一起学Hadoop——MapReduce原理
一致性Hash算法。
Hash算法是为了保证数据均匀的分布,例如有3个桶,分别是0号桶,1号桶和2号桶;现在有12个球,怎么样才能让12个球平均分布到3个桶中呢?使用Hash算法的做法是,将12个球从0开始编号,得到这样的一个序列:0,1,2,3,4,5,6,7,8,9,10,11。将这个序列中的每个值模3,不管数字是什么,得到的结果都是0,1,2,不会超过3,将结果为0的数字放入0号桶,结果为1的数子放入1号桶,结果为2的数字放入2号桶,12个球就均匀的分布到3个桶中,0,3,6,9,12号球放入0号桶,1,4,7,10号球放入1号桶,2,5,8,11号球放入2号桶。
一致性Hash算法是在Hash算法的基础上实现的,用于解决互联网中热点Hotspot问题,将来自网络上的流量动态的划分到不同的服务器处理。使用一致性Hash算法将流量均匀分发到不同服务器的做法是:
1、求出不同服务器的哈希值,然后映射到一个范围为0—2^32-1的数值空间的圆环中,即将首(0)和尾(2^32-1)相接的圆环,如图1。
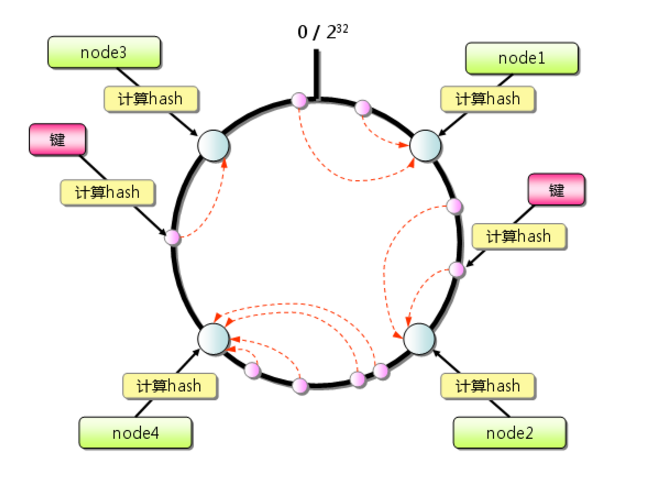
图1
2、当有一个李四的用户访问时,就会给该用户分配一个随机数,该随机数映射到圆环中的任意一个地方,按照圆环顺时针的方向查找距离最近的服务器,然后处理李四用户的请求。如果找不到服务器,则有第一台服务器来处理。
以上就是两种Hash算法的简单介绍,Hadoop也借助于这两种思想来处理大数据计算和海量数据存储。面对海量的问题时候,一般把这个问题会分成三类:一个是大数据量,一个是大流量,一个是大计算,大流量不属于本文讨论的范围,大数据量是属于HDFS的范畴,之后会写一篇文章讲解HDFS的原理。本文重点讲述大计算。MapReduce就会Hadoop中采用"分而治之"的思想解决大计算的问题。“分而治之”思想是理解MapReduce的核心,下面我们采用数钱的场景解释下“分而治之”的思想。
有一张桌子,上面洒满了面值100、50、20的钞票,我们如何能快速的知道这个桌子一共有多少钱呢?通常的做法是请103个人,其中100个人把自己面前的钞票按照100、50、20的面值整理好并排好序,100的一堆,50的一堆,20的一堆,并且按照100面值的在左边,50面值的在中间,20面值的在右边,这100人只负责按照钱的面值分好类别并整理整齐。整理好之后,这100个人执行下一个任务,分别把自己整理好的100元面值这一堆钱发给3个人中的=的A,把50元面值的钱发给3个人中的B,把20元面值的钱发给3个人中的C,这是这100个人的工作就结束。A,B,C这三个人就各自有了不同面值的钱,这三个人不需要去做加法就比如(100+100),只需要去数这个钱的张数,最后就出三个数字,然后把这三个数字加起来就是这一整个桌子的全额度总数。在这个例子中前后经历了两个过程,第一个过程是100个人,第二个过程是3个人,100人相当于就是做分解,把一整张桌子的钱去分解成100份,剩下这三个人就是做合并的作用。这就是“分而治之”的思想。
下面使用Hadoop给出的MapReduce运行图来解释上面数钱的流程:
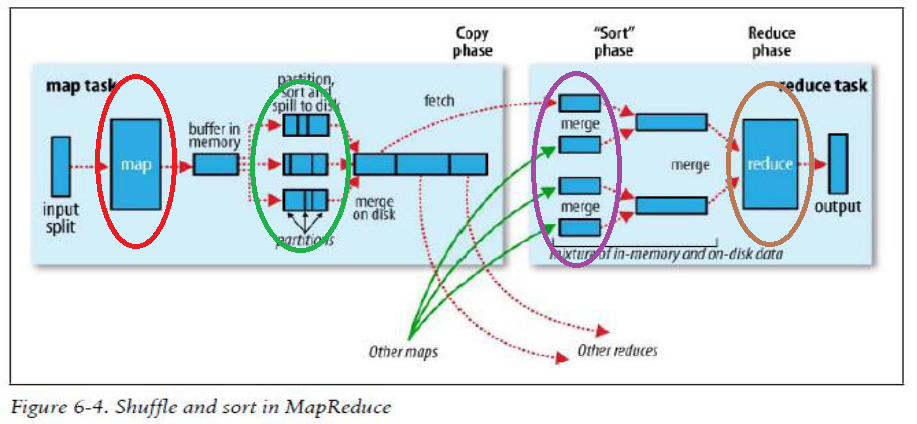
图2
上图中红色的椭圆框的map进程就是对应100个规整钱人中的其中一个,他将桌子上的钱拢到自己面前。绿色椭圆框就是开始规整钱的过程,按照100、50、20面值的钱分成3份,并且按照左边100,中间50,右边20的顺序排好序。紫色椭圆框是将就是将规整好的钱分发的过程,他将自己和其他99个人都将规整好的100元分发给A,把50元分发给B,把20元分发给C。褐色框就是汇总的过程,对应着上一过程中的A,计算出100面值的有多少张,B计算出50面值的有多少张,C计算20面值的有多少张。然后将A,B,C的的结果相加,就是桌子上钞票的总数。
其实一个MapReduce真正的运行过程比上述数钱的过程复杂得多,MapReduce的原理必须弄清楚,很多公司面试时都喜欢问MapReduce的运行原理,只有了解运行原理,才能在工作中对MapReduce进行调优,因此下图是每个学习Hadoop的人必须掌握的,下图的红色椭圆框是重点,也是优化大有可为之处。
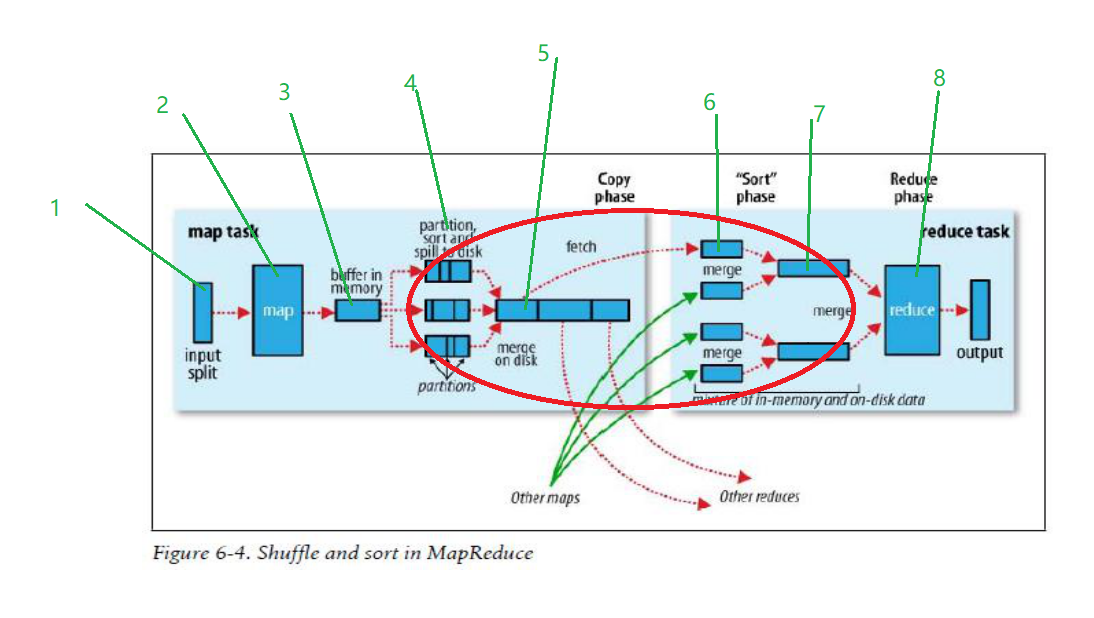
图3
数据按照箭头方向从左往右流动,
1、input split过程,通过InputFormat接口从HDFS中读取数据,然后输入到map中。默认情况下分片的大小和HDFS中block的大小一致,Hadoop1.x是64M,Hadoop2.x是128M。
2、map函数,一行一行的处理输入的数据,将每一行数据封装成<key,value>键值对形式。
3、Map进程中有一个内存缓冲区用于处理数据,默认是100M,当内存中的数据达到80M时,后台就开启一个进程,锁住80M的空间,将数据写入剩余的20M空间,同时将80M的数据溢出(spill)到磁盘。
4、在这个阶段涉及到数据的分区partition、排序和combiner,这也是mapreduce优化的重点。有几个partition就有几个reduce。当数据从内存缓存区往磁盘中写时,会生成很多小的spill文件,每个文件会分为好几个区,在数钱的例子中,一个spill文件会分为三个分区partition,每个分区中的文件使用快速排序算法按照key值进行排序。这里也可以执行combiner操作,但是一定要小心,如果是你求最大最小值,用combiner操作没问题,如果是求平均值,combiner操作会影响最终的结果。
5、map端归并文件,spill的小文件过多,达到阈值时,就使用归并排序算法将小的spill文件归并成大的spill文件,大的spill也是分好区,每个分区中的数据也是按照key值排好序。
6、当最后一个map任务执行完毕,生成最后一spill文件之后,就将spill文件中的分区往相应的reduce任务发送,例如partition0发送往reduce0,partition1发送往reduce1,partition2发送往reduce2,以此类推。
7、reduce端归并文件,将来自不同map端的同一个分区文件使用归并成一个大的文件。
8、reduce任务开始处理数据,将会后的结果写入到HDFS中。
图4是将不同map端同一个分区partition数据发送到reudce端的流程图。
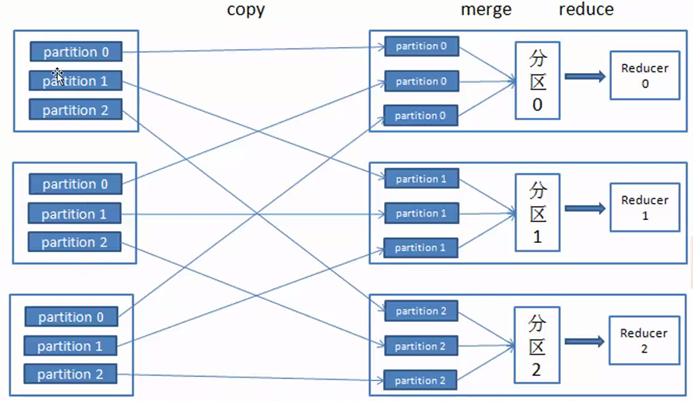
图4
现在重点介绍partition,sort and spill to disk过程,即分区,排序和溢写到磁盘过程。请看图5
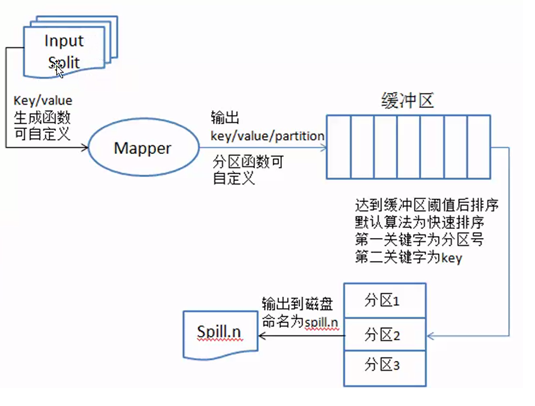
图5
数据从InputSplit进去到map进程,将数据处理成<key,value>键值对的形式,然后发送到内存缓存区,根据上面数钱的例子,会有很多如下形式的键值对,当有不同分区时,键值对为:<0,<100,1>>,<1,<50,1>>,<2,<20,1>>,当只有一个默认分区时,键值对为:<100,1>,<50,1>,<20,1>。从内存区往磁盘中写入数据时,先对键值对使用快速排序算法进行排序,第一关键字是分区号,第二关键字是key,排序的目的是为了将相同的key排到一块,为了后面的归并文件做好准备。把内存中排好序的数据输出到磁盘上,每次输出都会产生很多小的文件数据(spill.n),n表示数字,如图6所示。
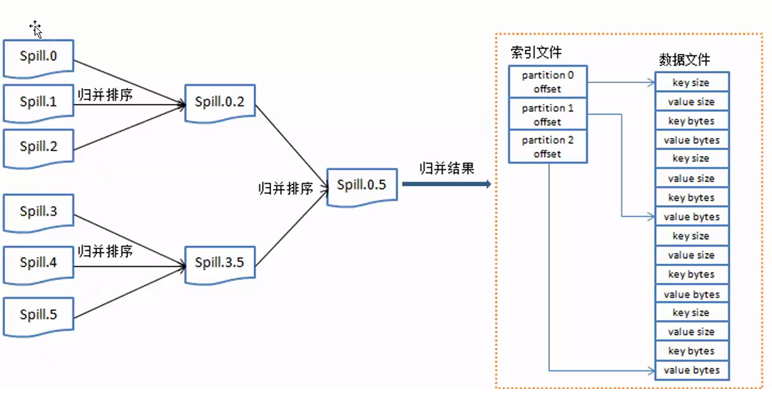
图6
当spill小文件过多时就执行归并排序,变成一个大的数据文件,归并完成后生成大的spill文件中的数据是按照key来做一个整体的排序。
作者:alunbar
出处:www.bigdata17.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
关注本人的公众号获取更多关于Java、pyhon爬虫大数据和AI方面的知识


 浙公网安备 33010602011771号
浙公网安备 33010602011771号