


理解 Python 的 Dataclasses第二篇(转)
原文:https://zhuanlan.zhihu.com/p/59658598
作者:没有50CM手臂
网站:知乎
这是 Python 最新的Dataclasses系列的第二部分内容。在第一部分里,我介绍了dataclasses的一般用法。这篇博客主要介绍另一个特征:dataclasses.field。
我们已经知道Dataclasses会生成他们自身的__init__方法。它同时把初始化的值赋给这些字段。以下是我们在上一篇博客里定义的内容:
- 变量名
- 数据类型
这些内容仅给我们有限的dataclass字段使用范围。让我们讨论一下这些局限性,以及它们如何通过dataclass.field被解决。
复合初始化
考虑以下情形:你想要初始化一个变量为列表。你如何实现它呢?一种简单的方式是使用__post_init__方法。

数据类Student产生了一个名为marks的列表。我们不传递marks的值,而是使用__post_init__方法初始化。这是我们定义的单一属性。此外,我们必须在__post_init__里调用get_random_marks函数。这些工作是额外的。
辛运的是,Python为我们提供了一个解决方案。我们可以使用dataclasses.field来定制化dataclass字段的行为以及它们在dataclass的影响。
仍然是上述的使用情形,让我们从__post_init__里去除get_random_marks的调用。以下是使用dataclasses.field的情形:

dataclasses.field接受了一个名为default_factory的参数,它的作用是:如果在创建对象时没有赋值,则使用该方法初始化该字段。
default_factory必须是一个可以调用的无参数方法(通常为一个函数)。
这样我们就可以使用复合形式初始化字段。现在,让我们考虑另一个使用场景。
使用全部字段进行数据比较
通过上篇博文,我们了解到,dataclass能够自动生成<,=,>,<=和>=这些比较方法。但是这些比较方法的一个缺陷是,它们使用类中的所有字段进行比较,而这种情况往往不常见。更经常地,这种比较方法会给我们使用dataclasses造成麻烦。
考虑以下的使用情形:你有一个数据类用于存放用户的信息。现在,它可能存在以下字段:
- 姓名
- 年龄
- 身高
- 体重
你仅想比较用户对象的年龄、身高和体重。你不想比较姓名。这是后端开发者经常会遇到的使用情景。

自动生成的比较方法会比较一下的数组:

这将会破坏我们的意图。我们不想让姓名(name)用于比较。那么,如何使用dataclasses.field来实现我们的想法呢?
下面是具体步骤:

默认情况下,所用的字段都用于比较,因此我们仅仅需要指定哪些字段用于比较,而实现方法是直接把不需要的字段定义为filed(compare=False)。
一个更为简单的应用情形也可以被讨论。让我们定义一个数据类,它被用来存储一个数字激起字符串表示。我们想让比较仅仅发生在该数字的值,而不是他的字符串表示。
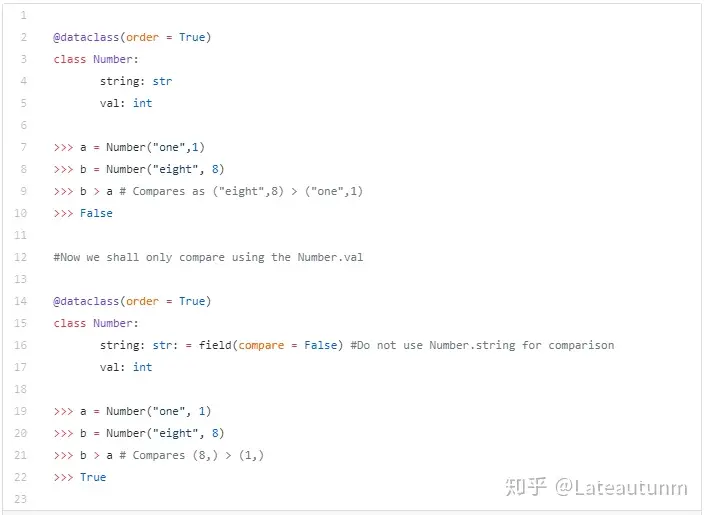
现在,我们有更大的自由来控制 dataclasses 的行为。看起来很棒!
使用全部字段进行数据表示
自动生成的__repr__方法使用所有的字段用于表示。当然,这也不是大多数情形下的理想选择,尤其是当你的数据类有大量的字段时。单个对象的表示会变得异常臃肿,对调试来说也不利。

想象一下在你的日志里看到这样的表示吧,然后还要写一个正则表达式来搜索它。太可怕了,对吧?
当然,我们也能够个性化这种行为。考虑一个类似的使用场景,也许最合适的用于表示的属性是姓名(name)。那么对__repr__,我们仅使用它:

这样看起来就很棒了。调试很方便,比较也有意义!
从初始化中省略字段
目前为止我们看到的所有例子,都有一个共同特点——即我们需要为所有被声明的字段传递值,除了有默认值之外。在那种情形下(指有默认值的情况下),我们可以选择传递值,也可以不传递。

但是,还有一种情形:我们可能不想在初始化时设定某个字段的值。这也是一种常见的使用场景。也许你在追踪一个对象的状态,并且希望它在初始化时一直被设为False。更一般地,这个值在初始化时不能够被传递。
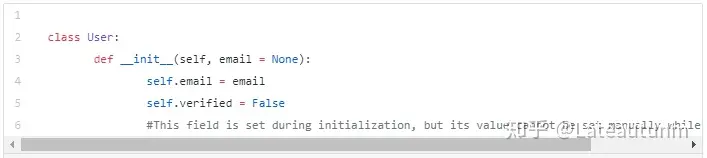
那么,我们如何实现上述想法呢?以下是具体内容:

瞧啊!我们现在对dataclasses的使用有了更大的灵活性。
总结
希望上两篇博文能够帮助你理解dataclass,希望你能尽快在项目中使用它们!
感谢你的阅读。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2015-04-20 PyMongo和MongoEngine
2015-04-20 PyMongo的使用(转)
2015-04-20 MongoDB的Python客户端PyMongo(转)
2015-04-20 对比MySQL,你究竟在什么时候更需要MongoDB(转)