
深入了解String,StringBuffer和StringBuilder三个类的异同
Java提供了三个类,用于处理字符串,分别是String、StringBuffer和StringBuilder。其中StringBuilder是jdk1.5才引入的。
这三个类有什么区别呢?他们的使用场景分别是什么呢?
本文的代码是在jdk12上运行的,jdk12和jdk5,jdk8有很大的区别,特别是String、StringBuffer和StringBuilder的实现。
jdk5和jdk8中String类的value类型是char[],到了jdk12,value类型变为byte[]。
jdk5、JDK6中的常量池是放在永久代的,永久代和Java堆是两个完全分开的区域。
到了jdk7及以后的版本,
我们先来看看这三个类的源码。
String类部分源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
@Stable
private final byte[] value;
public String(String original) {
this.value = original.value;
this.coder = original.coder;
this.hash = original.hash;
}
public native String intern();
String类由final修饰符修饰,所以String类是不可变的,对象一旦创建,不能改变。
String类中有个value的字节数组成员 变量,这个变量用于存储字符串的内容,也是用final修饰,一旦初始化,不可改变。
java提供了两种主要方式创建字符串:
//方式1
String str = "123";
//方式2
String str = new String("123");
java虚拟机规范中定义字符串都是存储在字符串常量池中,不管是用方式1还是方式2创建字符串,都会从去字符串常量池中查找,如果已经存在,直接返回,否则创建后返回。
java编译器在编译java类时,遇到“abc”,“hello”这样的字符串常量,会将这些常量放入类的常量区,类在加载时,会将字符串常量加入到字符串常量池中。
含有表达式的字符串常量,不会在编译时放入常量区,例如,String str = "abc" + a
常量池的最大作用是共享使用,提高程序执行效率。
看看下面几个案例。
案例1:
1 String str1 = "123";
2 String str2 = "123";
3 System.out.println(str1 == str2);
上面代码运行的结果为true。
运行第1行代码时,现在常量池中创建字符串123对象,然后赋值给str1变量。
运行第2行代码时,发现常量池已经存在123对象,则直接将123对象的地址返回给变量str2。
str1和str2变量指向的地址一样,他们是同一个对象,因此运行的结果为true。
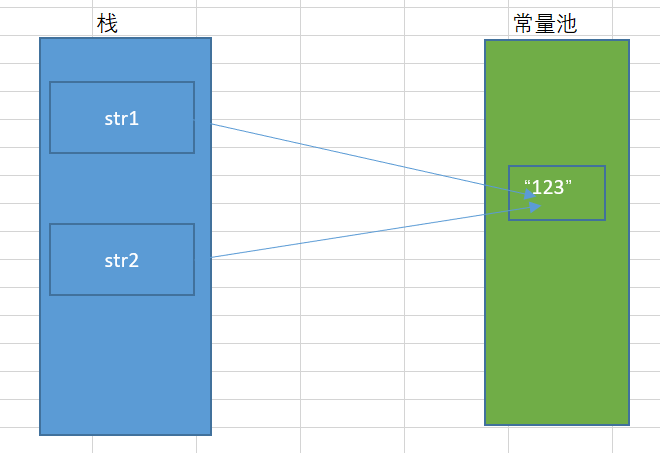
从图中可以看出,str1使用””引号(也是平时所说的字面量)创建字符串,在编译期的时候就对常量池进行判断是否存在该字符串,如果存在则不创建直接返回对象的引用;如果不存在,则先在常量池中创建该字符串实例再返回实例的引用给str1。
案例2:
1 String str1 = new String("123");
2 String str2 = new String("123");
3 String str3 = new String(str2);
4 System.out.println((str1==str2));
5 System.out.println((str1==str3));
6 System.out.println((str3==str2));
上面代码运行的结果是
false
false
false
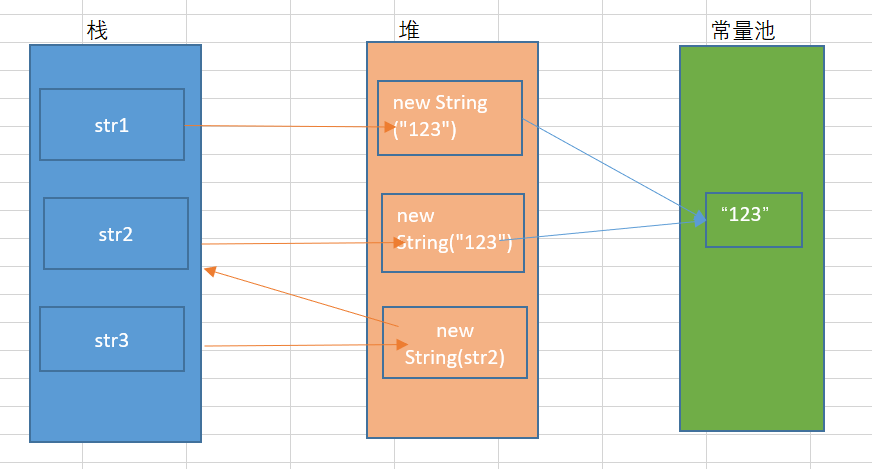
从上图可以看出,执行第1行代码时,创建了两个对象,一个存放在字符串常量池中,一个存在与堆中,还有一个对象引用str1存放在栈中。
执行第2行代码时,字符串常量池中已经存在“123”对象,所以只在堆中创建了一个字符串对象,并且这个对象的地址指向常量池中“123”对象的地址,同时在栈中创建一个对象引用str2,引用地址指向堆中创建的对象。
执行第3行代码时,在堆中创建一个字符串对象,这个对象的内存地址指向变量str2所执向的内存地址。
通过new方式创建的字符串对象,都会在堆中开辟一个新内存空间,用于存储常量池中的字符串对象。
对于对象而言,==操作是用于比较两个独享的内存地址是否一致,所以上面的代码执行的结果都是false。
案例3:
//这行代码编译后的效果等同于String str1 = "abcd";
String str1 = "ab" + "cd";
String str2 = "abcd";
System.out.println((str1 == str2));
上面代码执行的结果:true。
使用包含常量的字符串连接创建的也是常量,编译期就能确定了,类加载的时候直接进入字符串常量池,当然同样需要判断字符串常量池中是否已经存在该字符串。
案例4:
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2 + str3 + “1”;
String str5 = "abcd1";
System.out.println((str4==str5));
上面代码执行的结果:false。
当使用“+”连接字符串中含有变量时,由于变量的值是在运行时才能确定。
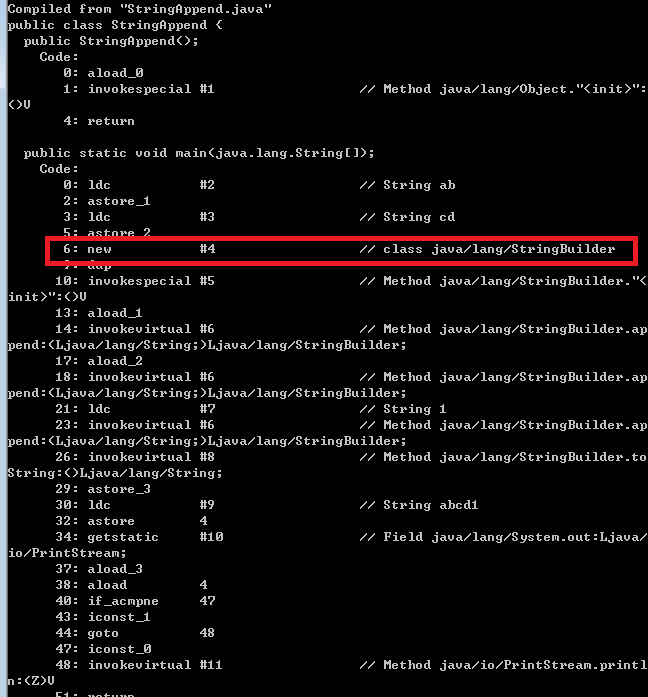
如果使用的jdk8以前版本的虚拟机,在拼接字符串时,会在jvm堆中生成StringBuilder对象,调用append方法拼接字符串,最后调用StringBuilder的toString方法在jvm堆中生成最终的字符串对象。
通过查看字节码就可以知道jdk8之前版本的"+"拼接字符串时通过StringBuilder实现的。通过查看字节码就可以知道,如下图所示:
而如果使用的是jdk9以后版本的虚拟机,则是调用虚拟机自带的InvokeDynamic拼接字符串,并且保存在堆中。字节码如下所示:
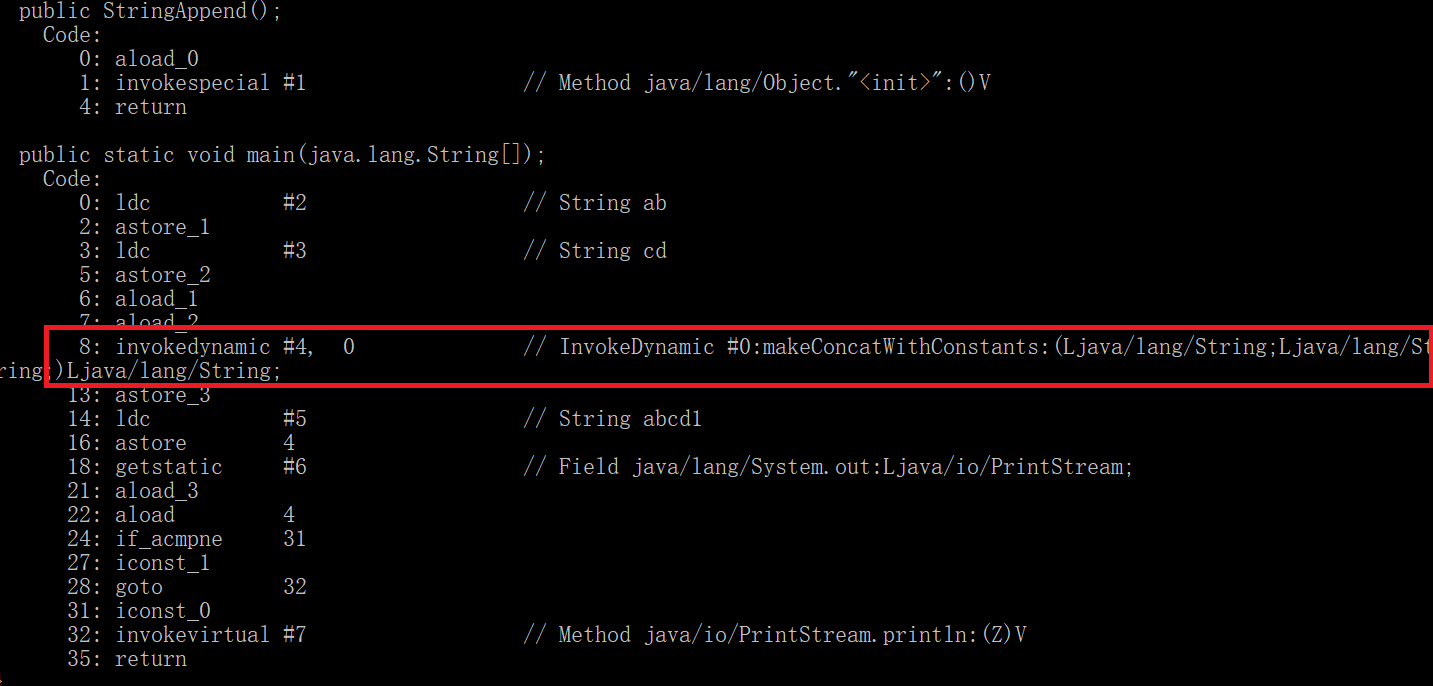
str4的对象在字符串常量池中,str5的对象在堆中,所以他们的不是同一个对象,所以返回的结果是false。
案例5:
String s5 = new String(“2”) + new String(“3”);
和案例4一样,因为new String("2")创建字符串,也是在运行时才能确定对象内存地址,和案例4一样。
案例6:
final String str1 = "b";
String str2 = "a" + str1;
String str3 = "ab";
System.out.println((str2 == str3));
上面代码执行的结果为true。
str1是常量变量,在编译期就确定,直接放入到字符串常量池中,上面的代码效果等同于:
String str2 = "a" + "b";
String str3 = "ab";
System.out.println((str2 == str3));
调用String类的intern()方法,会将堆中的字符串实例放入到字符串常量池中。
案例7:
String str2 = "ab";
String str3 = "cd";
String str4 = str2 + str3 + "1";
str4.intern();
String str5 = "abcd1";
System.out.println((str4==str5));
上面代码执行的结果:true。调用了str4.intern()方法后,将str4放入到字符串常量池中,和str5是同一个实例。
StringBuffer部分源码:
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuffer>, CharSequence
{
StringBuilder部分源码:
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuilder>, CharSequence
{
可见StringBuffer和StringBuilder都继承了AbstractStringBuilder类。
AbstractStringBuilder类源码:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
byte[] value;
AbstractStringBuilder也有一个字节数组的成员变量value,这个变量用于存储字符串的值,这个变量不是用final修饰,所以是可以改变的,这个是和String的最大区别。
在调用append方法的时候,会动态增加字节数组变量value的大小。
StringBuffer和StringBuilder功能是一样的,都是为了提高java中字符串连接的效率,因为直接使用+进行字符串连接的话,jvm会创建多个String对象,因此造成一定的开销。AbstractStringBuilder中采用一个byte数组来保存需要append的字符串,byte数组有一个初始大小,当append的字符串长度超过当前char数组容量时,则对byte数组进行动态扩展,也即重新申请一段更大的内存空间,然后将当前bute数组拷贝到新的位置,因为重新分配内存并拷贝的开销比较大,所以每次重新申请内存空间都是采用申请大于当前需要的内存空间的方式,这里是2倍。
StringBuffer和StringBuilder最大的区别是StringBuffer是线程安全,而StringBuilder是非线程安全的,从它们两个类的源码就可以知道,StringBuffer类的方法前面都是synchronized修饰符。
String一旦赋值或实例化后就不可更改,如果赋予新值将会重新开辟内存地址进行存储。
而StringBuffer和StringBuilder类使用append和insert等方法改变字符串值时只是在原有对象存储的内存地址上进行连续操作,减少了资源的开销。
总结:
1、频繁使用“+”操作拼接字符时,换成StringBuffer和StringBuilder类的append方法实现。
2、多线程环境下进行大量的拼接字符串操作使用StringBuffer,StringBuffer是线程安全的;
3、单线程环境下进行大量的拼接字符串操作使用StringBuilder,StringBuilder是线程不安全的。
作者:alunbar
出处:www.bigdata17.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
关注本人的公众号获取更多关于Java、pyhon爬虫大数据和AI方面的知识


 浙公网安备 33010602011771号
浙公网安备 33010602011771号