DRF过滤排序分页
过滤
-
DRF过滤使用种类:
-
内置过滤类
-
导入:
from rest_framework.filters import SearchFilter -
前提条件:使用内置过滤类,视图类需要继承GenericAPIView才能使用
-
步骤:
- 视图类内filter_backends中使用SearchFilter
- 类属性search_fields指定过滤的字段
-
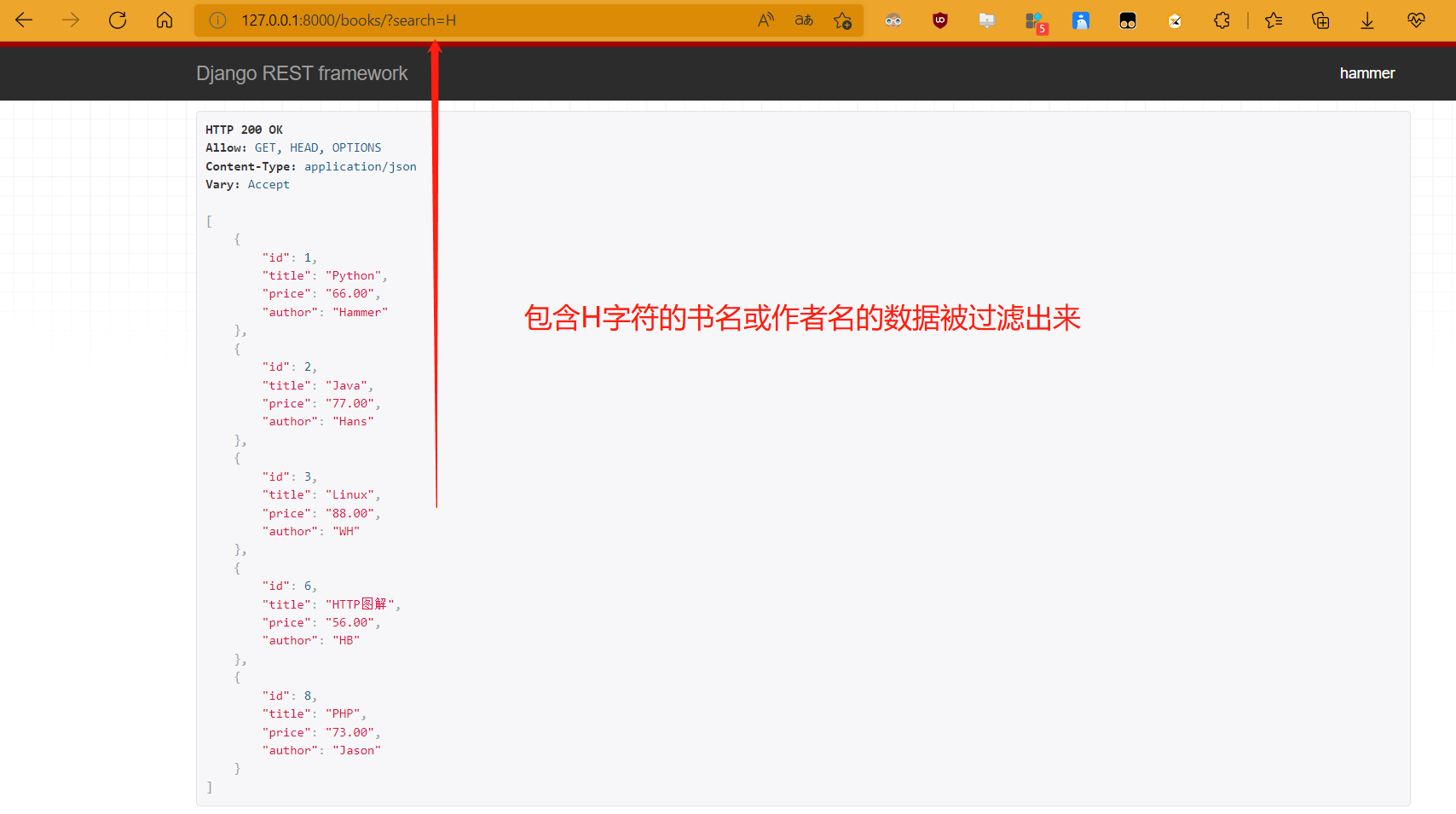
使用:链接?search=字段,且支持模糊查询
from rest_framework.generics import ListAPIView from rest_framework.viewsets import ViewSetMixin from rest_framework.filters import SearchFilter from .models import Book from .serializer import BookSerializer # 只有查询接口才需要过滤,内置过滤类的使用需要视图类继承GenericAPIView才能使用 class BookView(ViewSetMixin, ListAPIView): ''' 内置过滤类:1、filter_backends中使用SearchFilter 2、类属性search_fields指定过滤的字段 3、链接?search=字段,且支持模糊查询 ''' queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [SearchFilter,] # 过滤单个字段 search_fields = ['title',] -
注意:链接过滤的字段必须是search
# 过滤多个字段:书名和作者名 ''' 比如书名:Python 作者名:Pink,那么过滤search=P就都会过滤出来 ''' search_fields = ['title','author'] # http://127.0.0.1:8000/books/?search=H -
总结:
- 内置过滤类的使用,模糊查询会将包含过滤字段的数据都过滤出来,前提是在search_fields列表内指定的字段;
- 内置过滤的特点是模糊查询
- 过滤字段参数为search
-
-
第三方
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持
- 安装:
pip install django-filter - 导入:
from django_filters.rest_framework import DjangoFilterBackend - 在配置文件中增加过滤后端的设置:
INSTALLED_APPS = [ ... 'django_filters', # 需要注册应用, ] - 在视图中添加filter_fields属性,指定可以过滤的字段
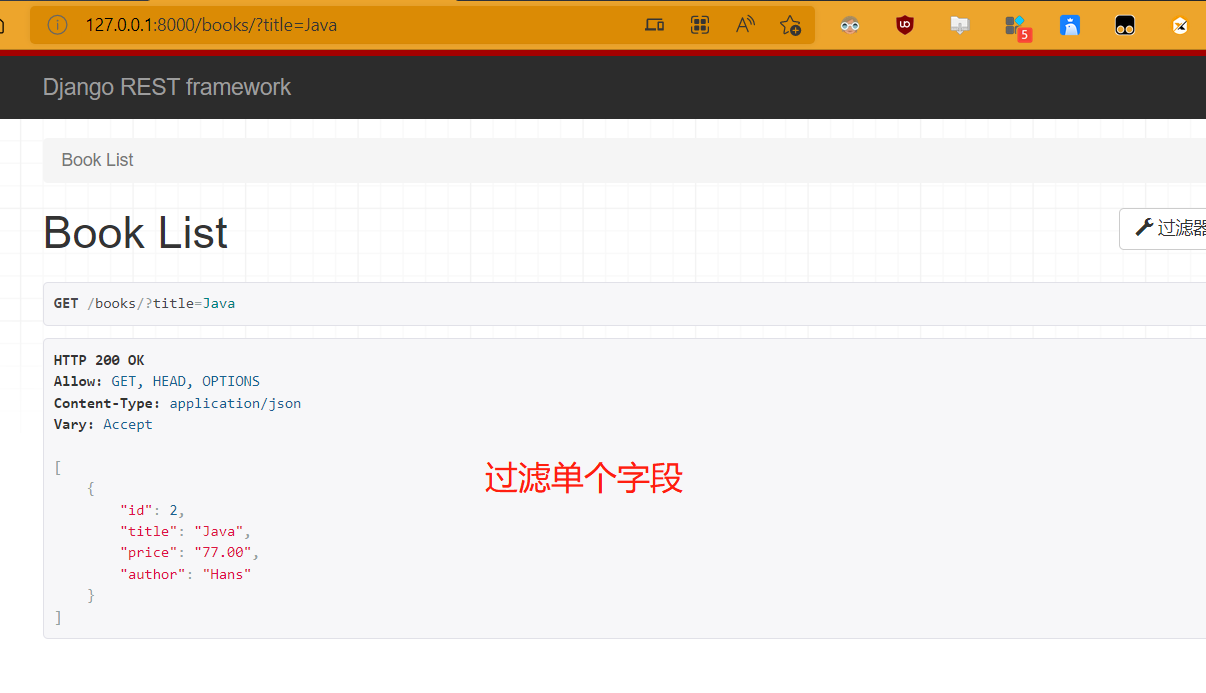
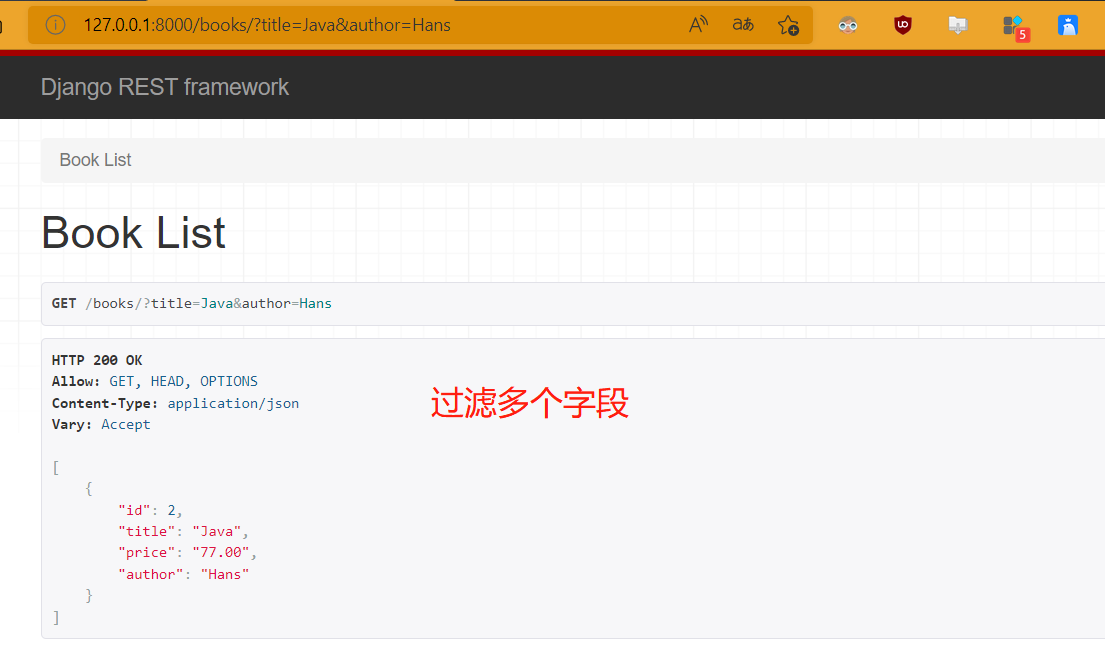
from django_filters.rest_framework import DjangoFilterBackend # 第三方过滤类 class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [DjangoFilterBackend,] filter_fields = ['title','author'] http://127.0.0.1:8000/books/?title=Java # 单个字段过滤 http://127.0.0.1:8000/books/?title=Java&author=HammerZe # 多个字段过滤 - 总结:
- 第三方过滤类在filter_backends字段中写,filter_fields字段指定过滤的字段
- 第三方过滤类不支持模糊查询,是精准匹配
- 第三方过滤类的使用,视图类也必须继承GenericAPIView才能使用
- 在链接内通过&来表示和的关系
- 安装:
-
自定义
- 步骤:
- 写一个类继承BaseFilterBackend,重写filter_queryset方法,返回queryset对象,qs对象是过滤后的
- 视图类中使用,且不需要重写类属性去指定过滤的字段
- 过滤使用,支持模糊查询(自己定制过滤方式),通过filter方法来指定过滤规则
- 自定义过滤类
'''filter.py''' from django.db.models import Q from rest_framework.filters import BaseFilterBackend # 继承BaseFilterBackend class MyFilter(BaseFilterBackend): # 重写filter_queryset方法 def filter_queryset(self, request, queryset, view): # 获取过滤参数 qs_title = request.query_params.get('title') qs_author = request.query_params.get('author') # title__contains:精确大小写查询,SQL中-->like BINARY # 利用Q查询构造或关系 if qs_title: queryset = queryset.filter(title__contains=qs_title) elif qs_author: queryset = queryset.filter(author__contains=qs_author) elif qs_title or qs_author: queryset = queryset.filter(Q(title__contains=qs_title)|Q(author__contains=qs_author)) return queryset - 视图
# 自定制过滤类 from .filter import MyFilter class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [MyFilter,] # 这里不需要写类属性指定字段了,因为自定义过滤类,过滤字段了 - 源码分析
我们知道过滤的前提条件是视图继承了GenericAPIView才能使用,那么在GenericAPIView中的执行流程是什么?
1、调用了GenericAPIView中的filter_queryset方法 2、filter_queryset方法源码: def filter_queryset(self, queryset): for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset ''' 1.backend是通过遍历该类的filter_backends列表的得到的,也就是我们指定的过滤类列表,那么backend就是我们的过滤类 2.通过实例化得到对象来调用了类内的filter_queryset返回了过滤后的对象 '''
- 步骤:
-
排序
REST framework提供了OrderingFilter过滤器来帮助我们快速指明数据按照指定字段进行排序。
- 导入:from rest_framework.filters import OrderingFilter
- 步骤:
- 视图类中配置,且视图类必须继承GenericAPIView
- 通过ordering_fields指定要排序的字段
- 排序过滤,-号代表倒序,且必须使用ordering指定排序字段
'''内置过滤和排序混用''' from rest_framework.filters import OrderingFilter from rest_framework.filters import SearchFilter class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [SearchFilter,OrderingFilter] # 先过滤后排序减少消耗 search_fields = ['title'] ordering_fields = ['id','price'] # 排序 http://127.0.0.1:8000/books/?ordering=price # 价格升序 http://127.0.0.1:8000/books/?ordering=-price # 价格降序 http://127.0.0.1:8000/books/?ordering=price,id # 价格id升序 http://127.0.0.1:8000/books/?ordering=price,-id # 价格升序id降序 ····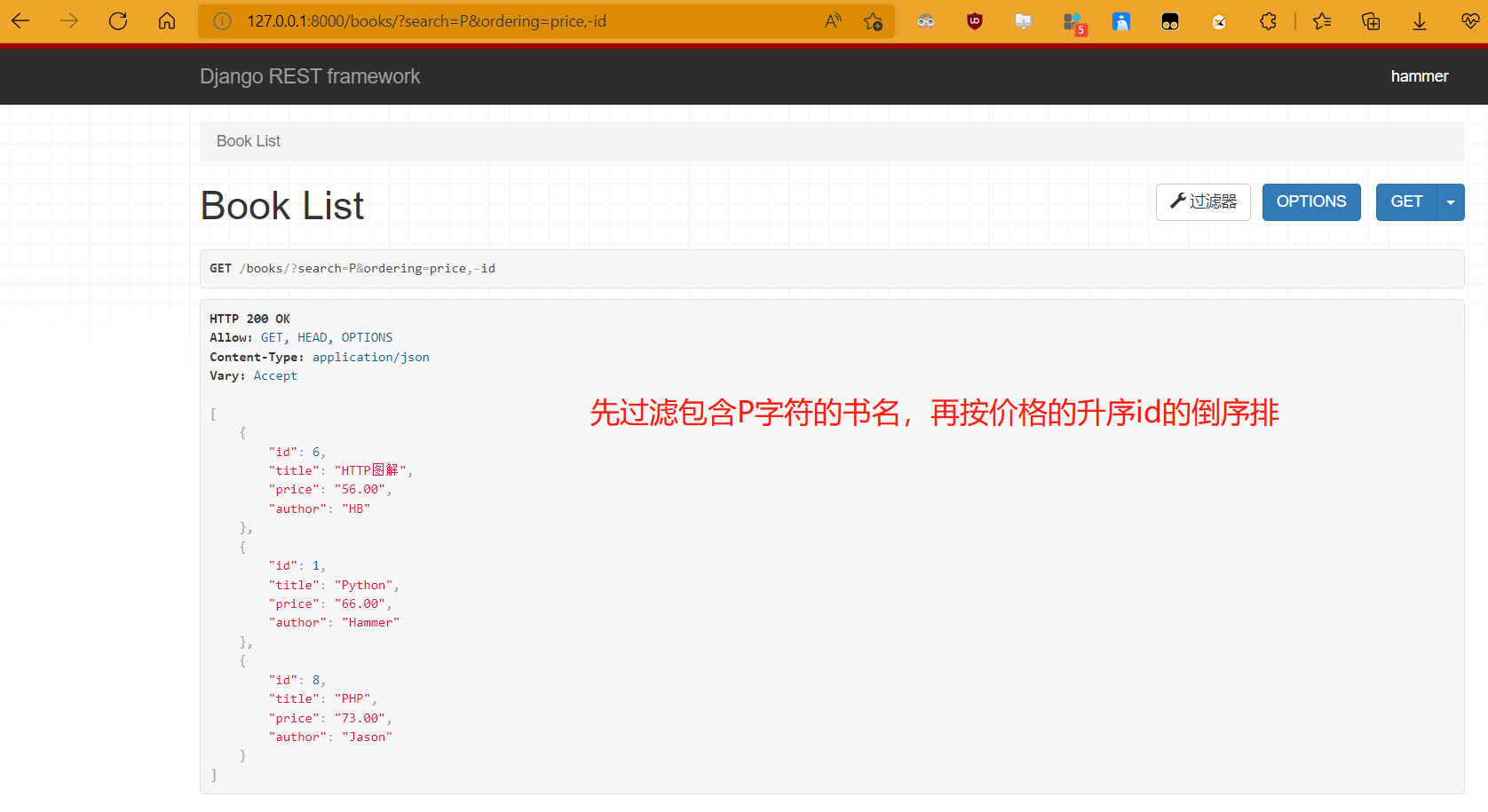
- 注意
过滤可以和排序同时使用,但是先执行过滤再执行排序,提升了代码的效率(先过滤后排序),因为如果先排序,那么数据库的数量庞大的话,直接操作了整个数据库,消耗资源,过滤完成后排序只是针对一小部分数据
分页
分页只在查询所有接口中使用
- 导入:
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination - 三种分页方式
-
基本分页:PageNumberPagination
- 步骤
-
自定义类,继承PageNumberPagination,重写四个类属性
- page_size:设置每页默认显示的条数
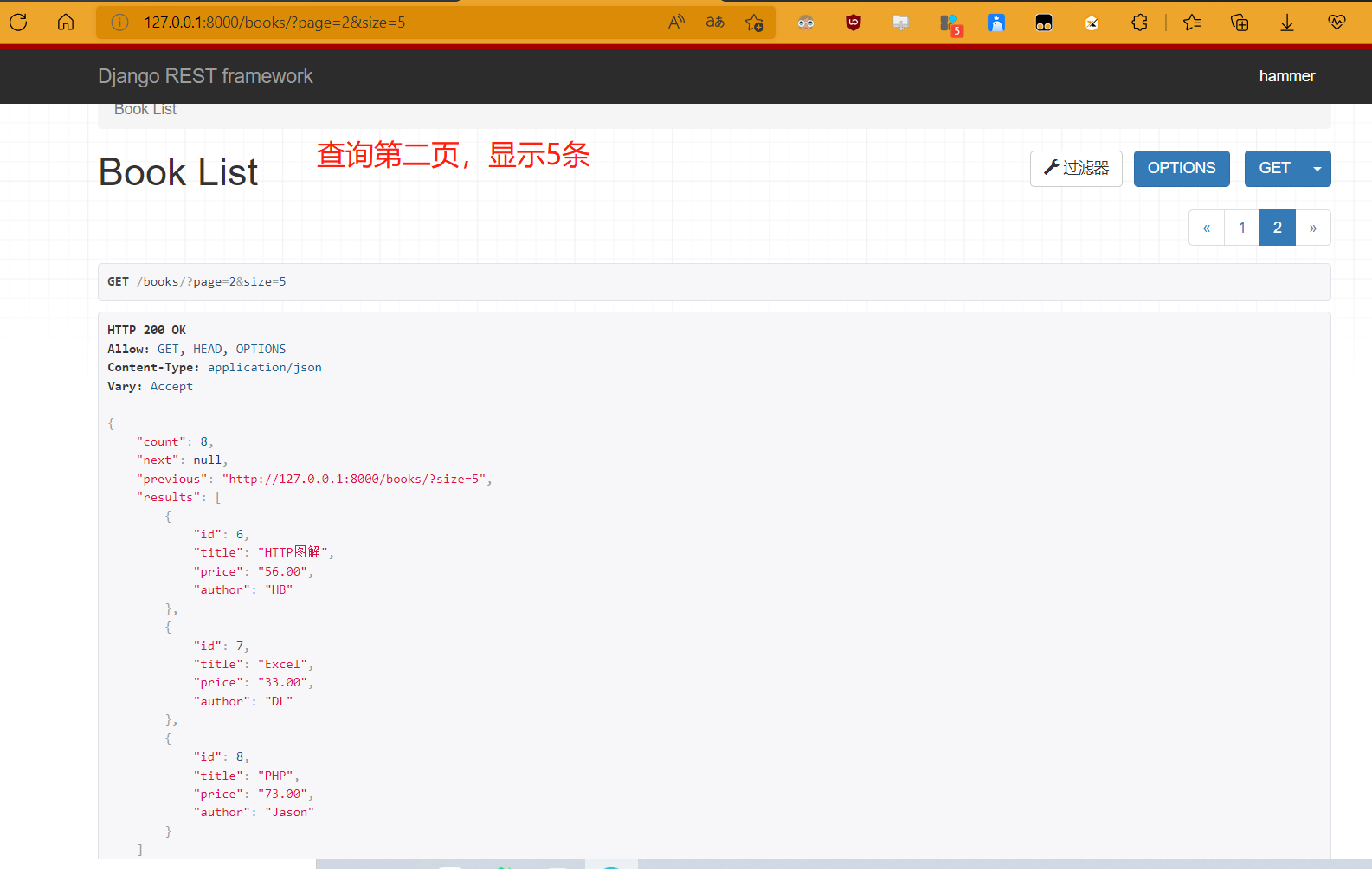
- page_query_param:url中的查询条件,books/?page=2表示第二页
- page_size_query_param:每页显示多少条的查询条件,books/?page=2&size=5,表示查询第二页,显示5条
- max_page_size:设置每页最多显示条数,不管查多少条,最大显示该值限制的条数
-
配置在视图类中,通过pagination_class指定,必须继承GenericAPIView才有
pagination_class = PageNumberPagination
-
- 分页
from rest_framework.pagination import PageNumberPagination class BookPagination(PageNumberPagination): page_size = 2 # 默认每页显示2条 page_query_param = 'page' # 查询条件,eg:page=3 page_size_query_param = 'size' # 查询条件参数size=5显示五条 max_page_size = 10 # 每页最大显示条数 - 视图
from rest_framework.filters import OrderingFilter from rest_framework.filters import SearchFilter from .page import BookPagination class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [SearchFilter,OrderingFilter] search_fields = ['title','author'] ordering_fields = ['id','price'] pagination_class = BookPagination # http://127.0.0.1:8000/books/?page=2&size=5
注意:pagination_class指定分页类不需要使用列表
- 步骤
-
偏移分页:LimitOffsetPagination
- 步骤
- 自定义类,继承LimitOffsetPagination,重写四个类属性
- default_limit:默认每页获取的条数
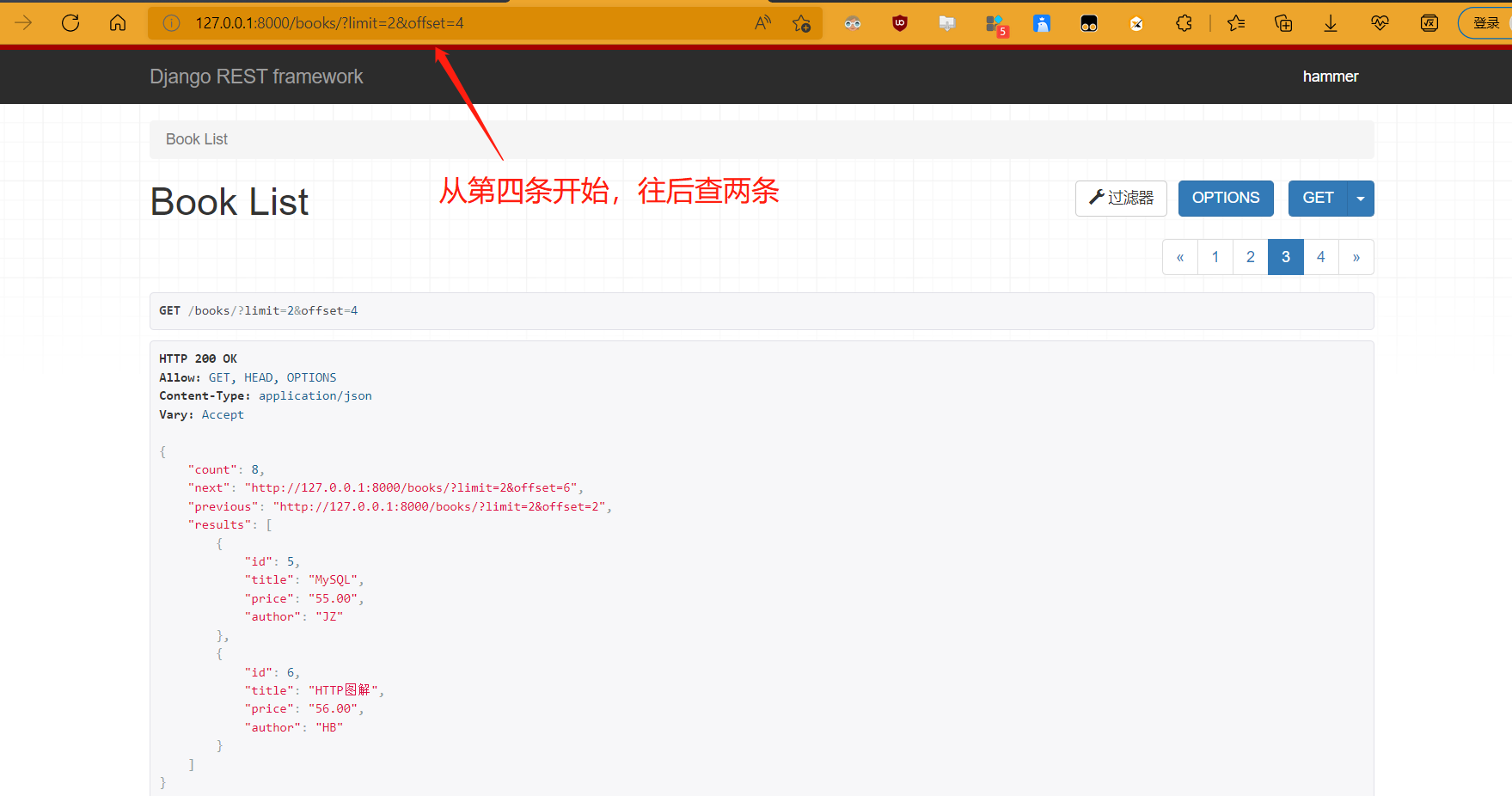
- limit_query_param:每页显示多少条的查询条件,比如?limit=3,表示获取三条,如果不写默认使用default_limit设置的条数
- offset_query_param:表示偏移量参数,比如?offset=3表示从第三条开始往后获取默认的条数
- max_limit:设置最大显示条数
- 视图类内配置,pagination_class参数指定,必须继承GenericAPIView才有
- 自定义类,继承LimitOffsetPagination,重写四个类属性
- 分页
class MyLimitOffsetPagination(LimitOffsetPagination): default_limit = 2 # 默认每页显示2条 limit_query_param = 'limit' # ?limit=3,查询出3条 offset_query_param = 'offset' # 偏移量,?offset=1,从第一条后开始 max_limit = 5 # 最大显示5条 - 视图
from rest_framework.filters import OrderingFilter from rest_framework.filters import SearchFilter from .page import MyLimitOffsetPagination class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [SearchFilter,OrderingFilter] # 先过滤后排序减少消耗 search_fields = ['title','author'] ordering_fields = ['id','price'] pagination_class = MyLimitOffsetPagination # http://127.0.0.1:8000/books/?limit=2&offset=4
- 步骤
-
游标分页:CursorPagination
-
步骤:
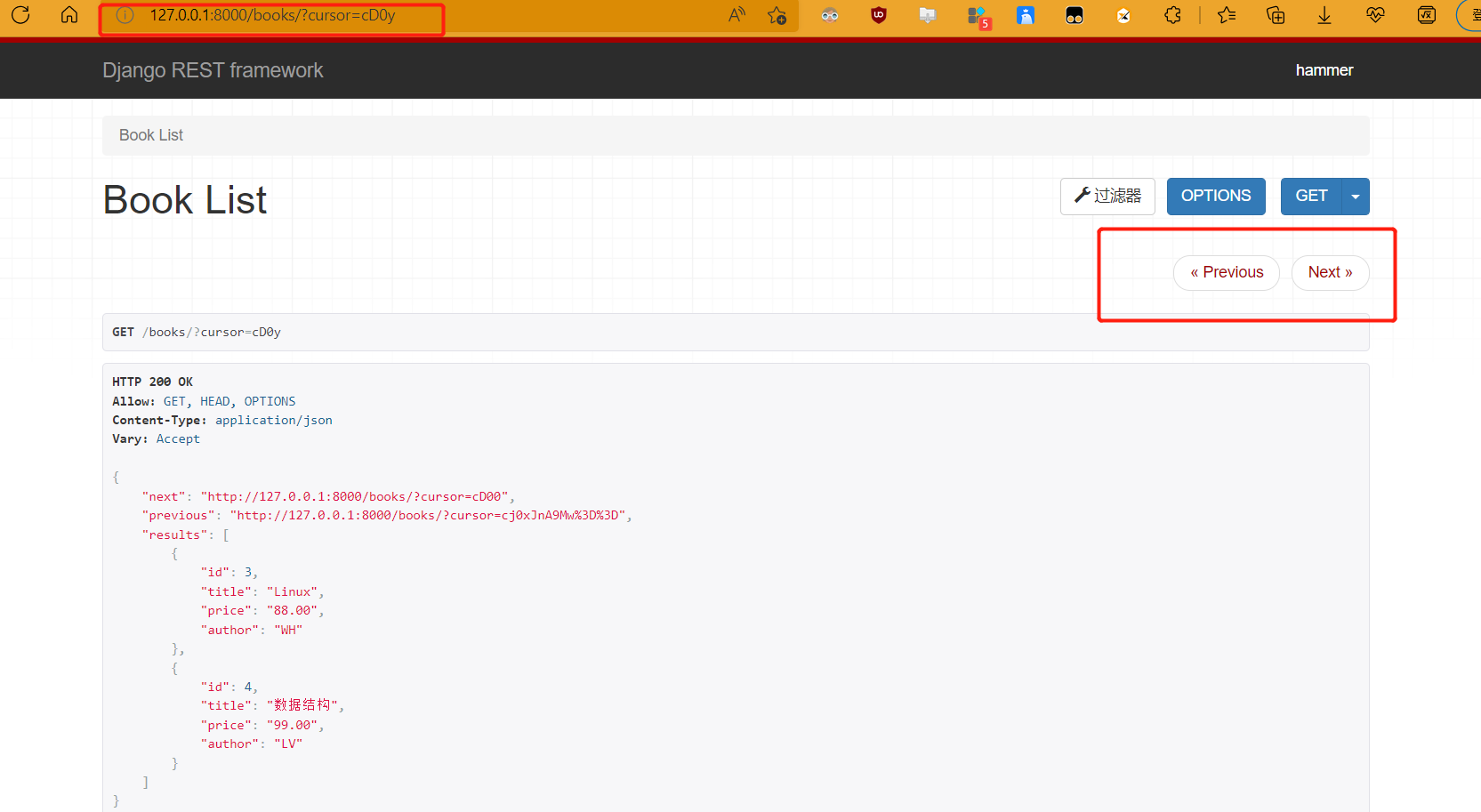
- 自定义类,继承CursorPagination,重写三个类属性
- page_size:每页显示的条数
- cursor_query_param:查询条件
- ordering:排序规则,指定排序字段
- 视图类内配置,pagination_class参数指定,必须继承GenericAPIView才有
- 自定义类,继承CursorPagination,重写三个类属性
-
分页
class MyCursorPagination(CursorPagination): cursor_query_param = 'cursor' page_size = 2 ordering = 'id' -
视图
from rest_framework.filters import SearchFilter from .page import MyCursorPagination class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [SearchFilter] search_fields = ['title','author'] pagination_class = MyCursorPagination ''' 注意:因为分页内指定了排序规则,那么视图内如果再指定了排序规则就会报错 ''' -
总结
分页类内指定了排序,视图内不要写排序规则,不然报错
-
-
分页总结
- 前两种分页都可以从中间位置获取一页,而最后一个分页类只能上一页或下一页
- 前两种在获取某一页的时候,都需要从开始过滤到要取的页面数的数据,本质是SQL中的limit··,查询出要跳过的页数显示要查的数据,相比第三种慢一点
- 第三种方式,本质是先排序,内部维护了一个游标,游标只能选择往前或者往后,在获取到一页的数据时,不需要过滤之前的数据,相比前两种速度较快,适合大数据量的分页
-
异常处理
REST framework提供了异常处理,我们可以自定义异常处理函数,不论正常还是异常,通过定制,我们可以返回我们想要返回的样子
- 步骤
- 自定义函数
- 在配置文件中配置函数
- 注意
如果没有配置自己处理异常的规则,会执行默认的,如下:
from rest_framework import settingsfrom rest_framework.views import exception_handler
默认配置流程怎么走?
# 1、 APIView源码 # dispatch方法源码 except Exception as exc: response = self.handle_exception(exc) # handle_exception方法源码 response = exception_handler(exc, context) # 2、views种的exception_handler方法 def exception_handler(exc, context): ··· # 3、 默认配置文件 'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler', - 自定义异常
源码exception_handler方法有两种情况,if判断第一种情况是处理了APIException对象的异常返回Reponse对象,第二种情况是处理了其他异常返回了None,这里我们针对这两种情况的异常进行定制处理
- exc:错误原因
- context:字典,包含了当前请求对象和视图类对象
- 自定义异常处理方法
from rest_framework.views import exception_handler from rest_framework.response import Response def myexception_handler(exc, context): # 先执行原来的exception_handler帮助我们处理 res = exception_handler(exc, context) if res: # res有值代表处理过了APIException对象的异常了,返回的数据再定制 res = Response(data={'code': 998, 'msg': res.data.get('detail', '服务器异常,请联系系统管理员')}) # res = Response(data={'code': 998, 'msg': '服务器异常,请联系系统管理员'}) # res.data.get从响应中获取原来的处理详细信息 else: res = Response(data={'code': 999, 'msg': str(exc)}) print(exc) # list index out of range '''模拟日志处理''' request = context.get('request') # 当次请求的request对象 view = context.get('view') # 当次执行的视图类对象 print('错误原因:%s,错误视图类:%s,请求地址:%s,请求方式:%s' % (str(exc), str(view), request.path, request.method)) '''结果: 错误原因:list index out of range,错误视图类:<app01.views.TestView object at 0x000001C3B1C7CA58>,请求地址:/test/,请求方式:GET ''' return res - 视图
from rest_framework.views import APIView from rest_framework.response import Response from rest_framework.exceptions import APIException # 测试异常视图 class TestView(APIView): def get(self,request): # 1、 其他报错 l = [1,2,3] print(l[100]) # 2、APIException异常 # raise APIException('APIException errors!') return Response('successfuly!') - 配置文件
REST_FRAMEWORK = { 'EXCEPTION_HANDLER': 'app01.exception.myexception_handler' # 再出异常,会执行自己定义的函数 }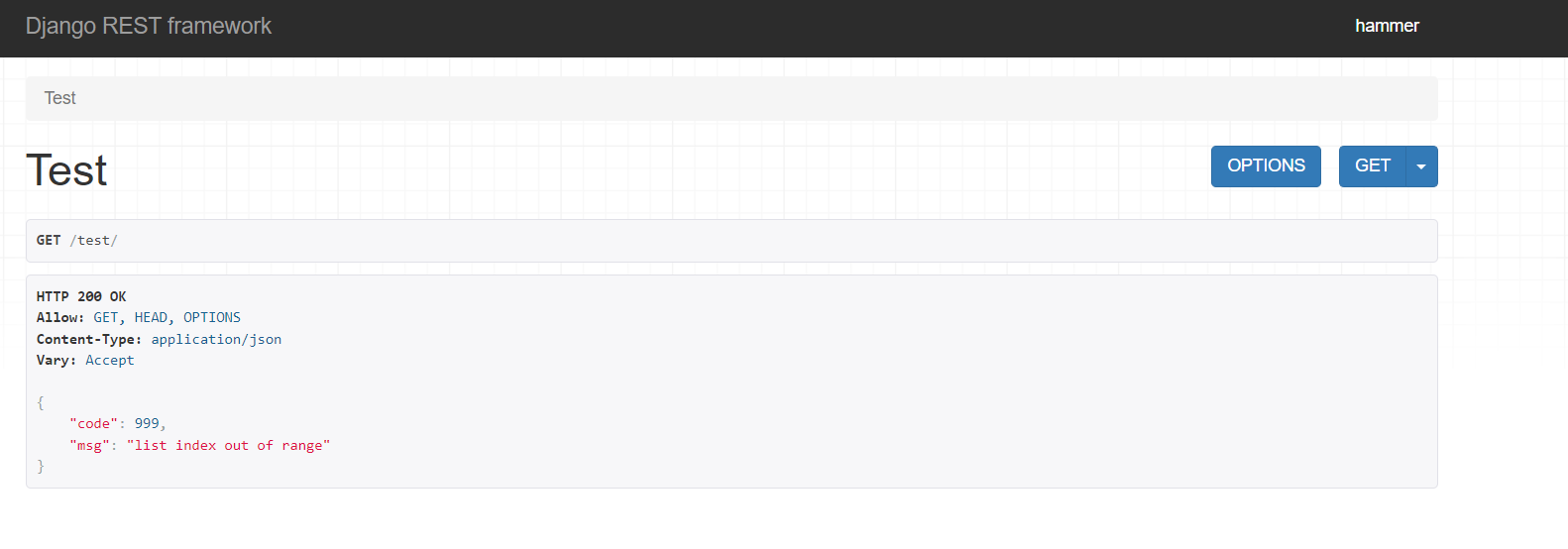
- REST framework定义的异常
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败

