Pandas的数据分组以及分组聚合函数操作
1、数据分组
分组基本操作案例:在水果列表里增加一列放入每种水果的平均值:
#进行数据分组,不显示分组情况 df.groupby(by=['item'],axis =0).group #---axis =0表示列 #例如:求每组水果的价格和平均值(mean()) df.groupby(by=['item'],axis =0).mean()# 每种水果的平均价格 s =df.groupby(by=['item'],axis =0)['price'].mean()
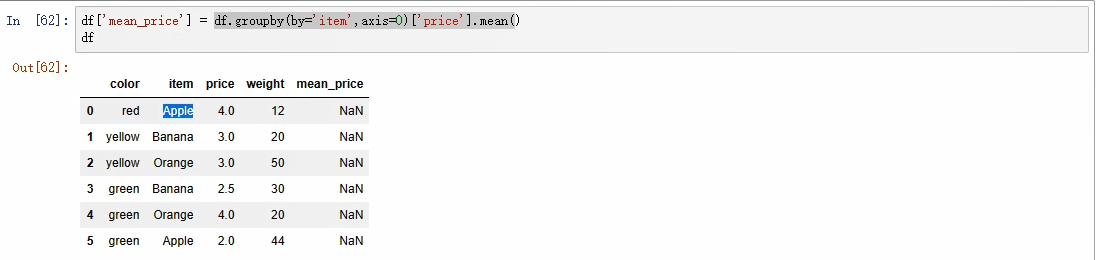
有NaN 映射关系不对!采用如下方式:
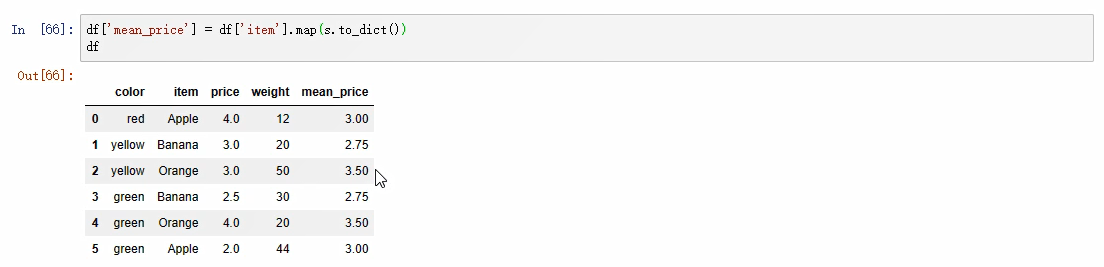
s.to_dict() # 将df数组转为字典:{'a':'123','b':'345','c':'567'}
创建一列,放入映射的值:df[‘mean’] = df['item'].map(s.to_dict())
2、统计函数
分组分析是指根据分组字段,将分析对象划分成不同的部分,以对比分析各组之间差异性的分析方法。分组分析常用的统计指标是计数、求和、平均值。
分组统计函数的语法格式如下:
groupby(by=[分组列1,分组列2,…])
[统计列1,统计列2,…]
.agg({统计列别名1:统计函数1,统计列别名2:统计函数2,…})
函数中的参数说明如下:
- by:用于分组的列;
- 中括号[ ]:用于统计的列;
- agg:统计别名用于显示统计值的名称,统计函数用于统计数据,常用的统计函数有计数(size)、求和(sum)和均值(mean)。
【例 1 】在 Employee_income.xls 文件中包含有职工号(emp_id)、性别(sex)、年龄(age)、学历(education)、参加工作时间(firstjob)、工作地区(region)、行业(industry)、职业(occupation)、月薪(salary)和月补贴(subsidy)等 10 列数据,要求分别按年龄、学历分组统计人数,并求月薪的均值、最大值和最小值。
其示例代码 test1 如下
import numpy as np from pandas import DataFrame; import pandas as pd df = pd.read_excel('d:\data\emp_income\Employee_income.xls', sheet_name='emp_income') age_result = df.groupby(by=['age'])['salary'].agg({ '人数':np.size, '平均月薪':np.mean, '最高月薪':np.max, '最低月薪':np.min }) print(age_result) edu_result = df.groupby(by=['education'])['salary'].agg({ '人数':np.size, '平均月薪':np.mean, '最高月薪':np.max, '最低月薪':np.min }) print(edu_result)
运行输出结果如下:
人数 平均月薪 最高月薪 最低月薪 education 大专 4 3700.000000 4500 3000 本科 5 4700.000000 5000 4500 研究生 2 7099.500000 7699 6500 高中 7 2685.714286 3500 2000
3、高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform和apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
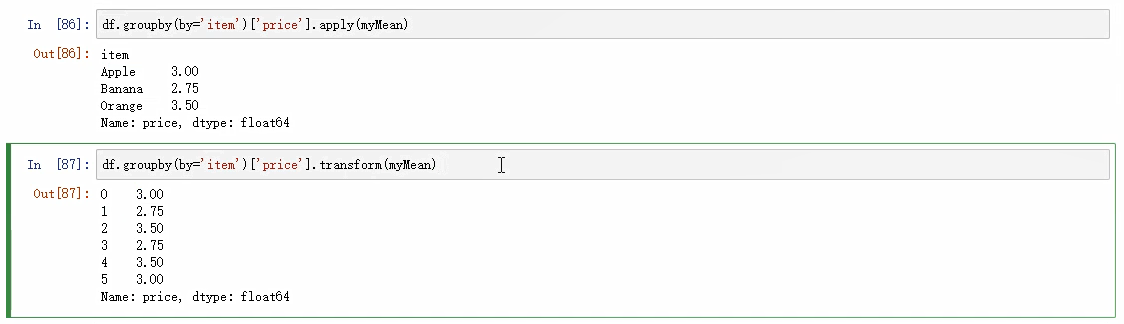
apply自定义函数实现案例:
def my_mean(s): #---参数必须有一个,s传入的是一个数组 sum =0 for i in s: sum += i return sum/len(s) # apply(my_mean)调用自定义函数:my_mean df.groupby(by=['item'],axis =0)['price'].apply(my_mean) # transform 封装了映射,transform返回值是经过映射的,可以直接往源数据里做汇总 df.groupby(by=['item'],axis =0)['price'].transform(my_mean)
4、分组聚合处理
在对数据进行分组之后,可以对分组后的数据进行聚合处理统计。
agg函数,agg的形参是一个函数会对分组后每列都应用这个函数。
import pandas as pd import numpy as np idx = [101,101,101,102,102,102,103,103,103] idx += [101,102,103] name = ["apple","pearl","orange", "apple","pearl","orange","apple","pearl","orange"] name += ["apple"] * 3 price = [1.0,2.0,3.0,4.00,5.0,6.0,7.0,8.0,9.0] price += [4] * 3 df0 = pd.DataFrame({ "fruit": name, "price" : price, "supplier" :idx}) print "*" * 30 print df0 print "*" * 30 dg1 = df0.groupby(["fruit", "supplier"]) for n, g in dg1: print "multiGroup on:", n, "\n|",g ,"|" print "*" * 30 print dg1.agg(np.mean)
程序的执行结果:
******************************
fruit price supplier
0 apple 1 101
1 pearl 2 101
2 orange 3 101
3 apple 4 102
4 pearl 5 102
5 orange 6 102
6 apple 7 103
7 pearl 8 103
8 orange 9 103
9 apple 4 101
10 apple 4 102
11 apple 4 103
******************************
multiGroup on: ('apple', 101)
| fruit price supplier
0 apple 1 101
9 apple 4 101 |
...
multiGroup on: ('pearl', 103)
| fruit price supplier
7 pearl 8 103 |
******************************
price
fruit supplier
apple 101 2.5
102 4.0
103 5.5
orange 101 3.0
102 6.0
103 9.0
pearl 101 2.0
102 5.0
103 8.0
请注意水果apple的输出。
- agg应用均值、求和、最大等示例。
import pandas as pd import numpy as np idx = [101,101,101,102,102,102,103,103,103] idx += [101,102,103] * 3 name = ["apple","pearl","orange", "apple","pearl","orange","apple","pearl","orange"] name += ["apple"] * 3 + ["pearl"] * 3 + ["orange"] * 3 price = [4.1,5.3,6.3,4.20,5.4,6.0,4.5,5.5,6.8] price += [4] * 3 + [5] * 3 + [6] * 3 df0 = pd.DataFrame({ "fruit": name, "price" : price, "supplier" :idx}) print "*" * 30 print df0 print "*" * 30 dg1 = df0.groupby(["fruit", "supplier"]) print dg1.agg(np.mean) print "*" * 30 print dg1.agg([np.mean, np.std, np.min, np.sum])
- 程序执行结果:
****************************** fruit price supplier 0 apple 4.1 101 ... 17 orange 6.0 103 ****************************** price fruit supplier apple 101 4.05 102 4.10 103 4.25 orange 101 6.15 102 6.00 103 6.40 pearl 101 5.15 102 5.20 103 5.25 ****************************** price mean std amin sum fruit supplier apple 101 4.05 0.070711 4 8.1 102 4.10 0.141421 4 8.2 103 4.25 0.353553 4 8.5 orange 101 6.15 0.212132 6 12.3 102 6.00 0.000000 6 12.0 103 6.40 0.565685 6 12.8 pearl 101 5.15 0.212132 5 10.3 102 5.20 0.282843 5 10.4 103 5.25 0.353553 5 10.5
各列用不同的处理函数。需要在agg函数里以字典的形式给出,分组后的那列用那个函数处理。
import pandas as pd import numpy as np idx = [101,101,101,102,102,102,103,103,103] idx += [101,102,103] * 3 name = ["apple","pearl","orange", "apple","pearl","orange","apple","pearl","orange"] name += ["apple"] * 3 + ["pearl"] * 3 + ["orange"] * 3 price = [4.1,5.3,6.3,4.20,5.4,6.0,4.5,5.5,6.8] price += [4] * 3 + [5] * 3 + [6] * 3 df0 = pd.DataFrame({ "fruit": name, "price" : price, "supplier" :idx}) print "*" * 30 print df0 print "*" * 30 dg1 = df0.groupby(["fruit"]) print dg1.agg(np.mean) print "*" * 30 print dg1.agg([np.mean, np.std, np.min, np.sum]) print "*" * 30 print dg1.agg({"price" : np.mean, "supplier" : np.max})
程序的执行结果:
****************************** fruit price supplier 0 apple 4.1 101 1 pearl 5.3 101 2 orange 6.3 101 3 apple 4.2 102 4 pearl 5.4 102 5 orange 6.0 102 6 apple 4.5 103 7 pearl 5.5 103 8 orange 6.8 103 9 apple 4.0 101 10 apple 4.0 102 11 apple 4.0 103 12 pearl 5.0 101 13 pearl 5.0 102 14 pearl 5.0 103 15 orange 6.0 101 16 orange 6.0 102 17 orange 6.0 103 ****************************** price supplier fruit apple 4.133333 102 orange 6.183333 102 pearl 5.200000 102 ****************************** price supplier mean std amin sum mean std amin sum fruit apple 4.133333 0.196638 4 24.8 102 0.894427 101 612 orange 6.183333 0.325064 6 37.1 102 0.894427 101 612 pearl 5.200000 0.228035 5 31.2 102 0.894427 101 612 ****************************** supplier price fruit apple 103 4.133333 orange 103 6.183333 pearl 103 5.200000
agg函数是对列而言的,如果打算对分组后列的数据进行处理可以使用tranform函数,见下一章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号