
Google,Baidu,Bing三大搜素引擎图片爬虫
Google,Baidu,Bing三大搜素引擎图片爬虫
参考https://mp.weixin.qq.com/s/75QDjRTDCKzuM68L4fg5Lg
这个爬虫由ID为sczhengyabin的用户整理,看头像就知道不好惹。

可以按要求爬取百度、Bing、Google上的图片
项目地址https://github.com/sczhengyabin/Image-Downloader
项目背景
对于很多初⼊深度学习计算机视觉领域的朋友来说,当前开源资料⾮常多,但有时候难以适从,其中很多资料都没有包含完整的项⽬流程,⽽只是对某个流程的部分截取,对能⼒的锻炼不够。图像分类是整个计算机视觉领域中最基础的任务,也是最重要的任务之⼀,最适合拿来进⾏学习实践。为了让新⼿们能够⼀次性体验⼀个⼯业级别的图像分类任务的完整流程,本次我们选择带领⼤家完成⼀个对图片中⼈脸进⾏表情识别的任务。
⼈脸表情识别(facial expression recognition, FER)作为⼈脸识别技术中的⼀个重要组成部分,近年来在⼈机交互、安全、机器⼈制造、⾃动化、医疗、通信和驾驶领域得到了⼴泛的关注,成为学术界和⼯业界的研究热点,是⼈脸属性分析的重点。
数据获取
很多实际项⽬我们不会有现成的数据集,虽然可以通过开源数据集获取,但是我们还是要学会⾃⼰从零开始获取和整理。下⾯讲述如何准备好本次项⽬所需要的数据集,包括以下部分:
- 学会使⽤爬⾍爬取图像。
- 对获得的图⽚数据进⾏整理,包括重命名,格式统⼀。
2.1 数据爬取
由于没有直接对应的开源数据集,或者开源数据集中的数据⽐较少,尤其是对于嘟嘴,⼤笑等类的数据。搜索引擎上有海量数据,所以我们可以从中爬取。下⾯开始讲述具体的步骤,我们的任务是⼀个表情分类任务,因此需要爬取相关图⽚,包括嘟嘴(pout),微笑(smile),⼤笑(openmouth)、无表情(none)等表情。
当前有很多开源的爬虫项目,即使你不懂爬虫的知识,也能够很容易的爬取互联网的资源,下文整理了一些常见的爬虫项目,可以参考进行学习。
【杂谈】深度学习必备,各路免费爬虫一举拿下
本项目使用的爬虫项目是:https://github.com/sczhengyabin/Image-Downloader ,可以按要求爬取百度、Bing、Google 上的图片,提供了非常人性化的 GUI 方便操作,使用方法如下:
-
下载爬虫工具
-
使用
python image_downloader_gui.py调用GUI界面,配置好参数(关键词,路径,爬取数目等),关键词可以直接在这里输入也可以选择从txt文件中选择。 -
可以配置需要爬取的样本数目,这里一次爬了2000张,妥妥的3分钟搞定。
该项目的 GUI 界面如下,我们尝试爬取“嘟嘴”的相关表情:
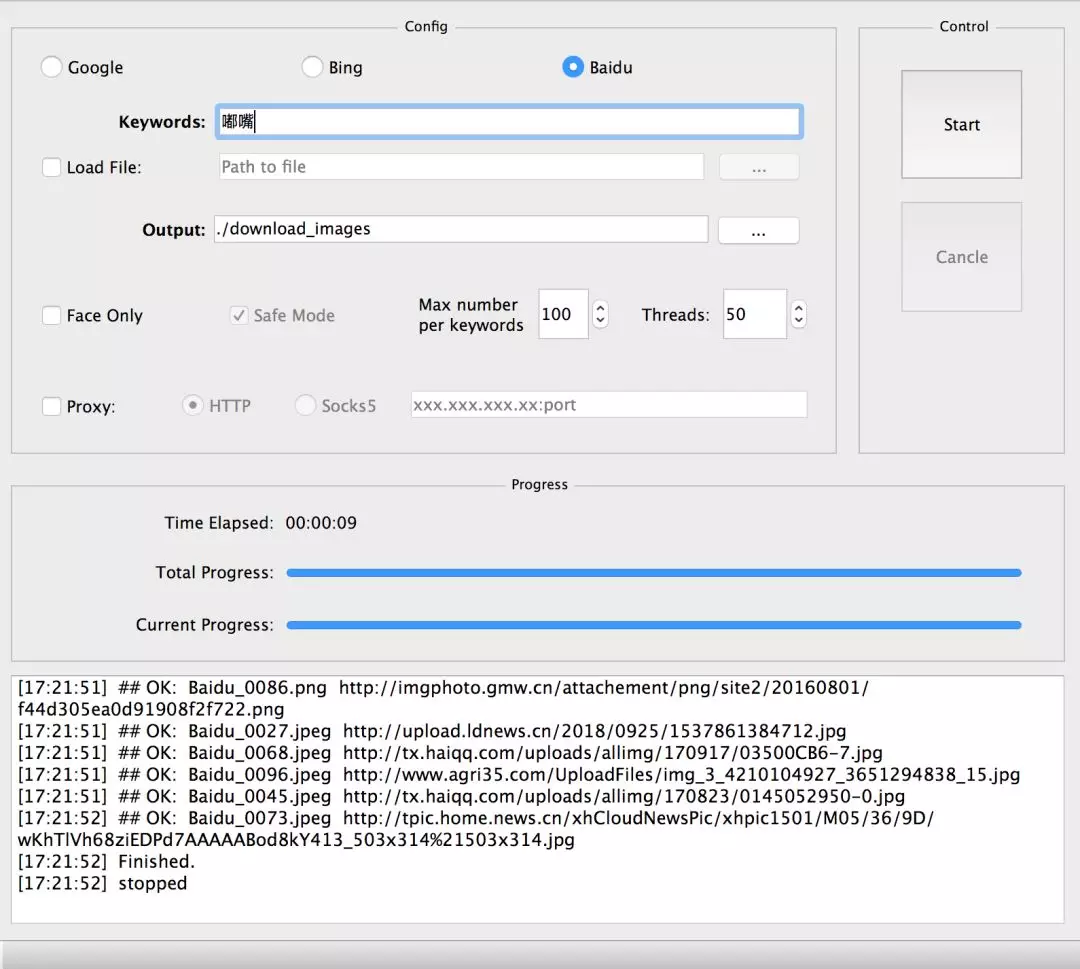
爬取图⽚结果如下:

⾃此就可以获得数千张图像
本文作者:薄书
本文链接:https://www.cnblogs.com/aimoboshu/p/15339675.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步