
基础构建类(同步/异步容器、阻塞队列、并发工具类)
前言
- Java平台类库包含了丰富的并发基础构建模块,如:线程安全的同步/并发容器、生产者-消费者模式的阻塞队列、协调线程控制流的同步工具类等,学习这些可以帮助我们轻松应对各种并发应用场景,编写高可用、高性能、健壮的代码。
- 本文记录的jdk为1.8版本。
基础介绍
同步容器类
- 同步容器类实现线程安全的方式是:将它们的状态封装起来,并对每个公有方法都进行同步synchronized,使得每次只有一个线程能访问容器的状态。
- 这样就导致当多线程竞争时,吞吐量严重降低,导致性能降低,所以通常情况下不推荐使用,而是使用并发容器类。
- 常见的同步容器类有:Vetor、HashTable、Collections.synchronizedXxx系列
并发容器类
- 并发容器类是用来代替同步容器类,改进同步容器类的性能问题,使用并发容器类可以极大的提高伸缩性并降低风险;
- 并发容器类使用Copy-On-Write写入时复制、Lock Striping分段锁、CAS、Queue队列等技术来保证线程安全;
- 并发容器类还提供了一些常用的复合操作的原子操作方法,如addIfAbsent()、removeIf()、putIfAbsent();
- 常见的并发容器类有:CopyOnWriteArrayList&Set、ConcurrentHashMap、ConcurrentLinkedQueue&Deque、ConcurrentSkipListMap&Set
阻塞队列
- 阻塞队列(BlockingQueue)提供了可阻塞的put和task方法,以及支持定时的offer和poll方法;队列可以是有界或者无界;
- 阻塞队列支持生产者-消费者这种设计模式,常见的应用场景为:Executor任务执行框架中线程池与工作队列的组合;
- 阻塞队列不仅能作为并发容器保存对象,还能作为同步工具类协调生产者和消费者等线程之间的控制流;(生产者-消费者设计模式:当数据生成时,生产者把数据放入队列,而当消费者准备处理数据时,将从队列中获取数据。生产者只需将数据放入队列,消费者只需从队列中获取数据。)
- 阻塞队列具体实现类:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue、DelayQueue、LinkedTransferQueue、LinkedBlockingDeque。
同步工具类
- 同步工具类可以是任何一个对象,只要它根据其自身的状态来协调线程的控制流;
- 所有的同步工具类都包含一些特定的结构化属性:它们封装了一些状态,这些状态将决定执行同步工具类的线程是继续执行还是等待,此外还提供了一些方法对状态进行操作,以及另一些方法用于高效的等待同步工具类进入到预期状态;
- 常用的同步工具类有:CountDownLatch、CyclicBarrier、Semaphore、FutureTask、CompletionStage、CompletionService、ForkJoinTask
详细说明
并发容器类
以CopyOnWriteArrayList、ConcurrentHashMap作为例子进行说明
CopyOnWriteArrayList&Set
- 说明
- “写入时复制”容器的线程安全性在于,只要正确的发布一个事实不可变的对象,那么在访问时不再需要进一步的同步,在每次修改时,都会创建并重新发布一个新的容器副本,从而实现可变性;
- 迭代器保留一个指向底层基础数组的引用,这个数组位于迭代器得起始位置,由于它不会被修改,所以在对其进行同步时只需确保数组内容的可见性;
- 返回的迭代器不会抛出ConcurrentModificationException,不需要对容器加锁,并且返回的元素与迭代器创建时的元素完全一致。
- 优缺点
- 优点:读操作不需要对容器进行加锁,读并发性能好
- 缺点是会造成额外的性能开销、内存占用、数据一致性的问题
- 额外的性能开销:每次修改时,都会创建并重新发布一个新的容器副本
- 内存占用:当容器本身容量大时,再发布一个新的容器副本容易频繁触发GC机制
- 数据一致性问题:写入的数据不能立马读取到,在写操作释放锁之前读操作读取到的元素都是旧数据
- 应用场景
- 读操作远多于写操作时
- 实现原理
- 如何保证数组的可见性:volatile修饰数组变量
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; /** * Gets the array. Non-private so as to also be accessible * from CopyOnWriteArraySet class. */ final Object[] getArray() { return array; } - 具体写操作实现:加锁-》获取原数组对象-》复制并扩容1生成新副本-》新副本写入数据-》改变原数组引用指向新数组-》释放锁
/** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
- 如何保证数组的可见性:volatile修饰数组变量
ConcurrentHashMap
- 说明
- ConcurrentHashMap在jdk1.7版本采用分段锁的加锁机制来实现更大程度的数据共享,但在jdk1.8版本后改用为CAS+对节点加synchronized锁来实现
- 分段锁:
- 定义:在某些情况下,可以将锁分解技术进一步扩展为对一组独立对象上的锁进行分解,这种情况被称为锁分段。
- 设计思想:通过减少锁粒度来减少锁的竞争,以实现更高的并发性。如jdk1.7版本的ConcurrentHashMap的实现中,使用了一个包含16个锁的数组,假设散列函数具有合理的分布性,并且关键字能够实现均匀分布,那么这大约能把对于锁的请求减少到原来的1/16。
- 优点:锁竞争减少,提高了吞吐量,进而提升了并发性能。
- 缺点:
- 要获取多个锁来实现独占访问将更加困难且开销更高;
- 同时存在多个不连续的分段锁时,内存空间占用大;
- 某一分段管理元素过多且访问量大时,也会比较影响性能。
- 分段锁:
- 返回的迭代器不会抛出ConcurrentModificationException,不需要对容器加锁;
- ConcurrentHashMap在jdk1.7版本采用分段锁的加锁机制来实现更大程度的数据共享,但在jdk1.8版本后改用为CAS+对节点加synchronized锁来实现
- 优缺点
- 优点:由于jdk1.8版本对synchronized性能进行了优化,采用CAS+synchronized锁不仅实现了线程安全提高了吞吐量,而且避免了之前采用分段锁带来的其他问题;
- 缺点:未实现对Map加锁以提供独占式访问,在需要此功能时仍需使用synchronizedMap(极少数情况下才会用到)
- 应用场景
- 除了需要加锁Map以进行独占访问之外的所有并发场景下都可以使用
- 实现原理
- 节点组成:采用volatile修饰节点值和下一个节点,保证可见性
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; Node(int hash, K key, V val, Node<K,V> next) { this.hash = hash; this.key = key; this.val = val; this.next = next; } public final K getKey() { return key; } public final V getValue() { return val; } public final int hashCode() { return key.hashCode() ^ val.hashCode(); } public final String toString(){ return key + "=" + val; } public final V setValue(V value) { throw new UnsupportedOperationException(); } public final boolean equals(Object o) { Object k, v, u; Map.Entry<?,?> e; return ((o instanceof Map.Entry) && (k = (e = (Map.Entry<?,?>)o).getKey()) != null && (v = e.getValue()) != null && (k == key || k.equals(key)) && (v == (u = val) || v.equals(u))); } /** * Virtualized support for map.get(); overridden in subclasses. */ Node<K,V> find(int h, Object k) { Node<K,V> e = this; if (k != null) { do { K ek; if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) return e; } while ((e = e.next) != null); } return null; } }- 添加元素实现:找到待添加元素的节点位置-》判断是否已存在元素-》未存在元素则CAS命令添加元素-》CAS添加失败或节点已存在元素,加synchronized锁-》在链表或者树结构上添加元素
public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); //1. 根据key的hashCode值计算所在节点的位置 int hash = spread(key.hashCode()); int binCount = 0; //2. 添加元素 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //2.1 插入第一个元素时初始化Node数组 if (tab == null || (n = tab.length) == 0) tab = initTable(); //2.2 若节点位置不存在元素 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //进行CAS添加元素 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //2.3 若需要扩容 else if ((fh = f.hash) == MOVED) //扩容操作 tab = helpTransfer(tab, f); //2.4 在节点位置后面添加元素 else { V oldVal = null; //2.4.1 对节点Node对象加同步锁 synchronized (f) { if (tabAt(tab, i) == f) { //2.4.1.1 链表结构则在链表后面添加元素 if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //2.4.1.2 树结构则在树中添加元素 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } //节点容量超过8个则由链表转为红黑树结构 if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } //2.3 元素数量+1 addCount(1L, binCount); return null; }- 获取元素实现(无锁)
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; //1. 计算节点位置 int h = spread(key.hashCode()); //2. 若节点存在元素,开始获取 if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { //2.1 判断节点位置的元素key是否相匹配 if ((eh = e.hash) == h) { //匹配则直接返回 if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //2.2 判断节点位置是否为树结构 else if (eh < 0) //调用树获取元素方法获取元素并返回 return (p = e.find(h, key)) != null ? p.val : null; //2.3 若非树结构则说明是链表,则循环遍历链表节点,直到找到对应元素并返回 while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } //3. 若节点不存在元素,返回null return null; }
阻塞队列
比较
| 阻塞队列名称 | 数据结构 | 是否有界 | 应用场景 | 出入队 | 线程安全机制 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组 | 有界(初始化时定义) | 生产数据固定 | 先入先出 | ReentrantLock锁 |
| LinkedBlockingQueue | 单链表 | 有界(默认Integer.MAX_VALUE,初始化时可定义容量) | 对生产的数据大小不定(时高时低),数据量较大 | 先入先出 | ReentrantLock锁 |
| PriorityBlockingQueue | 堆(完全二叉树) | 无界(会自动扩容) | 对生产的数据顺序有要求 | 按优先级排序 | ReentrantLock锁 |
| SynchronousQueue | 队列、堆栈 | 不存储元素 | 生产消费同步 | 线程阻塞匹配 | CAS |
| DelayQueue | 优先级队列 | 无界 | 任务不想立马执行,想等待一段时间才执行 | 按延时时间排序 | CAS |
| LinkedTransferQueue | 单链表 | 无界 | 生产消费同步,若不同步也可先放入队列中 | ReentrantLock锁 | |
| LinkedBlockingDeque | 双链表 | 有界(默认Integer.MAX_VALUE,初始化时可定义容量) | 工作窃取Working Stealing | 先入先出、先入后出 | ReentrantLock锁 |
结构
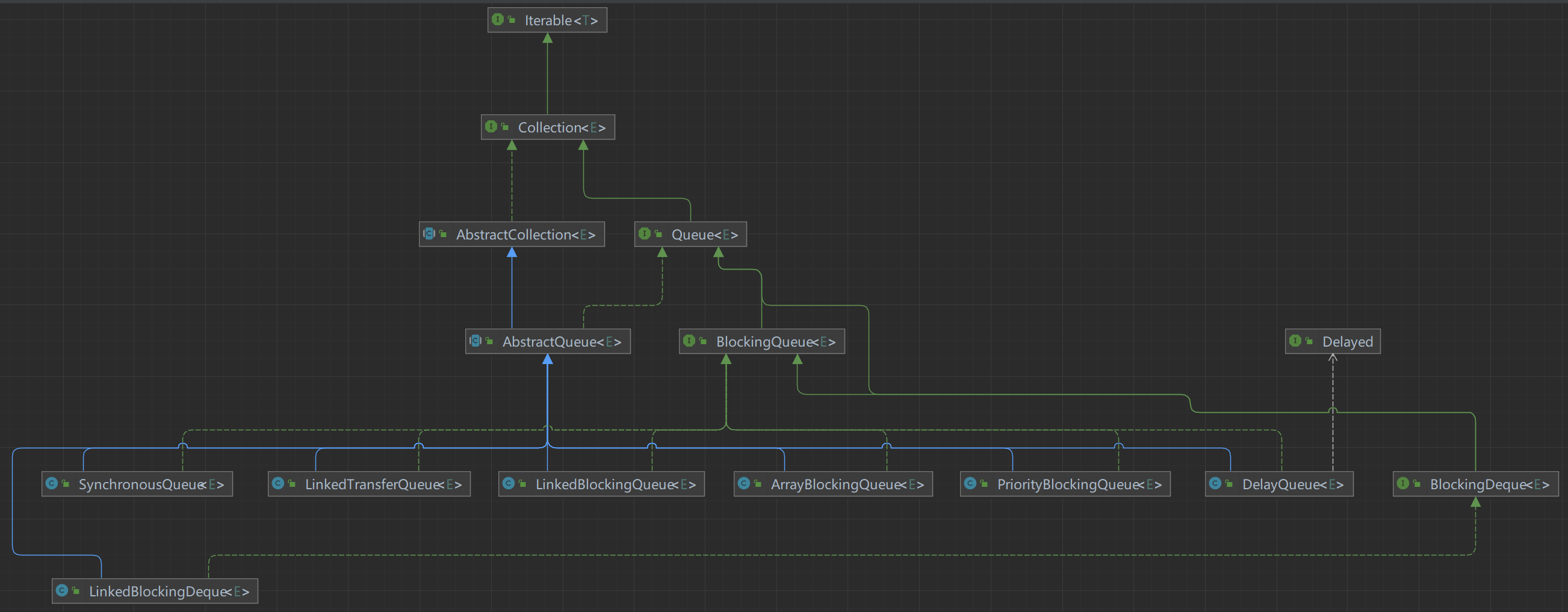
同步工具类
常用的同步工具类:CountDownLatch、CyclicBarrier、Semaphore、FutureTask、CompletionStage、CompletionService、ForkJoinTask
CountDownLatch
- 概述:倒计时门闩。通过计数器控制需等待的线程,计数器不能循环使用。
- 方法说明:
countDown()计数器减1;await()阻塞等待直到计数器减为0时继续执行 - 应用场景:线程需要等待其他线程执行完成后再执行(闭锁)
CyclicBarrier
- 概述:回环栅栏。通过计数器控制需阻塞的线程,计数器能循环使用。
- 方法说明:
await()计数器减1并阻塞等待,当计数器减为0时释放所有阻塞线程,同时重置计数器。 - 应用场景:控制多线程同时执行(高并发场景下的安全、性能测试)
Semaphore
- 概述:信号量。访问资源前先尝试获取许可,若获取到许可则访问资源,若未获取到许可则进入队列等待,资源访问完成后释放许可。
- 方法说明:
acquire()获取许可,若获取失败则阻塞等待;tryAcquire()尝试获取许可,若获取失败则继续往下执行;release()释放许可 - 应用场景:控制多线程访问资源的并发量(无界转有界队列、互斥锁)
FutureTask
- 概述:异步任务。继承Runnable和Future接口,通过Callable实现,能够获取异步任务执行结果,也可取消正在执行的异步任务。
- 方法说明:
get()阻塞获取异步任务执行结果;cancel()取消任务;isCancelled()检查异步任务是否取消;isDone()检查异步任务是否完成 - 应用场景:闭锁(在使用计算结果前启动异步任务,在使用计算结果处调用get方法获取结果)
CompletionStage
- 概述:完成阶段任务,能够按前后阶段任务依赖的情况分别进行处理,用以处理阶段任务。具体实现类为CompletableFuture
- 方法说明(提供了很多方法,这里简单记录一部分可能用到的)
- 串行(后一阶段任务依赖前一阶段任务执行完成)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
thenApply(Function<? super T,? extends U> fn)(方法后缀带Async表示异步执行) - 后者需要前者任务执行完成且生成正确的结果,并使用此结果以判断该执行什么操作:
thenAccept(Consumer<? super T> action) - 后者仅需要前者任务执行完成,不管执行结果:
thenRun(Runnable action)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
- 并行AND(后一阶段任务依赖前二阶段任务都执行完成)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn)(方法后缀带Async表示异步执行) - 后者需要前者任务执行完成且生成正确的结果,并使用此结果以判断该执行什么操作:
thenAcceptBoth(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action) - 后者仅需要前者任务执行完成,不管执行结果:
runAfterBoth(CompletionStage<?> other, Runnable action)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
- 并行OR(后一阶段任务依赖前二阶段任务任何一阶段执行完成)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action)(方法后缀带Async表示异步执行) - 后者需要前者任务执行完成且生成正确的结果,并使用此结果以判断该执行什么操作:
applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn) - 后者仅需要前者任务执行完成,不管执行结果:
runAfterEither(CompletionStage<?> other,Runnable action)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
- 异常(前一阶段可能出现异常情况)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
handle(BiFunction<? super T, Throwable, ? extends U> fn)(方法后缀带Async表示异步执行) - 后者需要前者任务执行完成且生成正确的结果,并使用此结果以判断该执行什么操作:
whenComplete(BiConsumer<? super T, ? super Throwable> action) - 前者必须执行异常:
exceptionally(Function<Throwable, ? extends T> fn)
- 后者需要前者任务执行完成且生成正确的结果,并使用此结果以执行新的函数获取新的结果:
- CompletableFuture构造
- 接收Runnable对象参数:
runAsync() - 接收Supplier对象参数:
supplyAsync()
- 接收Runnable对象参数:
- 串行(后一阶段任务依赖前一阶段任务执行完成)
- 应用场景:存在阶段性任务的场景(任务A在任务B完成之后再执行;任务C在任务A和任务B都完成之后再执行;任务C在任务A或任务B其中一个完成之后再执行)
CompletionService
- 概述:后期制作,能够将异步任务的执行过程和执行结果进行分离,任务执行完成的结果按执行完成顺序存入阻塞队列中,用以处理批量任务且获取执行结果的应用场景。具体实现类为ExecutorCompletionService。
- 方法说明:
submit()生产任务,接收Runnable和Callable对象;take()/poll()任务执行结果Future出队进行消费 - 应用场景:批量任务的处理(批量计算,批量执行且需获取执行结果)
ForkJoinTask
- 概述:分治任务,在ForkJoinPool中执行的抽象类,两个子类RecursiveAction和RecursiveTask,主要区别为RecursiveAction不返回结果而RecursiveTask返回结果。使用时均需要实现子类中的compute方法。用以处理分治任务
- 方法说明:
compute分治任务实现;fork()异步执行子任务;join()阻塞线程等待执行结果 - 应用场景:分而治之的处理(斐波那契数列、递归)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号