决策树分类算法
-
决策树概念:决策树类似于一个流程图的树结构;其中,欸个内部节点表示在一个属性上的测试,每个分支代表一个属性输出,而每一个树叶节点代表类或者类分布。书的最顶层是根节点
-
-
知识扩展(决策树分类算法核心底层实现)
-
熵
-
自信息量
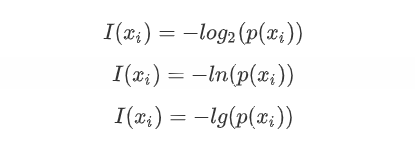
-
公式说明
-
底数为2时,I(x)的单位是bit,通信与信息论中常用
-
底数为e时,I(x)的单位是net,常用于理论推导
-
底数为10时,I(x)的单位是hat,常用于解决工程问题
-
多数情况下采用第一种计算自信息量;如果说概率p是对确定性的度量,那么信息就可以理解为对不确定性的度量
-
-
曲线样本
-
-
-
独立事件的信息
如果两个事件x和y相互独立,即
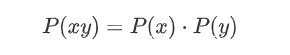
假设x和y的信息分别为I(x)和I(y),则二者同时发生的信息量应该为
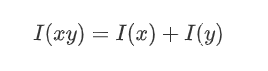
-
熵
自信息的期望,是对平均 不确定性的度量,P(x)表示各类特征占比(概率)
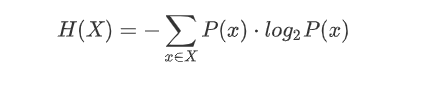
-
条件熵
-
概念:条件熵是在联合离散符号集XY上定义的,在一致随机变量Y的条件下,随机变量X的条件熵,记作H(X|Y)
-
公式:H(Y|X=x)表示X为x值,Y中的特征在x中的所占比转换为上述熵的求解
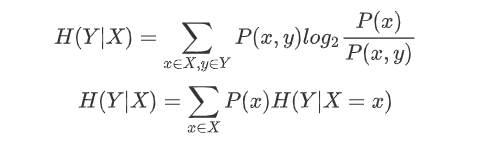
-
-
联合熵
-
概念:联合熵是联合离散符号集上的每个元素对$(x_i, y_i)$的联合自信息的数学期望,记作H(XY)
-
公式
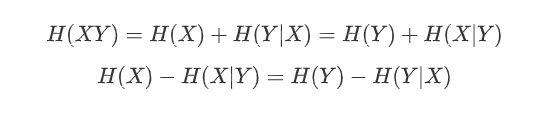
-
-
互信息
-
单一特征
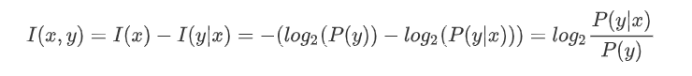
-
公式说明
-
I(y)是x发生前的信息,即自信息
-
I(y|x)是x发生后的信息,即条件信息
-
互信息是收信者收到信息x后,对信源发y的不确定性的消除
-
-
对称性
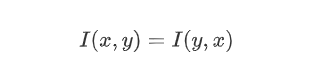
-
平均互信息:决策树中的信息增益
-
条件熵与平均互信息的关系
-
-
决策树归纳法
-
特征A对训练数据集D信息增益D(A, D)定义为集合D的经验熵H(D)与特征A给定条件下D的条件熵的差,即训练数据集D和特征A的互信息
-
遍历所有特征,选择信息增益最大的特征作为当前分裂特
-
-
信息增益率法
-
-
python第三方包实现
from sklearn.feature_extraction import DictVectorizer from sklearn import tree from sklearn import preprocessing from six import StringIO import csv import sys class MyTree: def __init__(self): # 处理特征使用的对象 self.vec = DictVectorizer() # 处理标签使用的对象 self.lb = preprocessing.LabelBinarizer() self.reader, self.headers = MyTree.load_data() self.feature_list, self.label_list = self.create_feature_array() self.clfPlay = self.clf_play() self.visualize_model() # 加载数据 @staticmethod def load_data(): elem_data = open(r"./dataset.csv") reader = csv.reader(elem_data) headers = reader.__next__() return reader, headers # 构建特征矩阵和标签向量 def create_feature_array(self): feature_list = [] label_list = [] for row in self.reader: label_list.append(row[len(row)-1]) row_dict = {} for i in range(1, len(row)-1): row_dict[self.headers[i]] = row[i] feature_list.append(row_dict) return feature_list, label_list # 向量化特征数据 def feature_vectorization(self): dummy_x = self.vec.fit_transform(self.feature_list).toarray() return dummy_x # 向量化标签数据 def label_vectorization(self): dummy_y = self.lb.fit_transform(self.label_list) return dummy_y # 使用信息熵进行分类 def clf_play(self): clfPlay = tree.DecisionTreeClassifier(criterion="entropy") clfPlay = clfPlay.fit(self.feature_vectorization(), self.label_vectorization()) return clfPlay def visualize_model(self): with open(r"./InformationGain.dot", "w") as f: f = tree.export_graphviz(self.clfPlay, feature_names=self.vec.get_feature_names(), out_file=f) tree.export_graphviz(self.clfPlay, feature_names=self.vec.get_feature_names(), out_file=sys.stdout) if __name__ == '__main__': my_tree = MyTree()
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号