和卸载函数中来实现)。
二、关于udev
2.4 内核使用devfs(设备文件系统)在设备初始化时创建设备文件,设备驱动程序可以指定设备号、所有者、用户空间等信息,devfs 运行在内核环境中,并有不少缺点:可能出现主/辅设备号不够,命名不灵活,不能指定设备名称等问题。
而自2.6 内核开始,引入了sysfs 文件系统。sysfs 把连接在系统上的设备和总线组织成一个分级的文件,并提供给用户空间存取使用。udev 运行在用户模式,而非内核中。udev 的初始化脚本在系统启动时创建设备节点,并且当插入新设备——加入驱动模块——在sysfs上注册新的数据后,udev会创新新的设备节点。
udev 是一个工作在用户空间的工具,它能根据系统中硬件设备的状态动态的更新设备文件,包括设备文件的创建,删除,权限等。这些文件通常都定义在/dev 目录下,但也可以在配置文件中指定。udev 必须内核中的sysfs和tmpfs支持,sysfs 为udev 提供设备入口和uevent 通道,tmpfs 为udev 设备文件提供存放空间。
注意,udev 是通过对内核产生的设备文件修改,或增加别名的方式来达到自定义设备文件的目的。但是,udev 是用户模式程序,其不会更改内核行为。也就是说,内核仍然会创建sda,sdb等设备文件,而udev可根据设备的唯一信息来区分不同的设备,并产生新的设备文件(或链接)。而在用户的应用中,只要使用新产生的设备文件即可。
三、udev和devfs设备文件的对比
提到udev,不能不提的就是devfs,下面看一下udev 与 devfs 的区别:
1、udev能够实现所有devfs实现的功能。但udev运行在用户模式中,而devfs运行在内核中。
2、当一个并不存在的 /dev 节点被打开的时候, devfs一样自动加载驱动程序而udev确不能。udev设计时,是在设备被发现的时候加载模块,而不是当它被访问的时候。 devfs这个功能对于一个配置正确的计算机是多余的。系统中所有的设备都应该产生hotplug 事件、加载恰当的驱动,而 udev 将会注意到这点并且为它创建对应的设备节点。如果你不想让所有的设备驱动停留在内存之中,应该使用其它东西来 管理你的模块 (如脚本, modules.conf, 等等) 。其中devfs 用的方法导致了大量无用的 modprobe 尝试,以此程序探测设备是否存在。每个试探性探测都新建一个运行 modprobe 的进程,而几乎所有这些都是无用的
3、udev是通过对内核产生的设备名增加别名的方式来达到上述目的的。前面说过,udev是用户模式程序,不会更改内核的行为。
因此,内核依然会我行我素地产生设备名如sda,sdb等。但是,udev可以根据设备的其他信息如总线(bus),生产商(vendor)等不同来区分不同的设备,并产生设备文件。udev只要为这个设备文件取一个固定的文件名就可以解决这个问题。在后续对设备的操作中,只要引用新的设备名就可以了。但为了保证最大限度的兼容,一般来说,
新设备名总是作为一个对内核自动产生的设备名的符号链接(link)来使用的。
例如:内核产生了sda设备名,而根据信息,这个设备对应于是我的内置硬盘,那我就可以制定udev规则,让udev除了产生/dev/sda设备文件 外,另外创建一个符号链接叫/dev/internalHD。这样,我在fstab文件中,就可以用/dev/internalHD来代替原来的 /dev/sda了。下次,由于某些原因,这个硬盘在内核中变成了sdb设备名了,那也不用着急,udev还会自动产生/dev/internalHD这 个链接,并指向正确的/dev/sdb设备。所有其他的文件像fstab等都不用修改。
而在在2.6内核以前一直使用的是 devfs,devfs挂载于/dev目录下,提供了一种类似于文件的方法来管理位于/dev目录下的所有设备,但是devfs文件系统有一些缺点,例 如:不确定的设备映射,有时一个设备映射的设备文件可能不同,例如我的U盘可能对应sda有可能对应sdb 。
四、udev 的工作流程图
下面先看一张流程图:
前面提到设备文件系统udev的工作过程依赖于sysfs文件系统。udev文件系统在用户空间工作,它可以根据sysfs文件系统导出的信息(设备号(dev)等),动态建立和删除设备文件。
sysfs文件系统特点:sysfs把连接在系统上的设备和总线组织成为一个分级的目录及文件,它们可以由用户空间存取,向用户空间导出内核数据结构以及它们的属性,这其中就包括设备的主次设备号。
那么udev 是如何建立设备文件的呢?
a -- 对于已经编入内核的驱动程序
当被内核检测到的时候,会直接在 sysfs 中注册其对象;对于编译成模块的驱动程序,当模块载入的时候才会这样做。一旦挂载了 sysfs 文件系统(挂载到 /sys),内建的驱动程序在 sysfs 注册的数据就可以被用户空间的进程使用,并提供给 udev 以创建设备节点。
udev 初始化脚本负责在 Linux 启动的时候创建设备节点,该脚本首先将 /sbin/udevsend 注册为热插拔事件处理程序。热插拔事件本不应该在这个阶段发生,注册 udev 只是为了以防万一。
然后 udevstart 遍历 /sys 文件系统(其属性文件dev中记录这设备的主设备号,与次设备号),并在 /dev 目录下创建符合描述的设备文件。
例如,/sys/class/tty/vcs/dev 里含有"7:0"字符串,udevstart 就根据这个字符串创建主设备号为 7 、次设备号为 0 的 /dev/vcs 设备。udevstart 创建的每个设备的名字和权限由 /etc/udev/rules.d/ 目录下的文件指定的规则来设置。如果 udev 找不到所创建设备的权限文件,就将其权限设置为缺省的 660 ,所有者为 root:root 。
b -- 编译成模块的驱动程序
前面我们提到了"热插拔事件处理程序"的概念,当内核检测到一个新设备连接时,内核会产生一个热插拔事件,并在 /proc/sys/kernel/hotplug 文件里查找处理设备连接的用户空间程序。udev 初始化脚本将 udevsend 注册为该处理程序。当产生热插拔事件的时候,内核让 udev 在 /sys 文件系统里检测与新设备的有关信息,并为新设备在 /dev 里创建项目。
大多数 Linux 发行版通过 /etc/modules.conf
配置文件来处理模块加载,对某个设备节点的访问导致相应的内核模块被加载。对 udev
这个方法就行不通了,因为在模块加载前,设备节点根本不存在。为了解决这个问题,在 LFS-Bootscripts 软件包里加入了 modules
启动脚本,以及 /etc/sysconfig/modules 文件。通过在 modules 文件里添加模块名,就可以在系统启动的时候加载这些模块,这样
udev 就可以检测到设备,并创建相应的设备节点了。如果插入的设备有一个驱动程序模块但是尚未加载,Hotplug 软件包就有用了,它就会响应上述的内核总线驱动热插拔事件并加载相应的模块,为其创建设备节点,这样设备就可以使用了。
五、创建和配置mdev
mdev是udev的简化版本,是busybox中所带的程序,最适合用在嵌入式系统,而udev一般都用在PC上的Linux中,相对mdev来说要复杂些;
1、我们应该明白,不管是udev还是mdev,他们就是一个应用程序,就跟其他应用程序一样(比如:Boa服务),配置了就可以使用了。为了方便起见,我们就使用busybox自带的一个mdev,这样在配置编译busybox时,只要将mdev的支持选项选上,编译后就包含了mdev设备文件系统的应用(当然你也可以不使用busybox自带的,去下载udev的源码进行编译移植。
|
|
|
|
2、udev或者mdev需要内核sysfs和tmpfs虚拟文件系统的支持,sysfs为udev提供设备入口和uevent通道,tmpfs为udev设备文件提供存放空间。所以在/etc/fstab配置文件中添加如下内容(红色部分):
|
|
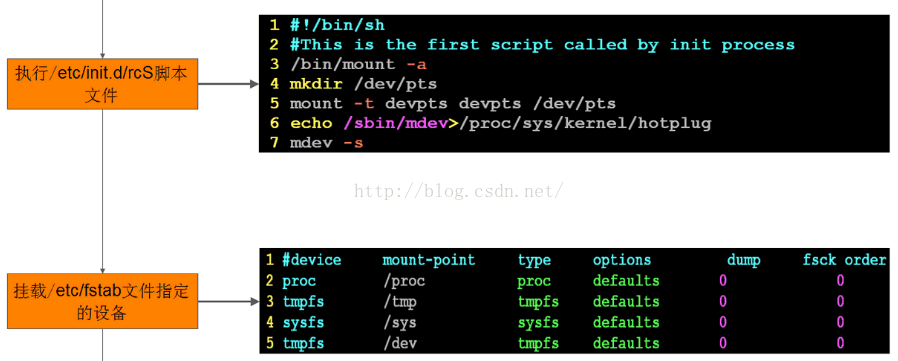
然后启动/sbin目录下的mdev应用对系统的设备进行搜索(红色部分)。
|
|
a -- " mdev -s " 的含义是扫描 /sys 中所有的类设备目录,如果在目录中有含有名为“dev”的文件,且文件中包含的是设备号,则mdev就利用这些信息为该设备在/dev下创建设备节点文件;
b -- "echo /sbin/mdev > /proc/sys/kernel/hotplug"
的含义是当有热插拔事件产生时,内核就会调用位于 /sbin 目录的 mdev 。这时 mdev 通过环境变量中的 ACTION
和DEVPATH,来确定此次热插拔事件的动作以及影响了 /sys
中的那个目录。接着,会看这个目录中是否有“dev”的属性文件。如果有就利用这些信息为这个设备在 /dev 下创建设备节点文件。
4、在设备驱动程序中加上对类设备接口的支持,即在驱动程序加载和卸载函数中实现设备文件的创建与销毁,这个在我们前面Linux 字符设备驱动结构(二)—— 自动创建设备节点 可以看到实例,下面在介绍一个
例如在之前篇幅的按键驱动中添加(红色部分):
- #include <linux/device.h> //设备类用到的头文件
- staticint device_major = DEVICE_MAJOR; //用于保存系统动态生成的主设备号
- staticstruct class *button_class; //定义一个类
- static int __init button_init(void)
- {
- //注册字符设备,这里定义DEVICE_MAJOR=0,让系统去分配,注册成功后将返回动态分配的主设备号
- device_major = register_chrdev(DEVICE_MAJOR, DEVICE_NAME,&buttons_fops);
- if(device_major< 0)
- {
- printk(DEVICE_NAME " register faild!/n");
- return device_major;
- }
- //注册一个设备类,使mdev可以在/dev/目录下建立设备节点
- button_class =class_create(THIS_MODULE, DEVICE_NAME);
- if(IS_ERR(button_class))
- {
- printk(DEVICE_NAME" create class faild!/n");
- return-1;
- }
- //创建一个设备节点,取名为DEVICE_NAME(即my2440_buttons)
- //注意2.6内核较早版本的函数名是class_device_create,现该为device_create
- device_create(button_class,NULL,MKDEV(device_major,0),NULL,DEVICE_NAME);
- return 0;
- }
- static void __exit button_exit(void)
- {
- //注销字符设备
- unregister_chrdev(device_major, DEVICE_NAME);
- //删除设备节点,注意2.6内核较早版本的函数名是class_device_destroy,现该为device_destroy
- device_destroy(button_class,MKDEV(device_major,0));
- //注销类
- class_destroy(button_class);
- }
5、至于mdev的配置文件/etc/mdev.conf,这个可有可无,只是设定设备文件的一些规则。我这里就不管他了,让他为空好了。
6、完成以上步骤后,重新编译文件系统,下载到开发板上,启动开发板后进入开发板的/dev目录查看,就会有很多系统设备节点在这里产生了,我们就可以直接使用这些设备节点了。
Linux 文件系统与设备文件系统 (二)—— sysfs 文件系统与Linux设备模型
提到 sysfs 文件系统 ,必须先需要了解的是Linux设备模型,什么是Linux设备模型呢?
一、Linux 设备模型
1、设备模型概述
从2.6版本开始,Linux开发团队便为内核建立起一个统一的设备模型。在以前的内核中没有独立的数据结构用来让内核获得系统整体配合的信息。尽管缺乏这些信息,在多数情况下内核还是能正常工作的。然而,随着拓扑结构越来越复杂,以及要支持诸如电源管理等新特性的需求,向新版本的内核明确提出了这样的要求:需要有一个对系统结构的一般性抽象描述,即设备模型。
目的
I 设备、驱动、总线等彼此之间关系错综复杂。如果想让内核运行流畅,那就必须为每个模块编码实现这些功能。如此一来,内核将变得非常臃肿、冗余。而设备模型的理念即是将这些代码抽象成各模块共用的框架,这样不但代码简洁了,也可让设备驱动开发者摆脱这本让人头痛但又必不可少的一劫,将有限的精力放于设备差异性的实现。
II 设备模型用类的思想将具有相似功能的设备放到一起管理,并将相似部分萃取出来,使用一份代码实现。从而使结构更加清晰,简洁。
III 动态分配主从设备号,有效解决设备号的不足。设备模型实现了只有设备在位时才为其分配主从设备号,这与之前版本为每个设备分配一个主从设备号不同,使得有限的资源得到合理利用。
IV 设备模型提供sysfs文件系统,以文件的方式让本是抽象复杂而又无法捉摸的结构清晰可视起来。同时也给用户空间程序配置处于内核空间的设备驱动提供了一个友善的通道。
V 程序具有随意性,同一个功能,不同的人实现的方法和风格各不相同,设备驱动亦是如此。大量的设备亦若实现方法流程均不相同,对以后的管理、重构将是难以想象的工作量。设备模型恰是提供了一个模板,一个被证明过的最优的思路和流程,这减少了开发者设计过程中不必要的错误,也给以后的维护扫除了障碍。
2、设备模型结构
如表,Linux设备模型包含以下四个基本结构:
|
类型 |
所包含的内容 |
内核数据结构 |
对应/sys项 |
|
设备(Devices) |
设备是此模型中最基本的类型,以设备本身的连接按层次组织 |
struct device |
/sys/devices/*/*/.../ |
|
驱动 (Drivers) |
在一个系统中安装多个相同设备,只需要一份驱动程序的支持 |
struct device_driver |
/sys/bus/pci/drivers/*/ |
|
总线 (Bus) |
在整个总线级别对此总线上连接的所有设备进行管理 |
struct bus_type |
/sys/bus/*/ |
|
类别(Classes) |
这是按照功能进行分类组织的设备层次树;如 USB 接口和 PS/2 接口的鼠标都是输入设备,都会出现在/sys/class/input/下 |
struct class |
/sys/class/*/ |
device、driver、bus、class是组成设备模型的基本数据结构。kobject是构成这些基本结构的核心,kset又是相同类型结构kobject的集合。kobject和kset共同组成了sysfs的底层数据体系。本节采用从最小数据结构到最终组成一个大的模型的思路来介绍。当然,阅读时也可先从Device、Driver、Bus、Class的介绍开始,先总体了解设备模型的构成,然后再回到kobject和kset,弄清它们是如何将Device、Driver、Bus、Class穿插链接在一起的,以及如何将这些映像成文件并最终形成一个sysfs文件系统。
二、sys 文件系统
sysfs是一个基于内存的文件系统,它的作用是将内核信息以文件的方式提供给用户程序使用。
sysfs可以看成与proc,devfs和devpty同类别的文件系统,该文件系统是虚拟的文件系统,可以更方便对系统设备进行管理。它可以产生一个包含所有系统硬件层次视图,与提供进程和状态信息的proc文件系统十分类似。
sysfs把连接在系统上的设备和总线组织成为一个分级的文件,它们可以由用户空间存取,向用户空间导出内核的数据结构以及它们的属性。sysfs的一个目的就是展示设备驱动模型中各组件的层次关系,其顶级目录包括block,bus,drivers,class,power和firmware等.
sysfs提供一种机制,使得可以显式的描述内核对象、对象属性及对象间关系。sysfs有两组接口,一组针对内核,用于将设备映射到文件系统中,另一组针对用户程序,用于读取或操作这些设备。表2描述了内核中的sysfs要素及其在用户空间的表现:
|
sysfs在内核中的组成要素 |
在用户空间的显示 |
|
内核对象(kobject) |
目录 |
|
对象属性(attribute) |
文件 |
|
对象关系(relationship) |
链接(Symbolic Link) |
sysfs目录结构:
|
/sys 下的子目录 |
所包含的内容 |
|
/sys/devices |
这是内核对系统中所有设备的分层次表达模型,也是/sys文件系统管理设备的最重要的目录结构; |
|
/sys/dev |
这个目录下维护一个按字符设备和块设备的主次号码(major:minor)链接到真实的设备(/sys/devices下)的符号链接文件; |
|
/sys/bus |
这是内核设备按总线类型分层放置的目录结构, devices 中的所有设备都是连接于某种总线之下,在这里的每一种具体总线之下可以找到每一个具体设备的符号链接,它也是构成 Linux 统一设备模型的一部分; |
|
/sys/class |
这是按照设备功能分类的设备模型,如系统所有输入设备都会出现在/sys/class/input 之下,而不论它们是以何种总线连接到系统。它也是构成 Linux 统一设备模型的一部分; |
|
/sys/kernel |
这里是内核所有可调整参数的位置,目前只有 uevent_helper, kexec_loaded, mm, 和新式的slab 分配器等几项较新的设计在使用它,其它内核可调整参数仍然位于sysctl(/proc/sys/kernel) 接口中; |
|
/sys/module |
这里有系统中所有模块的信息,不论这些模块是以内联(inlined)方式编译到内核映像文件(vmlinuz)中还是编译为外部模块(ko文件),都可能会出现在/sys/module 中:
|
|
/sys/power |
这里是系统中电源选项,这个目录下有几个属性文件可以用于控制整个机器的电源状态,如可以向其中写入控制命令让机器关机、重启等。 |
表3:sysfs目录结构
三、深入理解 sysfs 文件系统
sysfs是一个特殊文件系统,并没有一个实际存放文件的介质。
1、kobject结构
sysfs的信息来源是kobject层次结构,读一个sysfs文件,就是动态的从kobject结构提取信息,生成文件。重启后里面的信息当然就没了
sysfs文件系统与kobject结构紧密关联,每个在内核中注册的kobject对象都对应于sysfs文件系统中的一个目录。
Kobject 是Linux 2.6引入的新的设备管理机制,在内核中由struct
kobject表示。通过这个数据结构使所有设备在底层都具有统一的接口,kobject提供基本的对象管理,是构成Linux2.6设备模型的核心结构,Kobject是组成设备模型的基本结构。类似于C++中的基类,它嵌入于更大的对象的对象中,用来描述设备模型的组件。如bus,devices, drivers
等。都是通过kobject连接起来了,形成了一个树状结构。这个树状结构就与/sys向对应。
2、sysfs 如何读写kobject 结构
sysfs就是利用VFS的接口去读写kobject的层次结构,建立起来的文件系统。
kobject的层次结构的注册与注销XX_register()形成的。文件系统是个很模糊广泛的概念,
linux把所有的资源都看成是文件,让用户通过一个统一的文件系统操作界面,也就是同一组系统调用,对属于不同文件系统的文件进行操作。这样,就可以对用户程序隐藏各种不同文件系统的实现细节,为用户程序提供了一个统一的,抽象的,虚拟的文件系统界面,这就是所谓"VFS(Virtual
Filesystem Switch)"。这个抽象出来的接口就是一组函数操作。
我们要实现一种文件系统就是要实现VFS所定义的一系列接口,file_operations, dentry_operations, inode_operations等,供上层调用。
file_operations是描述对每个具体文件的操作方法(如:读,写);
dentry_operations结构体指明了VFS所有目录的操作方法;
inode_operations提供所有结点的操作方法。
举个例子,我们写C程序,open(“hello.c”, O_RDONLY),它通过系统调用的流程是这样的
open() -> 系统调用-> sys_open() -> filp_open()-> dentry_open() -> file_operations->open()
不同的文件系统,调用不同的file_operations->open(),在sysfs下就是sysfs_open_file()。我们使用不同的文件系统,就是将它们各自的文件信息都抽象到dentry和inode中去。这样对于高层来说,我们就可以不关心底层的实现,我们使用的都是一系列标准的函数调用。这就是VFS的精髓,实际上就是面向对象。
注意sysfs是典型的特殊文件。它存储的信息都是由系统动态的生成的,它动态的包含了整个机器的硬件资源情况。从sysfs读写就相当于向 kobject层次结构提取数据。
下面是详细分析:
a -- sysfs_dirent是组成sysfs单元的基本数据结构,它是sysfs文件夹或文件在内存中的代表。sysfs_dirent只表示文件类型(文件夹/普通文件/二进制文件/链接文件)及层级关系,其它信息都保存在对应的inode中。我们创建或删除一个sysfs文件或文件夹事实上只是对以sysfs_dirent为节点的树的节点的添加或删除。sysfs_dirent数据结构如下:
- struct sysfs_dirent {
- atomic_t s_count;
- atomic_t s_active;
- struct sysfs_dirent *s_parent; /* 指向父节点 */
- struct sysfs_dirent *s_sibling; /* 指向兄弟节点,兄弟节点是按照inode索引s_ino的大小顺序链接在一起的。*/
- const char *s_name; /* 节点名称 */
- union {
- struct sysfs_elem_dir s_dir; /* 文件夹,s_dir->kobj指向sysfs对象 */
- struct sysfs_elem_symlink s_symlink; /* 链接 */
- struct sysfs_elem_attr s_attr; /* 普通文件 */
- struct sysfs_elem_bin_attr s_bin_attr; /* 二进制文件 */
- };
- unsigned int s_flags;
- ino_t s_ino; /* inode索引,创建节点时被动态申请,通过此值和sysfs_dirent地址可以到inode散列表中获取inode结构 */
- umode_t s_mode;
- struct iattr *s_iattr;
- };
b -- inode(index node)中保存了设备的主从设备号、一组文件操作函数和一组inode操作函数。
文件操作比较常见:open、read、write等。inode操作在sysfs文件系统中只针对文件夹实现了两个函数一个是目录下查找inode函数(.lookup=sysfs_lookup),该函数在找不到inode时会创建一个,并用sysfs_init_inode为其赋值;另一个是设置inode属性函数(.setattr=sysfs_setattr),该函数用于修改用户的权限等。inode结构如下:
- struct inode {
- struct hlist_node i_hash; /* 散列表链节 */
- struct list_head i_list;
- struct list_head i_sb_list;
- struct list_head i_dentry; /* dentry链节 */
- unsigned long i_ino; /* inode索引 */
- atomic_t i_count;
- unsigned int i_nlink;
- uid_t i_uid;
- gid_t i_gid;
- dev_t i_rdev; /* 主从设备号 */
- const struct inode_operations *i_op; /* 一组inode操作函数,可用其中lookup查找目录下的inode,对应sysfs为sysfs_lookup函数 */
- const struct file_operations *i_fop; /* 一组文件操作函数,对于sysfs为sysfs的open/read/write等函数 */
- struct super_block *i_sb;
- struct list_head i_devices;
- union {
- struct pipe_inode_info *i_pipe;
- struct block_device *i_bdev;
- struct cdev *i_cdev;
- };
- };
c -- dentry(directory entry)的中文名称是目录项,是Linux文件系统中某个索引节点(inode)的链接。
这个索引节点可以是文件,也可以是目录。引入dentry的目的是加快文件的访问。dentry数据结构如下:
- struct dentry {
- atomic_t d_count; /* 目录项对象使用的计数器 */
- unsigned int d_flags; /* 目录项标志 */
- spinlock_t d_lock; /* 目录项自旋锁 */
- int d_mounted; /* 对于安装点而言,表示被安装文件系统根项 */
- struct inode *d_inode; /* 文件索引节点(inode) */
- /*
- * The next three fields are touched by __d_lookup. Place them here
- * so they all fit in a cache line.
- */
- struct hlist_node d_hash; /* lookup hash list */
- struct dentry *d_parent; /* parent directory */
- struct qstr d_name; /* 文件名 */
- /*
- * d_child and d_rcu can share memory
- */
- union {
- struct list_head d_child; /* child of parent list */
- struct rcu_head d_rcu;
- } d_u;
- void *d_fsdata; /* 与文件系统相关的数据,在sysfs中指向sysfs_dirent */
- unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 存放短文件名 */
- };
sysfs_dirent、inode、dentry三者关系:
如上图sysfs超级块sysfs_sb、dentry根目录root、sysfs_direct根目录sysfs_root都是在sysfs初始化时创建。
sysfs_root下的子节点是添加设备对象或对象属性时调用sysfs_create_dir/ sysfs_create_file创建的,同时会申请对应的inode的索引号s_ino。注意此时并未创建inode。
inode是在用到的时候调用sysfs_get_inode函数创建并依据sysfs_sb地址和申请到的s_ino索引计算散列表位置放入其中。
dentry的子节点也是需要用的时候才会创建。比如open文件时,会调用path_walk根据路径一层层的查找指定dentry,如果找不到,则创建一个,并调用父dentry的inodelookup函数(sysfs文件系统的为sysfs_lookup)查找对应的子inode填充指定的dentry。
这里有必要介绍一下sysfs_lookup的实现,以保证我们更加清晰地了解这个过程,函数主体如下:
- static struct dentry * sysfs_lookup(struct inode *dir, struct dentry *dentry, struct nameidata *nd)
- {
- struct dentry *ret = NULL;
- struct sysfs_dirent *parent_sd = dentry->d_parent->d_fsdata; //获取父sysfs_direct
- struct sysfs_dirent *sd;
- struct inode *inode;
- mutex_lock(&sysfs_mutex);
- /* 在父sysfs_direct查找名为dentry->d_name.name的节点 */
- sd = sysfs_find_dirent(parent_sd, dentry->d_name.name);
- /* no such entry */
- if (!sd) {
- ret = ERR_PTR(-ENOENT);
- goto out_unlock;
- }
- /* 这儿就是通过sysfs_direct获取对应的inode,sysfs_get_inode实现原理上面已经介绍过了 */
- /* attach dentry and inode */
- inode = sysfs_get_inode(sd);
- if (!inode) {
- ret = ERR_PTR(-ENOMEM);
- goto out_unlock;
- }
- /* 填充目录项,至此一个目录项创建完毕 */
- /* instantiate and hash dentry */
- dentry->d_op = &sysfs_dentry_ops; /* 填充目录项的操作方法,该方法只提供一释放inode函数sysfs_d_iput */
- dentry->d_fsdata = sysfs_get(sd); //填充sysfs_direct
- d_instantiate(dentry, inode); //填充inode
- d_rehash(dentry); //将dentry加入hash表
- out_unlock:
- mutex_unlock(&sysfs_mutex);
- return ret;
- }
四、实例分析
a -- sysfs文件open流程
open的主要过程是通过指定的路径找到对应的dentry,并从中获取inode,然后获取一个空的file结构,将inode中相关内容赋值给file,这其中包括将inode的fop赋给file的fop。因此接下来调用的filp->fop->open其实就是inode里的fop->open。新的file结构对应一个文件句柄fd,这会作为整个open函数的返回值。之后的read/write操作就靠这个fd找到对应的file结构了。
图3-2是从网上找到的,清晰地描述了file和dentry以及inode之间的关系
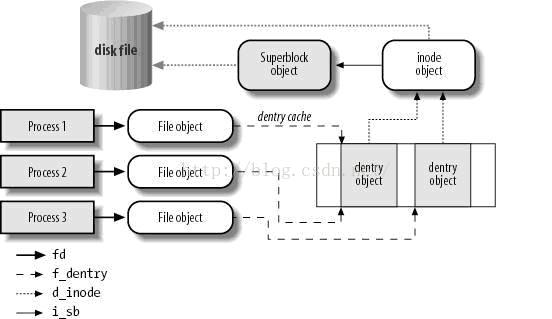
图3-2:file、dentry、inode关系
进程每打开一个文件,就会有一个file结构与之对应。同一个进程可以多次打开同一个文件而得到多个不同的file结构,file结构描述了被打开文件的属性,读写的偏移指针等等当前信息。
两个不同的file结构可以对应同一个dentry结构。进程多次打开同一个文件时,对应的只有一个dentry结构。dentry结构存储目录项和对应文件(inode)的信息。
在存储介质中,每个文件对应唯一的inode结点,但是,每个文件又可以有多个文件名。即可以通过不同的文件名访问同一个文件。这里多个文件名对应一个文件的关系在数据结构中表示就是dentry和inode的关系。
inode中不存储文件的名字,它只存储节点号;而dentry则保存有名字和与其对应的节点号,所以就可以通过不同的dentry访问同一个inode。
b -- sysfs文件read/write流程
sysfs与普通文件系统的最大差异是,sysfs不会申请任何内存空间来保存文件的内容。事实上再不对文件操作时,文件是不存在的。只有用户读或写文件时,sysfs才会申请一页内存(只有一页),用于保存将要读取的文件信息。如果作读操作,sysfs就会调用文件的父对象(文件夹kobject)的属性处理函数kobject->ktype->sysfs_ops->show,然后通过show函数来调用包含该对象的外层设备(或驱动、总线等)的属性的show函数来获取硬件设备的对应属性值,然后将该值拷贝到用户空间的buff,这样就完成了读操作。写操作也类似,都要进行内核空间ßà用户空间内存的拷贝,以保护内核代码的安全运行。
图为用户空间程序读sysfs文件的处理流程,其他操作类似:
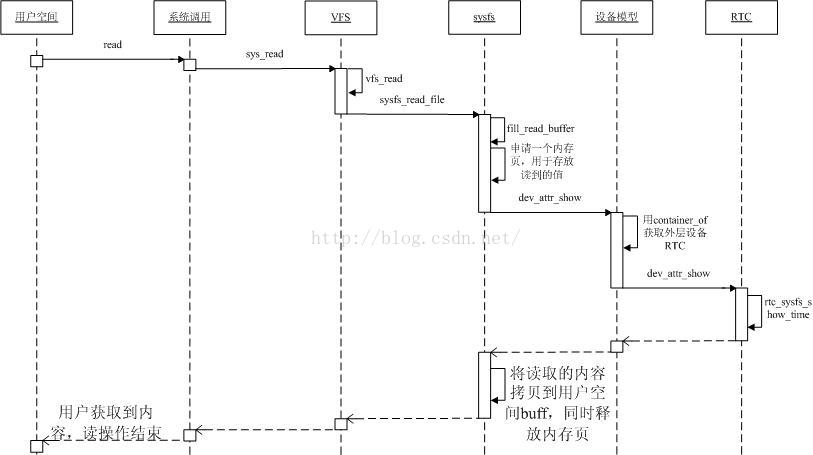
Linux 设备驱动开发 —— platform 设备驱动
一、platform总线、设备与驱动
在Linux 2.6 的设备驱动模型中,关心总线、设备和驱动3个实体,总线将设备和驱动绑定。在系统每注册一个设备的时候,会寻找与之匹配的驱动;相反的,在系统每注册一个驱动的时候,会寻找与之匹配的设备,而匹配由总线完成。
一个现实的Linux设备和驱动通常都需要挂接在一种总线上,对于本身依附于PCI、USB、I2C、SPI等的设备而言,这自然不是问题,但是在嵌入式系统里面,SoC系统中集成的独立的外设控制器、挂接在SoC内存空间的外设等确不依附于此类总线。基于这一背景,Linux发明了一种虚拟的总线,称为platform总线,相应的设备称为platform_device,而驱动成为 platform_driver。
注意,所谓的platform_device并不是与字符设备、块设备和网络设备并列的概念,而是Linux系统提供的一种附加手段,例如,在 S3C6410处理器中,把内部集成的I2C、RTC、SPI、LCD、看门狗等控制器都归纳为platform_device,而它们本身就是字符设备。
基于Platform总线的驱动开发流程如下:
a -- 定义初始化platform bus
b -- 定义各种platform devices
c -- 注册各种platform devices
d -- 定义相关platform driver
e -- 注册相关platform driver
f -- 操作相关设备
相关结构体定义:
1、平台相关结构 --- platform_device结构体
- struct platform_device {
- const char * name;/* 设备名 */
- u32 id;//设备id,用于给插入给该总线并且具有相同name的设备编号,如果只有一个设备的话填-1。
- struct device dev;//结构体中内嵌的device结构体。
- u32 num_resources;/* 设备所使用各类资源数量 */
- struct resource * resource;/* //定义平台设备的资源*/
- };
2、设备的驱动 --- platform_driver 结构体
这个结构体中包含probe()、remove()、shutdown()、suspend()、 resume()函数,通常也需要由驱动实现
- struct platform_driver {
- int (*probe)(struct platform_device *);
- int (*remove)(struct platform_device *);
- void (*shutdown)(struct platform_device *);
- int (*suspend)(struct platform_device *, pm_message_t state);
- int (*suspend_late)(struct platform_device *, pm_message_t state);
- int (*resume_early)(struct platform_device *);
- int (*resume)(struct platform_device *);
- struct pm_ext_ops *pm;
- struct device_driver driver;
- };
3、系统中为platform总线定义了一个bus_type的实例 --- platform_bus_type
- struct bus_type platform_bus_type = {
- .name = “platform”,
- .dev_attrs = platform_dev_attrs,
- .match = platform_match,
- .uevent = platform_uevent,
- .pm = PLATFORM_PM_OPS_PTR,
- };
- EXPORT_SYMBOL_GPL(platform_bus_type);
这里要重点关注其match()成员函数,正是此成员表明了platform_device和platform_driver之间如何匹配。
- static int platform_match(struct device *dev, struct device_driver *drv)
- {
- struct platform_device *pdev;
- pdev = container_of(dev, struct platform_device, dev);
- return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
- }
匹配platform_device和platform_driver主要看二者的name字段是否相同。对platform_device的定义通常在BSP的板文件中实现,在板文件中,将platform_device归纳为一个数组,最终通过platform_add_devices()函数统一注册。
platform_add_devices()函数可以将平台设备添加到系统中,这个函数的 原型为:
- int platform_add_devices(struct platform_device **devs, int num);
该函数的第一个参数为平台设备数组的指针,第二个参数为平台设备的数量,它内部调用了platform_device_register()函 数用于注册单个的平台设备。
a -- platform bus总线先被kenrel注册。
b -- 系统初始化过程中调用platform_add_devices或者platform_device_register,将平台设备(platform devices)注册到平台总线中(platform bus)
c -- 平台驱动(platform driver)与平台设备(platform device)的关联是在platform_driver_register或者driver_register中实现,一般这个函数在驱动的初始化过程调用。
通过这三步,就将平台总线,设备,驱动关联起来。
二.Platform初始化
系统启动时初始化时创建了platform_bus总线设备和platform_bus_type总线,platform总线是在内核初始化的时候就注册进了内核。
内核初始化函数kernel_init()中调用了do_basic_setup() ,该函数中调用driver_init(),该函数中调用platform_bus_init(),我们看看platform_bus_init()函数:
- int __init platform_bus_init(void)
- {
- int error;
- early_platform_cleanup(); //清除platform设备链表
- //该函数把设备名为platform 的设备platform_bus注册到系统中,其他的platform的设备都会以它为parent。它在sysfs中目录下.即 /sys/devices/platform。
- //platform_bus总线也是设备,所以也要进行设备的注册
- //struct device platform_bus = {
- //.init_name = "platform",
- //};
- error = device_register(&platform_bus);//将平台bus作为一个设备注册,出现在sys文件系统的device目录
- if (error)
- return error;
- //接着bus_register(&platform_bus_type)注册了platform_bus_type总线.
- /*
- struct bus_type platform_bus_type = {
- .name = “platform”,
- .dev_attrs = platform_dev_attrs,
- .match = platform_match,
- .uevent = platform_uevent,
- .pm = PLATFORM_PM_OPS_PTR,
- };
- */
- //默认platform_bus_type中没有定义probe函数。
- error = bus_register(&platform_bus_type);//注册平台类型的bus,将出现sys文件系统在bus目录下,创建一个platform的目录,以及相关属性文件
- if (error)
- device_unregister(&platform_bus);
- return error;
- }
总线类型match函数是在设备匹配驱动时调用,uevent函数在产生事件时调用。
platform_match函数在当属于platform的设备或者驱动注册到内核时就会调用,完成设备与驱动的匹配工作
- static int platform_match(struct device *dev, struct device_driver *drv)
- {
- struct platform_device *pdev = to_platform_device(dev);
- struct platform_driver *pdrv = to_platform_driver(drv);
- /* match against the id table first */
- if (pdrv->id_table)
- return platform_match_id(pdrv->id_table, pdev) != NULL;
- /* fall-back to driver name match */
- return (strcmp(pdev->name, drv->name) == 0);//比较设备和驱动的名称是否一样
- }
- static const struct platform_device_id *platform_match_id(struct platform_device_id *id,struct platform_device *pdev)
- {
- while (id->name[0]) {
- if (strcmp(pdev->name, id->name) == 0) {
- pdev->id_entry = id;
- return id;
- }
- id++;
- }
- return NULL;
- }
不难看出,如果pdrv的id_table数组中包含了pdev->name,或者drv->name和pdev->name名字相同,都会认为是匹配成功。id_table数组是为了应对那些对应设备和驱动的drv->name和pdev->name名字不同的情况。
再看看platform_uevent()函数:platform_uevent 热插拔操作函数
- static int platform_uevent(struct device *dev, struct kobj_uevent_env *env)
- {
- struct platform_device *pdev = to_platform_device(dev);
- add_uevent_var(env, "MODALIAS=%s%s", PLATFORM_MODULE_PREFIX, (pdev->id_entry) ? pdev->id_entry->name : pdev->name);
- return 0;
- }
添加了MODALIAS环境变量,我们回顾一下:platform_bus. parent->kobj->kset->uevent_ops为device_uevent_ops,bus_uevent_ops的定义如下
- static struct kset_uevent_ops device_uevent_ops = {
- .filter = dev_uevent_filter,
- .name = dev_uevent_name,
- .uevent = dev_uevent,
- };
当调用device_add()时会调用kobject_uevent(&dev->kobj, KOBJ_ADD)产生一个事件,这个函数中会调用相应的kset_uevent_ops的uevent函数
三.Platform设备的注册
我们在设备模型的分析中知道了把设备添加到系统要调用device_initialize()和platform_device_add(pdev)函数。
Platform设备的注册分两种方式:
a -- 对于platform设备的初注册,内核源码提供了platform_device_add()函数,输入参数platform_device可以是静态的全局设备,它是进行一系列的操作后调用device_add()将设备注册到相应的总线(platform总线)上,内核代码中platform设备的其他注册函数都是基于这个函数,如platform_device_register()、platform_device_register_simple()、platform_device_register_data()等。
b -- 另外一种机制就是动态申请platform_device_alloc()一个platform_device设备,然后通过platform_device_add_resources及platform_device_add_data等添加相关资源和属性。
无论哪一种platform_device,最终都将通过platform_device_add这册到platform总线上。区别在于第二步:其实platform_device_add()包括device_add(),不过要先注册resources,然后将设备挂接到特定的platform总线。
1、 第一种平台设备注册方式
platform_device是静态的全局设备,即platform_device结构的成员已经初始化完成。直接将平台设备注册到platform总线上。platform_device_register和device_register的区别:
a -- 主要是有没有resource的区别,前者的结构体包含后面,并且增加了struct resource结构体成员,后者没有。platform_device_register在device_register的基础上增加了struct resource部分的注册。
由此。可以看出,platform_device---paltform_driver_register机制与device-driver的主要区别就在于resource。前者适合于具有独立资源设备的描述,后者则不是。
b -- 其实linux的各种其他驱动机制的基础都是device_driver。只不过是增加了部分功能,适合于不同的应用场合.
- int platform_device_register(struct platform_device *pdev)
- {
- device_initialize(&pdev->dev);//初始化platform_device内嵌的device
- return platform_device_add(pdev);//把它注册到platform_bus_type上
- }
- int platform_device_add(struct platform_device *pdev)
- {
- int i, ret = 0;
- if (!pdev)
- return -EINVAL;
- if (!pdev->dev.parent)
- pdev->dev.parent = &platform_bus;//设置父节点,即platform_bus作为总线设备的父节点,其余的platform设备都是它的子设备
- //platform_bus是一个设备,platform_bus_type才是真正的总线
- pdev->dev.bus = &platform_bus_type;//设置platform总线,指定bus类型为platform_bus_type
- //设置pdev->dev内嵌的kobj的name字段,将platform下的名字传到内部device,最终会传到kobj
- if (pdev->id != -1)
- dev_set_name(&pdev->dev, "%s.%d", pdev->name, pdev->id);
- else
- dev_set_name(&pdev->dev, "%s", pdev->name);
- //初始化资源并将资源分配给它,每个资源的它的parent不存在则根据flags域设置parent,flags为IORESOURCE_MEM,
- //则所表示的资源为I/O映射内存,flags为IORESOURCE_IO,则所表示的资源为I/O端口。
- for (i = 0; i < pdev->num_resources; i++) {
- struct resource *p, *r = &pdev->resource[i];
- if (r->name == NULL)//资源名称为NULL则把设备名称设置给它
- r->name = dev_name(&pdev->dev);
- p = r->parent;//取得资源的父节点,资源在内核中也是层次安排的
- if (!p) {
- if (resource_type(r) == IORESOURCE_MEM) //如果父节点为NULL,并且资源类型为IORESOURCE_MEM,则把父节点设置为iomem_resource
- p = &iomem_resource;
- else if (resource_type(r) == IORESOURCE_IO)//否则如果类型为IORESOURCE_IO,则把父节点设置为ioport_resource
- p = &ioport_resource;
- }
- //从父节点申请资源,也就是出现在父节点目录层次下
- if (p && insert_resource(p, r)) {
- printk(KERN_ERR "%s: failed to claim resource %d\n",dev_name(&pdev->dev), i);ret = -EBUSY;
- goto failed;
- }
- }
- pr_debug("Registering platform device '%s'. Parent at %s\n",dev_name(&pdev->dev), dev_name(pdev->dev.parent));
- //device_creat() 创建一个设备并注册到内核驱动架构...
- //device_add() 注册一个设备到内核,少了一个创建设备..
- ret = device_add(&pdev->dev);//就在这里把设备注册到总线设备上,标准设备注册,即在sys文件系统中添加目录和各种属性文件
- if (ret == 0)
- return ret;
- failed:
- while (--i >= 0) {
- struct resource *r = &pdev->resource[i];
- unsigned long type = resource_type(r);
- if (type == IORESOURCE_MEM || type == IORESOURCE_IO)
- release_resource(r);
- }
- return ret;
- }
2、第二种平台设备注册方式
先分配一个platform_device结构,对其进行资源等的初始化;之后再对其进行注册,再调用platform_device_register()函数
- struct platform_device * platform_device_alloc(const char *name, int id)
- {
- struct platform_object *pa;
- /*
- struct platform_object {
- struct platform_device pdev;
- char name[1];
- };
- */
- pa = kzalloc(sizeof(struct platform_object) + strlen(name), GFP_KERNEL);//该函数首先为platform设备分配内存空间
- if (pa) {
- strcpy(pa->name, name);
- pa->pdev.name = pa->name;//初始化platform_device设备的名称
- pa->pdev.id = id;//初始化platform_device设备的id
- device_initialize(&pa->pdev.dev);//初始化platform_device内嵌的device
- pa->pdev.dev.release = platform_device_release;
- }
- return pa ? &pa->pdev : NULL;
- }
一个更好的方法是,通过下面的函数platform_device_register_simple()动态创建一个设备,并把这个设备注册到系统中:
- struct platform_device *platform_device_register_simple(const char *name,int id,struct resource *res,unsigned int num)
- {
- struct platform_device *pdev;
- int retval;
- pdev = platform_device_alloc(name, id);
- if (!pdev) {
- retval = -ENOMEM;
- goto error;
- }
- if (num) {
- retval = platform_device_add_resources(pdev, res, num);
- if (retval)
- goto error;
- }
- retval = platform_device_add(pdev);
- if (retval)
- goto error;
- return pdev;
- error:
- platform_device_put(pdev);
- return ERR_PTR(retval);
- }
该函数就是调用了platform_device_alloc()和platform_device_add()函数来创建的注册platform device,函数也根据res参数分配资源,看看platform_device_add_resources()函数:
- int platform_device_add_resources(struct platform_device *pdev,struct resource *res, unsigned int num)
- {
- struct resource *r;
- r = kmalloc(sizeof(struct resource) * num, GFP_KERNEL);//为资源分配内存空间
- if (r) {
- memcpy(r, res, sizeof(struct resource) * num);
- pdev->resource = r; //并拷贝参数res中的内容,链接到device并设置其num_resources
- pdev-> num_resources = num;
- }
- return r ? 0 : -ENOMEM;
- }
四.Platform设备驱动的注册
我们在设备驱动模型的分析中已经知道驱动在注册要调用driver_register(),platform driver的注册函数platform_driver_register()同样也是进行其它的一些初始化后调用driver_register()将驱动注册到platform_bus_type总线上.
- int platform_driver_register(struct platform_driver *drv)
- {
- drv->driver.bus = &platform_bus_type;//它将要注册到的总线
- /*设置成platform_bus_type这个很重要,因为driver和device是通过bus联系在一起的,
- 具体在本例中是通过 platform_bus_type中注册的回调例程和属性来是实现的,
- driver与device的匹配就是通过 platform_bus_type注册的回调例程platform_match ()来完成的。
- */
- if (drv->probe)
- drv-> driver.probe = platform_drv_probe;
- if (drv->remove)
- drv->driver.remove = platform_drv_remove;
- if (drv->shutdown)
- drv->driver.shutdown = platform_drv_shutdown;
- return driver_register(&drv->driver);//注册驱动
- }
然后设定了platform_driver内嵌的driver的probe、remove、shutdown函数。
- static int platform_drv_probe(struct device *_dev)
- {
- struct platform_driver *drv = to_platform_driver(_dev->driver);
- struct platform_device *dev = to_platform_device(_dev);
- return drv->probe(dev);//调用platform_driver的probe()函数,这个函数一般由用户自己实现
- //例如下边结构,回调的是serial8250_probe()函数
- /*
- static struct platform_driver serial8250_isa_driver = {
- .probe = serial8250_probe,
- .remove = __devexit_p(serial8250_remove),
- .suspend = serial8250_suspend,
- .resume = serial8250_resume,
- .driver = {
- .name = "serial8250",
- .owner = THIS_MODULE,
- },
- };
- */
- }
- static int platform_drv_remove(struct device *_dev)
- {
- struct platform_driver *drv = to_platform_driver(_dev->driver);
- struct platform_device *dev = to_platform_device(_dev);
- return drv->remove(dev);
- }
- static void platform_drv_shutdown(struct device *_dev)
- {
- struct platform_driver *drv = to_platform_driver(_dev->driver);
- struct platform_device *dev = to_platform_device(_dev);
- drv->shutdown(dev);
- }
总结:
1、从这三个函数的代码可以看到,又找到了相应的platform_driver和platform_device,然后调用platform_driver的probe、remove、shutdown函数。这是一种高明的做法:
在不针对某个驱动具体的probe、remove、shutdown指向的函数,而通过上三个过度函数来找到platform_driver,然后调用probe、remove、shutdown接口。
如果设备和驱动都注册了,就可以通过bus ->match、bus->probe或driver->probe进行设备驱动匹配了。
2、驱动注册的时候platform_driver_register()->driver_register()->bus_add_driver()->driver_attach()->bus_for_each_dev(),
对每个挂在虚拟的platform bus的设备作__driver_attach()->driver_probe_device()->drv->bus->match()==platform_match()->比较strncmp(pdev->name, drv->name, BUS_ID_SIZE),如果相符就调用platform_drv_probe()->driver->probe(),如果probe成功则绑定该设备到该驱动。
Linux 设备驱动开发 —— platform设备驱动应用实例解析
前面我们已经学习了platform设备的理论知识Linux 设备驱动开发 —— platform 设备驱动 ,下面将通过一个实例来深入我们的学习。
一、platform 驱动的工作过程
platform模型驱动编程,需要实现platform_device(设备)与platform_driver(驱动)在platform(虚拟总线)上的注册、匹配,相互绑定,然后再做为一个普通的字符设备进行相应的应用,总之如果编写的是基于字符设备的platform驱动,在遵循并实现platform总线上驱动与设备的特定接口的情况下,最核心的还是字符设备的核心结构:cdev、 file_operations(他包含的操作函数接口)、dev_t(设备号)、设备文件(/dev)等,因为用platform机制编写的字符驱动,它的本质是字符驱动。
我们要记住,platform 驱动只是在字符设备驱动外套一层platform_driver 的外壳。
在一般情况下,2.6内核中已经初始化并挂载了一条platform总线在sysfs文件系统中。那么我们编写platform模型驱动时,需要完成两个工作:
a -- 实现platform驱动
b -- 实现platform设备
然而在实现这两个工作的过程中还需要实现其他的很多小工作,在后面介绍。platform模型驱动的实现过程核心架构就很简单,如下所示:
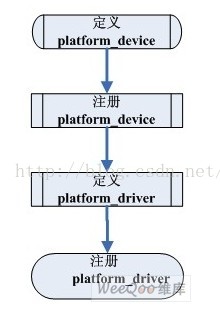
platform驱动模型三个对象:platform总线、platform设备、platform驱动。
platform总线对应的内核结构:struct bus_type-->它包含的最关键的函数:match() (要注意的是,这块由内核完成,我们不参与)
platform设备对应的内核结构:struct platform_device-->注册:platform_device_register(unregister)
platform驱动对应的内核结构:struct platform_driver-->注册:platform_driver_register(unregister)
那具体platform驱动的工作过程是什么呢:
设备(或驱动)注册的时候,都会引发总线调用自己的match函数来寻找目前platform总线是否挂载有与该设备(或驱动)名字匹配的驱动(或设备),如果存在则将双方绑定;
如果先注册设备,驱动还没有注册,那么设备在被注册到总线上时,将不会匹配到与自己同名的驱动,然后在驱动注册到总线上时,因为设备已注册,那么总线会立即匹配与绑定这时的同名的设备与驱动,再调用驱动中的probe函数等;
如果是驱动先注册,同设备驱动一样先会匹配失败,匹配失败将导致它的probe函数暂不调用,而是要等到设备注册成功并与自己匹配绑定后才会调用。
二、实现platform 驱动与设备的详细过程
1、思考问题?
在分析platform 之前,可以先思考一下下面的问题:
a -- 为什么要用 platform 驱动?不用platform驱动可以吗?
b -- 设备驱动中引入platform 概念有什么好处?
现在先不回答,看完下面的分析就明白了,后面会附上总结。
2、platform_device 结构体 VS platform_driver 结构体
这两个结构体分别描述了设备和驱动,二者有什么关系呢?先看一下具体结构体对比
|
设备(硬件部分):中断号,寄存器,DMA等
platform_device 结构体
|
驱动(软件部分)
platform_driver 结构体
|
|
struct platform_device {
const char *name; 名字
int id;
bool id_auto;
struct device dev; 硬件模块必须包含该结构体
u32 num_resources; 资源个数
struct resource *resource; 资源 人脉
const struct platform_device_id *id_entry;
/* arch specific additions */
struct pdev_archdata archdata;
};
|
struct platform_driver {
int (*probe)(struct platform_device *);
硬件和软件匹配成功之后调用该函数
int (*remove)(struct platform_device *);
硬件卸载了调用该函数
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*resume)(struct platform_device *);
struct device_driver driver;内核里所有的驱动程序必须包含该结构体
const struct platform_device_id *id_table; 八字
};
|
|
设备实例:
static struct platform_device hello_device=
{
.name = "bigbang",
.id = -1,
.dev.release = hello_release,
};
|
驱动实例:
static struct platform_driver hello_driver=
{
.driver.name = "bigbang",
.probe = hello_probe,
.remove = hello_remove,
};
|
前面提到,实现platform模型的过程就是总线对设备和驱动的匹配过程 。打个比方,就好比相亲,总线是红娘,设备是男方,驱动是女方:
a -- 红娘(总线)负责男方(设备)和女方(驱动)的撮合;
b -- 男方(女方)找到红娘,说我来登记一下,看有没有合适的姑娘(汉子)—— 设备或驱动的注册;
c -- 红娘这时候就需要看看有没有八字(二者的name 字段)匹配的姑娘(汉子)——match 函数进行匹配,看name是否相同;
d -- 如果八字不合,就告诉男方(女方)没有合适的对象,先等着,别急着乱做事 —— 设备和驱动会等待,直到匹配成功;
e -- 终于遇到八字匹配的了,那就结婚呗!接完婚,男方就向女方交代,我有多少存款,我的房子在哪,钱放在哪等等(
struct resource *resource),女方说好啊,于是去房子里拿钱,去给男方买菜啦,给自己买衣服、化妆品、首饰啊等等(int (*probe)(struct platform_device *) 匹配成功后驱动执行的第一个函数),当然如果男的跟小三跑了(设备卸载),女方也不会继续待下去的(
int (*remove)(struct platform_device *))。
3、设备资源结构体
在struct platform_device 结构体中有一重要成员 struct resource *resource
- struct resource {
- resource_size_t start; 资源起始地址
- resource_size_t end; 资源结束地址
- const char *name;
- unsigned long flags; 区分是资源什么类型的
- struct resource *parent, *sibling, *child;
- };
- #define IORESOURCE_MEM 0x00000200
- #define IORESOURCE_IRQ 0x00000400
flags 指资源类型,我们常用的是 IORESOURCE_MEM、IORESOURCE_IRQ 这两种。start 和 end 的含义会随着 flags而变更,如
a -- flags为IORESOURCE_MEM 时,start 、end 分别表示该platform_device占据的内存的开始地址和结束值;
b -- flags为 IORESOURCE_IRQ
时,start 、end 分别表示该platform_device使用的中断号的开始地址和结束值;
下面看一个实例:
- static struct resource beep_resource[] =
- {
- [0] = {
- .start = 0x114000a0,
- .end = 0x114000a0+0x4,
- .flags = IORESOURCE_MEM,
- },
- [1] = {
- .start = 0x139D0000,
- .end = 0x139D0000+0x14,
- .flags = IORESOURCE_MEM,
- },
- };
- static struct file_operations hello_ops=
- {
- .open = hello_open,
- .release = hello_release,
- .unlocked_ioctl = hello_ioctl,
- };
- static int hello_remove(struct platform_device *pdev)
- {
- 注销分配的各种资源
- }
- static int hello_probe(struct platform_device *pdev)
- {
- 1.申请设备号
- 2.cdev初始化注册,&hello_ops
- 3.从pdev读出硬件资源
- 4.对硬件资源初始化,ioremap,request_irq( )
- }
- static int hello_init(void)
- {
- 只注册 platform_driver
- }
- static void hello_exit(void)
- {
- 只注销 platform_driver
- }
- struct bus_type platform_bus_type = {
- .name = "platform",
- .dev_groups = platform_dev_groups,
- .match = platform_match,
- .uevent = platform_uevent,
- .pm = &platform_dev_pm_ops,
- };
- __platform_driver_register()
- {
- drv->driver.bus = &platform_bus_type; 536行
- }
- static int platform_match(struct device *dev, struct device_driver *drv)
- {
- struct platform_device *pdev = to_platform_device(dev);
- struct platform_driver *pdrv = to_platform_driver(drv);
- 匹配设备树信息,如果有设备树,就调用 of_driver_match_device() 函数进行匹配
- if (of_driver_match_device(dev, drv))
- return 1;
- 匹配id_table
- if (pdrv->id_table)
- return platform_match_id(pdrv->id_table, pdev) != NULL;
- 最基本匹配规则
- return (strcmp(pdev->name, drv->name) == 0);
- }
a -- 为什么要用 platform 驱动?不用platform驱动可以吗?
b -- 设备驱动中引入platform 概念有什么好处?
引入platform模型符合Linux 设备模型 —— 总线、设备、驱动,设备模型中配套的sysfs节点都可以用,方便我们的开发;当然你也可以选择不用,不过就失去了一些platform带来的便利;
设备驱动中引入platform 概念,隔离BSP和驱动。在BSP中定义platform设备和设备使用的资源、设备的具体匹配信息,而在驱动中,只需要通过API去获取资源和数据,做到了板相关代码和驱动代码的分离,使得驱动具有更好的可扩展性和跨平台性。
三、实例
这是一个蜂鸣器的驱动,其实前面已经有解析 Linux 字符设备驱动开发基础(二)—— 编写简单 PWM 设备驱动, 下面来看一下,套上platform 外壳后的程序:
1、device.c
- #include <linux/module.h>
- #include <linux/device.h>
- #include <linux/platform_device.h>
- #include <linux/ioport.h>
- static struct resource beep_resource[] =
- {
- [0] ={
- .start = 0x114000a0,
- .end = 0x114000a0 + 0x4,
- .flags = IORESOURCE_MEM,
- },
- [1] ={
- .start = 0x139D0000,
- .end = 0x139D0000 + 0x14,
- .flags = IORESOURCE_MEM,
- }
- };
- static void hello_release(struct device *dev)
- {
- printk("hello_release\n");
- return ;
- }
- static struct platform_device hello_device=
- {
- .name = "bigbang",
- .id = -1,
- .dev.release = hello_release,
- .num_resources = ARRAY_SIZE(beep_resource),
- .resource = beep_resource,
- };
- static int hello_init(void)
- {
- printk("hello_init");
- return platform_device_register(&hello_device);
- }
- static void hello_exit(void)
- {
- printk("hello_exit");
- platform_device_unregister(&hello_device);
- return;
- }
- MODULE_LICENSE("GPL");
- module_init(hello_init);
- module_exit(hello_exit);
2、driver.c
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- #include <linux/device.h>
- #include <linux/platform_device.h>
- #include <asm/io.h>
- static int major = 250;
- static int minor=0;
- static dev_t devno;
- static struct class *cls;
- static struct device *test_device;
- #define TCFG0 0x0000
- #define TCFG1 0x0004
- #define TCON 0x0008
- #define TCNTB0 0x000C
- #define TCMPB0 0x0010
- static unsigned int *gpd0con;
- static void *timer_base;
- #define MAGIC_NUMBER 'k'
- #define BEEP_ON _IO(MAGIC_NUMBER ,0)
- #define BEEP_OFF _IO(MAGIC_NUMBER ,1)
- #define BEEP_FREQ _IO(MAGIC_NUMBER ,2)
- static void fs4412_beep_init(void)
- {
- writel ((readl(gpd0con)&~(0xf<<0)) | (0x2<<0),gpd0con);
- writel ((readl(timer_base +TCFG0 )&~(0xff<<0)) | (0xff <<0),timer_base +TCFG0);
- writel ((readl(timer_base +TCFG1 )&~(0xf<<0)) | (0x2 <<0),timer_base +TCFG1 );
- writel (500, timer_base +TCNTB0 );
- writel (250, timer_base +TCMPB0 );
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x2 <<0),timer_base +TCON );
- }
- void fs4412_beep_on(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x9 <<0),timer_base +TCON );
- }
- void fs4412_beep_off(void)
- {
- writel ((readl(timer_base +TCON )&~(0xf<<0)) | (0x0 <<0),timer_base +TCON );
- }
- static void beep_unmap(void)
- {
- iounmap(gpd0con);
- iounmap(timer_base);
- }
- static int beep_open (struct inode *inode, struct file *filep)
- {
- fs4412_beep_on();
- return 0;
- }
- static int beep_release(struct inode *inode, struct file *filep)
- {
- fs4412_beep_off();
- return 0;
- }
- #define BEPP_IN_FREQ 100000
- static void beep_freq(unsigned long arg)
- {
- writel(BEPP_IN_FREQ/arg, timer_base +TCNTB0 );
- writel(BEPP_IN_FREQ/(2*arg), timer_base +TCMPB0 );
- }
- static long beep_ioctl(struct file *filep, unsigned int cmd, unsigned long arg)
- {
- switch(cmd)
- {
- case BEEP_ON:
- fs4412_beep_on();
- break;
- case BEEP_OFF:
- fs4412_beep_off();
- break;
- case BEEP_FREQ:
- beep_freq( arg );
- break;
- default :
- return -EINVAL;
- }
- return 0;
- }
- static struct file_operations beep_ops=
- {
- .open = beep_open,
- .release = beep_release,
- .unlocked_ioctl = beep_ioctl,
- };
- static int beep_probe(struct platform_device *pdev)
- {
- int ret;
- printk("match ok!");
- gpd0con = ioremap(pdev->resource[0].start,pdev->resource[0].end - pdev->resource[0].start);
- timer_base = ioremap(pdev->resource[1].start, pdev->resource[1].end - pdev->resource[1].start);
- devno = MKDEV(major,minor);
- ret = register_chrdev(major,"beep",&beep_ops);
- cls = class_create(THIS_MODULE, "myclass");
- if(IS_ERR(cls))
- {
- unregister_chrdev(major,"beep");
- return -EBUSY;
- }
- test_device = device_create(cls,NULL,devno,NULL,"beep");//mknod /dev/hello
- if(IS_ERR(test_device))
- {
- class_destroy(cls);
- unregister_chrdev(major,"beep");
- return -EBUSY;
- }
- fs4412_beep_init();
- return 0;
- }
- static int beep_remove(struct platform_device *pdev)
- {
- beep_unmap();
- device_destroy(cls,devno);
- class_destroy(cls);
- unregister_chrdev(major,"beep");
- return 0;
- }
- static struct platform_driver beep_driver=
- {
- .driver.name = "bigbang",
- .probe = beep_probe,
- .remove = beep_remove,
- };
- static int beep_init(void)
- {
- printk("beep_init");
- return platform_driver_register(&beep_driver);
- }
- static void beep_exit(void)
- {
- printk("beep_exit");
- platform_driver_unregister(&beep_driver);
- return;
- }
- MODULE_LICENSE("GPL");
- module_init(beep_init);
- module_exit(beep_exit);
3、makefile
- ifneq ($(KERNELRELEASE),)
- obj-m:=device.o driver.o
- $(info "2nd")
- else
- #KDIR := /lib/modules/$(shell uname -r)/build
- KDIR := /home/fs/linux/linux-3.14-fs4412
- PWD:=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- clean:
- rm -f *.ko *.o *.symvers *.mod.c *.mod.o *.order
- endif
4、test.c
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- main()
- {
- int fd,i,lednum;
- fd = open("/dev/beep",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- sleep(10);
- close(fd);
- }
Linux 设备驱动开发 —— 设备树在platform设备驱动中的使用
关与设备树的概念,我们在Exynos4412 内核移植(六)—— 设备树解析 里面已经学习过,下面看一下设备树在设备驱动开发中起到的作用
Device Tree是一种描述硬件的数据结构,设备树源(Device Tree Source)文件(以.dts结尾)就是用来描述目标板硬件信息的。Device Tree由一系列被命名的结点(node)和属性(property)组成,而结点本身可包含子结点。所谓属性,其实就是成对出现的name和value。在Device Tree中,可描述的信息包括(原先这些信息大多被hard code到kernel中)。
一、设备树基础概念
1、基本数据格式
device tree是一个简单的节点和属性树,属性是键值对,节点可以包含属性和子节点。下面是一个.dts格式的简单设备树。
- / {
- node1 {
- a-string-property = "A string";
- a-string-list-property = "first string", "second string";
- a-byte-data-property = [0x01 0x23 0x34 0x56];
- child-node1 {
- first-child-property;
- second-child-property = <1>;
- a-string-property = "Hello, world";
- };
- child-node2 {
- };
- };
- node2 {
- an-empty-property;
- a-cell-property = <1 2 3 4>; /* each number (cell) is a uint32 */
- child-node1 {
- };
- };
- };
该树并未描述任何东西,也不具备任何实际意义,但它却揭示了节点和属性的结构。即:
a -- 一个的根节点:'/',两个子节点:node1和node2;node1的子节点:child-node1和child-node2,一些属性分散在树之间。
b -- 属性是一些简单的键值对(key-value pairs):value可以为空也可以包含任意的字节流。而数据类型并没有编码成数据结构,有一些基本数据表示可以在device tree源文件中表示。
c -- 文本字符串(null 终止)用双引号来表示:string-property = "a string"
d -- “Cells”是由尖括号分隔的32位无符号整数:cell-property = <0xbeef 123 0xabcd1234>
e -- 二进制数据是用方括号分隔:binary-property = [0x01 0x23 0x45 0x67];
f -- 不同格式的数据可以用逗号连接在一起:mixed-property = "a string", [0x01 0x23 0x45 0x67], <0x12345678>;
g -- 逗号也可以用来创建字符串列表:string-list = "red fish", "blue fish";
二、设备在device tree 中的描述
系统中的每个设备由device tree的一个节点来表示;
1、节点命名
花些时间谈谈命名习惯是值得的。每个节点都必须有一个<name>[@<unit-address>]格式的名称。<name>是一个简单的ascii字符串,最长为31个字符,总的来说,节点命名是根据它代表什么设备。比如说,一个代表3com以太网适配器的节点应该命名为ethernet,而不是3com509。
如果节点描述的设备有地址的话,就应该加上unit-address,unit-address通常是用来访问设备的主地址,并在节点的reg属性中被列出。后面我们将谈到reg属性。
2、设备
接下来将为设备树添加设备节点:
- / {
- compatible = "acme,coyotes-revenge";
- cpus {
- cpu@0 {
- compatible = "arm,cortex-a9";
- };
- cpu@1 {
- compatible = "arm,cortex-a9";
- };
- };
- serial@101F0000 {
- compatible = "arm,pl011";
- };
- serial@101F2000 {
- compatible = "arm,pl011";
- };
- gpio@101F3000 {
- compatible = "arm,pl061";
- };
- interrupt-controller@10140000 {
- compatible = "arm,pl190";
- };
- spi@10115000 {
- compatible = "arm,pl022";
- };
- external-bus {
- ethernet@0,0 {
- compatible = "smc,smc91c111";
- };
- i2c@1,0 {
- compatible = "acme,a1234-i2c-bus";
- rtc@58 {
- compatible = "maxim,ds1338";
- };
- };
- flash@2,0 {
- compatible = "samsung,k8f1315ebm", "cfi-flash";
- };
- };
- };
在上面的设备树中,系统中的设备节点已经添加进来,树的层次结构反映了设备如何连到系统中。外部总线上的设备就是外部总线节点的子节点,i2c设备是i2c总线控制节点的子节点。总的来说,层次结构表现的是从CPU视角来看的系统视图。在这里这棵树是依然是无效的。它缺少关于设备之间的连接信息。稍后将添加这些数据。
设备树中应当注意:每个设备节点有一个compatible属性。flash节点的compatible属性有两个字符串。请阅读下一节以了解更多内容。 之前提到的,节点命名应当反映设备的类型,而不是特定型号。请参考ePAPR规范2.2.2节的通用节点命名,应优先使用这些命名。
3、compatible 属性
树中的每一个代表了一个设备的节点都要有一个compatible属性。compatible是OS用来决定绑定到设备的设备驱动的关键。
compatible是字符串的列表。列表中的第一个字符串指定了"<manufacturer>,<model>"格式的节点代表的确切设备,第二个字符串代表了与该设备兼容的其他设备。例如,Freescale MPC8349 SoC有一个串口设备实现了National Semiconductor ns16550寄存器接口。因此MPC8349串口设备的compatible属性为:compatible = "fsl,mpc8349-uart", "ns16550"。在这里,fsl,mpc8349-uart指定了确切的设备,ns16550表明它与National Semiconductor 16550 UART是寄存器级兼容的。
注:由于历史原因,ns16550没有制造商前缀,所有新的compatible值都应使用制造商的前缀。这种做法使得现有的设备驱动程序可以绑定到一个新设备上,同时仍能唯一准确的识别硬件。
4、编址
可编址的设备使用下列属性来将地址信息编码进设备树:
reg
#address-cells
#size-cells
每个可寻址的设备有一个reg属性,即以下面形式表示的元组列表:
reg = <address1 length1 [address2 length2] [address3 length3] ... >
每个元组,。每个地址值由一个或多个32位整数列表组成,被称做cells。同样地,长度值可以是cells列表,也可以为空。
既然address和length字段是大小可变的变量,父节点的#address-cells和#size-cells属性用来说明各个子节点有多少个cells。换句话说,正确解释一个子节点的reg属性需要父节点的#address-cells和#size-cells值。
5、内存映射设备
与CPU节点中的单一地址值不同,内存映射设备会被分配一个它能响应的地址范围。#size-cells用来说明每个子节点种reg元组的长度大小。
在下面的示例中,每个地址值是1 cell (32位) ,并且每个的长度值也为1 cell,这在32位系统中是非常典型的。64位计算机可以在设备树中使用2作为#address-cells和#size-cells的值来实现64位寻址。
- serial@101f2000 {
- compatible = "arm,pl011";
- reg = <0x101f2000 0x1000 >;
- };
- gpio@101f3000 {
- compatible = "arm,pl061";
- reg = <0x101f3000 0x1000
- 0x101f4000 0x0010>;
- };
- interrupt-controller@10140000 {
- compatible = "arm,pl190";
- reg = <0x10140000 0x1000 >;
- };
每个设备都被分配了一个基地址及该区域大小。本例中的GPIO设备地址被分成两个地址范围:0x101f3000~0x101f3fff和0x101f4000~0x101f400f。
三、设备树在platform设备驱动开发中的使用解析
我们仍以 Linux 设备驱动开发 —— platform设备驱动应用实例解析 文中的例子来解析设备树在platform设备驱动中如何使用;
1、设备树对platform中platform_device的替换
其实我们可以看到,Device Tree 是用来描述设备信息的,每一个设备在设备树中是以节点的形式表现出来;而在上面的 platform 设备中,我们利用platform_device 来描述一个设备,我们可以看一下二者的对比
|
fs4412-beep{
compatible = "fs4412,beep";
reg = <0x114000a0 0x4 0x139D0000 0x14>;
};
a -- fs4412-beep 为节点名,符合咱们前面提到的节点命名规范;
我们通过名字可以知道,该节点描述的设备是beep, 设备名是fs4412-beep;
b -- compatible = "fs4412,beep"; compatible 属性, 即一个字符串;
前面提到,所有新的compatible值都应使用制造商的前缀,这里是
fs4412;
c -- reg = <0x114000a0 0x4 0x139D0000
0x14>;
reg属性来将地址信息编码进设备树,表示该设备的地址范围;这里是我们用到的寄存器及偏移量;
|
static struct resource beep_resource[] =
{
[0] = {
.start = 0x114000a0,
.end = 0x114000a0+0x4,
.flags = IORESOURCE_MEM,
},
[1] = {
.start = 0x139D0000,
.end = 0x139D0000+0x14,
.flags = IORESOURCE_MEM,
},
};
static struct platform_device hello_device=
{
.name = "bigbang",//没用了
.id = -1,
.dev.release = hello_release,
.num_resources = ARRAY_SIZE(beep_resource ),
.resource = beep_resource,
};
|
可以看到设备树中的设备节点完全可以替代掉platform_device。
2、有了设备树,如何实现device 与 driver 的匹配?
我们在上一篇还有 platform_device 中,是利用 .name 来实现device与driver的匹配的,但现在设备树替换掉了device,那我们将如何实现二者的匹配呢?有了设备树后,platform比较的名字存在哪?
我们先看一下原来是如何匹配的 ,platform_bus_type 下有个match成员,platform_match 定义如下
- static int platform_match(struct device *dev, struct device_driver *drv)
- {
- struct platform_device *pdev = to_platform_device(dev);
- struct platform_driver *pdrv = to_platform_driver(drv);
- /* Attempt an OF style match first */
- if (of_driver_match_device(dev, drv))
- return 1;
- /* Then try ACPI style match */
- if (acpi_driver_match_device(dev, drv))
- return 1;
- /* Then try to match against the id table */
- if (pdrv->id_table)
- return platform_match_id(pdrv->id_table, pdev) != NULL;
- /* fall-back to driver name match */
- return (strcmp(pdev->name, drv->name) == 0);
- }
其中又调用了of_driver_match_device(dev, drv) ,其定义如下:
- static inline int of_driver_match_device(struct device *dev,
- const struct device_driver *drv)
- {
- return of_match_device(drv->of_match_table, dev) != NULL;
- }
其调用of_match_device(drv->of_match_table, dev) ,继续追踪下去,注意这里的参数drv->of_match_table
- const struct of_device_id *of_match_device(const struct of_device_id *matches,
- const struct device *dev)
- {
- if ((!matches) || (!dev->of_node))
- return NULL;
- return of_match_node(matches, dev->of_node);
- }
- EXPORT_SYMBOL(of_match_device);
又调用 of_match_node(matches, dev->of_node) ,其中matches 是struct of_device_id 类型的
- /**
- * of_match_node - Tell if an device_node has a matching of_match structure
- * @matches: array of of device match structures to search in
- * @node: the of device structure to match against
- *
- * Low level utility function used by device matching.
- */
- const struct of_device_id *of_match_node(const struct of_device_id *matches,
- const struct device_node *node)
- {
- const struct of_device_id *match;
- unsigned long flags;
- raw_spin_lock_irqsave(&devtree_lock, flags);
- match = __of_match_node(matches, node);
- raw_spin_unlock_irqrestore(&devtree_lock, flags);
- return match;
- }
- EXPORT_SYMBOL(of_match_node);
找到 match = __of_match_node(matches, node); 注意着里的node是struct device_node 类型的
- const struct of_device_id *__of_match_node(const struct of_device_id *matches,
- const struct device_node *node)
- {
- const struct of_device_id *best_match = NULL;
- int score, best_score = 0;
- if (!matches)
- return NULL;
- for (; matches->name[0] || matches->type[0] || matches->compatible[0]; matches++) {
- score = __of_device_is_compatible(node, matches->compatible,
- matches->type, matches->name);
- if (score > best_score) {
- best_match = matches;
- best_score = score;
- }
- }
- return best_match;
- }
继续追踪下去
- static int __of_device_is_compatible(const struct device_node *device,
- const char *compat, const char *type, const char *name)
- {
- struct property *prop;
- const char *cp;
- int index = 0, score = 0;
- /* Compatible match has highest priority */
- if (compat && compat[0]) {
- prop = __of_find_property(device, "compatible", NULL);
- for (cp = of_prop_next_string(prop, NULL); cp;
- cp = of_prop_next_string(prop, cp), index++) {
- if (of_compat_cmp(cp, compat, strlen(compat)) == 0) {
- score = INT_MAX/2 - (index << 2);
- break;
- }
- }
- if (!score)
- return 0;
- }
- /* Matching type is better than matching name */
- if (type && type[0]) {
- if (!device->type || of_node_cmp(type, device->type))
- return 0;
- score += 2;
- }
- /* Matching name is a bit better than not */
- if (name && name[0]) {
- if (!device->name || of_node_cmp(name, device->name))
- return 0;
- score++;
- }
- return score;
- }
看这句 prop = __of_find_property(device, "compatible", NULL);
可以发先追溯到底,是利用"compatible"来匹配的,即设备树加载之后,内核会自动把设备树节点转换成 platform_device这种格式,同时把名字放到of_node这个地方。
platform_driver 部分
- struct device_driver {
- const char *name;
- struct bus_type *bus;
- struct module *owner;
- const char *mod_name; /* used for built-in modules */
- bool suppress_bind_attrs; /* disables bind/unbind via sysfs */
- const struct of_device_id *of_match_table;
- const struct acpi_device_id *acpi_match_table;
- int (*probe) (struct device *dev);
- int (*remove) (struct device *dev);
- void (*shutdown) (struct device *dev);
- int (*suspend) (struct device *dev, pm_message_t state);
- int (*resume) (struct device *dev);
- const struct attribute_group **groups;
- const struct dev_pm_ops *pm;
- struct driver_private *p;
- }
- /*
- * Struct used for matching a device
- */
- struct of_device_id
- {
- char name[32];
- char type[32];
- char compatible[128];
- const void *data;
- };
匹配的方式发生了改变,那我们的platform_driver 也要修改了
基于设备树的driver的结构体的填充:
- static struct of_device_id beep_table[] = {
- {.compatible = "fs4412,beep"},
- };
- static struct platform_driver beep_driver=
- {
- .probe = beep_probe,
- .remove = beep_remove,
- .driver={
- .name = "bigbang",
- .of_match_table = beep_table,
- },
- };
原来的driver是这样的,可以对比一下
- static struct platform_driver beep_driver=
- {
- .driver.name = "bigbang",
- .probe = beep_probe,
- .remove = beep_remove,
- };
我们在 arch/arm/boot/dts/exynos4412-fs4412.dts 中添加
- fs4412-beep{
- compatible = "fs4412,beep";
- reg = <0x114000a0 0x4 0x139D0000 0x14>;
- };
|
make dtbs 在内核根目录
vim arch/arm/boot/dts/exynos4412-fs4412.dts
sudo cp arch/arm/boot/dts/exynos4412-fs4412.dtb /tftpboot/
|
然后,将设备树下载到0x42000000处,并加载驱动 insmod driver.ko, 测试下驱动。
Linux 设备驱动的并发控制
Linux 设备驱动中必须要解决的一个问题是多个进程对共享的资源的并发访问,并发的访问会导致竞态,即使是经验丰富的驱动工程师也常常设计出包含并发问题bug 的驱动程序。
一、基础概念
1、Linux 并发相关基础概念
a -- 并发(concurrency):并发指的是多个执行单元同时、并发被执行,而并发的执行单元对共享资源(硬件资源和软件上的全局变量、静态变量等)的访问则很容易导致竞态(race condition);
b -- 竞态(race condition) :竞态简单的说就是两个或两个以上的进程同时访问一个资源,同时引起资源的错误;
c -- 临界区(Critical Section):每个进程中访问临界资源的那段代码称为临界区;
d -- 临界资源 :一次仅允许一个进程使用的资源称为临界资源;多道程序系统中存在许多进程,它们共享各种资源,然而有很多资源一次只能供一个进程使用;
在宏观上并行或者真正意义上的并行(这里为什么是宏观意义的并行呢?我们应该知道“时间片”这个概念,微观上还是串行的,所以这里称为宏观上的并行),可能会导致竞争; 类似两条十字交叉的道路上运行的车。当他们同一时刻要经过共同的资源(交叉点)的时候,如果没有交通信号灯,就可能出现混乱。在linux 系统中也有可能存在这种情况:
2、并发产生的场合
a -- 对称多处理器(SMP)的多个CPU
SMP 是一种共享存储的系统模型,它的特点是多个CPU使用共同的系统总线,因此可访问共同的外设和储存器,这里可以实现真正的并行;
b -- 单CPU内进程与抢占它的进程
一个进程在内核执行的时候有可能被另一个高优先级进程打断;
c -- 中断和进程之间
中断可以打断正在执行的进程,如果中断处理函数程序访问进程正在访问的资源,则竞态也会发生;
3、解决竞态问题的途径
解决竞态问题的途径最重要的是保证对共享资源的互斥访问,所谓互斥访问是指一个执行单元在访问共享资源的时候,其他的执行单元被禁止访问。
Linux 设备中提供了可采用的互斥途径来避免这种竞争。主要有原子操作,信号量,自旋锁。
那么这三种有什么相同的地方,有什么区别呢?适用什么不同的场合呢?会带来什么边际效应?要彻底弄清楚这些问题,要从其所处的环境来进行细化分类处理。是UP(单CPU)还是SMP(多CPU);是抢占式内核还是非抢占式内核;是在中断上下文不是进程上下文。似交通信号灯一样的措施来避免这种竞争。
先看一下三种并发机制的简单概念:
原子锁:原子操作不可能被其他的任务给调开,一切(包括中断),针对单个变量。
自旋锁:使用忙等待锁来确保互斥锁的一种特别方法,针对是临界区。
信号量:包括一个变量及对它进行的两个原语操作,此变量就称之为信号量,针对是临界区。
二、并发处理途径详解
1、中断屏蔽
在单CPU范围内避免静态的一种简单而省事的方法是在进入临界区之前屏蔽系统的中断,这项功能可以保证正在执行的内核执行路径不被中断处理程序所抢占,防止某些竞争条件的发生。具体而言
a -- 中断屏蔽将使得中断和进程之间的并发不再发生;
b -- 由于Linux内核的进程调度等操作都依赖中断来实现,内核抢占进程之间的并发也得以避免;
中断屏蔽的使用方法:
- local_irq_disable()
- local_irq_enable()
- 只能禁止和使能本地CPU的中断,所以不能解决多CPU引发的竞态
- local_irq_save(flags)
- local_irq_restore(flags)
- 除了能禁止和使能中断外,还保存和还原目前的CPU中断位信息
- local_bh_disable()
- local_bh_disable()
- 如果只是想禁止中断的底半部,这是个不错的选择。
但是要注意:
a -- 中断对系统正常运行很重要,长时间屏蔽很危险,有可能造成数据丢失乃至系统崩溃,所以中断屏蔽后应尽可能快的执行完毕。
b -- 宜与自旋锁联合使用。
所以,不建议使用中断屏蔽。
2、原子操作
原子操作(分为原子整型操作和原子位操作)就是绝不会在执行完毕前被任何其他任务和时间打断,不会执行一半,又去执行其他代码。原子操作需要硬件的支持,因此是架构相关的,其API和原子类型的定义都在include/asm/atomic.h中,使用汇编语言实现。
在linux中,原子变量的定义如下:
typedef struct {
volatile int counter;
} atomic_t;
关键字volatile用来暗示GCC不要对该类型做数据优化,所以对这个变量counte的访问都是基于内存的,不要将其缓冲到寄存器中。存储到寄存器中,可能导致内存中的数据已经改变,而寄存其中的数据没有改变。
原子整型操作:
1)定义atomic_t变量:
#define ATOMIC_INIT(i) ( (atomic_t) { (i) } )
atomic_t v = ATOMIC_INIT(0); //定义原子变量v并初始化为0
2)设置原子变量的值:
#define atomic_set(v,i) ((v)->counter = (i))
void atomic_set(atomic_t *v, int i);//设置原子变量的值为i
3)获取原子变量的值:
#define atomic_read(v) ((v)->counter + 0)
atomic_read(atomic_t *v);//返回原子变量的值
4)原子变量加/减:
static __inline__ void atomic_add(int i, atomic_t * v); //原子变量增加i
static __inline__ void atomic_sub(int i, atomic_t * v); //原子变量减少i
5)原子变量自增/自减:
#define atomic_inc(v) atomic_add(1, v); //原子变量加1
#define atomic_dec(v) atomic_sub(1, v); //原子变量减1
6)操作并测试:
//这些操作对原子变量执行自增,自减,减操作后测试是否为0,是返回true,否则返回false
#define atomic_inc_and_test(v) (atomic_add_return(1, (v)) == 0)
static inline int atomic_add_return(int i, atomic_t *v)
原子操作的优点编写简单;缺点是功能太简单,只能做计数操作,保护的东西太少。下面看一个实例:
- static atomic_t v=ATOMIC_INIT(1);
- static int hello_open (struct inode *inode, struct file *filep)
- {
- if(!atomic_dec_and_test(&v))
- {
- atomic_inc(&v);
- return -EBUSY;
- }
- return 0;
- }
- static int hello_release (struct inode *inode, struct file *filep)
- {
- atomic_inc(&v);
- return 0;
- }
3、自旋锁
自旋锁是专为防止多处理器并发而引入的一种锁,它应用于中断处理等部分。对于单处理器来说,防止中断处理中的并发可简单采用关闭中断的方式,不需要自旋锁。
自旋锁最多只能被一个内核任务持有,如果一个内核任务试图请求一个已被争用(已经被持有)的自旋锁,那么这个任务就会一直进行忙循环——旋转——等待锁重新可用(忙等待,即当一个进程位于其临界区内,任何试图进入其临界区的进程都必须在进入代码连续循环)。要是锁未被争用,请求它的内核任务便能立刻得到它并且继续进行。自旋锁可以在任何时刻防止多于一个的内核任务同时进入临界区,因此这种锁可有效地避免多处理器上并发运行的内核任务竞争共享资源。
1)自旋锁的使用:
spinlock_t spin; //定义自旋锁
spin_lock_init(lock); //初始化自旋锁
spin_lock(lock); //成功获得自旋锁立即返回,否则自旋在那里直到该自旋锁的保持者释放
spin_trylock(lock); //成功获得自旋锁立即返回真,否则返回假,而不是像上一个那样"在原地打转"
spin_unlock(lock);//释放自旋锁
下面是一个实例:
- static spinlock_t lock;
- static int flag = 1;
- static int hello_open (struct inode *inode, struct file *filep)
- {
- spin_lock(&lock);
- if(flag !=1)
- {
- spin_unlock(&lock);
- return -EBUSY;
- }
- flag = 0;
- spin_unlock(&lock);
- return 0;
- }
- static int hello_release (struct inode *inode, struct file *filep)
- {
- flag = 1;
- return 0;
- }
自旋锁主要针对SMP或单CPU但内核可抢占的情况,对于单CPU和内核不支持的抢占的系统,自旋锁退化为空操作(因为自旋锁本身就需进行内核抢占)。在单CPU和内核可抢占的系统中,自旋锁持有期间内核的抢占将被禁止。由于内核可抢占的单CPU系统的行为实际很类似于SMP系统,因此,在这样的单CPU系统中使用自旋锁仍十分重要。
尽管用了自旋锁可以保证临界区不受别的CPU和本CPU内的抢占进程打扰,但是得到锁的代码路径在执行临界区的时候,还可能受到中断和底半部的影响。为了防止这种影响。为了防止影响,就需要用到自旋锁的衍生。
2)注意事项:
a -- 自旋锁是一种忙等待。它是一种适合短时间锁定的轻量级的加锁机制。
b -- 自旋锁不能递归使用。自旋锁被设计成在不同线程或者函数之间同步。这是因为,如果一个线程在已经持有自旋锁时,其处于忙等待状态,则已经没有机会释放自己持有的锁了。如果这时再调用自身,则自旋锁永远没有执行的机会了,即造成“死锁”。
【自旋锁导致死锁的实例】
1)a进程拥有自旋锁,在内核态阻塞的,内核调度进程b,b也要或得自旋锁,b只能自旋,而此时抢占已经关闭了,a进程就不会调度到了,b进程永远自旋。
2)进程a拥有自旋锁,中断来了,cpu执行中断,中断处理函数也要获得锁访问共享资源,此时也获得不到锁,只能死锁。
3)内核抢占
内核抢占是上面提到的一个概念,不管当前进程处于内核态还是用户态,都会调度优先级高的进程运行,停止当前进程;当我们使用自旋锁的时候,抢占是关闭的。
4)自旋锁有几个重要的特性:
a -- 被自旋锁保护的临界区代码执行时不能进入休眠。
b -- 被自旋锁保护的临界区代码执行时是不能被被其他中断中断。
c -- 被自旋锁保护的临界区代码执行时,内核不能被抢占。
从这几个特性可以归纳出一个共性:被自旋锁保护的临界区代码执行时,它不能因为任何原因放弃处理器。
4、信号量
linux中,提供了两种信号量:一种用于内核程序中,一种用于应用程序中。这里只讲属前者
信号量和自旋锁的使用方法基本一样。与自旋锁相比,信号量只有当得到信号量的进程或者线程时才能够进入临界区,执行临界代码。信号量和自旋锁的最大区别在于:当一个进程试图去获得一个已经锁定的信号量时,进程不会像自旋锁一样在远处忙等待。
信号量是一种睡眠锁。如果有一个任务试图获得一个已被持有的信号量时,信号量会将其推入等待队列,然后让其睡眠。这时处理器获得自由去执行其它代码。当持有信号量的进程将信号量释放后,在等待队列中的一个任务将被唤醒,从而便可以获得这个信号量。
1)信号量的实现:
在linux中,信号量的定义如下:
struct semaphore {
spinlock_t lock; //用来对count变量起保护作用。
unsigned int count; // 大于0,资源空闲;等于0,资源忙,但没有进程等待这个保护的资源;小于0,资源不可用,并至少有一个进程等待资源。
struct list_head wait_list; //存放等待队列链表的地址,当前等待资源的所有睡眠进程都会放在这个链表中。
};
2)信号量的使用:
static inline void sema_init(struct semaphore *sem, int val); //设置sem为val
#define init_MUTEX(sem) sema_init(sem, 1) //初始化一个用户互斥的信号量sem设置为1
#define init_MUTEX_LOCKED(sem) sema_init(sem, 0) //初始化一个用户互斥的信号量sem设置为0
定义和初始化可以一步完成:
DECLARE_MUTEX(name); //该宏定义信号量name并初始化1
DECLARE_MUTEX_LOCKED(name); //该宏定义信号量name并初始化0
当信号量用于互斥时(即避免多个进程同是在一个临界区运行),信号量的值应初始化为1。这种信号量在任何给定时刻只能由单个进程或线程拥有。在这种使用模式下,一个信号量有时也称为一个“互斥体(mutex)”,它是互斥(mutual exclusion)的简称。Linux内核中几乎所有的信号量均用于互斥。
使用信号量,内核代码必须包含<asm/semaphore.h> 。
3)获取(锁定)信号量:
void down(struct semaphore *sem);
int down_interruptible(struct semaphore *sem);
int down_killable(struct semaphore *sem);
4)释放信号量
void up(struct semaphore *sem);
下面看一个实例:
- //定义和初始化
- static struct semaphore sem;
- sema_init(&sem,1);
- static int hello_open (struct inode *inode, struct file *filep)
- {
- // p操作,获得信号量,保护临界区
- if(down_interruptible(&sem))
- {
- //没有获得信号量
- return -ERESTART;
- }
- return 0;
- }
- static int hello_release (struct inode *inode, struct file *filep)
- {
- //v操作,释放信号量
- up(&sem);
- return 0;
- }
三、自旋锁与信号量的比较
| 信号量 | 自旋锁 | |
| 1、开销成本 | 进程上下文切换时间 | 忙等待获得自旋锁时间 |
| 2、特性 | a -- 导致阻塞,产生睡眠 b -- 进程级的(内核是代表进程来争夺资源的) |
a -- 忙等待,内核抢占关闭 b -- 主要是用于CPU同步的 |
| 3、应用场合 | 只能运行于进程上下文 | 还可以出现中断上下文 |
| 4、其他 | 还可以出现在用户进程中 | 只能在内核线程中使用 |
从以上的区别以及本身的定义可以推导出两都分别适应的场合。只考虑内核态
后记:除了上述几种广泛使用的的并发控制机制外,还有中断屏蔽、顺序锁(seqlock)、RCU(Read-Copy-Update)等等,做个简单总结如下图:
Linux 设备驱动中的 I/O模型(一)—— 阻塞和非阻塞I/O
在前面学习网络编程时,曾经学过I/O模型 Linux 系统应用编程——网络编程(I/O模型),下面学习一下I/O模型在设备驱动中的应用。
回顾一下在Unix/Linux下共有五种I/O模型,分别是:
a -- 阻塞I/O
b -- 非阻塞I/O
c -- I/O复用(select和poll)
d -- 信号驱动I/O(SIGIO)
e -- 异步I/O(Posix.1的aio_系列函数)
下面我们先学习阻塞I/O、非阻塞I/O 、I/O复用(select和poll),先学习一下基础概念
a -- 阻塞
阻塞操作是指在执行设备操作时,若不能获得资源,则挂起进程知道满足可操作的条件后再进行操作;被挂起的进程进入休眠状态(放弃CPU),被从调度器的运行队列移走,直到等待的条件被满足;
b -- 非阻塞
非阻塞的进程在不能进行设备操作时,并不挂起(继续占用CPU),它或者放弃,或者不停地查询,直到可以操作为止;
二者的区别可以看应用程序的调用是否立即返回!
驱动程序通常需要提供这样的能力:当应用程序进行 read()、write() 等系统调用时,若设备的资源不能获取,而用户又希望以阻塞的方式访问设备,驱动程序应在设备驱动的xxx_read()、xxx_write() 等操作中将进程阻塞直到资源可以获取,此后,应用程序的 read()、write() 才返回,整个过程仍然进行了正确的设备 访问,用户并没感知到;若用户以非阻塞的方式访问设备文件,则当设备资源不可获取时,设备驱动的 xxx_read()、xxx_write() 等操作立刻返回, read()、write() 等系统调用也随即被返回。
因为阻塞的进程会进入休眠状态,因此,必须确保有一个地方能够唤醒休眠的进程,否则,进程就真的挂了。唤醒进程的地方最大可能发生在中断里面,因为硬件资源获得的同时往往伴随着一个中断。
阻塞I/O通常由等待队列来实现,而非阻塞I/O由轮询来实现。
一、阻塞I/O实现 —— 等待队列
1、基础概念
在Linux 驱动程序中,可以使用等待队列(wait queue)来实现阻塞进程的唤醒。wait queue 很早就作为一个基本的功能单位出现在Linux 内核里了,它以队列为基础数据结构,与进程调度机制紧密结合,能够实现内核中的异步事件通知机制。等待队列可以用来同步对系统资源的访问,上一篇文章所述的信号量在内核中也依赖等待队列来实现。
在Linux内核中使用等待队列的过程很简单,首先定义一个wait_queue_head,然后如果一个task想等待某种事件,那么调用wait_event(等待队列,事件)就可以了。
等待队列应用广泛,但是内核实现却十分简单。其涉及到两个比较重要的数据结构:__wait_queue_head,该结构描述了等待队列的链头,其包含一个链表和一个原子锁,结构定义如下:
struct __wait_queue_head
{
spinlock_t lock; /* 保护等待队列的原子锁 */
struct list_head task_list; /* 等待队列 */
};
typedef struct __wait_queue_head wait_queue_head_t;
__wait_queue,该结构是对一个等待任务的抽象。每个等待任务都会抽象成一个wait_queue,并且挂载到wait_queue_head上。该结构定义如下:
struct __wait_queue
{
unsigned int flags;
void *private; /* 通常指向当前任务控制块 */
/* 任务唤醒操作方法,该方法在内核中提供,通常为autoremove_wake_function */
wait_queue_func_t func;
struct list_head task_list; /* 挂入wait_queue_head的挂载点 */
};
Linux中等待队列的实现思想如下图所示,当一个任务需要在某个wait_queue_head上睡眠时,将自己的进程控制块信息封装到wait_queue中,然后挂载到wait_queue的链表中,执行调度睡眠。当某些事件发生后,另一个任务(进程)会唤醒wait_queue_head上的某个或者所有任务,唤醒工作也就是将等待队列中的任务设置为可调度的状态,并且从队列中删除。
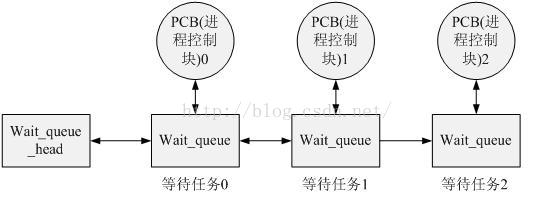
使用等待队列时首先需要定义一个wait_queue_head,这可以通过DECLARE_WAIT_QUEUE_HEAD宏来完成,这是静态定义的方法。该宏会定义一个wait_queue_head,并且初始化结构中的锁以及等待队列。当然,动态初始化的方法也很简单,初始化一下锁及队列就可以了。
一个任务需要等待某一事件的发生时,通常调用wait_event,该函数会定义一个wait_queue,描述等待任务,并且用当前的进程描述块初始化wait_queue,然后将wait_queue加入到wait_queue_head中。
函数实现流程说明如下:
a -- 用当前的进程描述块(PCB)初始化一个wait_queue描述的等待任务。
b -- 在等待队列锁资源的保护下,将等待任务加入等待队列。
c -- 判断等待条件是否满足,如果满足,那么将等待任务从队列中移出,退出函数。
d -- 如果条件不满足,那么任务调度,将CPU资源交与其它任务。
e -- 当睡眠任务被唤醒之后,需要重复b、c 步骤,如果确认条件满足,退出等待事件函数。
2、等待队列接口函数
1、定义并初始化
/* 定义“等待队列头” */
wait_queue_head_t my_queue;
/* 初始化“等待队列头”*/
init_waitqueue_head(&my_queue);
直接定义并初始化。init_waitqueue_head()函数会将自旋锁初始化为未锁,等待队列初始化为空的双向循环链表。
DECLARE_WAIT_QUEUE_HEAD(my_queue); 定义并初始化,可以作为定义并初始化等待队列头的快捷方式。
2、定义等待队列:
DECLARE_WAITQUEUE(name,tsk);
定义并初始化一个名为name的等待队列。
3、(从等待队列头中)添加/移出等待队列:
/* add_wait_queue()函数,设置等待的进程为非互斥进程,并将其添加进等待队列头(q)的队头中*/
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
/* 该函数也和add_wait_queue()函数功能基本一样,只不过它是将等待的进程(wait)设置为互斥进程。*/
void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait);
4、等待事件:
(1)wait_event()宏:
- /**
- * wait_event - sleep until a condition gets true
- * @wq: the waitqueue to wait on
- * @condition: a C expression for the event to wait for
- *
- * The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
- * @condition evaluates to true. The @condition is checked each time
- * the waitqueue @wq is woken up.
- *
- * wake_up() has to be called after changing any variable that could
- * change the result of the wait condition.
- */
- #define wait_event(wq, condition) \
- do { \
- if (condition) \
- break; \
- __wait_event(wq, condition); \
- } while (0)
在等待会列中睡眠直到condition为真。在等待的期间,进程会被置为TASK_UNINTERRUPTIBLE进入睡眠,直到condition变量变为真。每次进程被唤醒的时候都会检查condition的值.
(2)wait_event_interruptible()函数:
和wait_event()的区别是调用该宏在等待的过程中当前进程会被设置为TASK_INTERRUPTIBLE状态.在每次被唤醒的时候,首先检查condition是否为真,如果为真则返回,否则检查如果进程是被信号唤醒,会返回-ERESTARTSYS错误码.如果是condition为真,则返回0.
(3)wait_event_timeout()宏:
也与wait_event()类似.不过如果所给的睡眠时间为负数则立即返回.如果在睡眠期间被唤醒,且condition为真则返回剩余的睡眠时间,否则继续睡眠直到到达或超过给定的睡眠时间,然后返回0
(4)wait_event_interruptible_timeout()宏:
与wait_event_timeout()类似,不过如果在睡眠期间被信号打断则返回ERESTARTSYS错误码.
(5) wait_event_interruptible_exclusive()宏
同样和wait_event_interruptible()一样,不过该睡眠的进程是一个互斥进程.
5、唤醒队列
(1)wake_up()函数
- #define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
- /**
- * __wake_up - wake up threads blocked on a waitqueue.
- * @q: the waitqueue
- * @mode: which threads
- * @nr_exclusive: how many wake-one or wake-many threads to wake up
- * @key: is directly passed to the wakeup function
- */
- void __wake_up(wait_queue_head_t *q, unsigned int mode,
- int nr_exclusive, void *key)
- {
- unsigned long flags;
- spin_lock_irqsave(&q->lock, flags);
- __wake_up_common(q, mode, nr_exclusive, 0, key);
- spin_unlock_irqrestore(&q->lock, flags);
- }
- EXPORT_SYMBOL(__wake_up);
唤醒等待队列.可唤醒处于TASK_INTERRUPTIBLE和TASK_UNINTERUPTIBLE状态的进程,和wait_event/wait_event_timeout成对使用.(2)wake_up_interruptible()函数:
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
和wake_up()唯一的区别是它只能唤醒TASK_INTERRUPTIBLE状态的进程.,与wait_event_interruptible/wait_event_interruptible_timeout/ wait_event_interruptible_exclusive成对使用。
下面看一个实例:
- static ssize_t hello_read(struct file *filep, char __user *buf, size_t len, loff_t *pos)
- {
- /*
- 实现应用进程read的时候,如果没有数据就阻塞
- */
- if(len>64)
- {
- len =64;
- }
- wait_event_interruptible(wq, have_data == 1);
- if(copy_to_user(buf,temp,len))
- {
- return -EFAULT;
- }
- have_data = 0;
- return len;
- }
- static ssize_t hello_write(struct file *filep, const char __user *buf, size_t len, loff_t *pos)
- {
- if(len > 64)
- {
- len = 64;
- }
- if(copy_from_user(temp,buf,len))
- {
- return -EFAULT;
- }
- printk("write %s\n",temp);
- have_data = 1;
- wake_up_interruptible(&wq);
- return len;
- }
注意两个概念:
a -- 疯狂兽群
wake_up的时候,所有阻塞在队列的进程都会被唤醒,但是因为condition的限制,只有一个进程得到资源,其他进程又会再次休眠,如果数量很大,称为 疯狂兽群。
b -- 独占等待
等待队列的入口设置一个WQ_FLAG_EXCLUSIVE标志,就会添加到等待队列的尾部,没有设置设置的添加到头部,wake up的时候遇到第一个具有WQ_FLAG_EXCLUSIVE这个标志的进程就停止唤醒其他进程。
二、非阻塞I/O实现方式 —— 多路复用
1、轮询的概念和作用
在用户程序中,select() 和 poll() 也是设备阻塞和非阻塞访问息息相关的论题。使用非阻塞I/O的应用程序通常会使用select() 和 poll() 系统调用查询是否可对设备进行无阻塞的访问。select() 和 poll() 系统调用最终会引发设备驱动中的 poll()函数被执行。
2、应用程序中的轮询编程
在用户程序中,select()和poll()本质上是一样的, 不同只是引入的方式不同,前者是在BSD UNIX中引入的,后者是在System V中引入的。用的比较广泛的是select系统调用。原型如下:
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptionfds, struct timeval *timeout);
其中readfs,writefds,exceptfds分别是select()监视的读,写和异常处理的文件描述符集合,numfds的值是需要检查的号码最高的文件描述符加1,timeout则是一个时间上限值,超过该值后,即使仍没有描述符准备好也会返回。
struct timeval
{
int tv_sec; //秒
int tv_usec; //微秒
}
涉及到文件描述符集合的操作主要有以下几种:
1)清除一个文件描述符集 FD_ZERO(fd_set *set);
2)将一个文件描述符加入文件描述符集中 FD_SET(int fd,fd_set *set);
3)将一个文件描述符从文件描述符集中清除 FD_CLR(int fd,fd_set *set);
4)判断文件描述符是否被置位 FD_ISSET(int fd,fd_set *set);
最后我们利用上面的文件描述符集的相关来写个验证添加了设备轮询的驱动,把上边两块联系起来
3、设备驱动中的轮询编程
设备驱动中的poll() 函数原型如下
unsigned int(*poll)(struct file *filp, struct poll_table * wait);
第一个参数是file结构体指针,第二个参数是轮询表指针,poll设备方法完成两件事:
a -- 对可能引起设备文件状态变化的等待队列调用poll_wait()函数,将对应的等待队列头添加到poll_table,如果没有文件描述符可用来执行 I/O, 则内核使进程在传递到该系统调用的所有文件描述符对应的等待队列上等待。
b -- 返回表示是否能对设备进行无阻塞读、写访问的掩码。
位掩码:POLLRDNORM, POLLIN,POLLOUT,POLLWRNORM
设备可读,通常返回:(POLLIN | POLLRDNORM)
设备可写,通常返回:(POLLOUT | POLLWRNORM)
poll_wait()函数:用于向 poll_table注册等待队列
void poll_wait(struct file *filp, wait_queue_head_t *queue,poll_table *wait)
poll_wait()函数不会引起阻塞,它所做的工作是把当前进程添加到wait 参数指定的等待列表(poll_table)中。
真正的阻塞动作是上层的select/poll函数中完成的。select/poll会在一个循环中对每个需要监听的设备调用它们自己的poll支持函数以使得当前进程被加入各个设备的等待列表。若当前没有任何被监听的设备就绪,则内核进行调度(调用schedule)让出cpu进入阻塞状态,schedule返回时将再次循环检测是否有操作可以进行,如此反复;否则,若有任意一个设备就绪,select/poll都立即返回。
具体过程如下:
a -- 用户程序第一次调用select或者poll,驱动调用poll_wait并使两条队列都加入poll_table结构中作为下次调用驱动函数poll的条件,一个mask返回值指示设备是否可操作,0为未准备状态,如果文件描述符未准备好可读或可写,用户进程被会加入到写或读等待队列中进入睡眠状态。
b -- 当驱动执行了某些操作,例如,写缓冲或读缓冲,写缓冲使读队列被唤醒,读缓冲使写队列被唤醒,于是select或者poll系统调用在将要返回给用户进程时再次调用驱动函数poll,驱动依然调用poll_wait 并使两条队列都加入poll_table结构中,并判断可写或可读条件是否满足,如果mask返回POLLIN | POLLRDNORM或POLLOUT | POLLWRNORM则指示可读或可写,这时select或poll真正返回给用户进程,如果mask还是返回0,则系统调用select或poll继续不返回
下面是一个典型模板:
- static unsigned int XXX_poll(struct file *filp, poll_table *wait)
- {
- unsigned int mask = 0;
- struct XXX_dev *dev = filp->private_data; //获得设备结构指针
- ...
- poll_wait(filp, &dev->r_wait, wait); //加读等待对列头
- poll_wait(filp ,&dev->w_wait, wait); //加写等待队列头
- if(...)//可读
- {
- mask |= POLLIN | POLLRDNORM; //标识数据可获得
- }
- if(...)//可写
- {
- mask |= POLLOUT | POLLWRNORM; //标识数据可写入
- }
- ..
- return mask;
- }
4、调用过程:
Linux下select调用的过程:
1、用户层应用程序调用select(),底层调用poll())
2、核心层调用sys_select() ------> do_select()
最终调用文件描述符fd对应的struct file类型变量的struct file_operations *f_op的poll函数。
poll指向的函数返回当前可否读写的信息。
1)如果当前可读写,返回读写信息。
2)如果当前不可读写,则阻塞进程,并等待驱动程序唤醒,重新调用poll函数,或超时返回。
3、驱动需要实现poll函数
当驱动发现有数据可以读写时,通知核心层,核心层重新调用poll指向的函数查询信息。
poll_wait(filp,&wait_q,wait) // 此处将当前进程加入到等待队列中,但并不阻塞
在中断中使用wake_up_interruptible(&wait_q)唤醒等待队列。
4、实例分析
1、memdev.h
/*mem设备描述结构体*/
struct mem_dev
{
char *data;
unsigned long size;
wait_queue_head_t inq;
};
#endif /* _MEMDEV_H_ */
2、驱动程序 memdev.c
- #include <linux/module.h>
- #include <linux/types.h>
- #include <linux/fs.h>
- #include <linux/errno.h>
- #include <linux/mm.h>
- #include <linux/sched.h>
- #include <linux/init.h>
- #include <linux/cdev.h>
- #include <asm/io.h>
- #include <asm/system.h>
- #include <asm/uaccess.h>
- #include <linux/poll.h>
- #include "memdev.h"
- static mem_major = MEMDEV_MAJOR;
- bool have_data = false; /*表明设备有足够数据可供读*/
- module_param(mem_major, int, S_IRUGO);
- struct mem_dev *mem_devp; /*设备结构体指针*/
- struct cdev cdev;
- /*文件打开函数*/
- int mem_open(struct inode *inode, struct file *filp)
- {
- struct mem_dev *dev;
- /*获取次设备号*/
- int num = MINOR(inode->i_rdev);
- if (num >= MEMDEV_NR_DEVS)
- return -ENODEV;
- dev = &mem_devp[num];
- /*将设备描述结构指针赋值给文件私有数据指针*/
- filp->private_data = dev;
- return 0;
- }
- /*文件释放函数*/
- int mem_release(struct inode *inode, struct file *filp)
- {
- return 0;
- }
- /*读函数*/
- static ssize_t mem_read(struct file *filp, char __user *buf, size_t size, loff_t *ppos)
- {
- unsigned long p = *ppos;
- unsigned int count = size;
- int ret = 0;
- struct mem_dev *dev = filp->private_data; /*获得设备结构体指针*/
- /*判断读位置是否有效*/
- if (p >= MEMDEV_SIZE)
- return 0;
- if (count > MEMDEV_SIZE - p)
- count = MEMDEV_SIZE - p;
- while (!have_data) /* 没有数据可读,考虑为什么不用if,而用while */
- {
- if (filp->f_flags & O_NONBLOCK)
- return -EAGAIN;
- wait_event_interruptible(dev->inq,have_data);
- }
- /*读数据到用户空间*/
- if (copy_to_user(buf, (void*)(dev->data + p), count))
- {
- ret = - EFAULT;
- }
- else
- {
- *ppos += count;
- ret = count;
- printk(KERN_INFO "read %d bytes(s) from %d\n", count, p);
- }
- have_data = false; /* 表明不再有数据可读 */
- /* 唤醒写进程 */
- return ret;
- }
- /*写函数*/
- static ssize_t mem_write(struct file *filp, const char __user *buf, size_t size, loff_t *ppos)
- {
- unsigned long p = *ppos;
- unsigned int count = size;
- int ret = 0;
- struct mem_dev *dev = filp->private_data; /*获得设备结构体指针*/
- /*分析和获取有效的写长度*/
- if (p >= MEMDEV_SIZE)
- return 0;
- if (count > MEMDEV_SIZE - p)
- count = MEMDEV_SIZE - p;
- /*从用户空间写入数据*/
- if (copy_from_user(dev->data + p, buf, count))
- ret = - EFAULT;
- else
- {
- *ppos += count;
- ret = count;
- printk(KERN_INFO "written %d bytes(s) from %d\n", count, p);
- }
- have_data = true; /* 有新的数据可读 */
- /* 唤醒读进程 */
- wake_up(&(dev->inq));
- return ret;
- }
- /* seek文件定位函数 */
- static loff_t mem_llseek(struct file *filp, loff_t offset, int whence)
- {
- loff_t newpos;
- switch(whence) {
- case 0: /* SEEK_SET */
- newpos = offset;
- break;
- case 1: /* SEEK_CUR */
- newpos = filp->f_pos + offset;
- break;
- case 2: /* SEEK_END */
- newpos = MEMDEV_SIZE -1 + offset;
- break;
- default: /* can't happen */
- return -EINVAL;
- }
- if ((newpos<0) || (newpos>MEMDEV_SIZE))
- return -EINVAL;
- filp->f_pos = newpos;
- return newpos;
- }
- unsigned int mem_poll(struct file *filp, poll_table *wait)
- {
- struct mem_dev *dev = filp->private_data;
- unsigned int mask = 0;
- /*将等待队列添加到poll_table */
- poll_wait(filp, &dev->inq, wait);
- if (have_data) mask |= POLLIN | POLLRDNORM; /* readable */
- return mask;
- }
- /*文件操作结构体*/
- static const struct file_operations mem_fops =
- {
- .owner = THIS_MODULE,
- .llseek = mem_llseek,
- .read = mem_read,
- .write = mem_write,
- .open = mem_open,
- .release = mem_release,
- .poll = mem_poll,
- };
- /*设备驱动模块加载函数*/
- static int memdev_init(void)
- {
- int result;
- int i;
- dev_t devno = MKDEV(mem_major, 0);
- /* 静态申请设备号*/
- if (mem_major)
- result = register_chrdev_region(devno, 2, "memdev");
- else /* 动态分配设备号 */
- {
- result = alloc_chrdev_region(&devno, 0, 2, "memdev");
- mem_major = MAJOR(devno);
- }
- if (result < 0)
- return result;
- /*初始化cdev结构*/
- cdev_init(&cdev, &mem_fops);
- cdev.owner = THIS_MODULE;
- cdev.ops = &mem_fops;
- /* 注册字符设备 */
- cdev_add(&cdev, MKDEV(mem_major, 0), MEMDEV_NR_DEVS);
- /* 为设备描述结构分配内存*/
- mem_devp = kmalloc(MEMDEV_NR_DEVS * sizeof(struct mem_dev), GFP_KERNEL);
- if (!mem_devp) /*申请失败*/
- {
- result = - ENOMEM;
- goto fail_malloc;
- }
- memset(mem_devp, 0, sizeof(struct mem_dev));
- /*为设备分配内存*/
- for (i=0; i < MEMDEV_NR_DEVS; i++)
- {
- mem_devp[i].size = MEMDEV_SIZE;
- mem_devp[i].data = kmalloc(MEMDEV_SIZE, GFP_KERNEL);
- memset(mem_devp[i].data, 0, MEMDEV_SIZE);
- /*初始化等待队列*/
- init_waitqueue_head(&(mem_devp[i].inq));
- //init_waitqueue_head(&(mem_devp[i].outq));
- }
- return 0;
- fail_malloc:
- unregister_chrdev_region(devno, 1);
- return result;
- }
- /*模块卸载函数*/
- static void memdev_exit(void)
- {
- cdev_del(&cdev); /*注销设备*/
- kfree(mem_devp); /*释放设备结构体内存*/
- unregister_chrdev_region(MKDEV(mem_major, 0), 2); /*释放设备号*/
- }
- MODULE_AUTHOR("David Xie");
- MODULE_LICENSE("GPL");
- module_init(memdev_init);
- module_exit(memdev_exit);
3、应用程序 app-write.c
- #include <stdio.h>
- int main()
- {
- FILE *fp = NULL;
- char Buf[128];
- /*打开设备文件*/
- fp = fopen("/dev/memdev0","r+");
- if (fp == NULL)
- {
- printf("Open Dev memdev Error!\n");
- return -1;
- }
- /*写入设备*/
- strcpy(Buf,"memdev is char dev!");
- printf("Write BUF: %s\n",Buf);
- fwrite(Buf, sizeof(Buf), 1, fp);
- sleep(5);
- fclose(fp);
- return 0;
- }
4、应用程序 app-read.c
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <sys/ioctl.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <sys/select.h>
- #include <sys/time.h>
- #include <errno.h>
- int main()
- {
- int fd;
- fd_set rds;
- int ret;
- char Buf[128];
- /*初始化Buf*/
- strcpy(Buf,"memdev is char dev!");
- printf("BUF: %s\n",Buf);
- /*打开设备文件*/
- fd = open("/dev/memdev0",O_RDWR);
- FD_ZERO(&rds);
- FD_SET(fd, &rds);
- /*清除Buf*/
- strcpy(Buf,"Buf is NULL!");
- printf("Read BUF1: %s\n",Buf);
- ret = select(fd + 1, &rds, NULL, NULL, NULL);
- if (ret < 0)
- {
- printf("select error!\n");
- exit(1);
- }
- if (FD_ISSET(fd, &rds))
- read(fd, Buf, sizeof(Buf));
- /*检测结果*/
- printf("Read BUF2: %s\n",Buf);
- close(fd);
- return 0;
- }
Linux 设备驱动中的 I/O模型(二)—— 异步通知和异步I/O
阻塞和非阻塞访问、poll() 函数提供了较多地解决设备访问的机制,但是如果有了异步通知整套机制就更加完善了。
异步通知的意思是:一旦设备就绪,则主动通知应用程序,这样应用程序根本就不需要查询设备状态,这一点非常类似于硬件上“中断”的概念,比较准确的称谓是“信号驱动的异步I/O”。信号是在软件层次上对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是异步的,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。
阻塞I/O意味着移植等待设备可访问后再访问,非阻塞I/O中使用poll()意味着查询设备是否可访问,而异步通知则意味着设备通知自身可访问,实现了异步I/O。由此可见,这种方式I/O可以互为补充。
1、异步通知的概念和作用
影响:阻塞–应用程序无需轮询设备是否可以访问
非阻塞–中断进行通知
即:由驱动发起,主动通知应用程序
2、linux异步通知编程
2.1 linux信号
作用:linux系统中,异步通知使用信号来实现
函数原型为:
void (*signal(int signum,void (*handler))(int)))(int)
原型比较难理解可以分解为
typedef void(*sighandler_t)(int); sighandler_t signal(int signum,sighandler_t handler);
第一个参数是指定信号的值,第二个参数是指定针对前面信号的处理函数
2.2 信号的处理函数(在应用程序端捕获信号)
signal()函数
- //启动信号机制
- void sigterm_handler(int sigo)
- {
- char data[MAX_LEN];
- int len;
- len = read(STDIN_FILENO,&data,MAX_LEN);
- data[len] = 0;
- printf("Input available:%s\n",data);
- exit(0);
- }
- int main(void)
- {
- int oflags;
- //启动信号驱动机制
- signal(SIGIO,sigterm_handler);
- fcntl(STDIN_FILENO,F_SETOWN,getpid());
- oflags = fcntl(STDIN_FILENO,F_GETFL);
- fctcl(STDIN_FILENO,F_SETFL,oflags | FASYNC);
- //建立一个死循环,防止程序结束
- whlie(1);
- return 0;
- }
2.3 信号的释放 (在设备驱动端释放信号)
为了是设备支持异步通知机制,驱动程序中涉及以下3项工作
(1)、支持F_SETOWN命令,能在这个控制命令处理中设置filp->f_owner为对应的进程ID。不过此项工作已由内核完成,设备驱动无须处理。
(2)、支持F_SETFL命令处理,每当FASYNC标志改变时,驱动函数中的fasync()函数得以执行。因此,驱动中应该实现fasync()函数
(3)、在设备资源中可获得,调用kill_fasync()函数激发相应的信号
设备驱动中异步通知编程比较简单,主要用到一项数据结构和两个函数。这个数据结构是fasync_struct 结构体,两个函数分别是:
a -- 处理FASYNC标志变更
int fasync_helper(int fd,struct file *filp,int mode,struct fasync_struct **fa);
b -- 释放信号用的函数
void kill_fasync(struct fasync_struct **fa,int sig,int band);
和其他结构体指针放到设备结构体中,模板如下
- struct xxx_dev{
- struct cdev cdev;
- ...
- struct fasync_struct *async_queue;
- //异步结构体指针
- };
在设备驱动中的fasync()函数中,只需简单地将该函数的3个参数以及fasync_struct结构体指针的指针作为第四个参数传入fasync_helper()函数就可以了,模板如下
- static int xxx_fasync(int fd,struct file *filp, int mode)
- {
- struct xxx_dev *dev = filp->private_data;
- return fasync_helper(fd, filp, mode, &dev->async_queue);
- }
在设备资源可获得时应该调用kill_fasync()函数释放SIGIO信号,可读时第三个参数为POLL_IN,可写时第三个参数为POLL_OUT,模板如下
- static ssize_t xxx_write(struct file *filp,const char __user *buf,size_t count,loff_t *ppos)
- {
- struct xxx_dev *dev = filp->private_data;
- ...
- if(dev->async_queue)
- kill_fasync(&dev->async_queue,GIGIO,POLL_IN);
- ...
- }
最后在文件关闭时,要将文件从异步通知列表中删除
- int xxx_release(struct inode *inode,struct file *filp)
- {
- xxx_fasync(-1,filp,0);
- ...
- return 0;
- }
3、下面是个实例:
hello.c
- #include <linux/module.h>
- #include <linux/fs.h>
- #include <linux/cdev.h>
- #include <linux/device.h>
- #include <asm/uaccess.h>
- #include <linux/fcntl.h>
- static int major = 250;
- static int minor=0;
- static dev_t devno;
- static struct class *cls;
- static struct device *test_device;
- static char temp[64]={0};
- static struct fasync_struct *fasync;
- static int hello_open (struct inode *inode, struct file *filep)
- {
- return 0;
- }
- static int hello_release(struct inode *inode, struct file *filep)
- {
- return 0;
- }
- static ssize_t hello_read(struct file *filep, char __user *buf, size_t len, loff_t *pos)
- {
- if(len>64)
- {
- len =64;
- }
- if(copy_to_user(buf,temp,len))
- {
- return -EFAULT;
- }
- return len;
- }
- static ssize_t hello_write(struct file *filep, const char __user *buf, size_t len, loff_t *pos)
- {
- if(len>64)
- {
- len = 64;
- }
- if(copy_from_user(temp,buf,len))
- {
- return -EFAULT;
- }
- printk("write %s\n",temp);
- kill_fasync(&fasync, SIGIO, POLL_IN);
- return len;
- }
- static int hello_fasync (int fd, struct file * file, int on)
- {
- return fasync_helper(fd, file, on, &fasync);
- }
- static struct file_operations hello_ops=
- {
- .open = hello_open,
- .release = hello_release,
- .read =hello_read,
- .write=hello_write,
- };
- static int hello_init(void)
- {
- int ret;
- devno = MKDEV(major,minor);
- ret = register_chrdev(major,"hello",&hello_ops);
- cls = class_create(THIS_MODULE, "myclass");
- if(IS_ERR(cls))
- {
- unregister_chrdev(major,"hello");
- return -EBUSY;
- }
- test_device = device_create(cls,NULL,devno,NULL,"hello");//mknod /dev/hello
- if(IS_ERR(test_device))
- {
- class_destroy(cls);
- unregister_chrdev(major,"hello");
- return -EBUSY;
- }
- return 0;
- }
- static void hello_exit(void)
- {
- device_destroy(cls,devno);
- class_destroy(cls);
- unregister_chrdev(major,"hello");
- printk("hello_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(hello_init);
- module_exit(hello_exit);
test.c
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <signal.h>
- static int fd,len;
- static char buf[64]={0};
- void func(int signo)
- {
- printf("signo %d \n",signo);
- read(fd,buf,64);
- printf("buf=%s \n",buf);
- }
- main()
- {
- int flage,i=0;
- fd = open("/dev/hello",O_RDWR);
- if(fd<0)
- {
- perror("open fail \n");
- return ;
- }
- fcntl(fd,F_SETOWN,getpid());
- flage = fcntl(fd,F_GETFL);
- fcntl(fd,F_SETFL,flage|FASYNC);
- signal(SIGIO,func);
- while(1)
- {
- sleep(1);
- printf("%d\n",i++);
- }
- close(fd);
- }
- 一、概述
-
(1)udev是构建在linux的sysfs之上的是一个一个用户程序,它能够根据系统中的硬件设备的状态动态更新设备文件,包括设备文件的创建,删除等,设备文件通常放在/dev目录下。使用udev后,在/dev目录下就只包含系统中真正存在的设备。udev的的工作过程大致是这样的:
-
-
1. 当内核检测到在系统中出现了新设备后,内核会在sysfs文件系统中为该新设备生成一项新的记录,新记录是以文件或目录的方式来表示,每个文件都包含有特定的信息。
-
-
2. udev在系统中是以守护进程的方式运行,它通过某种途径检测到新设备的出现,通过查找设备对应的sysfs中的记录得到设备的信息。
-
-
3. udev会根据/etc/udev/udev.conf文件中的udev_rules指定的目录,逐个检查该目录下的文件,这个目录下的文件都是针对某类或某个设备应该施行什么措施的规则文件。udev读取文件是按照文件名的ASCII字母顺序来读取的,如果udev一旦找到了与新加入的设备匹配的规则,udev就会根据规则定义的措施对新设备进行配置。同时不再读后续的规则文件。
-
-
(2)udev的工作可以简单的概括为:监控系统中设备状态的变化,当有设备的状态发生变化时,根据用户的配置对设备文件执行相应的操作。
-
-
(3)udev的配置规则
-
udev的全局的配置文件是/etc/udev/udev.conf,该文件一般缺省有这样几项:
-
udev_root="/dev" #udev产生的设备文件的根目录是/dev
-
udev_rules="/etc/udev/rules.d" #用于指导udev工作的规则所在目录。
-
udev_log="err" #当出现错误时,用syslog记录错误信息。
-
其中最关键的就是规则文件,即/etc/udev/rules.d/目录下的文件,udev是按照文件名的ASCII字母顺序来读取的,一旦找到与设备匹配的规则,就运用该规则,并不再读后续的规则文件了。下面简单看下udev定义了那些规则,以及它是如何进行配置的,怎样去编写这种规则文件。
-
-
udev的规则文件以行为单位,以"#"开头的行代表注释行。其余的每一行代表一个规则。每个规则分成一个或多个“匹配”和“赋值”部分。“匹配”部分用“匹配“专用的关键字来表示,相应的“赋值”部分用“赋值”专用的关键字来表示。“匹配”关键字包括:ACTION,KERNEL,BUS,
SYSFS等等,“赋值”关键字包括:NAME,SYMLINK,OWNER等等。具体详细的描述可以阅读udev的man文档。下面通过一个具体的例子来说明,看如下的规则:
-
-
# PCI device 0x8086:0x1096 (e1000e)
-
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:19:21:ff:cc:7c", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
-
-
这个规则中的“匹配”部分有四项,分别是SUBSYSTEM,ACTION,DRIVERS,KERNEL。而"赋值"部分有一项,是NAME。这个规则就是说,当系统中出现的新硬件属于net子系统范畴,系统对该硬件采取的动作是加入这个硬件,且这个硬件在DRIVERS信息中的address="00:19:21:ff:cc:7c",dev_id="0x0",内核的命名为eth*时,udev会在建立新的网络设备,并命名为eth0。udev规则文件的编写可以参考man手册。
-
-
二、udev自动生成设备节点
-
生成设备文件节点的方法有三个:1.手动mknod 2.利用devfs 3.利用udev
-
-
udev是硬件平台无关的,属于user space的进程,它脱离驱动层的关联而建立在操作系统之上,基于这种设计实现,我们可以随时修改及删除/dev下的设备文件名称和指向,随心所欲地按照我们的愿望安排和管理设备文件系统,而完成如此灵活的功能只需要简单地修改udev的配置文件即可,无需重新启动操作系统。udev已经使得我们对设备的管理如探囊取物般轻松自如。
-
-
内核中定义了struct class 结构体,顾名思义,一个struct class 结构体类型变量对应一个类,内核同时提供了class_create() 函数,可以用它来创建一个类,这个类存放于sysfs 下面,一旦创建好了这个类,再调用device_create() 函数来在/dev目录下创建相应的设备节点。这样,加载模块的时候,用户空间中的udev会自动响应device_create() 函数,去/sysfs 下寻找对应的类从而创建设备节点。
-
-
struct class {
-
const char * name;
-
struct module * owner;
-
nbsp; struct kset subsys;
-
struct list_head devices;
-
struct list_head interfaces;
-
struct kset class_dirs;
-
struct semaphore sem; /* locks children, devices, interfaces */
-
struct class_attribute * class_attrs;
-
struct device_attribute * dev_attrs;
-
int ( * dev_uevent) ( struct device * dev, struct kobj_uevent_env * env) ;
-
void ( * class_release) ( struct class * class ) ;
-
void ( * dev_release) ( struct device * dev) ;
-
int ( * suspend) ( struct device * dev, pm_message_t state) ;
-
int ( * resume) ( struct device * dev) ;
-
} ;
-
-
//第一个参数指定类的所有者是哪个模块,第二个参数指定类名。
-
struct class * class_create( struct module * owner, const char * name)
-
{
-
struct class * cls;
-
int retval;
-
cls = kzalloc( sizeof ( * cls) , GFP_KERNEL) ;//分配一个类结构
-
if ( ! cls) {
-
retval = - ENOMEM;
-
goto error ;
-
}
-
cls- > name = name;
-
cls- > owner = owner;
-
cls- > class_release = class_create_release;
-
retval = class_register( cls) ;//注册这个类,即在/sys/class目录下添加目录
-
if ( retval)
-
goto error ;
-
return cls;
-
error :
-
kfree( cls) ;
-
return ERR_PTR( retval) ;
-
}
-
-
//第一个参数指定所要创建的设备所从属的类,第二个参数是这个设备的父设备,如果没有就指定为NULL,第三个参数是设备号,第四个参数是设备名称,第五个参数是从设备号。
-
struct device * device_create( struct class * class , struct device * parent,dev_t devt, const char * fmt, . . . )
-
{
-
va_list vargs;
-
struct device * dev;
-
va_start ( vargs, fmt);
-
//device_create_vargs函数流程:
-
//device_create-->device_create_vargs-->device_register-->device_add-->kobject_uevent(&dev->kobj, KOBJ_ADD);-->
-
//kobject_uevent_env(kobj, action, NULL);-->call_usermodehelper(argv[0], argv,env->envp, UMH_WAIT_EXEC);}
-
dev = device_create_vargs( class , parent, devt, NULL , fmt, vargs) ;
-
va_end ( vargs) ;
-
return dev;
-
}
-
-
三、事件通知
-
在device_add()例程,其用于将一个device注册到device model,其中调用了kobject_uevent(&dev->kobj, KOBJ_ADD)例程向用户空间发出KOBJ_ADD 事件并输出环境变量,以表明一个device被添加了。在《Linux设备模型浅析之设备篇》中介绍过rtc_device_register()例程 ,其最终调用device_add()例程添加了一个rtc0的device,我们就以它为例子来完成uevent的分析。让我们看看kobject_uevent()这个例程的代码,如下:
-
int kobject_uevent(struct kobject *kobj, enum kobject_action action)
-
{
-
return kobject_uevent_env(kobj, action, NULL);
-
}
-
它又调用了kobject_uevent_env()例程,部分代码如下:
-
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,char *envp_ext[])
-
{
-
struct kobj_uevent_env *env;
-
const char *action_string = kobject_actions[action]; // 本例是“add”命令
-
const char *devpath = NULL;
-
const char *subsystem;
-
struct kobject *top_kobj;
-
struct kset *kset;
-
struct kset_uevent_ops *uevent_ops;
-
u64 seq;
-
int i = 0;
-
int retval = 0;
-
pr_debug("kobject: '%s' (%p): %s\n",kobject_name(kobj), kobj, __func__);
-
-
top_kobj = kobj;
-
/* 找到其所属的 kset容器,如果没找到就从其父kobj找,一直持续下去,直到父kobj不存在 */
-
while (!top_kobj->kset && top_kobj->parent)
-
top_kobj = top_kobj->parent;
-
if (!top_kobj->kset) {
-
pr_debug("kobject: '%s' (%p): %s: attempted to send uevent ""without kset!\n", kobject_name(kobj), kobj,__func__);
-
return -EINVAL;
-
}
-
/* 在本例中是devices_kset容器 */
-
kset = top_kobj->kset;
-
uevent_ops = kset->uevent_ops; // 本例中uevent_ops = &device_uevent_ops
-
/* 回调 uevent_ops->filter ()例程,本例中是dev_uevent_filter()例程,主要是检查是否uevent suppress*/
-
/* skip the event, if the filter returns zero. */
-
if (uevent_ops && uevent_ops->filter)
-
if (!uevent_ops->filter(kset, kobj)) { // 如果不成功,即uevent suppress,则直接返回
-
pr_debug("kobject: '%s' (%p): %s: filter function ""caused the event to drop!\n",kobject_name(kobj), kobj, __func__);
-
return 0;
-
}
-
/* 回调 uevent_ops-> name (),本例中是dev_uevent_name()例程,获取bus或class的名字,本例中rtc0不存在bus,所以是class的名字“rtc”,后面分析 */
-
if (uevent_ops && uevent_ops->name)
-
subsystem = uevent_ops->name(kset, kobj);
-
else
-
subsystem = kobject_name(&kset->kobj);
-
if (!subsystem) {
-
pr_debug("kobject: '%s' (%p): %s: unset subsystem caused the ""event to drop!\n", kobject_name(kobj), kobj,__func__);
-
return 0;
-
}
-
// 获得用于存放环境变量的buffer
-
env = kzalloc(sizeof(struct kobj_uevent_env), GFP_KERNEL);
-
if (!env)
-
return -ENOMEM;
-
/* 获取该kobj在sysfs的路径,通过遍历其父kobj来获得,本例是/sys/devices/platform/s3c2410-rtc/rtc/rtc0 */
-
devpath = kobject_get_path(kobj, GFP_KERNEL);
-
if (!devpath) {
-
retval = -ENOENT;
-
goto exit;
-
}
-
// 添加 ACTION环境变量,本例是“add”命令
-
retval = add_uevent_var(env, "ACTION=%s", action_string);
-
if (retval)
-
goto exit;
-
// 添加 DEVPATH环境变量,本例是/sys/devices/platform/s3c2410-rtc/rtc/rtc0
-
retval = add_uevent_var(env, "DEVPATH=%s", devpath);
-
if (retval)
-
goto exit;
-
// 添加 SUBSYSTEM 环境变量,本例中是“rtc”
-
retval = add_uevent_var(env, "SUBSYSTEM=%s", subsystem);
-
if (retval)
-
goto exit;
-
/* keys passed in from the caller */
-
if (envp_ext) { // 为NULL,不执行
-
for (i = 0; envp_ext[i]; i++) {
-
retval = add_uevent_var(env, "%s", envp_ext[i]);
-
if (retval)
-
goto exit;
-
}
-
}
-
// 回调 uevent_ops->uevent(),本例中是dev_uevent()例程,输出一些环境变量,后面分析
-
if (uevent_ops && uevent_ops->uevent) {
-
retval = uevent_ops->uevent(kset, kobj, env);
-
if (retval) {
-
pr_debug("kobject: '%s' (%p): %s: uevent() returned ""%d\n", kobject_name(kobj), kobj,__func__, retval);
-
goto exit;
-
}
-
}
-
-
if (action == KOBJ_ADD)
-
kobj->state_add_uevent_sent = 1;
-
else if (action == KOBJ_REMOVE)
-
kobj->state_remove_uevent_sent = 1;
-
-
/* 增加event序列号的值,并输出到环境变量的buffer。该系列号可以从/sys/kernel/uevent_seqnum属性文件读取,至于uevent_seqnum属性文件及/sys/kernel/目录是怎样产生的,后面会分析 */
-
spin_lock(&sequence_lock);
-
seq = ++uevent_seqnum;
-
spin_unlock(&sequence_lock);
-
retval = add_uevent_var(env, "SEQNUM=%llu", (unsigned long long)seq);
-
if (retval)
-
goto exit;
-
/* 如果配置了网络,那么就会通过netlink socket 向用户空间发送环境标量,而用户空间则通过netlink socket 接收,然后采取一些列的动作。这种机制目前用在udev中,也就是pc机系统中,后面会分析*/
-
#if defined(CONFIG_NET)
-
/* 如果配置了net,则会在kobject_uevent_init()例程中将全局比昂俩uevent_sock 初试化为NETLINK_KOBJECT_UEVENT 类型的socket。*/
-
if (uevent_sock) {
-
struct sk_buff *skb;
-
size_t len;
-
/* allocate message with the maximum possible size */
-
len = strlen(action_string) + strlen(devpath) + 2;
-
skb = alloc_skb(len + env->buflen, GFP_KERNEL);
-
if (skb) {
-
char *scratch;
-
/* add header */
-
scratch = skb_put(skb, len);
-
sprintf(scratch, "%s@%s", action_string, devpath);
-
/* copy keys to our continuous event payload buffer */
-
for (i = 0; i < env->envp_idx; i++) {
-
len = strlen(env->envp[i]) + 1;
-
scratch = skb_put(skb, len);
-
strcpy(scratch, env->envp[i]);
-
}
-
NETLINK_CB(skb).dst_group = 1;
-
retval = netlink_broadcast(uevent_sock, skb, 0, 1,GFP_KERNEL); // 广播
-
} else
-
retval = -ENOMEM;
-
}
-
#endif
-
/* 对于嵌入式系统来说,busybox采用的是mdev,在系统启动脚本rcS 中会使用echo /sbin/mdev > /proc/sys/kernel/hotplug命令,而这个 hotplug文件通过一定的方法映射到了uevent_helper[]数组,所以uevent_helper[] = “/sbin/mdev” 。所以对于采用busybox的嵌入式系统来说会执行里面的代码,而pc机不会。也就是说内核会call用户空间的/sbin/mdev这个应用程序来做动作,后面分析 */
-
if (uevent_helper[0]) {
-
char *argv [3];
-
// 加入到环境变量buffer
-
argv [0] = uevent_helper;
-
argv [1] = (char *)subsystem;
-
argv [2] = NULL;
-
//添加HOME目录环境变量
-
retval = add_uevent_var(env, "HOME=/");
-
if (retval)
-
goto exit;
-
//添加PATH环境变量
-
retval = add_uevent_var(env,"PATH=/sbin:/bin:/usr/sbin:/usr/bin");
-
if (retval)
-
goto exit;
-
// 呼叫应用程序来处理, UMH_WAIT_EXEC表明等待应用程序处理完,dev会根据先前设置的环境变量进行处理
-
retval = call_usermodehelper(argv[0], argv,env->envp, UMH_WAIT_EXEC);
-
}
-
exit:
-
kfree(devpath);
-
kfree(env);
-
return retval;
-
}
-
-
-
kobject_uevent_env函数最后调用了mdev,mdev的入口函数在busybox的mdev_main
-
-
mdev_main
-
{
-
if (argv[1] && !strcmp(argv[1], "-s"))//先判断参数1是否为-s,如果为-s则表明mdev为开机执行的情况(mdev -s位于/etc/init.d/rcS中)
-
-
else
-
-
getenv //提取各个环境变量
-
-
make_device //根据action创建设备
-
-
/*对于设备,当我们创建其节点时,我们可以通过配置文件进行配置,该配置文件位于/etc/mdev.conf
-
-
*设备名称正则表达式用户id 组id 节点属性 创建的设备节点路径 shell命令
-
-
*配置方式为<device regex> <uid>:<gid> <octal permissions> [=path] [@|$|*<command>]
-
*/
-
-
parser = config_open2("/etc/mdev.conf", fopen_for_read); //打开/etc/mdev.conf文件
-
-
while (config_read(parser, tokens, 4, 3, "# \t", PARSE_NORMAL)) //分析mdev.conf文件内容,并执行相关操作command
-
-
{...}
-
-
mknod(device_name, mode | type, makedev(major, minor)) //调用mknod进行节点创建
-
}
-
-
-
四、示例
-
Udev获取和设置设备节点的信息是通过建立一个本地套接口来实现:socket(AF_LOCAL, SOCK_SEQPACKET|SOCK_NONBLOCK|SOCK_CLOEXEC, 0)。其中SOCK_SEQPACKET提供连续可信赖的数据包连接。然后通过sendmsg和recvmsg去发送和获取相应的信息。当获取到设备的相应信息后再根据用户设置的规则调用mknod函数去创建相应的设备节点。
-
Udev创建的所有设备节点的设备号都可以在/sys/dev/{block,char}目录中找到。如果驱动程序要让udev自动创建设备节点,那么你就必须保存在这个目录下有这个设备号。下面例举一个简单的例子:
-
#include <linux/module.h>
-
#include <linux/fs.h>
-
#include <linux/init.h>
-
#include <linux/cdev.h>
-
#include <linux/device.h>
-
static int mem_major = 240;
-
static struct class *test_class;
-
struct cdev cdev;
-
/*文件操作结构体*/
-
static const struct file_operations mem_fops =
-
{
-
.owner = THIS_MODULE,
-
};
-
-
/*设备驱动模块加载函数*/
-
static int memdev_init(void)
-
{
-
dev_t devno = MKDEV(mem_major, 0);
-
int result = register_chrdev_region(devno, 2, "memdev");
-
if (result < 0)
-
return result;
-
cdev_add(&cdev, MKDEV(mem_major, 0), 1);
-
test_class = class_create(THIS_MODULE, "juvi_test_class");//创建一个类,用来表示该设备文件是哪一种类型,创建成功会在/sys/class中出现。
-
device_create(test_class, NULL, devno, NULL, "test_udev");//创建设备文件,它会在/sys/dev/char中出现相应的设备接点号。然后dev目录下面会自动创建设备文件。
-
return result;
-
}
-
/*模块卸载函数*/
-
static void memdev_exit(void)
-
{
-
cdev_del(&cdev); /*注销设备*/
-
unregister_chrdev_region(MKDEV(mem_major, 0), 2); /*释放设备号*/
-
class_destroy(test_class);//删除这个类型的设备。
-
}
-
MODULE_LICENSE("GPL");
-
module_init(memdev_init);
-
module_exit(memdev_exit);
-
-
-
-
五、分析mdev
-
a、执行mdev -s命令时,mdev扫描/sys/block(块设备保存在/sys/block目录下,内核2.6.25版本以后,块设备也保存在/sys/class/block目录下。mdev扫描/sys/block是为了实现向后兼容)和/sys/class两个目录下的dev属性文件,从该dev属性文件中获取到设备编号(dev属性文件以"major:minor\n"形式保存设备编号),并以包含该dev属性文件的目录名称作为设备名device_name(即包含dev属性文件的目录称为device_name,而/sys/class和device_name之间的那部分目录称为subsystem。也就是每个dev属性文件所在的路径都可表示为/sys/class/subsystem/device_name/dev),在/dev目录下创建相应的设备文件。例如,cat /sys/class/tty/tty0/dev会得到4:0,subsystem为tty,device_name为tty0。
-
-
b、当mdev因uevnet事件(以前叫hotplug事件)被调用时,mdev通过由uevent事件传递给它的环境变量获取到:引起该uevent事件的设备action及该设备所在的路径device
path。然后判断引起该uevent事件的action是什么。若该action是add,即有新设备加入到系统中,不管该设备是虚拟设备还是实际物理设备,mdev都会通过device
path路径下的dev属性文件获取到设备编号,然后以device path路径最后一个目录(即包含该dev属性文件的目录)作为设备名,在/dev目录下创建相应的设备文件。若该action是remote,即设备已从系统中移除,则删除/dev目录下以device path路径最后一个目录名称作为文件名的设备文件。如果该action既不是add也不是remove,mdev则什么都不做。
-
-
由上面可知,如果我们想在设备加入到系统中或从系统中移除时,由mdev自动地创建和删除设备文件,那么就必须做到以下三点:1、在/sys/class的某一subsystem目录下,2、创建一个以设备名device_name作为名称的目录,3、并且在该device_name目录下还必须包含一个dev属性文件,该dev属性文件以"major:minor\n"形式输出设备编号。
-
-
-
int mdev_main(int argc UNUSED_PARAM, char **argv)
-
{
-
//#define RESERVE_CONFIG_BUFFER(buffer,len) char buffer[len]
-
//声明一个数组
-
RESERVE_CONFIG_BUFFER(temp, PATH_MAX + SCRATCH_SIZE);
-
-
/*
-
struct globals {
-
int root_major, root_minor;
-
char *subsystem;
-
#if ENABLE_FEATURE_MDEV_CONF
-
const char *filename;
-
parser_t *parser;
-
struct rule **rule_vec;
-
unsigned rule_idx;
-
#endif
-
struct rule cur_rule;
-
} FIX_ALIASING;
-
#define G (*(struct globals*)&bb_common_bufsiz1)
-
enum { COMMON_BUFSIZE = (BUFSIZ >= 256*sizeof(void*) ? BUFSIZ+1 : 256*sizeof(void*)) };
-
extern char bb_common_bufsiz1[COMMON_BUFSIZE];
-
#define INIT_G() do { \
-
IF_NOT_FEATURE_MDEV_CONF(G.cur_rule.maj = -1;) \
-
IF_NOT_FEATURE_MDEV_CONF(G.cur_rule.mode = 0660;) \
-
} while (0)
-
*/
-
//初始化结构体
-
INIT_G();
-
-
#if ENABLE_FEATURE_MDEV_CONF
-
G.filename = "/etc/mdev.conf";
-
#endif
-
-
/* We can be called as hotplug helper */
-
//阅读这个函数的源代码后,发现这里其实就是判断了/dev/null是否存在。如果打不开,那么就进入die状态。
-
bb_sanitize_stdio();
-
-
/* Force the configuration file settings exactly */
-
umask(0);//配置屏蔽位
-
-
xchdir("/dev");//切换到/dev目录
-
-
if (argv[1] && strcmp(argv[1], "-s") == 0) {//如果执行的是mdev -s,这是在shell里调用的。在系统启动时调用。创建所有设备驱动的节点。
-
struct stat st;
-
-
#if ENABLE_FEATURE_MDEV_CONF
-
/* Same as xrealloc_vector(NULL, 4, 0): */
-
G.rule_vec = xzalloc((1 << 4) * sizeof(*G.rule_vec));//给rule结构体分配空间
-
#endif
-
xstat("/", &st);//返回根目录文件状态信息
-
G.root_major = major(st.st_dev);//保存文件的设备号
-
G.root_minor = minor(st.st_dev);
-
-
if (access("/sys/class/block", F_OK) != 0) {//判断/sys/class/block这个文件或者目录是否存在。存在返回0,否则返回-1
-
//这个函数是递归函数,它会把/sys/block目录下的所有文件文件夹都去查看一遍,如果发现dev文件,那么将按照/etc/mdev.conf文件进行相应的配置。如果没有配置文件,那么直接创建设备节点。
-
recursive_action("/sys/block",ACTION_RECURSE | ACTION_FOLLOWLINKS | ACTION_QUIET,fileAction, dirAction, temp, 0);
-
}
-
//这个函数是递归函数,它会把/sys/class目录下的所有文件文件夹都去查看一遍,如果发现dev文件,那么将按照/etc/mdev.conf文件进行相应的配置。如果没有配置文件,那么直接创建设备节点。
-
recursive_action("/sys/class",ACTION_RECURSE | ACTION_FOLLOWLINKS,fileAction, dirAction, temp, 0);
-
} else {//通过hotplug通知mdev创建设备节点
-
char *fw;
-
char *seq;
-
char *action;
-
char *env_path;
-
static const char keywords[] ALIGN1 = "remove\0add\0";
-
enum { OP_remove = 0, OP_add };
-
smalluint op;
-
-
/* Hotplug:
-
* env ACTION=... DEVPATH=... SUBSYSTEM=... [SEQNUM=...] mdev
-
* ACTION can be "add" or "remove"
-
* DEVPATH is like "/block/sda" or "/class/input/mice"
-
经过驱动层分析,所得的环境变量为,这里是以spidev,0.0设备为例:
-
ACTION=add: kobject_actions[KOBJ_ADD]
-
DEVPATH=/class/spidev/spidev0.0/: kobject_get_path(kobj, GFP_KERNEL) /sys不存在,这里只统计到/sys目录下
-
SUBSYSTEM=spidev: dev->bus->name,dev->class->name,如果dev->bus不存在的情况下,那么才使用dev->class->name
-
MAJOR=MAJOR(dev->devt)
-
MINOR=MINOR(dev->devt)
-
PHYSDEVPATH=/devices/platform/atmel_spi.0/spi0.0/: kobject_get_path(&dev->parent->kobj, GFP_KERNEL) /sys不存在,这里只统计到/sys目录下
-
PHYSDEVBUS=/bus/spi/: dev->parent->bus->name /sys不存在,这里只统计到/sys目录下
-
PHYSDEVDRIVER=spidev: dev->parent->driver->name
-
SEQNUM=++uevent_seqnum
-
HOME=/
-
PATH=/sbin:/bin:/usr/sbin:/usr/bin
-
*/
-
//获得环境变量
-
action = getenv("ACTION");
-
env_path = getenv("DEVPATH");
-
G.subsystem = getenv("SUBSYSTEM");
-
if (!action || !env_path)
-
bb_show_usage();
-
fw = getenv("FIRMWARE");
-
op = index_in_strings(keywords, action);//比较keywords数组中和action,若是remove则返回0,若是add则返回1
-
seq = getenv("SEQNUM");
-
/*
-
内核不序列化热插拔事件,而是为每一个成功的热插拔调用增加了 SEQNUM
这个环境变量。通常情况下,mdev不在乎这个。这样也许可以重新对热插拔事件进行重调用,典型的症状就是有时某些设备节点不能像期待的那样被创建出来。不管怎么说,如果
/dev/mdev.seq 文件存在,mdev将比较它和SEQNUM的内容,它将重试直到有两个第二,等待他们匹配。如果他们精确的匹配(甚至连"\n"都不被允许),或者两个第二出现,mdev依旧运行,然后它用SEQNUM+1重写/dev/mdev.seq。
-
*/
-
if (seq) {
-
int timeout = 2000 / 32; /* 2000 msec */
-
do {
-
int seqlen;
-
char seqbuf[sizeof(int)*3 + 2];
-
//从mdev.seq文件中读出seq
-
seqlen = open_read_close("mdev.seq", seqbuf, sizeof(seqbuf) - 1);
-
if (seqlen < 0) {
-
seq = NULL;
-
break;
-
}
-
seqbuf[seqlen] = '\0';
-
if (seqbuf[0] == '\n' /* seed file? */|| strcmp(seq, seqbuf) == 0) { /* correct idx? */
-
break;
-
}
-
usleep(32*1000);
-
} while (--timeout);
-
}
-
-
//创建的设备路径名赋值给temp,例如/sys/class/spidev/spidev0.0/
-
snprintf(temp, PATH_MAX, "/sys%s", env_path);
-
if (op == OP_remove) {//删除节点
-
if (!fw)
-
make_device(temp, /*delete:*/ 1);
-
}
-
else if (op == OP_add) {//添加节点
-
make_device(temp, /*delete:*/ 0);
-
if (ENABLE_FEATURE_MDEV_LOAD_FIRMWARE) {
-
if (fw)
-
load_firmware(fw, temp);
-
}
-
}
-
-
if (seq) {//重写mdev.seq文件
-
xopen_xwrite_close("mdev.seq", utoa(xatou(seq) + 1));
-
}
-
}
-
-
if (ENABLE_FEATURE_CLEAN_UP)
-
RELEASE_CONFIG_BUFFER(temp);
-
-
return EXIT_SUCCESS;
-
}
-
-
//recursive_action("/sys/block",ACTION_RECURSE | ACTION_FOLLOWLINKS | ACTION_QUIET,fileAction, dirAction, temp, 0);
-
int FAST_FUNC recursive_action(const char *fileName,unsigned flags,int FAST_FUNC (*fileAction)(const char *fileName, struct stat *statbuf, void* userData, int depth),
-
int FAST_FUNC (*dirAction)(const char *fileName, struct stat *statbuf, void* userData, int depth),void* userData,unsigned depth)
-
{
-
struct stat statbuf;
-
unsigned follow;
-
int status;
-
DIR *dir;
-
struct dirent *next;
-
-
if (!fileAction)
-
fileAction = true_action;
-
if (!dirAction)
-
dirAction = true_action;
-
-
follow = ACTION_FOLLOWLINKS;
-
if (depth == 0)//第一次调用时传入depth参数为0
-
follow = ACTION_FOLLOWLINKS | ACTION_FOLLOWLINKS_L0;
-
-
follow &= flags;//也设置了ACTION_FOLLOWLINKS标志
-
-
//stat和lstat的区别:当文件是一个符号链接时,lstat返回的是该符号链接本身的信息;而stat返回的是该链接指向的文件的信息。
-
status = (follow ? stat : lstat)(fileName, &statbuf);//这里用stat读取目录或文件属性
-
if (status < 0) {
-
if ((flags & ACTION_DANGLING_OK)&& errno == ENOENT&& lstat(fileName, &statbuf) == 0) {/* Dangling link */
-
return fileAction(fileName, &statbuf, userData, depth);
-
}
-
goto done_nak_warn;
-
}
-
-
if (!S_ISDIR(statbuf.st_mode)) {//如果不是目录,则调用下边函数进行创建设备节点
-
return fileAction(fileName, &statbuf, userData, depth);
-
}
-
-
//ACTION_RECURSE标志设置过,不进行以下操作
-
if (!(flags & ACTION_RECURSE)) {
-
return dirAction(fileName, &statbuf, userData, depth);
-
}
-
-
//没有设置过ACTION_DEPTHFIRST
-
if (!(flags & ACTION_DEPTHFIRST)) {
-
status = dirAction(fileName, &statbuf, userData, depth);//返回TRUE=1
-
if (!status)
-
goto done_nak_warn;
-
if (status == SKIP)
-
return TRUE;
-
}
-
-
//执行到这里表明传入的参数是目录
-
dir = opendir(fileName);//打开目录
-
if (!dir) {
-
goto done_nak_warn;
-
}
-
status = TRUE;
-
while ((next = readdir(dir)) != NULL) {//读目录
-
char *nextFile;
-
-
nextFile = concat_subpath_file(fileName, next->d_name);//读目录下的文件
-
if (nextFile == NULL)
-
continue;
-
/* process every file (NB: ACTION_RECURSE is set in flags) */
-
if (!recursive_action(nextFile, flags, fileAction, dirAction,userData, depth + 1))//递归调用
-
status = FALSE;
-
free(nextFile);
-
}
-
closedir(dir);
-
-
//没有设置过ACTION_DEPTHFIRST,不会进去执行
-
if (flags & ACTION_DEPTHFIRST) {
-
if (!dirAction(fileName, &statbuf, userData, depth))
-
goto done_nak_warn;
-
}
-
-
return status;
-
-
done_nak_warn:
-
if (!(flags & ACTION_QUIET))
-
bb_simple_perror_msg(fileName);
-
return FALSE;
-
}
-
-
static int FAST_FUNC fileAction(const char *fileName,struct stat *statbuf UNUSED_PARAM,void *userData,int depth UNUSED_PARAM)
-
{
-
size_t len = strlen(fileName) - 4; /* can't underflow */
-
char *scratch = userData;
-
-
//检查传入进来的路径名的最后4个字符是否为“/dev”,即只有根据dev文件来创建设备节点
-
if (strcmp(fileName + len, "/dev") != 0 || len >= PATH_MAX)
-
return FALSE;
-
-
strcpy(scratch, fileName);//复制文件名
-
scratch[len] = '\0';//将最后的"/dev"去掉
-
make_device(scratch, /*delete:*/ 0);//进行创建设备节点
-
-
return TRUE;
-
}
-
-
static void make_device(char *path, int delete)
-
{
-
char *device_name, *subsystem_slash_devname;
-
int major, minor, type, len;
-
-
dbg("%s('%s', delete:%d)", __func__, path, delete);
-
major = -1;
-
if (!delete) {
-
char *dev_maj_min = path + strlen(path);//将dev_maj_min指针指向路径名的最后
-
-
//传入的路径名是最后dev文件的父目录,例如/sys/block/mtdblock0
-
strcpy(dev_maj_min, "/dev");//即将路径名添加“/dev”,即/sys/block/mtdblock0/dev确保读的文件时dev文件
-
len = open_read_close(path, dev_maj_min + 1, 64);//从dev文件中读出主设备号和次设备号存到dev_maj_min + 1地址处
-
*dev_maj_min = '\0';
-
if (len < 1) {
-
if (!ENABLE_FEATURE_MDEV_EXEC)
-
return;
-
} else if (sscanf(++dev_maj_min, "%u:%u", &major, &minor) != 2) {//主设备号和次设备号复制给major和minor
-
major = -1;
-
}
-
}
-
//调用strrchr() 函数查找字符在指定字符串中从后面开始的第一次出现的位置,即找到设备名
-
//例如:/sys/block/mtdblock0,返回的设备名就是mtdblock0
-
device_name = (char*) bb_basename(path);
-
-
type = S_IFCHR;
-
//判断是否为block设备
-
if (strstr(path, "/block/") || (G.subsystem && strncmp(G.subsystem, "block", 5) == 0))
-
type = S_IFBLK;
-
-
/* Make path point to "subsystem/device_name" */
-
subsystem_slash_devname = NULL;
-
//path路径名前移
-
if (strncmp(path, "/sys/block/", 11) == 0) /* legacy case */
-
path += sizeof("/sys/") - 1;
-
else if (strncmp(path, "/sys/class/", 11) == 0)
-
path += sizeof("/sys/class/") - 1;
-
else {
-
/* Example of a hotplug invocation:
-
* SUBSYSTEM="block"
-
* DEVPATH="/sys" + "/devices/virtual/mtd/mtd3/mtdblock3"
-
* ("/sys" is added by mdev_main)
-
* - path does not contain subsystem
-
*/
-
subsystem_slash_devname = concat_path_file(G.subsystem, device_name);
-
path = subsystem_slash_devname;
-
}
-
-
#if ENABLE_FEATURE_MDEV_CONF
-
G.rule_idx = 0; /* restart from the beginning (think mdev -s) */
-
#endif
-
for (;;) {
-
const char *str_to_match;
-
regmatch_t off[1 + 9 * ENABLE_FEATURE_MDEV_RENAME_REGEXP];
-
char *command;
-
char *alias;
-
char aliaslink = aliaslink; /* for compiler */
-
const char *node_name;
-
const struct rule *rule;
-
-
str_to_match = "";
-
//# define next_rule() (&G.cur_rule)
-
rule = next_rule();
-
//检查rule
-
#if ENABLE_FEATURE_MDEV_CONF
-
if (rule->maj >= 0) { /* @maj,min rule */
-
if (major != rule->maj)
-
continue;
-
if (minor < rule->min0 || minor > rule->min1)
-
continue;
-
memset(off, 0, sizeof(off));
-
goto rule_matches;
-
}
-
if (rule->envvar) { /* $envvar=regex rule */
-
str_to_match = getenv(rule->envvar);
-
dbg("getenv('%s'):'%s'", rule->envvar, str_to_match);
-
if (!str_to_match)
-
continue;
-
} else {
-
/* regex to match [subsystem/]device_name */
-
str_to_match = (rule->regex_has_slash ? path : device_name);
-
}
-
-
if (rule->regex_compiled) {
-
int regex_match = regexec(&rule->match, str_to_match, ARRAY_SIZE(off), off, 0);
-
dbg("regex_match for '%s':%d", str_to_match, regex_match);
-
-
if (regex_match != 0
-
/* regexec returns whole pattern as "range" 0 */
-
|| off[0].rm_so != 0
-
|| (int)off[0].rm_eo != (int)strlen(str_to_match)
-
) {
-
continue; /* this rule doesn't match */
-
}
-
}
-
/* else: it's final implicit "match-all" rule */
-
rule_matches:
-
#endif
-
dbg("rule matched");
-
-
/* Build alias name */
-
alias = NULL;
-
if (ENABLE_FEATURE_MDEV_RENAME && rule->ren_mov) {
-
aliaslink = rule->ren_mov[0];
-
if (aliaslink == '!') {
-
/* "!": suppress node creation/deletion */
-
major = -2;
-
}
-
else if (aliaslink == '>' || aliaslink == '=') {
-
if (ENABLE_FEATURE_MDEV_RENAME_REGEXP) {
-
char *s;
-
char *p;
-
unsigned n;
-
-
/* substitute %1..9 with off[1..9], if any */
-
n = 0;
-
s = rule->ren_mov;
-
while (*s)
-
if (*s++ == '%')
-
n++;
-
-
p = alias = xzalloc(strlen(rule->ren_mov) + n * strlen(str_to_match));
-
s = rule->ren_mov + 1;
-
while (*s) {
-
*p = *s;
-
if ('%' == *s) {
-
unsigned i = (s[1] - '0');
-
if (i <= 9 && off[i].rm_so >= 0) {
-
n = off[i].rm_eo - off[i].rm_so;
-
strncpy(p, str_to_match + off[i].rm_so, n);
-
p += n - 1;
-
s++;
-
}
-
}
-
p++;
-
s++;
-
}
-
} else {
-
alias = xstrdup(rule->ren_mov + 1);
-
}
-
}
-
}
-
dbg("alias:'%s'", alias);
-
-
command = NULL;
-
IF_FEATURE_MDEV_EXEC(command = rule->r_cmd;)
-
if (command) {
-
const char *s = "$@*";
-
const char *s2 = strchr(s, command[0]);
-
-
/* Are we running this command now?
-
* Run $cmd on delete, @cmd on create, *cmd on both
-
*/
-
if (s2 - s != delete) {
-
/* We are here if: '*',
-
* or: '@' and delete = 0,
-
* or: '$' and delete = 1
-
*/
-
command++;
-
} else {
-
command = NULL;
-
}
-
}
-
dbg("command:'%s'", command);
-
-
/* "Execute" the line we found */
-
node_name = device_name;
-
if (ENABLE_FEATURE_MDEV_RENAME && alias) {
-
node_name = alias = build_alias(alias, device_name);
-
dbg("alias2:'%s'", alias);
-
}
-
-
if (!delete && major >= 0) {//创建设备节点
-
dbg("mknod('%s',%o,(%d,%d))", node_name, rule->mode | type, major, minor);
-
if (mknod(node_name, rule->mode | type, makedev(major, minor)) && errno != EEXIST)//创建设备节点
-
bb_perror_msg("can't create '%s'", node_name);
-
if (major == G.root_major && minor == G.root_minor)
-
symlink(node_name, "root");
-
if (ENABLE_FEATURE_MDEV_CONF) {
-
chmod(node_name, rule->mode);
-
chown(node_name, rule->ugid.uid, rule->ugid.gid);
-
}
-
if (ENABLE_FEATURE_MDEV_RENAME && alias) {
-
if (aliaslink == '>') {
-
//TODO: on devtmpfs, device_name already exists and symlink() fails.
-
//End result is that instead of symlink, we have two nodes.
-
//What should be done?
-
symlink(node_name, device_name);
-
}
-
}
-
}
-
-
if (ENABLE_FEATURE_MDEV_EXEC && command) {
-
/* setenv will leak memory, use putenv/unsetenv/free */
-
char *s = xasprintf("%s=%s", "MDEV", node_name);
-
char *s1 = xasprintf("%s=%s", "SUBSYSTEM", G.subsystem);
-
putenv(s);
-
putenv(s1);
-
if (system(command) == -1)
-
bb_perror_msg("can't run '%s'", command);
-
bb_unsetenv_and_free(s1);
-
bb_unsetenv_and_free(s);
-
}
-
-
if (delete && major >= -1) {//删除节点
-
if (ENABLE_FEATURE_MDEV_RENAME && alias) {
-
if (aliaslink == '>')
-
unlink(device_name);
-
}
-
unlink(node_name);
-
}
-
-
if (ENABLE_FEATURE_MDEV_RENAME)
-
free(alias);
-
-
/* We found matching line.
-
* Stop unless it was prefixed with '-'
-
*/
-
if (!ENABLE_FEATURE_MDEV_CONF || !rule->keep_matching)
-
break;
-
} /* for (;;) */
-
-
free(subsystem_slash_devname);
- }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号