Python爬虫批量下载文献
 使用python批量下载NeurIPS文献
使用python批量下载NeurIPS文献
最近在看NeurIPS的文章,但是一篇篇下载太繁琐,希望能快速批量下载下来。
于是想到了之前一直听说的python爬虫,初次学着弄一下。
参考了python爬虫入门教程:http://c.biancheng.net/view/2011.html ;
用到了requests,BeautifulSoup,urllib.request包
先放最终运行的程序:
结果程序
import requests
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
import os
BASE_URL = 'https://proceedings.neurips.cc/'
# 打开网站并下载
def openAndDownload(url, title):
str_subhtml = requests.get(url)
soup1 = BeautifulSoup(str_subhtml.text, 'lxml')
subdata = soup1.select('body > div.container-fluid > div > div > a:nth-child(4)')
# print('subdata:', subdata)
downloadUrl = BASE_URL + subdata[0].get('href')
print(downloadUrl)
getFile(downloadUrl, title)
# 下载文件
def getFile(url, title):
title = replaceIllegalStr(title)
filename = title + '.pdf'
urlretrieve(url, './essay/%s' % filename.split('/')[-1])
print("Sucessful to download " + title)
# 替换非法命名字符
def replaceIllegalStr(str):
str = str.replace(':', '')
str = str.replace('?', '')
str = str.replace('/', '')
str = str.replace('\\', '')
return str
def main():
url = 'https://proceedings.neurips.cc/paper/2020'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('body > div.container-fluid > div > ul > li > a')
list = []
for item in data:
list.append([item.get_text(), item.get('href')])
name = ['title', 'link']
test = pd.DataFrame(columns=name, data=list)
print(test)
test.to_csv('./essayList.csv')
# 检查是否下载过
file_dir = os.path.join(os.getcwd(), 'essay')
downloaded_list = []
for root, dirs, files in os.walk(file_dir):
downloaded_list = files
for et, el in zip(test[name[0]], test[name[1]]):
essay_url = BASE_URL + el
checkname = et + '.pdf'
checkname = replaceIllegalStr(checkname)
if (checkname in downloaded_list):
print(checkname + ' has been downloaded! ')
else:
openAndDownload(essay_url, et)
if __name__ == '__main__':
main()
结果:
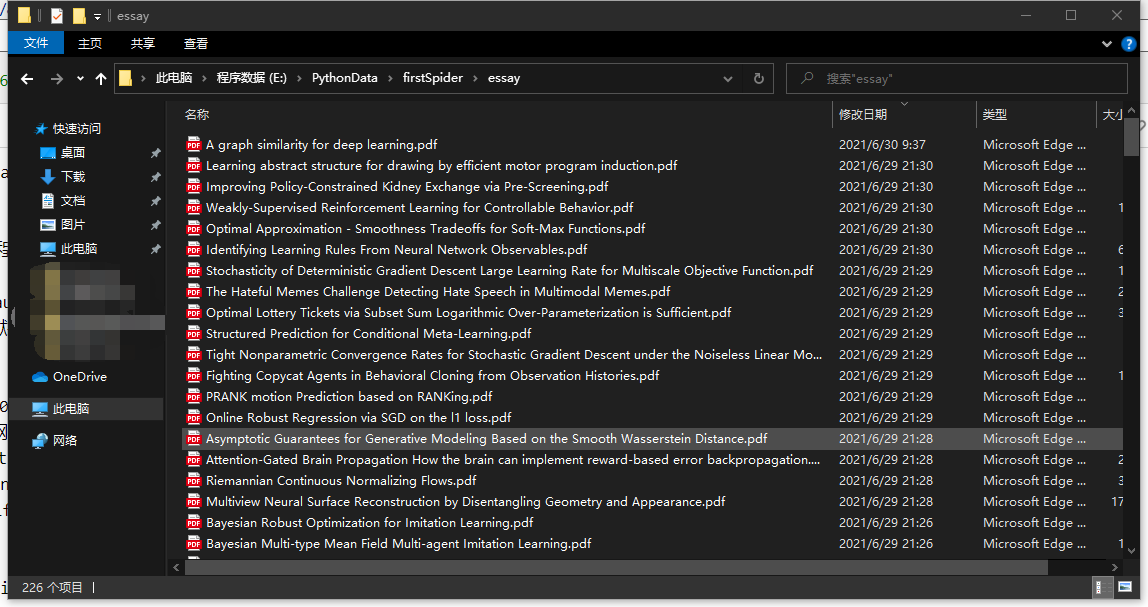
对于NeurIPS网页的文献批量下载编程
1. 对网页进行分析
目标是从NeurIPS2020会议的列表下载论文,2020年会议文章地址:https://proceedings.neurips.cc/paper/2020
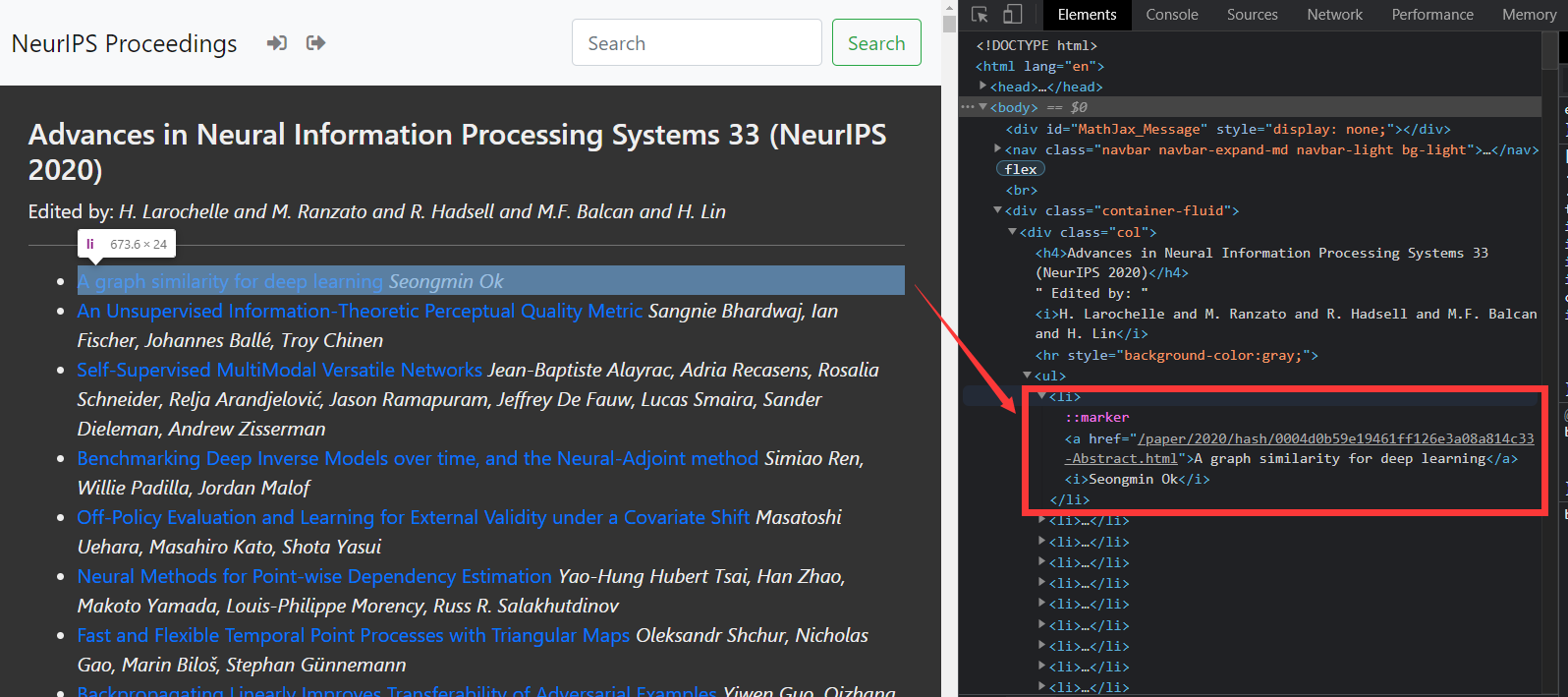
首先分析网页构成:打开网页后按F12调出开发者界面,可以看到网页的源码。
把鼠标放到右侧Elements代码里不同位置,左侧会有不同的控件高亮,以此找到一篇文章的所在位置,如下图所示
python中,使用BeautifulSoup来打开网页
Beautiful Soup 是 python 的一个库,其最主要的功能是从网页中抓取数据。Beautiful Soup 目前已经被移植到 bs4 库中,也就是说在导入 Beautiful Soup 时需要先安装 bs4 库。安装好 bs4 库以后,还需安装 lxml 库。尽管 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器又支持一些第三方解析器 lxml 库具有功能更加强大、速度更快的特点。
首先,HTML 文档将被转换成 Unicode 编码格式,然后 Beautiful Soup 选择最合适的解析器来解析这段文档,此处指定 lxml 解析器进行解析。解析后便将复杂的 HTML 文档转换成树形结构,并且每个节点都是 Python 对象。这里将解析后的文档存储到新建的变量 soup 中
import requests
from bs4 import BeautifulSoup
url = 'https://proceedings.neurips.cc/paper/2020'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
print(soup)
结果:
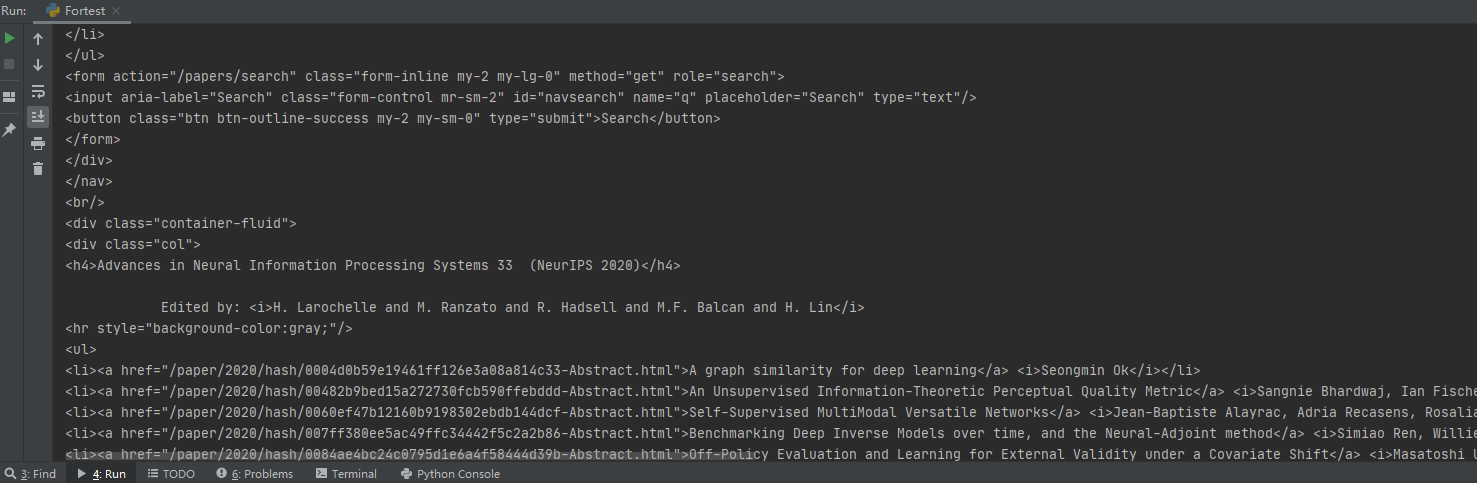
可以看到文献都是以某种列表的格式整齐排列。
通过BeautifulSoup的select函数将相关字段选出,select函数所需路径从开发者界面中使用Copy selector复制得到,如图所示:
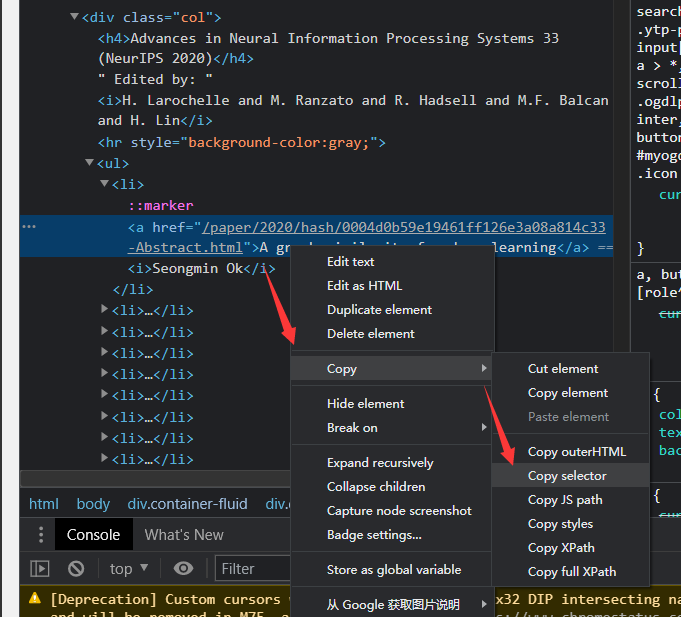
复制得
body > div.container-fluid > div > ul > li:nth-child(1) > a
其中li:nth-child(1),表示某一项。要获取整个列,只选li,代码结果如下:
data = soup.select('body > div.container-fluid > div > ul > li > a')
print(data)
结果:
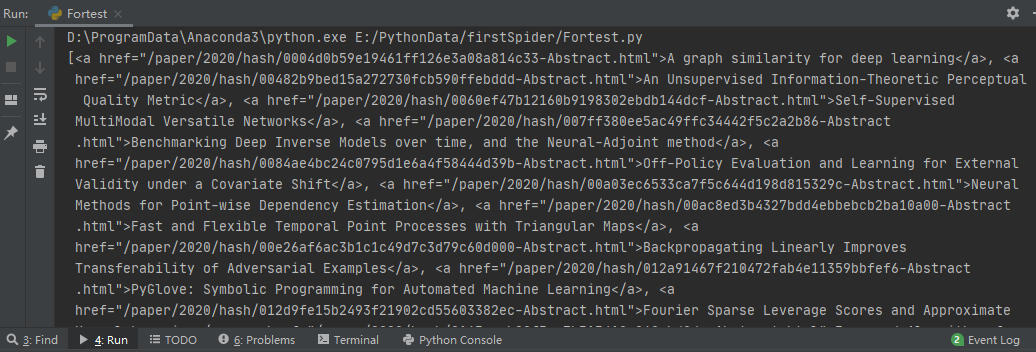
可以看到,每一个元素里面,有文章的名字和链接,正好是我们需要的。
文章名在标签< a >中,使用get_text()获取;链接在< a >标签的href属性中,使用get('href')获取。
将其全部提出来并保存为csv格式,以便之后查询使用。
list = []
for item in data:
list.append([item.get_text(), item.get('href')])
name = ['title', 'link']
test = pd.DataFrame(columns=name, data=list)
test.to_csv('./essaylist.csv')
结果:
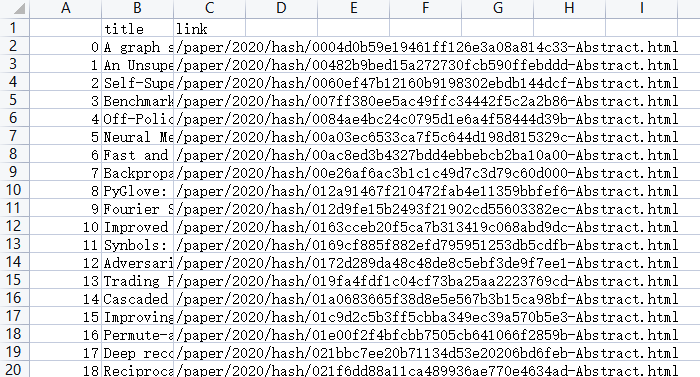
2. 单个文件下载
由于这个界面的超链接并不是文件的下载链接,打开后而是文章的详情页面:
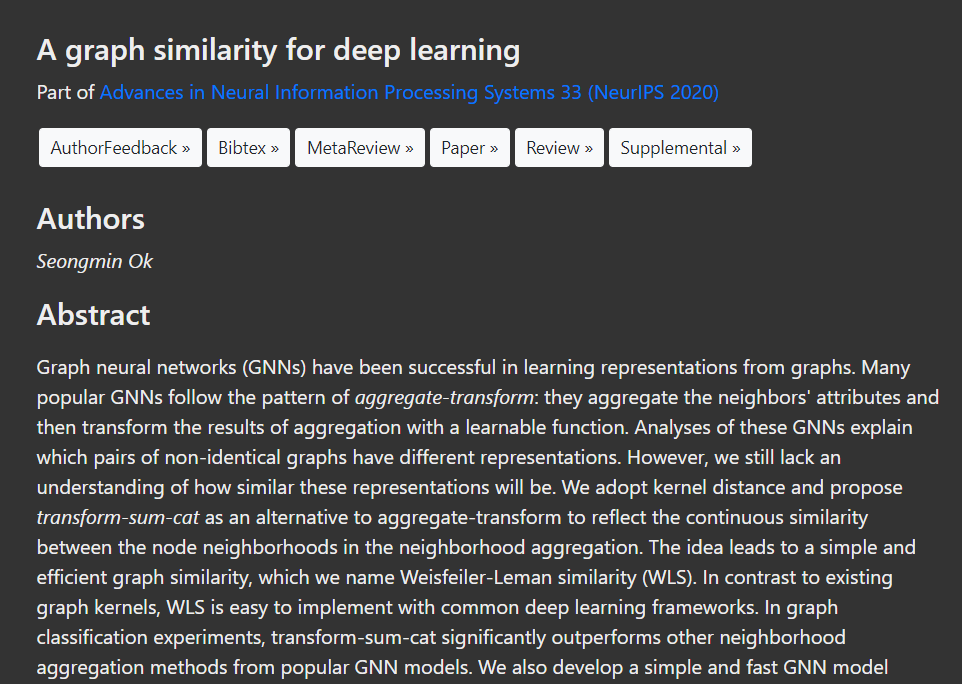
可以从这个页面爬出所需要的信息如摘要等,但目前我们只想下载paper,因此用与前文相同的Copy selector的方式选出文件下载地址的路径:

得到
body > div.container-fluid > div > div > a:nth-child(4)
此时不再需要去除nth-child(4),因为我们只需要这一项。获得了链接后还得与网站主地址组合起来形成完整的地址:
essay_url = 'https://proceedings.neurips.cc/' + test['link'][0]
str_subhtml = requests.get(essay_url)
soup1 = BeautifulSoup(str_subhtml.text, 'lxml')
subdata = soup1.select('body > div.container-fluid > div > div > a:nth-child(4)')
downloadUrl = 'https://proceedings.neurips.cc/' + subdata[0].get('href') # 拼接成完整url
print(downloadUrl)
结果:

接下来通过urlretrieve进行下载操作。
filename = test['title'][0] + '.pdf' # 补全文件格式
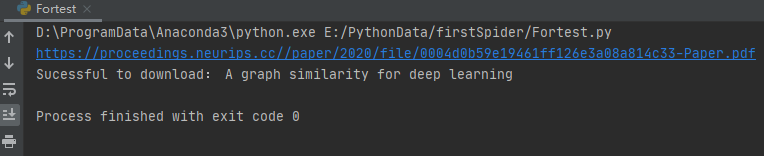
urlretrieve(downloadUrl, './%s' % filename.split('/')[-1])
print("Sucessful to download: " + test['title'][0])
即可下载成功:
3. 全部文件下载与改错
全部文件的下载加个循环即可,具体如最前面的结果程序所示。
另外在运行过程中发现了一些问题:
- 文件命名问题
下载过程中某些文件名只有前面几个单词,且文件不完整。
经过观察发现,出错的是文章名字带有':' , '?' , '\' 或 '/' 的,这些是文件命名所不允许的字符,因此在程序中将这些字符替换掉。 - 下载重复
文章实在有点多,一次可能下不完(或者有更高效的批量下载方式)。
于是修改了程序,通过遍历本地文件获得下载了的文献列表,使用checkname in downloaded_list的方式判断文献是否已经下载过,避免重复下载。
具体实现如最前面的结果程序所示。
待补充与改进
初次写爬虫,也许多了一些不必要的工作,下载方式和显示方式也还有待优化。
后面可以更有针对性的下载,如:根据文章关键词进行筛选后下载。
