go爬虫学习
1、使用http库
本人使用http库封装了Post请求和Get请求,并且封装成MyHttp库使用,可设置代理和请求头,返回响应包主体
Myhttp.go
package MyHttp
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"strings"
"time"
)
func Get(httpUri, proxyAddr string, params, header map[string]string) string {
// 如果需要代理验证,那么如下进行设置
// 否则直接设置为url.Parse("http://inproxy.sjtu.edu.cn:8000")
//proxyUri, err := url.Parse("http://username:password@inproxy.sjtu.edu.cn:8000")
proxy, err := url.Parse(proxyAddr)
if err != nil {
log.Fatal(err)
}
var netTransport *http.Transport
//如果代理不为空则设置代理
//如果代理不为空则设置代理
if proxyAddr != "" {
netTransport = &http.Transport{
Proxy: http.ProxyURL(proxy),
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Second * time.Duration(5),
}
} else {
netTransport = &http.Transport{
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Second * time.Duration(5),
}
}
client := &http.Client{
Timeout: time.Second * 10,
Transport: netTransport,
}
//设置参数
data := url.Values{}
for k, v := range params {
data.Set(k, v)
}
u, err := url.Parse(httpUri)
if err != nil {
fmt.Println("Error:url Parse err")
}
u.RawQuery = data.Encode()
//获取带参数get请求
fmt.Println(u.String())
req, _ := http.NewRequest("GET", u.String(), nil)
//添加头部、设置请求头
if header != nil {
for k, v := range header {
if k == "User-Agent" {
req.Header.Set(k, v)
} else {
req.Header.Add(k, v)
}
}
}
resp, err := client.Do(req)
if err != nil {
fmt.Println("Error:url request err", err)
}
if resp.StatusCode != 200 {
fmt.Println("StatusCode is", resp.StatusCode)
}
body, _ := ioutil.ReadAll(resp.Body)
defer resp.Body.Close()
return string(body)
}
/*
httpUrl:请求URL
proxyAddr:代理地址
header:请求头
*/
func Post(httpUrl, postStr, proxyAddr string, header map[string]string) string {
proxy, err := url.Parse(proxyAddr)
if err != nil {
log.Fatal(err)
}
var netTransport *http.Transport
//如果代理不为空则设置代理
if proxyAddr != "" {
netTransport = &http.Transport{
Proxy: http.ProxyURL(proxy),
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Second * time.Duration(5),
}
} else {
netTransport = &http.Transport{
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: time.Second * time.Duration(5),
}
}
client := &http.Client{
Timeout: time.Second * 10,
Transport: netTransport,
}
req, _ := http.NewRequest("POST", httpUrl, strings.NewReader(postStr))
//添加头部、设置请求头
if header != nil {
for k, v := range header {
if k == "User-Agent" {
req.Header.Set(k, v)
} else {
req.Header.Add(k, v)
}
}
}
resp, err := client.Do(req)
if resp.StatusCode != 200 {
fmt.Println("StatusCode is", resp.StatusCode)
}
if err != nil {
fmt.Println("Error:url request err:", err)
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("Error:", err)
}
defer resp.Body.Close()
return string(body)
}
需要生成go.mod
go mod init
引用实例
设置go.mod
module testgo
go 1.20
require MyHttp v0.0.0 //添加依赖包
replace MyHttp => ../MyHttp //指定依赖包为本地路径
Main.go
package main
import (
"MyHttp"
"fmt"
)
func main() {
proxyAddr := "http://127.0.0.1:8080"
httpUrl := "http://baidu.com"
params := make(map[string]string, 10)
params["cmd"] = "ipconfig"
header := make(map[string]string, 10)
header["User-Agent"] = "User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
header["cmd"] = "ipconfig"
header["Cookie"] = "TestCookie---"
poststr := "name=zhangsan"
//Get请求
//不使用代理直接传入空字符串即可
getBody := MyHttp.Get(httpUrl, "", params, header)
fmt.Println("Get:\n", getBody)
//Post请求
postBody := MyHttp.Post(httpUrl, poststr, proxyAddr, header)
fmt.Println("Post:\n", postBody)
}
2、正则匹配
在 Golang 中,有一个内置的正则表达式包: regexp 包,其中包含所有操作列表,如过滤、修改、替换、验证或提取
2.1、MatchString
package main
import (
"fmt"
"log"
"regexp"
)
func main() {
words := [...]string{"Seven", "even", "Maven", "Amen", "eleven"}
for _, word := range words {
found, err := regexp.MatchString(".*even", word)
if err != nil {
log.Fatal(err)
}
if found {
fmt.Printf("%s matches\n", word)
} else {
fmt.Printf("%s does not match\n", word)
}
}
}
输出:

不建议使用MatchString,性能低
2.2、 Compile
Compile 函数解析正则表达式,如果成功,则返回可用于匹配文本的 Regexp 对象。 编译的正则表达式产生更快的代码。
定义
func Compile(expr string) (*Regexp, error)
示例
package main
import (
"fmt"
"log"
"regexp"
)
func main() {
words := [...]string{"Seven", "even", "Maven", "Amen", "eleven"}
for _, word := range words {
//获取正则表达式对象
re, err := regexp.Compile(".*even")
if err != nil {
log.Fatal(err)
}
//正则匹配
found := re.MatchString(word)
if found {
fmt.Printf("%s matches\n", word)
} else {
fmt.Printf("%s does not match\n", word)
}
}
}
2.3、MustCompile
定义
func MustCompile(str string) *Regexp
区别
1、Compile函数基于错误处理设计,将正则表达式编译成有效的可匹配格式,适用于用户输入场景。当用户输入的正则表达式不合法时,该函数会返回一个错误。
2、MustCompile函数基于异常处理设计,适用于硬编码场景。当调用者明确知道输入不会引起函数错误时,要求调用者检查这个错误是不必要和累赘的。我们应该假设函数的输入一直合法,当调用者输入了不应该出现的输入时,就触发panic异常
示例
package main
import (
"fmt"
"regexp"
)
func main() {
words := [...]string{"Seven", "even", "Maven", "Amen", "eleven"}
re := regexp.MustCompile(".even")
for _, word := range words {
found := re.MatchString(word)
if found {
fmt.Printf("%s matches\n", word)
} else {
fmt.Printf("%s does not match\n", word)
}
}
}
运行结果

2.4、FindAllString
FindAllString 函数返回正则表达式的所有连续匹配的切片。
定义
func (re *Regexp) FindAllString(s string, n int) []string
我们使用 FindAllString 查找所有出现的已定义正则表达式。
n 是查找次数,负数表示不限次数。
第二个参数是要查找的最大匹配项; -1 表示搜索所有可能的匹配项
package main
import (
"fmt"
"regexp"
)
func main() {
content := "Foxes are omnivorous mammals belonging to several genera\nof the family Canidae. Foxes have a flattened skull, upright triangular ears,\na pointed, slightly upturned snout, and a long bushy tail. Foxes live on every\ncontinent except Antarctica. By far the most common and widespread species of\nfox is the red fox"
re := regexp.MustCompile(".e")
foundSlice := re.FindAllString(content, -1)
if foundSlice == nil {
fmt.Println("foundSlice is nil")
}
for _, s := range foundSlice {
fmt.Println(s)
}
}
输出:

提取fox复数
re := regexp.MustCompile("(?i)fox(es)?")
使用 (?i) 语法,正则表达式不区分大小写。 (es)?表示“es”字符可能包含零次或一次

2.5、FindAllStringIndex
定义
func (re *Regexp) FindAllStringIndex(s string, n int) [][]int
返回匹配的下标,
package main
import (
"fmt"
"regexp"
)
func main() {
content := "Foxes are omnivorous mammals belonging to several genera\nof the family Canidae. Foxes have a flattened skull, upright triangular ears,\na pointed, slightly upturned snout, and a long bushy tail. Foxes live on every\ncontinent except Antarctica. By far the most common and widespread species of\nfox is the red fox"
re := regexp.MustCompile("(?i)fox(es)?")
idx := re.FindAllStringIndex(content, -1)
fmt.Printf("%T\n", idx)
for _, j := range idx {
match := content[j[0]:j[1]]
fmt.Printf("%s at %d:%d\n", match, j[0], j[1])
}
}

2.6、Split
Split 函数将字符串切割成由定义的正则表达式分隔的子字符串。它返回这些表达式匹配之间的子字符串切片。
package main
import (
"fmt"
"log"
"regexp"
"strconv"
)
func main() {
var data = `22, 1, 3, 4`
fmt.Printf("%T\n", data)
sum := 0
re := regexp.MustCompile(",\\s*") //匹配逗号和任意数量的空格
vals := re.Split(data, -1) //根据上述正则表达式切割
fmt.Println(vals)
for _, val := range vals {
n, err := strconv.Atoi(val)//我们使用 strconv.Atoi 函数将每个字符串转换为整数
sum += n
if err != nil {
log.Fatal(err)
}
}
fmt.Println(sum)
}
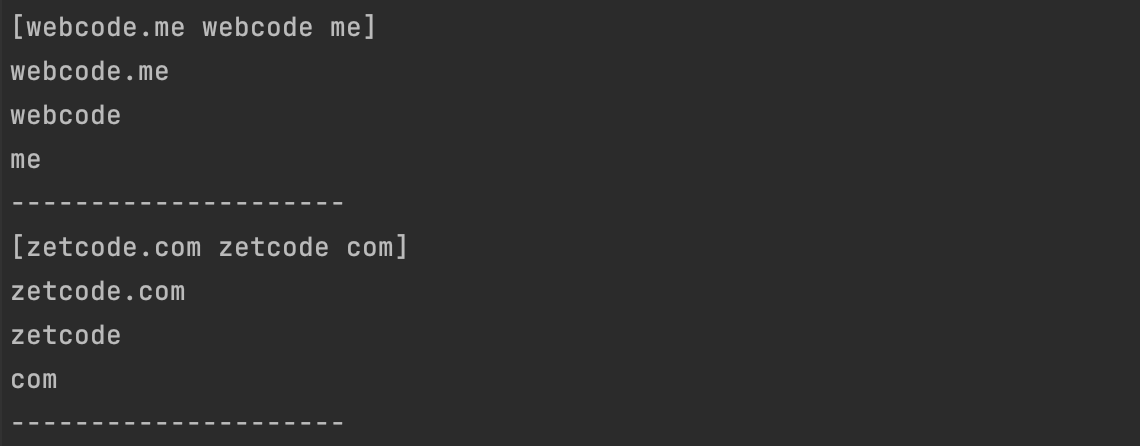
2.7、FindStringSubmatch
FindStringSubmatch 返回包含匹配项的字符串切片,包括来自捕获组的字符串。
package main
import (
"fmt"
"regexp"
)
func main() {
websites := [...]string{"webcode.me", "zetcode.com", "freebsd.org", "netbsd.org"}
re := regexp.MustCompile("(\\w+)\\.(\\w+)")
for _, website := range websites {
parts := re.FindStringSubmatch(website)
fmt.Println(parts)
for i, _ := range parts {
fmt.Println(parts[i])
}
fmt.Println("---------------------")
}
}
输出
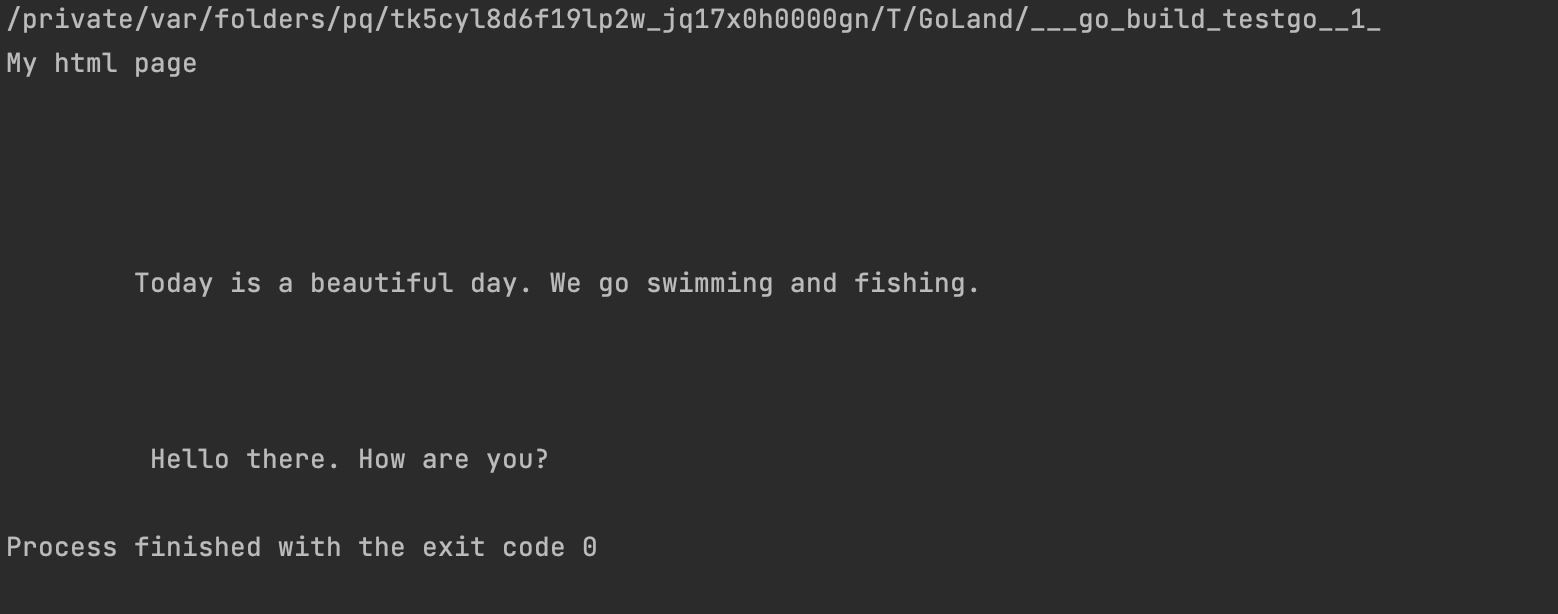
2.8、正则表达式替换字符串(ReplaceAllString)
可以用 ReplaceAllString 替换字符串。该方法返回修改后的字符串。
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"regexp"
"strings"
)
func main() {
resp, err := http.Get("http://webcode.me")
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
content := string(body)
re := regexp.MustCompile("<.*?>")//匹配题所有的<>
replaced := re.ReplaceAllString(content, "")//把匹配到的替换为空
fmt.Println(strings.TrimSpace(replaced))
}
输出
2.9、ReplaceAllStringFunc
ReplaceAllStringFunc 返回一个字符串的副本,其中正则表达式的所有匹配项都已替换为指定函数的返回值。
package main
import (
"fmt"
"regexp"
"strings"
)
func main() {
content := "an old eagle"
re := regexp.MustCompile(`[^a]`) //匹配除了a的任意字符,如:[^a-z]匹配除小写a到z字母外的所有字符
fmt.Println(re.ReplaceAllStringFunc(content, strings.ToUpper))
}
输出
aN OLD EaGLE
3、爬虫简单运用
获取网页的title
package main
import (
"MyHttp"
"fmt"
"regexp"
)
func main() {
httpUrl := "http://www.baidu.com"
params := make(map[string]string, 10)
header := make(map[string]string, 10)
header["User-Agent"] = "User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
header["Cookie"] = "TestCookie---"
//Get请求
//不使用代理直接传入空字符串即可
getBody := MyHttp.Get(httpUrl, "http://127.0.0.1:8080", params, header)
//匹配<title>
re, err := regexp.Compile("<title>.*?</title>")
if err != nil {
fmt.Println("Error:", err)
return
}
body := re.FindAllString(getBody, -1)
content := body[0]
re1, err := regexp.Compile("<.*?>")
if err != nil {
fmt.Println("Error:", err)
}
title := re1.ReplaceAllString(content, "")
fmt.Println(title)
}
输出

参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号