
R语言编程艺术#01#数据类型向量(vector)
R语言最基本的数据类型-向量(vector)
1、插入向量元素,同一向量中的所有的元素必须是相同的模式(数据类型),如整型、数值型(浮点数)、字符型(字符串)、逻辑型、复数型等。查看变量的类型可以用typeof(x)函数查询。
> #插入向量元素 > x <- c(88,5,12,13) > x [1] 88 5 12 13 > x <- c(x[1:3],168,x[4]) #插入168数字在13之前 > x [1] 88 5 12 168 13 >
2、删除向量中的元素,由于R中的向量是连续存储的,因此不能插入或删除元素(故上面的插入代码实际上重新创建了一个新的向量然后将x指向新的向量,类似于C中的指针)
> #删除向量中的元素 ^_^ > x [1] 88 5 12 168 13 > x <- c(88,5,168,13) > x [1] 88 5 168 13 >
3、获取向量的长量
> #获取向量的长量 > x [1] 88 5 168 13 > length(x) [1] 4 >
4、遍历向量里所有的元素
>#第一种方法 由于1:length(x)=(1,0),实际上做了两次迭代
> first1
function(x){
for(i in 1:length(x)){
if (x[i]==1) break
}
return(i)
}
> y
[1] 1 2 3 4 5 6 7 8
> first1(y)
[1] 1
>
>#第二种方法 用seq函数生成等差序列,元素间隔为1,解决了第一种效率不高的方法
> first2 <- function(x){
+ for(i in seq(x)){
+ if (x[i]==1) break
+ }
+ return(i)
+ }
>
> first2(y)
[1] 1
>
5、向量与数组、矩阵 数组与矩阵包括列表,在某种意义上实际上都是向量。只不过它们还有额外的类属性。如:矩阵有行数和更数等。
> m <- matrix(c(1,2,3,4),nrow = 2,byrow = T)
> m
[,1] [,2]
[1,] 1 2
[2,] 3 4
> m + 10:13
[,1] [,2]
[1,] 11 14
[2,] 14 17
>
在这里2x2的矩阵m中存储为一个四元向量,即(1,2,3,4),并且以存储为两行(默认是以列排序,以行排序加上byrow = T),然后对它加上(10,11,12,13),得最新的矩阵,等效于下面代码
> m <- matrix(c(1,3,2,4),nrow = 2)
> m
[,1] [,2]
[1,] 1 2
[2,] 3 4
> m + 10:13
[,1] [,2]
[1,] 11 14
[2,] 14 17
>
6、循环补齐 在对两个向量使用运算符时,如果要求这两个向量具有相同的长度,R会自动循环补齐(recycle),即重复较短的向量,直到它与另一个向量长度相匹配
> c(1,2,4) + c(6,0,9,20,22) [1] 7 2 13 21 24 Warning message: In c(1, 2, 4) + c(6, 0, 9, 20, 22) : longer object length is not a multiple of shorter object length >
等同于下列代码:
> c(1,2,4,1,2) + c(6,0,9,20,22) [1] 7 2 13 21 24 >
#矩阵
> x <- matrix(c(1,2,3,4,5,6),nrow = 3)
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> x + c(1,2)
[,1] [,2]
[1,] 2 6
[2,] 4 6
[3,] 4 8
>
#矩阵循环补齐
> x <- matrix(c(1,2,3,4,5,6),nrow = 3)
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> y <- matrix(c(1,2,1,2,1,2),nrow = 3)
> y
[,1] [,2]
[1,] 1 2
[2,] 2 1
[3,] 1 2
> x +y
[,1] [,2]
[1,] 2 6
[2,] 4 6
[3,] 4 8
>
相当于:
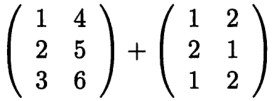
7、常用的向量运算 包括算术和逻辑运算、向量索引、创建向量等
#R是一种函数式语言,它的每个运处符(+ - * / 。。。)实际上都是函数
#加法
> 2+3
[1] 5
> "+"(2,3)
[1] 5
>
>c(1,2) + c(3,4)
>[1] 4 6
>
> "+"(2,3,4)
Error in `+`(2, 3, 4) : operator needs one or two arguments
>#乘法
> c(1,2) * c(3,4)
[1] 3 8
>#减法
> c(3,4) - c(1,2)
[1] 2 2
>#除法
> c(3,4) / c(1,2)
[1] 3 2
>#取余
> c(3,4) %% c(2,3)
[1] 1 1
>
8、向量索引 R中最重要也是最常的一个运算符就是索引,使用它来选择给定向量中特定索引的元素来构成子向量。索引向量的格式是 X[Y](X,Y均是向量),它返回的结果是,X中索引为Y的那些元素。
> y <- c(1.2,3.9,0.4,0.12) > y [1] 1.20 3.90 0.40 0.12 > y[2:3] #取Y向量中的2-3元素 [1] 3.9 0.4 > v <- 3:4 > y[v] [1] 0.40 0.12 > y[c(1,1,3)] #提取的元素是可以重复的 [1] 1.2 1.2 0.4 >
#负数的下标代表我们想剔除的元素,其它提取出来
> y [1] 1.20 3.90 0.40 0.12 > y[-1] #除第一个元素外,提取其它所有的元素 [1] 3.90 0.40 0.12 > y[-1:-2] #除1:2元素外 [1] 0.40 0.12 >
9、用运算符创建向量
#用 :能生成指定范围内数值构成的向量
> 5:8 [1] 5 6 7 8 > #注意运算符优先级别的问题 > i <- 5 > 1:i-1 #这个运算的意思是 (1:i)-1,不是1:(i-1) [1] 0 1 2 3 4 > 1:(i-1) [1] 1 2 3 4 > #查看运算符的优先级别 >?Syntax #可以在R帮助文档中查看
#用seq()创建向量
> seq(1:8) [1] 1 2 3 4 5 6 7 8 > 1:8 #等同于以上代码 [1] 1 2 3 4 5 6 7 8 > seq(from=5,to=20, by=3) #生成从5-20,且元素间隔为3 [1] 5 8 11 14 17 20 > seq(from=5,to=10, by=0.1) #生成从5-10,且元素间隔为0.1 [1] 5.0 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6.0 6.1 6.2 [14] 6.3 6.4 6.5 6.6 6.7 6.8 6.9 7.0 7.1 7.2 7.3 7.4 7.5 [27] 7.6 7.7 7.8 7.9 8.0 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 [40] 8.9 9.0 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9 10.0 >
> seq(from =1.1, to=2, length=10) [1] 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0 > seq(from =1.1, to=2, length=20) #生成1.1到2,共20个等比数列,常数为0.047368 [1] 1.100000 1.147368 1.194737 1.242105 1.289474 1.336842 1.384211 [8] 1.431579 1.478947 1.526316 1.573684 1.621053 1.668421 1.715789 [15] 1.763158 1.810526 1.857895 1.905263 1.952632 2.000000 >
#等比数列定义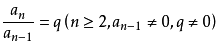
参照:百度百科-等比数列
11、使用 rep()重复向量常数 可以把同一常数放在长向量中,rep(x,times)即创建times*length(x)个元素向量,这个向量是x重复times次构成
> x <- rep(8,4) > x [1] 8 8 8 8 > rep(c(5,12,13),3) [1] 5 12 13 5 12 13 5 12 13 > rep(1:3,2) [1] 1 2 3 1 2 3 >
#each参数,与times参数不同的是,它指定x交替重复的次数
> rep(c(5,12,13),each=2) [1] 5 5 12 12 13 13 >
12、使用all()和any() 这两个函数分别判断其参数中是否至少有一个或全部为TRUE
> x <- 1:10 > any(x>8) [1] TRUE > all(x>8) [1] FALSE > any(x>20) [1] FALSE > all(x>20) [1] FALSE >
#any(x > 8) all(x > 8),分解,先执行下面运算,得到每个元素的逻辑值,any只要判断只要有一个为TRUE,其返回结果为:TRUE,否则为FALSE。all则相反,所有为TRUE时返回值才为:TRUE,否则为FALSE。
> x>8 [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE [10] TRUE >
13、向量化运算符
#向量输入、向量输出
向量化运算即使过运算符的(+,-,*,/,%%,>等),如果一个函数中使用了运算符,哪么这个函数就被向量化了,这样可以有效提高速度
# >运算符 >函数分别运用在u[1]和v[1]得到结果TRUE,然后u[2]和v[2]得到结果FALSE。。。
> u <- c(5,2,8) > v <- c(1,3,9) > u > v [1] TRUE FALSE FALSE >
#函数 平方根、对数、三角函数等都是向量化的
> w <- function(x) return(x + 1) > w(u) [1] 6 3 9 > > sqrt(1:9) [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 [7] 2.645751 2.828427 3.000000 >
#向量输入、矩阵输出
#matrix() 在z12函数中返回值就是一个八元向量(即输出结果是八个数组成的向量),需要通过matrix函数转换成矩阵,如以下代码,将结果转换成8*2的矩阵
> z12 <- function(z) return(c(z,z^2))
> x <- 1:8
> z12(x)
[1] 1 2 3 4 5 6 7 8 1 4 9 16 25 36 49 64
> matrix(z12(x),ncol = 2)
[,1] [,2]
[1,] 1 1
[2,] 2 4
[3,] 3 9
[4,] 4 16
[5,] 5 25
[6,] 6 36
[7,] 7 49
[8,] 8 64
>
#sapply() 该函数跟matrix功能一样,在这里转换成的是2*8的矩阵,其它参数以后再学习
> sapply(1:8,z12)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 1 2 3 4 5 6 7 8
[2,] 1 4 9 16 25 36 49 64
>
14、NA与NULL值
在R中NA表示:缺失值;NULL表示:不存在的值(而不是存在但未知的值)
#NA
由于以下代码中包含了一个NA元素(缺失值),导致mean()无法计算均值,但是可以通过参数na.rm = T(移除NA),计算其他元素的均值。
> x <- c(88,NA,12,168,13) > x [1] 88 NA 12 168 13 > mean(x) [1] NA >
>#NA在不同的向量中模式(数据类型)也不同
> x <- c(88,NA,12,168,13)
> x
[1] 88 NA 12 168 13
> mode(x[2])
[1] "numeric"
> x1 <- c("a","b",NA)
> x1
[1] "a" "b" NA
> mode(x1[3])
[1] "character"
>
#NULL
在R中会自动跳过NULL值,在R中NULL是一种特殊对象,没有类型,可用于变量的初始化值
> x <- c(88,NA,12,168,13) > x [1] 88 NA 12 168 13 > mean(x) [1] NA >
>#在R中NULL是一种特殊对象,没有类型 > x <- NULL > mode(x) [1] "NULL" > x NULL >
15、筛选
反映R函数式语言特性的另一特征是“筛选”(filtering),我们可以提取向量中满足一定条件的元素。
#生成筛选索引
>#要求R提取z中平方大于8的元素 >z <- c(5,2,-3,8) > z [1] 5 2 -3 8 > w <- z[z*z > 8] > w [1] 5 -3 8 > > #等同于以下分解代码 > > z <- c(5,2,-3,8) > z [1] 5 2 -3 8 > z*z > 8 [1] TRUE FALSE TRUE TRUE > z[c(TRUE,FALSE,TRUE,TRUE)] [1] 5 -3 8 >
>j <- z*z > 8
>z[j]
>[1] 5 -3 8
#用例:将x向量中所有大于>3的元素,替换为 0。
> x <- c(1,3,6,2,20) > x [1] 1 3 6 2 20 > x[x > 3] <- 0 > x [1] 1 3 0 2 0 >
#使用subset()函数筛选
当对向量使用subset函数时,它与普通的筛选方法的区别在于处理NA值的方式上,可以自动移除NA值
>#筛选出x中元素平方大于5的
> x <- c(6,1:3,NA,12) > x [1] 6 1 2 3 NA 12 > x[x > 5] [1] 6 NA 12 > subset(x,x > 5) [1] 6 12 >
#选择函数which()
在向量中提取满足一定条件的元素,返回值是元素的所在的位置。
> x [1] 6 1 2 3 NA 12 > which(x>5) [1] 1 6 #返回元素位置 > x[which(x>5)] [1] 6 12 >
16、向量化的ifelse()函数
在R语言中除了有“if-else"结构,还提供了另一个向量货的版本,ifelse()函数,格式为:ifelse(条件,为TRUE返回向量,为FALSE返回向量)
> x <- 1:10 > y <- ifelse(x %% 2 == 0,5,12)#对x值取模运算,偶数返回5,奇数返回12 > y [1] 12 5 12 5 12 5 12 5 12 5 >
17、测试向量相等
”==“仅对向量元素的值进行比较,identical()函数不仅对比元素的值还对比向量元素的数据类型,正如它字面意思一样必须完全相同,从下面的代码可以看出,:产生的元素是整数,c()产生的是浮点数
> x <- 1:2 > y <-c(1,2) > x==y [1] TRUE TRUE > identical(x,y) [1] FALSE > typeof(x) [1] "integer" > typeof(y) [1] "double" >
18、向量的名称
可以给向量元素随意指定名称,name()函数可以给向量中的元素命名,或查询向量元素的名称,将向量元素的名称赋值为NULL,可以将元素的名称移除
> x <- c(1,2,3,4)
> x
[1] 1 2 3 4
> names(x)
NULL
> names(x) <- c("a","b","c","d")
> names(x)
[1] "a" "b" "c" "d"
> x
a b c d
1 2 3 4
> names(x) <- NULL
> x
[1] 1 2 3 4
> names(x)
NULL
>
19、c()函数扩展
当传递到c()函数中的参数有不同类型时,则会被降级为同一类型,该类型最大限度地保留它们的共同的特性。各种类型的优先级排序是:NULL<raw<逻辑类型<整型<实数类型<复数类型<列表<表达式(把配对列表(pairlist)当作普通列表)
> c(1,2,"a") [1] "1" "2" "a" > c(1,2,list(a=3,b=4)) [[1]] [1] 1 [[2]] [1] 2 $a [1] 3 $b [1] 4 > c(1,2,c(3.1,4)) [1] 1.0 2.0 3.1 4.0 >
补充c(1,2,list(a=3,b=4))
> x<-c(1,2,list(a=3,b=4)) > x [[1]] [1] 1 [[2]] [1] 2 $a [1] 3 $b [1] 4 > x[[1]] [1] 1 > x[[2]] [1] 2 > x[3][1] $a [1] 3 > x[4][1] $b [1] 4 >

 浙公网安备 33010602011771号
浙公网安备 33010602011771号