

[学习笔记]基于PaddleDetection的voc数据集训练(螺丝螺母识别)
这是关于深度学习的第二篇博客。
依旧是百度的Paddle框架。
不过有细微的区别,就是没有代码了(笑)
不过学习时间是一点不比前面的短就是了。甚至还要长。
不得不说,百度的paddle框架的相关教程是真的很少,在csdn和博客园逛了有一周左右都没弄明白要从哪里下手。
好在最后终于是明白了要干什么,那就稍稍写以下吧。
0、目标识别与目标检测的区别
简单来说目标检测就是要在一个图片中找到想要的东西,所以数据集的准备要更加困难一些,需要人为标记出每个图片的目标位置。这个过程越准确越好。
好在,学长已经替我完成了这个过程(笑)
voc数据集的准备与处理:
数据集结构如下图:
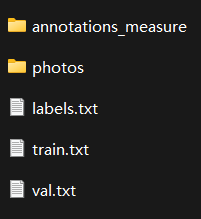
其中annotations_measure文件夹下存储的是每一张图片所包含的目标的信息/
photo中包含的就是每一张照片
labels.txt就是类别,这里内容如下:
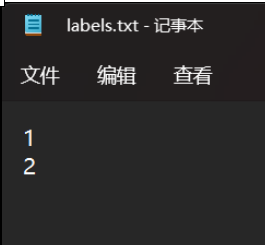
就是说,本数据集中只含有两个类别(螺丝螺母,具体哪个是1哪个是0我也记不得了,不过可以起更有标识性的名字,比如screw螺丝,nut螺母)
train.txt中包含的是每一张图片和其对应的annotations(标签)的相对路径。这是由python脚本乱序自动生成的。
val.txt同上。
因为我们的训练过程需要一一训练一边测试其LOSS(就是做一道题学习知识,再做一道题测试结果)所以需要两个文件来指明。
准备好数据集,我们就可以准备开始训练了。
这里又一次因为本机环境的问题,也因为算力问题,选择了百度的AI Studio进行训练。
文件结构如下:

│ command.txt
│ requirements.txt
│ setup.py
│ tree.txt
│
├─configs
│ │ runtime.yml
│ │
│ ├─datasets
│ │ coco_detection.yml
│ │ voc.yml
│ │
│ └─yolov3
│ │ README.md
│ │ yolov3_darknet53_270e_voc.yml
│ │
│ └─_base_
│ yolov3_reader.yml
│
├─dataset
│ └─VOC2007
│ voc.zip
│
├─deploy
│
└─tools
将刚刚处理好的数据集打成zip,放入datasets(外层的那个)中的VOC2007中
configs文件夹中的东西用来说明如何训练(使用什么网络,轮数,数据集类型等,下文会一一说明)
configs中的datasets文件夹中的文件(去除了一些,留下了两个相关的)就是说明数据集类型(coco数据集或是voc数据集),这里使用的是voc数据集,需要保留
yolov3文件夹中的那一串文件名表示的是:使用yolov3,darknet53网络,训练270轮,voc数据集进行训练。
继续向下,_base_中的yolov3_reader.yml内容如下:
1 worker_num: 2 2 TrainReader: 3 inputs_def: 4 num_max_boxes: 50 5 sample_transforms: 6 - Decode: {} 7 - Mixup: {alpha: 1.5, beta: 1.5} 8 - RandomDistort: {} 9 - RandomExpand: {fill_value: [123.675, 116.28, 103.53]} 10 - RandomCrop: {} 11 - RandomFlip: {} 12 batch_transforms: 13 - BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608], random_size: True, random_interp: True, keep_ratio: False} 14 - NormalizeBox: {} 15 - PadBox: {num_max_boxes: 50} 16 - BboxXYXY2XYWH: {} 17 - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} 18 - Permute: {} 19 - Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]} 20 batch_size: 1 21 shuffle: true 22 drop_last: true 23 mixup_epoch: 250 24 use_shared_memory: true 25 26 EvalReader: 27 inputs_def: 28 num_max_boxes: 50 29 sample_transforms: 30 - Decode: {} 31 - Resize: {target_size: [608, 608], keep_ratio: False, interp: 2} 32 - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} 33 - Permute: {} 34 batch_size: 32 35 36 TestReader: 37 inputs_def: 38 image_shape: [3, 608, 608] 39 sample_transforms: 40 - Decode: {} 41 - Resize: {target_size: [608, 608], keep_ratio: False, interp: 2} 42 - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} 43 - Permute: {} 44 batch_size: 1
其中20行的batch_size: 1与计算机的GPU显存有关,显存越大能开得越大,训练速度也会有所加快。这里直接拉到32
(Tesla V100*4,显存巨大,算得够快)
之后,将所有文件打包上传到AI Studio,运行环境后解压
需要注意得是:在AI Studio中,缺少一些相关得包,需要pip install一下,是这三个:pycocotools,lap,motmetrics
然后就可以开始训练了在AI Studio的终端里输入以下代码
python tools/train.py -c configs/yolov3/yolov3_darknet53_270e_voc.yml --use_vdl=True --eval
就可以开始训练了。
等待270轮结束后,就可以导出训练完的模型了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本