


一致性哈希(转)
add by zhj: 办法都是想出来的,很多时候都是相互借鉴。多读书,涉猎不同的学科,对自己的思维拓展大有好处。很多学科的理论,思想,其实都有一定的扩展性,
可以扩展到其它学科,这也是创新的一种。记得华为老总任正非谈管理时,提到熵,这个词是物理上的一个词汇,但它也适用于管理学。
一致性哈希使用圆比较完美的解决了添加/删除结点导致缓存全部失效的问题,用这种方法,其实也算是一种折中的办法,因为部分缓存还是会失效,但是失效的比例
比较小。其实很多时候没有完美的解决方案,是要折中的,创新绝大多数情况下不是从0到1,而是渐进式的。有总比无好,70分比20分好,因为拿100分有时成本太高
原文:https://www.jianshu.com/p/58fde9b2d0a3
前言
在分布式系统中,常常需要使用缓存,而且通常是集群,访问缓存和添加缓存都需要一个 hash 算法来寻找到合适的 Cache 节点。但,通常不是用取余hash,而是使用我们今天的主角—— 一致性 hash 算法。
今天楼主就来说说这个一致性 hash 算法。
1. 为什么普通的 hash 算法不行?
普通的 hash 算法通常都是对机器数量进行取余,比如集群环境中有 3 台 redis,当我们放入对象的时候,通常是对 3 进行取余。这种做法在大部分情况下是没有问题的。但是,注意:如果缓存机器需要增减,问题就来了。
什么问题呢?
假设原本是 3 个 redis,这时候,加了一台 redis,那么取余算法就变成了取余 4。
这样有什么问题呢?
答:当使用负载均衡的时候,负载均衡器根据对象的 key 对机器进行取余,这个时候,原有的 key 取余现有的机器数 4 就找不到那台机器了!笨一点的办法,就是在增加机器的时候,清除所有缓存,但这会导致缓存击穿甚至缓存雪崩,严重情况下引发 DB 宕机。
2. 一致性 hash 怎么解决这个问题?
很简单,既然问题出在对机器取余上,那么就不对机器取余。
具体怎么做呢?
答:我们可以假设有一个 2 的 32 次方的环形,缓存节点通过 hash 落在环上。而对象的添加也是使用 hash,但很大的几率是 hash 不到缓存节点的。怎么办呢?找离他最近的那个节点。 比如顺时针找前面那个节点。
能解决问题吗?想象一下:当增减机器时,环形节点变化的只会影响一个节点,就是新节点的顺时针方向的前面的节点。这个时候,我们只需要清除那一个节点的数据就足够了,不用想取余 hash 那样,清除所有节点的数据。
具体类似于下图:
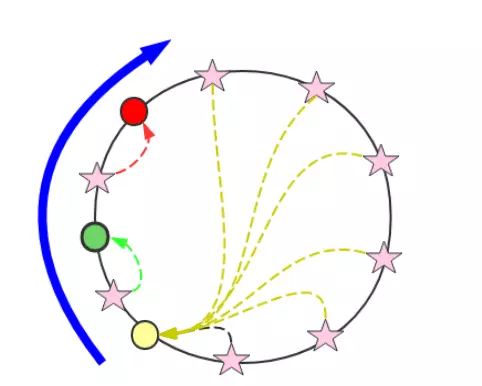
上图中,节点中的五角星代表对象,红绿黄代表节点,每个对象都会找他的上一个节点。如有增减,只影响一个节点。
如下图所示:
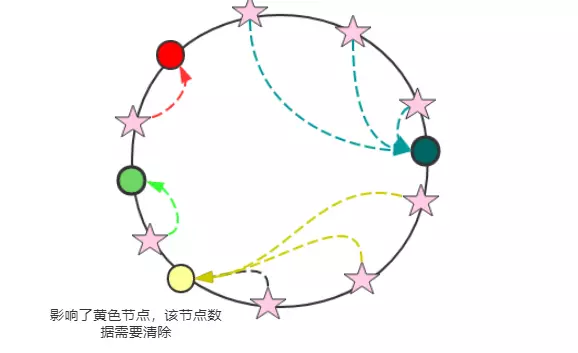
3. 一致性 hash 有什么问题呢?
是否这么做就完美了呢?
不是的。
如果认真看是上面的图的话,会发现,黄色节点的负载压力最大,这个集群环境负载不够均衡。
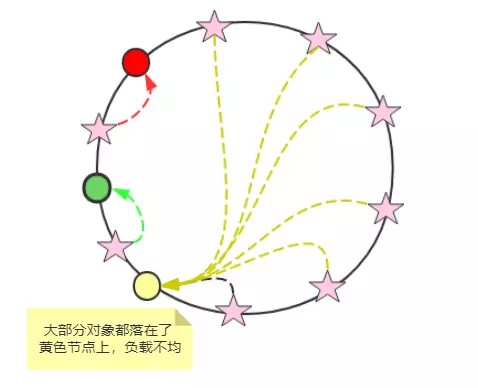
什么原因导致的呢?原因是:如果缓存节点分布不均匀,就会出现这样的情况。但是,你不能奢望是均匀的。
怎么办呢?
我们可以在不均的地方给他弄均匀。在空闲的地方加入 虚拟节点,这些节点的数据映射到真实节点上,就可以了,如下图所示:
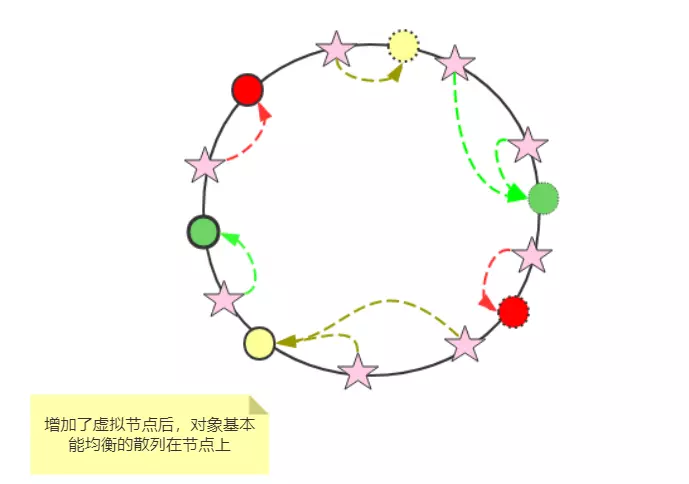
上图中,我们给每个节点都做了虚拟节点(虚线),从而让整个集群在 hash 环比较均匀,从图中也可以看出,这样现对比之前均匀多了,黄色节点的负载和绿色节点额的负载相同。
4. 总结
总的来说,一致性 hash 还是比较简单的。核心思想是,不使用对机器取余的算法。这样就能避免机器增减带来的影响。
同时,使用 就近寻址 的方式找到最近的节点。当然,这会引起负载不均衡,所以需要引入虚拟节点的方式,变相的增加节点,让整个集群的负载能够均衡。
后面,我们将自己写一个一致性 hash 算法以加深印象。
作者:莫那一鲁道
链接:https://www.jianshu.com/p/58fde9b2d0a3
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2016-07-19 webview与js交互(转)