

nginx 502报错详细分析
生产上偶发502,一周大概一两次
链路是client -->nginx(ingress) --> server
502日志报错

首先Google,发现可能跟keepalive配置有关
在sit环境进行复现
怎样才能复现呢?
通过tcpdump抓包发现,nginx --> server 这链路的keepalive 是60s,每隔60s, server端主动断开连接

那就通过脚本在client每隔60s进行请求一次
while 1:
file = open("502log.txt", 'a')
sys.stdout = file
print(time.asctime(),"开始请求。。。。。")
text = session.post(url=base_url,headers=headers,data=data)
# print("状态码。。。。")
if text.status_code != 200:
print(text.status_code)
print("响应内容。。。。")
print(time.asctime())
print(text.json())
print("睡眠60s。。。。")
file.close()
time.sleep(60.001)
同时在client端和server端进行抓包
#client host是对应的地址
tcpdump -S -nn -i eth0 host 192.168.x.x -C 50 -W 3 -w dump_client.cap
#server
tcpdump -S -nn -i eth0 host 172.160.X.0 -C 50 -W 3 -w dump_server.cap
终于在sit环境复现了!!!

这个时间点请求报502
然后分析client和server的tcpdump
client:
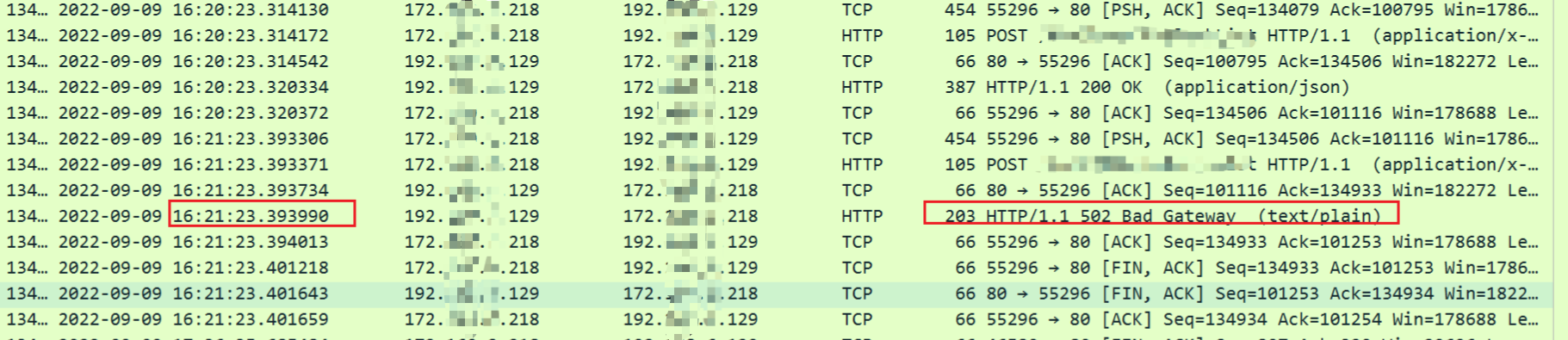
server:

通过时间比对刚好在这个时间点server发送了一个FIN包
解决方案:
nginx http中设置的keepalive_timeout


upstream 中设置的keepalive_timeout
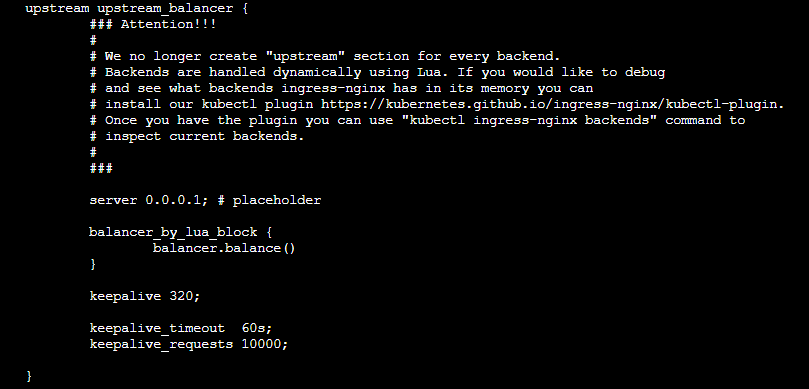

所以需要将upstream中的keepalive_timeout 大于http中设置的,最好是没有交集那种

