Linux伙伴算法
Linux内存管理伙伴算法
伙伴算法
Linux内核内存管理的任务包括:
-
遵从CPU的MMU(Memory Management Unit)机制
-
合理、有效、快速地管理内存
-
实现内存保护机制
-
实现虚拟内存
-
共享
-
重定位
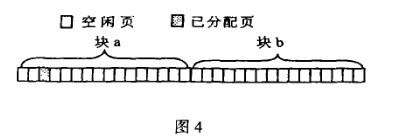
Linux内核通过伙伴算法来管理物理内存。伙伴系统(Buddy
System)在理论上是非常简单的内存分配算法。它的用途主要是尽可能减少外部碎片,同时允许快速分配与回收物理页面。为了减少外部碎片,连续的空闲页面,根据空闲块(由连续的空闲页面组成)大小,组织成不同的链表(或者orders)。这样所有的2个页面大小的空闲块在一个链表中,4个页面大小的空闲块在另外一个链表中,以此类推。

注意,不同大小的块在空间上,不会有重叠。当一个需求为4个连续页面时,检查是否有4个页面的空闲块而快速满足请求。若该链表上(每个结点都是大小为4页面的块)有空闲的块,则分配给用户,否则向下一个级别(order)的链表中查找。若存在(8页面的)空闲块(现处于另外一个级别的链表上),则将该页面块分裂为两个4页面的块,一块分配给请求者,另外一块加入到4页面的块链表中。这样可以避免分裂大的空闲块,而此时有可以满足需求的小页面块,从而减少外面碎片。

伙伴算法举例
假设我们的系统内存只有16个页面RAM。因为RAM只有16个页面,我们只需用四个级别(orders)的伙伴位图(因为最大连续内存大小为16个页面),如下图所示。


在order(0),第一个bit表示开始的2个页面,第二个bit表示接下来的2个页面,以此类推。因为页面4已分配,而页面5空闲,故第三个bit为1。
同样在order(1)中,bit3是1的原因是一个伙伴完全空闲(页面8和9),和它对应的伙伴(页面10和11)却并非如此,故以后回收页面时,可以合并。
分配过程
当我们需要order(1)的空闲页面块时,则执行以下步骤:
1、初始空闲链表为:
order(0): 5, 10
order(1): 8 [8,9]
order(2): 12 [12,13,14,15]
order(3):
2、从上面空闲链表中,我们可以看出,order(1)链表上,有一个空闲的页面块,把它分配给用户,并从该链表中删除。
3、当我们再需要一个order(1)的块时,同样我们从order(1)空闲链表上开始扫描。
4、若在order(1)上没有空闲页面块,那么我们就到更高的级别(order)上找,order(2)。
5、此时有一个空闲页面块,该块是从页面12开始。该页面块被分割成两个稍微小一些order(1)的页面块,[12,13]和[14,15]。[14,15]页面块加到order(1)空闲链表中,同时[12,13]页面块返回给用户。
6、最终空闲链表为:
order(0): 5, 10
order(1): 14 [14,15]
order(2):
order(3):
回收过程
当我们回收页面11(order 0)时,则执行以下步骤:
1、找到在order(0)伙伴位图中代表页面11的位,计算使用下面公示:
index = page_idx >> (order + 1)
= 11 >> (0 + 1)
= 5
2、检查上面一步计算位图中相应bit的值。若该bit值为1,则和我们临近的,有一个空闲伙伴。Bit5的值为1(注意是从bit0开始的,Bit5即为第6bit),因为它的伙伴页面10是空闲的。
3、现在我们重新设置该bit的值为0,因为此时两个伙伴(页面10和页面11)完全空闲。
4、我们将页面10,从order(0)空闲链表中摘除。
5、此时,我们对2个空闲页面(页面10和11,order(1))进行进一步操作。
6、新的空闲页面是从页面10开始的,于是我们在order(1)的伙伴位图中找到它的索引,看是否有空闲的伙伴,以进一步进行合并操作。使用第一步中的计算公司,我们得到bit 2(第3位)。
7、Bit 2(order(1)位图)同样也是1,因为它的伙伴页面块(页面8和9)是空闲的。
8、重新设置bit2(order(1)位图)的值,然后在order(1)链表中删除该空闲页面块。
9、现在我们合并成了4页面大小(从页面8开始)的空闲块,从而进入另外的级别。在order(2)中找到伙伴位图对应的bit值,是bit1,且值为1,需进一步合并(原因同上)。
10、从oder(2)链表中摘除空闲页面块(从页面12开始),进而将该页面块和前面合并得到的页面块进一步合并。现在我们得到从页面8开始,大小为8个页面的空闲页面块。
11、我们进入另外一个级别,order(3)。它的位索引为0,它的值同样为0。这意味着对应的伙伴不是全部空闲的,所以没有再进一步合并的可能。我们仅设置该bit为1,然后将合并得到的空闲页面块放入order(3)空闲链表中。
12、最终我们得到大小为8个页面的空闲块:

内存管理(二)伙伴算法
通常情况下,一个高级操作系统必须要给进程提供基本的、能够在任意时刻申请和释放任意大小内存的功能,就像malloc 函数那样,然而,实现malloc 函数并不简单,由于进程申请内存的大小是任意的,如果操作系统对malloc 函数的实现方法不对,将直接导致一个不可避免的问题,那就是内存碎片。
内存碎片就是内存被分割成很小很小的一些块,这些块虽然是空闲的,但是却小到无法使用。随着申请和释放次数的增加,内存将变得越来越不连续。最后,整个内存将只剩下碎片,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就可能无法满足,所以减少内存浪费的核心就是尽量避免产生内存碎片。
针对这样的问题,有很多行之有效的解决方法,其中伙伴算法被证明是非常行之有效的一套内存管理方法,因此也被相当多的操作系统所采用。
伙伴算法,简而言之,就是将内存分成若干块,然后尽可能以最适合的方式满足程序内存需求的一种内存管理算法,伙伴算法的一大优势是它能够完全避免外部碎片的产生。什么是外部碎片以及内部碎片,前面博文slab分配器后面已有介绍。申请时,伙伴算法会给程序分配一个较大的内存空间,即保证所有大块内存都能得到满足。很明显分配比需求还大的内存空间,会产生内部碎片。所以伙伴算法虽然能够完全避免外部碎片的产生,但这恰恰是以产生内部碎片为代价的。
Linux 便是采用这著名的伙伴系统算法来解决外部碎片的问题。把所有的空闲页框分组为 11 块链表,每一块链表分别包含大小为1,2,4,8,16,32,64,128,256,512 和 1024 个连续的页框。对1024 个页框的最大请求对应着 4MB 大小的连续RAM 块。每一块的第一个页框的物理地址是该块大小的整数倍。例如,大小为 16个页框的块,其起始地址是 16 * 2^12 (2^12 = 4096,这是一个常规页的大小)的倍数。
下面通过一个简单的例子来说明该算法的工作原理:
假设要请求一个256(129~256)个页框的块。算法先在256个页框的链表中检查是否有一个空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是,在512个页框的链表中找一个空闲块。如果存在这样的块,内核就把512的页框分成两等分,一般用作满足需求,另一半则插入到256个页框的链表中。如果在512个页框的块链表中也没找到空闲块,就继续找更大的块——1024个页框的块。如果这样的块存在,内核就把1024个页框块的256个页框用作请求,然后剩余的768个页框中拿512个插入到512个页框的链表中,再把最后的256个插入到256个页框的链表中。如果1024个页框的链表还是空的,算法就放弃并发出错误信号。
简而言之,就是在分配内存时,首先从空闲的内存中搜索比申请的内存大的最小的内存块。如果这样的内存块存在,则将这块内存标记为“已用”,同时将该内存分配给应用程序。如果这样的内存不存在,则操作系统将寻找更大块的空闲内存,然后将这块内存平分成两部分,一部分返回给程序使用,另一部分作为空闲的内存块等待下一次被分配。
以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为 b 的一对空闲伙伴块合并为一个大小为 2b 的单独块。满足以下条件的两个块称为伙伴:
- 两个快具有相同的大小,记作 b
- 它们的物理地址是连续的
- 第一块的第一个页框的物理地址是 2 * b * 2^12 的倍数
该算法是迭代的,如果它成功合并所释放的块,它会试图合并 2b 的块,以再次试图形成更大的块。
假设要释放一个256个页框的块,算法就把其插入到256个页框的链表中,然后检查与该内存相邻的内存,如果存在同样大小为256个页框的并且空闲的内存,就将这两块内存合并成512个页框,然后插入到512个页框的链表中,如果不存在,就没有后面的合并操作。然后再进一步检查,如果合并后的512个页框的内存存在大小为512个页框的相邻且空闲的内存,则将两者合并,然后插入到1024个页框的链表中。
简而言之,就是当程序释放内存时,操作系统首先将该内存回收,然后检查与该内存相邻的内存是否是同样大小并且同样处于空闲的状态,如果是,则将这两块内存合并,然后程序递归进行同样的检查。
下面通过一个例子,来深入地理解一下伙伴算法的真正内涵(下面这个例子并不严格表示Linux 内核中的实现,是阐述伙伴算法的实现思想):
假设系统中有 1MB 大小的内存需要动态管理,按照伙伴算法的要求:需要将这1M大小的内存进行划分。这里,我们将这1M的内存分为 64K、64K、128K、256K、和512K 共五个部分,如下图 a 所示
1.此时,如果有一个程序A想要申请一块45K大小的内存,则系统会将第一块64K的内存块分配给该程序(产生内部碎片为代价),如图b所示;
2.然后程序B向系统申请一块68K大小的内存,系统会将128K内存分配给该程序,如图c所示;
3.接下来,程序C要申请一块大小为35K的内存。系统将空闲的64K内存分配给该程序,如图d所示;
4.之后程序D需要一块大小为90K的内存。当程序提出申请时,系统本该分配给程序D一块128K大小的内存,但此时内存中已经没有空闲的128K内存块了,于是根据伙伴算法的原理,系统会将256K大小的内存块平分,将其中一块分配给程序D,另一块作为空闲内存块保留,等待以后使用,如图e所示;
5.紧接着,程序C释放了它申请的64K内存。在内存释放的同时,系统还负责检查与之相邻并且同样大小的内存是否也空闲,由于此时程序A并没有释放它的内存,所以系统只会将程序C的64K内存回收,如图f所示;
6.然后程序A也释放掉由它申请的64K内存,系统随机发现与之相邻且大小相同的一段内存块恰好也处于空闲状态。于是,将两者合并成128K内存,如图g所示;
7.之后程序B释放掉它的128k,系统也将这块内存与相邻的128K内存合并成256K的空闲内存,如图h所示;
8.最后程序D也释放掉它的内存,经过三次合并后,系统得到了一块1024K的完整内存,如图i所示。
有了前面的了解,我们通过Linux 内核源码(mmzone.h)来看看伙伴算法是如何实现的:
伙伴算法管理结构
- #define MAX_ORDER 11
- struct zone {
- ……
- struct free_area free_area[MAX_ORDER];
- ……
- }
- struct free_area {
- struct list_head free_list[MIGRATE_TYPES];
- unsigned long nr_free;//该组类别块空闲的个数
- };
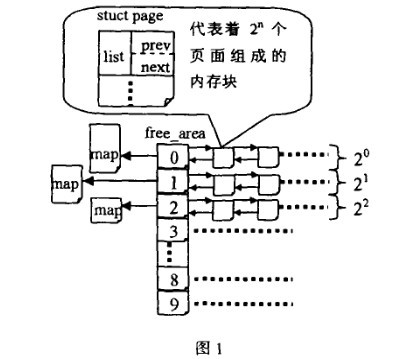
前面说到伙伴算法把所有的空闲页框分组为11块链表,内存分配的最大长度便是2^10页面。
上面两个结构体向我们揭示了伙伴算法管理结构。zone结构中的free_area数组,大小为11,分别存放着这11个组,free_area结构体里面又标注了该组别空闲内存块的情况。
将所有空闲页框分为11个组,然后同等大小的串成一个链表对应到free_area数组中。这样能很好的管理这些不同大小页面的块。
内存管理算法--Buddy伙伴算法【转】
Buddy算法的优缺点:
1)尽管伙伴内存算法在内存碎片问题上已经做的相当出色,但是该算法中,一个很小的块往往会阻碍一个大块的合并,一个系统中,对内存块的分配,大小是随机的,一片内存中仅一个小的内存块没有释放,旁边两个大的就不能合并。
2)算法中有一定的浪费现象,伙伴算法是按2的幂次方大小进行分配内存块,当然这样做是有原因的,即为了避免把大的内存块拆的太碎,更重要的是使分配和释放过程迅速。但是他也带来了不利的一面,如果所需内存大小不是2的幂次方,就会有部分页面浪费。有时还很严重。比如原来是1024个块,申请了16个块,再申请600个块就申请不到了,因为已经被分割了。
3)另外拆分和合并涉及到 较多的链表和位图操作,开销还是比较大的。
Buddy(伙伴的定义):
这里给出伙伴的概念,满足以下三个条件的称为伙伴:
1)两个块大小相同;
2)两个块地址连续;
3)两个块必须是同一个大块中分离出来的;
Buddy算法的分配原理:
假如系统需要4(2*2)个页面大小的内存块,该算法就到free_area[2]中查找,如果链表中有空闲块,就直接从中摘下并分配出去。如果没有,算法将顺着数组向上查找free_area[3],如果free_area[3]中有空闲块,则将其从链表中摘下,分成等大小的两部分,前四个页面作为一个块插入free_area[2],后4个页面分配出去,free_area[3]中也没有,就再向上查找,如果free_area[4]中有,就将这16(2*2*2*2)个页面等分成两份,前一半挂如free_area[3]的链表头部,后一半的8个页等分成两等分,前一半挂free_area[2]
的链表中,后一半分配出去。假如free_area[4]也没有,则重复上面的过程,知道到达free_area数组的最后,如果还没有则放弃分配。
Buddy算法的释放原理:
内存的释放是分配的逆过程,也可以看作是伙伴的合并过程。当释放一个块时,先在其对应的链表中考查是否有伙伴存在,如果没有伙伴块,就直接把要释放的块挂入链表头;如果有,则从链表中摘下伙伴,合并成一个大块,然后继续考察合并后的块在更大一级链表中是否有伙伴存在,直到不能合并或者已经合并到了最大的块(2*2*2*2*2*2*2*2*2个页面)。
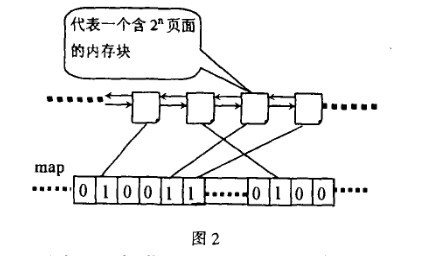
整个过程中,位图扮演了重要的角色,如图2所示,位图的某一位对应两个互为伙伴的块,为1表示其中一块已经分配出去了,为0表示两块都空闲。伙伴中无论是分配还是释放都只是相对的位图进行异或操作。分配内存时对位图的
是为释放过程服务,释放过程根据位图判断伙伴是否存在,如果对相应位的异或操作得1,则没有伙伴可以合并,如果异或操作得0,就进行合并,并且继续按这种方式合并伙伴,直到不能合并为止。
Buddy内存管理的实现:
提到buddy 就会想起linux 下的物理内存的管理 ,这里的memory pool 上实现的 buddy 系统
和linux 上按page 实现的buddy系统有所不同的是,他是按照字节的2的n次方来做block的size
实现的机制中主要的结构如下:
整个buddy 系统的结构:
struct mem_pool_table
{
#define MEM_POOL_TABLE_INIT_COOKIE (0x62756479)
uint32 initialized_cookie;
/* Cookie 指示内存已经被初始化后的魔数, 如果已经初始化设置为0x62756479*/
uint8 *mem_pool_ptr;/* 指向内存池的地址*/
uint32 mem_pool_size;
/* 整个pool 的size,下面是整个max block size 的大小*/
boolean assert_on_empty; /* 如果该值被设置成TRUE,内存分配请求没有完成就返回 并输出出错信息*/
uint32 mem_remaining; /* 当前内存池中剩余内存字节数*/
uint32 max_free_list_index; /* 最大freelist 的下标,*/
struct mem_free_hdr_type *free_lists[MAX_LEVELS];/* 这个就是伙伴系统的level数组*/
#ifdef FEATURE_MEM_CHECK
uint32 max_block_requested;
uint32 min_free_mem; /* 放mem_remaining */
#endif /* FEATURE_ONCRPC_MEM_CHECK*/
};
这个结构是包含在free node 或alloc node 中的结构:
其中check 和 fill 都被设置为某个pattern
用来检查该node 的合法性
#define MEM_HDR_CHECK_PATTERN ((uint16)0x3CA4)
#define MEM_HDR_FILL_PATTERN ((uint8)0x5C)
typedef struct tagBuddyMemBlockHeadType
{
mem_pool_type pool;
/*回指向内存池*/
uint16 check;
uint8 state; /* bits 0-3 放该node 属于那1级 bit 7 如果置1,表示已经分配(not
free)
uint8 fill;
} BUDDY_MEM_BLOCK_HEAD_TYPE;
这个结构就是包含node 类型结构的 free header 的结构:
typedef struct tagBuddyMemHeadType
{
mem_node_hdr_type hdr;
struct mem_free_hdr_type * pNext; /* next,prev,用于连接free header的双向 list*/
struct mem_free_hdr_type * pPrev;
} mem_free_hdr_type;
这个结构就是包含node 类型结构的 alloc header 的结构:
已分配的mem 的node 在内存中就是这样表示的
- typedef struct mem_alloc_hdr_type
- {
- mem_node_hdr_type hdr;
- #ifdef FEATURE_MEM_CHECK_OVERWRITE
- uint32 in_use_size;
- #endif
- } mem_alloc_hdr_type;
其中用in_use_size 来表示如果请求分配的size 所属的level上实际用了多少
比如申请size=2000bytes, 按size to level 应该是2048,实际in_use_size
为2000,剩下48byte 全部填充为某一数值,然后在以后free 是可以check
是否有overwite 到着48byte 中的数值,一般为了速度,只 检查8到16byte
另外为什么不把这剩下的48byte 放到freelist 中其他level 中呢,这个可能
因为本来buddy 系统的缺点就是容易产生碎片,这样的话就更碎了
关于free or alloc node 的示意图:
假设
最小块为2^4=16,着是由mem_alloc_hdr_type (12byte)决定的, 实际可分配4byte
如果假定最大max_block_size =1024,
如果pool 有mem_free_hdr_type[0]上挂了两个1024的block node
上图是free node, 下图紫色为alloc node

接下来主要是buddy 系统的操作主要包括pool init , mem alloc ,mem free
pool init :
1. 将实际pool 的大小去掉mem_pool_table 结构大小后的size 放到
mem_pool_size, 并且修改实际mem_pool_ptr指向前进mem_pool_table
结构大小的地址
2. 接下来主要将mem_pool_size 大小的内存,按最大块挂到free_lists 上
level 为0的list 上,然后小于该level block size 部分,继续挂大下一
级,循环到全部处理完成 (感觉实际用于pool的size ,应该为减去
mem_pool_table 的大小,然后和最大块的size 对齐,这样比较好,
但没有实际测试过)
mem alloc:
这部分相当简单,先根据请求mem的size ,实际分配时需要加上mem_alloc_hdr_type
这12byte ,然后根据调整后的size,计算实际应该在那个 level上分配,如果有相应级
很简单,直接返回,如果没有,一级一级循环查找,找到后,把省下的部分,在往下一级
一级插入到对应级的freelist 上
mem free:
其中free 的地址,减去12 就可以获得mem_alloc_hdr_type 结构
然后确定buddy 在该被free block 前,还是后面, 然后合并buddy,
循环寻找上一级的buddy ,有就再合并,只到最大block size 那级
关于这个算法,在<<The Art of Computer Programming>> vol 1,的
动态存储分配中有描述,对于那些只有OSAL 的小系统,该算法相当有用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号