操作系统中堆和栈的区别
操作系统中堆和栈的区别
可执行程序在存储时(没调入到内存)分为代码区,数据区和未初始化数据去(bss)三部分。
1)代码区:存放cpu执行的机器指令。一般代码区可共享(另外的执行程序可调用它),因为对于频繁被执行的程序,只需在内存中由一份代码即可。并且,代码区通常只读,原因时防止程序意外修改其指令。还有代码区还规划了局部变量相关信息。
2)全局初始化数据区/静态数据区:包含了在程序中明确被初始化的全局变量、静态变量(包括全局静态变量和局部静态变量)和常量数据。
比如一个不在任何函数内的声明(全局数据):
int maxcount=99;
使得变量maxcount根据其初值被存储到初始化数据区中。
又或者说是:
static mincount=100;
这声明了一个静态数据,如果是在函数体外声明,则表示其为一个全局静态变量,如果在函数体内,则表示其为一个局部静态变量。另外,如果在函数名前加上static,则表示此函数只能在当前文件中被调用。
3)未初始化数据区(bbs):存入的是全局未初始化变量。BSS区的数据在程序开始执行之前被内核初始化为0或者空指针(NULL)。例如一个不在任何函数内的声明:
long sum[1000];
将变量sum存储到未初始化数据区。
下面的图就是可执行代码存储时结构和运行时结构的对照图,而一个正在运行着的C编译程序占用的内存除了包含代码区、初始化数据区、未初始化数据区,还有堆区和栈区:
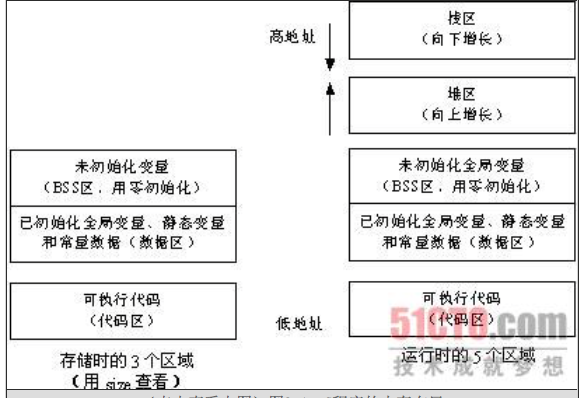
1)代码区:代码区指令根据程序设计流程依次执行,对于顺序指令,每个进程只会执行一次,如果反复,则需要使用跳转指令,如果进行递归,则需要借助栈来实现。
代码区的指令中包括操作码和要操作的对象(或对象地址引用)。如果是立即数(即具体的数值,如5),将直接包含在代码中;如果是局部数据,将在栈区分配空间,然后引用该数据地址;如果是BSS区和数据区,在代码中同样将引用该数据地址。
(2)全局初始化数据区/静态数据区:只初始化一次。
(3)未初始化数据区(BSS):在运行时改变其值。
(4)栈区(stack):由编译器自动分配释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。每当一个函数被调用,该函数返回地址和一些关于调用的信息,比如某些寄存器的内容,被存储到栈区。然后这个被调用的函数再为它的自动变量和临时变量在栈区上分配空间,这就是C实现函数递归调用的方法。每执行一次递归函数调用,一个新的栈框架就会被使用,这样这个新实例栈里的变量就不会和该函数的另一个实例栈里面的变量混淆。
(5)堆区(heap):用于动态内存分配。堆在内存中位于bss区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
分了这么5个区域来存放数据,主要有以下几个考虑:
1)一个进程在运行过程中,代码是根据流程依次执行的,只需访问一次,不过跳转和递归有可能使代码执行多次。而数据一般都需要访问多次,因此单独开辟空间以方便访问和节约空间。
2)临时数据以及需再次使用的代码在运行时放入栈区中,生命周期短。
3)全局数据和静态数据有可能在整个程序执行过程中都需要访问,因此单独存储管理。
4)堆区是由用户自由分配的,以便管理。
下面通过一段简单的代码来查看C程序执行时的内存分配情况。相关数据在运行时的位置如注释所述。

堆和栈的区别
前面已经讲过,栈是由编译器在需要时分配的,不需要时自动清除的变量存储区。里面的变量通常是局部变量、函数参数等。堆是由malloc()函数(C++语言为new运算符)分配的内存块,内存释放由程序员手动控制,在C语言为free函数完成(C++中为delete)。
堆和栈的主要区别:
(1)管理方式不同。
栈编译器自动管理,无需程序员手工控制;而堆空间的申请释放工作由程序员控制,容易产生内存泄漏。
(2)空间大小不同。
栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,当申请的空间超过栈的剩余空间时,将提示溢出。因此,用户能从栈获得的空间较小。
堆是向高地址扩展的数据结构,是不连续的内存区域。因为系统是用链表来存储空闲内存地址的,且链表的遍历方向是由低地址向高地址。由此可见,堆获得的空间较灵活,也较大。栈中元素都是一一对应的,不会存在一个内存块从栈中间弹出的情况。
(3)是否产生碎片。
对于堆来讲,频繁的malloc/free(new/delete)势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低(虽然程序在退出后操作系统会对内存进行回收管理)。对于栈来讲,则不会存在这个问题。
(4)增长方向不同。
堆的增长方向是向上的,即向着内存地址增加的方向;栈的增长方向是向下的,即向着内存地址减小的方向。
(5)分配方式不同。
堆都是程序中由malloc()函数动态申请分配并由free()函数释放的;栈的分配和释放是由编译器完成的,栈的动态分配由alloca()函数完成,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行申请和释放的,无需手工实现。
(6)分配效率不同。
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行。堆则是C函数库提供的,它的机制很复杂,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大的空间,如果没有足够大的空间(可能是由于内存碎片太多),就有需要操作系统来重新整理内存空间,这样就有机会分到足够大小的内存,然后返回。显然,堆的效率比栈要低得多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号