Flink源码学习(2) 启动入口
RPCService
RPC主要在flink-rpc模块下,涉及到
RpcGateway 路由,Rpc的老祖宗,所有Rpc组件都是GateWay的子类
RpcServer RpcService和RpcEndpoint之间的粘合层
RpcEndpoint 业务逻辑的载体,对应actor
RpcService 对应actorSystem
Flink RPC主要在flink-rpc模块中

主要看RpcService,他是对应ActorSystem的封装。Flink 使用了 Akka 框架的 actor 模型来实现其
RpcServiceAkka框架的actor模型是啥
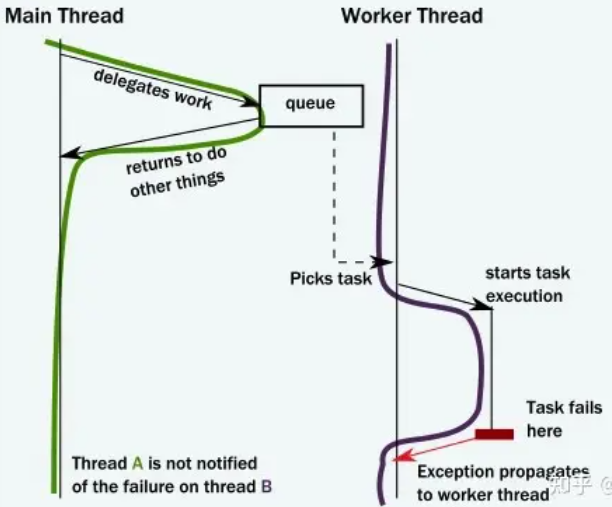
目的:Actor模型被提出的初衷是解决并行处理的问题。在传统的面向对象模型下,完成一套复杂的逻辑/功能,我们需要创建一些对象,每个对象包含一些方法,然后方法之间调来调去。在这个框架下,通常通过多线程来实现并行计算,这就涉及了线程阻塞的问题,以及资源冲突和锁的问题,让代码的设计和编写变得复杂解决方法:Akka模型把复杂功能拆成不同的actor,不同的actor能完成不同的逻辑,actor之间通过消息传递来交互,是异步的,不需要等待返回结果,因此发送完消息就马上继续,避免了阻塞。
- Java并发模型:Java中并发模型是通过共享内存来实现,cpu中会利用cache来加速主存的访问,为了解决缓存不一致的问题,在java中一般会通过使用volatile或者Atmoic来标记变量,让jmm的happens before机制来保障多线程间共享变量的可见性。因此从某种意义上来说是没有共享内存的,而是通过cpu将cache line的数据刷新到主存的方式来实现可见
- 优化点: 因此与其去通过标记共享变量或者加锁的方式,依赖cpu缓存更新,倒不如每个并发实例之间只保存local的变量,而在不同的实例之间通过message来传递。
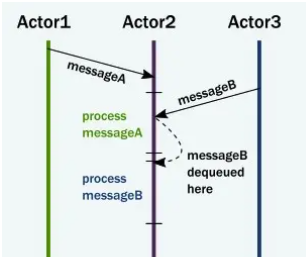
- actor之间互相发送message
- actor在收到message之后存储mailbox中
- actor中mailbox中提取消息,执行自己内部的方法,修改内部状态
- 给其他actor发送消息
- actor内部的执行流程是顺序的,同一时刻只有一个message再进行处理,也就是actor的内部逻辑可实现无锁化变成。actor和线程数解耦,可以创建很多的actor绑定一个线程池来处理,no lock,no block的方式能减少资源开销,并提升并发性能
- 通过监督者来观察是否失败
- 也可以建立链接,不同actor之间感知连接对方状态ACTOR模型可以实现故障检测机制,以便在ACTOR失败时及时检测到。
- 故障检测系统,一旦检测到故障,系统可以触发恢复机制,比如通过复制ACTOR的状态到新的进程,或者将任务重新分配给其他ACTOR
通过这些方法可以解决进程失败如何通知其他进程的问题
Call back方法:
actor模型:
RpcEndpoint
是业务逻辑的载体,业务逻辑卸载RpcEndpoint里面,类似actor的封装
OnStart
/** * User overridable callback which is called from {@link #internalCallOnStart()}. * * <p>This method is called when the RpcEndpoint is being started. The method is guaranteed to * be executed in the main thread context and can be used to start the rpc endpoint in the * context of the rpc endpoint's main thread. * * <p>IMPORTANT: This method should never be called directly by the user. * * @throws Exception indicating that the rpc endpoint could not be started. If an exception * occurs, then the rpc endpoint will automatically terminate. */ protected void onStart() throws Exception {}
只要当前RpcEndpoint被实例化成功后,就会调用onStart方法
OnStop
RpcEndpoint要被销毁的时候,在销毁之前执行onStop方法
RpcEndpoint可以被看作是akka中的actor
因此一个节点完成各种工作,可以写成多个RpcEndpoins,然后被RpcService管理
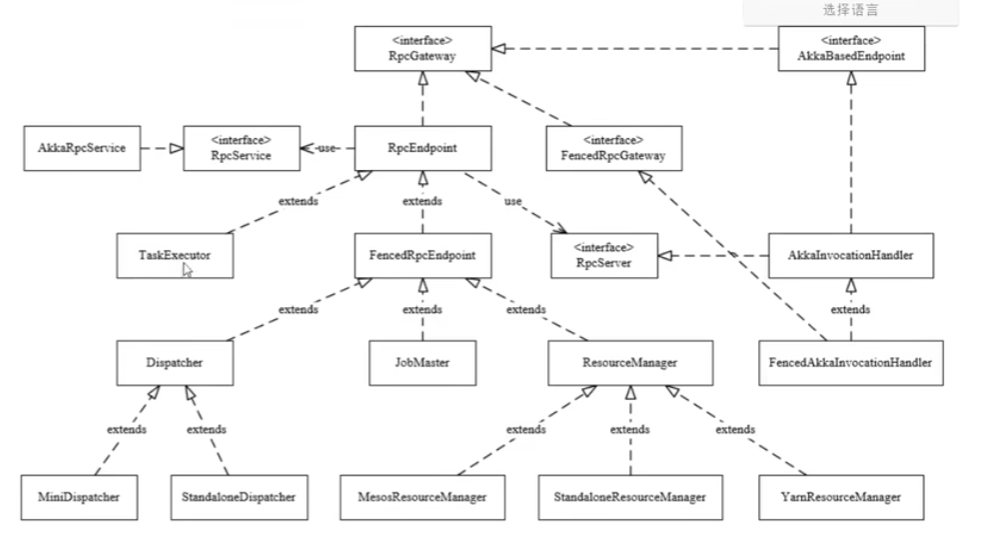
四个重要的子类:
Dispatcher和JobMaster和Resource Manager和TaskExecutor都是RpcEndpoint的子类
当在任意地方发现要创建这四个组件的实例对象的时候,都会要执行onStart方法
启动囧群的时候,很多工作流程都在onStart方法里面
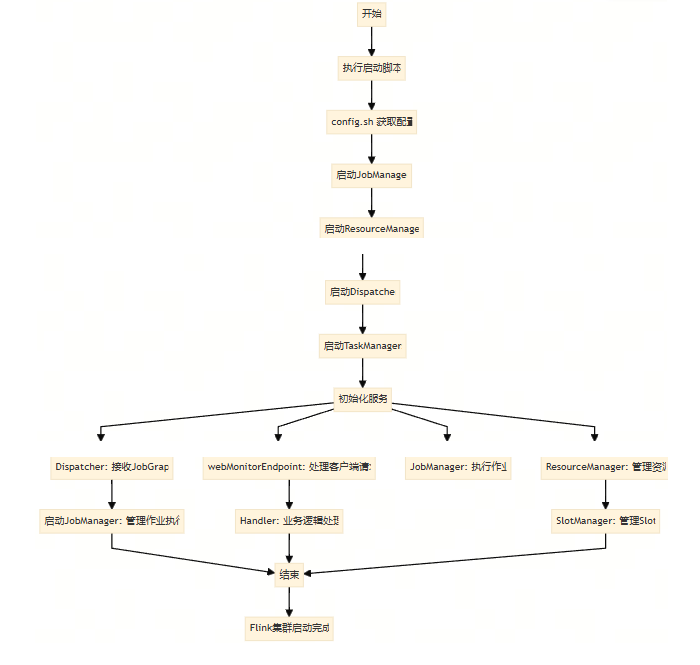
Flink集群启动脚本
flink-dist子项目,里面就是flink常用启动脚本
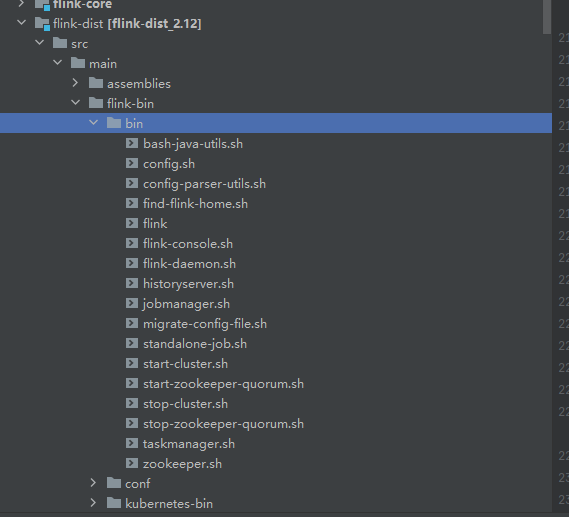
启动脚本
就是start-cluster.sh这个脚本启动下面三个脚本
config.sh taskmanager.sh jobmanager.sh
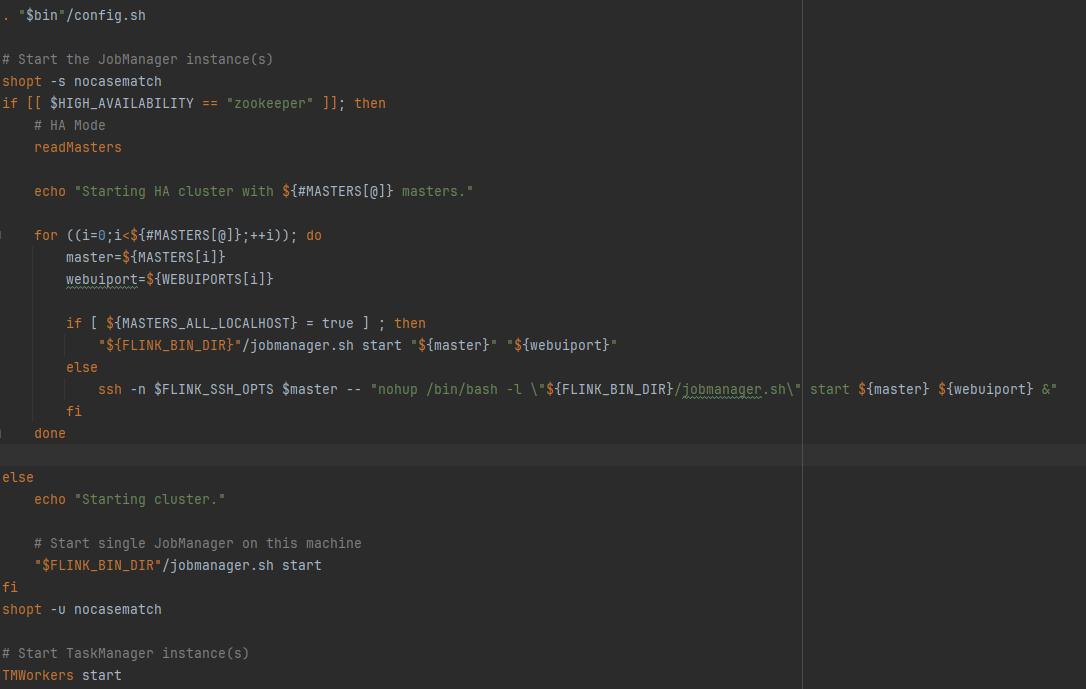
- 首先执行. "$bin"/config.sh,来获取master和worker的信息
-
然后再启动jobmanager,可能启动多个,
- 如果是启动本地:"${FLINK_BIN_DIR}"/jobmanager.sh start "${master}" "${webuiport}"
- 启动远程:ssh -n $FLINK_SSH_OPTS $master -- "nohup /bin/bash -l \"${FLINK_BIN_DIR}/jobmanager.sh\" start ${master} ${webuiport} &"
- 在job manager.sh中
-
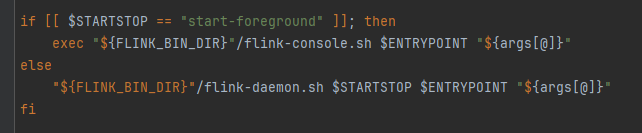
相当于flink-daemon.sh start standalonesession,实现类是Stand alone session cluster entry point你是在启动一个独立的 Flink 会话,也就是在单机模式下启动 Flink。Flink 会在当前节点上启动一个 JobManager 和一个 TaskManager。JobManager 负责接收提交的作业(Job),管理作业的调度和执行状态,而 TaskManager 则负责执行具体的任务和数据的处理。
-
启动所有的taskManager,这方法在config中
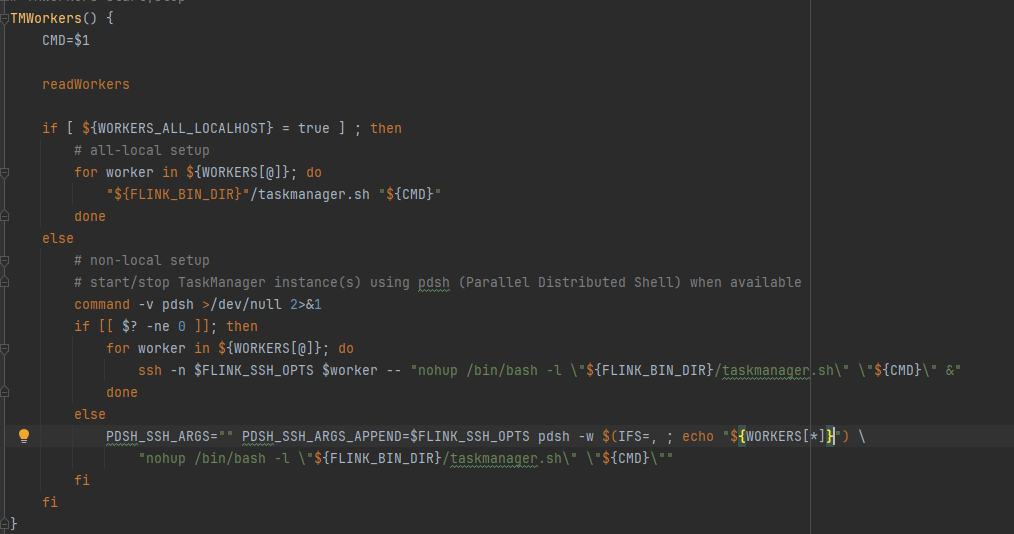
- TMWorker start在config中
- TMWorkers()的作用是读取配置文件获取所有worker节点
- 如果是本地:"${FLINK_BIN_DIR}"/taskmanager.sh "${CMD}"
- 如果是远程:ssh -n $FLINK_SSH_OPTS $worker -- "nohup /bin/bash -l \"${FLINK_BIN_DIR}/taskmanager.sh\" \"${CMD}\" &"
- 实现类是task manager Runner
- 在taskmananger.sh里面最终执行的是flink-daemon.sh
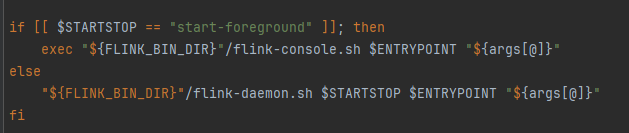
- 所以启动jobmanager和taskmanager都是调用的是flink-daemon.sh
-
flink-daemon.sh脚本
- taskManager:CLASS_TO_RUN=org.apache.flink.runtime.taskexecutor.TaskManagerRunner
- jobManager:CLASS_TO_RUN=org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
- 最后调用到JAVA_RUN=$JAVA_HOME/bin/java去启动

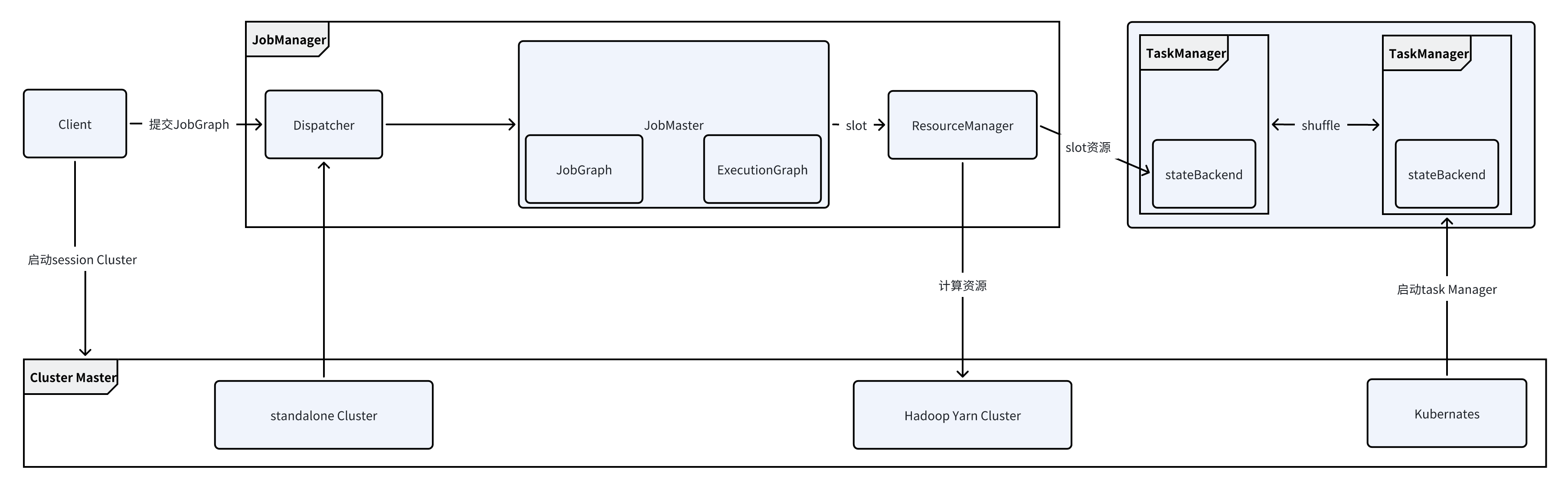
流程分析
启动了Job manager包含三大组件,flink主节点主要启动下面几个组件
初始化各种服务
ResourceManager:集群资源管理器,也启动一个slotmanager管理slot
Dispatcher:接受用户提交的JobGraph,提交一个job的话是生成一个Grapgh,这个组件负责启动一个JobManager来管理
Job Manager:负责一个具体的Job执行:负责一个具体的Job的执行
webMonitorEndpoint:维护了很多的Handler,如果客户端通过flink run的方式提交一个job到flink集群,由webMonitorEndpoint来接受并决定使用哪个Handler来执行处理
主要函数的代码入口
Flink集群的主节点内部运行ResourceManager和Dispatcher,当提交一个job之后Dispatcher会负责拉起一个JobManager负责这个Job的Task的执行,执行的资源由JobManager向Resource Manager申请
-
StandaloneSessionClusterEntrypoint
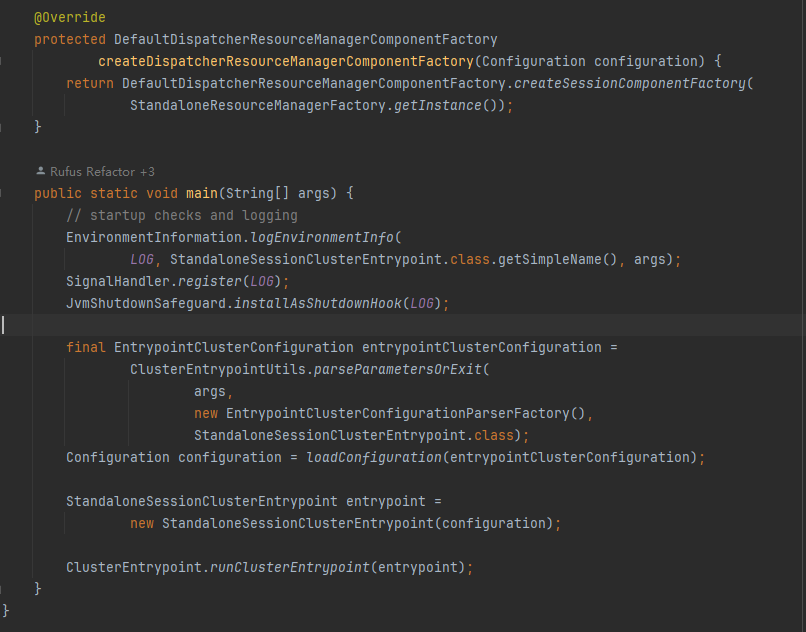
-
clusterEntrypoint->runCluster->初始化各种服务initializeServices,然后调用createDispatcherResourceManagerComponentFactory方法,跳转到StandaloneSessionClusterEntrypoint
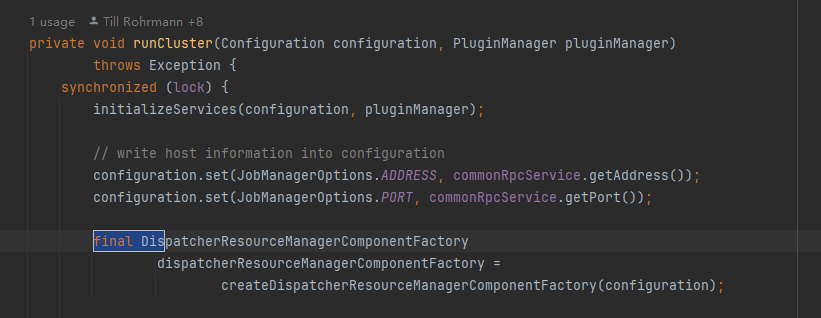
-
创建Dispatcher和ResourceManager的Factory
- 创建DispatcherRunnerFactory工厂对象
- 创建ResourceManagerFactory工厂对象
- 创建RestEndpointFactory,也就是WebMonitorEndpoint的工厂对象
-
返回一个DefaultDispatcherResourceManagerComponentFactory
-
在里面创建webMonitorEndpoint
webMonitorEndpoint = restEndpointFactory.createRestEndpoint( configuration, dispatcherGatewayRetriever, resourceManagerGatewayRetriever, blobServer, executor, metricFetcher, highAvailabilityServices.getClusterRestEndpointLeaderElection(), fatalErrorHandler); -
启动resourceManager
resourceManagerService = ResourceManagerServiceImpl.create( resourceManagerFactory, configuration, resourceId, rpcService, highAvailabilityServices, heartbeatServices, delegationTokenManager, fatalErrorHandler, new ClusterInformation(hostname, blobServer.getPort()), webMonitorEndpoint.getRestBaseUrl(), metricRegistry, hostname, ioExecutor);
-
启动dispatcher
dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner( highAvailabilityServices.getDispatcherLeaderElection(), fatalErrorHandler, new HaServicesJobPersistenceComponentFactory(highAvailabilityServices), ioExecutor, rpcService, partialDispatcherServices);
-
工厂模式
Java中最常用的设计模式,方便的创建对象,无需指定要创建的具体类,不暴露创建对象的具体逻辑,而是将逻辑封装在一个函数中,那么这个函数就可以被视为一个工厂将实际创建对象的代码与使用代码分离思路:定义一个创建对象的接口,让子类自己决定实例化哪一个工厂类使用场景:在不同的条件下创建不同的实例的时候使用实现方法:子类实现工厂接口,创建的过程在子类执行适用举例:在一个 A 类中通过 new 的方式实例化了类 B,那么 A 类和 B 类之间就存在关联。当需要修改B类的代码,在构造函数中传入参数,那么A类也需要修改,如果有很多个类依赖B,那么修改的地方要很多例子:定义一个接口 public interface Factory { void create(); } 定义一个接口的实体类 public class FactoryDetail1 implements Factory{ @Override public void create() { System.out.println("create factory 1"); } } 定义一个工厂 public class Factorymeme { public Factory getfactory(int type){ if(type==1){ return new FactoryDetail1(); } else{ return null; } } } 使用工厂创建 public class FactoryDemo { public static void main(String[] args){ Factorymeme factorymeme = new Factorymeme(); Factory factory1 = factorymeme.getfactory(1); factory1.create(); } }