算法集锦(三)
开放定址散列表的实现

#include<stdio.h>
#include"fatal.h"
typedef char* ElementType;
typedef unsigned int Index;
typedef Index Position;
struct HashTbl;
typedef struct HashTbl *HashTable;
HashTable InitializeTable(int TableSize);
void DestroyTable(HashTable H);
Position Find(ElementType key,HashTable H);
void Insert(ElementType key,HashTable H);
ElementType Retrieve(Position P,HashTable H);
HashTable Rehash(HashTable H);
enum KindOfEntry {Legitimate,Empty,Deleted};
struct HashEntry
{
ElementType Element;
enum KindOfEntry Info;
};
typedef struct HashEntry Cell;
struct HashTbl
{
int TableSize;
Cell *TheCells;
};
int MinTableSize=23;
HashTable InitializeTable(int TableSize)
{
HashTable H;
int i;
if(TableSize<MinTableSize)
{
Error("Table size too small!");
return NULL;
}
H=malloc(sizeof(struct HashTbl));
if(H==NULL)
FatalError("Out of space !!!");
H->TableSize=TableSize;
H->TheCells=malloc(sizeof(Cell)*H->TableSize);
if(H->TheCells==NULL)
FatalError("Out of space !!");
for(i=0;i<H->TableSize;i++)
H->TheCells[i].Info=Empty;
return H;
}
int Hash(ElementType key,int TableSize)
{
unsigned int HashVal=0;
while(*key!='\0')
{
HashVal=(HashVal<<5)+*key++;
}
HashVal=HashVal%TableSize;
return HashVal;
}
Position Find(ElementType key,HashTable H)
{
Position CurrentPos;
int CollisionNum;
CollisionNum=0;
CurrentPos=Hash(key,H->TableSize);
while(H->TheCells[CurrentPos].Info!=Empty&&H->TheCells[CurrentPos].Element!=key)
{
CurrentPos+=2*++CollisionNum-1;
if(CurrentPos>=H->TableSize)
CurrentPos-=H->TableSize;
}
return CurrentPos;
}
void Insert(ElementType key,HashTable H)
{
Position Pos;
Pos=Find(key,H);
if(H->TheCells[Pos].Info!=Legitimate)
{
H->TheCells[Pos].Info=Legitimate;
H->TheCells[Pos].Element=key;
}
}
ElementType Retrieve(Position P,HashTable H)
{
if(H->TheCells[P].Info!=Empty)
return H->TheCells[P].Element;
else
return NULL;
}
HashTable rehash(HashTable H)
{
int i,OldSize;
Cell* OldCells;
OldCells=H->TheCells;
OldSize=H->TableSize;
H=InitializeTable(2*OldSize);
for(i=0;i<OldSize;i++)
if(OldCells[i].Info==Legitimate)
Insert(OldCells[i].Element,H);
free(OldCells);
return H;
}
直接插入排序(带哨兵和不带哨兵)
前言
插入排序(insertion sort)的基本思想:每次将一个待排序的记录,按其关键字大小插入到前面已经排序好的序列中,直到全部记录插入完成为止.
直接插入排序
基本思想
排序方法
- 若R[j]的关键字大于R[i]的关键字,则将R[j]后移一个位置
- 若R[j]的关键字小于或等于R[i]的关键字,则查找过程结束,j + 1即为R[i]插入位置
c语言实现代码
InsertSort.c
#include<stdio.h>
typedef int ElementType;
ElementType arr[10]={2,87,39,49,34,62,53,6,44,98};
ElementType arr1[11]={0,2,87,39,49,34,62,53,6,44,98};
//不使用哨兵,每一次循环需要比较两次
void InsertSort(ElementType A[],int N)
{
int i,j;
ElementType temp;
for(i=1;i<N;i++)
{
temp=A[i];
for(j=i;j>0;j--)
{
if(A[j-1]>temp)
A[j]=A[j-1];
else
break;
}
A[j]=temp;
}
}
/*
使用A[0]作为哨兵,哨兵有两个作用:
1 暂时存放待插入的元素
2 防止数组下标越界,将j>0与A[j]>temp结合成只有一次比较A[j]>A[0],
这样for循环只做了一次比较,提高了效率,无哨兵的情况需要比较两次,for循环有两个判断条件
*/
void WithSentrySort(ElementType A[],int N)
{
int i,j;
for(i=2;i<N;i++)
{
A[0]=A[i];
for(j=i-1;A[j]>A[0];j--)
{
A[j+1]=A[j];
}
A[j+1]=A[0];
}
}
void Print(ElementType A[],int N)
{
int i;
for(i=0;i<N;i++)
{
printf(" %d ",A[i]);
}
}
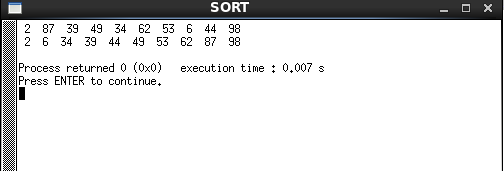
int main()
{
Print(arr,10);
printf("\n");
InsertSort(arr,10);
Print(arr,10);
printf("\n");
WithSentrySort(arr1,11);
Print(arr1,11);
printf("\n");
return 0;
}
运行结果如下:
希尔排序
通过比较相距一定间隔的元素来工作,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。所以希尔排序也叫缩小增量排序。希尔排序使用一个序列h1,h2,....,hn,叫做增量序列,只要h1=1,任何增量序列都是可以的,不过有些增量序列比另外一些增量序列更好。在使用增量hk的一趟排序后,对于每一个i,我们有A[i] <= A[i+hk],即所有相隔hk的元素都被排序,此时和排序文件是hk-排序的。希尔排序的一个重要性质是:一个hk-排序的文件保持它的hk-排序性。如果情况不是这样的话,希尔排序也就没有意义了。
hk-排序的一般做法是:对于hk,hk+1,...,N-1中的每一个位置i,把其上的元素放到i,i-hk,i-2*hk....中间的正确位置上。一趟hk排序的作用就是对hk个独立的子数组执行一次插入排序。
希尔排序的运行时间依赖于增量序列,但最坏情形下的运行时间为O(N^2),但对于有些增量序列,其时间可减少到O(N^1.2)。以下是以增量序列:1,2,4,N/2的一种实现:
Shellsort.c
#include<stdio.h>
typedef int ElementType;
ElementType arr[10]={2,87,39,49,34,62,53,6,44,98};
ElementType arr1[11]={0,2,87,39,49,34,62,53,6,44,98};
void Shellsort(ElementType A[], int N)
{
int i, j, Increment;
ElementType Tmp;
for (Increment = N / 2; Increment > 0; Increment /= 2){
for (i = Increment; i < N; ++i){
Tmp = A[i];
for (j = i; j >= Increment; j -= Increment){
if(Tmp < A[j-Increment])
A[j] = A[j - Increment];
else
break;
}
A[j] = Tmp;
}
}
}
void Print(ElementType A[],int N)
{
int i;
for(i=0;i<N;i++)
{
printf(" %d ",A[i]);
}
}
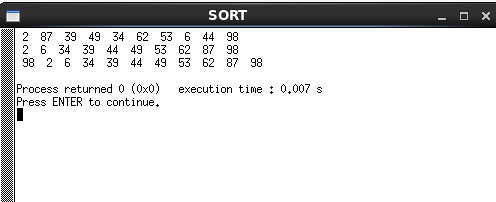
int main()
{
Print(arr,10);
printf("\n");
Shellsort(arr,10);
Print(arr,10);
printf("\n");
return 0;
}
堆排序-C语言实现
堆排序
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆。
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无须区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到



 20和16交换后导致16不满足堆的性质,因此需重新调整
20和16交换后导致16不满足堆的性质,因此需重新调整
 这样就得到了初始堆。
这样就得到了初始堆。
 此时3位于堆顶不满堆的性质,则需调整继续调整
此时3位于堆顶不满堆的性质,则需调整继续调整









#include<stdio.h>
typedef int ElementType;
int arr1[11]={0,2,87,39,49,34,62,53,6,44,98};
#define LeftChild(i) (2 * (i) + 1)
void Swap(int* a,int* b)
{
int temp=*a;
*a=*b;
*b=temp;
}
void PercDown(int A[], int i, int N)
{
int child;
ElementType Tmp;
for (Tmp = A[i]; 2*i+1 < N; i = child){
child = 2*i+1; //注意数组下标是从0开始的,所以左孩子的求发不是2*i
if (child != N - 1 && A[child + 1] > A[child])
++child; //找到最大的儿子节点
if (Tmp < A[child])
A[i] = A[child];
else
break;
}
A[i] = Tmp;
}
void HeapSort(int A[], int N)
{
int i;
for (i = N / 2; i >= 0; --i)
PercDown(A, i, N); //构造堆
for(i=N-1;i>0;--i)
{
Swap(&A[0],&A[i]); //将最大元素(根)与数组末尾元素交换,从而删除最大元素,重新构造堆
PercDown(A, 0, i);
}
}
void Print(int A[],int N)
{
int i;
for(i=0;i<N;i++)
{
printf(" %d ",A[i]);
}
}
int main()
{
int arr[10]={2,87,39,49,34,62,53,6,44,98};
Print(arr,10);
printf("\n");
HeapSort(arr,10);
Print(arr,10);
printf("\n");
return 0;
}
运行结果: