使用Node.js爬虫存储MySQL数据库
第一次使用node爬虫,发帖记录下
1.在MySQL中新建book数据库,创建book表
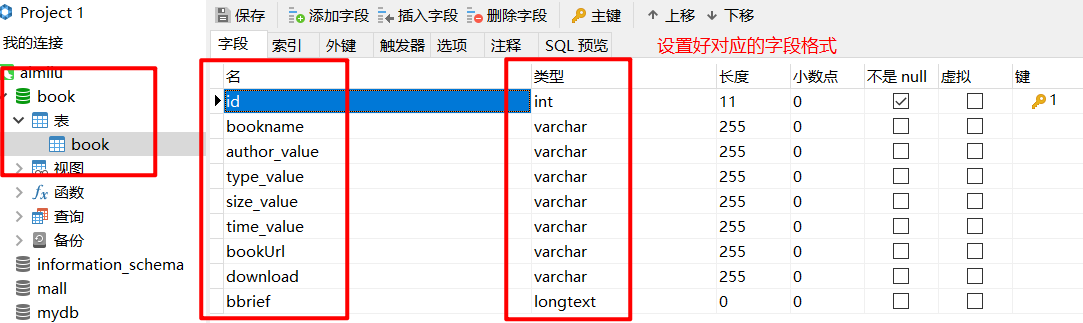
2.创建index.js,使用npm安装导入模块:mysql、axios、cheerio、request、iconv-lite
let request = require('request')
let iconv = require('iconv-lite')
let mysql = require('mysql');
let axios = require('axios');
let cheerio = require('cheerio');
3.测试使用node.js连接本地MySQL数据库
let mysql = require("mysql");
let options = {
host:'localhost',
port:'3306',//可选,默认是3306
user:'root', //数据库名
password:'root', //数据库密码
//database:'book' //选择连接指定的数据库
}
// 创建与数据库的连接的对象,传递参数
let con = mysql.createConnection(options);
// 建立连接
con.connect((err) => {
// 如果建立连接失败
if (err) {
console.log(err);
}else {
console.log('数据库连接成功');
}
})
// 执行数据库语句
// 创建库
let strSql4 = "create database mall";
con.query(strSql4,(err,result) => {
console.log(err);
console.log(result);
})
// 创建表:ps这里不同编译器可能会因为转义符产生报错
let strSql5 = 'CREATE TABLE `mall`.`Untitled` (\n' +
' `id` int NOT NULL AUTO_INCREMENT,\n' +
' `username` varchar(255) NULL,\n' +
' `password` varchar(255) NULL,\n' +
' `email` varchar(255) NULL,\n' +
' PRIMARY KEY (`id`)\n' +
');';
con.query(strSql5,(err,result) => {
console.log(err);
console.log(result);
})
4.找到网站所有书籍对应的css标签并解析URL
5.根据URL找到css标签解析小说的详细信息(书名、作者、简介等)
6.完整代码
1 let request = require('request') 2 let iconv = require('iconv-lite') 3 let mysql = require('mysql'); 4 let axios = require('axios'); 5 let cheerio = require('cheerio'); 6 7 let page = 77013; 8 var count = 1; 9 let options = { 10 host:'localhost', 11 port:'3306',//可选,默认是3306 12 user:'root', 13 password:'root', 14 database:'book' 15 } 16 let con = mysql.createConnection(options) 17 con.connect((err) => { 18 // 如果建立连接失败 19 if (err) { 20 console.log(err); 21 }else { 22 console.log('数据库连接成功'); 23 } 24 }) 25 26 //获取第n个页面所有书籍的链接 27 async function getPageUrl(callback) { 28 // let httpUrl = "http://www.qishus.com/txt/" + 69011 + '.html' 29 let httpUrl = "http://www.qishus.com/" 30 let res = await axios.get(httpUrl) 31 // console.log(res.data) 32 let $ = cheerio.load(res.data) 33 $("ul>li>a").each((i,ele) => { 34 var url = "http://www.qishus.com" + $(ele).attr("href") 35 // console.log(i); 36 // console.log(url); 37 callback(url) 38 }) 39 } 40 41 42 getPageUrl(function (url) { 43 // console.log(url); 44 request({url: url, encoding: null}, (error, res, body) => { 45 let html = iconv.decode(body, 'gb2312'); 46 let $ = cheerio.load(html, {decodeEntities: false}) 47 // 书名 48 let bookname = $(".pageMainArea #downInfoTitle").text() 49 bookname = bookname.substring(0, bookname.length - 7) 50 // 简介 51 let bbrief = $(".mainstory #mainSoftIntro p").text() 52 // 小说类型 53 let type = $(".downInfoRowL b:nth-child(5) ").text() 54 // 小说类型-value 55 let type_value = $(".downInfoRowL").html() 56 // console.log('打印'+type_value); 57 if (type_value === null) { 58 console.log('打印结束'); 59 return 60 } 61 type_value = type_value.split("<b>小说类型:</b>")[1] 62 let type_index = type_value.lastIndexOf(' 63 \n' + 64 '<b>小说作者') 65 type_value = type_value.substring(0, type_index) 66 // 小说作者 67 let author = $(".downInfoRowL b:nth-child(7) ").text() 68 // 小说作者-value 69 let author_value = $(".downInfoRowL").html() 70 author_value = author_value.split("小说作者:</b>")[1] 71 let author_index = author_value.lastIndexOf(' 72 \n' + 73 '<b>小') 74 author_value = author_value.substring(0, author_index) 75 // 小说大小 76 let size = $(".downInfoRowL b:nth-child(9) ").text() 77 // 小说大小-value 78 let size_value = $(".downInfoRowL").html() 79 size_value = size_value.split("小说大小:</b>")[1] 80 let size_index = size_value.lastIndexOf(' 81 \n' + 82 '<b>推荐') 83 size_value = size_value.substring(0, size_index) 84 // 更新时间 85 let time = $(".downInfoRowL b:nth-child(17) ").text() 86 // 更新时间-value 87 let time_value = $(".downInfoRowL").html() 88 time_value = time_value.split("更新时间:</b>")[1] 89 let time_index = time_value.lastIndexOf(' 90 \n' + 91 '<b>分 享 到') 92 time_value = time_value.substring(0, time_index) 93 // 下载 94 let download = $("#downAddress").html() 95 download = download.split('href=\"')[1] 96 let index = download.lastIndexOf('\" target') 97 download = download.substring(0, index) 98 // url链接 99 let bookUrl = url; 100 // console.log(bookname,time,time_value,download,size,size_value,author,author_value,type,type_value); 101 102 103 let arr = [bookname, author_value, type_value, size_value, time_value, bookUrl, download, bbrief]; 104 console.log(arr); 105 // 插入数据库 106 let strSql = "insert into book (bookname,author_value,type_value,size_value,time_value,bookUrl,download,bbrief) values (?,?,?,?,?,?,?,?)" 107 con.query(strSql, arr, (err, result) => { 108 if (err) { 109 console.log(err); 110 } else { 111 console.log(result); 112 } 113 }) 114 }) 115 });
代码到这里结束了,后面将数据进行处理开发图书馆web,如有错误还望多多指教

 浙公网安备 33010602011771号
浙公网安备 33010602011771号