


字节序和比特序(转)
add by zhj: 文章核心内容是:对于开发者来说,只用考虑字节序即可,没有位序
原文:https://www.cnblogs.com/lidabo/p/8513666.html
作者:DoubleLi
字节序(byte order)和位序(bit order)
在网络编程中经常会提到网络字节序和主机序,也就是说当一个对象由多个字节组成的时候需要注意对象的多个字节在内存中的顺序。
以前我也基本只了解过字节序,但是有一天当我看到ip.h中对IP头部结构体struct iphdr的定义时,我发现其中竟然对一个字节中的8个比特位也区分了大小端,这时我就迷糊了,不是说大小端只有在多个字节之间才会有区分的吗,为什么这里的定义却对一个字节中的比特位也区分大小端呢?
下面我们先看一下struct iphdr的定义,后文会解惑为什么要在一个字节中区分大小端。
struct iphdr { #if defined(__LITTLE_ENDIAN_BITFIELD) __u8 ihl:4, version:4; #elif defined (__BIG_ENDIAN_BITFIELD) __u8 version:4, ihl:4; #else #error "Please fix <asm/byteorder.h>" #endif __u8 tos; __be16 tot_len; __be16 id; __be16 frag_off; __u8 ttl; __u8 protocol; __sum16 check; __be32 saddr; __be32 daddr; /*The options start here. */ };
- 字节序(Byte order)
关于字节序的文章已经有很多了,在我这篇文章中不打算过多的说字节序,但是也不能完全脱离字节序因为后面的重点部分比特序跟字节序也有一定的相似度和联系。
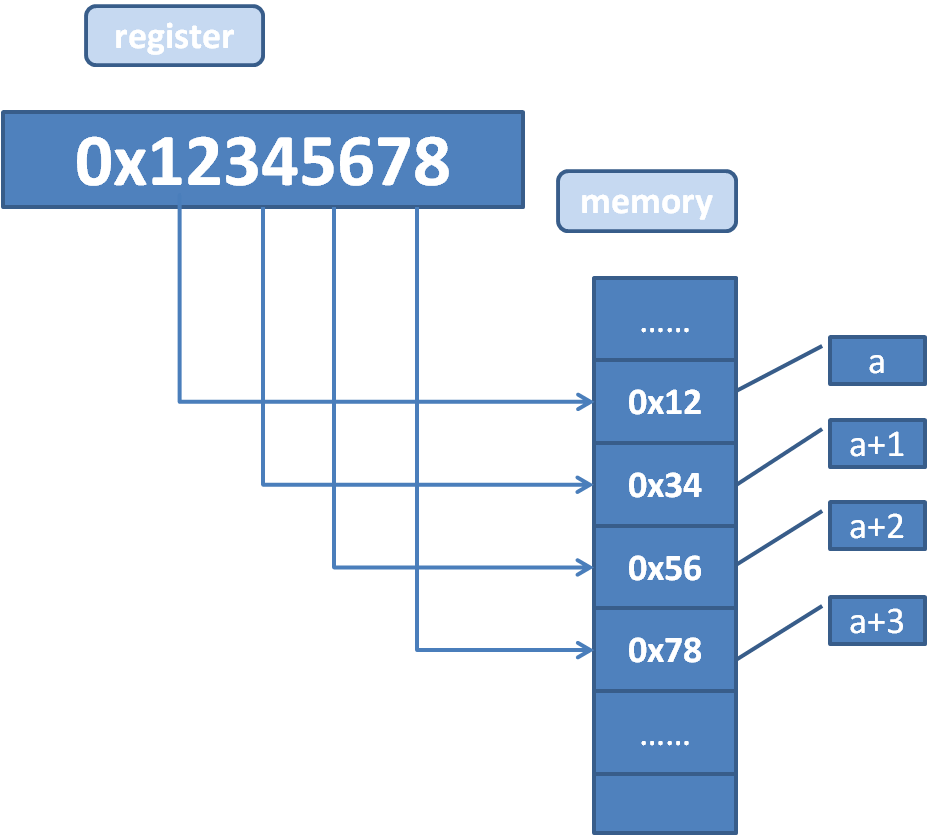
字节序就是说一个对象的多个字节在内存中如何排序存放,比如我们要想往一个地址a中写入一个整形数据0x12345678,那么最后在内存中是如何存放这四个字节的呢?
0x12这个字节值为最高有效字节,也就是整数值的最高位(在本文中0x12=0x12000000),0x78为最低有效字节。
图1:大端字节序
上图是大端字节序的示意图,所谓”大端字节序”,便是指最高有效字节落在低地址上的字节存放方式。
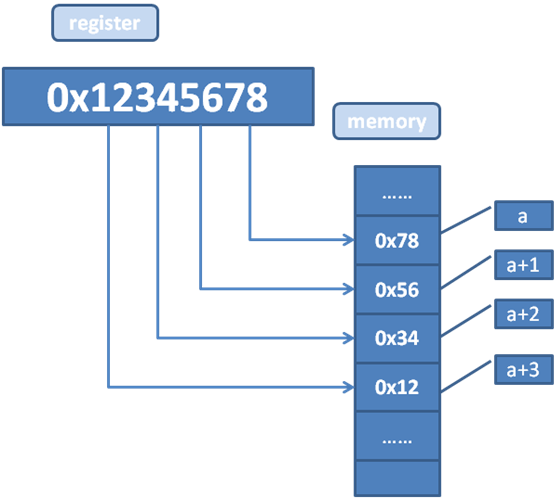
图2:小端字节序
而小端字节序就是最低有效字节落在低地址上的字节存放方式。
0x12345678=0x12000000 + 0x340000 + 0x5600 + 0x78,所以要想保持一个对象的值在大小端系统之间不变,那么就必须确保不同的系统能够正确的识别最高有效字节和最低有效字节(不能错误的识别最高、最低有效字节)。
同样的字节序12 34 56 78在大端序机器中会识别为0x12345678(0x12000000 + 0x340000 + 0x5600 + 0x78=0x12345678),在小端序机器中识别为0x78563412(0x12 + 0x3400 + 0x5600 00+ 0x78000000=0x78563412)。
所以要想两者保持一致就必须确保系统能够正确的识别最高有效字节0x12和最低有效字节0x78,那么在小端系统中字节存放的顺序应该为78 56 34 12。 - 比特序(bit order)
字节序是一个对象中的多个字节之间的顺序问题,比特序就是一个字节中的8个比特位(bit)之间的顺序问题。一般情况下系统的比特序和字节序是保持一致的。
一个字节由8个bit组成,这8个bit也存在如何排序的情况,跟字节序类似的有最高有效比特位、最低有效比特位。
比特序1 0 0 1 0 0 1 0在大端系统中最高有效比特位为1、最低有效比特位为0,字节的值为0x92。在小端系统中最高、最低有效比特位则相反为0、1,字节的值为0x49。
跟字节序类似,要想保持一个字节值不变那么就要使系统能正确的识别最高、最低有效比特位。 - 字节序转换函数ntohl(s)、htonl(s)
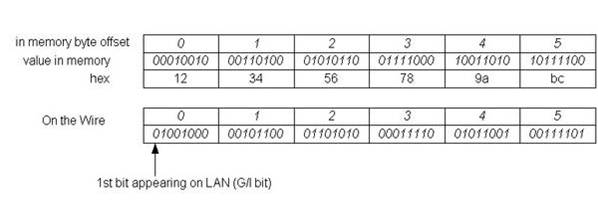
在socket编程中经常要用到网络字节序转换函数ntohl、htonl来进行主机序和网络序(大端序)的转换,在主机序为小端的系统中字节序列78 56 34 12(val=0x12345678)经过htonl转换后字节序列变成12 34 56 78:
图3:htonl函数
字节序转换后我在想是不是比特序也一同进行了转换?
为什么会有这个疑问呢,因为前文可知系统的比特序和字节序是一致的,现在字节序已经从小端变成了大端那么比特序应该也要一起转换。而且如果比特序不变化那么当这些字节到了目标大端序系统中后每一个字节的值都会发生变化,因为同样的比特序列在小端和大端系统中识别的字节值会不一样。
首先从htonl、ntohl的源码来看确实只进行了字节序的转换并没有进行比特序的转换,再有就是以前socket编程的时候只调用了ntohl、htonl等函数并没有调用(而且系统也没有提供)比特序转换函数,但是最后的结果都是正确的,并没有发现上面提到的字节值发生变化的问题。
那么这个”神奇”的事情是怎么解决的呢,好像系统本身就给我们”悄悄”的解决了我担心的问题。
答案我们下文揭晓。 - 比特(bit)的发送和接收顺序
比特的发送、接收顺序是指一个字节中的bit在网络电缆中是如何发送、接收的。在以太网(Ethernet)中,是从最低有效比特位到最高有效比特位的发送顺序,也就是最低有效比特位首先发送,参考资料:frame。
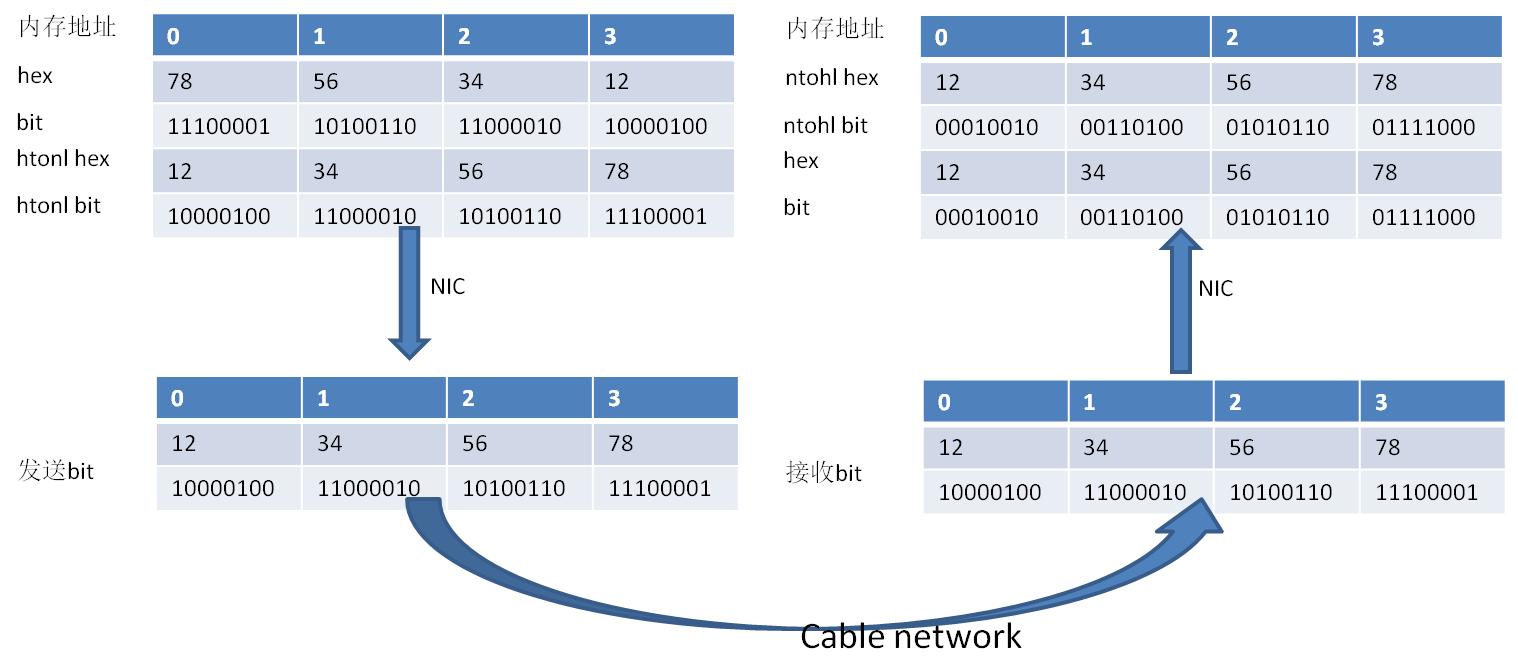
在以太网中这个规定有点奇怪,因为字节序我们是按照大端序来发送,但是比特序却是按照小端序的方式来发送,下图是直接从网上找来的一张图,主机序本身是大端序:
图4:比特发送、接受示意图
比特的发送、接收顺序对CPU、软件都是不可见的,因为我们的网卡会给我们处理这种转换,在发送的时候按照小端序发送比特位,在接收的时候会把接收到的比特序转换成主机的比特序,下面是一个小端机器发送一个int整型给一个大端机器的示意图:
图5:小端->大端比特发送示例
因为对网卡对比特序的发送、接收所做的转换没有深入的了解所以上图很有可能会有错误之处。
现在来回答一下第3节中的那个疑问:
- htonl、ntohl函数肯定是不会同步转换一个字节中的比特序的,因为如果比特序也发生了转换的话那么这个字节的值也就发生了变化,记住htonl、ntohl只是字节序转换函数。
- 比特序按照小端的方式发送,首先发送的是最低有效比特位,最后发送的是最高有效比特位,接收端的网卡在接收到比特序列后按照主机的比特序把接收到的”小端序”比特流转换成主机对应的比特序列。
可以假设存在ntohb、htonb(b代表bit)这样的两个函数,网卡进行了比特序的转换,不过是这两个函数是网卡自动调用的,我们平时不用关注。 - 按照规则,发送、接收的时候进行比特序的转换,那么就能保证在不同的机器之间进行通信不会发生我担心的字节值发生变化的问题。
- 结构体的位域
关于C语言中结构体的位域可以参考这篇文章:http://tonybai.com/2013/05/21/talk-about-bitfield-in-c-again/,对于位域的具体用法、语法参考这篇文章即可有。
对于位域有一个约定:在C语言的结构体中如果包含了位域,如果位域A定义在位域B之前,那么位域A总是出现在低序的比特位。
在计算机中可寻址的最小单位为字节,bit是无法寻址的,但是为了抽象我们可以把计算机的最小寻址单位变成bit,也就是我们可以单独获得一个bit位。
我们有如下的一段代码:

#include<stdio.h> struct bit_order{ unsigned char a: 2, b: 3, c: 3; }; int main(int argc, char *argv[]) { unsigned char ch = 0x79; struct bit_order *ptr = (struct bit_order *)&ch; printf("bit_order->a : %u\n", ptr->a); printf("bit_order->b : %u\n", ptr->b); printf("bit_order->c : %u\n", ptr->c); return 0; }
我们把代码在gentoo(intel小端机器)、hu-unix(大端机器)两个机器上面编译、运行,结果如下:
liuxingen@ V6-Dev ~/station $ ./bitfiled
bit_order->a : 1
bit_order->b : 6
bit_order->c : 3
下面是hp-unix的运行结果
# ./bitfiled
bit_order->a : 1
bit_order->b : 7
bit_order->c : 1
我们先分析一下gentoo上面的结果: 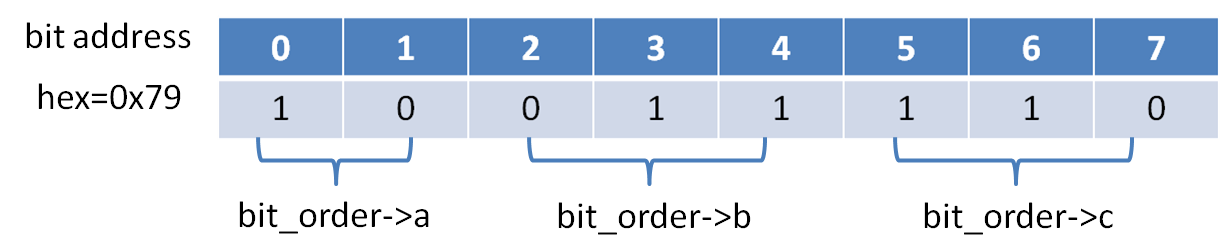
图6:小端机器的位域示例
从上图中我们很容易就能理解gentoo上面的输出结果,下面是hp-unix上面示意图: 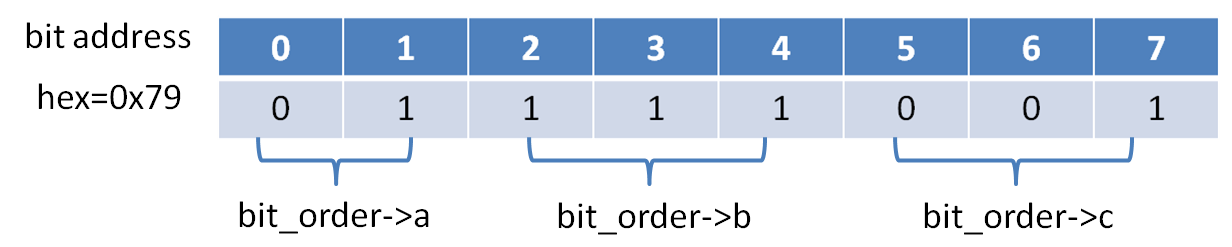
图7:大端机器的位域示例
从上面的输出可以看到同样的代码在不同的机器中输出了不同的结果,也就是说我们的代码在不同的平台不能直接移植,导致这个问题的原因就是我们前面提到的关于位域的一个约定,定义在前面的位域总是出现在低地址的bit位中,因为不同的平台的比特序是不同的,但是我们定义的位域没有根据平台的大小端进行转换,最后就导致了问题。那么如何解决这个问题,那就是在定义结构体中的位域时判断平台的大小端:
#include<stdio.h> #include<asm/byteorder.h> struct bit_order{ #if defined(__LITTLE_ENDIAN_BITFIELD) unsigned char a: 2, b: 3, c: 3; #elif defined (__BIG_ENDIAN_BITFIELD) unsigned char c: 3, b: 3, a: 2; #else #error "Please fix <asm/byteorder.h>" #endif }; int main(int argc, char *argv[]) { unsigned char ch = 0x79; struct bit_order *ptr = (struct bit_order *)&ch; printf("bit_order->a : %u\n", ptr->a); printf("bit_order->b : %u\n", ptr->b); printf("bit_order->c : %u\n", ptr->c); return 0; }
到此我们也就解释了文章开头关于struct iphdr定义中的那个疑问。
最后给大家隆重介绍一篇文章,对我启发很大,文中的很多知识来自于它:byte order and bit order
