虚拟化云计算的相关概念汇总
一、《kvm篇》
1、kvm虚拟化简介
精简置备:我先在我系统里面去声明我要一个50G的空间,但是呢,我不会把50G都分给你,你用多少,我分给你多少,但是最多不能超过50G.
厚置备:直接把50G都分给你。
1u是指的服务器的厚度
什么是虚拟化:
通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统(虚拟出来的计算机都具有单独的操作系统,跟我们宿主机是相互隔离的),并且应用程序都可以在相互独立的空间内运行而互不影响。
虚拟化的优势:
重新定义划分IT资源,可以实现IT资源的动态分配,灵活调度,跨域共享
提高IT资源利用率
虚拟化的种类:
根据用途分
完全虚拟化:含有hypervisor的一种软件,VMware和微软的VirtualPC是代表该方法的两个商用商品。
准虚拟化:完全虚拟化是一项处理器密集型技术,因为他要求hypervisor管理各个虚拟服务器,并让他们彼此独立。准虚拟化代表:Xen
系统虚拟化:没有独立的hypervisor层,主机操作系统本身负责多个虚拟服务器之间的资源分配。
桌面虚拟化:比如上机考试的电脑,他本地是没有操作系统,而是远端有一个中心机房,把操作系统投射到你屏幕里,进行统一管理。
根据架构分
1型虚拟化:hypervisor直接部署在服务器的硬件上。典型代表:ESXi,Xen
2型虚拟化:首先在你的硬件上部署一个Linux操作系统,在这个操作系统上部署我们hypervisor软件。典型代表:(KVM,VirtualBox,VMWare Workstation)
kvm是怎么进行管理的?
kvm是基于CPU的类型进行管理。
简述一下kvm的原理?
kvm全称“基于内核的虚拟机”,是一个开源的软件,基于内核的虚拟化技术,实际是嵌入系统的一个虚拟化模块,通过优化内核来使用虚拟技术,该内核模块使得Linux变成一个hypervisor,虚拟机使用Linux自身的调度器进行管理。(就是说Linux要部署一个kvm模块,他才能变成hypervisor层)。
kvm空间有哪些东西?
用户空间:指的是用户得到一个虚拟机
内核空间:指的是你的kvm宿主机里面它部署的虚拟化的软件,是通过驱动内核来实现的
虚机:指的是用户的得到一个虚拟机层
Guest:指的我们虚拟机,也称VM
kvm:运行在内核空间,提供CPU和内存的虚拟
QEMU(扩展软件):帮我们提供了虚拟机的I/O设备(CPU 内存 显示器),其他的硬件虚拟化
kvm.ko是什么?
kvm有一个内核模块叫kvm.ko,它来提供我们CPU和内存
Libvirt是什么?
kvm的管理工具
Libvirt包含些什么?
1 后台daemon程序libvirtd:libvirtd是服务程序,接受和处理API请求
2 API(软件的接口,可以根据这个接口开发管理的软件,调用这个程序)库
3 命令行工具virsh
2、kvm虚拟机管理
virsh有哪两种模式?
命令模式
交互模式
kvm是怎么透传的?
让虚拟机中处理器对 VT 功能的支持达到透传的效果,也就是说KVM 是将物理 CPU 的特性全部传给虚拟机,所有理论上可以嵌套 N 多层。
3、kvm存储管理
kvm的存储虚拟化是通过什么来管理的?
存储池(storage pool)和卷(volume)
Storage Pool最常用的类型是什么?
文件目录类型
kvm默认的storage pool存放在哪?为什么是这个位置?
/var/lib/libvirt/images/
因为每个pool都有一个xml文件,该文件dir字段内定义了pool的存放路径。
KVM 支持多种 Volume 文件格式:
raw:是默认格式,即原始磁盘镜像格式,移植性好,性能好,但大小固定,不能节省磁盘空间。
qcow2:是推荐使用的格式,cow 表示 copy on write,能够节省磁盘空间,支持 AES 加密,支持 zlib 压缩,支持多快照,功能很多。
vmdk:是 VMWare 的虚拟磁盘格式,也就是说 VMWare 虚机可以直接在 KVM上 运行。
4、kvm虚拟机迁移
什么是迁移?
在源主机上实时备份操作系统和应用程序的状态,然后把存储介质连接到目标主机上,最后在目标主机上恢复系统。
什么是完整备份,增量备份?
完整备份{全部备份},增量备份{只备份新增加的内容}
迁移的目的?
简化系统维护管理、提高系统负载均衡、增强系统错误容忍度、优化系统电源管理
什么是热迁移?
热迁移又叫动态迁移、实时迁移,即虚拟机保存/恢复
迁移的种类?
P2P :物理机之间的迁移
V2P :虚拟机迁到物理机
P2V :物理机迁到虚拟机
V2V :虚拟机迁到虚拟机
热迁移的应用有哪些?
1、虚拟机的热迁移技术最初是被用于双机容错或者负载均衡
2、系统硬件维护
3、数据库备份
4、环境重现
5、计算机共享
热迁移的优缺点?
优点:可伸缩性比较强,减低服务器的总体能耗
缺点:VMotion 在进行迁移之前,管理软件会检测目标服务器的 X86 架构是否与原服务器兼容。CPU 的类型也要一样,不仅不能一个是英特尔,一个是 AMD ,甚至相同厂商不同产品线的CPU 也不行,比如英特尔至强和奔腾。
如何衡量迁移的效率?
1、整体迁移时间
2、服务器停机时间
3、对服务的性能影响
热迁移有哪些注意事项?
1、源宿主机和目的宿主机直接尽量用网络共享的存储系统来保存客户机磁盘镜像。
2、为了提高动态迁移的成功率,尽量在同类型 cpu的主机上面进行动态迁移。
3、64 位的客户机只能运行在 64 宿主机之间的迁移,而 32 位客户机可以在 32 宿主机和 64 位宿主机之间迁移。
4、目的宿主机和源宿主机的软件尽可能的相同。也就是同为 Vmware , KVM , Xen 等。
5、在进行动态迁移时,被迁移客户机的名称是唯一的,在目的宿主机上不能有与源宿主机被迁移客户机同名的客户机存在。
5、kvm虚拟机网卡管理
LAN是什么?
本地局域网
LAN中的计算机通常怎么去连接?
使用Hub集线器和Switch交换机
一个 LAN 表示一个广播域(路由器组播广播域)。
其含义是:LAN 中的所有成员都会收到任意一个成员发出的广播包
VLAN表示什么?
虚拟的网络段,一个带有 VLAN 功能的switch 能够将自己的端口划分出多个 LAN
简单地说,VLAN 将一个交换机分成了多个交换机,限制了广播的范围
在二层将计算机隔离到不同的 VLAN 中
通常交换机的端口有哪两种配置模式?
Access 和 Trunk
什么是网卡bond?
也称作网卡捆绑。就是将两个或者更多的物理网卡绑定成一个虚拟网卡。网卡是通过把多张网卡绑定为一个逻辑网卡,实现本地网卡的冗余,带宽扩容和负载均衡,在应用部署中是一种常用的技术。
网卡绑定的目的是什么?
1、提高网卡的吞吐量。
2、增强网络的高可用,同时也能实现负载均衡。
bond模式一共有几种?常用的是哪几种?
7种
mode=0:平衡负载模式,有自动备援,但需要”Switch”支援及设定。
mode=1:自动备援模式,其中一条线若断线,其他线路将会自动备援。
mode=6:平衡负载模式,有自动备援,不必”Switch”支援及设定。
二、《openstack篇》
1、openstack简介
目前主要的openstack的商业版本有哪些?
m版
openstack版本命名规则以及版本发布日期?
26个英文字母命名,每半年更新一次
Openstacck和云计算是什么?
OpenStack是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。
云计算是一个按使用量付费的商业模式,他这个模式根据用户的需求不同用户只要通过互联网,可以从云计算里面获取不同的资源(资源包括网络,服务器计算,存储,应用软件,服务)。
Openstack有哪些组件及作用?
身份服务:Keystone:为访问openstack各个组建提供认证和授权功能
计算: Nova:负责创建、调度、销毁云主机
镜像服务: Glance :装机使用
网络 & 地址管理: Neutron:负责实现SDN
对象存储: Swift:目录结构存储数据
块存储 : Cinder :提供持久化块存储
UI 界面 : Horizon:web展示界面操作平台
测量 : Ceilometer
部署编排 : Heat
openstack共享服务组建有哪些?
数据库服务:MairaDB 及 MongoDB (部署度量服务时用到)
消息传输:RabbitMQ
缓存: Memcached
时间:NTP
存储:ceph、GFS、LVM、ISICI等
高可用及负载均衡:pacemaker、HAproxy、keepalive、lvs等
云计算分为哪三个阶段?
物理服务器阶段
虚拟化架构阶段
云计算技术阶段
云计算提供的三个层次?
saas把在线软件作为一种服务
paas把平台作为一种服务
iaas把硬件设备作为一种服务
什么是中间件?
工作在两个或者多个软件之间的软件,就像是中介一样,承上启下,常见的中间件,rabbitmq(负责两个组件之间通信用的)tomcat(解释java程序),memcache(做网站缓存),redis(做网站缓存)
什么是耦合,解耦合?
比如拿一个应用来说,你有一个服务,那么这个服务最后达成一个应用的话,底层有很多很多小组件,必须相互之间去联系配合,才能提供服务,这些小组件之间必须有一定的关系的联系起来,这些关系就是耦合,这些小组件关系性越强,其中的某一个坏掉了,那么其他的就不能正常工作了,
所以说,松耦合性越高,依赖性越低。
2、Rabbitmq
什么是MQ?
是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息,(针对应用程序的数据)来通信,而无需专用连接来链接它们。
什么是AMQP?
高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
什么是rabbitmq?
属于一个流行的开源消息队列系统。属于AMQP( 高级消息队列协议 ) 标准的一个实现。
是应用层协议的一个开放标准,为面向消息的中间件设计。
用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
rabbitmq特点?
使用Erlang编写
支持持久化
支持HA
提供C#
rabbitmq工作原理?
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性,声明我这个交换机承载什么样的队列。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
(6)exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
rabbitmq的元数据?
元数据可以持久化在 RAM 或 Disc. 从这个角度可以把 RabbitMQ 集群中的节点分成两种
RAM Node和 Disk Node.
RAM Node 只会将元数````据存放在RAM
Disk node 会将元数据持久化到磁盘。
rabbitmq中概念名词?
Broker 简单来说就是消息队列服务器实体
Exchange 消息交换机,它指定消息按什么规则,路由到哪个队列
Queue 消息队列载体,每个消息都会被投入到一个或多个队列
Binding 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
Routing Key 路由关键字, exchange根据这个关键字进行消息投递
vhost 虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离
producer 消息生产者,就是投递消息的程序
consumer 消息消费者,就是接受消息的程序
channel 消息通道,在客户端的每个连接里,可建立多个channel
每个channel代表一个会话任务
3、memcached
缓存系统是怎么使用的呢?
一般是在大型海量的并发网站里面,或者是openstack这个云环境,当你的集群规模达到很大的时候,因为不管是你网站还是openstack也好,他底层都有数据库,一般我们都是用关系型数据库,尤其是大型的关系型数据库的话,如果对其进行每秒上万次的并发访问,每次都会去访问后台的数据库,那么对你的数据库而言会产生很大访问压力,数据库他的并发量并不支持很多,也就几百次,并且每次访问都在一个有上亿条记录的数据表中查询某条记录时,其效率会非常低,对数据库而言,这也是无法承受的。
Memcached缓存流程
client向apache发起一个网页访问,那么apache会先在memcache里面检索client访问的数据存不存在,如果存在,直接返回给client,如果不存在,memcache就去访问数据库,在数据库里找到了你要的数据,memcache会在缓存里缓存一份,同时发送给你client。
Memcached概念?
Memcached 是一个开源的、高性能的分布式内存对象缓存系统、Memcached是一种内存缓存、当Memcached服务器节点的物理内存剩余空间不足,Memcached将使用最近最少使用算法(LRU,LastRecentlyUsed)对最近不活跃的数据进行清理,从而整理出新的内存空间存放需要存储的数据。
Memcached功能特点?
协议简单
基于 libevent 的事件处理(记录日志)
内置的内存管理方式
节点相互独立的分布式
使用Memcached应该考虑哪些因素?
Memcached服务单点故障
存储空间限制
存储单元限制
数据碎片
利旧算法局限性
数据访问安全性
keystone是什么?
keystone 是OpenStack的组件之一,用于为OpenStack家族中的其它组件成员提供统一的认证服务,包括身份验证、令牌的发放和校验、服务列表、用户权限的定义等等。
4、keystone
keystone之间的关系?
假如说我要投资一个酒店的项目(这里就是project),它是做服务的(这里对应到了service),我提供住宿洗浴等服务,那么我要开始宣传了,把我的地址宣传出去(这里就是Endpoint,服务端点,你想要享受服务,就得找到我的服务地址),在这这个项目里,我(是user),因为我是项目发起人,所以我的role是董事长,来住我酒店的人也是user,可是他们的role是贵客,普通用户。来了以后你把你的身份信息提供给我(就是credentials),而后我做授权(authentication),我查看你预定价位的套房,从而给你授权给你相应的token(记录了用户的权限和信息)。
openstack系统基本角色有哪两个?
一个是管理员admin
一个是租户_member_
Keystone基本架构?
Token: 用来生成和管理token
Catalog:用来存储和管理service/endpoint
Identity:用来管理tenant/user/role和验证
Policy:用来管理访问权限
5、Glance
glance是什么?
Glance是Openstack项目中负责镜像管理的模块,其功能包括虚拟机镜像的查找、注册和检索等
Glance服务是负责管理镜像,不负责镜像的存储,它要把镜像存储到Glance服务运行的服务器的某一个目录下面,或者对接不同的后端。所以搭完Glance服务后要给它指定镜像保存的方式。
什么是image?
Image 是一个模板,里面包含了基本的操作系统和其他的软件。就是把一个现成的虚拟机装好后做成镜像,上传到Glance服务里面,这就好比kvm的clone,直接基于某一个虚拟机去克隆他,可以达到秒级的或分钟级的。
什么是image service?它的具体功能是什么?
Image Service 的功能是管理 Image,让用户能够发现、获取和保存 Image。在 OpenStack 中,提供 Image Service 的是 Glance
1、提供 REST API 让用户能够查询和获取 image 的元数据和 image 本身
2、支持多种方式存储 image,包括普通的文件系统、Swift、Amazon S3 等
3、对 Instance 执行 Snapshot 创建新的 image
什么是glance-api?
glance-api 是系统后台运行的服务进程。 对外提供 REST API,响应 image 查询、获取和存储的调用。是负责用户检索的大门。
glance-api 不会真正处理请求。 如果操作是与 image metadata(元数据)相关,glance-api 会把请求转发给 glance-registry;如果操作是与 image 自身存取相关,glance-api 会把请求转发给该 image 的 store backend。
什么是glance-registry ?
glance-registry 是系统后台运行的服务进程。负责处理和存取 image 的 metadata,例如 image 的大小和类型。在控制节点上可以查看 glance-registry 进程
什么是Database?
Image 的 metadata 会保持到 database 中,默认是 MySQL。 在控制节点上可以查看 glance 的 database 信息
什么是Store backend(后端存储)?
Glance 自己并不存储 image。 真正的 image 是存放在 backend 中的。 Glance 支持多种 backend,包括:
1.A directory on a local file system(这是默认配置)
2.GridFS
3.Ceph RBD
4.Amazon S3
5.Sheepdog
6.OpenStack Block Storage (Cinder)
7.OpenStack Object Storage (Swift)
8.VMware ESX
6、nova
nova是什么?
Nova 是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源。OpenStack 作为 IaaS 的云操作系统,虚拟机生命周期管理也就是通过 Nova 来实现的。计算资源只是内存跟cpu。
nova的用途和功能是什么?
1) 实例生命周期管理
2) 管理计算资源
3) 网络和认证管理
4) REST 风格的 API(拥有自己的AIP,Nova-api)
5) 异步的一致性通信
6)Hypervisor 透明:支持Xen,XenServer/XCP,KVM, UML, VMware vSphere and Hyper-V
nova-api?
是整个 Nova 组件的门户,接收和响应客户的 API 调用。所有对 Nova 的请求都首先由 nova-api 处理。nova-api 向外界暴露若干 HTTP REST API 接口,在 keystone 中我们可以查询 nova-api 的 endponits。
Nova-api 对接收到的 HTTP API 请求会做什么处理?
1. 检查客户端传入的参数是否合法有效
2. 调用 Nova 其他子服务的处理客户端 HTTP 请求
3. 格式化 Nova 其他子服务返回的结果并返回给客户端
nova-scheduler?
虚机调度服务,负责决定在哪个计算节点上运行虚机。创建 Instance 时,用户会提出资源需求,
例如 CPU、内存、磁盘各需要多少。OpenStack 将这些需求定义在 flavor 中,用户只需要指定用哪个 flavor 就可以了。
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为哪两步?
1. 通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
2. 通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance。
Nova 允许使用第三方 scheduler,配置 scheduler_driver 即可。 这又一次体现了OpenStack的开放性。
nova-compute?
nova-compute 是管理虚机的核心服务,在计算节点上运行。通过调用Hypervisor API实现节点上的 instance的生命周期管理。
OpenStack 对 instance 的操作,最后都是交给 nova-compute 来完成的。
nova-compute 与 Hypervisor 一起实现 OpenStack 对 instance 生命周期的管理。
nova-conductor?
nova-compute 经常需要更新数据库,比如更新和获取虚机的状态。出于安全性和伸缩性的考虑,nova-compute 并不会直接访问数据库,而是将这个任务委托给 nova-conductor。
nova-console: 用户可以通过多种方式访问虚机的控制台
nova-novncproxy: 基于 Web 浏览器的 VNC 访问
nova-spicehtml5proxy: 基于 HTML5 浏览器的 SPICE 访问
nova-xvpnvncproxy: 基于 Java 客户端的 VNC 访问
nova-consoleauth: 负责对访问虚机控制台请求提供 Token 认证
nova-cert: 提供 x509 证书支持
Message Queue?
在前面我们了解到 Nova 包含众多的子服务,这些子服务之间需要相互协调和通信。为解耦各个子服务,Nova 通过 Message Queue 作为子服务的信息中转站。 所以在架构图上我们看到了子服务之间没有直接的连线,是通过 Message Queue 联系的。
OpenStack 默认是用 RabbitMQ 作为 Message Queue。 MQ 是 OpenStack 的核心基础组件,我们后面也会详细介绍。
从学习 Nova 的角度看,虚机创建是一个非常好的场景,涉及的 nova-* 子服务很全,下面是流程。
1.客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(nova-api)发送请求:“帮我创建一个虚机”
2.API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个虚机”
3.Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A
4.Scheduler 向 Messaging 发送了一条消息:“在计算节点 A 上创建这个虚机”
5.计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然后在本节点的 Hypervisor 上启动虚机。
6.在虚机创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向 Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。
以上是创建虚机最核心的步骤, 这几个步骤向我们展示了 nova-* 子服务之间的协作的方式,也体现了 OpenStack 整个系统的分布式设计思想,掌握这种思想对我们深入理解 OpenStack 会非常有帮助
7、Neutron(还需整理)
什么是SDN?
软件定义网络的统称,把物理环境中的网络设备用软件来实现它的功能。
Neutron的设计目标是什么?
网络即服务
local网络类型是什么样的?
本地宿主机网络,就是说我这个计算节点起的虚拟机,指定它用的是local网络,那么这个计算节点里面的虚拟机只可以跟它同在同一个宿主机里面的其他虚拟机通信,它不能跨节点通信。
flat网络类型?
flat 网络中的实例能与位于同一网络的实例通信,并且可以跨多个节点。它无vlan标记。
vlan网络类型?
同一 vlan 中的 instance 可以通信,不同 vlan 只能通过 router 通信。vlan 网络可跨节点,是应用最广泛的网络类型。它具有802.1q标记。
vxlan网络类型?
vxlan 是基于隧道技术的 overlay(覆盖) 网络。vxlan 网络通过唯一的 segmentation ID(分割ID)(也叫 VNI)与其他 vxlan 网络区分。vxlan 中数据包会通过 VNI 封装成 UDP 包进行传输。因为二层的包通过封装在三层传输,能够克服 vlan 和物理网络基础设施的限制。
gre网络类型?
gre 是与 vxlan 类似的一种 overlay 网络。主要区别在于使用 IP 包而非 UDP 进行封装。
什么是subnet?
subnet 是一个 IPv4 或者 IPv6 地址段。instance 的 IP 从 subnet 中分配。每个 subnet 需要定义 IP 地址的范围和掩码。
什么是port?
port 可以看做虚拟交换机上的一个端口。port 上定义了 MAC 地址和 IP 地址,当 instance 的虚拟网卡 VIF(Virtual Interface) 绑定到 port 时,port 会将 MAC 和 IP 分配给 VIF。
Neutron提供了什么功能?
Neutron 为整个 OpenStack 环境提供网络支持,包括二层交换,三层路由,负载均衡,防火墙和 VPN 等。
Neutron 通过 dnsmasq 提供 DHCP 服务,而 dnsmasq 通过 Linux Network Namespace 独立的为每个 network 服务隔离
虚拟机连接外网的流量图走向(南北流向)?
vm要出外网,要经过一个tap设备,连接到了Linux bridge网桥上,这个Linux bridge叫qbr1b4cd,qbr1b4cd又要连接到br-int上,他俩之间有两个接口,Linux bridge的接口是qvb1b4cd,br-int的接口是qvo1fb4cd,而后br-int又通过qr接口连接到ruter路由上,ruter路由通过qg接口连接到br-ex上,通过你的物理网卡就出去了。
虚拟机连接虚拟机的流量走向?
虚拟机跨节点通信流量走向(东西流向)?
8、cinder(还需整理)
cinder是什么?
cinder-api?
接收 API 请求, 调用 cinder-volume 。是整个 Cinder 组件的门户,所有 cinder 的请求都首先由 cinder-api 处理。cinder-api 向外界暴露若干 HTTP REST API 接口。在 keystone 中我们可以查询 cinder-api 的 endponits。
cinder-volume?
管理 volume 的服务,与 volume provider 协调工作,管理 volume 的生命周期。
运行 cinder-volume 服务的节点被称作为存储节点。
cinder-volume 在存储节点上运行,OpenStack 对 Volume 的操作,最后都是交给 cinder-volume 来完成的。
cinder-volume 自身并不管理真正的存储设备,存储设备是由 volume provider 管理的。
cinder-volume 与 volume provider 一起实现 volume 生命周期的管理。
Scheduler 调度服务?
Cinder 可以有多个存储节点,当需要创建 volume 时,cinder-scheduler 会根据存储节点的属性和资源使用情况选择一个最合适的节点来创建 volume。
Worker 工作服务
调度服务只管分配任务,真正执行任务的是 Worker 工作服务。
在 Cinder 中,这个 Worker 就是 cinder-volume 了。这种 Scheduler 和 Worker 之间职能上的划分使得 OpenStack 非常容易扩展:当存储资源不够时可以增加存储节点(增加 Worker)。 当客户的请求量太大调度不过来时,可以增加 Scheduler。
通过的 Driver 架构。 cinder-volume 为这些 volume provider 定义了统一的接口,volume provider 只需要实现这些接口,就可以 Driver 的形式即插即用到 OpenStack 系统中。
9、horizon
什么是horizon?
Horizon 为 Openstack 提供一个 WEB 前端的管理界面 (UI 服务 ),通过 Horizone 所提供的 DashBoard 服务 ,管理员可以使用通过 WEB UI 对 Openstack 整体云环境进行管理 , 并可直观看到各种操作结果与运行状态。
区域(Region)?
1、地理上的概念,可以理解为一个独立的数据中心,每个所定义的区域有自己独立的Endpoint;
2、区域之间是完全隔离的,但多个区域之间共享同一个Keystone和Dashboard(目前Openstack中的Dashboard还不支持多个区域);
3、除了提供隔离的功能,区域的设计更多侧重地理位置的概念,用户可以选择离自己更新的区域来部署自己的服务,选择不同的区域主要是考虑那个区域更靠近自己,如用户在美国,可以选择离美国更近的区域;
4、区域的概念是由Amazon在AWS中提出,主要是解决容错能力和可靠性;
可用性区域(Availability Zone)?
1、AZ是在Region范围内的再次切分,例如可以把一个机架上的服务器划分为一个AZ,划分AZ是为了提高容灾能力和提供廉价的隔离服务;
2、AZ主要是通过冗余来解决可用性的问题,在Amazon的声明中,Instance不可用是指用户所有AZ中的同一个Instance都不可达才表明不可用;
3、AZ是用户可见的一个概念,并可选择,是物理隔离的,一个AZ不可用不会影响其他的AZ,用户在创建Instance的时候可以选择创建到那些AZ中;
Host Aggreates?
一组具有共同属性的节点集合,如以CPU作为区分类型的一个属性,以磁盘(SSD\SAS\SATA)作为区分类型的一个属性,以OS(Windows\Linux)为作区分类型的一个属性;
Cell?
nova为了增加横向扩展以及分布式、大规模(地理位置级别)部署的能力,同时又不增加数据库和消息中间件的复杂度,引入了cell的概念,并引入了nova-cell服务。
1、主要是用来解决OpenStack的扩展性和规模瓶颈;
2、每个Cell都有自己独立的DB和AMQP,不与其他模块共用DB和AMQP,解决了大规模环境中DB和AMQP的瓶颈问题;
3、Cell实现了树形结构(通过消息路由)和分级调度(过滤算法和权重算法),Cell之间通过RPC通讯,解决了扩展性问题。
10、ceph(还需整理)
什么是分布式存储?
我在一个环境当中,有很多很多的服务器,服务器上也有它自己很多的硬盘,我通过软件的形式把若干服务器都收集起来,部署成一个软件,在这个逻辑的软件里可以同时看到我若干服务器的磁盘的空间,这个逻辑的软件对外就像是一个整体一样,这个整体叫storage spool,用户呢有一天想用这个空间了,用户直接去对应这个存储池提供的接口,这用的话,用户保存一个文件,实际上保存在若干个服务器里,文件会随机存到第一个服务器的第一块硬盘里,下一次就可能存到第二个服务器的第三块硬盘里。它会把文件进行打散,分成不同的小块,每块存放的位置可能是不同的服务器上的不同硬盘里。
ceph的特点?
高性能:
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架、感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
高可用性:
a. 副本数可以灵活控制。(就是说让副本保存份数可以多份,在正常的生产环境是保存3副本)
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。(假如说我这个文件设置的是3副本,如果后端服务器坏掉,副本数不够3,它会自动补充至3副本)
高可扩展性:
a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
特性丰富:
a. 支持三种存储接口:块存储(我得到的是硬盘)、文件存储(目录)、对象存储(有可能给你对接的是一个挂载的目录,但是后端怎么去存的,它会把数据打散,采用键值对形式存储)。
b. 支持自定义接口,支持多种语言驱动。
ceph提供的功能有哪些?
对象存储(RADOSGW):提供RESTful接口,也提供多种编程语言绑定。兼容S3(是AWS里的对象存储)、Swift(是openstack里的对象存储);
块存储(RDB):由RBD提供,可以直接作为磁盘挂载,内置了容灾机制;
文件系统(CephFS):提供POSIX兼容的网络文件系统CephFS,专注于高性能、大容量存储;什么是块存储/对象存储/文件系统存储?
一个文件在ceph里怎么做的读取和存储?
首先用户把一个文件放到ceph集群后,先把文件进行分割,分割为等大小的小块,小块叫object,让后这些小块跟据一定算法跟规律,算法是哈希算法,放置到PG组里,就是归置组,然后再把归置组放到OSD里面。
三、《docker篇》
1、docker简介
什么是docker?
docker是一个技术的类别,docker就像云计算里的openstack一样,它是虚拟化里的一款软件。
docker是以什么样的形式存在操作系统中?
进程
docker的目标是什么?
一次封装,到处运行
docker特点?
优点:
1、启动快,资源占用小 , 资源利用高,快速构建标准化运行环境 。
2、创建分布式应用程序时快速交付和部署,更轻松的迁移和扩展,更简单的更新管理。
局限:
1、Docker 是基于 Linux 64bit 的,无法在 windows/unix (是Linux系统的鼻祖)或 32bit 的 linux环境下使用。
2、LXC 是基于 cgroup 等 linux kernel 功能的,因此 container 的 guest 系统只能是 linux。
3、隔离性相比 KVM(因为kvm是完全的虚拟化,它中间有hypervirson独立的虚拟化层来管理上层的kvm虚拟机,但是容易是寄托于宿主机里面的进程,它就是宿主机里的一个进程,假如说你宿主机坏了,那么你这个容器也就不能用了,但是kvm的宿主机坏了,可以把kvm的文件copy出来还可以使用) 之类的虚拟化方案还是有些欠缺,所有 container 公用一部分的运行库 。
4、管理相对简单,主要是基于 namespace 隔离。
5、cgroup 的 cpu 和 cpuset 提供的 cpu 功能相比 KVM 的等虚拟化方案相比难以度量 ( 所以 dotcloud 主要是按内存收费 ) 。
6、docker 对 disk 的管理比较有限 。
7、container 随着用户进程的停止而销毁, container 中的 log 等用户数据不便收集。
docker与虚拟机比较?
1、启动快比虚拟机 , 可以秒级启动,像虚拟机启动,需要有开机的流程。
2、对资源占用小 , 宿主机上可运行千台容器。
3、方便用户获取 , 分布 , 和更新应用镜像(生成容器的基础,就像我们给虚拟机安装操作系统一样,你得有一个iso的基础镜像,你才能装操作系统,容易也一样,但容器的镜像不是iso文件) , 指令简单 , 学习费用低。
4、通过 Dockerfile 配置文件来灵活的自动创建和部署镜像 & 容器 , 提高工作效率。
5、Docker 除了运行其中应用外 , 基本不消耗其他系统资源 , 保证应用性能同时 , 尽量减小系统开销(如果我们在宿主机里运行一台kvm虚拟机,那么这个kvm虚拟机的操作系统本身也会占用宿主机一定的资源,你如果再在kvm上部署一个mysql或者apache,那么他俩也会占用宿主机的系统资源,但是容器不一样,如果你这个容器运行的是mysql,那么只有mysql会占用你系统的资源,容器本身是不占用的)。
docker镜像为什么要分层?
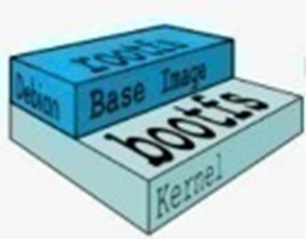
这个就是我们最新下载的镜像,它底层运行的kernel(内核),还有bootfs(开启引导项的一个文件系统)这是我们的基础镜像层,第二层是怎么来的,有一天对这个镜像做了一个更改,比如说我想以后我启动的这个容器/root目录下都有相同的一个文件,那我得对这个镜像做更改,不更改的话,我以后生成的容易,就没有我想要的这个文件了。我做的这个修改会在二层之上累加一层,如图

把我对这个原来的镜像所作的操作变化、新添加的东西都保存在最上层,你每做的一次更改,它都会往高的累加。我现在/root添加了一个文件,那么我还想在/root创建一个目录,那么它会在上一个状态的基础上又多一层,新状态的最上层,记录了我创建这个目录的记录,如图。

可以看到,新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。
docker底层依赖哪些核心技术?
命名空间 (Namespaces) :实现了容器间资源的隔离。
控制组 (Control Groups) :CGroups 是 Linux 内核的一个特性 ,主要用来对 共享资源进行隔离、限制、审计等 。cgroups 允许对于进程或进程组公平 ( 不公平 ) 的分配 CPU 时间、内存分配和 I/O 带宽。
联合文件系统 (Union File System) :控制为每一个成员目录设定只读 / 读写 / 写出权限。
Linux 虚拟网络支持:本地和容器内创建虚拟接口
2、docker存储和网络
docker有哪两种存储资源类型?
(1)Data Volume (数据卷)
(2)Data Volume Dontainers --- 数据卷容器
什么是Data Volume?
Data Volume 本质上是 Docker Host 文件系统中的目录或文件,使用类似与 Linux 下对目录或者文件进行 mount 操作。数据卷可以在容器之间共享和重用,对数据卷的更改会立马生效,对数据卷的更新不会影响镜像,卷会一直存在,直到没有容器使用。
Data Volume 的特点有哪些
a)Data Volume 是目录或文件,而并非格式化的磁盘(块设备)。
b)容器可以读写 volume 中的数据。
c)volume 数据可以被永久的保存,即使使用它的容器已经销毁。
什么是Data Volume Dontainers?
如果用户需要在容器之间共享一些持续更新的数据,最简单的方法就是使用数据卷容器,其实数据卷容器就是一个普通的容器,只不过是专门用它提供数据卷供其他容器挂载使用。
Docker--none网络
none 网络就是什么都没有的网络。挂在这个网络下的容器除了 lo,没有其他任何网卡。
Docker host 网络
host 网络连接到 host 网络的容器,共享 docker host 的网络栈,容器的网络配置与 host 完全一样。
Docker Bridge网络
docker 安装时会创建一个 命名为 docker0 的 linux bridge。如果不指定 --network,创建的容器默认都会挂到 docker0 上。
四、《kubernetes篇》
Kubernetes 的几个重要概念
Cluster
Cluster 是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用。
Master (其实Master是一个服务,也是一个节点,可以理解为控制节点)
Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master。
Node (计算节点)
Node 的职责是运行容器应用。Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
Pod
假如说下图是k8s的一个生态环境,那么这套系统里运行着很多的容器(小圆圈代表容器),那么我们k8s集群要管理这些零散的容器,它不是直接去调用容器,而是把容器放到一个盒子里,一个调度单元里,它管理你集群是管理你的调度单元,调度单元里可以运行一个容器,也可以运行多个容器。
Pod 是 Kubernetes 的最小工作单元。每个 Pod 包含一个或多个容器。Pod 中的容器会作为一个整体被 Master 调度到一个 Node 上运行。
Kubernetes 引入 Pod 主要基于下面两个目的:
1、可管理性。
有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。
2、 通信和资源共享。
Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
Pods 有两种使用方式:
1、运行单一容器。
one-container-per-Pod 是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod。即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器。
2、运行多个容器。
哪些容器应该放到一个 Pod 中? 这些容器联系必须 非常紧密,而且需要 直接共享资源。
Controller (组件)
Kubernetes 通常不会直接创建 Pod,而是通过 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本,在什么样的 Node 上运行等。为了满足不同的业务场景,Kubernetes 提供了多种 Controller类型,包括 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等
Deployment 是最常用的 Controller,比如前面在线教程中就是通过创建 Deployment 来部署应用的。Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。
ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,我们通常不需要直接使用 ReplicaSet。
DaemonSet 用于每个 Node 最多只运行一个 Pod 副本的场景。正如其名称所揭示的,DaemonSet 通常用于运行 daemon。
StatefuleSet 能够保证 Pod 的每个副本在整个生命周期中名称是不变的。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。
Job 用于运行结束就删除的应用。而其他 Controller 中的 Pod 通常是长期持续运行。
Service
Deployment 可以部署多个副本,每个 Pod 都有自己的 IP,外界如何访问这些副本呢?
通过 Pod 的 IP 吗?
要知道 Pod 很可能会被频繁地销毁和重启,它们的 IP 会发生变化,用 IP 来访问不太现实。
答案是 Service。
Kubernetes Service 定义了外界访问一组特定 Pod 的方式。Service 有自己的 IP 和端口,Service 为 Pod 提供了负载均衡。
Kubernetes 运行容器(Pod)与访问容器(Pod)这两项任务分别由 Controller 和 Service 执行。
Namespace
如果有多个用户或项目组使用同一个 Kubernetes Cluster,如何将他们创建的 Controller、Pod 等资源分开呢?
答案就是 Namespace。
Namespace 可以将一个物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同 Namespace 里的资源是完全隔离的。
Kubernetes 默认创建了三个 Namespace。
default -- 创建资源时如果不指定,将被放到这个 Namespace 中。
kube-system -- Kubernetes 自己创建的系统资源将放到这个 Namespace 中。
kube-public -- Kubernetes 公共的系统资源将放到这个 Namespace 中。
如果一组 Pod 对外提供服务(比如 HTTP),它们的 IP 很有可能发生变化,那么客户端如何找到并访问这个服务呢?
Kubernetes 给出的解决方案是 Service。
在k8s里面,比如我们运行了一个服务,这个服务是启动了3副本,客户端要访问这个服务的时候,不是直接访问你的pod,而是访问pod对外提供的代表,service,service会固定一个IP地址,即使你的pod怎么去销毁重新创建,没关系,我service对外提供服务,你只要访问我service这个固定IP就好。(你访问service的时候,不是说三个pod同时对外提供服务,它会把你请求呢根据一定的算法,转发到你后端的三个pod里面,有可能你这个访问的是第一个pod给你提供的实际服务,有可能第二次就是第二个pod给你提供的服务,那么类似于负载均衡这个工作是kube-proxy做的。)
Service Cluster IP 是一个虚拟 IP,是由 Kubernetes 节点上的 iptables 规则管理的。
外网如何访问 Service?
除了 Cluster 内部可以访问 Service,很多情况我们也希望应用的 Service 能够暴露给 Cluster 外部。Kubernetes 提供了多种类型的 Service,默认是 ClusterIP。
ClusterIP
Service 通过 Cluster 内部的 IP 对外提供服务,只有 Cluster 内的节点和 Pod 可访问,这是默认的 Service 类型,前面实验中的 Service 都是 ClusterIP。
NodePort
Service 通过 Cluster 节点的静态端口对外提供服务。Cluster 外部可以通过 <NodeIP>:<NodePort> 访问 Service。
LoadBalancer
Service 利用 cloud provider 特有的 load balancer 对外提供服务,cloud provider 负责将 load balancer 的流量导向 Service。目前支持的 cloud provider 有 GCP、AWS、Azur 等。
Kubernetes Cluster 由两种类型的节点来组成的,一种是 Master节点,一种是 Node节点
Master 节点
Master 是 Kubernetes Cluster 的大脑,运行着如下 Daemon(进程) 服务:kube-apiserver(接口)、kube-scheduler(调度)、kube-controller-manager(控制管理)、etcd(数据库[kunbernetes的数据库是键值对的数据库]) 和 Pod 网络(例如 flannel)。
API Server(kube-apiserver)
API Server 提供 HTTP/HTTPS RESTful API,即 Kubernetes API。API Server 是 Kubernetes Cluster 的前端接口,各种客户端工具(CLI 或 UI)以及 Kubernetes 其他组件可以通过它管理 Cluster 的各种资源。
Scheduler(kube-scheduler)
Scheduler 负责决定将 Pod 放在哪个 Node 上运行(也就是决定你哪个容器运行在哪个计算节点上)。Scheduler 在调度时会充分考虑 Cluster 的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
Controller Manager(kube-controller-manager)(控制管理)
Controller Manager 负责管理 Cluster 各种资源,保证资源处于预期的状态。Controller Manager 由多种 controller 组成,包括 replication controller、endpoints controller、namespace controller、serviceaccounts controller 等。
不同的 controller 管理不同的资源。例如 replication controller 管理 Deployment、StatefulSet、DaemonSet 的生命周期,namespace controller 管理 Namespace 资源。
etcd
etcd 负责保存 Kubernetes Cluster 的配置信息和各种资源的状态信息。当数据发生变化时,etcd 会快速地通知 Kubernetes 相关组件。
Pod 网络
Pod 要能够相互通信,Kubernetes Cluster 必须部署 Pod 网络,flannel 是其中一个可选方案。
node节点
Node 是 Pod 运行的地方,Kubernetes 支持 Docker、rkt 等容器 Runtime。 Node上运行的 Kubernetes 组件有 kubelet、kube-proxy 和 Pod 网络(例如 flannel)。
kubelet
kubelet 是 Node 的 agent,当 Scheduler 确定在某个 Node 上运行 Pod 后,会将 Pod 的具体配置信息(image、volume 等)发送给该节点的 kubelet,kubelet 根据这些信息创建和运行容器,并向 Master 报告运行状态。
kube-proxy
service 在逻辑上代表了后端的多个 Pod,外界通过 service 访问 Pod。service 接收到的请求是如何转发到 Pod 的呢?这就是 kube-proxy 要完成的工作。
每个 Node 都会运行 kube-proxy 服务,它负责将访问 service 的 TCP/UPD 数据流转发到后端的容器。如果有多个副本,kube-proxy 会实现负载均衡。
Pod 网络
Pod 要能够相互通信,Kubernetes Cluster 必须部署 Pod 网络,flannel 是其中一个可选方案。
kubernetes创建资源的两种方式
基于命令行的方式:
- 简单直观快捷,上手快。
- 适合临时测试或实验。
基于配置文件的方式:
- 配置文件描述了创建应用的过程,即应用最终要达到的状态。
- 配置文件提供了创建资源的模板,能够重复部署。
- 可以像管理代码一样管理部署。
- 适合正式的、跨环境的、规模化部署。
- 这种方式要求熟悉配置文件的语法,有一定难度。
后面我们都将采用配置文件的方式,大家需要尽快熟悉和掌握。
kubectl apply 不但能够创建 Kubernetes 资源,也能对资源进行更新,非常方便。不过 Kubernets 还提供了几个类似的命令,例如 kubectl create(他只是一个简单的创建过程)、kubectl replace、kubectl edit 和 kubectl patch。
为避免造成不必要的困扰,我们会尽量只使用 kubectl apply(因为它可以对资源进行更新),此命令已经能够应对超过 90% 的场景,事半功倍。
openstack命令
openstack-service restart #重启openstack服务
openstack endpoint-list #查看openstack的端口
nova的常用命令
nova list #列举当前用户所有虚拟机
nova show ID #列举某个虚机的详细信息
nova delete ID #直接删除某个虚机
nova service-list #获取所有服务列表
nova image-list #获取镜像列表
nova flavor-list #列举所有可用的类型
nova volume-list #列举所有云硬盘
nova volume-show #显示指定云硬盘的详细信息
nova volume-create #创建云硬盘
nova volume-delete #删除云硬盘
nova volume-snapshot-create #创建云硬盘快照
nova volume-snapshot-delete #删除云硬盘快照
nova live-migration ID node #热迁移
nova migrate ID node #冷迁移
nova migration-list #列出迁移列表
nova get-vnc-console ID novnc #获取虚机的vnc地址
nova reset-state --active ID #标识主机状态
neutron常用命令
neutron agent-list #列举所有的agent
neutron agent-show ID #显示指定agent信息
neutron port-list #查看端口列表
neutron net-list #列出当前租户所有网络
neutron net-list --all-tenants #列出所有租户所有网络
neutron net-show ID #查看一个网络的详细信息
neutron net-delete ID #删除一个网络
ip netns #查看命名空间
ip netsn exec haproxy ip a #查看haproxy的ip
cinder命令
cinder list #列出所有的volumes
cinder service-list #列出所有的服务
cinder snapshot-list #列出所有的快照
cinder backup-list #列出所有备份
cinder type-list #列出所有volume类型
cinder show
cinder delete
ceph命令
ceph -s #查看osd状态
ceph osd tree #查看osd
ceph osd down osd.0 #终止osd.0
ceph osd rm 0 #删除osd.0
ceph health detail #查看集群健康状况
ceph auth list #获取权限列表
ceph auth caps client.lucy mon 'allow r' mds 'allwo r, allow rw path=/lucy, allow rw path=/jerry_share' osd 'allow rw' #修改clent.lucy用户权限
ceph auth get-key client.lucy #获取某个用户的key
systemctl status ceph-osd.target #重启osd服务
systemctl status ceph-osd@5.service #查看osd.5的状态
rabbitmq命令
rabbitmqctl cluster_status #查看消息队列集群状态
rabbitmqctl start_app #启动
rabbitmqctl stop_app #停止
rabbitmqctl reset #重置
rabbitmqctl list_queues #查看rabbitmq队列
systemctl status rabbitmq-service.service #查看rabbitmq的状态
镜像格式转换
qemu-img convert -f qcow2 -0 raw Win10_1803_chinese_x64_glance.qcow2 Win10_1803_chinese_x64_glance.raw
上传镜像
openstack image create "name" --file cirros-0.3.5-x86_64-disk.img --disk-format qcow2 --container-format bare --public
镜像上传后存放路径
/var/lib/glance/images
openstack各服务日志路径
/var/log/keystone/keystone.log
/var/log/glance/...
/var/log/neutron/...
/var/log/nova/...
/var/log/cinder/...
/var/log/apache2/ #dashboard日志
#swift存储日志
/var/log/syslog
/var/log/messages
修改时间和时区
timedatectl #显示各项当前时间
timedatectl list-timezones #显示系统所支持的时间区域
timedatectl set-timezone Asia/Shanghai #设置当前系统的时间区域
date -s "20190328 14:56:30" #修改时间
/etc/ntp.conf #ntp文件路径
hwclock -w #同步硬件时间
hwclock –r #查看时间
查看各服务状态
crm status #查看高可用集群状态
systemctl | grep neutron #找出neutron的各个服务
systemctl | grep nova #找出nova的各个服务
systemctl | grep cinder #找出cinder 的各个服务
systemctl status ......
rbd info volume/volume-ID #检索映射信息
rbd rm volume/volume-ID #删除
/etc/init.d/ceph status #查看ceph状态
/etc/init.d/network restart #重启网络服务
ethtool eth0 #查看网口设置
