小文件合并
一、项目背景
在实际项目中,输入数据往往是由许多小文件组成,这里的小文件是指小于HDFS系统Block大小的文件(默认128M), 然而每一个存储在HDFS中的文件、目录和块都映射为一个对象,存储在NameNode服务器内存中,通常占用150个字节。 如果有1千万个文件,就需要消耗大约3G的内存空间。如果是10亿个文件呢,简直不可想象。所以我们要了解一下 hadoop 处理小文件的各种方案,然后选择一种适合的方案来解决本项目的小文件问题。
二、项目介绍
本地 D:\data\73目录下有 2012-09-17 至 2012-09-23 一共7天的数据集,我们需要将这7天的数据集按日期合并为7个大文件上传至 HDFS。
三、项目数据集
四、项目思路分析
基于项目的需求,我们通过下面几个步骤完成:
1、首先通过 globStatus()方法过滤掉 svn 格式的文件,获取 D:\data\73 目录下的其它所有文件路径。
2、然后循环第一步的所有文件路径,通过globStatus()方法获取所有 txt 格式文件路径。
3、最后通过IOUtils.copyBytes(in, out, 4096, false)方法将数据集合并为7个大文件,并上传至 HDFS。
五、编写项目程序参考步骤
第一步:首先自定义 RegexExcludePathFilter 类实现 PathFilter,通过 accept 方法过滤掉D:\data\73目录下的svn文件
第二步:自定义 RegexAcceptPathFilter 类实现 PathFilter,比如只接受D:\data\73\2012-09-17日期目录下txt格式的文件。
第三步:实现主程序 list 方法,完成数据集的合并,并上传至 HDFS。
在此过程中遇到一个坑。 我用的linux的系统,大讲堂教程是windows系统的
路径出现了一些小问题
【图1】 模仿windows中的写法
【图2】 出现查找不到文件集的情况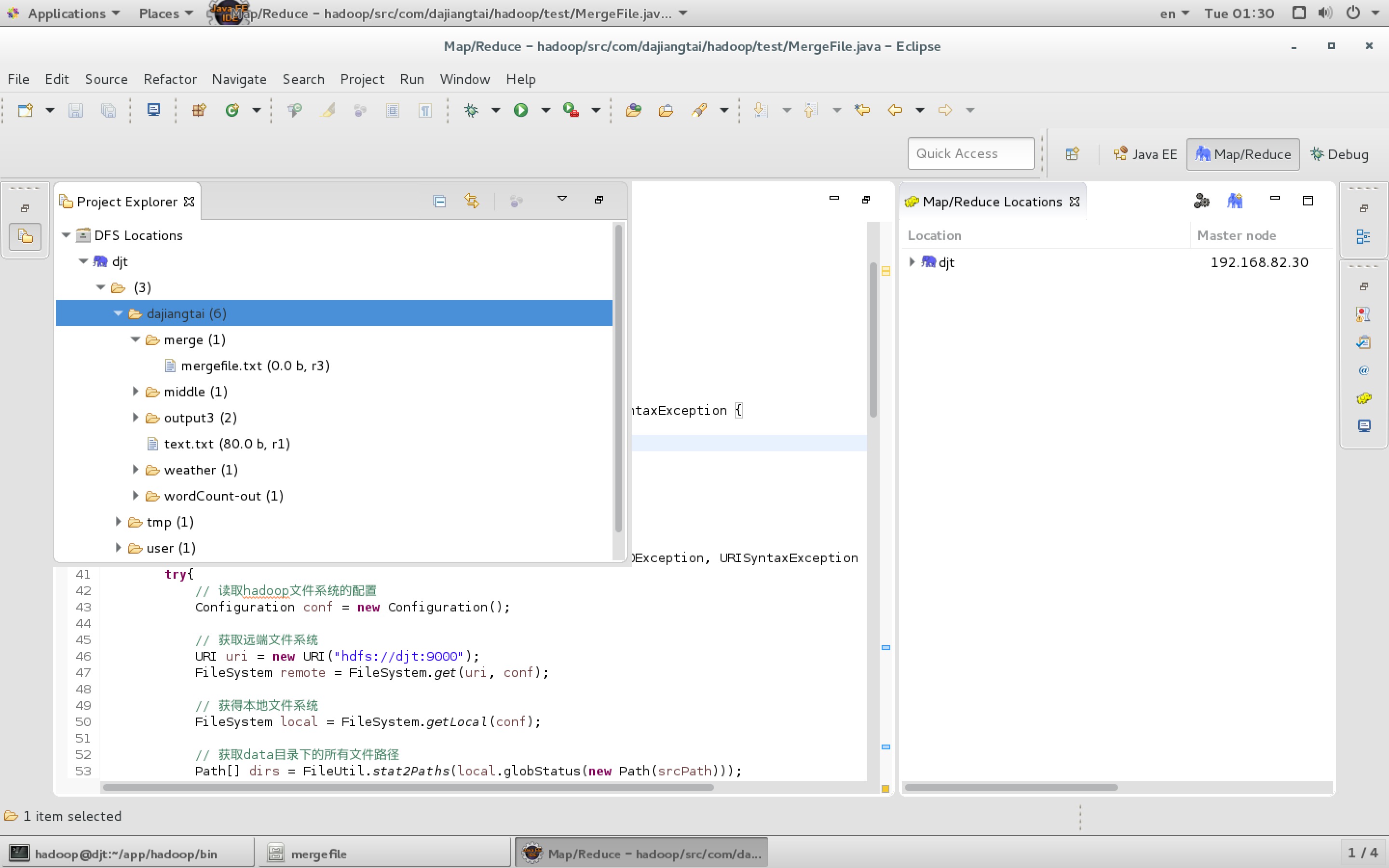
完整且正确的代码:
重点在于linux路径后应该+ /*
package com.dajiangtai.hadoop.test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FileUtil; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.PathFilter; import org.apache.hadoop.io.IOUtils; /** * function 合并小文件至 HDFS * * */ public class MergeFile { private static FileSystem fs = null; private static FileSystem local = null; /** * @function main * @param args * @throws IOException * @throws URISyntaxException */ public static void main(String[] args) throws IOException, URISyntaxException { list("/home/hadoop/mergefile/*","/dajiangtai/merge"); } /** * * @throws IOException * @throws URISyntaxException */ public static void list(String srcPath,String destPath) throws IOException, URISyntaxException { try{ // 读取hadoop文件系统的配置 Configuration conf = new Configuration(); // 获取远端文件系统 URI uri = new URI("hdfs://djt:9000"); FileSystem remote = FileSystem.get(uri, conf); // 获得本地文件系统 FileSystem local = FileSystem.getLocal(conf); // 获取data目录下的所有文件路径 Path[] dirs = FileUtil.stat2Paths(local.globStatus(new Path(srcPath))); FSDataOutputStream out = null; FSDataInputStream in = null; for (Path dir : dirs) { // 文件名称 String fileName = dir.getName().replace("-", ""); // 只接受目录下的.txt文件 FileStatus[] localStatus = local.globStatus(new Path(dir + "/*"), new RegexAcceptPathFilter("^.*txt$")); // 获得目录下的所有文件 Path[] listedPaths = FileUtil.stat2Paths(localStatus); // 输出路径 Path block = new Path(destPath + "/" + fileName + ".txt"); // 打开输出流 out = remote.create(block); for (Path p : listedPaths) { // 打开输入流 in = local.open(p); // 复制数据 IOUtils.copyBytes(in, out, 4096, false); // 关闭输入流 in.close(); } if (out != null) { // 关闭输出流 out.close(); } } }catch(Exception e){ e.getMessage(); } } /** * * @function 过滤 regex 格式的文件 * */ public static class RegexExcludePathFilter implements PathFilter { private final String regex; public RegexExcludePathFilter(String regex) { this.regex = regex; } @Override public boolean accept(Path path) { // TODO Auto-generated method stub boolean flag = path.toString().matches(regex); return !flag; } } /** * * @function 接受 regex 格式的文件 * */ public static class RegexAcceptPathFilter implements PathFilter { private final String regex; public RegexAcceptPathFilter(String regex) { this.regex = regex; } @Override public boolean accept(Path path) { // TODO Auto-generated method stub boolean flag = path.toString().matches(regex); return flag; } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号