树链剖分基础
写在最前面,本文作者水平有限,若有不足需要补充处,望友善讨论
本文主要用于梳理树链剖分的基本原理,若想要进行刷题练习,请进入进阶内容
另外,基础内容中可能会涉及一些线段树的内容,推荐了解一些线段树基础
若想进入进阶内容,至少需要会基础线段树,其余需要较难的线段树操作,可以边写边学
原理
想了解一个算法,我们首先看看这个算法的原理,这样才能对算法进行更合理的改编与应用。
问题引入
我们用一个问题引入树链剖分。
这里用的是AcWing2568. 树链剖分
这里将问题简单陈述一下。
给定一棵树,树中包含 n 个节点(编号 1∼n),其中第 i 个节点的权值为 \(a_i\)。
初始时,1号节点为树的根节点。
现在要对该树进行 m 次操作,操作分为以下 4种类型:
1 u v k,修改路径上节点权值,将节点 u 和节点 v 之间路径上的所有节点(包括这两个节点)的权值增加 k。2 u k,修改子树上节点权值,将以节点 u 为根的子树上的所有节点的权值增加 k。3 u v,询问路径,询问节点 u 和节点 v 之间路径上的所有节点(包括这两个节点)的权值和。4 u,询问子树,询问以节点 u 为根的子树上的所有节点的权值和。
我们先不考虑带修操作,即忽略1,2,来看看如何写这道题目。
对于3,询问路径,询问节点 u 和节点 v 之间路径上的所有节点(包括这两个节点)的权值和。
不难想到,求树上路径,求LCA是必须的了。
我们可以用倍增法求lca(u,v),在维护fa[i][j]的同时维护一个数组sum[i][j],其表示从i向上跳\(2^j\)步中间的所有点的点权和。
不多说,这并不麻烦。
对于4,询问子树,询问以节点 u 为根的子树上的所有节点的权值和。
这个就非常简单了,我们可以再维护一个数组res[i]。从根节点跑DFS就可以知道以i为根的子树的点权和了。
当然如果问题到这里,那也就结束了,但并不是的,我们现在回头看1,2。
我们会发现如果带修,那每次求3,4的时候,我们都要重新跑一次DFS,时间直接爆炸。
此时,我们将这个问题的背景改变一下,将树变为区间,我们来重新改写一下问题。
给定一个区间,区间中包含 n 个节点(编号 1∼n),其中第 i 个点的权值为 \(a_i\)。
现在要对该区间进行 m 次操作,操作分为以下 2种类型:
1 u v k,修改区间权值,将节点 u 和节点 v 之间区间中的所有节点(包括这两个节点)的权值增加 k。2 u v,询问路径,询问节点 u 和节点 v 之间区间中的所有节点(包括这两个节点)的权值和。
这就是一个经典的区间加的线段树的问题了。那问题就是,我们如何将对1,2,3,4的树上操作变为区间操作
这时候,我们引入树链剖分。来看看如何用树链剖分解决问题。
树链剖分原理
我们将反复强调这句话,理解树剖的目的时请谨记住。
我们用树链剖分是将树的结构拆成了区间结构,也就是说我们把树上问题变为了区间问题
我刚开始学的时候,看到树剖的一大堆数组头就大,所以我们这里不直接写代码,我们来看看树剖是怎么做的,一步步把数组加上。但请一定记住我们的目的。
我们利用的是重链剖分与DFS序来完成我们的目的。那我们就先来讲讲重链剖分。
重链剖分
对一个节点而言,其下边有很多的儿子,其中子树节点最多的儿子就是重儿子。而其他的儿子就是其他重链头结点
那重链是什么呢?即为从其头结点向下以此连接重儿子的链
没明白?什么问题都不如看看图。
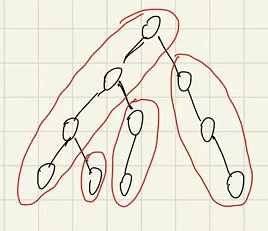
结合着定义与图片的理解,我们发现,我们需要的有五个基础数组。
sz[u],以u为根的子树下的节点个数son[u],u节点下的重儿子top[u],u节点所在的重链的头结点dep[u],u节点的深度fa[u],u节点的父节点
请记住,到这里,只是重链剖分,但我们需要知道我们能用重链剖分干什么。
我们可以用\(O(logN)\)的时间找到从u至v的一条路径,即找到lca(u,v),与倍增时间相同,但比倍增常数更小。
重链剖分实现
我们可以发现,top数组,需要依托于son数组,而son数组需要依托于sz数组,而fa与dep都可以在维护sz的时候顺便维护了。
因此,我们要进行两次dfs
dfs1解决的是以下四个数组的问题。
sz[u],以u为根的子树下的节点个数son[u],u节点下的重儿子dep[u],u节点的深度fa[u],u节点的父节点
dfs2解决的是
top[u],u节点所在的重链的头结点
来看代码。
这部分应该是基础的,要理解。结合图多理解一下。
void dfs1(int u,int pa,int depth)
{
dep[u]=depth,fa[u]=pa,sz[u]=1;
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(j==pa) continue;
dfs1(j,u,depth+1);
sz[u]+=sz[j];
if(sz[son[u]]<sz[j]) son[u]=j;//更新重儿子
}
}
void dfs2(int u,int tp)
{
top[u]=tp;//记录u所在重链的头结点
if(!son[u]) return;//若没有重儿子,则到叶节点了,记得返回。
dfs2(son[u],tp);//先遍历重儿子,这样才能扫出对于此时的重链而言的完整重链
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(son[u]==j||j==fa[u]) continue;//防止扫回父节点,同时反复扫到重儿子
dfs2(j,j);//其余的轻儿子,是其他重链的头结点
}
}
//在主函数中,我们这么写。我们假设root为根,且只有一棵树,若是森林,就相应的多操作几次就行。
dfs1(root,-1,1);
dfs2(root,root)//因为root一定是最开始的重链的头结点
用重链剖分求LCA
\(时间复杂度O(logN)\)
我们利用与倍增类似的思路
- 先将
u和v翻到同一根链上 - 在一条链上后,深度小的即为
lca(u,v)
这里我们直接看代码,细节在代码中体现
int lca(int u,int v)
{
while(top[u]!=top[v])//若u,v还未翻倒一条链
{
if(dep[top[u]]<dep[top[v]]) swap(u,v);//若u所在的重链头节点深度比v的小,交换u,v。这里是为了操作方便,可以不换,调整一下代码即可。
u = fa[top[u]]//跳到重链的头结点的父节点处,即向上跳到另一条链上。
}
return dep[u]<dep[v]?u:v;//深度小的即为答案
}
DFS序
接下来,我们来说树剖中另一组成部分,DFS序
其定义即为,按照dfs时所到的节点顺序,对节点重新进行编号。
因此,我们发现我们又多了一个数组。
id[u],u节点的dfs序
需要强调的是,此时已经有了一个性质。
对于某个节点u其下边的子树dfs序已经连续了
即为:[id[u],id[u]+sz[u]-1]
树链剖分实现
那我们如何利用重链剖分和DFS序实现我们的目的呢?再次强调一次目的。
我们用树链剖分是将树的结构拆成了区间结构,也就是说我们把树上问题变为了区间问题
我们按照扫描重链的方式来建立DFS序。即在dfs2中,增添一个对dfs序的求解,直接看看代码。
void dfs2(int u,int tp)
{
id[u] = ++cnt,top[u]=tp;//按照扫描重链的方式,来建立dfs序
if(!son[u]) return;
dfs2(son[u],tp);
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(son[u]==j||j==fa[u]) continue;
dfs2(j,j);
}
}
那这样做有什么用呢?
它为我们提供了另一个性质。
重链内的dfs序也是连续的
即为:[id[top[u]],id[u]]
那我们就知道树链剖分有两个性质了。
- 对于某个节点
u其下边的子树dfs序已经连续,即为:[id[u],id[u]+sz[u]-1] - 重链内的
dfs序也是连续的,即为:[id[top[u]],id[u]]
那,我们就可以完成以下两个操作。
- 利用第一个性质,此时对某个节点下边子树的操作问题,就可以转化为区间问题了。
- 利用第二个性质,还记得我们求LCA的过程嘛?在不断上翻的过程中,我们经过的所有重链其内部
dfs序也连续,我们就可以将树上路径问题,转化为一段段连续区间的问题了。
而区间问题,我们就可以用很多操作了,例如最常见的与线段树结合
刚开始学会迷糊的点,我们强调一下
- 完成连续操作的是
dfs序,因此我们线段树内部是以这些点的dfs序来进行维护的
树链剖分板子
那我们给出最终的树链剖分的板子,请记住,这只是最基础的,一定要理解原理,这样可以随意增添数组。
int h[N],e[M],ne[M],idx;//链式向前星存图,笔者个人习惯
int fa[N],son[N],dep[N],sz[N];//dfs1所维护的数组
int top[N],id[N],cnt;//dfs2所维护的数组
int n;//点数
void add(int a,int b)//加边函数
{
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void dfs1(int u,int pa,int depth)
{
dep[u]=depth,fa[u]=pa,sz[u]=1;
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(j==pa) continue;
dfs1(j,u,depth+1);
sz[u]+=sz[j];
if(sz[son[u]]<sz[j]) son[u]=j;
}
}
void dfs2(int u,int tp)
{
id[u] = ++cnt,top[u]=tp;
if(!son[u]) return;
dfs2(son[u],tp);
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(son[u]==j||j==fa[u]) continue;
dfs2(j,j);
}
}
回归问题
现在我们已经学会了使用树剖,我们回归问题,对树剖进行一个简单练习。
不用再向上翻了,我们再把问题打一遍。
给定一棵树,树中包含 n 个节点(编号 1∼n),其中第 i 个节点的权值为 \(a_i\)。
初始时,1号节点为树的根节点。
现在要对该树进行 m 次操作,操作分为以下 4种类型:
1 u v k,修改路径上节点权值,将节点 u 和节点 v 之间路径上的所有节点(包括这两个节点)的权值增加 k。2 u k,修改子树上节点权值,将以节点 u 为根的子树上的所有节点的权值增加 k。3 u v,询问路径,询问节点 u 和节点 v 之间路径上的所有节点(包括这两个节点)的权值和。4 u,询问子树,询问以节点 u 为根的子树上的所有节点的权值和。
此时,再重新看这个问题就很好说了。
简练一下问题。
我们需要对树上路径以及以u为根的子树进行区间加并且维护权值和。
本题的思路就出来了。
- 利用树链剖分,将树上问题转为区间问题
- 接下来,我们利用线段树对区间进行维护。
还是直接看代码,来理解。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10,M = N*2;
typedef long long LL;
struct node
{
int l,r;
LL add,sum;
}tr[N*4];//线段树结构体
int h[N],e[M],ne[M],idx;//链式向前星存图,笔者个人习惯
int fa[N],son[N],dep[N],sz[N];//dfs1所维护的数组
int top[N],id[N],nw[N],cnt;//dfs2所维护的数组,其中需要强调的是,nw数组是节点对应的dfs序下的权值。
int n,m;
void add(int a,int b)
{
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void dfs1(int u,int pa,int depth)
{
dep[u]=depth,fa[u]=pa,sz[u]=1;
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(j==pa) continue;
dfs1(j,u,depth+1);
sz[u]+=sz[j];
if(sz[son[u]]<sz[j]) son[u]=j;
}
}
void dfs2(int u,int tp)
{
id[u] = ++cnt,nw[cnt] = w[u],top[u]=tp;//注意看,nw记录的是什么。
if(!son[u]) return;
dfs2(son[u],tp);
for(int i=h[u];~i;i=ne[i])
{
int j = e[i];
if(son[u]==j||j==fa[u]) continue;
dfs2(j,j);
}
}
void push_up(int u)
{
tr[u].sum=tr[u<<1].sum+tr[u<<1|1].sum;
}
void push_down(int u)
{
auto &root = tr[u],&left = tr[u<<1],&right = tr[u<<1|1];
if(!root.add) return;
left.add+=root.add,left.sum+=root.add*(left.r-left.l+1);
right.add+=root.add,right.sum+=root.add*(right.r-right.l+1);
root.add=0;
}
void build(int u,int l,int r)
{
tr[u]={l,r,0,nw[r]};//线段树维护的是树的各节点的dfs序,因此初始化的时候,应当用dfs序对应的节点的权值
if(l==r) return ;
int mid = l + r >> 1;
build(u<<1,l,mid),build(u<<1|1,mid+1,r);
push_up(u);
}
void modify(int u,int l,int r,int d)
{
if(l<=tr[u].l&&tr[u].r<=r)
{
tr[u].add+=d;
tr[u].sum+=d*(tr[u].r - tr[u].l + 1);
return ;
}
int mid = tr[u].l + tr[u].r >> 1;
push_down(u);
if(l<=mid) modify(u<<1,l,r,d);
if(r>mid) modify(u<<1|1,l,r,d);
push_up(u);
}
LL query(int u,int l,int r)
{
if(l<=tr[u].l&&tr[u].r<=r) return tr[u].sum;
push_down(u);
int mid = tr[u].l + tr[u].r >> 1;
LL res = 0;
if(l<=mid) res+=query(u<<1,l,r);
if(r>mid) res+=query(u<<1|1,l,r);
return res;
}
int main()
{
cin>>n;
memset(h, -1, sizeof h);
for(int i=1;i<=n;i++) cin>>w[i];
for(int i=0;i<n-1;i++)
{
int u,v;
cin>>u>>v;
add(u,v),add(v,u);
}
dfs1(1,-1,1);
dfs2(1,1);
build(1,1,n);
cin>>m;
while (m -- )
{
int t,u,v,k;
cin>>t;
if(t==1)
{
cin>>u>>v>>k;
while (top[u] != top[v])//不断上翻
{
if (dep[top[u]] < dep[top[v]]) swap(u, v);
modify(1, id[top[u]], id[u], k);//其中上翻过程中,每一条重链内部是连续的。
u = fa[top[u]];
}
if (dep[u] < dep[v]) swap(u, v);
modify(1, id[v], id[u], k);
}
else if(t==2)
{
cin>>u>>k;
modify(1, id[u], id[u] + sz[u] - 1, k);//对于以u为根的子树,其子树内部dfs序连续
}
else if(t==3)
{
cin>>u>>v;
LL res = 0;
while (top[u] != top[v])//这个就不多解释了,与上修改操作相同
{
if (dep[top[u]] < dep[top[v]]) swap(u, v);
res += query(1, id[top[u]], id[u]);
u = fa[top[u]];
}
if (dep[u] < dep[v]) swap(u, v);
res += query(1, id[v], id[u]);
cout<<res<<endl;
}
else
{
cin>>u;
cout<<query(1, id[u], id[u] + sz[u] - 1)<<endl;//与修改相同
}
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号