一 背景
1 什么是雪崩效应
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,因此可能出现某个基础服务不可用而造成整个系统不可用的情况,这种现象被称为雪崩效应。
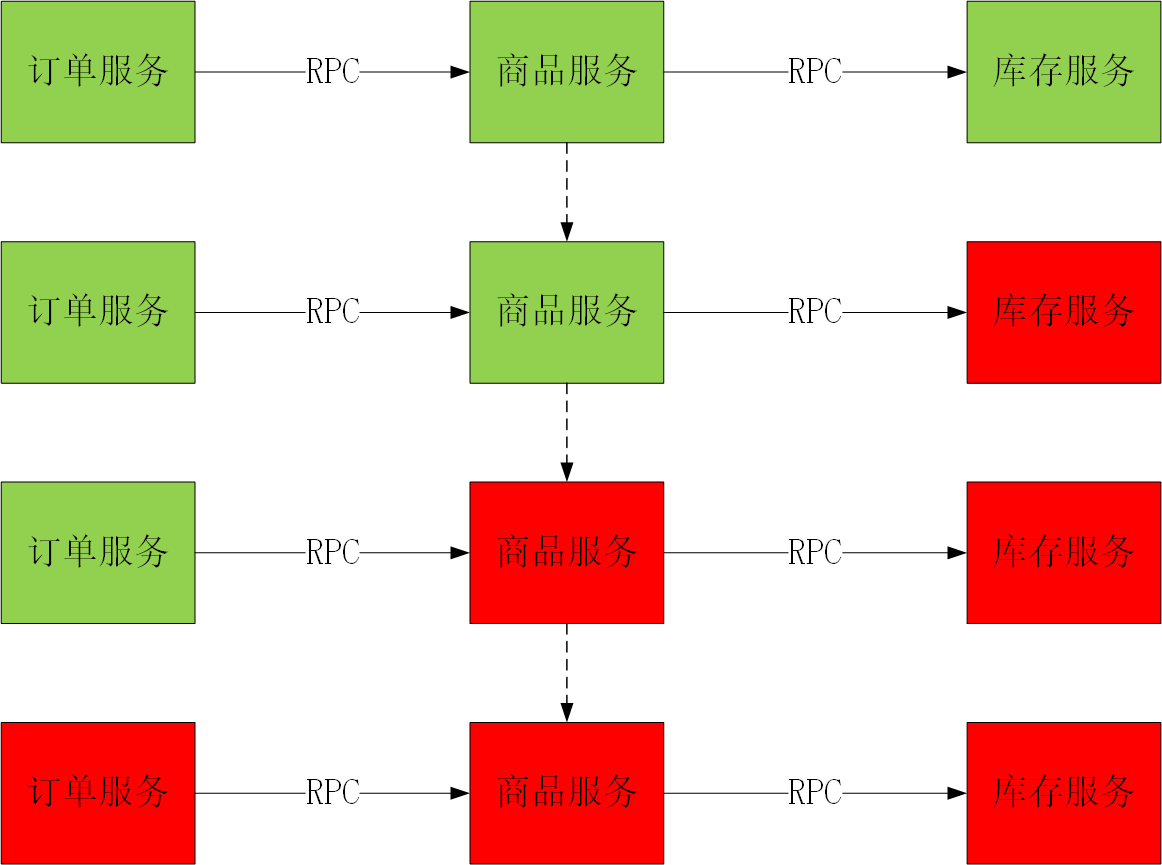
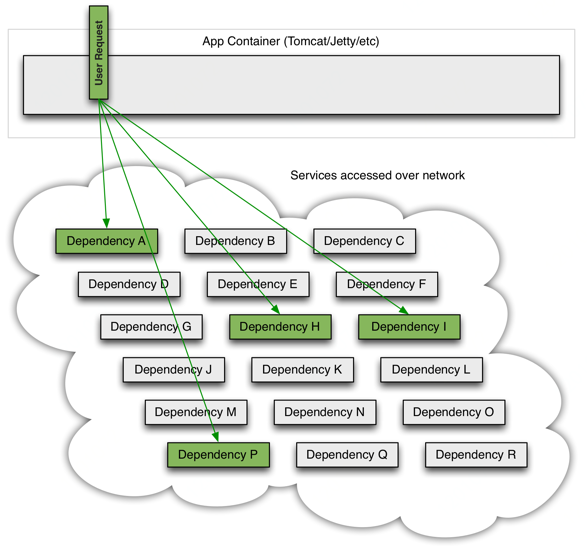
当所有的服务都是正常的时候,服务之间的请求情况可能是如下所示:
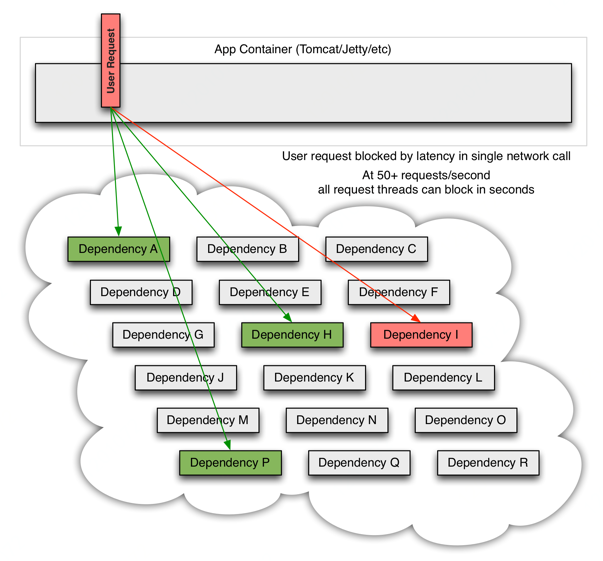
当其中一个服务不可用时,可能会导致整个用户请求的阻塞:
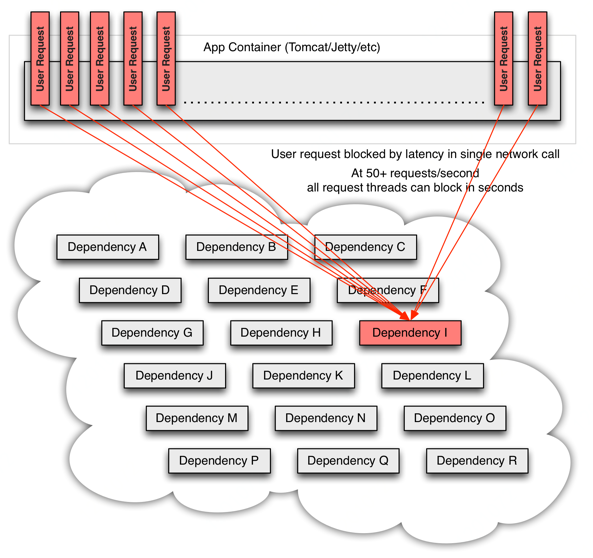
最终可能会导致所有的用户请求阻塞,导致上层服务不可用:
2 雪崩效应形成的原因
把服务雪崩的参与者简化为 服务提供者 和 服务调用者, 并将服务雪崩产生的过程分为以下三个阶段来分析形成的原因:1. 服务提供者不可用,2. 重试加大流量,3. 服务调用者不可用。每个阶段都可能由不同的原因造成的:
1. 服务提供者不可用 的原因有:
硬件故障:硬件故障可能为硬件损坏造成的服务器主机宕机,网络硬件故障造成的服务提供者的不可访问。
程序Bug:如程序逻辑导致内存泄漏,JVM长时间FullGC等。
缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时。大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用.
用户大量请求:在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用.
2. 重试加大流量 的原因有:
用户重试:在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单.
代码逻辑重试:服务调用端的会存在大量服务异常后的重试逻辑.
这些重试都会进一步加大请求流量.
3. 服务调用者不可用 产生的主要原因是:
同步等待造成的资源耗尽:当服务调用者使用 同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
雪崩效应常见场景
- 硬件故障:如服务器宕机,机房断电,光纤被挖断等。
- 流量激增:如异常流量,重试加大流量等。
- 缓存穿透:一般发生在应用重启,所有缓存失效时,以及短时间内大量缓存失效时。大量的缓存不命中,使请求直击后端服务,造成服务提供者超负荷运行,引起服务不可用。
- 程序BUG:如程序逻辑导致内存泄漏,JVM长时间FullGC等。
- 同步等待:服务间采用同步调用模式,同步等待造成的资源耗尽。
3 服务雪崩的应对策略
针对造成服务雪崩的不同原因, 可以使用不同的应对策略:1. 流量控制,2. 改进缓存模式,3. 服务自动扩容,4. 服务调用者降级服务
1. 流量控制 的具体措施包括:
网关限流:因为Nginx的高性能, 目前一线互联网公司大量采用Nginx+Lua的网关进行流量控制, 由此而来的OpenResty也越来越热门.
用户交互限流:用户交互限流的具体措施有: 1. 采用加载动画,提高用户的忍耐等待时间。 2. 提交按钮添加强制等待时间机制。
关闭重试
2. 改进缓存模式 的措施包括:
缓存预加载
同步改为异步刷新
3. 服务自动扩容 的措施主要有:
AWS的auto scaling
4. 服务调用者降级服务 的措施包括:
资源隔离:资源隔离主要是对调用服务的线程池进行隔离。
对依赖服务进行分类:我们根据具体业务,将依赖服务分为: 强依赖和弱依赖。强依赖服务不可用会导致当前业务中止,而弱依赖服务的不可用不会导致当前业务的中止。
不可用服务的调用快速失败:不可用服务的调用快速失败一般通过 超时机制,熔断器 和熔断后的 降级方法 来实现。
针对造成雪崩效应的不同场景,可以使用不同的应对策略,参考如下:
- 硬件故障:多机房容灾、异地多活等。
- 流量激增:服务自动扩容、流量控制(限流、关闭重试)等。
- 缓存穿透:缓存预加载、缓存异步加载等。
- 程序BUG:修改程序bug、及时释放资源等。
- 同步等待:资源隔离、MQ解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
综上所述,如果一个应用不能对来自依赖的故障进行隔离,那该应用本身就处在被拖垮的风险中。 因此,为了构建稳定、可靠的分布式系统,我们的服务应当具有自我保护能力,当依赖服务不可用时,当前服务启动自我保护功能,从而避免发生雪崩效应。本文将重点介绍使用Hystrix解决同步等待的雪崩问题。
二 使用Hystrix预防服务雪崩
1 Hystrix介绍
Hystrix是Netflix开源的一款容错框架,具有自我保护能力。为了实现容错和自我保护,下面我们看看Hystrix如何设计和实现的。
Hystrix设计目标:
1. 对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的。
2. 阻止故障的连锁反应。
3. 快速失败并迅速恢复。
4. 回退并优雅降级。
5. 提供近实时的监控与告警。
Hystrix遵循的设计原则:
1. 防止任何单独的依赖耗尽资源(线程)
2. 过载立即切断并快速失败,防止排队
3. 尽可能提供回退以保护用户免受故障
4. 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
5. 通过近实时的指标,监控和告警,确保故障被及时发现
6. 通过动态修改配置属性,确保故障及时恢复
7. 防止整个依赖客户端执行失败,而不仅仅是网络通信
Hystrix如何实现这些设计目标?
1. 使用命令模式将所有对外部服务(或依赖关系)的调用包装在HystrixCommand或HystrixObservableCommand对象中,并将该对象放在单独的线程中执行;
2. 每个依赖都维护着一个线程池(或信号量),线程池被耗尽则拒绝请求(而不是让请求排队)。即线程隔离。
3. 记录请求成功,失败,超时和线程拒绝。
4. 服务错误百分比超过了阈值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。
5. 请求失败,被拒绝,超时或熔断时执行降级逻辑。
6. 近实时地监控指标和配置的修改。
Hystrix解决服务雪崩的原理:
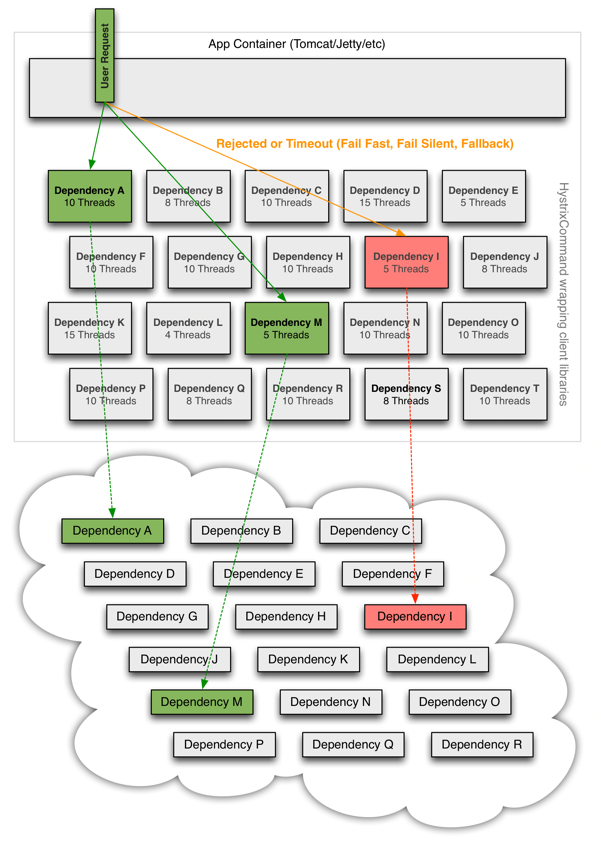
2 Hystrix简单入门
开始深入Hystrix原理之前,我们先简单看一个示例。
第一步,继承HystrixCommand实现自己的command,在command的构造方法中需要配置请求被执行需要的参数,并组合实际发送请求的对象,代码如下:
public class MyHystrixCommand extends HystrixCommand<List<User>> { private final static Logger logger = LoggerFactory.getLogger(MyHystrixCommand.class); private UserService userService; private static int count = 0; public MyHystrixCommand(UserService userService) { super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("userService")) .andCommandKey(HystrixCommandKey.Factory.asKey("queryByOrderId")) .andCommandPropertiesDefaults(HystrixCommandProperties.Setter() .withCircuitBreakerRequestVolumeThreshold(10)//至少有10个请求,熔断器才进行错误率的计算 .withCircuitBreakerSleepWindowInMilliseconds(5000)//熔断器中断请求5秒后会进入半打开状态,放部分流量过去重试 .withCircuitBreakerErrorThresholdPercentage(50)//错误率达到50开启熔断保护 .withExecutionTimeoutEnabled(true)) .andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter().withCoreSize(10)));//服务线程池数量 this.userService = userService; } @Override protected List<User> run() throws Exception { logger.info("执行方法抛异常count = " + count++); throw new Exception("Hystrix抛异常"); } @Override protected List<User> getFallback() { logger.info("快速失败方法count = " + count); return new ArrayList<>(); } }
第二步,调用HystrixCommand的执行方法发起实际请求。
@RunWith(SpringRunner.class) @SpringBootTest @Slf4j public class SpringTests { @Autowired UserService userService; @Test public void testQueryByOrderIdCommand() { for (int i =0;i<1000 ;i++){ List<User> r = new MyHystrixCommand(userService).execute(); log.info("result:{}", r); } } }
输出结果如下:

可以看出,执行失败后调用了getFallback,并且失败次数达到一定比例后,便不再执行run()方法,而是直接执行getFallback()方法,即发生了熔断。
3 Hystrix处理流程
1. 命令模式
从上面的示例代码可以看出,Hystrix使用命令模式(继承HystrixCommand类)来包裹具体的服务调用逻辑(run方法),并在命令模式中添加了服务调用失败后的降级逻辑(getFallback)。同时我们在Command的构造方法中可以定义当前服务线程池和熔断器的相关参数。在使用了Command模式构建了服务对象之后,服务便拥有了熔断器和线程池的功能。

2. Hystrix内部处理逻辑

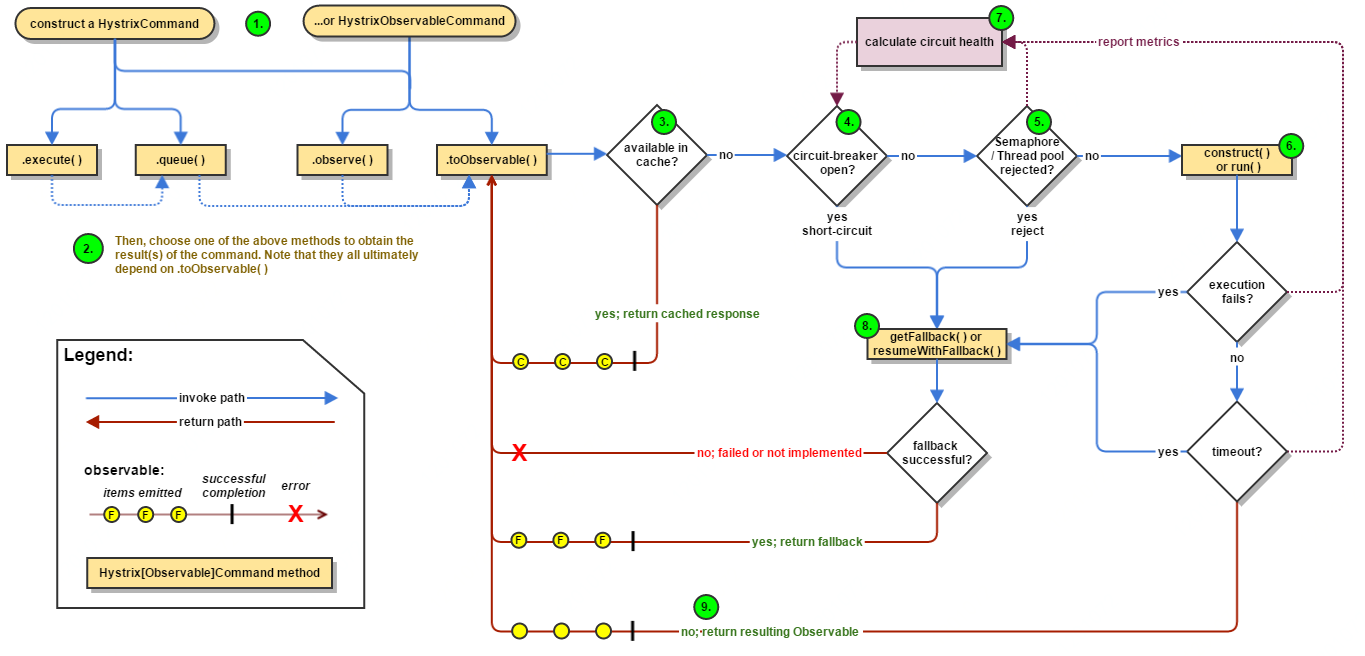
1. 构造一个 HystrixCommand或HystrixObservableCommand对象,用于封装请求,并在构造方法配置请求被执行需要的参数;
2. 执行命令,Hystrix提供了4种执行命令的方法,后面详述;
3. 判断是否使用缓存响应请求,若启用了缓存,且缓存可用,直接使用缓存响应请求。Hystrix支持请求缓存,但需要用户自定义启动;
4. 判断熔断器是否打开,如果打开,跳到第8步;
5. 判断线程池/队列/信号量是否已满,已满则跳到第8步;
6. 执行HystrixObservableCommand.construct()或HystrixCommand.run(),如果执行失败或者超时,跳到第8步;否则,跳到第9步;
7. 统计熔断器监控指标;
8. 走Fallback备用逻辑,, 并将执行结果上报Metrics更新服务健康状况。
9. 返回请求响应
4 Hystrix执行命令的几种方法
Hystrix提供了4种执行命令的方法,execute()和queue() 适用于HystrixCommand对象,而observe()和toObservable()适用于HystrixObservableCommand对象。
1. execute()
以同步阻塞方式执行HystrixCommand的run()方法,只支持接收一个值对象。hystrix会从线程池中取一个线程来执行run(),并等待返回值。
2. queue()
以异步非阻塞方式执行run(),只支持接收一个值对象。调用queue()就直接返回一个Future对象。可通过 Future.get()拿到run()的返回结果,但Future.get()是阻塞执行的。若执行成功,Future.get()返回单个返回值。当执行失败时,如果没有重写fallback,Future.get()抛出异常。
3. observe()
事件注册前执行run()/construct(),支持接收多个值对象,取决于发射源。调用observe()会返回一个hot Observable,也就是说,调用observe()自动触发执行run()/construct(),无论是否存在订阅者。
如果继承的是HystrixCommand,hystrix会从线程池中取一个线程以非阻塞方式执行run();如果继承的是HystrixObservableCommand,将以调用线程阻塞执行construct()。
observe()使用方法:
调用observe()会返回一个Observable对象
调用这个Observable对象的subscribe()方法完成事件注册,从而获取结果
4. toObservable()
事件注册后执行run()/construct(),支持接收多个值对象,取决于发射源。调用toObservable()会返回一个cold Observable,也就是说,调用toObservable()不会立即触发执行run()/construct(),必须有订阅者订阅Observable时才会执行。
如果继承的是HystrixCommand,hystrix会从线程池中取一个线程以非阻塞方式执行run(),调用线程不必等待run();如果继承的是HystrixObservableCommand,将以调用线程堵塞执行construct(),调用线程需等待construct()执行完才能继续往下走。
toObservable()使用方法:
调用observe()会返回一个Observable对象
调用这个Observable对象的subscribe()方法完成事件注册,从而获取结果
需注意的是,HystrixCommand也支持toObservable()和observe(),但是即使将HystrixCommand转换成Observable,它也只能发射一个值对象。只有HystrixObservableCommand才支持发射多个值对象。
几种方法的关系
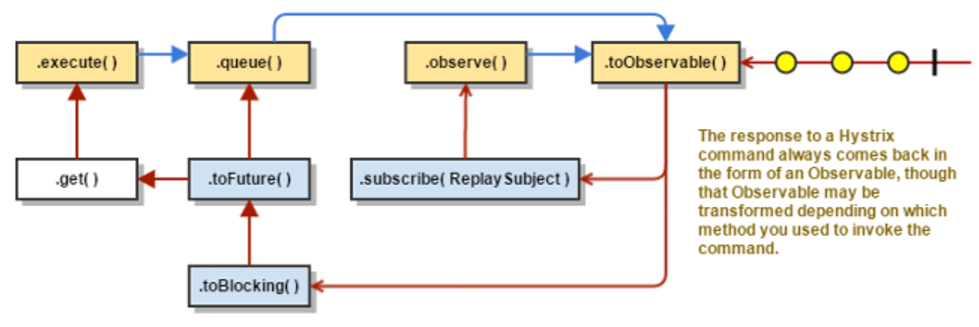
execute()实际是调用了queue().get()
queue()实际调用了toObservable().toBlocking().toFuture()
observe()实际调用toObservable()获得一个cold Observable,再创建一个ReplaySubject对象订阅Observable,将源Observable转化为hot Observable。因此调用observe()会自动触发执行run()/construct()。
Hystrix总是以Observable的形式作为响应返回,不同执行命令的方法只是进行了相应的转换。
三 Hystrix容错
Hystrix的容错主要是通过添加容许延迟和容错方法,帮助控制这些分布式服务之间的交互。 还通过隔离服务之间的访问点,阻止它们之间的级联故障以及提供回退选项来实现这一点,从而提高系统的整体弹性。Hystrix主要提供了以下几种容错方法:1. 资源隔离,2. 熔断,3. 降级。
1 资源隔离
资源隔离主要指对线程的隔离。Hystrix提供了两种线程隔离方式:线程池和信号量。
1. 线程隔离 - 线程池
Hystrix通过命令模式对发送请求的对象和执行请求的对象进行解耦,将不同类型的业务请求封装为对应的命令请求。如订单服务查询商品,查询商品请求->商品Command;商品服务查询库存,查询库存请求->库存Command。并且为每个类型的Command配置一个线程池,当第一次创建Command时,根据配置创建一个线程池,并放入ConcurrentHashMap,如商品Command:
final static ConcurrentHashMap<String, HystrixThreadPool> threadPools = new ConcurrentHashMap<String, HystrixThreadPool>(); ... if (!threadPools.containsKey(key)) { threadPools.put(key, new HystrixThreadPoolDefault(threadPoolKey, propertiesBuilder)); }
后续查询商品的请求创建Command时,将会重用已创建的线程池。线程池隔离之后的服务依赖关系:

通过将发送请求线程与执行请求的线程分离,可有效防止发生级联故障。当线程池或请求队列饱和时,Hystrix将拒绝服务,使得请求线程可以快速失败,从而避免依赖问题扩散。
线程池隔离优缺点
优点:
1. 保护应用程序以免受来自依赖故障的影响,指定依赖线程池饱和不会影响应用程序的其余部分。
2. 当引入新客户端lib时,即使发生问题,也是在本lib中,并不会影响到其他内容。
3. 当依赖从故障恢复正常时,应用程序会立即恢复正常的性能。
4. 当应用程序一些配置参数错误时,线程池的运行状况会很快检测到这一点(通过增加错误,延迟,超时,拒绝等),同时可以通过动态属性进行实时纠正错误的参数配置。
5. 如果服务的性能有变化,需要实时调整,比如增加或者减少超时时间,更改重试次数,可以通过线程池指标动态属性修改,而且不会影响到其他调用请求。
6. 除了隔离优势外,hystrix拥有专门的线程池可提供内置的并发功能,使得可以在同步调用之上构建异步门面(外观模式),为异步编程提供了支持(Hystrix引入了Rxjava异步框架)。
注意:尽管线程池提供了线程隔离,我们的客户端底层代码也必须要有超时设置或响应线程中断,不能无限制的阻塞以致线程池一直饱和。
缺点:
线程池的主要缺点是增加了计算开销。每个命令的执行都在单独的线程完成,增加了排队、调度和上下文切换的开销。因此,要使用Hystrix,就必须接受它带来的开销,以换取它所提供的好处。
通常情况下,线程池引入的开销足够小,不会有重大的成本或性能影响。但对于一些访问延迟极低的服务,如只依赖内存缓存,线程池引入的开销就比较明显了,这时候使用线程池隔离技术就不适合了,我们需要考虑更轻量级的方式,如信号量隔离。
2. 线程隔离 - 信号量
上面提到了线程池隔离的缺点,当依赖延迟极低的服务时,线程池隔离技术引入的开销超过了它所带来的好处。这时候可以使用信号量隔离技术来代替,通过设置信号量来限制对任何给定依赖的并发调用量。下图说明了线程池隔离和信号量隔离的主要区别:
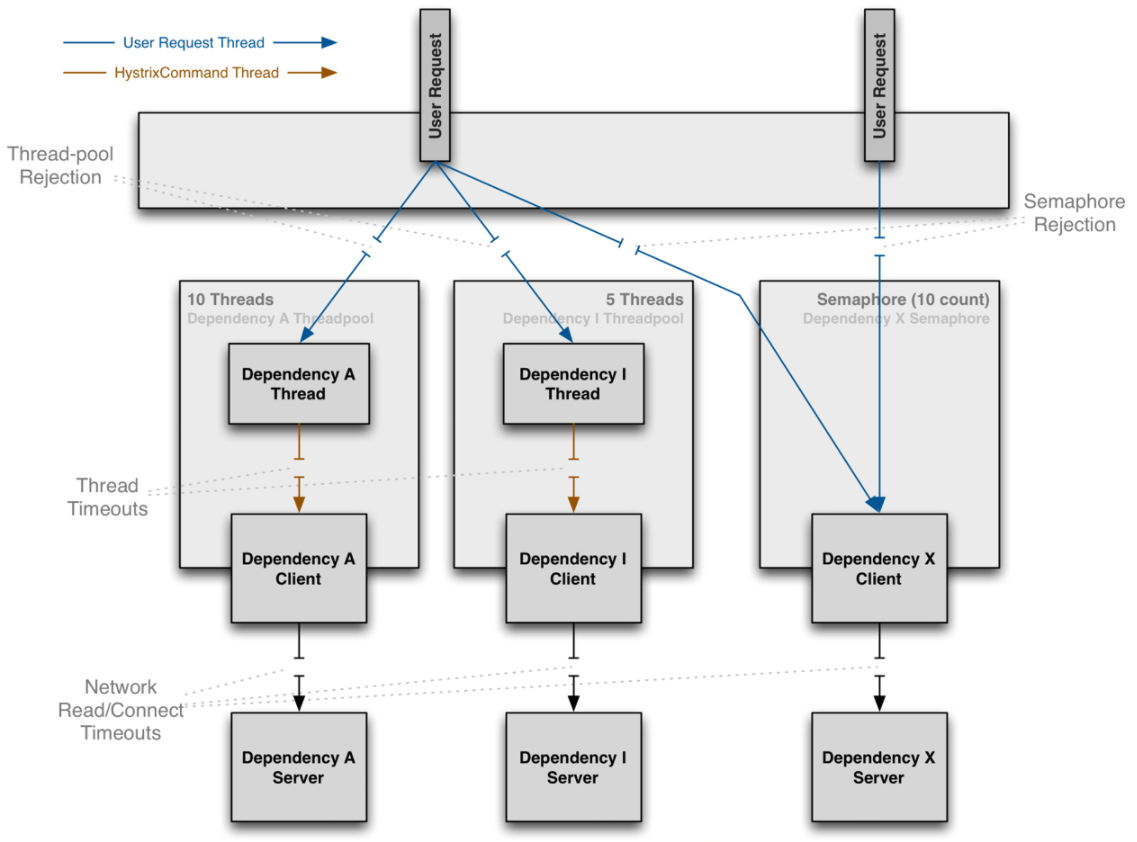
使用线程池时,发送请求的线程和执行依赖服务的线程不是同一个,而使用信号量时,发送请求的线程和执行依赖服务的线程是同一个,都是发起请求的线程。先看一个使用信号量隔离线程的示例:
public class MyHystrixCommandSemaphore extends HystrixCommand<List> { private final static Logger logger = LoggerFactory.getLogger(MyHystrixCommandSemaphore.class); private UserService userService; public MyHystrixCommandSemaphore(UserService userService) { super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("orderService")) .andCommandKey(HystrixCommandKey.Factory.asKey("queryByOrderId")) .andCommandPropertiesDefaults(HystrixCommandProperties.Setter() .withCircuitBreakerRequestVolumeThreshold(10)////至少有10个请求,熔断器才进行错误率的计算 .withCircuitBreakerSleepWindowInMilliseconds(5000)//熔断器中断请求5秒后会进入半打开状态,放部分流量过去重试 .withCircuitBreakerErrorThresholdPercentage(50)//错误率达到50开启熔断保护 .withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.SEMAPHORE) .withExecutionIsolationSemaphoreMaxConcurrentRequests(10)));//最大并发请求量 this.userService = userService; } @Override protected List<User> run() { return userService.findUserByProc(""); } @Override protected List getFallback() { return new ArrayList(); } }
由于Hystrix默认使用线程池做线程隔离,使用信号量隔离需要显示地将属性execution.isolation.strategy设置为ExecutionIsolationStrategy.SEMAPHORE,同时配置信号量个数,默认为10。
客户端需向依赖服务发起请求时,首先要获取一个信号量才能真正发起调用,由于信号量的数量有限,当并发请求量超过信号量个数时,后续的请求都会直接拒绝,进入fallback流程。
信号量隔离主要是通过控制并发请求量,防止请求线程大面积阻塞,从而达到限流和防止雪崩的目的。
3. 线程隔离总结
线程池和信号量都可以做线程隔离,但各有各的优缺点和支持的场景,对比如下:
| 线程切换 | 支持异步 | 支持超时 | 支持熔断 | 限流 | 开销 | |
| 信号量 | 否 | 否 | 否 | 是 | 是 | 小 |
| 线程池 | 是 | 是 | 是 | 是 | 是 | 大 |
线程池和信号量都支持熔断和限流。相比线程池,信号量不需要线程切换,因此避免了不必要的开销。但是信号量不支持异步,也不支持超时,也就是说当所请求的服务不可用时,信号量会控制超过限制的请求立即返回,但是已经持有信号量的线程只能等待服务响应或从超时中返回,即可能出现长时间等待。线程池模式下,当超过指定时间未响应的服务,Hystrix会通过响应中断的方式通知线程立即结束并返回。
2 熔断
1. 熔断器简介
现实生活中,可能大家都有注意到家庭电路中通常会安装一个保险盒,当负载过载时,保险盒中的保险丝会自动熔断,以保护电路及家里的各种电器,这就是熔断器的一个常见例子。Hystrix中的熔断器(Circuit Breaker)也是起类似作用,Hystrix在运行过程中会向每个commandKey对应的熔断器报告成功、失败、超时和拒绝的状态,熔断器维护并统计这些数据,并根据这些统计信息来决策熔断开关是否打开。如果打开,熔断后续请求,快速返回。隔一段时间(默认是5s)之后熔断器尝试半开,放入一部分流量请求进来,相当于对依赖服务进行一次健康检查,如果请求成功,熔断器关闭。
2. 熔断器配置
Circuit Breaker主要包括如下6个参数:
(1)circuitBreaker.enabled
是否启用熔断器,默认是TRUE。
(2)circuitBreaker.forceOpen
熔断器强制打开,始终保持打开状态,不关注熔断开关的实际状态。默认值FLASE。
(3)circuitBreaker.forceClosed
熔断器强制关闭,始终保持关闭状态,不关注熔断开关的实际状态。默认值FLASE。
(4)circuitBreaker.errorThresholdPercentage
错误率,默认值50%,例如一段时间(10s)内有100个请求,其中有54个超时或者异常,那么这段时间内的错误率是54%,大于了默认值50%,这种情况下会触发熔断器打开。
(5)circuitBreaker.requestVolumeThreshold
默认值20。含义是一段时间内至少有20个请求才进行errorThresholdPercentage计算。比如一段时间了有19个请求,且这些请求全部失败了,错误率是100%,但熔断器不会打开,总请求数不满足20。
(6)circuitBreaker.sleepWindowInMilliseconds
半开状态试探睡眠时间,默认值5000ms。如:当熔断器开启5000ms之后,会尝试放过去一部分流量进行试探,确定依赖服务是否恢复。
3. 熔断器工作原理
下图展示了HystrixCircuitBreaker的工作原理:

熔断器工作的详细过程如下:
第一步,调用allowRequest()判断是否允许将请求提交到线程池
(1)如果熔断器强制打开,circuitBreaker.forceOpen为true,不允许放行,返回。
(2)如果熔断器强制关闭,circuitBreaker.forceClosed为true,允许放行。此外不必关注熔断器实际状态,也就是说熔断器仍然会维护统计数据和开关状态,只是不生效而已。
第二步,调用isOpen()判断熔断器开关是否打开
(1)如果熔断器开关打开,进入第三步,否则继续;
(2)如果一个周期内总的请求数小于circuitBreaker.requestVolumeThreshold的值,允许请求放行,否则继续;
(3)如果一个周期内错误率小于circuitBreaker.errorThresholdPercentage的值,允许请求放行。否则,打开熔断器开关,进入第三步。
第三步,调用allowSingleTest()判断是否允许单个请求通行,检查依赖服务是否恢复
(1)如果熔断器打开,且距离熔断器打开的时间或上一次试探请求放行的时间超过circuitBreaker.sleepWindowInMilliseconds的值时,熔断器器进入半开状态,允许放行一个试探请求;否则,不允许放行。
此外,为了提供决策依据,每个熔断器默认维护了10个bucket,每秒一个bucket,当新的bucket被创建时,最旧的bucket会被抛弃。其中每个blucket维护了请求成功、失败、超时、拒绝的计数器,Hystrix负责收集并统计这些计数器。

服务的健康状况 = 请求失败数 / 请求总数。熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的。熔断器的开关能保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待。并且熔断器能在一段时间后继续侦测请求执行结果, 提供恢复服务调用的可能。
3 回退降级
1. 降级情况
降级,通常指务高峰期,为了保证核心服务正常运行,需要停掉一些不太重要的业务,或者某些服务不可用时,执行备用逻辑从故障服务中快速失败或快速返回,以保障主体业务不受影响。Hystrix提供的降级主要是为了容错,保证当前服务不受依赖服务故障的影响,从而提高服务的健壮性。要支持回退或降级处理,可以重写HystrixCommand的getFallBack方法或HystrixObservableCommand的resumeWithFallback方法。
Hystrix在以下几种情况下会走降级逻辑:
(1)执行construct()或run()抛出异常
(2)熔断器打开导致命令短路
(3)命令的线程池和队列或信号量的容量超额,命令被拒绝
(4)命令执行超时
2. 降级回退方式
(1)Fail Fast快速失败
快速失败是最普通的命令执行方法,命令没有重写降级逻辑。 如果命令执行发生任何类型的故障,它将直接抛出异常。
(2)Fail Silent 无声失败
指在降级方法中通过返回null,空Map,空List或其他类似的响应来完成。
@Override protected Integer getFallback() { return null; } @Override protected List<Integer> getFallback() { return Collections.emptyList(); } @Override protected Observable<Integer> resumeWithFallback() { return Observable.empty(); }
(3)Fallback: Static
指在降级方法中返回静态默认值。 这不会导致服务以“无声失败”的方式被删除,而是导致默认行为发生。如:应用根据命令执行返回true / false执行相应逻辑,但命令执行失败,则默认为true
@Override protected Boolean getFallback() { return true; } @Override protected Observable<Boolean> resumeWithFallback() { return Observable.just( true ); }
四 Hystrix Metrics(衡量指标)的实现
Hystrix的Metrics中保存了当前服务的健康状况,包括服务调用总次数和服务调用失败次数等。根据Metrics的计数,熔断器从而能计算出当前服务的调用失败率,用来和设定的阈值比较从而决定熔断器的状态切换逻辑。因此Metrics的实现非常重要。
1 1.4之前的滑动窗口实现
Hystrix在这些版本中的使用自己定义的滑动窗口数据结构来记录当前时间窗的各种事件(成功、失败、超时、线程池拒绝等)的计数。事件产生时,数据结构根据当前时间确定使用旧桶还是创建新桶来计数,并在桶中对计数器经行修改。这些修改是多线程并发执行的,代码中有不少加锁操作,逻辑较为复杂。

2 1.5之后的滑动窗口实现
Hystrix在这些版本中开始使用RxJava的Observable.window()实现滑动窗口。RxJava的window使用后台线程创建新桶,避免了并发创建桶的问题。同时RxJava的单线程无锁特性也保证了计数变更时的线程安全,从而使代码更加简洁。以下为我使用RxJava的window方法实现的一个简易滑动窗口Metrics, 短短几行代码便能完成统计功能,足以证明RxJava的强大:
@Test public void timeWindowTest() throws Exception{ Observable<Integer> source = Observable.interval(50, TimeUnit.MILLISECONDS).map(i -> RandomUtils.nextInt(2)); source.window(1, TimeUnit.SECONDS).subscribe(window -> { int[] metrics = new int[2]; window.subscribe(i -> metrics[i]++, InternalObservableUtils.ERROR_NOT_IMPLEMENTED, () -> System.out.println("窗口Metrics:" + JSON.toJSONString(metrics))); }); TimeUnit.SECONDS.sleep(3); }
参考
Hystrix原理与实战 https://my.oschina.net/7001/blog/1619842
防雪崩利器:熔断器 Hystrix 的原理与使用 https://segmentfault.com/a/1190000005988895
Hystrix 1.5 滑动窗口实现原理总结 https://www.sczyh30.com/posts/%E9%AB%98%E5%8F%AF%E7%94%A8%E6%9E%B6%E6%9E%84/netflix-hystrix-1-5-sliding-window/
Hystrix系列之熔断器的实现原理 https://mp.weixin.qq.com/s/SYn4ipWZIrQmzn96BmP2Kg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号