pandas重塑层次化索引(stack()和unstack()函数解析)
在数据处理时,有时需要对数据的结构进行重排,也称作是重塑(Reshape)或者轴向旋转(Pivot)。而运用层次化索引可为 DataFrame 的数据重排提供良好的一致性。在 pandas 中提供了实现重塑的两个函数,即 stack() 函数和 unstack() 函数。
常见的数据层次化结构有两种,一种是表格,如图 1 所示;另一种是“花括号”,如图 2 所示
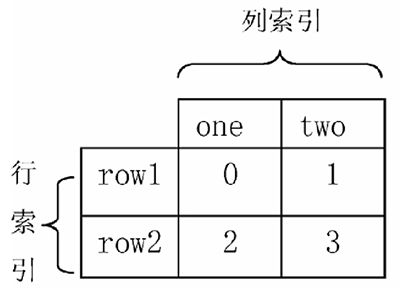
图 1:表格结构
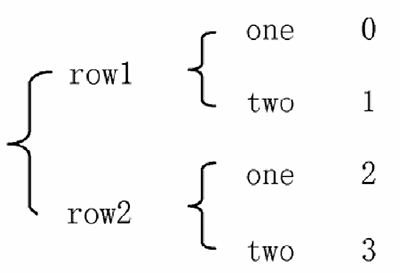
图 2:花括号结构
表格在行列方向上均有索引(类似于 DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的 Series),结构更加偏向于堆叠(Series-stack)。
stack() 函数会将数据从“表格结构”变成“花括号结构”,即将其行索引变成列索引,反之,
unstack() 函数将数据从“花括号结构”变成“表格结构”,即要将其中一层的列索引变成行索引。
stack() 函数
stack() 函数的语法格式如下:
DataFrame.stack(level=-1,dropna=True)
函数中的参数说明如下:
- level:接收 int、str、list,默认为 -1,表示从列轴到索引轴堆叠的级别,定义为一个索引或标签,或者索引或标签列表;
- dropna:接收布尔值,默认为 True,表示是否在缺失值的结果框架/系列中删除行。将列级别堆叠到索引轴上可以创建原始数据帧中缺失的索引值和列值的组合。
函数返回值为 DataFrame 或 Series。
unstack() 函数
unstack() 函数的语法格式如下:
DataFrame.unstack(level=-1, fill_value=None)
或
Series.unstack(level=-1, fill_value=None)
函数中的参数说明如下:
- level:接收 int、string 或其中的列表,默认为 -1(最后一级),表示 unstack 索引的级别或级别名称。
- fill_value:如果取消堆栈,则用此值替换 NaN 缺失值,默认为 None。
函数返回值为 DataFrame 或 Series。
使用 stack()、unstack() 函数的示例代码 example1.py 如下
import numpy as np import pandas as pd #创建DataFrame data = pd.DataFrame(np.arange(4).reshape((2, 2)), index=pd.Index(['row1', 'row2'], name='rows'), columns=pd.Index(['one', 'two'], name='cols')) print(data) cols one two rows row1 0 1 row2 2 3
#使用stack()函数改变data层次化结构 result = data.stack() print('data改变成"花括号"结构','\n',result) data改变成"花括号"结构 rows cols row1 one 0 two 1 row2 one 2 two 3
print('恢复到原来结构','\n',result.unstack()) 恢复到原来结构 cols one two rows row1 0 1 row2 2 3 print(result.unstack(0)) rows row1 row2 cols one 0 2 two 1 3 print(result.unstack('rows'))
#创建Series s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd']) s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e']) data2 = pd.concat([s1, s2], keys=['one', 'two']) print(data2) print('将data2改变成表格结构','\n',data2.unstack()) #使用stack()函数改变成"花括号"结构,并删除缺失值行 print(data2.unstack().stack()) #使用stack()函数改变成"花括号"结构,不删除缺失值行 print(data2.unstack().stack(dropna=False)) #用字典创建DataFrame df = pd.DataFrame({'left': result, 'right': result + 3}, columns=pd.Index(['left', 'right'], name='side')) print(df) #使用unstack()、stack()函数 print(df.unstack('rows')) print(df.unstack('rows').stack('side'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号