注意:上一节学习到了Flink启动流程,包括initialize初始化组件。然后创建工厂对象,生产三个实例,也就是webMonitor,ResourceManager和Dispatcher三个对象。
具体过程如下
initializeServices
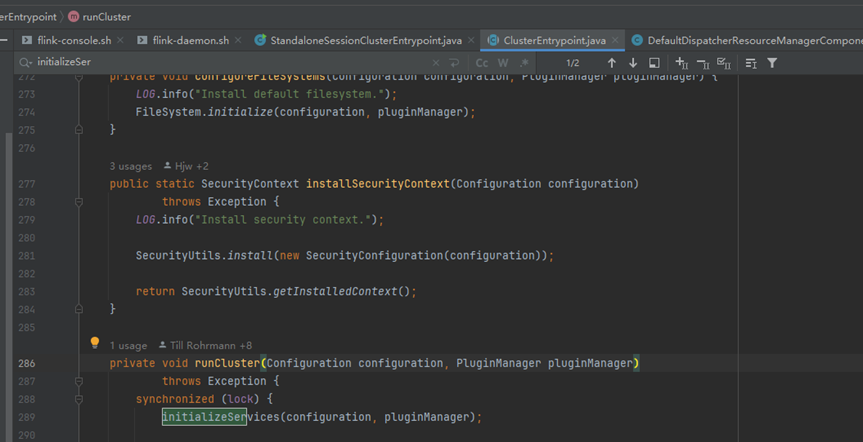
-
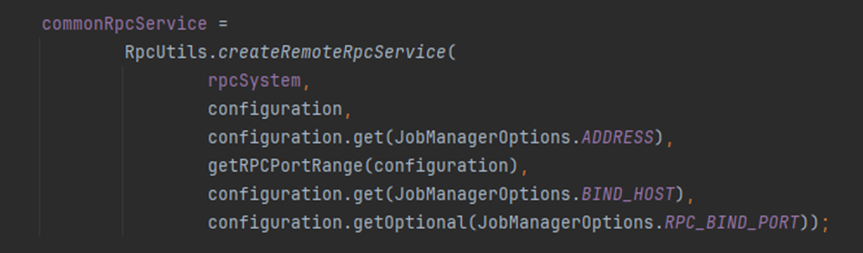
commonRpcService负责处理 Flink 集群内部节点之间的远程过程调用(RPC)
-
commonRpcService基于Akka的RpcService实现。RPC服务启动Akka参与者来接受从RpcGateway调用RPC
- 主要的作用就是启动一个actorSystem
-
具体步骤
- 构建一个builder对象构造器
- 绑定主机名和端口号
-
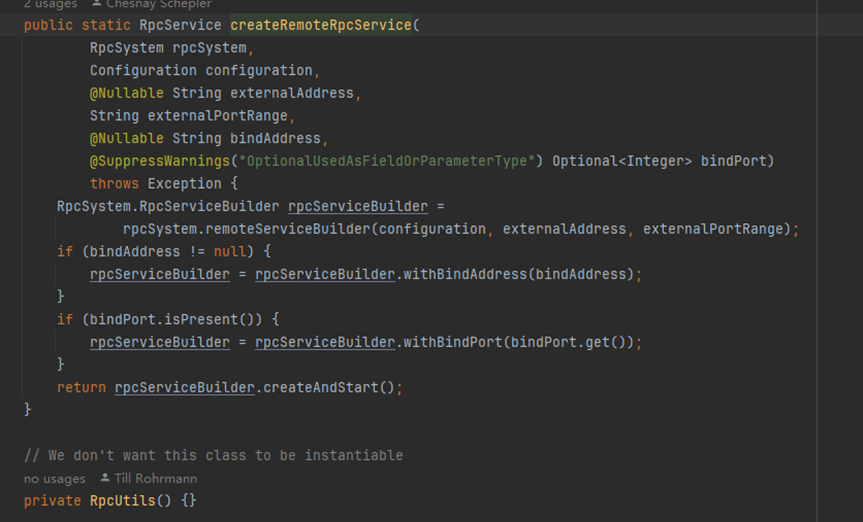
启动rpcservice
- 实现类akkaRpcService
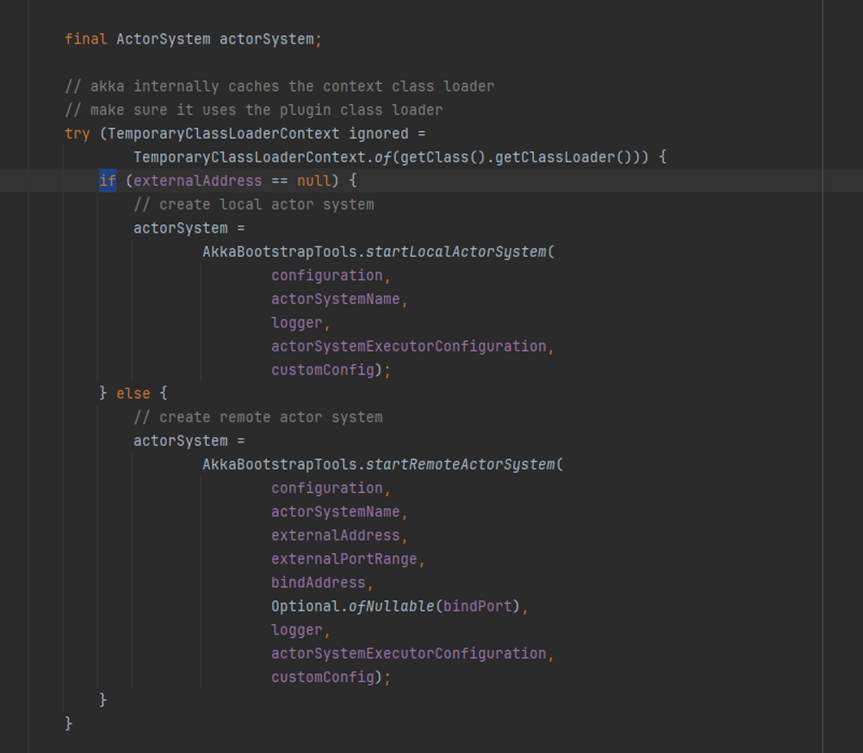
- akkaRpcServiceUtils初始化actorsystem,一般情况创建remote actor system
-
启动一个actor
-
返回一个AkkaRpcService类
return constructor.apply( actorSystem, AkkaRpcServiceConfiguration.fromConfiguration(configuration), RpcService.class.getClassLoader());- 进入之后检查端口号IP地址等操作
-
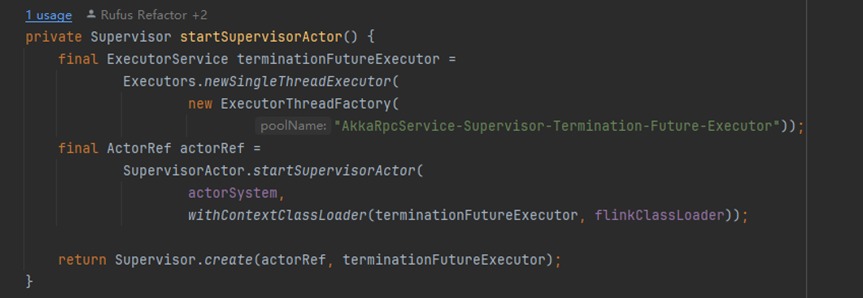
启动一个supervisor = startSupervisorActor();
- 查看代码
- 启动一个单线程的线程池
- 返回一个supervisor,是一个actor
-
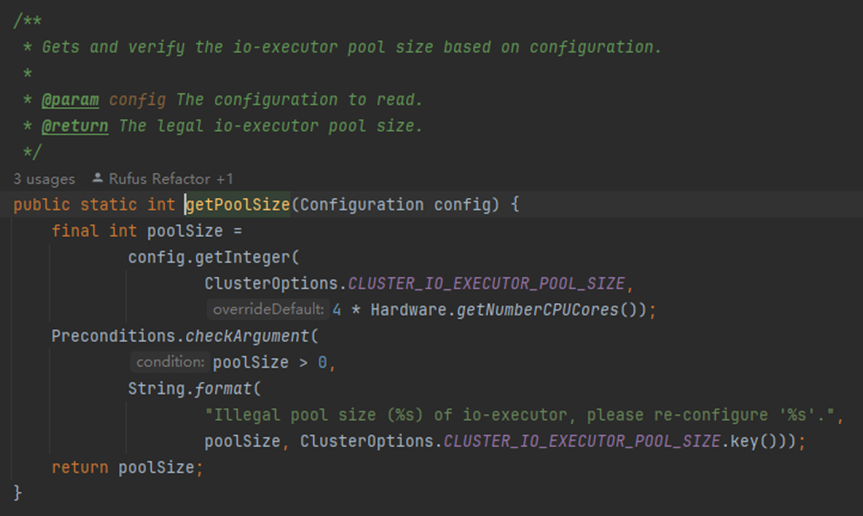
newFixedThreadPool专门负责做io
- 初始化一个io线程池
- 线程池的数量是cpu核数*4,如果当前节点有n个cpu那么当前这个ioExecutor线程数量为4n
-
hasServices:高可用服务
haServices = createHaServices(configuration, ioExecutor, rpcSystem);
具体的代码,主要是包装一个zookeeper对象,用的curatorFrameworkWrapper
public static HighAvailabilityServices createHighAvailabilityServices(
Configuration configuration,
Executor executor,
AddressResolution addressResolution,
RpcSystemUtils rpcSystemUtils,
FatalErrorHandler fatalErrorHandler)
throws Exception {
//在flink-conf中正常来说配置zookeeper
HighAvailabilityMode highAvailabilityMode = HighAvailabilityMode.fromConfig(configuration);
switch (highAvailabilityMode) {
case NONE:
final Tuple2<String, Integer> hostnamePort = getJobManagerAddress(configuration);
final String resourceManagerRpcUrl =
rpcSystemUtils.getRpcUrl(
hostnamePort.f0,
hostnamePort.f1,
RpcServiceUtils.createWildcardName(
ResourceManager.RESOURCE_MANAGER_NAME),
addressResolution,
configuration);
final String dispatcherRpcUrl =
rpcSystemUtils.getRpcUrl(
hostnamePort.f0,
hostnamePort.f1,
RpcServiceUtils.createWildcardName(Dispatcher.DISPATCHER_NAME),
addressResolution,
configuration);
final String webMonitorAddress =
getWebMonitorAddress(configuration, addressResolution);
return new StandaloneHaServices(
resourceManagerRpcUrl, dispatcherRpcUrl, webMonitorAddress);
case ZOOKEEPER:
return createZooKeeperHaServices(configuration, executor, fatalErrorHandler);
case KUBERNETES:
return createCustomHAServices(
"org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory",
configuration,
executor);
case FACTORY_CLASS:
return createCustomHAServices(configuration, executor);
default:
throw new Exception("Recovery mode " + highAvailabilityMode + " is not supported.");
}
}
-
blobServices:大文件传输服务
主要管理jar包,TM上传log文件
blobServer =
BlobUtils.createBlobServer(
configuration,
Reference.borrowed(workingDirectory.unwrap().getBlobStorageDirectory()),
haServices.createBlobStore());
blobServer.start();
-
heartbeatServices:心跳服务
在主节点中,有很多角色都有心跳服务,这些角色的心跳服务都是在这个服务的基础之上创建,这个是专门给各个组件提供一个心跳服务的实例的。这个服务是提供心跳服务的服务。
heartbeatServices = createHeartbeatServices(configuration);
-
metricRegistry:监控服务
系统监控,跟踪性能监控服务,跟踪所有已注册的metric
metricRegistry.startQueryService(metricQueryServiceRpcService, null);
-
executionGraphInfoStore :存储ExecutreJobGraph
executionGraphInfoStore =
createSerializableExecutionGraphStore(
configuration, commonRpcService.getScheduledExecutor());
负责存储和管理作业的执行图(Execution Graph)信息
目的是用来存储execution Graph的服务,有两种形式
memory主要是在内存中缓存
file会持久化到文件中,默认是文件
-
创建工厂实例clusterComponent
用于创建:
webMonitor
ResourceManager
dispatcherResource
-
webMonotor
用于接受客户端的请求
创建一个对象,是一个RpcEndpoint子类
public WebMonitorEndpoint<DispatcherGateway> createRestEndpoint(
Configuration configuration,
LeaderGatewayRetriever<DispatcherGateway> dispatcherGatewayRetriever,
LeaderGatewayRetriever<ResourceManagerGateway> resourceManagerGatewayRetriever,
TransientBlobService transientBlobService,
ScheduledExecutorService executor,
MetricFetcher metricFetcher,
LeaderElectionService leaderElectionService,
FatalErrorHandler fatalErrorHandler)
throws Exception {
final RestHandlerConfiguration restHandlerConfiguration =
RestHandlerConfiguration.fromConfiguration(configuration);
return new DispatcherRestEndpoint(
dispatcherGatewayRetriever,
configuration,
restHandlerConfiguration,
resourceManagerGatewayRetriever,
transientBlobService,
executor,
metricFetcher,
leaderElectionService,
RestEndpointFactory.createExecutionGraphCache(restHandlerConfiguration),
fatalErrorHandler);
}
注意,webMonitorEndpoint并不是RpcEndpoint的子类
接受客户端各种提交的请求
父类是RestServerEndpoint,作用是初始化很多Handler
观察webMonitorEndpoint,初始化了一堆Handler
@Override
protected List<Tuple2<RestHandlerSpecification, ChannelInboundHandler>> initializeHandlers(
final CompletableFuture<String> localAddressFuture) {
ArrayList<Tuple2<RestHandlerSpecification, ChannelInboundHandler>> handlers =
new ArrayList<>(30);
final Collection<Tuple2<RestHandlerSpecification, ChannelInboundHandler>>
webSubmissionHandlers = initializeWebSubmissionHandlers(localAddressFuture);
handlers.addAll(webSubmissionHandlers);
final boolean hasWebSubmissionHandlers = !webSubmissionHandlers.isEmpty();
final Duration asyncOperationStoreDuration =
clusterConfiguration.get(RestOptions.ASYNC_OPERATION_STORE_DURATION);
final Time timeout = restConfiguration.getTimeout();
ClusterOverviewHandler clusterOverviewHandler =
new ClusterOverviewHandler(
leaderRetriever,
timeout,
responseHeaders,
ClusterOverviewHeaders.getInstance());
DashboardConfigHandler dashboardConfigHandler =
new DashboardConfigHandler(
leaderRetriever,
timeout,
responseHeaders,
DashboardConfigurationHeaders.getInstance(),
restConfiguration.getRefreshInterval(),
hasWebSubmissionHandlers,
restConfiguration.isWebCancelEnabled());
JobIdsHandler jobIdsHandler =
new JobIdsHandler(
leaderRetriever,
timeout,
responseHeaders,
JobIdsWithStatusesOverviewHeaders.getInstance());
JobStatusHandler jobStatusHandler =
new JobStatusHandler(
leaderRetriever,
timeout,
responseHeaders,
JobStatusInfoHeaders.getInstance());
……
这些Handler的作用就是flink web业务的rest服务,Handler==Servlet
然后看父类的RestEndpoint
启动的时候都会进行选举
获胜的角色会调用isLeader方法=》this.grantLeaderShip(),失败notLeader
然后进行一个定时任务
这个定时任务专门用来cleanup这些文件是否超过生命周期,要被删除
总结:
这个服务是用来启动native服务端,绑定后处理器,如果接到客户端restful请求,由webmonitor接受处理,看对应请求执行对应handler
-
resourceManager
首先:创建ResourceManager,启动ManagerService
leader Election Service选举后调用isLeader方法
主节点启动,进入HeartbeatMonitor,如果从节点返回心跳,会被加入heartbeatMonitor
管理所有的心跳目标对象
- 开启定时任务checkTaskManageTimeouts检查TaskManager的心跳
- 开启第二个定时任务,检查slotRequest
-
Dispatcher
主要职责:负责接收用户提交的JobGraph然后启动一个JobManager
在ZooKeeperLeaderElectionService中defaultDispatcherRunner
- 先stopDispatcherLeaderProcess停掉现有的
-
runActionIfRunning开启dispatcher服务,startNewDispatcherLeaderProcess
- 执行onStart方法,启动JobGraphStore,一个用来存储JobGraph的存储组件
-
在SessionDispatcherLeaderProcess中启动了createDispatcherIfRunning
-
createDispatcher方法
//调用dispatcherGatewayServiceFactory
Dispatcher = dispatcherFactory.CREATEdISPATCHER
dispatcher.start()
调用初始化
dispatcherBootstraph.initialize
把所有中断的job恢复执行。如果重新启动的话把之前的执行一半的程序恢复起来,底层调用函数恢复中断任务的执行
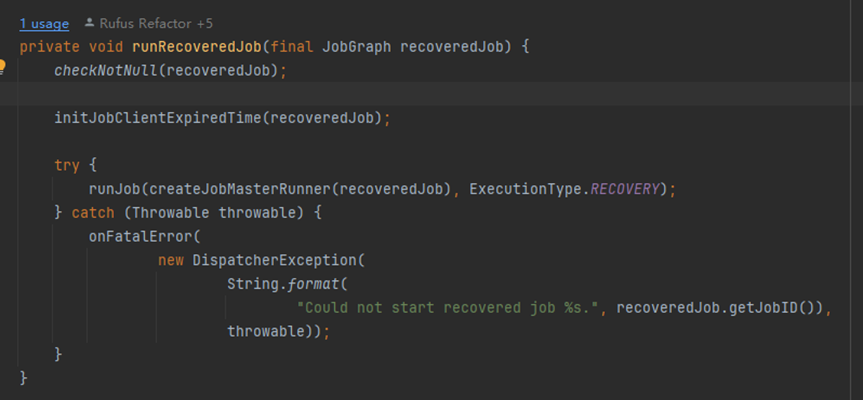
正常提交一个job的时候,由dispatcher接收到来继续提交执行
提交一个job的时候,startJobManagerRunner来启动一个jobManager
因此Dispatcher启动的时候有一件重要的事情,就是恢复节点宕机的任务


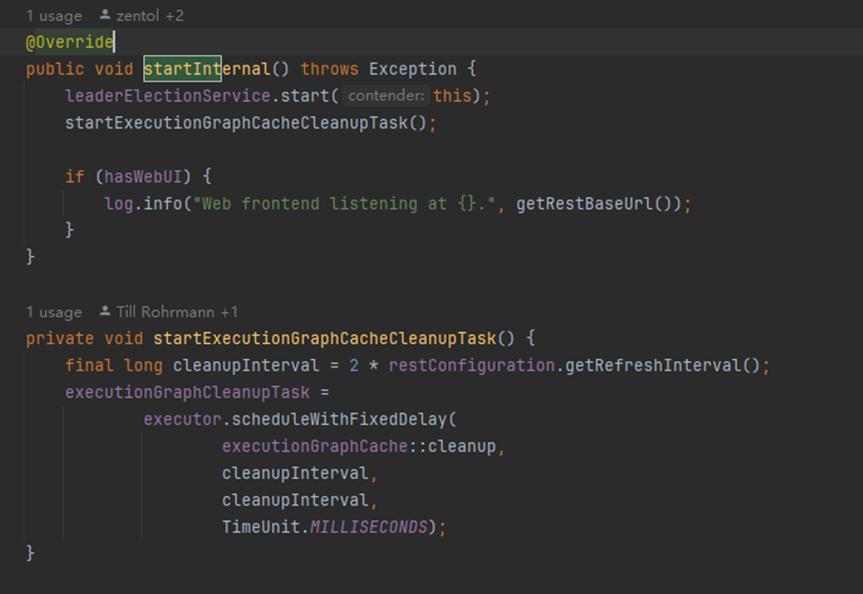 启动的时候都会进行选举获胜的角色会调用isLeader方法=》this.grantLeaderShip(),失败notLeader
启动的时候都会进行选举获胜的角色会调用isLeader方法=》this.grantLeaderShip(),失败notLeader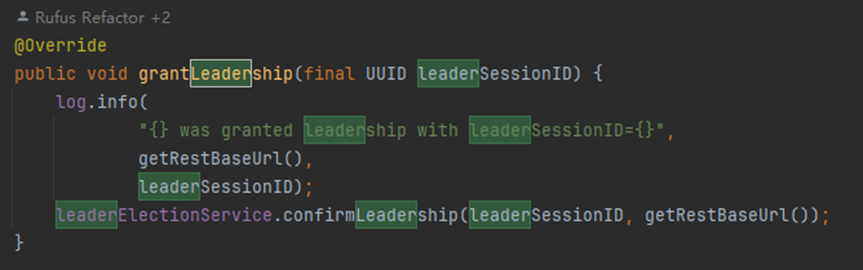 然后进行一个定时任务这个定时任务专门用来cleanup这些文件是否超过生命周期,要被删除总结:这个服务是用来启动native服务端,绑定后处理器,如果接到客户端restful请求,由webmonitor接受处理,看对应请求执行对应handler
然后进行一个定时任务这个定时任务专门用来cleanup这些文件是否超过生命周期,要被删除总结:这个服务是用来启动native服务端,绑定后处理器,如果接到客户端restful请求,由webmonitor接受处理,看对应请求执行对应handler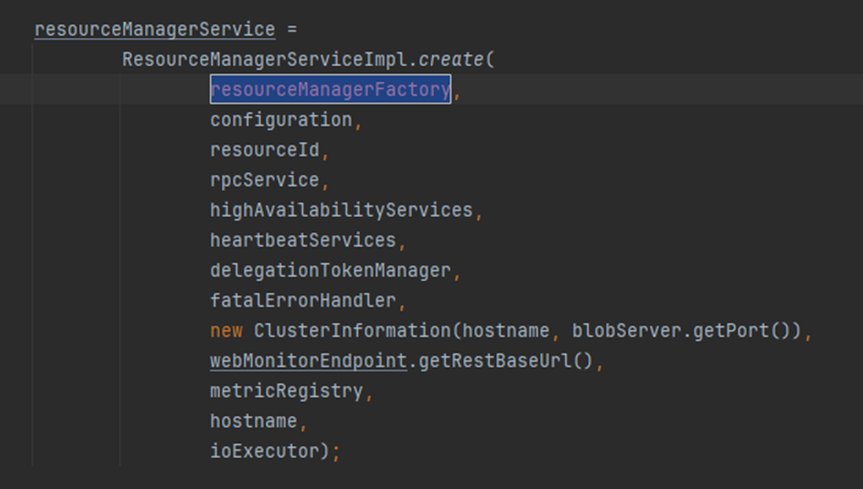 首先:创建ResourceManager,启动ManagerServiceleader Election Service选举后调用isLeader方法主节点启动,进入HeartbeatMonitor,如果从节点返回心跳,会被加入heartbeatMonitor管理所有的心跳目标对象
首先:创建ResourceManager,启动ManagerServiceleader Election Service选举后调用isLeader方法主节点启动,进入HeartbeatMonitor,如果从节点返回心跳,会被加入heartbeatMonitor管理所有的心跳目标对象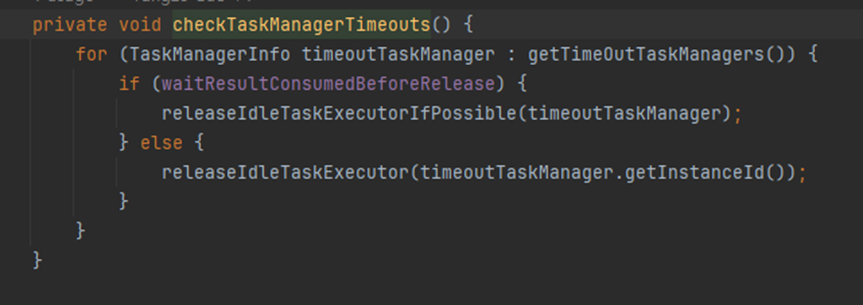
 正常提交一个job的时候,由dispatcher接收到来继续提交执行提交一个job的时候,startJobManagerRunner来启动一个jobManager因此Dispatcher启动的时候有一件重要的事情,就是恢复节点宕机的任务
正常提交一个job的时候,由dispatcher接收到来继续提交执行提交一个job的时候,startJobManagerRunner来启动一个jobManager因此Dispatcher启动的时候有一件重要的事情,就是恢复节点宕机的任务
