
python深拷贝与浅拷贝
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用
一般有三种方法,
alist=[1,2,3,["a","b"]]
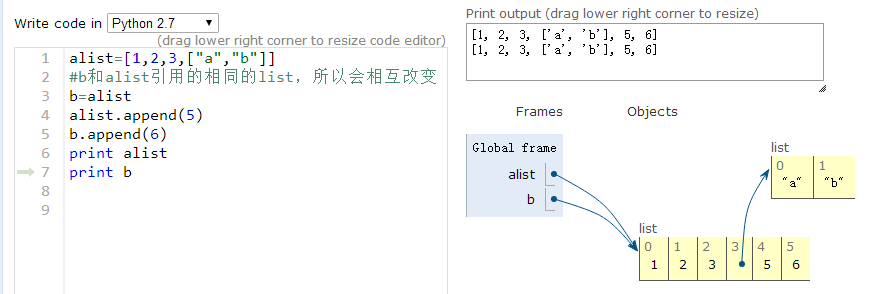
(1)直接赋值,默认浅拷贝传递对象的引用而已,原始列表改变,被赋值的b也会做相同的改变
>>> b=alist
>>> print b
[1, 2, 3, ['a', 'b']]
>>> alist.append(5)
>>> print alist;print b
[1, 2, 3, ['a', 'b'], 5]
[1, 2, 3, ['a', 'b'], 5]
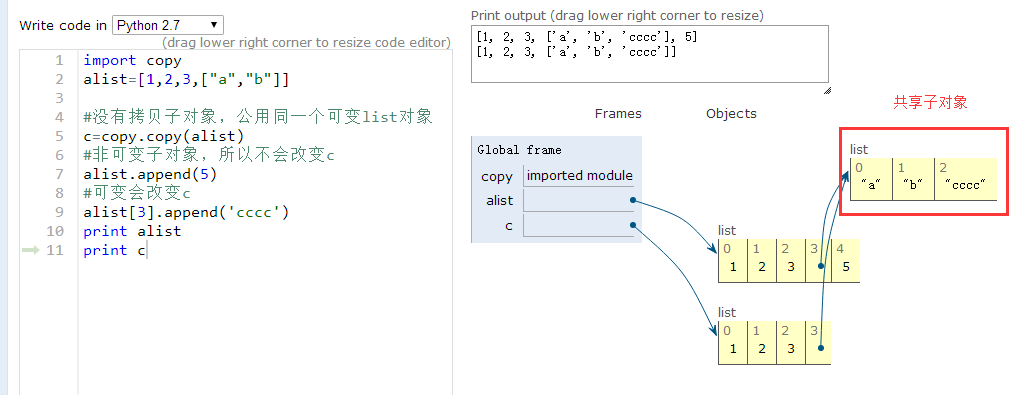
(2)copy浅拷贝,没有拷贝子对象,所以原始数据改变,子对象会改变
>>> import copy
>>> c=copy.copy(alist)
>>> print alist;print c
[1, 2, 3, ['a', 'b']]
[1, 2, 3, ['a', 'b']]
>>> alist.append(5)
>>> print alist;print c
[1, 2, 3, ['a', 'b'], 5]
[1, 2, 3, ['a', 'b']]
>>> alist[3]
['a', 'b']
>>> alist[3].append('cccc')
>>> print alist;print c
[1, 2, 3, ['a', 'b', 'cccc'], 5]
[1, 2, 3, ['a', 'b', 'cccc']] 里面的子对象被改变了
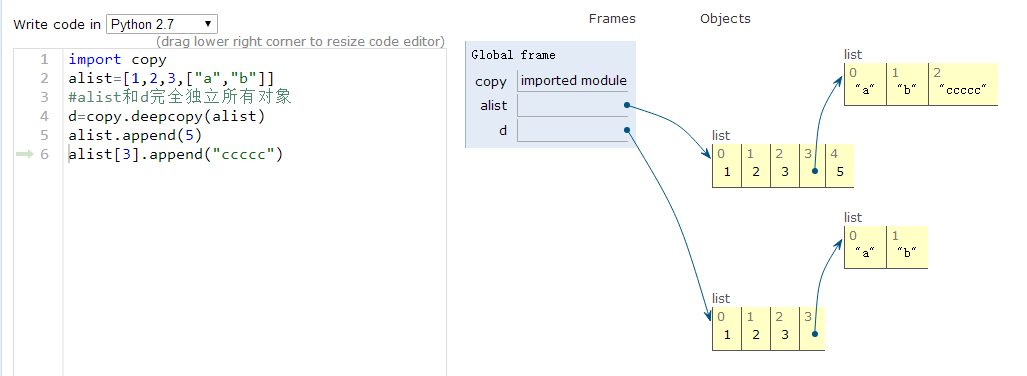
(3)深拷贝,包含对象里面的自对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变
>>> import copy
>>> d=copy.deepcopy(alist)
>>> print alist;print d
[1, 2, 3, ['a', 'b']]
[1, 2, 3, ['a', 'b']]始终没有改变
>>> alist.append(5)
>>> print alist;print d
[1, 2, 3, ['a', 'b'], 5]
[1, 2, 3, ['a', 'b']]始终没有改变
>>> alist[3]
['a', 'b']
>>> alist[3].append("ccccc")
>>> print alist;print d
[1, 2, 3, ['a', 'b', 'ccccc'], 5]
[1, 2, 3, ['a', 'b']] 始终没有改变
2. python的复制,深拷贝和浅拷贝的背景与意义?
不像matlab一样,比如b=a,就是单纯用a给b赋值,之后a怎么变,b不会变化。c语言也是一样。
如果想a怎么变,b就怎么变,c语言里就提出了引用的概念,相当于别名了。
example:
int a; int &ra=a; //定义引用ra,它是变量a的引用,即别名
okay!这篇文章有详解浅拷贝与深拷贝的本质原因:重新开辟内存来存储
https://www.jianshu.com/p/9ed9b5ce7bb0
https://baijiahao.baidu.com/s?id=1627356407968660842&wfr=spider&for=pc
这篇文章提出pythond的这个设计可以防止数据篡改,或者灵活改变
在Python中,对对象有一种很通俗的说法,万物皆对象。说的就是构造的任何数据类型都是一个对象,无论是数字、字符串、还是函数,甚至是模块、Python都对当做对象处理。
所有Python对象都拥有三个属性:身份、类型、值。
-
name="Li J"
-
print(type(name))
-
print(id(name))
-
print(name)
-
-
#输出:
-
#<type 'str'>
-
#140334394101408
-
#Li J
可变与不可变对象
在Python中,按更新对象的方式,可以将对象分为2大类:可变对象与不可变对象。
可变对象: 列表、字典、集合。所谓可变是指可变对象的值可变,身份是不变的。
不可变对象:数字、字符串、元组。不可变对象就是对象的身份和值都不可变。新创建的对象被关联到原来的变量名,旧对象被丢弃,垃圾回收器会在适当的时机回收这些对象。
-
var1="python" #字符串类型是不可变的
-
print(id(var1))
-
var1="java"
-
print(id(var1))
-
-
a=[3,4] #list是可变的,
-
print(id(a))
-
a.append(3)
-
print(id(a))
-
-
#输出结果:
-
140591145210096
-
140591145211632
-
140590909362688
-
140590909362688
引用
在Python程序中,每个对象都会在内存中申请开辟一块空间来保存该对象,该对象在内存中所在位置的地址被称为引用。在开发程序时,所定义的变量名实际就对象的地址引用。
引用实际就是内存中的一个数字地址编号,在使用对象时,只要知道这个对象的地址,就可以操作这个对象,但是因为这个数字地址不方便在开发时使用和记忆,所以使用变量名的形式来代替对象的数字地址。在Python中,变量就是地址的一种表示形式,并不开辟开辟存储空间。
就像 IP 地址,在访问网站时,实际都是通过 IP 地址来确定主机,而 IP 地址不方便记忆,所以使用域名来代替 IP 地址,在使用域名访问网站时,域名被解析成 IP 地址来使用。
通过一个例子来说明变量和变量指向的引用就是一个东西:
-
b=18
-
print(id(b))
-
print(id(18))
-
-
输出:
-
29413312
-
29413312
浅拷贝:
-
print("浅拷贝:")
-
import copy
-
b=[1,2,3,4,5]
-
print("id b:",id(b))
-
h=copy.copy(b)
-
print("id h",id(h))
-
print(h)
-
h.append(6)
-
print(h)
-
print("id h",id(h))
-
print(b) #浅拷贝新的列表h改变了,原来的b没变。
-
-
b[1]='n' #列表元素改变后,新的列表也没变
-
print(h)
-
-
输出:
-
浅拷贝:
-
('id b:', 140165805110552)
-
('id h', 140165805110480)
-
[1, 2, 3, 4, 5]
-
[1, 2, 3, 4, 5, 6]
-
('id h', 140165805110480)
-
[1, 2, 3, 4, 5]
-
[1, 2, 3, 4, 5, 6]
-
a = [1, 2]
-
l1 = [3, 4, a]
-
l2 = copy.copy(l1)
-
print(l1)
-
print(l2)
-
print(id(l1))
-
print(id(l2))
-
a[0] = 11
-
-
print(id(l1))
-
print(id(l2))
-
print(l1)
-
print(l2)
-
输出:
-
[3, 4, [1, 2]]
-
[3, 4, [1, 2]]
-
140624327425704
-
140624326197400
-
140624327425704
-
140624326197400
-
[3, 4, [11, 2]]
-
[3, 4, [11, 2]]

可以看出浅拷贝,相当于只拷贝了一层,到a那里,a变化了,其值也就变化了。
Python中有多种方式实现浅拷贝,copy模块的copy函数、对象的copy函数、工厂方法、切片等;大多数情况下,编写程序时都是使用浅拷贝,除非有特定的需求;浅拷贝的优点:拷贝速度快,占用空间少,拷贝效率高。
深拷贝
区别于浅拷贝只拷贝顶层引用,深拷贝会逐层进行拷贝,直到拷贝的所有引用都是不可变引用为止。

-
a = [1, 2]
-
l1 = [3, 4, a]
-
l2 = copy.deepcopy(l1)
-
print(l1)
-
print(l2)
-
print(id(l1))
-
print(id(l2))
-
a[0] = 11
-
-
print(id(l1))
-
print(id(l2))
-
print(l1)
-
print(l2)
-
-
输出:
-
[3, 4, [1, 2]]
-
[3, 4, [1, 2]]
-
140673014398488
-
140672779715720
-
140673014398488
-
140672779715720
-
[3, 4, [11, 2]]
-
[3, 4, [1, 2]]
为什么Python默认的拷贝方式是浅拷贝?
时间角度:浅拷贝花费时间更少;
空间角度:浅拷贝花费内存更少;
效率角度:浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号