
Java 泛型,你了解类型擦除吗?(转)
add by zhj: 对泛型的实现原理解释的非常好,醍醐灌顶
作者:frank909
https://blog.csdn.net/briblue/article/details/76736356
泛型,一个孤独的守门者。
大家可能会有疑问,我为什么叫做泛型是一个守门者。这其实是我个人的看法而已,我的意思是说泛型没有其看起来那么深不可测,它并不神秘与神奇。泛型是 Java 中一个很小巧的概念,但同时也是一个很容易让人迷惑的知识点,它让人迷惑的地方在于它的许多表现有点违反直觉。
文章开始的地方,先给大家奉上一道经典的测试题。
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());
请问,上面代码最终结果输出的是什么?不了解泛型的和很熟悉泛型的同学应该能够答出来,而对泛型有所了解,但是了解不深入的同学可能会答错。
正确答案是 true。
上面的代码中涉及到了泛型,而输出的结果缘由是类型擦除。先好好说说泛型。
泛型是什么?
泛型的英文是 generics,generic 的意思是通用,而翻译成中文,泛应该意为广泛,型是类型。所以泛型就是能广泛适用的类型。
但泛型还有一种较为准确的说法就是为了参数化类型,或者说可以将类型当作参数传递给一个类或者是方法。
那么,如何解释类型参数化呢?
public class Cache {
Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
假设 Cache 能够存取任何类型的值,于是,我们可以这样使用它。
Cache cache = new Cache();
cache.setValue(134);
int value = (int) cache.getValue();
cache.setValue("hello");
String value1 = (String) cache.getValue();
使用的方法也很简单,只要我们做正确的强制转换就好了。
但是,泛型却给我们带来了不一样的编程体验。
public class Cache<T> {
T value;
public Object getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
这就是泛型,它将 value 这个属性的类型也参数化了,这就是所谓的参数化类型。再看它的使用方法。
Cache<String> cache1 = new Cache<String>();
cache1.setValue("123");
String value2 = cache1.getValue();
Cache<Integer> cache2 = new Cache<Integer>();
cache2.setValue(456);
int value3 = cache2.getValue();
最显而易见的好处就是它不再需要对取出来的结果进行强制转换了。但,还有另外一点不同。

泛型除了可以将类型参数化外,而参数一旦确定好,如果类似不匹配,编译器就不通过。
上面代码显示,无法将一个 String 对象设置到 cache2 中,因为泛型让它只接受 Integer 的类型。
所以,综合上面信息,我们可以得到下面的结论。
-
与普通的 Object 代替一切类型这样简单粗暴而言,泛型使得数据的类别可以像参数一样由外部传递进来。它提供了一种扩展能力。它更符合面向抽象开发的软件编程宗旨。
-
当具体的类型确定后,泛型又提供了一种类型检测的机制,只有相匹配的数据才能正常的赋值,否则编译器就不通过。所以说,它是一种类型安全检测机制,一定程度上提高了软件的安全性防止出现低级的失误。
-
泛型提高了程序代码的可读性,不必要等到运行的时候才去强制转换,在定义或者实例化阶段,因为
Cache<String>这个类型显化的效果,程序员能够一目了然猜测出代码要操作的数据类型。
下面的文章,我们正常介绍泛型的相关知识。
泛型的定义和使用
泛型按照使用情况可以分为 3 种。
1. 泛型类。
2. 泛型方法。
3. 泛型接口。
泛型类
我们可以这样定义一个泛型类。
public class Test<T> {
T field1;
}
尖括号 <> 中的 T 被称作是类型参数,用于指代任何类型。事实上,T 只是一种习惯性写法,如果你愿意。你可以这样写。
public class Test<Hello> {
Hello field1;
}
但出于规范的目的,Java 还是建议我们用单个大写字母来代表类型参数。常见的如:
1. T 代表一般的任何类。
2. E 代表 Element 的意思,或者 Exception 异常的意思。
3. K 代表 Key 的意思。
4. V 代表 Value 的意思,通常与 K 一起配合使用。
5. S 代表 Subtype 的意思,文章后面部分会讲解示意。
如果一个类被 <T> 的形式定义,那么它就被称为是泛型类。
那么对于泛型类怎么样使用呢?
Test<String> test1 = new Test<>();
Test<Integer> test2 = new Test<>();
只要在对泛型类创建实例的时候,在尖括号中赋值相应的类型便是。T 就会被替换成对应的类型,如 String 或者是 Integer。你可以相像一下,当一个泛型类被创建时,内部自动扩展成下面的代码。
public class Test<String> {
String field1;
}
当然,泛型类不至接受一个类型参数,它还可以这样接受多个类型参数。
public class MultiType <E,T>{
E value1;
T value2;
public E getValue1(){
return value1;
}
public T getValue2(){
return value2;
}
}
泛型方法
public class Test1 {
public <T> void testMethod(T t){
}
}
泛型方法与泛型类稍有不同的地方是,类型参数也就是尖括号那一部分是写在返回值前面的。<T> 中的 T 被称为类型参数,而方法中的 T 被称为参数化类型,它不是运行时真正的参数。
当然,声明的类型参数,其实也是可以当作返回值的类型的。
public <T> T testMethod1(T t){
return null;
}
泛型类与泛型方法的共存现象
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <T> T testMethod1(T t){
return t;
}
}
上面代码中,Test1<T> 是泛型类,testMethod 是泛型类中的普通方法,而 testMethod1 是一个泛型方法。而泛型类中的类型参数与泛型方法中的类型参数是没有相应的联系的,泛型方法始终以自己定义的类型参数为准。
所以,针对上面的代码,我们可以这样编写测试代码。
Test1<String> t = new Test1();
t.testMethod("generic");
Integer i = t.testMethod1(new Integer(1));
泛型类的实际类型参数是 String,而传递给泛型方法的类型参数是 Integer,两者不想干。
但是,为了避免混淆,如果在一个泛型类中存在泛型方法,那么两者的类型参数最好不要同名。比如,Test1<T> 代码可以更改为这样
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <E> E testMethod1(E e){
return e;
}
}
泛型接口
泛型接口和泛型类差不多,所以一笔带过。
public interface Iterable<T> {
}
通配符 ?
除了用 <T> 表示泛型外,还有 <?> 这种形式。? 被称为通配符。
可能有同学会想,已经有了 <T> 的形式了,为什么还要引进 <?> 这样的概念呢?
class Base{}
class Sub extends Base{}
Sub sub = new Sub();
Base base = sub;
上面代码显示,Base 是 Sub 的父类,它们之间是继承关系,所以 Sub 的实例可以给一个 Base 引用赋值,那么
List<Sub> lsub = new ArrayList<>();
List<Base> lbase = lsub;
最后一行代码成立吗?编译会通过吗?
答案是否定的。
编译器不会让它通过的。Sub 是 Base 的子类,不代表 List<Sub> 和 List<Base> 有继承关系。
但是,在现实编码中,确实有这样的需求,希望泛型能够处理某一范围内的数据类型,比如某个类和它的子类,对此 Java 引入了通配符这个概念。
所以,通配符的出现是为了指定泛型中的类型范围。
通配符有 3 种形式。
-
<?>被称作无限定的通配符。 -
<? extends T>被称作有上限的通配符。 -
<? super T>被称作有下限的通配符。
无限定通配符
public void testWildCards(Collection<?> collection){
}
上面的代码中,方法内的参数是被无限定通配符修饰的 Collection 对象,它隐略地表达了一个意图或者可以说是限定,那就是 testWidlCards() 这个方法内部无需关注 Collection 中的真实类型,因为它是未知的。所以,你只能调用 Collection 中与类型无关的方法。
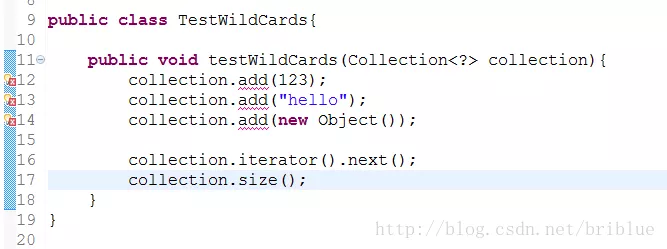
我们可以看到,当 <?> 存在时,Collection 对象丧失了 add() 方法的功能,编译器不通过。
我们再看代码。
List<?> wildlist = new ArrayList<String>();
wildlist.add(123);// 编译不通过
有人说,<?> 提供了只读的功能,也就是它删减了增加具体类型元素的能力,只保留与具体类型无关的功能。它不管装载在这个容器内的元素是什么类型,它只关心元素的数量、容器是否为空?我想这种需求还是很常见的吧。
有同学可能会想,<?> 既然作用这么渺小,那么为什么还要引用它呢?
个人认为,提高了代码的可读性,程序员看到这段代码时,就能够迅速对此建立极简洁的印象,能够快速推断源码作者的意图。
<? extends T>
<?> 代表着类型未知,但是我们的确需要对于类型的描述再精确一点,我们希望在一个范围内确定类别,比如类型 A 及 类型 A 的子类都可以。
public void testSub(Collection<? extends Base> para){
}
上面代码中,para 这个 Collection 接受 Base 及 Base 的子类的类型。
但是,它仍然丧失了写操作的能力。也就是说
para.add(new Sub());
para.add(new Base());
仍然编译不通过。
没有关系,我们不知道具体类型,但是我们至少清楚了类型的范围。
<? super T>
这个和 <? extends T> 相对应,代表 T 及 T 的超类。
public void testSuper(Collection<? super Sub> para){
}
<? super T> 神奇的地方在于,它拥有一定程度的写操作的能力。
public void testSuper(Collection<? super Sub> para){
para.add(new Sub());//编译通过
para.add(new Base());//编译不通过
}
通配符与类型参数的区别
一般而言,通配符能干的事情都可以用类型参数替换。
比如
public void testWildCards(Collection<?> collection){}
可以被
public <T> void test(Collection<T> collection){}
取代。
值得注意的是,如果用泛型方法来取代通配符,那么上面代码中 collection 是能够进行写操作的。只不过要进行强制转换。
public <T> void test(Collection<T> collection){
collection.add((T)new Integer(12));
collection.add((T)"123");
}
需要特别注意的是,类型参数适用于参数之间的类别依赖关系,举例说明。
public class Test2 <T,E extends T>{
T value1;
E value2;
}
public <D,S extends D> void test(D d,S s){
}
E 类型是 T 类型的子类,显然这种情况类型参数更适合。
有一种情况是,通配符和类型参数一起使用。
public <T> void test(T t,Collection<? extends T> collection){
}
如果一个方法的返回类型依赖于参数的类型,那么通配符也无能为力。
public T test1(T t){
return value1;
}
类型擦除
泛型是 Java 1.5 版本才引进的概念,在这之前是没有泛型的概念的,但显然,泛型代码能够很好地和之前版本的代码很好地兼容。
这是因为,泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。
通俗地讲,泛型类和普通类在 java 虚拟机内是没有什么特别的地方。回顾文章开始时的那段代码
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());
打印的结果为 true 是因为 List<String> 和 List<Integer> 在 jvm 中的 Class 都是 List.class。
泛型信息被擦除了。
可能同学会问,那么类型 String 和 Integer 怎么办?
答案是泛型转译。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}
Erasure 是一个泛型类,我们查看它在运行时的状态信息可以通过反射。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());
打印的结果是
erasure class is:com.frank.test.Erasure
Class 的类型仍然是 Erasure 并不是 Erasure<T> 这种形式,那我们再看看泛型类中 T 的类型在 jvm 中是什么具体类型。
Field[] fs = eclz.getDeclaredFields();
for ( Field f:fs) {
System.out.println("Field name "+f.getName()+" type:"+f.getType().getName());
}
打印结果是
Field name object type:java.lang.Object
那我们可不可以说,泛型类被类型擦除后,相应的类型就被替换成 Object 类型呢?
这种说法,不完全正确。
我们更改一下代码。
public class Erasure <T extends String>{
// public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}
现在再看测试结果:
Field name object type:java.lang.String
我们现在可以下结论了,在泛型类被类型擦除的时候,之前泛型类中的类型参数部分如果没有指定上限,如 <T> 则会被转译成普通的 Object 类型,如果指定了上限如 <T extends String> 则类型参数就被替换成类型上限。
所以,在反射中。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
public void add(T object){
}
}
add() 这个方法对应的 Method 的签名应该是 Object.class。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());
Method[] methods = eclz.getDeclaredMethods();
for ( Method m:methods ){
System.out.println(" method:"+m.toString());
}
打印结果是
method:public void com.frank.test.Erasure.add(java.lang.Object)
也就是说,如果你要在反射中找到 add 对应的 Method,你应该调用 getDeclaredMethod("add",Object.class) 否则程序会报错,提示没有这么一个方法,原因就是类型擦除的时候,T 被替换成 Object 类型了。
类型擦除带来的局限性
类型擦除,是泛型能够与之前的 java 版本代码兼容共存的原因。但也因为类型擦除,它会抹掉很多继承相关的特性,这是它带来的局限性。
理解类型擦除有利于我们绕过开发当中可能遇到的雷区,同样理解类型擦除也能让我们绕过泛型本身的一些限制。比如
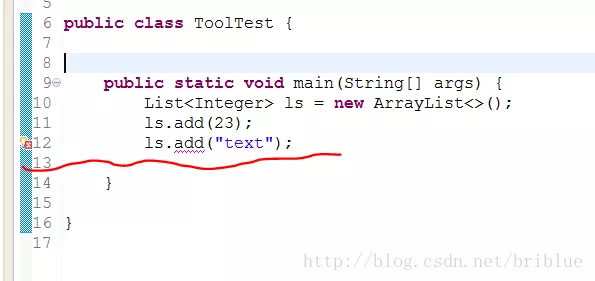
正常情况下,因为泛型的限制,编译器不让最后一行代码编译通过,因为类似不匹配,但是,基于对类型擦除的了解,利用反射,我们可以绕过这个限制。
public interface List<E> extends Collection<E>{
boolean add(E e);
}
上面是 List 和其中的 add() 方法的源码定义。
因为 E 代表任意的类型,所以类型擦除时,add 方法其实等同于
boolean add(Object obj);
那么,利用反射,我们绕过编译器去调用 add 方法。
public class ToolTest {
public static void main(String[] args) {
List<Integer> ls = new ArrayList<>();
ls.add(23);
// ls.add("text");
try {
Method method = ls.getClass().getDeclaredMethod("add",Object.class);
method.invoke(ls,"test");
method.invoke(ls,42.9f);
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for ( Object o: ls){
System.out.println(o);
}
}
}
打印结果是:
23
test
42.9
可以看到,利用类型擦除的原理,用反射的手段就绕过了正常开发中编译器不允许的操作限制。
泛型中值得注意的地方
泛型类或者泛型方法中,不接受 8 种基本数据类型。
所以,你没有办法进行这样的编码。
List<int> li = new ArrayList<>();
List<boolean> li = new ArrayList<>();
需要使用它们对应的包装类。
List<Integer> li = new ArrayList<>();
List<Boolean> li1 = new ArrayList<>();
对泛型方法的困惑
public <T> T test(T t){
return null;
}
有的同学可能对于连续的两个 T 感到困惑,其实 <T> 是为了说明类型参数,是声明,而后面的不带尖括号的 T 是方法的返回值类型。
你可以相像一下,如果 test() 这样被调用
test("123");
那么实际上相当于
public String test(String t);
Java 不能创建具体类型的泛型数组
这句话可能难以理解,代码说明。
List<Integer>[] li2 = new ArrayList<Integer>[];
List<Boolean> li3 = new ArrayList<Boolean>[];
这两行代码是无法在编译器中编译通过的。原因还是类型擦除带来的影响。
List<Integer> 和 List<Boolean> 在 jvm 中等同于List<Object> ,所有的类型信息都被擦除,程序也无法分辨一个数组中的元素类型具体是 List<Integer>类型还是 List<Boolean> 类型。
但是,
List<?>[] li3 = new ArrayList<?>[10];
li3[1] = new ArrayList<String>();
List<?> v = li3[1];
借助于无限定通配符却可以,前面讲过 ? 代表未知类型,所以它涉及的操作都基本上与类型无关,因此 jvm 不需要针对它对类型作判断,因此它能编译通过,但是,只提供了数组中的元素因为通配符原因,它只能读,不能写。比如,上面的 v 这个局部变量,它只能进行 get() 操作,不能进行 add() 操作,这个在前面通配符的内容小节中已经讲过。
泛型,并不神奇
我们可以看到,泛型其实并没有什么神奇的地方,泛型代码能做的非泛型代码也能做。
而类型擦除,是泛型能够与之前的 java 版本代码兼容共存的原因。
可量也正因为类型擦除导致了一些隐患与局限。
但,我还是要建议大家使用泛型,如官方文档所说的,如果可以使用泛型的地方,尽量使用泛型。
毕竟它抽离了数据类型与代码逻辑,本意是提高程序代码的简洁性和可读性,并提供可能的编译时类型转换安全检测功能。
类型擦除不是泛型的全部,但是它却能很好地检测我们对于泛型这个概念的理解程度。
我在文章开头将泛型比作是一个守门人,原因就是他本意是好的,守护我们的代码安全,然后在门牌上写着出入的各项规定,及“xxx 禁止出入”的提醒。但是同我们日常所遇到的那些门卫一般,他们古怪偏执,死板守旧,我们可以利用反射基于类型擦除的认识,来绕过泛型中某些限制,现实生活中,也总会有调皮捣蛋者能够基于对门卫们生活作息的规律,选择性地绕开他们的监视,另辟蹊径溜进或者溜出大门,然后扬长而去,剩下守卫者一个孤独的身影。
所以,我说泛型,并不神秘,也不神奇。
推荐去我的博客阅读更多:
2.Spring MVC、Spring Boot、Spring Cloud 系列教程
3.Maven、Git、Eclipse、Intellij IDEA 系列工具教程
觉得不错,别忘了点赞+转发哦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号