Floyd算法(一)之 C语言详解
本章介绍弗洛伊德算法。和以往一样,本文会先对弗洛伊德算法的理论论知识进行介绍,然后给出C语言的实现。后续再分别给出C++和Java版本的实现。
目录
1. 弗洛伊德算法介绍
2. 弗洛伊德算法图解
3. 弗洛伊德算法的代码说明
4. 弗洛伊德算法的源码
转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
弗洛伊德算法介绍
和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
基本思想
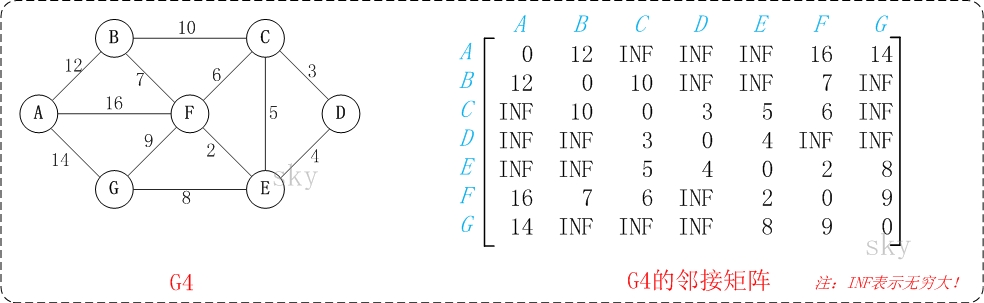
通过Floyd计算图G=(V,E)中各个顶点的最短路径时,需要引入一个矩阵S,矩阵S中的元素a[i][j]表示顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
假设图G中顶点个数为N,则需要对矩阵S进行N次更新。初始时,矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。
接下来开始,对矩阵S进行N次更新。第1次更新时,如果"a[i][j]的距离" >
"a[i][0]+a[0][j]"(a[i][0]+a[0][j]表示"i与j之间经过第1个顶点的距离"),则更新a[i][j]为"a[i][0]+a[0][j]"。
同理,第k次更新时,如果"a[i][j]的距离" >
"a[i][k]+a[k][j]",则更新a[i][j]为"a[i][k]+a[k][j]"。更新N次之后,操作完成!
单纯的看上面的理论可能比较难以理解,下面通过实例来对该算法进行说明。
弗洛伊德算法图解
![]()
以上图G4为例,来对弗洛伊德进行算法演示。
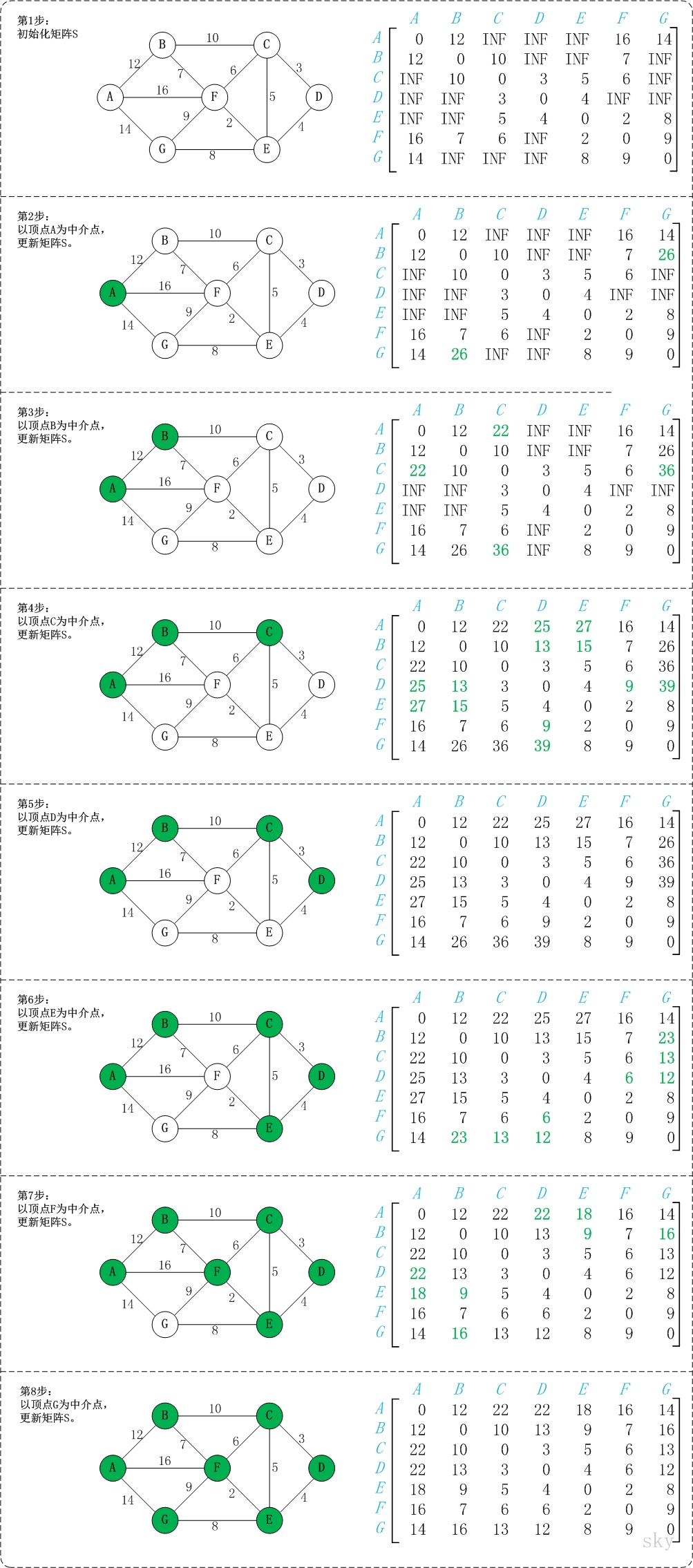
![]()
初始状态:S是记录各个顶点间最短路径的矩阵。
第1步:初始化S。
矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。实际上,就是将图的原始矩阵复制到S中。
注:a[i][j]表示矩阵S中顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
第2步:以顶点A(第1个顶点)为中介点,若a[i][j] > a[i][0]+a[0][j],则设置a[i][j]=a[i][0]+a[0][j]。
以顶点a[1]6,上一步操作之后,a[1][6]=∞;而将A作为中介点时,(B,A)=12,(A,G)=14,因此B和G之间的距离可以更新为26。
同理,依次将顶点B,C,D,E,F,G作为中介点,并更新a[i][j]的大小。
弗洛伊德算法的代码说明
以"邻接矩阵"为例对弗洛伊德算法进行说明,对于"邻接表"实现的图在后面会给出相应的源码。
1. 基本定义
// 邻接矩阵
typedef struct _graph
{
char vexs[MAX]; // 顶点集合
int vexnum; // 顶点数
int edgnum; // 边数
int matrix[MAX][MAX]; // 邻接矩阵
}Graph, *PGraph;
Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
2. 弗洛伊德算法
/*
* floyd最短路径。
* 即,统计图中各个顶点间的最短路径。
*
* 参数说明:
* G -- 图
* path -- 路径。path[i][j]=k表示,"顶点i"到"顶点j"的最短路径会经过顶点k。
* dist -- 长度数组。即,dist[i][j]=sum表示,"顶点i"到"顶点j"的最短路径的长度是sum。
*/
void floyd(Graph G, int path[][MAX], int dist[][MAX])
{
int i,j,k;
int tmp;
// 初始化
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
dist[i][j] = G.matrix[i][j]; // "顶点i"到"顶点j"的路径长度为"i到j的权值"。
path[i][j] = j; // "顶点i"到"顶点j"的最短路径是经过顶点j。
}
}
// 计算最短路径
for (k = 0; k < G.vexnum; k++)
{
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
// 如果经过下标为k顶点路径比原两点间路径更短,则更新dist[i][j]和path[i][j]
tmp = (dist[i][k]==INF || dist[k][j]==INF) ? INF : (dist[i][k] + dist[k][j]);
if (dist[i][j] > tmp)
{
// "i到j最短路径"对应的值设,为更小的一个(即经过k)
dist[i][j] = tmp;
// "i到j最短路径"对应的路径,经过k
path[i][j] = path[i][k];
}
}
}
}
// 打印floyd最短路径的结果
printf("floyd: \n");
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
printf("%2d ", dist[i][j]);
printf("\n");
}
}
弗洛伊德算法的源码
这里分别给出"邻接矩阵图"和"邻接表图"的弗洛伊德算法源码。
1.邻接矩阵源码 matrix_udg.c
/**
* C: Floyd算法获取最短路径(邻接矩阵)
*
* @author skywang
* @date 2014/04/25
*/
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
//#define MAX 100 // 矩阵最大容量
#define MAX 100 // 矩阵最大容量
#define INF (~(0x1<<31)) // 最大值(即0X7FFFFFFF)
#define isLetter(a) ((((a)>='a')&&((a)<='z')) || (((a)>='A')&&((a)<='Z')))
#define LENGTH(a) (sizeof(a)/sizeof(a[0]))
// 邻接矩阵
typedef struct _graph
{
char vexs[MAX]; // 顶点集合
int vexnum; // 顶点数
int edgnum; // 边数
int matrix[MAX][MAX]; // 邻接矩阵
}Graph, *PGraph;
// 边的结构体
typedef struct _EdgeData
{
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
}EData;
/*
* 返回ch在matrix矩阵中的位置
*/
static int get_position(Graph G, char ch)
{
int i;
for(i=0; i<G.vexnum; i++)
if(G.vexs[i]==ch)
return i;
return -1;
}
/*
* 读取一个输入字符
*/
static char read_char()
{
char ch;
do {
ch = getchar();
} while(!isLetter(ch));
return ch;
}
/*
* 创建图(自己输入)
*/
Graph* create_graph()
{
char c1, c2;
int v, e;
int i, j, weight, p1, p2;
Graph* pG;
// 输入"顶点数"和"边数"
printf("input vertex number: ");
scanf("%d", &v);
printf("input edge number: ");
scanf("%d", &e);
if ( v < 1 || e < 1 || (e > (v * (v-1))))
{
printf("input error: invalid parameters!\n");
return NULL;
}
if ((pG=(Graph*)malloc(sizeof(Graph))) == NULL )
return NULL;
memset(pG, 0, sizeof(Graph));
// 初始化"顶点数"和"边数"
pG->vexnum = v;
pG->edgnum = e;
// 初始化"顶点"
for (i = 0; i < pG->vexnum; i++)
{
printf("vertex(%d): ", i);
pG->vexs[i] = read_char();
}
// 1. 初始化"边"的权值
for (i = 0; i < pG->vexnum; i++)
{
for (j = 0; j < pG->vexnum; j++)
{
if (i==j)
pG->matrix[i][j] = 0;
else
pG->matrix[i][j] = INF;
}
}
// 2. 初始化"边"的权值: 根据用户的输入进行初始化
for (i = 0; i < pG->edgnum; i++)
{
// 读取边的起始顶点,结束顶点,权值
printf("edge(%d):", i);
c1 = read_char();
c2 = read_char();
scanf("%d", &weight);
p1 = get_position(*pG, c1);
p2 = get_position(*pG, c2);
if (p1==-1 || p2==-1)
{
printf("input error: invalid edge!\n");
free(pG);
return NULL;
}
pG->matrix[p1][p2] = weight;
pG->matrix[p2][p1] = weight;
}
return pG;
}
/*
* 创建图(用已提供的矩阵)
*/
Graph* create_example_graph()
{
char vexs[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int matrix[][9] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}};
int vlen = LENGTH(vexs);
int i, j;
Graph* pG;
// 输入"顶点数"和"边数"
if ((pG=(Graph*)malloc(sizeof(Graph))) == NULL )
return NULL;
memset(pG, 0, sizeof(Graph));
// 初始化"顶点数"
pG->vexnum = vlen;
// 初始化"顶点"
for (i = 0; i < pG->vexnum; i++)
pG->vexs[i] = vexs[i];
// 初始化"边"
for (i = 0; i < pG->vexnum; i++)
for (j = 0; j < pG->vexnum; j++)
pG->matrix[i][j] = matrix[i][j];
// 统计边的数目
for (i = 0; i < pG->vexnum; i++)
for (j = 0; j < pG->vexnum; j++)
if (i!=j && pG->matrix[i][j]!=INF)
pG->edgnum++;
pG->edgnum /= 2;
return pG;
}
/*
* 返回顶点v的第一个邻接顶点的索引,失败则返回-1
*/
static int first_vertex(Graph G, int v)
{
int i;
if (v<0 || v>(G.vexnum-1))
return -1;
for (i = 0; i < G.vexnum; i++)
if (G.matrix[v][i]!=0 && G.matrix[v][i]!=INF)
return i;
return -1;
}
/*
* 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1
*/
static int next_vertix(Graph G, int v, int w)
{
int i;
if (v<0 || v>(G.vexnum-1) || w<0 || w>(G.vexnum-1))
return -1;
for (i = w + 1; i < G.vexnum; i++)
if (G.matrix[v][i]!=0 && G.matrix[v][i]!=INF)
return i;
return -1;
}
/*
* 深度优先搜索遍历图的递归实现
*/
static void DFS(Graph G, int i, int *visited)
{
int w;
visited[i] = 1;
printf("%c ", G.vexs[i]);
// 遍历该顶点的所有邻接顶点。若是没有访问过,那么继续往下走
for (w = first_vertex(G, i); w >= 0; w = next_vertix(G, i, w))
{
if (!visited[w])
DFS(G, w, visited);
}
}
/*
* 深度优先搜索遍历图
*/
void DFSTraverse(Graph G)
{
int i;
int visited[MAX]; // 顶点访问标记
// 初始化所有顶点都没有被访问
for (i = 0; i < G.vexnum; i++)
visited[i] = 0;
printf("DFS: ");
for (i = 0; i < G.vexnum; i++)
{
//printf("\n== LOOP(%d)\n", i);
if (!visited[i])
DFS(G, i, visited);
}
printf("\n");
}
/*
* 广度优先搜索(类似于树的层次遍历)
*/
void BFS(Graph G)
{
int head = 0;
int rear = 0;
int queue[MAX]; // 辅组队列
int visited[MAX]; // 顶点访问标记
int i, j, k;
for (i = 0; i < G.vexnum; i++)
visited[i] = 0;
printf("BFS: ");
for (i = 0; i < G.vexnum; i++)
{
if (!visited[i])
{
visited[i] = 1;
printf("%c ", G.vexs[i]);
queue[rear++] = i; // 入队列
}
while (head != rear)
{
j = queue[head++]; // 出队列
for (k = first_vertex(G, j); k >= 0; k = next_vertix(G, j, k)) //k是为访问的邻接顶点
{
if (!visited[k])
{
visited[k] = 1;
printf("%c ", G.vexs[k]);
queue[rear++] = k;
}
}
}
}
printf("\n");
}
/*
* 打印矩阵队列图
*/
void print_graph(Graph G)
{
int i,j;
printf("Martix Graph:\n");
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
printf("%10d ", G.matrix[i][j]);
printf("\n");
}
}
/*
* prim最小生成树
*
* 参数说明:
* G -- 邻接矩阵图
* start -- 从图中的第start个元素开始,生成最小树
*/
void prim(Graph G, int start)
{
int min,i,j,k,m,n,sum;
int index=0; // prim最小树的索引,即prims数组的索引
char prims[MAX]; // prim最小树的结果数组
int weights[MAX]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = G.vexs[start];
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (i = 0; i < G.vexnum; i++ )
weights[i] = G.matrix[start][i];
// 将第start个顶点的权值初始化为0。
// 可以理解为"第start个顶点到它自身的距离为0"。
weights[start] = 0;
for (i = 0; i < G.vexnum; i++)
{
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
j = 0;
k = 0;
min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < G.vexnum)
{
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min)
{
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = G.vexs[k];
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < G.vexnum; j++)
{
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && G.matrix[k][j] < weights[j])
weights[j] = G.matrix[k][j];
}
}
// 计算最小生成树的权值
sum = 0;
for (i = 1; i < index; i++)
{
min = INF;
// 获取prims[i]在G中的位置
n = get_position(G, prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (j = 0; j < i; j++)
{
m = get_position(G, prims[j]);
if (G.matrix[m][n]<min)
min = G.matrix[m][n];
}
sum += min;
}
// 打印最小生成树
printf("PRIM(%c)=%d: ", G.vexs[start], sum);
for (i = 0; i < index; i++)
printf("%c ", prims[i]);
printf("\n");
}
/*
* 获取图中的边
*/
EData* get_edges(Graph G)
{
int i,j;
int index=0;
EData *edges;
edges = (EData*)malloc(G.edgnum*sizeof(EData));
for (i=0;i < G.vexnum;i++)
{
for (j=i+1;j < G.vexnum;j++)
{
if (G.matrix[i][j]!=INF)
{
edges[index].start = G.vexs[i];
edges[index].end = G.vexs[j];
edges[index].weight = G.matrix[i][j];
index++;
}
}
}
return edges;
}
/*
* 对边按照权值大小进行排序(由小到大)
*/
void sorted_edges(EData* edges, int elen)
{
int i,j;
for (i=0; i<elen; i++)
{
for (j=i+1; j<elen; j++)
{
if (edges[i].weight > edges[j].weight)
{
// 交换"第i条边"和"第j条边"
EData tmp = edges[i];
edges[i] = edges[j];
edges[j] = tmp;
}
}
}
}
/*
* 获取i的终点
*/
int get_end(int vends[], int i)
{
while (vends[i] != 0)
i = vends[i];
return i;
}
/*
* 克鲁斯卡尔(Kruskal)最小生成树
*/
void kruskal(Graph G)
{
int i,m,n,p1,p2;
int length;
int index = 0; // rets数组的索引
int vends[MAX]={0}; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。
EData rets[MAX]; // 结果数组,保存kruskal最小生成树的边
EData *edges; // 图对应的所有边
// 获取"图中所有的边"
edges = get_edges(G);
// 将边按照"权"的大小进行排序(从小到大)
sorted_edges(edges, G.edgnum);
for (i=0; i<G.edgnum; i++)
{
p1 = get_position(G, edges[i].start); // 获取第i条边的"起点"的序号
p2 = get_position(G, edges[i].end); // 获取第i条边的"终点"的序号
m = get_end(vends, p1); // 获取p1在"已有的最小生成树"中的终点
n = get_end(vends, p2); // 获取p2在"已有的最小生成树"中的终点
// 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路
if (m != n)
{
vends[m] = n; // 设置m在"已有的最小生成树"中的终点为n
rets[index++] = edges[i]; // 保存结果
}
}
free(edges);
// 统计并打印"kruskal最小生成树"的信息
length = 0;
for (i = 0; i < index; i++)
length += rets[i].weight;
printf("Kruskal=%d: ", length);
for (i = 0; i < index; i++)
printf("(%c,%c) ", rets[i].start, rets[i].end);
printf("\n");
}
/*
* Dijkstra最短路径。
* 即,统计图(G)中"顶点vs"到其它各个顶点的最短路径。
*
* 参数说明:
* G -- 图
* vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。
* prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。
* dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。
*/
void dijkstra(Graph G, int vs, int prev[], int dist[])
{
int i,j,k;
int min;
int tmp;
int flag[MAX]; // flag[i]=1表示"顶点vs"到"顶点i"的最短路径已成功获取。
// 初始化
for (i = 0; i < G.vexnum; i++)
{
flag[i] = 0; // 顶点i的最短路径还没获取到。
prev[i] = 0; // 顶点i的前驱顶点为0。
dist[i] = G.matrix[vs][i];// 顶点i的最短路径为"顶点vs"到"顶点i"的权。
}
// 对"顶点vs"自身进行初始化
flag[vs] = 1;
dist[vs] = 0;
// 遍历G.vexnum-1次;每次找出一个顶点的最短路径。
for (i = 1; i < G.vexnum; i++)
{
// 寻找当前最小的路径;
// 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。
min = INF;
for (j = 0; j < G.vexnum; j++)
{
if (flag[j]==0 && dist[j]<min)
{
min = dist[j];
k = j;
}
}
// 标记"顶点k"为已经获取到最短路径
flag[k] = 1;
// 修正当前最短路径和前驱顶点
// 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。
for (j = 0; j < G.vexnum; j++)
{
tmp = (G.matrix[k][j]==INF ? INF : (min + G.matrix[k][j])); // 防止溢出
if (flag[j] == 0 && (tmp < dist[j]) )
{
dist[j] = tmp;
prev[j] = k;
}
}
}
// 打印dijkstra最短路径的结果
printf("dijkstra(%c): \n", G.vexs[vs]);
for (i = 1; i < G.vexnum; i++)
printf(" shortest(%c, %c)=%d\n", G.vexs[vs], G.vexs[i], dist[i]);
}
/*
* floyd最短路径。
* 即,统计图中各个顶点间的最短路径。
*
* 参数说明:
* G -- 图
* path -- 路径。path[i][j]=k表示,"顶点i"到"顶点j"的最短路径会经过顶点k。
* dist -- 长度数组。即,dist[i][j]=sum表示,"顶点i"到"顶点j"的最短路径的长度是sum。
*/
void floyd(Graph G, int path[][MAX], int dist[][MAX])
{
int i,j,k;
int tmp;
// 初始化
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
dist[i][j] = G.matrix[i][j]; // "顶点i"到"顶点j"的路径长度为"i到j的权值"。
path[i][j] = j; // "顶点i"到"顶点j"的最短路径是经过顶点j。
}
}
// 计算最短路径
for (k = 0; k < G.vexnum; k++)
{
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
// 如果经过下标为k顶点路径比原两点间路径更短,则更新dist[i][j]和path[i][j]
tmp = (dist[i][k]==INF || dist[k][j]==INF) ? INF : (dist[i][k] + dist[k][j]);
if (dist[i][j] > tmp)
{
// "i到j最短路径"对应的值设,为更小的一个(即经过k)
dist[i][j] = tmp;
// "i到j最短路径"对应的路径,经过k
path[i][j] = path[i][k];
}
}
}
}
// 打印floyd最短路径的结果
printf("floyd: \n");
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
printf("%2d ", dist[i][j]);
printf("\n");
}
}
void main()
{
int prev[MAX] = {0}; // 用于保存dijkstra路径
int dist[MAX] = {0}; // 用于保存dijkstra长度
int path[MAX][MAX] = {0}; // 用于保存floyd路径
int floy[MAX][MAX] = {0}; // 用于保存floyd长度
Graph* pG;
// 自定义"图"(输入矩阵队列)
//pG = create_graph();
// 采用已有的"图"
pG = create_example_graph();
//print_graph(*pG); // 打印图
//DFSTraverse(*pG); // 深度优先遍历
//BFS(*pG); // 广度优先遍历
//prim(*pG, 0); // prim算法生成最小生成树
//kruskal(*pG); // kruskal算法生成最小生成树
// dijkstra算法获取"第4个顶点"到其它各个顶点的最短距离
//dijkstra(*pG, 3, prev, dist);
// floyd算法获取各个顶点之间的最短距离
floyd(*pG, path, floy);
}
2.邻接表源码 list_udg.c
/**
* C: Floyd算法获取最短路径(邻接表)
*
* @author skywang
* @date 2014/04/25
*/
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
#define MAX 100
#define INF (~(0x1<<31)) // 最大值(即0X7FFFFFFF)
#define isLetter(a) ((((a)>='a')&&((a)<='z')) || (((a)>='A')&&((a)<='Z')))
#define LENGTH(a) (sizeof(a)/sizeof(a[0]))
// 邻接表中表对应的链表的顶点
typedef struct _ENode
{
int ivex; // 该边的顶点的位置
int weight; // 该边的权
struct _ENode *next_edge; // 指向下一条弧的指针
}ENode, *PENode;
// 邻接表中表的顶点
typedef struct _VNode
{
char data; // 顶点信息
ENode *first_edge; // 指向第一条依附该顶点的弧
}VNode;
// 邻接表
typedef struct _LGraph
{
int vexnum; // 图的顶点的数目
int edgnum; // 图的边的数目
VNode vexs[MAX];
}LGraph;
/*
* 返回ch在matrix矩阵中的位置
*/
static int get_position(LGraph G, char ch)
{
int i;
for(i=0; i<G.vexnum; i++)
if(G.vexs[i].data==ch)
return i;
return -1;
}
/*
* 读取一个输入字符
*/
static char read_char()
{
char ch;
do {
ch = getchar();
} while(!isLetter(ch));
return ch;
}
/*
* 将node链接到list的末尾
*/
static void link_last(ENode *list, ENode *node)
{
ENode *p = list;
while(p->next_edge)
p = p->next_edge;
p->next_edge = node;
}
/*
* 创建邻接表对应的图(自己输入)
*/
LGraph* create_lgraph()
{
char c1, c2;
int v, e;
int i, p1, p2;
int weight;
ENode *node1, *node2;
LGraph* pG;
// 输入"顶点数"和"边数"
printf("input vertex number: ");
scanf("%d", &v);
printf("input edge number: ");
scanf("%d", &e);
if ( v < 1 || e < 1 || (e > (v * (v-1))))
{
printf("input error: invalid parameters!\n");
return NULL;
}
if ((pG=(LGraph*)malloc(sizeof(LGraph))) == NULL )
return NULL;
memset(pG, 0, sizeof(LGraph));
// 初始化"顶点数"和"边数"
pG->vexnum = v;
pG->edgnum = e;
// 初始化"邻接表"的顶点
for(i=0; i<pG->vexnum; i++)
{
printf("vertex(%d): ", i);
pG->vexs[i].data = read_char();
pG->vexs[i].first_edge = NULL;
}
// 初始化"邻接表"的边
for(i=0; i<pG->edgnum; i++)
{
// 读取边的起始顶点,结束顶点,权
printf("edge(%d): ", i);
c1 = read_char();
c2 = read_char();
scanf("%d", &weight);
p1 = get_position(*pG, c1);
p2 = get_position(*pG, c2);
// 初始化node1
node1 = (ENode*)malloc(sizeof(ENode));
node1->ivex = p2;
node1->weight = weight;
// 将node1链接到"p1所在链表的末尾"
if(pG->vexs[p1].first_edge == NULL)
pG->vexs[p1].first_edge = node1;
else
link_last(pG->vexs[p1].first_edge, node1);
// 初始化node2
node2 = (ENode*)malloc(sizeof(ENode));
node2->ivex = p1;
node2->weight = weight;
// 将node2链接到"p2所在链表的末尾"
if(pG->vexs[p2].first_edge == NULL)
pG->vexs[p2].first_edge = node2;
else
link_last(pG->vexs[p2].first_edge, node2);
}
return pG;
}
// 边的结构体
typedef struct _edata
{
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
}EData;
// 顶点
static char gVexs[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
// 边
static EData gEdges[] = {
// 起点 终点 权
{'A', 'B', 12},
{'A', 'F', 16},
{'A', 'G', 14},
{'B', 'C', 10},
{'B', 'F', 7},
{'C', 'D', 3},
{'C', 'E', 5},
{'C', 'F', 6},
{'D', 'E', 4},
{'E', 'F', 2},
{'E', 'G', 8},
{'F', 'G', 9},
};
/*
* 创建邻接表对应的图(用已提供的数据)
*/
LGraph* create_example_lgraph()
{
char c1, c2;
int vlen = LENGTH(gVexs);
int elen = LENGTH(gEdges);
int i, p1, p2;
int weight;
ENode *node1, *node2;
LGraph* pG;
if ((pG=(LGraph*)malloc(sizeof(LGraph))) == NULL )
return NULL;
memset(pG, 0, sizeof(LGraph));
// 初始化"顶点数"和"边数"
pG->vexnum = vlen;
pG->edgnum = elen;
// 初始化"邻接表"的顶点
for(i=0; i<pG->vexnum; i++)
{
pG->vexs[i].data = gVexs[i];
pG->vexs[i].first_edge = NULL;
}
// 初始化"邻接表"的边
for(i=0; i<pG->edgnum; i++)
{
// 读取边的起始顶点,结束顶点,权
c1 = gEdges[i].start;
c2 = gEdges[i].end;
weight = gEdges[i].weight;
p1 = get_position(*pG, c1);
p2 = get_position(*pG, c2);
// 初始化node1
node1 = (ENode*)malloc(sizeof(ENode));
node1->ivex = p2;
node1->weight = weight;
// 将node1链接到"p1所在链表的末尾"
if(pG->vexs[p1].first_edge == NULL)
pG->vexs[p1].first_edge = node1;
else
link_last(pG->vexs[p1].first_edge, node1);
// 初始化node2
node2 = (ENode*)malloc(sizeof(ENode));
node2->ivex = p1;
node2->weight = weight;
// 将node2链接到"p2所在链表的末尾"
if(pG->vexs[p2].first_edge == NULL)
pG->vexs[p2].first_edge = node2;
else
link_last(pG->vexs[p2].first_edge, node2);
}
return pG;
}
/*
* 深度优先搜索遍历图的递归实现
*/
static void DFS(LGraph G, int i, int *visited)
{
int w;
ENode *node;
visited[i] = 1;
printf("%c ", G.vexs[i].data);
node = G.vexs[i].first_edge;
while (node != NULL)
{
if (!visited[node->ivex])
DFS(G, node->ivex, visited);
node = node->next_edge;
}
}
/*
* 深度优先搜索遍历图
*/
void DFSTraverse(LGraph G)
{
int i;
int visited[MAX]; // 顶点访问标记
// 初始化所有顶点都没有被访问
for (i = 0; i < G.vexnum; i++)
visited[i] = 0;
printf("DFS: ");
for (i = 0; i < G.vexnum; i++)
{
if (!visited[i])
DFS(G, i, visited);
}
printf("\n");
}
/*
* 广度优先搜索(类似于树的层次遍历)
*/
void BFS(LGraph G)
{
int head = 0;
int rear = 0;
int queue[MAX]; // 辅组队列
int visited[MAX]; // 顶点访问标记
int i, j, k;
ENode *node;
for (i = 0; i < G.vexnum; i++)
visited[i] = 0;
printf("BFS: ");
for (i = 0; i < G.vexnum; i++)
{
if (!visited[i])
{
visited[i] = 1;
printf("%c ", G.vexs[i].data);
queue[rear++] = i; // 入队列
}
while (head != rear)
{
j = queue[head++]; // 出队列
node = G.vexs[j].first_edge;
while (node != NULL)
{
k = node->ivex;
if (!visited[k])
{
visited[k] = 1;
printf("%c ", G.vexs[k].data);
queue[rear++] = k;
}
node = node->next_edge;
}
}
}
printf("\n");
}
/*
* 打印邻接表图
*/
void print_lgraph(LGraph G)
{
int i,j;
ENode *node;
printf("List Graph:\n");
for (i = 0; i < G.vexnum; i++)
{
printf("%d(%c): ", i, G.vexs[i].data);
node = G.vexs[i].first_edge;
while (node != NULL)
{
printf("%d(%c) ", node->ivex, G.vexs[node->ivex].data);
node = node->next_edge;
}
printf("\n");
}
}
/*
* 获取G中边<start, end>的权值;若start和end不是连通的,则返回无穷大。
*/
int get_weight(LGraph G, int start, int end)
{
ENode *node;
if (start==end)
return 0;
node = G.vexs[start].first_edge;
while (node!=NULL)
{
if (end==node->ivex)
return node->weight;
node = node->next_edge;
}
return INF;
}
/*
* prim最小生成树
*
* 参数说明:
* G -- 邻接表图
* start -- 从图中的第start个元素开始,生成最小树
*/
void prim(LGraph G, int start)
{
int min,i,j,k,m,n,tmp,sum;
int index=0; // prim最小树的索引,即prims数组的索引
char prims[MAX]; // prim最小树的结果数组
int weights[MAX]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = G.vexs[start].data;
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (i = 0; i < G.vexnum; i++ )
weights[i] = get_weight(G, start, i);
for (i = 0; i < G.vexnum; i++)
{
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
j = 0;
k = 0;
min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < G.vexnum)
{
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min)
{
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = G.vexs[k].data;
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < G.vexnum; j++)
{
// 获取第k个顶点到第j个顶点的权值
tmp = get_weight(G, k, j);
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && tmp < weights[j])
weights[j] = tmp;
}
}
// 计算最小生成树的权值
sum = 0;
for (i = 1; i < index; i++)
{
min = INF;
// 获取prims[i]在G中的位置
n = get_position(G, prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (j = 0; j < i; j++)
{
m = get_position(G, prims[j]);
tmp = get_weight(G, m, n);
if (tmp < min)
min = tmp;
}
sum += min;
}
// 打印最小生成树
printf("PRIM(%c)=%d: ", G.vexs[start].data, sum);
for (i = 0; i < index; i++)
printf("%c ", prims[i]);
printf("\n");
}
/*
* 获取图中的边
*/
EData* get_edges(LGraph G)
{
int i,j;
int index=0;
ENode *node;
EData *edges;
edges = (EData*)malloc(G.edgnum*sizeof(EData));
for (i=0; i<G.vexnum; i++)
{
node = G.vexs[i].first_edge;
while (node != NULL)
{
if (node->ivex > i)
{
edges[index].start = G.vexs[i].data; // 起点
edges[index].end = G.vexs[node->ivex].data; // 终点
edges[index].weight = node->weight; // 权
index++;
}
node = node->next_edge;
}
}
return edges;
}
/*
* 对边按照权值大小进行排序(由小到大)
*/
void sorted_edges(EData* edges, int elen)
{
int i,j;
for (i=0; i<elen; i++)
{
for (j=i+1; j<elen; j++)
{
if (edges[i].weight > edges[j].weight)
{
// 交换"第i条边"和"第j条边"
EData tmp = edges[i];
edges[i] = edges[j];
edges[j] = tmp;
}
}
}
}
/*
* 获取i的终点
*/
int get_end(int vends[], int i)
{
while (vends[i] != 0)
i = vends[i];
return i;
}
/*
* 克鲁斯卡尔(Kruskal)最小生成树
*/
void kruskal(LGraph G)
{
int i,m,n,p1,p2;
int length;
int index = 0; // rets数组的索引
int vends[MAX]={0}; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。
EData rets[MAX]; // 结果数组,保存kruskal最小生成树的边
EData *edges; // 图对应的所有边
// 获取"图中所有的边"
edges = get_edges(G);
// 将边按照"权"的大小进行排序(从小到大)
sorted_edges(edges, G.edgnum);
for (i=0; i<G.edgnum; i++)
{
p1 = get_position(G, edges[i].start); // 获取第i条边的"起点"的序号
p2 = get_position(G, edges[i].end); // 获取第i条边的"终点"的序号
m = get_end(vends, p1); // 获取p1在"已有的最小生成树"中的终点
n = get_end(vends, p2); // 获取p2在"已有的最小生成树"中的终点
// 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路
if (m != n)
{
vends[m] = n; // 设置m在"已有的最小生成树"中的终点为n
rets[index++] = edges[i]; // 保存结果
}
}
free(edges);
// 统计并打印"kruskal最小生成树"的信息
length = 0;
for (i = 0; i < index; i++)
length += rets[i].weight;
printf("Kruskal=%d: ", length);
for (i = 0; i < index; i++)
printf("(%c,%c) ", rets[i].start, rets[i].end);
printf("\n");
}
/*
* Dijkstra最短路径。
* 即,统计图(G)中"顶点vs"到其它各个顶点的最短路径。
*
* 参数说明:
* G -- 图
* vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。
* prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。
* dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。
*/
void dijkstra(LGraph G, int vs, int prev[], int dist[])
{
int i,j,k;
int min;
int tmp;
int flag[MAX]; // flag[i]=1表示"顶点vs"到"顶点i"的最短路径已成功获取。
// 初始化
for (i = 0; i < G.vexnum; i++)
{
flag[i] = 0; // 顶点i的最短路径还没获取到。
prev[i] = 0; // 顶点i的前驱顶点为0。
dist[i] = get_weight(G, vs, i); // 顶点i的最短路径为"顶点vs"到"顶点i"的权。
}
// 对"顶点vs"自身进行初始化
flag[vs] = 1;
dist[vs] = 0;
// 遍历G.vexnum-1次;每次找出一个顶点的最短路径。
for (i = 1; i < G.vexnum; i++)
{
// 寻找当前最小的路径;
// 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。
min = INF;
for (j = 0; j < G.vexnum; j++)
{
if (flag[j]==0 && dist[j]<min)
{
min = dist[j];
k = j;
}
}
// 标记"顶点k"为已经获取到最短路径
flag[k] = 1;
// 修正当前最短路径和前驱顶点
// 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。
for (j = 0; j < G.vexnum; j++)
{
tmp = get_weight(G, k, j);
tmp = (tmp==INF ? INF : (min + tmp)); // 防止溢出
if (flag[j] == 0 && (tmp < dist[j]) )
{
dist[j] = tmp;
prev[j] = k;
}
}
}
// 打印dijkstra最短路径的结果
printf("dijkstra(%c): \n", G.vexs[vs].data);
for (i = 0; i < G.vexnum; i++)
printf(" shortest(%c, %c)=%d\n", G.vexs[vs].data, G.vexs[i].data, dist[i]);
}
/*
* floyd最短路径。
* 即,统计图中各个顶点间的最短路径。
*
* 参数说明:
* G -- 图
* path -- 路径。path[i][j]=k表示,"顶点i"到"顶点j"的最短路径会经过顶点k。
* dist -- 长度数组。即,dist[i][j]=sum表示,"顶点i"到"顶点j"的最短路径的长度是sum。
*/
void floyd(LGraph G, int path[][MAX], int dist[][MAX])
{
int i,j,k;
int tmp;
// 初始化
for (i = 0; i < G.vexnum; i++) {
for (j = 0; j < G.vexnum; j++) {
dist[i][j] = get_weight(G, i, j);// "顶点i"到"顶点j"的路径长度为"i到j的权值"。
path[i][j] = j; // "顶点i"到"顶点j"的最短路径是经过顶点j。
}
}
// 计算最短路径
for (k = 0; k < G.vexnum; k++)
{
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
// 如果经过下标为k顶点路径比原两点间路径更短,则更新dist[i][j]和path[i][j]
tmp = (dist[i][k]==INF || dist[k][j]==INF) ? INF : (dist[i][k] + dist[k][j]);
if (dist[i][j] > tmp)
{
// "i到j最短路径"对应的值设,为更小的一个(即经过k)
dist[i][j] = tmp;
// "i到j最短路径"对应的路径,经过k
path[i][j] = path[i][k];
}
}
}
}
// 打印floyd最短路径的结果
printf("floyd: \n");
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
printf("%2d ", dist[i][j]);
printf("\n");
}
}
void main()
{
int prev[MAX] = {0};
int dist[MAX] = {0};
int path[MAX][MAX] = {0}; // 用于保存floyd路径
int floy[MAX][MAX] = {0}; // 用于保存floyd长度
LGraph* pG;
// 自定义"图"(自己输入数据)
//pG = create_lgraph();
// 采用已有的"图"
pG = create_example_lgraph();
//print_lgraph(*pG); // 打印图
//DFSTraverse(*pG); // 深度优先遍历
//BFS(*pG); // 广度优先遍历
//prim(*pG, 0); // prim算法生成最小生成树
//kruskal(*pG); // kruskal算法生成最小生成树
// dijkstra算法获取"第4个顶点"到其它各个顶点的最短距离
//dijkstra(*pG, 3, prev, dist);
// floyd算法获取各个顶点之间的最短距离
floyd(*pG, path, floy);
}
| //#define MAX 100 // 矩阵最大容量 |
| #define MAX 100 // 矩阵最大容量 |
| #define INF (~(0x1<<31)) // 最大值(即0X7FFFFFFF) |
| #define isLetter(a) ((((a)>='a')&&((a)<='z')) || (((a)>='A')&&((a)<='Z'))) |
| #define LENGTH(a) (sizeof(a)/sizeof(a[0])) |
| int matrix[MAX][MAX]; // 邻接矩阵 |
| static int get_position(Graph G, char ch) |
| for(i=0; i<G.vexnum; i++) |
| int i, j, weight, p1, p2; |
| printf("input vertex number: "); |
| printf("input edge number: "); |
| if ( v < 1 || e < 1 || (e > (v * (v-1)))) |
| printf("input error: invalid parameters!\n"); |
| if ((pG=(Graph*)malloc(sizeof(Graph))) == NULL ) |
| memset(pG, 0, sizeof(Graph)); |
| for (i = 0; i < pG->vexnum; i++) |
| printf("vertex(%d): ", i); |
| pG->vexs[i] = read_char(); |
| for (i = 0; i < pG->vexnum; i++) |
| for (j = 0; j < pG->vexnum; j++) |
| // 2. 初始化"边"的权值: 根据用户的输入进行初始化 |
| for (i = 0; i < pG->edgnum; i++) |
| p1 = get_position(*pG, c1); |
| p2 = get_position(*pG, c2); |
| printf("input error: invalid edge!\n"); |
| pG->matrix[p1][p2] = weight; |
| pG->matrix[p2][p1] = weight; |
| Graph* create_example_graph() |
| char vexs[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; |
| /*A*//*B*//*C*//*D*//*E*//*F*//*G*/ |
| /*A*/ { 0, 12, INF, INF, INF, 16, 14}, |
| /*B*/ { 12, 0, 10, INF, INF, 7, INF}, |
| /*C*/ { INF, 10, 0, 3, 5, 6, INF}, |
| /*D*/ { INF, INF, 3, 0, 4, INF, INF}, |
| /*E*/ { INF, INF, 5, 4, 0, 2, 8}, |
| /*F*/ { 16, 7, 6, INF, 2, 0, 9}, |
| /*G*/ { 14, INF, INF, INF, 8, 9, 0}}; |
| if ((pG=(Graph*)malloc(sizeof(Graph))) == NULL ) |
| memset(pG, 0, sizeof(Graph)); |
| for (i = 0; i < pG->vexnum; i++) |
| for (i = 0; i < pG->vexnum; i++) |
| for (j = 0; j < pG->vexnum; j++) |
| pG->matrix[i][j] = matrix[i][j]; |
| for (i = 0; i < pG->vexnum; i++) |
| for (j = 0; j < pG->vexnum; j++) |
| if (i!=j && pG->matrix[i][j]!=INF) |
| * 返回顶点v的第一个邻接顶点的索引,失败则返回-1 |
| static int first_vertex(Graph G, int v) |
| if (v<0 || v>(G.vexnum-1)) |
| for (i = 0; i < G.vexnum; i++) |
| if (G.matrix[v][i]!=0 && G.matrix[v][i]!=INF) |
| * 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1 |
| static int next_vertix(Graph G, int v, int w) |
| if (v<0 || v>(G.vexnum-1) || w<0 || w>(G.vexnum-1)) |
| for (i = w + 1; i < G.vexnum; i++) |
| if (G.matrix[v][i]!=0 && G.matrix[v][i]!=INF) |
| static void DFS(Graph G, int i, int *visited) |
| printf("%c ", G.vexs[i]); |
| // 遍历该顶点的所有邻接顶点。若是没有访问过,那么继续往下走 |
| for (w = first_vertex(G, i); w >= 0; w = next_vertix(G, i, w)) |
| void DFSTraverse(Graph G) |
| int visited[MAX]; // 顶点访问标记 |
| for (i = 0; i < G.vexnum; i++) |
| for (i = 0; i < G.vexnum; i++) |
| //printf("\n== LOOP(%d)\n", i); |
| int visited[MAX]; // 顶点访问标记 |
| for (i = 0; i < G.vexnum; i++) |
| for (i = 0; i < G.vexnum; i++) |
| printf("%c ", G.vexs[i]); |
| queue[rear++] = i; // 入队列 |
| j = queue[head++]; // 出队列 |
| for (k = first_vertex(G, j); k >= 0; k = next_vertix(G, j, k)) //k是为访问的邻接顶点 |
| printf("%c ", G.vexs[k]); |
| void print_graph(Graph G) |
| printf("Martix Graph:\n"); |
| for (i = 0; i < G.vexnum; i++) |
| for (j = 0; j < G.vexnum; j++) |
| printf("%10d ", G.matrix[i][j]); |
| * start -- 从图中的第start个元素开始,生成最小树 |
| void prim(Graph G, int start) |
| int index=0; // prim最小树的索引,即prims数组的索引 |
| char prims[MAX]; // prim最小树的结果数组 |
| int weights[MAX]; // 顶点间边的权值 |
| // prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。 |
| prims[index++] = G.vexs[start]; |
| // 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。 |
| for (i = 0; i < G.vexnum; i++ ) |
| weights[i] = G.matrix[start][i]; |
| // 可以理解为"第start个顶点到它自身的距离为0"。 |
| for (i = 0; i < G.vexnum; i++) |
| // 由于从start开始的,因此不需要再对第start个顶点进行处理。 |
| // 在未被加入到最小生成树的顶点中,找出权值最小的顶点。 |
| // 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。 |
| if (weights[j] != 0 && weights[j] < min) |
| // 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。 |
| prims[index++] = G.vexs[k]; |
| // 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。 |
| // 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。 |
| for (j = 0 ; j < G.vexnum; j++) |
| // 当第j个节点没有被处理,并且需要更新时才被更新。 |
| if (weights[j] != 0 && G.matrix[k][j] < weights[j]) |
| weights[j] = G.matrix[k][j]; |
| for (i = 1; i < index; i++) |
| n = get_position(G, prims[i]); |
| // 在vexs[0...i]中,找出到j的权值最小的顶点。 |
| m = get_position(G, prims[j]); |
| printf("PRIM(%c)=%d: ", G.vexs[start], sum); |
| for (i = 0; i < index; i++) |
| EData* get_edges(Graph G) |
| edges = (EData*)malloc(G.edgnum*sizeof(EData)); |
| for (i=0;i < G.vexnum;i++) |
| for (j=i+1;j < G.vexnum;j++) |
| edges[index].start = G.vexs[i]; |
| edges[index].end = G.vexs[j]; |
| edges[index].weight = G.matrix[i][j]; |
| void sorted_edges(EData* edges, int elen) |
| if (edges[i].weight > edges[j].weight) |
| int get_end(int vends[], int i) |
| int index = 0; // rets数组的索引 |
| int vends[MAX]={0}; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。 |
| EData rets[MAX]; // 结果数组,保存kruskal最小生成树的边 |
| sorted_edges(edges, G.edgnum); |
| for (i=0; i<G.edgnum; i++) |
| p1 = get_position(G, edges[i].start); // 获取第i条边的"起点"的序号 |
| p2 = get_position(G, edges[i].end); // 获取第i条边的"终点"的序号 |
| m = get_end(vends, p1); // 获取p1在"已有的最小生成树"中的终点 |
| n = get_end(vends, p2); // 获取p2在"已有的最小生成树"中的终点 |
| // 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路 |
| vends[m] = n; // 设置m在"已有的最小生成树"中的终点为n |
| rets[index++] = edges[i]; // 保存结果 |
| // 统计并打印"kruskal最小生成树"的信息 |
| for (i = 0; i < index; i++) |
| length += rets[i].weight; |
| printf("Kruskal=%d: ", length); |
| for (i = 0; i < index; i++) |
| printf("(%c,%c) ", rets[i].start, rets[i].end); |
| * 即,统计图(G)中"顶点vs"到其它各个顶点的最短路径。 |
| * vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。 |
| * prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。 |
| * dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。 |
| void dijkstra(Graph G, int vs, int prev[], int dist[]) |
| int flag[MAX]; // flag[i]=1表示"顶点vs"到"顶点i"的最短路径已成功获取。 |
| for (i = 0; i < G.vexnum; i++) |
| flag[i] = 0; // 顶点i的最短路径还没获取到。 |
| prev[i] = 0; // 顶点i的前驱顶点为0。 |
| dist[i] = G.matrix[vs][i];// 顶点i的最短路径为"顶点vs"到"顶点i"的权。 |
| // 遍历G.vexnum-1次;每次找出一个顶点的最短路径。 |
| for (i = 1; i < G.vexnum; i++) |
| // 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。 |
| for (j = 0; j < G.vexnum; j++) |
| if (flag[j]==0 && dist[j]<min) |
| // 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。 |
| for (j = 0; j < G.vexnum; j++) |
| tmp = (G.matrix[k][j]==INF ? INF : (min + G.matrix[k][j])); // 防止溢出 |
| if (flag[j] == 0 && (tmp < dist[j]) ) |
| printf("dijkstra(%c): \n", G.vexs[vs]); |
| for (i = 1; i < G.vexnum; i++) |
| printf(" shortest(%c, %c)=%d\n", G.vexs[vs], G.vexs[i], dist[i]); |
| * path -- 路径。path[i][j]=k表示,"顶点i"到"顶点j"的最短路径会经过顶点k。 |
| * dist -- 长度数组。即,dist[i][j]=sum表示,"顶点i"到"顶点j"的最短路径的长度是sum。 |
| void floyd(Graph G, int path[][MAX], int dist[][MAX]) |
| for (i = 0; i < G.vexnum; i++) |
| for (j = 0; j < G.vexnum; j++) |
| dist[i][j] = G.matrix[i][j]; // "顶点i"到"顶点j"的路径长度为"i到j的权值"。 |
| path[i][j] = j; // "顶点i"到"顶点j"的最短路径是经过顶点j。 |
| for (k = 0; k < G.vexnum; k++) |
| for (i = 0; i < G.vexnum; i++) |
| for (j = 0; j < G.vexnum; j++) |
| // 如果经过下标为k顶点路径比原两点间路径更短,则更新dist[i][j]和path[i][j] |
| tmp = (dist[i][k]==INF || dist[k][j]==INF) ? INF : (dist[i][k] + dist[k][j]); |
| // "i到j最短路径"对应的值设,为更小的一个(即经过k) |
| for (i = 0; i < G.vexnum; i++) |
| for (j = 0; j < G.vexnum; j++) |
| printf("%2d ", dist[i][j]); |
| int prev[MAX] = {0}; // 用于保存dijkstra路径 |
| int dist[MAX] = {0}; // 用于保存dijkstra长度 |
| int path[MAX][MAX] = {0}; // 用于保存floyd路径 |
| int floy[MAX][MAX] = {0}; // 用于保存floyd长度 |
| pG = create_example_graph(); |
| //print_graph(*pG); // 打印图 |
| //DFSTraverse(*pG); // 深度优先遍历 |
| //prim(*pG, 0); // prim算法生成最小生成树 |
| //kruskal(*pG); // kruskal算法生成最小生成树 |
| // dijkstra算法获取"第4个顶点"到其它各个顶点的最短距离 |
| //dijkstra(*pG, 3, prev, dist); |
}



 浙公网安备 33010602011771号
浙公网安备 33010602011771号