
各种排序算法性能比较
插入排序包括直接插入排序、希尔排序。
1、直接插入排序:
如何写成代码:
首先设定插入次数,即循环次数,for(int i=1;i<length;i++),1个数的那次不用插入。
设定插入数和得到已经排好序列的最后一个数的位数。insertNum和j=i-1。
从最后一个数开始向前循环,如果插入数小于当前数,就将当前数向后移动一位。
将当前数放置到空着的位置,即j+1。
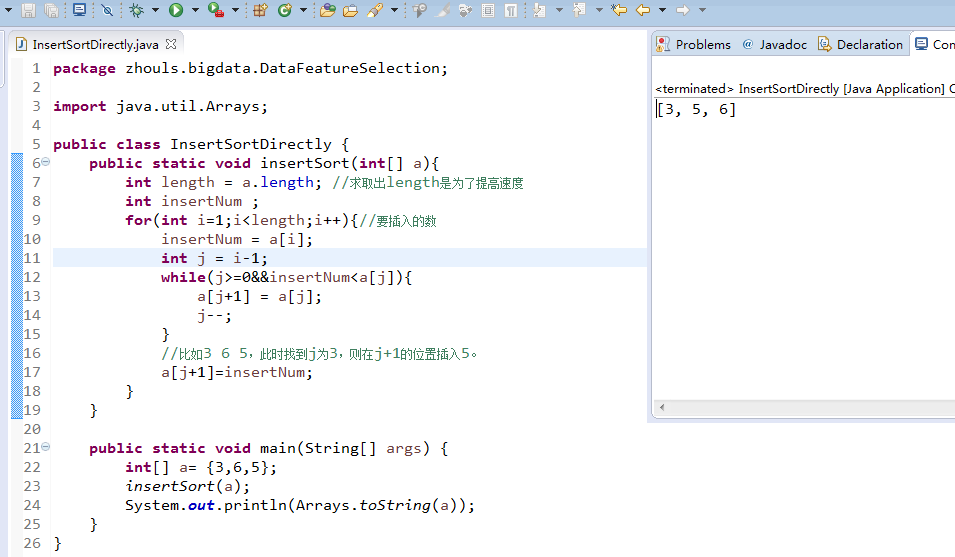
代码实现如下:

package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class InsertSortDirectly {
public static void insertSort(int[] a){
int length = a.length; //求取出length是为了提高速度
int insertNum ;
for(int i=1;i<length;i++){//要插入的数
insertNum = a[i];
int j = i-1;
while(j>=0&&insertNum<a[j]){
a[j+1] = a[j];
j--;
}
//比如3 6 5,此时找到j为3,则在j+1的位置插入5。
a[j+1]=insertNum;
}
}
public static void main(String[] args) {
int[] a= {3,6,5};
insertSort(a);
System.out.println(Arrays.toString(a));
}
}
直接插入排序,最好的情况是数据元素已经全部排好序,那么内循环次数为0,外循环次数为n-1,所以,最好的情况下时间复杂度为O(N)。最坏的情况是原始数据元素集合反序排列,此时,算法中内层while循环的循环次数每次均为i。因此,最坏的情况下时间复杂度为O(N^2)。直接插入排序的空间复杂度为O(1),显然直接插入排序是一种稳定的排序算法。
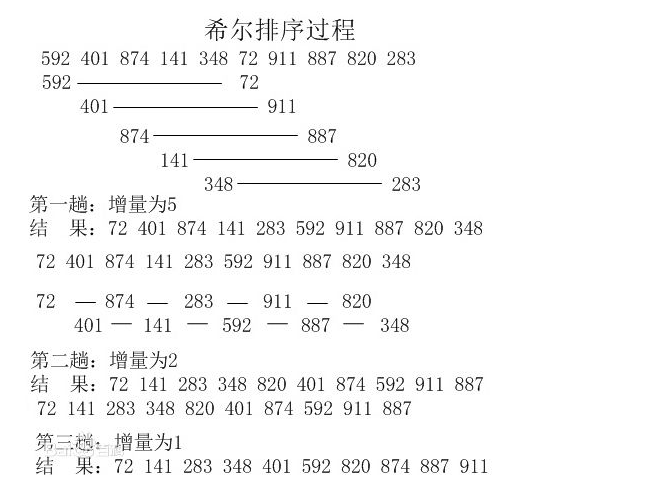
2、希尔排序:
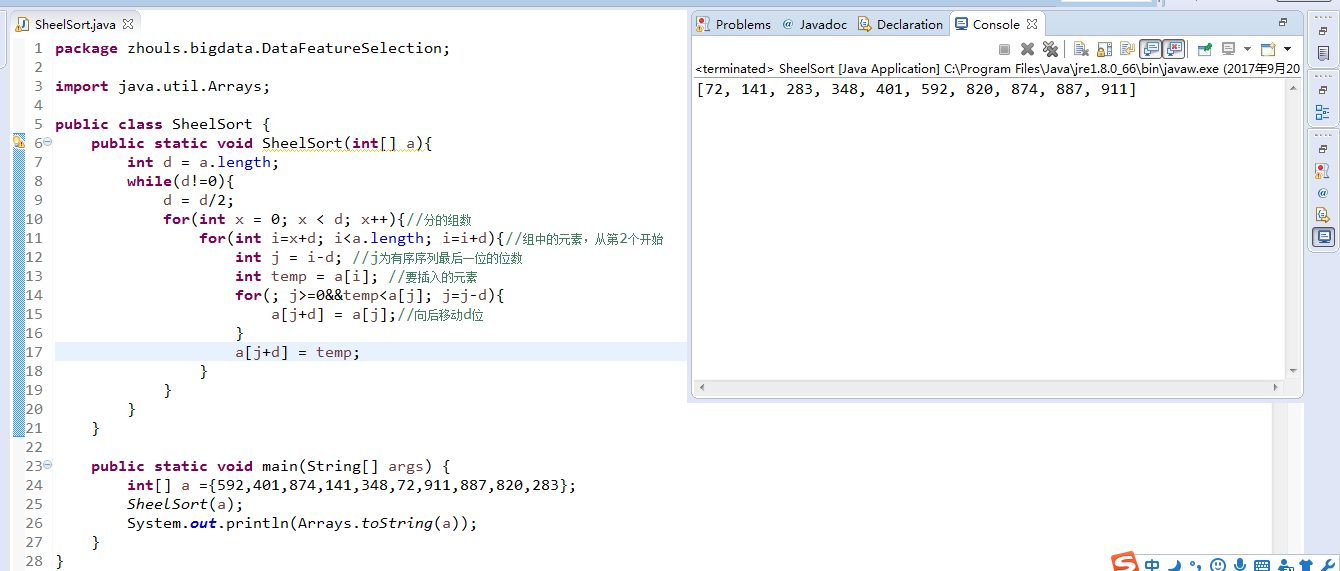
package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class SheelSort {
public static void SheelSort(int[] a){
int d = a.length;
while(d!=0){
d = d/2;
for(int x = 0; x < d; x++){//分的组数
for(int i=x+d; i<a.length; i=i+d){//组中的元素,从第2个开始
int j = i-d; //j为有序序列最后一位的位数
int temp = a[i]; //要插入的元素
for(; j>=0&&temp<a[j]; j=j-d){
a[j+d] = a[j];//向后移动d位
}
a[j+d] = temp;
}
}
}
}
public static void main(String[] args) {
int[] a ={592,401,874,141,348,72,911,887,820,283};
SheelSort(a);
System.out.println(Arrays.toString(a));
}
}
希尔排序虽然用了四重循环,但是其实前两层的循环次数很少,后两层就是直接插入排序,由于希尔排序小组内数据基本有序,因此内部的直接插入排序很快就排好。所以,希尔排序的时间复杂度为O(nlbn),空间复杂度为O(1),由于希尔排序算法是按增量分组进行的排序,所以,希尔排序是一种不稳定的排序算法。如5,1,1,5,如果采用步长为2,则两个1相对位置进行了交换。
选择排序包括直接选择排序和堆排序。
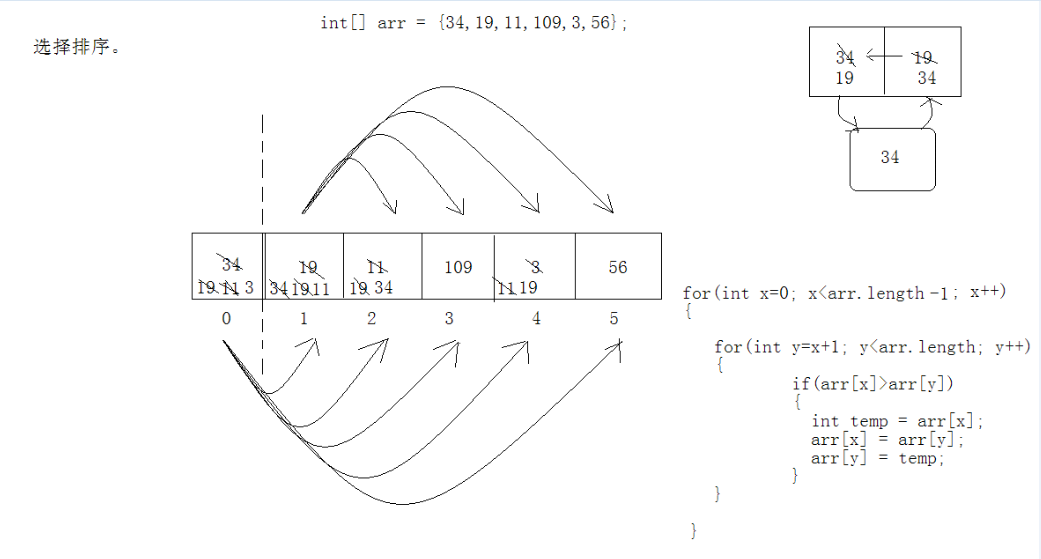
3、直接选择排序
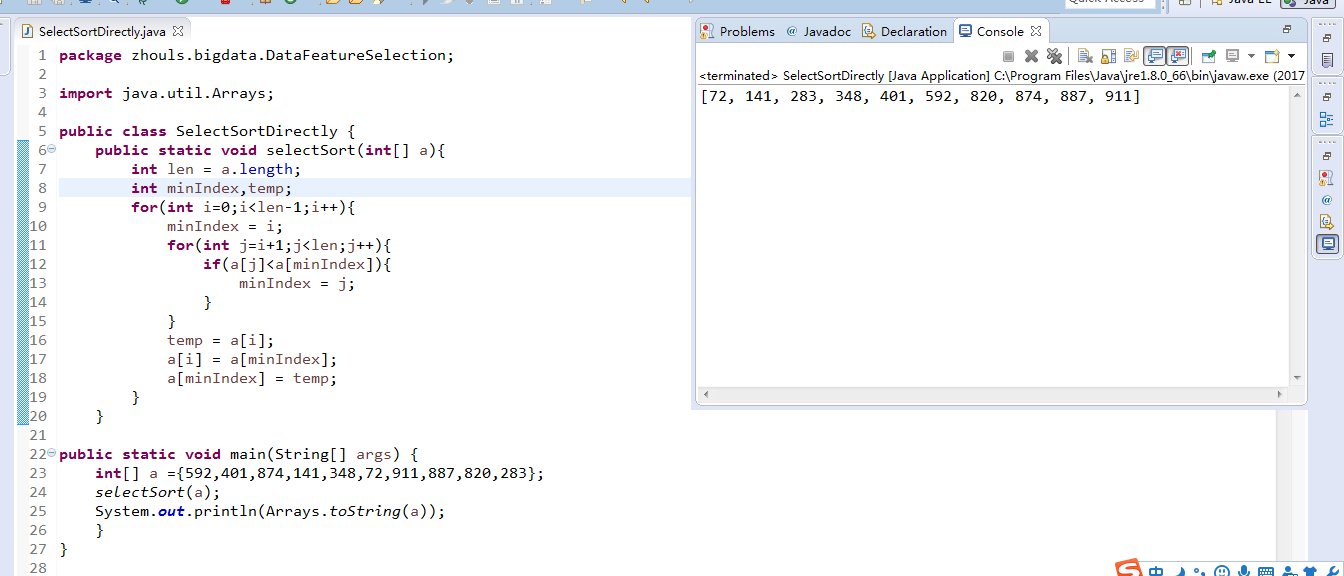
package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class SelectSortDirectly {
public static void selectSort(int[] a){
int len = a.length;
int minIndex,temp;
for(int i=0;i<len-1;i++){
minIndex = i;
for(int j=i+1;j<len;j++){
if(a[j]<a[minIndex]){
minIndex = j;
}
}
temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
public static void main(String[] args) {
int[] a ={592,401,874,141,348,72,911,887,820,283};
selectSort(a);
System.out.println(Arrays.toString(a));
}
}
直接选择排序的时间复杂度是O(N^2),空间复杂度是O(1),它是一种不稳定的排序算法。比如2 2 2 1,这样选出最小数1和第一个2交换,那么2的相对位置发生了改变。如果在选出最小记录后,将它前面的无序记录依次后移,然后再将最小记录放在有序区的后面,这样就能保证排序算法的稳定性。
4、堆排序
对简单选择排序的优化。
将序列构建成大顶堆。
将根节点与最后一个节点交换,然后断开最后一个节点。
重复第一、二步,直到所有节点断开。
堆排序关键要理解,从下往上,调整节点,比如说,这棵树一共3层,那么将第2层的树作为根节点,保证它的子节点都小于它,此时,如果调整第1层,若其左节点是最大值,必然会将第一层根节点和左节点进行交换,以保证第1层满足最大堆的结构,但此时,有可能会破坏第1层的左节点的最大堆结构,因此需要对这个第1层的左节点的堆进行重新调整。-------------这是关键要理解的地方!

package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class HeapSort {
public HeapSort(){
}
public static void heapSort(int[] a){
System.out.println("开始排序");
int arrayLength=a.length;
//循环建堆
for(int i=0;i<arrayLength-1;i++){
//建堆
buildMaxHeap(a,arrayLength-1-i);
//交换堆顶和最后一个元素
swap(a,0,arrayLength-1-i);
}
}
private static void swap(int[] data, int i, int j) {
//TODO Auto-generated method stub
int tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
//对data数组从0到lastIndex建大顶堆
private static void buildMaxHeap(int[] data, int lastIndex) {
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//k保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//若果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
//如果不理解,那么请使用打断点的方式来运行,则可发现,当i=0时,由于节点1和节点0发生了交换,因此需要重新调整1节点的堆结构,保证
//1节点的值仍然大于其左右节点的值
k=biggerIndex;
}else{
break;
}
}
}
}
public static void main(String[] args) {
int a[] = {7,13,6,43,5,23,4};
heapSort(a);
System.out.println(Arrays.toString(a));
}
}
堆排序算法是基于完全二叉树的排序,其时间复杂度是O(nlbn),其空间复杂度是O(1),堆排序是一种不稳定的排序算法,比如5 5 5,这样,构建好最大堆后,第1个5和最后一个5要进行交换,因此,堆排序是一种不稳定的排序算法。
利用交换数据元素的位置进行排序的方法是交换排序。常用的交换排序有冒泡排序和快速排序。快速排序是一种分区交换排序方法。
5、冒泡排序
将序列中所有元素两两比较,将最大的放在最后面。
将剩余序列中所有元素两两比较,将最大的放在最后面。
重复第二步,直到只剩下一个数。
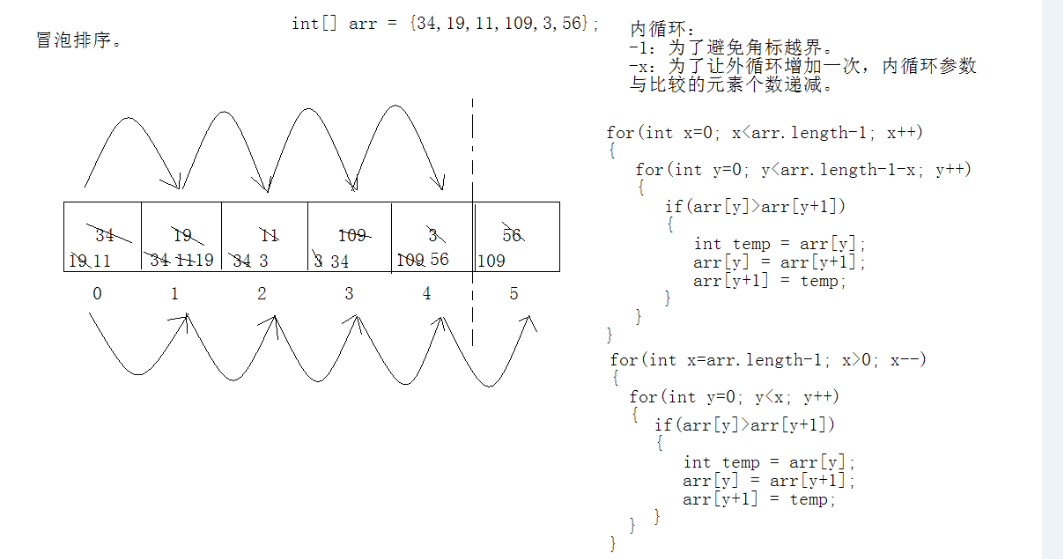
如何写成代码:
设置循环次数。
设置开始比较的位数,和结束的位数。
两两比较,将最小的放到前面去。
重复2、3步,直到循环次数完毕。
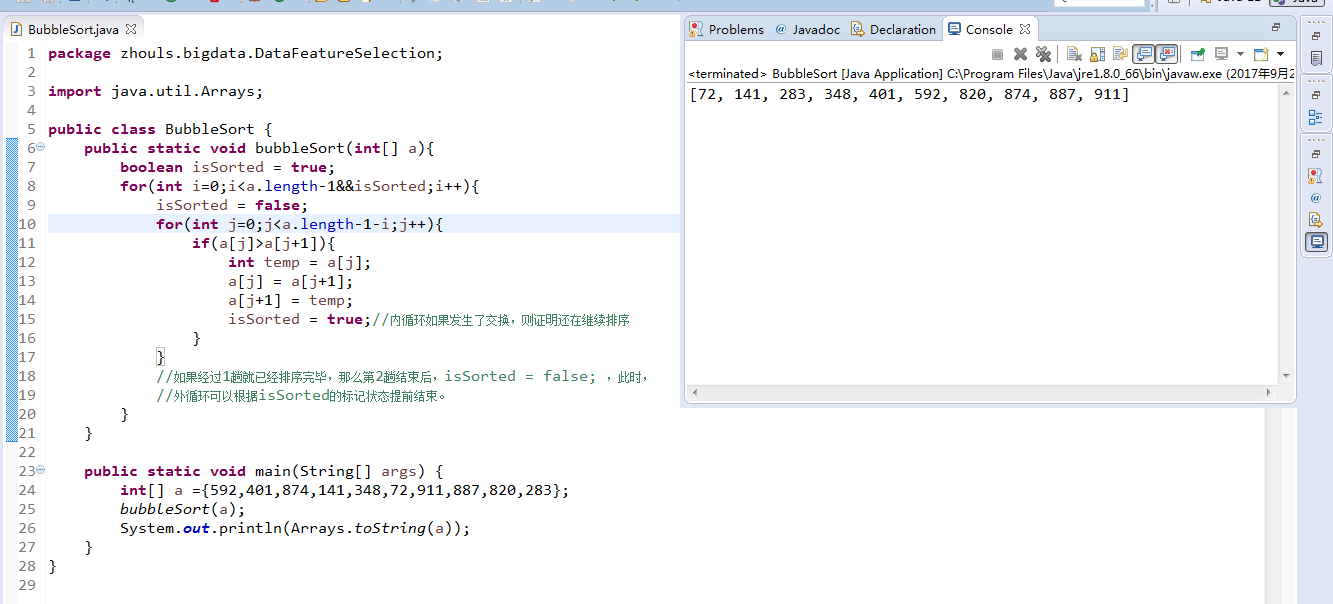
package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class BubbleSort {
public static void bubbleSort(int[] a){
boolean isSorted = true;
for(int i=0;i<a.length-1&&isSorted;i++){
isSorted = false;
for(int j=0;j<a.length-1-i;j++){
if(a[j]>a[j+1]){
int temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
isSorted = true;//内循环如果发生了交换,则证明还在继续排序
}
}
//如果经过1趟就已经排序完毕,那么第2趟结束后,isSorted = false; ,此时,
//外循环可以根据isSorted的标记状态提前结束。
}
}
public static void main(String[] args) {
int[] a ={592,401,874,141,348,72,911,887,820,283};
bubbleSort(a);
System.out.println(Arrays.toString(a));
}
}
冒泡排序的时间复杂度是O(n^2),空间复杂度为O(1),冒泡排序是一种稳定的排序算法。
快速排序是一种二叉树结构的交换排序方法。
6、快速排序
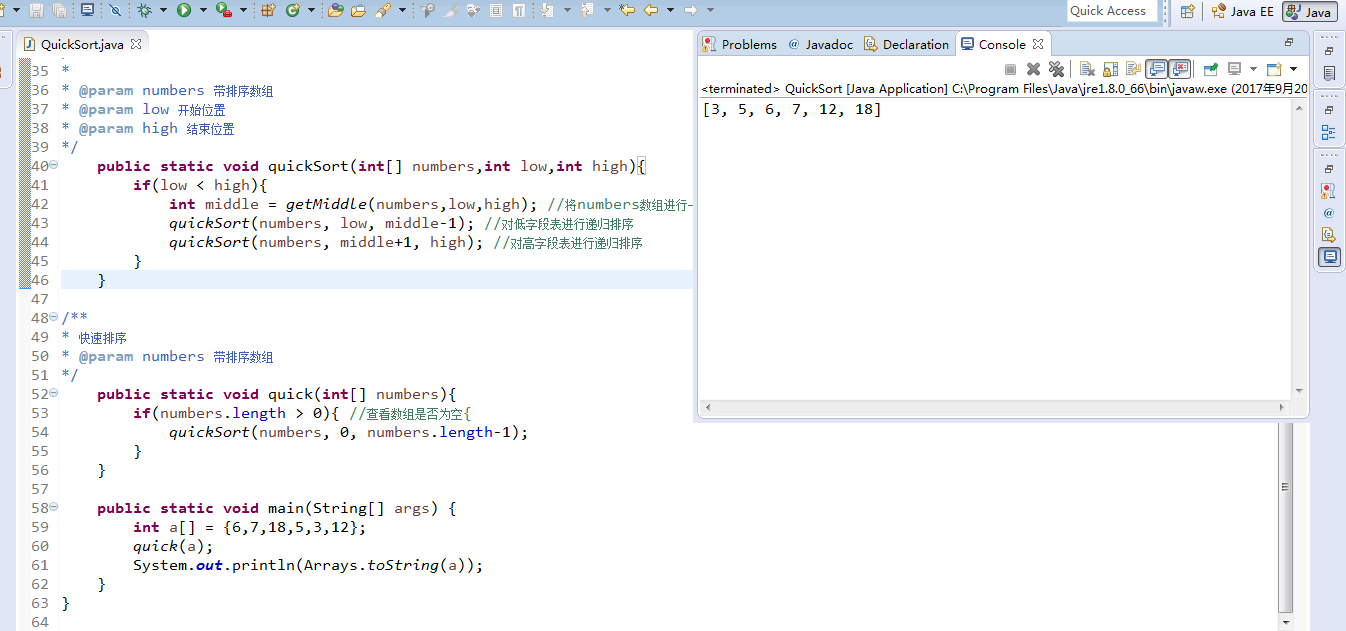
package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class QuickSort {
/**
* 查找出中轴(默认是最低位low)的在numbers数组排序后所在位置
*
* @param numbers 带查找数组
* @param low 开始位置
* @param high 结束位置
* @return 中轴所在位置
*/
public static int getMiddle(int[] numbers, int low,int high){
int temp = numbers[low]; //数组的第一个作为中轴
while(low < high){
while(low < high && numbers[high] > temp){
high--;
}
if(low<high){
numbers[low++] = numbers[high];//强制塞值并向前移一位
}
while(low < high && numbers[low] < temp){
low++;
}
if(low<high){
numbers[high--] = numbers[low] ; //强制塞值并向前移一位
}
}
numbers[low] = temp ; //中轴记录到尾
return low ; // 返回中轴的位置
}
/**
*
* @param numbers 带排序数组
* @param low 开始位置
* @param high 结束位置
*/
public static void quickSort(int[] numbers,int low,int high){
if(low < high){
int middle = getMiddle(numbers,low,high); //将numbers数组进行一分为二
quickSort(numbers, low, middle-1); //对低字段表进行递归排序
quickSort(numbers, middle+1, high); //对高字段表进行递归排序
}
}
/**
* 快速排序
* @param numbers 带排序数组
*/
public static void quick(int[] numbers){
if(numbers.length > 0){ //查看数组是否为空{
quickSort(numbers, 0, numbers.length-1);
}
}
public static void main(String[] args) {
int a[] = {6,7,18,5,3,12};
quick(a);
System.out.println(Arrays.toString(a));
}
}
快速排序如果每次选取的标准元素都能均分两个子数组区间长度,这样的快速排序过程是一个完全二叉树结构。最好情况下快速排序算法时间复杂度是O(nlbn)。快速排序最坏的情况是,数据元素已经全部有序,此时数组根节点的分解次数构成一颗二叉退化树,所以,最坏情况下快速排序算法的时间复杂度是O(n^2)。
由于快速排序算法需要堆栈空间临时保存递归调用参数,堆栈空间的使用个数和递归调用的次数有关,由于二叉树有可能是单支二叉树,而单支二叉树的深度为n-1,所以,最坏情况下快速排序算法的空间复杂度是O(n)。
7、归并排序


package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
public class MergeSort {
/**
* 归并排序
* 简介:将两个(或两个以上)有序表合并成一个新的有序表 即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列
* 时间复杂度为O(nlogn)
* 稳定排序方式
* @param nums 待排序数组
* @return 输出有序数组
*/
public static int[] sort(int[] nums, int low, int high) {
int mid = (low + high) / 2;
if (low < high) {
//左边
sort(nums, low, mid);
//右边
sort(nums, mid + 1, high);
//左右归并
merge(nums, low, mid, high);
}
return nums;
}
public static void merge(int[] nums, int low, int mid, int high) {
int[] temp = new int[high - low + 1];
int i = low;// 左指针
int j = mid + 1;// 右指针
int k = 0;
//把较小的数先移到新数组中
while (i <= mid && j <= high) {
if (nums[i] < nums[j]) {
temp[k++] = nums[i++];
} else {
temp[k++] = nums[j++];
}
}
//把左边剩余的数移入数组
while (i <= mid) {
temp[k++] = nums[i++];
}
//把右边边剩余的数移入数组
while (j <= high) {
temp[k++] = nums[j++];
}
//把新数组中的数覆盖nums数组
for (int k2 = 0; k2 < temp.length; k2++) {
nums[k2 + low] = temp[k2];
}
}
//归并排序的实现
public static void main(String[] args) {
int[] nums = { 2, 7, 8, 3, 1, 6, 9, 0, 5, 4 };
MergeSort.sort(nums, 0, nums.length-1);
System.out.println(Arrays.toString(nums));
}
}
归并排序的时间复杂度是O(nlbn),由于归并排序使用了n个临时内存单元存放数据元素,所以,归并排序算法的空间复杂度是O(n)。
归并排序是一种稳定的排序算法。前面的几个时间复杂度是O(nlbn)的排序算法都是不稳定的排序算法,而归并排序算法不仅时间复杂度是O(nlbn),而且还是一种稳定的排序算法。这是归并排序算法的最大特点。
8、基数排序
基数排序,因为要求进出桶中的数据元素要满足先入先出的原则,因此,这里所说的桶其实就是队列。
package zhouls.bigdata.DataFeatureSelection;
import java.util.Arrays;
/*
* 对于一个int数组,请编写一个基数排序算法,对数组元素排序。
* 给定一个int数组A及数组的大小n,请返回排序后的数组。保证元素均小于等于2000。
*
测试样例:
[1,2,3,5,2,3],6
[1,2,2,3,3,5]
*/
public class RadisSort {
//各位装通法
public static int[] radixSort(int[] A, int n) {
//首先确定排序的趟数;
int max=A[0];
for(int i=1;i<n;i++){
if(A[i]>max){
max=A[i];
}
}
int time=0;
//判断位数;
while(max>0){
max/=10;
time++;
}
int length = n;
int divisor = 1;// 定义每一轮的除数,1,10,100...
int[][] bucket = new int[10][length];// 定义了10个桶,以防每一位都一样全部放入一个桶中
int[] count = new int[10];// 统计每个桶中实际存放的元素个数
int digit;// 获取元素中对应位上的数字,即装入那个桶
for (int i = 1; i <= time; i++) {// 经过4次装通操作,排序完成
for (int temp : A) {// 计算入桶
digit = (temp / divisor) % 10;
bucket[digit][count[digit]++] = temp;
}
int k = 0;// 被排序数组的下标
for (int b = 0; b < 10; b++) {// 从0到9号桶按照顺序取出
if (count[b] == 0)// 如果这个桶中没有元素放入,那么跳过
continue;
for (int w = 0; w < count[b]; w++) {
A[k++] = bucket[b][w];
}
count[b] = 0;// 桶中的元素已经全部取出,计数器归零
}
divisor *= 10;
}
return A;
}
public static void main(String[] args) {
int a[] = {1,2,3,5,2,3};
System.out.println(Arrays.toString(radixSort(a, a.length)));
}
}
基数排序时间复杂度是O(mn),m是数字的最大位数,由于基数排序算法中要m次使用n个节点临时存放n个数据元素,因此,基数排序算法的空间复杂度为O(n)。
基数排序是一种稳定的排序算法。
总结:
排序分内部排序和外部排序两种。内部排序是指把待排数据元素全部调入内存中进行的排序。如果数据元素的数量太大,需要分批导入内存中。分批导入内存的数据元素排好序后再分批导出到磁盘的排序方法称作外部排序。两者排序算法原理很大地方都相同,但是内存中的读写速度和在外存的读写速度差别很大,所以评价标准差别很大。这里只讨论内部排序。
排序算法优劣的标准:
1、时间复杂度。
2、空间复杂度:算法中使用的辅助存储空间是多少。当排序算法中使用的辅助存储空间与要排序数据元素的个数n无关时,其空间复杂度为O(1)。
3、稳定性。
各种排序算法性能比较:
排序方法 最好时间 平均时间 最坏时间 最坏辅助空间 稳定性
直接插入排序 O(n) O(n^2) O(n^2) O(1) 稳定
希尔排序 O(nlbn) O(nlbn) O(nlbn) O(1) 不稳定
直接选择排序 O(n^2) O(n^2) O(n^2) O(1) 不稳定
堆排序 O(nlbn) O(nlbn) O(nlbn) O(1) 不稳定
冒泡排序 O(n) O(n^2) O(n^2) O(1) 稳定
快速排序 O(nlbn) O(nlbn) O(n^2) O(n) 不稳定
归并排序 O(nlbn) O(nlbn) O(nlbn) O(n) 稳定
基数排序 O(mn) O(mn) O(mn) O(n) 稳定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号