第二次作业
学习笔记:
第一章 模式识别
模式识别的定义:根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。其本质上是一种推理过程。
模式识别可分为字符识别、交通标志识别、动作识别等等。
数学解释:模式识别可以看做一种函数映射f(x),将待识别模式x从输入空间映射到输出空间。函数f(x)是关于已有知识的表达。f(x)既可解析表达,也可以是难以解析表达的,其输出为确定值和概率值。
输入空间:
原始输入数据x所在的空间。
输出空间:输出的类别y所在的空间。
模型:关于已有知识的一种表达方式,即f(x)
模型用于回归,判别公式用于分类。
特征具有鲁棒性
点积:xy=xT y=yTx。
点积可以表征两个特征向量的共线性也就是方向上的相似程度。
残差向量:向量x分解到向量y方向上得到的投影向量与x向量的误差。
欧氏距离:d(x,y)=(x-y)转置(x-y)
训练样本:每个训练样本都是通过采样得到的一个模式,即输入特征空间中的一个向量;通常是高维度
模型可分为线性模型,非线性模型。
模型的泛化能力:训练得到的模型不仅要对训练样本具有决策能力,也要对信的模式具有决策能力。
过拟合:在训练阶段表现很好,但是在测试阶段表现很差
提高泛化能力的方法:模型选择,正则化,调节超参数。
评估模型性能的方法:
留出法:随机划分:将数据集随机分为两组:训练集和测试集。利用训练集训练模型,然后利用测试集评估模型的量化标准
取统计值
K折交叉验证:将数据集分割成K个子集,选单个作为测试集,其它子集作为训练集。
交叉验证重复K次,将k次的评估值取平均,作为结果。
留一验证:
每次只取一个样本做测试集,剩余的做训练集。
第二章
基于距离的决策:把测试样本到每个类之间的距离作为决策模型,将测试样本判定为与其距离最近的类。
距离度量有:欧氏距离,曼哈顿距离,加权欧氏距离等
MED分类器指:最小欧氏距离分类器
特征正交白化的目的是:去除特征变化的不同及特征之间的相关性。
解耦:通过W1实现协方差矩阵对角化,去除特诊之间的相关性。
白化:通过W2对上一步变换后的特征再进行尺度变换,实现所有特征具有相同方差。
MICD分类器:

MICD分类器的问题:
当两个类均值一样时,MICD偏向于方差大的类。
第三章:
MAP分类器:将测试样本决策分类给后验概率最大的那个类

监督式学习法:
分为参数化方法,非参数化方法。
参数估计方法:最大似然估计,贝叶斯估计
贝叶斯估计:给定参数0分布的先验概率以及训练样本,估计参数0分布的后验概率。
贝叶斯估计具有不断学习的能力。它允许最初的基于少量训练样本的、不太准的估计。
常用 的五参数技术主要有:
K近邻法、直方图技术、核密度估计

KNN估计的问题
容易受噪声影响。
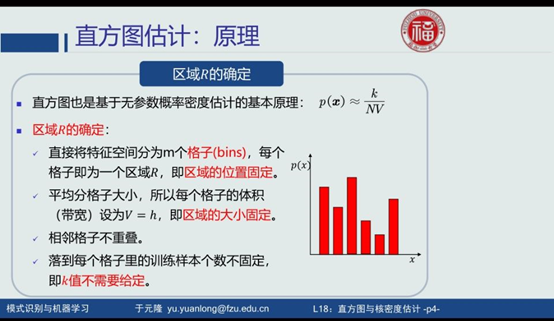

直方图估计优点:
减少由于噪声污染造成的估计误差。
不想要存储训练样本
缺点:
对于落在相邻格子的交界区域,统计和概率估计不准确。
缺乏自适应能力,导致过于尖锐或平滑。
核密度估计也是基于无参数概率密度估计的基本原理
第四章
生成模型:给定训练样本(x),直接在输入空间内学习其概率密度函数p(x)。
判别模型:给定训练样本,直接在输入空间内估计后验概率p(C1|x)
判别模型是线性函数的,则称之为线性判据
F(x)=wTx+w0
找最优解方法:目标函数,加入约束条件
感知机算法目的是学习模型参数
梯度更新算法
Fisher基本原理是找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少
类间样本的差异程度:用均值之差度量 离散程度:用协方差矩阵表征
位于超平面二和一上的样本被称为支持向量
支持向量机的目标:最大化总间隔
拉格朗日解决条件优化问题
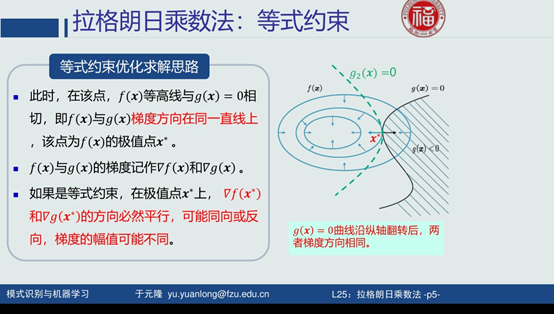
对偶函数给出了主问题最优值的下界
对偶函数是逐点最小值函数
逐点最小值函数是凹函数
对偶问题是凸优化问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号