
【阿里天池云-龙珠计划】薄书的机器学习笔记——朴素贝叶斯(Naive Bayes)Task02
【阿里天池云-龙珠计划】薄书的机器学习笔记——朴素贝叶斯(Naive Bayes)Task02
【给各位看官请安】
大家一起来集齐七龙珠召唤神龙吧!!!
学习地址:AI训练营机器学习-阿里云天池
推荐一下我由此上车的公众号:AI蜗牛车,时空序列相关文章挺多的。
Task01:基于逻辑回归模型的多分类场景预测实战
Task02:朴素贝叶斯(Naive Bayes)
【现在开始笔记】
1. 实验室介绍
1.1 实验环境
1. python3.7
2. numpy >= '1.16.4'
3. sklearn >= '0.23.1'
1.2 朴素贝叶斯的介绍
朴素贝叶斯算法(Naive Bayes, NB) 是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件分类都是基于朴素贝叶斯分类器识别的。
什么是条件概率,我们从一个摸球的例子来理解。我们有两个桶:灰色桶和绿色桶,一共有7个小球,4个蓝色3个紫色,分布如下图: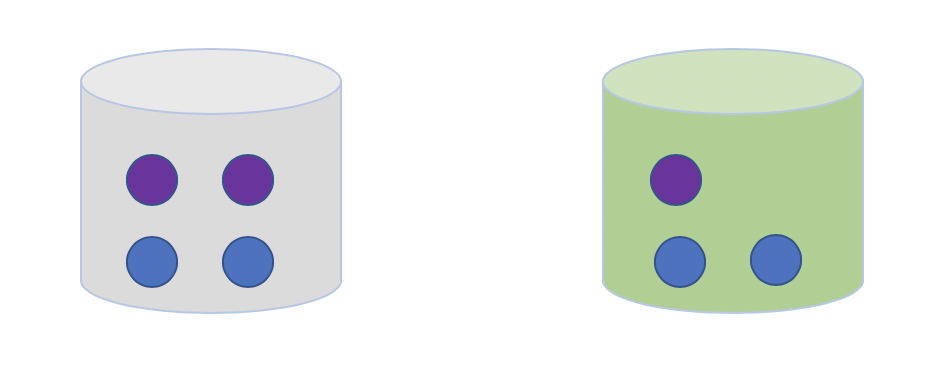
从这7个球中,随机选择1个球是紫色的概率p是多少?选择过程如下:
- 先选择桶
- 再从选择的桶中选择一个球
上述我们选择小球的过程就是条件概率的过程,在选择桶的颜色的情况下是紫色的概率,另一种计算条件概率的方法是贝叶斯准则。
p(A,B):表示事件A和事件B同时发生的概率。
p(B):表示事件B发生的概率,叫做先验概率;p(A):表示事件A发生的概率。
p(A|B):表示当事件B发生的条件下,事件A发生的概率叫做后验概率。
p(B|A):表示当事件A发生的条件下,事件B发生的概率。
我们用一句话理解贝叶斯:世间很多事都存在某种联系,假设事件A和事件B。人们常常使用已经发生的某个事件去推断我们想要知道的之间的概率。
例如,医生在确诊的时候,会根据病人的舌苔、心跳等来判断病人得了什么病。对病人来说,只会关注得了什么病,医生会通道已经发生的事件来
确诊具体的情况。这里就用到了贝叶斯思想,A是已经发生的病人症状,在A发生的条件下是B_i的概率。
1.3 朴素贝叶斯的应用
朴素贝叶斯算法假设所有特征的出现相互独立互不影响,每一特征同等重要,又因为其简单,而且具有很好的可解释性一般。相对于其他精心设计的更复杂的分类算法,朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。
2. 实验室手册
2.1 学习目标
- 掌握朴素贝叶斯公式
- 结合两个实例了解朴素贝叶斯的参数估计
- 掌握朴素贝叶斯估计
2.2 代码流程
-
Part 1. 莺尾花数据集--贝叶斯分类
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练
- Step4: 模型预测
- Step5: 原理简析
-
Part 2. 模拟离散数据集--贝叶斯分类
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练&可视化
- Step4: 原理简析
2.3 算法实战
莺尾花数据集--贝叶斯分类
Step1: 库函数导入
import warnings
warnings.filterwarnings('ignore')
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
sklearn库提供了三个朴素贝叶斯分类算法:
- 高斯朴素贝叶斯(GaussianNB):特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度;
- 类目朴素贝叶斯(CategoricalNB):专用于离散数据集;
- 多项式朴素贝叶斯(MultinomialNB):特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。不支持负数,所以输入变量特征的时候,别用StandardScaler进行标准化数据,可以使用MinMaxScaler进行归一化。多项式朴素贝叶斯是以单词为粒度,会计算在某个文件中的具体次数,适用于文本分类;
- 伯努利朴素贝叶斯(BernoulliNB):不支持负数,所以输入变量特征的时候,别用StandardScaler进行标准化数据,可以使用MinMaxScaler进行归一化。伯努利朴素贝叶斯是以文件为粒度,如果该单词在某文件中出现了即为 1,否则为 0。常见于文本分类场景。
Step2: 数据导入&分析
# sklearn内置的dataset支持直接返回自变量与因变量
X, y = datasets.load_iris(return_X_y=True)
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
我们需要计算两个概率分别是:条件概率:和类目的先验概率:。
通过分析发现训练数据是数值类型的数据,这里假设每个特征服从高斯分布,因此我们选择高斯朴素贝叶斯来进行分类计算。
Step3: 模型训练
# 使用高斯朴素贝叶斯进行计算
clf = GaussianNB(var_smoothing=1e-8) # var_smoothing进行拉普拉斯平滑,方便有效的避免零概率问题
clf.fit(X_train, y_train)
GaussianNB假设特征的先验概率为正态分布,即如下式:
高斯朴素贝叶斯假设每个特征都服从高斯分布,我们把一个随机变量服从数学期望为,方差为的数据分布称为高斯分布。对于每个特征我们一般使用平均值来估计和使用所有特征的方差估计。
其中为Y的第k类类别。为需要从训练集估计的值。
GaussianNB会根据训练集求出。 为在样本类别中,所有的平均值。为在样本类别中,所有的方差。
GaussianNB类的主要参数仅有一个,即先验概率priors ,对应Y的各个类别的先验概率。这个值默认不给出,如果不给出此时。其中m为训练集样本总数量,为输出为第k类别的训练集样本数。如果给出的话就以priors 为准。
PS 出了一个BUG:
执行上面代码时:
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-6-0fbe6888a702> in <module> 1 # 使用高斯朴素贝叶斯进行计算 ----> 2 clf = GaussianNB(var_smoothing=1e-8) 3 clf.fit(X_train, y_train) TypeError: __init__() got an unexpected keyword argument 'var_smoothing'大家说是scikit-learn版本问题,就查看了一下版本,装成0.23.0就好了
pip show scikit-learnName: scikit-learn Version: 0.23.2 Summary: A set of python modules for machine learning and data mining Home-page: http://scikit-learn.org Author: None Author-email: None License: new BSD Location: /opt/conda/lib/python3.6/site-packages Requires: joblib, numpy, scipy, threadpoolctl Required-by: sklearn, lightgbm, imbalanced-learn Note: you may need to restart the kernel to use updated packages.pip install scikit-learn==0.23
Step4: 模型预测
# 评估
y_pred = clf.predict(X_test)
acc = np.sum(y_test == y_pred) / X_test.shape[0] #准确率:正确的加一,然后除以数目
print("Test Acc : %.3f" % acc)
# 预测
y_proba = clf.predict_proba(X_test[:1])
print(clf.predict(X_test[:1]))
print("预计的概率值:", y_proba) #可输出各种类别的置信概率
Test Acc : 0.967
[2]
预计的概率值: [[1.63542393e-232 2.18880483e-006 9.99997811e-001]]
从上述例子中的预测结果中,我们可以看到类别2对应的后验概率值最大,所以我们认为类目2是最优的结果。
Step5: 原理简析
高斯朴素贝叶斯假设每个特征都服从高斯分布,我们把一个随机变量X服从数学期望为μ,方差为σ2的数据分布称为高斯分布。对于每个特征我们一般使用平均值来估计μ和使用所有特征的方差估计σ2。
模拟离散数据集--贝叶斯分类
Step1: 库函数导入
import random
import numpy as np
# 使用基于类目特征的朴素贝叶斯
from sklearn.naive_bayes import CategoricalNB
from sklearn.model_selection import train_test_split
Step2: 数据导入&分析
# 模拟数据
rng = np.random.RandomState(1)
# 随机生成600个100维的数据,每一维的特征都是[0, 4]之前的整数
X = rng.randint(5, size=(600, 100))
y = np.array([1, 2, 3, 4, 5, 6] * 100)
data = np.c_[X, y]
print(X.shape)
print(y.shape)
# X和y进行整体打散
random.shuffle(data)
X = data[:,:-1]
y = data[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
所有的数据特征都是离散特征,我们引入基于离散特征的朴素贝叶斯分类器。
Step3: 模型训练&预测
clf = CategoricalNB(alpha=1)
# 当 alpha=1 时,使用的是 Laplace 平滑; 当 0<alpha<1 时,使用的是 Lidstone 平滑
clf.fit(X_train, y_train)
acc = clf.score(X_test, y_test)
print("Test Acc : %.3f" % acc)
Test Acc : 0.592
# 随机数据测试,分析预测结果,贝叶斯会选择概率最大的预测结果
# 比如这里的预测结果是4,4对应的概率最大,由于我们是随机数据
# 读者运行的时候,可能会出现不一样的结果。
x = rng.randint(5, size=(1, 100))
print(clf.predict_proba(x))
print(clf.predict(x))
[[3.82014808e-06 1.44340537e-05 5.76583825e-06 9.98436676e-01
4.86954128e-04 1.05235024e-03]]
[4]
2.4 原理简析
2.4.1 结果分析
这里的测试数据的准确率没有任何意义,因为数据是随机生成的,不一定具有贝叶斯先验性,这里只是作为一个列子引导大家如何使用。
alpha=1这个参数表示什么?
我们知道贝叶斯法一定要计算两个概率:条件概率:和类目的先验概率:。
对于离散特征:
我们可以看出就是对每一个变量的多加了一个频数alpha。当alphaλ=0时,就是极大似然估计。通常取值alpha=1,这就是拉普拉斯平滑(Laplace smoothing),这有叫做贝叶斯估计,主要是因为如果使用极大似然估计,如果某个特征值在训练数据中没有出现,这时候会出现概率为0的情况,导致整个估计都为0,因为引入贝叶斯估计。
其中:
:表示第j个特征的个数。
:表示第i个样本的第j维元素。
:第i个样本的label。
2.4.2 朴素贝叶斯算法
朴素贝叶斯法 = 贝叶斯定理 + 特征条件独立。
输入空间是n维向量集合,输出空间. 所有的X和y都是对应空间上的随机变量. 是X和Y的联合概率分布. 训练数据集(由独立同分布产生):
计算测试数据x的列表,我们需要依次计算,取概率最大的值,就是x对应的分类。
我们一般这样解释,当给定的条件下,的概率,这就是条件概率. 这就简单了,我们只需要每个的x,计算其对应的的概率,选择最大的概率作为这个x的类别进行了.
通过贝叶斯公式进行变形,得到预测的概率计算公式:
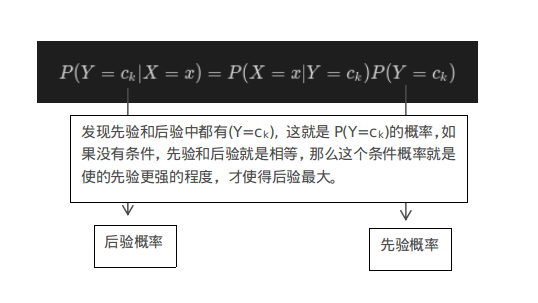
我们只需要计算以下两个概率即可,又由于朴素贝叶斯假设条件独立,我们可以单独计算每个特征的条件概率:和类目的先验概率:。为了更好的理解这个公式,看下图解释:
其中:
当涉及到多个条件时,朴素贝叶斯有一个提前的假设,我们称之为 条件独立性假设(或者 简单假设:Naive):公式如下
这个公式是朴素贝叶斯的基础假设,即各个条件概率是相互独立的,A不影响B,B不影响A。
而对这里来说,假设
由此原式可以等价为:
我们为了选择后验概率最大的结果,进行概率的比较,由于分母一致,这里直接去掉分母,得到最后的计算公式。
我们来看一个实例,更好的理解贝叶斯的计算过程,根据天气和是否是周末预测一个人是否会出门。
| index | 天气的好坏 | 是否周末 | 是否出门 |
|---|---|---|---|
| 1 | 好 | 是 | 出门 |
| 2 | 好 | 否 | 出门 |
| 3 | 好 | 是 | 不出门 |
| 4 | 好 | 否 | 出门 |
| 5 | 不好 | 是 | 出门 |
| 6 | 不好 | 否 | 不出门 |
根据上述数据,为了更好的理解计算过程,我们给出几个计算公式:
a. 当出门的条件下,是天气不好的概率:
b. 出门的概率
c. 天气不好的概率、
d. 在天气不好的情况下,出门的概率:
f. 在天气不好的情况下,不出门的概率:
2.4.3 朴素贝叶斯的优缺点
优点:
朴素贝叶斯算法主要基于经典的贝叶斯公式进行推倒,具有很好的数学原理。而且在数据量很小的时候表现良好,数据量很大的时候也可以进行增量计算。由于朴素贝叶斯使用先验概率估计后验概率具有很好的模型的可解释性。
缺点:
朴素贝叶斯模型与其他分类方法相比具有最小的理论误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进,例如为了计算量不至于太大,我们假定每个属性只依赖另外的一个。解决特征之间的相关性,我们还可以使用数据降维(PCA)的方法,去除特征相关性,再进行朴素贝叶斯计算。
本文作者:薄书
本文链接:https://www.cnblogs.com/aimoboshu/p/14192655.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具