
莫烦tensorflow学习记录 (6)卷积神经网络 CNN (Convolutional Neural Network)
卷积 和 神经网络
莫烦大佬的原文章https://mofanpy.com/tutorials/machine-learning/tensorflow/intro-CNN/
我的理解就是千层饼,鸡蛋烧,特征叠叠高。
“卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 也加深了神经网络对图片的理解.
具体来说, 卷积神经网络有一个扫描仪, 持续不断的在图片上滚动扫描图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现, 比如这时的神经网络能看到一些边缘的图片信息, 然后在以同样的步骤, 用类似的批量过滤器扫过产生的这些边缘信息, 神经网络从这些边缘信息里面总结出更高层的信息结构,比如说总结的边缘能够画出眼睛,鼻子等等. 再经过一次过滤, 脸部的信息也从这些眼睛鼻子的信息中被总结出来.
最后我们再把这些信息套入几层普通的全连接神经层进行分类, 这样就能得到输入的图片能被分为哪一类的结果了.
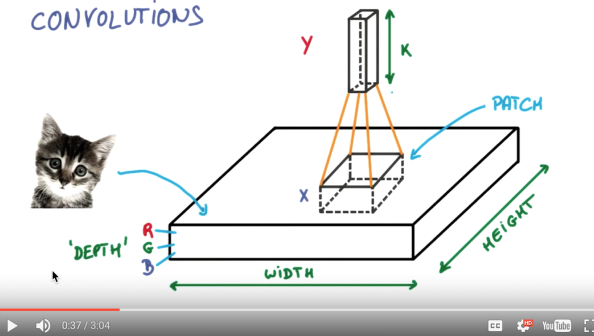
具体说说图片是如何被卷积的. 下面是一张猫的图片, 图片有长, 宽, 高 三个参数.我们以彩色照片为例子. 过滤器就是影像中不断移动的东西, 他不断在图片收集小批小批的像素块, 收集完所有信息后, 输出的值, 我们可以理解成是一个高度更高,长和宽更小的”图片”. 这个图片里就能包含一些边缘信息. 然后以同样的步骤再进行多次卷积, 将图片的长宽再压缩, 高度再增加, 就有了对输入图片更深的理解. 将压缩,增高的信息嵌套在普通的分类神经层上,我们就能对这种图片进行分类了.
池化(pooling)
我的理解就是:卷积的时候就是千层饼不切,鸡蛋烧呢一层一层淋蛋液,到了池化层pooling的时候切出一块最好吃的
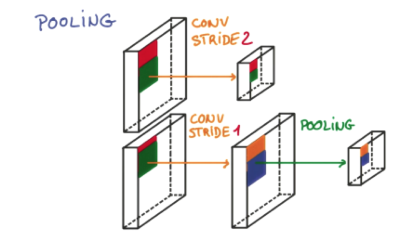
研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担 (具体细节参考). 也就是说在卷集的时候, 我们不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,我们就可以搭建一个属于我们自己的卷积神经网络啦.
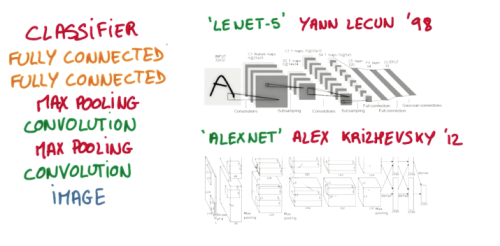
从下到上的顺序, 首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测.
CNN卷积神经网络实践
卷积神经网络包含输入层、隐藏层和输出层,隐藏层又包含卷积层和pooling层,图像输入到卷积神经网络后通过卷积来不断的提取特征,每提取一个特征就会增加一个feature map,所以会看到视频教程中的立方体不断的增加厚度,那么为什么厚度增加了但是却越来越瘦了呢,哈哈这就是pooling层的作用喽,pooling层也就是下采样,通常采用的是最大值pooling和平均值pooling,因为参数太多喽,所以通过pooling来稀疏参数,使我们的网络不至于太复杂。

# coding: utf-8 import tensorflow as tf import numpy as np from utils import * from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 以one-hot编码读取mnist数据集 num_steps = 1000 # 训练迭代步数 # 接着呢,我们定义Weight变量,输入shape,返回变量的参数。其中我们使用tf.truncted_normal产生随机变量来进行初始化: def weight_variable(shape): initial = tf.truncated_normal(shape,stddev=0.1) return tf.Variable(initial) # 同样的定义biase变量,输入shape ,返回变量的一些参数。其中我们使用tf.constant常量函数来进行初始化: def bias_variable(shape): initial = tf.constant(0.1,shape=shape) return tf.Variable(initial) def conv2d(x, W): # tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重, return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') # 然后定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的两个1是默认值, # 中间两个1代表padding时在x方向运动一步,y方向运动一步, # padding采用的方式是SAME。 # 定义pooling函数,向下采样 # 接着定义池化pooling,为了得到更多的图片信息,padding时我们选的是一次一步,也就是strides[1]=strides[2]=1, # 这样得到的图片尺寸没有变化,而我们希望压缩一下图片也就是参数能少一些从而减小系统的复杂度,因此我们采用pooling来 # 稀疏化参数,也就是卷积神经网络中所谓的下采样层。pooling 有两种,一种是最大值池化,一种是平均值池化, # 本例采用的是最大值池化tf.max_pool()。 # 池化的核函数大小为2x2,ksize 为池化窗口大小,因此ksize=[1,2,2,1]。步长为2,因此strides=[1,2,2,1]: def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') class mnistmodel(object): def __init__(self): self._build_model() def _build_model(self): self.images = tf.placeholder(tf.float32, [None, 784]) # 设置图片占位符 self.labels = tf.placeholder(tf.float32, [None, 10]) # 设置标签占位符 with tf.variable_scope('feature_extractor'): # 特征提取部分(包含两个卷积层) self.processimages = tf.reshape(self.images, [-1, 28, 28, 1]) # 将输入图片reshape成[28,28,1]形状 # 网络第一层 W_conv0 = weight_variable([5, 5, 1, 32]) # 该层有32个5*5卷积核 b_conv0 = bias_variable([32]) # 32个bias h_conv0 = tf.nn.relu(conv2d(self.processimages, W_conv0) + b_conv0) # 卷积操作,使用relu激活函数 h_pool0 = max_pool_2x2(h_conv0) # max pooling操作 # 网络第二层,与第一层类似 W_conv1 = weight_variable([5, 5, 32, 48]) b_conv1 = bias_variable([48]) h_conv1 = tf.nn.relu(conv2d(h_pool0, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) # 将第二层输出reshape为二维矩阵以便输入全连接层 self.feature = tf.reshape(h_pool1, [-1, 7 * 7 * 48]) with tf.variable_scope('label_predictor'): # 标签预测部分(两层全连接层) # 从7*7*48映射到100 W_fc0 = weight_variable([7 * 7 * 48, 100]) b_fc0 = bias_variable([100]) h_fc0 = tf.nn.relu(tf.matmul(self.feature, W_fc0) + b_fc0) # 从100映射到10,以便之后分类操作 W_fc1 = weight_variable([100, 10]) b_fc1 = bias_variable([10]) logits = tf.matmul(h_fc0, W_fc1) + b_fc1 self.pred = tf.nn.softmax(logits) # 使用Softmax将连续数值转化成相对概率 # 使用交叉熵做标签预测损失 self.pred_loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=self.labels) graph = tf.get_default_graph() with graph.as_default(): model = mnistmodel() learning_rate = tf.placeholder(tf.float32, []) pred_loss = tf.reduce_mean(model.pred_loss) # 随机梯度下降对loss进行优化 train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(pred_loss) # 计算标签预测准确率 correct_label_pred = tf.equal(tf.argmax(model.labels, 1), tf.argmax(model.pred, 1)) label_acc = tf.reduce_mean(tf.cast(correct_label_pred, tf.float32)) with tf.Session(graph=graph) as sess: tf.global_variables_initializer().run() saver = tf.train.Saver(max_to_keep=1) # 创建saver对象来保存训练的模型 max_acc = 0 is_train = True # training loop if is_train: for i in range(num_steps): lr = 0.0001 # 调用mnist自带的next_batch函数生成大小为100的batch batch = mnist.train.next_batch(100) _, p_loss, l_acc = sess.run([train_op, pred_loss, label_acc], feed_dict={model.images: batch[0], model.labels: batch[1], learning_rate: lr}) print('step:{} pred_loss:{} l_acc: {}'.format(i, p_loss, l_acc)) if i % 100 == 0: test_acc = sess.run(label_acc, feed_dict={model.images: mnist.test.images, model.labels: mnist.test.labels}) print('step: {} test_acc: {}'.format(i, test_acc)) # 计算当前模型在测试集上准确率,最终保存准确率最高的一次模型 if test_acc > max_acc: max_acc = test_acc saver.save(sess, './ckpt/mnist.ckpt', global_step=i + 1) # 读取模型日志文件进行测试 else: model_file = tf.train.latest_checkpoint('./ckpt/') saver.restore(sess, model_file) test_acc = sess.run(label_acc, feed_dict={model.images: mnist.test.images, model.labels: mnist.test.labels}) print('test_acc: {}'.format(test_acc))
本文作者:薄书
本文链接:https://www.cnblogs.com/aimoboshu/p/13817946.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步