
JS性能优化
一般来说:运算为10^8级,花费时间为一秒。
内存管理
-
内存:由可读写单元组成,表示一片可操作
-
空间管理:人为的去操作一片空间的申请、使用和释放
-
内存管理:开发者主动申请空间、使用空间、释放空间
-
管理流程:申请―使用―释放
内存泄漏现象
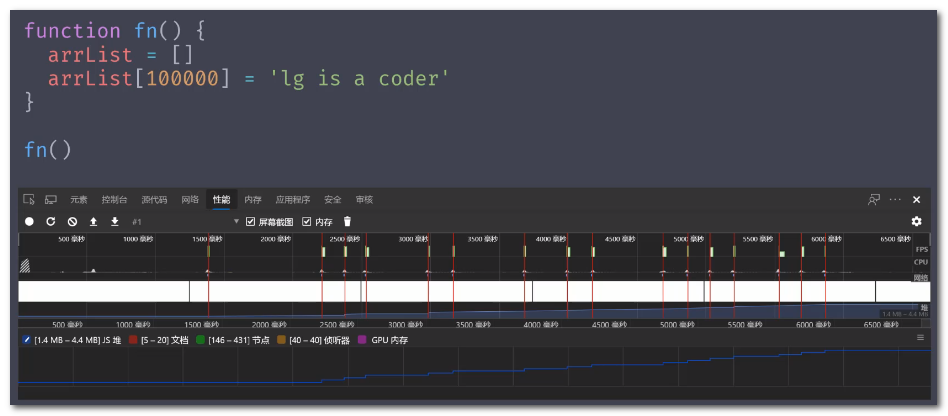
内存的泄漏:当对象持续申请初始化空间时,给予对象进行大量赋值,会造成内存持续性上升
JavaScript中的垃圾
-
JavaScript中内存管理是自动的,当对象不再被引用时被标记为垃圾
-
对象不能从根(全局)上访问到时是垃圾
JavaScript 中的可达对象
-
可以访问到的对象就是可达对象(引用、作用域链)
-
可达的标准就是从根出发是否能够被找到
-
JavaScript 中的根就可以理解为是全局变量对象
引用和可达
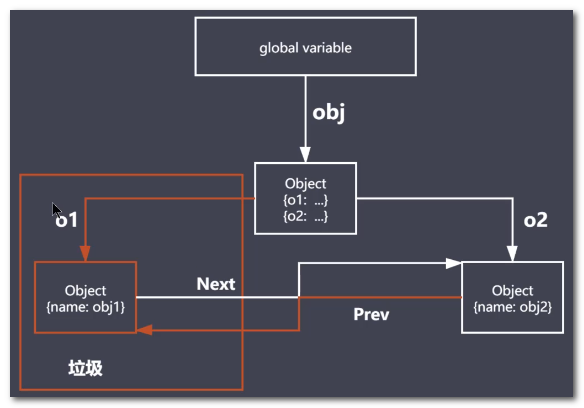
function objGroup (obj1, obj2) { obj1.next = obj2; obj2.prev = obj1; return { o1: obj1, o2: obj2 } } let object = objGroup( {name: 'obj1'}, {name: 'obj2'}
GC算法
GC触发的机制
Javascript GC机制:
概念定义:找出不再使用的变量,然后释放掉其占用的内存,但是这个过程不是实时的,因为其开销比较大,所以垃圾回收器会按照固定的时间间隔周期性的执行。
什么时候触发GC?
垃圾回收周期性运行,如果分配的内存非常多,那么回收工作也会很艰巨,确定垃圾回收时间间隔就变成了一个值得思考的问题。IE6的垃圾回收是根据内存分配量运行的,当环境中存在256个变量、4096个对象、64K的字符串任意一种情况的时候就会触发垃圾回收器工作,看起来很科学,不用按一段时间就调用一次,有时候会没必要,这样按需调用不是很好嘛?但是如果环境中就是有这么多变量一直存在,现在脚本如此复杂,很正常,那么结果就是垃圾回收器一直在工作,这样浏览器就没法玩了。
微软在IE7中做了调整,触发条件不再是固定的,而是动态修改的,初始值和IE6相同,如果垃圾回收器回收的内存分配晕低于程序占用内存的15%,说明大部分内存不可被回收,设的垃圾回收触发条件过于敏感,这时候把临界条件翻倍,如果回收的内存高于85%,说明大部分内存早就该清理了,这时候把触发条件置回。这样就使垃圾回收工作智能了很多。
总结:
-
JavaScript使用垃圾回收机制来自动管理内存,代码最终由JS引擎来完成执行,所以回收也由不同的平台决定
-
GC回收内存,这句话中的内存一般指的是存放在堆栈空间的内存(引用类型存放位置)
-
代码执行时会不断的向执行栈当中加入不同的执行上下文(函数调用)
-
某个执行上下文中的代码运行结束之后,原则上就会回收该上下文中所引用的堆内存空间(闭包例外)
-
当执行JS的引擎不同,依据不同的算法又存在不同的回收时机,总体说,回收空间时就是GC工作时

-
GC是一种机制,垃圾回收器完成具体的工作
-
工作的内容就是查找垃圾释放空间、回收空间
-
算法就是工作时查找和回收所遵循的规则
引用计数
核心思想:设置引用数,判断当前引用数是否为0
引用计数器,与其他算法性能差别的主要因素
引用关系改变时修改引用数字,引用加1,不引用时-1
引用数字为0时立即回收
总结:变量靠引用对象是否继续存储来判断是否回收
引用计数算法优点
-
发现垃圾时立即回收:时刻监控计数器为零的对象
-
最大限度减少程序暂停:当内存快要爆满时,立即找到引用为零的对象
引用计数算法缺点
-
无法回收循环引用的对象
-
时间开销大
标记清除(V8常用)
核心思想:分标记和清除二个阶段完成
-
遍历所有对象找标记活动对象:和引用、可达一样
-
遍历所有对象清除没有标记对象,顺便把1阶段的标记对象抹掉
-
回收相应空间

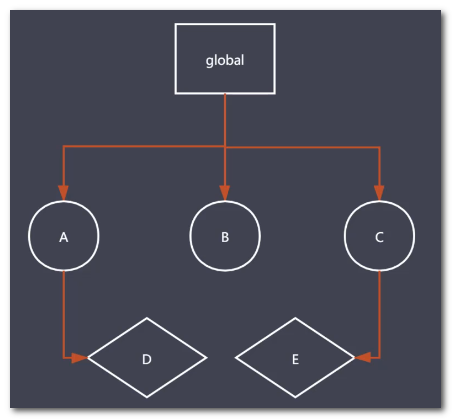
被global继续引用不会回收,进入封闭地自循环被垃圾回收
优点:
-
相对于引用计数,可以解决循环引用问题
缺点:
-
相对于引用计数,会出现空间碎片化问题,释放的空间不连续,导致后续申请空间的对象无法指定超过于在碎片中的空间
-
不会立即回收垃圾对象
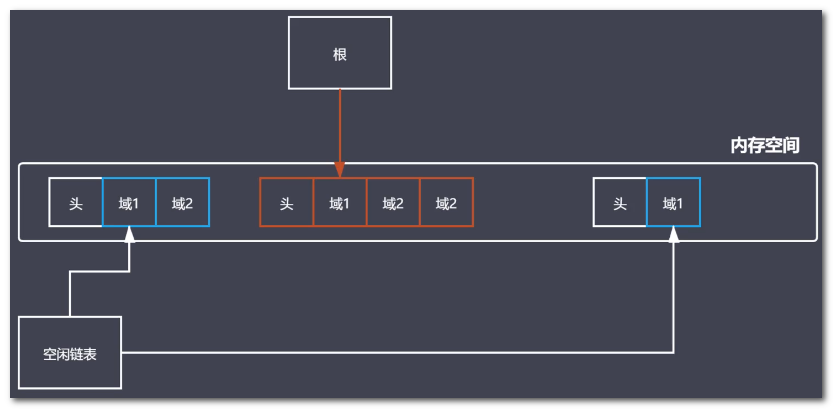
标记整理(V8常用)
标记整理可以看做是标记清除的增强
标记阶段的操作和标记清除一致
清除阶段会先执行整理,移动对象位置
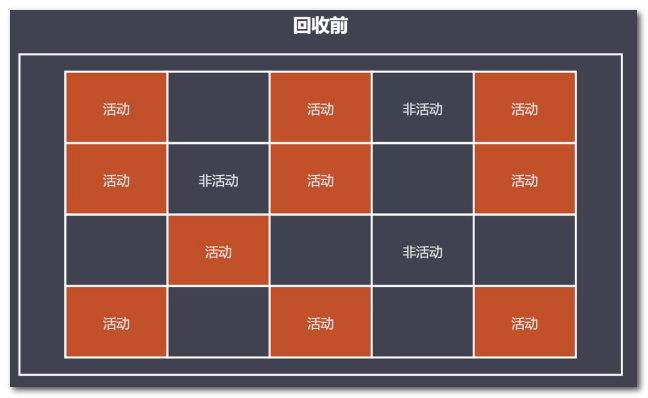
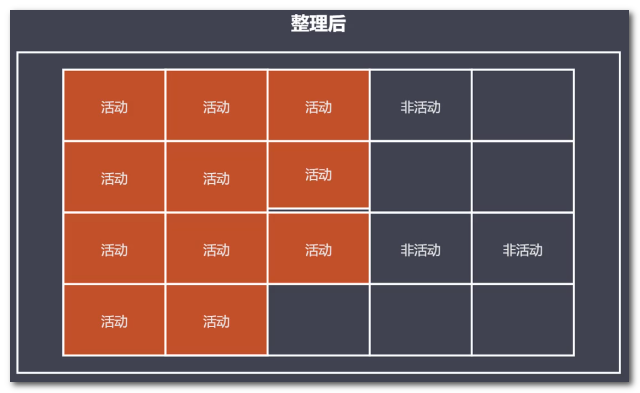
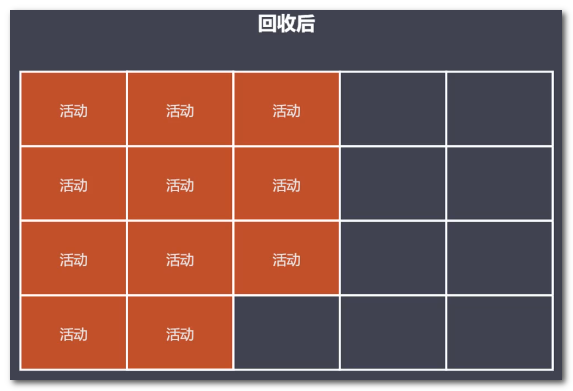
优点:减少碎片化空间
缺点:不会立即回收垃圾对象
分代回收(V8):新生代和年老代的协作
浏览器原理和V8引擎
输入URL到展示的简略过程
-
输入URI,解析主机域名,资源定位(URI解析&DNS解析/URL解析)
输入URI(统一资源标识符)后解析出协议、主机、端口、路径等信息,并构造一个HTTP请求。然后对URL进行解析,找到主机IP地址。【强缓存、协商缓存】
-
发送HTTP报文的过程
-
把HTTP的传输操作交给操作系统的协议栈【协议栈组成:TCP(需要连接)、UDP(不需要连接)、IP(传输网络包指定路由)】,在HTTP报文头加入TCP头部、IP头部和MAC头部构造请求网络包。
-
资源可靠传输TCP、主机远程定位IP、交换机两点传输MAC
-
网卡:把网络包二进制包加上报头和起始帧分界符,末尾加上用于检测错误的帧校验序列FCS,最后把二进制包转化电信号发送给交换机
-
交换机:将电信号转化为数字信号,然后根据MAC地址表查找MAC地址将信号发送到相应的端口,直到抵达路由器。
-
路由器:接收传给自己的数据包,去除MAC头部,根据路由表的网关列判断主机地址,进行发送。
-
-
TCP三次握手,建立网络连接(TCP三次握手,{[SYN],[SYN,ACK],[ACK]【一确认客户端的发送能力,确认服务端的发送能力和接收能力,确认客户端的接收能力】]})
-
客户端发送请求(发送HTTP报文GET /HTTP/1.1)
-
服务器处理响应请求,返回HTTP报文,客户端确认(服务端TCP发送ACK给客户端确认,返回Http/1.1 200 OK报文,客户端TCP发送ACK给服务器确认)
-
浏览器加载/渲染页面
-
关闭浏览器,等待一段时间后断开TCP连接
浏览器构成
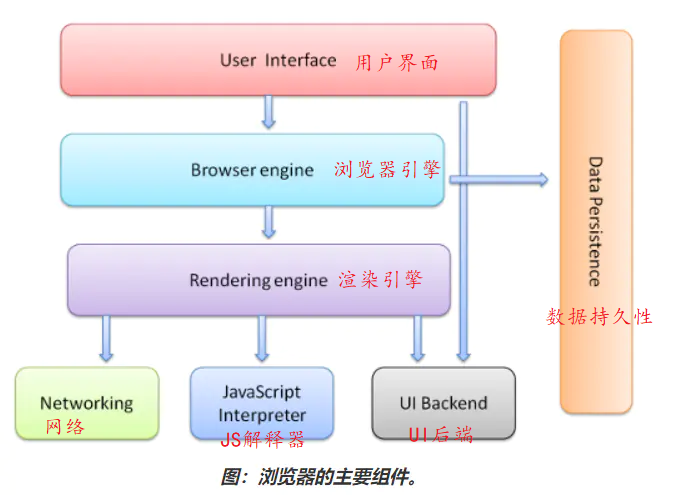
浏览器内核
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。
浏览器的内核是指支持浏览器运行的最核心的程序,分为两个部分:渲染引擎,JS的V8引擎
渲染引擎
渲染引擎:能够将HTML/CSS/JavaScript文本及相应的资源文件转换成图像结果。渲染引擎的主要作用是将资源文件转化为用户可见的结果。在浏览器的发展过程中,不同的厂商开发了不同的渲染引擎,如Tridend(IE)、Gecko(FF)、WebKit(Safari,Chrome,Andriod浏览器)等。
WebKit的大致结构

实线框内模块是所有移植的共有部分,虚线框内不同的厂商可以自己实现。
WebCore 是各个浏览器使用的共享部分,包括HTML解析器、CSS解析器、DOM和SVG等。
WebKit Ports是WebKit中的非共享部分,由于平台差异、第三方库和需求的不同等原因,不同的移植导致了
WebKit不同版本行为不一致,它是不同浏览器性能和功能差异的关键部分。
WebKit嵌入式编程接口,供浏览器调用,与移植密切相关,不同的移植有不同的接口规范。
网页渲染流程

渲染过程
-
解析HTML,生成DOM树,解析CSS,生成CSSOM树
-
将DOM树和CSSOM树结合,生成渲染树(Render Tree)
-
Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小)
-
Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
-
Display:将像素发送给GPU,展示在页面上。(这一步其实还有很多内容,比如会在GPU将多个合成层合并为同一个层,并展示在页面中。而css3硬件加速的原理则是新建合成层,这里我们不展开,之后有机会会写一篇博客)

网页渲染的三阶段
地址栏输入URL,WebKit调用资源加载器加载相应资源;
加载器依赖网络模块建立连接,发送请求并接收答复;
WebKit接收各种网页或者资源数据,其中某些资源可能同步或异步获取;
网页交给HTML解析器转变为词法;
解释器根据词法构建节点,形成DOM树;
如果节点是JavaScript代码,调用JavaScript引擎解释并执行;
JavaScript代码可能会修改DOM树结构;
如果节点依赖其他资源,如图片\css、视频等,调用资源加载器加载它们,但这些是异步加载的,不会阻碍当前DOM树继续创建;如果是JavaScript资源URL(没有标记异步方式),则需要停止当前DOM树创建,直到JavaScript加载并被JavaScript引擎执行后才继续DOM树的创建。
CSS文件被CSS解释器解释成内部表示;
CSS解释器完成工作后,在DOM树上附加样式信息,生成RenderObject树;
RenderObject节点在创建的同时,WebKit会根据网页层次结构构建RenderLayer树,同时构建一个虚拟绘图上下文。
绘图上下文是一个与平台无关的抽象类,它将每个绘图操作桥接到不同的具体实现类,也就是绘图具体实现类;
绘图实现类也可能有简单的实现,也可能有复杂的实现,软件渲染、硬件渲染、合成渲染等;
绘图实现类将2D图形库或者3D图形库绘制结果保存,交给浏览器界面进行展示。
上述是一个完整的渲染过程,现代网页很多都是动态的,随着网页与用户的交互,浏览器需要不断的重复渲染过程。
HTML和CSS渲染
解析HTMI为DOM树
html字节流变成字符
词法分析:将字符流解析为一个个词语
语法分析:通过不同的标签生成node节点
构建DOM树:将node节点组织成DOM树
解析外部CSS文件及style标签中的样式信息,得到元素最匹配的样式:
1)经过词法分析和语法分析,生成一个CSS规则
2)进行规则匹配
渲染树结构
生成RenderObject树:由DOM树构建RenderObject树,并将CSS得到的元素匹配样式存入到RenderObject树中
布局渲染树
根据RenderObject中的样式属性,计算根据框模型,计算布局
绘制渲染树
先绘制元素背景,然后是浮动,最后是前景。最终得到用户可见区域(ViewPort)的内存表示
页面加载过程中HTML,CSS,JavaScript加载顺序
通常页面的加载速度会受HTML,CSS ,JS 的影响
-
浏览器接收到HTML模板文件,开始从上到下解析HTML
-
遇到样式表文件style.css,这时候浏览器停止解析HTML,接着去请求CSS文件
-
服务端返回CSS文件,浏览器开始解析CSS文件
-
浏览器解析完CSS,继续往下解析HTML,碰到DOM节点,解析DOM
-
浏览器发现img,向服务器发送请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码
-
服务器返回图片文件,由于图片占据了一定的面积,影响了页面排布,因此浏览器需要回过头来重新渲染这部分代码
reflow(重排/回流):当浏览器发现页面中某个部分发生了点变化影响了布局,需要倒回去重新渲染,这个过程为reflow。改变元素的几何信息(元素在视口内的位置和 尺寸大小),浏览器重新计算元素在视口内几何信息的过程叫重排。
repaint(重绘):改变某个元素的背景色,字体颜色,边框颜色等等不会影响布局的时候,屏幕的一部分呢需要重画,但是元素的布局不会发生变化。经过了重排,浏览器知道了节点的几何信息,可以将渲染树的每个节点转换维屏幕上实际的像素,这个阶段叫重绘。
-
碰到脚本文件,这时停止所有的加载与解析,去请求脚本文件,并执行脚本
-
加载完所有的HTML,CSS,JS后,页面就出现在屏幕上了
渲染引擎会尽可能早的将内容呈现到屏幕上,并不会等到所有的html解析完后才去构建和布局render树。它是解析完一部分就下载一部分,同时还可能在下载别的内容
如何减少重排和重绘
-
最小化重绘和重排:样式集中重绘,使用.class和cassText一次性更改替换全部样式。
-
缓存操作DOM
-
使元素脱离文档流
-
开启GPU,使用tranform、translate移动
-
使用tranform代替top
-
使用visibility替换display:none
-
不要把节点属性值放在一个循环中当成循环变量
-
不使用table布局
-
实现动画的选择,动画速度越快,回流速度越多,使用requestAnimationFrame
-
CSS选择符从右向左匹配查找,避免节点层级过多
-
将频繁重绘或回流的节点设置为图层,图层能够阻止当前页面渲染的行为影响到别的节点(使用will-change,video、iframe标签)
思考
在如何不考虑缓存和优化协议的情况下,如何提高页面的渲染速度?
当发生DOMContentLoaded事件后,就会生成渲染树,生成渲染树就可以进行渲染节点了。
提高渲染速度需要考虑到的点
-
文件的大小
-
script标签的使用
-
HTML和CSS的写法来考虑
-
从下载内容是否需要在首屏上使用来考虑
如何提高渲染速度
-
发生渲染的前提是生成渲染树,首先降低初始时需要进行渲染的文件大小,并且扁平层级,优化选择器,避免HTML和CS阻塞渲染。
-
尽量减少页面频繁的发生重绘和回流
-
把script标签放在body标签底部,这是因为浏览器在解析script标签时,会暂停构建DOM,完成后才会从暂停的地方从新开始(想首屏渲染越快,就越不能在首屏加载的地方加载js文件)
-
避免直接操作DOM
-
采用虚拟DOM:当页面需要发生更改时首先在虚拟DOM中进行对比,如果节点发生改变,则更新原来的虚拟DOM树
-
使用requestAnimationFrame方式去循环的插入DOM
-
采用虚拟滚动
-
如何测量渲染有没有加速呢
查看浏览器页面的加载速度来判断渲染有没有加速
关于CSS阻塞和JS阻塞
1.CSS会阻塞渲染吗?
从浏览器的渲染原理来看,渲染引擎会将css构建成CSSOM Tree然后再去渲染页面,也就是说css会阻塞页面的渲染。
但是css不会阻塞页面的解析,因为需要具有DOM以及CSSOM才会构建渲染树
2.JS会阻塞渲染吗?
加载或执行js代码时,会阻塞构建DOM树,只有等到js执行完毕,浏览器才会继续解析DOM。
没有DOM树,浏览器就无法渲染,所以当加载很大的JS文件时,可以看到页面很长时间时一片空白。
这是因为在加载js的过程中会操作DOM节点,这些操作会对DOM树产生影响,如果不阻塞,等浏览器解析完标签生成DOM树后,JS修改了某些节点,那么浏览器又得重新解析,然后重新生成DOM树,耗费性能。
3.解决JS阻塞DOM树生成
defer 和 async 都是作用于外链JS的。对内部JS是没有效果的。
defer 和 async 都是异步的,主要的区别在于执行的顺序以及执行的时间
async 标志的脚本文件一旦加载完成后就会立即执行,并且不会按照书写顺序,谁下载好了就直接执行。所以适应于那些没有代码依赖顺序,并且没有DOM操作的脚本文件
defer 标志的脚本文件会严格按照书写顺序去执行,并且会在页面DOM加载完成时执行,适用于有DOM操作,或者是有代码依赖顺序的脚本文件。
V8引擎
-
V8是一款主流的JavaScript执行引擎
-
V8采用即时编译:将源码直接翻译成可执行的机器码
-
V8内存设限:64位不超过1.5G;32位不超过800M
V8垃圾回收策略
-
采用分代回收的思想
-
内存分为新生代、老生代
-
针对不同对象采用不同算法
策略:分代回收、空间复制、标记清除、标记整理和标记增量
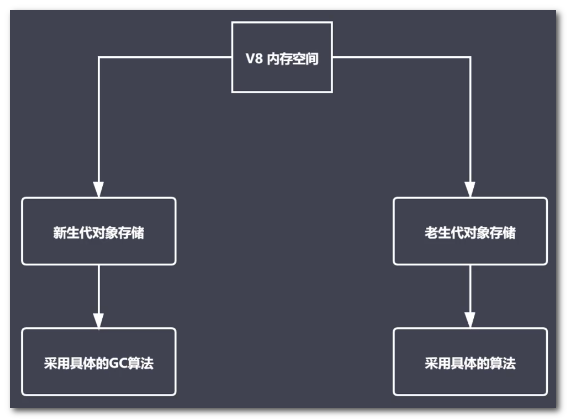
V8内存分配
-
V8内存空间一分为二
-
小空间用于存储新生代对象 64位和32位(32M|16M)
-
新生代指的是存活时间较短的对象
新生代对象回收实现
-
回收过程采用复制算法+标记整理
-
新生代内存区分为二个等大小空间
-
使用空间为From,空闲空间为To
-
活动对象存储于From空间
-
标记整理后将活动对象拷贝至To
-
From与To交换空间完成释放
回收细节说明
-
拷贝过程中可能出现晋升
-
晋升就是将新生代对象移动至老生代
-
一轮GC还存活的新生代需要晋升
-
To空间的使用率超过25%
老年代对象说明
-
老年代对象存放在右侧老生代区域
-
64位操作系统1.4G,32操作系统700M·
-
老年代对象就是指存活时间较长的对象
老年代对象回收实现
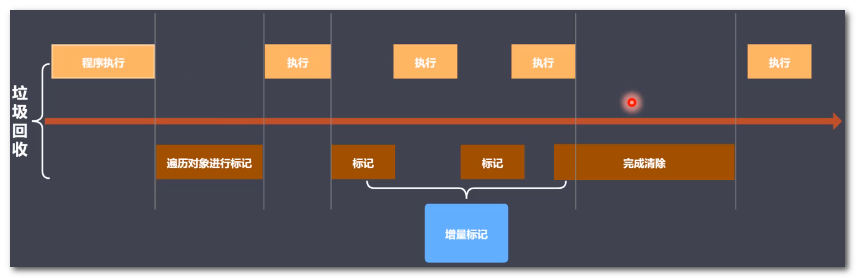
-
主要采用标记清除、标记整理、增量标记算法
-
首先使用标记清除完成垃圾空间的回收
-
采用标记整理进行空间优化,新生往老年代晋升时空间不足时,触发该机制
-
采用增量标记进行效率优化,把以前一次性执行标记,再清除拆成小部分进行
新老回收细节对比
-
新生代区域垃圾回收使用空间换时间,分配空间较小,可容忍空闲空间消耗
-
老生代区域垃圾回收不适合复制算法,因为老生内存大,放置对象存储多,进行复制操作,太消耗时间
内存问题的体现
-
页面出现延迟加载或经常性暂停:底层伴随着大量的垃圾回收出现,存在一些代码会让内存瞬间爆掉
-
页面持续性出现糟糕的性能:可能存在着内存膨胀,渲染页面请求的内存空间超过了当前设备所能提供的大小
-
页面的性能随时间延长越来越差:内存泄漏,内存随着时间越来越少
-
使用Performance监控内存空间,分析内存情况
监控内存的几种方式
内存泄露:内存使用持续升高,内存升高没有下降
内存膨胀:在多数设备上都存在性能问题,要判断是设备问题还是程序的问题
频繁垃圾回收:通过内存变化图进行分析
监控内存的几种方式
浏览器任务管理器:内存用来判断DOM节点的操作大小,js内存用来判断代码执行的情况
Timeline时序图记录内存:结合脚本进行判断
堆快照查找分离DOM(Heap snapshot)
-
界面元素存活在DOM树上
-
垃圾对象时的 DOM节点
-
分离状态的 DOM节点
使用浏览器Momory,拍摄快照,筛选deta,查看Dom有无用节点是否在浏览器中留存的情况
判断是否存在频繁的垃圾回收
-
GC工作时应用程序是停止的
-
频繁且过长的GC会导致应用假死
-
用户使用中感知应用卡顿
频繁垃圾回收现象
-
Timeline中频繁的上升下降
-
任务管理器中数据频繁的增加减小
引用计数属于一种计算方法,整体来说属于GC工作流程中的一个环节
-
GC是垃圾回收的简称,表示—件程序执行过程中要完成的事情
-
引用计数是完成这件事情的一种统计方法。用于统计哪些内容属于“垃圾”
-
引用计数发现某个变量引用数为0之后认定它是“垃圾",GC机制开始工作,回收它占用的空间
对于“标记整理"和“标记清除"算法,是否一次遍历即可标记所有可达对象?(递归遍历多次)
-
—次遍历不一定找到所有的可达对象
-
对象之间存在互相引用或者对象本身存在“子引用”
增量标记:整合标记清除和标记整理,分段处理垃圾,而不一次性清理。
视频中说老生代GC主要使用"标记清除"算法,什么时候进行内存整理?什么时候使用增量标记?
1.上面观点中已经认为增量标记是在“标记清除"和“标记整理”二个算法基础之上。
2.增量标记可以看做是V8引擎本身最终采用的一种优化后的GC算法,所以认为最终使用的都是增量标记
3.增量标记工作过程中需要用到的就是标记清除,增量标记主要是对于时间调度的制定
8)视频中并没有对""复制算法""作详细解释,这是一个在总结中出现的新词汇,非常欠解释
1.复制算法可以从常见的“GC算法"来记忆,和语言或者平台没有关系
2.复制算法的工作方式在新生代对象回牧时说明,就是将内存一分为二,然后把A空间内做垃圾回收
9)常见内存问题时的举例都是为了举例而举例如a[1000000],举点实际开发中用的例子。
推荐一篇文章,里面描述了很多关于实际开发过程中JavaScript 内容泄漏的问题:https://zhuanlan.zhihu.com/p/60538328,
后台管理前端切换菜单中的页面后,堆内存只增不减
vue中响应式数据,如果有很多响应式数据,减少响应式数据 o Object.freeze
V8引擎执行流程
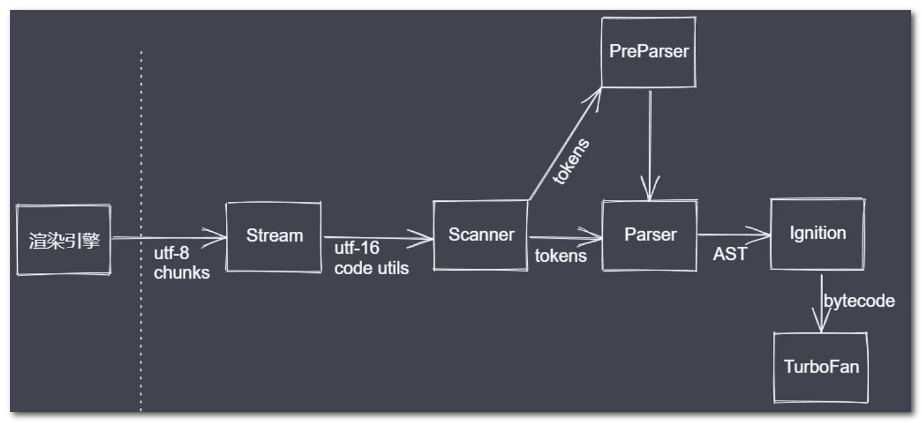

-
Blink:会将下载好的源码交给V8引擎
-
Stream:获取到源码并进行编码转换
-
Scanner是一个扫描器:对于纯文本的js代码进行词法分析(lexical analysis),词法分析会将代码转换成tokens
-
Parser是一个解析器:把词法分析的结果tokens进行语法分析,将tokens转成AST树结构。在分析中还进行语法校验,如果有错误进行抛出。
-
进行解析可以分两种情况:直接用Parser进行全量解析或执行PerParser预解析
-
PerParser预解析:当代码中存在一些声明,但后面又不用使用到(函数没有被调用到)
预解析(PreParser)
-
跳过未被使用的代码
-
不生成AST(抽象语法树),创建无变量引用和声明的scopes
-
依据规范抛出特定错误
-
解析速度更快
为什么要进行预解析
-
因为并不是所有的JavaScript代码在一开始就会被执行, 如果一开始就对所有的代码进行解析,必然会影响网页的运行效率。
-
所以V8引擎就实现了Lazy Parsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行。
全量解析(Parser)
-
解析被使用的代码
-
生成AST
-
构建具体scopes信息,变量引用、声明等
-
抛出所有语法错误
//声明时未调用,因此会被认为是不被执行的代码,进行预解析
function foo() {
console.log( 'foo' )
}
//声明时未调用,因此会被认为是不被执行的代码,进行预解析
function fn(){}
//函数立即执行,只进行一次全量解析
(function bar() {
})()
//执行foo,那么需要重新对foo 函数进行全量解析,此时foo函数被解析了两次
foo()//嵌套层级太深的话会导致多次解析操作
Ignition是V8提供的一个解释器:把之前AST转变为bytecode(字节码),同时还收集为下一阶段所需要的信息,如行内的js代码中的函数会被保存在解释器环境。
TurboFan是V8提供的编译器模块:把之前得到信息和字节码编译汇编码,开始堆栈执行过程
堆栈操作
准备阶段
-
JS执行环境:最初执行代码会在内存开辟一个空间
-
执行环境栈(ECStack, execution context stack)
-
执行上下文:划分空间,隔离变量
-
VO(G),全局变量对象:全局变量存取
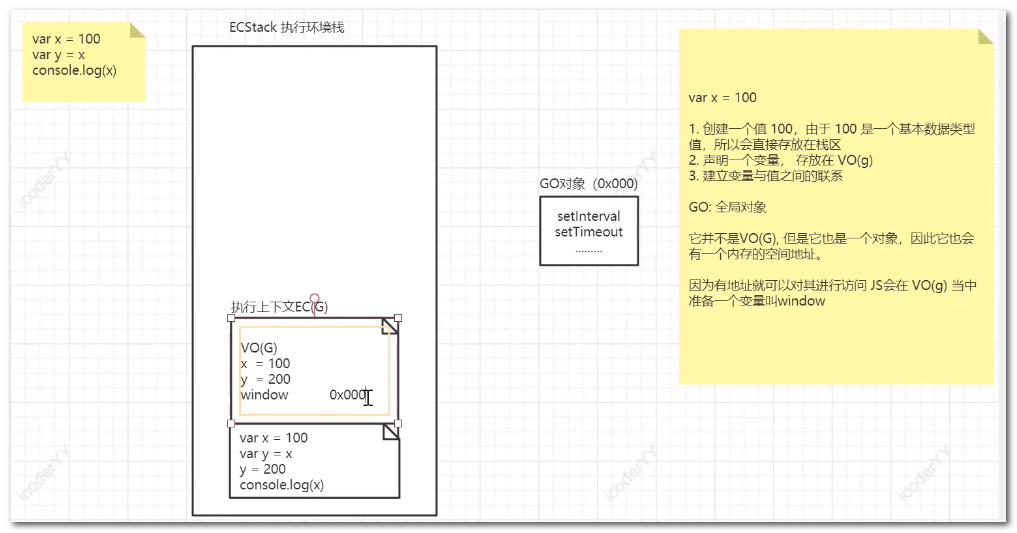
01基本数据类型是按值进行操作
02基本数据类型值是存放在栈区的
03无论我们当前看到的栈内存,还是后续引用数据类型会使用的堆内存都属于计算机内存
04 GO() window全局对象
引用类型堆栈处理
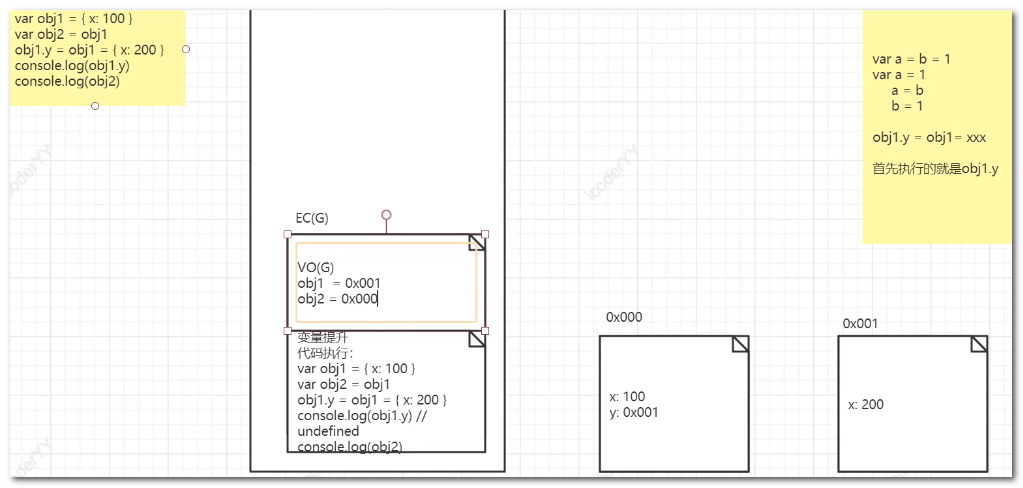
由于obj1.y的运算优先级比较高,首先执行 obj1.y
函数类型堆栈处理
01函数创建
--可以将函数名称看做是变量,存放在VO当中,同时它的值就是当前函数对应的内存地址
--函数本身也是一个对象,创建时会有一个内存地址,空间内存放的就是函数体代码(字符串形式的)
02函数执行
--函数执行时会形成一个全新私有上下文,它里面有一个AO用于管理这个上下文当中的变量
--步骤:
-
01作用域链<当前丸行上下文,上级作用域所在的执行上下文>
-
02确定this
-
03初始化arguments(对象)
-
04形参赋值:它就相当于是变量声明,然后将声明的变量放置于A005变量提升
-
06代码执行
闭包类型堆栈处理
-
闭包:是一种机制:
-
保护:当前上下文当中的变量与其它的上下文中变量互不干扰
-
保存:当前上下文中的数据(堆内存)被当前上下文以外的上下文中的变量所引用,这个数据就保存下来
-
函数调用形成了一个全新的私有上下文,在函数调用之后当前上下文不被释放就是闭包(临时不被释放)
闭包与垃圾处理
-
浏览器都自有垃圾回收(内存管理,V8)
-
栈空间、堆空间
-
堆:当前堆内存如果被占用,就能释放掉,但如果确定后续不再使用这个内存的数据,就可以主动置空,然后浏览器就会对其进行回收
-
栈:当前上下文中是否有内容,被其他上下问的变量所占用,如果有则无法释放(闭包)
优化性能
-
大多数优化是以空间换时间,所以要考虑选那个指标,两者一般不可兼得。
循环添加事件的四种方法
1 var btn = document.querySelectorAll('button'); 2 //1 使用闭包进行循环,要主动在后面不用时,赋值null,才不会造成内存占用,浪费空间 3 for(var i = 0; btn.length; i++){ 4 (function (i){ 5 btn[i].onclick = function(){ 6 console.log(i) 7 } 8 })(i); 9 } 10 btn = null; 11 //2 12 for(var i = 0; btn.length; i++){ 13 btn[i].onclick = (function (){ 14 console.log(i); 15 })(i); 16 } 17 //3 18 for(let i = 0; btn.length; i++){ 19 btn[i].onclick = function (){ 20 console.log(i); 21 }; 22 } 23 //4 自定义属性存储 不会在点击后开辟额外的堆来存储属性,比闭包节约内存空间 24 for(var i = 0; btn.length; i++){ 25 btn[i].index = i; 26 btn[i].onclick = function (){ 27 console.log(this.index); 28 } 29 } 30 //事件委托,进行访问储存,查找作用域链的深浅,完全不用开辟堆来存储对象 31 <button index='1'>btn1<button> 32 <button index='2'>btn2<button> 33 <button index='3'>btn3<button> 34 document.body.onclick = function (ev) [ 35 var target = ev.target, 36 targetDom = target.tagName 37 if( targetDom === 'BUTTON') { 38 var index = target.getAttribute('index'); 39 console.log(index); 40 } 41 ]
循环添加事件时:使用闭包是一种便捷编程方式,但在循环中使用过程中要注意在闭包结束时,把上下文变量的引用赋值为null,主动释放空间。使用自定义属性替代闭包时,可以在之前获取button开辟的堆中,设置属性,不用在点击时额外开辟堆来存储对象,比闭包节约些空间。使用事件委托时,完全不用为每个button开辟堆存储,进行访问时,可以靠作用域链的深浅来储存对象,是循环添加事件的最优选择方案。
JSBench.me在线工具,可用来测试JS执行效率,更多的只看一下大概时间,不用过分关注。
变量局部化:减少声明和语句数
当变量可以放在私有的作用域时,尽量放在上面,这样可以节约数据访问时查找的路径,提高执行效率。
1 //数据的存储和读取 2 var i, str = ""//全局变量 3 function packageDom( ) { 4 for (i = 0; i < 1000; i++){ 5 str += i 6 } 7 } 8 packageDom() 9 //使用局部变量,代码执行速度比全局变量快 10 function packageDom( ) { 11 let str = ''//局部变量 12 for (let i = 0; i< 1000; i++){ 13 str += i 14 } 15 } 16 packageDom()
因为使用var定义全局变量时,由于私有上下文的隔离,每次循环都要根据作用域链,往上找EC(G),需要查找较多路径。局部变量,进行变量提升到当前私有上下文AO对象作用域中,可直接找到。
缓存数据:作用域链查找变快
1 //假设在当前的函数体当中需要对 className 的值进行多次使用,那么我们就可以将它提前缓存起来 2 var oBox = document.getElementById('skip'); 3 function hasclassName(ele,cls) { 4 // console.log(ele.lassName); 5 return ele.className == cls 6 } 7 // console.log(hasclassName(oBox,'skip')) 8 //进行缓存 9 function hasclassName( ele, cls) { 10 var clsName = ele.className//缓存 11 // console.log(className); 12 return clsName =cls 13 } 14 console.log(hasclassName( oBox,'skip ' )) //多次调用时,进行缓存,可提高效率
减少访问层级
1 function Person() { 2 this.name = 'icoder' 3 this.age = 18 4 this.getAge = function() { 5 return this.age 6 } 7 } 8 9 const p1 = new Person() 10 const a = p1.getAge() 11 //减少访问层 12 function Person() { 13 this.name = 'icoder' 14 this.age = 18 15 } 16 const p2 = new Person() 17 const b = p2.age
减少判断层级
1 function doSomething (part, chapter) { 2 const parts = ['ES2016', '工程化', 'Vue', 'React', 'Node'] 3 if (part) { 4 if (parts.includes(part)) { 5 console.log('属于当前课程') 6 if (chapter > 5) { 7 console.log('您需要提供 VIP 身份') 8 } 9 } 10 } else { 11 console.log('请确认模块信息') 12 } 13 } 14 15 doSomething('ES2016', 6) 16 function doSomething (part, chapter) { 17 const parts = ['ES2016', '工程化', 'Vue', 'React', 'Node'] 18 if (!part) { 19 console.log('请确认模块信息') 20 return 21 } 22 if (!parts.includes(part)) return 23 console.log('属于当前课程') 24 if (chapter > 5) { 25 console.log('您需要提供 VIP 身份') 26 } 27 } 28 29 doSomething('ES2016', 6)
减少循环体活动
1 var test = () => { 2 var i 3 var arr = ['zce', 38, '我为前端而活'] 4 for(i=0; i<arr.length; i++) { 5 console.log(arr[i]) 6 } 7 } 8 //优化1 把要进行判断的代码缓存起来,减少调用 9 var test = () => { 10 var i 11 var arr = ['zce', 38, '我为前端而活'] 12 var len = arr.length 13 for(i=0; i<len; i++) { 14 console.log(arr[i]) 15 } 16 } 17 18 //优化2 从后往前,减少判断 19 var test = () => { 20 var arr = ['zce', 38, '我为前端而活'] 21 var len = arr.length 22 while(len--) { 23 console.log(arr[len]) 24 } 25 } 26 test()
字面量与构造式
1 //引用类型构造式 2 let test = () => { 3 let obj = new Object() 4 obj.name = 'zce' 5 obj.age = 38 6 obj.slogan = '我为前端而活' 7 return obj 8 } 9 //优化 引用类型字面量 直接赋值 10 let test = () => { 11 let obj = { 12 name: 'zce', 13 age: 38, 14 slogan : '我为前端而活' 15 } 16 return obj 17 } 18 console.log(test()) 19 //基本类型构造式 20 var str2 = new String('zce说我为前端而活') 21 //基本类型字面量 22 var str1 = 'zce说我为前端而活'
采用字面量创建变量比new对象耗时更低。引用类型差别不大,基本类型差别较大,更推荐基本类型进行使用字面量创建变量。
防抖与节流
在一些高频率事件触发的场景下我们不希望对应的事件处理函数多次执行场景;
-
滚动事件:输入的模糊匹配轮播图切换点击操作,浏览器默认情况下都会有自己的监听事件间隔(4~6ms),如果检测到多次事件的监听执行,那么就会造成不必要的资源浪费
-
前置的场景:界面上有一个按钮,可以连续多次点击,而不频繁触发事件

debounce (防抖):
1 function debounce(fn, delay){ 2 let timer = null; 3 return function(){ 4 clearTimeout(timer); 5 timer = setTimeout(()=>{ 6 fn.apply(this, arguments); 7 }, delay); 8 } 9 }
throttle(节流):
1 function throttle(fn, delay) { 2 let stateValve = true; 3 return function(){ 4 if(stateValve){ 5 setTimeout(()=>{ 6 fn.apply(this, arguments); 7 stateValve = true; 8 }, delay); 9 stateValve = false; 10 } 11 } 12 }
图片优化
DNS预解析 <link rel="dns-prefetch" href="//..">
预加载 <link rel="preload" href="//.."> 强制浏览器请求资源,不会阻塞onload事件,兼容性不好
预渲染 <link rel="prerender" href="//..">将下载的文件预先在后台进行渲染
懒执行 通过定时器或事件调用来唤醒,将某些逻辑延迟到需要使用时再计算
懒加载 将不关键的资源延后加载,先将需要延迟的图片src设置占位符,等进入特定区域时将自定义属性替换成src目标路径。
CDN 原理:尽可能在各个地方分布机房缓存数据。将静态资源尽量使用CDN加载(浏览器对单个域名有并发请求上限,考虑使用多个CDN域名)
浏览器缓存
缓存位置
-
Service Worker 浏览器内置的一个工作线程,可以用来设计缓存时间
-
Memory Cache 内存缓存
-
Disk Cache 磁盘缓存
-
Push Cache session中存在的缓存
-
网络请求 请求资源
缓存策略
强缓存(Expires,Cache-Control)
指定客端缓存存在的期限,当缓存过期时才主动向服务端发送请求更新资源
协商缓存([Last-Modified,If-Modified-Since],[E-Tag,If-None-Match])
服务端对缓存的二次校验,根据对比客户端缓存和服务端资源,来判断客户端缓存是否需要进行更新。
实际运用
如果对于频繁发生变动的资源,可以把Cache-Control设置为no-control,然后配合ETag或者Last-Modified来验证资源是否有效。
JS语法全局机制
预处理:
-
JS引擎执行代码前,会对脚本、模块和函数体中的语句进行预处理。
-
预处理过程提前处理var、函数声明、class、const和let语句,确定变量的含义
-
var的作用域可以穿透除脚本、模块和函数体作用域的一切语句结构
1 var a = 2; 2 //一个语句 3 function foo() { 4 var o = {a:3} 5 with(o) { 6 var a = 1; 7 } 8 console.log(a);//undefined 9 console.log(o.a);//1 10 } 11 foo();
-
在预处理阶段,var穿透with作用域,创建了a这个变量,没有赋值
-
在执行阶段,当执行到var a =1时,作用域变成了with,这时a被认为访问到对象o的属性a执行 o.a = 1
-
解决var引入了立即执行函数来产生作用域,约束var的穿透
-
function作用域类似于var,但不同的是在于function声明会产生变量,还会进行赋值
1 console.log(foo)//foo 2 function foo (){}
function在if语句中,预处理阶段仍会产生变量,但不被提前赋值
1 console.log(foo);//undefined 2 if(true){function foo(){}}
function在预处理时,穿透作用域,产生变量,在执行阶段,发生赋值行为
class在预处理时,也会穿透作用域,在作用域中创建变量,并要求在访问它时抛出错误,但不会穿透if等判断语句,只有在全局环境时,才会有作用域声明
1 var a = 1; 2 function () { 3 console.log(a);//报错 4 class c {};//除去该语句,正常打印 1 5 }
指令序言(DIrective Prologs):
脚本和模块都支持一种特别的语法,最早是为use strict严格模式设计的,规定js添加元信息的方式
1 'use strict';//指令序言要写在最前 2 function foo() { 3 console.log(this);//打印null 4 } 5 foo.call(null);//去掉严格模式时,打印global对象
JS的语法
语句
-
规则遵循一般编程语言的“语句”-“表达式”的规则,分成了声明和语句两种类别
-
声明型语句有var 、let、const、class和函数声明(function、asyn、generator和async generator函数)其余为普通声明语句。
左值表达式
-
PrimaryExpression主要表达式(直接量):任何表达式加入圆括号,都被认为主要表达式,优先级最高。
"abc"; flase; null; ({}); (function(){}); (calss{}); []; /abc/g; -
MemberExpression成员表达式:通常用于访问对象成员
-
new.target新加入语法,用来判断函数是否new被调用
-
super.b是构造函数中,用来访问父类的属性方法
-
-
NewExpression NEW表达式:由成员表达式加上new
1 class Cls { 2 constructor (a){ 3 console.log('This first Cls:', a);//This first Cls: 1 4 return class { 5 constructor (b) { 6 console.log('This second Cls:',b);//This first Cls: undefined 7 } 8 } 9 } 10 } 11 new new Cls(1);//等价于 new (new Cls(1));
-
CallExpression 函数调用表达式:由成员表达式后加上一个括号的参数表达式或用super关键字代替成员表达式
a.b(c); super(); a.b(c)(d)(e); a.b(c)[3]; a.b(c).d; a.b(c)`xyz`;
-
LeftHandSideExpression 左值表达式: 可以放到等号左边的表达式,NEW表达和Call表达式是左值表达式
a() = b; a().c = b;
用来提供返回引用类型的函数
-
AssignmentExpression 赋值表达式:等号赋值,尽量避免连续赋值
a = b; a += b; a = b = c = d//右结合 等级于 a = ((b = )c = d)
-
Expressin 表达式:使用逗号进行运算符连接的表达式,优先级最低,尽量避免使用
-
export后只能跟赋值表达式,就是表达式中不能含有逗号
-
a = b, b = 1, null;//整个表达式变量的值为后面null的值
右值表达式
-
UpdateExpression 更新表达式: 前后自增和前后自减四种
-
UnaryExpression 一元运算表达式:更新表达式搭配一元运算符
delete a.b; void a; typeof a; - a; ~ a; ! a; await a; -
ExponentiatioinExpression 乘法运算表达式: 由更新表达式使用**构成
++i ** 30; 4 ** 3 ** 2;//等价于 4 ** (3 ** 2)使用 -2 ** 30 会报错,要加括号
-
MultiplicativeExpression 乘法表达式:乘号、除号或取余运算符连接
-
AdditiveExpreesion 加法表达式:加减号运算符连接
-
FhiftExpression 移位表达式: <<左移 >>右移 >>>无符号向右移
-
RelationalExpression 关系表达式: <、>、<=、>=、in和instanceof
-
EqualityExpression 等号表达式: ==、!=等
==运算三条规则:
undefined和null相等
字符串和bool都转换化位数字再比较
对象转化为primitive类型再比较
-
位运算表达式: & ^ |
-
逻辑与或表达式: || &&
-
ConditionalExpression条件表达式: 三目运算符:?
| 表达式 | 优先级 |
|---|---|
| PrimaryExpression 主要表达式 | 1 |
| MemberedExpression 成员表达式 | 2 |
| NewExpression NEW表达式 | 3 |
| CallExpression 函数回调表达式 | 4 |
| LeftHandSideExpression 左表达式 | |
| AssignmentExpression 等号赋值表达式 | 7 |
| Expression 逗号表达式 |
