
Flink源码学习(4) TaskManager从节点启动分析
taskManager是flink的worker节点,负责slot的资源管理和task执行
一个taskManager就是一台服务器的抽象
TaskManager基本资源单位是slot,一个作业的task会部署在一个TM的slot上运行,TM会负责维护本地的slot资源列表,并与Master和JobManager进行通信
启动主类:TaskManagerRunner
TaskManagerRunner.main()
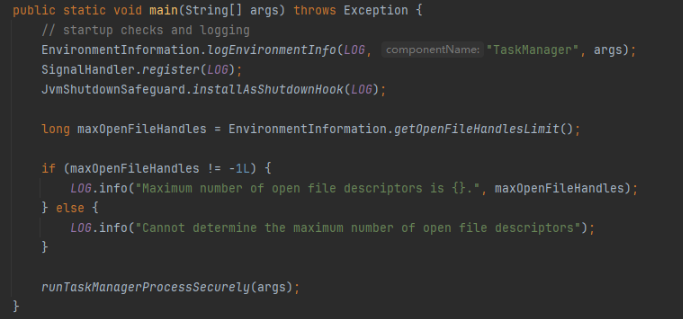
启动函数:runTaskManagerProcessSecurely(args);
Flink集群主节点和从节点,每个节点都有一个全局的唯一ID,叫ResourceID
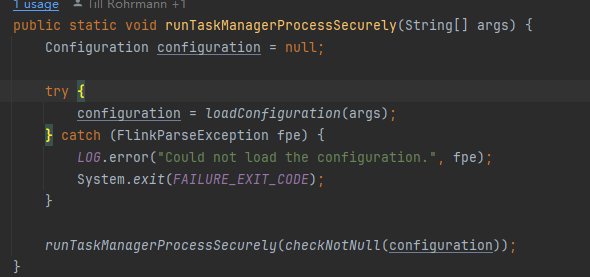
- load解析main方法参数和flink-conf.yaml配置信息
-
runTaskManagerProcessSecurely

- 在主节点启动的时候启动了PluginManager
-
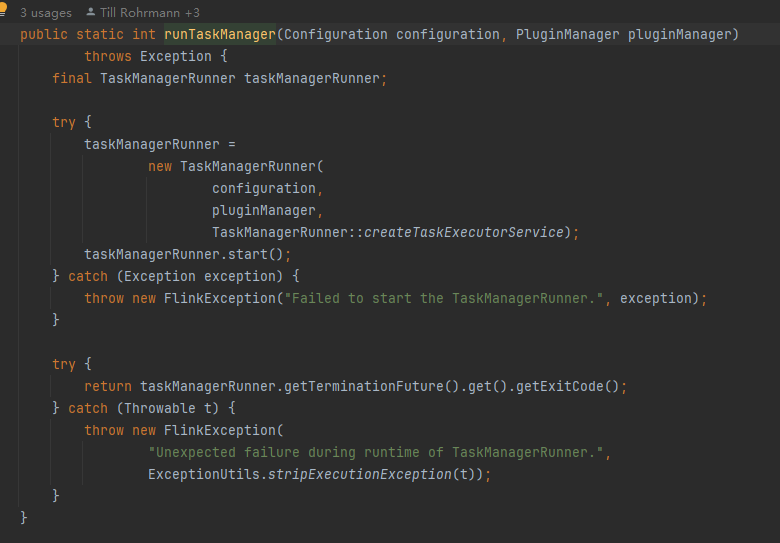
然后再runTaskManager里面通过线程来启动TaskManager
SecurityUtils.getInstalledContext() .runSecured(() -> runTaskManager(configuration, pluginManager)); -
构建tm实例,taskManagerRunner是standalone下TaskManager的可执行入口点。构造相关组件(network,IO,memoryManager,RPCService等)并启动
-
New TaskManagerRunner初始化各种基础服务组件
- 初始化各种组件
- WebMonitorEndpoint
- Dispatcher
- resourceManager
- start方法是发送一个start消息确认启动
-
TaskManager启动分三件事
-
启动基础服务
- 启动7大基础服务
-
初始化taskManagerService
- startTaskManager
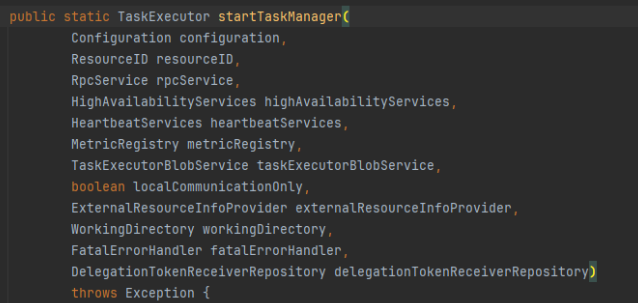 启动中启动了很多服务,同时也启动了TaskExecutor
启动中启动了很多服务,同时也启动了TaskExecutor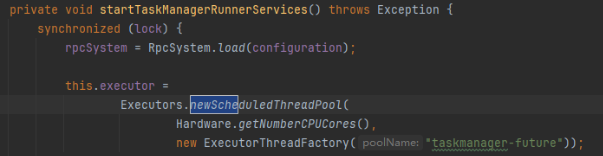
- 线程池,处理回调
- Flink中大量的异步编程
- CompletableFeature大量提交请求的执行和回调的执行都是由线程池执行
- feature.xxx(()->xxx(),executor)
- 定时的线程池(NewScheduledThreadPool):创建一个线程池,它可安排在延迟时间后运行命令或者定期地执行
-
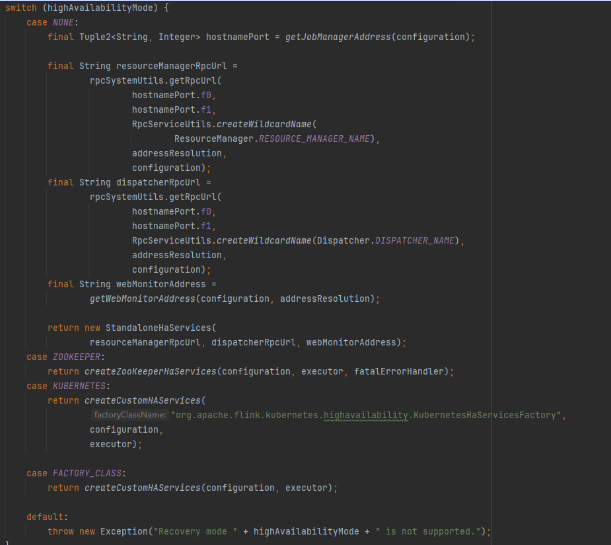
HA高可用服务,用zookeeper来做,在flink-conf.yaml中配置high-availability = zookeeper模式
highAvailabilityServices = HighAvailabilityServicesUtils.createHighAvailabilityServices( configuration, executor, AddressResolution.NO_ADDRESS_RESOLUTION, rpcSystem, this);
-
createRpcService
- createAndStart初始化actor System
-
使用了代理模式
- 代理模式是一种结构型设计模式,它允许一个对象代表另一个对象,从而控制对这个对象的访问。在Flink的RPC服务中,代理模式被用于创建远程调用的代理对象,以便在客户端和服务器之间进行通信。
- 具体来说,在Flink的RPC框架中,RpcService负责创建和启动RpcEndpoint组件的RpcServer,并且提供了与远程RpcServer建立连接的能力。当调用RpcService的connect方法时,它会创建一个代理对象,这个代理对象实现了RpcGateway接口,用于与远程的RpcEndpoint进行通信。
- 当一个TaskManager需要与ResourceManager通信时,它会通过RpcService创建一个连接。RpcService会使用Akka框架创建一个ActorRef,然后通过这个ActorRef创建一个AkkaInvocationHandler或者FencedAkkaInvocationHandler。这个InvocationHandler会被用来创建一个RpcGateway的代理对象,该代理对象可以在本地代表远程的RpcEndpoint
-
heartbeat服务
- taskExecutor心跳组件启动,跟resourceManager维持心跳
- jobMaster心跳组件启动,跟resourceManager维持心跳
- interval=10s并且timeout=50s,也就是连续5次心跳没有就挂了,在flink-conf.yaml设置
- metrics监控服务
-
Blob资源删除服务:两个定时任务,定时检查,删除过期的job资源文件,通过引用计数法来判断文件是否过期
- 主节点启动BlobServer
- 从节点启动BlobCacheService
-
在startTaskManager的最后,初始化TaskExecutor
-
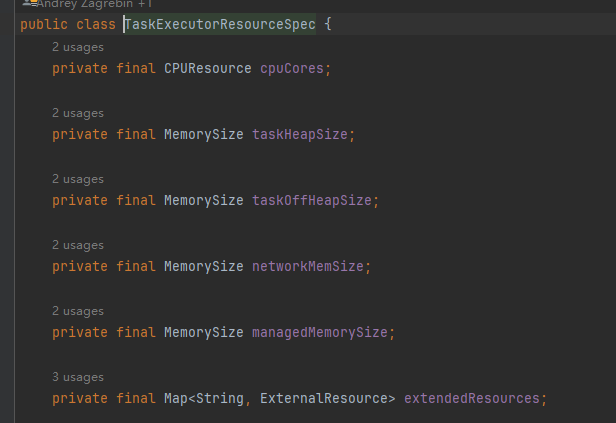
Task资源
final TaskExecutorResourceSpec taskExecutorResourceSpec = TaskExecutorResourceUtils.resourceSpecFromConfig(configuration); -
1台物理节点的资源:cpu,memory。network
-
-
taskManagerService
- 初始化了很多的taskManager要运行过程中需要的服务,真正需要的用来对外提供服务的组件
TaskManagerServices taskManagerServices = TaskManagerServices.fromConfiguration( taskManagerServicesConfiguration, taskExecutorBlobService.getPermanentBlobService(), taskManagerMetricGroup.f1, ioExecutor, fatalErrorHandler, workingDirectory);
-
里面有个shuffleEnvironment,上下游StreamTask有shuffle动作,在过程中,许哟啊很组件工作,这个组件为shuffle提供创建组件的环境支持
-
TaskSlotTable<Task> taskSlotTable
- 哪些task在哪些slot里执行,使用table关联
- 当一个slot被调度执行了一个task,就会生成taskslot对象
- 一个task是由一个线程执行
- Flink:resourceManager+taskManager(slot管理+task执行)
-
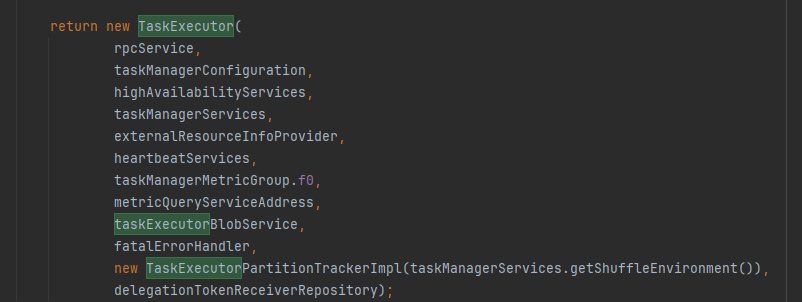
方法返回TaskExecutor,初始化taskManager最重要的目标就是启动taskExecutor
return new TaskExecutor( rpcService, taskManagerConfiguration, highAvailabilityServices, taskManagerServices, externalResourceInfoProvider, heartbeatServices, taskManagerMetricGroup.f0, metricQueryServiceAddress, taskExecutorBlobService, fatalErrorHandler, new TaskExecutorPartitionTrackerImpl(taskManagerServices.getShuffleEnvironment()), delegationTokenReceiverRepository);
- 额外
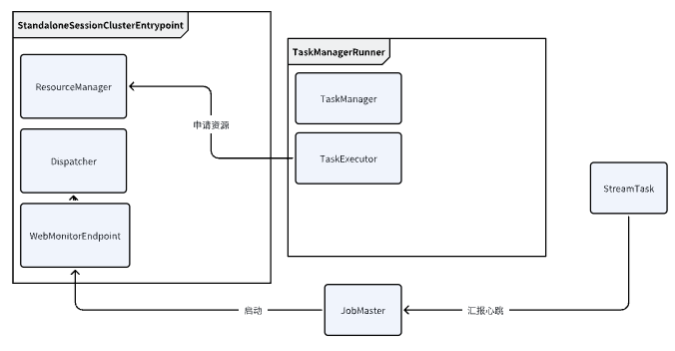
Flink集群主从架构:JobManager,TaskManagerResourceManager(心跳,线程池)+taskExecutor(slot管理,task执行)不管是主节点JobManager还是从节点TaskManager除了关于资源管理和调度意外,还需要其他的服务JobManager是逻辑概念上的主节点,实际上类叫clusterEntryPoint,然后具体叫JobMaster
Standalone
1个Yarn Container
JobManager
启动ResourceManager
启动Dispatcher
其他的 Yarn Container
TaskExecutor
应用程序提交的时候,启动一个JobMaster,再去调度StreamTask执行,向JobMaster汇报心跳
Dispatcher调度一个JobMaster,
-
TaskManager/TaskExecutor注册和心跳
总结:taskManager是一个逻辑抽象,代表一台服务器,启动必然会包含一些服务,另外包含一个TaskExecutor存在于内部,真实ide帮助Task Manager完成各种核心操作:
- 提交task
- 申请和释放slot
创建TaskManager实际上返回的是TaskExecutor
TaskExecutor本身是RpcEndpoint的子类
-
TaskExecutor的初始化:
- 初始化2个心跳管理器,jobManagerHeartbeat resourceManagerHeartbeat
-
hardware Description把硬件资源抽象成一个对象
this.hardwareDescription = HardwareDescription.extractFromSystem(taskExecutorServices.getManagedMemorySize());
-
onStart方法
- 继承的RpcEndpoint,所以需要执行这个方法
-
启动taskExecutorService
-
监控ResourceManager
- resourceManagerLeaderRetriever启动,该服务会监听ResourceManager的领导者变化,以便TaskExecutor能够及时与当前的ResourceManager领导者进行通信。连接ResourceManager
- 注册
-
维持心跳
-
关于Flink中主从节点的心跳
- 首先启动RM,HeartbeatManager,每10s针对那个注册的TaskExecutor执行,发送心跳请求
- 再启动TaskExecutor,首先启动一个超时检查任务5min,启动好了之后会进行注册,接收到心跳之后,相当于RM跟TaskExecutor之间就维持了正常的心跳
- TaskExecutor每次接受到RM心跳请求之后就重置自己的超时任务
-
- 当前TaskExecutor会监控RM的变更
-
启动TaskSlotTable服务
taskSlotTable是TaskExecutor中用于管理任务槽的组件,startTaskExecutorServices方法会调用其start方法,从而初始化任务槽并准备接受任务分配-
核心职责
- 跟踪任务槽状态:TaskSlotTable维护着TaskExecutor上所有可用和已分配的任务槽的状态信息。它记录哪些任务槽是空闲的、哪些正在被使用以及正在运行的任务是什么。
- 任务分配:当JobManager分配新任务给TaskExecutor时,TaskSlotTable负责找到合适的空闲任务槽来运行这些任务。它会根据任务的需求和TaskExecutor的资源情况,智能地分配任务槽。
- 任务槽生命周期管理:TaskSlotTable管理任务槽的整个生命周期,包括任务的启动、停止和重新分配。当一个任务完成或者失败时,TaskSlotTable会释放相应的任务槽,使其回到可用状态。
- 资源隔离:每个任务槽代表TaskExecutor上的一个固定资源子集,包括CPU、内存等。TaskSlotTable确保每个任务槽拥有独立的资源,从而实现任务之间的资源隔离。
- 任务执行监控:TaskSlotTable还负责监控任务的执行状态,包括进度、性能指标等。这些信息对于故障诊断、资源优化和作业调度都是非常重要的。
- 与ResourceManager通信:TaskSlotTable需要与ResourceManager进行通信,报告TaskExecutor上的任务槽使用情况,以便ResourceManager能够做出合理的资源调度决策。
-
监控JobMaster
jobLeaderService是负责与JobMaster通信的服务,它会在startTaskExecutorServices方法中启动。该服务负责监听作业的状态变化,并在TaskExecutor负责执行作业的一部分时,提供必要的领导和管理功能
-
启动FileCache
FileCache是TaskExecutor的文件缓存服务,它在startTaskExecutorServices方法中被创建,用于管理临时文件和缓存,以支持任务的执行- 如果运行了Task,需要jar,配置等,要FileCache管理
- 其实是包装了BlobServer
-

