Linux基础(三)
- Linux 编译安装、压缩打包、定时任务
- 磁盘管理
- Linux 三剑客之grep
- Linux三剑客之sed
- Linux三剑客之grep
- 三剑客练习题
- 1、找出/proc/meminfo文件中以s开头的行,至少用三种方式忽略大小写
- 2、显示当前系统上的root,centos或者use开头的信息
- 3、找出/etc/init.d/function文件下包含小括号的行
- 4、输出指定目录的基名
- 5、找出网卡信息中包含的数字
- 6、找出/etc/passwd下每种解析器的用户个数
- 7、过去网卡中的ip,用三种方式实现
- 8、搜索/目录下,所有的.html或.php文件中main函数出现的次数
- 9、过滤掉php.ini中注释的行和空行
- 10、找出文件中至少有一个空格的行
- 11、过滤文件中以#开头的行,后面至少有一个空格
- 12、查询出/etc目录中包含多少个root
- 13、查询出所有的qq邮箱
- 14、查询系统日志中所有的error
- 15、删除某文件中以s开头的行的最后一个词
- 16、删除一个文件中的所有数字
- 17、显示奇数行
- 18、删除passwd文件中以bin开头的行到nobody开头的行
- 19、从指定行开始,每隔两行显示一次
- 20、每隔5行打印一个空格
- 21、不显示指定字符的行
- 22、将文件中1到5行中aaa替换成AAA
- 23、显示用户id为奇数的行
- 24、显示系统普通用户,并打印系统用户名和id
- 25、统计nginx日志中访问量(ip唯独计算)
- 26、实时打印nginx的访问ip
- 27、统计php.ini中每个词的个数
- 28、统计1分钟内访问nginx次数超过10次的ip
- 29、找出nginx访问的峰值,按每个小时计算
- 30、统计访问nginx前10的ip
Linux 编译安装、压缩打包、定时任务#
知识储备
-
wget命令
- 简介
wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。 - 格式
wget [选项] [参数]
- 简介
-
编译安装#
- 特点
- 可以自定制软件
- 按需构建软件
- 编译安装的步骤
👉[nginx官网](nginx: download)以nginx为例
# 1、下载源代码包 wget https://nginx.org/download/nginx-1.20.2.tar.gz # 2、解压 tar -xf nginx-1.20.2.tar.gz # 3、设置系统参数 cd nginx-1.20.2 # 4、自定制404界面 vim ./src/core/nginx.h # 修改的内容如下图 # 4.1、设置系统参数 ./configure # 4.2、执行./configure命令可能会"checking for C compiler .. not found" 解决方法:安装依赖>>>sudo apt-get install build-essential gcc openssl # 5、编译 make # 6、安装 make install # 安装好后,目录/usr/local下就会多了nginx目录 # 7、启动 /usr/local/nginx/sbin/nginx # 7.1、关闭服务 /usr/local/nginx/sbin/nginx -s stop systemctl stop nginx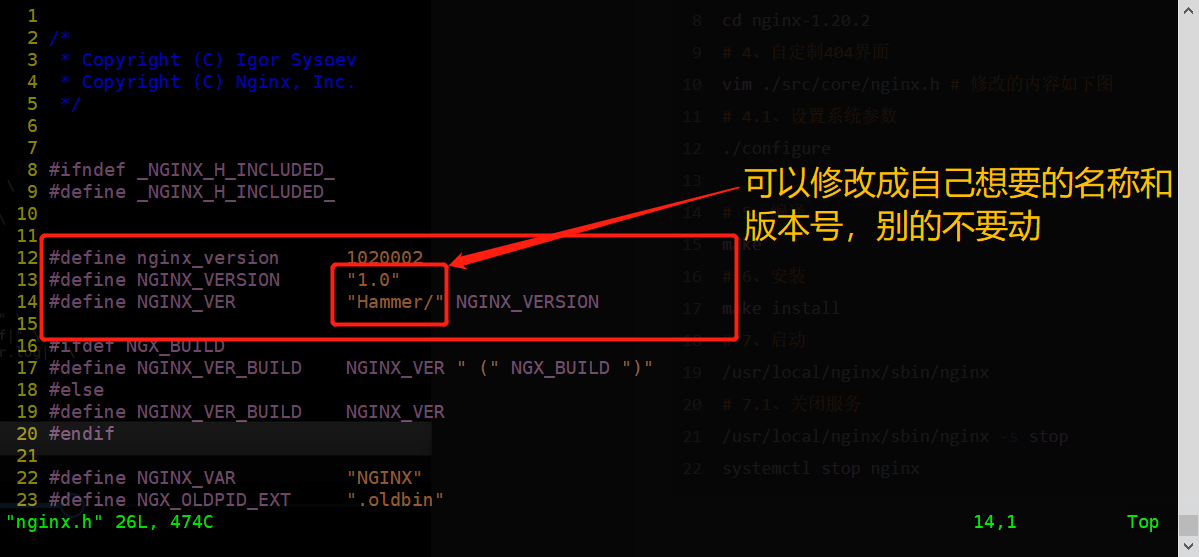
- 特点
-
压缩打包#
-
gzip压缩#
- 命令:
- 压缩:gzip [压缩文件]
- 解压:gzip -d [解压文件]
# a.txt 是我提前建好的 # 压缩 [root@localhost test]# gzip a.txt [root@localhost test]# ls a.txt.gz # 解压 [root@localhost test]# gzip -d a.txt.gz [root@localhost test]# ls a.txt
- 命令:
-
bzip2压缩#
- 命令:
- 压缩:bzip2 [压缩文件]
- 解压:bzip2 -d [压缩包]
# 压缩 [root@localhost test]# bzip2 a.txt [root@localhost test]# ls a.txt.bz2 # 解压 [root@localhost test]# bzip2 -d a.txt.bz2 [root@localhost test]# ls a.txt
由于gzip和bzip2无法压缩目录,使用tar命令# 无法压缩命令 [root@localhost ~]# gzip test gzip: test is a directory -- ignored - 命令:
-
tar打包#
- 命令
- tar [参数] [打包文件]
- 参数:
- -f : 指定打包的包名称
- -c : 打包--不压缩
- -v : 显示打包的过程
- -z : 使用gzip压缩压缩包
- -j : 使用bzip2压缩压缩包
- -x : 解压(解压不需要指定压缩类型)
- -t : 查看压缩包内部的内容
- -P :忽略使用绝对路径时报出的错误
注意
- 压缩时是什么路径,解压缩时就是什么路径,所以为了安全不要使用绝对路径压缩。
- -f参数后面永远跟压缩包名称(-f放最后)
# -fc参数的使用,指定打包的包名称,并打包 [root@localhost ~]# tar -cf test.tar test [root@localhost ~]# ll -rw-r--r-- 1 root root 10240 Dec 17 19:26 test.tar # 使用gzip压缩 [root@localhost ~]# gzip test.tar [root@localhost ~]# ll -rw-r--r-- 1 root root 211 Dec 17 19:26 test.tar.gz # 使用参数直接打包压缩 [root@localhost ~]# tar -czf test.tar.gz test [root@localhost ~]# ll -rw-r--r-- 1 root root 202 Dec 17 19:40 test.tar.gz # 解压 [root@localhost ~]# tar -xf test.tar.gz
-
-
定时任务#
自动完成操作命令,定时备份系统数据信息等功能
- 目录下写可执行文件(x.sh),就会自动执行
- 系统定时任务周期:每小时
- 控制定时任务目录:
/etc/cron.hourly[root@localhost cron.hourly]# cd /etc/cron.hourly/ [root@localhost cron.hourly]# ll total 4 -rwxr-xr-x. 1 root root 392 Aug 9 2019 0anacron
- 控制定时任务目录:
- 系统定时任务周期:每一天
- 控制定时任务目录:
/etc/cron.daily[root@localhost cron.hourly]# cd /etc/cron.daily/ [root@localhost cron.daily]# ll total 8 -rwx------. 1 root root 219 Apr 1 2020 logrotate -rwxr-xr-x. 1 root root 618 Oct 30 2018 man-db.cron
- 控制定时任务目录:
- 系统定时任务周期:每一周
- 控制定时任务目录:
/etc/cron.weekly[root@localhost cron.monthly]# cd /etc/cron.weekly/
- 控制定时任务目录:
- 系统定时任务周期:每个月
- 控制定时任务目录:
/etc/cron.monthly[root@localhost cron.daily]# cd /etc/cron.monthly/
- 控制定时任务目录:
- 系统定时任务的配置文件之一 :
/etc/crontab
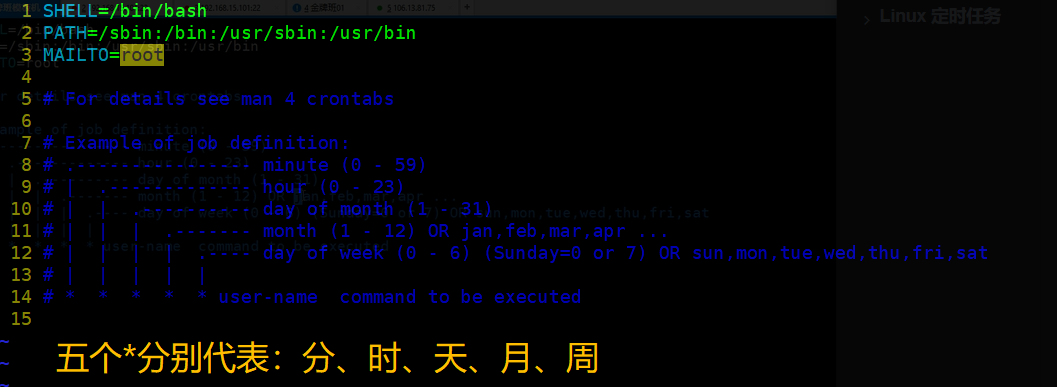
- 实际操作:
- 添加定时任务:
crontab -e - 查看定时任务:
crontab -lroot@ip82:/home/user# select-editor Select an editor. To change later, run 'select-editor'. 1. /bin/ed 2. /bin/nano <---- easiest 3. /usr/bin/vim.basic 4. /usr/bin/vim.tiny Choose 1-4 [2]: 3 # * * * * * : crontab表达式 # 案例:每天的凌晨2:50执行/root/1.sh '''50 02 * * * /root/1.sh # 1.sh必须拥有可执行权限''' # 在1.sh中添加执行语句 # 添加任务 [root@localhost etc]# crontab -e # 查看定时任务 [root@localhost etc]# crontab -l #Timing synchronization time 0 */1 * * * /usr/sbin/ntpdate ntp1.aliyun.com &>/dev/null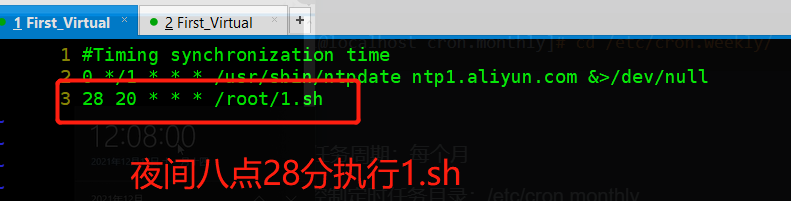
- 添加定时任务:
- 定时任务配置文件 :
/var/spool/cron/root每一个用户的定时任务是相对隔离,在/var/spool/cron目录下,以当前用户的用户名命名的文件。
- 定时任务格式
# * 代表每的意思 基础格式 : * * * * * 每隔2分钟执行 */2 * * * * 每天的2,4,6,8,10这4个小时的1分钟执行 01 2,4,6,10 * * * 每天的2到6点执行 00 2-6 * * * 每天的2到6点中每隔2小时执行 00 2-6/2 * * * 00 02 * * 02 : 每天的2点时执行,但是这天必须时周二 - 定时任务服务运行记录日志文件 :
/var/log/cron- 查看日志命令:
- head/tail
- -n : 查看指定多少行,默认查十行
- tail/tail -f
- -f : 监控文件变化
- less
- 按q退出
- head/tail
- 查看日志命令:
- 定时任务服务禁止用户运行名单 :
/etc/cron.deny(定时任务黑名单)
磁盘管理#
-
windows 下的分区#
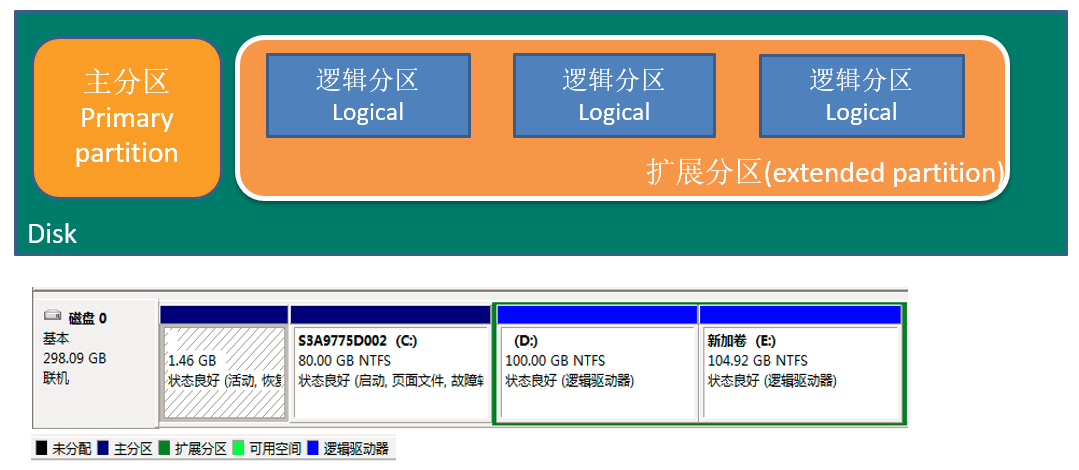
-
磁盘管理#
Linux系统中磁盘管理就是将硬盘通过挂载的方式挂载到Linux文件系统中
-
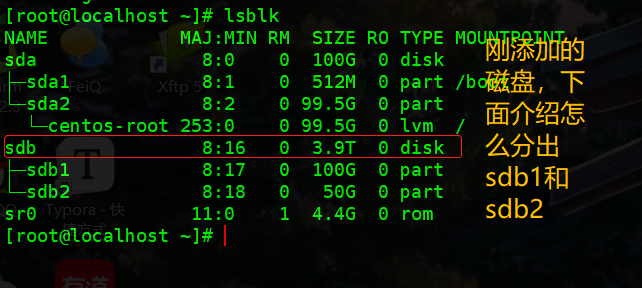
相关命令#
- lsblk:用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系数据来源-/sys/dev/block
- df -h:df可显示磁盘的文件系统与使用情形,-h是格式化输出
- 分区命令:
- fdisk:分区2TB以下的磁盘,最多可以分4个分区
- gdisk:分区2TB以上的磁盘,最多可以分128个分区
注.fdisk和gdisk,2TB不是限制,有时候超过2TB分区不稳定所以建议使用gdisk
- 格式化文件系统:mkfs.xfs
- 挂载(卸载)命令:mount / umount
-
分区及挂载实现步骤#
- 添加硬盘(虚拟机编辑设置)
- 创建分区(fdisk/gdisk)
- 格式化文件系统(mkfs.xfs)
- 挂载(mount)
-
添加硬盘#
- 打开VMware,选择编辑虚拟机设置
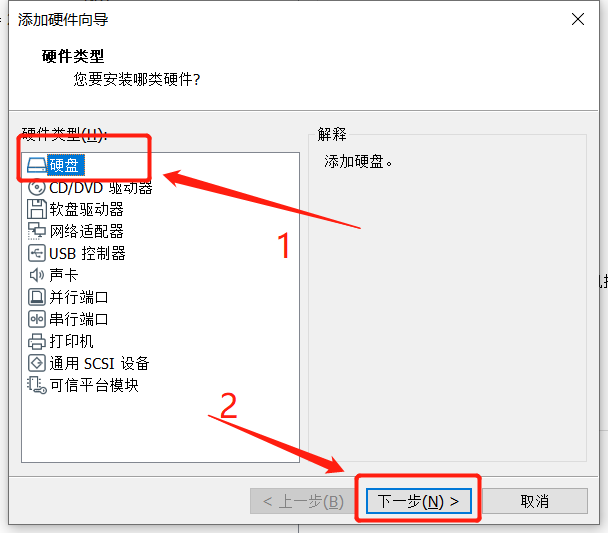
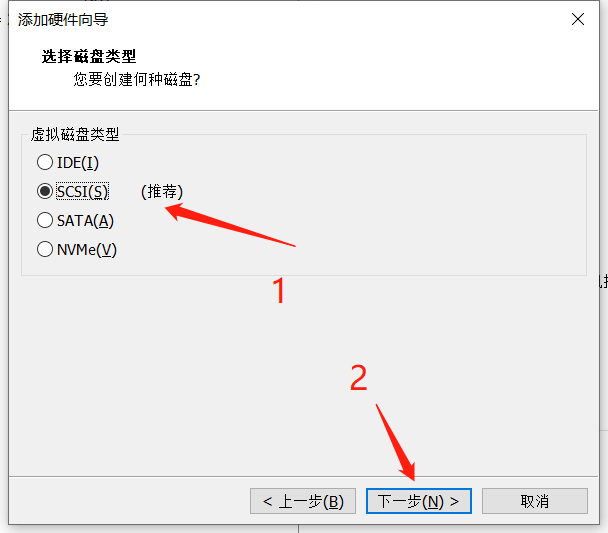
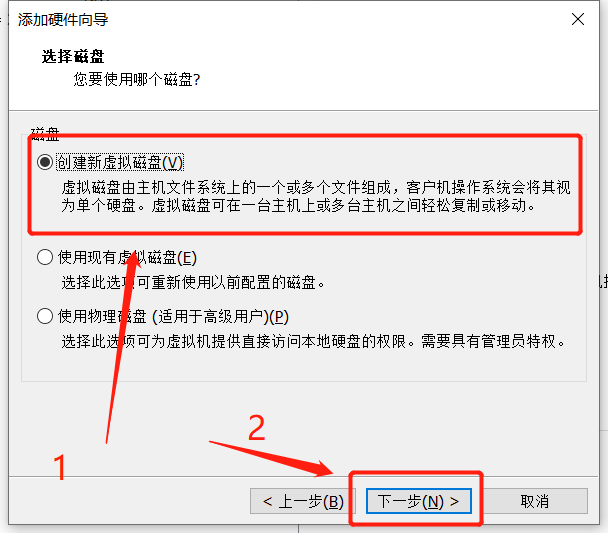
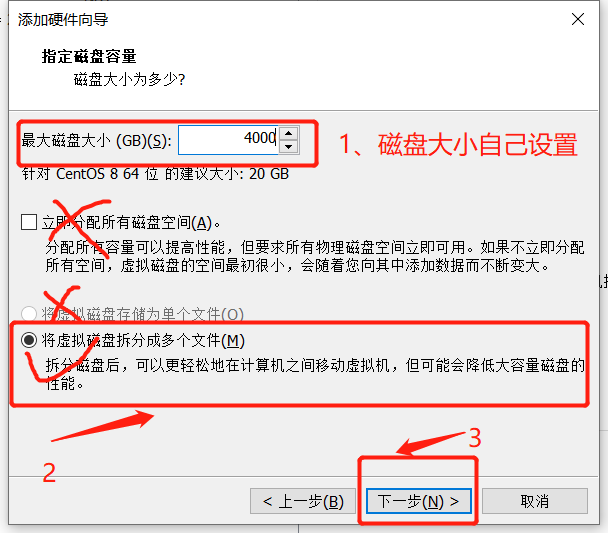
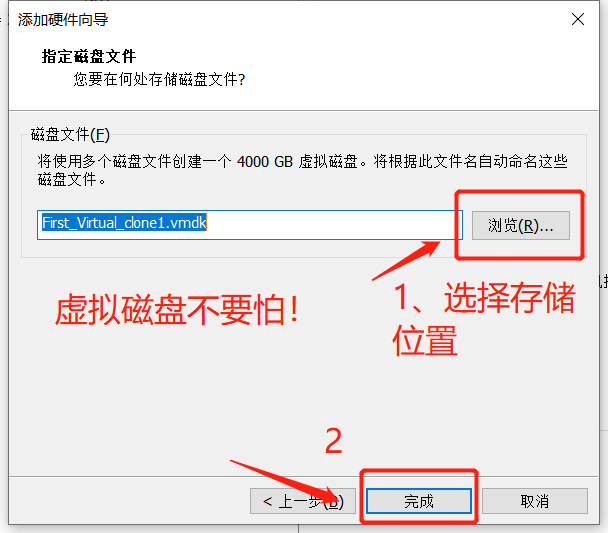
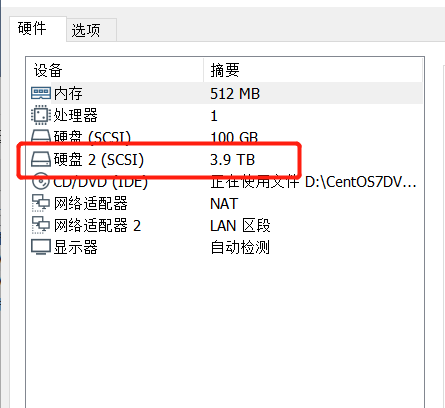
- 打开VMware,选择编辑虚拟机设置
-
分区步骤#
创建分区fdisk /dev/sdb或gdisk /dev/sdb
Command action a toggle a bootable flag b edit bsd disklabel c toggle the dos compatibility flag d delete a partition g create a new empty GPT partition table G create an IRIX (SGI) partition table l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id u change display/entry units v verify the partition table w write table to disk and exit x extra functionality (experts only) # 用啥大家翻译一下吧,鄙人也得翻译 # 常用的如下: n : 新建一个分区 p : 打印分区表 w : 写入磁盘并退出 q : 退出 d : 删除一个分区步骤
[root@localhost ~]# fdisk /dev/sdb Command (m for help): n # ---添加新分区 Select (default p): p # ---默认为p,可以不输入 Partition number (3,4, default 3): # 默认值为3,因为前面分了两个了 First sector (314574848-4294967295, default 314574848): # 起始区,这里默认值就行了 Last sector, +sectors or +size{K,M,G} (314574848-4294967294, default 4294967294): +10G Partition 3 of type Linux and of size 10 GiB is set # 终止分区,自己添加,这里我添加10G作为例子 Command (m for help): w # ---写入磁盘并退出 The partition table has been altered!通过lsblk查看分区情况

-
挂载步骤#
- 格式化文件系统
[root@localhost ~]# mkfs.xfs /dev/sdb3 - 挂载
[root@localhost ~]# mount /dev/sdb3 /root/sdb3 [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 223M 0 223M 0% /dev tmpfs 235M 0 235M 0% /dev/shm tmpfs 235M 5.5M 229M 3% /run tmpfs 235M 0 235M 0% /sys/fs/cgroup /dev/mapper/centos-root 100G 3.4G 97G 4% / /dev/sda1 509M 142M 368M 28% /boot tmpfs 47M 0 47M 0% /run/user/0 /dev/sdb3 10G 33M 10G 1% /root/sdb3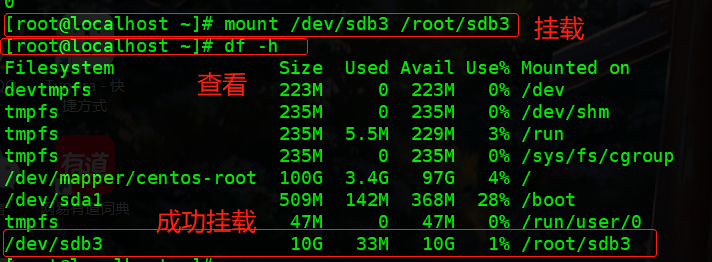
- 卸载
[root@localhost ~]# umount /dev/sdb3 [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 223M 0 223M 0% /dev tmpfs 235M 0 235M 0% /dev/shm tmpfs 235M 5.5M 229M 3% /run tmpfs 235M 0 235M 0% /sys/fs/cgroup /dev/mapper/centos-root 100G 3.4G 97G 4% / /dev/sda1 509M 142M 368M 28% /boot tmpfs 47M 0 47M 0% /run/user/0注:卸载挂载易错点: 1、卸载的时候不能进入挂载的路径,也就是说,如果你现在挂载到/root/sdb3里面,但是你进到/root/sdb3里面的时候卸载时也会报错。 2、卸载光写卸载的目录路径就行,不用写挂载时的路径,例如卸载/root/sdb3,光写umount /root/sdb3[root@localhost ~]# umount /dev/sdb3 [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 223M 0 223M 0% /dev tmpfs 235M 0 235M 0% /dev/shm tmpfs 235M 5.5M 229M 3% /run tmpfs 235M 0 235M 0% /sys/fs/cgroup /dev/mapper/centos-root 100G 3.4G 97G 4% / /dev/sda1 509M 142M 368M 28% /boot tmpfs 47M 0 47M 0% /run/user/0
- 格式化文件系统
-
卸载分区步骤#
# 查看 [root@localhost ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 100G 0 disk ├─sda1 8:1 0 512M 0 part /boot └─sda2 8:2 0 99.5G 0 part └─centos-root 253:0 0 99.5G 0 lvm / sdb 8:16 0 3.9T 0 disk ├─sdb1 8:17 0 100G 0 part ├─sdb2 8:18 0 50G 0 part ├─sdb3 8:19 0 10G 0 part └─sdb4 8:20 0 30G 0 part sr0 11:0 1 4.4G 0 rom # 卸载sdb4,主要内容粘贴如下: [root@localhost ~]# fdisk /dev/sdb Command (m for help): d # ---删除 Partition number (1-4, default 4): 4 # 删除sdb4 Command (m for help): w # 写入,保存 # 查看 [root@localhost ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 100G 0 disk ├─sda1 8:1 0 512M 0 part /boot └─sda2 8:2 0 99.5G 0 part └─centos-root 253:0 0 99.5G 0 lvm / sdb 8:16 0 3.9T 0 disk ├─sdb1 8:17 0 100G 0 part ├─sdb2 8:18 0 50G 0 part └─sdb3 8:19 0 10G 0 part sr0 11:0 1 4.4G 0 rom # 成功卸载! - 补充:
- lsblk和df的区别:
- lsblk 查看的是block device,也就是逻辑磁盘大小。
- df查看的是file system, 也就是文件系统层的磁盘大小。
- 永久挂载:
mount是临时挂载,重启就没了
- 命令 fdisk-l,查看未挂载硬盘
- 硬盘uuid查看命令:blkid [路径]
- 查看到UUID写入 /etc/fstab文件
- lsblk和df的区别:
Linux 三剑客之grep#
-
搭配命令-find#
find命令是根据文件的名称或者属性查找文件,并不会显示文件内容
- 格式:find [查找范围] [参数]
- 参数:
- -name: 按照文件的名字查找文件
- -iname :按照文件的名字查找文件(忽略大小写)
- -size :按照文件的大小查询文件(搭配size使用得符号:+表示大于,-表示小于,没符号表示等于)
- -mtime :按照修改时间去查询(+3:三天前;-3:三天内)
- -atime : 按照访问时间查找
- -ctime :按照修改属性时间查找
- -user : 按照用户的属主查询
- -group : 按照用户的属组查询
- -type :按照文件的类型查询
- -perm :按照文件权限查询(777)
- -inum :按照indexnode号码查询
- 不能单独使用
- -a :并且(可以省略,默认就是并且)
- -o :或者
- -maxdepth : 查询目录深度(必须放置在第一个参数位)
- 知识补充:
-exec : 将find处理好的结果交给其他命令继续处理。 dd if=/dev/zero of=100.txt bs=10M count=10 dd : 生成文件 if : 从什么地方读 of : 写入到什么文件 bs : 每次写入多少内容 count: 写入多少次 - 案例:
案例1:查询/etc目录下hosts文件 [root@localhost ~]# find /etc/ -name 'hosts' /etc/hosts 案例2:查询/etc目录下名称中包含hosts文件 [root@localhost ~]# find /etc/ -name '*hosts*' 案例3:要求把/etc目录下,所有的普通文件打包压缩到/tmp目录 [root@localhost /tmp]# tar -czPf /tmp/etcv2.tar.gz `find /etc/ -type f | xargs` # 知识补充: ``:表示得是提前执行命令,然后把结果交给其他命令处理
-
三剑客之grep:#
grep是Linux三剑客之一,区别find命令,grep是全面搜索,可以过滤输出文本内容,是一种强大的文本搜索工具,通常和正则一起使用,并把匹配的行打印出来。
- 格式:
- grep [参数] [匹配规则] [操作对象]
- 参数:
参数字符 功能描述 -n 过滤文本时,将过滤出来的内容在文件内的行号显示出来 -c 只显示匹配成功的行数 -o 只显示匹配成功的内容 -v 反向过滤(类似-o的取反操作) -q 静默输出(不显示,可以通过echo $?查看结果真假) -i 忽略大小写 -l 匹配成功之后,将文本的名称打印出来 -R/ -r 递归匹配 -E 使用拓展正则 等价于 egrep -A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。 -B 除了显示符合范本样式的那一行之外,并显示该行之前的内容。 -C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。 - 实操
root@ubuntumachine01:/tmp# grep -n -C 2 'hhhh' 1.txt 显示hhhh匹配到的文本前后各两行 - 知识拓展
知识储备: $? : 上一行命令执行的结果,0代表执行成功,其他数字代表执行失败。 wc : 匹配行数 -l : 打印匹配行数 -c : 打印匹配的字节数 在/etc目录下,有多少个文件包含root。 grep -rl 'root' /etc/ | wc -l
- 格式:
-
正则表达式:#
在Linux中,使用正则,分为普通正则表达式,拓展正则表达式
- 普通正则表达式
^ : 以某字符开头 $ : 以某字符结尾 . : 匹配除换行符之外的任意单个字符 * :匹配前导字符的任意个数 [] : 某组字符串的任意一个字符 [^] : 取反 [a-z] : 匹配小写字母 [A-Z] : 匹配大写字母 [a-zA-Z] : 匹配字母 [0-9] : 匹配数字 \ : 取消转义 () : 分组 \n : 代表第n个分组 - 拓展正则表达式
{} :匹配的次数 {n} : 匹配n次 {n,} :至少匹配n次 {n,m} :匹配 n 到 m 次 {,m} :最多匹配m次 + :匹配至少有一个前导字符 ? : 匹配一个或零个前导字符 | :或 - 案例如下:
案例1:在/etc/passwd文件中,匹配以ftp开头的行 grep '^ftp' /etc/passwd 案例2:在/etc/passwd文件中,匹配以bash结尾的行 grep 'bash$' /etc/passwd 案例3:匹配本机中有哪些ip ip a | grep -oE "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}" 或 ip a | grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}' 案例4:要求将/etc/fstab中的去掉包含 # 开头的行,且要求 # 后至少有一个空格 grep -vE '^#\ +' /etc/fstab 案例5:找出文件中至少有一个空格的行 grep -E '\ +' xxx 案例6:将 nginx.conf 文件中以#开头的行和空行,全部删除 grep -vE '^\ *#|^$' /etc/nginx/nginx.conf 案例7: |: 前面一个命令的结果丢给后面的一个命令处理,管道 xargs:把处理的文本变成以空格分割的一行 ``: 提前执行命令,然后将结果交给其他命令处理 tar -zcPf xxx.tar.gz `find /etc/ -type f | xargs`
- 普通正则表达式
Linux三剑客之sed#
-
命令补充#
-
sort命令#
对文本文件的内容,以行为单位来排序,比较原则是从一行的首个字符依次向后,按照字符对应的ASCII码值进行比较,默认升序
- 格式:sort [参数] [-o 输出文件]
- 参数:
- -b: 不包括开头的空白字符,从第一个可见字符比较
- -n:按照数值的大小排序
- -r:以相反的顺序来排序
- -t<分隔字符> : 指定排序时所用的栏位分隔字符
- -o<输出文件> : 将排序后的结果存入指定的文件
- -k: 选择以哪个列进行排序
- -f: 排序时,忽略大小写字母
- -u:排序过程中去除重复的行
- 示例
# 常用参数演示,文件内容自己编写 # 排序 [root@localhost ~]# cat 1.sh aa ab ac ad [root@localhost ~]# sort 1.sh aa ab ac ad # -n按照数值大小排序 [root@localhost ~]# sort -n 1.sh 1aa 22ab 32ac 42ad # -r 以相反的顺序来排序,降序输出 [root@localhost ~]# sort -r 1.sh aaa 4ad 32ac 22ab 1aa 1 # 按第一列排序 [root@localhost ~]# sort -k1 1.sh 1 1aa 22ab 32ac 4ad aaa # -t:指定分割符,默认是以空格为分隔符 # 注:分隔符排序前有空格行 [root@localhost ~]# cat 3.sh |1|2|3|5|6|2|1|3|7|8 |3|4|4|5|4|6|7|8|9|8 |2|3|4|5|4|6|5|7 |3|4|6|8|9|0|7|0|7 |3|2|4|2|4|2|4|2|3|4 [root@localhost ~]# sort -n -r -k2 -t '|' 3.sh |3|4|6|8|9|0|7|0|7 |3|4|4|5|4|6|7|8|9|8 |3|2|4|2|4|2|4|2|3|4 |2|3|4|5|4|6|5|7 |1|2|3|5|6|2|1|3|7|8 # `-u`:排序过程中去除重复的行 [root@localhost ~]# cat 4.sh aaaaaa aaaaaa bbbbbb bbbbbb cccccc cccccc [root@localhost ~]# sort -u 4.sh aaaaaa bbbbbb cccccc # -o<输出文件> : 将排序后的结果存入指定的文件 [root@localhost ~]# sort -u 4.sh > 5.sh [root@localhost ~]# cat 5.sh aaaaaa bbbbbb cccccc
-
uniq命令#
用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用(只能去重紧挨着的)
- 格式:uniq [参数] [文件]
- 参数:
- -c: 在输出行前面加上每行在输入文件中出现的次数
- -d:仅显示重复出现的行列
- -u:仅显示不重复行列
- 示例:
# 去重 [root@localhost ~]# cat 4.sh aaaaaa aaaaaa bbbbbb bbbbbb cccccc cccccc [root@localhost ~]# uniq 4.sh aaaaaa bbbbbb cccccc # 注意,去重是相邻重复内容去重,所以先排序再去重 [root@localhost ~]# cat 5.sh 123 124 123 123 123 124 124 124 125 126 [root@localhost ~]# uniq 5.sh 123 124 123 124 125 126 # 这样的话就没有达到去重的效果,需要搭配sort使用 [root@localhost ~]# sort -n 5.sh|uniq 123 124 125 126 # -c: 在输出行前面加上每行在输入文件中出现的次数 [root@localhost ~]# sort -n 5.sh|uniq -c 4 123 4 124 1 125 1 126 # -u:仅显示不重复行列 [root@localhost ~]# sort -n 5.sh|uniq -u 125 126
-
cut命令#
cut命令用来输出每一行中的指定部分,删除(剪切)文件中指定字节,字段
- 格式:cut [-b/c/f] [file]
注.必须指定-b,-c,-f其中一种
- 定位方法:
- -b:字节
- -c:字符
- -f:域
- 参数:
-b:以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志-c:以字符为单位进行分割-d:自定义分隔符,默认为制表符(Tab)-f:与-d一起使用,指定显示哪个区域-n:取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除。
- 实例如下
-b字节(英文数字)模式如下
# 用当前登录用户信息举例 [root@localhost ~]# who root tty1 2021-12-21 18:47 root pts/0 2021-12-21 16:52 (192.168.15.1) # -b 模式提取字节 [root@localhost ~]# who | cut -b 3 o o # 提取第1,2,3列的字节 [root@localhost ~]# who | cut -b 1,2,3 roo roo [root@localhost ~]# who | cut -b 1-3 roo roo # cut命令如果使用了-b选项,那么执行此命令时,cut会先把-b后面所有的定位进行从小到大排序,然后再提取。不能颠倒定位的顺序。 [root@localhost ~]# who | cut -b -3,3- root tty1 2021-12-21 18:47 root pts/0 2021-12-21 16:52 (192.168.15.1) # -3表示从第一个字节到第三个字节,3-表示从第三个字节到行尾 # 执行上述语句,第三个字节不会重叠输出-c模式字符(汉字可用)如下:
[root@localhost ~]# cat a.txt 路飞 山治 索隆 娜美 黑胡子 白胡子 # 如果用b模式就会不完全输出 [root@localhost ~]# cut -b 2 a.txt · ± ´ ¨ » # 用c模式,区别就看出来了 [root@localhost ~]# cut -c 2 a.txt 飞 治 隆 美 胡 胡 # -c则会以字符为单位,输出正常;而-b只会傻傻的以字节(8位二进制位)来计算,输出就是乱码。 # 使用-n搭配b模式使用,解决乱码 [root@localhost ~]# cut -nb 2 a.txt 飞 治 隆 美 胡 胡-f模式,-b和-c只能在固定格式的文档中提取信息,而对于非固定格式的信息则束手无策,这时候使用-f模式,在使用的时候注意设置间隔符
# 提取用户名 [root@localhost ~]# head -n 5 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@localhost ~]# head -n 5 /etc/passwd | cut -d : -f 1 root bin daemon adm lp
- 格式:cut [-b/c/f] [file]
-
tr命令#
用一个字符来替换另一个字符,或者可以完全删除一些字符,替换等
- 格式:tr [OPTION]... SET1 [SET2]
- 参数:
- -c :用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
- -d:删除指令字符
- -s:缩减连续重复的字符成指定的单个字符
- -t:削减 SET1 指定范围,使之与 SET2 设定长度相等
- 实例如下:
# 替换 [root@localhost ~]# cat 2.sh +a+b+c+d +e+f+g +h+i+j+k +1+2+a+s+d+a+s +a+b+c+1+2+3 # 将2.sh中的'+'替换成'|' [root@localhost ~]# cat 2.sh | tr + '|' |a|b|c|d |e|f|g |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 将2.sh小写字母替换成大写字母 [root@localhost ~]# cat 2.sh | tr a-z A-Z |A|B|C|D |E|F|G |H|I|J|K |1|2|A|S|D|A|S |A|B|C|1|2|3 # 删除 # -d 删除2.sh中的ab字母 [root@localhost ~]# cat 2.sh | tr -d "ab" > new_file [root@localhost ~]# cat new_file |||c|d |e|fffff|g |h|i|j|k |1|2||s|d||s |||c|1|2|3 # -s 删除连续的字符,相当于去重,只保留第一个 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 [root@localhost ~]# cat 2.sh | tr -s [a-z] > new_file [root@localhost ~]# cat new_file |a|b|c|d |e|f|bg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # -s还有替换的功能,将2.sh中的'|',替换成'-' [root@localhost ~]# cat 2.sh | tr -s "|" "-" -aaaaaaaaa-bbbbbbb-c-d -e-fffff-bbbbbg -h-i-j-k -1-2-a-s-d-a-s -a-b-c-1-2-3
-
wc命令#
wc指令可以计算文件的字节数,词数,或者列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
- 注:在Linux系统中,一段连续的数字或字母组合为一个词
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数
- 格式:wc [OPTION]... [FILE]...
- 参数:
- -c:统计文件的字节(Bytes)数
- -l:统计文件的行数
- -w:统计文件中的单词个数,默认以空白字符作为分隔符
- 实例如下:
# 统计bytes # 查看2.sh内容 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 单文件 [root@localhost ~]# wc 2.sh 5 5 76 2.sh # 对应数字:行数,单词数,字节数 [root@localhost ~]# wc -c 2.sh 76 2.sh # bytes数 [root@localhost ~]# wc -w 2.sh 5 2.sh # 单词数 [root@localhost ~]# wc -l 2.sh 5 2.sh # 行数 # 多文件 # 不加参数默认都输出 [root@localhost ~]# wc 2.sh 3.sh 4.sh 5 5 76 2.sh # 第一个5代表行数未5,单词数5,字节数76 5 5 99 3.sh 6 6 42 4.sh 16 16 217 total [root@localhost ~]# cat 2.sh 3.sh 4.sh | wc 16 16 217 # 这样相当于将三个文件的行数,单词书,字节数求和输出 # 加参数 [root@localhost ~]# wc -c 2.sh 3.sh 4.sh 76 2.sh # 文件字节总和 99 3.sh 42 4.sh 217 total [root@localhost ~]# wc -l 2.sh 3.sh 4.sh 5 2.sh # 文件行数总和 5 3.sh 6 4.sh 16 total [root@localhost ~]# wc -w 2.sh 3.sh 4.sh 5 2.sh # 文件单词数总和 5 3.sh 6 4.sh 16 total # 上面的例子是多文件统计
- 注:在Linux系统中,一段连续的数字或字母组合为一个词
-
-
sed命令#
sed,三大剑客之一,sed是一款流媒体编辑器,用来对文本进行过滤,修改操作等
- 注:grep用来过滤文本,sed用来修改文本,awk用来处理文本
- 格式:sed [参数] '处理规则' [操作对象]
- 参数:
- -e:允许多个脚本被执行,多项编辑
- -n:取消默认输出,就是静默输出
- -i:就地编辑,直接修改源文件(慎用)
- -r:使用拓展正则表达式(和egrep一样)
- -f:指定sed匹配规则脚本文件
- 编辑模式:
- d:删除模式
- p:打印(P打印第一行)
- a:在当前行后添加一行或多行
- i:在当前行上一行插入文本(直接修改,原文内容 也会更改)
- r:从文件中读取
- w:将指定行写入文件
- y:将字符转换成另一个字符
- s:替换指定的字符(每一行只替换一次)
- g:获得内存缓冲区的内容,并替代当前,相当于全部执行
- i:忽略大小写(和s模式一起使用的时候,不是单独使用)
- &:已经匹配字符串标记
- 定位:(使用两个斜线)
- 定位分类:
- 数字定位:sed ‘行号+模式’ file -- 指定行定位
sed '3,4d' 2.sh # 第三行第四行删除 - 正则定位:sed ‘正则+模式’ file-- 正则指定开头内容
sed '/^g/d' 2.sh # 斜杠之间写正则 - 数字和正则定位:sed ‘数字,正则+模式’ file -- 指定行,和开头
sed '3,/^g/d' 2.sh # 从第三行到正则匹配到的行删除,逗号分割 - 正则和正则定位:sed ‘正则,正则+模式’ file -- 指定以g和k开头
sed '/^g/,/^j/d' 2.sh # 从第一个正则到第二个正则的行删除,逗号分割 处理规则可以使用正则,也可以使用-f指定文件
- 数字定位:sed ‘行号+模式’ file -- 指定行定位
- 实例如下:
-
d模式——删除模式#
# 删除 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 删除第二行 [root@localhost ~]# sed '2d' 2.sh |aaaaaaaaa|bbbbbbb|c|d |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 删除第一行和第二行 [root@localhost ~]# sed '1,2d' 2.sh |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # -e参数,多个脚本同时操作,删除1到2行,和五行 [root@localhost ~]# sed -e '1,2d' -e '5d' 2.sh |h|i|j|k |1|2|a|s|d|a|s # -n参数,静默 [root@localhost ~]# sed -n -e '1,2d' -e '5d' 2.sh [root@localhost ~]# echo $? 0 # 0代表成功,非0代表相反 # -f参数,搭配文件使用 # 在r.sh 中编写正则:/b/d --删除带有b的行 [root@localhost ~]# sed -r '/b/d' 2.sh |h|i|j|k |1|2|a|s|d|a|s [root@localhost ~]# sed -f r.txt 2.sh |h|i|j|k |1|2|a|s|d|a|s # 这样两种结果是一样的 -
p模式——打印#
# 查看2.sh [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 打印第一行 [root@localhost ~]# sed "1p" 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # -n,静默输出 [root@localhost ~]# sed -n "1p" 2.sh |aaaaaaaaa|bbbbbbb|c|d # 这样就只打印p模式指定的那行 # -e ,多项操作 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 删除第一行,打印第五行 [root@localhost ~]# sed -e "1d" -e "5p" 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # -i,直接修改源文件,就地编辑 # 修改前 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 # 修改 [root@localhost ~]# sed -i "7p" 2.sh # 修改后增加了一行 [root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 -
a模式,在当前行后添加一行或多行#
# 在第一行下添加xxxx [root@localhost ~]# sed '1axxxxxxx' 2.sh |aaaaaaaaa|bbbbbbb|c|d xxxxxxx |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 -
i模式,在指定行前一行插入#
[root@localhost ~]# sed '7i马叉虫' 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s 马叉虫 |a|b|c|1|2|3 |a|b|c|1|2|3 -
c模式,替换当前行#
[root@localhost ~]# cat 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 # 替换第一行 [root@localhost ~]# sed '1cxxxxxxx' 2.sh xxxxxxx |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 -
r模式,在文件中读内容#
[root@localhost ~]# cat 3.sh |1|2|3|5|6|2|1|3|7|8 |3|4|4|5|4|6|7|8|9|8 |2|3|4|5|4|6|5|7 |3|4|6|8|9|0|7|0|7 |3|2|4|2|4|2|4|2|3|4 # 在3.sh中读取2.sh [root@localhost ~]# sed '5r 2.sh' 3.sh |1|2|3|5|6|2|1|3|7|8 |3|4|4|5|4|6|7|8|9|8 |2|3|4|5|4|6|5|7 |3|4|6|8|9|0|7|0|7 |3|2|4|2|4|2|4|2|3|4 |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 -
w模式,将指定行写入文件#
# 把第一行到第七行写入到input文件中 [root@localhost ~]# sed '1,7w input.txt' 2.sh |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 [root@localhost ~]# cat input.txt |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |aaaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 -
y模式,将字符替换成另外一个#
# 将第一行到第三行的a替换成A,有a就替换 [root@localhost ~]# sed '1,3y/a/A/' 2.sh |AAAAAAAAA|bbbbbbb|c|d |AAAAAAAAA|bbbbbbb|c|d |AAAAAAAAA|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 -
s模式,字符串转换#
# 将字符串转换成另一个字符串(每一行只替换一次) [root@localhost ~]# sed 's/a/啊/' 2.sh |啊aaaaaaaa|bbbbbbb|c|d |啊aaaaaaaa|bbbbbbb|c|d |啊aaaaaaaa|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|啊|s|d|a|s |啊|b|c|1|2|3 |啊|b|c|1|2|3 -
g模式,全部执行#
# 全部替换 [root@localhost ~]# sed 's/a/啊/g' 2.sh |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|啊|s|d|啊|s |啊|b|c|1|2|3 |啊|b|c|1|2|3 -
i模式,忽略大小写,与s模式协同使用#
# 和s模式一起使用 [root@localhost ~]# cat 2.sh |AAAAAAAAA|bbbbbbb|c|d |AAAAAAAAA|bbbbbbb|c|d |AAAAAAAAA|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|a|s|d|a|s |a|b|c|1|2|3 |a|b|c|1|2|3 # 忽略大小写 [root@localhost ~]# sed 's/a/啊/gi' 2.sh |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |啊啊啊啊啊啊啊啊啊|bbbbbbb|c|d |e|fffff|bbbbbg |h|i|j|k |1|2|啊|s|d|啊|s |啊|b|c|1|2|3 |啊|b|c|1|2|3 -
&的使用,代表前面匹配到的内容#
将nginx.conf中每一行之前增加注释 [root@localhost ~]# sed 's/.*/#&/g' /etc/nginx/nginx.conf
-
- 练习
# 将nginx.conf中的注释行全部去掉 sed '/^ *#/d' /etc/nginx/nginx.conf # 将nginx.conf中每一行之前增加注释 sed 's/.*/#&/g' /etc/nginx/nginx.conf # 一键修改本机的ip # 要求如下: # 192.168.15.100 ---> 192.168.15.101 # 172.16.1.100 ---> 172.16.1.101 sed -i 's/.100/.101/g' /etc/sysconfig/network-scripts/ifcfg-eth[01] # 将/etc/passwd中的root修改成ROOT sed -i 's/root/ROOT/g' /etc/passwd
Linux三剑客之grep#
-
应用场景
过滤,统计,计算,统计日志
-
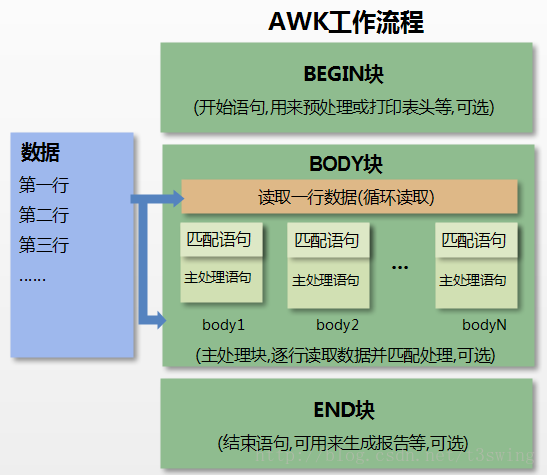
awk执行流程图#
-
awk读取文件之前执行BEGIN,注意BEGIN读取文件之前就可以执行,后面不跟文件,也可以执行
# 直接执行BEGIN,不跟文件 [root@localhost ~]# awk 'BEGIN{print "直接执行"}' 直接执行 -
awk读取文件时,执行BODY块
-
awk读取文件后,执行END块
-
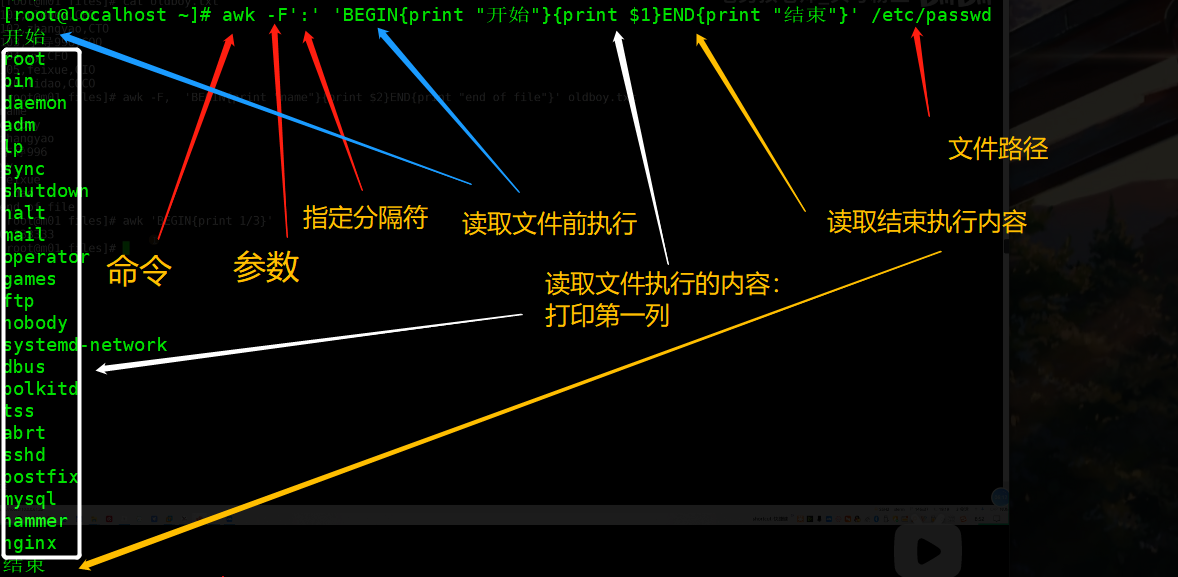
格式:
awk [参数] 'BEGIN{读取文件前执行的内容}条件{读取文件执行的动作}END{读取完文件执行的内容}' [文件路径]
完整流程示例(无条件要求演示):
-
-
awk生命周期#
grep、sed和awk都是读一行处理一行,直至处理完成
# 生命周期如下: 接收一行作为输入 把刚刚读入进来得到文本进行分解 使用处理规则处理文本 输入一行,赋值给$0,直至处理完成($0代表当前行的内容) 把处理完成之后的所有的数据交给END{}来再次处理 -
awk内置(预定义)变量#
内置变量符号 功能描述 $0 代表当前行 $n 代表第n列 NF 记录当前行的字段数(当前行的列数),$NF表示最后一列 NR 用来记录行号(相当于计数器) FS 指定文本内容字段分隔符(默认是空格) RS 文本分割符 默认为换行符 OFS 指定打印字段分隔符(默认空格) ORS 输出的记录分隔符 默认为换行符 -
行与列描述#
名称 描述 说明 行 记录record 每一行结尾默认通过回车分隔 列 记录字段/域field 列与列默认以空格分隔,可以指定分隔符 -
取行#
awk取行字符 描述 NR==1 取出第1行 NR>=1&&NR<=5 取出1到5行 ---范围取 //,// 正则取,谁开头到谁结尾 符号 > < >= <= == != # 输出第一行 [root@localhost ~]# awk 'NR==1' a.sh asdfgdghgf aadadadad # 输出1到5行 [root@localhost ~]# awk 'NR>=1&&NR<=5{print NR,$0}' a.sh 1 asdfgdghgf aadadadad 2 sdasdasda hjhjjg 3 asd adas sdasdas asdasdahgf 4 asdas asdasdad adasdasd 5 baaaaaaaaaaaaaaaaaaaabbbbbbbb # 正则取,h开头的行,到m开头的行 [root@localhost ~]# cat a.sh | nl 1 hammerze 2 hanswang 3 jianiubi 4 guangtou 5 meimei 6 zhengyu 7 xuegongzi [root@localhost ~]# awk '/^h/,/^m/ {print NR,$0}' a.sh 1 hammerze 2 hanswang 3 jianiubi 4 guangtou 5 meimei -
取列#
- -F:指定分隔符,指定每一列结束标记(默认是空格,连续的空格Tab键),-F后也支持正则(案例4)
- -v:修改变量
- $数字:表示取出某一列
- $0:表示整行的内容
- 补充知识:column -t格式化输出,美化操作

awk '{print $0}' a.sh 输出的内容和cat的效果一样
[root@localhost ~]# awk '{print $0}' a.sh hammerze hanswang jianiubi guangtou meimei zhengyu xuegongzi [root@localhost ~]# cat a.sh hammerze hanswang jianiubi guangtou meimei zhengyu xuegongzi案例1:取出/etc/passwd文件中的第一列和最后一列
# 为例节省占用文章空间,这里输出5行 [root@localhost ~]# awk -F: '{print NR,$1,$NF}' /etc/passwd | column -t | head -n5 1 root /bin/bash 2 bin /sbin/nologin 3 daemon /sbin/nologin 4 adm /sbin/nologin 5 lp /sbin/nologin案例2:美化操作
[root@localhost ~]# awk -F: '{print NR,"用户名:"$1,"解释器:"$NF}' /etc/passwd | column -t | head -n5 1 用户名:root 解释器:/bin/bash 2 用户名:bin 解释器:/sbin/nologin 3 用户名:daemon 解释器:/sbin/nologin 4 用户名:adm 解释器:/sbin/nologin 5 用户名:lp 解释器:/sbin/nologin案例3:将/etc/passwd文件的最后一列和第一列互换位置
[root@localhost ~]# awk -F':' '{print $NF,$2,$3,$4,$5,$6,$1}' /etc/passwd | head -n5 /bin/bash x 0 0 root /root root /sbin/nologin x 1 1 bin /bin bin /sbin/nologin x 2 2 daemon /sbin daemon /sbin/nologin x 3 4 adm /var/adm adm /sbin/nologin x 4 7 lp /var/spool/lpd lp # 这样得到的结果,和原来文件内容不一样缺少冒号 # 用-vOFS=:,这样空格就修改称原来的冒号就加回来了,`-F: == -vOFS=:` [root@localhost ~]# awk -F: -vOFS=: '{print $NF,$2,$3,$4,$5,$6,$1}' /etc/passwd | head -n5 /bin/bash:x:0:0:root:/root:root /sbin/nologin:x:1:1:bin:/bin:bin /sbin/nologin:x:2:2:daemon:/sbin:daemon /sbin/nologin:x:3:4:adm:/var/adm:adm /sbin/nologin:x:4:7:lp:/var/spool/lpd:lp案例4:取行和取列实现了文本内容“指哪打哪”,取行又取列
# 精确取ip [root@localhost ~]# ip a | awk -F "[ /]+" 'NR==3{print $3}' 127.0.0.1 # 剖析命令 awk : 命令 -F"[ /]+" : 选项 NR==3: 条件 {print $3} : 模式(动作)取行和取列主要用到的是比较,大于小于等于···
-
-
awk中的函数#
-
print函数:打印
-
printf函数:格式化打印
-
函数搭配字符
搭配字符 功能 %s 代表字符串 %d 代表数字 - 左对齐 + 右对齐 n 占用字符 eg:15代表占用15个字符长度 # 格式化输出,以|为分隔符,换行对齐输出,没有空格补齐,超出就怼出去 [root@localhost ~]# awk -F: 'BEGIN{OFS=" | "}{printf "|%+15s|%-15s|\n", $NF,$1}' /etc/passwd # OFS输出分隔符,上面的结果打印5行看看 [root@localhost ~]# awk -F: 'BEGIN{OFS=" | "}{printf "|%+15s|%-15s|\n", $NF,$1}' /etc/passwd |head -n5 | /bin/bash|root | | /sbin/nologin|bin | | /sbin/nologin|daemon | | /sbin/nologin|adm | | /sbin/nologin|lp |
-
-
条件的分类#
- 运算符参考表
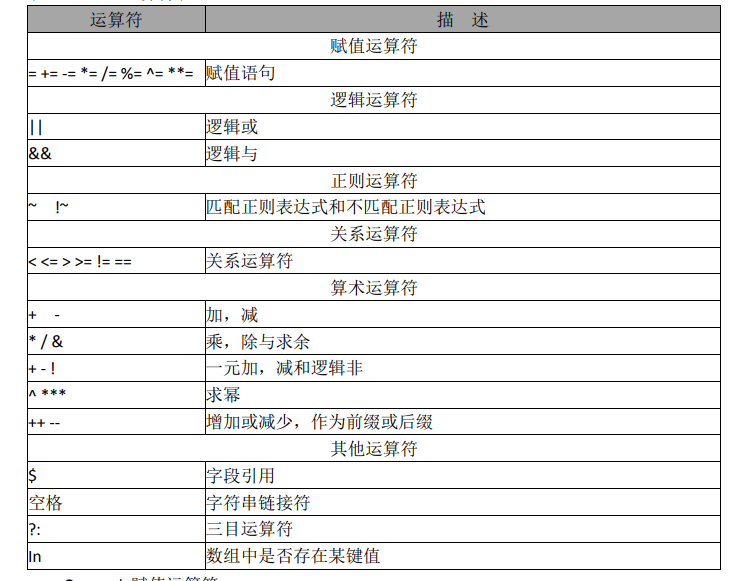
- 格式:
awk [参数] 'BEGIN{读取文件前执行的内容}条件{读取文件执行的动作}END{读取完文件执行的内容}' [文件路径]
- 格式:
-
awk正则详细:#
-
//内写正则 -
awk正则可以精确到某一行,某一列中包含什么内容,或这行不包含什么内容
-
~:包含 -
!~:不包含普通正则和awk正则区别
正则 awk正则 示例 ^代表以什么开头的行某一列的开头 $3~/^hammer/:第三列以hammer开头的行**` 正则 awk正则 -------------------------- ---------------- ------------------------------------------ 代表以什么结尾的行** | 某一列的结尾 | $3~/hammer$/:第三列以hammer结尾的行^$ 代表空行 某一列是空的 # 第三列以1开头的行 [root@localhost ~]# awk -F: '$3~/^1/{print $0}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin abrt:x:173:173::/etc/abrt:/sbin/nologin hammer:x:1000:1000::/home/hammer:/bin/bash # 第三列以1或者2开头的行,用|表示或注意写法,不要写成^1|2,写成^(1|2) [root@localhost ~]# awk -F: '$3~/^[12]/{print $0}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin abrt:x:173:173::/etc/abrt:/sbin/nologin mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin hammer:x:1000:1000::/home/hammer:/bin/bash # 最后一列以bash结尾的行 [root@localhost ~]# awk -F: '$NF~/bash$/{print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash hammer:x:1000:1000::/home/hammer:/bin/bash
-
-
范围表达式#
- /哪里开始/哪里结束/ -- 字符取范围,也是正则,经常用
NR==1,NR==5:数字表示范围,第一行开始到第五行结束,类似sed -n '1,5p'# 从root开头的行开始,到以ftp开头的行结束 [root@localhost ~]# awk -F: '/^root/,/^ftp/{print $0}' /etc/passwd # 从第一行开始到第五行结束 [root@localhost ~]# awk -F: 'NR==1,NR==5' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
逻辑表达式#
- &&:逻辑与
- ||:逻辑或
- |:逻辑非
[root@localhost ~]# awk -F: '$3 + $4 > 2000 && $3 * $4 > 2000{print $0}' /etc/passwd [root@localhost ~]# awk -F: '$3 + $4 > 2000 || $3 * $4 > 2000{print $0}' /etc/passwd [root@localhost ~]# awk -F: '!($3 + $4 > 2000){print $0}' /etc/passwd
-
算术表达式#
- +:加
- -:减
- *:乘
- /:除
- %:取模
案例:要求属组 + 属主的ID 大于 2000 [root@localhost ~]# awk -F: '$3 + $4 > 2000{print $0}' /etc/passwd 案例:要求属组 * 属主的ID 大于 2000 [root@localhost ~]# awk -F: '$3 * $4 > 2000{print $0}' /etc/passwd 案例:要求打印偶数行 [root@localhost ~]# awk -F: 'NR % 2 == 0{print $0}' /etc/passwd 案例:要求打印奇数行 [root@localhost ~]# awk -F: 'NR % 2 == 1{print $0}' /etc/passwd 案例:要求每隔5行打印------- [root@localhost ~]# awk -F: '{if(NR%5==0){print "----------------"}print $0}' /etc/passwd
- 运算符参考表
-
特殊模式BEGIN{}和END{}#
模式 含义 应用场景 BEGIN awk读文件之前执行 1、进行统计,变量初始化,不涉及读取文件等
2、处理文件之前添加表头
3、用来定义awk变量(不常用)END awk读文件之后执行 1、用来接收前面的结果,统计输出结果(常用)
2、awk使用数组,用来接收和输出数组的结果(常用)-
END{}用于统计计算
-
统计方法如下
统计方法 简写 描述 示例描述 i=i+1 i++ 计数,统计次数 1-100一共几个数 sum = sum+数值 sum+=数值 求和,累加 前100n项和 注意,i和sum都是变量随便写 # 统计/etc/services里面的空行个数 [root@localhost ~]# awk '/^$/' /etc/services | wc -l 17 # 用累计的方式统计空行 [root@localhost ~]# awk '/^$/{i++}END{print i}' /etc/services 17 # 显示累计过程 [root@localhost ~]# awk '/^$/{i++;print i}' /etc/services 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 求和示例,100前n项和 [root@localhost ~]# seq 100 | awk '{sum=sum+$1}END{print sum}' 5050可以把END前{}理解为循环
-
-
awk数组#
-
统计日志:主要应用为统计日志,类似于统计每个ip出现次数,统计每种状态码出现的次数·····
-
累加求和,统计
awk数组 形式 使用 格式:arry[] arry[0]=hammer arry[1]=ze print arry[0] arry[1] 批量输出数组内容 for(i in arry) print i (i是数组下标)
print arry[i] (这样是打印数组内容)文件用数组统计 arry[$列号]++ for (i in arry)
print i,arry[i]arry[]++,统计什么就写到[]内,如果统计出现次数,arry[i]代表次数,i代表内容 [root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";print a[0],a[1]}' hammer ze # 注意,数组赋值字母要用引号,不然会被认为是变量,数字没事 # 批量输出 # 打印i显示行号 [root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print i }' 0 1 # 打印a[i]显示数组内容 [root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print a[i]}' hammer ze # 整体显示 [root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print i,a[i]}' 0 hammer 1 ze # 数组统计出现次数,看前五行 [root@localhost log]# awk '{a[$NF]++;}END{for(i in a) print i,a[i]}' messages |sort -rnk2|head -n5 0 1220 lint[0x1]) 1152 disabled) 1143 0x1000] 756 registered 450 -
区别shell数组
shell数组 形式 使用 格式:arry[] arry[0]=hammer arry[1]=ze echo ${arry[0] $arry[1]}
-
-
awk 的 判断、循环#
-
if循环#
- 格式:
- 单分支:if(条件)
- 双分支:if(条件){执行命令}else{}
- 多分支: if(){}else if(){}else{}
[root@localhost /]# awk '{if(NR%2==1)print NR,$0}' /root/a.sh [root@localhost /]# awk 'NR%2==1{print NR,$0}' /root/a.sh 1 asdfgdghgf aadadadad 3 asd adas sdasdas asdasdahgf 5 baaaaaaaaaaaaaaaaaaaabbbbbbbb 7 ppppp 9 das1231423434gfdgfgfdgdf 11 s1111ssss asdsgfh 13 sagdfg3356fff
- 格式:
-
循环#
- for循环和while循环
- 格式:
- for循环格式:for(i="初始值";条件判断;游标){}
- while格式:while(条件判断){}
# for循环示例 [root@localhost log]# awk 'BEGIN{for (i=1;i<=100;i++)sum+=i;print sum}' 5050 [root@localhost ~]# awk -F: '{for(i=10;i>0;i--){print $0}}' /etc/passwd # while循环示例 [root@localhost ~]# awk -F: '{i=1; while(i<10){print $0, i++}}' /etc/passwd
-
-
练习#
# -F参数的使用,打印/etc/passwd第1列 [root@localhost ~]# awk -F":" '{ print $1 }' /etc/passwd # 打印/etc/passwd的第1列和第三列 [root@localhost ~]# awk -F":" '{ print $1 $3}' /etc/passwd # 打印/etc/passwd的第一列和第三列,列中间输出'-' [root@localhost ~]# awk -F":" '{ print $1 "-" $3 }' /etc/passwd # 格式化输出用户名和uid [root@localhost ~]# awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd|column -t #知识补充:column -t 格式化,美化输出,打印几行看看效果 [root@localhost ~]# awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd|column -t | head -n 5 username: root uid:0 username: bin uid:1 username: daemon uid:2 username: adm uid:3 username: lp uid:4 # 要求打印属组ID大于属主ID的行 [root@localhost ~]# awk -F: '$4 > $3{print $0}' /etc/passwd # 结尾包含bash [root@localhost ~]# awk -F: '$NF ~ /bash/{print $0}' /etc/passwd # 结尾不包含bash [root@localhost ~]# awk -F: '$NF !~ /bash/{print $0}' /etc/passwd内置变量示例如下:
# $0与NR变量的使用,$0代表当前行 [root@localhost ~]# awk -F: 'NR == 2{print $0}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin # $n的使用 [root@localhost ~]# awk -F: '{print $1}' /etc/passwd|head -n 5 root bin daemon adm lp # NF的使用 [root@localhost ~]# awk -F: '{print NF}' /etc/passwd|head -n5 7 7 7 7 7 [root@localhost ~]# awk -F: 'NF==7{print $1}' /etc/passwd|head -n5 root bin daemon adm lp # NR的使用 [root@localhost ~]# awk -F: '{print NR}' /etc/passwd|head -n5 1 2 3 4 5 [root@localhost ~]# awk -F: 'NR==5{print $0}' /etc/passwd lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin # FS的使用(指定冒号,但是优先级比-F的高) [root@localhost ~]# awk 'BEGIN{FS=":"}{print $NF, $1}' /etc/passwd|head -n5 /bin/bash root /sbin/nologin bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp # OFS的使用 [root@localhost ~]# awk -F: 'BEGIN{OFS=" 嘿"}{print $1, $2}' /etc/passwd|head -n5 root 嘿x bin 嘿x daemon 嘿x adm 嘿x lp 嘿x- 易错点:
- 字段分隔符要指定,单个字符的时候有时候可以不指定,比如冒号;
- {}外单引号内要用双引号;
- -F如果不指定分隔符建议不要写
- FS指定分隔符建议不要写-F,防止冲突
- 三剑客中是对行操作,不要混淆
- 数组赋值字母要用引号,不然会被认为是变量,数字没事
- 易错点:
三剑客练习题#
-
1、找出/proc/meminfo文件中以s开头的行,至少用三种方式忽略大小写#
# 第一种方式 [root@localhost ~]# grep -Ei '^s' /proc/meminfo SwapCached: 0 kB SwapTotal: 0 kB SwapFree: 0 kB Shmem: 5552 kB Slab: 33204 kB SReclaimable: 13648 kB SUnreclaim: 19556 kB # 第二种方式 [root@localhost ~]# awk '/^(s|S)/{print $0}' /proc/meminfo [root@localhost ~]# awk '/^s|^S/{print $0}' /proc/meminfo [root@localhost ~]# awk '/^[sS]/{print $0}' /proc/meminfo SwapCached: 0 kB SwapTotal: 0 kB SwapFree: 0 kB Shmem: 5584 kB Slab: 33536 kB SReclaimable: 13736 kB SUnreclaim: 19800 kB # 第三种方式 [root@localhost ~]# sed -nr '/^(s|^S)/p' /proc/meminfo SwapCached: 0 kB SwapTotal: 0 kB SwapFree: 0 kB Shmem: 5584 kB Slab: 33536 kB SReclaimable: 13736 kB SUnreclaim: 19800 kB -
2、显示当前系统上的root,centos或者use开头的信息#
[root@localhost ~]# grep -Er '^(centos|root|user)' / -
3、找出/etc/init.d/function文件下包含小括号的行#
[root@localhost etc]# grep -E '\(|\)' /etc/init.d/functions -
4、输出指定目录的基名#
[root@localhost etc]# pwd | awk -F '/' '{print $NF}' -
5、找出网卡信息中包含的数字#
[root@localhost etc]# ip a | grep -oE '[0-9]+' -
6、找出/etc/passwd下每种解析器的用户个数#
[root@localhost ~]# awk -F':' '{print $NF}' /etc/passwd | sort | uniq -c |column -t 2 /bin/bash 1 /bin/sync 1 /sbin/halt 18 /sbin/nologin 1 /sbin/shutdown -
7、过去网卡中的ip,用三种方式实现#
# 第一种 [root@localhost ~]# ip a | grep -oE '([0-9]{1,3}\.+){3}[0-9]{1,3}' 127.0.0.1 192.168.15.100 192.168.15.255 172.16.1.100 172.16.15.255 # 第二种 # 第三种 -
8、搜索/目录下,所有的.html或.php文件中main函数出现的次数#
# /etc目录下没有以.html或以.php结尾的文件 # 我从根查的 [root@localhost ~]# grep -Eo 'main' `find / -type f -regex ".*\.\(html\|php\)"` | wc -l [root@localhost ~]# grep -oE 'main' `find / -name '*.html' -o -name '*.php'` | wc -l -
9、过滤掉php.ini中注释的行和空行#
[root@localhost etc]# grep -vE '^\ *;|^$' /etc/php.ini -
10、找出文件中至少有一个空格的行#
[root@localhost ~]# grep -E '\ +' a.sh -
11、过滤文件中以#开头的行,后面至少有一个空格#
[root@localhost ~]# grep -E '^#\ +' a.sh -
12、查询出/etc目录中包含多少个root#
[root@localhost ~]# grep -Eor 'root' /etc/ | wc -l -
13、查询出所有的qq邮箱#
[root@localhost ~]# grep -Er "[0-9a-zA-Z-_\.]+@qq\.com" a.sh -
14、查询系统日志中所有的error#
[root@localhost /]# grep -orE 'error' /var/log/messages -
15、删除某文件中以s开头的行的最后一个词#
[root@localhost /]# grep -E '^s' /etc/passwd|sed -r 's/[0-9a-zA-Z]+$//g' [file] -
16、删除一个文件中的所有数字#
[root@localhost /]# sed -r 's/[0-9]+//g' /root/a.sh -
17、显示奇数行#
[root@localhost /]# awk '{if(NR%2==1)print NR,$0}' /root/a.sh [root@localhost /]# awk 'NR%2==1{print NR,$0}' /root/a.sh 1 asdfgdghgf aadadadad 3 asd adas sdasdas asdasdahgf 5 baaaaaaaaaaaaaaaaaaaabbbbbbbb 7 ppppp 9 das1231423434gfdgfgfdgdf 11 s1111ssss asdsgfh 13 sagdfg3356fff -
18、删除passwd文件中以bin开头的行到nobody开头的行#
[root@web02 ~]# sed -r '/^bin/,/^nobody/d' /etc/passwd -
19、从指定行开始,每隔两行显示一次#
awk -F: '{if(NR>3){num=(NR-3)%2; if(num){print $0}}}' /etc/passwd # 没写 -
20、每隔5行打印一个空格#
[root@localhost /]# awk -F: '{if(NR%5==0){print " "}print $0}' /root/a.sh -
21、不显示指定字符的行#
[root@localhost /]# grep -Ev 'g' a.sh -
22、将文件中1到5行中aaa替换成AAA#
[root@localhost /]# sed -r '1,5 s/a/A/g' /root/a.sh | head -n5 Asdfgdghgf AAdAdAdAd sdAsdAsdA hjhjjg Asd AdAs sdAsdAs AsdAsdAhgf AsdAs AsdAsdAd AdAsdAsd bAAAAAAAAAAAAAAAAAAAAbbbbbbbb -
23、显示用户id为奇数的行#
[root@localhost /]# awk -F: '{if ($3%2==1) print NR,$0}' /etc/passwd 2 bin:x:1:1:bin:/bin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 8 halt:x:7:0:halt:/sbin:/sbin/halt 10 operator:x:11:0:operator:/root:/sbin/nologin 13 nobody:x:99:99:Nobody:/:/sbin/nologin 15 dbus:x:81:81:System message bus:/:/sbin/nologin 16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin 17 tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin 18 abrt:x:173:173::/etc/abrt:/sbin/nologin 20 postfix:x:89:89::/var/spool/postfix:/sbin/nologin 21 mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin -
24、显示系统普通用户,并打印系统用户名和id#
[root@localhost /]# awk -F: '{if($3>=1000){print "用户名:" $1"用户id:"$3}}' /etc/passwd 用户名:hammer用户id:1000 -
25、统计nginx日志中访问量(ip唯独计算)#
[root@localhost ~]# awk '/([0-9]{1,3}\.){3}[0-9]{1,3}/{arr[$1]++}END{for(i in arr){print i}}' access.log -
26、实时打印nginx的访问ip#
[root@localhost ~]# grep -oE '[0-9a-zA-Z]+' /etc/php.ini | awk '{arr[$1]++}END{for(i in arr){printf "%-15s | %-5d\n", i, arr[i]}}' -
27、统计php.ini中每个词的个数#
[root@localhost ~]# egrep -o "[a-Z]+" php.ini | wc -l -
28、统计1分钟内访问nginx次数超过10次的ip#
#!/bin/bash NGINX_LOG=/var/log/nginx/access.log TIME=`date +%s` DATE=`echo $TIME - 3600 | bc` declare -A IP while read line do timestamp=`echo $line | grep -oE '[0-9]{4}.*T[0-9]{2}:[0-9]{2}:[0-9]{2}'` timestamp=`date -d "$timestamp" +%s` if (( $TIME >= $timestamp && $DATE <= $timestamp ));then ip=`echo $line| grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}'` number=`echo ${IP["$ip"]} | wc -L` [ $number -eq 0 ] && IP["$ip"]=0 num=${IP["$ip"]} IP["$ip"]=`echo "$num + 1" | bc` fi done < $NGINX_LOG for i in ${!IP[*]} do if (( ${IP[$i]} >= 10 ));then echo $i fi done -
29、找出nginx访问的峰值,按每个小时计算#
#!/bin/bash NGINX_LOG=/var/log/nginx/access.log declare -A IP while read line do timestamp=`echo $line | grep -oE '[0-9]{4}.*T[0-9]{2}:[0-9]{2}:[0-9]{2}'` timestamp=`date -d "$timestamp" +%Y%m%d%H` number=`echo ${IP["$timestamp"]} | wc -L` [ $number -eq 0 ] && IP["$timestamp"]=0 num=${IP["$timestamp"]} IP["$timestamp"]=`echo "$num + 1" | bc` done < $NGINX_LOG for i in ${!IP[*]} do if (( ${IP[$i]} >= 10 ));then echo "$i ${IP[$i]}" fi done -
30、统计访问nginx前10的ip#
grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}' /var/log/nginx/access.log | sort | uniq -c | sort -r | head



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)