
《Detection of Malicious Code Variants Based on Deep Learning》
Abstract
随着互联网的发展,恶意代码攻击呈指数级增长,其中恶意代码变种被列为互联网安全的关键威胁之一。检测恶意代码变体的能力对于防范安全漏洞、数据窃取和其他危险至关重要。现有的方法里,恶意代码识别的检测精度低、速度慢。本文提出了一种利用深度学习来提高恶意代码变种检测的新方法。在之前的研究中,深度学习在图像识别中表现出了卓越的性能。为了实现我们提出的检测方法,我们将恶意代码转换为灰度图像。然后,使用能够自动提取恶意软件图像特征的卷积神经网络(CNN)对图像进行识别和分类;此外,利用 bat 算法解决了不同恶意软件类别之间的数据不平衡问题。为了测试我们的方法,我们在恶意软件图像数据上进行了一系列实验。实验结果表明,与其他恶意软件检测模型相比,该模型取得了较好的准确率和速度。
Index Terms
Malware variants, grayscale image, deep learning, convolution neural network, bat algorithm.
1. Introduce
随着信息技术的快速发展,恶意代码呈指数级增长,已成为互联网安全的主要威胁之一。Symantec 最近的一份报告显示,2016年发现了4.01亿个恶意代码,其中包括3.57亿个新的恶意代码变种[22]。移动设备和物联网中恶意软件的出现也迅速增长。截至目前,已有68个新的恶意代码派别和超过10000个恶意代码被报告。这种增长对云计算环境下的恶意代码检测也提出了挑战[14],[15]。
恶意代码变种的发现作为安全防护的关键环节尤为具有挑战性。恶意软件检测方法主要包括静态检测和动态检测两类。静态检测采用 disassembling (反汇编)对恶意代码进行组装,分析其执行逻辑。动态检测通过在安全的虚拟环境或沙箱中执行恶意代码来分析恶意代码的行为。
静态检测和动态检测都是基于特征的检测方法。首先提取恶意代码的文本或行为特征,然后通过分析这些特征对恶意代码进行检测或分类。近年来,已有学者利用数据挖掘方法对[28]恶意代码进行特征分析。与传统的启发式检测方法相比,该方法具有效率高、误报率低的优点,已成为恶意软件检测的主流方法。图1展示了使用数据挖掘检测恶意代码的过程。

不幸的是,基于特征分析的方法经常被 disrupted。静态特征分析的有效性可能会受到混淆技术的阻碍,这些混淆技术将恶意软件的二进制文件转换为自压缩或结构独特的二进制文件。动态特征分析经常受到各种防护措施的挑战,导致结果不可靠。此外,某些类型的恶意代码可能由于执行环境不符合规则而无法被动态分析发现。
最近,Nataraj等人提出了一种基于图像处理技术的恶意软件可视化方法,而不是专注于用不可见的特征进行恶意软件辨别。该工作将经过打包的二进制样本转换为二维(2-D)灰度图像,然后利用图像特征进行分类。此外,针对恶意代码分析[20],我们对比研究了两种不同的特征设计策略。结果表明,基于二进制纹理的策略提供了与动态分析技术大致相当的性能,但检测时间更短。
challenge:恶意代码检测方法主要依赖于对恶意代码特征(如静态特征和动态特征)的分析。基于各种机器学习技术的更强大的检测方法也使用这些特征来发现恶意代码或其变种。然而,这些方法在检测恶意代码变种或未知恶意代码时效果不佳。恶意代码可视化方法可以解决代码混淆问题,但提取复杂的图像纹理特征(如 GIST 和 GLCM)需要较高的时间成本。此外,这些特征提取方法在暴露于大数据集时也显示出低效率。构建恶意软件检测模型的挑战是寻找一种有效且自动地提取特征的方法。
Challenge:此外,数据不平衡问题还带来了另一个挑战。在每年产生的大量恶意软件中,有相当一部分的恶意软件变体是属于现存的恶意代码派别的。不同的代码家族中恶意代码变种的数量通常存在较大差异。当前的挑战:建立一个通用的检测模型,可以处理大量的变种,以便它可以很好地跨派别检测出恶意代码。
Contributions:针对上述挑战,本文提出了以下贡献
- 我们介绍了一个用于将恶意软件二进制文本转化为图像的技术,从而将恶意软件检测问题转化为图像分类问题。
- 我们提出了一种新的方法,即用 CNN 去检测恶意软件的变体。
- 为了解决不同恶意软件派别的数据的不平衡性,我们设计了一种高效的数据均衡算法 bat。
- 大量的实验结果表明,我们提出的方法是一种有效且高效的恶意软件检测方法。
本文其余部分的结构如下:第二部分回顾了相关工作,第三部分详细介绍了基于 CNN 的恶意代码检测方法。第四节提出了基于 bat 算法和数据增强的数据均衡方法。第五节给出了所提出方法的实验评估。最后,第六节对本文进行了总结。
II. RELATED WORK
在本节中将介绍恶意软件的相关研究,包括基于特征分析的恶意软件检测、恶意代码可视化、恶意软件检测的图像处理技术以及基于深度学习的恶意软件检测。
A. Malware Detection Based on Feature Analysis
如前所述,恶意软件检测的特征分析技术主要有两大类:静态分析和动态分析。在静态分析方面,通过对代码的分析,提出了几种方法。例如,Isohara等人[12]开发了一个基于内核行为分析的检测系统,在检测未知应用程序的恶意行为方面表现良好。然而,这种静态方法容易受到混淆技术[18]的欺骗。
针对这一问题,Christodorescu 等人[4]提出了一种新的恶意软件检测算法,该算法使用轨迹语义来表征恶意软件的行为。这种方法被证明在对抗指令混淆方面是有效的(例如,指令重排、插入垃圾代码和注册重新分配)。然而,该方法局限于指令级的有限元分析。此外,模式匹配比较复杂。
动态分析通过评估应用程序的行为(如访问私有数据和使用受限的API调用)来监控和分析应用程序的运行时特征。根据这些信息,建立行为模型来检测恶意代码。这些技术提高了检测性能,但仍然受到各种产生不可靠结果的对策的挑战。此外,动态分析的计算开销大,耗时长,在面对大数据集时效率低下。
B. Malicious Code Visualization
目前,有许多工具可以可视化和操作二进制数据,例如普通的文本编辑器和二进制编辑器。一些研究建议将恶意软件可视化进而进行恶意软件检测[24]。Yoo等人采用自组织映射来可视化计算机病毒[29]。Trinius等人提出了一种类似但内容更丰富的方法:使用两种可视化技术 —— 树图和线程图 —— 来检测和分类恶意软件[23]。Goodall等人并不是单一的检测结果,而是将不同的恶意软件分析工具的结果聚合到一个可视化的环境中,增加了单一恶意软件工具的漏洞检测覆盖率[10]。
上述研究主要集中于恶意软件行为的可视化,但软件源代码可能蕴含着更有意义的模式。如前所述,Nataraj等人提出了一种基于二进制纹理分析的恶意代码检测可视化方法。首先,他们将恶意软件可执行文件转换为灰度图像。然后,他们根据这些图像的纹理特征识别恶意软件。与动态分析方法相比,该方法产生了与动态分析方法相当的结果。在类似的工作中,Han等人将恶意软件二进制信息转换为彩色图像矩阵,并使用一种图像处理方法对恶意软件派别进行分类[11]。
C. Image Processing Techniques for Malware Detection
一旦恶意软件被可视化为灰度图像,恶意软件检测就可以转化为图像识别问题。在[19]中,Nataraj等人使用 GIST 算法对恶意软件图像进行特征提取。然而,GIST 算法耗时较长。近年来,越来越多的图像处理技术被提出。
Daniel等人[8]开发了一种由生物启发的并行实现,用于在二值的二维图像中寻找同调群的代表性几何对象。对于图像融合,Miao等人提出了一种基于shearlet和遗传算法的图像融合算法[17]。在该方法中,采用遗传算法对融合规则中的加权因子进行优化。实验结果表明,该方法能够获得比其他方法更好的融合质量。
然而,这些传统的方法受到了复杂图像纹理特征提取所需的高时间成本的挑战。为了解决这一挑战,我们采用深度学习来有效地识别和分类图像。在下一小节中,我们将介绍我们在基于深度学习的恶意软件检测方面的研究。
D. Malware Detection Based on Deep Learning
深度学习[21]是近年来人工神经网络工作中出现的机器学习研究领域。神经网络可以通过学习深度非线性网络结构逼近复杂函数来解决复杂问题。深度学习使用深度神经网络来模拟人类大脑的学习过程,它比反向传播(BP)更强大。深度学习能够从样本集中学习数据集的本质特征。深度学习作为人工智能的有力工具,在手写数字识别、语音识别、图像识别等领域得到了广泛应用。
由于其强大的特征学习能力,许多学者已将深度学习应用于恶意软件检测。Yuan等人利用深度学习技术设计并实现了一个在线恶意软件检测原型系统Droid-Sec[30],他们的模型通过学习从Android应用程序的静态分析和动态分析中提取的特征,达到了很高的准确性。David等人[7]提出了一种类似但更引人注目的方法,不需要了解恶意软件行为类型。他们的工作基于深度信念网络(DBN),用于恶意软件特征的自动生成和分类。与传统的恶意代码检测方法相比,他们的方法在检测新的恶意代码变种方面具有更高的准确性。
遗憾的是,这些方法都是基于静态分析和动态分析提取的特征进行分析。因此,它们或多或少都受到了特征提取的限制。为了解决这个问题,采用CNN网络学习恶意软件图像特征并自动分类。
III. MALWARE DETECTION BASED ON A CNN
本节介绍了我们改进的基于CNN的恶意代码变种检测方法,包括:
- 将恶意代码映射为灰度图
- 利用 CNN 进行灰度图像检测
图2给出了这两个过程的概述。首先,将恶意代码的二进制文件转化为灰度图像;然后,利用卷积神经网络对图像进行识别和分类;根据图像分类的结果,实现恶意软件的自动识别和分类。
A. Binary Malware to Gray Image
一般来说,有几种方法可以将二进制代码转换为图像。该文采用可视化的.exe类型的恶意软件的二进制文件[19]。一个恶意软件的二进制位串可以被分割成许多长度为8位的子串。每个子字符串都可以看作一个像素,因为其中的8位可以被解释为0 ~ 255之间的无符号整数。例如,位串为 0110000010101100,则执行过程为 0110000010101100 → 01100000,10101100 → 96 172。八位二进制数 \(B = (b7, b6, b5, b4, b3, b2, b1, b0)\) 可以转换为十进制位 \(I\) 如下所示:
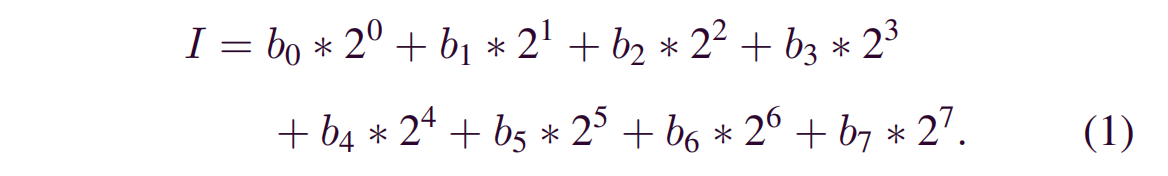
经过二进制转换后,二进制恶意软件位串被转换为十进制数的一维向量。根据指定的宽度,一维数组可以被视为具有一定宽度的二维矩阵。最后,将恶意代码矩阵解释为灰度图像。为简单起见,图像的宽度是固定的,而图像的高度则取决于文件的大小。表1摘自[19],根据经验观察,给出了针对不同文件大小的一些推荐图像宽度。
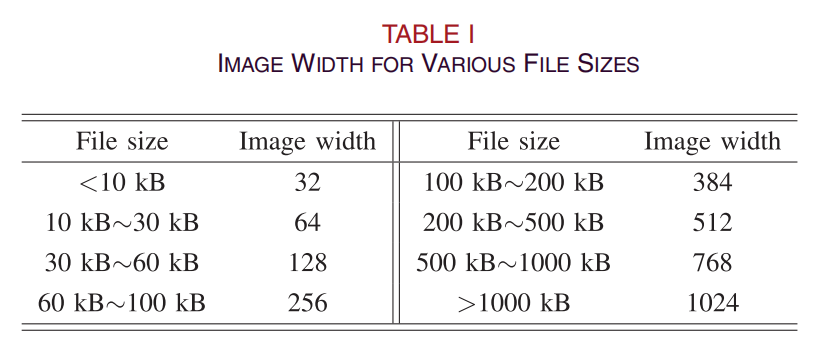
图3显示了来自不同家族[19]的恶意软件图像示例。正如我们所看到的,相同恶意软件家族的图像在视觉上是相似的,并且它们与属于另一个家族的图像则明显不同。例如,图3(a)显示了恶意软件代理的四种变体,称为 Agent。可以发现,虽然每个成员的规模都不一样,但他们仍然有相似之处,因为新的恶意软件通常是由旧软件创建的。此外,当恶意软件派别相似时,图像可以清楚地显示他们的差异。例如,swizzor.gen!的I族,swizzor.gen!的E族有黑色条纹。受恶意软件图像视觉相似性的启发,我们可以利用图像识别方法对恶意软件进行分类和检测。在我们目前的工作中,我们使用卷积神经网络(CNN)来识别恶意软件图像。
B. Malware Image Classification Based on CNN
CNN 作为语音分析和图像识别领域的研究热点其发展迅速。他们的局部感知
权值共享的网络结构降低了模型工作的复杂性和权值的数量。CNN 甚至有
当输入是多维的时候,还有更多的优势。在我们的工作中,图像可以被认为是网络的输入。
与传统的识别算法相比,该方法不受复杂的特征提取和数据重建的阻碍。卷积网络是一个多层感知器,用于识别的二维形状,且对于图像的变形 (例如平移、缩放和旋转) CNN 都能够保持鲁棒性。
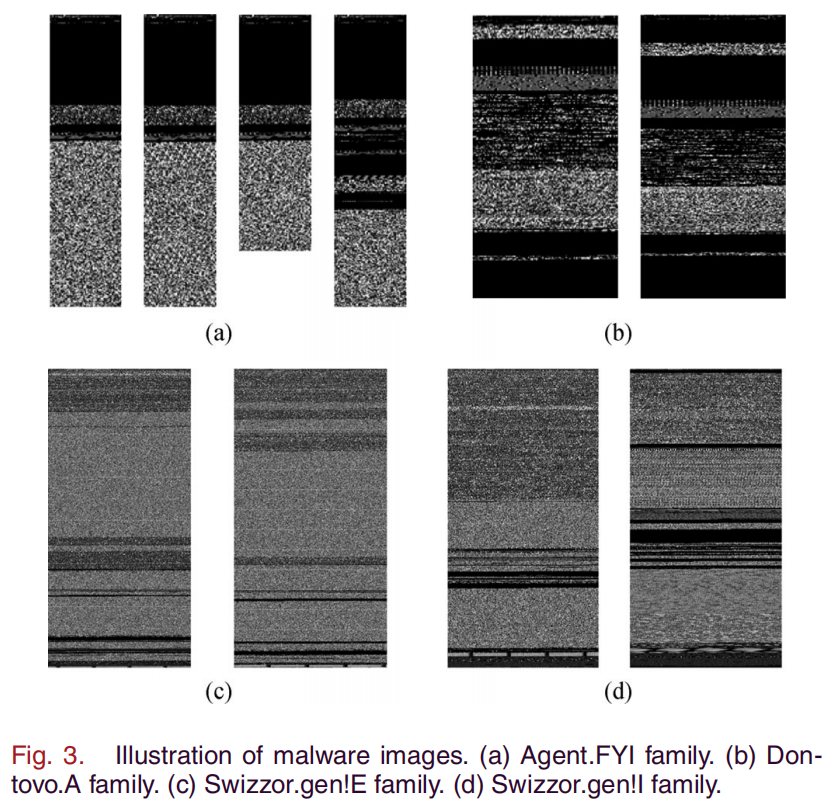
- Conv Layer:本文中,我们开发了一个 CNN 来对恶意软件进行分类。用于灰度图像识别的 CNN 结构由多个组件组成,如图4所示。首先是输入层,它将训练图像输入神经网络。接下来是卷积层和下采样层。前一层可以增强信号特征,降低噪声;后者可以减少数据处理量,同时保留有用信息。然后,有几个全连接层,它们将 2-D 特征转换为符合分类器标准的 1-D 特征。最后,分类器根据恶意软件图像的特征将其识别并分类为不同的家族。各层的详细迭代公式如下:
卷积的传递公式这里就不列举了... 应该普遍都会
- subsampling layers:子采样层也称为池化层。通常会军训最大池化或者平均池化,并且该层不通过反向传播进行修改。这一层可以削弱图像变形的影响(例如:平移、缩放和旋转)。降低了特征图的维数,提高了模型的精度,避免了过拟合。在CNN中,对于采样层的每个输出,特征图的计算如下所示:
下采样的公式也略了...
到目前为止,我们可以得到CNN的权重更新公式,并使用它对恶意软件图像进行分类。然而,在CNN中,结构化网络需要固定大小的图像,因为全连接层的连接矩阵W在训练后是固定大小的。例如,如果从卷积层到全连接层的输入和输出大小分别为30和20个神经元,那么权重矩阵的大小必须为(30,20)。不幸的是,恶意软件的图像大小不是固定的,而是随着软件的大小而变化。因此,我们不能直接将这些恶意软件图像输入CNN。
针对这一问题,将恶意软件图像重构为固定大小的正方形图像(如4848、9696)。通过这种方式,恶意软件图像被归一化后,可以直接输入到 CNN 网络中进行分类。归一化的优点在于它有效地降低了图像的维度,更有利于模型的训练。在降维过程中,不可避免地会丢失一些特征信息。
对于恶意软件数据集中的大多数图像,无论是放大还是缩小,纹理特征都能有效地保持。Dontovo的变体就是一个例子。如图5(a)所示。原始图像大小为64*257。经过压缩(24*24和48*48)或膨胀(96*96和192*192)后,纹理特征保持尖锐(上部为黑色,底部为灰色)。然而,对于纹理特征较小的大图像,重塑操作可能会造成关键信息的丢失。例如,swizzor.gen!E 对应图5(b) 却因压缩过多(从512*718压缩到24*24或48*48)而损坏。
IV. MALWARE IMAGE DATA EQUILIBRIUM
高质量的数据是机器学习和深度学习的关键。粗糙的样本数据会影响模型的质量。相比之下,由高质量数据训练的模型更鲁棒(避免过拟合),并可以加快模型训练速度。恶意软件通常由多个家族组成,每个家族的样本数量差异很大。这种数据上的差异会导致训练模型的准确率低、鲁棒性差。为了解决这个问题,我们采用了一种数据增强技术来提高数据质量。针对不同恶意代码派别之间的数据不平衡问题,提出了一种基于智能优化算法的数据均衡方法(即基于bat算法的动态重采样)。
A. Image Data Augmentation (IDA) Technology
在深度学习中,为了避免过拟合,我们通常需要输入足够的数据来训练模型。如果数据样本比较小,可以利用数据增广来增加样本,从而抑制不平衡数据的影响。适当的数据增强方法可以有效避免过拟合问题,提高模型的鲁棒性。
通常,通过对原始图像数据的变换(改变图像像素的位置并确保特征保持不变)来生成新数据。有许多种类的图像数据增强技术,例如:旋转反射,翻转,缩放,平移,缩放,对比度,噪声和颜色转换。
设 \(A = [a1, a2,…]\) 就是这些技术的集合。\(Mi = am,…,an\) 是操作序列,\(i\) 是 \(M\) 的长度。\(M_2 = a_1, a_2\) 表示使用旋转变换和翻转变换进行数据增广。
通常,每种增强技术都有一个权重 \(λ_i\),因此加权数据增强技术的操作序列可以由 \(M_i = λ_m a_m ,..., λ_n a_n\) 表示:
其中 \(λ_m\) 是增强技术的权重,\(a_m⊆a\)。通常,需要执行多个数据查询。对于灰度图像矩阵 \(m\), \(M_k(m)\) 表示k次增广。图6显示了为恶意软件 swizzor.gen!E 族进行数据增强。显然,大多数新生成的图像保留了原始的文本特征。然而,一些图像由于不恰当的过渡(即过度旋转)而丢失了一些信息。比如左下角的图像就缺少 swizzor.gen!E 族的特征。
B. Data Equalization Based on a Bat Algorithm
不平衡数据是机器学习中常见的问题,在分类问题中会影响模型的准确率。在本文中,恶意软件图像数据非常不均匀的,如图7所示。最大比值约为36:1。例如,Allaple.A 族有2949张图片,而 Skintrim.N 族仅有80个。这种差异对CNN在图像分类中的性能有非常大的影响。若是仅根据两个族的数据训练分类模型,当所有测试样本都是未识别的 Skintrim.N 时,可以达到 97% 的准确率。但是这种情况只能识别部分数据,因此并不是一个非常合理的分类器。

V. EXPERIMENTAL EVALUATION
在本节中,我们对所提出方法的有效性进行了评估。我们的实验基于视觉研究实验室[19]的恶意软件数据集。采用Caffe[13]神经网络框架创建并训练CNN。我们在具有Intel Core i5-4590 CPU (3.3 GHz)、Nvidia GeForce GTX 750Ti GPU (2 GB)和8 GB RAM的PC上运行实验。
A. Dataset and Experimental Setting
该数据集由25个恶意软件族[19]的9342张灰度图像组成。每个家族的样本数量不同。如图7所示,原始数据样本数量存在很大的不平衡。因此,有必要使用数据平衡方法来平衡训练样本的数量。
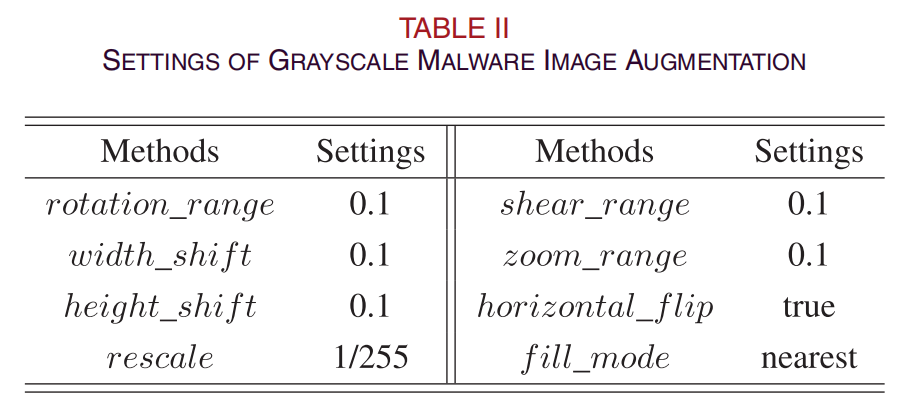
首先,利用数据增强技术提高小样本数据的质量;小样本数据的扩展可以有效地解决训练数据不平衡带来的问题(如过拟合)。图像增强的具体设置如表2所示。
VI. CONCLUSION AND FUTURE WORK
文中提出了一种通过应用深度学习来提高恶意代码变种检测的新方法。首先,该方法将恶意代码转换为灰度图像;然后,使用能够自动提取恶意软件图像特征的 CNN 对图像进行识别和分类;由于CNN在识别恶意软件图像方面的有效性和效率,我们的模型的检测速度明显快于其他方法实现的速度。此外,该模型为不同恶意软件系列之间的数据不平衡问题提供了有效的解决方案。在25个恶意软件家族的9342张灰度图像上的实验结果表明,所提方法在保证检测速度的同时达到了94.5%的准确率。
在这项研究中,CNN框架要求所有输入图像都具有固定的大小,这限制了我们的模型。在未来的工作中,我们希望使用 SPP-net 模型来允许任何大小的图像作为输入。由于其池化层结构, SPP-net 可以在可变尺度上提取特征。我们可以在最后的子采样层和全连接层之间将该层引入模型,以提高模型的灵活性。此外,恶意代码到彩色图像的转换也是一个很好的研究课题。
在表II中,旋转范围表示旋转范围,宽度变换t为水平平移范围,高度变换t为垂直平移范围,rescale为图像放大或缩小的比例,shear范围为水平或垂直方向上投影变换的范围,zoom范围为随机缩放图像的比例。此外,在翻转或展开图像时,我们使用最近方法来填充图像。
对于我们的模型,我们为不同大小的恶意代码图像设计了不同的CNN架构。对于24*24 的输入,我们的模型有7层,包括5个隐藏层。具体结构如下:
- C1:8*20*20
- S2:8*10*10
- C3:16*8*8
- S4:16*4*4
- C5:80*1*1
每种类型的卷积核对应一种类型的特征图。每层的映射指的是每层的特征映射的数量。对于其他尺寸的输入,layers的数量随着尺寸的增加而增加。此外,我们使用 MATLAB R2017a 中带有插值方法 bicubic(默认) 的 imresize 函数来调整图像大小/归一化。
初始学习率设置为0.01,衰减策略设置为inv,最大迭代次数为10000次。最后,利用GPU进行训练。此外,在图像数据平衡方法DRBA中,对于BA,种群规模为20,其他参数与[2]相同。对于评估指标,我们使用准确率、精确率和召回率。这些评价指标在研究界被频繁采用,以提供对不平衡学习问题的全面评估。这些指标定义如下:
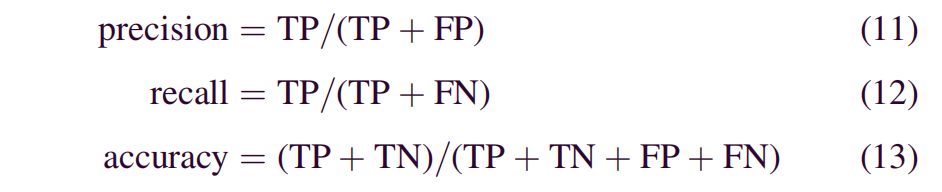
其中,真阳性(TP)和假阳性(FP)分别是被正确分类和被错误分类为恶意文件样本的数量。类似地,真阴性(TN)和假阴性(FN)分别是被正确分类为良性和错误分类为良性的文件样本的数量。
B. Experimental Results
为了验证所提方法的有效性和效率,设计了实验:
- 验证数据均衡方法的效率
- 确定恶意软件图像大小对结果的影响
- 将所提方法与其他恶意代码检测方法的结果进行比较
1. Efficiency of Malware Image Data Equalization:
为了验证我们提出的数据均衡方法的有效性,包括IDA技术和DRBA技术,我们将不使用均衡方法(nothing)与使用IDA、DRBA、IDA+DRBA的模型进行了比较。不同分类模型在训练集上的表现如图8所示。从图8(a)可以看出,即使不对数据集进行处理,所有方法在准确率方面都取得了较好的结果。nothing方法可能会显示过拟合。损失曲线如图8(b)所示,四种方法的结果相似。
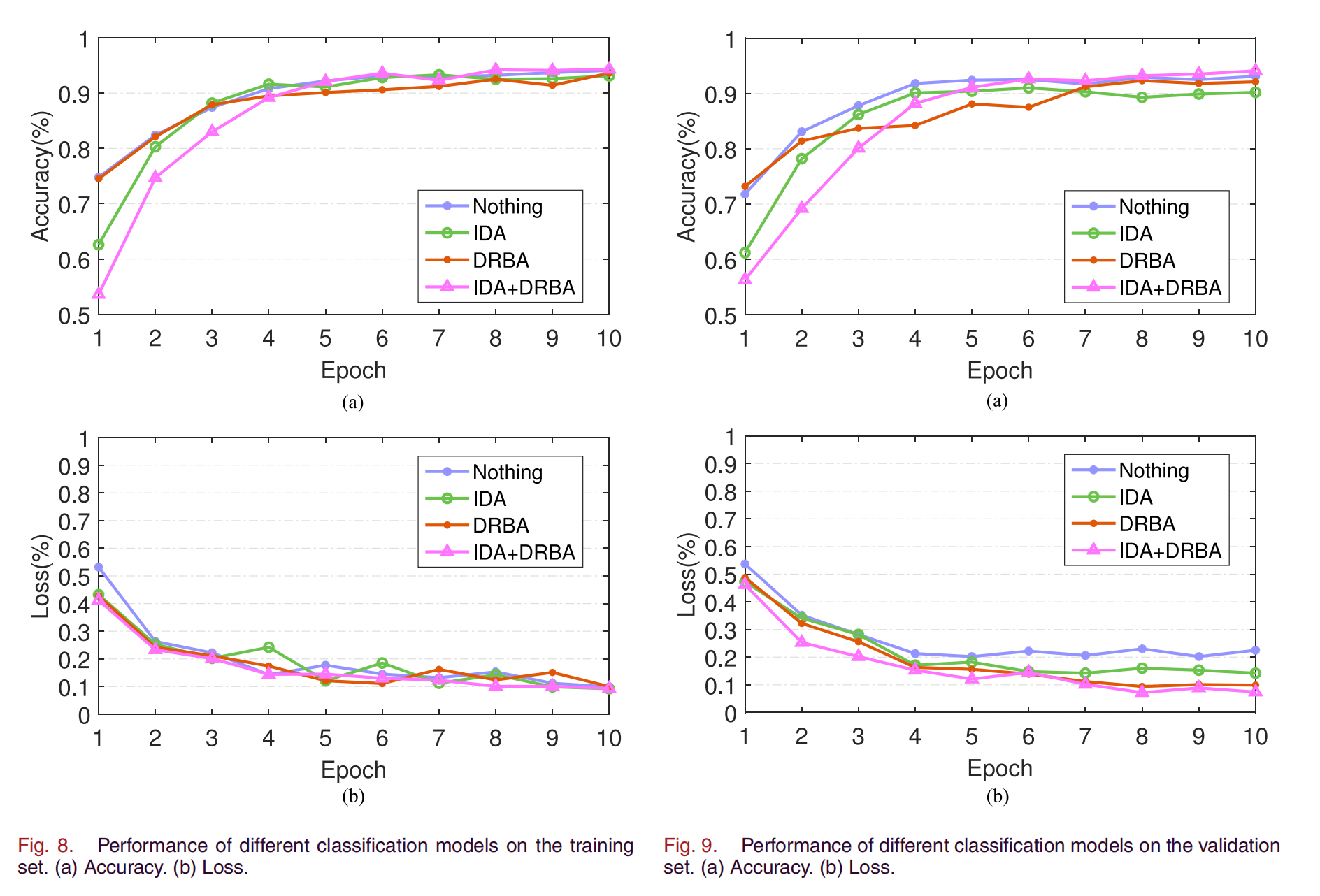
图9显示了不同分类模型在验证集上的性能。从图9(a)可以看出,nothing方法反映了基本 CNN 模型对所有数据的分类。由于样本的不平衡性,容易造成过拟合,因此nothing方法显得精度较高。DRBA法的准确度最好。随着历元的增加,准确率不断提高。IDA方法的精度不如其在训练集上的表现,可能是由于图像在变换过程中丢失了一些图像的特征。训练数据和测试数据之间存在一定差异。从图9(b)可以看出,DRBA和IDA+DRBA的损失曲线呈下降趋势,而nothing的损失曲线在一定范围内振荡,属于过拟合。
2. Model Performance With Different Malware Image Size:
CNN 框架要求所有输入图像具有固定的大小。因此,我们将恶意软件图像重构为固定大小的方形图像。变换后的图像越小,纹理特征破坏越明显。相比之下,较大的图像保真度好,纹理特征清晰。我们进行了实验,将恶意软件图像分别设置为24*24、48*48、96*96和192*192。混淆矩阵如图10所示。

从结果可以看出,随着图像的增大,我们的模型表现得更好。然而,更大的图像需要更多的训练时间。我们注意到96*96和192*192的性能相似,如图10(c)所示。由于使用更大的图像训练分类模型需要更多的时间,因此96*96的图像是在这个恶意软件数据集上训练的一个很好的选择。
3. Comparison of Our Method With Other Malicious Code
Detection Methods:
为了验证所提方法的有效性和效率,我们将所提模型与其他四种使用常见图像特征提取方法的恶意软件检测模型进行了比较。这些方法都提取了恶意软件图像的特征,然后应用机器学习算法(如 KNN 和 SVM)对恶意软件进行识别和分类。为了进行比较,我们使用了一个基于 DRBA 的模型,输入图像为96*96。
表III给出了本文方法与GIST+KNN、GIST+SVM、GLCM+KNN和GLCM+SVM四种组合模型的比较结果。可以看出,我们的方法具有更高的准确率和更快的检测速度。其他方法由于使用GIST或GLCM的方法比较复杂和耗时,性能较差。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号