
【阿里天池云-龙珠计划】薄书的机器学习笔记——基于逻辑回归模型的多分类场景预测实战
【阿里天池云-龙珠计划】薄书的机器学习笔记——基于逻辑回归模型的多分类场景预测实战
【给各位看官请安】
大家一起来集齐七龙珠召唤神龙吧!!!
学习地址:AI训练营机器学习-阿里云天池
推荐一下我由此上车的公众号:AI蜗牛车,时空序列相关文章挺多的。
博客园:薄书的机器学习笔记——基于逻辑回归模型的多分类场景预测实战
【现在开始笔记】
1 逻辑回归的介绍和应用
1.1 逻辑回归的介绍
逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。
而对于逻辑回归而且,最为突出的两点就是其模型简单和模型的可解释性强。
逻辑回归模型的优劣势:
- 优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低;
- 缺点:容易欠拟合,分类精度可能不高
1.2 逻辑回归的应用
逻辑回归模型广泛用于各个领域,包括机器学习,大多数医学领域和社会科学。例如,最初由Boyd 等人开发的创伤和损伤严重度评分(TRISS)被广泛用于预测受伤患者的死亡率,使用逻辑回归基于观察到的患者特征(年龄,性别,体重指数,各种血液检查的结果等)分析预测发生特定疾病(例如糖尿病,冠心病)的风险。逻辑回归模型也用于预测在给定的过程中,系统或产品的故障的可能性。还用于市场营销应用程序,例如预测客户购买产品或中止订购的倾向等。在经济学中它可以用来预测一个人选择进入劳动力市场的可能性,而商业应用则可以用来预测房主拖欠抵押贷款的可能性。条件随机字段是逻辑回归到顺序数据的扩展,用于自然语言处理。
逻辑回归模型现在同样是很多分类算法的基础组件,比如 分类任务中基于GBDT算法+LR逻辑回归实现的信用卡交易反欺诈,CTR(点击通过率)预估等,其好处在于输出值自然地落在0到1之间,并且有概率意义。模型清晰,有对应的概率学理论基础。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。但同时由于其本质上是一个线性的分类器,所以不能应对较为复杂的数据情况。很多时候我们也会拿逻辑回归模型去做一些任务尝试的基线(基础水平)。
举个简单的逻辑回归模型的例子就是sigmoid函数。
说了这些逻辑回归的概念和应用,大家应该已经对其有所期待了吧,那么我们现在开始吧!!!
2 学习目标
- 了解 逻辑回归 的理论
- 掌握 逻辑回归 的 sklearn 函数调用使用并将其运用到鸢尾花数据集预测
3 代码流程
Part1 Demo实践
- Step1:库函数导入
```
## 基础函数库
import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
```
- Step2:模型训练
##Demo演示LogisticRegression分类
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]]) # 输入的特征集6*2,6个数据每个数据两个特征,自变量
y_label = np.array([0, 0, 0, 1, 1, 1]) # 6个输入的各自分类类别,因变量
print('x_fearures:', x_fearures.shape, x_fearures)
print('y_label:', y_label)
## 调用逻辑回归模型
lr_clf = LogisticRegression()
## 用逻辑回归模型拟合构造的数据集
lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2,相当于一个层,一个神经元
数据集显示
x_fearures: [[-1 -2]
[-2 -1]
[-3 -2]
[ 1 3]
[ 2 1]
[ 3 2]]
y_label: [0 0 0 1 1 1]
- Step3:模型参数查看
## 查看其对应模型的权重w
print('the weight of Logistic Regression:',lr_clf.coef_)
## 查看其对应模型的偏置w0
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)
结果
the weight of Logistic Regression: [[0.73462087 0.6947908 ]]
the intercept(w0) of Logistic Regression: [-0.03643213]
- Step4:数据和模型可视化
## 可视化构造的数据样本点
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') # 参数详解:x坐标取数据的第0列,y坐标第1列,颜色选择由y提供的类别来决定,点size大小,画布选择
plt.title('Dataset') # 可视化画布标题'Dataset'
plt.show()
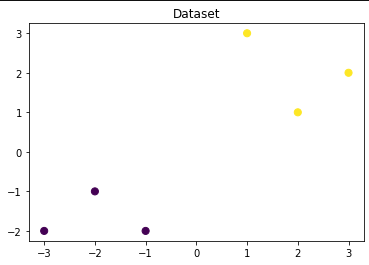
可以看到不同类别的数据点用不同颜色标注了。
# 可视化决策边界
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
nx, ny = 200, 100
x_min, x_max = plt.xlim() # (-3,3)取可视化窗口的上下界
y_min, y_max = plt.ylim() # (-2,3)
x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
# numpy.meshgrid()——生成网格点坐标矩阵:具体解释(https://www.cnblogs.com/lemonbit/p/7593898.html)
# [X,Y] = meshgrid(x,y) 将向量x和y定义的区域转换成矩阵X和Y,其中矩阵X的行向量是向量x的简单复制,
# 而矩阵Y的列向量是向量y的简单复制。假设x是长度为m的向量,y是长度为n的向量,则最终生成的矩阵X和Y的维度都是 n*m (注意不是m*n)
# 既生成两个100*200的矩阵。
print('x_grid, y_grid 的shape:',x_grid.shape,y_grid.shape)
display(x_grid, y_grid)
z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
print(z_proba.shape)
print('z_proba的第1列',z_proba[:, 1])
# np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。https://blog.csdn.net/yj1556492839/article/details/79031693
# ravel()将矩阵压扁。https://blog.csdn.net/tymatlab/article/details/79009618
# 共两个特征所以输入的是20000*2的数组, predict_proba由于标签共两类返回的是一个 20000行 2列的数组, https://blog.csdn.net/u011630575/article/details/79429757
# 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
z_proba = z_proba[:, 1].reshape(x_grid.shape)
print('reshape后的z_proba',z_proba.shape)
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()
输出
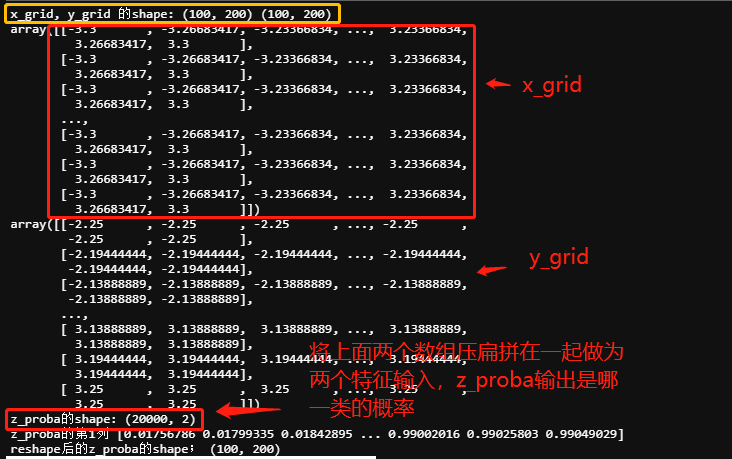
x_grid, y_grid 的shape: (100, 200) (100, 200)
array([[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ],
[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ],
[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ],
...,
[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ],
[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ],
[-3.3 , -3.26683417, -3.23366834, ..., 3.23366834,
3.26683417, 3.3 ]])
array([[-2.25 , -2.25 , -2.25 , ..., -2.25 ,
-2.25 , -2.25 ],
[-2.19444444, -2.19444444, -2.19444444, ..., -2.19444444,
-2.19444444, -2.19444444],
[-2.13888889, -2.13888889, -2.13888889, ..., -2.13888889,
-2.13888889, -2.13888889],
...,
[ 3.13888889, 3.13888889, 3.13888889, ..., 3.13888889,
3.13888889, 3.13888889],
[ 3.19444444, 3.19444444, 3.19444444, ..., 3.19444444,
3.19444444, 3.19444444],
[ 3.25 , 3.25 , 3.25 , ..., 3.25 ,
3.25 , 3.25 ]])
(20000, 2)
z_proba的第1列 [0.01756786 0.01799335 0.01842895 ... 0.99002016 0.99025803 0.99049029]
reshape后的z_proba (100, 200)
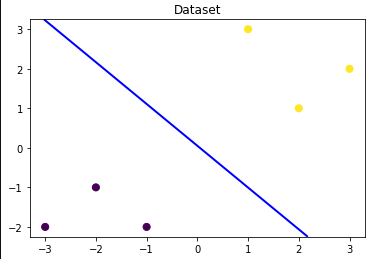
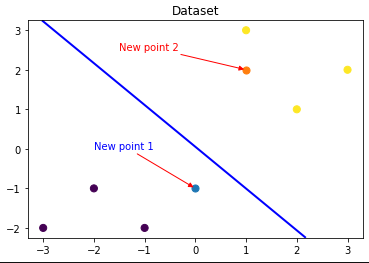
### 可视化预测新样本
plt.figure()
## new point 1
x_fearures_new1 = np.array([[0, -1]]) # 新样本一,有两个特征(0,-1)
plt.scatter(x_fearures_new1[:,0],x_fearures_new1[:,1], s=50, cmap='viridis') # 将这个新样本显示在画布上
plt.annotate(text='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
# plt.annotate的介绍https://www.jianshu.com/p/0f56caf4f859
## new point 2
x_fearures_new2 = np.array([[1, 2]])
plt.scatter(x_fearures_new2[:,0],x_fearures_new2[:,1], s=50, cmap='viridis')
plt.annotate(text='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
## 训练样本
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
# 可视化决策边界
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()
- Step5:模型预测
## 在训练集和测试集上分别利用训练好的模型进行预测
y_label_new1_predict = lr_clf.predict(x_fearures_new1)
y_label_new2_predict = lr_clf.predict(x_fearures_new2)
print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)
## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所以我们可以利用 predict_proba 函数预测其概率。y_label_new1_predict_proba会得到两个数分别是两个类别的概率,y_label_new1_predict就是这两个概率最大的那个类别。
y_label_new1_predict_proba = lr_clf.predict_proba(x_fearures_new1)
y_label_new2_predict_proba = lr_clf.predict_proba(x_fearures_new2)
print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba)
print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba)
The New point 1 predict class:
[0]
The New point 2 predict class:
[1]
The New point 1 predict Probability of each class:
[[0.67507358 0.32492642]]
The New point 2 predict Probability of each class:
[[0.11029117 0.88970883]]
y_label_new1_predict_proba中可以看到前者比较大,所以表示这个样本属于[0]的概率大,所以y_label_new1_predict=0.
可以发现训练好的回归模型将X_new1预测为了类别0(判别面左下侧),X_new2预测为了类别1(判别面右上侧)。其训练得到的逻辑回归模型的概率为0.5的判别面为上图中蓝色的线。
Part1 基于鸢尾花(iris)数据集的逻辑回归分类实践
在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。
- Step1:库函数导入
## 基础函数库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。seaborn的介绍
本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。
| 变量 | 描述 |
|---|---|
| sepal length | 花萼长度(cm) |
| sepal width | 花萼宽度(cm) |
| petal length | 花瓣长度(cm) |
| petal width | 花瓣宽度(cm) |
| target | 鸢尾的三个亚属类别,'setosa'(0), 'versicolor'(1), 'virginica'(2) |
- Step2:数据读取/载入
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
- Step3:数据信息简单查看
## 利用.info()查看数据的整体信息
iris_features.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部
iris_features.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
iris_features.tail() # .tail()尾部
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
## 其对应的类别标签为,其中0,1,2分别代表'setosa', 'versicolor', 'virginica'三种不同花的类别。
iris_target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
## 利用value_counts函数查看每个类别数量
pd.Series(iris_target).value_counts()
2 50
1 50
0 50
dtype: int64
## 对于特征进行一些统计描述,可以看到平均值,标准差,最大值,最小值等。
iris_features.describe()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
从统计描述中我们可以看到不同数值特征的变化范围。
- Step4:可视化描述
## 合并标签和特征信息
iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_target
## 特征与标签组合的散点可视化
sns.pairplot(data=iris_all,diag_kind='hist', hue= 'target', palette="husl", ["o", "s", "D"])
plt.show()
diag_kind='hist'指定对角图形式
hue= 'target'使用指定变量为分类变量画图。参数类型:string (变量名);
palette="husl"使用调色板,参数举例:Paired;husl;hls;dark,不添加参数会有个默认。
markers=["o", "s", "D"]使用不同的形状,参数类型:list
将四个特征两两组合,通过可视化可以表示出特征与标签的相关性。
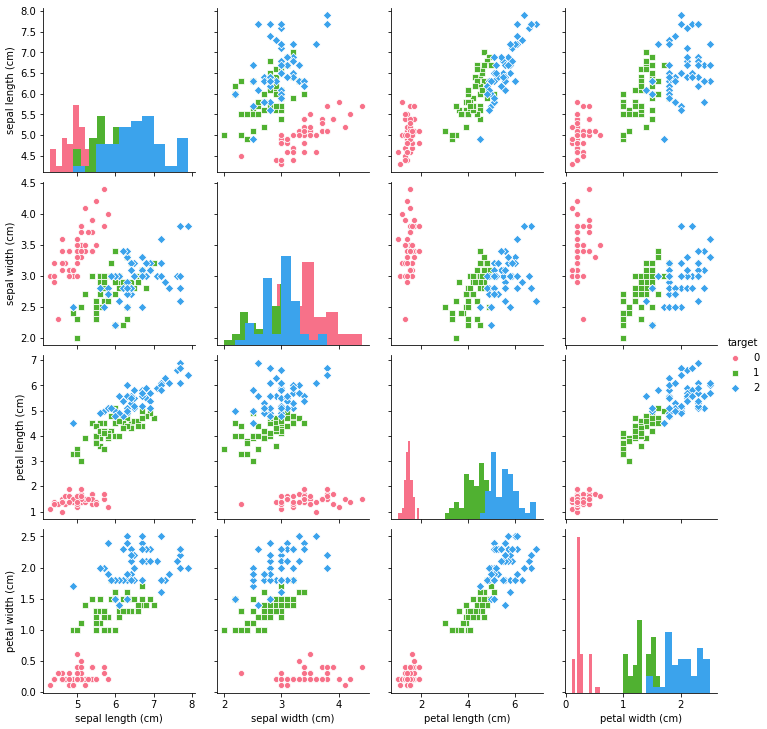
从上图可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。
for col in iris_features.columns:
sns.boxplot(x='target', y=col, saturation=0.5,palette='pastel', data=iris_all)
plt.title(col)
plt.show()
对iris_features的每一列画图,x为标签,y为特征。
palette="Blues" 调色板
saturation 饱和度
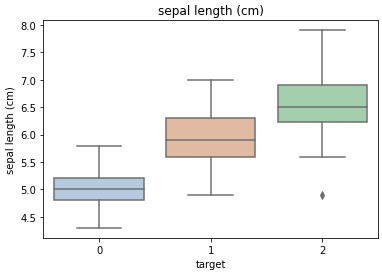
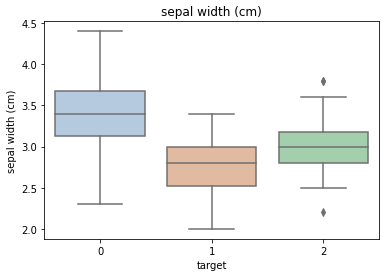
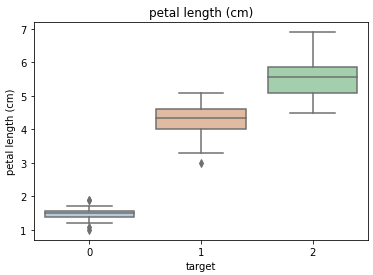
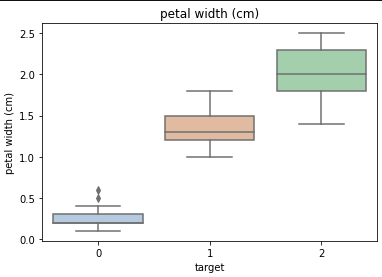
利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况,可以看到0这一类比较有区分度。
# 选取其前三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target']==0].values
iris_all_class1 = iris_all[iris_all['target']==1].values
iris_all_class2 = iris_all[iris_all['target']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa')
ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor')
ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica')
plt.legend()
plt.show()
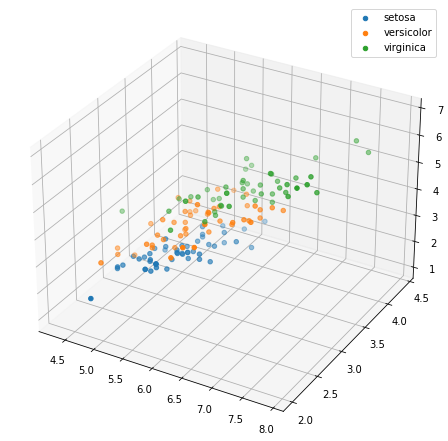
这个三维图在这个例子上表示的效果并没有很明显。
- Step5:利用 逻辑回归模型 在二分类上 进行训练和预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)总共150个样本,前100个就是0和1的样本。
iris_features_part = iris_features.iloc[:100]
iris_target_part = iris_target[:100]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020)
# 参数解释(自变量,因变量,测试集比例,随机数随意设置)
## 从sklearn中导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
## 定义 逻辑回归模型
clf = LogisticRegression(random_state=0, solver='lbfgs')
sklearn逻辑回归(Logistic Regression,LR)类库使用小结
solver选择解释:
'liblinear' 适用于小样本数据集;'sag'与'saga' 更迅速,适用于数据量较大场景.
多分类场景选择'newton-cg', 'sag', 'saga' 和 'lbfgs'; 'liblinear' 仅适用于双分类需求
'newton-cg', 'lbfgs' 和 'sag'只针对 L2 正则(模型默认penalty=L2), 而'liblinear' 和'saga' 针对 L1 正则化(需另设参数)
# 在训练集上训练逻辑回归模型
clf.fit(x_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=0, solver='lbfgs', tol=0.0001,
verbose=0, warm_start=False)
## 查看其对应的w
print('the weight of Logistic Regression:',clf.coef_)
## 查看其对应的w0
print('the intercept(w0) of Logistic Regression:',clf.intercept_)
the weight of Logistic Regression: [[ 0.45244919 -0.81010583 2.14700385 0.90450733]]
the intercept(w0) of Logistic Regression: [-6.57504448]
4个特征对应4个权重(w),只有一个神经元也就只有一个偏置。
## 在训练集和测试集上分别利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 由于逻辑回归模型是概率预测模型(软分类),所以我们可以利用 predict_proba 函数预测其概率
train_predict_proba = clf.predict_proba(x_train)
test_predict_proba = clf.predict_proba(x_test)
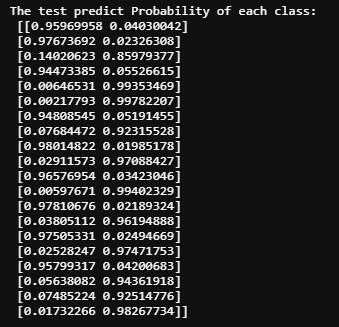
print('The test predict Probability of each class:\n',test_predict_proba)
## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The train_predict accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The test_predict accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
The accuracy of the Logistic Regression is: 1.0
The accuracy of the Logistic Regression is: 1.0
The confusion matrix result:
[[ 9 0]
[ 0 11]]
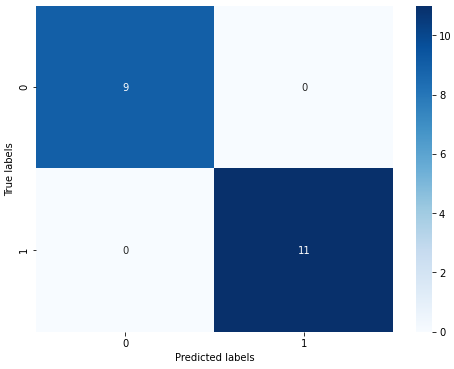
我们可以发现其准确度为1,代表所有的样本都预测正确了。
- Step6:利用 逻辑回归模型 在三分类上 进行训练和预测(和二分类差不多)
### 完整代码
## 基础函数库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 从sklearn中导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
## 从sklearn中导入计算包,为了用其中准确率的计算函数
from sklearn import metrics
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
## 利用.info()查看数据的整体信息
iris_features.info()
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部
iris_features.head()
iris_features.tail()
## 其对应的类别标签为,其中0,1,2分别代表'setosa', 'versicolor', 'virginica'三种不同花的类别。
iris_target
## 利用value_counts函数查看每个类别数量
pd.Series(iris_target).value_counts()
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size = 0.2, random_state = 2020)
## 定义 逻辑回归模型
clf = LogisticRegression(random_state=0, solver='lbfgs')
# 在训练集上训练逻辑回归模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 由于逻辑回归模型是概率预测模型(软分类),所以我们可以利用 predict_proba 函数预测其概率
train_predict_proba = clf.predict_proba(x_train)
test_predict_proba = clf.predict_proba(x_test)
print('The test predict Probability of each class:\n',test_predict_proba)
## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 在测试集上分类错误的数据一览
contrast = pd.DataFrame()
contrast['origin'] = y_test
contrast['predict'] = test_predict
contrast[contrast['origin'] != contrast['predict']]
print('The contrast:\n',contrast[contrast['origin'] != contrast['predict']] )
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB
The test predict Probability of each class:
[[1.32525870e-04 2.41745142e-01 7.58122332e-01]
[7.02970475e-01 2.97026349e-01 3.17667822e-06]
[3.37367886e-02 7.25313901e-01 2.40949311e-01]
[5.66207138e-03 6.53245545e-01 3.41092383e-01]
[1.06817066e-02 6.72928600e-01 3.16389693e-01]
[8.98402870e-04 6.64470713e-01 3.34630884e-01]
[4.06382037e-04 3.86192249e-01 6.13401369e-01]
[1.26979439e-01 8.69440588e-01 3.57997319e-03]
[8.75544317e-01 1.24437252e-01 1.84312617e-05]
[9.11209514e-01 8.87814689e-02 9.01671605e-06]
[3.86067682e-04 3.06912689e-01 6.92701243e-01]
[6.23261939e-03 7.19220636e-01 2.74546745e-01]
[8.90760124e-01 1.09235653e-01 4.22292409e-06]
[2.32339490e-03 4.47236837e-01 5.50439768e-01]
[8.59945211e-04 4.22804376e-01 5.76335679e-01]
[9.24814068e-01 7.51814638e-02 4.46852786e-06]
[2.01307999e-02 9.35166320e-01 4.47028801e-02]
[1.71215635e-02 5.07246971e-01 4.75631465e-01]
[1.83964097e-04 3.17849048e-01 6.81966988e-01]
[5.69461042e-01 4.30536566e-01 2.39269631e-06]
[8.26025475e-01 1.73971556e-01 2.96936737e-06]
[3.05327704e-04 5.15880492e-01 4.83814180e-01]
[4.69978972e-03 2.90561777e-01 7.04738434e-01]
[8.61077168e-01 1.38915993e-01 6.83858427e-06]
[6.99887637e-04 2.48614010e-01 7.50686102e-01]
[5.33421842e-02 8.31557126e-01 1.15100690e-01]
[2.34973018e-02 3.54915328e-01 6.21587370e-01]
[1.63311193e-03 3.48301765e-01 6.50065123e-01]
[7.72156866e-01 2.27838662e-01 4.47157219e-06]
[9.30816593e-01 6.91640361e-02 1.93708074e-05]]
The accuracy of the Logistic Regression is: 0.9583333333333334
The accuracy of the Logistic Regression is: 0.8
The contrast:
origin predict
5 2 1
11 2 1
21 2 1
22 1 2
26 1 2
27 1 2
The confusion matrix result:
[[10 0 0]
[ 0 7 3]
[ 0 3 7]]
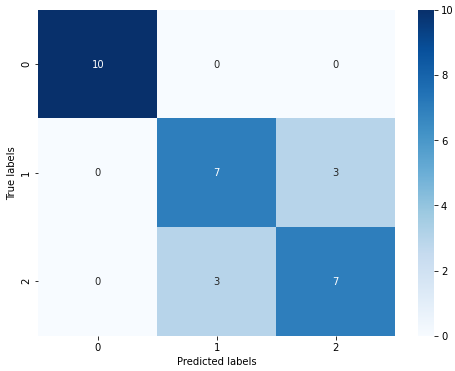
通过结果我们可以发现,其在三分类的结果的预测准确度上有所下降,1和2的这两类分类错误了6个样本,准确率(24/30=0.8),其在测试集上的准确度为:80%,这是由于受到'versicolor'(1)和 'virginica'(2)这两个类别的特征影响,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所以在这两类的预测上出现了一定的错误。
不过已经不错了,就一个神经元就有这个效果。
4 重要知识点
逻辑回归 原理简介:
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
其对应的函数图像可以表示如下:
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5,5,0.01)
y = 1/(1+np.exp(-x))
plt.plot(x,y)
plt.xlabel('z')
plt.ylabel('y')
plt.grid()
plt.show()

通过上图我们可以发现 Logistic 函数是单调递增函数,并且在z=0的时候取值为0.5,并且函数的取值范围为(0,1)。
而回归的基本方程为,
将回归方程写入其中为:
所以,
逻辑回归从其原理上来说,逻辑回归其实是实现了一个决策边界:对于函数,当 时,,分类为1,当时,,分类为0,其对应的值我们可以视为类别1的概率预测值.
对于模型的训练而言:实质上来说就是利用数据求解出对应的模型的特定的。从而得到一个针对于当前数据的特征逻辑回归模型。
而对于多分类而言,将多个二分类的逻辑回归组合,即可实现多分类。
END
本文作者:薄书
本文链接:https://www.cnblogs.com/aimoboshu/p/14170133.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具