
调试器工作原理
调试器工作原理(1):基础篇
本文是一系列探究调试器工作原理的文章的第一篇。我还不确定这个系列需要包括多少篇文章以及它们所涵盖的主题,但我打算从基础知识开始说起。
关于本文
我打算在这篇文章中介绍关于Linux下的调试器实现的主要组成部分——ptrace系统调用。本文中出现的代码都在32位的Ubuntu系统上开发。请注意,这里出现的代码是同平台紧密相关的,但移植到别的平台上应该不会太难。
动机
要想理解我们究竟要做什么,试着想象一下调试器是如何工作的。调试器可以启动某些进程,然后对其进行调试,或者将自己本身关联到一个已存在的进程之上。它可以单步运行代码,设置断点然后运行程序,检查变量的值以及跟踪调用栈。许多调试器已经拥有了一些高级特性,比如执行表达式并在被调试进程的地址空间中调用函数,甚至可以直接修改进程的代码并观察修改后的程序行为。
尽管现代的调试器都是复杂的大型程序,但令人惊讶的是构建调试器的基础确是如此的简单。调试器只用到了几个由操作系统以及编译器/链接器提供的基础服务,剩下的仅仅就是简单的编程问题了。(可查阅维基百科中关于这个词条的解释,作者是在反讽)

Linux下的调试——ptrace
Linux下调试器拥有一个瑞士军刀般的工具,这就是ptrace系统调用。这是一个功能众多且相当复杂的工具,能允许一个进程控制另一个进程的运行,而且可以监视和渗入到进程内部。ptrace本身需要一本中等篇幅的书才能对其进行完整的解释,这就是为什么我只打算通过例子把重点放在它的实际用途上。让我们继续深入探寻。
遍历进程的代码
我现在要写一个在“跟踪”模式下运行的进程的例子,这里我们要单步遍历这个进程的代码——由CPU所执行的机器码(汇编指令)。我会在这里给出例子代码,解释每个部分,本文结尾处你可以通过链接下载一份完整的C程序文件,可以自行编译执行并研究。从高层设计来说,我们要写一个程序,它产生一个子进程用来执行一个用户指定的命令,而父进程跟踪这个子进程。首先,main函数是这样的:
代码相当简单,我们通过fork产生一个新的子进程。随后的if语句块处理子进程(这里称为“目标进程”),而else if语句块处理父进程(这里称为“调试器”)。下面是目标进程:
这部分最有意思的地方在ptrace调用。ptrace的原型是(在sys/ptrace.h):
第一个参数是request,可以是预定义的以PTRACE_打头的常量值。第二个参数指定了进程id,第三以及第四个参数是地址和指向数据的指针,用来对内存做操作。上面代码段中的ptrace调用使用了PTRACE_TRACEME请求,这表示这个子进程要求操作系统内核允许它的父进程对其跟踪。这个请求在man手册中解释的非常清楚:
“表明这个进程由它的父进程来跟踪。任何发给这个进程的信号(除了SIGKILL)将导致该进程停止运行,而它的父进程会通过wait()获得通知。另外,该进程之后所有对exec()的调用都将使操作系统产生一个SIGTRAP信号发送给它,这让父进程有机会在新程序开始执行之前获得对子进程的控制权。如果不希望由父进程来跟踪的话,那就不应该使用这个请求。(pid、addr、data被忽略)”
我已经把这个例子中我们感兴趣的地方高亮显示了。注意,run_target在ptrace调用之后紧接着做的是通过execl来调用我们指定的程序。这里就会像我们高亮显示的部分所解释的那样,操作系统内核会在子进程开始执行execl中指定的程序之前停止该进程,并发送一个信号给父进程。
因此,是时候看看父进程需要做些什么了:
通过上面的代码我们可以回顾一下,一旦子进程开始执行exec调用,它就会停止然后接收到一个SIGTRAP信号。父进程通过第一个wait调用正在等待这个事件发生。一旦子进程停止(如果子进程由于发送的信号而停止运行,WIFSTOPPED就返回true),父进程就去检查这个事件。
父进程接下来要做的是本文中最有意思的地方。父进程通过PTRACE_SINGLESTEP以及子进程的id号来调用ptrace。这么做是告诉操作系统——请重新启动子进程,但当子进程执行了下一条指令后再将其停止。然后父进程再次等待子进程的停止,整个循环继续得以执行。当从wait中得到的不是关于子进程停止的信号时,循环结束。在正常运行这个跟踪程序时,会得到子进程正常退出(WIFEXITED会返回true)的信号。
icounter会统计子进程执行的指令数量。因此我们这个简单的例子实际上还是做了点有用的事情——通过在命令行上指定一个程序名,我们的例子会执行这个指定的程序,然后统计出从开始到结束该程序执行过的CPU指令总数。让我们看看实际运行的情况。
实际测试
我编译了下面这个简单的程序,然后在我们的跟踪程序下执行:
令我惊讶的是,我们的跟踪程序运行了很长的时间然后报告显示一共有超过100000条指令得到了执行。仅仅只是一个简单的printf调用,为什么会这样?答案非常有意思。默认情况下,Linux中的gcc编译器会动态链接到C运行时库。这意味着任何程序在运行时首先要做的事情是加载动态库。这需要很多代码实现——记住,我们这个简单的跟踪程序会针对每一条被执行的指令计数,不仅仅是main函数,而是整个进程。
因此,当我采用-static标志静态链接这个测试程序时(注意到可执行文件因此增加了500KB的大小,因为它静态链接了C运行时库),我们的跟踪程序报告显示只有7000条左右的指令被执行了。这还是非常多,但如果你了解到libc的初始化工作仍然先于main的执行,而清理工作会在main之后执行,那么这就完全说得通了。而且,printf也是一个复杂的函数。
我们还是不满足于此,我希望能看到一些可检测的东西,例如我可以从整体上看到每一条需要被执行的指令是什么。这一点我们可以通过汇编代码来得到。因此我把这个“Hello,world”程序汇编(gcc -S)为如下的汇编码:
这就足够了。现在跟踪程序会报告有7条指令得到了执行,我可以很容易地从汇编代码来验证这一点。
深入指令流
汇编码程序得以让我为大家介绍ptrace的另一个强大的功能——详细检查被跟踪进程的状态。下面是run_debugger函数的另一个版本:
同前个版本相比,唯一的不同之处在于while循环的开始几行。这里有两个新的ptrace调用。第一个读取进程的寄存器值到一个结构体中。结构体user_regs_struct定义在sys/user.h中。这儿有个有趣的地方——如果你打开这个头文件看看,靠近文件顶端的地方有一条这样的注释:
/* 本文件的唯一目的是为GDB,且只为GDB所用。对于这个文件,不要看的太多。除了GDB以外不要用于任何其他目的,除非你知道你正在做什么。*/
现在,我不知道你是怎么想的,但我感觉我们正处于正确的跑道上。无论如何,回到我们的例子上来。一旦我们将所有的寄存器值获取到regs中,我们就可以通过PTRACE_PEEKTEXT标志以及将regs.eip(x86架构上的扩展指令指针)做参数传入ptrace来调用。我们所得到的就是指令。让我们在汇编代码上运行这个新版的跟踪程序。
OK,所以现在除了icounter以外,我们还能看到指令指针以及每一步的指令。如何验证这是否正确呢?可以通过在可执行文件上执行objdump –d来实现:
用这份输出对比我们的跟踪程序输出,应该很容易观察到相同的地方。
关联到运行中的进程上
你已经知道了调试器也可以关联到已经处于运行状态的进程上。看到这里,你应该不会感到惊讶,这也是通过ptrace来实现的。这需要通过PTRACE_ATTACH请求。这里我不会给出一段样例代码,因为通过我们已经看到的代码,这应该很容易实现。基于教学的目的,这里采用的方法更为便捷(因为我们可以在子进程刚启动时立刻将它停止)。
代码
本文给出的这个简单的跟踪程序的完整代码(更高级一点,可以将具体指令打印出来)可以在这里找到。程序通过-Wall –pedantic –std=c99编译选项在4.4版的gcc上编译。
结论及下一步要做的
诚然,本文并没有涵盖太多的内容——我们离一个真正可用的调试器还差的很远。但是,我希望这篇文章至少已经揭开了调试过程的神秘面纱。ptrace是一个拥有许多功能的系统调用,目前我们只展示了其中少数几种功能。
能够单步执行代码是很有用处的,但作用有限。以“Hello, world”为例,要到达main函数,需要先遍历好几千条初始化C运行时库的指令。这就不太方便了。我们所希望的理想方案是可以在main函数入口处设置一个断点,从断点处开始单步执行。下一篇文章中我将向您展示该如何实现断点机制。
参考文献
写作本文时我发现下面这些文章很有帮助:
调试器工作原理(2):实现断点
本文是关于调试器工作原理探究系列的第二篇。在开始阅读本文前,请先确保你已经读过本系列的第一篇(基础篇)。
本文的主要内容
这里我将说明调试器中的断点机制是如何实现的。断点机制是调试器的两大主要支柱之一 ——另一个是在被调试进程的内存空间中查看变量的值。我们已经在第一篇文章中稍微涉及到了一些监视被调试进程的知识,但断点机制仍然还是个迷。阅读完本文之后,这将不再是什么秘密了。
软中断
要在x86体系结构上实现断点我们要用到软中断(也称为“陷阱”trap)。在我们深入细节之前,我想先大致解释一下中断和陷阱的概念。
CPU有一个单独的执行序列,会一条指令一条指令的顺序执行。要处理类似IO或者硬件时钟这样的异步事件时CPU就要用到中断。硬件中断通常是一个专门的电信号,连接到一个特殊的“响应电路”上。这个电路会感知中断的到来,然后会使CPU停止当前的执行流,保存当前的状态,然后跳转到一个预定义的地址处去执行,这个地址上会有一个中断处理例程。当中断处理例程完成它的工作后,CPU就从之前停止的地方恢复执行。
软中断的原理类似,但实际上有一点不同。CPU支持特殊的指令允许通过软件来模拟一个中断。当执行到这个指令时,CPU将其当做一个中断——停止当前正常的执行流,保存状态然后跳转到一个处理例程中执行。这种“陷阱”让许多现代的操作系统得以有效完成很多复杂任务(任务调度、虚拟内存、内存保护、调试等)。
一些编程错误(比如除0操作)也被CPU当做一个“陷阱”,通常被认为是“异常”。这里软中断同硬件中断之间的界限就变得模糊了,因为这里很难说这种异常到底是硬件中断还是软中断引起的。我有些偏离主题了,让我们回到关于断点的讨论上来。
关于int 3指令
看过前一节后,现在我可以简单地说断点就是通过CPU的特殊指令——int 3来实现的。int就是x86体系结构中的“陷阱指令”——对预定义的中断处理例程的调用。x86支持int指令带有一个8位的操作数,用来指定所发生的中断号。因此,理论上可以支持256种“陷阱”。前32个由CPU自己保留,这里第3号就是我们感兴趣的——称为“trap to debugger”。
不多说了,我这里就引用“圣经”中的原话吧(这里的圣经就是Intel’s Architecture software developer’s manual, volume2A):
“INT 3指令产生一个特殊的单字节操作码(CC),这是用来调用调试异常处理例程的。(这个单字节形式非常有价值,因为这样可以通过一个断点来替换掉任何指令的第一个字节,包括其它的单字节指令也是一样,而不会覆盖到其它的操作码)。”
上面这段话非常重要,但现在解释它还是太早,我们稍后再来看。
使用int 3指令
是的,懂得事物背后的原理是很棒的,但是这到底意味着什么?我们该如何使用int 3来实现断点机制?套用常见的编程问答中出现的对话——请用代码说话!
实际上这真的非常简单。一旦你的进程执行到int 3指令时,操作系统就将它暂停。在Linux上(本文关注的是Linux平台),这会给该进程发送一个SIGTRAP信号。
这就是全部——真的!现在回顾一下本系列文章的第一篇,跟踪(调试器)进程可以获得所有其子进程(或者被关联到的进程)所得到信号的通知,现在你知道我们该做什么了吧?
就是这样,再没有什么计算机体系结构方面的东东了,该写代码了。
手动设定断点
现在我要展示如何在程序中设定断点。用于这个示例的目标程序如下:
我现在使用的是汇编语言,这是为了避免当使用C语言时涉及到的编译和符号的问题。上面列出的程序功能就是在一行中打印“Hello,”,然后在下一行中打印“world!”。这个例子与上一篇文章中用到的例子很相似。
我希望设定的断点位置应该在第一条打印之后,但恰好在第二条打印之前。我们就让断点打在第一个int 0x80指令之后吧,也就是mov edx, len2。首先,我需要知道这条指令对应的地址是什么。运行objdump –d:
通过上面的输出,我们知道要设定的断点地址是0x8048096。等等,真正的调试器不是像这样工作的,对吧?真正的调试器可以根据代码行数或者函数名称来设定断点,而不是基于什么内存地址吧?非常正确。但是我们离那个标准还差的远——如果要像真正的调试器那样设定断点,我们还需要涵盖符号表以及调试信息方面的知识,这需要用另一篇文章来说明。至于现在,我们还必须得通过内存地址来设定断点。
看到这里我真的很想再扯一点题外话,所以你有两个选择。如果你真的对于为什么地址是0x8048096,以及这代表什么意思非常感兴趣的话,接着看下一节。如果你对此毫无兴趣,只是想看看怎么设定断点,可以略过这一部分。
题外话——进程地址空间以及入口点
坦白的说,0x8048096本身并没有太大意义,这只不过是相对可执行镜像的代码段(text section)开始处的一个偏移量。如果你仔细看看前面objdump出来的结果,你会发现代码段的起始位置是0x08048080。这告诉了操作系统要将代码段映射到进程虚拟地址空间的这个位置上。在Linux上,这些地址可以是绝对地址(比如,有的可执行镜像加载到内存中时是不可重定位的),因为在虚拟内存系统中,每个进程都有自己独立的内存空间,并把整个32位的地址空间都看做是属于自己的(称为线性地址)。
如果我们通过readelf工具来检查可执行文件的ELF头,我们将得到如下输出:
注意,ELF头的“entry point address”同样指向的是0x8048080。因此,如果我们把ELF文件中的这个部分解释给操作系统的话,就表示:
1. 将代码段映射到地址0x8048080处
2. 从入口点处开始执行——地址0x8048080
但是,为什么是0x8048080呢?它的出现是由于历史原因引起的。每个进程的地址空间的前128MB被保留给栈空间了(注:这一部分原因可参考Linkers and Loaders)。128MB刚好是0x80000000,可执行镜像中的其他段可以从这里开始。0x8048080是Linux下的链接器ld所使用的默认入口点。这个入口点可以通过传递参数-Ttext给ld来进行修改。
因此,得到的结论是这个地址并没有什么特别的,我们可以自由地修改它。只要ELF可执行文件的结构正确且在ELF头中的入口点地址同程序代码段(text section)的实际起始地址相吻合就OK了。
通过int 3指令在调试器中设定断点
要在被调试进程中的某个目标地址上设定一个断点,调试器需要做下面两件事情:
1. 保存目标地址上的数据
2. 将目标地址上的第一个字节替换为int 3指令
然后,当调试器向操作系统请求开始运行进程时(通过前一篇文章中提到的PTRACE_CONT),进程最终一定会碰到int 3指令。此时进程停止,操作系统将发送一个信号。这时就是调试器再次出马的时候了,接收到一个其子进程(或被跟踪进程)停止的信号,然后调试器要做下面几件事:
1. 在目标地址上用原来的指令替换掉int 3
2. 将被跟踪进程中的指令指针向后递减1。这么做是必须的,因为现在指令指针指向的是已经执行过的int 3之后的下一条指令。
3. 由于进程此时仍然是停止的,用户可以同被调试进程进行某种形式的交互。这里调试器可以让你查看变量的值,检查调用栈等等。
4. 当用户希望进程继续运行时,调试器负责将断点再次加到目标地址上(由于在第一步中断点已经被移除了),除非用户希望取消断点。
让我们看看这些步骤如何转化为实际的代码。我们将沿用第一篇文章中展示过的调试器“模版”(fork一个子进程,然后对其跟踪)。无论如何,本文结尾处会给出完整源码的链接。
这里调试器从被跟踪进程中获取到指令指针,然后检查当前位于地址0x8048096处的字长内容。运行本文前面列出的汇编码程序,将打印出:
目前为止一切顺利,下一步:
注意看我们是如何将int 3指令插入到目标地址上的。这部分代码将打印出:
注意,“Hello,”在断点之前打印出来了——同我们计划的一样。同时我们发现子进程已经停止运行了——就在这个单字节的陷阱指令执行之后。
这会使子进程打印出“world!”然后退出,同之前计划的一样。
注意,我们这里并没有重新加载断点。这可以在单步模式下执行,然后将陷阱指令加回去,再做PTRACE_CONT就可以了。本文稍后介绍的debug库实现了这个功能。
更多关于int 3指令
现在是回过头来说说int 3指令的好机会,以及解释一下Intel手册中对这条指令的奇怪说明。
“这个单字节形式非常有价值,因为这样可以通过一个断点来替换掉任何指令的第一个字节,包括其它的单字节指令也是一样,而不会覆盖到其它的操作码。”
x86架构上的int指令占用2个字节——0xcd加上中断号。int 3的二进制形式可以被编码为cd 03,但这里有一个特殊的单字节指令0xcc以同样的作用而被保留。为什么要这样做呢?因为这允许我们在插入一个断点时覆盖到的指令不会多于一条。这很重要,考虑下面的示例代码:
假设我们要在dec eax上设定断点。这恰好是条单字节指令(操作码是0x48)。如果替换为断点的指令长度超过1字节,我们就被迫改写了接下来的下一条指令(call),这可能会产生一些完全非法的行为。考虑一下条件分支jz foo,这时进程可能不会在dec eax处停止下来(我们在此设定的断点,改写了原来的指令),而是直接执行了后面的非法指令。
通过对int 3指令采用一个特殊的单字节编码就能解决这个问题。因为x86架构上指令最短的长度就是1字节,这样我们可以保证只有我们希望停止的那条指令被修改。
封装细节
前面几节中的示例代码展示了许多底层的细节,这些可以很容易地通过API进行封装。我已经做了一些封装,使其成为一个小型的调试库——debuglib。代码在本文末尾处可以下载。这里我只想介绍下它的用法,我们要开始调试C程序了。
跟踪C程序
目前为止为了简单起见我把重点放在对汇编程序的跟踪上了。现在升一级来看看我们该如何跟踪一个C程序。
其实事情并没有很大的不同——只是现在有点难以找到放置断点的位置。考虑如下这个简单的C程序:
跟预计的情况一模一样!
代码
这里是完整的源码。在文件夹中你会发现:
debuglib.h以及debuglib.c——封装了调试器的一些内部工作。
bp_manual.c —— 本文一开始介绍的“手动”式设定断点。用到了debuglib库中的一些样板代码。
bp_use_lib.c—— 大部分代码用到了debuglib,这就是本文中用于说明跟踪一个C程序中的循环的示例代码。
结论及下一步要做的
我们已经涵盖了如何在调试器中实现断点机制。尽管实现细节根据操作系统的不同而有所区别,但只要你使用的是x86架构的处理器,那么一切变化都基于相同的主题——在我们希望停止的指令上将其替换为int 3。
我敢肯定,有些读者就像我一样,对于通过指定原始地址来设定断点的做法不会感到很激动。我们更希望说“在do_stuff上停住”,甚至是“在do_stuff的这一行上停住”,然后调试器就能照办。在下一篇文章中,我将向您展示这是如何做到的。
调试器工作原理(3):调试信息
本文是调试器工作原理探究系列的第三篇,在阅读前请先确保已经读过本系列的第一和第二篇。
本篇主要内容
在本文中我将向大家解释关于调试器是如何在机器码中寻找C函数以及变量的,以及调试器使用了何种数据能够在C源代码的行号和机器码中来回映射。
调试信息
现代的编译器在转换高级语言程序代码上做得十分出色,能够将源代码中漂亮的缩进、嵌套的控制结构以及任意类型的变量全都转化为一长串的比特流——这就是机器码。这么做的唯一目的就是希望程序能在目标CPU上尽可能快的运行。大多数的C代码都被转化为一些机器码指令。变量散落在各处——在栈空间里、在寄存器里,甚至完全被编译器优化掉。结构体和对象甚至在生成的目标代码中根本不存在——它们只不过是对内存缓冲区中偏移量的抽象化表示。
那么当你在某些函数的入口处设置断点时,调试器如何知道该在哪里停止目标进程的运行呢?当你希望查看一个变量的值时,调试器又是如何找到它并展示给你呢?答案就是——调试信息。
调试信息是在编译器生成机器码的时候一起产生的。它代表着可执行程序和源代码之间的关系。这个信息以预定义的格式进行编码,并同机器码一起存储。许多年以来,针对不同的平台和可执行文件,人们发明了许多这样的编码格式。由于本文的主要目的不是介绍这些格式的历史渊源,而是为您展示它们的工作原理,所以我们只介绍一种最重要的格式,这就是DWARF。作为Linux以及其他类Unix平台上的ELF可执行文件的调试信息格式,如今的DWARF可以说是无处不在。
ELF文件中的DWARF格式
根据维基百科上的词条解释,DWARF是同ELF可执行文件格式一同设计出来的,尽管在理论上DWARF也能够嵌入到其它的对象文件格式中。
DWARF是一种复杂的格式,在多种体系结构和操作系统上经过多年的探索之后,人们才在之前的格式基础上创建了DWARF。它肯定是很复杂的,因为它解决了一个非常棘手的问题——为任意类型的高级语言和调试器之间提供调试信息,支持任意一种平台和应用程序二进制接口(ABI)。要完全解释清楚这个主题,本文就显得太微不足道了。说实话,我也不理解其中的所有角落。本文我将采取更加实践的方法,只介绍足量的DWARF相关知识,能够阐明实际工作中调试信息是如何发挥其作用的就可以了。
ELF文件中的调试段
首先,让我们看看DWARF格式信息处在ELF文件中的什么位置上。ELF可以为每个目标文件定义任意多个段(section)。而Section header表中则定义了实际存在有哪些段,以及它们的名称。不同的工具以各自特殊的方式来处理这些不同的段,比如链接器只寻找它关注的段信息,而调试器则只关注其他的段。
我们通过下面的C代码构建一个名为traceprog2的可执行文件来做下实验。
每行的第一个数字表示每个段的大小,而最后一个数字表示距离ELF文件开始处的偏移量。调试器就是利用这个信息来从可执行文件中读取相关的段信息。现在,让我们通过一些实际的例子来看看如何在DWARF中找寻有用的调试信息。
定位函数
当我们在调试程序时,一个最为基本的操作就是在某些函数中设置断点,期望调试器能在函数入口处将程序断下。要完成这个功能,调试器必须具有某种能够从源代码中的函数名称到机器码中该函数的起始指令间相映射的能力。
这个信息可以通过从DWARF中的.debug_info段获取到。在我们继续之前,先说点背景知识。DWARF的基本描述实体被称为调试信息表项(Debugging Information Entry —— DIE),每个DIE有一个标签——包含它的类型,以及一组属性。各个DIE之间通过兄弟和孩子结点互相链接,属性值可以指向其他的DIE。
我们运行
没错,从反汇编结果来看0x8048604确实就是函数do_stuff的起始地址。因此,这里调试器就同函数和它们在可执行文件中的位置确立了映射关系。
定位变量
假设我们确实在do_stuff中的断点处停了下来。我们希望调试器能够告诉我们my_local变量的值,调试器怎么知道去哪里找到相关的信息呢?这可比定位函数要难多了,因为变量可以在全局数据区,可以在栈上,甚至是在寄存器中。另外,具有相同名称的变量在不同的词法作用域中可能有不同的值。调试信息必须能够反映出所有这些变化,而DWARF确实能做到这些。
我不会涵盖所有的可能情况,作为例子,我将只展示调试器如何在do_stuff函数中定位到变量my_local。我们从.debug_info段开始,再次看看do_stuff这一项,这一次我们也看看其他的子项:
注意每一个表项中第一个尖括号里的数字,这表示嵌套层次——在这个例子中带有<2>的表项都是表项<1>的子项。因此我们知道变量my_local(以DW_TAG_variable作为标签)是函数do_stuff的一个子项。调试器同样还对变量的类型感兴趣,这样才能正确的显示变量的值。这里my_local的类型根据DW_AT_type标签可知为<0x4b>。如果查看objdump的输出,我们会发现这是一个有符号4字节整数。
要在执行进程的内存映像中实际定位到变量,调试器需要检查DW_AT_location属性。对于my_local来说,这个属性为DW_OP_fberg: -20。这表示变量存储在从所包含它的函数的DW_AT_frame_base属性开始偏移-20处,而DW_AT_frame_base正代表了该函数的栈帧起始点。
函数do_stuff的DW_AT_frame_base属性的值是0x0(location list),这表示该值必须要在location list段去查询。我们看看objdump的输出:
关于位置信息,我们这里感兴趣的就是第一个。对于调试器可能定位到的每一个地址,它都会指定当前栈帧到变量间的偏移量,而这个偏移就是通过寄存器来计算的。对于x86体系结构,bpreg4代表esp寄存器,而bpreg5代表ebp寄存器。
让我们再看看do_stuff的开头几条指令:
注意,ebp只有在第二条指令执行后才与我们建立起关联,对于前两个地址,基地址由前面列出的位置信息中的esp计算得出。一旦得到了ebp的有效值,就可以很方便的计算出与它之间的偏移量。因为之后ebp保持不变,而esp会随着数据压栈和出栈不断移动。
那么这到底为我们定位变量my_local留下了什么线索?我们感兴趣的只是在地址0x8048610上的指令执行过后my_local的值(这里my_local的值会通过eax寄存器计算,而后放入内存)。因此调试器需要用到DW_OP_breg5: 8 基址来定位。现在回顾一下my_local的DW_AT_location属性:DW_OP_fbreg: -20。做下算数:从基址开始偏移-20,那就是ebp – 20,再偏移+8,我们得到ebp – 12。现在再看看反汇编输出,注意到数据确实是从eax寄存器中得到的,而ebp – 12就是my_local存储的位置。
定位到行号
当我说到在调试信息中寻找函数时,我撒了个小小的谎。当我们调试C源代码并在函数中放置了一个断点时,我们通常并不会对第一条机器码指令感兴趣。我们真正感兴趣的是函数中的第一行C代码。
这就是为什么DWARF在可执行文件中对C源码到机器码地址做了全部映射。这部分信息包含在.debug_line段中,可以按照可读的形式进行解读:
不难看出C源码同反汇编输出之间的关系。第5行源码指向函数do_stuff的入口点——地址0x8040604。接下第6行源码,当在do_stuff上设置断点时,这里就是调试器实际应该停下的地方,它指向地址0x804860a——刚过do_stuff的开场白。这个行信息能够方便的在C源码的行号同指令地址间建立双向的映射关系。
1. 当在某一行上设定断点时,调试器将利用行信息找到实际应该陷入的地址(还记得前一篇中的int 3指令吗?)
2. 当某个指令引起段错误时,调试器会利用行信息反过来找出源代码中的行号,并告诉用户。
libdwarf —— 在程序中访问DWARF
通过命令行工具来访问DWARF信息这虽然有用但还不能完全令我们满意。作为程序员,我们希望知道应该如何写出实际的代码来解析DWARF格式并从中读取我们需要的信息。
自然的,一种方法就是拿起DWARF规范开始钻研。还记得每个人都告诉你永远不要自己手动解析HTML,而应该使用函数库来做吗?没错,如果你要手动解析DWARF的话情况会更糟糕,DWARF比HTML要复杂的多。本文展示的只是冰山一角而已。更困难的是,在实际的目标文件中,这些信息大部分都以非常紧凑和压缩的方式进行编码处理。
因此我们要走另一条路,使用一个函数库来同DWARF打交道。我知道的这类函数库主要有两个:
1. BFD(libbfd),GNU binutils就是使用的它,包括本文中多次使用到的工具objdump,ld(GNU链接器),以及as(GNU汇编器)。
2. libdwarf —— 同它的老大哥libelf一样,为Solaris以及FreeBSD系统上的工具服务。
我这里选择了libdwarf,因为对我来说它看起来没那么神秘,而且license更加自由(LGPL,BFD是GPL)。
由于libdwarf自身非常复杂,需要很多代码来操作。我这里不打算把所有代码贴出来,但你可以下载,然后自己编译运行。要编译这个文件,你需要安装libelf以及libdwarf,并在编译时为链接器提供-lelf以及-ldwarf标志。
这个演示程序接收一个可执行文件,并打印出程序中的函数名称同函数入口点地址。下面是本文用以演示的C程序产生的输出:
libdwarf的文档非常好(见本文的参考文献部分),花点时间看看,对于本文中提到的DWARF段信息你处理起来就应该没什么问题了。
结论及下一步
调试信息只是一个简单的概念,具体实现细节可能相当复杂。但最终我们知道了调试器是如何从可执行文件中找出同源代码之间的关系。有了调试信息在手,调试器为用户所能识别的源代码和数据结构同可执行文件之间架起了一座桥。
本文加上之前的两篇文章总结了调试器内部的工作原理。通过这一系列文章,再加上一点编程工作就应该可以在Linux下创建一个具有基本功能的调试器。
至于下一步,我还不确定。也许我会就此终结这一系列文章,也许我会再写一些高级主题比如backtrace,甚至Windows系统上的调试。读者们也可以为今后这一系列文章提供意见和想法。不要客气,请随意在评论栏或通过Email给我提些建议吧。
几个主要软件调试方法及调试原则
调试(Debug)
软件调试是在进行了成功的测试之后才开始的工作,它与软件测试不同,调试的任务是进一步诊断和改正程序中潜在的错误。
调试活动由两部分组成:
u 确定程序中可疑错误的确切性质和位置
u 对程序(设计,编码)进行修改,排除这个错误
调试工作是一个具有很强技巧性的工作
软件运行失效或出现问题,往往只是潜在错误的外部表现,而外部表现与内在原因之间常常没有明显的联系,如果要找出真正的原因,排除潜在的错误,不是一件易事。
可以说,调试是通过现象,找出原因的一个思维分析的过程。
调试步骤:
(1) 从错误的外部表现形式入手,确定程序中出错位置
(2) 研究有关部分的程序,找出错误的内在原因
(3) 修改设计代码,以排除这个错误
(4) 重复进行暴露了这个错误的原始测试或某些有关测试。
从技术角度来看查找错误的难度在于:
u 现象与原因所处的位置可能相距甚远
u 当其他错误得到纠正时,这一错误所表现出的现象可能会暂时消失,但并为实际排除
u 现象实际上是由一些非错误原因(例如,舍入不精确)引起的
u 现象可能是由于一些不容易发现的人为错误引起的
u 错误是由于时序问题引起的,与处理过程无关
u 现象是由于难于精确再现的输入状态(例如,实时应用中输入顺序不确定)引起
u 现象可能是周期出现的,在软,硬件结合的嵌入式系统中常常遇到
几种主要的调试方法
调试的关键在于推断程序内部的错误位置及原因,可以采用以下方法:
强行排错
这种调试方法目前使用较多,效率较低,它不需要过多的思考,比较省脑筋。例如:
u 通过内存全部打印来调试,在这大量的数据中寻找出错的位置。
u 在程序特定位置设置打印语句,把打印语句插在出错的源程序的各个关键变量改变部位,重要分支部位,子程序调用部位,跟踪程序的执行,监视重要变量的变化
u 自动调用工具,利用某些程序语言的调试功能或专门的交互式调试工具,分析程序的动态过程,而不必修改程序。
应用以上任一种方法之前,都应当对错误的征兆进行全面彻底的分析,得出对出错位置及错误性质的推测,再使用一种适当的调试方法来检验推测的正确性。
回溯法调试
这是在小程序中常用的一种有效的调试方法,一旦发现了错误,人们先分析错误的征兆,确定最先发现“症状“的位置
然后,人工沿程序的控制流程,向回追踪源程序代码,直到找到错误根源或确定错误产生的范围,
例如,程序中发现错误处是某个打印语句,通过输出值可推断程序在这一点上变量的值,再从这一点出发,回溯程序的执行过程,反复思考:“如果程序在这一点上的状态(变量的值)是这样,那么程序在上一点的状态一定是这样···“直到找到错误所在。
归纳法调试
归纳法是一种从特殊推断一般的系统化思考方法,归纳法调试的基本思想是:从一些线索(错误征兆)着手,通过分析它们之间的关系来找出错误
u 收集有关的数据,列出所有已知的测试用例和程序执行结果,看哪些输入数据的运行结果是正确的,哪些输入数据的运行经过是有错误的
u 组织数据
由于归纳法是从特殊到一般的推断过程,所以需要组织整理数据,以发现规律
常以3W1H形式组织可用的数据
“What“列出一般现象
“Where“说明发现现象的地点
“When“列出现象发生时所有已知情况
“How“说明现象的范围和量级
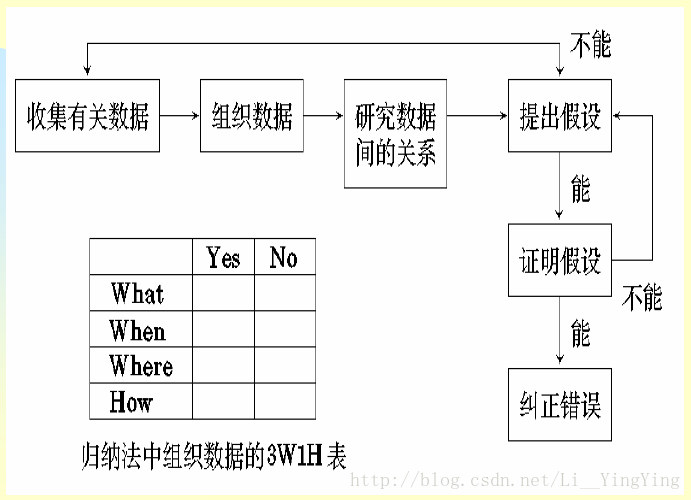
“Yes“描述出现错误的3W1H;
“No“作为比较,描述了没有错误的3W1H,通过分析找出矛盾来
u 提出假设
分析线索之间的关系,利用在线索结构中观察到的矛盾现象,设计一个或多个关于出错原因的假设,如果一个假设也提不出来,归纳过程就需要收集更多的数据,此时,应当再设计与执行一些测试用例,以获得更多的数据。
u 证明假设
把假设与原始线索或数据进行比较,若它能完全解释一切现象,则假设得到证明,否则,认为假设不合理,或不完全,或是存在多个错误,以致只能消除部分错误
演绎法调试
演绎法是一种从一般原理或前提出发,经过排除和精华的过程来推导出结论的思考方法,演绎法排错是测试人员首先根据已有的测试用例,设想及枚举出所有可能出错的原因作为假设,然后再用原始测试数据或新的测试,从中逐个排除不可能正确的假设,最后,再用测试数据验证余下的假设确是出错的原因。
u 列举所有可能出错原因的假设,把所有可能的错误原因列成表,通过它们,可以组织,分析现有数据
u 利用已有的测试数据,排除不正确的假设
仔细分析已有的数据,寻找矛盾,力求排除前一步列出所有原因,如果所有原因都被排除了,则需要补充一些数据(测试用例),以建立新的假设。
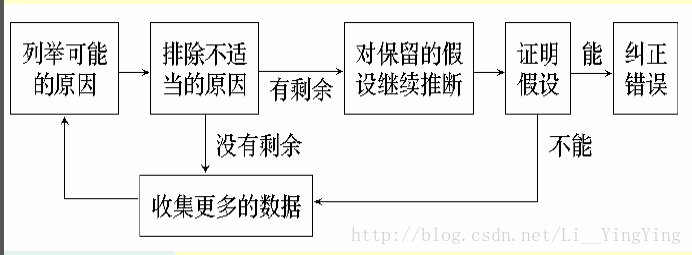
u 改进余下的假设
利用已知的线索,进一步改进余下的假设,使之更具体化,以便可以精确地确定出错位置
u 证明余下的假设
调试原则
n 在调试方面,许多原则本质上是心理学方面的问题,调试由两部分组成,调试原则也分成两组。
n 确定错误的性质和位置的原则
u 用头脑去分析思考与错误征兆有关的信息
u 避开死胡同
u 只把调试工具当做辅助手段来使用,利用调试工具,可以帮助思考,但不能代替思考
u 避免用试探法,最多只能把它当做最后手段
n 修改错误的原则
u 在出现错误的地方,很有可能还有别的错误
u 修改错误的一个常见失误是只修改了这个错误的征兆或这个错误的表现,而没有修改错误的本身。
u 当心修正一个错误的同时有可能会引入新的错误
u 修改错误的过程将迫使人们暂时回到程序设计阶段
u 修改源代码程序,不要改变目标代码
调试手段及原理
本文将从应用程序、编译器和调试器三个层次来讲解,在不同的层次,有不同的方法,这些方法有各自己的长处和局限。了解这些知识,一方面满足一下新手的好奇心,另一方面也可能有用得着的时候。
从应用程序的角度
最好的情况是从设计到编码都扎扎实实的,避免把错误引入到程序中来,这才是解决问题的根本之道。问题在于,理想情况并不存在,现实中存在着大量有内存错误的程序,如果内存错误很容易避免,JAVA/C#的优势将不会那么突出了。
对于内存错误,应用程序自己能做的非常有限。但由于这类内存错误非常典型,所占比例非常大,所付出的努力与所得的回报相比是非常划算的,仍然值得研究。
前面我们讲了,堆里面的内存是由内存管理器管理的。从应用程序的角度来看,我们能做到的就是打内存管理器的主意。其实原理很简单:
对付内存泄露。重载内存管理函数,在分配时,把这块内存的记录到一个链表中,在释放时,从链表中删除吧,在程序退出时,检查链表是否为空,如果不为空,则说明有内存泄露,否则说明没有泄露。当然,为了查出是哪里的泄露,在链表还要记录是谁分配的,通常记录文件名和行号就行了。
对付内存越界/野指针。对这两者,我们只能检查一些典型的情况,对其它一些情况无能为力,但效果仍然不错。其方法如下(源于《Comparing
and contrasting the runtime error detection technologies》):
l 首尾在加保护边界值
Header
Leading guard(0xFC)
User data(0xEB)
Tailing guard(0xFC)
在内存分配时,内存管理器按如上结构填充分配出来的内存。其中Header是管理器自己用的,前后各有几个字节的guard数据,它们的值是固定的。当内存释放时,内存管理器检查这些guard数据是否被修改,如果被修改,说明有写越界。
它的工作机制注定了有它的局限性: 只能检查写越界,不能检查读越界,而且只能检查连续性的写越界,对于跳跃性的写越界无能为力。
l 填充空闲内存
空闲内存(0xDD)
内存被释放之后,它的内容填充成固定的值。这样,从指针指向的内存的数据,可以大致判断这个指针是否是野指针。
它同样有它的局限:程序要主动判断才行。如果野指针指向的内存立即被重新分配了,它又被填充成前面那个结构,这时也无法检查出来。
从编译器的角度
boundschecker和purify的实现都可以归于编译器一级。前者采用一种称为CTI(compile-time
instrumentation)的技术。VC的编译不是要分几个阶段吗?boundschecker在预处理和编译两个阶段之间,对源文件进行修改。它对所有内存分配释放、内存读写、指针赋值和指针计算等所有内存相关的操作进行分析,并插入自己的代码。比如:
Before
if (m_hsession) gblHandles->ReleaseUserHandle( m_hsession );
if (m_dberr) delete m_dberr;
After
if (m_hsession) {
_Insight_stack_call(0);
gblHandles->ReleaseUserHandle(m_hsession);
_Insight_after_call();
}
_Insight_ptra_check(1994, (void **) &m_dberr, (void *) m_dberr);
if (m_dberr) {
_Insight_deletea(1994, (void **) &m_dberr, (void *) m_dberr, 0);
delete m_dberr;
}
Purify则采用一种称为OCI(object code insertion)的技术。不同的是,它对可执行文件的每条指令进行分析,找出所有内存分配释放、内存读写、指针赋值和指针计算等所有内存相关的操作,用自己的指令代替原始的指令。
boundschecker和purify是商业软件,它们的实现是保密的,甚至拥有专利的,无法对其研究,只能找一些皮毛性的介绍。无论是CTI还是OCI这样的名称,多少有些神秘感。其实它们的实现原理并不复杂,通过对valgrind和gcc的bounds
checker扩展进行一些粗浅的研究,我们可以知道它们的大致原理。
gcc的bounds
checker基本上可以与boundschecker对应起来,都是对源代码进行修改,以达到控制内存操作功能,如malloc/free等内存管理函数、memcpy/strcpy/memset等内存读取函数和指针运算等。Valgrind则与Purify类似,都是通过对目标代码进行修改,来达到同样的目的。
Valgrind对可执行文件进行修改,所以不需要重新编译程序。但它并不是在执行前对可执行文件和所有相关的共享库进行一次性修改,而是和应用程序在同一个进程中运行,动态的修改即将执行的下一段代码。
Valgrind是插件式设计的。Core部分负责对应用程序的整体控制,并把即将修改的代码,转换成一种中间格式,这种格式类似于RISC指令,然后把中间代码传给插件。插件根据要求对中间代码修改,然后把修改后的结果交给core。core接下来把修改后的中间代码转换成原始的x86指令,并执行它。
由此可见,无论是boundschecker、purify、gcc的bounds checker,还是Valgrind,修改源代码也罢,修改二进制也罢,都是代码进行修改。究竟要修改什么,修改成什么样子呢?别急,下面我们就要来介绍:
管理所有内存块。无论是堆、栈还是全局变量,只要有指针引用它,它就被记录到一个全局表中。记录的信息包括内存块的起始地址和大小等。要做到这一点并不难:对于在堆里分配的动态内存,可以通过重载内存管理函数来实现。对于全局变量等静态内存,可以从符号表中得到这些信息。
拦截所有的指针计算。对于指针进行乘除等运算通常意义不大,最常见运算是对指针加减一个偏移量,如++p、p=p+n、p=a[n]等。所有这些有意义的指针操作,都要受到检查。不再是由一条简单的汇编指令来完成,而是由一个函数来完成。
有了以上两点保证,要检查内存错误就非常容易了:比如要检查++p是否有效,首先在全局表中查找p指向的内存块,如果没有找到,说明p是野指针。如果找到了,再检查p+1是否在这块内存范围内,如果不是,那就是越界访问,否则是正常的了。怎么样,简单吧,无论是全局内存、堆还是栈,无论是读还是写,无一能够逃过出工具的法眼。
代码赏析(源于tcc):
对指针运算进行检查:
void *__bound_ptr_add(void *p, int offset)
{
unsigned long addr = (unsigned long)p;
BoundEntry *e;
#if defined(BOUND_DEBUG)
printf("add: 0x%x %d\n", (int)p, offset);
#endif
e = __bound_t1[addr >> (BOUND_T2_BITS + BOUND_T3_BITS)];
e = (BoundEntry *)((char *)e +
((addr >> (BOUND_T3_BITS - BOUND_E_BITS)) &
((BOUND_T2_SIZE - 1) << BOUND_E_BITS)));
addr -= e->start;
if (addr > e->size) {
e = __bound_find_region(e, p);
addr = (unsigned long)p - e->start;
}
addr += offset;
if (addr > e->size)
return INVALID_POINTER;
return p + offset;
}
static void __bound_check(const void *p, size_t size)
{
if (size == 0)
return;
p = __bound_ptr_add((void *)p, size);
if (p == INVALID_POINTER)
bound_error("invalid pointer");
}
重载内存管理函数:
void *__bound_malloc(size_t size, const void *caller)
{
void *ptr;
ptr = libc_malloc(size + 1);
if (!ptr)
return NULL;
__bound_new_region(ptr, size);
return ptr;
}
void __bound_free(void *ptr, const void *caller)
{
if (ptr == NULL)
return;
if (__bound_delete_region(ptr) != 0)
bound_error("freeing invalid region");
libc_free(ptr);
}
重载内存操作函数:
void *__bound_memcpy(void *dst, const void *src, size_t size)
{
__bound_check(dst, size);
__bound_check(src, size);
if (src >= dst && src < dst + size)
bound_error("overlapping regions in memcpy()");
return memcpy(dst, src, size);
}
从调试器的角度
现在有OS的支持,实现一个调试器变得非常简单,至少原理不再神秘。这里我们简要介绍一下win32和linux中的调试器实现原理。
在Win32下,实现调试器主要通过两个函数:WaitForDebugEvent和ContinueDebugEvent。下面是一个调试器的基本模型(源于:
《Debugging Applications for Microsoft .NET and Microsoft Windows》)
void main ( void )
{
CreateProcess ( ..., DEBUG_ONLY_THIS_PROCESS ,... ) ;
while ( 1 == WaitForDebugEvent ( ... ) )
{
if ( EXIT_PROCESS )
{
break ;
}
ContinueDebugEvent ( ... ) ;
}
}
由调试器起动被调试的进程,并指定DEBUG_ONLY_THIS_PROCESS标志。按Win32下事件驱动的一贯原则,由被调试的进程主动上报调试事件,调试器然后做相应的处理。
在linux下,实现调试器只要一个函数就行了:ptrace。下面是个简单示例:(源于《Playing with ptrace》)。
#include <sys/ptrace.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <linux/user.h>
int main(int argc, char *argv[])
{ pid_t traced_process;
struct user_regs_struct regs;
long ins;
if(argc != 2) {
printf("Usage: %s <pid to be traced>\n",
argv[0], argv[1]);
exit(1);
}
traced_process = atoi(argv[1]);
ptrace(PTRACE_ATTACH, traced_process,
NULL, NULL);
wait(NULL);
ptrace(PTRACE_GETREGS, traced_process,
NULL, ®s);
ins = ptrace(PTRACE_PEEKTEXT, traced_process,
regs.eip, NULL);
printf("EIP: %lx Instruction executed: %lx\n",
regs.eip, ins);
ptrace(PTRACE_DETACH, traced_process,
NULL, NULL);
return 0;
}
由于篇幅有限,这里对于调试器的实现不作深入讨论,主要是给新手指一个方向。以后若有时间,再写个专题来介绍linux下的调试器和ptrace本身的实现方法。
一般调试器工作原理
调试器简介
严格的讲,调试器是帮助程序员跟踪,分隔和从软件中移除bug的工具。它帮助程序员更进一步理解程序。一开始,主要是开发人员使用它,后来测试人员,维护人员也开始使用它。
调试器的发展历程:
- 1. 静态存储
- 2. 交互式存储分析器
- 3. 二进制调试器
- 4. 基本的符号调试器(源码调试器)
- 5. 命令行符号调试器
- 6. 全屏文本模式调试器
- 7. 图形用户接口调试器
- 8. 集成开发环境调试器
调试器的设计和开发要遵循四个关键的原则:
- 1. 在开发过程中,不能改变被调试程序的行为;
- 2. 提供真实可靠的调试信息;
- 3. 提供详细的信息,是调试人员知道他们调试到代码的哪一行并且知道他们是怎么到达的;
- 4. 非常不幸的是,我们使用的调试总是不能满足我们的需求。
按照划分的标准不同,调试器主要分为一下几类:
- 1. 源码调试器与机器码调试器
- 2. 单独的调试器与集成开发环境的调试器
- 3. 第四代语言调试器与第三代语言调试器
- 4. 操作系统内核调试器与应用程序调试器
- 5. 利用处理器提供的功能的调试器与利用自行仿真处理器进行调试的调试器
调试器的架构
调试器之间的区别更多的是体现在他们展现给用户的窗口。至于底层结构都是很相近的。下图展示了调试器的总体架构:
调试器内核
调试器服务于所有的调试器视图。包括进程控制,执行引擎,表达式计算,符号表管理四部分。
操作系统接口
调试器内核为了访问被调试程序,必须使用操作系统提供的一系列例程。
硬件调试功能
调试器控制被调试程序的能力主要是依靠硬件支持和操作系统的调试机制。调试器需要最少三种的硬件功能的支持:
1. 提供设置断点的方法;
2. 通知操作系统发生中断或者陷阱的功能;
3. 当中断或者陷阱发生时,直接读写寄存器,包括程序计数器。
通用的硬件调试机制
1. 断点支持
断点功能是通过特定的指令来实现的。对于变长指令的处理器,断点指令通常是最短的指令,下图给出了四个处理器的断点指令:
2. 单步调试支持
单步调试是指执行一条指令就产生一次中断,是用户可以查找每条指令的执行状态。一般的处理器都提供一个模式位来实现单步调试功能。
3. 错误检测支持
错误检测功能是指当操作系统检测到错误发生时,他通知调试器被它调试的程序发生了错误。
4. 检测点支持
用来查看被调试程序的地址空间(数据空间)。
5. 多线程支持
6. 多处理器支持
调试器的操作系统支持功能
为了控制一个被调试程序的过程,调试器需要一种机制去通知操作系统该可执行文件希望被控制。即一旦被调试程序由于某些原因停止的时候,调试器需要获取详细的信息使得他知道被调试程序是什么原因造成他停止的。
调试器是用户级的程序,并不是操作系统的一部分,并不能运行特权级指令,因此,它只能通过调用操作系统的系统调用来实现对特权级指令的访问。
调试器运行被调试程序,并将控制权转交给被调试程序,需要进行上下文切换。在一个简单的断点功能实现,有6个主要的转换:
1. 当调试器运行到断点指令的时候,产生陷阱跳转到操作系统;
2. 通过操作系统,跳转到调试器,调试器开始运行;
3. 调试器请求被调试程序的状态信息,该请求送到操作系统进行处理;
4. 转换到被调试程序文本以获取信息,被调试程序激活;
5. 返回信息给操作系统;
6. 转换到调试器以处理信息。
一旦使用图形界面调试器,过程会更加的复杂。
对于多线程调试的支持;
l 一旦进程创建和删除,操作系统必须通知调试器;
l 能够询问和设置特定进程的进程状态;
l 能够检测到应用程序停止,或者线程停止。
例子:UNIX ptrace()
UNIX ptrace 是操作系统支持调试器的一个真实的API。
控制执行
调试器的核心是它的进程控制和运行控制。为了能够调试程序,调试器必须能够对被调试程序进行状态设置,断点设置,运行进程,终止进程。
控制执行主要包含一下几个功能:
1. 创建被调试程序
调试器做的第一件工作,就是创建被调试程序。一般通过两种手段:一种是为调试程序创建被调试进程,另一种是将调试器附到被调试进程上。
2. 附到被调试进程
当一个进程发生错误异常,并且在被刷出(内存刷新)内存的时候,允许调试器挂到出错进程以此来检查内存镜像。这个时候,用户不能再继续执行进程。
3. 设置断点
设置断点的功能是在可执行文本中插入特殊的指令来实现的。当程序执行到该特殊指令的时候,就产生陷阱,陷到操作系统。
4. 使被调试程序运行
当调试中断产生的时候,调试器属于激活进程,而被调试程序属于未激活进程。调试器产生一个系统中断请求恢复被调用函数的执行,操作系统对被调试程序进行上下文切换,恢复被调用程序的现场状态,然后执行被调用程序。
执行区间的调试事件生成类型:
l 断点,单步调试事件
l 线程创建/删除事件
l 进程创建/删除事件
l 检测点事件
l 模块加载/卸载事件
l 异常事件
l 其他事件
断点和单步调试
断点通常需要两层的表示:
l 逻辑表示:指在源代码中设置的断点,用来告诉用户的;
l 物理表示:指真实的在机器码中写入,是用来告诉物理机器的。断点必须存储写入位置的机器指令,以便能够在移除断点的时候恢复原来的指令。
断点存在条件断点。
断点存在多对一的关系,即多个用户在同一个地方设置断点(多个逻辑断点对应一个物理断点),当然也有多对多的关系。下图展示了这样的一个关系:
临时断点
临时断点是指只运行一次的断点。
内部断点
内部断点对用户是不可见的。他们是被调试器设置的。
一般主要用于:
l 单步调试:内部断点和运行到内部断点;
l 跳出函数:在函数返回地址设置内部断点;
l 进入函数
查看程序的上下文信息
一般要查找程序的上下文信息主要有以下几种方法:
- 源代码窗口
通过源代码查看程序执行到代码的那一部分
- 程序堆栈
程序堆栈是由硬件,操作系统和编译器共同支持的:
硬件: 提供堆栈指针;
操作系统:为每个进程建立堆栈空间,并管理堆栈。一旦堆栈溢出,而产生一个错误;
- 汇编级调试:反汇编,查看寄存器,查看内存
结合程序崩溃后的core文件分析bug
引言
- 内存访问出错,这类问题的典型代表就是数组越界。
- 非法内存访问,出现这类问题主要是程序试图访问内核段内存而产生的错误。
- 栈溢出, Linux默认给一个进程分配的栈空间大小为8M,因此你的数组开得过大的话会出现这种问题。
$ ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7884
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7884
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
core文件
何为core文件.
如何产生core文件
$ ulimit -c 0 <--------- c选项指定修改core文件的大小
$ ulimit -c 1000 <--------指定了core文件大小为1000KB, 如果设置的大小小于core文件,则对core文件截取
$ ulimit -c unlimited <---------------对core文件的大小不做限制
- 进程是设置-用户-ID,而且当前用户并非程序文件的所有者;
- 进程是设置-组-ID,而且当前用户并非该程序文件的组所有者;
- 用户没有写当前工作目录的许可权;
- 文件太大。core文件的许可权(假定该文件在此之前并不存在)通常是用户读/写,组读和其他读。
为什么需要core文件
core文件的名称和生成路径
- 文件内容为1,表示添加pid作为扩展名,生成的core文件格式为core.PID
- 为0则表示生成的core文件统一命名为core.
$ echo "0" > /proc/sys/kernel/core_uses_pid
- %p 出core进程的PID
- %u 出core进程的UID
- %s 造成core的signal号
- %t 出core的时间,从1970-01-0100:00:00开始的秒数
- %e 出core进程对应的可执行文件名
如何阅读core文件
$ file core.4244
core.4244: ELF 64-bit LSB core file x86-64, version 1 (SYSV), SVR4-style, from '/home/fireway/study/temp/a.out'
$ readelf -h core.4244
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: CORE (Core 文件)
Machine: Advanced Micro Devices X86-64
Version: 0x1
入口点地址: 0x0
程序头起点: 64 (bytes into file)
Start of section headers: 0 (bytes into file)
标志: 0x0
本头的大小: 64 (字节)
程序头大小: 56 (字节)
Number of program headers: 19
节头大小: 0 (字节)
节头数量: 0
字符串表索引节头: 0
$ gdb exec_file core_file
$ objdump -x core.4244 | tail
26 load16 00001000 00007ffff7ffe000 0000000000000000 0003f000 2**12
CONTENTS, ALLOC, LOAD
27 load17 00801000 00007fffff7fe000 0000000000000000 00040000 2**12
CONTENTS, ALLOC, LOAD
28 load18 00001000 ffffffffff600000 0000000000000000 00841000 2**12
CONTENTS, ALLOC, LOAD, READONLY, CODE
SYMBOL TABLE:
no symbols <----------------- 表明当前的ELF格式文件中没有符号表信息
Reading symbols from mycat...(no debugging symbols found)...done.
warning: core file may not match specified executable file.
[New LWP 2037]
Core was generated by `./mycat_debug'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x0000000000400957 in main ()
GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1
Copyright (C) 2014 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from mycat_debug...done.
[New LWP 2037]
Core was generated by `./mycat_debug'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 main () at io1.c:16
16 int n = 0;
(gdb) info f
Stack level 0, frame at 0x7ffc4b59d670:
rip = 0x400957 in main (io1.c:16); saved rip = 0x7fc5c0d5aec5
source language c.
Arglist at 0x7ffc4b59d660, args:
Locals at 0x7ffc4b59d660, Previous frame's sp is 0x7ffc4b59d670
Saved registers:
rbp at 0x7ffc4b59d660, rip at 0x7ffc4b59d668
(gdb) x/5i 0x400957 或者x/5i $rip
=> 0x400957 <main+26>:movl $0x0,-0x800014(%rbp)
0x400961 <main+36>:lea -0x800010(%rbp),%rax
0x400968 <main+43>:mov $0x800000,%edx
0x40096d <main+48>:mov $0x0,%esi
0x400972 <main+53>:mov %rax,%rdi
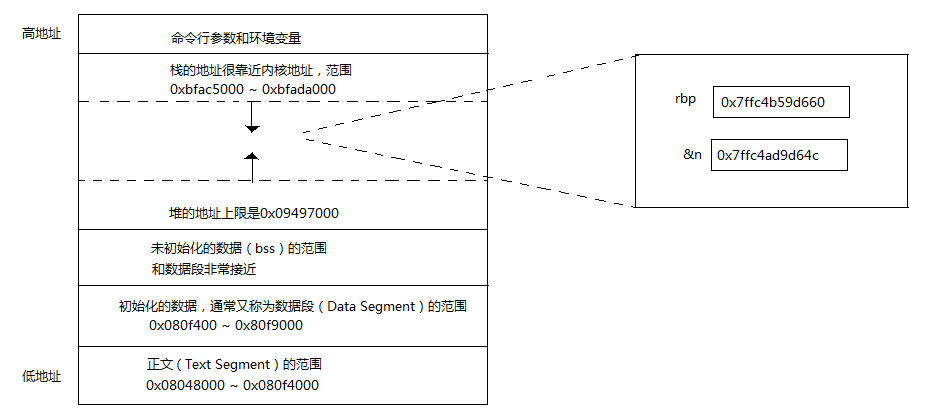
(gdb) x /b 0x7ffc4ad9d64c
0x7ffc4ad9d64c: Cannot access memory at address 0x7ffc4ad9d64c
ulimit命令参数及用法
- -a 显示目前资源限制的设定。
- -c 设定core文件的最大值,单位为KB。
- -d <数据节区大小> 程序数据节区的最大值,单位为KB。
- -f <文件大小> shell所能建立的最大文件,单位为区块。
- -H 设定资源的硬性限制,也就是管理员所设下的限制。
- -m <内存大小> 指定可使用内存的上限,单位为KB。
- -n <文件数目> 指定同一时间最多可开启的文件数。
- -p <缓冲区大小> 指定管道缓冲区的大小,单位512字节。
- -s <堆叠大小> 指定堆叠的上限,单位为KB。
- -S 设定资源的弹性限制。
- -t 指定CPU使用时间的上限,单位为秒。
- -u <程序数目> 用户最多可开启的程序数目。
- -v <虚拟内存大小> 指定可使用的虚拟内存上限,单位为KB。
参考
详解coredump
一,什么是coredump
我们经常听到大家说到程序core掉了,需要定位解决,这里说的大部分是指对应程序由于各种异常或者bug导致在运行过程中异常退出或者中止,并且在满足一定条件下(这里为什么说需要满足一定的条件呢?下面会分析)会产生一个叫做core的文件。
通常情况下,core文件会包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息还有各种函数调用堆栈信息等,我们可以理解为是程序工作当前状态存储生成第一个文件,许多的程序出错的时候都会产生一个core文件,通过工具分析这个文件,我们可以定位到程序异常退出的时候对应的堆栈调用等信息,找出问题所在并进行及时解决。
二,coredump文件的存储位置
core文件默认的存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到core文件的存在位置:
cat /proc/sys/kernel/core_pattern
缺省值是core
注意:这里是指在进程当前工作目录的下创建。通常与程序在相同的路径下。但如果程序中调用了chdir函数,则有可能改变了当前工作目录。这时core文件创建在chdir指定的路径下。有好多程序崩溃了,我们却找不到core文件放在什么位置。和chdir函数就有关系。当然程序崩溃了不一定都产生 core文件。
如下程序代码:则会把生成的core文件存储在/data/coredump/wd,而不是大家认为的跟可执行文件在同一目录。

通过下面的命令可以更改coredump文件的存储位置,若你希望把core文件生成到/data/coredump/core目录下:
echo “/data/coredump/core”> /proc/sys/kernel/core_pattern
注意,这里当前用户必须具有对/proc/sys/kernel/core_pattern的写权限。
缺省情况下,内核在coredump时所产生的core文件放在与该程序相同的目录中,并且文件名固定为core。很显然,如果有多个程序产生core文件,或者同一个程序多次崩溃,就会重复覆盖同一个core文件,因此我们有必要对不同程序生成的core文件进行分别命名。
我们通过修改kernel的参数,可以指定内核所生成的coredump文件的文件名。例如,使用下面的命令使kernel生成名字为core.filename.pid格式的core dump文件:
echo “/data/coredump/core.%e.%p” >/proc/sys/kernel/core_pattern
这样配置后,产生的core文件中将带有崩溃的程序名、以及它的进程ID。上面的%e和%p会被替换成程序文件名以及进程ID。
如果在上述文件名中包含目录分隔符“/”,那么所生成的core文件将会被放到指定的目录中。 需要说明的是,在内核中还有一个与coredump相关的设置,就是/proc/sys/kernel/core_uses_pid。如果这个文件的内容被配置成1,那么即使core_pattern中没有设置%p,最后生成的core dump文件名仍会加上进程ID。
三,如何判断一个文件是coredump文件?
在类unix系统下,coredump文件本身主要的格式也是ELF格式,因此,我们可以通过readelf命令进行判断。

可以看到ELF文件头的Type字段的类型是:CORE (Core file)
可以通过简单的file命令进行快速判断: 
四,产生coredum的一些条件总结
1, 产生coredump的条件,首先需要确认当前会话的ulimit –c,若为0,则不会产生对应的coredump,需要进行修改和设置。
ulimit -c unlimited (可以产生coredump且不受大小限制)
若想甚至对应的字符大小,则可以指定:
ulimit –c [size]

可以看出,这里的size的单位是blocks,一般1block=512bytes
如:
ulimit –c 4 (注意,这里的size如果太小,则可能不会产生对应的core文件,笔者设置过ulimit –c 1的时候,系统并不生成core文件,并尝试了1,2,3均无法产生core,至少需要4才生成core文件)
但当前设置的ulimit只对当前会话有效,若想系统均有效,则需要进行如下设置:
Ø 在/etc/profile中加入以下一行,这将允许生成coredump文件
ulimit-c unlimited
Ø 在rc.local中加入以下一行,这将使程序崩溃时生成的coredump文件位于/data/coredump/目录下:
echo /data/coredump/core.%e.%p> /proc/sys/kernel/core_pattern
注意rc.local在不同的环境,存储的目录可能不同,susu下可能在/etc/rc.d/rc.local
更多ulimit的命令使用,可以参考:http://baike.baidu.com/view/4832100.htm
这些需要有root权限, 在ubuntu下每次重新打开中断都需要重新输入上面的ulimit命令, 来设置core大小为无限.
2, 当前用户,即执行对应程序的用户具有对写入core目录的写权限以及有足够的空间。
3, 几种不会产生core文件的情况说明:
The core file will not be generated if
(a) the process was set-user-ID and the current user is not the owner of the program file, or
(b) the process was set-group-ID and the current user is not the group owner of the file,
(c) the user does not have permission to write in the current working directory,
(d) the file already exists and the user does not have permission to write to it, or
(e) the file is too big (recall the RLIMIT_CORE limit in Section 7.11). The permissions of the core file (assuming that the file doesn't already exist) are usually user-read and user-write, although Mac OS X sets only user-read.
五,coredump产生的几种可能情况
造成程序coredump的原因有很多,这里总结一些比较常用的经验吧:
1,内存访问越界
a) 由于使用错误的下标,导致数组访问越界。
b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串没有正常的使用结束符。
c) 使用strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,将目标字符串读/写爆。应该使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防止读写越界。
2,多线程程序使用了线程不安全的函数。
应该使用下面这些可重入的函数,它们很容易被用错:
asctime_r(3c) gethostbyname_r(3n) getservbyname_r(3n)ctermid_r(3s) gethostent_r(3n) getservbyport_r(3n) ctime_r(3c) getlogin_r(3c)getservent_r(3n) fgetgrent_r(3c) getnetbyaddr_r(3n) getspent_r(3c)fgetpwent_r(3c) getnetbyname_r(3n) getspnam_r(3c) fgetspent_r(3c)getnetent_r(3n) gmtime_r(3c) gamma_r(3m) getnetgrent_r(3n) lgamma_r(3m) getauclassent_r(3)getprotobyname_r(3n) localtime_r(3c) getauclassnam_r(3) etprotobynumber_r(3n)nis_sperror_r(3n) getauevent_r(3) getprotoent_r(3n) rand_r(3c) getauevnam_r(3)getpwent_r(3c) readdir_r(3c) getauevnum_r(3) getpwnam_r(3c) strtok_r(3c) getgrent_r(3c)getpwuid_r(3c) tmpnam_r(3s) getgrgid_r(3c) getrpcbyname_r(3n) ttyname_r(3c)getgrnam_r(3c) getrpcbynumber_r(3n) gethostbyaddr_r(3n) getrpcent_r(3n)
3,多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成coredump
4,非法指针
a) 使用空指针
b) 随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump。
5,堆栈溢出
不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
六,利用gdb进行coredump的定位
其实分析coredump的工具有很多,现在大部分类unix系统都提供了分析coredump文件的工具,不过,我们经常用到的工具是gdb。
这里我们以程序为例子来说明如何进行定位。
1, 段错误 – segmentfault
Ø 我们写一段代码往受到系统保护的地址写内容。

Ø 按如下方式进行编译和执行,注意这里需要-g选项编译。

可以看到,当输入12的时候,系统提示段错误并且core dumped
Ø 我们进入对应的core文件生成目录,优先确认是否core文件格式并启用gdb进行调试。

从红色方框截图可以看到,程序中止是因为信号11,且从bt(backtrace)命令(或者where)可以看到函数的调用栈,即程序执行到coremain.cpp的第5行,且里面调用scanf 函数,而该函数其实内部会调用_IO_vfscanf_internal()函数。
接下来我们继续用gdb,进行调试对应的程序。
记住几个常用的gdb命令:
l(list) ,显示源代码,并且可以看到对应的行号;
b(break)x, x是行号,表示在对应的行号位置设置断点;
p(print)x, x是变量名,表示打印变量x的值
r(run), 表示继续执行到断点的位置
n(next),表示执行下一步
c(continue),表示继续执行
q(quit),表示退出gdb
启动gdb,注意该程序编译需要-g选项进行。

注: SIGSEGV 11 Core Invalid memoryreference
七,附注:
1, gdb的查看源码
显示源代码
GDB 可以打印出所调试程序的源代码,当然,在程序编译时一定要加上-g的参数,把源程序信息编译到执行文件中。不然就看不到源程序了。当程序停下来以后,GDB会报告程序停在了那个文件的第几行上。你可以用list命令来打印程序的源代码。还是来看一看查看源代码的GDB命令吧。
list<linenum>
显示程序第linenum行的周围的源程序。
list<function>
显示函数名为function的函数的源程序。
list
显示当前行后面的源程序。
list -
显示当前行前面的源程序。
一般是打印当前行的上5行和下5行,如果显示函数是是上2行下8行,默认是10行,当然,你也可以定制显示的范围,使用下面命令可以设置一次显示源程序的行数。
setlistsize <count>
设置一次显示源代码的行数。
showlistsize
查看当前listsize的设置。
list命令还有下面的用法:
list<first>, <last>
显示从first行到last行之间的源代码。
list ,<last>
显示从当前行到last行之间的源代码。
list +
往后显示源代码。
一般来说在list后面可以跟以下这些参数:
<linenum> 行号。
<+offset> 当前行号的正偏移量。
<-offset> 当前行号的负偏移量。
<filename:linenum> 哪个文件的哪一行。
<function> 函数名。
<filename:function>哪个文件中的哪个函数。
<*address> 程序运行时的语句在内存中的地址。
2, 一些常用signal的含义
SIGABRT:调用abort函数时产生此信号。进程异常终止。
SIGBUS:指示一个实现定义的硬件故障。
SIGEMT:指示一个实现定义的硬件故障。EMT这一名字来自PDP-11的emulator trap 指令。
SIGFPE:此信号表示一个算术运算异常,例如除以0,浮点溢出等。
SIGILL:此信号指示进程已执行一条非法硬件指令。4.3BSD由abort函数产生此信号。SIGABRT现在被用于此。
SIGIOT:这指示一个实现定义的硬件故障。IOT这个名字来自于PDP-11对于输入/输出TRAP(input/outputTRAP)指令的缩写。系统V的早期版本,由abort函数产生此信号。SIGABRT现在被用于此。
SIGQUIT:当用户在终端上按退出键(一般采用Ctrl-/)时,产生此信号,并送至前台进
程组中的所有进程。此信号不仅终止前台进程组(如SIGINT所做的那样),同时产生一个core文件。
SIGSEGV:指示进程进行了一次无效的存储访问。名字SEGV表示“段违例(segmentationviolation)”。
SIGSYS:指示一个无效的系统调用。由于某种未知原因,进程执行了一条系统调用指令,但其指示系统调用类型的参数却是无效的。
SIGTRAP:指示一个实现定义的硬件故障。此信号名来自于PDP-11的TRAP指令。
SIGXCPUSVR4和4.3+BSD支持资源限制的概念。如果进程超过了其软C P U时间限制,则产生此信号。
SIGXFSZ:如果进程超过了其软文件长度限制,则SVR4和4.3+BSD产生此信号。
3, Core_pattern的格式
可以在core_pattern模板中使用变量还很多,见下面的列表:
%% 单个%字符
%p 所dump进程的进程ID
%u 所dump进程的实际用户ID
%g 所dump进程的实际组ID
%s 导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h 主机名
%e 程序文件名
利用Core Dump调试程序
[描述]
这里介绍Linux环境下使用gdb结合core dump文件进行程序的调试和定位。
[简介]
当用户程序运行,可能会由于某些原因发生崩溃(crash),这个时候可以产生一个Core
Dump文件,记录程序发生崩溃时候内存的运行状况。这个Core
Dump文件,一般名称为core或者core.pid(pid就是应用程序运行时候的pid号),它可以帮助我们找出程序崩溃的原因。
对于一个运行出错的程序,我们可以有多种方法调试它,以便发生错误的原因:a)通过阅读代码;b)通过在代码中设置一些打印语句(插旗子);c)通过使用gdb设置断点来跟踪程序的运行。但是这些方法对于调试程序运行崩溃这样类似的错误,定位都不够迅速,如果程序代码很多的话,显然前面的方法有很多缺陷。在后面,我们来看看另外一种可以定位错误的方法:d)使用gdb结合Core
Dump文件来迅速定位到这个错误。这个方法,如果程序运行崩溃,那么可以迅速找到导致程序崩溃的原因。
当然,调试程序,没有哪个方法是最好的,这里只对最后一种方法重点讲解,实际过程中,往往根据需要和其他方法结合使用。
[举例]
下面,给出一个实际的操作过程,描述我们使用gdb调试工具,结合Core Dump文件,定位程序崩溃的位置。
一、程序源代码
下面是我们的程序源代码:
1 #include <iostream>
2 using std::cerr;
3 using std::endl;
4
5 void my_print(int d1, int d2);
6 int main(int argc, char *argv[])
7 {
8 int a = 1;
9 int b = 2;
10 my_print(a,b);
11 return 0;
12 }
13
14 void my_print(int d1, int d2)
15 {
16 int *p1=&d1;
17 int *p2 = NULL;
18 cerr<<"first is:"<<*p1<<",second is:"<<*p2<<endl;
19 }
这里,程序代码很少,我们可以直接通过代码看到这个程序第17行的p2是NULL,而18行却用*p2来进行引用,明显这样访问一个空的地址是一个错误(也许我们的初衷是使用p2来指向d2)。
我们可以有多种方法调试这个程序,以便发生上面的错误:a)通过阅读代码;b)通过在代码中设置一些打印语句(插旗子);c)通过使用gdb设置断点来跟踪程序的运行。但是这些方法对于这个程序中类似的错误,定位都不够迅速,如果程序代码很多的话,显然前面的方法有很多缺陷。在后面,我们来看看另外一种可以定位错误的方法:d)使用gdb结合Core
Dump文件来迅速定位到这个错误。
二、编译程序:
编译过程如下:
[root@lv-k test]# ls
main.cpp
[root@lv-k test]# g++ -g main.cpp
[root@lv-k test]# ls
a.out main.cpp
这样,编译main.cpp生成了可执行文件a.out,一定注意,因为我们要使用gdb进行调试,所以我们使用'g++'的'-g'选项。
三、运行程序
运行过程如下:
[root@lv-k test]# ./a.out
段错误
[root@lv-k test]# ls
a.out main.cpp
这里,如我们所期望的,会打印段错误的信息,但是并没有生成Core Dump文件。
配置生成Core Dump文件的选项,并生成Core Dump:
[root@lv-k test]# ulimit -c unlimited
[root@lv-k test]# ./a.out
段错误 (core dumped)
[root@lv-k test]# ls
a.out core.30557 main.cpp
这里,我们看到,使用'ulimit'配置之后,程序崩溃的时候就会生成Core Dump文件了,这里的文件是core.30557,文件名称不同的系统生成的名称有一点不同,这里linux生成的名称是:"core"+".pid"。
四、调试程序
使用Core Dump文件,结合gdb工具进行调试,过程如下:
1)初步定位:
[root@lv-k test]# gdb a.out core.30557
GNU gdb (GDB) Red Hat Enterprise Linux (7.0.1-23.el5_5.2)
Copyright (C) 2009 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i386-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/test/a.out...done.
Reading symbols from /usr/lib/libstdc++.so.6...(no debugging symbols found)...done.
Loaded symbols for /usr/lib/libstdc++.so.6
Reading symbols from /lib/libm.so.6...(no debugging symbols found)...done.
Loaded symbols for /lib/libm.so.6
Reading symbols from /lib/libgcc_s.so.1...(no debugging symbols found)...done.
Loaded symbols for /lib/libgcc_s.so.1
Reading symbols from /lib/libc.so.6...(no debugging symbols found)...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...(no debugging symbols found)...done.
Loaded symbols for /lib/ld-linux.so.2
Core was generated by `./a.out'.
Program terminated with signal 11, Segmentation fault.
#0 0x0804870e in my_print (d1=1, d2=2) at main.cpp:18
18 cerr<<"first is:"<<*p1<<",second is:"<<*p2<<endl;
这里,我们就进入了gdb的调试交互界面,看到gdb直接定位到导致程序出错的位置了。我们还可以使用如下命令:"#gdb a.out --core=core.30557"。
通过错误,我们知道程序由于"signal 11"导致终止,如果想要大致了解"signal 11",那么我们可查看signal的man手册:
#man 7 signal
这样,在输出的信息中我们可以看见“SIGSEGV 11 Core Invalid memory
reference”这样的字样,意思是说,signal(信号)11表示非法内存引用。注意这里使用"man 7 signal"而不是"man
signal",因为我们要查看的不是signal函数或者signal命令,而是signal的其他信息,其他的信息在man手册的第7节,具体需要了解一些使用man的命令。
2)查看具体调用关系
(gdb) bt
#0 0x0804870e in my_print (d1=1, d2=2) at main.cpp:18
#1 0x08048799 in main (argc=<value optimized out>, argv=<value optimized out>) at main.cpp:10
这里,我们通过backtrace(简写为bt)命令可以看到,导致崩溃那条语句是通过什么调用途径被调用到的。
3)设置断点,并进行调试等:
(gdb) b main.cpp:10
Breakpoint 1 at 0x8048787: file main.cpp, line 10.
(gdb) r
Starting program: /root/test/a.out
Breakpoint 1, main (argc=<value optimized out>, argv=<value optimized out>) at main.cpp:10
10 my_print(a,b);
(gdb) s
my_print (d1=1, d2=2) at main.cpp:16
16 int *p1=&d1;
(gdb) n
17 int *p2 = NULL;
(gdb) n
18 cerr<<"first is:"<<*p1<<",second is:"<<*p2<<endl;
(gdb) p d1
$1 = 1
(gdb) p d2
$2 = 2
(gdb) p *p1
$1 = 1
(gdb) p *p2
Cannot access memory at address 0x0
(gdb) n
Program received signal SIGSEGV, Segmentation fault.
0x0804870e in my_print (d1=1, d2=2) at main.cpp:18
18 cerr<<"first is:"<<*p1<<",second is:"<<*p2<<endl;
这里,我们在开始初步的定位的基础上,通过设置断点(break),运行(run),gdb的单步跟进(step),单步跳过(next),变量的打印(print)等各种gdb命令,来了解产生崩溃时候的具体情况,确定产生崩溃的原因。
4)退出gdb:
(gdb) q
A debugging session is active.
Inferior 3 [process 30584] will be killed.
Inferior 1 [process 1] will be killed.
Quit anyway? (y or n) y
Quitting: Couldn't get registers: 没有那个进程.
[root@lv-k test]#
[root@lv-k test]# ls
a.out core.30557 core.30609 main.cpp
这里,我们看到又产生了一个core文件。因为刚才调试,导致又产生了一个core文件。实际,如果我们只使用"gdb a.out core.30557"初步定位之后,不进行调试就退出gdb的话,就不会再生成core文件。
五、修正错误
1)通过上面的过程我们最终修正错误,得到正确的源代码如下:
1 #include <iostream>
2 using std::cerr;
3 using std::endl;
4
5 void my_print(int d1, int d2);
6 int main(int argc, char *argv[])
7 {
8 int a = 1;
9 int b = 2;
10 my_print(a,b);
11 return 0;
12 }
13
14 void my_print(int d1, int d2)
15 {
16 int *p1=&d1;
17 //int *p2 = NULL;//lvkai-
18 int *p2 = &d2;//lvkai+
19 cerr<<"first is:"<<*p1<<",second is:"<<*p2<<endl;
20 }
2)编译并运行这个程序,最终产生结果如下:
[root@lv-k test]# g++ main.cpp
[root@lv-k test]# ls
a.out main.cpp
[root@lv-k test]# ./a.out
first is:1,second is:2
这里,得到了我们预期的结果。
另外,有个小技巧,如果对Makefile有些了解的话可以充分利用make的隐含规则来编译单个源文件的程序,
过程如下:
[root@lv-k test]# ls
main.cpp
[root@lv-k test]# make main
g++ main.cpp -o main
[root@lv-k test]# ls
main main.cpp
[root@lv-k test]# ./main
first is:1,second is:2
这里注意,make的目标参数必须是源文件"main.cpp"去掉后缀之后的"main",等价于"g++ main.cpp -o main",这样编译的命令比较简单。
[其它]
其它内容有待添加。
认真地工作并且思考,是最好的老师。在工作的过程中思考自己所缺乏的技术,以及学习他人的经验,才能在工作中有所收获。这篇文章原来是工作中我的一个同事加朋友的经验,我站在这样的经验的基础上,进行了这样总结。
一,什么是coredump
我们经常听到大家说到程序core掉了,需要定位解决,这里说的大部分是指对应程序由于各种异常或者bug导致在运行过程中异常退出或者中止,并且在满足一定条件下(这里为什么说需要满足一定的条件呢?下面会分析)会产生一个叫做core的文件。
通常情况下,core文件会包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息还有各种函数调用堆栈信息等,我们可以理解为是程序工作当前状态存储生成第一个文件,许多的程序出错的时候都会产生一个core文件,通过工具分析这个文件,我们可以定位到程序异常退出的时候对应的堆栈调用等信息,找出问题所在并进行及时解决。
二,coredump文件的存储位置
core文件默认的存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到core文件的存在位置:
cat /proc/sys/kernel/core_pattern
缺省值是core
注意:这里是指在进程当前工作目录的下创建。通常与程序在相同的路径下。但如果程序中调用了chdir函数,则有可能改变了当前工作目录。这时core文件创建在chdir指定的路径下。有好多程序崩溃了,我们却找不到core文件放在什么位置。和chdir函数就有关系。当然程序崩溃了不一定都产生 core文件。
如下程序代码:则会把生成的core文件存储在/data/coredump/wd,而不是大家认为的跟可执行文件在同一目录。
通过下面的命令可以更改coredump文件的存储位置,若你希望把core文件生成到/data/coredump/core目录下:
echo “/data/coredump/core”> /proc/sys/kernel/core_pattern
注意,这里当前用户必须具有对/proc/sys/kernel/core_pattern的写权限。
缺省情况下,内核在coredump时所产生的core文件放在与该程序相同的目录中,并且文件名固定为core。很显然,如果有多个程序产生core文件,或者同一个程序多次崩溃,就会重复覆盖同一个core文件,因此我们有必要对不同程序生成的core文件进行分别命名。
我们通过修改kernel的参数,可以指定内核所生成的coredump文件的文件名。例如,使用下面的命令使kernel生成名字为core.filename.pid格式的core dump文件:
echo “/data/coredump/core.%e.%p” >/proc/sys/kernel/core_pattern
这样配置后,产生的core文件中将带有崩溃的程序名、以及它的进程ID。上面的%e和%p会被替换成程序文件名以及进程ID。
如果在上述文件名中包含目录分隔符“/”,那么所生成的core文件将会被放到指定的目录中。 需要说明的是,在内核中还有一个与coredump相关的设置,就是/proc/sys/kernel/core_uses_pid。如果这个文件的内容被配置成1,那么即使core_pattern中没有设置%p,最后生成的core dump文件名仍会加上进程ID。
三,如何判断一个文件是coredump文件?
在类unix系统下,coredump文件本身主要的格式也是ELF格式,因此,我们可以通过readelf命令进行判断。
可以看到ELF文件头的Type字段的类型是:CORE (Core file)
可以通过简单的file命令进行快速判断:
四,产生coredum的一些条件总结
1, 产生coredump的条件,首先需要确认当前会话的ulimit –c,若为0,则不会产生对应的coredump,需要进行修改和设置。
ulimit -c unlimited (可以产生coredump且不受大小限制)
若想甚至对应的字符大小,则可以指定:
ulimit –c [size]
可以看出,这里的size的单位是blocks,一般1block=512bytes
如:
ulimit –c 4 (注意,这里的size如果太小,则可能不会产生对应的core文件,笔者设置过ulimit –c 1的时候,系统并不生成core文件,并尝试了1,2,3均无法产生core,至少需要4才生成core文件)
但当前设置的ulimit只对当前会话有效,若想系统均有效,则需要进行如下设置:
Ø 在/etc/profile中加入以下一行,这将允许生成coredump文件
ulimit-c unlimited
Ø 在rc.local中加入以下一行,这将使程序崩溃时生成的coredump文件位于/data/coredump/目录下:
echo /data/coredump/core.%e.%p> /proc/sys/kernel/core_pattern
注意rc.local在不同的环境,存储的目录可能不同,susu下可能在/etc/rc.d/rc.local
更多ulimit的命令使用,可以参考:http://baike.baidu.com/view/4832100.htm
这些需要有root权限, 在ubuntu下每次重新打开中断都需要重新输入上面的ulimit命令, 来设置core大小为无限.
2, 当前用户,即执行对应程序的用户具有对写入core目录的写权限以及有足够的空间。
3, 几种不会产生core文件的情况说明:
The core file will not be generated if
(a) the process was set-user-ID and the current user is not the owner of the program file, or
(b) the process was set-group-ID and the current user is not the group owner of the file,
(c) the user does not have permission to write in the current working directory,
(d) the file already exists and the user does not have permission to write to it, or
(e) the file is too big (recall the RLIMIT_CORE limit in Section 7.11). The permissions of the core file (assuming that the file doesn't already exist) are usually user-read and user-write, although Mac OS X sets only user-read.
五,coredump产生的几种可能情况
造成程序coredump的原因有很多,这里总结一些比较常用的经验吧:
1,内存访问越界
a) 由于使用错误的下标,导致数组访问越界。
b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串没有正常的使用结束符。
c) 使用strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,将目标字符串读/写爆。应该使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防止读写越界。
2,多线程程序使用了线程不安全的函数。
应该使用下面这些可重入的函数,它们很容易被用错:
asctime_r(3c) gethostbyname_r(3n) getservbyname_r(3n)ctermid_r(3s) gethostent_r(3n) getservbyport_r(3n) ctime_r(3c) getlogin_r(3c)getservent_r(3n) fgetgrent_r(3c) getnetbyaddr_r(3n) getspent_r(3c)fgetpwent_r(3c) getnetbyname_r(3n) getspnam_r(3c) fgetspent_r(3c)getnetent_r(3n) gmtime_r(3c) gamma_r(3m) getnetgrent_r(3n) lgamma_r(3m) getauclassent_r(3)getprotobyname_r(3n) localtime_r(3c) getauclassnam_r(3) etprotobynumber_r(3n)nis_sperror_r(3n) getauevent_r(3) getprotoent_r(3n) rand_r(3c) getauevnam_r(3)getpwent_r(3c) readdir_r(3c) getauevnum_r(3) getpwnam_r(3c) strtok_r(3c) getgrent_r(3c)getpwuid_r(3c) tmpnam_r(3s) getgrgid_r(3c) getrpcbyname_r(3n) ttyname_r(3c)getgrnam_r(3c) getrpcbynumber_r(3n) gethostbyaddr_r(3n) getrpcent_r(3n)
3,多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成coredump
4,非法指针
a) 使用空指针
b) 随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump。
5,堆栈溢出
不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
六,利用gdb进行coredump的定位
其实分析coredump的工具有很多,现在大部分类unix系统都提供了分析coredump文件的工具,不过,我们经常用到的工具是gdb。
这里我们以程序为例子来说明如何进行定位。
1, 段错误 – segmentfault
Ø 我们写一段代码往受到系统保护的地址写内容。
Ø 按如下方式进行编译和执行,注意这里需要-g选项编译。
可以看到,当输入12的时候,系统提示段错误并且core dumped
Ø 我们进入对应的core文件生成目录,优先确认是否core文件格式并启用gdb进行调试。
从红色方框截图可以看到,程序中止是因为信号11,且从bt(backtrace)命令(或者where)可以看到函数的调用栈,即程序执行到coremain.cpp的第5行,且里面调用scanf 函数,而该函数其实内部会调用_IO_vfscanf_internal()函数。
接下来我们继续用gdb,进行调试对应的程序。
记住几个常用的gdb命令:
l(list) ,显示源代码,并且可以看到对应的行号;
b(break)x, x是行号,表示在对应的行号位置设置断点;
p(print)x, x是变量名,表示打印变量x的值
r(run), 表示继续执行到断点的位置
n(next),表示执行下一步
c(continue),表示继续执行
q(quit),表示退出gdb
启动gdb,注意该程序编译需要-g选项进行。
注: SIGSEGV 11 Core Invalid memoryreference
七,附注:
1, gdb的查看源码
显示源代码
GDB 可以打印出所调试程序的源代码,当然,在程序编译时一定要加上-g的参数,把源程序信息编译到执行文件中。不然就看不到源程序了。当程序停下来以后,GDB会报告程序停在了那个文件的第几行上。你可以用list命令来打印程序的源代码。还是来看一看查看源代码的GDB命令吧。
list<linenum>
显示程序第linenum行的周围的源程序。
list<function>
显示函数名为function的函数的源程序。
list
显示当前行后面的源程序。
list -
显示当前行前面的源程序。
一般是打印当前行的上5行和下5行,如果显示函数是是上2行下8行,默认是10行,当然,你也可以定制显示的范围,使用下面命令可以设置一次显示源程序的行数。
setlistsize <count>
设置一次显示源代码的行数。
showlistsize
查看当前listsize的设置。
list命令还有下面的用法:
list<first>, <last>
显示从first行到last行之间的源代码。
list ,<last>
显示从当前行到last行之间的源代码。
list +
往后显示源代码。
一般来说在list后面可以跟以下这些参数:
<linenum> 行号。
<+offset> 当前行号的正偏移量。
<-offset> 当前行号的负偏移量。
<filename:linenum> 哪个文件的哪一行。
<function> 函数名。
<filename:function>哪个文件中的哪个函数。
<*address> 程序运行时的语句在内存中的地址。
2, 一些常用signal的含义
SIGABRT:调用abort函数时产生此信号。进程异常终止。
SIGBUS:指示一个实现定义的硬件故障。
SIGEMT:指示一个实现定义的硬件故障。EMT这一名字来自PDP-11的emulator trap 指令。
SIGFPE:此信号表示一个算术运算异常,例如除以0,浮点溢出等。
SIGILL:此信号指示进程已执行一条非法硬件指令。4.3BSD由abort函数产生此信号。SIGABRT现在被用于此。
SIGIOT:这指示一个实现定义的硬件故障。IOT这个名字来自于PDP-11对于输入/输出TRAP(input/outputTRAP)指令的缩写。系统V的早期版本,由abort函数产生此信号。SIGABRT现在被用于此。
SIGQUIT:当用户在终端上按退出键(一般采用Ctrl-/)时,产生此信号,并送至前台进
程组中的所有进程。此信号不仅终止前台进程组(如SIGINT所做的那样),同时产生一个core文件。
SIGSEGV:指示进程进行了一次无效的存储访问。名字SEGV表示“段违例(segmentationviolation)”。
SIGSYS:指示一个无效的系统调用。由于某种未知原因,进程执行了一条系统调用指令,但其指示系统调用类型的参数却是无效的。
SIGTRAP:指示一个实现定义的硬件故障。此信号名来自于PDP-11的TRAP指令。
SIGXCPUSVR4和4.3+BSD支持资源限制的概念。如果进程超过了其软C P U时间限制,则产生此信号。
SIGXFSZ:如果进程超过了其软文件长度限制,则SVR4和4.3+BSD产生此信号。
3, Core_pattern的格式
可以在core_pattern模板中使用变量还很多,见下面的列表:
%% 单个%字符
%p 所dump进程的进程ID
%u 所dump进程的实际用户ID
%g 所dump进程的实际组ID
%s 导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h 主机名
%e 程序文件名



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架