

循环、递归、概率
递归是程序设计中的一种算法。一个过程或函数直接调用自己本身或通过其他的过程或函数调用语句间接地调用自己的过程或函数,称为递归过程或函数。
例子一:打靶
面试1:一个射击运动员打靶,靶一共有10环,连开10枪打中90环的可能性有多少种?
解析:靶上一共有10种可能——1环到10环,还有可能脱靶,那就是0环,加在一起公有11种可能。
方法1:使用循环

for(i1=0;i1<=10;i1++)
for(i2=0;i2<=10;i2++)
for(i3=0;i3<=10;i3++)
...
for(i10=0;i10<=10;i10++)
{
if(i1+i2+i3+...+i10==90)
print();
}
但是,上面的循环程序虽然解决了问题,但时间复杂度和空间复杂度无疑是很高的,比较好的办法当然是采用递归的方式。
方法二:
递归的条件由以下4步完成:
1)如果出现这种情况,即使后面每枪都打10环也无法打够总环数90,这种情况下就不用再打了,则退出递归。代码如下:
if(score<0||score>(num+1)*10) //次数num为0~9
{
return;
}
2)如果满足条件且打到最后一次(因为必须打10次),代码如下:
if(num==0)
{
output();
return;
}
3)如果没有出现以上两种情况则执行递归,代码如下:
for(int i=0;i<=10;++i)
{
//这里实际上为了方便把顺序倒了过来,store[num]是最后一次打的出现的环数
//store[9]第10次打出现的环数,store[8]第9次打出现的环数,...,store[0]第一次打出现的环数
store[num]=i;//每一次打都11种环数可以选择
Cumput(score-i,num-1,store);
}
4)打印函数,符号要求的则把它打印出来,代码如下:
void output(int [] store)
{
for(int i=9;i>=0;--i)
cout<<store[i]<<" ";
cout<<endl;
sum++;
}
完整代码:
#include<iostream>
#include<vector>
using namespace std;
long long global=0;
vector<vector<int> > res;
void Cumput(int score,int n,vector<int> &tmp)
{
if(score<0||score>(n+1)*10)
return;
if(n==0)
{
global++;
tmp.push_back(score);
res.push_back(tmp);
tmp.pop_back();
return;
}
for(int i=0;i<11;i++)
{
tmp.push_back(i);
Cumput(score-i,n-1,tmp);
tmp.pop_back();
}
}
int main()
{
vector<int> tmp;
Cumput(90,9,tmp);
cout<<global<<endl;
for(auto a:res)
{
for(auto v:a)
cout<<v<<" ";
cout<<endl;
}
}
#include<iostream>
#include<vector>
using namespace std;
vector<vector<int> > res;
void Cumput(int score,int n,vector<int> &tmp)
{
if(score<0||score>n*10)
return;
if(n==0&&score==0)
{
res.push_back(tmp);
return;
}
for(int i=0;i<11;i++)
{
tmp.push_back(i);
Cumput(score-i,n-1,tmp);
tmp.pop_back();
}
}
int main()
{
vector<int> tmp;
Cumput(90,10,tmp);
cout<<res.size()<<endl;
}
例子二:
八皇后问题:
从每一行开始填充皇后检查是否满足要求,因此,如果是有效的皇后满足的条件是:
1)选择的列与前面已经防止皇后的列不在同一列。
2)检查从改行开始的第一行的主对角线是否满足要求
3)检查从该行开始到第一行的副对角线是否满足要求
#include<iostream>
#include<string>
#include<vector>
using namespace std;
class Solution
{
public:
vector<vector<string> > solveNQueens(int n)
{
vector<string> str(n,string(n,'.'));
vector<vector<string> > res;
helper(str,n,0,res);
return res;
}
void helper(vector<string> &str,int n,int start,vector<vector<string> > &res)
{
if(start==n)
{
res.push_back(str);
return;
}
for(int col=0; col<n; col++)
{
if(isValid(str,start,col))
{
str[start][col]='Q';
helper(str,n,start+1,res);
str[start][col]='.';
}
}
}
bool isValid(vector<string> &str,int row,int col)
{
int i,j;
for(i=0; i<row; i++)
{
if(str[i][col]=='Q')
return false;
}
for(i=row-1,j=col-1; i>=0&&j>=0; i--,j--)
{
if(str[i][j]=='Q')
return false;
}
for(i=row-1,j=col+1; i>=0&&j<(int)str.size(); i--,j++)
{
if(str[i][j]=='Q')
return false;
}
return true;
}
};
int main()
{
Solution s;
vector<vector<string> > result=s.solveNQueens(8);
cout<<result.size()<<endl;
for(auto a:result)
{
for(auto v:a)
cout<<v<<endl;
cout<<endl;
}
}
例子三:求字符子集
见:http://www.cnblogs.com/wuchanming/p/4149941.html
例子四:0-1背包问题
#include<iostream>
#include<vector>
using namespace std;
void helper(vector<int> &num,int m,int n,int start,vector<vector<int> > &res)
{
if(m==0)
{
res.push_back(num);
return;
}
if(m<0)
return;
for(int i=start; i<=n; i++)
{
num.push_back(i);
helper(num,m-i,n,i+1,res);
num.pop_back();
}
}
vector<vector<int> > calFun(int n,int m)
{
vector<vector<int> > res;
vector<int> num;
helper(num,m,n,1,res);
return res;
}
int main()
{
vector<vector<int> > res=calFun(7,8);
cout<<res.size()<<endl;
for(auto a:res)
{
for(auto v:a)
cout<<v<<" ";
cout<<endl;
}
}
迷途指针 new delete
编程中有一种很难发现的错误是迷途指针。迷途指针也叫悬浮指针、失控指针,是党对一个指针进行delete操作后——这样会释放它所指向的内存——并没有把它设置为空时产生的。而后,如果你没有重新赋值就试图再次使用该指针,引起的结果是不可预料的。
空指针和迷途指针的区别?
当delete一个指针的时候,实际上仅是让编译器释放内存,但指针本身依然存在。这时它就是一个迷途指针。
当使用以下语句时,可以把迷途指针改为空指针:
myPtr=0;
通常,如果在删除一个指针后又把它删除一次,程序就会变得非常不稳定,任何情况都有可能发生。但是如果你只是删除了一个空指针,则什么事都不会发生,这样做非常安全。
使用迷途指针或空指针(如果myPtr=0)是非法的,而且有可能造成程序崩溃。如果指针是空指针,尽管同样是崩溃,但它同迷途指针的崩溃相比是一种可预料的崩溃。这样调试起来会方便得多。
例如,
#include<iostream>
#include<new>
using namespace std;
typedef unsigned short int USHORT;
int main()
{
USHORT *pInt=new USHORT;
*pInt=10;
cout<<*pInt<<endl;
delete pInt;
//pInt=0;
long *pLong=new long;
*pLong=90000;
cout<<"*Plong: "<<*pLong<<endl;
*pInt=20;
cout<<"*pInt: "<<*pInt<<endl;
cout<<"*pLong: "<<*pLong<<endl;
delete pLong;
}
此时运行结果:
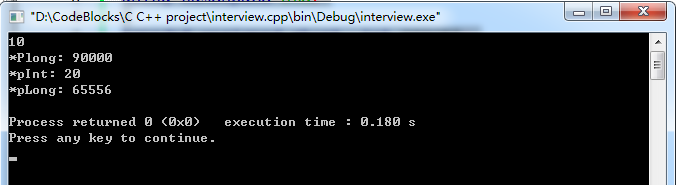
*pInt还是指向原来的内存,因此将pLong的数据修改了,但是结果是错误的而并没有保存。。
加入将pInt=0;这句加上,此时运行结果直接报错,因为pInt指向空指针,不能访问空指针。
C++中已经有了malloc/free,为什么还需要new/delete?
malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用malloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任何强加于malloc/free。
因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理和释放内存工作的运算符delete。new/delete不是库函数,而是运算符。
C++函数的传入参数是指针的指针(**)的详解
要修改变量的值,需要使用变量类型的指针作为参数或者变量的引用。如果变量是一般类型的变量,例如int,则需要使用int 类型的指针类型int *作为参数或者int的引用类型int&。但是如果变量类型是指针类型,例如char*,那么需要使用该类型的指针,即指向指针的指针类型 char* *,或者该类型的引用类型char*&。
首先要清楚 不管是指针还是值传入函数后都会创建一个副本,函数结束后值内容不能传出来是因为值的副本,而传入的值并没被修改,指针能传出来是因为我们修改的是指针指向的内容而不是指针指向的地址。
我们既然要举例子 就找一个比较经典的实用例子。
在我们进行内存管理的时候,如果想创建一个分配空间的函数,函数中调用了malloc方法申请一块内存区域。
先将一个错误的例子,如下:
void GetMemory1(char *p,int num)
{
p=malloc(sizeof(int)*num);
return;
}
void Test1()
{
char *p=NULL;
GetMemory(p);
}
上述例子 是很普通的 将一个指针作为参数来申请一个动态内存空间,可是这个程序是错误的。
错误的原因:
由于其中的*p实际上是Test1中p的一个副本,编译器总是要为函数的每个参数制作临时副本。在本例中,p申请了新的内存,只是把p所指向的内存地址改变了,但是Test1中p丝毫未变。因为函数GetMemory1没有返回值,因此Test1中p并不指向申请的那段内存。
因为malloc的工作机制是在堆中寻找一块可用内存区,返回指向被分配内存的指针。
所以这时p指向了这个申请的内存的地址。由于在指针作为传入参数的时候会在函数体中创建一个副本指针_p
_p指针和p指针的联系就是他们指向同一个内存区域,但是malloc的函数使得_p指向了另外一个内存区域,而这个内存区域并没有座位传出参数传给p,
所以p并没有发生任何改变,仍然为NULL。
如何才能解决上述问题呢?
使用下述办法可以解决问题:
void GetMemory2(char **p,int num)
{
* p=malloc(sizeof(int)*num);
return;
}
void Test2()
{
char *p=NULL;
GetMemory(&p);
}
下面开始分析GetMemory2()和 Test2()的原理:
char **p 可以进行拆分(从左向右拆分) char* *p ,所以可以认为*p是一个char *的指针(注意这里不是p而是*p)。那么p的内容就是一个指向char*的指针的地址,换句话来说p是指向这个char*指针的指针。
从test2可以看出 p是一个char*的指针, &p则是这个char*指针的地址,换句话来说 &p是指向这个char*p的指针的指针,与GetMemory2()定义相符。所以在调用时候要使用&p而不是p。
在GetMemory2()中 *p=malloc(sizeof(int)*num);
其中*p保存了 这个分配的内存的地址,那么p就是指向这个分配的内存地址的指针。
其实在为什么要用指针的指针的道理很简单:
因为VC内部机制是将函数的传入参数都做一个副本,如果我们传入的用来获取malloc分配内存地址的副本变化了,而我们的参数并不会同步,除非使用函数返回值的方式才能传出去。
所以我们就要找一个不变的可以并能用来获取malloc内存地址的参数,
如果能够创建另外一个指针A,这个指针指向GetMemory1(char * p,int ...)中的传入参数指针p,那么 就算*p的内容变了,而p的地址没变,我们仍然可以通过这个指针A来对应得到p的地址并获得*p所指向的分配的内存地址,没错这个指针A就是本文想要讲的指向(char *)指针的指针(char **)。
于是我们创建了一个char *的指针*p(注意这里不是char *的指针p),这个p作为传入参数,在进入函数后,系统会为该指针创建一个副本_p,我们让*_p指向malloc分配的内存的地址(注意这里是*_p而不是_p),_p作为指向这个分配的内存地址指针的指针,这样在分配过程中_p并没有变化。
另外注意在void Test2()中的char *p 的p是指向的是malloc分配的内存的地址,通过GetMemory2()函数后&p作为传入参数没有变化被返回回来,依据&p将p指针指向了真正分配的内存空间。
最后还要注意一个要点,void Test2()中 GetMemory(&p);和void GetMemory2(char **p,int num)这个函数的定义,很容易有一个迷惑,在使用处的变量和定义处的变量是如何一一对应的。
下面来做解释:
不对应关系:其实这两个p不是一个p,&p中的p是一个char *的指针,而char**p中的p却是指向char *指针的指针。
对应关系:其实这个对应关系就是 在void Test2()调用的时候传入参数&p是指向char *指针的指针,GetMemory2()定义中的char **p也是指向char*指针的指针,所以说 在调用时候传入的参数和在定义时候使用的传入参数必须是匹配的。
如果看了上面的文字还是比较混乱的话就用一句话来总结下重点:
1,VC的函数机制传入的参数都是会创建一个副本 不管是指针还是值;如果是值A则直接创建另外一个值B,值B拥有和A相同的值;如果是传入参指针C创建另外一个指针的副本D,那么D所指向的地址是和C相同的地址。
2,第1条总结可知指针传参比值传参的多出的功能是可以通过修改指针D所指向的地址的内容来讲函数的运算结果告知指针C,因为C和D指向相同的地址。
3,第2跳总结的指针C和D所共用的指向地址可以是值类型,也可以是另外一个指针的地址(也就是上面所讲的**)。


