
redis学习笔记
数据库的发展过程
1、单机Mysql
场景:网站访问量、数据量不大
瓶颈:无法解决数据量大,数据B树索引内存放不下,单机数据库无法承受访问量
2、memcached缓存+读写分离
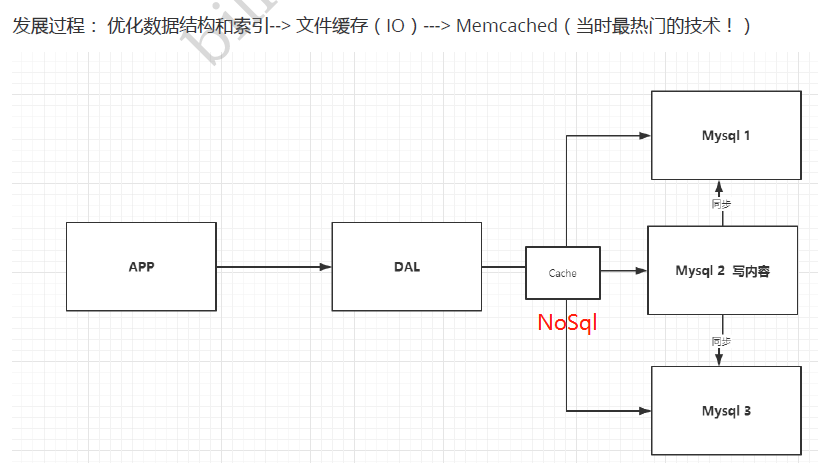
瓶颈:表锁导致性能差,无法承受日益增长的数据量的需求
3、mysql集群+分库分表
场景:解决第二步瓶颈
瓶颈:数据爆发式增长,包括数据类型,数据量,数据结构变化很快,效率低
4、Nosql+RDBMS
解耦
方便扩展(数据之间没有关系,很好扩展!)
大数据量高性能(Redis 一秒写8万次,读取11万,NoSQL的缓存记录级,是一种细粒度的缓存,性
能会比较高!)
数据类型是多样型的!(不需要事先设计数据库!随取随用!如果是数据量十分大的表,很多人就无
法设计了!)
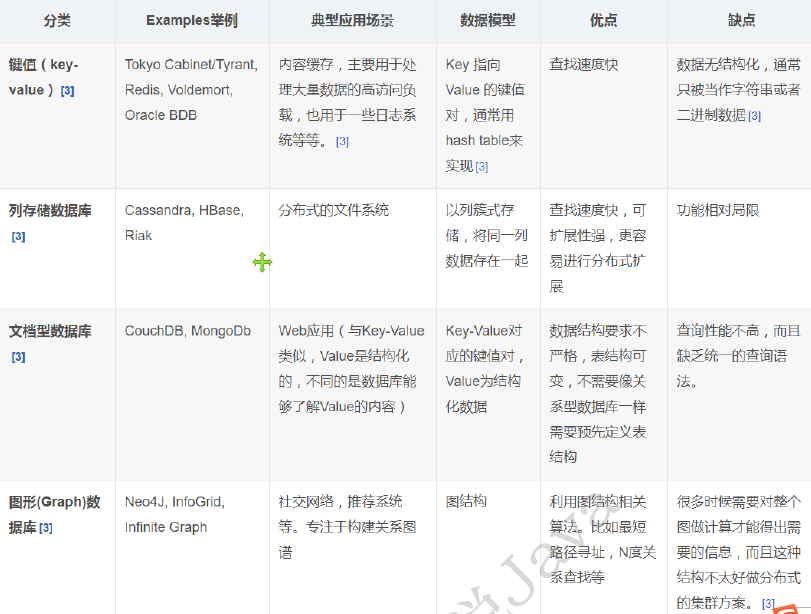
传统 RDBMS 和 NoSQL

redis基于单线程的内存读写,一秒写8万次,读11万次,细粒度缓存,高性能。
特性:持久化,集群,事务
3V+3高
海量Volume
多样Variety
实时Velocity
高并发、高可扩、高性能
redis的应用场景
1、会话缓存(最常用)
2、消息队列,比如支付
3、活动排行榜或计数
4、发布、订阅消息(消息通知)
5、商品列表、评论列表等
6、个人信息、社交网络、地理位置
五种数据类型
String
key value,注意一个键值只能存储512MB。
Set
是string类型的无序集合,也不可重复
List
字符串列表,它按插入顺序排序
Hash
一个键值对的集合, 是一个string类型的field和value的映射表,适合用于存储对象
ZSet
是string类型的有序集合,也不可重复
sorted set中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序,sorted set 因此非常适合实现排名
基础知识
默认16个DB 通过select 切换
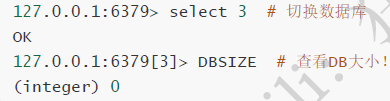
flushdb 清除当前DB
fulshall 清除全部DB
keys * 查看所有k
exists key 是否存在k
getset key value 先get再set
move key k数量
expire key 秒数 设置k的过期时间
ttl key 查看k的剩余时间
append key value 追加字符串,不存在则set
strlen key 获取长度
set views 0 浏览量
incr views 默认自增1
decr views 默认自减1
incrby views 步长
decrby views 步长
getrange key 0 -1 获取指定位置或全部字符串
setrange key 0 -1 替换指定位置或全部字符串
setex (set with expire) 设置过期时间
setnx (set if not exist) 不存在在设置(在分布式锁中会常常使用!)
mset k1 v1 k2 v2 k3 v3 同时设置多个值
mget k1 k2 k3 同时获取多个值
msetnx k1 v1 k4 v4 # msetnx 是一个原子性的操作,要么一起成功,要么一起失败!
# 对象
set user:1 {name:zhangsan,age:3} 设置一个user:1 对象 值为 json字符来保存一个对象!
# 这里的key是一个巧妙的设计: user:{id}:{filed}
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 2
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"

