软件工程第一次个人任务总结 2018.3.30
任务概述
要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
基本功能
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'\0'不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
个人报告
需求分析
根据老师提出的要求来看,这个项目的实现难度并不大。简单来说就是读取文件,辨识单词,储存并记录,实际编码过程中也采取了同样的思路。但仍有以下几个问题:
1. 单词成立的要求较为严格。单纯忽视大小写其实较为简单,库中已有 stricmp() 函数实现了该功能。但对于不同的数字后缀,要求视作同一个单词,例如 Windows98 和 Windows2000 是一个单词,且输出的时候要按照字典顺序输出最小的。因此对于单词成立的逻辑判断较为复杂,后续编写和调试中也是的确在这上面吃了大亏。
2. 数据量较大。助教提供了180M 的测试样例和对应的测试结果,可以看到,单词数量达到千万量级,字符数目上亿。不排除在后期还会检测时还会使用更大的测试集。因此,对于每个单词的储存和查找是会占据大量的时间。单纯的链式储存结构显然是不行的,考虑使用字典树或者哈希表来储存。
3. 在完成 Windows 平台的代码调试和优化后,自以为万事俱备。却突然接到了正式代码是在 Linux 平台下测试,突如其来的移植要求成为了压垮骆驼的最后一根稻草。
根据需求,大致规划了 PSP 表格如下:
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 25 | 25 |
| Development | 开发 | 1145 | 1950 |
| · Analysis | · 需求分析 (包括学习新技术) | 60+180 | 60+240 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 15 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 60 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 600 |
| Reporting | 报告 | 100 | 180 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 110 |
| 合计 | 1270 | 2155 |
设计思路
首先以前并未进行过目录下的文件遍历,经过百度后,大致认为可将所有的文件名装入一个 string 类的 vector 中,然后再遍历 vector 对每一个文件进行统计。
对于每一个文件,按照需求读出每一个单词,再插入哈希表,统计频次。首先哈希表中储存每一个出现过的单词及其频数。
对于词组的统计,考虑与单词同步进行,同样采取哈希表结构。开始时,曾考虑同样储存每一个词组。但仔细思考后,否决了这个提议,原因有二:
一、词组的复杂程度大概要比单词大一个数量级,因此直接储存会占用大量的空间,可能会出现内存不足的问题。
二、每一个词组的比较需要调用两次 stricmp() 函数,会占用大量的时间。
因此,笔者采取了一种用单词在哈希表中的位置来表示一个单词的方式,也就是说,词组中仅仅储存两个单词在单词的哈希表中的哈希值和一个偏移量。笔者采用了哈希开散列方式,当哈希值冲突时会向下拉链扩充,偏移量即表示该单词在拉链中的位置。
不得不说,这个方法效果很好。后续的检测报告中也可看出,明明是复杂度更大,更复杂的词组,占用的时间却远小于单词的哈希表插入,这点也算是笔者略微有些得意的地方了。
最后就是按照要求统计出前十的单词和词组,这点简单对哈希表进行遍历就可做到,实际的性能分析中,这也并非瓶颈,故不再过多赘述。
代码实现
起初时,笔者准备使用c++中自带的 unordered_map 但由于实在是没有c++基础,对于结构体的自定义不慎熟练,无法获得我满意的结构体。故一气之下(无可奈何)地选择自己进行整个哈希表的编写,这也是我为何我编写代码的时间大大超过预期的原因。
首先定义两个结构体如下:
typedef struct Words { string Word; //单词本体 string Number; //数字后缀 int count = 0; Words *next; }Words; //储存单词的结构体 typedef struct Phrases { int Key1 = 0; int Offset1 = 0; int Key2 = 0; int Offset2 = 0; int count = 0; Phrases *next; }Phrases; //储存短语的结构体
可见,短语的结构体较为简单,实现了笔者前述的储存方式。同时, int 之间的比较也大大提升了速度。
main函数
int main(int argc, char *argv[]) { string DATA_DIR = argv[1]; vector<string> files; char * DistAll = "D:\\result.txt"; GetAllFiles(DATA_DIR, files); Findmax(DistAll); }
main 函数部分较为简单,也算是比较符合老师课上提出的代码要求了。仅调用了两个函数,现一一分析其相应功能。
GetAllFiles(DATA_DIR, files)


void GetAllFiles(string path, vector<string>& files) { long hFile = 0; //文件句柄 struct _finddata_t fileinfo; string p, tmp; if ((hFile = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1) { do { if ((fileinfo.attrib & _A_SUBDIR)) //如果是文件夹 { if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0) { files.push_back(p.assign(path).append("\\").append(fileinfo.name)); GetAllFiles(p.assign(path).append("\\").append(fileinfo.name), files); } } else { files.push_back(p.assign(path).append("\\").append(fileinfo.name)); tmp = p.assign(path).append("\\").append(fileinfo.name); const int len = tmp.length(); char *c = new char[len + 1]; strcpy(c, tmp.c_str()); Read(c); //读入该文件 free(c); } } while (_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } }
说来惭愧,该段代码基本是完全仿照 CSDN 上的代码所写的,因本人课外代码量为零,文件读取这个在考试不怎么考察的点并没有很好的掌握,就算是仿照改编,也消耗了我相当多的时间。
其中 Read() 函数,传入的参数为每个文件名,代码如下:
Read(char * Filename)
void Read(char * Filename) { FILE *f = fopen(Filename, "rb"); if (f != NULL) { fseek(f, 0, SEEK_END); long pos = ftell(f); fseek(f, 0, SEEK_SET); char *bytes = (char*)malloc(pos); fread(bytes, pos, 1, f); fclose(f); Findwords(bytes, pos); free(bytes); // free allocated memory } }
笔者并未采取 fgetc() 的方式来从文件中一个一个的读取字符,而是采用了 fread() 函数一次性将整个文件读入。曾在数据结构课上做过哈希表处理大数据的笔者有过使用这两个函数的经历,知道 fread() 在这样的大样本的情况下, 速度是远快于 fgetc() 的。笔者在动笔进行博客写作前,阅读了一些班级中其余同学的分析报告,看到他们在 fgetc() 上耗费了大量的时间,个人认为这个选择还是正确的。
但是,在测试过程中是,对于非典型文件,笔者的数据与助教给出的执行文件测试所得的数据差距较大,考虑是一次性不判断读入后,由于编码问题导致的判断结果偏差。可以说是有失有得了。
其中 Findwords 函数即为笔者所写的从文件中寻找单词并统计的函数,可以说几乎有大部分的心血都消耗在了上面。过程中甚至还有对题目理解错误,导致在提交截止前四个小时整个修改判断逻辑的事情。可以说是很不愉快了,现贴出代码如下:
Findwords(char * bytes, long Len)
void Findwords(char * bytes, long Len) { string word1, number1; //两个 string 分别储存单词的前面字母部分和数字后缀部分 int Key1 = 0, Key2 = 0, Offset1 = 0, Offset2 = 0; int flag = 1; for (int i = 0; i < Len; i++) //对于整个文件的每一个字符进行遍历 { if (bytes[i] > 31 && bytes[i] < 127) char_number++; else if (bytes[i] == 10) line_number++; //判断字符数目和换行符数目 if (((bytes[i] > 64 && bytes[i] < 91) || (bytes[i] > 96 && bytes[i] < 123))) { //如果是字母 if (flag) { //如果前面未出现过数字 if (!(number1.empty())) word1 += number1, number1.clear(); word1 += bytes[i]; } } else{ if (bytes[i] > 47 && bytes[i] < 58) { //如果是数字 if (flag) { if (word1.length() < 4) { word1.clear(); number1.clear(); flag = 0; continue; } number1 += bytes[i]; } } else { //那么久肯定是分隔符了 if (word1.length() > 3) { //如果满足单词的条件 word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); //插入单词的哈希表 if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); //和前一个单词一起插入词组的哈希表 Key2 = Key1; Offset2 = Offset1; } word1.clear(); number1.clear(); flag = 1; } } } if (word1.length() > 3) { //如果最后一个单词后面没有分隔符,无法进入上一个判断逻辑的最后,再判断一次 word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); word1.clear(); number1.clear(); } line_number++; //文件的行数+1 }
可见,笔者的判断逻辑中有一个非常奇怪的部分,就是 flag 标志。现简述其原因及作用:
笔者的单词判断逻辑大概如下:
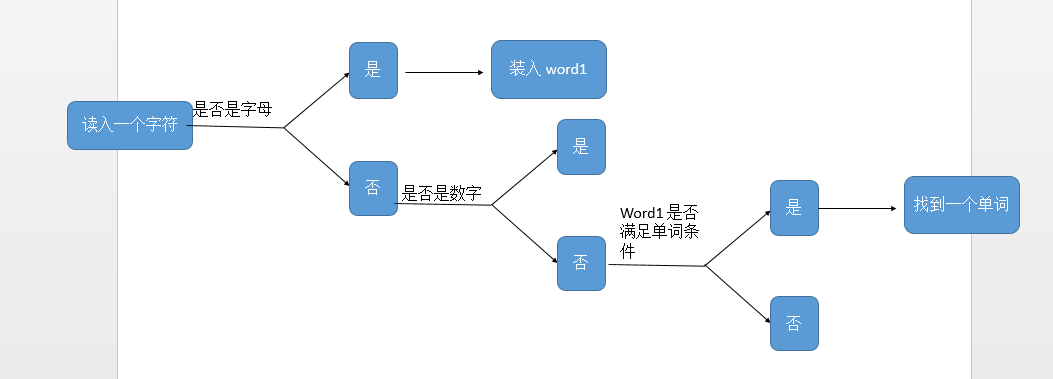
后来,发现了一个致命问题,就是例如出现了“1234abcd123”这样的,按理说应该不是单词,但以笔者的判断逻辑,会把后面的 abcd123 当作单词输出,因此笔者采取了 flag 标识符,即,如果出现了上图的情况,即在没有连续出现四个字母时,就已经出现了数字,会把 flag 置零,直到出现下一个分隔符时,才把 flag 置 1,避免了如上情况的发生。
建立及插入哈希表的函数,只能说是循规蹈矩的代码,便不再做过多赘述,将函数同一贴出,读者可自行参考
哈希函数
int InsertHash(string word, string number,int key) { int Offset = 0; int k; Words *p; if (List[key] == NULL) { p = new(Words); p->Word = word; p->Number = number; p->count++; p->next = NULL; List[key] = p; } else { p = List[key]; while ((k = _stricmp(p->Word.c_str(), word.c_str())) && p->next) Offset++,p = p->next; if (k) { p->next = new(Words); p = p->next; p->Word = word; p->Number = number; p->count++; p->next = NULL; Offset++; } else { if (p->Word > word) p->Word = word; if (p->Number > number) p->Number = number; p->count++; } } return Offset; } void InsertPhraseHash(int Key1, int Offset1, int Key2, int Offset2) { int key = (hash<int>{}(Key1*5 + Offset1*3 + Key2*11 + Offset2*7) % N2); int k = 0; Phrases *p; if (PList[key] == NULL) { { p = new(Phrases); p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; PList[key] = p; } } else { p = PList[key]; while (!(k = ((Key1 == p->Key1 && Offset1 == p->Offset1) && (Key2 == p->Key2 && Offset2 == p->Offset2))) && p->next) p = p->next; if (!k) { { p->next = new(Phrases); p = p->next; p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; } } else { p->count++; } } }
Findmax()
void Findmax(char * DistAll) { ofstream ofn(DistAll); Words Max[10]; Phrases PMax[10]; Words *p = NULL; Phrases *P = NULL; ofn << "char_number:" << char_number << endl << "line_number:" << line_number << endl << "word_num:" << word_num << endl << endl; for (int i = 0; i < N1; i++) { p = List[i]; while (p) { WordSort(p, Max); p = p->next; } } for (int i = 0; i < N2; i++) { P = PList[i]; while (P) { PhraseSort(P, PMax); P = P->next; } } //Output ofn << "the top ten frequency of word :" << endl << endl << endl;; for (int i = 9; i >= 0; i--) { ofn << Max[i].Word <<Max[i].Number<< " " << Max[i].count << endl; } ofn << endl << endl << "the top ten frequency of phrase : " << endl << endl << endl; for (int i = 9; i >= 0 && PMax[i].count != 0; i--) { p = List[PMax[i].Key1]; for (int j = 0; j < PMax[i].Offset1; j++, p = p->next); ofn << p->Word << p->Number << " "; p = List[PMax[i].Key2]; for (int j = 0; j < PMax[i].Offset2; j++, p = p->next); ofn << p->Word << p->Number << " "; ofn << PMax[i].count << endl; } }
该函数也是一个简单遍历两个哈希表,得出最大的是个值的函数,便直接将代码贴出。
为便于读者直接使用,现将完整代码贴出以供参考
// WordStatistics.cpp: 定义控制台应用程序的入口点。 // #include "stdafx.h" #include "targetver.h" #include <stdio.h> #include <io.h> #include <fstream> #include <string> #include <vector> #include <iostream> #include <tchar.h> #include <stdlib.h> #include <numeric> #include <functional> #include <unordered_map> #include <time.h> using namespace std; typedef struct Words { string Word; string Number; int count = 0; Words *next; }Words; typedef struct Phrases { int Key1 = 0; int Offset1 = 0; int Key2 = 0; int Offset2 = 0; int count = 0; Phrases *next; }Phrases; void Read(char * Filename); void Findwords(char * bytes, long Len); void GetAllFiles(string path, vector<string>& files); #define N1 500000 #define N2 1000000 Words *List[N1 + 1]; Phrases *PList[N2 + 1]; clock_t Start,End; long char_number = 0, line_number = 0, word_num = 0; void GetAllFiles(string path, vector<string>& files) { long hFile = 0; struct _finddata_t fileinfo; string p, tmp; if ((hFile = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1) { do { if ((fileinfo.attrib & _A_SUBDIR)) { if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0) { files.push_back(p.assign(path).append("\\").append(fileinfo.name)); GetAllFiles(p.assign(path).append("\\").append(fileinfo.name), files); } } else { files.push_back(p.assign(path).append("\\").append(fileinfo.name)); tmp = p.assign(path).append("\\").append(fileinfo.name); const int len = tmp.length(); char *c = new char[len + 1]; strcpy(c, tmp.c_str()); Read(c); free(c); } } while (_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } } void Read(char * Filename) { FILE *f = fopen(Filename, "rb"); if (f != NULL) { fseek(f, 0, SEEK_END); long pos = ftell(f); fseek(f, 0, SEEK_SET); char *bytes = (char*)malloc(pos); fread(bytes, pos, 1, f); fclose(f); Findwords(bytes, pos); free(bytes); // free allocated memory } } int GetHashkey(string word) { int j = 0; int k = 0; int flag = word.length(); for (j = 0; j < flag; j++) { k = (k * 31 + (word[j] > 92 ? word[j] - 32 : word[j]))% N1; } return k; } int InsertHash(string word, string number,int key) { int Offset = 0; int k; Words *p; if (List[key] == NULL) { p = new(Words); p->Word = word; p->Number = number; p->count++; p->next = NULL; List[key] = p; } else { p = List[key]; while ((k = _stricmp(p->Word.c_str(), word.c_str())) && p->next) Offset++,p = p->next; if (k) { p->next = new(Words); p = p->next; p->Word = word; p->Number = number; p->count++; p->next = NULL; Offset++; } else { if (p->Word > word) p->Word = word; if (p->Number > number) p->Number = number; p->count++; } } return Offset; } void InsertPhraseHash(int Key1, int Offset1, int Key2, int Offset2) { int key = (hash<int>{}(Key1*5 + Offset1*3 + Key2*11 + Offset2*7) % N2); int k = 0; Phrases *p; if (PList[key] == NULL) { { p = new(Phrases); p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; PList[key] = p; } } else { p = PList[key]; while (!(k = ((Key1 == p->Key1 && Offset1 == p->Offset1) && (Key2 == p->Key2 && Offset2 == p->Offset2))) && p->next) p = p->next; if (!k) { { p->next = new(Phrases); p = p->next; p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; } } else { p->count++; } } } void Findwords(char * bytes, long Len) { string word1, number1, word2, number2; int Key1 = 0, Key2 = 0, Offset1 = 0, Offset2 = 0; int flag = 1; for (int i = 0; i < Len; i++) { if (bytes[i] > 31 && bytes[i] < 127) char_number++; else if (bytes[i] == 10) line_number++; if (((bytes[i] > 64 && bytes[i] < 91) || (bytes[i] > 96 && bytes[i] < 123))) { if (flag) { if (!(number1.empty())) word1 += number1, number1.clear(); word1 += bytes[i]; } } else{ if (bytes[i] > 47 && bytes[i] < 58) { if (flag) { if (word1.length() < 4) { word1.clear(); number1.clear(); flag = 0; continue; } number1 += bytes[i]; } } else { if (word1.length() > 3) { word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); Key2 = Key1; Offset2 = Offset1; } word1.clear(); number1.clear(); flag = 1; } } } if (word1.length() > 3) { word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); word1.clear(); number1.clear(); } line_number++; } void WordSort(Words *p,Words *Max) { int i, j; for (i = 0; p->count > Max[i].count && i < 10; i++); for (j = 0; j < i - 1; j++) { Max[j] = Max[j + 1]; } if (i == 10){ Max[9] = *p; } else{ if (p->count == Max[i].count) { if (p->Word < Max[i].Word) { if (i != 0) { Max[i - 1] = Max[i]; } Max[i] = *p; } else { if (i != 0) Max[i - 1] = *p; } } else { if (i != 0) Max[i - 1] = *p; } } } int JudgePheasesEqual(Phrases *P1,Phrases *P2) { string word1, word2, word3, word4; Words *p1 = List[P1->Key1], *p2 = List[P1->Key2]; Words *p3 = List[P2->Key1], *p4 = List[P2->Key2]; for (int i = 0; i < P1->Offset1; p1 = p1->next, i++); word1 = p1->Word; for (int i = 0; i < P1->Offset2; p2 = p2->next, i++); word2 = p2->Word; for (int i = 0; i < P2->Offset1; p3 = p3->next, i++); word3 = p3->Word; for (int i = 0; i < P2->Offset2; p4 = p4->next, i++); word4 = p4->Word; if (word1 < word3 || ((word1 == word3) && word2 < word4)) return 1; else return 0; } void PhraseSort(Phrases *p,Phrases *Max) { int i, j; for (i = 0; p->count > Max[i].count && i < 10; i++); for (j = 0; j < i - 1; j++) { Max[j] = Max[j + 1]; } if (i == 10) { Max[9] = *p; } else { if (p->count == Max[i].count) { if (JudgePheasesEqual(p,&Max[i])) { if (i != 0) { Max[i - 1] = Max[i]; } Max[i] = *p; } else { if (i != 0) Max[i - 1] = *p; } } else { if (i != 0) Max[i - 1] = *p; } } } void Findmax(char * DistAll) { ofstream ofn(DistAll); Words Max[10]; Phrases PMax[10]; Words *p = NULL; Phrases *P = NULL; ofn << "char_number:" << char_number << endl << "line_number:" << line_number << endl << "word_num:" << word_num << endl << endl; for (int i = 0; i < N1; i++) { p = List[i]; while (p) { WordSort(p, Max); p = p->next; } } for (int i = 0; i < N2; i++) { P = PList[i]; while (P) { PhraseSort(P, PMax); P = P->next; } } //Output ofn << "the top ten frequency of word :" << endl << endl << endl;; for (int i = 9; i >= 0; i--) { ofn << Max[i].Word <<Max[i].Number<< " " << Max[i].count << endl; } ofn << endl << endl << "the top ten frequency of phrase : " << endl << endl << endl; for (int i = 9; i >= 0 && PMax[i].count != 0; i--) { p = List[PMax[i].Key1]; for (int j = 0; j < PMax[i].Offset1; j++, p = p->next); ofn << p->Word << p->Number << " "; p = List[PMax[i].Key2]; for (int j = 0; j < PMax[i].Offset2; j++, p = p->next); ofn << p->Word << p->Number << " "; ofn << PMax[i].count << endl; } } int main(int argc, char *argv[]) { string DATA_DIR = argv[1]; vector<string> files; char * DistAll = "D:\\result.txt"; GetAllFiles(DATA_DIR, files); Findmax(DistAll); }
// WordStatistics.cpp: 定义控制台应用程序的入口点。 // #include <stdio.h> #include <dirent.h> #include <fstream> #include <string.h> #include <vector> #include <iostream> #include <stdlib.h> #include <numeric> #include <functional> #include <unordered_map> #include <time.h> using namespace std; typedef struct Words { string Word; string Number; int count = 0; Words *next; }Words; typedef struct Phrases { int Key1 = 0; int Offset1 = 0; int Key2 = 0; int Offset2 = 0; int count = 0; Phrases *next; }Phrases; void Read(char * Filename); void Findwords(char * bytes, long Len); void GetAllFiles(string path, vector<string>& files); #define N1 1000000 #define N2 5000000 Words *List[N1 + 1]; Phrases *PList[N2 + 1]; clock_t Start,End; long char_number = 0, line_number = 0, word_num = 0; void listDir(char *path){ DIR *pDir; struct dirent *ent; int i=0; char childpath[512]; pDir = opendir(path); memset(childpath,0,sizeof(childpath)); while((ent=readdir(pDir))!=NULL){ if(ent->d_type&DT_DIR){ if(strcmp(ent->d_name,".")==0 || strcmp(ent->d_name,"..")==0) continue; sprintf(childpath,"%s/%s",path,ent->d_name); listDir(childpath); } else{ sprintf(childpath,"%s/%s",path,ent->d_name); Read(childpath); } } closedir(pDir); } void Read(char * Filename) { FILE *f = fopen(Filename, "rb"); if (f != NULL) { fseek(f, 0, SEEK_END); long pos = ftell(f); fseek(f, 0, SEEK_SET); char *bytes = (char*)malloc(pos); fread(bytes, pos, 1, f); fclose(f); Findwords(bytes, pos); free(bytes); // free allocated memory } } int GetHashkey(string word) { int j = 0; int k = 0; int flag = word.length(); for (j = 0; j < flag; j++) { k = (k * 31 + (word[j] > 92 ? word[j] - 32 : word[j]))% N1; } return k; } int InsertHash(string word, string number,int key) { int Offset = 0; int k; Words *p; if (List[key] == NULL) { p = new(Words); p->Word = word; p->Number = number; p->count++; p->next = NULL; List[key] = p; } else { p = List[key]; while ((k = strcasecmp(p->Word.c_str(), word.c_str())) && p->next) Offset++,p = p->next; if (k) { p->next = new(Words); p = p->next; p->Word = word; p->Number = number; p->count++; p->next = NULL; Offset++; } else { if (p->Word > word) p->Word = word; if (p->Number > number) p->Number = number; p->count++; } } return Offset; } void InsertPhraseHash(int Key1, int Offset1, int Key2, int Offset2) { int key = (hash<int>{}(Key1*5 + Offset1*3 + Key2*11 + Offset2*7) % N2); int k = 0; Phrases *p; if (PList[key] == NULL) { { p = new(Phrases); p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; PList[key] = p; } } else { p = PList[key]; while (!(k = ((Key1 == p->Key1 && Offset1 == p->Offset1) && (Key2 == p->Key2 && Offset2 == p->Offset2))) && p->next) p = p->next; if (!k) { { p->next = new(Phrases); p = p->next; p->Key1 = Key1; p->Key2 = Key2; p->Offset1 = Offset1; p->Offset2 = Offset2; p->count++; p->next = NULL; } } else { p->count++; } } } void Findwords(char * bytes, long Len) { string word1, number1, word2, number2; int Key1 = 0, Key2 = 0, Offset1 = 0, Offset2 = 0; int flag = 1; for (int i = 0; i < Len; i++) { if (bytes[i] > 31 && bytes[i] < 127) char_number++; else if (bytes[i] == 10) line_number++; if (((bytes[i] > 64 && bytes[i] < 91) || (bytes[i] > 96 && bytes[i] < 123))) { if (flag) { if (!(number1.empty())) word1 += number1, number1.clear(); word1 += bytes[i]; } } else{ if (bytes[i] > 47 && bytes[i] < 58) { if (flag) { if (word1.length() < 4) { word1.clear(); number1.clear(); flag = 0; continue; } number1 += bytes[i]; } } else { if (word1.length() > 3) { word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); Key2 = Key1; Offset2 = Offset1; } word1.clear(); number1.clear(); flag = 1; } } } if (word1.length() > 3) { word_num++; Key1 = GetHashkey(word1); Offset1 = InsertHash(word1, number1, Key1); if (Key2 != 0) InsertPhraseHash(Key2, Offset2, Key1, Offset1); word1.clear(); number1.clear(); } line_number++; } void WordSort(Words *p,Words *Max) { int i, j; for (i = 0; p->count > Max[i].count && i < 10; i++); for (j = 0; j < i - 1; j++) { Max[j] = Max[j + 1]; } if (i == 10){ Max[9] = *p; } else{ if (p->count == Max[i].count) { if (p->Word < Max[i].Word) { if (i != 0) { Max[i - 1] = Max[i]; } Max[i] = *p; } else { if (i != 0) Max[i - 1] = *p; } } else { if (i != 0) Max[i - 1] = *p; } } } int JudgePheasesEqual(Phrases *P1,Phrases *P2) { string word1, word2, word3, word4; Words *p1 = List[P1->Key1], *p2 = List[P1->Key2]; Words *p3 = List[P2->Key1], *p4 = List[P2->Key2]; for (int i = 0; i < P1->Offset1; p1 = p1->next, i++); word1 = p1->Word; for (int i = 0; i < P1->Offset2; p2 = p2->next, i++); word2 = p2->Word; for (int i = 0; i < P2->Offset1; p3 = p3->next, i++); word3 = p3->Word; for (int i = 0; i < P2->Offset2; p4 = p4->next, i++); word4 = p4->Word; if (word1 < word3 || ((word1 == word3) && word2 < word4)) return 1; else return 0; } void PhraseSort(Phrases *p,Phrases *Max) { int i, j; for (i = 0; p->count > Max[i].count && i < 10; i++); for (j = 0; j < i - 1; j++) { Max[j] = Max[j + 1]; } if (i == 10) { Max[9] = *p; } else { if (p->count == Max[i].count) { if (JudgePheasesEqual(p,&Max[i])) { if (i != 0) { Max[i - 1] = Max[i]; } Max[i] = *p; } else { if (i != 0) Max[i - 1] = *p; } } else { if (i != 0) Max[i - 1] = *p; } } } void Findmax() { ofstream ofn("result.txt"); Words Max[10]; Phrases PMax[10]; Words *p = NULL; Phrases *P = NULL; ofn << "char_number:" << char_number << endl << "line_number:" << line_number << endl << "word_num:" << word_num << endl << endl; for (int i = 0; i < N1; i++) { p = List[i]; while (p) { WordSort(p, Max); p = p->next; } } for (int i = 0; i < N2; i++) { P = PList[i]; while (P) { PhraseSort(P, PMax); P = P->next; } } //Output ofn << "the top ten frequency of word :" << endl << endl << endl; for (int i = 9; i >= 0 && Max[i].count != 0; i--) { ofn << Max[i].Word <<Max[i].Number<< " " << Max[i].count << endl; } ofn << endl << endl << "the top ten frequency of phrase : " << endl << endl << endl; for (int i = 9; i >= 0 && PMax[i].count != 0; i--) { p = List[PMax[i].Key1]; for (int j = 0; j < PMax[i].Offset1; j++, p = p->next); ofn << p->Word << p->Number << " "; p = List[PMax[i].Key2]; for (int j = 0; j < PMax[i].Offset2; j++, p = p->next); ofn << p->Word << p->Number << " "; ofn << PMax[i].count << endl; } } int main(int argc, char *argv[]) { string DATA_DIR = argv[1]; vector<string> files; listDir(argv[1]); Findmax(); }
性能分析及代码优化
首先贴出 Visual Studio 的性能分析报告: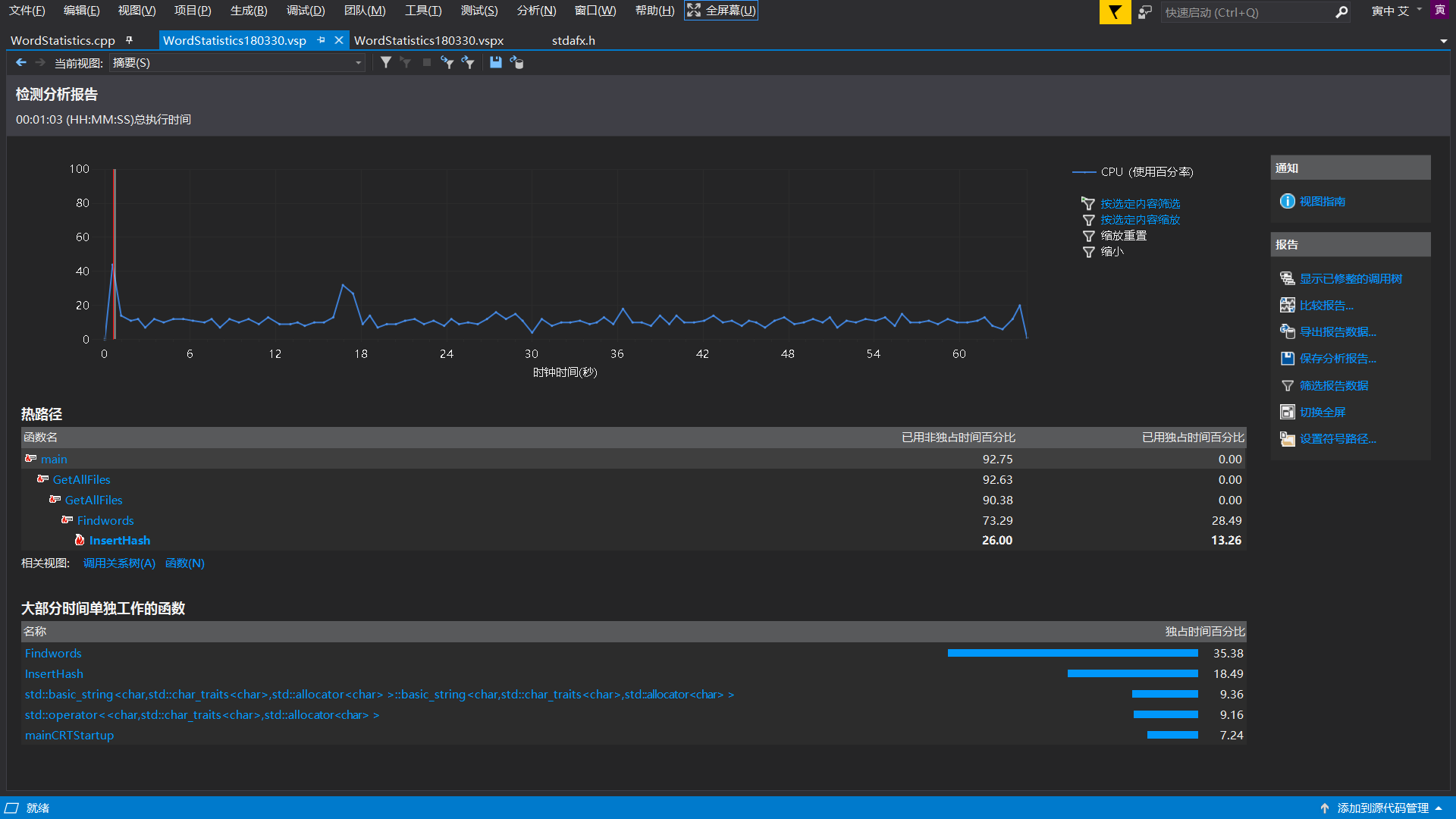
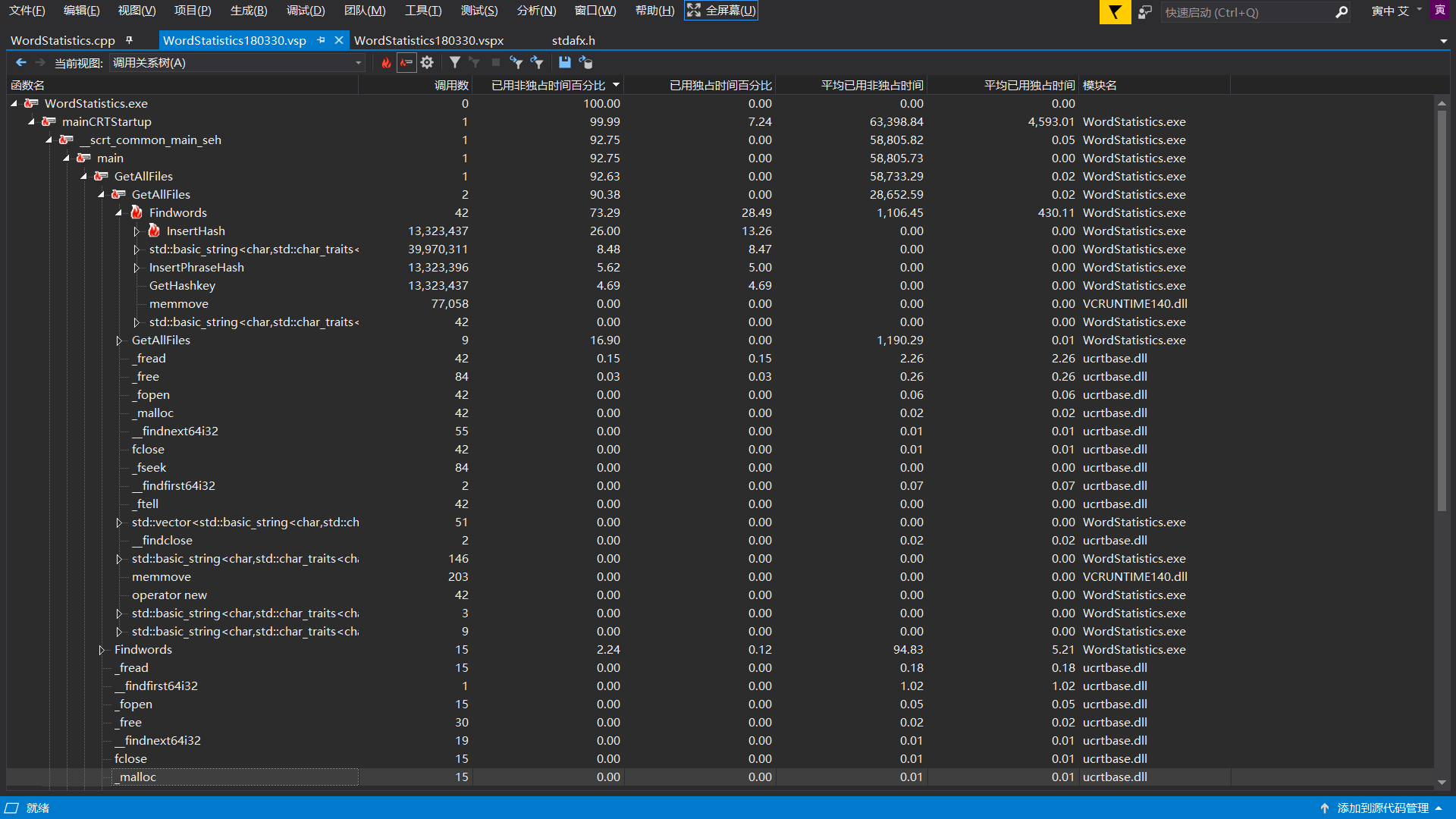
参考上面的代码,可见,所得出的热行并未超过笔者预料:
Findwords() 在该函数中要对所有的字符进行遍历,故占据 1/3 的时间也是正常情况
InsertHash() 这是插入单词哈希表的函数,在改函数中大量调用了字符串的比较函数 stricmp () ,时间占用多也属正常情况
同时可见,两个插入哈希表的函数,调用次数几乎完全一样,但单词的函数占用时间是短语的函数占用的时间的 2.6 倍,差距明显。笔者如果仍然采用开始的想法,即在词组的哈希表中也储存整个词组,那么就应该是词组的时间反而是单词的时间的两倍了。

代码优化
因为曾有过哈希表处理大规模数据的编程经验,所以笔者可以说是在看到任务的第一时间,就考虑到了哈希表的实现方式。过程中也可以说是避开了一些坑,例如 IO 的耗时。在曾经那个任务中,笔者采取了 ofstream 的输入输出,结果别人的程序都是 ms 级别的,而我需要十几秒,后来在上网查询后,得知了相关的结果,便将函数全部更改,才有了正常的速度。这次笔者也是一上来就选择了 fread() 函数,提高了速度
还有一个优化点,就是在 InsertHash 函数中
1 void InsertPhraseHash(int Key1, int Offset1, int Key2, int Offset2) { 2 int key = (hash<int>{}(Key1*5 + Offset1*3 + Key2*11 + Offset2*7) % N2); 3 int k = 0; 4 Phrases *p; 5 if (PList[key] == NULL) { 6 { p = new(Phrases); 7 p->Key1 = Key1; 8 p->Key2 = Key2; 9 p->Offset1 = Offset1; 10 p->Offset2 = Offset2; 11 p->count++; 12 p->next = NULL; 13 PList[key] = p; } 14 } 15 else { 16 p = PList[key]; 17 while (!(k = ((Key1 == p->Key1 && Offset1 == p->Offset1) && (Key2 == p->Key2 && Offset2 == p->Offset2))) && p->next) p = p->next; 18 if (!k) { 19 { p->next = new(Phrases); 20 p = p->next; 21 p->Key1 = Key1; 22 p->Key2 = Key2; 23 p->Offset1 = Offset1; 24 p->Offset2 = Offset2; 25 p->count++; 26 p->next = NULL; } 27 } 28 else { 29 p->count++; 30 } 31 } 32 }
如图 在 17 行的判断条件中,笔者采取了用一个 k 去接收 stricmp 的值,可以直接使用这个值来判断,避免了在后面再次调用该函数,也算是提高了一点效率
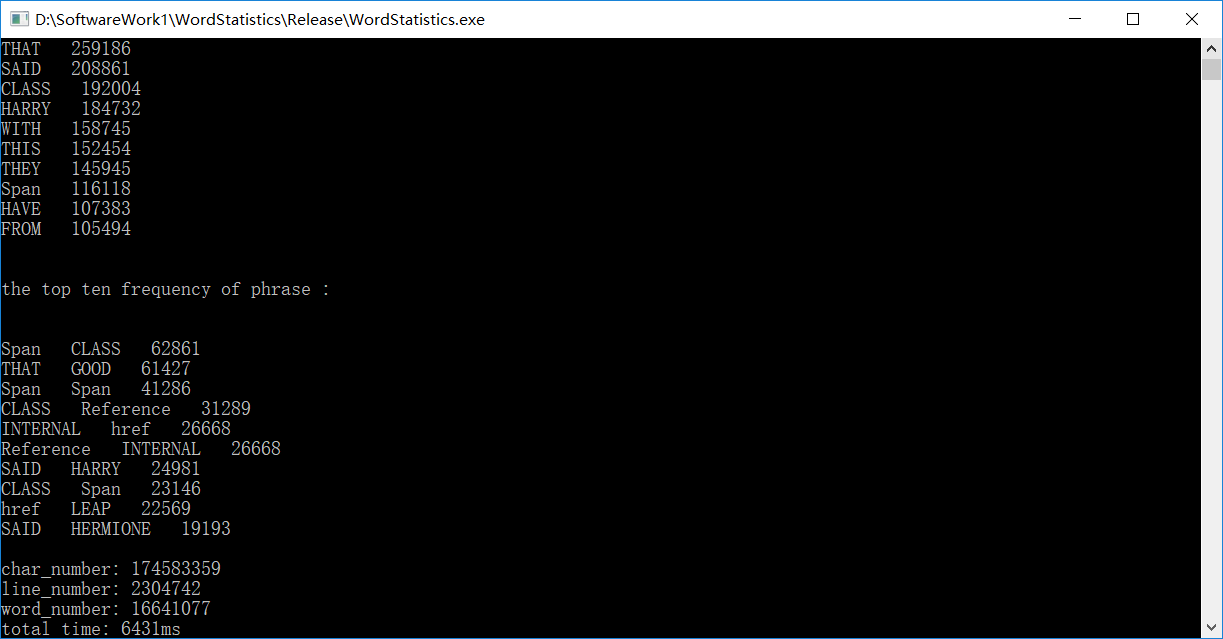
最终测试结果,应该说多亏了 vs 对于多次测试的代码会有优化?(第一遍跑要50多s,第二次就时间短了很多
关于我的数据和参考答案的差别,个人认为问题出在对于一些格式的文件,例如 .jpg .png,使用 fread 和 fgetc 的结果有差别。例如,下图是我尝试用记事本去打开一个 .jpg 文件
个人认为,是这些文件对测试结果产生了较大的影响。
单元测试
空文件
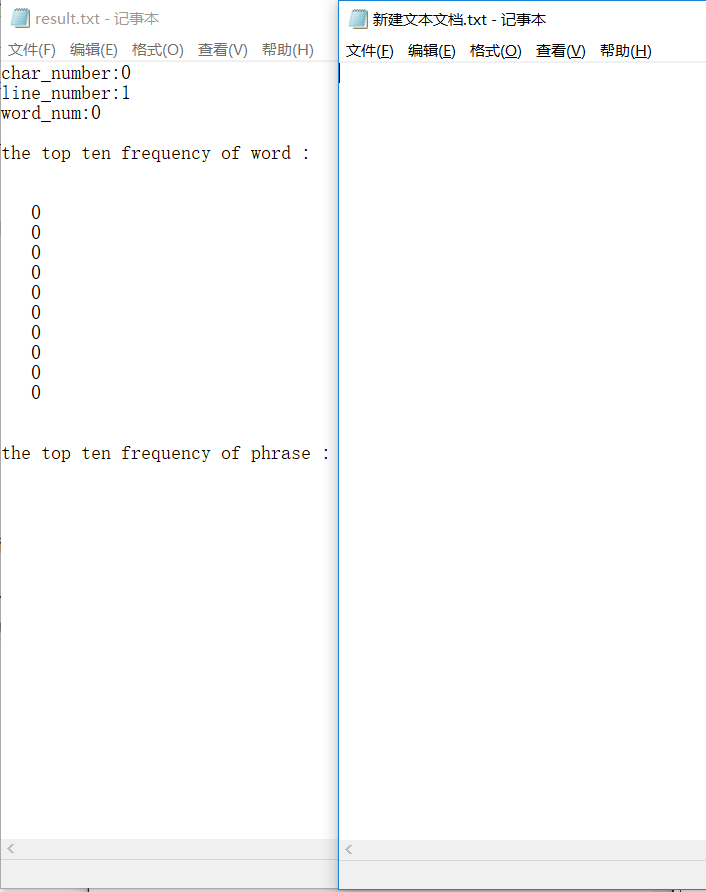
忘记对于空文件的行数问题做处理,且在对单词做输出的时候,也忘记对于词频为0的情况做判断了。(之所以对于短语做了相关处理,是因为短语输出的时候是要根据单词的位置去单词表里面找的,如果为零的话,寻找时就会报错,结果改了以后忘记回来修改单词了)。
可能是因为自己沉迷去跑助教给的大规模测试集了,反而对于这种问题忽视了。
测试字典顺序输出
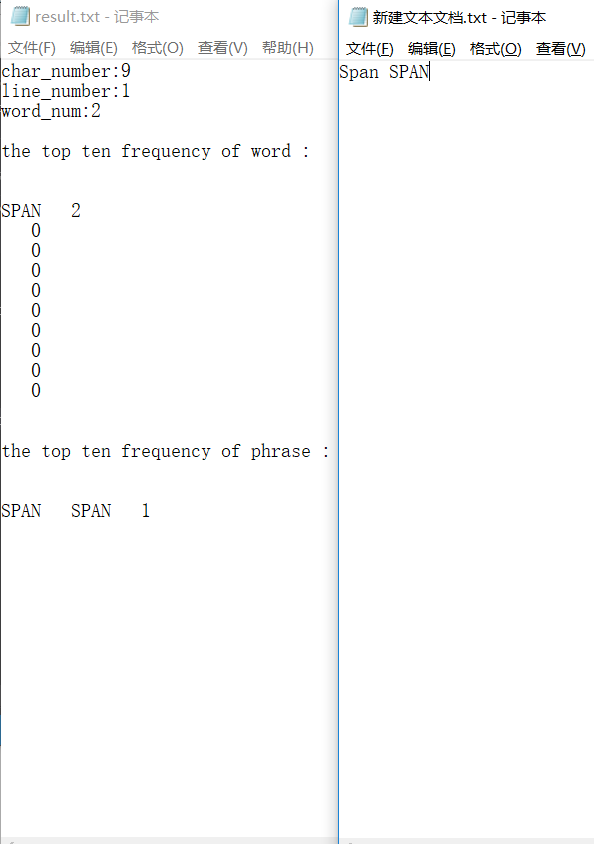
测试无误
添加数字后缀
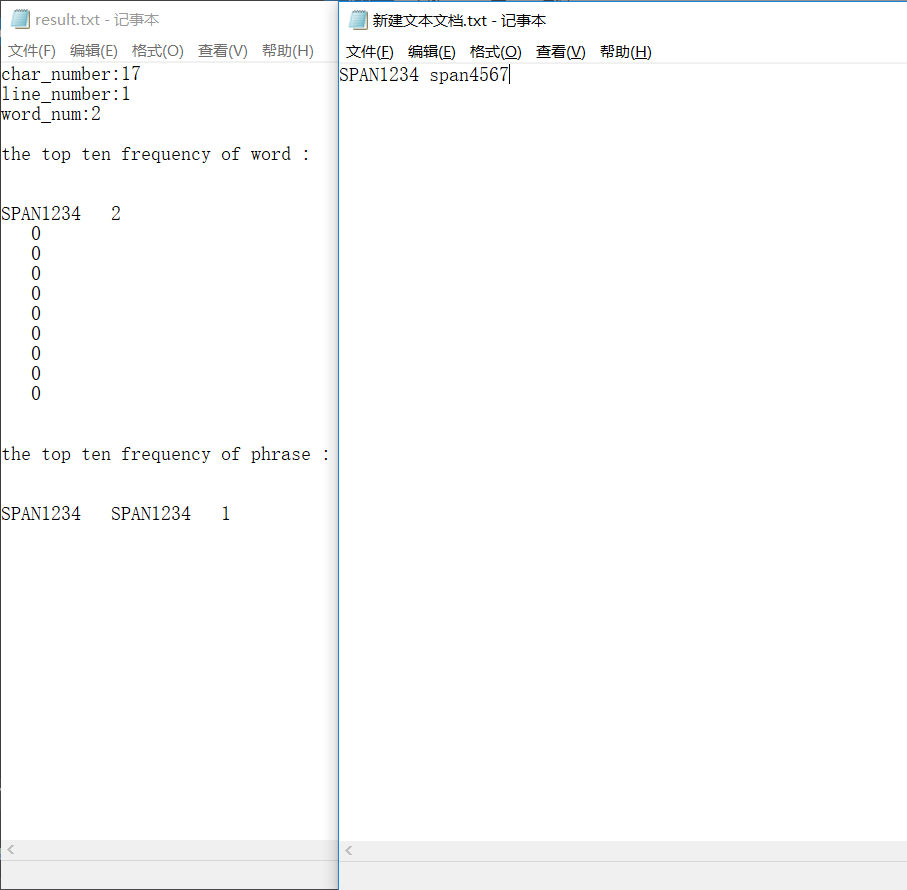
检测无误
典型文件
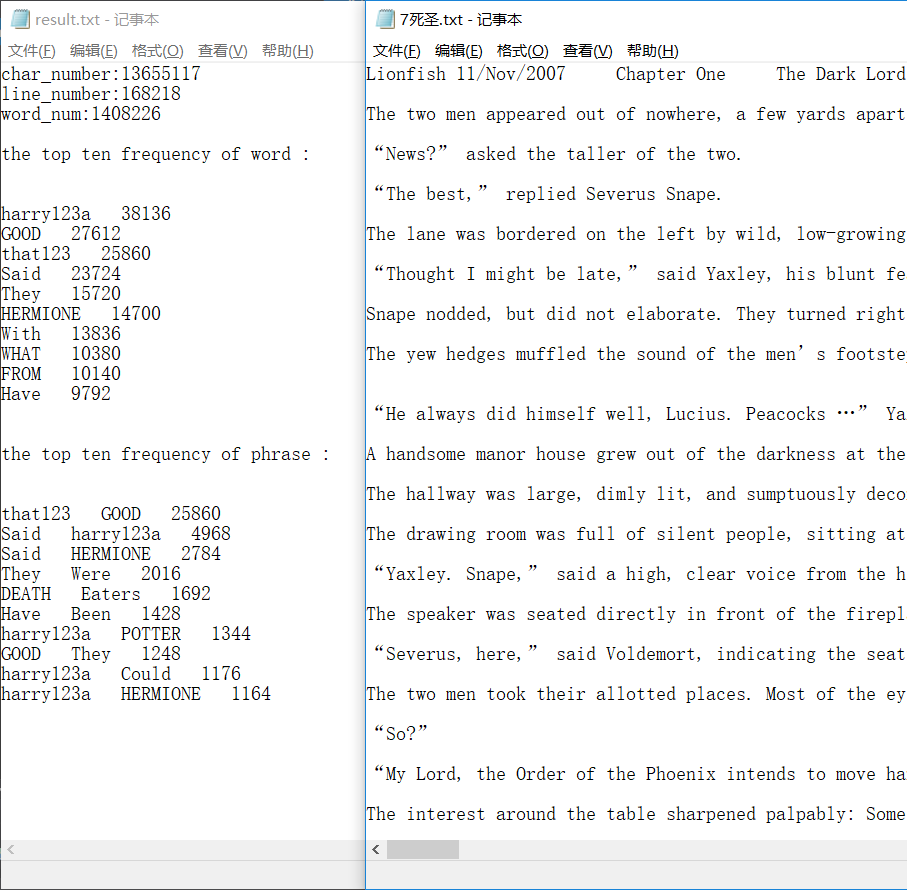
结果正常
总结与思考
这次任务整体来说并不算难,但由 PSP 表格可见,实际使用的时间远远超出了预估。不得不说,编程这事情真的是个熟练活。一段时间不去亲自敲键盘,就手生的不行。例如在做 linux 系统下的移植时,由于自己对于 linux 系统是第一次使用,远不如 vs 顺手,层出不穷的报错整的我焦头烂额。甚至最后被一个变量名的拼写错误折腾了半天,可以说是很不愉快的经历了。大致总结一下,算是有如下几点收获
1. 集成的东西真的很好用,不用担心越界之类的。但如果要追求速度,还是最底层的效率最高,二者不可兼得。也怪不得一些核心程序要用汇编语言来写了
2. 图形化界面真的是让电脑使用变得简单了起来(来自于使用 linux 的怨念
3. 单元测试的重要性。一开始并没有特别重视单元测试,导致当时除了很严重的 bug(上文中在 Findwords 函数部分有提到) 最后是拿着助教给的执行程序,找一个文件不断的二分删除和标准结果比较,最后才发现了问题。还是自己在测试时随便写几个文件敷衍了事,没有考虑测试文件典型性。
4. 承接上一条,就是旁边有大佬真的能很快帮忙解决问题,决心以后更加抱紧大腿了。(特此想要感谢两位大佬,一位帮我找出了那个致命的bug,另一个教我完成了 linux 系统下的移植

 浙公网安备 33010602011771号
浙公网安备 33010602011771号