MySQL索引
一:基本概念
MySQL为了优化查询效率,更快的查询目标集合,定义了索引。索引是存储引擎用于高效获取数据的一种数据结构(有序)。用于快速找出在某个列中有一特定值的行。
工作原理:
索引类似于一本书的目录,如果要在书中找特定的知识,首先根据目录找到对应的页码。MySQL中存储引擎用类似的方法使用索引,先在索引找到对应值,再根据索引记录找到对应的数据行。
索引的优点
1.大大减少MySQL需要扫描的数据量,提高数据检索效率。
- 当没有使用索引的时候,MySQL查找数据是进行全表扫面,而使用索引的情况只要从索引的根节点开始搜索即可。
2.索引可以帮助MySQL避免排序和临时表
3.可以将随机IO变为顺序IO
4.能够加快表与表之间的连接速度
二:索引类型
按照索引的存储结构进行分类,常见的索引类型有:BTree索引、Hash索引、full-text全文索引、RTree索引(空间数据索引)。
Btree索引:
B-Tree 索引是最常见的索引之一,大多数存储引擎都支持BTree索引。
Btree索引的底层是使用B+tree种数据结构
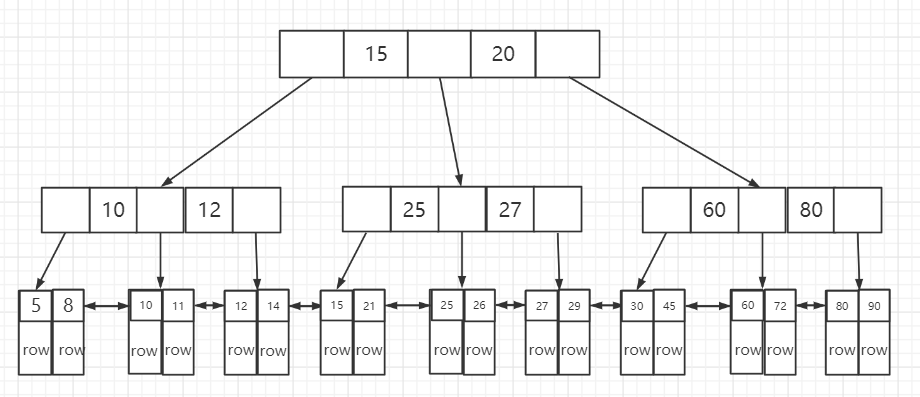
使用场景:
1.全值匹配:对索引中的所有列进行匹配
2.匹配最左前缀:只使用索引的第一列
3.匹配列前缀:只匹配某一列的值的开头部分
4.匹配范围值:查找在某个区间内的值
Hash索引
Hash索引是基于哈希表实现,仅支持精确匹配索引所有列的查询,不支持范围查询。对每行数据,存储索引都会对所有的索引列计算出一个哈希码。哈希索引将所有的哈希码存储在索引中,同时保存指向每个数据行的指针。
-MyISAM: 常见的存储引擎中,MyISAM存储引擎显式支持哈希索引,如果多个列的哈希索引相同,哈希索引会以链表的方式存放多个记录指针到同一哈希条目中。
-InnoDB:InnoDB存储引擎会根据表的使用情况自定义在内存中基于BTree索引上再创建一个哈希索引。
使用场景:
1.精确匹配所有列:如果精确查找某个数据,数据库会先计算出要查找数据的哈希值,然后在索引中查找对应索引,通过索引对应的 value 去原表进行具体值获取和对比。
使用Hash索引的时候还会产生一些问题:
1.当发生很多哈希冲突的时候,索引的维护成本很高,尽量避免在选择性低的字段上创建哈希索引。
2.无法利用索引完成排序操作
空间数据索引 R-Tree
常见的存储引擎中,MyISAM 存储引擎支持空间索引,主要用作地理数据存储,使用较少。
全文索引
种特殊类型的索引,通过建立倒排索引,查找的是文本中的关键字,并不是直接并比较索引中的值,更类似于搜索引擎,并不是简单的 where 条件匹配。
三:索引语法
按照索引的应用层次进行分类,可分为:主键索引、唯一索引、普通索引、组合索引。下面来介绍这几种索引
主键索引
数据表的主键列使用的就是主键索引
在 MySQL的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
唯一索引
加速查询 + 列值唯一(可以有null)
唯一索引是不允许其中任何两行具有相同索引值的索引,当现有数据存在大量的重复的键值的时候,大多数数据库不允许唯一索引与表一起保存,数据库还可能防止添加将表中创建重复键值的新数据。
创建唯一索引
create unique index 索引名 on 表名(字段名)
create unique index in_index on table_name(name);
删除唯一索引
drop unique index 索引名 on 表名
drop unique index in_index on table_name;
普通索引
仅加速查询
创建索引
create index 索引名称 on 表名(字段名)
#在 table_name表 的字段name添加索引 in_index
create index in1_index on table_name(name);
删除索引
drop index 索引名称 on 表名
drop index in_index on table_name;
查看SQL的执行计划
explain select name,email from in1 where name='user';
查看索引
show index from 表名
show index from table_name;
组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询
创建组合索引
create index in_index on table_name(name,email);
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
最后,让我们来看看InnoDB存储引擎索引:
在InnoDB存储引擎中,根据索引的存储形式,可以分为聚集索引和二级索引
1.聚集索引:将数据存储与索引放在一块,索引结构的叶子节点保存了行数据,必须有且只能有一个。
2.二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个。
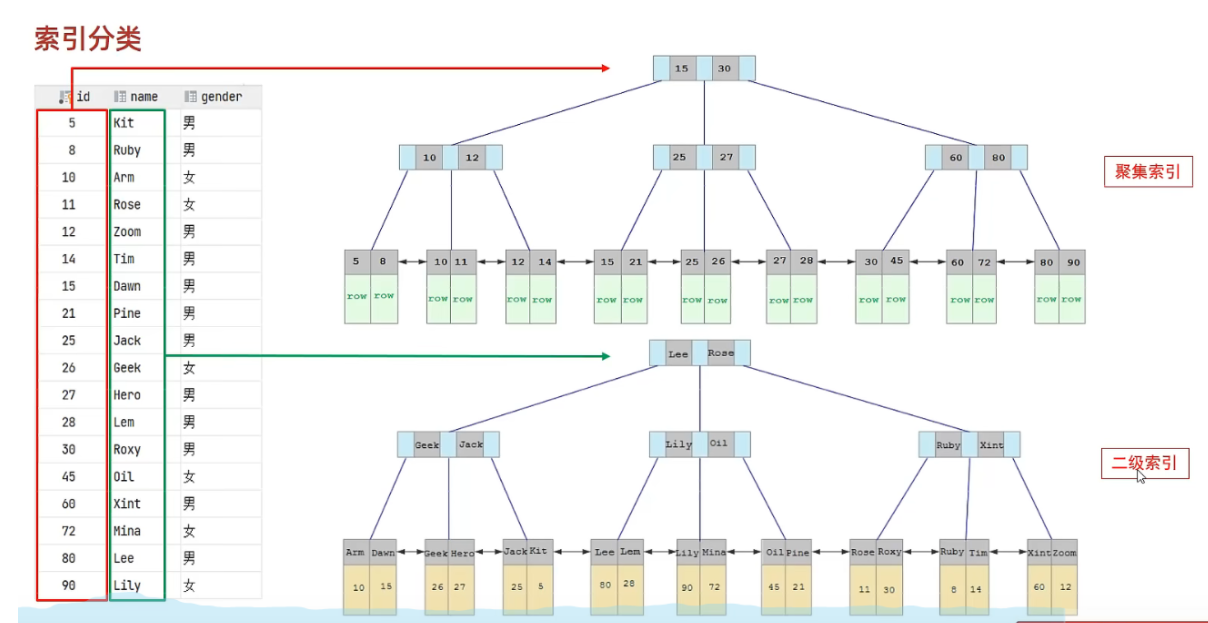
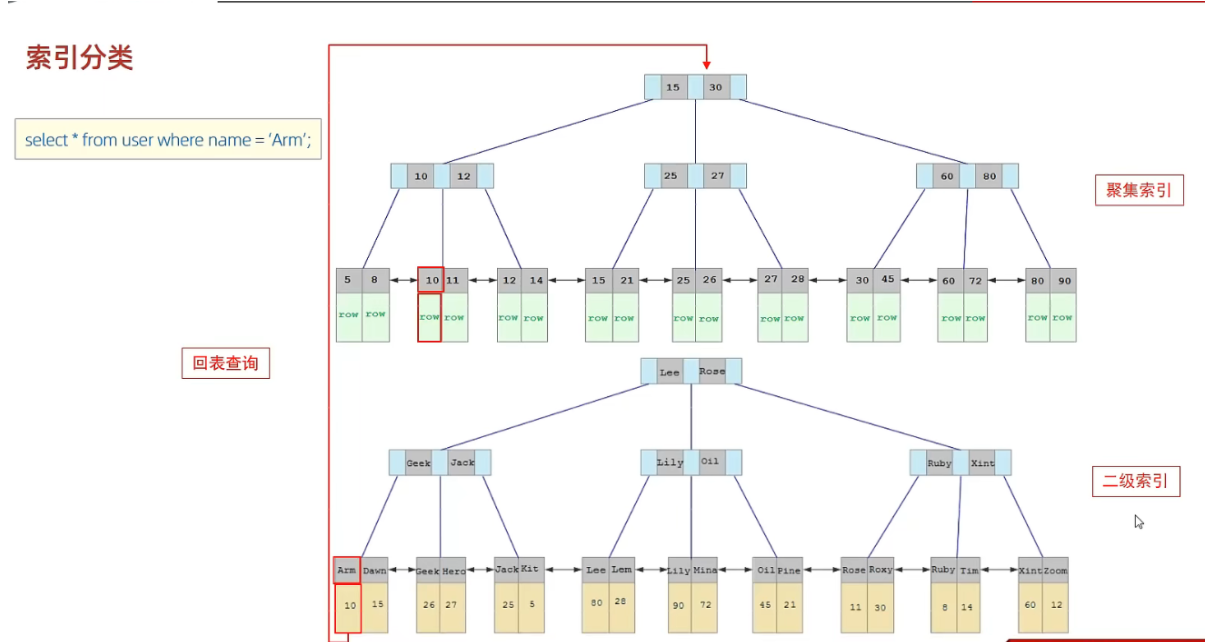
在使用二级索引的执行过程会发生回表查询,所以直接查询聚集索引效率比查找二级索引更高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号