并发无锁队列
并发无锁队列学习之一【开篇】
1、前言
队列在计算机中非常重要的一种数据结构,尤其在操作系统中。队列典型的特征是先进先出(FIFO),符合流水线业务流程。在进程间通信、网络通信之间经常采用队列做缓存,缓解数据处理压力。结合自己在工作中遇到的队列问题,总结一下对不同场景下的队列实现。根据操作队列的场景分为:单生产者——单消费者、多生产者——单消费者、单生产者——多消费者、多生产者——多消费者四大模型。其实后面三种的队列,可以归纳为一种多对多。根据队列中数据分为:队列中的数据是定长的、队列中的数据是变长的。
2、队列操作模型
(1)单生产者——单消费者

(2)多生产者——单消费者
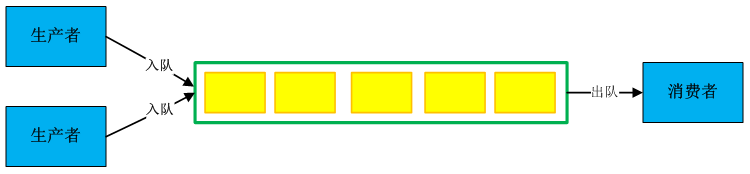
(3)单生产者——多消费者
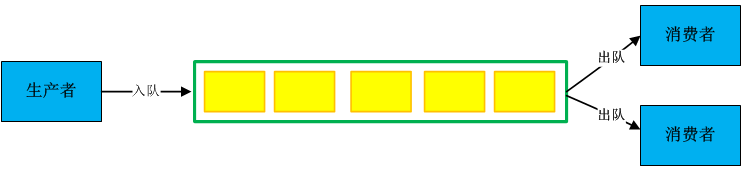
(4)多生产者——多消费者

3、队列数据定长与变长
(1)队列数据定长

(2)队列数据变长

4、并发无锁处理
(1)单生产者——单消费者模型
此种场景不需要加锁,定长的可以通过读指针和写指针进行控制队列操作,变长的通过读指针、写指针、结束指针控制操作。具体实现可以参考linux内核提供的kfifo的实现。可以参考:
http://blog.csdn.net/linyt/article/details/5764312
(2)(一)多对多(一)模型
正常逻辑操作是要对队列操作进行加锁处理。加锁的性能开销较大,一般采用无锁实现。无锁实现原理是CAS、FAA等机制。定长的可以参考:
http://coolshell.cn/articles/8239.html
变长的可以参考intel dpdk提供的rte_ring的实现。
http://blog.csdn.net/linzhaolover/article/details/9771329
无锁队列的实现
关于无锁队列的实现,网上有很多文章,虽然本文可能和那些文章有所重复,但是我还是想以我自己的方式把这些文章中的重要的知识点串起来和大家讲一讲这个技术。下面开始正文。
关于CAS等原子操作
 在开始说无锁队列之前,我们需要知道一个很重要的技术就是CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
在开始说无锁队列之前,我们需要知道一个很重要的技术就是CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
这个操作用C语言来描述就是下面这个样子:(代码来自Wikipedia的Compare And Swap词条)意思就是说,看一看内存*reg里的值是不是oldval,如果是的话,则对其赋值newval。
int compare_and_swap (int* reg, int oldval, int newval){ int old_reg_val = *reg; if (old_reg_val == oldval) *reg = newval; return old_reg_val;}这个操作可以变种为返回bool值的形式(返回 bool值的好处在于,可以调用者知道有没有更新成功):
bool compare_and_swap (int *accum, int *dest, int newval){ if ( *accum == *dest ) { *dest = newval; return true; } return false;}与CAS相似的还有下面的原子操作:(这些东西大家自己看Wikipedia吧)
- Fetch And Add,一般用来对变量做 +1 的原子操作
- Test-and-set,写值到某个内存位置并传回其旧值。汇编指令BST
- Test and Test-and-set,用来低低Test-and-Set的资源争夺情况
注:在实际的C/C++程序中,CAS的各种实现版本如下:
1)GCC的CAS
GCC4.1+版本中支持CAS的原子操作(完整的原子操作可参看 GCC Atomic Builtins)
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)2)Windows的CAS
在Windows下,你可以使用下面的Windows API来完成CAS:(完整的Windows原子操作可参看MSDN的InterLocked Functions)
InterlockedCompareExchange ( __inout LONG volatile *Target, __in LONG Exchange, __in LONG Comperand);3) C++11中的CAS
C++11中的STL中的atomic类的函数可以让你跨平台。(完整的C++11的原子操作可参看 Atomic Operation Library)
template< class T >bool atomic_compare_exchange_weak( std::atomic* obj, T* expected, T desired );template< class T >bool atomic_compare_exchange_weak( volatile std::atomic* obj, T* expected, T desired );无锁队列的链表实现
下面的东西主要来自John D. Valois 1994年10月在拉斯维加斯的并行和分布系统系统国际大会上的一篇论文——《Implementing Lock-Free Queues》。
我们先来看一下进队列用CAS实现的方式:
EnQueue(x) //进队列{ //准备新加入的结点数据 q = new record(); q->value = x; q->next = NULL; do { p = tail; //取链表尾指针的快照 } while( CAS(p->next, NULL, q) != TRUE); //如果没有把结点链在尾指针上,再试 CAS(tail, p, q); //置尾结点}我们可以看到,程序中的那个 do- while 的 Re-Try-Loop。就是说,很有可能我在准备在队列尾加入结点时,别的线程已经加成功了,于是tail指针就变了,于是我的CAS返回了false,于是程序再试,直到试成功为止。这个很像我们的抢电话热线的不停重播的情况。
你会看到,为什么我们的“置尾结点”的操作(第12行)不判断是否成功,因为:
- 如果有一个线程T1,它的while中的CAS如果成功的话,那么其它所有的 随后线程的CAS都会失败,然后就会再循环,
- 此时,如果T1 线程还没有更新tail指针,其它的线程继续失败,因为tail->next不是NULL了。
- 直到T1线程更新完tail指针,于是其它的线程中的某个线程就可以得到新的tail指针,继续往下走了。
这里有一个潜在的问题——如果T1线程在用CAS更新tail指针的之前,线程停掉或是挂掉了,那么其它线程就进入死循环了。下面是改良版的EnQueue()
EnQueue(x) //进队列改良版{ q = new record(); q->value = x; q->next = NULL; p = tail; oldp = p do { while (p->next != NULL) p = p->next; } while( CAS(p.next, NULL, q) != TRUE); //如果没有把结点链在尾上,再试 CAS(tail, oldp, q); //置尾结点}我们让每个线程,自己fetch 指针 p 到链表尾。但是这样的fetch会很影响性能。而通实际情况看下来,99.9%的情况不会有线程停转的情况,所以,更好的做法是,你可以接合上述的这两个版本,如果retry的次数超了一个值的话(比如说3次),那么,就自己fetch指针。
好了,我们解决了EnQueue,我们再来看看DeQueue的代码:(很简单,我就不解释了)
DeQueue() //出队列{ do{ p = head; if (p->next == NULL){ return ERR_EMPTY_QUEUE; } while( CAS(head, p, p->next) != TRUE ); return p->next->value;}我们可以看到,DeQueue的代码操作的是 head->next,而不是head本身。这样考虑是因为一个边界条件,我们需要一个dummy的头指针来解决链表中如果只有一个元素,head和tail都指向同一个结点的问题,这样EnQueue和DeQueue要互相排斥了。
")
注:上图的tail正处于更新之前的装态。
CAS的ABA问题
所谓ABA(见维基百科的ABA词条),问题基本是这个样子:
- 进程P1在共享变量中读到值为A
- P1被抢占了,进程P2执行
- P2把共享变量里的值从A改成了B,再改回到A,此时被P1抢占。
- P1回来看到共享变量里的值没有被改变,于是继续执行。
虽然P1以为变量值没有改变,继续执行了,但是这个会引发一些潜在的问题。ABA问题最容易发生在lock free 的算法中的,CAS首当其冲,因为CAS判断的是指针的地址。如果这个地址被重用了呢,问题就很大了。(地址被重用是很经常发生的,一个内存分配后释放了,再分配,很有可能还是原来的地址)
比如上述的DeQueue()函数,因为我们要让head和tail分开,所以我们引入了一个dummy指针给head,当我们做CAS的之前,如果head的那块内存被回收并被重用了,而重用的内存又被EnQueue()进来了,这会有很大的问题。(内存管理中重用内存基本上是一种很常见的行为)
这个例子你可能没有看懂,维基百科上给了一个活生生的例子——
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机去了。
这就是ABA的问题。
解决ABA的问题
维基百科上给了一个解——使用double-CAS(双保险的CAS),例如,在32位系统上,我们要检查64位的内容
1)一次用CAS检查双倍长度的值,前半部是指针,后半部分是一个计数器。
2)只有这两个都一样,才算通过检查,要吧赋新的值。并把计数器累加1。
这样一来,ABA发生时,虽然值一样,但是计数器就不一样(但是在32位的系统上,这个计数器会溢出回来又从1开始的,这还是会有ABA的问题)
当然,我们这个队列的问题就是不想让那个内存重用,这样明确的业务问题比较好解决,论文《Implementing Lock-Free Queues》给出一这么一个方法——使用结点内存引用计数refcnt!
SafeRead(q){ loop: p = q->next; if (p == NULL){ return p; } Fetch&Add(p->refcnt, 1); if (p == q->next){ return p; }else{ Release(p); } goto loop;}其中的 Fetch&Add和Release分是是加引用计数和减引用计数,都是原子操作,这样就可以阻止内存被回收了。
用数组实现无锁队列
本实现来自论文《Implementing Lock-Free Queues》
使用数组来实现队列是很常见的方法,因为没有内存的分部和释放,一切都会变得简单,实现的思路如下:
1)数组队列应该是一个ring buffer形式的数组(环形数组)
2)数组的元素应该有三个可能的值:HEAD,TAIL,EMPTY(当然,还有实际的数据)
3)数组一开始全部初始化成EMPTY,有两个相邻的元素要初始化成HEAD和TAIL,这代表空队列。
4)EnQueue操作。假设数据x要入队列,定位TAIL的位置,使用double-CAS方法把(TAIL, EMPTY) 更新成 (x, TAIL)。需要注意,如果找不到(TAIL, EMPTY),则说明队列满了。
5)DeQueue操作。定位HEAD的位置,把(HEAD, x)更新成(EMPTY, HEAD),并把x返回。同样需要注意,如果x是TAIL,则说明队列为空。
算法的一个关键是——如何定位HEAD或TAIL?
1)我们可以声明两个计数器,一个用来计数EnQueue的次数,一个用来计数DeQueue的次数。
2)这两个计算器使用使用Fetch&ADD来进行原子累加,在EnQueue或DeQueue完成的时候累加就好了。
3)累加后求个模什么的就可以知道TAIL和HEAD的位置了。
如下图所示:
")
小结
以上基本上就是所有的无锁队列的技术细节,这些技术都可以用在其它的无锁数据结构上。
1)无锁队列主要是通过CAS、FAA这些原子操作,和Retry-Loop实现。
2)对于Retry-Loop,我个人感觉其实和锁什么什么两样。只是这种“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构。
还有一些和Lock Free的文章你可以去看看:
- Code Project 上的雄文 《Yet another implementation of a lock-free circular array queue》
- Herb Sutter的《Writing Lock-Free Code: A Corrected Queue》– 用C++11的std::atomic模板。
- IBM developerWorks的《设计不使用互斥锁的并发数据结构》
intel dpdk api ring 模块源码详解
摘要
intel dpdk 提供了一套ring 队列管理代码,支持单生产者产品入列,单消费者产品出列;多名生产者产品入列,多产品消费这产品出列操作;
我们以app/test/test_ring.c文件中的代码进行讲解,test_ring_basic_ex()函数完成一个基本功能测试函数;
1、ring的创建
- rp = rte_ring_create("test_ring_basic_ex", RING_SIZE, SOCKET_ID_ANY,
- RING_F_SP_ENQ | RING_F_SC_DEQ);
调用rte_ring_create函数去创建一个ring,
第一参数"test_ring_basic_ex"是这个ring的名字,
第二个参数RING_SIZE是ring的大小;
第三个参数是在哪个socket id上创建 ,这指定的是任意;
第四个参数是指定此ring支持单入单出;
我看一下rte_ring_create函数主要完成了哪些操作;
- rte_rwlock_write_lock(RTE_EAL_TAILQ_RWLOCK);
执行读写锁的加锁操作;
- mz = rte_memzone_reserve(mz_name, ring_size, socket_id, mz_flags);
预留一部分内存空间给ring,其大小就是RING_SIZE个sizeof(struct rte_ring)的尺寸;
- r = mz->addr;
- /* init the ring structure */
- memset(r, 0, sizeof(*r));
- rte_snprintf(r->name, sizeof(r->name), "%s", name);
- r->flags = flags;
- r->prod.watermark = count;
- r->prod.sp_enqueue = !!(flags & RING_F_SP_ENQ);
- r->cons.sc_dequeue = !!(flags & RING_F_SC_DEQ);
- r->prod.size = r->cons.size = count;
- r->prod.mask = r->cons.mask = count-1;
- r->prod.head = r->cons.head = 0;
- r->prod.tail = r->cons.tail = 0;
- TAILQ_INSERT_TAIL(ring_list, r, next);
将获取到的虚拟地址给了ring,然后初始化她,prod 代表生成者,cons代表消费者;
生产者最大可以生产count个,其取模的掩码是 count-1; 目前是0个产品,所以将生产者的头和消费者头都设置为0;其尾也设置未0;
- rte_rwlock_write_unlock(RTE_EAL_TAILQ_RWLOCK);
执行读写锁的写锁解锁操作;
2、ring的单生产者产品入列
- rte_ring_enqueue(rp, obj[i])
ring的单个入列;
- __rte_ring_sp_do_enqueue
最终会调用到上面这个函数,进行单次入列,我们看一下它的实现;
- prod_head = r->prod.head;
- cons_tail = r->cons.tail;
暂时将生产者的头索引和消费者的尾部索引交给临时变量;
- free_entries = mask + cons_tail - prod_head;
计算还有多少剩余的存储空间;
- prod_next = prod_head + n;
- r->prod.head = prod_next;
如果有足够的剩余空间,我们先将临时变量prod_next 进行后移,同事将生产者的头索引后移n个;
- /* write entries in ring */
- for (i = 0; likely(i < n); i++)
- r->ring[(prod_head + i) & mask] = obj_table[i];
- rte_wmb();
执行写操作,将目标进行入队操作,它并没有任何大数据量的内存拷贝操作,只是进行指针的赋值操作,因此dpdk的内存操作很快,应该算是零拷贝;
- r->prod.tail = prod_next;
成功写入之后,将生产者的尾部索引赋值为prox_next ,也就是将其往后挪到n个索引;我们成功插入了n个产品;目前是单个操作,索引目前n=1;
3、ring的单消费者产品出列
- rte_ring_dequeue(rp, &obj[i]);
同样出队也包含了好几层的调用,最终定位到__rte_ring_sc_do_dequeue函数;
- cons_head = r->cons.head;
- prod_tail = r->prod.tail;
先将消费者的头索引和生产者的头索引赋值给临时变量;
- entries = prod_tail - cons_head;
计算目前ring中有多少产品;
- cons_next = cons_head + n;
- r->cons.head = cons_next;
如果有足够的产品,就将临时变量cons_next往后挪到n个值,指向你想取出几个产品的位置;同时将消费者的头索引往后挪到n个;这目前n=1;因为是单个取出;
- /* copy in table */
- rte_rmb();
- for (i = 0; likely(i < n); i++) {
- obj_table[i] = r->ring[(cons_head + i) & mask];
- }
执行读取操作,同样没有任何的大的数据量拷贝,只是进行指针的赋值;
- r->cons.tail = cons_next;
最后将消费者的尾部索引也像后挪动n个,最终等于消费者的头索引;
4、ring的多生产者产品入列
多生产者入列的实现是在 __rte_ring_mp_do_enqueue()函数中;在dpdk/lib/librte_ring/rte_ring.h 文件中定义;其实这个函数和单入列函数很相似;
- /* move prod.head atomically */
- do {
- /* Reset n to the initial burst count */
- n = max;
- .................
- prod_next = prod_head + n;
- success = rte_atomic32_cmpset(&r->prod.head, prod_head,
- prod_next);
- } while (unlikely(success == 0));
在单生产者中时将生产者的头部和消费者的尾部直接赋值给临时变量,去求剩余存储空间;最后将生产者的头索引往后移动n个,
但在多生产者中,要判断这个头部是否和其他的生产者发出竞争,
success = rte_atomic32_cmpset(&r->prod.head, prod_head,
prod_next);
是否有其他生产者修改了prod.head,所以这要重新判断一下prod.head是否还等于prod_head,如果等于,就将其往后移动n个,也就是将prod_next值赋值给prod.head;
如果不等于,就会失败,就需要进入do while循环再次循环一次;重新刷新一下prod_head和prod_next 以及prod.head的值 ;
- /* write entries in ring */
- for (i = 0; likely(i < n); i++)
- r->ring[(prod_head + i) & mask] = obj_table[i];
- rte_wmb();
执行产品写入操作;
写入操作完成之后,如是单生产者应该是直接修改生产者尾部索引,将其往后顺延n个,但目前是多生产者操作;是怎样实现的呢?
- /*
- * If there are other enqueues in progress that preceeded us,
- * we need to wait for them to complete
- */
- while (unlikely(r->prod.tail != prod_head))
- rte_pause();
- r->prod.tail = prod_next;
这也先进行判断,判断当前的生产者尾部索引是否还等于,存储在临时变量中的生产者头索引,
如果不等于,说明,有其他的线程还在执行,而且应该是在它之前进行存储,还没来得及更新prod.tail;等其他的生产者更新tail后,就会使得prod.tail==prod_head;
之后再更新,prod.tail 往后挪动n个,最好实现 prod.tail==prod.head==prod_next==prod_head+n;
5、ring的多消费者产品出列
多个消费者同时取产品是在__rte_ring_mc_do_dequeue()函数中实现;定义在dpdk/lib/librte_ring/rte_ring.h文件中;
- /* move cons.head atomically */
- do {
- /* Restore n as it may change every loop */
- n = max;
- cons_head = r->cons.head;
- prod_tail = r->prod.tail;
- ...................
- cons_next = cons_head + n;
- success = rte_atomic32_cmpset(&r->cons.head, cons_head,
- cons_next);
- } while (unlikely(success == 0));
和多生产者一样,在外面多包含了一次do while循环,防止多消费者操作发生竞争;
在循环中先将消费者的头索引和生产者的为索引赋值给临时变量;让后判断有多少剩余的产品在循环队列,
如有n个产品,就将临时变量cons_next 往后挪动n个,然后判断目前的消费者头索引是否还等于刚才的保存在临时变量cons_head 中的值,如相等,说明没有发生竞争,就将cons_next赋值给
消费者的头索引 r->cons.head,如不相等,就需要重新做一次do while循环;
- /* copy in table */
- rte_rmb();
- for (i = 0; likely(i < n); i++) {
- obj_table[i] = r->ring[(cons_head + i) & mask];
- }
在成功更新消费者头索引后,执行读取产品操作,这并没有大的数据拷贝操作,只是进行指针的重新赋值操作;
- /*
- * If there are other dequeues in progress that preceded us,
- * we need to wait for them to complete
- */
- while (unlikely(r->cons.tail != cons_head))
- rte_pause();
- __RING_STAT_ADD(r, deq_success, n);
- r->cons.tail = cons_next;
读取完成后,就要更新消费者的尾部索引;
为了避免竞争,就要判是否有其他的消费者在更新消费者尾部索引;如果目前的消费者尾部索引不等于刚才保存的在临时变量cons_head 的值,就要等待其他消费者修改这个尾部索引;
如相等,机可以将当前消费者的尾部索引往后挪动n个索引值了,
实现 r->cons.tail=r->cons.head=cons_next=cons_head+n;
6、ring的其他判定函数
- rte_ring_lookup("test_ring_basic_ex")
验证以test_ring_basic_ex 为名的ring是否创建成功;
- rte_ring_empty(rp)
判断ring是否为空;
- rte_ring_full(rp)
判断ring是否已经满;
- rte_ring_free_count(rp)
判断当前ring还有多少剩余存储空间;
并发无锁队列学习之二【单生产者单消费者】
1、前言
最近工作比较忙,加班较多,每天晚上回到家10点多了。我不知道自己还能坚持多久,既然选择了就要做到最好。写博客的少了。总觉得少了点什么,需要继续学习。今天继续上个开篇写,介绍单生产者单消费者模型的队列。根据写入队列的内容是定长还是变长,分为单生产者单消费者定长队列和单生产者单消费者变长队列两种。单生产者单消费者模型的队列操作过程是不需要进行加锁的。生产者通过写索引控制入队操作,消费者通过读索引控制出队列操作。二者相互之间对索引是独享,不存在竞争关系。如下图所示:

2、单生产者单消费者定长队列
这种队列要求每次入队和出队的内容是定长的,即生产者写入队列和消费者读取队列的内容大小事相同的。linux内核中的kfifo就是这种队列,提供了读和写两个索引。单生产者单消费者队列数据结构定义如下所示:

typedef struct
{
uint32_t r_index; /*读指针*/
uint32_t w_index; /*写指针*/
uint32_t size; /*缓冲区大小*/
char *buff[0]; /*缓冲区起始地址*/
}ring_buff_st;
为了方便计算位置,设置队列的大小为2的次幂。这样可以将之前的取余操作转换为位操作,即r_index = r_index % size 与 r_index = r_index & (size -1)等价。位操作非常快,充分利用了二进制的特征。
(1)队列初始状态,读写索引相等,此时队列为空。

(2)写入队列
写操作即进行入队操作,入队有三种场景,
2.1 写索引大于等于读索引


2.2写索引小于读索引

2.3.写索引后不够写入一个

(3)读取队列
读队列分为三种场景
3.1写索引大于等于读索引

3.2写索引小于读索引
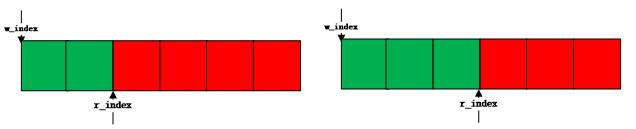
3.3.读索引后面不够一个

3、单生产者单消费者变长队列
有些时候生产者每次写入的数据长度是不确定的,导致写入队列的数据时变长的。这样为了充分利用队列,需要增加一个结束索引,保证队列末尾至少能够写入一个数据。变长队列数据结构定义如下:
typedef struct
{
uint32_t r_index; /*读指针*/
uint32_t w_index; /*写指针*/
uint32_t e_index; /*队列结束指针*/
uint32_t size; /*缓冲区大小*/
char *buff[0]; /*缓冲区起始地址*/
}ring_buff_st;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号