
莫烦tensorflow学习记录 (2)激励函数Activation Function
https://mofanpy.com/tutorials/machine-learning/tensorflow/intro-activation-function/
这里的 AF 就是指的激励函数. 激励函数拿出自己最擅长的”掰弯利器”, 套在了原函数上 用力一扭, 原来的 Wx 结果就被扭弯了.
其实这个 AF, 就是一个非线性函数. 比如说relu, sigmoid, tanh. 嵌套在原有的结果之上, 强行把原有的线性结果给扭曲了. 使得输出结果 y 也有了非线性的特征.
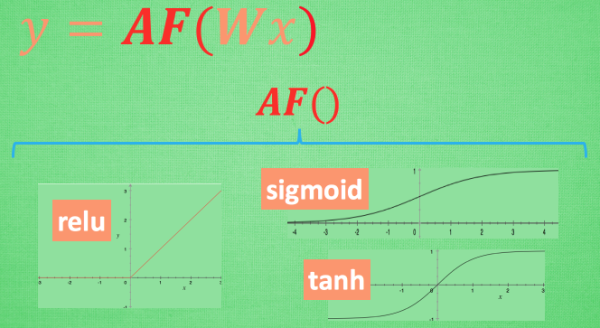
可以创造自己的激励函数来处理自己的问题,只要激励函数是可以微分的, 因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去.
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经网络, 在掰弯的时候, 往往不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题.
在具体的例子中, 我们默认首选的激励函数是哪些. 在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中推荐的是 tanh 或者是 relu。
常用激励函数

def sigmoid(x): return 1 / (1 + np.exp(-x)) def sigmoid_grad(x): return (1.0 - sigmoid(x)) * sigmoid(x) def relu(x): return np.maximum(0, x) def relu_grad(x): grad = np.zeros(x) grad[x>=0] = 1 return grad def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.T x = x - np.max(x) # 溢出对策 return np.exp(x) / np.sum(np.exp(x))
本文作者:薄书
本文链接:https://www.cnblogs.com/aimoboshu/p/13805513.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步