js-正则
创建正则表达式
JS的正则表达式类型叫RegExp,有2种创建方式:
var reg1 = /a/g; // 双斜杠法,这种方法书写更方便
var reg2 = new RegExp('a', 'g'); // 传统写法,这种方法更正统
console.log(/a/g instanceof RegExp); // 输出true
这2种方式没有任何区别,但是,当正则表达式的内容是动态的时候,用RegExp会更方便一点,用双斜杠法的话你可能需要使用eval来创建。
上面的g表示修饰符,完整修饰符包括:
- g: 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)
- i: 忽略大小写
- m: 允许多行匹配
这3个修饰符没有先后顺序,可以随便写,我一般习惯写成gim:
var reg1 = /a/gim;
var reg2 = new RegExp('a', 'gim');
JS中所有支持正则表达式的方法
2.1. 字符串的4个和正则相关方法
2.1.1. str.match(reg)
返回所有匹配的结果并放入数组中,如果没找到,返回null,示例:
'aaa_aa_a_bbb_bb'.match(/a+_/g); // ["aaa_", "aa_", "a_"]
2.1.2. str.replace(reg, newStr|fn)
replace的第1个参数可以是一个正则表达式,也可以是一个普通的字符串,replace的第2个参数可以是一个字符串,也可以是一个function,返回需要替换成的目标字符串:
'http://blog.haoji.me/index.html?a=1'.replace(/(https?):\/\/([^\/]+)([^\?]+)/g, function(m, $1, $2, $3, idx, str) {
console.log(m, $1, $2, $3, idx, str);
return m;
});
这个function的参数依次是:
- m:本次匹配到的结果;
- $1:第一个
()匹配到的结果; - \(2:第二个`()`匹配到的结果(以此类推,有多少个括号就有多少个\),最多9个);
- idx:本次匹配的结果在原始字符串中的索引;
- str:原始字符串;
2.1.3. str.search(reg)
返回某个字符串第一个匹配处的索引,有点类似于indexOf,但indexOf不支持正则,示例:
'aaa_aa_a_bbb_bb'.search(/b+_/g); // 9
2.1.4. str.split(char|reg)
对字符串进行分割,可以传入一个正则:
'aaa_aa-a_bbb+bb'.split(/[-_\+]/g); // ["aaa", "aa", "a", "bbb", "bb"]
2.2. 正则下的2个方法
2.2.1. reg.exec(str)
每执行一次,返回一次当前匹配的结果(放入数组,输入内容为[m, $1, $2, ...]),每次会记住上次的位置(通过reg.lastIndex属性),全部匹配完之后又从头开始,示例:
var reg = /a(\w+?)_/g;
var str = 'abb_acc_ad_bbb_bb';
console.log(reg.exec(str)); // ["abb_", "bb"]
console.log(reg.exec(str)); // ["acc_", "cc"]
console.log(reg.exec(str)); // ["ad_", "d"]
console.log(reg.exec(str)); // null
console.log(reg.exec(str)); // ["abb_", "bb"]
关于lastIndex,参见后文。
2.2.2. reg.test(str)
这个可能用的最多了,用以测试某个字符串是否满足某个正则表达式,示例:
/^1[345789]\d{9}$/g.test('18911112222'); // 测试手机号
匹配包括换行符在内的任意字符
由于.*只是匹配除\n之外的任何字符,所以要匹配包括换行符在内的任意字符的话,最常见做法是[\s\S]*(以此类推还可以[\d\D]*、[\w\W]*),或者(.|\n)*,但是后面一种写法有一个缺点就是会将匹配的结果放到$1-$9中去,影响其它顺序,不推荐。
var str = '<div>\ntest</div>';
console.log(/<div>[\s\S]*<\/div>/gim.test(str)); // 输出true
console.log(/<div>(.|\n)*<\/div>/gim.test(str)); // 输出true
有人会提出,为什么不用[.\n]*呢,因为在中括号[]中,.只是表示普通的英文字母点,加不加斜杠都一样,证明如下:
console.log('.aaa.bbb.ccc'.match(/[.]\w/g)); // 输出 [".a", ".b", ".c"]
console.log('.aaa.bbb.ccc'.match(/[\.]\w/g)); // 输出 [".a", ".b", ".c"]
正则表达式对象是会“变”的
当然,这里所说的会“变”是打了引号的,为了更好描述问题,我们先来看个例子:
var reg = /a\w/g;
console.log(reg.exec('abbaccadd')[0]); // 输出ab
console.log(reg.exec('abbaccadd')[0]); // 输出ac
console.log(reg.exec('abbaccadd')[0]); // 输出ad
console.log(/a\w/g.exec('abbaccadd')[0]); // 输出ab
console.log(/a\w/g.exec('abbaccadd')[0]); // 输出ab
解释:
每一个RegExp对象都会有一个lastIndex字段(详情可以查看w3cschool上面有关lastIndex的介绍),当你每执行完一遍exec,它都会将最新匹配到的位置保存到对象的lastIndex中,所以每次结果都不一样,直接使用/a\w/g的话相当于是每次都new了一个RegExp对象。
var reg = /a\w/g;
console.log(reg.lastIndex); // 输出 0
console.log(reg.exec('abbaccadd')[0]); // 输出ab
console.log(reg.lastIndex); // 输出 2
特别说明:
- 不具有标志
g和不表示全局模式的 RegExp 对象不能使用 lastIndex 属性。 - 如果在成功地匹配了某个字符串之后就开始检索另一个新的字符串,需要手动地把这个属性设置为 0。
所以为了避免出现上述情况,我们有3种方法避免:
// 第一种方法,每次都使用新的RegExp对象,推荐
console.log(/a\w/g.exec('abbaccadd')[0]); // 输出ab
console.log(/a\w/g.exec('abbaccadd')[0]); // 输出ab
console.log(/a\w/g.exec('abbaccadd')[0]); // 输出ab
// 第二种方法,不使用g标志,推荐
var reg = /a\w/;
console.log(reg.exec('abbaccadd')[0]); // 输出ab
console.log(reg.exec('abbaccadd')[0]); // 输出ab
console.log(reg.exec('abbaccadd')[0]); // 输出ab
// 第三种方法,每次调用完之后手动重置lastIndex为0,不推荐
var reg = /a\w/g;
console.log(reg.exec('abbaccadd')[0]); // 输出ab
reg.lastIndex = 0;
console.log(reg.exec('abbaccadd')[0]); // 输出ab
reg.lastIndex = 0;
console.log(reg.exec('abbaccadd')[0]); // 输出ab
使用test时特别注意undefined
看下面的例子:
var str = '';
if(!/^\w+$/g.test(str)) console.error('str只能是字母、数字或下划线!');
else console.log('您的输入合法!')
表面看没什么问题,但是如果把str换成var str = undefined;时会发现也会测试通过,所以使用reg.text(str)切记要先判断str不能是undefined,否则会出现问题。
语法篇
6.1. JS不支持反向预查
预查,又叫零宽断言,一共有4种,最大的作用就是匹配结果不包含括号里面的内容。
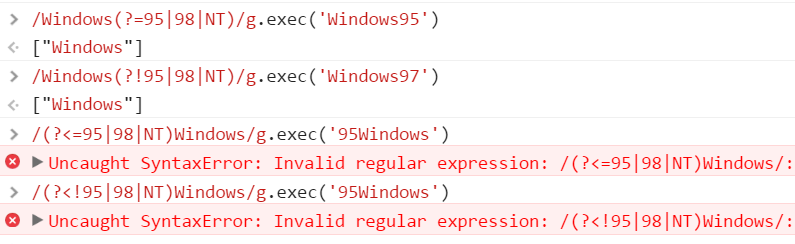
(?=pattern):正向肯定预查,如Windows(?=95|98|NT)可以匹配Windows95中的Windows;(?!pattern):正向否定预查,如Windows(?!95|98|NT)能匹配Windows97中的Windows;(?<=pattern):反向肯定预查,如(?<=95|98|NT)Windows可以匹配95Windows中的Windows;(?:反向否定预查,如(?能匹配97Windows中的Windows;
放在前面的叫正向预查(有的地方叫先行断言),放在后面的叫反向预查(有的地方叫后行断言)
需要特别注意的是,JS是不支持后面2种的!也就是说JS不支持(?<=pattern)和`(?:
Uncaught SyntaxError: Invalid regular expression:/(?<=95|98|NT)Windows/: Invalid group(…)
关于为什么不支持,有的人说是设计者忘了,有的人说是出于性能考虑,具体是为什么也没人知道,反正知道至今JS仍然不支持这个就对了,其他语言(比如Java、C#)都是支持的。
特别说明:ES6已经开始支持反向预查了(Chrome 62已经开始支持)。
常见示例
7.1. HTML标签匹配
匹配title和description:
var html = 'xxx';
var title = /<head>[\s\S]*?<title>([\s\S]*?)<\/title>[\s\S]*?<\/head>/gim.exec(html);
var description = /<head>[\s\S]*?<meta.*?name="description".*?content="(.*)".*?>[\s\S]*?<\/head>/gim.exec(html);
7.2. 邮箱匹配
邮箱格式:账号@域名
其中:
- 帐号只能以字母或数字开头,可包含字母、数字、下划线、中划线和点(允许多个下划线、中划线和点相连);
- 域名分为域名前缀和域名后缀;
- 域名的前缀只可以是字母、数字和中划线,且中划线不能开头、不能结尾、不能连续2个中划线在一起;
- 域名的后缀只可以是小数点和字母,且必须是点开头,不能点结尾,不能连续2个点连在一起。
- 无论是账号还是域名都不区分大小写,也就是无论大小写最终多会转化成小写,所以在校验的时候大写是合法的,需要把大写考虑进去。
以下邮箱规则在网易邮箱亲测过合法。
合法的邮箱:
123---@qq.com
123...@qq.com
123---@qq.com
aBc.def@qq.com
abc@qQ-bb.com
不合法的邮箱:
-abc@qq.com
abc@qq--bb.com
abc@-qq.com
abc@qq..com
abc@qq.com.
abc@qq.123com
我的答案(2个答案都可以):
/^[a-zA-Z\d][\w-\.]*@([\da-zA-Z](-[\da-zA-Z])?)+(\.[a-zA-Z]+)+$/g.test('teAte@cdn-test.qq.com.cn')
/^[a-zA-Z\d][\w-\.]*@[\da-zA-Z]+(-[\da-zA-Z]+)*(\.[a-zA-Z]+)+$/g.test('teAte@cdn-test.qq.com.cn')
网上答案(都不完全准确):
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
/^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+(\.{1,2}[a-z]+)+$/
7.3. URL地址匹配
下面这个还不完全正确,有待完善:
var result = /^(https?:)\/\/([^\/:]+?)(:\d{1,5})?(\/[^\?]*)(\?[^#]+)?(#.*)?$/g.exec(location.href);
result[1] == location.protocol
result[2] == location.host
result[3] == location.port
result[4] == location.pathname
result[5] == location.search
result[6] == location.hash

 浙公网安备 33010602011771号
浙公网安备 33010602011771号