

高中生能看懂的详细通俗讲解卡尔曼滤波Kalman Filter原理及Python实现教程
接触过传感器数据的同学一定不可避免见到一个名字“卡尔曼滤波”。这是何方神圣?请看后面分晓。很多时候看不懂一个算法是因为里面很多概念上的问题你没了解,就直接看细节了当然看不懂。最关键的事就是你得先了解卡尔曼滤波到底有啥用,它的初衷是什么?接下来我就是想讲讲破解卡尔曼滤波的一些概念上的认知障碍这个事。
破解概念上的认知枷锁:卡尔曼滤波做的事
卡尔曼滤波做的事就是:举个例子,已知上个时刻飞机的位置,知道现在这个时刻收到的雷达测量的飞机的位置。用前面两个数据来估计此时飞机的位置。精简的说就是知道上个时刻状态,又知道测量数据,融合这两个数据来求当前状态。
你一定会问现在知道当前时刻的测量数据那么我认为当前状态就是测量数据不就好了么?换句话说:“你一定会觉得雷达测量到的飞机位置不就是当前飞机的位置嘛?为何要用卡尔曼滤波来估计飞机当前的位置?”。
答:现在这个时刻收到的雷达信号测量的飞机的位置还真不一定是飞机当前的真实位置。首先雷达信号测量有误差。其次你想想我现在收到雷达信号,那是之前发射过去然后返回的信号。这个过程是不是要时间?这段时间飞机说不定以超2倍音速飞行,说不定直接坠机,这些都有可能**。也就是说即使收到测量数据但是还是不确飞机位置在哪**。于是我得需要根据前一个时刻的位置估计出当前时刻的飞机位置 结合 测量数据 综合考虑来 估计当前飞机位置。这就是卡尔曼滤波的作用。
那么你一定会问根据前一个时刻估计的飞机位置怎么就可以估计现在这个时刻的飞机位置了?
答:卡尔曼认为所有的状态变化(位置变化)都是线性的。什么叫做线性?上个时刻位置是0.3,速度是0.2。那么我估计下个时刻的位置就是0.5。这就叫做线性。
接下来你一定会问那并不是所有的状态变化都是线性的怎么办?你像风速变化它就不是线性的。
答:恭喜你发明了新的算法。事实上别人已经为这个算法命名了叫做扩展卡尔曼滤波。现在我们要学习的是卡尔曼滤波。你只需要记住卡尔曼滤波就是认为所有变化都是线性的。
那么现在我知道了怎么用上个时刻飞机的位置估计当前时刻的飞机位置,也知道了还得借助当前时刻收到的测量数据来综合考虑来估计当前飞机的位置。那么怎么综合考虑呢?这就涉及到一个比例。到底这两个数据占比多少?这就是卡尔曼滤波的核心精髓。卡尔曼滤波算法要动态的调这个比例。(有种中庸之道的调调,既不只信测量数据,也不只信上个时刻的位置所估算的当前时刻位置。)
滤波算法的思路发展?
如果不理解滤波思路那么今天学会了一个卡尔曼滤波明天还有一个通尔曼滤波要你学。如果学会这些滤波算法的思路,把他们联系在一起然后记忆那就简单多了。滤波算法本质上就是利用多个数据来融合估计真实状态。下面举两个从浅到深的例子。
如何结合“飞机的速度和雷达测量的飞机的位置 ”来估计飞机在时刻的位置?
下面有个一个飞机只会水平飞行。我们已知上个时刻飞机的位置和速度.而且雷达可以测量到此时飞机的位置。那么我们估计飞机的位置那就有两种方法:“一是认为飞机是匀速()直线运动得到现在飞机位置为,另一种是认为飞机位置就是测量值”。如果按第一种那么万一飞机不是匀速走呢?如果按第二种万一雷达很不准呢?我们得采取一种折中的方法。
我们认为飞机在时刻的位置为。这个需要我们自己设置。如果我们相信雷达不准那就赋值很低比如为0.1.如果我们相信雷达很准那么就设置为很接近1的值比如0.9。你会发现越接近0,那么所估计的位置越是接近认为飞机匀速走的那个思路。越接近1那么所估计的位置越接近雷达测量值(等于1就是认为飞机在时刻的位置就是雷达测量值)。
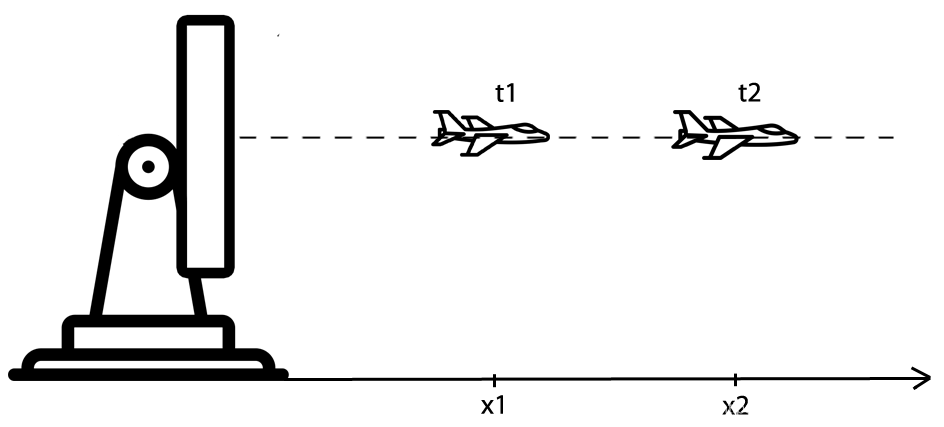
但是飞机的速度怎么估计啊?因为飞机不一定是匀速走。我们得根据
现在我想估计飞机的速度。
速度估计的方式有两种:
- 假设飞机是匀速运动。也就是说到这段时间内飞机速度等于在时刻估计出的飞机速度。即
- 由于雷达也收到了一个测量数据,它测量到雷达距离飞机位置是。也就是说在雷达看来从到这段时间内飞机走过了这么远的距离。所以根据雷达的判断,我们可以估计出飞机的一个速度。
这两种速度很可能不同。这有两个原因:“一是飞机并不是匀速运动,二是雷达根本就测量的距离不准”。到底是哪个对呢?
真实速度需要综合考虑这两个数值,根据上一个例子总结的滤波器模式第N次算出的估计值=上次的估计值+ 因子a ×(测量值-上次估计值)。我们知道真实的速度肯定可以这么表达。至于这个到底取多少这是我们自己赋值。比如我们觉得测量的值是更准确的,那可以设置大一点比如0.9。如果我们觉得雷达不准那就设置小一点比如0.1。
所以我们得到速度的估计公式:
,其中。
然后我们又可以根据这个求得的速度来更精确的估计飞机的位置
如何结合“飞机的速度,加速度,雷达测量的飞机的位置” 来估计飞机的位置?
在前面我们一直做的假设是飞机是匀速走的。但是飞机很可能会发生加速或者减速。这就不得不考虑加速度的问题了。
在高中我们学过位移与速度和加速度之间的关系是:。其中是从到这段时间的加速度。
所以飞机的位置可以融合速度、加速度这样来估计:。
可以看到和前面那个例子的位置估计公式:
相比,只是将原来的根据速度估计位移变成了根据速度和加速度来估计位移。
在前面提到了我们的速度可以根据测量数进行动态更新:
,其中。
当然我们的加速度也是可以根据测量数据进行动态更新的
。其中,这个是根据加速度的定义所得来的,加速度=速度变化量除以时间间隔。
可以看到滤波思路是一环扣一环,它要平衡每个环节中的 根据之前状态所估计出当前状态值 和 测量值之间的在最终结果中的占比。
而那些滤波算法要做的事就是设计合理的占比到底取多少比较合适。而且是需要根据不同情况动态的设置占比。前面提到的例子中占比变量有三个,你学习滤波算法时只需要关注这几个占比值是怎么计算的就可以了。
像卡尔曼滤波,拓展的卡尔曼滤波,Particle Filter,贝叶斯滤波等等都是前面提到滤波思路这种形式。
卡尔曼滤波怎么进行滤波的?
我们先把前面总结的滤波算法规律复制过来看看:
- 估计当前时刻位置:
- 估计当前时刻速度:
,其中 - 估计当前时刻加速度:
。其中
前面我们提到了那些种类繁多的滤波算法,无非就是提出了各种确定具体取值的计算方法而已。
我们看看卡尔曼滤波是怎么确定这三个值的。
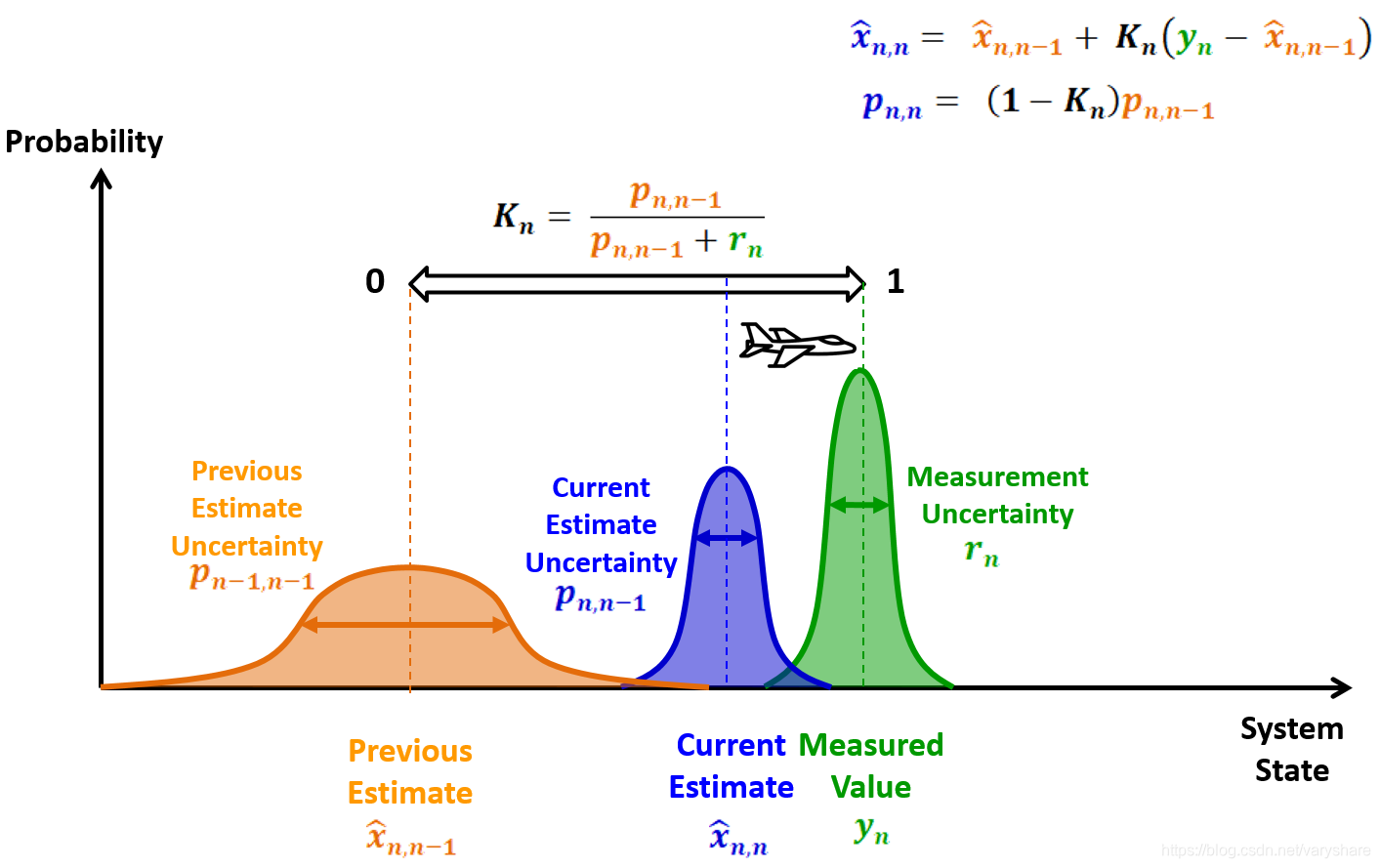
- 这个是用来调节 根据上个位置估计出的当前位置值 与 测量值 在最终结果中的占比用的。这个在卡尔曼滤波中叫做卡尔曼增益。当然既然叫卡尔曼增益了肯定变量名就不叫做了而是叫做。
- 是用来调节根据上个时刻速度估计出的当前时刻速度值 与 根据测量值算出的速度 在最终结果中的这两个数占比用的。在卡尔曼滤波中它认为物体就是匀速运动的。所以当前时刻速度和上个时刻速度一样,即。
- 上面那句话提到了物体是匀速运动的所以没有加速度。
于是卡尔曼滤波可以这么写:
- 估计当前时刻位置:
- 估计当前时刻速度:
那么怎么计算呢?
橘黄色虚线是根据市上个状态计算出当前状态的估计值,绿色虚线是测量值,紫色虚线是最终结果。而这个数字就是调节紫色虚线到底是靠近另外两条线中的哪个。
现在我们得到了新的位置估计值,那么根据这个来估计下一个位置它的方差是多少呢?由于根据上个状态算出当前状态这个数字在最终结果的占比只占了这么多。所以方差
由上面这段话可以看出,卡尔曼滤波最关键的是需要求出两种方差。一是纯粹依赖估计的这种方法的方差。二是测量仪器的方差。只要知道了这两个值那就可以知道估计值和测量值在最终结果中的占比。算方差的方法在不同应用场景是不同的需要以实际情况而定。
注意:根据上个状态估计当前时刻的位置方法不是只有根据速度和加速度来估计这一种方法。还有其他很多种。比如我可以根据飞机发动机此时的推动力和这段时间内燃烧了的汽油来估计飞机飞行了的距离(能量守恒定律,推动力×距离=做功)。
Python编程实践卡尔曼滤波
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
NUM_POINTS = 500
NUM_TIME = 40
time = np.linspace(0, NUM_TIME, NUM_POINTS) #0-40均匀取500点
realpos = np.sin(time/5) # 真实位置值
def takeMeasurement(realpos):
'''
function:
---------
模拟生成一个测量值。生成方法:给真实位置值加高斯噪声。
为何加高斯噪声?因为噪声一般是服从高斯分布的
parameter:
----------
@realpos: float, 某个时刻的真实位置.
returns:
--------
@z: float, 某个时刻的位置测量值.
'''
measurementNoise = .15
z = np.random.normal(realpos, measurementNoise)
return z
def takeOdometry(realpos_prev, realpos_curr):
'''
function:
---------
生成一个上个时刻到当前时刻走过的距离估计值(即速度,单位时间内走过的距离不就是速度么?)。
(在这里为了简化问题我们就不加入速度,就直接随机生成一个速度)
parameters:
-----------
@realpos_prev: float, 前一个时刻位置真实值.
@realpos_curr: float, 当前时刻位置真实值.
returns:
--------
@u: float, 上个时刻到当前时刻走过的距离估计值
'''
processNoise = .05
if realpos_prev == realpos_curr:
u = 0
else:
u = np.random.normal(realpos_curr - realpos_prev, processNoise)
return u
processNoise = 0.1;# 估计误差,初始化
measurementNoise = 0.1;# 测量误差,初始化
estimated_position = [] # list of best-guess estimates
x = realpos[0] # 真实位置x,初始化
p = processNoise # 方差,根据上个时刻位置估计出的当前位置的方差
unfilterOdometryReading = realpos[0] # raw odometer readings
unfilterOdometry = [] # list of odometry estimates
unfilterMeasurements = [] # list of measurements
measurement_time = []
for i in range(len(time)):
# step 1: 生成上个时刻到当前时刻这段时间走过的估计距离
if i == 0:
u = takeOdometry(realpos[i], realpos[i])
else:
u = takeOdometry(realpos[i - 1], realpos[i])
x += u
# 记录纯靠估计值所估计出的位置,用作后面的对比
unfilterOdometryReading += u
unfilterOdometry.append(unfilterOdometryReading)
p += processNoise
# 每10步进行一次测量
if i % 10 == 0:
z = takeMeasurement(realpos[i])#模拟一次测量
# 存档测量值,用作后面的对比
measurement_time.append(time[i])
unfilterMeasurements.append(z)
# 根据测量值修正位置估计值
y = z - x
k = p / (p + measurementNoise)
x = x + k * y
p = (1 - k)*p
# 记录修正后的位置估计值
estimated_position.append(x)
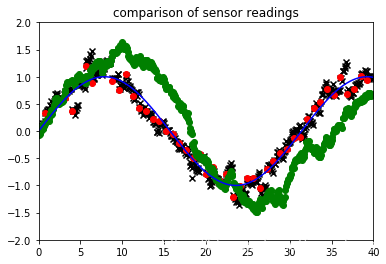
# 对比三种情况下的位置,和真实位置之间的差异
plt.plot(time, realpos, color = 'b') # groundtruth
plt.scatter(time, estimated_position, color = 'k', marker = 'x') # best guess
plt.scatter(measurement_time, unfilterMeasurements, color = 'r') # measurements
plt.scatter(time, unfilterOdometry, color = 'g') # odometer
plt.title('comparison of sensor readings')
plt.ylim(-2, 2)
plt.xlim(0, 40)
数学小知识:
数学期望值与平均值的区别?
大家平常把这两个等价为一个好像并没什么很大影响。事实上他们两个确实差不多。但是又有微小的差异。
假设有个2个硬币:1元,5元。你说它平均值是3元这个没错。但是你不能说它期望值是3元。因为这个硬币它整体我们已经可以看完了。而且期望值是针对那些样本整体我们没法看完的情况,我们对他们整体的平均值的一个估计。平均值一般是用希腊字母(读音:miu)表示,期望值一般用表示。这个符号很关键。因为作者写公式的时候就隐含了这些信息。他默认你知道这个概念认知。
方差与标准差?
方差就是一个数。这个数可以衡量样本集中各个样本值与平均值之间的波动大小。(还记得平均值用什么符号表示么?平均值用)。怎么衡量与平均值波动大小?很简单我减去平均值然后平方不就好了么。然后由于是要衡量整个样本集中的样本,那就得把那个平方求和然后除以样本个数(关于到底除N还是N-1,可以看看这篇文章Why divide the sample variance by N-1?)。我们熟悉的方差公式出来啦:。注意:(含义:sigma的平方)这个表示方差。N表示样本的个数。是样本集的平均值。表示第n个样本。
标准差也是一个数。它就是方差开根号。和方差没啥区别。还记得方差是什么吗?它是sigma的平方。标准差是方差开根号,也就是说标准差就是sigma。即用符号表示就是,这就是标准差。
标准差有什么用?
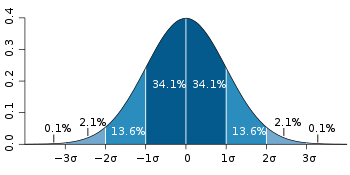
衡量样本值与平均值之间的波动大小这个你肯定高中就知道了。我想说的是另外一个作用:根据样本估计真实值的范围。
假设我们抽样了溶液x的样本数据。测量他们的电压。然后他们的分布如下所示。根据这些我们可以得出一个结论:溶液x电压值在之间的概率是34.1%。溶液x的电压在之间的概率是68.2%。也就是说溶液x的电压大概率在范围内?而就是标准差。是不是很有用?我们可以根据所收集的很多测量值,算他们的均值和标准差来估计真实值的范围。这个原理就是滤波算法的很常用的原理。
正态分布不清楚?
下面这个图就是正态分布。横坐标是在本例中是飞机的速度v,纵坐标是当前速度是v的概率。其实这些你编程就调用一个服从正态分布的随机函数就是了。正态分布函数用公式表示就是。这个函数,表示的是当前速度为的概率是。还记得是什么吗?是平均值,是标准差。这两个是常数,你编程的时候需要告诉程序,告诉它生成的随机数平均值是多少,标准差是多少。一般生成正态分布随机数代码是这么写的v = normalrand(u,s)
参考文献:
[1] http://web.mit.edu/kirtley/kirtley/binlustuff/literature/control/Kalman filter.pdf
[2] https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
[3] https://en.wikipedia.org/wiki/Kalman_filter
[4] http://www.cl.cam.ac.uk/~rmf25/papers/Understanding the Basis of the Kalman Filter.pdf
[5] https://www.kalmanfilter.net/alphabeta.html

